2.1. Basic Probabilistic Framework
To integrate different approaches to causation within a unified formalism, we adopt a general probabilistic framework. In order to simplify our framework, and to compare and contrast measures, our formalism is applied in self-contained Markov chains, where we can always assume that the previous global state (at time t) caused the successor global state (at ). Our purpose is then in quantifying how “strong” or “powerful” or “informative” the causal relationship reflected by this state transition is.
Therefore, let be a finite set representing all possible system states in such a Markov chain. We define two random variables over this space: C, denoting causes (typically the system state at time t); and E, denoting effects (e.g., the system state at time ). These are related through a transition probability in a Markov process, which describes the probability of transitioning to state e at time given that the system was in state c at time t.
Throughout this work, we interpret
as an interventional probability—that is, the probability of
e occurring when
c is imposed via intervention. In the formalism of Pearl, this corresponds to
[
1]. The use of the do operator signifies that
c is not merely observed but enacted, independent of its prior history. Under this assumption, the system’s dynamics are fully specified by a transition probability matrix (TPM), which encodes
for all pairs
. This perspective is shared by other causal frameworks [
8,
36,
37], where the TPM is taken as the basic object encoding the causal model.
To compute the causal measures, one must also specify a distribution over the possible causes
C, denoted
, which we refer to as the
intervention distribution [
22]. This distribution represents the space of interventions used to evaluate counterfactuals—e.g., the probability of obtaining an effect
e if a cause
c had not occurred. In
Section 2.4, we examine different choices for
, but for now we assume it is fixed. All quantities that follow, such as
and
, are to be understood relative to this distribution.
Given the transition probability
and a choice of
, we can define the marginal (or “unconditioned”) probability of an effect
e:
where we write
instead of
to emphasize its dependence on the intervention distribution. For readability, we omit the “do” notation hereafter, with the understanding that all conditionals
are interventional.
To evaluate counterfactuals—such as the probability of
e given that
c did not occur—we define a renormalized distribution over the remaining causes
:
This allows us to compute the counterfactual probability:
This formal setup provides the framework for defining the causal primitives—sufficiency, necessity and others—that we introduce in the following section.
2.2. Causal Primitives
2.2.1. Sufficiency and Necessity
Here we propose causation should be viewed not as an irreducible single relation between a cause and an effect but rather as having two dimensions: sufficiency and necessity [
1,
38].
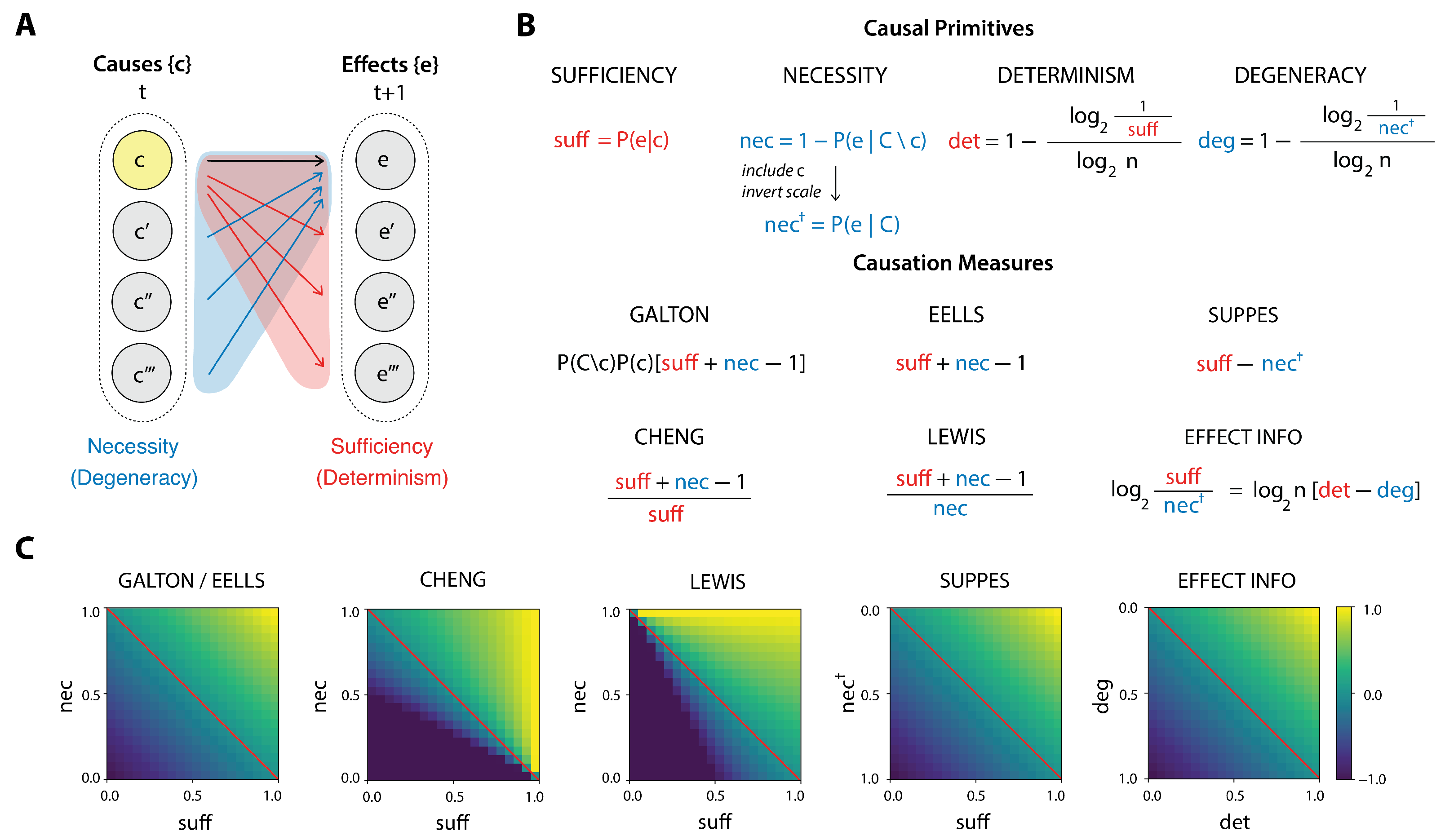
For any cause
c, we can always ask, on one hand, how sufficient
c is for the production of an effect
e. A sufficient relation means that whenever
c occurs,
e also follows (
Figure 1A, red region). Separately, we can also ask how necessary
c is to bring about
e, that is, whether there are different ways than through
c to produce
e (
Figure 1A, blue region). Yet these properties are orthogonal: a cause
c may be sufficient to produce
e, and yet there may be other ways to produce
e. Similarly,
c may only sometimes produce
e, but is the only way to produce it. Thus, causation occurs when sufficiency and necessity between a cause
c and an effect
e are jointly obtained. If this conception is correct, causal measures should then aim to quantify the degree of the joint presence of this two aspects.
