1. Introduction
E-commerce live streaming has swiftly become one of China’s most vibrant retail channels: platforms like Douyin host over nine million live broadcasts each month and facilitate the sale of more than ten billion items through these sessions [
1]. At the same time, hosts frequently employ “morphs”—subtle phonetic or semantic alterations and filler insertions—to evade real-time moderation and make unsubstantiated claims (e.g., implying medicinal properties of ordinary products). Resolving these morphs in real time is therefore essential to protect consumers and uphold industry standards [
2,
3].
Existing work on morph resolution has largely focused on written obfuscations in social media commentary or underground domains such as illegal gambling and adult content [
4,
5,
6]. Those studies define morphs as text-level transformations designed to bypass keyword filters (e.g., splitting or substituting characters) and target entirely different subject areas (news, politics, vice industries). By contrast, the live-streaming context presents two key distinctions:
Modality and Purpose: Morphs here occur in speech, exploiting ASR weaknesses—presenters may split characters (‘‘胡’’ (hú)->‘‘古月’’(gǔ yùe)) or insert meaningless fillers (‘‘手术’’(shǒu shù, surgery)->‘‘手某术’’(shǒu mǒu shù, surgery)) to disrupt censoring systems.
Domain: Live commerce skews heavily toward health- and medical-related claims, where undetected false advertising can directly harm consumers.
In this paper, we study the Live Auditory Morph Resolution (LiveAMR) task. One recent work transformed the task into a text-to-text generation problem [
7]. In the era of Large Language Models (LLMs), some works have explored the possibility of LLMs to enhance the performance of small large models [
8,
9,
10,
11]. Building upon this foundation, we propose a simple but effective LLM-enhanced training framework that mines three forms of explanation information from an off-the-shelf large language model and injects them into a lightweight LiveAMR model:
Morph Types. We prompt the LLM with a predefined schema of structural and semantic morph categories. These explicit type labels help the small model narrow its correction search space.
Reference Corrections. Although LLM-generated corrections are not used verbatim, they serve as intermediate “hints” that guide the small model toward more accurate outputs.
Natural-Language Explanations. Constrained by rationality and comprehensiveness criteria, the LLM produces clear analyses of each morph error—offering soft supervision on why and how to correct.
We then concatenate these LLM-derived annotations with the original (noisy) input and feed the combined text into the small LiveAMR model during training and inference. This approach “mines” the LLM’s stored morph-resolution knowledge without any LLM fine-tuning, while preserving the efficiency and task alignment of supervised learning for the downstream model.
Our contributions are twofold:
Novel Paradigm. We introduce the first LLM-enhanced training framework for LiveAMR, systematically extracting morph types, references, and explanations from an off-the-shelf LLM and integrating them into a small model.
Performance and Efficiency. We evaluate our framework on the publicly released LiveAMR dataset [
7], which consists of 6,236 positive and 76,554 negative training examples, along with both in-domain and out-of-domain test sets. We show that incorporating LLM-derived annotations—without additional LLM fine-tuning—significantly boosts small-model accuracy while keeping training costs low.
2. Related Work
Morph Resolution in English: Computational morphology in English focuses on tasks such as segmentation, lemmatization, tagging, and disambiguation. Morphological tagging assigns morphosyntactic features (e.g.,
runs → V;PRES;3P;SG) [
12]. Disambiguation systems then select the correct parse from multiple analyses based on context [
12,
13,
14]. Early approaches used rule-based or finite-state methods, while modern techniques rely on neural or statistical models. Unsupervised methods like Morfessor infer morpheme boundaries from raw text [
12] and neural taggers jointly learn features and parts of speech. High-quality morphological analysis is shown to benefit downstream tasks like parsing and machine translation. These works emphasize the integration of morph analysis with other NLP tasks.
Morph Resolution in Chinese: Chinese differs significantly due to its lack of inflectional morphology [
15]. Characters represent minimal semantic units, and words are formed by segmenting character sequences. As a result, Chinese NLP systems often employ character-based models and joint segmentation-POS tagging strategies [
15]. Morph resolution in Chinese can also involve decoding slang, puns, or disguised terms—especially in online or censored contexts.
You et al. [
5] use context-aware autoencoders to resolve invented morphs in Chinese social media. Zhang et al. [
16] propose a context-aware entity morph decoding framework that links morphs to canonical entities. These methods rely heavily on contextual embeddings and background knowledge to resolve ambiguous or creative variants in text.
Live Auditory Morph Resolution (LiveAMR): Zhu et al. [
7] introduce the Live Auditory Morph Resolution (LiveAMR) task to normalize speech-transcribed morphs in Chinese e-commerce live streams. They treat LiveAMR as a sequence generation task and demonstrate that LLM-generated synthetic data improves small model performance.
