1. Introduction
Autonomous navigation systems have become an essential area of research in robotics, enabling robots to move and operate in diverse environments without human intervention [
1]. In many applications, such systems must navigate spaces where GPS signals are unavailable or unreliable, such as indoors areas [
2,
3]. Vision-based navigation systems, particularly those utilizing RGB-D sensors, have become a cornerstone technology in this area [
4,
5,
6]. These systems enable robots to perceive their surroundings in 3D, offering a richer and more detailed understanding than traditional 2D imaging [
7]. The depth data provided by RGB-D cameras enhances the robot’s ability to perform critical tasks such as obstacle avoidance, path planning, and complex scene understanding [
8].
Traditional approaches to autonomous navigation, such as Simultaneous Localization and Mapping (SLAM), have made significant progress in addressing tasks like self localization and mapping [
9]. Specifically, the integration of machine learning into these systems has introduced new possibilities for improving decision-making, such as path planning and obstacle avoidance, particularly in visual SLAM (vSLAM) systems [
10]. Another approach is the use of machine learning models to interpret sensory data and make navigation decisions based on learned patterns, offering a data-driven alternative to classical rule-based systems [
11,
12,
13,
14]. These models can be combined with low-level controllers when a mobile robot navigates in presence of disturbance and uncertainties [
15,
16] or the system requires to adjust its feedback in real time [
17].
Despite these advancements, several challenges persist in vision-based robotic navigation. One major issue is the computational complexity associated with processing high volumes of data from RGB-D sensors in real time [
11,
18,
19]. Effective navigation requires not only recognizing and avoiding obstacles but also identifying optimal paths and making split-second decisions [
20]. Traditional methods of point cloud registration used in SLAM techniques [
21,
22], such as the Iterative Closest Point (ICP) algorithm and its variants, often involve intensive computations to align and compare 3D models from different viewpoints [
23]. These processes can be prohibitively slow for applications where timely response is critical.
The integration of visual memory, which allows robots to recall and recognize previously observed environments, further empowers navigation systems, enabling more adaptive and intelligent behavior in dynamic settings [
24]. However, while visual memory systems enhance a robot’s navigation capabilities, they also introduce challenges in terms of memory management and data retrieval [
25,
26]. Efficiently indexing and accessing relevant spatial data from a robot’s memory without overloading the system’s computational resources is crucial for real-time performance [
25,
27]. Additionally, maintaining the accuracy and reliability of topological representation of the environment in constantly changing environments remains a significant hurdle, complicating the localization processes that are foundational for autonomous navigation [
28].
1.1. Proposed System
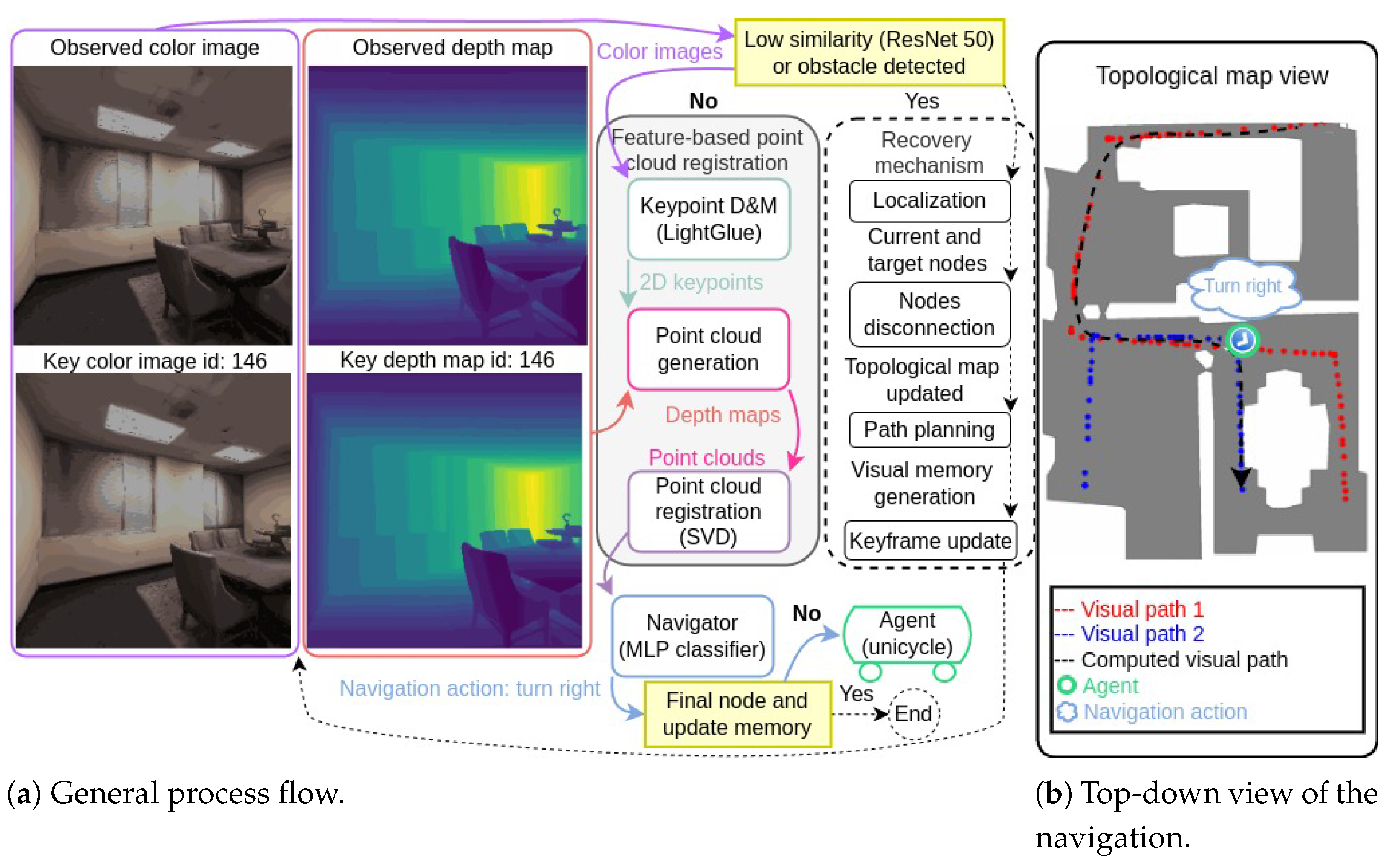
This work proposes a modular, vision-based navigation system that leverages RGB-D data for autonomous navigation, addressing the core tasks of localization, path planning, and obstacle avoidance. Central to the system is a machine learning-based navigator that interprets RGB-D data to suggest navigation actions, enabling real-time decision-making. The system organizes navigable paths using a topological map, where nodes represent keyframes (pairs of color images and depth maps) and edges correspond to navigable connections between them, facilitating efficient path planning. An overview of the proposed system during autonomous navigation is illustrated in
Figure 1. The general process flow and the RGB-D data—including the observed color image and depth map (or “observed frame”) at the top, and the keyframe from the topological map (node 146) at the bottom—are included in
Figure 1a. The similarity and obstacle detection modules assess whether the agent should initiate a recovery procedure. If recovery is unnecessary, the feature-based point cloud (or “PC” in the Figure) registration module estimates the relative pose and registration error through three steps: (1) keypoint detection and matching (or “D&M”) using LightGlue [
