1. Introduction
For a convex set
with relative interior
and a strictly convex function
differentiable on
, the Bregman divergence induced by
is the function
defined by
Two common examples of Bregman divergences are:
The squared Mahalanobis distance , where is a positive-definite matrix. The function is given by . The special case gives the squared Euclidean distance. This divergence may be defined on .
The Kullback–Leibler (KL) divergence , where and are probability vectors. Here, is the simplex . The KL divergence is induced by the negative entropy function . This divergence can be extended to general convex subsets of with formula for . When computing the KL divergence, we use the convention .
While it is possible to extend the definition of Bregman divergences to Banach spaces [
1], in this note we focus on divergences whose domains are convex subsets of
. In this setting, it is possible to interpret the Bregman divergence as a comparison between the difference
on the one hand and the linearized approximation of this difference about
given by
on the other.
Like metrics, Bregman divergences are positive-definite:
with equality if and only if
. Unlike metrics, Bregman divergences are not in general symmetric and do not in general satisfy a triangle inequality, though they do satisfy a “law of cosines” and a generalized Pythagorean theorem [
2]. Bregman divergences are locally distance-like in that they induce a Riemannian metric on
obtained by the small-
expansion
where
is a small perturbation vector and
is the Hessian of
at
. Because
is strictly convex,
is positive-definite and defines a Riemannian metric on
[
3]; much work in information geometry [
4] pursues the geometry induced by this metric and its connections to statistical inference. Bregman divergences [
5] also play fundamental roles in machine learning, optimization, and information theory. They are the unique class of distance-like losses for which iterative, centroid-based clustering algorithms (such as
k-means) always reduce the global loss [
2,
6] Bregman divergences are central in the formulation of mirror-descent methods for convex optimization [
7] and have a connection via convex duality to Fenchel-Young loss functions [
4,
8]. See Reem et al. [
9] for a more detailed review of Bregman divergences.
Bregman divergences provide one natural route through which to generalize Shannon information theory, with the differentiable function
taking on the role of the Shannon entropy. Indeed, generalized entropies play a role in describing the the asymptotic performance of learning algorithms; there exist a number of inequalities relating Bregman divergences to these generalized entropies [
10,
11]. Multiple characterization theorems exist for many information-theoretic quantities, including entropy [
12,
13,
14], mutual information [
15,
16], and the Kullback–Leibler divergence [
17,
18]. This author, however, is aware of only one extant characterization of the class of Bregman divergences, due to Banerjee et al. [
6]: Bregman divergences are the unique class of loss functions that render conditional expectations uniquely loss-minimizing in stochastic prediction problems. This characterization is the foundation of the connection between Bregman divergences and iterative centroid-based clustering algorithms noted above.
In this short note, we prove a new characterization of the class of Bregman divergences. This characterization is based on an equality of two common formulations of information content in weighted collections of finite-dimensional vectors.
2. Bregman Divergences Relate Two Informations
Let be a probability measure over n points . We collect these points into a matrix , and in a small abuse of notation, we consider this matrix to be an element of . We now define two standard formulations of information, each of which we consider as a function . The first formulation compares a weighted sum of strictly convex loss function evaluations on data points to the same loss function evaluated at the data centroid.
Definition 1 (Jensen Gap Information)
. Let be a strictly convex function on . The Jensen gap information is the function given bywhere . If we define
X to be a random vector that takes value
with probability
, Jensen’s inequality states that
, with equality holding only if
X is constant (i.e., if there exists
i such that
). The Jensen gap information is a measure of the difference of the two sides of this inequality; indeed,
[
2,
6]. This formulation makes clear that
is non-negative and that
if and only if
whenever
and
.
Another standard formulation expresses information content as a weighted mean of divergences of data points from their centroid.
Definition 2 (Divergence). A function is a divergence if for any , with equality if and only if .
Definition 3 (Divergence Information)
. Let d be a divergence. The divergence information is the function given bywhere . In this definition, we assume that
; as noted by Banerjee et al. [
2], this assumption is not restrictive since the set
can be replaced with the convex hull of the data
without loss of generality. The divergence information measures the
-weighted average divergence of
from the centroid
. This divergence information is related to the characterization result for Bregman divergences by Banerjee et al. [
6]: a divergence
d is a Bregman divergence if and only if the vector
is the unique minimizer of the function
appearing on the righthand side of Equation (
1) for any choice of
and
.
There are several important cases in which the Jensen gap information and the divergence information coincide.