As we will show, popular measures of causation indeed almost always put these two causal primitives in some sort of relationship (e.g., a difference or a ratio). This ensures such measures are mathematically quite similar, indeed, sometimes unknowingly identical. This consilience across measures leads us to refer to sufficiency and necessity as causal primitives of causation.
Let us now define the primitives formally. To begin, we define the sufficiency of the cause
c as the probability:
This increases as c is more capable of bringing about e, reaching 1 when c is fully sufficient to produce e. While in classical logic, sufficiency (and necessity) are binary, absolute relations, here we have graded degrees of sufficiency (e.g., a cause might bring about its effect only some of the time), reflecting the probabilistic treatment of causation.
Comparably, the necessity of the cause for the effect we define as the probability:
This gives the inverse probability of e occuring given that something other than c occurred. Necessity is 1 when c is absolutely necessary for e. In such cases there is no other candidate cause but c that can produce e. Note that unlike sufficiency, some definition of counterfactuals needs to be made explicit for the calculation of necessity (more on this in later sections, where possible counterfactuals are represented as viable interventions).
2.2.2. Determinism and Degeneracy
The two causal primitives of sufficiency and necessity each have an extension from the probabilistic to the information-theoretic setting; namely, the determinism and degeneracy coefficients [
8]. These extensions allow for quantifying causation in terms of how uncertainty and noise constrains the state space of causes and effects.
We can define determinism as the opposite of noise (or randomness); that is, the certainty of causal relationships. Specifically, it is based on the entropy of the probability distribution of the effects given the occurrence of a cause:
This entropy term is zero if a cause has a single deterministic effect (with ), and the entropy is maximal, i.e., , if a cause has a totally random effect (i.e., its effects are uniformly distributed as ). We therefore define the determinism of a cause c to be . Note that determinism is based on sufficiency, with as the central term.
To see the difference between sufficiency and determinism, consider a system of four states , wherein state a transitions to the other states b, c, or d, and also back to itself, a, with probability each. The sufficiency of each individual transition from a (e.g., to b) is , indicating the probability that a produces that specific effect. However, the determinism of a is zero, because the entire distribution is uniform, yielding maximal entropy. In other words, knowing that the system was in state a tells us nothing about what state will follow—it is indistinguishable from random selection.
This illustrates that sufficiency captures the strength of a specific transition, while determinism reflects how concentrated or selective the entire effect distribution is for a given cause (although the contribution of each transition to the determinism term can be calculated). And unlike sufficiency, the determinism term is influenced by the number of considered possibilities (i.e., size of the state space). Generally, we normalize the term to create a determinism coefficient that ranges, like sufficiency, between 0 (fully random) and 1 (fully deterministic), for a given cause:
And with this in hand, we can define a determinism coefficient for individual transitions as
as well as a system-level determinism coefficient by averaging across all possible causes:
In turn, degeneracy is the information-theoretic extension of necessity. Essentially, while determinism captures how targeted effects are to their causes, degeneracy captures how targeted causes are to their effects (see
Figure 1A). It is also based on an entropy term:
Here, instead of (sufficiency), the central term is . To see the connection of this term to necessity (), we first note that degeneracy is inversely related to necessity. Second, while necessity asks whether e depends uniquely on a particular c, degeneracy reflects whether many causes tend to converge on the same effect. The quantity thus represents a “softened” or average form of , accounting for all causes. We are considering whether e can be produced not just in the absence of c, but all the ways, including via c itself, that e can occur (we write to emphasize its relationship to ).
Proceeding analogously as before, we can define the degeneracy coefficient of an individual effect e as
This quantity is maximal (equal to 1) when P(e ∣ C) = 1, and minimal (equal to 0) when
, i.e., when the effect is uniformly probable across causes. Using this, the system-level degeneracy can be written as the expectation over effects:
Degeneracy is zero when no effect has a greater probability than any other (assuming an equal probability across the full set of causes). Degeneracy is high if certain effects are “favored”, in that more causes lead to them (and therefore those causes are less necessary).
2.3. Measures of Causation
In the following section, we show how the basic causal primitives of sufficiency and necessity (or their info-theoretic alternatives, i.e., determinism and necessity) underlie the independent popular measures of causation we have examined. For the probabilistic measures we build on the compendium made by Fitelson and Hitchcock [
39].
2.3.1. Humean Constant Conjunction
One of the earliest and most influential approaches to a modern view of causation was David Hume’s regularity account. Hume famously defined a cause as “an object, followed by another, and where all the objects, similar to the first, are followed by objects similar to the second” [
40]. In other words, causation stems from patterns of succession between events [
41].
Overall, the “constant conjunction” of an event
c followed by an event
e, would lead us to
expect e once observing
c, and therefore to infer
c to be the cause of
e. There are a number of modern formalisms of this idea. Here we follow Judea Pearl, who interprets Hume’s notion of “regularity of succession” as amounting to what we today call correlation between events [
1]. This can be formalized as the observed statistical covariance between a candidate cause
c and effect
e:
If we substitute the indicator function
(and
), which is 1 if
c (respectively,
e) occurs and 0 otherwise, in the equation above we obtain
where we have used the fact that
) can be decomposed into two weighted sums, i.e., over
c and over
. Following others’ nomenclature [
2], we refer to the observed statistical covariance that captures Humean conjunction as the “Galton measure” of causal strength, since it resembles the formalism for heredity of traits in biology. This expression can be rewritten to show its dependence on the causal primitives:
While this does not imply a strict reduction to the primitives—since it includes a specific weighting by —it illustrates that both sufficiency and necessity jointly influence the Galton measure. It is worth noting that, even though it is considered one of the simplest (and incomplete) notions of causation, the regularity account of causation can be stated in terms of the underlying causal primitives.