29] (input: color images; output: 2D keypoint locations), (2) point cloud generation (input: depth maps and 2D keypoint locations; output: point clouds), and (3) point cloud registration using Singular Value Decomposition (SVD) to estimate the relative pose and registration error. Based on the relative pose estimation and registration error, the navigator—a Multi-Layer Perceptron (MLP) classifier—predicts the next navigation action. In the illustrated case, the predicted action is “turn right”. If the predicted action were “update memory” and the key RGB-D data corresponded to the final node, the navigation would conclude. The agent, modeled as a unicycle vehicle equipped with an RGB-D camera, executes the action and the process iterates. If the agent needs to recover, the system localizes the agent within the topological map using RGB-D data to determine the closest node by index (id). This node and the failed one are then disconnected from the topological map. Path planning is performed by finding a new path using Dijkstra’s algorithm over the updated topological map. This new path becomes the visual memory, consisting of a sequence of keyframes (pairs of color images and depth maps). The key RGB-D data is updated, and a new iteration of the process begins.
Figure 1b presents a top-down view of the agent navigating the environment. Red and blue dots represent nodes of the topological map, containing two visual paths (1 and 2). The computed path (black arrow) is derived from the topological map and serves as a reference for the agent to reach the final key location using RGB-D data exclusively. The green circle marks the agent’s current position, with the predicted navigation action displayed above it.
The contributions of this paper are threefold:
A machine learning-based navigator that utilizes RGB-D data and feature-based point cloud registration for navigation decision-making.
The system employs a topological map to model the environment, integrating visual and geometric data from the RGB-D sensor to ensure reliable performance when searching for navigable paths.
The system was validated across four simulation environments using the Habitat-lab framework [
30,
31,
32], demonstrating its ability to perform navigation tasks autonomously.
1.2. Paper Structure
The remainder of this paper is organized as follows.
Section 2 reviews recent works in robotic navigation focusing on visual sensors.
Section 3 and
Section 4 detail the two main processes utilized by the system and present the system overview, respectively. In
Section 5, the experiments conducted to select the best feature algorithm and assess the system across four different environments in the Habitat simulator are described. Then, the system’s main characteristics, advantages, limitations, and challenges are discussed in
Section 6. Finally, this paper provides a brief conclusion in
Section 7.
2. Related Work
This paper extends the problem of Visual Teach and Repeat (VTR) [
33], which traditionally relies on path retracing based on visual memory, by incorporating a topological map that enables the system to perform localization, path planning, and obstacle avoidance. The rest of the section reviews related navigation methodologies, including SLAM, topological navigation, point cloud registration, reinforcement learning (RL), and vision-language navigation (VLN) systems. Then, the proposed system is introduced, and its capabilities—such as environment representation, localization, and navigation—are compared with those existing in the literature.
Conventional global information-based navigation methods, known as SLAM, are widely used in robotics and autonomous driving to build maps of the environment while simultaneously localizing the vehicle within them [
34]. Recent advancements in SLAM techniques have incorporated RGB-D sensors, enabling more robust scene understanding and dense mapping. Some of these advancements focus on enhancing high-fidelity reconstructions and accelerating rendering processes by utilizing explicit volumetric representations and leveraging the structured regularities in environments [
35,
36,
37]. Despite these improvements, SLAM often faces considerable computational challenges, including time-consuming map updates, reliance on accurate sensor data for local mapping, and difficulties in adapting to unforeseen changes in the environment [
38,
39,
40].
