1. Introduction
Binary neural networks (BNNs) are one of the recent directions in deep neural networks (DNNs) edge implementations, which are proposed to save energy and improve computational efficiency [
1,
2,
3,
4,
5]. BNNs, as an extreme form of quantized neural networks, require only 1 bit of two discrete values
to represent the network’s weights and/or activations. Since the 1-bit convolution operation can be efficiently implemented by XNOR and Bitcount operations, BNNs can significantly speed up and save energy in inference. However, such extreme constraints often lead to underfitting, making BNNs simultaneously disadvantageous in terms of training difficulties and accuracy degradation.
Batch Normalization (BN) [
6] is a widely used technique in deep learning and most of BNNs contain BN layers because they are infeasible to train without BN layers [
7]. Unlike full-precision neural networks, BNNs restrict activations to discrete values
, so that the forward pass is not affected by the scale of the input distribution, but only by the location of the distribution. For BNNs, scaling in BN layers prevents gradient explosion, while bias in BN layers determines the choice of activation values between 1 and −1, which is very different from full-precision neural networks. In addition, BNNs usually use the sign function as the activation function, which has insufficient nonlinear fitting ability and is not differentiable. Although back-propagation is possible using gradient approximation methods, the difference between the actual function and the approximated function can lead to gradient mismatch problems. These challenges create opportunities for optimizing the BN layer in BNNs, providing an impetus for BN research and improvements targeting BNNs.
In this work, we introduce the self-attention mechanism into the BN layer in BNNs by proposing Attention-based Batch Normalization for BNNs (ABN), a lightweight and input-adaptive normalization method specifically designed for BNNs.Due to the introduction of the self-attention mechanism, the ABN method has a more significant ability to highlight the unique features of each category compared to the baseline BN method. And, ABN enhances the ability of the network to capture complex patterns and nonlinear relationships in the data from the point of view of additional activation functions due to the use of sigmoid functions in the self-attention mechanism. In addition, in our experiments, we observe that our ABN approach further increases the imbalance of the binary activation distribution compared to the baseline BN method. This allows BNNs to exploit the diversity of data more effectively, enhance the model’s generalization ability, and improve the model’s performance on various tasks.
Contributions. In summary, our contributions are as follows:
We propose a lightweight attention-based batch normalization method tailored for Binary Neural Networks (BNNs), named Attention-based Batch Normalization (ABN). While prior works have explored attention mechanisms within BN, ABN is, to our knowledge, the first to replace the learnable scaling factor with a parameter-free, input-dependent attention function specifically designed for binary activations.
ABN rescales the normalized activations using a sigmoid-based self-attention mechanism derived directly from the input, which enhances the network’s ability to capture complex patterns and nonlinear relationships, increases the imbalance of binary activation distributions, and improves generalization.
ABN is a plug-and-play module that can directly replace standard BN in binary activation networks, and it can be easily integrated into existing binary architectures without modifying the overall design.
Extensive experiments demonstrate that ABN consistently outperforms standard BN across three benchmark datasets and two commonly used network backbones.
2. Related Work
2.1. Batch Normalization in BNNs
Batch Normalization (BN) [
6] is a widely used technique in deep learning that helps to train DNNs faster and more consistently [
8,
9]. Different normalization variants differ in how they partition input data (e.g., by instances [
10], channels [
11], groups [
12], positions [
13], and image domains [
14,
15]). These variants typically have the same learnable linear transformation module, and the output is not constrained to obey zero-mean and unit-variance distributions, improving the ability to fit real-world data distributions.
In the realm of full-precision networks, it is widely acknowledged that BN operates by aligning the first and second moments of input and output distributions. This correction process effectively addresses covariate bias and restrains the gradient, ultimately leading to a smoother optimization process [
8]. BN layers exhibit different effects in Binary neural networks (BNNs) compared to full-precision networks For training BNNs to converge, BN is essential, and as argued by Sari et al., it plays a crucial role in preventing gradient explosion [
7].
In the case of BNNs employing sign activation, it’s worth noting that the scale of the input distribution does not impact the forward pass; rather, it’s the bias that assumes a pivotal role. According to Sari et al.’s argument, when inference is executed, the BN layers followed by the sign function effectively function as a thresholding mechanism [
7]. Furthermore, the magnitude of the bias within BN layers holds a significant influence over the resulting activation values.
