

Improving the Minimum Free Energy Principle to the Maximum Information Efficiency Principle

Abstract
1. Introduction
- Bio-organisms have purposes and can predict environments and control outcomes. The FEP can express subjective and objective coincidence. The subjective and objective approaches are bidirectional and dynamic.
- Loss functions are expressed in terms of information or entropy measures, transforming the active inference issue into the inverse problem of sample learning.
- There exist multi-task coordination and tradeoffs requiring the inference of latent variables.
- Its convergence theory is flawed;
- It is prone to cause misunderstanding because of the use of “free energy”;
- It has a limitation in that it only uses likelihood functions as constraints and utilizes the KL divergence between the subjective and objective probability distributions to assess how well they match when the bio-organism predicts and adapts to (including intervenes in) the environment.
- Mathematically clarifying the theoretical and practical inconsistencies in VB and the FEP.
- Explaining the relationships between Shannon MI, semantic MI, VFE, physical entropy, and free energy from the perspectives of G theory and statistical physics.
- Providing experimental evidence by mixture model examples (including one used by Neal and Hinton [2]) to demonstrate that VFE may increase during the convergence of mixture models and explain why this occurs.
2. Two Typical Tasks of Machine Learning
2.1. Sheep Clustering: Mixture Models
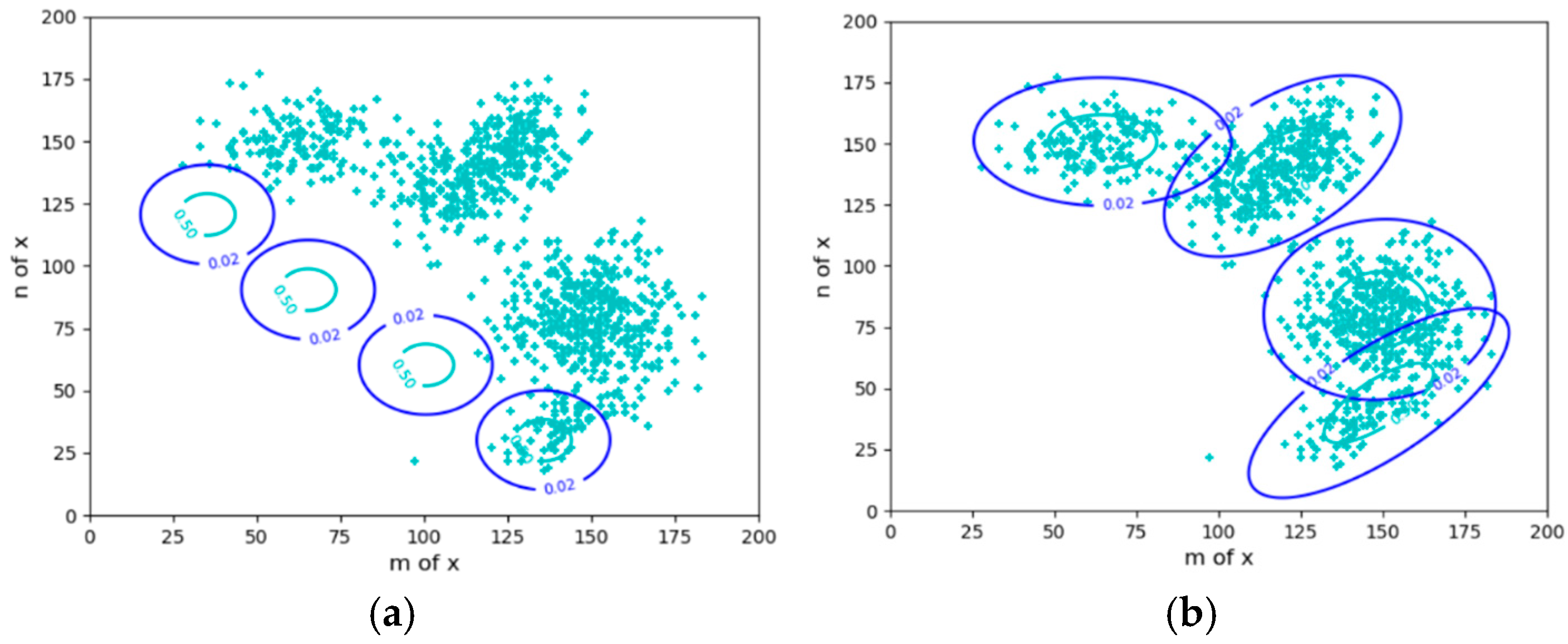
2.2. Driving Sheep to Pastures: Constrained Control and Active Inference
