1. Introduction
The exponential expansion of social media platforms has generated an abundance of digital content while simultaneously diversifying information access channels. News has also spread rapidly in multimodal format with the universal benefit of comprehensive content [
1], with multimodal news being more eye-catching and persuasive compared to text-only news [
2]. However, this simultaneously facilitates the growth of a considerable quantity of fake news, defined as misinformation that is intentionally fabricated or distorted to mislead or deceive news consumers [
3]. From an information-theoretic standpoint, the increasing volume and diversity of accessible information directly increase the uncertainty, complexity, and entropy inherent in fake news detection tasks. Consequently, automated fake news detection systems have been developed to identify misinformation on social media platforms, aiming to mitigate its harmful societal effects while ensuring that users receive authentic information.
The essence of the fake news detection problem is regarded as a binary classification problem, where the traditional content-based methods generally determine the authenticity of fake news by analyzing its content through different modalities. Initially, automated fake news detection approaches generally used the textual content to complete semantic feature modeling in order to make judgments [
4]. Due to multimedia technology decreasing the accuracy of unimodal detection approaches, researchers then attempted to extract multimodal features for fake news detection [
5,
6]. Specifically, multimodal learning models [
7] have been developed to comprehensively capture both textual and visual features through variational encoders [
8] and self-attention mechanisms [
9], reducing the cross-modal fusion gap [
10]. Moreover, because the background features of the news entity may impact detection accuracy, knowledge graphs have been introduced as additional information to support detection frameworks [
11].
The above-mentioned methods simply take into consideration the content without mining the deeper intrinsic structural relations [
12]; thus, structure-aware methods have been designed to solve such issues. Specifically, traditional neural network approaches such as RNN and CNN have been utilized to explore the potential structural features. In detail, social relationships are collected for application in the field of fake news detection [
13]; these relationships generally consist of the comments following news, the forwarding users, and their additional comments. Moreover, GAT and GCN have proved to be effective at reflecting the structural features of social relations and accurately obtaining representations of node features [
14].
Although current approaches have achieved satisfying performance, there remain two main shortcomings. First, simply extracting the feature vectors from text and images fails to capture the entire semantic information, potentially leading to semantic bias in the fusion process of cross-modal features. For example, in the second news story in
Figure 1, hardly any clues can be found to prove that it is fake only through the text and image. However, negative opinions arguing that the news may be fake can be read in the comments of different users. Second, the noise in the social relation graphs may lead to bias during information aggregation of nodes by traditional GNNs, resulting in decreased model performance. For example, it is evident that there is a common user (user 2) commenting on all news stories in
Figure 1, and their comments on both the first and second news stories take the same position. Obviously, this means there is a high probability that the last news story is fake, even though its text and image provide no evidence to prove that it is. Similarly, there may be some insignificant comments below each news story, such as the first comment on the first news story, the third comment on the second news story, etc. Overall, these comments are irrelevant to the news and could influence the performance of models; thus, they should be removed.
All of the above discussions are centered on the multimodal fake news detection task. Multimodal fake news detection is essentially a simple binary classification task performed to identify whether posts are true or false. Specifically, it aims to map posts to the most likely labels by learning their rich feature inputs, including unimodal features, multimodal features, and social relations. Compared with previous binary classification problems, its uniqueness lies in the use of features from different modalities to improve detection efficiency. For example, text, images, and social relations are all modalities, and the interactive fusion generated among them constitutes multimodal feature fusion, which is a non-negligible factor affecting the classification effect.
In this study, we propose a novel Semantic-enhanced Cross-modal Co-attention Network (SCCN) for multimodal fake news detection. It not only utilizes entity extraction to semantically enhance news but also enables the effective integration of text, images, and social relations. To better capture the structural features, we first model social relations as a graph and make some improvements to GAT. On one hand, we detect latent connections among nodes to enhance the social relation graph while simultaneously reducing noise interference. On the other, we introduce a sign strategy to capture neighbor-to-node correlations and amplify the positive–negative feedback to optimize the node representation. Unlike social relations, we encode text and images directly in addition to enhancing them with entity features. Next, we map their feature vectors to the same semantic space by performing cross-modal alignment operations on different modalities. Finally, self-supervised loss and co-attention mechanisms are introduced to reduce noise and improve the fused feature representation for cross-modal fusion. By learning the social relation graph representation and cross-modal fusion, we can enhance the capability of the model for fake news detection.
The main contributions in this study are summarized as follows:
We propose a novel Semantic-enhanced Cross-modal Co-attention Network for multimodal fake news detection, which focuses on utilizing the entity features for semantic enhancement and exploring the social relation graph.
We narrow the gap between different modalities by combining the entities and semantics of different modalities. In addition, we introduce self-supervised learning along with co-attention mechanisms for denoising, ultimately enhancing news semantics.
We introduce social relations as the structural features and design an improved GAT to process the social relation graph, thereby improving the representations from learning social relation graphs through enhanced neighborhood aggregation.
The rest of this paper is organized as follows:
Section 2 reviews the existing approaches for fake news detection and analyzes their shortcomings;
Section 3 introduces our proposed SCCN approach;
Section 4 provides the experimental details, including the research questions, datasets, baselines, and experimental setup;
Section 5 analyzes the results of experiments and discusses the findings of our experiments from different perspectives; finally,
Section 6 concludes our current study and outlines prospects for future studies.
2. Related Studies
Existing studies on multimodal fake news detection can be categorized into two types: those with semantic-based features and those with structural-based features.
Semantic-based features are expressed not only in text but also in images [
15]. This is due to evidence showing that multimodal approaches outperform unimodal approaches in fake news detection [
16]. In detail, Wang et al. [
2] proposed EANN, an end-to-end model capable of capturing features that are robust to event variations. However, its reliance on annotated data and computationally intensive training processes could limit scalability and training stability. Another end-to-end network is MVAE [
1], which utilizes a bimodal variational framework to learn a probabilistic latent variable model. However, its dependence on paired multimodal data and complex architecture could limit its applicability in scenarios with incomplete or single-modality content. In addition, QSAN [
17] employs quantum-inspired text analysis and a unique attention system to accurately identify rumors while making its decisions understandable through clear explanations and by highlighting relevant user comments. Due to its complex design and quantum-based computations, this model requires more computing power than traditional detection approaches. Furthermore, Zhou et al. [
15] evaluated both the internal relationships within each modality and the cross-modal similarities between text and images for fake news detection. Chen et al. [
18] solved the misclassification problem caused by inconsistency across modalities with cross-modal ambiguity learning. In [
18], an attention-guided module was proposed to realize more accurate modal alignment and increase the interpretability of modal relationships [
19].
