
Contrastive Learning Pre-Training and Quantum Theory for Cross-Lingual Aspect-Based Sentiment Analysis


Abstract
1. Introduction
- This work proposes an innovative approach to cross-lingual ABSA that integrates contrastive learning pre-training with quantum mechanisms to enhance cross-lingual adaptability. To the best of our knowledge, this study is the earliest attempt to integrate these methodologies into aspect-based sentiment classification across multiple languages.
- In the quantum mechanism module, we employ a dynamic gate based on language similarity to establish quantum entanglement states, which more effectively capture the varying degrees of similarity between languages.
- We evaluated our CLQT model on the SemEval-2016 dataset [1]. The experimental results demonstrate the robustness of our proposed framework. Furthermore, a comprehensive evaluation was performed to analyze the contribution of each key module. The analysis further demonstrates the framework’s strong capability in transferring knowledge across languages.
2. Related Work
2.1. Cross-Lingual Aspect-Based Sentiment Analysis
2.2. Contrastive Learning
2.3. Quantum Neural Network
3. Method
3.1. Problem Definition
3.2. Contrastive Learning Pre-Training
| Algorithm 1 Contrastive learning Pre-training |
|
3.3. Quantum Theory
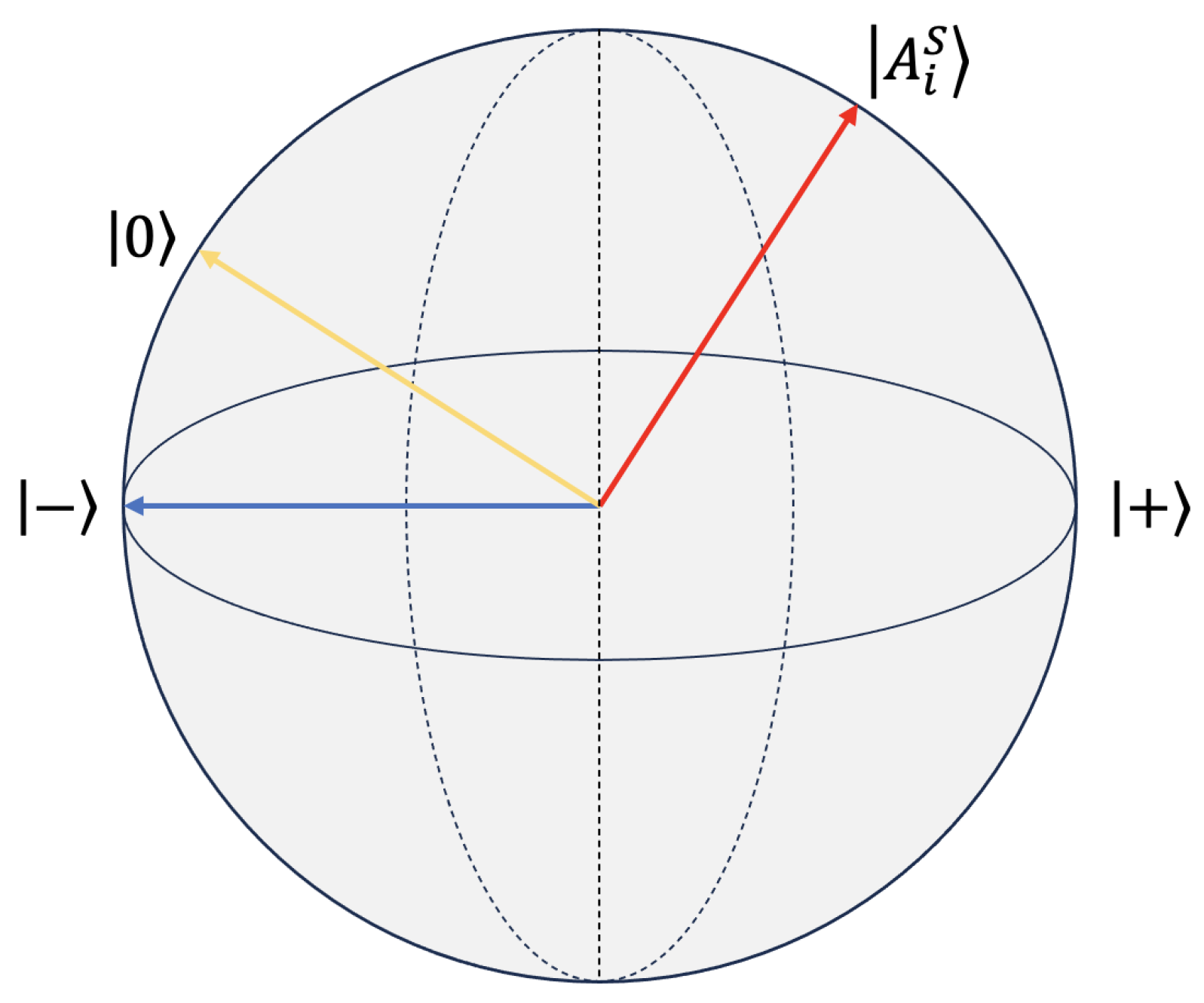
3.3.1. The Fundamental Knowledge of Quantum Theory
Quantum Projection
Quantum Superposition
Quantum Measurement
Quantum Entanglement
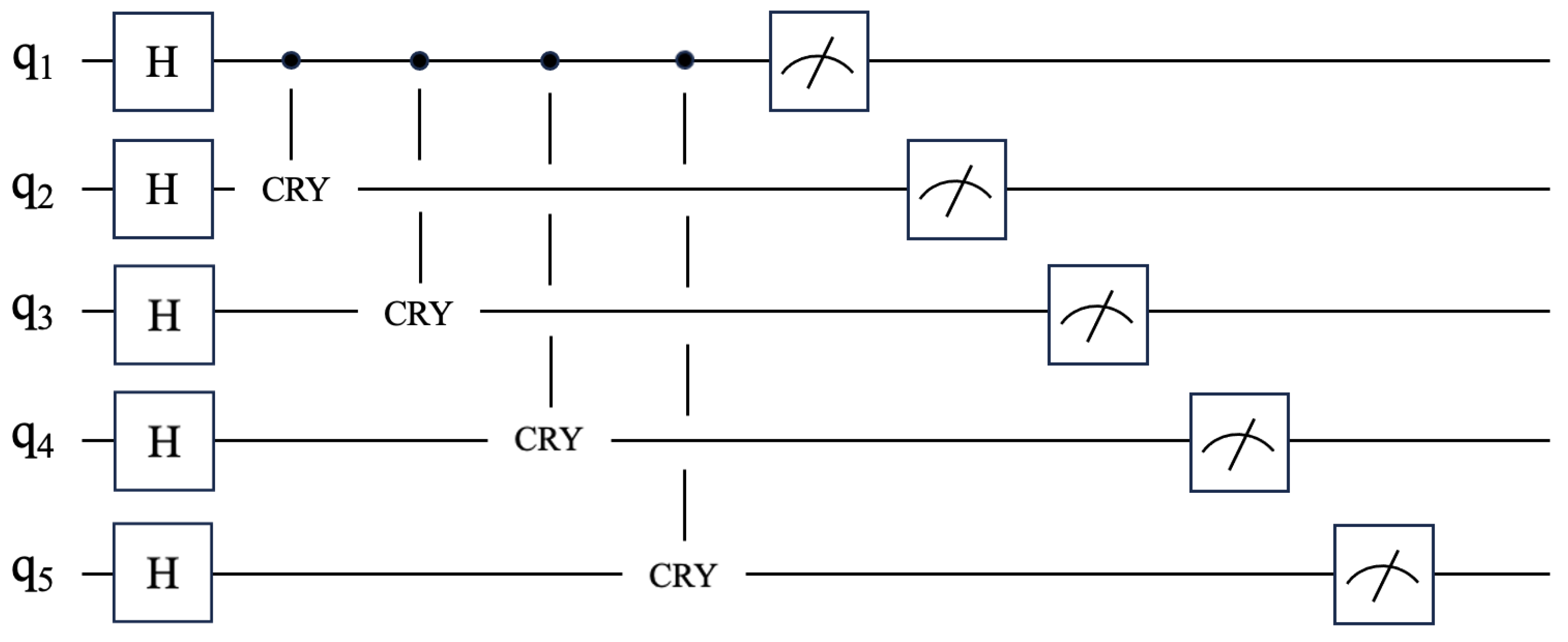
3.3.2. Quantum Module Design
Quantum Projection Module
Quantum Entanglement Module
Language Similarity Calculation
Fusion of Quantum Entanglement and Quantum Projection
3.3.3. Resource Estimation for the Quantum Circuit