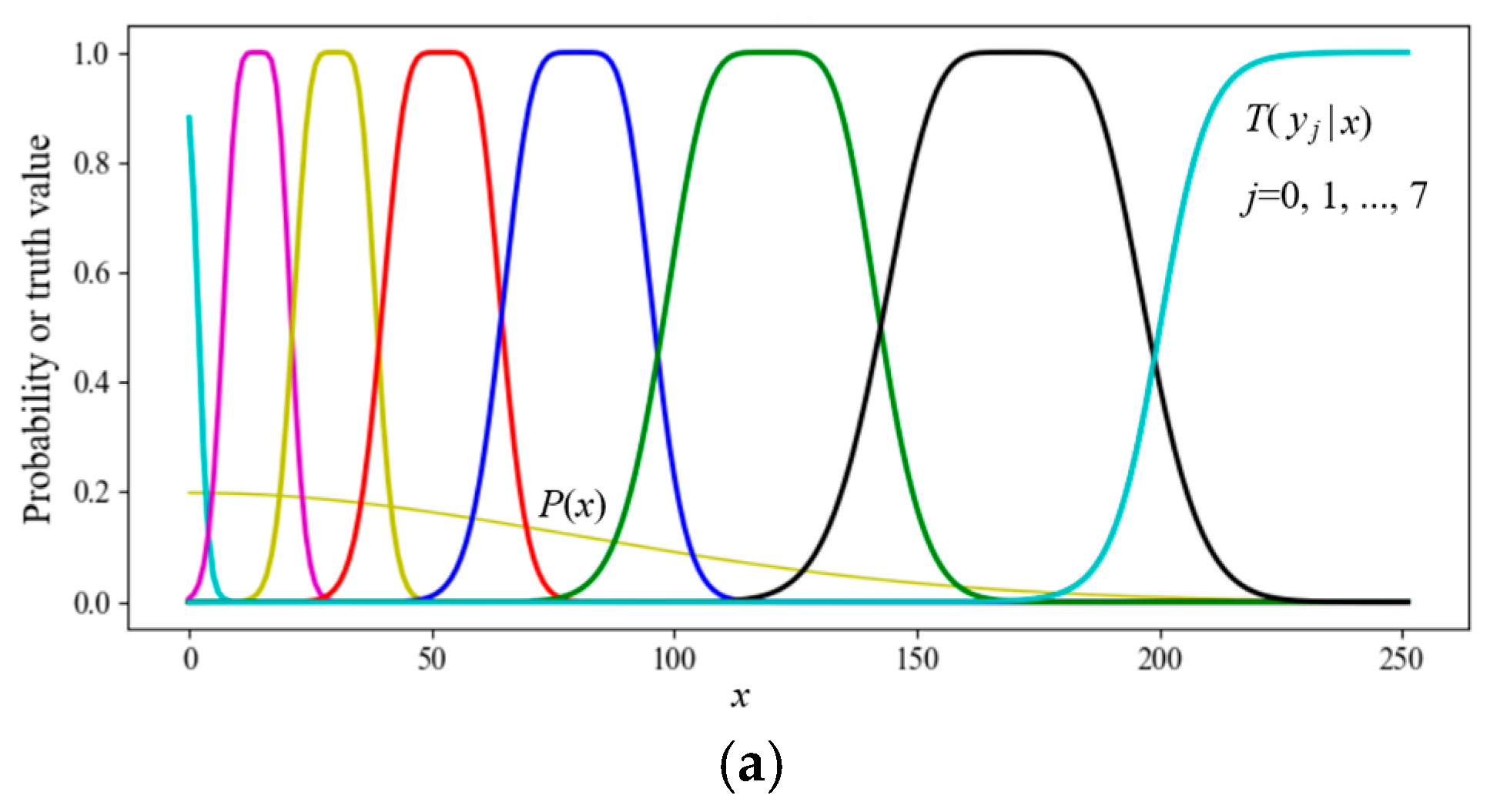
- The objectives are expressed by the probability distributions P(x|θj) (j = 1, 2, 3, 4). Given P(x) and P(x|θj), we solve the Shannon channel P(y|x) and the herd ratio P(y). It is required that P(x|yj) is close to P(x|θj) and that P(y) minimizes the control cost.
- The objectives are expressed by the fuzzy ranges. P(x|θj) (j = 1, 2, …) can be obtained from P(x) and the fuzzy ranges, and the others are the same.
3. The Semantic Information G Theory and the Maximum Information Efficiency Principle
3.1. The P-T Probability Framework
- U = {x1, x2, …} is a set of instances, X∈U is a random variable;
- V = {y1, y2, …} is a set of labels or hypotheses, Y∈V is a random variable;
- B = {θ1, θ2, …} is the set of subsets of U; every subset θj has a label yj∈V;
- P is the probability of an element in U or V, i.e., the statistical probability as defined by Mises [40] with “=“, such as P(xi) = P(X = xi);
- T is the probability of a subset of U or an element in B, i.e., the logical probability as defined by Kolmogorov [41] with “∈”, such as T(yj) = P(X∈θj).
- The P-T probability framework enables us to use truth, membership, similarity, and distortion functions as constraints for solving latent variables in wider applications.
- The truth function can represent a label’s semantics or a bio-organism’s purpose and can be used to make semantic probability predictions [27];
3.2. The Semantic Information Measure
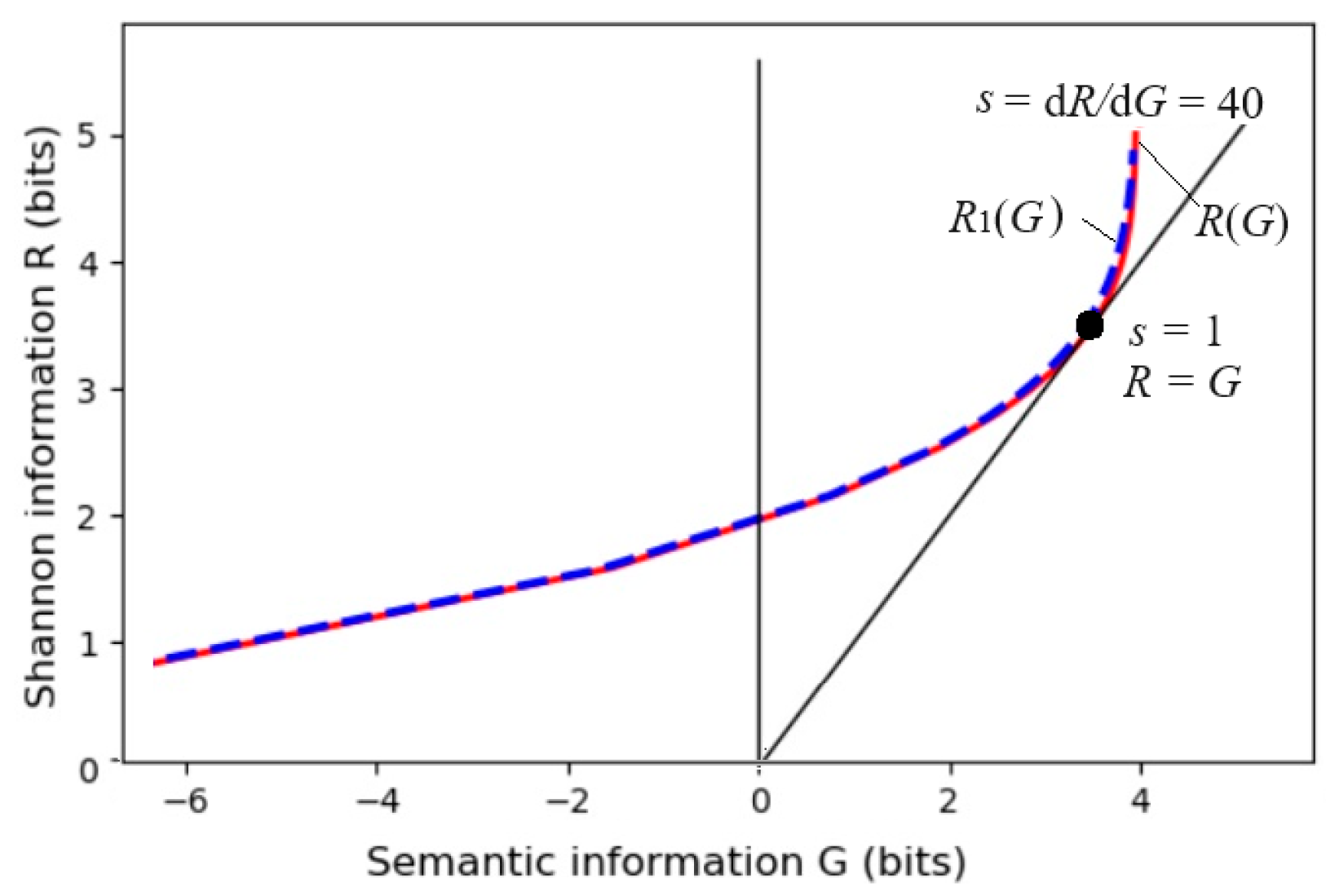
3.3. From the R(D) Function to the R(G) Function
3.4. Semantic Variational Bayes and the Maximum Information Efficiency Principle