In contrast to SLAM methods, topological map-based approaches [
41,
42] provide a more scalable solution, focusing on capturing the connectivity and layout of an environment rather than detailed metric information [
27]. This method uses less computational resources and adapts more readily to changes within the environment [
43,
44]. For instance, Bista et al. [
45] developed a topological navigation system for a resource-constrained robot that uses image memory for localization within a topological graph and has demonstrated reliable navigation in real-world environments without the need for accurate mapping. Similarly, Muravyev et al. [
46] proposed NavTopo, a navigation pipeline that leverages topological maps for efficient path planning, achieving significant reductions in memory usage and computational demands compared to traditional metric-based methods. Additionally, Rodríguez et al. [
47] proposed a navigation system, which generates navigable visual paths from aerial images of the scene, using photometric information and a topological map. Furthermore, Liu et al. [
48] introduced a learning-based visual navigation framework that employs online topological maps enhanced with neural odometry and perceptual similarity measures, combining spatial proximity and perceptual resemblance. Their method also introduces a neural-based topological memory extraction technique (TMFT) for navigation decision-making, utilizing graph neural networks and a multi-factor attention mechanism to extract task-specific memory features, leading to improved navigation performance in complex environments. However, the approach has some limitations, as it depends on the quality of nodes representations (e.g., images), is susceptible to changes in the environment, and requires manual intervention for mapping [
45].
One pivotal technique in global information-based navigation methods is the Iterative Closest Point (ICP) [
49] algorithm which is particularly used for enhancing the accuracy of mapping in localization tasks and widely exploited in RGB-D-based systems [
50]. This technique is often employed to align 3D point clouds, a crucial step in creating detailed and accurate maps from LIDAR and RGB-D sensors [
22]. For instance, ref. [
51] illustrates the implementation of a local ICP-SLAM aimed at improving computation time and localization accuracy by partitioning the environment into smaller segments. However, the ICP algorithm demands substantial computational resources as the environment size expands, potentially degrading localization and mapping performance [
51]. Recent advances in optimization-based point cloud registration have introduced more efficient methods to address the high computational demands of ICP. For instance, ref. [
52] proposed a novel algorithm that eliminates the need for complex matrix operations, significantly reducing computation time by up to 80%. Nevertheless, when the number of points becomes too large, using a feature-based algorithm can be less computationally expensive compared to the combinatory approach of optimization-based point cloud registration. For instance, Liu et al. [
53] introduced a feature detection and matching technique that improves speed and accuracy by extracting feature points, applying Fast Point Feature Histogram (FPFH) features, and using the RANSAC algorithm to eliminate incorrect point pairs.
Reinforcement learning (RL) and end-to-end approaches in robotic navigation represent a significant shift from traditional methods, focusing on learning optimal actions directly through interactions with the environment. These methods utilize deep RL to train agents in simulations, enabling them to translate sensory inputs directly into control commands without the need for explicit environmental models [
32]. By interacting with the environment and collecting sample data during navigation, mobile robots can learn effective strategies, leveraging deep learning’s perception abilities without requiring prior model information [
19]. Particularly, RL has led to the emergence of various visual navigation techniques that integrate visual and depth cues from RGB-D data to build semantic augmented metric maps, combining environmental structure, appearance, and object semantics to enhance robotic navigation [
54]. Additionally, some methods incorporate auxiliary tasks during training and utilize unsupervised topological simultaneous localization and mapping (SLAM) alongside memory networks to enable navigation in unseen environments without relying on pose information [
27]. Despite these advancements, end-to-end learning-based methods face substantial challenges, including high sample complexity and low data efficiency, necessitating large amounts of training data [
18,
40]. Moreover, they often struggle with transferability and generalization, tending to memorize object locations and appearances specific to the training environments, which limits their applicability in real-world scenarios that differ from their training conditions [
26,
40].
In recent years, VLN systems have emerged as a significant development, enabling agents to navigate across 3D environments by following human instructions. These systems integrate visual and linguistic inputs, allowing for more natural human–robot interactions. However, current VLN agents often struggle with long-term planning and understanding complex scene geometries. To address these challenges, structured approaches like Structured Scene Memory (SSM), BEV Scene Graph (BSG), and Volumetric Environment Representation (VER) have been proposed, offering improved scene representation and planning capabilities by capturing comprehensive geometric and semantic information during navigation [
12,
13,
55]. Specifically, VER quantizes the environment into structured 3D cells, enabling better grounding of instructions in the 3D context and enhancing navigation performance in complex environments [
55]. Additionally, multitask agents like VIENNA are designed to handle multiple embodied navigation tasks, including VLN, using a unified model for decision-making across different input modalities [
14]. Furthermore, LANA introduces a language-capable navigation agent that not only follows navigation instructions but also generates route descriptions to humans by simultaneously learning instruction following and generation tasks with a single model, enhancing explainability and human–robot communication in VLN [
56]. Despite these advancements, VLN still struggles with effectively integrating multi-modal information, without escalating system complexity, and with mitigating hallucination issues where agents may generate non-existent objects or inaccurate instructions [
57,
58].
The proposed vision-based navigation system integrates a machine learning-based navigator with a topological map and feature-based point cloud registration, enabling autonomous navigation using RGB-D data only. Unlike traditional SLAM methods, which often face computational challenges and difficulties adapting to environmental changes [
38,
39,
40], the system leverages a topological map that captures the environment’s connectivity without requiring detailed metric information, significantly reducing computational overhead. Furthermore, the system incorporates both visual and geometric criteria when establishing connections between nodes. Specifically, it uses cosine similarity of ResNet50-embedded vectors for the visual criterion and considers the agent’s kinematic constraints for the geometric criterion. This dual-criteria method improves the reliability of path planning and execution compared to methods that rely solely on visual information [
59]. Moreover, the system distinguishes itself from point cloud registration techniques that rely on computationally intensive algorithms like ICP by utilizing feature-based point cloud registration with LightGlue and SVD. This approach reduces computational demands, making it suitable for real-time applications on resource-constrained platforms. Additionally, unlike end-to-end reinforcement learning approaches that require extensive training data and struggle with generalization to unseen environments [
18,
40], the proposed modular system achieves efficient navigation without the high sample complexity, offering a practical and adaptable solution for autonomous navigation tasks.
