1. Introduction
Text analysis is an important element of evaluating distributed intelligent systems (DISs), which combine natural and artificial intelligence agents [
1,
2,
3]. Short messages, which agents can modify during their communication, are not only carriers of some contextual information but also a way to convey emotions and moods in DIS. Consequently, the effective functioning of DIS, which also includes elements of decision making, performed under uncertainty, should necessarily include natural language processing tools and methods [
4]. Currently, the most popular areas in the field of text classification and analysis include machine learning (ML) methods and large language models. ML methods for text classification should be highlighted here [
5,
6]; among them, the use of TF-IDF (term frequency-inverse document frequency) analysis methods and neural network technologies prevail. Recently, the focus in the study of natural language processing has shifted to the field of large language models (LLMs) positioned as general methods for analyzing textual information and designed to solve a wide range of tasks. LLMs, such as BERT, the GPT family, and YaLM, have begun to actively replace techniques adapted to solving specific problems [
7,
8,
9]. They are based on a neural network with a large number of parameters, trained on very large (huge) amounts of unlabeled data. LLMs are based on the architecture of transformers, and one of their most important features is multi-modal learning, which allows them to form more accurate representations based on data from different sources—text, audio, graphics, etc. [
10]. Although such models are considered common for various text analysis tasks, they often require training. For example, BERT needs training to perform sentiment analysis. In addition, a major limitation of using LLMs is their high demand on computational resources.
Despite significant advances, they are usually not universal, and most text classification methods involve a number of limitations. To solve specific problems, LLMs and ML methods require the training of computational models and the processing of large amounts of data, and therefore significant computational resources. These limitations complicate their widespread practical application.
At present, the field of text data analysis, which is related to the use of methods of quantum probability theory, actively develops and promises good results to be obtained [
11,
12,
13]. We especially highlight the impact of the project on quantum-like information retrieval (see [
11,
14]). In particular, a work [
11] describes in detail the development of a quantum approach to text analysis and classification. In this field, quantum formalism is not considered a means of describing the subatomic world but a mathematical apparatus adapted to work under conditions of uncertainty. Therefore, the use of quantum mechanical methods can reduce the dimensionality of data or improve classification accuracy and successfully replace or complement ML methods and LLMs, reducing the resource intensity of text data analysis algorithms.
An alternative to ML in text classification tasks can be the use of heuristic (quantum-like or quantum-inspired) algorithms. The application of such algorithms is based on the use of interference effects for the wave function, which is well known in quantum mechanics. In particular, the quantum-like interference approach can be used to successfully explain certain effects in cognitive sciences and decision-making problems under uncertainty, e.g., [
15,
16,
17,
18]. The quantum-like interference approach becomes useful for big data analysis; here, we emphasize applications of quantum-like clustering for medical data used for diagnostics of neurological disorders, epilepsy, and schizophrenia [
19].
The article is arranged as follows.
Section 2 introduces the spherical wave-based model underlying our approach and describes the corresponding semantic text classification algorithm.
Section 3 is divided into two subsections.
Section 3.1 outlines the core of the experimental setup and compares the classification accuracy of the proposed method with that of conventional ML techniques. For this study, we used a dataset of 500 customer reviews from Amazon.com.
Section 3.2 discusses the experimental results. The proposed method achieved relatively high classification performance, with an F-score of approximately 0.8. We also analyze the impact of interference effects in semantic space on classification quality.
Section 4 addresses the issue of computational efficiency. By employing an integrated optimization strategy, we demonstrate how the algorithm’s time complexity can be reduced to
. In
Section 5, we summarize the results that we obtained.
2. Theoretical Background
In this study, for text representation, we have developed the wave-like model, which is based on the concept of a wave function,
; it allows text interpretation as a wave packet consisting of a group of waves (wave functions)—semantic units able to interfere with their semantics, cf. [
20].
The model that we use below relates to spherical waves. In physics, they represent the solution of the Helmholtz equation (cf. [
21,
22,
23])
where
is the Laplacian,
is the wavenumber, and
is the frequency. In general, the solution to (
1) for the function
involves finding dependencies on three variables,
, and
, that relate to the spherical coordinates. In quantum mechanics, spherical waves are considered within scattering theory, cf. [
21,
24]. The variable
r, for our purposes, specifies the semantic distance. However, the meaning of the phase variables in our problem is not so clear. We can exclude these variables from consideration if we assume that the function
depends on
; see e.g., [
22,
23]. In a more general case, we can consider solutions in the form of free spherical waves, which implies that the quantum orbital number is equal to zero.