2.3.2. Eells’s Measure of Causation as Probability Raising
Ellery Eells proposed that a condition for
c to be a cause of
e is that the probability of
e in the presence of
c must be higher than its probability in its absence:
[
42]. This can be formalized in a measure of causal strength as the difference between the two quantities:
When
, the cause is traditionally said to be a negative or preventive cause [
41], or in another interpretation, such negative values should not be considered a cause at all [
3].
2.3.3. Suppes’s Measure of Causation as Probability Raising
Another notion of causation as probability raising was defined by Patrick Suppes, a philosopher and scientist [
43]. Translated into our formalism, his measure is
The difference between the
and
measures involves a shift from measuring how causally
necessary c is for
e—whether it can be produced by other causes than
c—to assessing how
degenerate is the space of ways to bring
e about. Both are valid measures, and in fact turn out to be equivalent in some contexts [
39].
2.3.4. Cheng’s Causal Attribution
Patricia Cheng has proposed a popular psychological model of causal attribution, where reasoners go beyond assessing pure covariation between events to estimate the “causal power” of a candidate cause producing (or preventing) an effect [
44]. In her account, the causal power of
c to produce
e is given by
Cheng writes: “The goal of these explanations of and is to yield an estimate of the (generative or preventive) power of c”. While originally proposed as a way to estimate causes from data based off of observables, it is worth noting that, in our application of this measure, we have access to the real probabilities given by the transition probability matrix , and the measure therefore yields a true assessment of causal strength, not an estimation.
2.3.5. Good’s Measure of Causation
I. J. Good gave not only the earliest explicit measure of causal power (according to [
45]), but sought to derive a unique quantitative measure starting from general assumptions: “The main result is to show that, starting from very reasonable desiderata, there is a unique meaning, up to a continuous increasing transformation, that can be attached to ‘the tendency of one event to cause another one’” [
46]. Good’s measure corresponds to the Bayesian ‘weight of evidence’ against
c if
e does not occur:
2.3.6. Lewis’s Counterfactual Theory of Causation
Another substantive and influential account of causation based on counterfactuals was given by philosopher David Lewis [
47]. In its basic form, Lewis’s account states that if events
c and
e both occur, then
c is a cause of
e if, had
c not occurred,
e would not have occurred. Lewis also extended his theory for “chancy worlds”, where
e can follow from
c probabilistically [
48].
Following [
2], who interpret Lewis’s own remarks, we formalize his conception of causal strength as the ratio
Lewis’s ratio-based formulation expresses how much more likely the effect
e is in the presence of
c than in its absence. This definition is also known as “relative risk”: “it is the risk of experiencing
e in the presence of
c, relative to the risk of
e in the absence of
c” [
2]. This measure can be normalized to obtain a measure ranging from −1 to 1 using the mapping
as
Again we see that Lewis’s basic notion, once properly formalized, is based on the comparison of a small set of causal primitives. Also note that these definitions do not rely on a specification of a particular possible world. In other work, Lewis specifies that the counterfactual not-
c is taken to be the closest possible world where
c did not occur. That notion, which specifies a rationale for how to calculate the counterfactual, is formalized in
Section 2.3.8.
2.3.7. Judea Pearl’s Measures of Causation
If our claim for consilience in the study of causation is true, then authors should regularly rediscover previous measures. Indeed, this is precisely what occurs. Consider Judea Pearl, who in his work on causation has defined the previous measures , , and (in some of these terms apparently knowingly, in others not).
Within his structural model semantics framework [
1], he defines the “probability of necessity” as the counterfactual probability that
e would not have occurred in the absence of
c, given that
c and
e did in fact occur, which in his notation is written as
(where the bar stands for the complement operator, i.e.,
). Meanwhile, he defines the “probability of sufficiency” as the capacity of
c to produce
e and it is defined as the probability that
e would have occurred in the presence of
c, given that
c and
e did not occur:
.
Finally, both aspects are combined to measure both the sufficiency and the necessity of c to produce e as , such that the following relation holds: .
In general, these quantities require a structural model to be evaluated. However, in special cases—specifically under assumptions such as exogeneity and monotonicity—Pearl shows that simplified expressions for them can be derived:
In this setting, these measures reduce, respectively, to
,
, and
, as noted by [
2]. That is, within his broad framework, Pearl independently rediscovered previous measures.
Finally, to avoid terminological overlap, we reserve the terms “sufficiency” and “necessity” for their simpler probabilistic definitions (i.e., and ), and refer to Pearl’s measures by name or by their original references to preserve their distinction and provenance.
Overall, this consilience should increase our confidence that measures based on the combinations of causal primitives are good candidates for assessing causation.
2.3.8. Closest-Possible-World Causation
As stated previously, David Lewis traditionally gives a counterfactual theory of causation, wherein the counterfactual is specified as the closest possible world where
c did not occur [
47]. In order to formalize this idea, we need to add further structure beyond solely probability transitions. That is, such a measurement requires a notion of distance between possible states of affairs (or “worlds”). One simple way to achieve this is to use binary labels of states to induce a metric using the Hamming distance [
49], which is the number of bit flips needed to change one binary string into the other. In this way we induce a metric in a state space so that we can define Lewis’ notion of a closest possible world:
where
x and
y are two state labels with
N binary digits (e.g.,
and
,
, such that
). With such a distance notion specified, the counterfactual taken as the “closest possible world” where
c did not occur is given by
And with this in hand, we can define another measure based closely on Lewis’s account of causation as reasoned about from a counterfactual of the closest possible world:
2.3.9. Bit-Flip Measures
Another measure that relies on a notion of distance between states is the idea of measuring the amount of difference created by a minimal change in the system. For instance, the outcome of flipping of a bit from some local perturbation. In [
50] such a measure is given as “the average Hamming distance between the perturbed and unperturbed state at time
when a random bit is flipped at time
t”. While originally introduced with an assumption of determinism, here we extend their measure to non-deterministic systems as
where
corresponds to the state where the
bit is flipped (e.g., if
, then
).
