1. Introduction
The problem of private information retrieval (PIR), introduced by Chor et al. in [
1], seeks to find the most efficient way for a user to privately retrieve a single message from a set of
K messages from
N fully replicated and non-communicating databases. PIR schemes are designed to download a
mixture of all
K messages, with the least number of overhead downloaded bits, such that no single database can infer the identity of the desired message. The user accomplishes this task by sending a query to each database. The databases respond truthfully to the submitted query with an answer string. The user can then reconstruct the desired message from jointly
decoding the returned answer strings. Recently, the problem of PIR has received growing interest from the information and coding theory communities. The classical PIR problem is reformulated using information-theoretic measures in the seminal work of Sun–Jafar [
2]. In there, the performance metric of the PIR scheme is the retrieval rate, which is the ratio of the number of the desired message symbols to the total number of downloaded bits. The supremum of this ratio is denoted by the PIR capacity,
C. Sun and Jafar characterize the PIR capacity of the classical PIR model to be
Following [
2], the capacity (or its reciprocal, the normalized download cost) of many variations of the problem have been investigated; see [
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17], and the surveys in [
18,
19].
In all these works, the user is assumed to have no information about the desired message prior to retrieval. Thus, the queries are designed independently of the message contents. This is not always the case in practice. To see that, consider the following classical motivational example of PIR: in the stock market, investors need to privately retrieve some of the stock records since showing interest in a specific record may undesirably affect its value. PIR is a natural solution to this problem. Now, consider the case when an investor has already retrieved a specific stock record some time ago but this record has been changed. The investor needs to update the record at his/her side. A trivial solution to this problem is to reapply the original PIR scheme again. Nevertheless, this solution overlooks the fact that stock records are
correlated in time. Another example arises in the context of private federated submodel learning [
20], in which a user needs to retrieve the up-to-date desired submodel without leaking any information about its identity. The weights of each submodel are usually correlated in time as in the stock market example. In both examples, it is interesting to investigate whether or not the investor (user) can exploit the correlation between the outdated record (submodel) and its up-to-date counterpart to drive down the download cost. In this work, we focus our attention on a specific type of correlation, in which the up-to-date message is a distorted version of the outdated message according to a
Hamming distortion measure.
The most closely related works to this problem are the PIR problems with side information, e.g., [
21,
22,
23,
24,
25,
26,
27]. We also assume that the user has access to a private local cache containing equal portions of each message. Caching systems of this variety have been explored before in the PIR setting, e.g., [
28,
29], but not in conjunction with other forms of side information (outdated or updated). In the works regarding PIR with side information, the user has side information in the form of a subset of
undesired messages, which are utilized to assist in privately retrieving the desired message. This is different from our setting, in which the user possesses side information in the form of an outdated
desired message. Furthermore, these works differ from each other in whether the privacy of the side information should be maintained or not. This is different from our problem in which the identity of the desired and side information is the same, and therefore the privacy constraint in our problem is modified to reflect this fact.
In this work, we introduce the problem of
cache-aided private updating with unknown prefetching for an
L-bit length message out of a
K-message library from
N replicated and non-colluding databases. In this problem, the user has an
outdated version
of the desired message
, and wishes to update it to its up-to-date version
. Furthermore, the user has information about the
maximum Hamming distance
f between the up-to-date message and its outdated counterpart, i.e., the user possesses
, which differs in
at most f bits from the desired up-to-date message
. Based on
and
f, the user needs to design a query set to reliably and privately decode the up-to-date version of the desired message
with the least number of downloaded bits. Equivalently, the user needs to privately retrieve an
auxiliary message that corresponds to the flipped bit positions in the desired message. Similar to the works of [
30,
31], we assume that the databases can construct a
mapping from the original library of messages into a more appropriate form that can assist the user in the retrieval process (in this work, we assume that the databases are
semi-honest, in the sense that they truthfully obey the retrieval process, but the databases are curious to learn the identity of the desired file). The user also has access to a private cache
Z containing
ℓ linear combinations of each message, with
being the caching ratio. The structure of such linear combinations is pre-specified to facilitate the retrieval procedure. By jointly designing the prefetching (i.e., the structure of the aforementioned cache contents) and the updating procedures, we aim at characterizing the optimal download cost needed to update
to
given
Z without disclosing the desired message index
to any of the databases for arbitrary
K,
N,
f,
L, and
r.