4. Experiments
4.1. Dataset
4.2. Experiment Setting
4.3. Baseline Model
- Zero-shot model [39]: This method employs annotated examples from English and utilizes them directly for predictions in another language.
- Translation-TA and Bilingual-TA [10]: These approaches leverage pseudo-labeled samples obtained via translation from a high-resource language and integrate both original and translated text for model training.
- Translation-AF and Bilingual-AF [10]: These approaches emphasize transferring labels across languages without requiring precise word-level alignment.
- ACS, ACS-DISTILL-S, and ACS-DISTILL-M [10]: These models propose a non-aligned label projection method, outperforming translation-based methods in performance. They introduce a code-switching mechanism to enrich knowledge transfer between languages using bilingual sentences.
- XLM-RoBERTa [8]: This is a transformer-based multilingual pre-trained language model that extends RoBERTa to over 100 languages, trained with a masked language modeling objective on a large-scale CommonCrawl corpus. It serves as a robust encoder for cross-lingual transfer tasks.
- CL-XABSA [20]: This model proposes two contrastive learning methods based on token labels and sentiment polarity, respectively, and integrates knowledge distillation with attention-based multilingual models to achieve cross-lingual aspect-based sentiment classification.
- CAPIT [40]: The model achieves knowledge transfer from one language to another by integrating contrastive learning with a generative prompt-based large language model.
- QPEN [12]: This quantum-enhanced network model employs quantum mechanics to solve the cross-lingual ABSA task and achieves the best performance.