Our work builds on this by proposing the first LLM-enhanced training framework for LiveAMR. Instead of relying on runtime LLM inference or fine-tuning, we query an off-the-shelf LLM to extract morph types, references, and explanations, which are injected into a small model’s training process. This approach significantly improves both accuracy and efficiency—by distilling LLM knowledge without incurring its inference cost.
3. Method
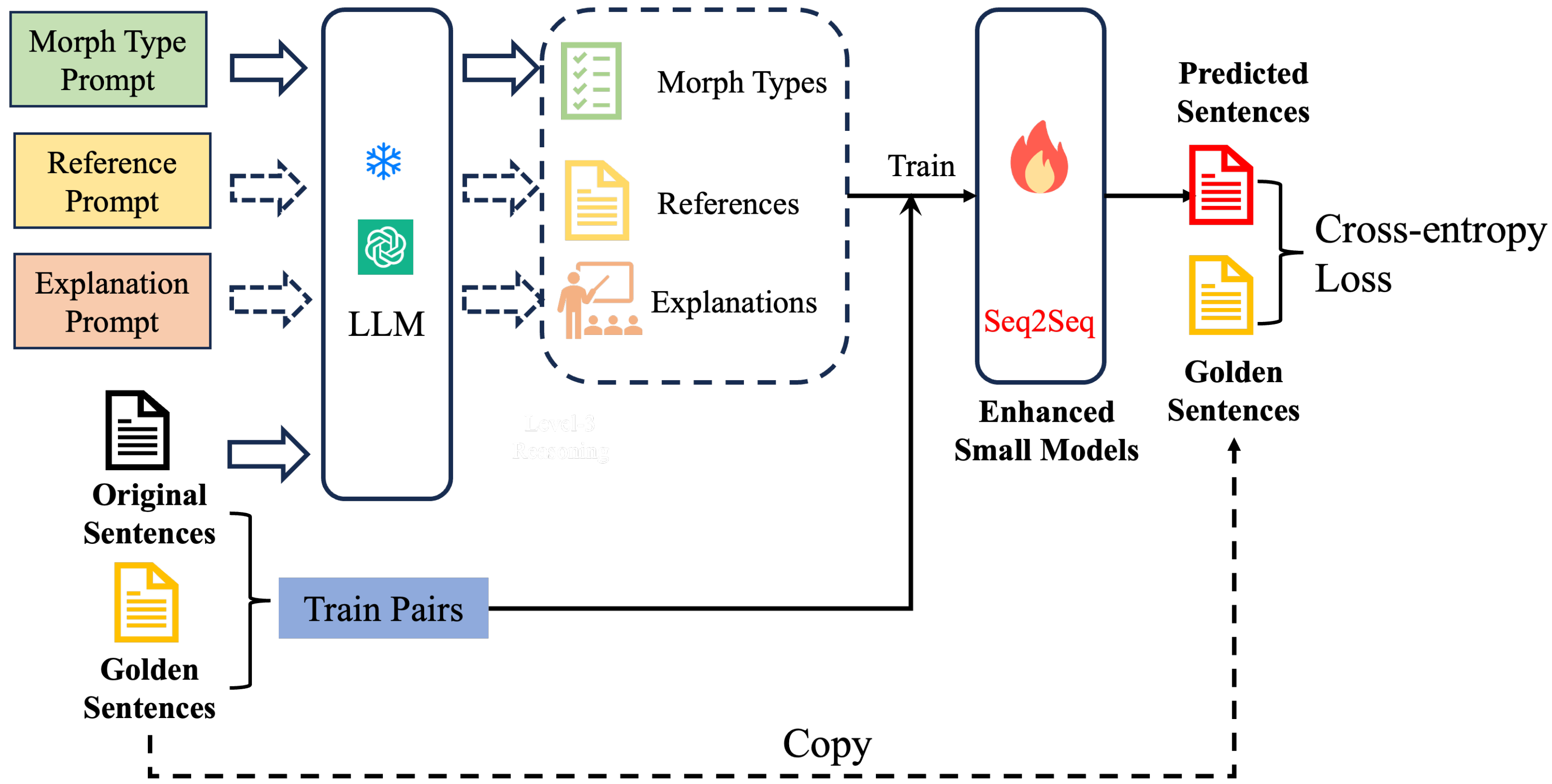
Figure 1 illustrates our LLM-enhanced training framework for LiveAMR. First, each morphed sentence is issued three tailored prompts (Morph Type, Reference, and Explanation) to a frozen LLM in a zero- or few-shot setting, where “frozen LLM” implies its parameters are not updated during the training process of the small model. The LLM returns a morph-type label, a pseudo-label reference correction, and a natural-language rationale. These three outputs are concatenated with the original sentence to form enriched input–output pairs. Finally, we train a compact T5 model on these enhanced examples, leveraging its unified text-to-text framework for a consistent input/output representation, its powerful span-corruption pre-training to jump-start language understanding, its availability in lightweight configurations (e.g., 60M parameters) to ensure computational efficiency, and its broad community support for easy reproducibility—thereby internalizing the LLM’s knowledge for fast, accurate inference.