However, the aforementioned approaches ignore the rich structural features in news and the plentiful factual information in knowledge graphs. To better explore the structural features in news, researchers have explored ways of representing news content through graph-based structures [
20]. For example, EBGCN [
21] boosts detection accuracy by dynamically adjusting unreliable edges in rumor propagation graphs; however, its Bayesian framework requires more training data to stabilize probabilistic inferences compared to deterministic models. The GLAN model [
13] effectively merges local semantic relationships with global structural patterns through attention mechanisms, achieving superior rumor detection performance. However, its effectiveness can be compromised by noisy data in early propagation phases, and requires precise hyperparameter tuning to maintain optimal performance. Based on Yuan et al. [
13], Qian et al. [
22] integrated the modalities to capture important information in posts and further utilized a learning principal of knowledge-aware multimodal graphs to adaptively learn features from news stories. MPFN [
5] improves fake news identification through the layered integration of text and image data, but requires greater processing power due to its advanced architecture and multi-stage blending components. Finally, MFAN [
10] advances rumor detection through its novel integration of multimodal features and attention mechanisms; yet, its effectiveness depends on comprehensive data coverage across all modalities, and requires substantial computational resources for optimal operation.
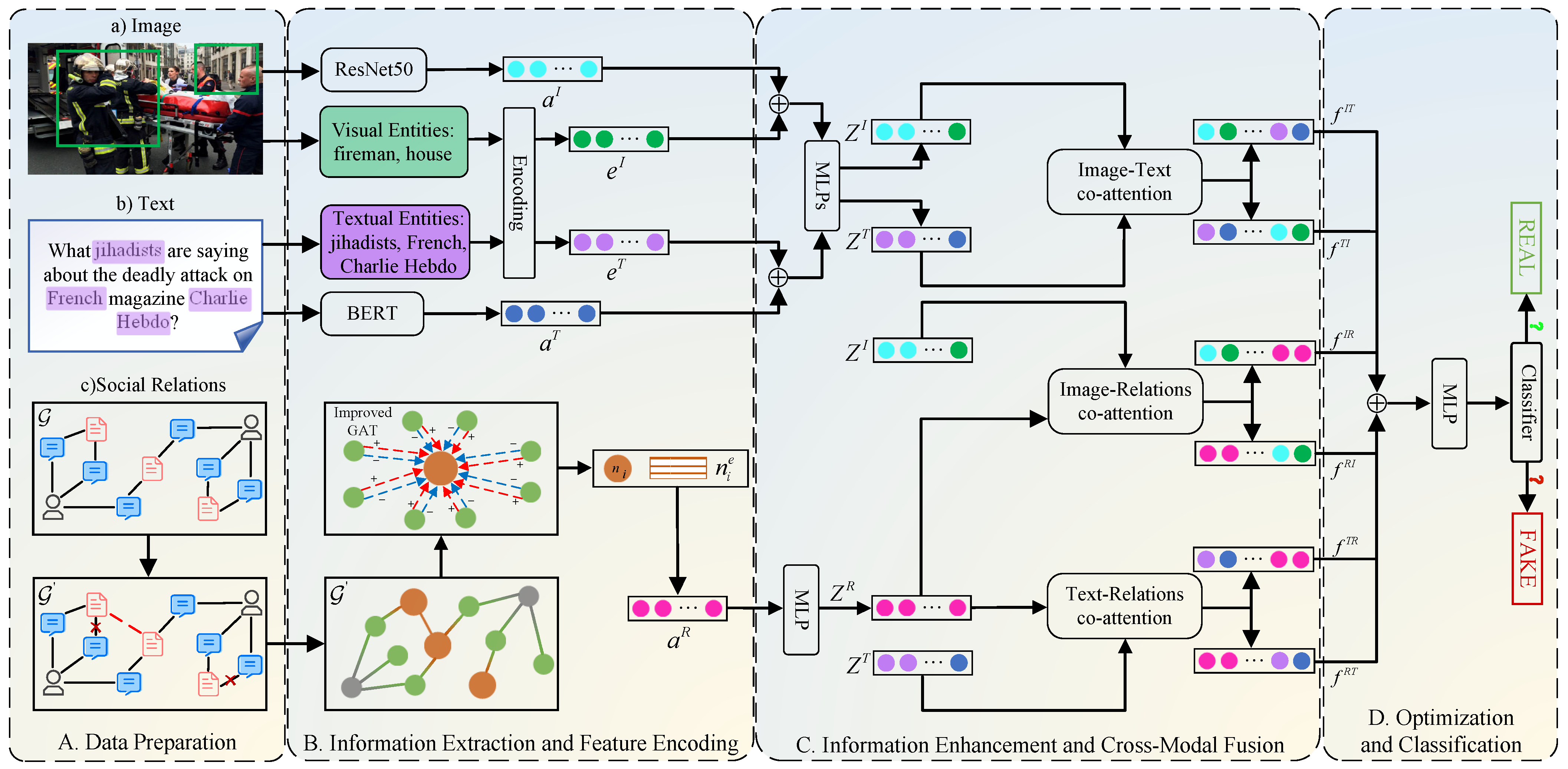
3. Approach
In this section, we detail the proposed SCCN, the framework of which is presented in
Figure 2. As demonstrated in
Figure 2, SCCN comprises four fundamental components. First, data preparation (
Section 3.1) includes the preparation of images, text, and relations along with the problem definition. Second, information extraction and feature encoding (
Section 3.2) extracts and encodes the entities from image and text, respectively. In addition, the feature vectors of visual, textual, and social relations are obtained by the corresponding encoders. Third, information enhancement and cross-modal fusion (
Section 3.3) enhance the text and image features through entity extraction; meanwhile, an improved GAT is utilized to refine the characteristics of social relations. In addition, we utilize a co-attention mechanism to realize the integration of images, text, and social relations. Finally, optimization and classification (
Section 3.4) is mainly used to optimize the cross-modal fusion features and realize fake news detection through classifiers.
Below, we denote the data by mathematical symbols for convenience of description. Specifically, let
be a set of news on social media containing multimodal features and their labels, which can be denoted as
and
, respectively. For each news
, which is a quadruple,
,
,
, and
represent the text, images, users, and comments, respectively. Moreover,
denotes the set of comments on news
, where each comment
corresponds to a user
. To better understand the mathematical symbols mentioned above, we take
Figure 1 as an example to illustrate the specific meaning of each symbol corresponding to
Figure 1. First, the three posts and their labels can be represented as
and
, respectively. Then, we focus on the first post (
), where
is the text “Syrian girl selling chewing gum in the street of Jordan”,
is the image in this post,
contains two users (user 1 and user 2), and
includes three comments posted by two users. To highlight the connections between news, users, and comments, we build a heterogeneous graph
, called a social relation graph, where
V represents the set of nodes, including the above-mentioned three types of nodes. Moreover,
is an adjacency matrix which reflects the connections between nodes, i.e., the value is 1 if there is a link between nodes and 0 if there is none, with
E as the set of edges between nodes.
In this paper, we define fake news detection as a binary classification task. The value of label y is 0 or 1, where represents fake news and legitimate news. The objective of our study is to predict the label of a given news item D through our proposed SCCN model.
3.1. Data Preparation
Real-world news stories posted on social media contain rich content and structural features such as images, text, and social relations [
23]. Specifically, each news story contains various entities and covers different abundant modalities. The special relationships between different modalities, including images, text, and social relations, provide us with ideas for fake news detection.