5. Experimental Setup and Evaluation
The goal of the experimentation is two-fold: (1) to identify and select the best feature algorithm based on specific criteria, such as illumination robustness, low inference time, and keypoint matching accuracy for implement it to the system and (2) to evaluate the proposed system. To this end, two evaluations were considered: feature algorithm assessing and navigation tasks.
The experimentation was conducted on an OMEN HP Gaming Laptop equipped with a 13th Gen Intel processor with 13GB of RAM and an NVIDIA GeForce RTX 4050 GPU, running Ubuntu 18.04 and Python 3.9 for compatibility reasons. For the first evaluation, the Multi-Illumination Images in the Wild dataset [
68] was employed, while four virtual environments from Habitat [
31,
32] were utilized for the second evaluation. Specifically, the Multi-Illumination Dataset was chosen because it contains scenes whose content is constant, but the illumination varies. The data in the Multi-Illumination Dataset was collected using a setup comprising a Sony
mirrorless camera equipped with a 24 mm lens, offering a
horizontal and
vertical field of view. Illumination was provided by a Sony HVL-F60M external flash unit, precisely controlled via two servo motors to alter the flash direction across 25 predetermined positions uniformly distributed over the upper hemisphere [
68]. Four traditional feature algorithms—AKAZE, BRISK, ORB [
69], and SIFT [
70]—and two learned-feature algorithms—SuperGlue [
71] and LightGlue [
29]—were evaluated in the first experiment and the best one was implemented to evaluate the system performance in the second experiment. The rest of the section details the setup and the experimental evaluation.
5.1. Information-Theoretic Evaluation of Feature Algorithms
Feature matching can be interpreted as a noisy channel that “transmits’’ geometric information from the image domain to the descriptor domain. Using Shannon’s seminal framework [
72] and the treatment of entropy and mutual information in [
73], six candidate algorithms —AKAZE, BRISK, ORB, SIFT, SuperGlue, and LightGlue— are assessed from an
information-theory (IT) point of view instead of purely geometric error.
Given the illumination grid of the Multi-Illumination Dataset, we treat every image pair as one use of a binary channel whose output indicates a successful correspondence. A match is counted as true positive when the distance between the paired keypoints is below the 10-pixel; otherwise, it is a false positive. Three IT quantities are computed:
Confidence entropy: averaged over all 625 pairs, where . Low values mean the matcher is confident.
Mutual information: between the Bernoulli variable if both images share the same illumination (diagonal of the grid) and otherwise. This measures how much a method’s success depends on lighting.
Information-gain rate: where is the mean inference time. It rewards methods that deliver lots of useful information per second.
Table 1 summarizes the scores obtained by first summing, for every algorithm, the
illumination-condition matrices into one
match-count matrix and the corresponding elapsed-time arrays into a single vector. From that matrix, true positive (TP) and false positive (FP) counts for each of the 625 image pairs were extracted, converted them to success probabilities
, and then applied the three information-theoretic formulas described above: (i) the per-pair Shannon entropy
averaged over all pairs; (ii) the mutual information
between the binary variable
S that denotes “same illumination” (diagonal of the matrix) and the Bernoulli outcome
Z of a successful match; and (iii) the information-gain rate
, where
is the mean inference time computed from the flattened elapsed-time vector.
LightGlue yields both the lowest average uncertainty and the highest information-gain rate (10.6 bits s−1), while its illumination dependence is negligible. Although ORB is extremely fast, its high entropy () reveals that it is essentially guessing on many pairs. BRISK and AKAZE appear highly sensitive to flash direction, as evidenced by their saturated , whereas SIFT and SuperGlue are slower and less informative overall. Consequently, LightGlue is adopted in the navigation pipeline.
Figure 4 gives a visual impression of the illumination sensitivity that drives the IT scores. Under varying flash positions, ORB produces many spurious correspondences (
Figure 4a), whereas same-lighting pairs on the diagonal (
Figure 4b) remain reliable.
5.2. System Evaluation
This experiment aimed to train and select the navigator, and to deploy it along with the topological map, across four distinct environments within the Habitat simulator: an apartment, Van Gogh room, Skokloster Castle, and a house (identified as 17DRP5sb8fy in the Matterport3D or MP3D dataset [
74]). The LightGlue algorithm was employed for feature extraction throughout these tasks (see
Section 5.1). It is important to note that one observed frame is acquired at each step or iteration in the simulation and the resolution of every color image and depth map in these experiments is (256, 256) pixels. Furthermore, the simulation parameters corresponding to the agent movement, i.e.,
and
, are fixed for the entire experimentation.
The model training phase was conducted exclusively in the Skokloster Castle environment, where multiple MLP classifiers were trained and tested from the collected data. The classifier that achieved the highest F-1 score (Equation (
19)) during this phase was selected as the navigator, as detailed in
Section 4.1. The selected navigator was then utilized in conjunction with a topological map to guide the autonomous navigation process in each of the four environments. Trained models, animations, and codes are provided as
Supplementary Materials.
5.2.1. Model Training and Navigator Selection
The model training phase began by collecting RGB-D data by manually controlling the agent through two different paths through the Skokloster Castle, which consisted of 730 and 731 iterations, respectively, as depicted in
Section 4.1.1. This process resulted in two groups of observed frames
and
that served to generate the training visual memories
and
, consisting of 94 and 93 keyframes, respectively, as depicted in the visual memory construction process (
Section 4.1.2), setting
which was experimentally defined. It is important to note that the key locations are used for visualization purposes only and are not taken into account by the proposed system. Later, the paths were manually retraced using
and
as reference, as depicted in
Section 4.1.3, in 868 and 831 iterations, respectively. For this process, two CSV files were generated whose columns included the translation vector
, the rotation in quaternion
, the registration error
e, and the navigation action
a. Finally, the files were appended and the dataset
resulted in a tensor of shape
after removing the two instances of
finish.