To that end, we propose a novel achievable scheme that is based on the
syndrome decoding idea introduced in [
32], and adapt it to our setting to exploit the correlation between
and
. Hence, syndrome decoding is used to
compress the desired message based on the user’s side information (i.e., the outdated message
). More specifically, the databases apply a linear transformation to the stored library of messages using the parity check matrix of a linear block code with carefully chosen parameters. The existence of such a code can be readily inferred from the Gilbert–Varshamov and the Hamming bounds [
33]. This transformation, in effect, maps the messages into their corresponding syndromes. Thus, the problem is reduced to retrieving the syndrome representation of the messages (i.e., the auxiliary messages) that comprises
bits, where
L is the original message length.
In the case of
, we directly apply the PIR scheme in [
34] to the auxiliary messages of length
, which is optimal under the message length constraints. In the case where
r satisfies
(denoted as very low
r),
(denoted as very high
r), we extend the PIR scheme in [
34] to the cache-aided setting in [
29], and develop a novel
cache-aided arbitrary message length PIR scheme to solve our problem. We also present an achievable scheme for the mid-range
r, satisfying
, tailored for the case of
messages, and discuss possible extensions for arbitrary
K afterwards. Like with the
case, we can then use this new cache-aided arbitrary message length scheme to download the auxiliary messages of length
with an effective caching ratio of
. This is in effect a higher caching ratio than
r, which in turns lead to a lower download cost as in [
29]. For each of these cases, we confirm the validity of our proposed scheme by deriving a matching converse proof. Our converse proof is inspired by the converse proof of the cache-aided PIR problem with unknown and uncoded prefetching in [
29], with the main difference being the fact that in addition to a private cache, the user has access to the outdated message
, the index of which they wish to keep private. Consequently, we show that the optimal download cost is perfectly characterized for very high caching ratios, and is characterized within a maximum gap of only 2 bits otherwise. Notably, such a gap is 0 if
is an integer. This justifies the efficacy of using syndromes as a message-mixing technique in our setting. Furthermore, our results show that performing direct PIR on the original library of messages is strictly sub-optimal as long as the maximum Hamming distance
.
The rest of the paper is organized as follows. Our system model is described in
Section 2. The main results are presented in
Section 3, with the main converse proof following in
Section 4, and the achievability proofs in
Section 5 and
Section 6.
Section 7 includes a discussion on extending our achievability results, and the paper is concluded in
Section 8.
2. System Model
We consider a classical PIR problem with
K independent, uncoded, messages
, with each message consisting of
L independent and uniformly distributed bits. We have
The
K messages are stored in
N replicated and non-communicating databases. The user (retriever) has a local copy of one of the messages whose index
is known to the user (
denotes the set
) but not the database (this is true if message
, for example, has been previously obtained in a private manner). However, this message stored locally is
outdated, and the user wishes to update it so that it is consistent with the copies in the databases without revealing to any of the databases what the message index is.
The user also has a local cache memory whose contents are denoted by a random variable
Z. The cache is populated through a
prefetching phase in which the user caches pre-specified linear combinations from each message
,
, with
bits (specifically, we consider the case when the prefetching and retrieval strategies can be jointly designed, i.e., we assume that the information source performing the prefetching may provide a linear combination of its content with any desired structure to assist the user in minimizing the download cost in the retrieval phase). Such linear combinations are represented by a matrix multiplication
, where
is of dimension
. Thus, we have
The explicit design of
,
is specified along the lines of the achievability proof. We assume that the contents of the cache are
unknown to the databases, as in, e.g., [
21,
27,
29]. We define the
caching ratio as
Observe that the number of cached bits pertaining to each message is equal to
. It now follows that
The setting described above defines the cache-aided private updating problem with unknown prefetching.