Thus, the
spherical wave-like model is specified in this work in the following form:
where
A is the amplitude,
r is the distance from the source, and
is the initial phase.
According to the quantum description [
25], the wave function reflects the quantum-like state of the semantic unit as an object in a Hilbert space, and we can find an object at a given point in space with the following probability density:
Notably, spherical wave-like model (
2) enables accounting for the weakening of the probability density
. In a more general form, it is possible to assume that
obeys a power-law distribution
, where
. Such probability density functions are capable of dealing with complex, highly fluctuating systems. These systems are encountered in our daily lives. They relate to the social sciences, economics, linguistics, etc.; see e.g., [
26,
27]. Notably, at a low
m, the power-law distribution exhibits so-called “thick tails”, which contribute to essential differences in the behavior of complex systems compared to the familiar Gaussian distribution [
28]. To be more specific, in this work, we examine the limit of
. In particular, the model described by (
2) performed well with Russian-language data; cf. [
29]. For this reason, we are using the same model for the English data. Notably, it is also possible to recognize
m as an additional fitting parameter that enables the tuning of the probability density for the set of objects; see below. The solution to this problem is likely to be more complex, as it will involve adapting (optimizing)
m to particular empirical data, cf. [
30]. This issue will be examined in detail in future publications.
Considering the quantum states of a group of
M waves, the probability density of detecting a set of objects at a given point in space is given as follows:
where
M is the number of objects, and we created a definition,
In Equations (
4) and (
5),
characterizes the contribution of quantum-like interference in total probability density; cf. [
31]. In particular, interference of probabilities is constructive if
. The first sum in (
4), that is
gives the classical probability that we can recognize in the absence of interference. The possibility of employing a constructive interference of probabilities is one of the main distinguishing features of quantum probability calculus (see [
32] in the discussion of the role of constructive interference in approaching supremacy in quantum calculations). Studying constructive interference of probabilities in semantic text classification can result in novel information technologies. We stress that our model needs no quantum computers; it is implemented on classical digital ones.
Equation (
4), which characterizes the behavior of a wave packet in a Hilbert space, can be adapted to describe textual data in a semantic space by appropriate interpretation of parameters. In this case, the number of objects
M is considered the number of non-repeating semantic units of the text, amplitude
A is the number of repetitions of each semantic unit, distances
specify the semantic distances from each semantic unit of the text to the point in space where the probability density,
, is calculated, wave numbers,
, are some parameters of the semantic units of the text, which we denote as “wave number” and which require separate consideration.
Wave numbers of semantic units cannot be determined directly from the text; however, they can be calculated on the basis of the following considerations. The function described by Equation (
4) obviously involves an irregular set of maxima and minima, and the maxima correspond to the regions with the highest probability densities of detection of objects represented by this function.
Let us assume that we know a certain point at which the probability density should reach a maximum. For example, such a point can be the subject of the text if it is known in advance, as is often the case with sentiment analysis problems. Knowing this point, we can determine the distance,
, to it from each word of the text, as the semantic distances between the corresponding concepts. If such a specific point cannot be found, the centroid of the text can be used as it. A text, as a set of words, can be represented in semantic space as a three-dimensional object; the relative distances between individual words determine the positions of the vertices. In this case, the distances from each word of the text to its centroid can be calculated using Formula (
7):
where
is the semantic distance between two words of the text. The interference maximum is achieved when the phases of all wave functions at a given point are equal (
8):
where
is some constant that represents a fitting parameter of the model. In this case, the wave numbers of each semantic unit can be calculated as follows:
where
ki is the wave number of the
i-th word;
rci is the distance from the
i-th word to the maximum point of the function
.
In the calculations, we use . This is based on the assumption that the text should be localized near a specific point chosen for calculating wave numbers. Furthermore, we assume that the main maximum of the should be located at this point; the other maxima will then be in areas semantically close to the text.