4. The MIE Principle for Mixture Models and Constrained Control
4.1. New Explanation of the EM Algorithm for Mixture Models (About Sheep Clustering)
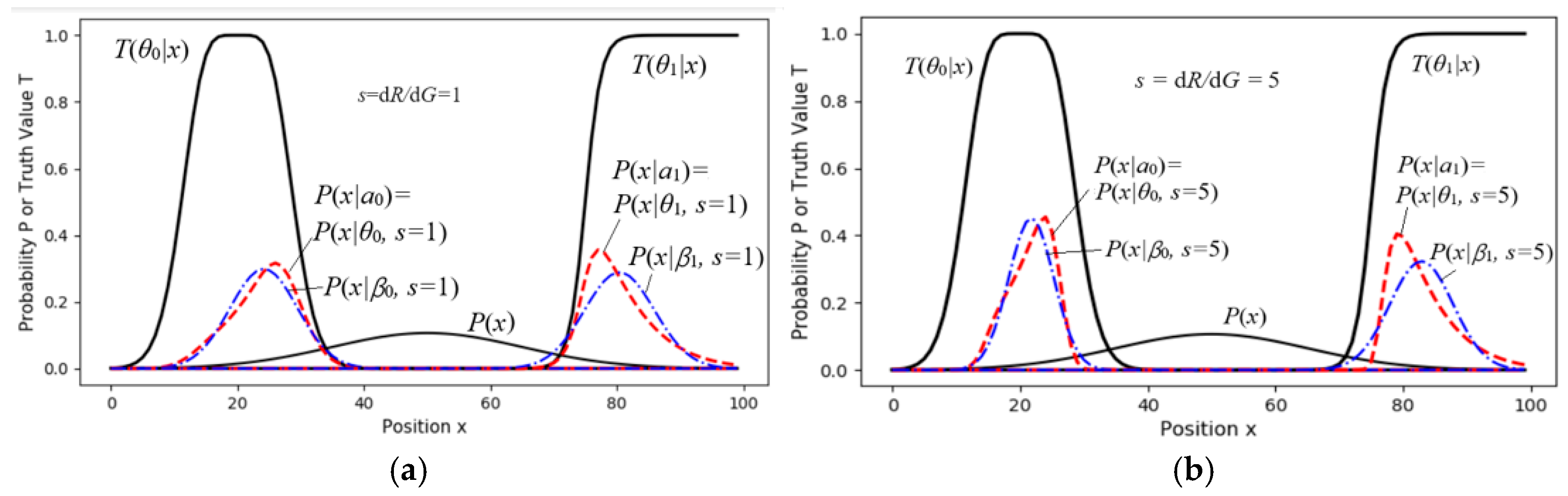
4.2. Goal-Oriented Information and Active Inference (About Sheep Herding)
- “The grain production should be close to or exceed 7500 kg/hectare”;
- “The age of death of the population should preferably exceed 80 years old”;
- “The cruising range of electric vehicles should preferably exceed 500 km”;
- “The error of train arrival time should preferably not exceed 1 min”.
4.3. Comparison of R(G), Mixture Models, Active Inference, VB, and SVB
5. The Relationship Between Information and, Physical Entropy and, Free Energy
5.1. Entropy, Information, and Semantic Information in Local Non-Equilibrium and Equilibrium Thermodynamic Systems
5.2. Information, Free Energy, Work Efficiency, and Information Efficiency
6. The FEP and Inconsistency Between Theory and Practice
6.1. VFE as the Objective Function and VB for Solving Latent Variables
6.2. The Minimum Free Energy Principle
- μ: internal state, which parametrizes the approximate posterior distribution or variational density over external states; in SVB, it is the likelihood function P(x|θj) to be optimized by the sampling distribution.
- a: subjective action; in SVB, it is y (for prediction) and a (for constraint control).
- s: perception; that is, the above observed datum x.
- η: external state, which is objective y and P(x|y); when SVB is used for constraint control, it is the external response P(x|βj), which is expected to be equal to P(x|θj).