The aggregated dataset , with a tensor shape of , was subsequently divided into training and test sets split in a ratio of 80-20. The distribution of classes within the training set was relatively imbalanced, with 516 instances of left, 481 of forward, 212 of right, and 148 of update. The test set maintained a similar distribution pattern, containing 129 instances of left, 121 of forward, 53 of right, and 37 of update. To enhance the model’s performance, the features were standardized using the StandardScaler, ensuring that each feature contributed equally to the training process. The scaling parameters were fitted on the training data and subsequently applied to both the training and test sets to maintain consistency.
An MLP classifier was employed to model the navigation actions, with hyperparameters optimized through a grid search approach (
Section 4.1.4). The parameter grid encompassed variations in activation functions and solvers with two hidden layer consisting of 100 and 50 units, respectively, in a maximum of 1500 iterations. Specifically, the grid included
The tanh activation function and the sgd solver yielded the highest weighted F-1 score of 0.92, and thus, this trained model, with a total size of 120.2 KB, was selected and implemented as the navigator.
5.2.2. Topological Map and Autonomous Navigation
In this part of the experiment, the capabilities of the system—such as keyframe selection, path planning, obstacle avoidance, and autonomous navigation—were evaluated through eight autonomous navigation tasks covering four different virtual environments.
The system performance is evaluated using the goal distance, defined as the distance between the final key location and the agent’s final location. The latter occurs when
a = “finish”, as described in
Section 4.3.4, and is denoted by (×). The animations corresponding to these tasks are provided as
Supplementary Material. The threshold related to the geometric criteria used in the topological map generation (
Section 4.2.2) are experimentally fixed to
m,
m, and
, through all the navigation tasks. The results of the experiments are summarized in
Table 2. During autonomous navigation, the feature-based point cloud registration process (
Section 3.2) takes approximately 0.31 ± 0.08 s and the navigator (
Section 4.3.4) inference time is approximately 0.721 ± 0.47 milliseconds. Other processes such as localization (
Section 4.3.1) and path planning (
Section 4.3.2) may vary according to the number of nodes and edges in the Topological Map.
Apartment
This scene portrays an urban apartment divided into three distinct areas: a living room furnished with contemporary furniture and plants, an empty hallway that connects the two primary areas through open doors, and a dining room centered around a large table. This environment was chosen to evaluate the system in two path retracing tasks. Unlike generating a topological map representing the environment as a graph, the path retracing tasks consist of following a predefined visual path as a sequence of key locations depicted by keyframes in a visual memory.
In this experiment, two visual memories,
and
, were generated, and the navigator was implemented to autonomously follow the visual paths. Specifically, the visual memories were constructed by manually controlling the agent through the environment and selecting consecutive keyframes
as described in
Section 4.1.2. These visual memories were stored as numpy files (.npy), with
and
having sizes of 15.7 MB and 21.1 MB, respectively. Then, the navigator, trained as detailed in
Section 5.2.1, autonomously retraced both paths using
and
as references. The navigation tasks executed in this environment are illustrated in
Figure 5.
Task 1 and Task 2: Path Retracing
Initially, the agent was placed at the right side (task-1) and at the left side (task-2) of the living room and manually controlled, through 451 and 92 steps, respectively, to the opposite sides of the dining room. Subsequently, and were constructed from the observed frames and by setting , resulting in and keyframes, respectively. This corresponds to selecting one keyframe approximately every eight and two observed frames, respectively.
The autonomous navigation phase began by experimentally defining the thresholds and , which trigger the recovery mechanism. Then, the agent was placed at the original initial locations (⋆), and the autonomous navigation began by localizing the agent. The navigator retraced both paths in 223 and 151 steps, covering distances of 45.1 m and 33.29 m, respectively. The distances between the agent final locations and the two final key locations were 0.09 and 0.07 meters.
Van Gogh Room
This environment represents the personal bedroom of the renowned artist Vincent van Gogh, meticulously recreated to reflect the late 19th-century aesthetic and spatial layout. It features a confined space with multiple objects placed around the room; therefore, it was considered ideal to evaluate the topological map and autonomous navigation through three tasks: task-3, task-4, and task-5.
During the topological map generation phase, the agent was placed at the left side of the room once and at the right side four times, and manually controlled to the center of the room in 29, 28, 24, 20, and 24 steps, respectively. Five visual memories were then constructed by setting , resulting in , , , , and keyframes. This led to the selection of approximately one or two keyframes for every observed frame.
The topological map was generated by associating each keyframe with a node and connecting them if the visual and geometric criteria were satisfied (see
Section 4.2), with thresholds set at
,
, and
. The 96 nodes, stored as pairs of color images and depth maps, had a total size of 44.1 MB and were stored as numpy files (.npy), while the edges, also stored as .npy, had a total size of 73.9 KB. Once the topological map was created, the thresholds that trigger the recovery mechanism were defined as
and
. The autonomous navigation tasks conducted in this environment are illustrated in
Figure 6.
Task 3: Short-Range Navigation
The agent started at the center of the room, aiming to reach a keyframe close to it but outside its field of view. The node was defined as the end node, and the system began by localizing the agent near node . The path planning process computed the path , resulting in a visual memory composed of the keyframes . In this task, the agent ended up 0.02 m away from the final key location after traveling a distance of 1.03 meters.