In the data preparation section, we extract the data that our proposal requires from the datasets, such as images, text, users, and comments. For the users and their comments on the news, we visualize the relationship between them in a graph, which can be called the social relation graph. To infer hidden links and remove noisy links, it is necessary to process the social relation graph. According to the homogeneity of graph neural networks, we assume that similar nodes are more likely to be associated with each other than dissimilar nodes [
24]. Therefore, it is possible to infer the links between nodes with high similarity and remove noisy links between nodes with low similarity by calculating the similarity of features between different nodes.
Specifically, for the embeddings of nodes in , the vectors of text in news and the vectors of sentences in comments are used as the initial embeddings of news nodes and comment nodes, respectively. Then, we adopt the mean value of all comment embeddings published by one user as this user’s embedding vector. To facilitate the subsequent computation, we construct the node embedding matrix , where each row represents the embedding of one node and d represents the dimension size of the embeddings.
After that, we use the cosine similarity to calculate the similarity coefficient
between nodes
and
, as follows:
where
and
denote the embeddings of nodes
and
, respectively.
Based on the findings of a previous study [
10], we argue that if there is currently no link between nodes, the potential link may exist if the similarity coefficient is above 0.5. Moreover, if there is already a link between nodes, this link can be regarded as noise if the similarity coefficient is below 0.2. This can be formulated as follows:
where
is a transition variable that measures the similarity between nodes
and
.
Next, we improve the original adjacency matrix
A based on
, i.e., removing the noisy links and adding the potential links, which can be formulated as follows:
where
and
are the elements in the initial and improved adjacency matrices
A and
, respectively.
Up to this point, we have enhanced the performance of the model and reduced its training time by removing distracting noise such as malicious comments and bot users from the social relation graph. In this way, we obtain the improved social relation graph and input the image, text, and graph to the next step.
3.2. Information Extraction and Feature Encoding
In the information extraction and feature encoding module, we adopt a synchronous processing mode for processing the input data to obtain the required feature vectors, i.e., learning the text and image representations and the social relation graph representation.
3.2.1. Text and Image Representations
First, we extract the corresponding entities from the image and text of each news story using the existing entity linking tool TAGME (
https://sobigdata.d4science.org/group/tagme/ (accessed on 27 March 2023)), which can precisely identify the entities and provide their confidence coefficient. Then, we retain the entities with confidence coefficients larger than 0.2 as the final entity extraction results. In addition, a pretrained TransE model [
25] attaches them to the Freebase [
26] knowledge graph to obtain the background knowledge features
and
as the entity embeddings.
Subsequently, we extract the feature vectors from the text and image using the respective encoders. Specifically, we utilize the pretrained BERT [
27] and ResNet-50 [
28] as the encoders for text and image, respectively. However, the length of the text generally varies for different news stories. Therefore, to facilitate subsequent operations, we set the text of different news to be of the same length, i.e.,
L, through padding or truncating, which can be denoted as follows:
where
d is the dimension of the word embeddings and
is the text embedding of the
i-th news item, which consists of
L word embeddings.
Next, this embedding sequence is fed into Bi-LSTM [
29] to obtain the text feature vector
, as follows:
where
is the learnable weight matrix and
is the bias vector.
For the image, we extract the output of the second-last layer of ResNet-50 [
28] and subsequently feed it through a fully connected layer to generate a feature vector
with the same dimensions as the text feature
. This can be formulated as
where
is the output of the second-last layer of ResNet-50 and
is the weight matrix of the fully connected layer.
3.2.2. Social Relation Graph Representation
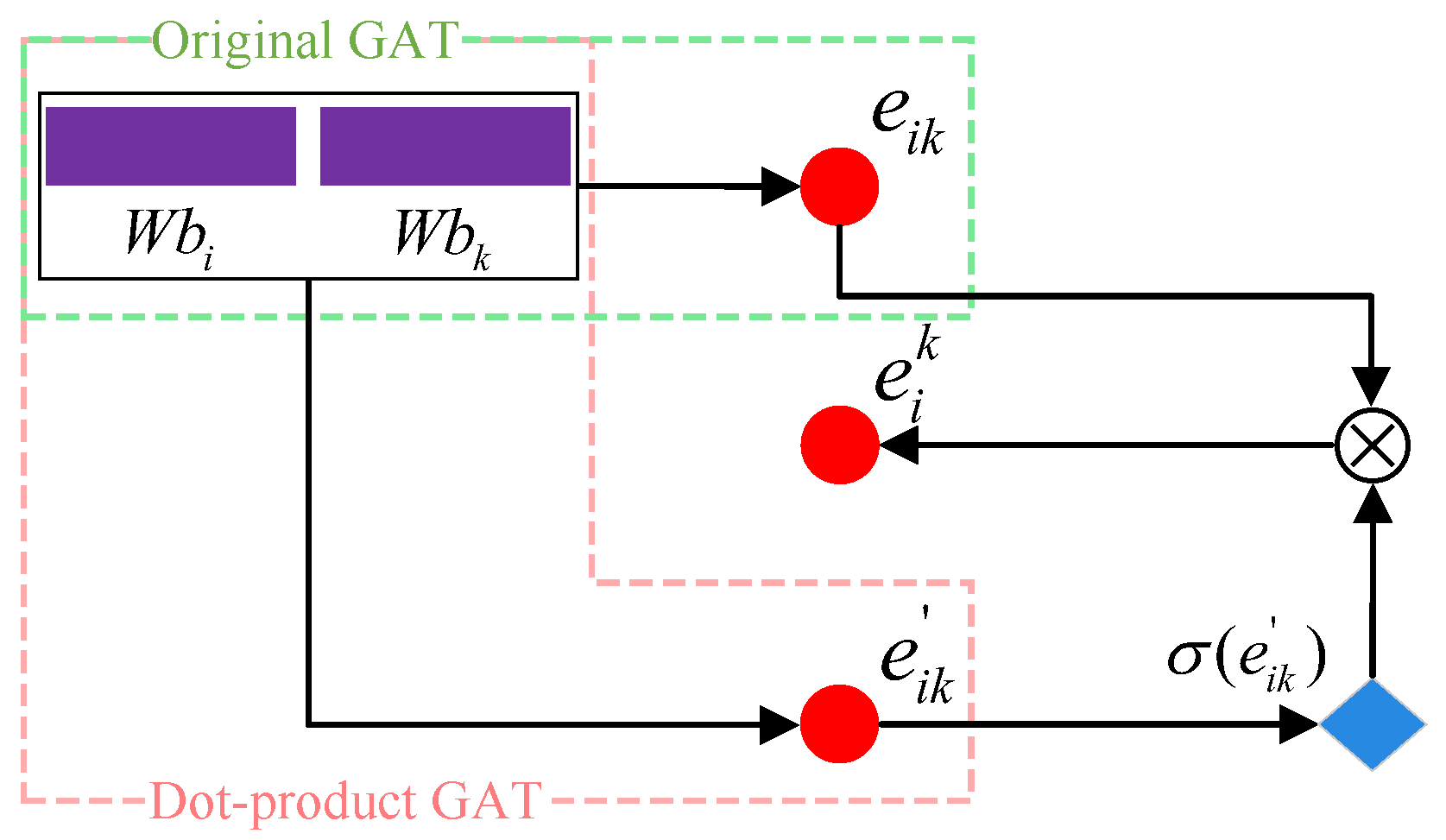
Unlike the above two types of representations, the social relation graph contains abundant structural features. Inspired by Velickovic et al. [
30], Graph Attention (GAT) networks can capture the graph structure features for graph processing. However, traditional GAT suffers from poor interpretability and inconsistent performance across datasets when the processed graphs are complicated [
24]. Thus, we propose an improved GAT to capture the correlations of the neighbor nodes for better graph feature representation, the pipeline of which is shown in
Figure 3.