4.4. Experimental Results
5. Analysis and Discussion
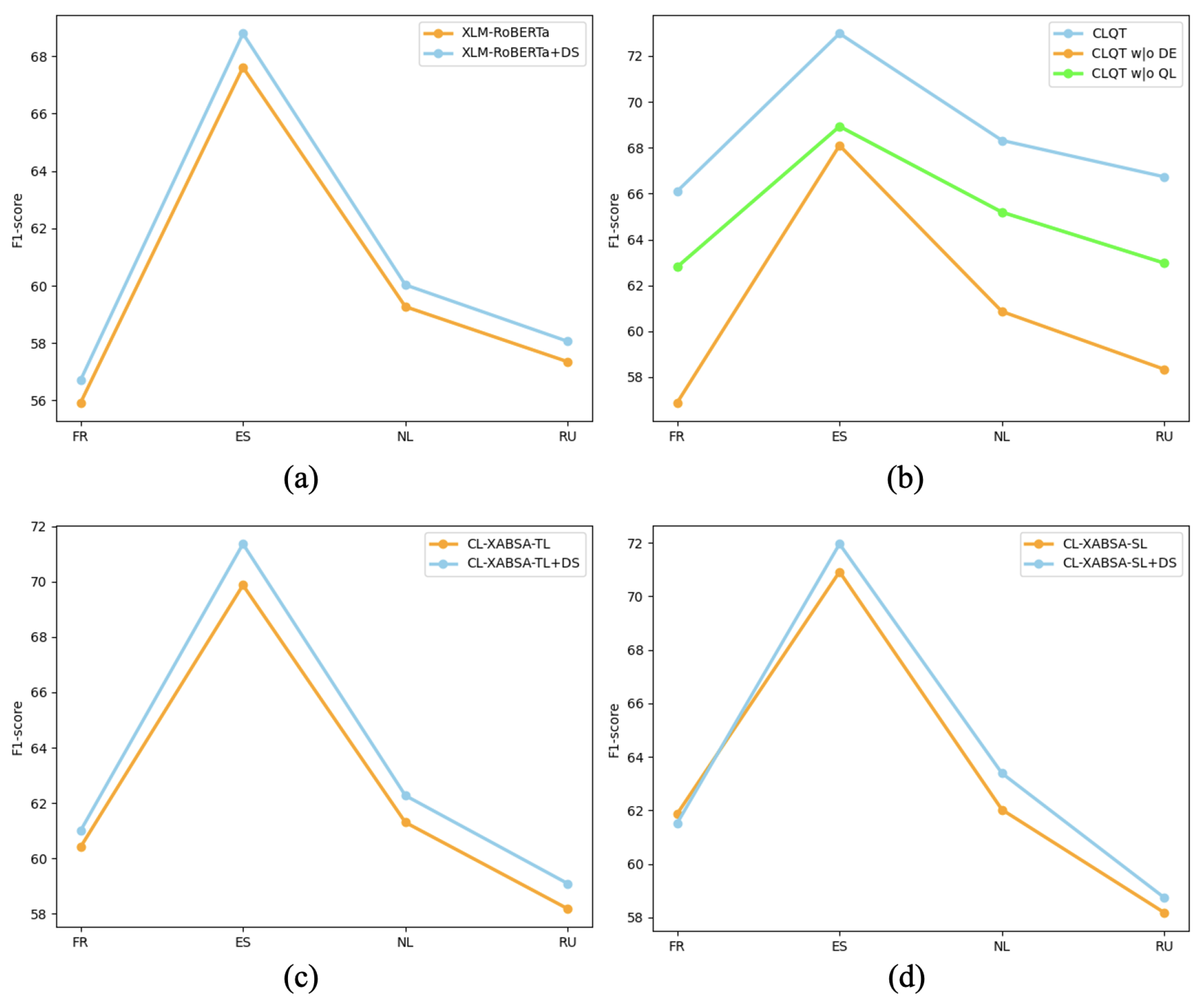
5.1. The Effectiveness of the Contrastive Learning Pre-Training
5.2. The Effectiveness of Quantum Mechanism Dynamic Entanglement
5.3. Ablation Study
5.4. Case Study
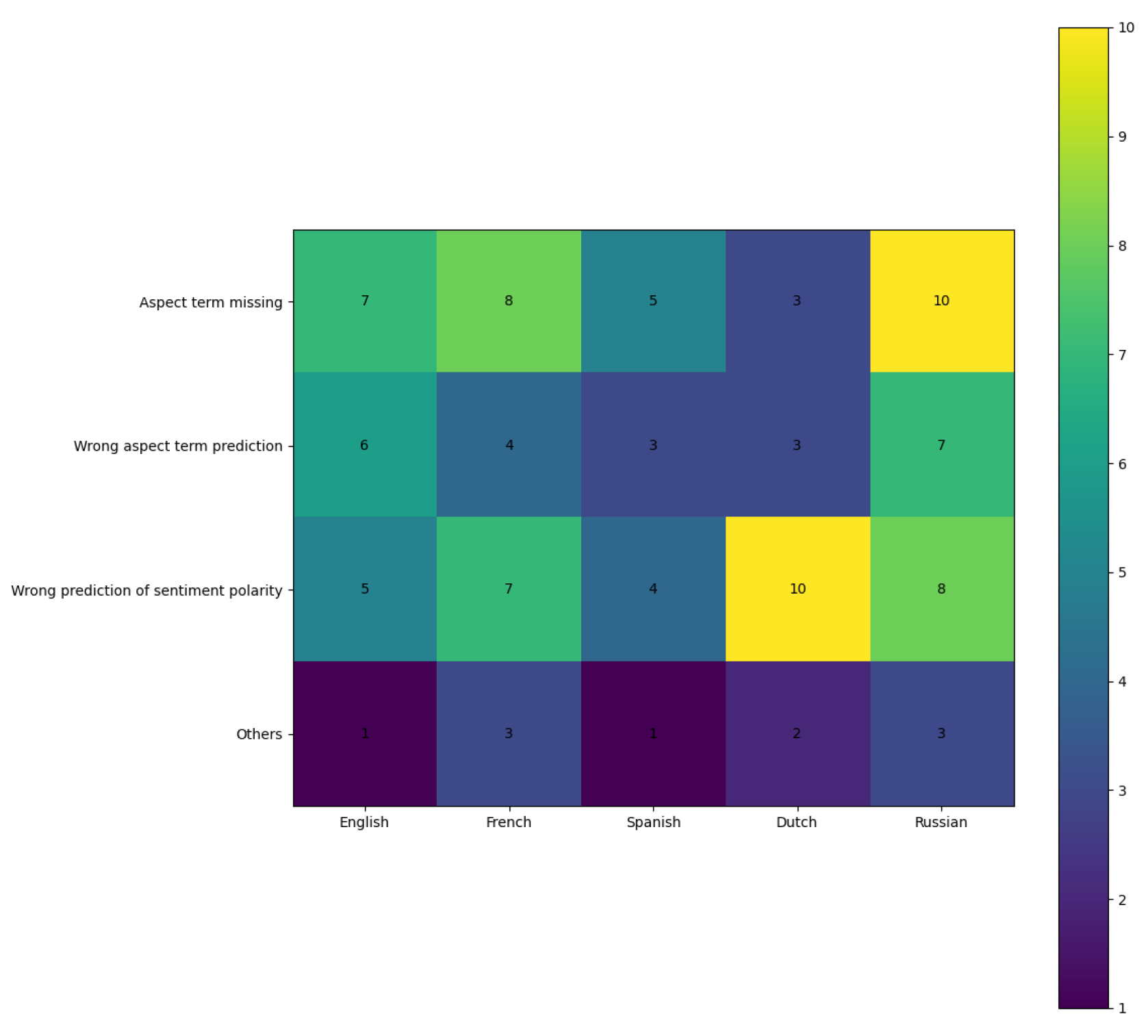
5.5. Error Analysis
- Aspect item missing: Such errors are common and may arise from variations in language distribution, particularly due to structural inconsistencies across languages. It leads to a loss of crucial knowledge during the transfer from the source language to the target language, which impacts performance.
- Wrong aspect item prediction: Incorrect aspect word predictions indicate a deviation in cross-lingual knowledge transfer, and the use of quantum projection and superposition introduces noise that further compromises the accuracy of this process.
- Wrong prediction of emotional polarity: Incorrect predictions of emotional polarity are frequently observed, particularly in texts that are challenging to interpret, such as those containing satirical expressions.
- Other errors
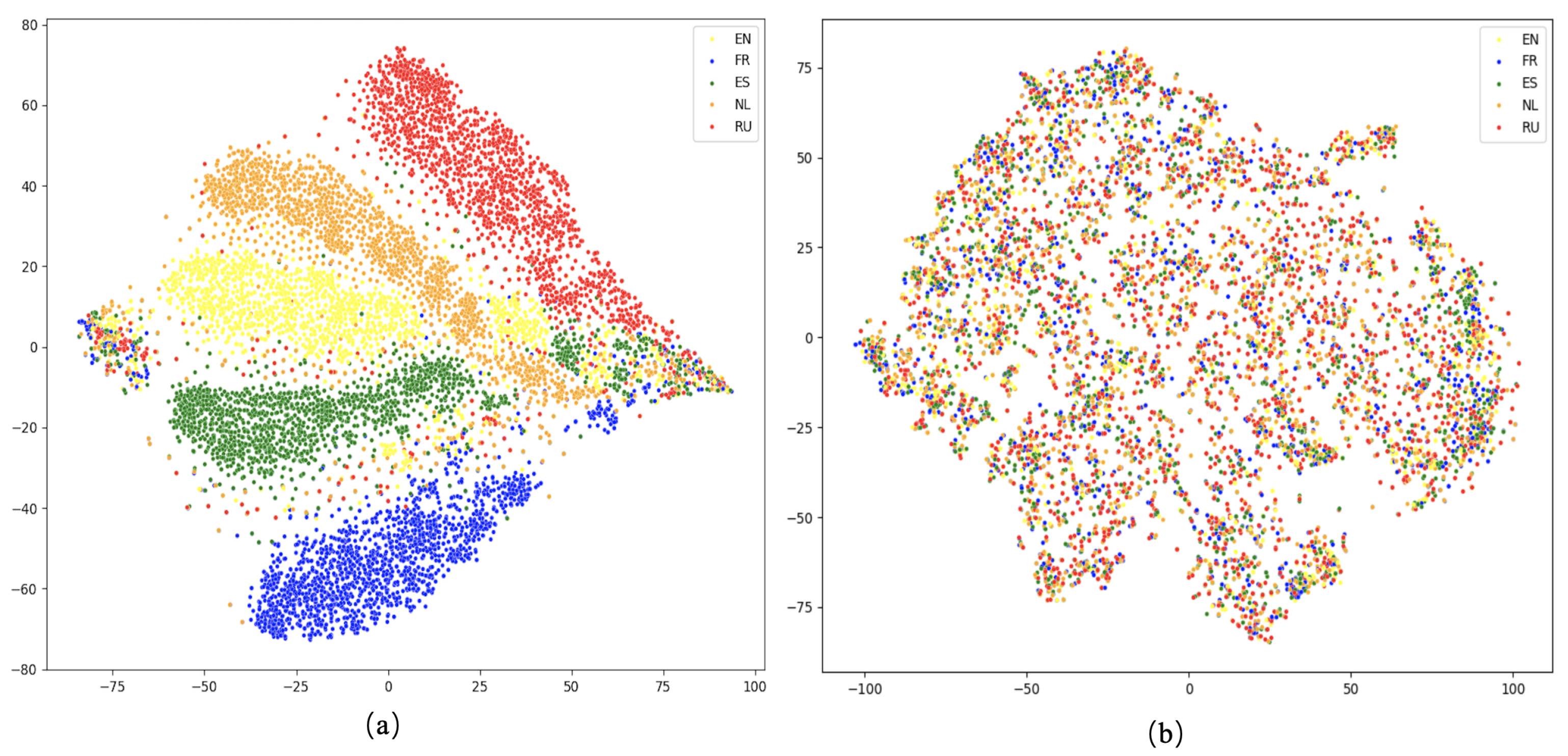
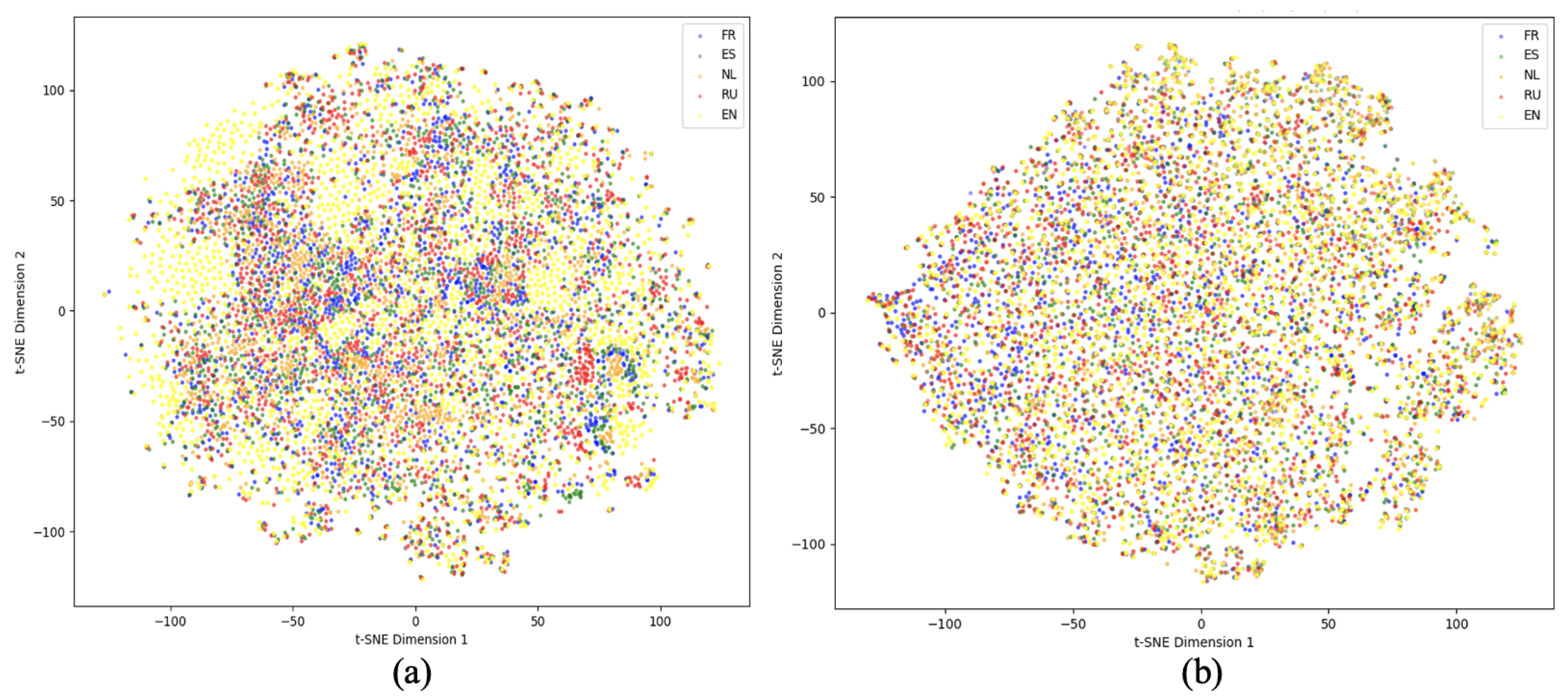
5.6. Visualization
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; Al-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O.; et al. Semeval-2016 task 5: Aspect based sentiment analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 19–30. [Google Scholar]
- Zhang, W.; Li, X.; Deng, Y.; Bing, L.; Lam, W. A survey on aspect-based sentiment analysis: Tasks, methods, and challenges. IEEE Trans. Knowl. Data Eng. 2022, 35, 11019–11038. [Google Scholar] [CrossRef]
- Zhao, Z.; Tang, M.; Zhao, F.; Zhang, Z.; Chen, X. Incorporating semantics, syntax and knowledge for aspect based sentiment analysis. Appl. Intell. 2023, 53, 16138–16150. [Google Scholar] [CrossRef]
- Zhao, C.; Wu, M.; Yang, X.; Zhang, W.; Zhang, S.; Wang, S.; Li, D. A systematic review of cross-lingual sentiment analysis: Tasks, strategies, and prospects. ACM Comput. Surv. 2024, 56, 1–37. [Google Scholar] [CrossRef]
- Panchendrarajan, R.; Zubiaga, A. Claim detection for automated fact-checking: A survey on monolingual, multilingual and cross-lingual research. Nat. Lang. Process. J. 2024, 7, 100066. [Google Scholar] [CrossRef]
