
Federated Semi-Supervised Learning with Uniform Random and Lattice-Based Client Sampling


Abstract
1. Introduction
1.1. Background
1.2. Related Works
1.3. Contributions
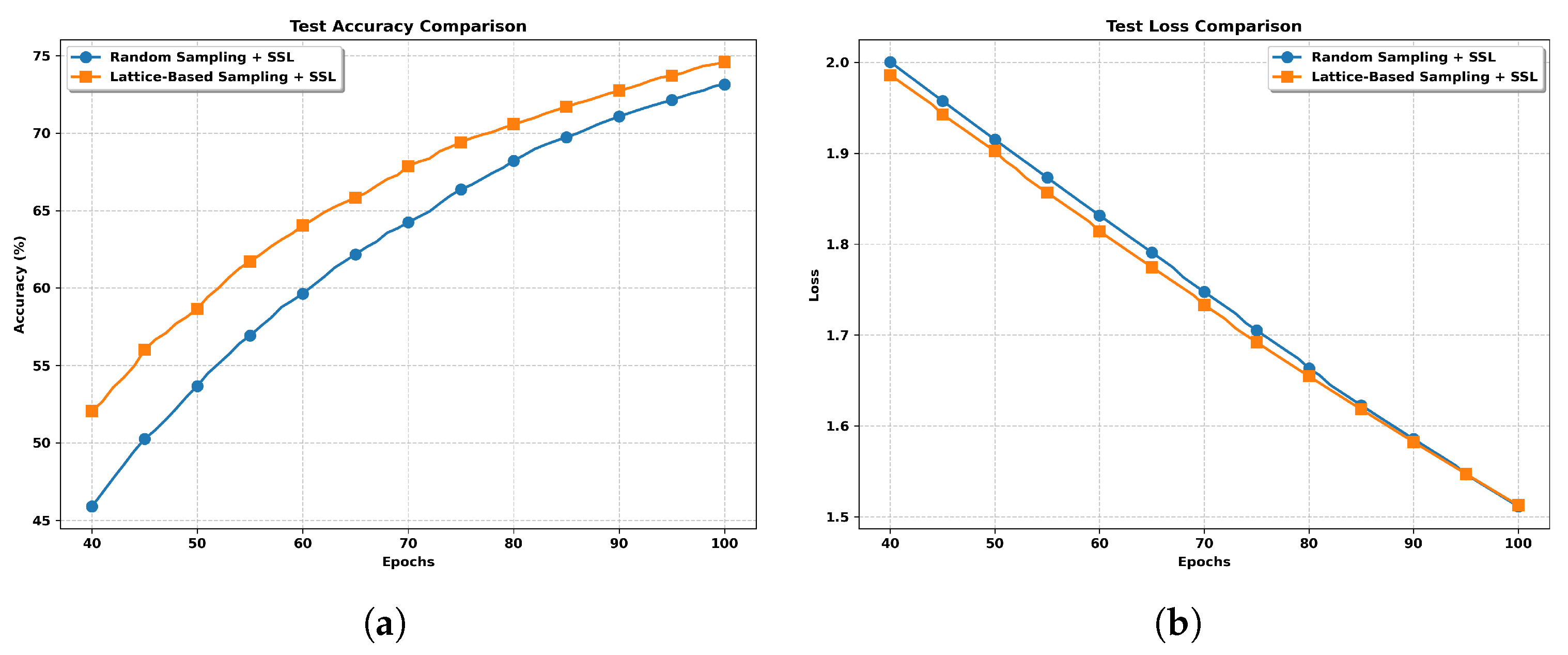
- We propose an efficient federated learning algorithm, FedAvg-SSL, which incorporates partial client participation and alternates between updating the global model and refining pseudo-labels on local clients. The algorithm supports both uniform random sampling and a more structured lattice-based sampling strategy at the server side. While uniform sampling ensures simplicity and unbiased selection, the lattice-based approach offers more balanced client participation, which improves model stability under non-i.i.d. data.
- We establish a rigorous convergence analysis for FedAvg-SSL, demonstrating a sublinear convergence rate and linear speedup under partial client participation.
- Experimental results validate the performance of the proposed algorithm, showing its consistency with theoretical findings and illustrating the relationship between algorithm performance, the number of participating clients, and the number of local steps.