Recent studies have explored incorporating attention mechanisms into batch normalization to improve its adaptability. For instance, Liang et al. proposed Instance Enhancement Batch Normalization (IEBN) [
16], which uses learnable instance-specific modulation to handle noisy data, while Martinez et al. [
17] applied a channel-wise attention mechanism via a multi-layer gating structure, achieving improved performance in BNNs. However, these methods often introduce additional parameters and increase network complexity. Meanwhile, several works have focused on optimizing or replacing BN for better efficiency in BNNs. Chen et al. [
18] proposed a BN-free training scheme using gradient clipping and weight standardization. Vorabbi et al. [
19] introduced BNN-Clip to reduce BN-induced latency and data width, and Rege et al. [
20] designed an in-memory BN method for hardware-efficient BNN deployment. These developments highlight the need for lightweight and adaptive normalization, motivating our attention-based BN approach designed specifically for BNNs.
2.2. Unbalanced Activation Distribution in BNNs
Given that BNNs only have two activation values (+1 and −1), the distribution of binary activations has been demonstrated to be a critical factor in their performance. The main focus of Ding et al.’s [
21] work was to regulate the distribution of pre-activation values, with a particular emphasis on avoiding extreme cases where all pre-activation values share the same sign. Liu et al. [
5] suggested balancing the distribution of binary activation by reshaping it with trainable thresholds and activation functions.
After conducting extensive experimental analysis, Kim et al. [
22] come to the conclusion that unbalanced activation distributions can, in fact, enhance the accuracy of neural networks. As is widely recognized, most DNN models tend to employ the ReLU activation function as opposed to sigmoid or Tanh functions. The output distributions of the sigmoid and Tanh functions are symmetric with respect to zero, whereas the ReLU function replaces all negative values with zero, resulting in a highly skewed output distribution. However, when binarized activations are utilized, the sign function is employed instead, which leads to a symmetric distribution of binarized activations. Therefore, it was hypothesized that the symmetry of the sign function may contribute to the degradation of BNN performance.
2.3. Self-Attention Mechanism
The advantages of the self-attention mechanism include better capture of important information in the input vectors [
23,
24,
25], smooth nonlinear properties [
26], better handling of nonlinear relationships in the input vectors [
26], etc., which will help to improve the underfitting of the BNNs due to extreme constraints. The sigmoid function is a widely employed tool in attention mechanisms for calculating attention weights. It is utilized to transform the input attention score into a normalized range, specifically between 0 and 1, thereby representing the significance of each pixel. In addition, the incorporation of the sigmoid function in the self-attention mechanism introduces a valuable nonlinear transformation that significantly enhances the model’s ability to capture intricate relationships within an image.
Binary neural networks lose a large amount of information during training due to their binary nature and also have limited nonlinear fitting ability due to their usual use of symbolic functions as activation functions [
27]. Incorporating the self-attention mechanism into BN layers of BNNs brings about dual advantages. Firstly, by combining the self-attention mechanism with the BN layer, BNNs can benefit from both the attention-important feature of self-attention and the standardization property of BN, thus enhancing the representation capability of the network. Secondly, the presence of the self-attention mechanism with its inherent nonlinear function enhances the network’s ability to perform nonlinear fitting, enabling it to model complex relationships in the data.
3. Preliminaries
3.1. STE-Based Binary Neural Networks
The main operation in deep neural networks is expressed as:
where
indicates the weight vector,
indicates the input activation vector computed by the previous network layer.
The goal of network binarization is to represent the floating-point weights and/or activations with 1-bit. And we usually use
function to get
:
With the quantized weights and activations, the vector multiplications in the forward propagation can be reformulated as
where ⊙ denotes the inner product for vectors with bitwise operations XNOR and Bitcount.