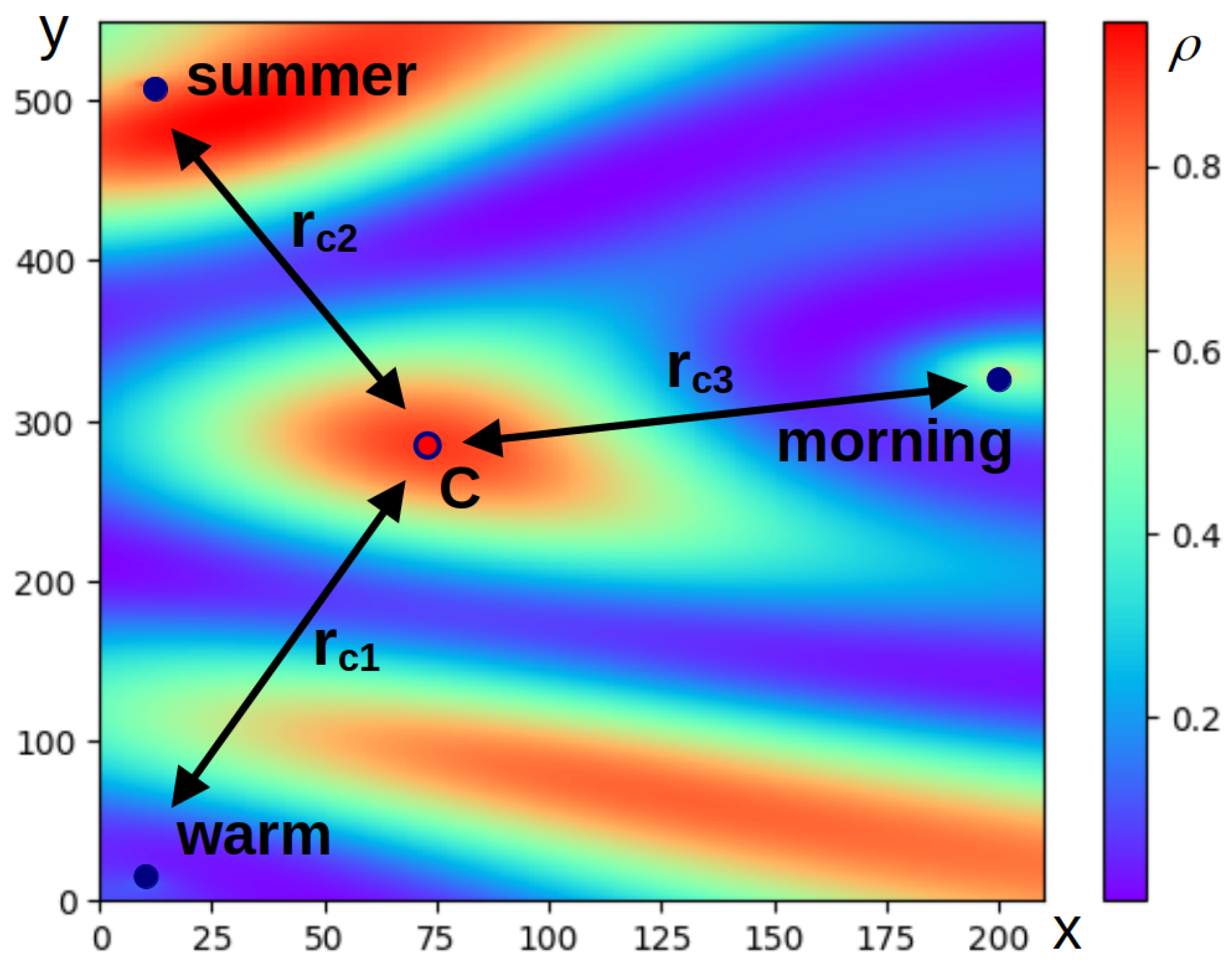
To illustrate the described approach, the process of determining the wavenumbers in the phrase “warm summer morning” should be considered.
Figure 1 shows the relative arrangement of the words of the phrase in question according to their mutual semantic distances, as well as a variant of the color map of function
. The coordinates along the axes of the plots and the levels of the color map are given in conventional units. The maximum point of the function
is the centroid of a triangle whose vertices are determined by the words of the phrase. The wave numbers of the words are calculated by Equations (
7) and (
9) for
. This value has been chosen to improve the visualization of the interference pattern that occurs when exploring an artificial phrase consisting of only three words. In this case, a less visible picture is obtained with lower values of
. The difference between
n and the value used in the calculations made it possible to demonstrate the approach to calculating wave numbers clearly here.