1.4. Organization
2. Problem Formulation
3. FedAvg-SSL Algorithm
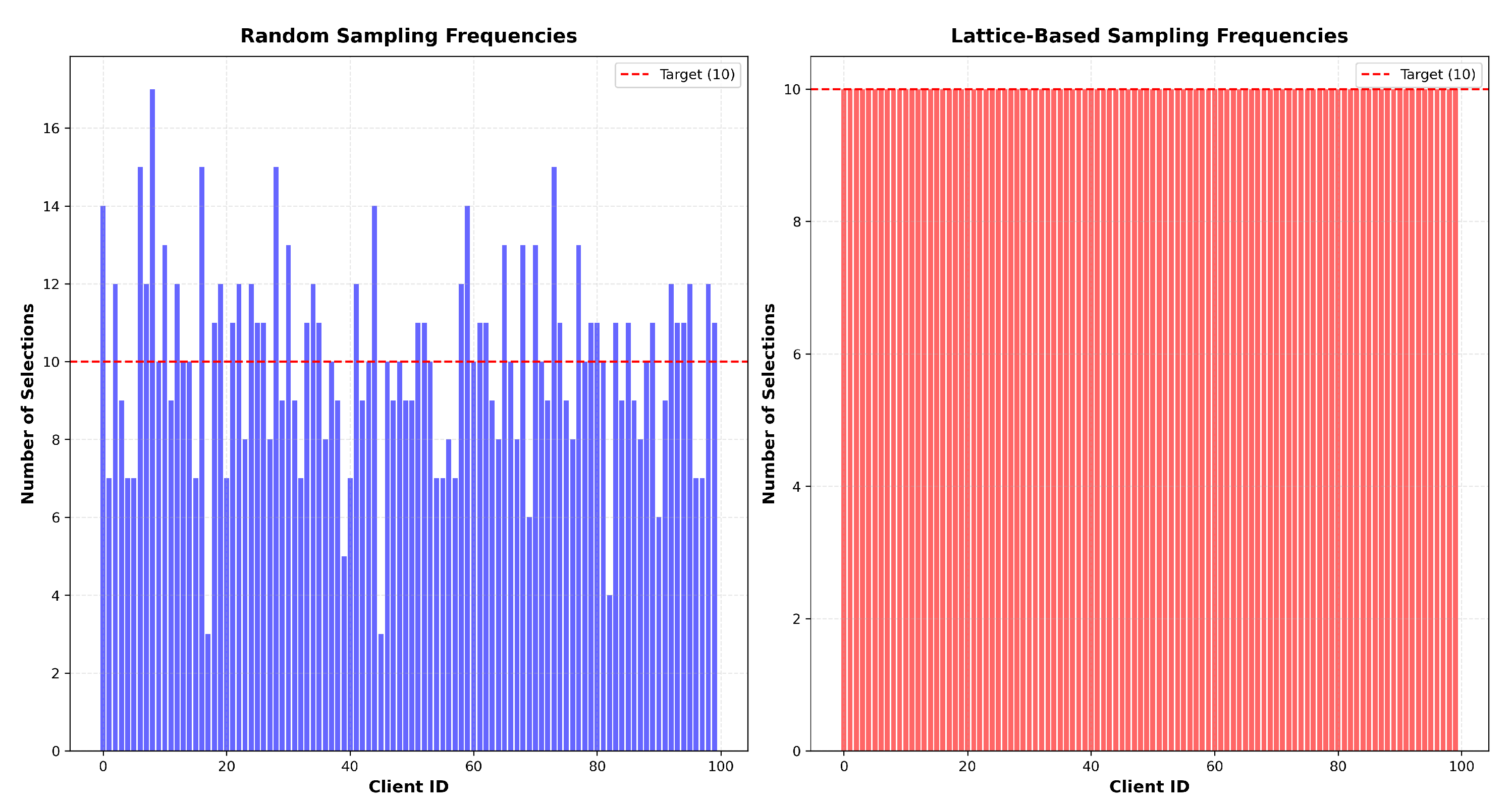
3.1. Random Sampling Method
3.2. Lattice-Based Sampling Method
- (1)
- Let denote the element in the t-th row and k-th column of the matrix U for all ;
- (2)
- Each level appears equally often in every column.
3.3. The Proposed Federated SSL Algorithm
- Samples mini-batches of labeled data and unlabeled data uniformly at random from and , respectively.
