

Insulator Defect Detection in Complex Environments Based on Improved YOLOv8


Abstract
1. Introduction
- (1)
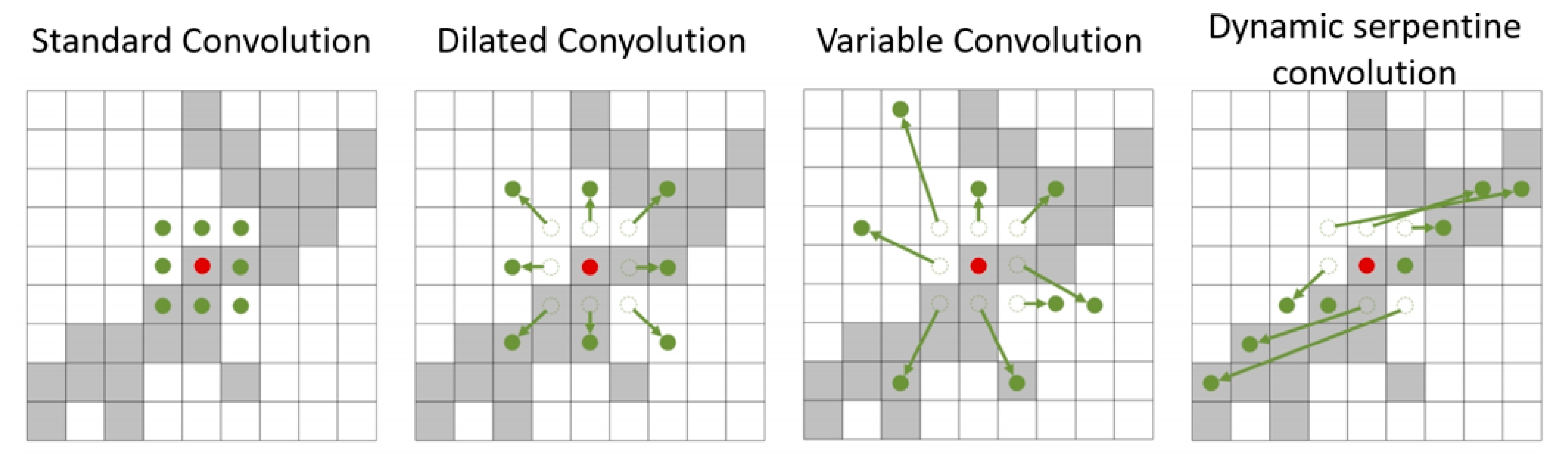
- To tackle the intricate morphology of insulators, a new C2f_DSC network module was designed, combining a dynamic snake convolution (DSConv) kernel [29] with entropy-regulated feature compression. This convolution kernel structure can better capture the basic features of insulator defect areas, improve the perception ability of subtle defect targets, and enhance the robustness and accuracy of the algorithm.
- (2)
- To address the entropy imbalance and feature fusion in insulator defect detection, BiFPN [30] was improved by adjusting its parameters and connections for multi-scale feature fusion, prioritizing defect-related features, and thereby enhancing recognition accuracy.
- (3)
- The EMA mechanism [31] was integrated into the model, incorporating high-information–content features and performing weighted average processing on feature maps during training, highlighting key information, and improving the model’s attention to insulator defect areas. This integration enhances the model’s self-adaptive feature adjustment ability, enabling it to maintain good performance under different conditions.
- (4)
- The EIOU loss function [32] was applied to YOLOv8. Compared with conventional CIOU (Complete Intersection over Union) [33], it explicitly incorporated geometric discrepancies between the target and the anchor boxes and further minimized geometric differences (e.g., center distance and aspect ratio) in a statistically guided manner, thereby improving the model’s convergence speed, accuracy, and stability.