To determine the semantic distances between the semantic units of a text, vector language models can be used, which allow for calculating the semantic proximity as the cosine distance between the corresponding terms. In this case, the semantic distance is the value inversely proportional to the semantic (cosine) proximity of the corresponding vectors. In this work, we also suppose that the wave function (
2) is normalized; i.e.,
where
is the volume of the semantic space containing all the meanings represented in a given language. In our case, the vector language model can be considered a relevant representation of the semantic space. So, Formula (
10) can be represented as follows:
is the number of vectors in the vector language model.
are the semantic distances between the vectors of the corresponding words of the text and the
i vector of the language model.
Notably, in text classification tasks, including sentiment analysis, the basis for determining the most preferred classes is not the absolute value of probability density
but its ratio in the class domains, which automatically accounts for the normalization conditions (
10) and (
11).
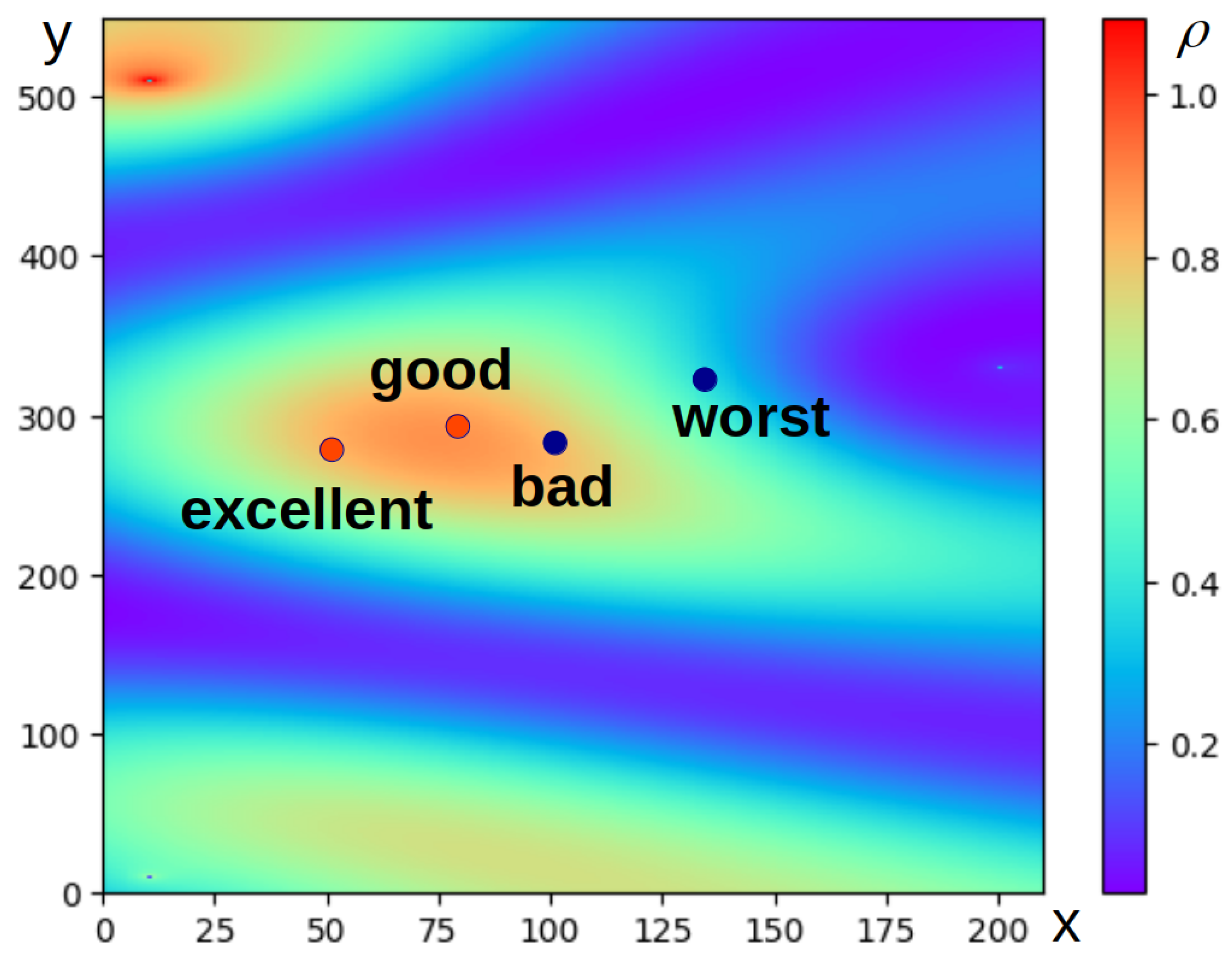
Thus, we have described the wave model of the representation of textual information in the form of a set of waves. This model allows for estimating the probability density of text recognition in regions of semantic space defined by specified semantic concepts. This means that the model presented is suitable for classifying text in terms of semantic categories. One of these semantic categories can be the emotional tonality of the text, i.e., this model is suitable for solving problems of sentiment analysis.