- Computes the stochastic gradient of the local loss function
- Updates its local model copy using SGD.
| Algorithm 1 FedAvg SSL [Server] |
|
| Algorithm 2 FedAvg SSL [Client] |
|
4. Convergence Analysis with Partial Client Participation
4.1. Assumptions
4.2. Convergence Analysis of FedAvg-SSL
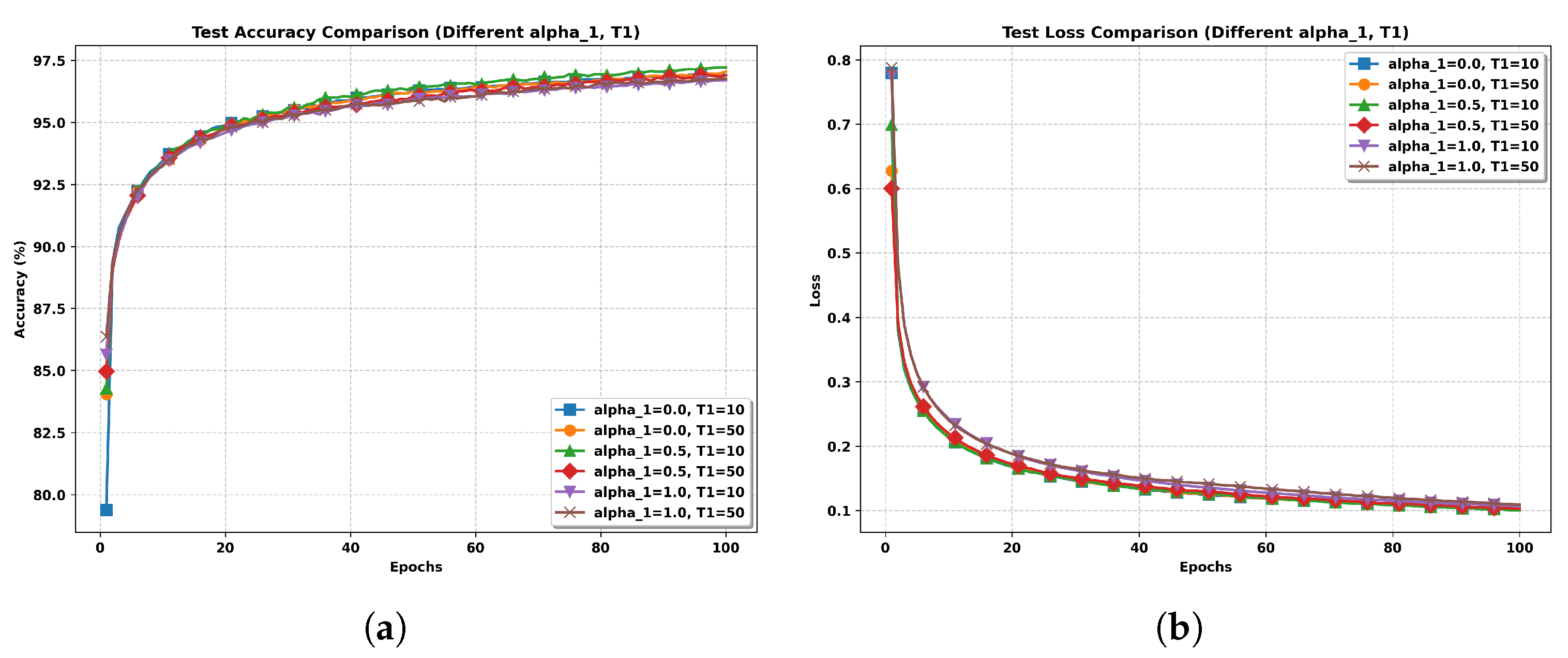
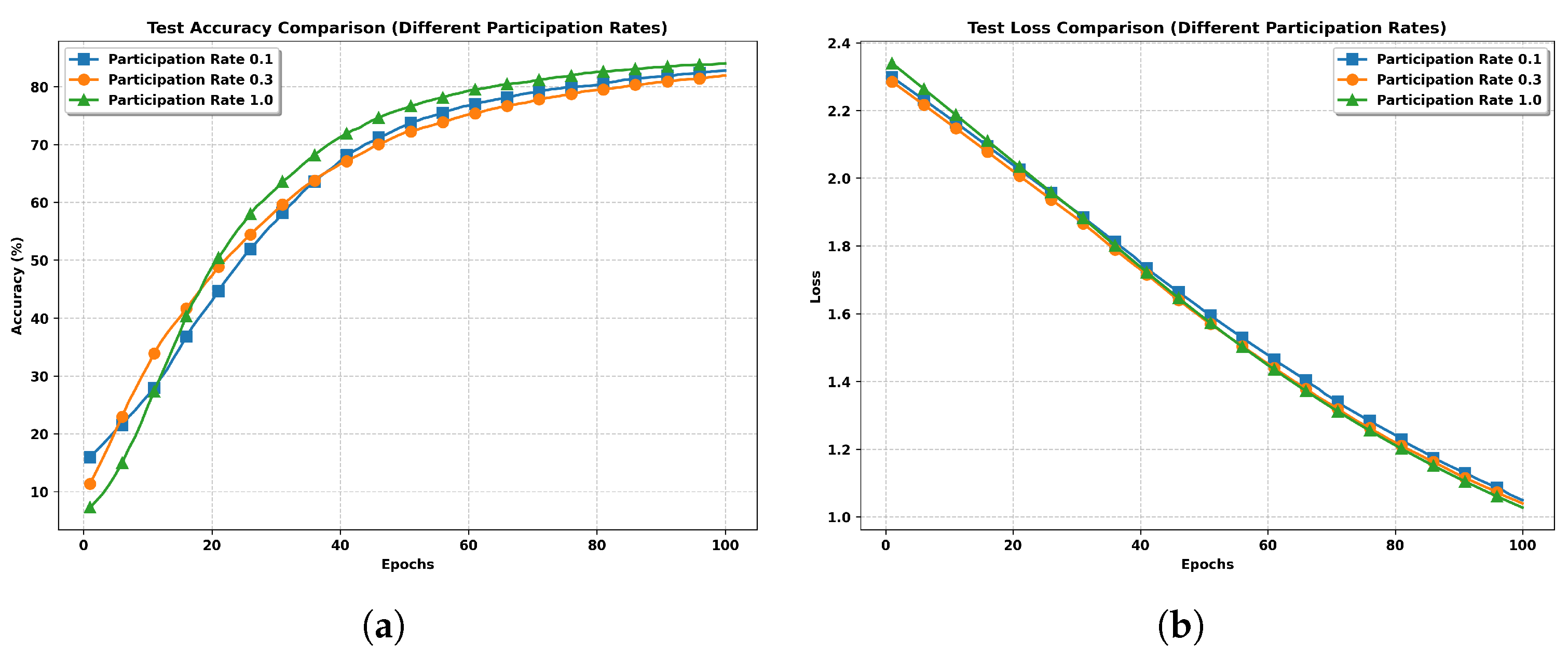
- Number of participating clients (M): When all clients participate in each round, i.e., , the term in the bound becomes zero. As a result, the convergence rate improves, demonstrating the benefit of increased client participation.