Specifically, for node
and its set of neighbor nodes
in graph
, we first calculate the attention weights
, where the element
denotes the attention weight between
and
. In detail, it can be seen in
Figure 3 that we integrate two common attention mechanisms of the traditional GAT, i.e., the single-layer neural network and the dot product [
30]. This can be formulated as
where ‖ is the concatenation operation,
is a parameter in the single-layer neural network,
W is a learnable weight matrix, and
and
are the embeddings of node
and its neighbor node
, respectively.
Next, to facilitate the following calculation, we employ the softmax function to normalize the obtained attention weight set . In addition, we note that some of the attention weights become very small after normalization, which means that these neighbor nodes have very little influence on node . Such situations generally occur when the attention weights are negative. In fact, the attention weights objectively reflect the potential influence of the neighbor nodes on node , which include both positive and negative influences, and these influences’ reflection in the values of the attention weights is correspondingly positive or negative. However, the direct application of the softmax function ignores the negative influence, which we also need to focus on.
For instance, given a specific node
, we obtain its attention weights as
; the subsequently obtained attention coefficients after normalization are
. It can be observed that the neighbor node with attention weight
has a normalized attention coefficient
, which indicates that its contribution to the output is almost negligible. This large negative influence implies that the embeddings of these two nodes are in opposite directions, which may be beneficial for fake news detection. This situation may be an instance of “cheating” or “camouflage” [
14]. In certain cases, there may be paid-for real comments on fake news stories or malicious comments added to discredit real news [
14].
As a result, inspired by [
17], we introduce a sign mechanism to correctly handle the positive and negative relations between nodes. In detail, we obtain
after taking the opposite number of attention weights
for node
, i.e.,
. Afterwards, normalization is implemented with the softmax function for the two attention weights
and
to obtain the corresponding attention coefficients. This can be formulated as follows:
where
and
are the two attention coefficients.
To completely capture the interactions between nodes, we obtain the weighted aggregation of the neighbor nodes of
with
and
, respectively. Subsequently, the above vectors are concatenated and fed into a fully connected layer to obtain the final vector representation of node
. Note that we utilize multihead attention in order to adapt to the complex graph structure in this process. This allows the model to fully take into account the correlation and importance between different nodes, resulting in improved expressive ability. The multihead attention can be formulated as follows:
where
K is the number of heads,
is the activation function,
is the weight matrix of the fully connected layer of the
k-th head, and
is the embedding matrix of the neighbor nodes.
To this point, the final embeddings of all nodes are calculated by Equation (
9) and denoted as the node embedding matrix
. Finally, the multihead attention mechanism [
31] is employed to acquire the features of the social relation graph as follows:
where
K is the number of heads and the
i-th column of
G denotes the graph feature of the
i-th news item.
3.3. Information Enhancement and Cross-Modal Fusion
In this section, we perform information enhancement and cross-modal fusion using the feature vectors obtained from
Section 3.2 for text, image, and the social relation graph. For the feature vectors of the text and images, we use their entity embeddings to implement self-information enhancement. Specifically, taking an image as an example, we concatenate
and
before feeding them into a multilayer perceptron to obtain the information-enhanced feature vector
. Moreover, the information-enhanced feature vector
of the text can be calculated in the same way. For the social relation graph, we acquire the feature vector
with the same dimension as
by feeding
G into a multilayer perceptron [
31]. This can be formulated as
where
is the activation function,
,
, and
are the learnable weights matrix, and
,
, and
are the bias vectors.
It cannot be ignored that performing the cross-modal fusion operations inevitably causes intrinsic loss of information between modalities, which should be intrinsic to the representation of different modalities in the original news story. This leads to the features extracted from disparate modalities potentially exhibiting substantial semantic gaps. To address this issue, a novel cross-modal alignment with self-supervised loss is introduced to refine the feature representations. For example, we map the produced feature vectors
and
to the same semantic space as, follows:
where
and
are the learnable parameters. After this, we adopt the MSE loss to narrow the distance between
and
:
where
n is the total number of news stories.
Similarly, we can map
and
along with
and
to the same semantic space and calculate their MSE loss as
and
, respectively. Then, we add the above three losses to obtain the final loss of the cross-modal alignment, as follows:
Up to this point, we have obtained the cross-modal aligned graph feature vectors of images, text, and social relations as
,
, and
, respectively. In addition, considering that there are three feature vectors from different modalities, we need to integrate their embeddings in order to improve the credibility before detection. Inspired by Lu et al. [
32], we adopt a cross-modal fusion approach with a co-attention mechanism.
Specifically, we adopt the co-attention mechanism between every two modalities to obtain the cross-modal features containing the key information between the two corresponding modalities. Taking the fusion of text and images as an example, we use , , and to calculate the query matrix, key matrix, and value matrix, respectively. In this case, , , and are the linear transformation matrices, where K is the number of heads and d is the dimension of the feature vectors.
Then, we can produce the cross-modal feature
between the text and images, calculated as follows:
where
represents the linear transformation matrix.
However, it is evident that
is actually the visual feature enhanced by a textual feature, which does not fully reflect the characteristics and relations between the two modalities. Therefore, we exchange the representation of text and image in Equation (
15) to obtain another cross-modal feature
, which is the textual feature enhanced by the visual feature. For the other two groups of modalities, we obtain the mutually reinforced cross-modal features in the same way. For convenience of distinction, we denote these as
,
,
, and
, respectively. Finally, we concatenate them as the final multimodal fusion feature, as follows:
3.4. Optimization and Classification
In the optimization and classification module, we feed the final multimodal fusion feature
Z into a fully connected layer to predict the labels of news stories, as follows:
where
denotes the predicted scores.
In our model, the entropy can be used to measure the dispersion and uncertainty of the experimental results. In the proposed framework, high entropy reflects significant divergence between detection results and ground-truth labels, whereas low entropy indicates stable convergence. Information theory offers quantitative frameworks for three critical aspects of probabilistic systems: entropy for uncertainty assessment, KL divergence for distributional differences, and mutual information for dependency measurement. Inspired by the theoretical understanding of entropy in information theory, we adopt the cross-entropy loss function as the loss function for this binary classification problem. The optimization strategy of SCCN explicitly targets entropy minimization through cross-modal feature learning, as follows:
where
y indicates the ground truth of the fake news detection label.