In this paper, we propose the following general workflow for text classification based on the proposed wave model of text; see
Figure 2.
At the first step of the algorithm, the text is transformed into an array of semantic units. At this stage, it is important to take into account the peculiarities of the language of the text in question and its belonging to one of the types of language: synthetic, analytical, or agglutinative. The type of language determines the algorithm for segmenting the text into semantic units. For example, Russian belongs to the type of synthetic languages in which the main carriers of semantics are words, regardless of word order and environment in the text. For English, an analytical type of language, the order of words in a sentence, word combinations, phrases with structural words, and intonation are important.
Since, in Russian, the main carriers of semantics are individual words, simple lemmatization algorithms can be used to segment the text into semantic units, i.e., to split the text into individual words and convert them into normal form. For example, we can use the rulemma (url:
https://github.com/Koziev/rulemma, accessed on 29 March 2025) or NLTK (Natural Language ToolKit) (url:
https://www.nltk.org/, accessed on 29 March 2025) libraries for the Russian language.
For analytical languages, simple lemmatization can lead to a significant loss in the meaning of the text, embedded in the word order in the sentence and phrases, taking into account the structural words. Therefore, segmentation of the text into phrases, where punctuation marks, conjunctions, and other words separating semantic units of the text act as separators, seems more promising. In this case, the question arises of how to determine the vector of the semantic unit of the text, which is a phrase that arises when the vector language model used provides only vectors of individual words. The simplest, and as shown later, quite effective approach may be to represent the vector of a phrase as the sum of the vectors of the words included in it.
After determining the semantic units of the text and calculating the corresponding vectors, the maximum point of the probability density of text recognition can be set, and the wave numbers of the text can be calculated with (
9). Then, the probability densities of text recognition in the areas of terms defining classes in the semantic space are calculated, and the classes are ranked in descending probability density. Thus, the task of semantic text classification is considered to be solved.
4. Optimization of Calculations
The classification of texts using the wave representation model and calculation of the probability density of the text proximity to the class according to Equation (
4) leads to the complexity of the algorithm
, where
n is the number of semantic units in the text. This complexity is explained by the presence of nested loops in the algorithm and the calculation of the cosine in the body of the loop.
Here, we are discussing possible optimization methods for the calculation of trigonometric functions in the body of nested loops and their potential impact on the time cost of the algorithm and the accuracy of the calculations.
To reduce the time required for the use of nested loops, computational parallelization was applied [
36,
37]. Since parallel computing in Python is associated with problems of exclusive access to resources through the GIL (Global Interpreter Lock) system, parallelization was performed through a multiprocessing system (not multi-threading) on a computer with a 10-core processor.
The use of parallel computing allows us to achieve significant results in data processing, not only in terms of speed and other indicators—for example, the scalability of the big data solution. Non-parallelized computations are usually performed in sequential mode on a single processor core, unless the compiler uses parallelization automatically.
Parallel computing provides an accuracy increase. This non-obvious result of parallelization is often overlooked because optimizing the computational process requires reducing the cost of data storage and processing; a possible solution in this case is to reduce the accuracy of data. For example, the number of decimal places can be decreased. Parallelization provides the processing of large values, and in some cases, this may be an opportunity to neglect storage savings.
Flexibility and the efficient use of resources are some of the current trends in computing. Due to parallelization, it is possible not only to use available resources efficiently but also to use cloud solutions freely.