Since each message is a string of
L bits, the problem can be formulated as privately determining which subset of the message bits need to be flipped in order to fully update it. To model this, we use
to represent the locally stored outdated message,
to represent the subset of bit indices that need to be flipped, and
f to represent the
maximum Hamming distance between
and
(clearly,
must hold; otherwise, there is no need to update
). Therefore, in order to update message
, the user needs to flip
at most f bits, i.e.,
takes a value out of
choices. We assume that such choices are uniformly distributed and independently realized from
. Based on this model, the following holds:
where
denotes cardinality. We assume that the maximum Hamming distance
f between the outdated and updated message is known to the user. By (9), one can see that
bits should be sufficient to update
. Hence, one can set a maximum value on the number of cached bits from each message as follows (in case the number of cached bits is greater than this bound in (
13), the extra bits can be ignored by the user):
In order to retrieve
, the user sends a set of queries
to the
N databases to efficiently obtain
. The queries are generated according to
,
f, and
Z, and are jointly independent of the realizations of the
messages and
given
. Therefore we have (we use the notation
to denote the collection of
)
Upon receiving the query
, the
nth database replies with an answering string
, which is a function of
and all the
K messages stored. Therefore,
, we have
To ensure that individual databases do not know which message is being updated, we need to satisfy the following
privacy constraint,
:
where ∼ denotes statistical equivalence. After receiving the answering strings
from all the
N databases, the user needs to decode the desired information
with no uncertainty, satisfying the following
correctness constraint:
The overall system model is depicted in
Figure 1. We also include a list of notation with their definitions in
Table 1 for ease of presentation.
For fixed
N,
K,
f, and
r, a pair
is
achievable if there exists a cache-aided private updating with unknown prefetching scheme for messages of length
L bits long satisfying the privacy constraint (
16) and the correctness constraint (
17). In this pair,
represents the expected number of downloaded bits received from the
N databases independently via the answering strings
, i.e.,
Our goal is to characterize the optimal download cost for the cache-aided private updating problem with unknown prefetching for fixed arbitrary L, N, K, f, and r. That is, we solve for
Clearly, the user can ignore its outdated message
and re-download the whole new message
using standard cache-aided PIR schemes [
2,
29]. Our main result, however, shows that we can use
to do strictly better.
3. Main Results
Our first result characterizes a converse bound for the optimal download cost for general N, K, f, and r.
Theorem 1 (Converse)
. In the cache-aided private updating problem with unknown prefetching, the optimal download cost is lower bounded by with defined in (9). The proof of Theorem 1 is provided in
Section 4.
For our next result, we characterize an achievability bound for specific values of the caching ratios, and otherwise general
L,
N,
K, and
f. Before we present our result, we need to introduce some notation. Specifically, as in [
29], for
, we define a caching ratio
as
Now, we say that a caching ratio
r is
very low if
,
very high if
, and
mid-range otherwise. We are now ready to present our first achievability result.
Theorem 2 (Very Low and Very High Achievability)
. In the cache-aided private updating problem with unknown prefetching, for very low caching ratios, the optimal download cost is upper bounded byand for very high caching ratios, the optimal download cost is upper bounded bywith defined in (9). The proof of Theorem 2 is provided in
Section 5.
Combining the achievability bounds in Theorem 2 with the converse bound in Theorem 1, we obtain a fairly tight, up to a ceiling difference of , characterization of the optimal download cost for very low and very high caching ratios. This is stated in the following corollary.
Corollary 1. In the cache-aided private updating problem with unknown prefetching, for very low caching ratios, we haveand for very high caching ratios, we have Proof. The right-hand side inequality of (
24) is given directly by Theorem 2. By choosing
in (
20), we obtain the left-hand side inequality in (
24). Similarly, by choosing
in (
20), we obtain the result in (
25) (note that
is an integer, and so in this case, the converse and achievability bounds match). This concludes the proof. □
We now have the following remarks.