6.3. The Progress from the ME Principle to the FEP
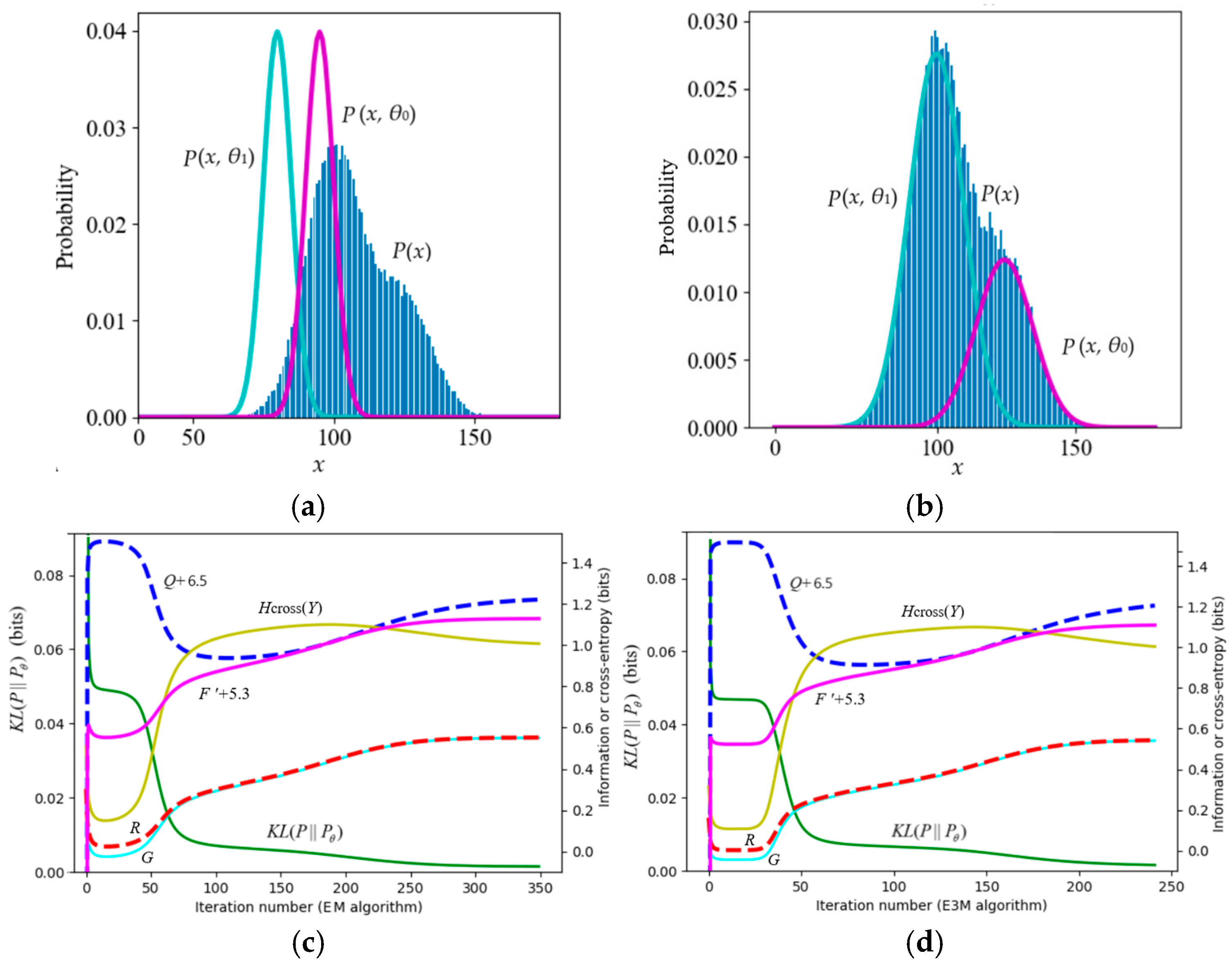
6.4. Why May VFE Increase During the Convergence of Mixture Models?
7. Experimental Results
7.1. Proving Information Difference Monotonically Decreases During the Convergence of Mixture Models Rather than VFE
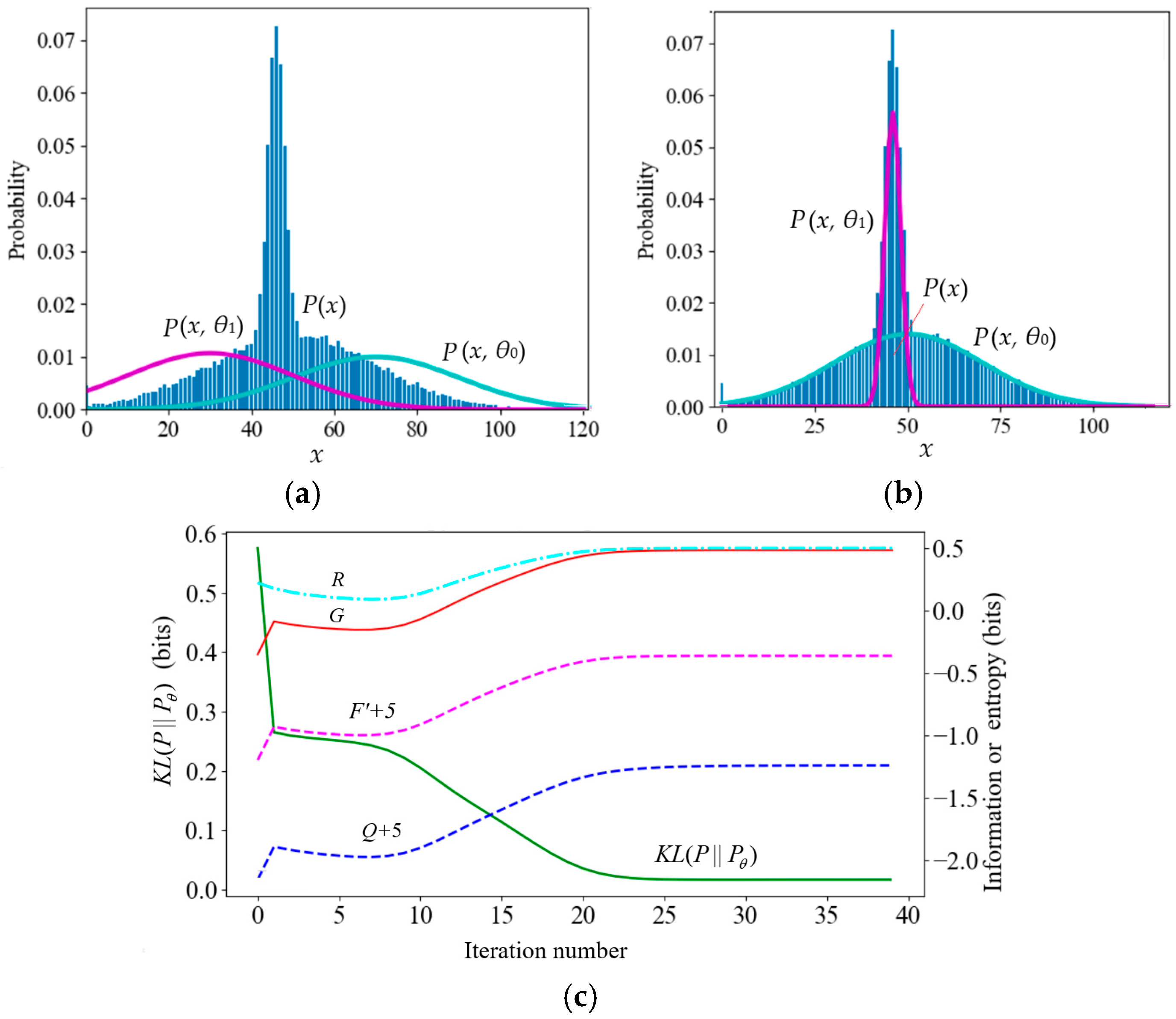
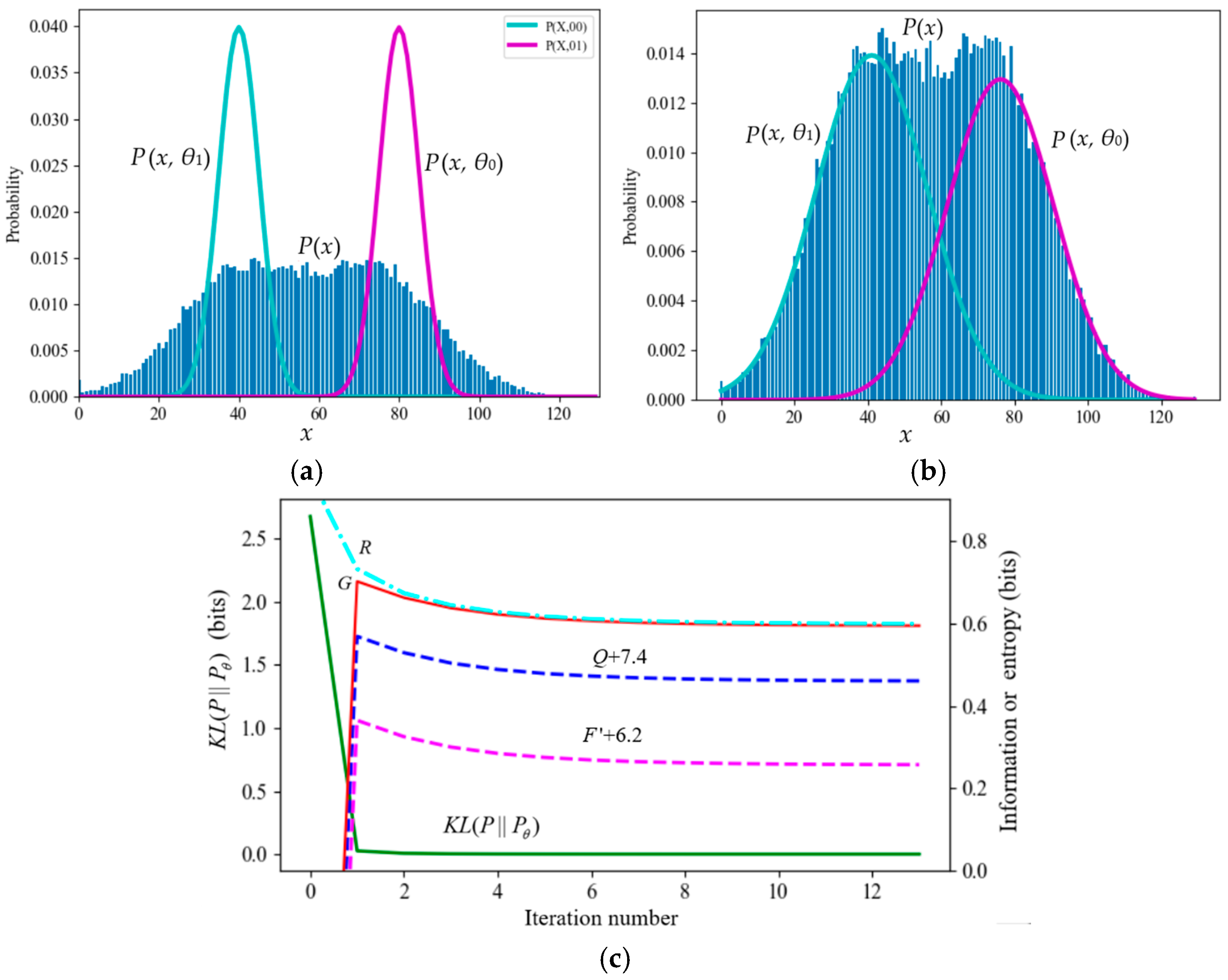
7.1.1. Neal and Hinton’s Example: Mixture Ratios Cause F′ and Q to Decrease
7.1.2. A Typical Counterexample Against VB and the FEP
7.1.3. A Mixture Model with Poor Convergence
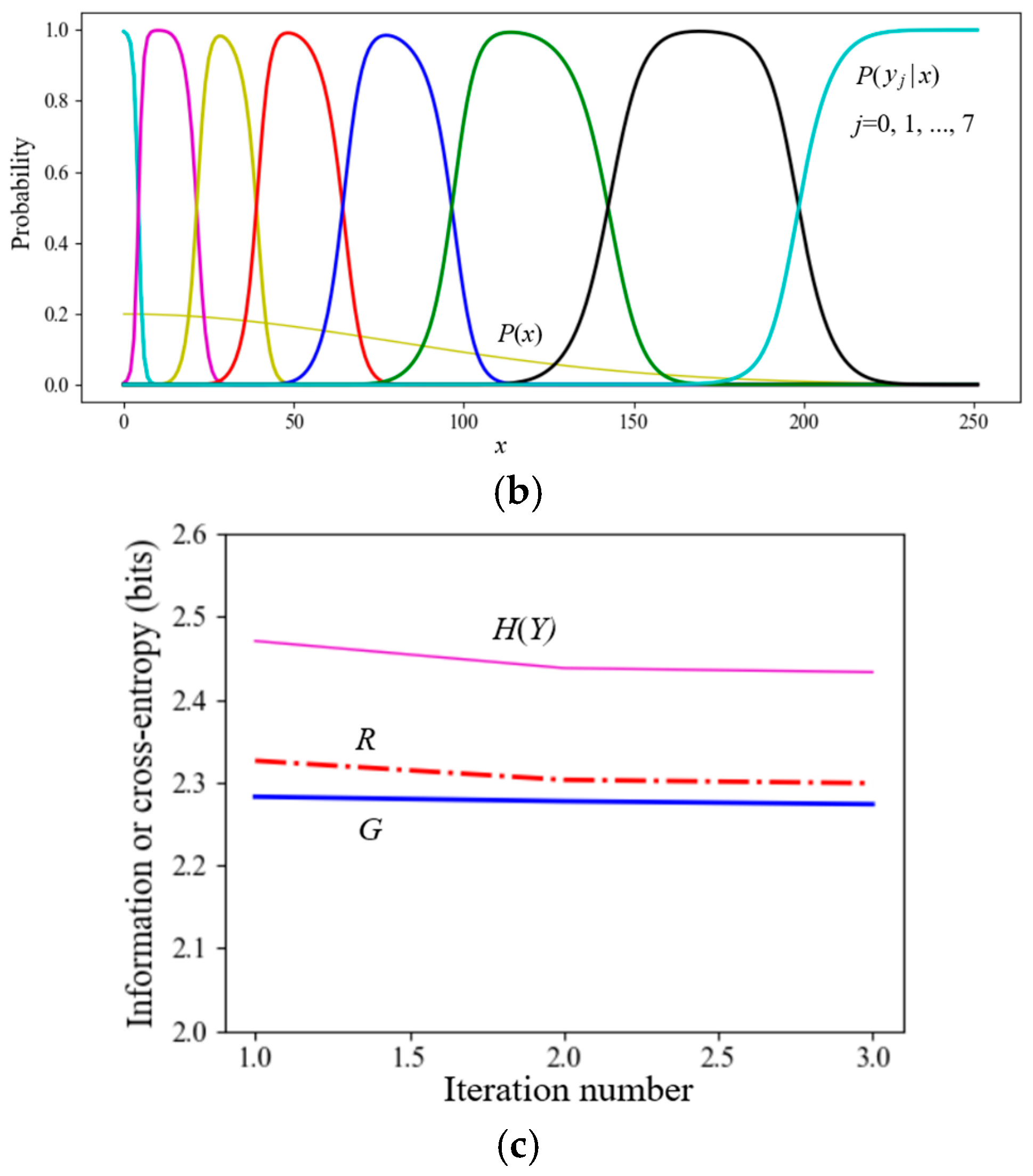
7.2. Simplified SVB (The En Algorithm) for Data Compression