Considering that cross-modal alignment is conducted to narrow the semantic gaps between modalities, the generated loss may contribute less to the final classification. Thus, we introduce two parameters,
and
, to respectively regulate
and
in the total loss function. We then combine
and
to compute the final loss function of SCCN, as follows:
However, we find that the text of some news items does not strictly follow the grammar rules in practice, which may reduce the efficiency of our model to some extent. To resolve this issue, we add an adversarial perturbation mechanism, i.e., the Projected Gradient Descent (PGD) [
33], to enhance the robustness of our model when extracting the text embeddings. The effectiveness of PGD has been proven by Madry et al. [
33]. In detail, we compute the gradients of the text features in training and add perturbations to the text features. We then recalculate its gradient and repeat the above process
T times. Finally, all the adversarial perturbations are accumulated into the original gradient and the parameters are updated.
More details of the PGD are provided in Algorithm 1. Specifically, in this algorithm,
is a function that returns the sign of the gradient
g, indicating the direction in which the input should be perturbed in order to maximize the loss. Moreover,
and
are functions which respectively ensure that the perturbations are within acceptable bounds and that the perturbed inputs are projected back into the valid data space.
| Algorithm 1 Procedure of PGD |
- Require:
The original dataset . The initialized model parameter . Set the epoch number T, the step size and the perturbation limit . - Ensure:
The model parameter . - 1:
Initialize randomly. - 2:
for each epoch to T do - 3:
for each batch in D do - 4:
Calculate the gradient of the loss function: - 5:
. - 6:
Compute the perturbation in the direction of the gradient: - 7:
- 8:
Apply the perturbation to the data, ensuring it does not exceed the limit : - 9:
- 10:
Project the perturbed data back into the valid data space: - 11:
- 12:
Update the model parameter : - 13:
- 14:
end for - 15:
end for - 16:
return the updated .
|
5. Results and Discussion
In
Section 5.1, we evaluate the overall performance of our proposed SCCN and the baselines. Following that, we conduct an ablation study to investigate the impact of each component within our proposal in
Section 5.2. We then perform a quantitative analysis to visually evaluate the performance of the SCCN and its variants in
Section 5.3 based on an ablation study, as well as comparing it to several baselines for further verification of its validity. Next, we perform a convergence analysis to verify the overfitting risk of the proposed SCCN in
Section 5.4. In
Section 5.5, we analyze the influence of hyperparameters on our model from different angles. Finally, to further understand our SCCN model, we conduct case studies in
Section 5.6.
5.1. Overall Performance
First of all, we evaluate the fake news detection performance of the SCCN as well as the baselines in
Table 2.
For the discussed baselines, we find that the performance of the models that consider social relations is much better than that of the other methods. Note that the baselines listed here are all multimodal fake news detection methods. In detail, the KMAGCN model achieves up to 3.1% and 1.1% performance improvement over the MPFN model on the PHEME and Weibo datasets, respectively. This illustrates the importance of capturing structural information from social relations for fake news detection.
Next, we zoom in on the comparisons of our SCCN against the baselines. Generally, it is evident that SCCN exhibits superior performance in comparison to all the baselines on both the PHEME and Weibo datasets. For instance, SCCN achieves respective performance improvements of up to 1.7% and 1.6% over the best baseline method on the PHEME and Weibo datasets. We consider that the advantage of SCCN is due to its ability to combine the entities and semantics of different modalities along with its optimized representation of social relation graphs.
Because the PHEME dataset is sourced from Twitter, most of the posts are related to specific things and the correlations between them are minor; as a result, this dataset is more likely to result in overfitting. Nevertheless, SCCN performs better on both datasets. This advantage can be explained by the fact that SCCN leverages a co-attention mechanism to enhance text and image representations with entity features. Thus, it can refine feature vectors, which is more conducive to subsequent fusion. In addition, we introduce social relation graphs consisting of news, users, and their comments in order to extract the potential structure features from news items, allowing SCCN to further complete the feature representation.
To further explore the practical deployability of SCCN, we use the three metrics of time, inference latency, and memory.
Table 3 shows the time, inference latency, and memory of SCCN on the PHEME and Weibo datasets, respectively. Based on these results, all three capability metrics for our model are within a reasonable range of intervals, showing good potential for practical deployment.
5.2. Ablation Study
Next, we perform an ablation study to gain deeper insights into each component of our proposed SCCN and the different modal embeddings contained within it.
5.2.1. Effect of Modules
To assess the impacts of key components of SCCN on detection performance, we construct the following model variants: (1) SCCN w/o DPS: Removes the processing of all raw data in the data preparation section and replaces it with the direct utilization of raw data as input. (2) SCCN w/o SRG: Eliminates the social relations component, considering only the text and image modalities for final fake news detection. (3) SCCN w/o IEM: Replaces the output of the information enhancement modules with the original embedding vectors for the subsequent cross-modal fusion operation. (4) SCCN w/o CMF: Replaces the output of the cross-modal fusion module with the sum of the feature vectors for text, images, and social relations.
Table 4 shows the results of the ablation experiments. We use the accuracy and F1 score indicators, as these most clearly reflect the performance of the different models. Overall, the different SCCN variants all underperform the original model in terms of accuracy and F1 score, suggesting that each module in our model makes a significant contribution to the final performance. Specifically, we summarize the following points:
Comparing the four variants of SCCN, we find that the SCCN w/o DPS, SCCN w/o SRG, and SCCN w/o IEM variants all show obvious performance drops, indicating that introducing data processing, social relations, and information enhancement strengthens the performance of our model. From an information-theoretic perspective, greater performance degradation indicates higher uncertainty and entropy in the variants, demonstrating enhanced effectiveness of our model architecture when incorporating the proposed modules. Moreover, the results of the ablation study indicate that combining text, images, and social relations can facilitate cross-modal feature fusion in a way that is crucial for fake news detection.
The performance decrease for the SCCN w/o CMF variant proves that the cross-modal fusion module implemented with the co-attention mechanism helps to improve the performance of our model. Furthermore, all variants show similar performances on both the PHEME and Weibo datasets, while the complete SCCN model performs better on Weibo than PHEME dataset, demonstrating that these modules play a greater role in the Weibo dataset.
5.2.2. Effects of Different Types of Modal Embeddings
To more deeply investigate the effects of different modalities and fusion strategies on detection efficacy, the next experiment removes specific modalities from the model. In
Figure 4,
-Text indicates the removal of the text modality,
-Image indicates the removal of the image modality, and
-Relations indicates the removal of the social relations modality.
As shown in
Figure 4, the full SCCN model outperforms all other variants with different types of modal embeddings. Moreover, in comparing the three variants it can be seen that the detection effect is greatly reduced by removing the text modality, which means that the textual content is more important for fake news detection. We consider the cause of this phenomenon to be the fact that the textual description usually reflects the essential features of a post more accurately, while visual features and social relations may be contaminated by less critical or even irrelevant information [
36]. Similarly,
-Image outperforms
-Relations, which is due to the social relation graph containing comment nodes. Moreover, comment nodes contain information about users’ comments, which is also represented as textual content. Thus, the text modality assumes a more prominent role in detection.