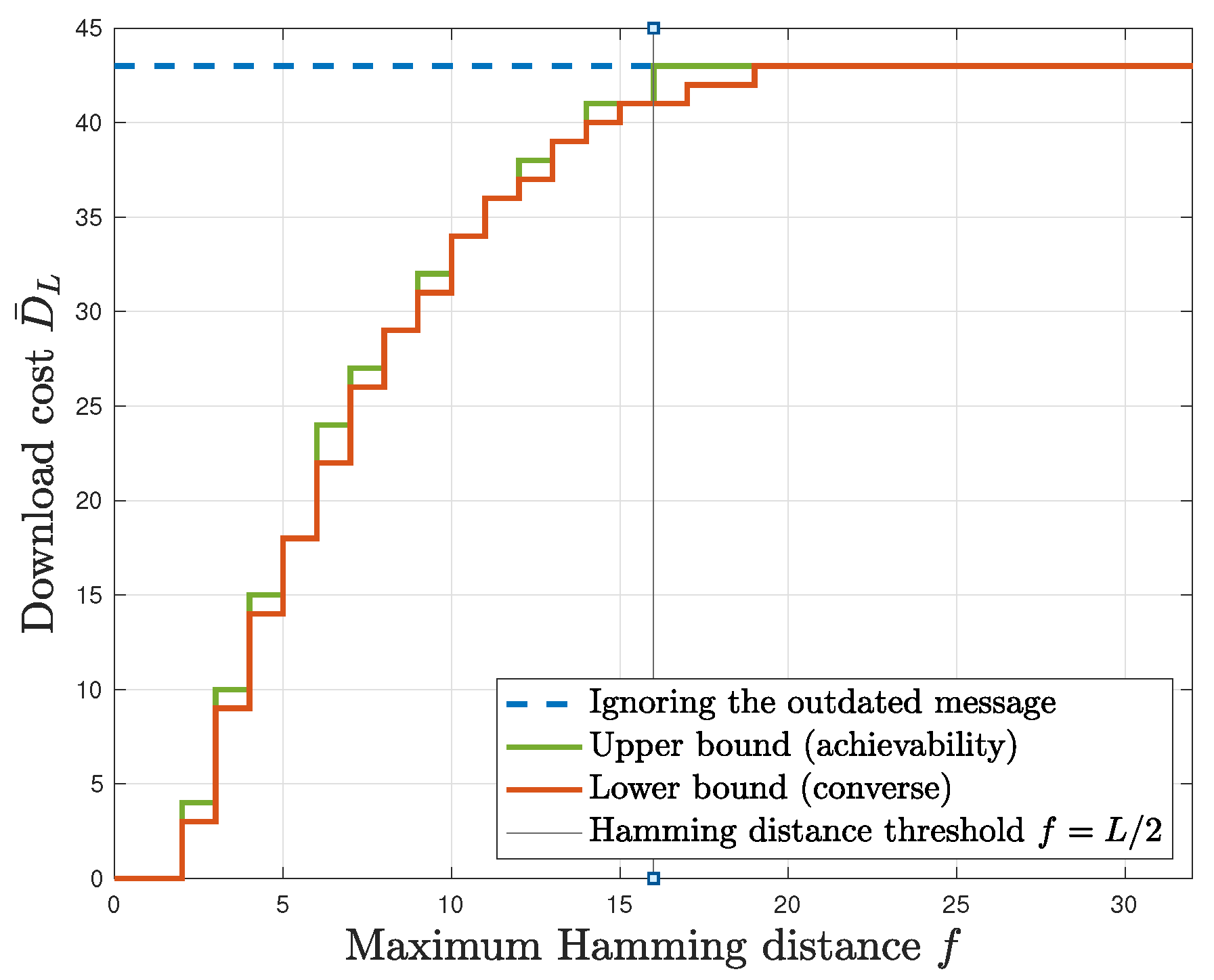
Remark 1. The result in Corollary 1 generalizes our preliminary work on the private updating problem with no caching involved [35]. Specifically, plugging in in Corollary 1 directly gives ([35], Theorem 1). Remark 2. Consider the result in (24). From (9) and (12), it follows that for all values of , and that for all values of (this can be readily shown using the binomial theorem; details are in Appendix A). Combining this with the results in ([29], Corollary 2) (which is the analog of our result in case the user does not have an outdated message), this means that there is a Hamming distance threshold
of beyond which there is no advantage to using a private updating strategy, and below which there will always be some savings in download cost. This can be seen in Figure 2, where we also note that the non-linearity of the upper and lower bounds are a result of the ceiling functions that appear in these bounds. Remark 3. If L and f are such that , then the upper and lower bounds in (24) match. We will see that this holds if a perfect code
(a code that attains the Hamming bound with equality [33]) by which the queries are sent exists (cf. Section 5). Otherwise, if , one can show using similar arguments as in ([34], Section 7.2) that the two bounds are within 2 bits for databases. Next, we have the following achievability result regarding mid-range caching ratios.
Theorem 3 (Mid-Range Achievability)
. In the cache-aided private updating problem with unknown prefetching with messages, for mid-range effective caching ratios, the optimal download cost is upper bounded bywith defined in (9). The proof of Theorem 3 is provided in
Section 6. In
Section 7, we include a discussion on extending the above achievability result for arbitrary
K.