2.3.10. Actual Causation and the Effect Information
Recently a framework was put forward [
3] for assessing actual causation on dynamical causal networks, using information theory. According to this framework, a candidate cause must raise the probability of its effect compared to its probability when the cause is not specified (again, we see similarities to previous measures). The central quantity is the
effect information, given by
Note that the effect information is actually just the log of
, again indicating consilience as measures of causation are rediscovered by later authors. It is also the individual transition contribution of the previously defined “effectiveness” given in previous work on causal emergence [
8].
The effect information is thus, on one hand, a bit-measure version of the probabilistic Suppes measure, and on the other, a non-normalized difference between degeneracy and determinism.
2.3.11. Effective Information
Effective information (
) was first introduced by Giulio Tononi and Olaf Sporns as a measure of causal interaction, in which random perturbations of the system are used in order to go beyond statistical dependence [
51]. It was rediscovered without reference to prior usage and called “causal specificity” [
52].
The effective information is simply the expected value of the effect information over all the possible cause–effect relationships of the system:
As a measure of causation, the
captures how effectively (deterministically and uniquely) causes produce effects in the system, and how selectively causes can be identified from effects [
8].
Effective information is an assessment of the causal power of
c to produce
e—as measured by the
effect information—for all transitions between possible causes and possible effects, considering a maximum-entropy intervention distribution on causes (the notion of an intervention distribution is discussed in the next section). More simply, it is the non-normalized difference between the system’s determinism and degeneracy. Indeed, we can normalize the effective information by its maximum value,
, to obtain the
effectiveness of the system:
2.4. Intervention Distributions
As we have seen, measures of causation, which can be interpreted as “strength” or “influence” or “informativeness” or “power” or “work” (depending on the measure) are based on a combination of causal primitives. However, both the calculations of the measures themselves, as well as the causal primitives, involve further background assumptions in order to apply them.
Luckily, there are tools to formalize the issue. Previous research has introduced a formalism capable of dealing with this issue in the form of an
intervention distribution [
22]. An intervention distribution is a probability distribution over possible interventions (which may be entirely hypothetical) that a modeler or experimenter considers. Effectively, rather than considering a single
operator [
1], it is a probability distribution over some applied set of them. The intervention distribution fixes
, the probability of causes, which is in fact necessary to calculate all the proposed causal measures. This can also be conceptualized as the space of available counterfactuals, where counterfactuals are equivalent to hypothetical interventions.
To give an intuition pump for how we apply intervention distributions and how those also represent counterfactuals in our framework: consider a simple causal model that details how a light switch controls a light bulb. The model consists of two binary variables, each with two states, {UP, DOWN} and {ON, OFF}, respectively. Suppose the system is currently in the state where the switch is UP and the light is ON. To assess the necessity of switch = UP for light = ON, we apply an intervention that sets the switch to DOWN and observe the outcome. If the light bulb continues to be ON when the switch is changed to DOWN, then switch = UP is not necessary for light = ON. Conversely, if the bulb turns OFF, this supports the necessity of switch = UP for the effect. In this case, intervening to set switch = DOWN yields , so the necessity is . This relationship can be encoded in a transition matrix, wherein and . More generally, calculating necessity corresponds to evaluating , where the effect is tested under counterfactual interventions excluding the cause in question.
However, once we move beyond simple binary cases and instead face a system where many distinct counterfactual states are possible, a further question arises: How should these alternative states be weighed relative to the actual one? Are all possible alternative causes equally relevant? Should some be prioritized over others? This is precisely the role of the intervention distribution: it specifies how the counterfactual space is explored and allows us to define quantities like or in a principled way.
We point out that a modeler or experimenter essentially has three choices for specifying an intervention distribution. The first, and most natural, is the
observational distribution. Sometimes also called the “observed distribution”, in the dynamical systems we consider this corresponds to the stationary distribution over system states, obtained as the long-run limit of applying the transition matrix
T (encoded in
) to an initial distribution
:
Intuitively, this is the distribution the system converges to under its own dynamics. Equivalently, it satisfies the fixed-point equation , with . In this case, is entirely determined by the system’s endogenous dynamics.
However, this choice suffers from serious problems—indeed, much has been made of the fact that analyzing causation must explicitly be about what
did not happen, i.e., departures from dynamics, and the observational distribution misses this [
53]. As an example, a dynamical system with point attractors has no causation under this assumption, nor does a cycle of COPY gates which all are in the same state. This is because the gain from mere observation to perturbing or intervening is lost when the intervention distribution equals the observational distribution. Finally, it is worth noting that definable stationary distributions rarely exist in the real world.
To remedy this, measures of causation often implicitly assume the second choice: an unbiased distribution of causes over
, totally separate from the dynamics of the system. In its simplest form, this is described as a
maximum-entropy interventional distribution:
where
. The maximum-entropy distribution has been made explicit in the calculations of, for instance, integrated information theory [
36] or the previously described effective information of
Section 2.3.11 [
51]. There are a number of advantages to this choice, at least when compared to the observational distribution. First, it allows for the appropriate analysis of counterfactuals. Second, it is equivalent to randomization or noise injection, which severs common causes. Third, it is the maximally informative set of interventions (in that maximum entropy has been “injected” into the system).
However, it also has some disadvantages. Using a maximum-entropy intervention distribution faces the difficulty that if is too large, it might be too computationally expensive to compute. More fundamentally, using can lead to absurdity. To give a classic example: you go away and ask a friend to water your plant. They do not, and the plant dies. Counterfactually, if your friend had intervened to water the plant, it would still be alive, and therefore your friend not watering the plant caused its death. However, if the Queen of England had intervened to water the plant, it would also still be alive, and therefore it appears your plant’s death was caused just as much by the Queen of England. That is, , taken literally, involves very distant and unlikely possible states of affairs. However, in cases where the causal model has already been implicitly winnowed to be over events that are considered likely, related, or sensible—such an already defined or constructed or bounded causal model, like a set of connected logic gates, gene regulations, or neuronal connections— allows for a clear application and comparison of measures of causation.