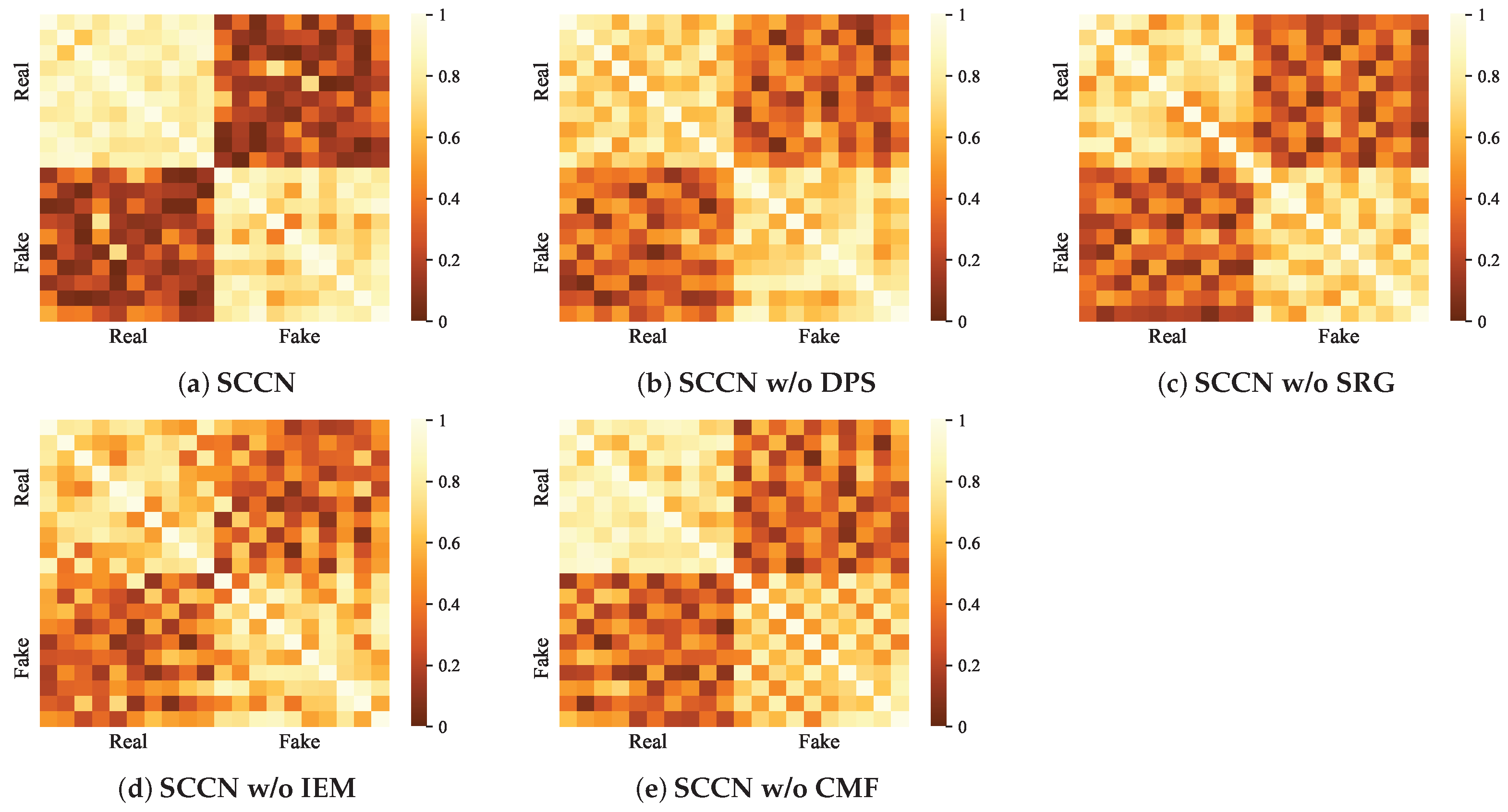
5.3. Quantitative Analysis
The ablation experiments allow us to obtain a basic view of the respective impacts of the different modules on the whole model. To more intuitively show the contribution of each module in our model, we visualize the SCCN and its variants on the PHEME dataset. In detail, we adopt heat maps to realize data visualization for the PHEME dataset. Considering that most of the posts in the PHEME dataset are related to some specific events, we randomly select twenty news items from the dataset, including ten pieces of real news and ten pieces of fake news, then input them into the SCCN model and its variants to obtain
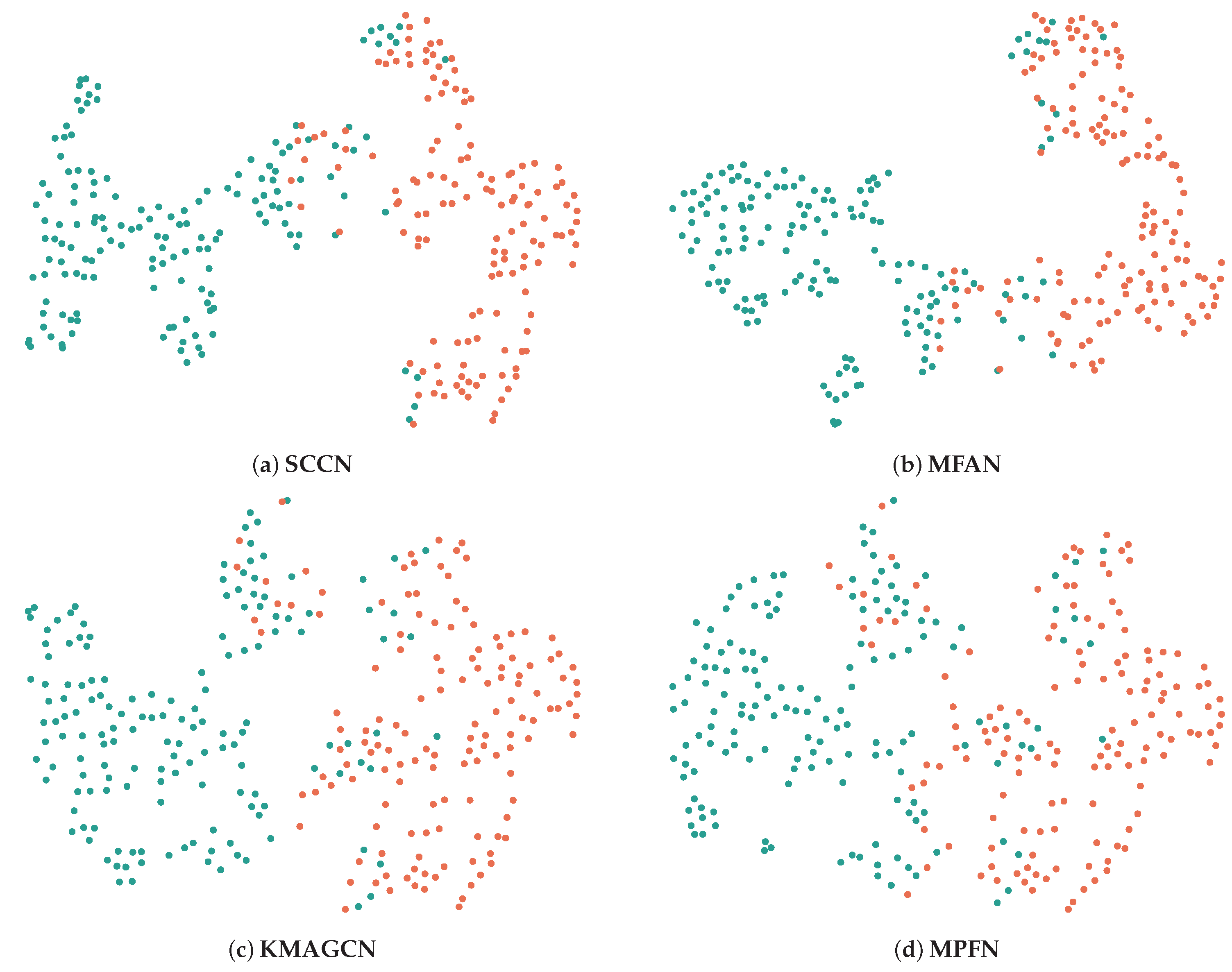
Figure 5. Meanwhile, we use t-SNE visualization to perform an in-depth analysis of the features learned by SCCN and several baselines, with the results shown in
Figure 6.