Task 4: Medium-Range Navigation
The agent started next to the bed with the goal of reaching a keyframe (associated with node ) located at the center of the room, requiring a longer traversal than in the previous task. The autonomous navigation phase began by localizing the agent near node . The computed path was , which was converted into a visual memory . The navigator successfully followed this path in 25 steps, traveling a distance of 4.3 m and concluding the task 0.01 m away from the final key location.
Task 5: Long-Range Navigation with Obstacle Avoidance
The agent started next to the bed, aiming to reach a keyframe (associated with node ) near the table located at the left corner of the room. Initially, the system localized the agent near node , and the path was computed and converted into visual memory . However, an obstacle was detected when attempting to reach node , triggering the recovery mechanism (marked with ). Consequently, the edge was disconnected, the agent was re-localized near , and the path was recomputed as . The agent then successfully reached this node in two additional steps, completing the task in a total of 40 steps, covering a distance of 5.7 m, and arriving within 0.01 m of the final key location.
Skokloster Castle
This virtual replica showcases expansive areas such as grand halls, ornate chambers, extensive corridors, and a central table located in the main hall. The environment maintains consistent lighting conditions and is rich in textures. However, it features repetitive patterns in the flooring and similar content on opposing walls, which can pose unique challenges for feature detection and matching algorithms. The castle was chosen to evaluate the system through two tasks: task-6 and task-7.
During the topological map generation phase, the agent was manually controlled across four paths consisting of 323, 315, 325, and 362 steps, covering most parts of the castle. Four visual memories were then constructed by setting , resulting in , , , and keyframes. This corresponds to selecting approximately one keyframe every ten to thirteen observed frames.
The keyframes composing the visual memories were associated with nodes in the topological map and connected if the visual and geometric criteria were satisfied, with thresholds set at
,
, and
. The 131 nodes, stored as pairs of color images and depth maps, occupied 60.1 MB as numpy files (.npy), while the edges, also stored as .npy, required 137.4 KB or memory space. The thresholds that trigger the recovery mechanism were defined as
and
. The two next tasks are illustrated in
Figure 7 and detailed below.
Task 6: Long-Distance Navigation with Path Replanning
This task involved traversing the castle from one door to another located at opposite sides, combining key locations from two different paths traversed during the topological map generation phase. Initially, the final node was set to , and the agent was localized near node (⋆). The system computed the path , and the navigator attempted to follow it. The agent successfully reached the first four nodes, but a low similarity score was attained when attempting to reach , triggering the recovery mechanism (). The edge was disconnected, and the path was recomputed from the current node to the end node , resulting in . The agent successfully followed the new path, covering a distance of 11.1 m and completing the task in a total of 60 steps, ultimately stopping 0.21 m from the final key location.
Task 7: Extended Navigation
This task involved navigating through the castle by following an elliptical path around the central table, maintaining a consistent distance between the walls and the table, in a clockwise direction. The same values for the thresholds used in the previous task were used in this task as well. The final node was defined as , and the system localized the agent near (⋆). The path computed was , composed of 38 nodes. The visual memory was directly generated from . The navigator successfully conducted the agent through the entire path, covering a larger distance of 50.43 m, successfully concluding the task in 167 steps and ending up within 0.15 m of the final key location.
MP3D House
This virtual environment represents a common indoor space with multiple rooms, including one bedroom, two bathrooms, one toilet, a TV room, a dining room, an entryway, a living room, a family room or lounge, and a kitchen (The MP3D house can be visualized in:
https://aspis.cmpt.sfu.ca/scene-toolkit/scans/house-viewer?condition=mpr3d&modelId=mp3d.17DRP5sb8fy) (visited on 1 May 2025). The environment features various pieces of furniture and household items, providing a rich set of visual textures and spatial configurations. It was chosen because it represents a typical indoor setting with multiple interconnected rooms, allowing the evaluation of the system’s navigation capabilities in a complex but common scenario. The environment was used to evaluate the system through
task-8.
During the topological map generation phase, the agent was manually controlled across two paths consisting of 79 and 71 steps, respectively. The first path went from the family room to the dining room, traversing the bedroom and living room. The second path went from the bedroom to the entryway, passing through the living room and dining room. Two visual memories were then constructed by setting , resulting in and keyframes. This corresponds to selecting approximately one keyframe every one to two observed frames.
The keyframes composing the visual memories were associated with nodes in the topological map and connected if the visual and geometric criteria were satisfied, with thresholds set at , , and . The 116 nodes, stored as pairs of color images and depth maps, occupied 53.2 MB as numpy files (.npy). The threshold that triggers the recovery mechanism for distance was defined as , and the similarity threshold was experimentally set to .
Task 8: Traversing the House Across the Main Corridor
This task involved navigating the house through the main corridor that connects multiple rooms, requiring the computation of a path that combines both visual memories
and
. The agent was manually placed in the family room and aimed to reach node
. The autonomous navigation began by correctly localizing the agent close to node
and then computing the path
. The recovery mechanism was triggered four times, at steps: 16, 69, 71, and 74. Particularly, from steps 13 to 15, the agent incorrectly attempted to reach nodes
and
(as shown in
Figure 8), but the recovery mechanism was triggered at step 16 due to a low similarity score (see
Section 4.3.3). The edge
was disconnected, and the path was corrected by assigning
as the next keyframe.
The final path followed by the agent in 114 steps was
. After traveling 39.5 m, the agent ended up 0.28 m away from the final key location, mainly due to its the kinematic constraints. This task is illustrated in
Figure 9.