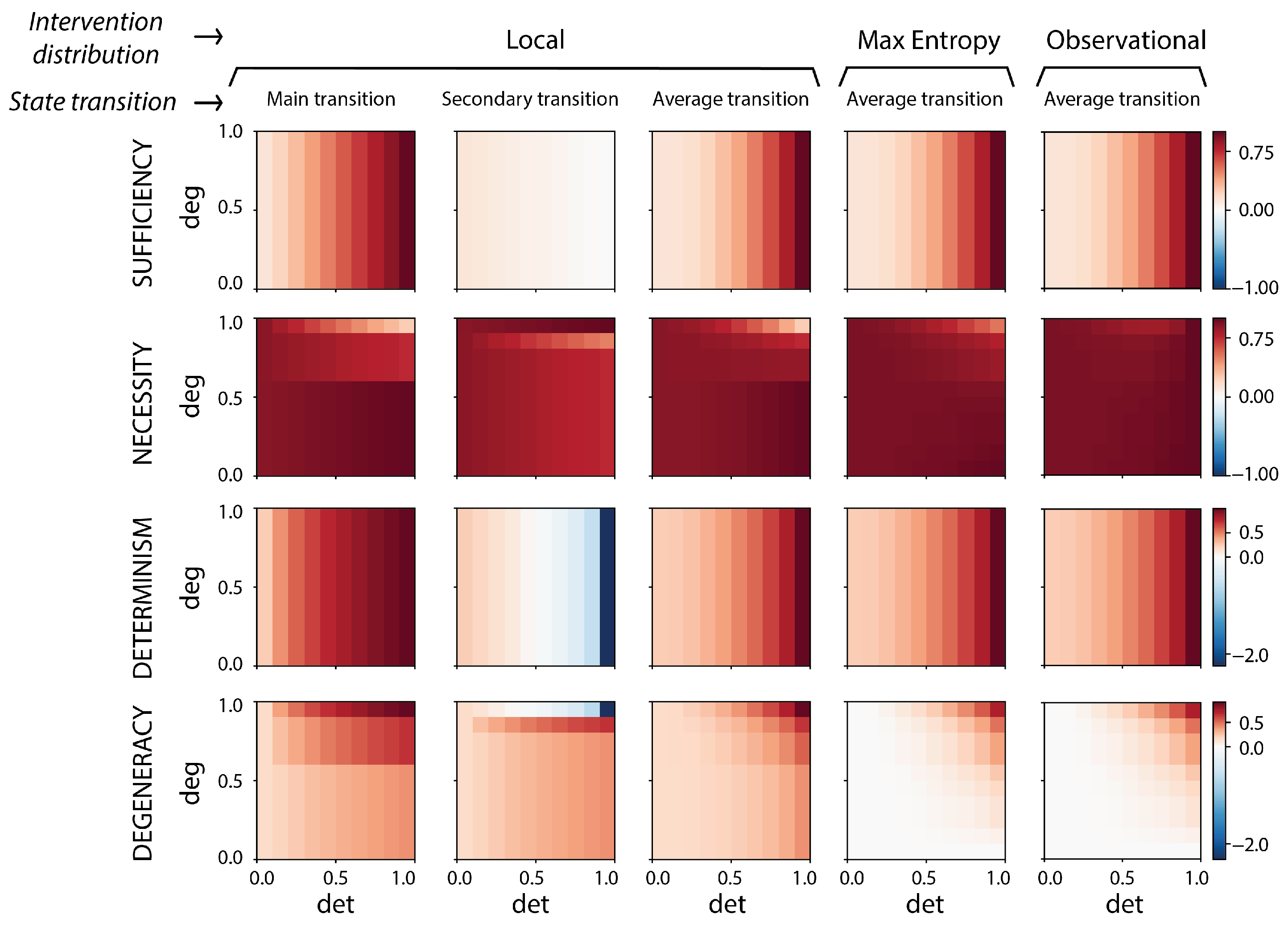
We point out there is a third possible construction of an intervention distribution. This is to take a local sampling of the possible world space (wherein locality is distance in possible worlds, states of affairs, the state space of the system, or even based on some outside non-causal information about the system). There are a number of measures of causation that are based on the idea of a
local intervention distribution. E.g., one of the earliest and most influential is David Lewis’s idea of using the closest possible world as the counterfactual by which to reason about causation (
Section 2.3.8). Other examples that implicitly take a local intervention approach include the bit-flip measure [
50] of
Section 2.3.9, as well as the “causal geometry” extension of effective information in continuous systems [
10]. We formalize the assumptions behind these approaches as representing choosing a local intervention distribution to evaluate counterfactuals, which are then possible states of affairs that are similar (or “close”) to the current state or dynamics of the system, but still range across a different set from the observed distribution.
For example, to calculate Lewis’s measure, we can compute locality using the Hamming distance [
49]. Rather than simply picking a single possible counterfactual
(which in Lewis’s measure would be only the closest possible world from
Section 2.3.8), we can instead create a local intervention distribution which is a local sampling of states of affairs where
c did not occur (i.e., the local set of possible worlds). This is equivalent to considering all states which are a Hamming distance less or equal to
from the actual state:
where
. For example, if we want to locally intervene within a distance
around an actual state
, then
and
, so that the intervention distribution is
over the four states and 0 elsewhere.