To apply back-propagation through a
function which is nondifferentiable, the straight-through-estimator (STE) [
28] concept is introduced. The function of STE is defined as follows
With STE, it is possible to train BNNs directly using the same gradient descent method as normal full-precision neural networks. This
function acts as an activation function in the network. However, when using the
function in backpropagation, if the absolute value of the full-precision activation is greater than 1, it cannot be updated in backpropagation. Therefore an identity function is used to approximate the derivative of the sign fnction:
where
is the real-valued input to the activation function and
is the binarized output of the activation function.
is the indicator function that evaluates to 1 if
and 0 otherwise. With this approach, the binary neural network can be used to update the parameters using a powerful back propagation (BP) algorithm based on gradient descent.
3.2. Batch Normalization
Batch Normalization (BN) is a technique used to improve the training of deep neural networks. It involves normalizing the activations of each layer in a mini-batch before applying any learnable transformation. Consider a mini-batch
of activations for a given layer, where
m is the mini-batch size.
Let the normalized values be
, and their linear transformations be
.
Ioffe et al. [
6] present the BN Transform in Algorithm 1. In the algorithm,
is the mini-batch mean;
is the mini-batch variance;
is a constant added to the mini-batch variance for numerical stability;
and
are trainable affine transformation parameters (scale and shift).
| Algorithm 1 BN: Batch Normalization |
Input: Values of x over a mini-batch: ; Parameters to be learned: output:
|
This Batch Normalization process helps stabilize and accelerate the training of neural networks.
4. Method
4.1. Attention-Based Batch Normalization
Batch Normalization (BN) plays a crucial role in fitting the distribution of input data by recovering its statistics. In the recovery step, BN learns a pair of per-channel parameters,
and
, to adjust the mean and variance of each channel.
However, using only two parameters to fit the input distribution and recover the representation ability for each channel is challenging, particularly when the input contains complex scenes. This is because in such cases, the statistical data of each channel may be influenced by other channels, and the input data distribution may be more complex and diverse. Therefore, the BN method with only two parameters may not be sufficient to handle such situations, and more complex and flexible methods are needed to deal with complex input data. To address this issue, we propose to use the sigmoid function, which is widely used in attention mechanisms, to enhance the linear transformation of the BN layer and improve its expressive power as follows:
where the sigmoid function is defined as:
represents the input feature after normalization. When
passes through this sigmoid activation, it undergoes a transformation that confines its output within the desired range of
, which yields the attention score. The output of the sigmoid function can be readily interpreted as the degree of the corresponding pixel being significant or important within the context of the given task. In ABN, we replace the learnable scaling parameter
in the original BN formulation with an attention score computed as
, and retain the learnable bias parameter
. As a result, the modulation of
becomes input-dependent, introducing nonlinearity into the normalization process.For a detailed description of ABN see Algorithm 2.
| Algorithm 2 ABN: Attention-Based Batch Normalization |
Input: Values of x over a mini-batch: ; Parameters to be learned: output:
|
4.2. Why Does the Attention-Based BatchNorm Work?
The Attention-based BatchNorm (ABN) is the first specialized BN algorithm proposed for BNN our knowledge. In this subsection, we further elaborate on its advantages over existing mechanisms.