Combining the mid-range achievability bound in Theorem 3 and the converse bound in Theorem 1 for
, we characterize the optimal download cost for
for mid-range caching ratios when
. Furthermore, combining this characterization with the result of Corollary 1 gives a complete characterization of
when
for
any caching ratio. To this end, we define the
converse bound
and the
achievability bound
to express this characterization:
We have now proved the following corollary.
Corollary 2 (
Characterization)
. In the cache-aided private updating problem with unknown prefetching where , for any caching ratio, we have 4. Proof of Theorem 1: Converse
In this section, we derive the general (converse) lower bound for the download cost in Theorem 1. To do so, we prove two useful lemmas, analogues to their counterparts in the cache-aided PIR setting of [
29], for the case of our cache-aided private updating problem. The two lemmas are then combined to prove the general lower bound. The key difference between our lemmas and those in [
29] is that in addition to some uniform portion of each message being cached, the user is given an outdated message
, requiring careful handling of the correlation between
and
.
Lemma 1 (Interference Lower Bound)
. In the cache-aided private updating problem with unknown prefetching, the interference from undesired messages within the answering strings, , satisfiesfor all . Proof. We start with the right-hand side of (
30),
This concludes the proof. □
Note that if privacy was not a constraint, then and the interference from undesired messages would be non-existent. However, when the privacy constraint is present, characterizes the number of bits that will be downloaded and used as side information to preserve privacy from the databases in a given scheme.
Lemma 2 (Induction Lemma)
. For all , the mutual information term in Lemma 1 can be inductively lower bounded as Proof. We start with the left-hand side of (
42),
Now, for the first term in (45), we have
Note that (58) follows from a similar argument in Lemma 1 starting at (37). Next, for the second term in (45), we have
Combining the above results concludes the proof. □
We now apply the result of Lemma 2 recursively on that of Lemma 1 to get the general lower bound through the following series of inequalities:
Next, since the bound in (66) is valid for arbitrary
k, it is still valid for
k corresponding to the maximum possible lower bound, i.e., (66) gives
K intersecting line segments, therefore, the download cost
is lower bounded by their maximum value
Since (
67) lower bounds the download cost
for
any cache-aided private updating with unknown prefetching scheme, it also lower bounds the download cost of the
optimal private updating scheme
. Finally, since
is an integer, we take the ceiling of (
67) to get (
20).
This concludes the converse proof.
5. Proof of Theorem 2: Achievability for Very Low and Very High Caching Ratios
Our achievability scheme makes use of the correlation between
and
through the knowledge of their maximum Hamming distance
f in order to reduce the download cost. This approach is related to the problem tackled in [
32] (without privacy constraints), in which a source is compressed given that it is correlated with some side information that is available only at the decoder. The retrieving user represents the decoder in our case, with side information
. By the Slepian–Wolf coding theorem [
36], one can noiselessly compress the source
at the rate of
. The
compressed source is treated as a
new message to be downloaded using a PIR scheme, as opposed to downloading the whole message
. Such a scheme, however, has a message length constraint (unlike most of the PIR works in the literature). For that reason, we leverage tools from the PIR scheme with an arbitrary message length in [
34], and extend them to work in the caching setting at hand, to accomplish our task.
While our achievability schemes make use of the local cache
Z, we will first give some motivating examples without the user having knowledge of
Z, which represents the case
tackled in our preliminary work [
35].
5.1. Motivating Examples Without Caching
5.1.1. , , , , and
In this example, we have
, and
(from (
1)). Setting
in (
22), we need to show that
bits is achievable. We first start by constructing a
linear block code, which is in this case a repetition code with generator matrix
and parity check matrix
given by
Note that such code is capable of correcting at most
error. The syndromes associated with this code are
. Observe that the length of
is exactly
.
Instead of requesting
, the user retrieves the index of the coset in which
resides in the code’s standard array. That is, its corresponding syndrome
The user then compares
to all the words in that coset, and decodes
as the one closest in Hamming distance. This is guaranteed to yield the unique correct message [
32]. Therefore, the syndrome
efficiently represents the flipped bits’ indices
, and one is able to reduce the effective message length from
to
by dealing with the syndrome
instead of
.
Let
, and
. The syndromes (the new messages) are given by
Assume
. Since
, we can apply a
non-symmetric PIR scheme [
34] to decode
. This scheme is shown in
Table 2, and has a download cost of
bits, which is optimal in this case since it meets the converse bound.