6. Discussion
The proposed modular, vision-based navigation system demonstrates the feasibility of using RGB-D data and a neural network-based navigator for autonomous navigation tasks in indoor environments. By leveraging a topological map composed of interconnected keyframes and simplifying the decision-making process, the system effectively integrates conventional vision-based navigation with end-to-end learning approaches. Notably, a single MLP trained only on the Castle scene achieved successful navigation in all four environments, highlighting strong out-of-domain generalization. Future work will consider transfer learning or reinforcement learning if new modules are introduced to deal with more challenging environments.
Compared to traditional SLAM methods, which often require exhaustive exploration and precise metric representations [
75], the proposed system significantly reduces computational resources by representing the environment through a graph of interconnected keyframes (
Section 4.2). This approach eliminates the need for complete environmental representations and avoids the accumulation of errors from positional sensors such as odometry or GPS. By focusing on navigable paths rather than detailed maps, the system addresses the loop closure problem inherent in SLAM and reduces memory requirements.
The information-theoretic evaluation clarifies why LightGlue, rather than merely performing well geometrically, offers the most suitable trade-off for the navigation task. Its low
indicates that, across the full illumination grid, LightGlue’s match decisions carry little internal uncertainty, while the very small
shows that this confidence is essentially lighting-invariant. ORB’s high information-gain rate is driven almost entirely by its micro-second runtime; the large entropy value (
) exposes that many of those rapid decisions are near random and therefore propagate noise into the relative-pose estimator. BRISK and AKAZE achieve impressively low entropy, yet their saturated
scores reveal a strong, highly undesirable coupling between success and the exact flash position—an artifact that would translate into brittle behaviour under real-world lighting changes. The IT metrics therefore corroborate the empirical navigation results: LightGlue maximizes useful pose information per second without introducing environment-specific biases, explaining its consistent advantage when the system is deployed in previously unseen scenes. According to [
76], LightGlue remains faster than OmniGlue. OmniGlue’s foundation-model guidance, however, promises greater robustness on unseen domains and may be preferred when that priority outweighs strict real-time constraints.
The MLP-based navigator, trained as a classifier on relative pose estimations and kinematic constraints, proved effective in predicting navigation actions. Despite being trained on a small dataset collected from a single environment, the navigator was successfully deployed across four simulated environments without additional training. This generalization capability suggests that the decision-making process, simplified through relative pose estimation and imitation learning, is robust to changes in environmental contexts. In contrast, end-to-end methods and reinforcement learning approaches typically require large datasets and intensive training phases for each new environment [
77]. For instance, the dataset used in [
78] for training and evaluating their CNN-based navigation system using an imitation learning approach comprised 14,412 color images at a resolution of (320, 160) pixels, occupying approximately 2.11 GB in storage. In comparison, the navigator was trained using two CSV files (
Section 5.2.1) (The relevant columns of the CSV files were:
x,
y,
z,
q0,
q1,
q2,
q3,
rmse, and
action), one file per manual path retracing as explained in
Section 4.1.3. These files consisted of 1697 rows and 10 columns: the translation vector
as in Equation (
13), the rotation (Equation (
12)) expressed in quaternion form
, the registration error
e as in Equation (
14), and a reference visual memory index that was not utilized during training. The total memory footprint of these files was 303.7 KB, representing approximately 0.01% (10,000 times less) of the dataset size used in [
78]. Despite being a significantly smaller dataset, the navigator, trained in one environment, was able to guide the agent through the four environments while preserving a mean goal error of 0.10 m (
Section 5.2.2).
The system extensively employs image similarity for generating visual memories, constructing the topological map, and triggering the recovery mechanism (
Section 4). To compute image similarity, feature embeddings are extracted from color images (
Section 3.1). Vision Transformers (ViT) were considered for this task due to their advantages in modeling long-range dependencies and adaptability to different input sizes [
79]. However, ViTs involve higher computational complexity and face scalability challenges, which conflict with the cost-effectiveness aspect of the proposed system. Therefore, CNNs were preferred because they offer lower computational demands and have a proven track record of effectiveness. Importantly, the modular design of our system allows for the future integration of ViTs as needed, accommodating evolving requirements and advancements in deep learning technologies. Empirically, setting the low-similarity threshold to
enabled successful navigation across all tasks, while the keyframe density stayed consistent for
(
Section 5.2.2). Introducing an
adaptive visual-link threshold—e.g., via cosine-distance clustering [
80]—could automatically tune
and thus preserve robust node connectivity while avoiding manual tuning. Furthermore, methods like Viewpoint-Invariant Adversarial Training (VIAT) [
81] could enhance the robustness of ResNet50 to viewpoint changes when computing visual similarity, while ResNet50 combined with AugMix [
82] could help reduce sensitivity to illumination variations [
83] when the system gets implemented in real environments.
The use of the Habitat simulated environment facilitated the evaluation process by providing built-in tools for easy implementation and testing of the navigation system (
Section 5.2). Its provision of direct global positioning data simplified development and allowed for accurate assessment of the system’s performance in realistic virtual indoor settings. When deploying the system in real environments, images with poor sharpness (detected via the robust blur metric of [
84]) plan to be skipped, mitigating motion-blur failures without extra computation. When blur is unavoidable (e.g., during fast turns) a lightweight DBLRNet [
85] module can be employed to deblur images during autonomous navigation, while low-illuminance frames can be enhanced by MB-TaylorFormer [
86] before feature extraction. Furthermore, Gridformer [
87] is consider to be used in outdoor environment for image restoration under adverse weather conditions which can potentially affect some key processes, such as localization and recovery mechanism (
Section 4.3).