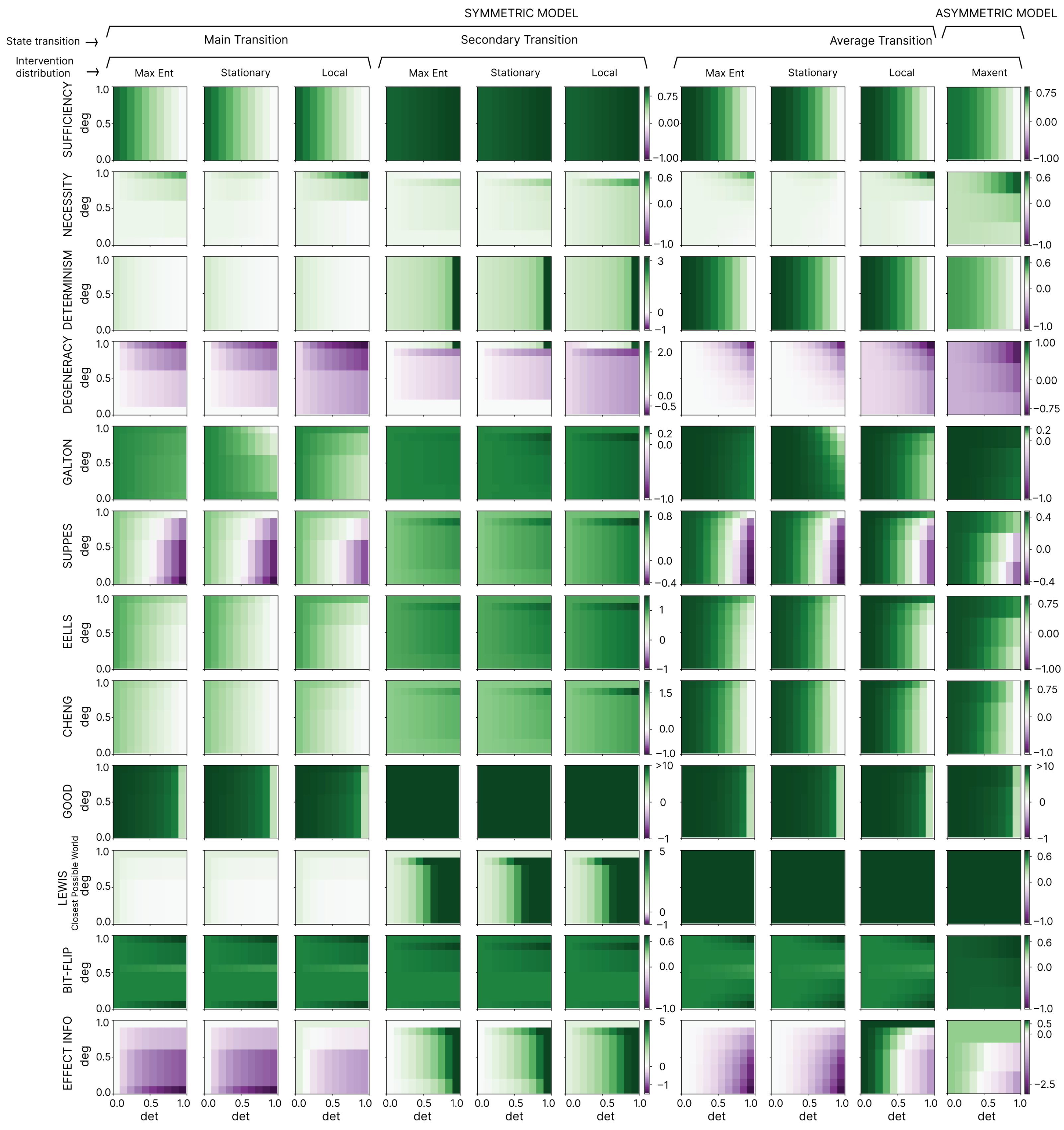
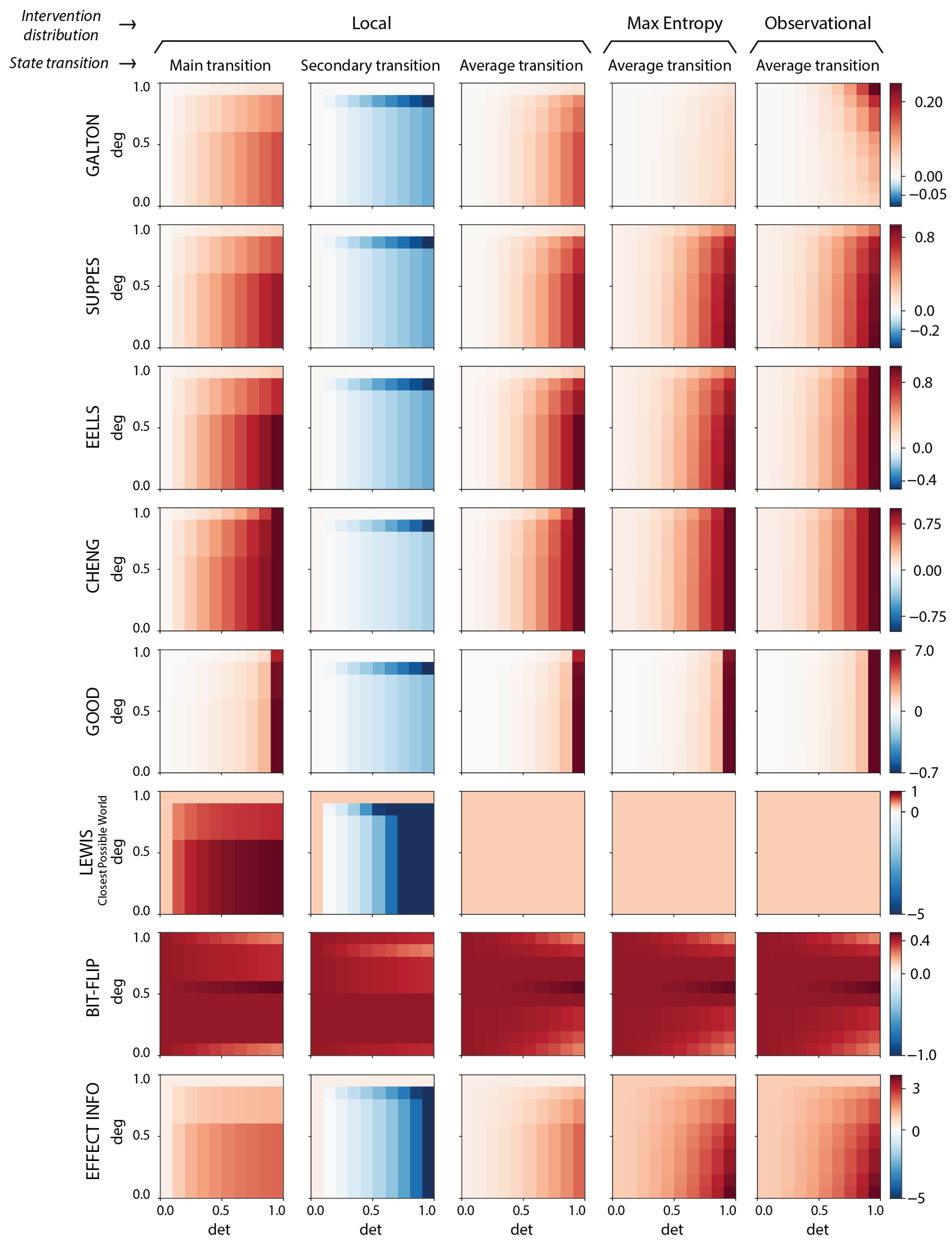
We note that local interventions avoid many of the challenging edge cases of measuring causation (albeit they do not automatically solve the question of “How local is correct?”). Therefore, we use local interventions for our main text and figures to highlight their advantages. But in our full analysis we take an exhaustive approach and consider all three choices of intervention distributions for the dozen measures. Our results reveal that (a) across the three choices of applicability of the measures regarding “What counts as a counterfactual or a viable intervention?”, the measures still behave quite similarly, and also (b), in fact, instances of causal emergence, as we will show, occur across different choices of intervention distributions. In other words, while there is always some subjectivity around assessing causation based on background assumptions or even the chosen measure, subjectivity is not the source of causal emergence.