4.2.1. Capturing Discriminative Features
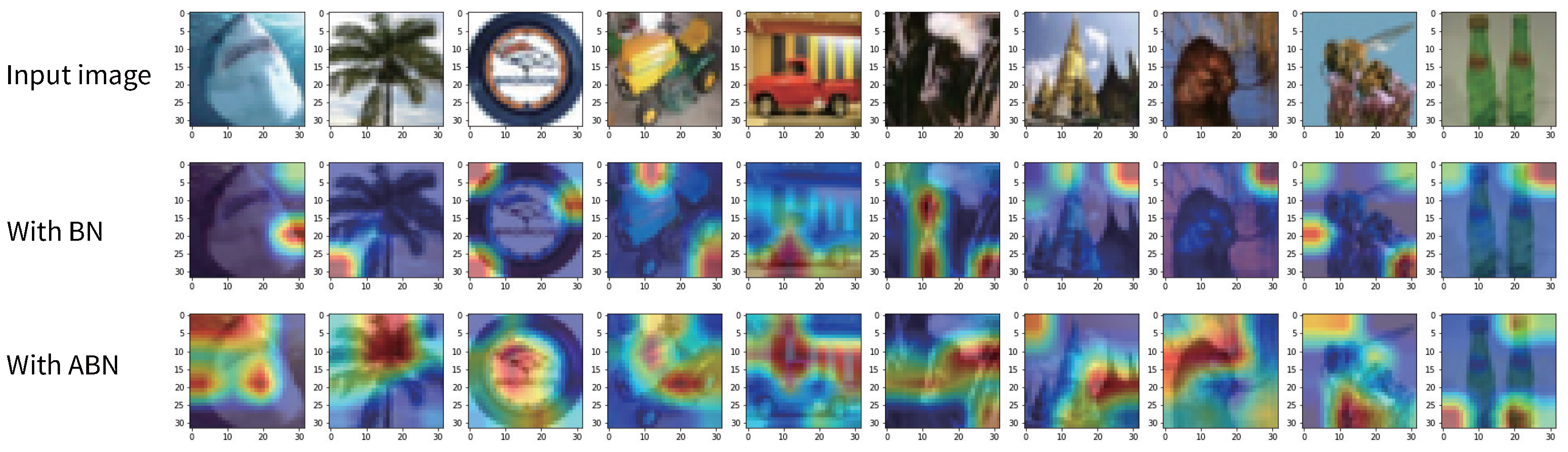
To study the ability of ABN to capture and exploit features of a given target, we apply Grad-CAM [
29] to compare the regions where different BN methods localize with respect to their target prediction. Grad-CAM is a technique that generates a heatmap to highlight the areas of network attention using the gradient related to the given target. In BNNs, the representational power of the model is somewhat limited by the fact that the weights are restricted to binary values (typically +1 and −1). However, by using Grad-CAM, we can still understand the distribution of attention of a binary neural network on a given image. This allows us to speculate on how the model makes classification decisions and which regions are critical to the classification results.
Figure 1 shows the visualization results of BinaryNet applying the original BN and our ABN on the CIFAR-100 validation set. The red regions indicate the areas of an image that are most important for the network to obtain a high target score, while the blue regions represent the areas that are less relevant for the target score. This suggests that the ABN approach may have a more remarkable ability to highlight each class’s distinctive features than the baseline BN approach. Therefore, it is logical to conclude that ABN provides an additional boost to the final classification performance, as the ability to distinguish between different features is critical for accurate classification. This is further supported by the experimental results of image classification presented in
Section 5.
4.2.2. Providing Additional Activation Functions
Typically, the activation function is applied after Batch Normalization to introduce nonlinearity into the network. This enhances the network’s expressive power, allowing it to handle more complex problems than just stacking linear transformations in deep neural networks.
Binary Neural Networks (BNNs) use the STE method to handle the non-differentiability of the Sign function. STE enables approximate gradients in BNNs, facilitating valid backpropagation and efficient training of binary weights. However, a drawback of STE is its impact on traditional activation functions within the network. To enable the use of approximate gradients, binary neural networks commonly adopt a hard Tanh function as the activation function. The hard Tanh function modifies the traditional Tanh function by constraining its output to the range of [−1, 1] and truncating inputs beyond this range, causing the function to have a flat output in this truncated region. This hard restriction leads to the activation function having zero derivatives in that region, making it prone to the gradient vanishing problem during training. As a consequence, the effectiveness of the traditional activation function is weakened.
In contrast to the standard Batch Normalization (BN), our proposed ABN introduces a sigmoid activation into the normalization layer, enabling a data-dependent nonlinear transformation. This design allows the network to better capture complex patterns and intricate relationships within the data. To illustrate the effect of this transformation, we visualize the evolution of activation distributions in
Figure 2. The figure shows three stages of the normalization process—raw input
, standardized output
, and final transformed output
—stacked across training epochs (
Y-axis). It is evident that the data distribution undergoes a more significant transformation through ABN compared to the linear transformation produced by the baseline BN. Although
is normalized to zero mean and unit variance, the actual value range may exceed
due to natural variation in input statistics. The stronger nonlinearity induced by ABN, especially in early training epochs, allows the network to emphasize informative features more effectively, thereby improving convergence stability and performance on complex tasks.