Figure 5 compares the fake news detection capabilities of our model and its variants using the PHEME dataset. We observe that SCCN provides clear boundaries between real and fake news while showing similarities between the classes. However, the rest of the methods tend to blur the boundaries between real news and fake news, meaning that their performance is poorer and that they are less likely to recognize fake news. The visualization results here are similar to those of the ablation experiments in
Section 5.2, with both showing that the performance of the SCCN w/o SRG and SCCN w/o IEM variants is inferior to that of SCCN w/o DPS and SCCN w/o CMF. This suggests that our visualization experiments are consistent with the performance results of the ablation experiments, providing a certain degree of credibility. Social relations are not considered by the SCCN w/o SRG variant, which only integrates text and image features are; this may result in some critical information hidden in the comments being missed. Moreover, the lack of structure information can lead to difficulty in excavating the correlations between news stories to some extent, resulting in reduced model performance. Compared to the SCCN, the SCCN w/o IEM variant not only fails to utilize entity features for the information enhancement of text and image modalities but also struggles to process the information in the social relation graphs without the improved GAT. This can lead to the omission of important information when processing modal information; in other words, it can amplify the noise generated by non-essential information, which can seriously affect model performance. In general, each module of our proposed model plays a favorable role in fake news detection in both the ablation experiments and the quantitative analysis.
Unlike the above format, we next use the t-SNE visualization method to visualize the test set data of the Weibo dataset, as shown in
Figure 6. We choose the three most representative baselines for comparison with our model, of which only MPFN does not utilize social relations. Specifically, the boundary between real news and fake news is clear and obviously noticeable with SCCN, indicating that its classification effect is the best among the different models. Similarly, the boundaries obtained with MPFN seem rather indistinct compared to the first three models. It is hypothesized that this phenomenon may be attributable to underutilization of certain social relationships within the dataset, such as users and comments. From an information-theoretic perspective, when feature representations from distinct categories appear in close proximity within the visualization space, this suggests reduced inter-class informational divergence and increased mutual information between categories, both of which represent undesirable characteristics for effective classification. Additionally, the visualization results show general consistency with those in
Table 2, demonstrating the rigor of our experiments.
5.4. Convergence Analysis
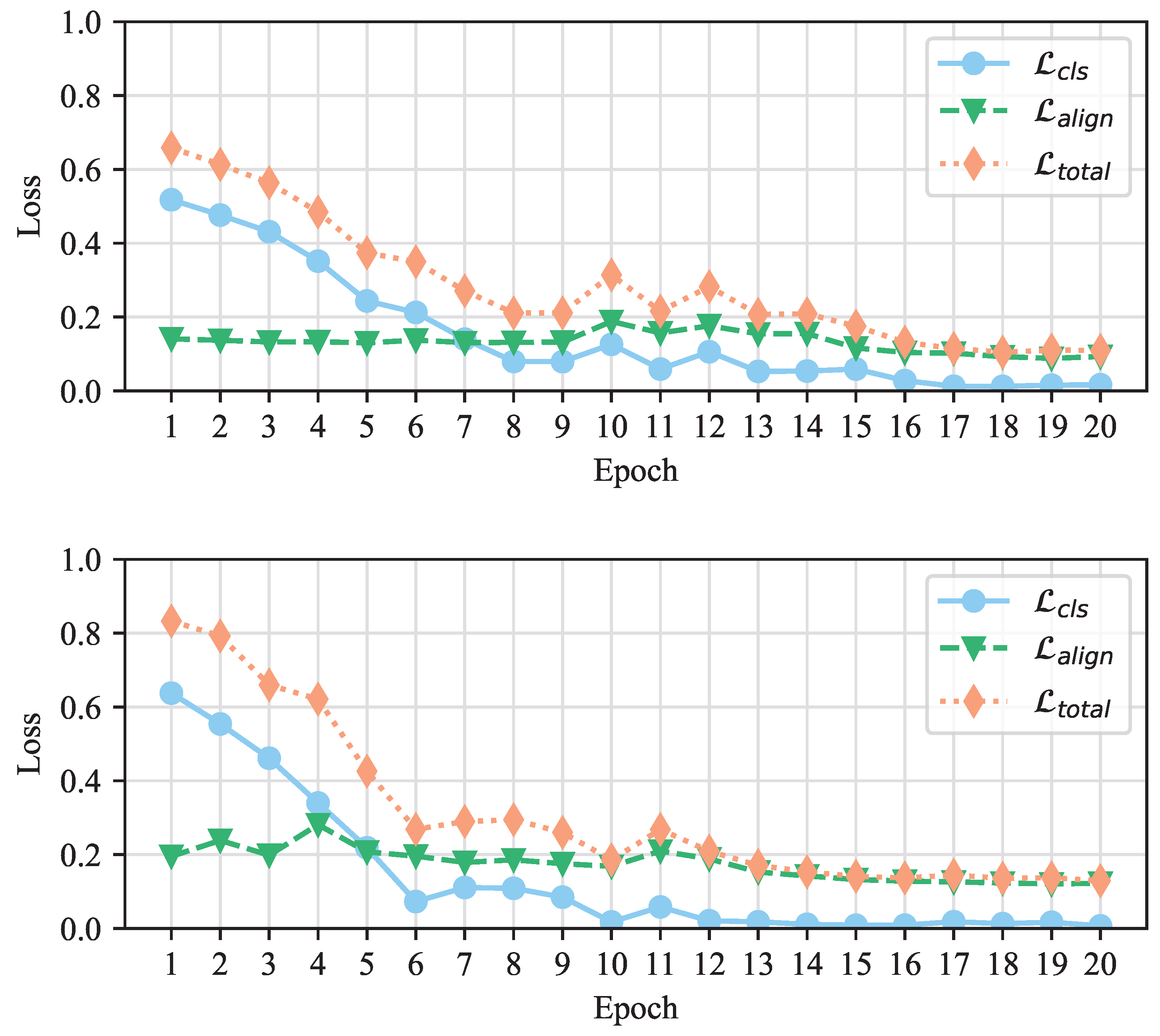
To assess the contributions of
and
during training and verify the convergence of our SCCN model, we generate average loss curves for SCCN in
Figure 7. It is evident that the total loss results on both the PHEME and Weibo datasets show a decreasing trend before eventually stabilizing. This is an effective indication that our model has good stability and robustness. In addition, we provide the values of
and
at each epoch, finding that the initial value of
is higher and the overall downward trend is more obvious than that of
. We believe that the reason for this phenomenon is that there are too many modules in the model. This causes large classification loss in the whole process, although it still plays an important role in training.