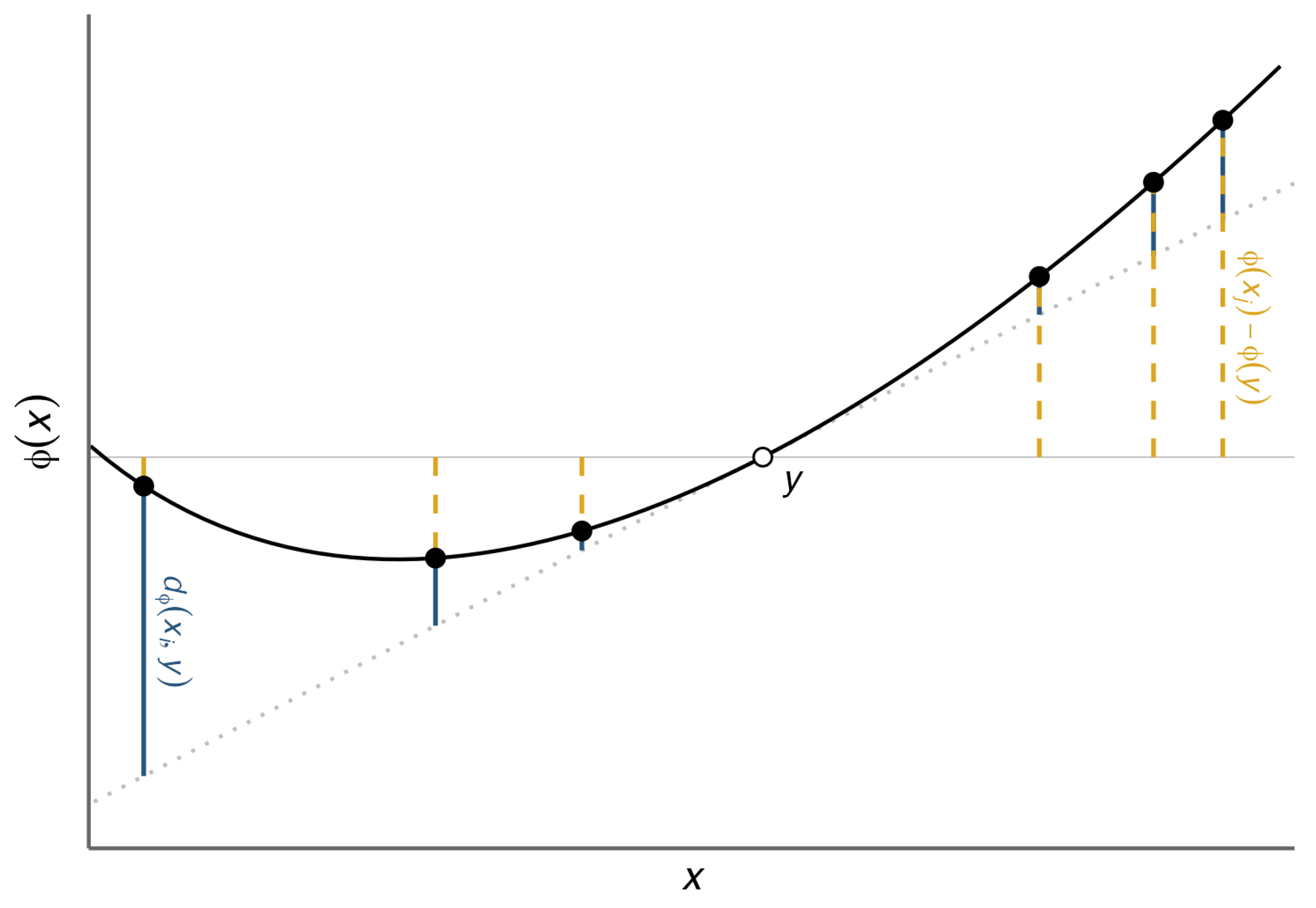
Definition 4 (Information Equivalence)
. We say that a pair comprising a strictly convex function and a divergence satisfies the information equivalence property if, for all , it holds that A graphical illustration of information equivalence is shown in
Figure 1.
Lemma 1 (Information Equivalence with Bregman Divergences [
2,
6])
. The pair satisfies the information equivalence property. The proof is a direct calculation and is provided by Banerjee et al. [
2]. When
and
is the squared Euclidean distance, the information equivalence property (
2) is the identity
The righthand side of (
3) is the weighted sum-of-squares loss of the data points
with respect to their centroid
, which is often used in statistical tests and clustering algorithms. Equation (
3) asserts that this loss may also be computed from a weighted average of the norms of the data points.