4.2.3. Reshaping the Activation Distribution
In neural networks, activations are dynamic and influenced by the input data. For Binary Neural Networks (BNNs), the distribution of binary activation values is considered a crucial factor that impacts their performance. Existing research has demonstrated that having unbalanced activation values in BNNs can lead to improved accuracy in the network.
Unbalanced activation values refer to situations where the binary activations have an unequal distribution of +1 and −1 values. This non-uniform distribution of activations provides the network with the ability to effectively capture and represent complex patterns in the data. It allows the network to learn more discriminative features and make better decisions when classifying different data samples.
In our experiments, we have observed that our ABN method further increases the imbalance of the binary activation distribution compared to the baseline BN method.
Figure 3 illustrates the data distribution of full-precision activations and their binary activations before the binary convolution is computed and summed over the binary activations. The Y-axis in
Figure 3 represents the training epoch index, increasing from top to bottom. Each horizontal slice corresponds to the activation distribution at a specific training epoch. The data distribution is most balanced when the absolute value of the sum is zero. However, upon closer examination of the figure, we can observe that the sum of binary activation values gradually decreases during the training process, regardless of whether BN or ABN is used. In other words, the distribution of binary activations becomes more and more unbalanced as the training progresses. By having an unbalanced distribution of activation values, BNNs can exploit the diversity in the data more effectively, enhancing the model’s ability to generalize and improve its performance on various tasks.
5. Experiments
In this section, our primary emphasis revolves around one of the fundamental objectives of deep learning—the image classification task. This task stands as a cornerstone in the domain of artificial intelligence, playing a pivotal role in enabling machines to comprehend and interpret visual information. We start by providing a detailed description of the implementation of our experiments (refer to
Section 5.1). This allows for a clear understanding of the methodology employed in our study. We then illustrate the tailor-made nature of our ABN for BNNs through a series of experiments (refer to
Section 5.2). Subsequently, to assess the impact of the scaling factor
and bias
in ABN, we conduct an ablation analysis (refer to
Section 5.3). Through this analysis, we aim to identify the significance of these components in our proposed method. Finally, we present the results of a comprehensive experiment where we compare our ABN with the baseline BN (Batch Normalization) method, validating the superiority of our proposed approach (refer to
Section 5.4).
5.1. Implementation Details
To evaluate our Attention-based Batch Normalization (ABN), we conduct extensive experiments on three public benchmark datasets, including CIFAR10 [
30], CIFAR100 [
30], and TinyImageNet [
31], and use standard data augmentation (i.e., random crop and horizontal flip). The details of the datasets and their corresponding experiment setups are given in
Table 1.
The BinaryNet, initially proposed by Courbariaux et al. [
2], represents the pioneering structure in the realm of BNNs. On the other hand, ResNet-18 [
32] introduced the concept of residual blocks, proving highly beneficial in training deeper neural networks. Consequently, many subsequent BNN structures have been built upon the ResNet-18 architecture due to its wide acceptance and success. In this paper, we leverage the prevalence of BinaryNet and ResNet-18 to demonstrate the applicability of ABN in BNNs. In both networks, the weights and activations are binary, with the exception of the first and last layers where full-precision weights are retained. To clarify the proportion of the binary weights in the network, we give in
Table 2 the number of binary and full-precision trainable parameters for BinaryNet and ResNet-18 on different datasets.
In the experiments of this paper, we use the baseline BN, which is often used in BNN studies, to conduct a comparative study experiment with our ABN. Our method is implemented in PyTorch [
33] on a single NVIDIA 2080Ti GPU and is developed based on the software framework released by BinaryNet’s authors We use the BNN code available at
https://github.com/itayhubara/BinaryNet.pytorch (accessed on 8 June 2025).
Our results show that the accuracy obtained by the ABN method on both BinaryNet and ResNet-18 network structures consistently outperforms baseline BN in experiments on these three datasets.
5.2. Exclusively Tailored for Binary Neural Networks
To validate the effectiveness of our ABN approach tailored specifically for BNNs, we carried out an experimental comparison between different neural network architectures(binary and full-precision) on the CIFAR-100 dataset. The results of the experiment are shown in
Figure 4, where “binary” represents the BinaryNet model, a binary neural network model similar to VGG-11, and “full-precision” represents VGG-11. The two models are cross-compared using BN and ABN methods, respectively.