5.5. Parameter Analysis
Our proposed SCCN method adopts fixed lengths for the text and convolution kernel sizes; thus, selecting these hyperparameters may have a significant effect on its performance. In the next experiments, we examine the parameter sensitivity in order to analyze the influence of different hyperparameters in our model. According to the principle of control variables, we minimize the influence of other irrelevant parameters. We then demonstrate the feasibility of the parameter settings by performing parameter sensitivity experiments on the text length and the size of the convolution kernel.
5.5.1. Length of Text
Based on the objective fact of text length in the datasets, we set the length of text
and record the accuracy and F1 score.
Table 5 demonstrates the performance of the model with different text lengths. It can be seen that the text length has an effect on our model to some extent. In detail, the performance of SCCN decreases if the text length is too short or too long. A possible reason for this trend is that when the text length is too short, it cannot provide sufficient information for SCCN to accurately distinguish fake news. Moreover, although longer text lengths can provide enough information, they introduce noise which may affect the performance of the model.
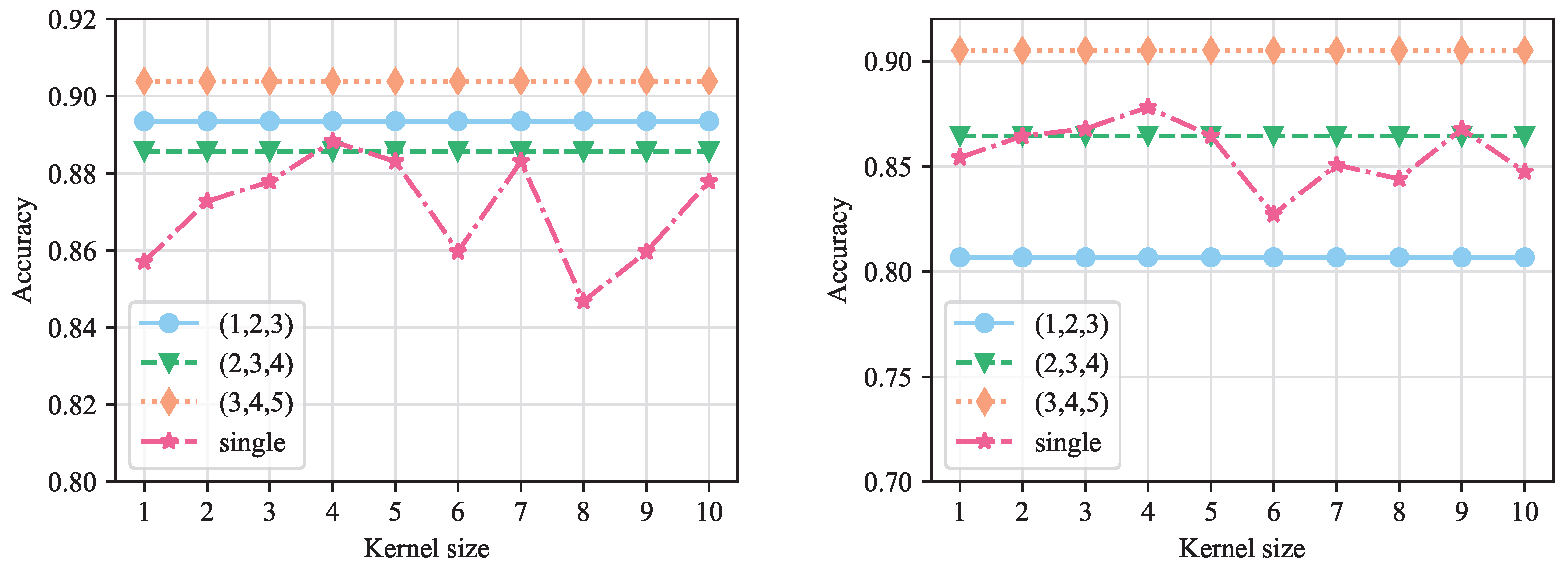
5.5.2. Size of the Convolution Kernel
Figure 8 shows the accuracy comparison of different convolution kernel sizes on the PHEME and Weibo, where the x-axis indicates the kernel size. Experiments on both datasets indicate that when the kernel size is set to a single fixed value, the performance increases as the kernel size increases, peaking around sizes of 3 and 4. In addition, we conduct comparative experiments utilizing various convolutional kernel configurations. The results demonstrate that a hybrid architecture incorporating kernel sizes of 3, 4, and 5 yields optimal detection accuracy; consequently this configuration is implemented in the full SCCN model. The effectiveness of combining multiple convolution kernel sizes can be understood based on the fact that different kernel sizes can help the model to capture distinctive information from multiple perspectives, which is conducive to promoting the exploration of potential key information.
5.6. Case Studies
To further illustrate the importance of social relations and entity extraction in the proposed SCCN, we provide some examples of fake news identified by our model to demonstrate its effectiveness.
Figure 9 shows an example of fake news detected by our proposed SCCN model on the PHEME test set. In
Figure 9a,b, the attached image and text examples appear normal without any anomalies, and there is no significant difference in the content that they intend to convey. This provides reasonable grounds to consider them real news. However, our model identifies irregularities in their social relations, leading to their classification as fake news. Specifically, the comment section under the news post in
Figure 9a exhibits a pattern of highly repetitive user interactions, with multiple comments containing identical or near-identical minimal responses (e.g., “Seems these cops think too much and know too little.”). Similarly,
Figure 9b exhibits an analogous pattern, indicating that our model can effectively identify evidence of fake news from social relationships and flag news items accordingly.
Although social relations have proven instrumental in fake news detection, the intrinsic characteristics of textual and visual entities remain indispensable and should not be neglected. In
Figure 9c,d, “Ottawa”, “Sydney”, and “Lindt Cafe” are key pieces of information that enable readers to recognize whether the news is true or not. Nevertheless, not all readers are familiar with the meaning of these entities. Moreover, it is not possible to determine via simple observation whether entities in the text and images convey similar messages to readers. Our model can extract entities from both images and text while performing comprehensive analysis of textual and visual features, thereby contributing to more effective fake news detection.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}