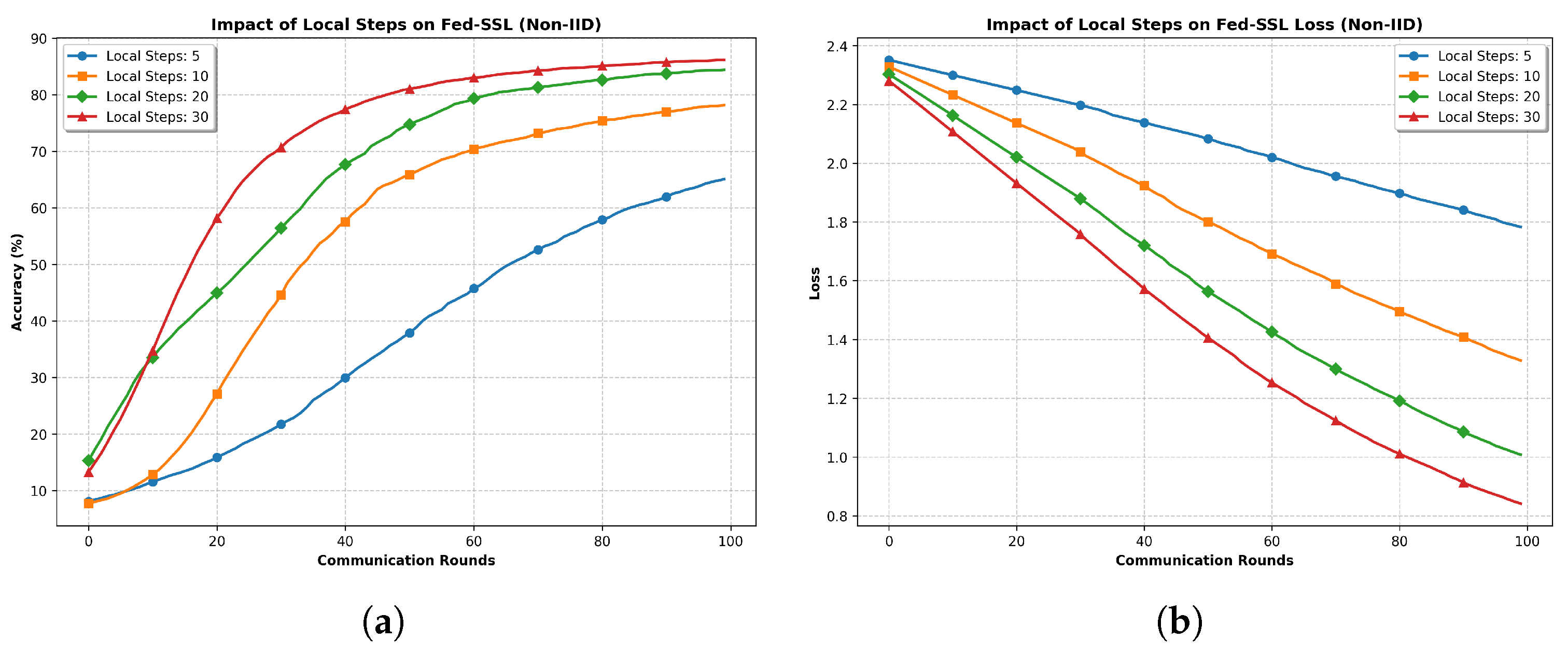
- Number of local steps (Q): As Q increases, the accumulated local update noise can affect convergence. Theorem 1 suggests that in such cases, the global and local learning rates η and should be chosen smaller to maintain stability and ensure convergence.
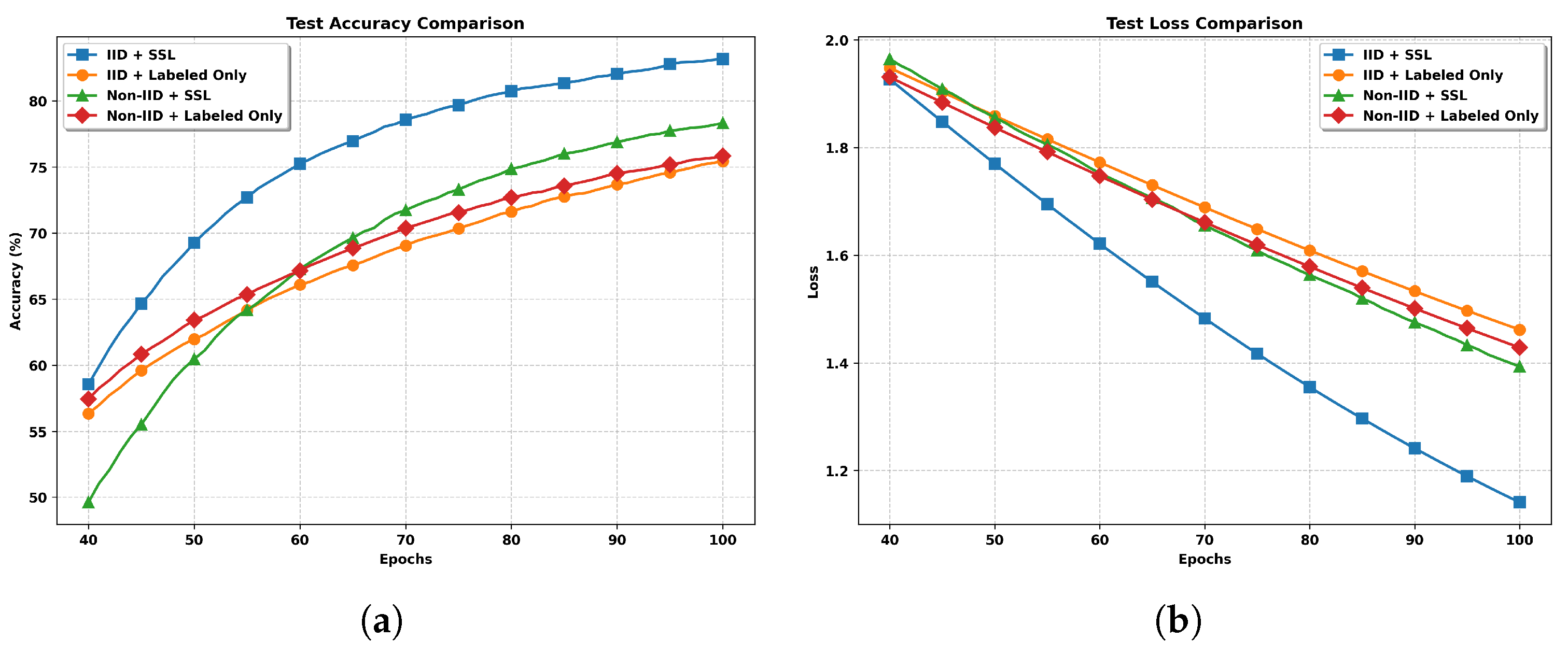