- Přibáň, P.; Šmíd, J.; Steinberger, J.; Mištera, A. A comparative study of cross-lingual sentiment analysis. Expert Syst. Appl. 2024, 247, 123247. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar]
- Wu, S.; Dredze, M. Beto, Bentz, Becas: The surprising cross-lingual effectiveness of Bert. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP, Hong Kong, China, 3–7 November 2019; pp. 833–844. [Google Scholar]
- Zhang, W.; He, R.; Peng, H.; Bing, L.; Lam, W. Cross-lingual aspect-based sentiment analysis with aspect term code-switching. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 9220–9230. [Google Scholar]
- Hämmerl, K.; Libovický, J.; Fraser, A. Understanding Cross-Lingual Alignment—A Survey. In Proceedings of the Findings of the Association for Computational Linguistics ACL, Bangkok, Thailand, 11–16 August 2024; pp. 10922–10943. [Google Scholar]
- Zhao, X.; Wan, H.; Qi, K. QPEN: Quantum projection and quantum entanglement enhanced network for cross-lingual aspect-based sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–28 February 2024. [Google Scholar]
- Liu, B. Sentiment Analysis and Opinion Mining; Synthesis Lectures on Human Language Technologies; Springer: Cham, Switzerland, 2012; Volume 5, p. 1. [Google Scholar]
- D’Aniello, G.; Gaeta, M.; La Rocca, I. KnowMIS-ABSA: An overview and a reference model for applications of sentiment analysis and aspect-based sentiment analysis. Artif. Intell. Rev. 2022, 55, 5543–5574. [Google Scholar] [CrossRef]
- Hazem, A.; Bouhandi, M.; Boudin, F.; Daille, B. Cross-lingual and cross-domain transfer learning for automatic term extraction from low resource data. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022. [Google Scholar]
- Zhou, X.; Wan, X.; Xiao, J. CLOpinionMiner: Opinion target extraction in a cross-language scenario. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 619–630. [Google Scholar] [CrossRef]
- Zhou, H.; Chen, L.; Shi, F.; Huang, D. Learning bilingual sentiment word embeddings for cross-language sentiment classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015. [Google Scholar]
- Ruder, S.; Vulić, I.; Søgaard, A. A survey of cross-lingual word embedding models. J. Artif. Intell. Res. 2019, 65, 569–631. [Google Scholar] [CrossRef]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021. [Google Scholar]