2.6. Causal Emergence
To identify cases of causal emergence, traditionally a microscale and further set of candidate macroscales must be defined (it should be noted that the theory is scale-relative, in that one can start with a microscale that is not necessarily some fundamental physical microscale). In neuroscience, for instance, the “microscale” may be the scale of individual synapses. A macroscale is some dimensional reduction of the microscale, like coarse-graining (an averaging) [
8] or black-boxing (only including a subset of variables in the macroscale) [
54], or more generally just any summary statistic that recasts the system with less parameters while preserving the dynamics as much as possible [
12,
32]. e.g., in the neurosciences a macroscale may be a local field potential or neuronal population or even entire brain regions. Previous research has laid out clear examples and definitions of macroscales in different system types [
8,
12,
22].
Note that our handling of causal emergence here is simpler than definitions that either search across the set of macroscales [
8], or estimate the results of such a search [
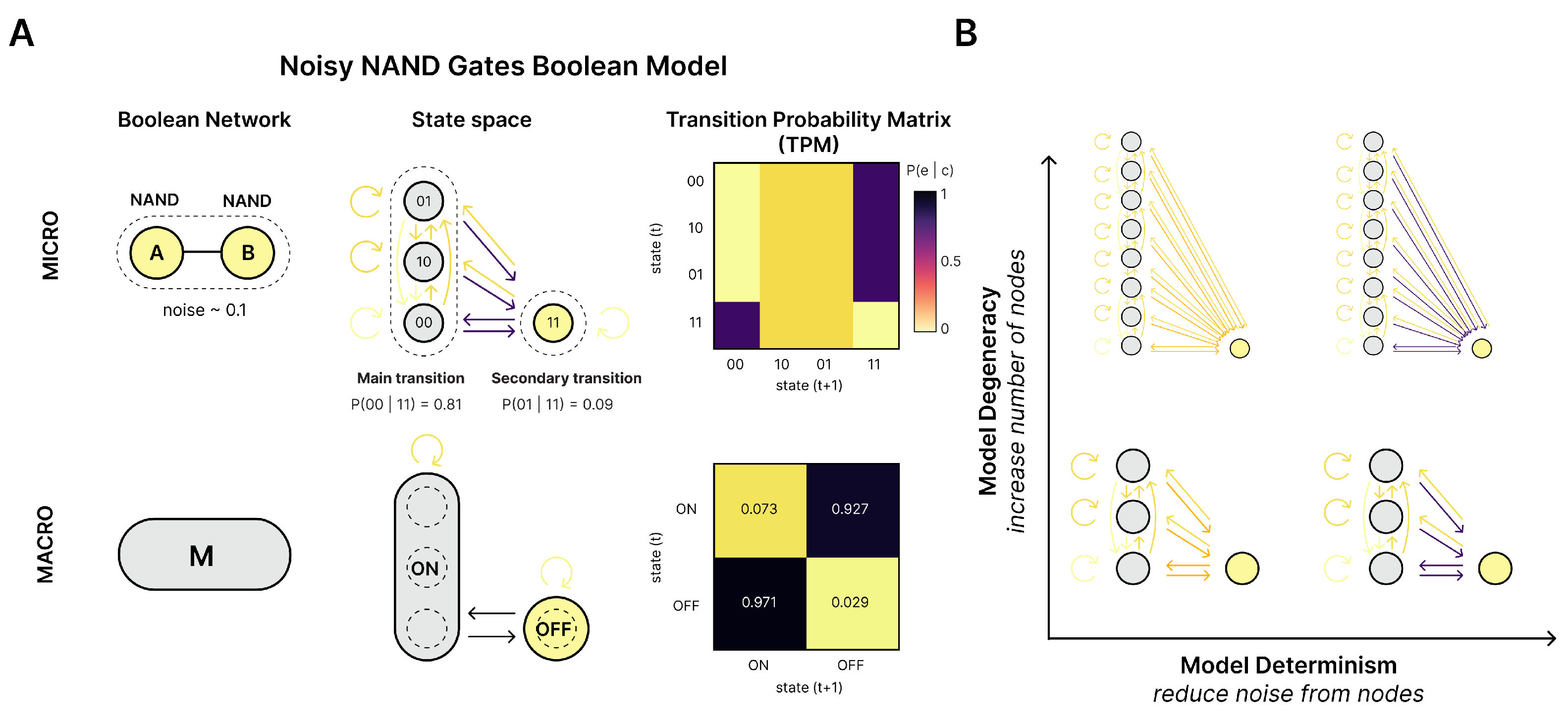
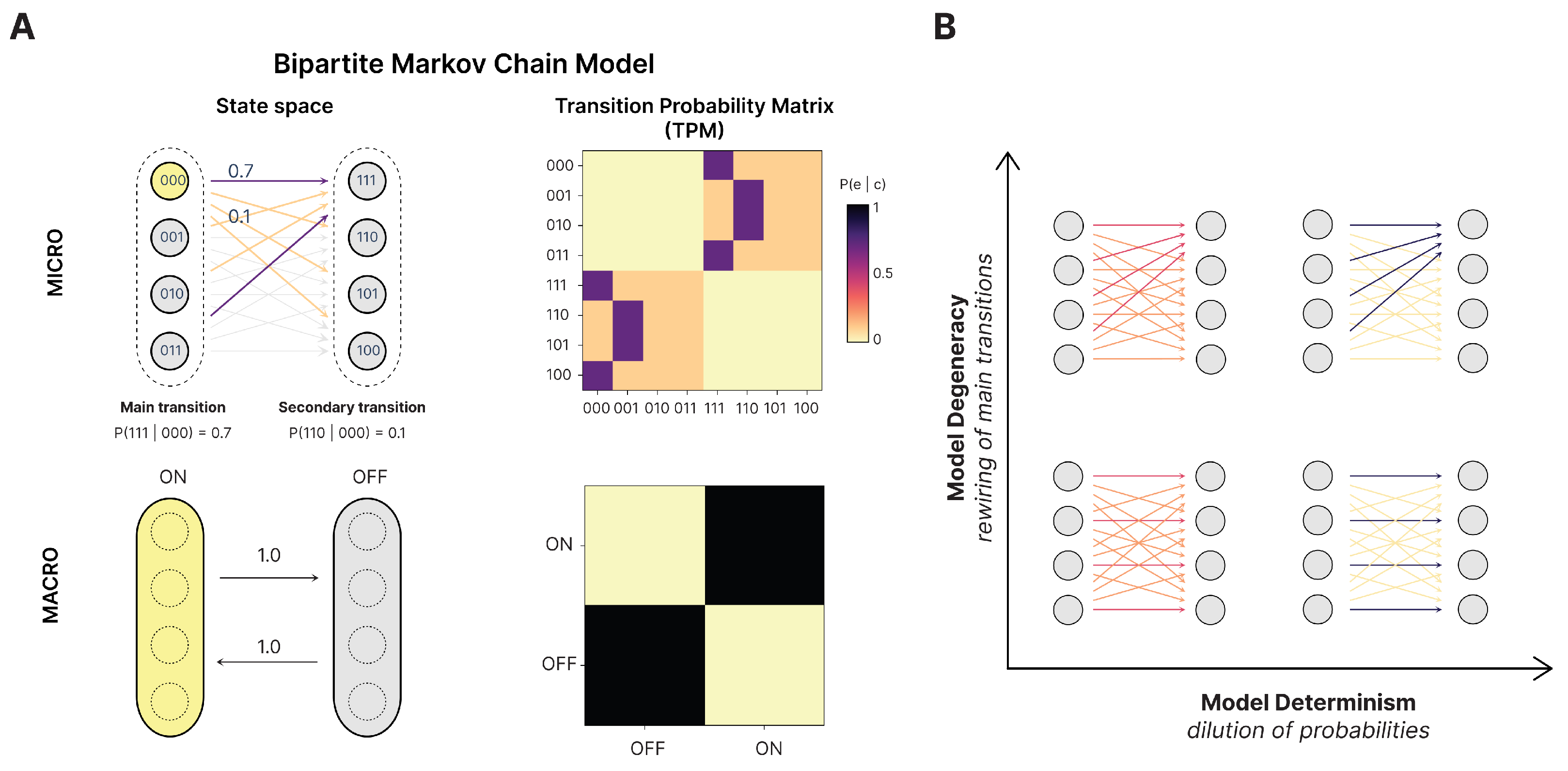
55]. We can leave such issues aside in our model system by simply grouping each side of the bipartition and using that as the macroscale. Specifically, we use a microscale with
microstates
and two macrostates
defined by the coarse-graining function
, with
and
(
Figure 2B).
This coarse-grains the bipartite model into a simple two-state system at the macroscale, which trades off between the two macrostates (essentially, the same dynamics as a NOT gate with a self-loop). This macroscale is deterministic (each macrostate transitions solely to the other) and non-degenerate (each macrostate has only one possible cause). This means that, for the bipartite model, the macroscale is deterministic, non-degenerate, and dynamically consistent no matter the underlying microscale. Conceptually, its dynamical consistency comes from how, no matter the underlying microstate, the bipartite model always transitions to a different microstate on the other “side” of the bipartite