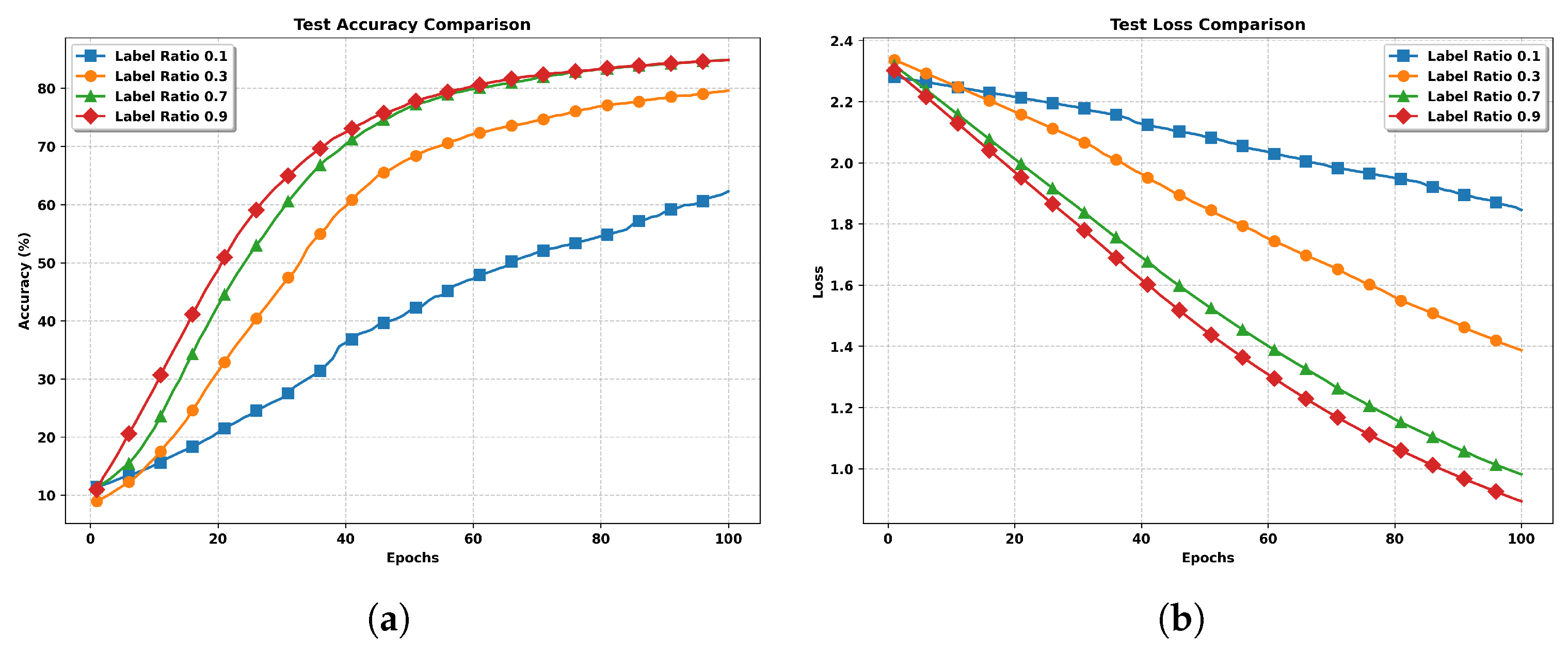
5. Simulation Results
- IID Setting: The training data is randomly and uniformly distributed across clients, ensuring each client receives approximately equal amounts of both labeled and unlabeled samples. This setting serves as our baseline distribution.