However, the system does present certain limitations. Latency profiling shows feature registration 0.31 ± 0.08 s and navigation inference 0.72 ± 0.47 ms; LightGlue’s architecture enables users to balance the performance-speed ratio to match the embedded computer limitations. Setting thresholds such as
and
proved challenging, as they vary depending on the environment. Additionally, the navigator was not trained to perform complex maneuvers requiring sequential actions to avoid obstacles. Incorporating architectures capable of handling temporal sequences, such as Long Short-Term Memory (LSTM) networks [
88], could address this limitation in future work. For kinesthetic realism, the action set can be extended with “forward-slow” and arc motions that map directly to wheel velocities, retaining discrete learning while approximating continuous control.
The experiments were conducted in static, simulated environments with consistent illumination, which does not fully reflect the variability encountered in real-world settings. Dynamic environments with moving obstacles or varying lighting conditions were not tested and represent an area for future exploration. Implementing the system on real hardware will introduce additional challenges, including handling computation flow, sensor communication, and environmental changes such as illumination variations and dynamic objects. Future work will port the pipeline to a real RGB-D platform and couple the existing recovery mechanism with a dynamic recognition module [
89] that detects and avoids pedestrians without triggering the recovery mechanism, thus maintaining the topological map connections (
Section 4.3). Moreover, other metrics such as navigation success, goal-error statistics, power consumption, and control loop frequency will measure the system performance in real implementation.
The density of the topological map impacts the system’s reliability. A practical extension is to monitor edge-failure frequency and automatically spawn additional keyframes around any chokepoint (as in [
90]), incrementally densifying the graph whenever sparse connectivity threatens recovery. Nonetheless, this approach will require a more intensive mapping phase (
Section 4.2). Complementarily, an age-based pruning policy, powered by semantic segmentation [
91], could retire obsolete nodes and edges, allowing the map to evolve with furniture rearrangements or other long-term changes. The system’s efficiency is demonstrated by its traversal of 190.44 m across eight navigation tasks in the Habitat environment, achieving an average goal distance of approximately 0.1 m per task, despite relying on low-resolution data and a limited number of keyframes. However, sparse maps may limit the recovery mechanism’s effectiveness if the agent cannot replan a path or if movement constraints prevent certain maneuvers.
In terms of computational efficiency, the system showed potential for real-time application. Particularly, the relative pose estimation combined with the navigator’s prediction also contributes to computational load but did not impede the system’s performance in the conducted experiments (
Section 5.2.2). This efficiency offers practical benefits, such as enabling the use of lower-power hardware, reducing both cost and energy consumption. By reducing reliance on expensive sensors like LiDAR and heavy computational resources, the system potentially becomes more accessible and appealing for broader societal applications. Additionally, efficient resource usage extends battery life and enhances adaptability across various robotic platforms [
92].
Future work includes deploying the system on real hardware to assess its performance in dynamic and variable environments. Enhancements to the localization process, such as integrating feature embeddings and cosine similarity, could improve robustness. Transitioning to RGB cameras with depth estimation through deep learning techniques, e.g., Marigold [
93], may reduce hardware requirements. Moreover, if the depth channel becomes unreliable (e.g., at long range or on reflective glass) frames whose registration error exceeds a threshold could be discarded and the recovery module temporarily would switch to RGB-only localization. Depth is re-introduced only when confidence improves, with missing values filled by Marigold predictions, so localization remains continuous even under severe depth noise. Incorporating additional modules for user interaction, object recognition, obstacle avoidance, and exploiting depth maps more effectively are also potential avenues for improvement. Additionally, we plan to implement adaptive thresholds jointly with visual features, replacing hand-tuned
values by confidence-aware predictors.
Overall, the system demonstrates a promising approach to autonomous navigation using RGB-D data and a modular design. Its ability to generalize across different environments without retraining suggests that it could be a practical solution for indoor navigation tasks, provided that future work addresses the identified limitations and challenges.
7. Conclusions
This paper introduced a modular, vision-based navigation system that leverages RGB-D data and a neural network-based navigator for autonomous navigation in indoor environments. By constructing a topological map composed of interconnected keyframes and simplifying the decision-making process to relative pose estimation and kinematic constraints, the system navigates effectively without requiring exhaustive environmental mapping or extensive training data.
An information-theoretic evaluation—using confidence entropy, mutual information, and information-gain rate—was employed to choose LightGlue as the feature algorithm, ensuring that the visual approach uses a reliable and time-efficient algorithm. The system demonstrated the ability to generalize across different simulated environments without retraining the navigator, indicating its potential applicability for practical indoor navigation tasks. The use of a simple MLP classifier, trained on a small dataset from a single environment, contrasts with other methods that depend on large datasets and intensive training phases. The modular design also allows for scalability and the future integration of additional modules, such as user interaction or object recognition.
Despite its promising performance, the system has limitations that warrant further investigation. The need to manually set thresholds for keyframe connections and visual similarity can affect performance across different environments. Additionally, the navigator was not trained to handle complex maneuvers requiring sequential actions, limiting its effectiveness in dynamic or more complex settings. Incorporating advanced architectures like recurrent neural networks and testing in real-world environments with dynamic elements are important next steps.
Future work will focus on deploying the system on real hardware to evaluate its performance under variable conditions, including dynamic obstacles and changing illumination. Enhancements to the localization process, such as integrating feature embeddings and cosine similarity measures, may improve robustness. Exploring the use of RGB cameras with depth estimation techniques could reduce hardware requirements and increase applicability.
In conclusion, the proposed system offers a viable approach to autonomous indoor navigation using RGB-D data within a modular framework. By reducing hardware complexity and simplifying training requirements, it provides a foundation for developing reliable and cost-effective navigation solutions suitable for a range of indoor environments.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}