When
is the probability simplex,
is the negative entropy, and
is the KL divergence, the information equivalence property (
2) expresses the equality of two equivalent formulations of the mutual information for discrete random variables. Let
A and
B be discrete random variables on alphabets
of size
n and
of size
ℓ, respectively. Suppose that their joint distribution is
. Let
be the vector with entries
; then,
is the marginal distribution of
B. The Jensen gap information
is
which expresses the mutual information
between random variables
A and
B in the entropy-reduction formulation,
[
19]. On the other hand, the divergence information
is
which expresses the mutual information
instead as the weighted sum of KL divergences of
from
.
Our contribution in this paper is to prove a converse to Lemma 1: the Bregman divergence is the only divergence that satisfies information equivalence with .
3. Main Result
Theorem 1. If the pair satisfies the information equivalence property (2), then d is the Bregman divergence induced by ϕ: for any and . Let
satisfy information equivalence (
2). For any
and
, we can write
for some unknown function
. We aim to show that
for all
and
.
Our first step is to show that
f is an affine function of its first argument
on
. To do so, we observe that if
and
are such that
, then we have
where the first line follows from information equivalence. It follows that
Fix
. Let
, and for any
let
. Pick
sufficiently small that, for all
, it holds that both
and
; this is possible due to the relative openness of
. For notational compactness, let
. Since
is the intersection of a Euclidean ball with convex set
, it is also convex.
Consider the function
given by
. The condition (
5) implies that
for any
such that
.
To show that is affine, it suffices to show that the function is linear on . We do this through two short lemmas. In each, we characterize the behavior of on the relative ball before extending this characterization to the entire domain .
Lemma 2. For any vector and scalar α such that , we have .
Proof. We will first prove the lemma in the restricted case that
and
. By Equation (
6), we have that
from which it follows that
. Let us now assume that
but that
is general; we will then use this to prove the more general setting
. We proceed by cases.
. The previous argument implies that .
. Since
, an application of Equation (
6) gives
; isolating
and applying the previous argument proves the case.
. This case follows by applying the proof of the previous case, replacing with .
Now, assume only that . Choose so that and ; is one sufficient choice. Then, by our previous argument, we have , from which we infer . Using this, we can compute , which proves the lemma. □
Lemma 3. The function is linear on : for any and vectors such that , it holds that Proof. Let us first assume that
and
. Applying Equation (
6) gives
from which applying Lemma 2 gives the result under these hypotheses.
We now consider the general case. For each
i, choose
so that
and
. Let
. Define the vector
with entries
. Then, by construction,
for each
i. Applying Lemma 2 and the restricted case above, we can then compute
which completes the proof. □
Proof of Theorem 1. Fix
. The preceding lemmas prove that the function
is linear on
. Since for constant
the function
f in (
4) is a translation of
in its first argument, it follows that
f is affine as a function of its first argument
. We may therefore write, for all
and
,
for some functions
and
.
We now determine these functions. First, since
is differentiable on
and
is affine in
,
is differentiable in its first argument on
. Since
d is a divergence,
is a critical point of the function
on
. It follows that
, the gradient of
d with respect to its first argument, is orthogonal to
at
:
for any
. We can compute
explicitly; it is
, which combined with (
8) gives
for any
and
.
Now, the condition that
implies that
. Using Equations (
9) and (
7), we then compute
Recalling the definition of
f in (
4), we conclude that
which is the Bregman divergence induced by
. This completes the proof. □
4. Discussion
We have shown that the class of Bregman divergences is the unique class of divergences that induce agreement between the Jensen gap and divergence informations. This result offers some further perspective on the role for Bregman divergences in data clustering and quantization [
2]. The Jensen gap information
is a natural loss function for such tasks, with one motivation as follows. Suppose that we wish to measure the complexity of a set of data points
with weights
using a weighted per-observation loss function and a term that depends only on the centroid
of the data:
A natural stipulation for the loss function
L is that replacing two data points
and
with their weighted mean
should strictly decrease the loss when
; this requirement is equivalent to strict convexity of the function
. If we further require that
when each row of
is identical, we find that
and that our loss function is the Jensen gap information:
. The present result shows that this natural formulation fully determines the choice of how to perform pairwise comparisons between individual data points; only the corresponding Bregman divergence can serve as a positive-definite comparator that is consistent with the Jensen gap information.
An extension of this result to the setting of Bregman divergences defined on more general spaces, such as Banach spaces [
1], would be of considerable interest for problems in functional data clustering [
20].



{kind=link}