model in the next timestep, and the two macrostates simply are the two sides. This allows us to compare a consistent macroscale against parameterizations of noise, like increases in indeterminism and degeneracy at the microscale, while keeping the macroscale fixed. Additionally, the stationary intervention distribution, maximum-entropy distribution, and local intervention distribution can be easily assessed at the macroscale in the bipartite model, ensuring clear comparisons.
The bipartite model has a further advantage. In previous research on causal emergence, there is a further check of candidate macroscales to ensure they are dynamically consistent with their underlying microscale. This means that the macroscale is not just derivable from the microscale (supervenience) but also that the macroscale behaves identically or similarly (in terms of its trajectory, dynamics, or state transitions over time). Mathematical definitions of consistency between scales have been previously proposed [
12], and later work has also proposed similar notions to consistency by using the “lumpability” of Markov chains to analyze the issue of dynamical consistency between microscales and their macroscales [
31]. Here, however, we can again eschew this issue. This is because the macroscale for the bipartite model we use automatically ensures dynamical consistency.
For these reasons, we focus on a simplified definition of causal emergence in the form of instances of macroscale causation in our bipartite model without a search across scales or an accompanying causal apportioning schema that distributes out macroscale causation across multiple scales, as in [
56]. Here causal emergence (
) is computed as merely the difference between the macroscale causal relationships and the microscale causal relationships, with respect to a given measure of causation.
If is positive, there is causal emergence. This can be interpreted as the macroscale doing more causal work, being more powerful, strong, or more informative, depending on how the chosen measure of causation is itself interpreted. A negative value of indicates causal reduction.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}