7.3. Experimental Results of Constraint Control (Active Inference)
8. Discussion
8.1. Three Defects in the FEP and Remedies
8.2. Similarities and Differences Between SVB and VB
- Optimization Criteria: Both VB and SVB optimize model parameters using the maximum likelihood criterion. When optimizing P(y), VB nominally follows the MFE criterion but, in practice, employs the minimum KL divergence criterion (i.e., minimizing KL(P∣∣Pθ) to make mixture models converge). This criterion is equivalent to the MIE criterion used in SVB.
- Variational Methods: VB uses either P(y) or P(y∣x) as the variation, whereas SVB alternatively uses P(y∣x) and P(y) as the variations.
8.3. Optimizing the Shannon Channel with the MFE or MIE Criterion for Communication
8.4. Two Directions Worth Exploring
8.4.1. Using High-Dimensional Truth Functions to Express VFE or H(X|Yθ)
- When P(x) is changed, the optimized truth function is still valid.
- The transit probability function P(yj|x) is often approximately proportional to a Gaussian function (its maximum is 1) rather than the Gaussian distribution (its sum is 1), whereas P(x|yj) is not. In these cases, it is better to use the Gaussian function rather than the Gaussian distribution as the learning function, obtaining T*(θj|x) ∝ P(yj|x).