- Lin, N.; Fu, Y.; Lin, X.; Zhou, D.; Yang, A.; Jiang, S. Cl-xabsa: Contrastive learning for cross-lingual aspect-based sentiment analysis. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 2935–2946. [Google Scholar] [CrossRef]
- Sattar, K.; Umer, Q.; Vasbieva, D.G.; Chung, S.; Latif, Z.; Lee, C. A multi-layer network for aspect-based cross-lingual sentiment classification. IEEE Access 2021, 9, 133961–133973. [Google Scholar] [CrossRef]
- Hu, H.; Wang, X.; Zhang, Y.; Chen, Q.; Guan, Q. A comprehensive survey on contrastive learning. Neurocomputing 2024, 610, 128645. [Google Scholar] [CrossRef]
- Mohtarami, M.; Glass, J.; Nakov, P. Contrastive Language Adaptation for Cross-Lingual Stance Detection. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Guo, Z.; Liu, Z.; Ling, Z.; Wang, S.; Jin, L.; Li, Y. Text classification by contrastive learning and cross-lingual data augmentation for alzheimer’s disease detection. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020. [Google Scholar]
- Li, Z.; Zou, Y.; Zhang, C.; Zhang, Q.; Wei, Z. Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021. [Google Scholar]
- Luo, Y.; Guo, F.; Liu, Z.; Zhang, Y. Mere Contrastive Learning for Cross-Domain Sentiment Analysis. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022. [Google Scholar]
- Zhou, J.; Zhou, J.; Zhao, J.; Wang, S.; Shan, H.; Gui, T.; Zhang, Q.; Huang, X. A soft contrastive learning-based prompt model for few-shot sentiment analysis. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024. [Google Scholar]
- Qin, L.; Chen, Q.; Xie, T.; Li, Q.; Lou, J.G.; Che, W.; Kan, M.Y. GL-CLeF: A Global–Local Contrastive Learning Framework for Cross-lingual Spoken Language Understanding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022. [Google Scholar]
- Li, Q.; Gkoumas, D.; Sordoni, A.; Nie, J.Y.; Melucci, M. Quantum-inspired neural network for conversational emotion recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 19–21 May 2021; Volume 35, No. 15. pp. 13270–13278. [Google Scholar]
- Yan, G.; Wu, H.; Yan, J. Quantum 3D graph learning with applications to molecule embedding. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 2677–2686. [Google Scholar]