The repetition code used in this example is a perfect code. While this makes an integer, and meets the converse bound, perfect codes are scarce. In the next example, we show how the proposed scheme performs with non-perfect codes.
5.1.2. , , , , and
In this example, we have
, and
. We show that
bits is achievable. As in the previous example, we start by constructing a
linear block code. Differently though, this is not a repetition code, and is characterized by
The syndromes
have length
. Specifically,
Since
, we follow the methodology in [
34]; we privately download
bits (
and
) using the non-symmetric PIR scheme in the previous example, and then privately download the remaining 1 bit (
) using the scheme in [
37]. The technique in [
37] in this case is such that the user requests random linear combinations of
from database 1 using a random binary vector
h, and the same from database 2 yet with
, where
is the
ith standard basis vector. The full PIR scheme is shown in
Table 3, and it has a download cost of
bits, which is 1 bit away from the converse bound since the code used is non-perfect.
5.2. The General Scheme with Caching
For general
L,
N,
K, and
f, we construct an
linear block code. From the Gilbert–Varshamov bound [
33], we know that such a code exists if
In addition, such a code must satisfy the Hamming bound [
33]:
By the definition of
in (9), both (
75) and (
76) are satisfied, and so the code exists and is able to correct
f bit flips.
Next, we map each message to its corresponding syndrome of the constructed code, which is of length
. The user then retrieves the syndrome
according to a PIR scheme with
N databases,
K messages, and
message length. For the case
, by ([
34], Theorem 1), a download cost of
is achievable in this case. Finally, correctness is guaranteed since querying for the syndrome
allows the user to decode
as the unique word in the syndrome’s coset with the least Hamming distance from
[
32]. This shows that (
22) holds specifically when
.
For the case when
, the user will have access to cached linear combinations of
for all
. These cached linear combinations are given by
, where
is a matrix of dimension
. For the purposes of our cache-aided achievability, we let
where
is the parity check matrix of the code.
This means that during the prefetching phase, bits from our desired syndrome are being cached, and what is left to download is the remaining
bits.
To this end, we develop some novel schemes for cache-aided PIR with an arbitrary message length that utilize the results from [
29]. In particular, for all
, we define the message length of a cache-aided PIR scheme from [
29] with caching ratio
as
and the normalized download cost of such a scheme as
For very low caching ratio
r, we recall from [
29] that the optimal normalized download cost of a cache-aided PIR scheme is
and that for very high caching ratio
r (in the context of this work), the optimal normalized download cost of a cache-aided PIR scheme is
With these tools in hand, in the remainder of this section, we describe our achievable schemes for very low and very high caching ratios for cache-aided PIR with arbitrary message length, and show that they achieve the download costs in Theorem 2.
5.3. Very Low Caching Ratio: Proof of (22)
What follows is a cache-aided achievable scheme for retrieving an arbitrary
L bits for very low caching ratios (
). We first use an optimal cache-aided PIR scheme with message size
. Within the desired
L bits (including the cached bits), we view each
bits as a group, and proceed until the number of desired bits remaining is strictly less than
. To this end, we have
where
and
. If
, then the retrieval is completed. If not, then for the
bits that remain, we use an optimal asymmetric PIR scheme with message size
(without caching). Within the remaining
desired bits, we view each
bits as a group, and proceed until the number of desired bits remaining is strictly less than
. To this end, we have
where
and
. If
, then the retrieval is completed. If not, then for the
bits that remain, we use the scheme in [
37] with
N databases and message size
. Within the remaining
bits, we view each
bits as a group, and proceed until the number of desired bits remaining is strictly less than
. To this end, we have
where
and
. If
, then the retrieval is completed. If
bits still remain, we use the scheme in [
37] with
databases and message size
. Therefore, the message size and the achievable download cost are
We next show that the achievable download cost in (86) satisfies
. To this end, we have the following lemma.
Lemma 3. For two very low caching ratios and with , we havewhere . Proof. We begin from the left-hand side of (
87) and use (
80) to write
Defining
concludes the proof. □
Now towards proving
, it suffices to show that
for two cases. For the first case, let
. We wish to show that
First, we group the terms in (
92); we need to show that
Focusing on the left-hand side of (
93), we use Lemma 3 to simplify the expression, while noting that
, as follows:
Note that
is the number of cached bits, and that
is the number of times a cache-aided PIR scheme is used. For very low caching ratios, these quantities are equal, and so we have
Now, substituting (98) back into (93), we now need to show
If
, then
, and so (
99) clearly follows. For the case when
, plugging in
to the right-hand side of (
99) gives
We wish to find a lower bound for (101). To this end, we want to maximize
and minimize
. We know that
, but this also means that
from (
84). Plugging these values into (101) gives
and so (
99) holds for
.