8.4.2. Trying to Explain Sensory Adaptability by Using the MIE Principle
9. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviation | Original Text |
| EM | Expectation–Maximization |
| En | Expectation-n (n means n times) |
| EnM | Expectation-n-Maximization |
| EST | Evolutionary System Theory |
| FEP | Free Energy Principle, i.e., Minimum Free Energy Principle. |
| G theory | Semantic information G theory (G means generalization) |
| KL | Kullback–Leibler |
| LBI | Logical Bayesian Inference |
| ME | Maximum Entropy |
| MFE | Minimum Free Energy |
| MI | Mutual Information |
| MID | Minimum Information Difference |
| MIE | Maximum Information Efficiency |
| SVB | Semantic Variational Bayes |
| VFE | Variational Free Energy |
| VB | Variational Bayes |
Appendix A. Python Source Codes Download Address
Appendix B. Logical Bayesian Inference
Appendix C. The Proof of Equation (25)
References
- Hinton, G.E.; van Camp, D. Keeping the neural networks simple by minimizing the description length of the weights. In Proceedings of the COLT’93: Sixth Annual Conference on Computational Learning Theory, Santa Cruz, CA, USA, 26–28 July 1993; pp. 5–13. [Google Scholar]
- Neal, R.; Hinton, G. A view of the EM algorithm that justifies incremental, sparse, and other variants. In Learning in Graphical Models; Michael, I.J., Ed.; MIT Press: Cambridge, MA, USA, 1999; pp. 355–368. [Google Scholar]
- Beal, M.J. Variational Algorithms for Approximate Bayesian Inference. Ph.D. Thesis, University College London, London, UK, 2003. [Google Scholar]
- Tran, M.; Nguyen, T.; Dao, V. A Practical Tutorial on Variational Bayes. Available online: https://arxiv.org/pdf/2103.01327 (accessed on 20 January 2025).
- Wikipedia, Variational Bayesian Methods. Available online: https://en.wikipedia.org/wiki/Variational_Bayesian_methods (accessed on 8 February 2025).
- Friston, K. The free-energy principle: A unified brain theory? Nat. Rev. Neurosci. 2010, 11, 127–138. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.J.; Parr, T.; de Vries, B. The graphical brain: Belief propagation and active inference. Netw. Neurosci. 2017, 1, 381–414. [Google Scholar] [CrossRef] [PubMed]
- Parr, T.; Pezzulo, G.; Friston, K.J. Active Inference: The Free Energy Principle in Mind, Brain, and Behavior; The MIT Press: Cambridge, MA, USA, 2022. [Google Scholar] [CrossRef]
- Thestrup Waade, P.; Lundbak Olesen, C.; Ehrenreich Laursen, J.; Nehrer, S.W.; Heins, C.; Friston, K.; Mathys, C. As One and Many: Relating Individual and Emergent Group-Level Generative Models in Active Inference. Entropy 2025, 27, 143. [Google Scholar] [CrossRef]
- Rifkin, T.; Howard, T. Thermodynamics and Society. In Entropy: A New World View; Viking: New York, NY, USA, 1980. [Google Scholar]
- Ramstead, M.J.D.; Badcock, P.B.; Friston, K.J. Answering Schrödinger’s question: A free-energy formulation. Phys. Life Rev. 2018, 24, 1–16. [Google Scholar] [CrossRef]
- Schrödinger, E. What Is Life? Cambridge University Press: Cambridge, UK, 1944. [Google Scholar]
- Huang, G.T. Is This a Unified Theory of the Brain? 28 May 2008 from NewScientist Print Edition. Available online: https://www.fil.ion.ucl.ac.uk/~karl/Is%20this%20a%20unified%20theory%20of%20the%20brain.pdf (accessed on 10 January 2025).
- Portugali, J. Schrödinger’s What is Life?—Complexity, cognition and the city. Entropy 2023, 25, 872. [Google Scholar] [CrossRef]
- Haken, H.; Portugali, J. Information and Selforganization: A Unifying Approach and Applications. Entropy 2016, 18, 197. [Google Scholar] [CrossRef]
- Haken, H.; Portugali, J. Information and Selforganization II: Steady State and Phase Transition. Entropy 2021, 23, 707. [Google Scholar] [CrossRef]
- Martyushev, L.M. Living systems do not minimize free energy: Comment on “Answering Schrödinger’s question: A free-energy formulation” by Maxwell James Dèsormeau Ramstead et al. Phys. Life Rev. 2018, 24, 40–41. [Google Scholar] [CrossRef] [PubMed]
- Silverstein, S.D.; Pimbley, J.M. Minimum-free-energy method of spectral estimation: Autocorrelation-sequence approach. J. Opt. Soc. Am. 1990, 3, 356–372. [Google Scholar] [CrossRef]
- Gottwald, S.; Braun, D.A. The Two Kinds of Free Energy and the Bayesian Revolution. Available online: https://arxiv.org/abs/2004.11763 (accessed on 20 January 2025).
- Jaynes, E.T. Information Theory and Statistical Mechanics. Phys. Rev. 1957, 106, 620. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information Theory and Statistical Mechanics II. Phys. Rev. II 1957, 108, 171. [Google Scholar] [CrossRef]
- Lu, C. Shannon Equations Reform and Applications. Busefal 1990, 44, 45–52. Available online: https://www.listic.univ-smb.fr/production-scientifique/revue-busefal/version-electronique/ebusefal-44/ (accessed on 5 March 2019).