- Zhou, N.R.; Zhang, T.F.; Xie, X.W.; Wu, J.Y. Hybrid quantum–classical generative adversarial networks for image generation via learning discrete distribution. Signal Process. Image Commun. 2023, 110, 116891. [Google Scholar] [CrossRef]
- Gong, L.H.; Pei, J.J.; Zhang, T.F.; Zhou, N.R. Quantum convolutional neural network based on variational quantum circuits. Opt. Commun. 2024, 550, 129993. [Google Scholar] [CrossRef]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. An Interactive Multi-Task Learning Network for End-to-End Aspect-Based Sentiment Analysis. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Li, X.; Bing, L.; Zhang, W.; Lam, W. Exploiting BERT for End-to-End Aspect-based Sentiment Analysis. In Proceedings of the 5th Workshop on Noisy User-generated Text (W-NUT 2019), Hong Kong, China, 4 November 2019. [Google Scholar]
- Busemeyer, J.R.; Bruza, P.D. Quantum Models of Cognition and Decision; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Fell, L.; Dehdashti, S.; Bruza, P.; Moreira, C. An Experimental Protocol to Derive and Validate a Quantum Model of Decision-Making. In Proceedings of the Annual Meeting of the Cognitive Science Society, Montreal, QC, Canada, 24–27 July 2019. [Google Scholar]
- Miller, D.M.; Thornton, M.A. QMDD: A decision diagram structure for reversible and quantum circuits. In Proceedings of the 36th International Symposium on Multiple-Valued Logic (ISMVL’06), Singapore, 17–20 May 2006. [Google Scholar]
- Keung, P.; Lu, Y.; Szarvas, G.S.; Smith, N.A. The Multilingual Amazon Reviews Corpus. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020. [Google Scholar]
- Li, X.; Bing, L.; Zhang, W.; Li, Z.; Lam, W. Unsupervised cross-lingual adaptation for sequence tagging and beyond. arXiv 2020, arXiv:2010.12405. [Google Scholar]
- Zhao, W.; Yang, Z.; Yu, S.; Zhu, S.; Li, L. Contrastive pre-training and instruction tuning for cross-lingual aspect-based sentiment analysis. Appl. Intell. 2025, 55, 358. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sub-Register | Logical Objects | Physical Encoding | Qubit Count |
|---|---|---|---|
| Language register | languages | 1 qubit per language | 5 |
| Sentiment register | 3-level () | mapped post-entanglement | 2 |