For the second case, let
. We wish to show that
First, we group the terms in (
104); we need to show that
By (
98), we substitute the left-hand side of (
105) so that we have
Since
, we have
, and so (
106) holds by (103). This completes the proof that
for very low caching ratios.
Since the above PIR scheme is constructed as a concatenation of several PIR schemes that are both correct and private, by ([
34], Theorem 4), the above scheme is both correct and private. To conclude our proof, we define a normalized version of
r:
as the
effective caching ratio. Clearly, by (
13),
. Now, since the above PIR scheme retrieves
L bits (including cached bits) at a download cost of
, this scheme can be used to retrieve
bits (including some
cached bits) at a download cost of
. Expanding this statement gives
which is precisely (
22).
5.4. Very High Caching Ratio: Proof of (23)
What follows is a cache-aided achievable scheme for retrieving an arbitrary L bits, for very high caching ratios (). In this scheme, we only use an optimal cache-aided PIR scheme with message size . We note that in this scheme, for each bit we have cached, we can download 1 bit from each of the N databases to get a total of N unknown bits at a download cost of N bits.
Within the desired
L bits (including cached bits), we view each
bits as a group, and proceed until the number of desired and
unknown bits remaining is strictly less than
N. To this end, we have
where
, and
. We define
as the number of
unused cached bits thus far in our scheme. If we have
, then we have all of our desired information, and we are done. Otherwise, we still have
bits left to download. Since the caching ratio
r is very high, we have
, and so we can use this bit, as noted above, to download 1 bit from
databases each to obtain the remaining
unknown bits at a download cost of
bits. Therefore, the message size and the achievable download cost are
We next show that the achievable download cost in (113) satisfies
. To this end, it it suffices to show that
, or more specifically, that
First, we rearrange the terms in (
114) as
and then we reduce the left-hand side of (
115) as follows
Thus, (
114) holds, and so this completes the proof that
for very high caching ratios.
Again, since the above PIR scheme is constructed as a concatenation of several PIR schemes that are both correct and private, by ([
34], Theorem 4), the above scheme is both correct and private. Furthermore, since the above PIR scheme retrieves
L bits (including cached bits) at a download cost of
, this scheme can be used to retrieve
bits (including some
cached bits) at a download cost of
. Expanding this statement gives
which is precisely (
23).
6. Proof of Theorem 3: Achievability for with Mid-Range Caching Ratios
What follows is a cache-aided achievable scheme for retrieving an arbitrary L bits, for mid-range caching ratios given fixed setting . This scheme leverages cache-aided PIR schemes for very high and very low caching ratios but within an asymmetric PIR setting instead.
First, consider the asymmetric cache-aided PIR scheme with
and
in
Table 4. This scheme does not utilize all of the databases, nor does it utilize the cache in full. This scheme downloads one useful bit privately at a cost of 1 bit, and it is an asymmetric version of the cache-aided PIR scheme for very high caching ratios. This scheme can be repeated up to five more times to get up to five more useful bits, and each additional bit is obtained privately.
Next, consider the asymmetric cache-aided PIR scheme with
and
in
Table 5. While this scheme does utilize all of the databases, it has asymmetric traffic between the databases, and it also does not utilize the cache in full. This scheme downloads
useful bits at a cost of
, and it is an asymmetric version of the cache-aided PIR scheme for very low caching ratios. Once again, this scheme can be repeated up to five more times to get up to
more useful bits, and each additional set of
bits is obtained privately.
In these examples, we see that each scheme can be used a total of times. Now, note that these two schemes can be used in conjunction with one another, and that rather than repeating the same scheme over and over again, we can just use them interchangeably to suit our needs.
Consider a cache-aided PIR example where
,
, and
. Note that
r is now mid-range. We can use a combination of the asymmetric very high caching ratio scheme and very low caching ratio scheme to download the remaining 12 useful bits as shown in
Table 6. First, we use the asymmetric very high caching ratio scheme four times to obtain four useful bits at a cost of 4 bits total. Then, we use the the asymmetric very low caching ratio scheme two times to download the remaining
useful bits at a cost of
, and so the total download cost is 14.