- Non-IID Setting: Labeled data is randomly shuffled and split into twice as many shards as there are clients, with each client randomly assigned two unique shards. This ensures that each client receives a distinct, non-overlapping subset of the labeled data, with each shard containing a random mix of classes. The unlabeled data is distributed using a Dirichlet distribution () to further enhance the non-IID nature of the data across clients.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proof of Theorem 1
Appendix A.1. Some Auxiliary Lemmas
Appendix A.2. The Proof of Theorem 1
References
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Zeng, Y.; Wang, Z.; Bai, J.; Shen, X. An accelerated stochastic ADMM for nonconvex and nonsmooth finite-sum optimization. Automatica 2024, 163, 111554. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Chang, T.H.; Li, J.; Luo, Z.Q. Distributed stochastic consensus optimization with momentum for nonconvex nonsmooth problems. IEEE Trans. Signal Process. 2021, 69, 4486–4501. [Google Scholar] [CrossRef]
- Stich, S.U. Local SGD converges fast and communicates little. arXiv 2018, arXiv:1805.09767. [Google Scholar]
- Yin, Q.; Feng, Z.; Li, X.; Chen, S.; Wu, H.; Han, G. Tackling data-heterogeneity variations in federated learning via adaptive aggregate weights. Knowl.-Based Syst. 2024, 304, 112484. [Google Scholar] [CrossRef]
- Yang, H.; Fang, M.; Liu, J. Achieving linear speedup with partial worker participation in non-iid federated learning. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. In Proceedings of the Conference on Machine Learning and Systems, Austin, TX, USA, 2–4 March 2020. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. SCAFFOLD: Stochastic controlled averaging for federated learning. In Proceedings of the International Conference on Machine Learning, Virtual Event, 2020; pp. 5132–5143. [Google Scholar]
- Wang, J.; Liu, Q.; Liang, H.; Joshi, G.; Poor, H.V. Tackling the objective inconsistency problem in heterogeneous federated optimization. arXiv 2020, arXiv:2007.07481. [Google Scholar] [CrossRef]
- Wang, S.; Ji, M. A unified analysis of federated learning with arbitrary client participation. Adv. Neural Inf. Process. Syst. 2022, 35, 19124–19137. [Google Scholar]
- Ribero, M.; Vikalo, H. Reducing communication in federated learning via efficient client sampling. Pattern Recognit. 2024, 148, 110122. [Google Scholar] [CrossRef]
- Cohen, I.; Cozman, F.G.; Sebe, N.; Cirelo, M.C.; Huang, T.S. Semisupervised learning of classifiers: Theory, algorithms, and their application to human-computer interaction. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1553–1566. [Google Scholar] [CrossRef]
- Zhu, X.J. Semi-Supervised Learning Literature Survey; Technical report; Department of Computer Sciences, University of Wisconsin-Madison: Madison, WI, USA, 2005. [Google Scholar]
- Chapelle, O.; Scholkopf, B.; Zien, A. Semi-supervised learning. IEEE Trans. Neural Netw. 2009, 20, 542. [Google Scholar] [CrossRef]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML, Atlanta, GA, USA, 21 June 2013. [Google Scholar]
- Rasmus, A.; Berglund, M.; Honkala, M.; Valpola, H.; Raiko, T. Semi-supervised learning with ladder networks. Adv. Neural Inf. Process. Syst. 2015, 28, 3546–3554. [Google Scholar]
- Laine, S.; Aila, T. Temporal ensembling for semi-supervised learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30, 1195–1204. [Google Scholar]
- Miyato, T.; Maeda, S.i.; Koyama, M.; Ishii, S. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1979–1993. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Wu, B.; Feng, Y.; Fan, Y.; Jiang, Y.; Li, Z.; Xia, S.T. Semi-supervised robust training with generalized perturbed neighborhood. Pattern Recognit. 2022, 124, 108472. [Google Scholar] [CrossRef]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C. Mixmatch: A holistic approach to semi-supervised learning. arXiv 2019, arXiv:1905.02249. [Google Scholar]
- Du, G.; Zhang, J.; Zhang, N.; Wu, H.; Wu, P.; Li, S. Semi-supervised imbalanced multi-label classification with label propagation. Pattern Recognit. 2024, 150, 110358. [Google Scholar] [CrossRef]
- Wang, J.; Ruan, D.; Li, Y.; Wang, Z.; Wu, Y.; Tan, T.; Yang, G.; Jiang, M. Data augmentation strategies for semi-supervised medical image segmentation. Pattern Recognit. 2025, 159, 111116. [Google Scholar] [CrossRef]