Problem Definition: Let
be our annotated corpus of live-streamed Chinese sentences, where each
may contain one or more
morphs—lexical alterations introduced by hosts to evade moderation—and
is the intended, de-morphed version. The LiveAMR task seeks to learn a function
that recovers all original terms faithfully. Accurately modeling
f is challenging because morphs can take diverse forms (structural, or semantic substitutions) and context matters in disambiguating them.
Rationale for LLM-Generated Explanations: Large language models (LLMs) trained on massive multilingual corpora encode deep knowledge of linguistic structure, phonetics, and semantics. When prompted appropriately, they can not only correct errors but also articulate the reasoning behind each correction. We exploit this capability by defining an
annotation function
which extracts from
x:
A high-level morph type t, narrowing the model’s focus to a specific class of error.
A pseudo-label reference sentence r, providing an example “ideal” correction.
A natural-language explanation e, conveying the LLM’s diagnostic reasoning.
Injecting into small-model training has two main benefits:
Search Space Reduction: Knowing t limits the candidate corrections the model must consider.
Auxiliary Supervision: The pair serves as pseudo-labels and rationales, guiding the small model toward human-like correction strategies without expensive LLM inference during deployment.
Explanation Information Mined from LLMs: For each sentence
x, we query the LLM in a zero- or few-shot prompt to compute the following:
where the prompt templates are shown in
Appendix A.
We further elaborate each component:
Morph Types: We pre-define two non-overlapping morph categories—structural and semantic. Structural morphs include homophonic substitutions or character insertions (e.g., “白褂褂” equals “医生”), while semantic morphs replace words with near-synonyms. The LLM is constrained to choose exactly one label from . This explicit label t informs the small model of the type of transformation to apply, reducing ambiguity.
Reference Corrections: Although LLM outputs can vary, they often produce fluent and accurate corrections. We collect the LLM’s best-guess corrected sentence r as a pseudo-label. While r is not used as the ground-truth target, presenting r alongside the original x provides the small model with a concrete exemplar of how the morphs should be resolved, acting as soft guidance.
Explanations: We prompt the LLM to articulate a rationale e for each correction, subject to three quality criteria:
Rationality: The explanation must be coherent and written in clear, natural Chinese.
Comprehensiveness: All morphs present in x should be addressed.
Specificity: Each erroneous term in x must be directly linked to its corrected form.
By including e, we transfer the LLM’s diagnostic insight into the training data, enabling the small model to learn not only what the correction is, but also why.
Training Process of Small Modeling: We build an enriched input sequence
where “||” denotes string concatenation with delimiters. This concatenation ensures the model receives all LLM-provided signals in a structured format.
We fine-tune a pre-trained T5 encoder–decoder model
on
by minimizing the cross-entropy loss
Inference Process: At test time, for an unseen sentence x:
Compute via the LLM prompts.
Construct .
Generate the final correction using the fine-tuned T5 model.
This pipeline ensures that at inference, no LLM fine-tuning or heavy computation is required beyond the initial annotation step, enabling efficient, accurate LiveAMR resolution in production settings.
4. Experiment
4.1. Experimental Setup
Metrics. The model is expected to change only the morphological elements in the target sentences, leaving all other components untouched. Evaluation is conducted at the sentence level with strict criteria: a positive sample counts as correct only if all morphological forms are accurately restored, while a negative sample is considered correct only if the model leaves the sentence completely unchanged. We choose three common metrics to evaluation: Precision, Recall, and .
Dataset. The dataset [
7] is chosen for training and evaluation. The statistical information of the dataset is shown in
Table 1. It includes two Tests (Test1 and Test2), where Test set 1 and the training set are from the same live room, and test set 2 and the training set are from different live rooms.
Baselines. The following models were selected as the baseline for comparison:
(1) Large Language Models (LLMs): To assess the effectiveness of LLMs in resolving morphological ambiguities, three prominent models known for their Chinese language understanding capabilities were chosen: GPT-3.5-turbo (
https://openai.com/ (accessed on 2 January 2025)), Deepseek-V2 (
https://platform.deepseek.com/ (accessed on 2 January 2025)), and GLM4-Plus (
https://chatglm.cn/ (accessed on 2 January 2025)). These models are all large, pre-trained transformer-based architectures. Eight examples from the training dataset—comprising six positive and two negative instances—were manually chosen and incorporated into the prompts as contextual examples. The temperature setting was consistently fixed at 0.7.