It is also worth noting that in the same scenario, but with
and
, we can use almost the almost the same query structure as in
Table 6. The only difference is that we
truncate the given scheme by not making the query for
. In this particular case, this truncation strategy can be performed again to obtain an
,
query structure.
In general, one can use a combination of very high and very low caching ratio schemes, and then if the remaining number of useful bits left to download is some ℓ with , use a truncated very low caching ratio scheme. Otherwise, just a normal very high or very low caching ratio scheme can be used.
In order to determine the number of times these very high and very low schemes are used, along with the number of bits that are downloaded via the truncation strategy, we define three terms as follows:
The
term is the number of times a very high caching ratio scheme is used, while
is the number of times a very low caching ratio scheme is used. The
term is the number of bits obtained from the truncation strategy when it is used. According to these terms, it follows that the message size and the achievable download cost are
Lastly, for mid-range caching ratios with
, we recall from [
29] that the optimal normalized download cost of a cache-aided PIR scheme is
We next show that the achievable download cost in (126) satisfies
. To this end, it suffices to show that
for two cases. For the first case, let
. We wish to show that
Reducing the left-hand side of (
128), we have
Substituting (134) into (
128), we need to show that
which clearly holds by (123). It follows that (
128) holds when
. To show that this is also the case when
, we use a lemma.
Lemma 4. In the setting, for any caching ratio r with , we have Now, for the second case, let
. We wish to show that
By (134), we substitute the left-hand side of (
137) so that we have
which holds by Lemma 4. Thus, this completes the proof that
for mid-range caching ratios in the
setting.
Since the above PIR scheme is constructed as a concatenation of several PIR schemes that are both correct and private (by [
34], Theorem 4), the above scheme is both correct and private. Furthermore, since the above PIR scheme retrieves
L bits (including cached bits) at a download cost of
, this scheme can be used to retrieve
bits (including some
cached bits) at a download cost of
. Expanding this statement gives
which is precisely (
26).
7. Discussion
As seen in Corollary 1, for very low and very high effective caching ratios, we obtain full characterizations of the optimal download cost
for fixed
and
f. What remains is to perform the same for an effective caching ratio
, defined in (
107), with
, i.e., such caching ratios that are
mid-range. With Theorem 3 and Corollary 2, this has been performed for the
case. However, this is still an open question for when
K is arbitrary.
Our approach for our achievability when
has been to describe an arbitrary message length PIR scheme for a setting with unknown prefetching, and then show that the download cost
D of such a scheme satisfies
. This approach mirrors what was performed in [
34] for the classical PIR setting.
From [
29], for
and
with
, we define
We know that
for very low and very high caching ratio
r, and this is used in our approach for Theorem 2. This is likewise the case for mid-range caching ratios
r when
in Theorem 3. For when
, as is the case for most mid-range caching ratios, we can still attempt to describe a scheme, and show that the download cost
to obtain some useful result.
Our goal in this section is to present a motivating example that shows what these results may look like. Consider the following example setting:
,
, and
. We have
and
, and so a caching ratio is mid-range in this setting if
. However, for our purposes, we will focus on the subset of mid-range caching ratios
r satisfying
. With this in mind, let us consider some scenarios with a caching ratio
starting with the case when the number of cached bits is 3, and so the total message length is 21. Using the methods found in this work, we have a scheme satisfying
given in
Table 7.
Using these same methods, if there are two cached bits with a total message length of 14, then we also have a scheme satisfying
using a subset of the queries in
Table 7. However, for the case when there is only one cached bit with a total message length of seven, we have no scheme satisfying
, not with using the methods in this work at least. It is worth noting that for some other mid-range caching ratios with this setting, the scheme from [
37] can be used to produce some satisfactory results (
for example) but not for the case when
in this setting. This is discussed in more detail in [
38].
The question remains: why does this pattern break, and why it is difficult to find an alternative query structure? The answer we have come to is that it has not to do with with the value of the r, but with the number number of cached bits . More specifically, there may be some additional limitation on how low of a download cost can be achieved with a cache-aided arbitrary message length PIR scheme when is relatively low (or in this case, when ). Investigating such limitations is left to future works.





{kind=link}
{kind=link}