- Lu, C. A Generalized Information Theory; China Science and Technology University Press: Hefei, China, 1993; ISBN 7-312-00501-2. (In Chinese) [Google Scholar]
- Lu, C. A generalization of Shannon’s information theory. Int. J. Gen. Syst. 1999, 28, 453–490. [Google Scholar] [CrossRef]
- Lu, C. Semantic Information G Theory and Logical Bayesian Inference for Machine Learning. Information 2019, 10, 261. [Google Scholar] [CrossRef]
- Lu, C. The P–T probability framework for semantic communication, falsification, confirmation, and Bayesian reasoning. Philosophies 2020, 5, 25. [Google Scholar] [CrossRef]
- Lu, C. A Semantic generalization of Shannon’s information theory and applications. Entropy 2025, 27, 461. [Google Scholar] [CrossRef]
- Kolchinsky, A.; Marvian, I.; Gokler, C.; Liu, Z.-W.; Shor, P.; Shtanko, O.; Thompson, K.; Wolpert, D.; Lloyd, S. Maximizing Free Energy Gain. Entropy 2025, 27, 91. [Google Scholar] [CrossRef]
- Da Costa, L.; Friston, K.; Heins, C.; Pavliotis, G.A. Bayesian mechanics for stationary processes. Proc. R. Soc. A Math. Phys. Eng. Sci. 2021, 477, 2256. [Google Scholar] [CrossRef]
- Friston, K.; Heins, C.; Ueltzhöffer, K.; Da Costa, L.; Parr, T. Stochastic Chaos and Markov Blankets. Entropy 2021, 23, 1220. [Google Scholar] [CrossRef]
- Friston, K.; Da Costa, K.; Sajid, N.; Heins, C.; Ueltzhöffer, K.; Pavliotis, G.A.; Parr, T. The free energy principle made simpler but not too simple. Phys. Rep. 2023, 1024, 1–29. [Google Scholar] [CrossRef]
- Ueltzhöffer, K.; Da Costa, L.; Friston, K.J. Variational free energy, individual fitness, and population dynamics under acute stress: Comment on “Dynamic and thermodynamic models of adaptation” by Alexander N. Gorban et al. Phys. Life Rev. 2021, 37, 111–115. [Google Scholar] [CrossRef]
- Shannon, C.E. Coding theorems for a discrete source with a fidelity criterion. IRE Nat. Conv. Rec. 1959, 4, 142–163. [Google Scholar]
- Lu, C. Semantic Variational Bayes Based on a Semantic Information Theory for Solving Latent Variables. arXiv 2014, arXiv:2408.13122. [Google Scholar]
- Lu, C. Using the Semantic Information G Measure to Explain and Extend Rate-Distortion Functions and Maximum Entropy Distributions. Entropy 2021, 23, 1050. [Google Scholar] [CrossRef]
- Berger, T. Rate Distortion Theory; Prentice-Hall: Enklewood Cliffs, NJ, USA, 1971. [Google Scholar]
- Zhou, J.P. Fundamentals of Information Theory; People’s Posts and Telecommunications Press: Beijing, China, 1983. (In Chinese) [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. Ser. B 1997, 39, 1–38. [Google Scholar] [CrossRef]
- Ueda, N.; Nakano, R. Deterministic annealing EM algorithm. Neural Netw. 1998, 11, 271–282. [Google Scholar] [CrossRef] [PubMed]
- von Mises, R. Probability, Statistics and Truth, 2nd ed.; George Allen and Unwin Ltd.: London, UK, 1957. [Google Scholar]
- Kolmogorov, A.N. Grundbegriffe der Wahrscheinlichkeitrechnung; Ergebnisse Der Mathematik (1933); translated as Foundations of Probability; Dover Publications: New York, NY, USA, 1950. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Davidson, D. Truth and meaning. Synthese 1967, 17, 304–323. [Google Scholar] [CrossRef]
- Belghazi, M.I.; Baratin, A.; Rajeswar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, R.D. MINE: Mutual information neural estimation. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1–44. [Google Scholar] [CrossRef]
- Oord, A.V.D.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. Available online: https://arxiv.org/abs/1807.03748 (accessed on 10 January 2025).
- Ben-Naim, A. Can Entropy be Defined for and the Second Law Applied to the Entire Universe? Available online: https://arxiv.org/abs/1705.01100 (accessed on 20 March 2025).
- Wikipedia, Maxwell-Boltzmann Statistics. Available online: https://en.wikipedia.org/wiki/Maxwell%E2%80%93Boltzmann_statistics (accessed on 20 March 2025).
- Bahrani, M. Exergy. Available online: https://www.sfu.ca/~mbahrami/ENSC%20461/Notes/Exergy.pdf (accessed on 23 March 2025).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task or Method | R(G) | Mixture Models | Active Inference | VB | SVB |
|---|---|---|---|---|---|
| Optimize P(x|θj) | may | yes | may | yes | yes |
| Optimize P(y) and P(y|x) | yes | yes | yes | yes | yes |
| Use s | yes | no | may | not yet | yes |
| Use Constraint T(y|x) | yes | may | may | not yet | yes |
| Change P(x) | no | no | yes | yes | yes |
| x1 | x2 | x3 | x4 | H(X|θj) (Bits) | |
|---|---|---|---|---|---|
| P(x|θj) | 0.1 | 0.4 | 0.4 | 0.1 | |
| P(x|yj) | 0 | 0.5 | 0.5 | 0 | log(10/4) = 1.32 |
| P(x|yj) = P(x|θj) | 0.1 | 0.4 | 0.4 | 0.1 | 0.2log(10) + 0.8log(10/4) = 1.72 |
| True Model’s Parameters | Initial Parameters | |||||
|---|---|---|---|---|---|---|
| μ* | σ* | P*(y) | μ | σ | P(y) | |
| y1 | 46 | 2 | 0.7 | 30 | 20 | 0.5 |
| y2 | 50 | 20 | 0.3 | 70 | 20 | 0.5 |
| The True Model’s Parameters | Initial Parameters | |||||
|---|---|---|---|---|---|---|
| μ* | σ* | P*(Y) | μ | σ | P(Y) | |
| y1 | 40 | 15 | 0.5 | 40 | 5 | 0.5 |
| y2 | 75 | 15 | 0.5 | 80 | 5 | 0.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, C. Improving the Minimum Free Energy Principle to the Maximum Information Efficiency Principle. Entropy 2025, 27, 684. https://doi.org/10.3390/e27070684
Lu C. Improving the Minimum Free Energy Principle to the Maximum Information Efficiency Principle. Entropy. 2025; 27(7):684. https://doi.org/10.3390/e27070684
Chicago/Turabian StyleLu, Chenguang. 2025. "Improving the Minimum Free Energy Principle to the Maximum Information Efficiency Principle" Entropy 27, no. 7: 684. https://doi.org/10.3390/e27070684
APA StyleLu, C. (2025). Improving the Minimum Free Energy Principle to the Maximum Information Efficiency Principle. Entropy, 27(7), 684. https://doi.org/10.3390/e27070684