As shown in the figure, the experimental outcomes for BinaryNet employing the ABN method demonstrate a notable improvement compared to BinaryNet using BN. This observation serves as compelling evidence supporting the effectiveness of our ABN approach when applied specifically to BNNs. Additionally, it is worth noting that in the context of full-precision neural networks, a divergent trend emerges. Specifically, when our ABN method is applied within the full-precision network, it exhibits inferior performance compared to the BN method on the validation set. These experimental results distinctly indicate that our ABN method is tailored exclusively for binary neural networks and does not yield the same benefits when integrated into full-precision neural networks. In fact, its presence within full-precision networks appears to have a detrimental effect on their performance.
In summary, our experiments unequivocally demonstrate that the ABN method significantly enhances the performance of Binary Neural Networks while exhibiting contrasting effects on full-precision networks, where it tends to degrade their performance. This highlights the specificity of the ABN method, underlining its effectiveness as an optimization tool uniquely suited to BNN models.
5.3. Ablation Study
In this section, we undertake ablation experiments within the ABN framework to investigate the impact of the scaling factor
and bias
, which are integral components of the baseline BN method. We perform two distinct experiments, the results of which are shown in
Figure 5.
Initially, we introduce the trainable parameter into ABN, yet intriguingly, its presence did not yield any discernible enhancement in network performance based on the experimental outcomes. Conversely, when we removed the trainable parameter from the ABN method, a significant deterioration in network performance was observed. This observation strongly suggests that while is dispensable for ABN, plays a crucial and indispensable role.
In summary, our ablation experiments with ABN provide valuable insights: the absence of a discernible impact from implies its non-essential nature within the ABN, while the substantial performance drop upon removal underscores its necessity for the effectiveness of ABN. We consider the trainable parameter to be the threshold that determines whether the binary activation value flips between and . These findings contribute to a clearer understanding of the intricate dynamics within the ABN method and guide its further refinement and application.
5.4. Comparison
We conducted experiments to compare our ABN method with the benchmark BN method using two binary neural network models, BinaryNet and ResNet-18 (
https://github.com/itayhubara/BinaryNet.pytorch, accessed on 8 June 2025), across three benchmark datasets: CIFAR-10 and CIFAR-100 (Canadian Institute for Advanced Research, Toronto, ON, Canada), and TinyImageNet (Stanford University, Stanford, CA, USA).
All results (except for TinyImageNet) are averaged over five independent runs with different random seeds to ensure statistical reliability. For TinyImageNet, due to computational constraints, we report results from a representative single run. We did not use k-fold cross-validation; instead, a fixed 10% of the training data was used as a validation set during training, which is a common practice in BNN evaluation.
Table 2 lists the parameter scales and validation set classification experimental results of the two models on the three datasets.
From the experimental outcomes, it is evident that our ABN method consistently outperforms the benchmark BN. Moreover, on the CIFAR dataset, our ABN method exhibits the least variance in validation accuracy. This observation suggests that ABN yields more stable classification results, underscoring the algorithm’s enhanced robustness in comparison to the benchmark BN.
6. Conclusions
In this paper, we propose a dedicated Batch Normalization method designed specifically for BNNs, i.e., ABN, which achieves competitive advanced performance compared to the most common baseline BN. Specifically, we introduce a self-attention mechanism that rescales the corresponding output channels of the BN according to the existing distribution of activation values and retains trainable bias parameters to provide thresholds for flipping activation values. In addition, for the effective mechanism of ABN action in BNNs we performed a detailed experimental analysis. We identify that the self-attention mechanism in ABN significantly improves its ability to highlight image features; the additional presence of activation-like functions in the method enables the network to capture complex patterns and nonlinear relationships in the data; ABN also amplifies the imbalance in the binary activation distribution, which contributes to improved model generalization and enhanced performance across a range of tasks. With the contribution of these techniques together, the experimental results of our ABN method are significantly improved compared to the baseline BN method on the CIFAR-10, CIFAR-100, and TinyImageNet image classification datasets. Our future work will continue to dig into the deeper mechanisms of BNNs optimization.