To test the speed of data processing, we created a synthetic dataset containing 10 million parameter values of the wave model of text representation (wave numbers and proximity of semantic units). The data was stored in text format.
The data was processed in Python version 3.11, well known for its significantly optimized compiler for machine code.
We implemented the algorithm of the computation function of (
4) in sequential and parallel. To generalize the solution used, the number of processes available for operation is read from the system data, and two processes are reserved for the needs of the operating system, so that the measurement indicators do not depend on the current system processes.
The calculations are distributed over the resulting number of processes. In this case, there were 12 processes available on a 6-core AMD Ryzen 5 5600H Radeon Graphics 3.30 GHz processor, of which 2 processes were excluded. It should be noted that parallelization between processes, rather than between cores, proved to be optimal, although it is clear that two processes on the same core already represent a parallelization option.
Several cosine optimization techniques were also investigated: the Taylor expansion
using the first two, four, and six terms (
n), the use of pre-filled tables with values in 100, 1000, and 10,000 rows, and linear interpolation on the segments
,
. The cosine calculation using the built-in function was used as a reference. For each of the optimization methods, the change in execution time (in % relative to the reference) and the maximum deviation of the calculated value from the reference value were estimated. The results are presented in
Table 6.
The worst results were obtained for the Taylor expansion—high time cost with low accuracy. The use of the tabular method proved to be the most promising—it reduces the time cost by about 40%, and at the same time, the accuracy can be easily adjusted by changing the number of rows in
Table 6. Linear interpolation provides a good performance boost, but it is characterized by a high error. A further reduction in time costs (about 10%) can be achieved by taking into account well-known properties of the cosine—equality to zero, one, and minus one at points that are multiples of
, even and odd numbers of
, respectively.
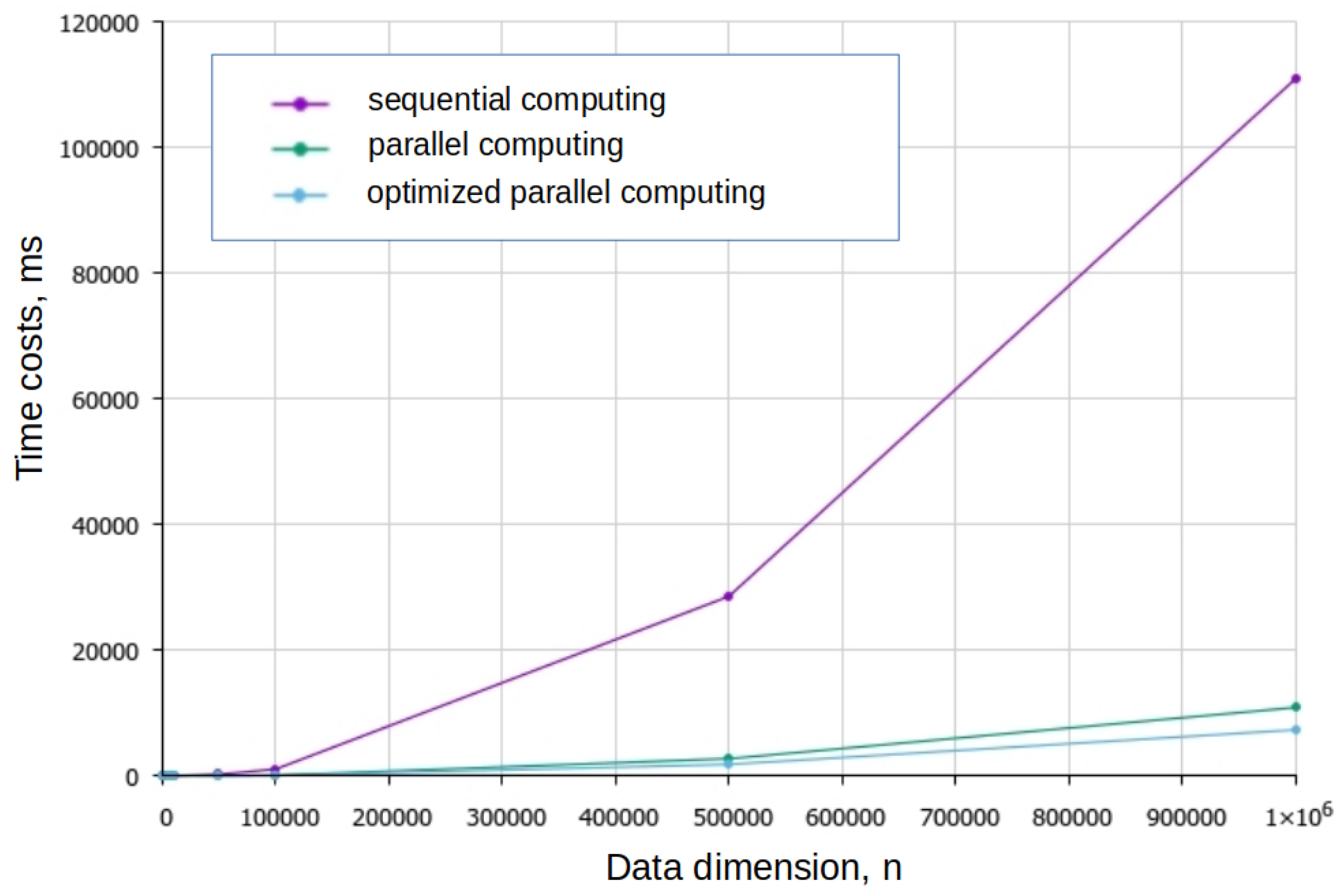
As a result, an integrated approach was used to optimize the algorithm, combining the use of parallel computing with a tabular method to calculate the cosine and take into account the known characteristics of the function. The plots of the dependence of the computation time on the dimension of the data are shown in
Figure 4.
The use of parallel computing combined with optimization of cosine computation allows a significant reduction in time costs and achievement of a work intensity close to . After optimization, the running time of the algorithm became proportional to , where M is the number of words in the text.
5. Conclusions
We have studied the possibility of using a quantum-like (wave) model of text representation for the sentimental analysis of English-language customer reviews. The proposed model is based on the representation of semantic units of a text in the form of wave functions in a Hilbert space, and it allows for taking into account the interference of semantics. Based on this model, we have developed a text classification algorithm that uses a pre-trained universal vector language model requiring no additional training.