- Diao, E.; Ding, J.; Tarokh, V. Semifl: Semi-supervised federated learning for unlabeled clients with alternate training. Adv. Neural Inf. Process. Syst. 2022, 35, 17871–17884. [Google Scholar]
- Albaseer, A.; Ciftler, B.S.; Abdallah, M.; Al-Fuqaha, A. Exploiting Unlabeled Data in Smart Cities using Federated Learning. arXiv 2020, arXiv:2001.04030. [Google Scholar] [CrossRef]
- Jeong, W.; Yoon, J.; Yang, E.S.; Hwang, J. Federated Semi-Supervised Learning with Inter-Client Consistency & Disjoint Learning. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Wang, S.; Xu, Y.; Yuan, Y.; Quek, T.Q. Toward Fast Personalized Semi-Supervised Federated Learning in Edge Networks: Algorithm Design and Theoretical Guarantee. IEEE Trans. Wirel. Commun. 2023, 23, 1170–1183. [Google Scholar] [CrossRef]
- Liang, X.; Lin, Y.; Fu, H.; Zhu, L.; Li, X. Rscfed: Random sampling consensus federated semi-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 10154–10163. [Google Scholar]
- Zhu, S.; Ma, X.; Sun, G. Two-stage sampling with predicted distribution changes in federated semi-supervised learning. Knowl.-Based Syst. 2024, 295, 111822. [Google Scholar] [CrossRef]
- Cong, Y.; Zeng, Y.; Qiu, J.; Fang, Z.; Zhang, L.; Cheng, D.; Liu, J.; Tian, Z. FedGA: A greedy approach to enhance federated learning with Non-IID data. Knowl.-Based Syst. 2024, 301, 112201. [Google Scholar] [CrossRef]
- Wang, S.; Ji, M. A Lightweight Method for Tackling Unknown Participation Statistics in Federated Averaging. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Jhunjhunwala, D.; Sharma, P.; Nagarkatti, A.; Joshi, G. Fedvarp: Tackling the variance due to partial client participation in federated learning. In Proceedings of the Uncertainty in Artificial Intelligence, PMLR, Eindhoven, The Netherlands, 1–5 August 2022; pp. 906–916. [Google Scholar]
- Niederreiter, H. Random Number Generation and Quasi-Monte Carlo Methods; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1992. [Google Scholar]
- Fang, K.T.; Wang, Y. Number-Theoretic Methods in Statistics; Chapman and Hall: London, UK, 1994. [Google Scholar]
- Zhang, M.; Zhou, Y.; Zhou, Z.; Zhang, A. Model-free subsampling method based on uniform designs. IEEE Trans. Knowl. Data Eng. 2024, 36, 1210–1220. [Google Scholar] [CrossRef]
- Zhou, Z.; Yang, Z.; Zhang, A.; Zhou, Y. Efficient model-free subsampling method for massive data. Technometrics 2024, 66, 240–252. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, X.; Sun, R.; Chang, T.H. Federated semi-supervised learning with class distribution mismatch. arXiv 2021, arXiv:2111.00010. [Google Scholar] [CrossRef]
- Fang, K.T.; Li, R.; Sudjianto, A. Design and Modeling for Computer Experiments; Chapman and Hall/CRC: Boca Raton, FL, USA, 2006. [Google Scholar]
- Fang, K.; Liu, M.Q.; Qin, H.; Zhou, Y.D. Theory and Application of Uniform Experimental Designs; Springer: Singapore, 2018. [Google Scholar]
- Zhang, A.; Li, H.; Quan, S.; Yang, Z. UniDOE: Uniform Design of Experiments. R Package Version 1.0.2. 2018. Available online: https://cran.r-project.org/src/contrib/Archive/UniDOE/ (accessed on 24 July 2025).
- Shalev-Shwartz, S.; Singer, Y. Logarithmic Regret Algorithms for Strongly Convex Repeated Games; The Hebrew University: Jerusalem, Israel, 2007. [Google Scholar]
- Chen, L.; Zhao, D.; Tao, L.; Wang, K.; Qiao, S.; Zeng, X.; Tan, C.W. A credible and fair federated learning framework based on blockchain. IEEE Trans. Artif. Intell. 2024, 6, 301–316. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 96.91% | 97.21% | |
| 97.5% | 96.89% | |
| 96.71% | 96.76% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Yang, F. Federated Semi-Supervised Learning with Uniform Random and Lattice-Based Client Sampling. Entropy 2025, 27, 804. https://doi.org/10.3390/e27080804
Zhang M, Yang F. Federated Semi-Supervised Learning with Uniform Random and Lattice-Based Client Sampling. Entropy. 2025; 27(8):804. https://doi.org/10.3390/e27080804
Chicago/Turabian StyleZhang, Mei, and Feng Yang. 2025. "Federated Semi-Supervised Learning with Uniform Random and Lattice-Based Client Sampling" Entropy 27, no. 8: 804. https://doi.org/10.3390/e27080804
APA StyleZhang, M., & Yang, F. (2025). Federated Semi-Supervised Learning with Uniform Random and Lattice-Based Client Sampling. Entropy, 27(8), 804. https://doi.org/10.3390/e27080804