| controlled rotations and read-out | transient | reused and reset | ≤1 |
| English | French | Spanish | Dutch | Russian | ||
|---|---|---|---|---|---|---|
| Train | No.Sen | 2000 | 1664 | 2070 | 1722 | 3655 |
| No.Asp | 1743 | 1641 | 1856 | 1231 | 3077 | |
| Test | No.Sen | 676 | 668 | 881 | 575 | 1209 |
| No.Asp | 612 | 650 | 713 | 373 | 949 |
| Methods | mBert | ||||
|---|---|---|---|---|---|
| French | Spanish | Dutch | Russian | Avgerage | |
| Zero-shot | 45.60 | 57.32 | 42.68 | 36.01 | 45.40 |
| Translation-TA | 40.76 | 50.74 | 47.13 | 41.67 | 45.08 |
| Bilingual-TA | 41.00 | 51.23 | 49.72 | 43.67 | 46.41 |
| Translation-AF | 48.03 | 59.74 | 49.73 | 50.17 | 51.92 |
| Binglingual-AF | 48.05 | 60.23 | 49.83 | 51.24 | 52.34 |
| ACS | 49.65 | 59.99 | 51.19 | 52.09 | 53.23 |
| ACS-Distill-S | 52.23 | 62.04 | 52.72 | 53.00 | 55.00 |
| ACS-Distill-M | 52.25 | 62.91 | 53.40 | 54.58 | 55.79 |
| CL-XABSA-TL | 48.53 | 60.64 | 50.96 | 50.77 | 52.73 |
| CL-XABSA-SL | 49.50 | 61.62 | 50.64 | 50.65 | 53.10 |
| QPEN | 53.27 | 63.84 | 54.61 | 55.36 | 56.77 |
| CLQT (ours) | 54.34 | 65.01 | 55.73 | 56.27 | 57.84 |
| Methods | XLM-R | ||||
|---|---|---|---|---|---|
| French | Spanish | Dutch | Russian | Avgerage | |
| Zero-shot | 56.43 | 67.10 | 59.03 | 56.80 | 59.84 |
| Translation-TA | 47.00 | 58.10 | 56.19 | 50.34 | 52.91 |
| Bilingual-TA | 49.34 | 61.87 | 58.64 | 52.89 | 55.69 |
| Translation-AF | 57.07 | 66.61 | 61.26 | 59.55 | 61.12 |
| Binglingual-AF | 57.91 | 68.04 | 60.80 | 60.81 | 61.89 |
| ACS | 59.39 | 67.32 | 62.83 | 60.97 | 62.63 |
| ACS-Distill-S | 61.00 | 68.93 | 62.89 | 60.97 | 63.45 |
| ACS-Distill-M | 59.90 | 69.24 | 63.74 | 62.02 | 63.73 |
| CL-XABSA-TL | 60.41 | 69.87 | 61.30 | 58.82 | 62.60 |
| CL-XABSA-SL | 61.87 | 70.95 | 62.03 | 58.18 | 63.26 |
| QPEN | 63.21 | 71.59 | 66.16 | 64.52 | 65.79 |
| CLQT (ours) | 66.10 | 72.98 | 68.32 | 66.73 | 68.53 |
| Methods | German | Spanish | French | Japanese | Chinese | Avgerage |
|---|---|---|---|---|---|---|
| CAPIT-base | 76.99 | 75.64 | 75.36 | 73.48 | 68.78 | 74.09 |
| CAPIT-large | 78.34 | 75.56 | 76.90 | 73.54 | 70.60 | 75.00 |
| XLM-RoBERTa | 55.52 | 51.96 | 52.42 | 51.30 | 48.86 | 50.86 |
| ACS-Distill-S | 68.71 | 67.29 | 64.02 | 61.85 | 58.67 | 64.05 |