Our studies are based on previous experiments that demonstrated the effectiveness of the proposed model in sentiment analysis of Russian-language texts.
Five hundred customer reviews of the online store Amazon.com were randomly selected for our experiments. For the obtained data set, classification was carried out in the context of the classes “positive” and “negative” with the developed algorithm. According to the results of the experiments, the classification accuracy was 80%, and the precision, recall, and F-Score were about 0.8. At the same time, the classification metrics are well balanced for the negative and positive classes. A noticeable dependence of the classification quality on the algorithm for dividing the text into semantic units was revealed. The best result was obtained by splitting the text not into individual words, but into phrases, which confirms the features of the English language as belonging to the analytical class. However, to achieve the best possible classification, it was necessary to manually isolate semantically significant phrases. We have also studied the influence of semantic interference in a Hilbert space and on classification quality. To do this, the experimental dataset was classified without interference. As a result, it was found that the quantum-like interference effect leads to an increase of 15% in accuracy. Other classification metrics also increase proportionally. Thus, semantic interference has a significant impact on the quality of classification. A further improvement in the suggested algorithm requires an optimization procedure for interference phase . We will consider this problem in further publications.
In this work, we took into account the peculiarities of the English language to classify the texts. In particular, it was demonstrated that classification metrics depend on the choice of algorithm used to divide text into semantic units. By examining various models of text decomposing into semantic units and using a quantum-like (wave) text representation for classification, we have achieved a classification accuracy of 80.4%. This indicator is even slightly better than the accuracy obtained earlier for the Russian language (79.3%), which successfully competes with the accuracy of ML methods.
We have also studied the reduction in time costs associated with algorithms based on the wave model of text representation. It was found that the proposed model lends itself well to optimization and that using an integrated approach—incorporating parallel computing and optimizing cosine calculation—reduces the estimated time costs from to . This makes the algorithm more accessible for use in data analysis.
In general, the quantum-like (wave) text representation model has proven to be a worthy alternative to costly ML methods. This model needs no special training and uses a universal pre-trained vector language model; therefore, it does not require large machine and human resources for development and operation. At the same time, our model demonstrates high indicators of text classification quality metrics. Thus, we can conclude that the developed model can be used effectively in the tasks of text analysis and classification.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}