Author Contributions
Conceptualization, S.G.; Methodology, S.G. and G.Z.; Software, S.G.; Validation, C.J.; Investigation, C.J.; Visualization, C.J.; Writing—original draft preparation, S.G.; Writing—review and editing, S.G.; Supervision, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
References
- Courbariaux, M.; Bengio, Y.; David, J.P. BinaryConnect: Training Deep Neural Networks with Binary Weights during Propagations. Adv. Neural Inf. Process. Syst. 2015, 28, 3123–3131. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV. Springer: Berlin/Heidelberg, Germany, 2016; pp. 525–542. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Liu, Z.; Shen, Z.; Savvides, M.; Cheng, K.T. Reactnet: Towards precise binary neural network with generalized activation functions. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 143–159. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Sari, E.; Belbahri, M.; Nia, V.P. How does batch normalization help binary training? arXiv 2019, arXiv:1909.09139. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How Does Batch Normalization Help Optimization? Adv. Neural Inf. Process. Syst. 2018, 31, 2483–2493. [Google Scholar]
- Bjorck, N.; Gomes, C.P.; Selman, B.; Weinberger, K.Q. Understanding Batch Normalization. Adv. Neural Inf. Process. Syst. 2018, 31, 7694–7705. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Pan, X.; Luo, P.; Shi, J.; Tang, X. Two at once: Enhancing learning and generalization capacities via ibn-net. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 464–479. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, B.; Wu, F.; Weinberger, K.Q.; Belongie, S. Positional Normalization. Adv. Neural Inf. Process. Syst. 2019, 32, 1620–1632. [Google Scholar]
- Li, Y.; Wang, N.; Shi, J.; Hou, X.; Liu, J. Adaptive batch normalization for practical domain adaptation. Pattern Recognit. 2018, 80, 109–117. [Google Scholar] [CrossRef]
- Zhuang, Z.; Wei, L.; Xie, L.; Zhang, T.; Zhang, H.; Wu, H.; Ai, H.; Tian, Q. Rethinking the distribution gap of person re-identification with camera-based batch normalization. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 140–157. [Google Scholar]
- Liang, S.; Huang, Z.; Liang, M.; Yang, H. Instance enhancement batch normalization: An adaptive regulator of batch noise. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4819–4827. [Google Scholar]
- Martinez, B.; Yang, J.; Bulat, A.; Tzimiropoulos, G. Training binary neural networks with real-to-binary convolutions. arXiv 2020, arXiv:2003.11535. [Google Scholar]
- Chen, T.; Zhang, Z.; Ouyang, X.; Liu, Z.; Shen, Z.; Wang, Z. “BNN-BN=?”: Training Binary Neural Networks Without Batch Normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 11–15 June 2021; pp. 4619–4629. [Google Scholar]
- Vorabbi, L.; Maltoni, D.; Santi, S. Optimizing Data Flow in Binary Neural Networks. Sensors 2024, 24, 4780. [Google Scholar] [CrossRef] [PubMed]
- Rege, P.; Yin, M.; Parihar, S.; Versaggi, J.; Nemawarkar, S. An in-Memory-Computing Binary Neural Network Architecture with In-Memory Batch Normalization. IEEE Access 2024, 12, 190889–190896. [Google Scholar] [CrossRef]
- Ding, R.; Chin, T.W.; Liu, Z.; Marculescu, D. Regularizing activation distribution for training binarized deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11408–11417. [Google Scholar]
- Kim, H.; Park, J.; Lee, C.; Kim, J.J. Improving accuracy of binary neural networks using unbalanced activation distribution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7862–7871. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3286–3295. [Google Scholar]
- Figurnov, M.; Collins, M.D.; Zhu, Y.; Zhang, L.; Huang, J.; Vetrov, D.; Salakhutdinov, R. Spatially adaptive computation time for residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1039–1048. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G.; Kossaifi, J.; Pantic, M. Improved training of binary networks for human pose estimation and image recognition. arXiv 2019, arXiv:1904.05868. [Google Scholar]
- Bengio, Y.; Léonard, N.; Courville, A. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv 2013, arXiv:1308.3432. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009; Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 16 June 2025).
- Le, Y.; Yang, X. Tiny imagenet visual recognition challenge. CS 231N 2015, 7, 3. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}