| ACS-Distill-M | 70.58 | 68.97 | 66.35 | 63.14 | 60.72 | 65.95 |
| CL-XABSA-TL | 68.32 | 67.70 | 63.47 | 61.16 | 57.89 | 63.71 |
| CL-XABSA-SL | 69.59 | 69.04 | 64.70 | 62.63 | 58.07 | 64.80 |
| QPEN | 78.98 | 78.84 | 75.93 | 72.19 | 68.20 | 74.83 |
| CLQT | 82.02 | 81.85 | 79.19 | 75.77 | 71.93 | 78.15 |
| Methods | mBert | ||||
|---|---|---|---|---|---|
| French | Spanish | Dutch | Russian | Average | |
| Variant1 | 46.01 | 57.19 | 43.05 | 36.24 | 45.62 |
| Variant2 | 46.82 | 59.71 | 43.94 | 37.65 | 47.03 |
| Variant3 | 53.27 | 63.84 | 54.61 | 55.36 | 56.97 |
| Variant4 | 53.80 | 64.27 | 55.14 | 55.92 | 57.28 |
| CLQT (ours) | 54.34 ± 0.95 | 65.01 ± 1.30 | 55.73 ± 1.35 | 56.27 ± 0.52 | 57.84 ± 1.03 |
| Methods | XLM-R | ||||
|---|---|---|---|---|---|
| French | Spanish | Dutch | Russian | Average | |
| Variant1 | 55.92 | 67.61 | 59.27 | 57.35 | 60.04 |
| Variant2 | 56.88 | 68.10 | 60.86 | 58.34 | 61.05 |
| Variant3 | 63.21 | 71.59 | 66.16 | 64.52 | 66.37 |
| Variant4 | 64.36 | 71.93 | 67.25 | 65.49 | 67.26 |
| CLQT (ours) | 66.10 ± 1.47 | 72.98 ± 1.14 | 68.32 ± 1.84 | 66.73 ± 1.23 | 68.53 ± 1.42 |
| Languages | Sentences | QPEN | CLQT |
|---|---|---|---|
| SP | La comida estuvo muy sabrosa. | (comida 1) | (comida 1) |
| FR | Le cadre et le personnel sont agréables. | (cadre 1, personnel, 1) | (cadre 1, personnel, 1) |
| DU | Geen kennis van de wijnkaart laat staan van de wijnen per glass. | (wijnkaart −1) | (wijnkaart −1, wijnen per glass −1) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Zhang, K. Contrastive Learning Pre-Training and Quantum Theory for Cross-Lingual Aspect-Based Sentiment Analysis. Entropy 2025, 27, 713. https://doi.org/10.3390/e27070713
Li X, Zhang K. Contrastive Learning Pre-Training and Quantum Theory for Cross-Lingual Aspect-Based Sentiment Analysis. Entropy. 2025; 27(7):713. https://doi.org/10.3390/e27070713
Chicago/Turabian StyleLi, Xun, and Kun Zhang. 2025. "Contrastive Learning Pre-Training and Quantum Theory for Cross-Lingual Aspect-Based Sentiment Analysis" Entropy 27, no. 7: 713. https://doi.org/10.3390/e27070713
APA StyleLi, X., & Zhang, K. (2025). Contrastive Learning Pre-Training and Quantum Theory for Cross-Lingual Aspect-Based Sentiment Analysis. Entropy, 27(7), 713. https://doi.org/10.3390/e27070713