(2) Seq2Seq Models: Convseq2seq [
17] and BART [
18] were chosen as the backbone architectures for sequence-to-sequence modeling and fine-tuned.
(3) Kenlm and Seq2Edit: To further demonstrate that sequence-to-sequence models are more appropriate for the morph resolution task, the statistical language model Kenlm [
19] and the BERT-based editing model Seq2Edit [
20] were also chosen.
(4)
T5 and DataAug: T5 and DataAug [
7] were based on T5 (mengzi-T5-base [
21]). In addition to using the annotated training data, DataAug also leverages data constructed by an LLM to augment the training set and participates in model training. The newly added morph dataset contains 11,280 positive samples and 2155 negative samples.
(5) Our method: The small modeling is the same as the T5 and DataAug methods. The LLM modeling is called by OpenAI’s API, and the version of LLM is “gpt-4o-mini-2024-07-18”, chosen for its balance of performance and efficiency in generating high-quality explanations. During the training process, the maximum length of the input sequence is set to 128, and the initial learning rate is set to . We train the model for 20 epochs on a 24GB Nvidia 3090Ti GPU with the batch size set to 32. We use the AdamW optimizer, and the model employs a cosine annealing learning rate schedule.
4.2. Results Analysis
Table 2 compares our LLM-enhanced framework against a variety of baselines on both Test1 (in-domain) and Test2 (out-of-domain). Several key observations emerge as follows:
These models (GPT, Deepseek, GLM) achieve moderate precision but suffer from low recall on Test1 (e.g., GPT: , , ; Deepseek: , , ). On Test2, recall improves slightly (up to for GLM), but precision remains inconsistent, yielding sub-60% scores. This indicates that generic LLMs—though knowledgeable—are not specialized enough for robust morph resolution without task-specific fine-tuning.
KenLM attains reasonable precision () but very low recall (), reflecting its inability to generate novel corrections. Seq2Edit achieves near-perfect precision () by only performing high-confidence edits, but its recall remains below , leading to . Both methods underscore that surface-level edits or n-gram scoring alone are insufficient for comprehensive morph recovery.
ConvSeq2Seq yields extremely high precision () but moderate recall (), giving on Test1 and dropping to on Test2. BART balances precision and recall more evenly (, , on Test1; on Test2). These results confirm that pre-trained generative models better capture diverse morph patterns but still exhibit domain sensitivity.
A vanilla T5 model fine-tuned on the annotated dataset achieves high precision () and decent recall () on Test1 () but suffers a severe recall drop to on Test2. DataAug, which incorporates LLM-generated pseudo-examples into training, raises recall to on Test1 () and partially mitigates the drop on Test2 (, ). This demonstrates that data-level augmentation alone can improve generalization but has limited impact on out-of-domain recall.
On Test1, our method attains the highest precision () and recall (), yielding , which represents a +7.1 gain over T5 and +3.6 over DataAug. Crucially, on the out-of-domain Test2, we achieve and , outperforming T5 by +26.0 and DataAug by +5.4 in . These gains highlight that structured LLM-derived signals—morph types, reference corrections, and detailed explanations—provide robust, generalizable guidance that improves morph resolution under domain shift.
In summary, our LLM-enhanced training framework consistently delivers superior precision-first performance across both in-domain and out-of-domain tests, validating the effectiveness of mining and injecting LLM explanations into small-model training.
4.3. Ablation Study
Table 3 reports an ablation of our LLM-enhanced framework on Test1, measured by
. Augmenting the base T5 model with LLM-predicted morph-type labels yields a substantial jump in
from 87.20 to 93.70 (+6.50). This highlights that explicit morph-type information drastically narrows the model’s search space, enabling more accurate and targeted corrections.
Incorporating natural-language explanations on top of morph types provides a modest further gain (from 93.70 to 93.90, +0.20). The small increase indicates that rationales help the model refine its decisions, but much of the benefit has already been captured by knowing the error class.
Finally, including the LLM-generated reference corrections boosts to 94.34 (+0.44 over explanations). Reference pseudo-labels offer concrete exemplars of the desired output, giving the model additional guidance beyond abstract explanations.
Overall, the ablation study shows that each annotation type contributes positively: morph-type labels yield the largest improvement, while explanations and references offer incremental yet complementary benefits. Together, they enable our small T5 model to achieve state-of-the-art precision-first performance on LiveAMR.




{kind=link}