2. Materials and Methods
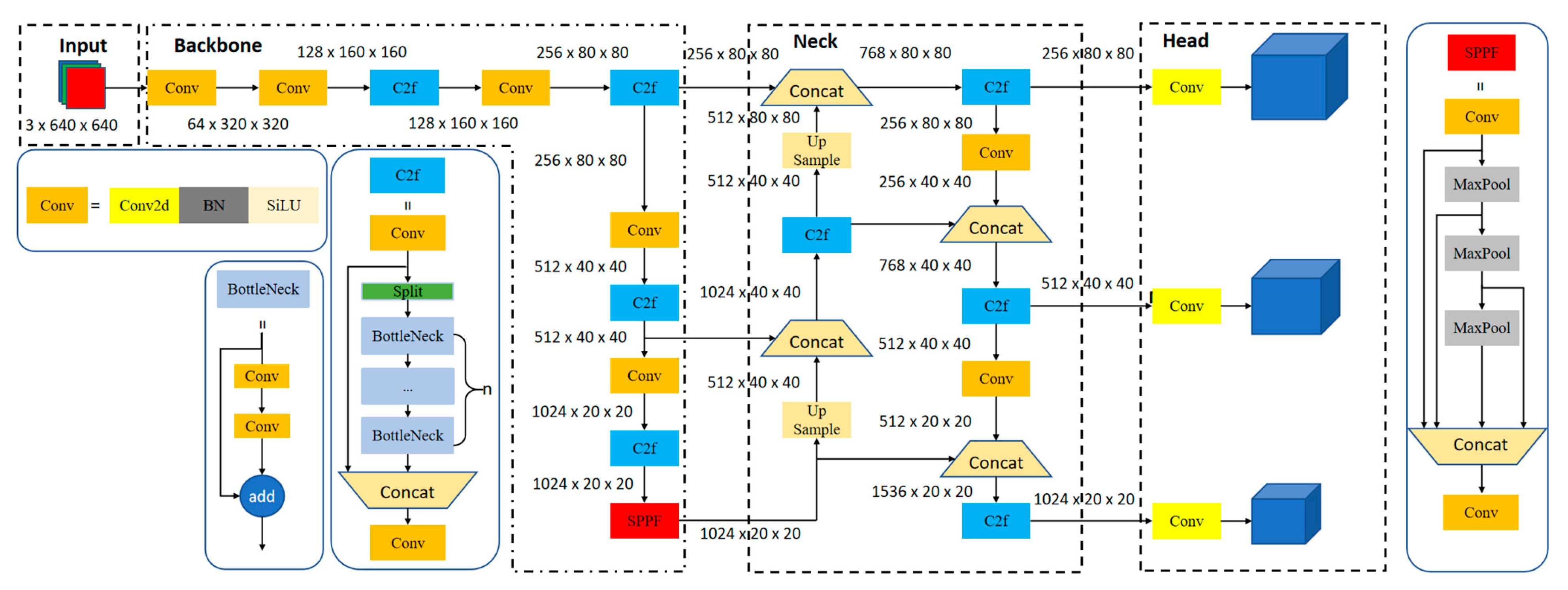
2.1. YOLOv8 Algorithm
2.2. Improved YOLOv8 Target Detection Network for Insulator Defects
2.2.1. Entropy-Driven Information-Guided Augmentation
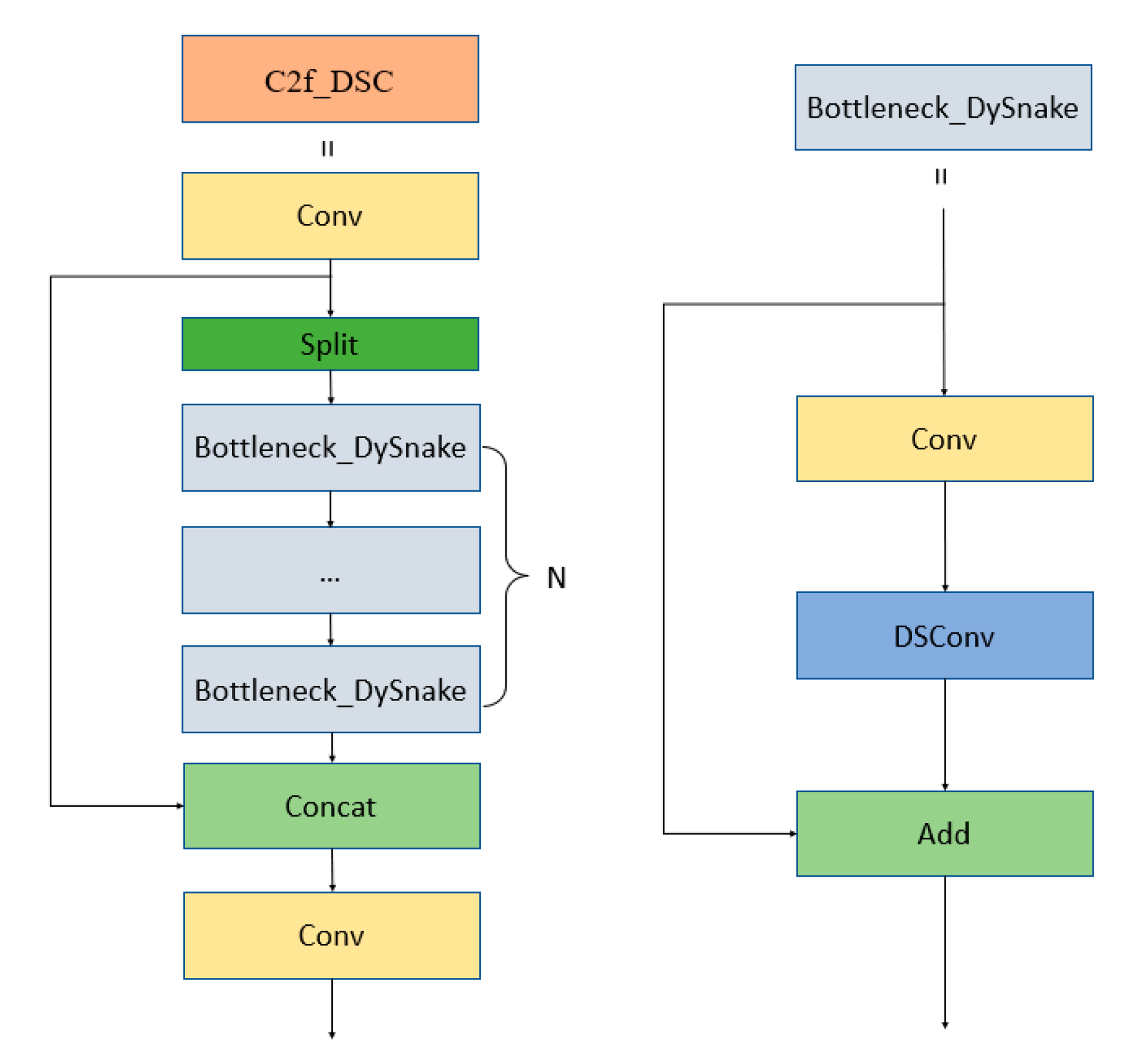
2.2.2. C2f_DSC Module
2.2.3. EMA Mechanism
2.2.4. Improved Feature Fusion Layer
- (1)
- Entropy-constrained adaptive weighting is introduced to optimize feature transmission. BiFPN maximizes mutual information flow across scales by dynamically learning feature weights based on local information density, improving feature expressiveness, and reducing information entropy loss during fusion.
- (2)
- Fine-grained features are preserved by pruning low-information pathways (high entropy noise) while reinforcing high-information channels. This entropy-driven selection elevates detection accuracy.
- (3)
- Feature weights are adjusted dynamically using entropy-minimized criteria, ensuring fusion prioritizes semantically rich (low entropy) regions. This flexibility adapts to target scale variations and occlusions in complex scenes.
2.2.5. Improved Loss Function
3. Results and Discussion
3.1. Experimental Dataset
3.2. Experimental Environment
3.3. Evaluation Indicators
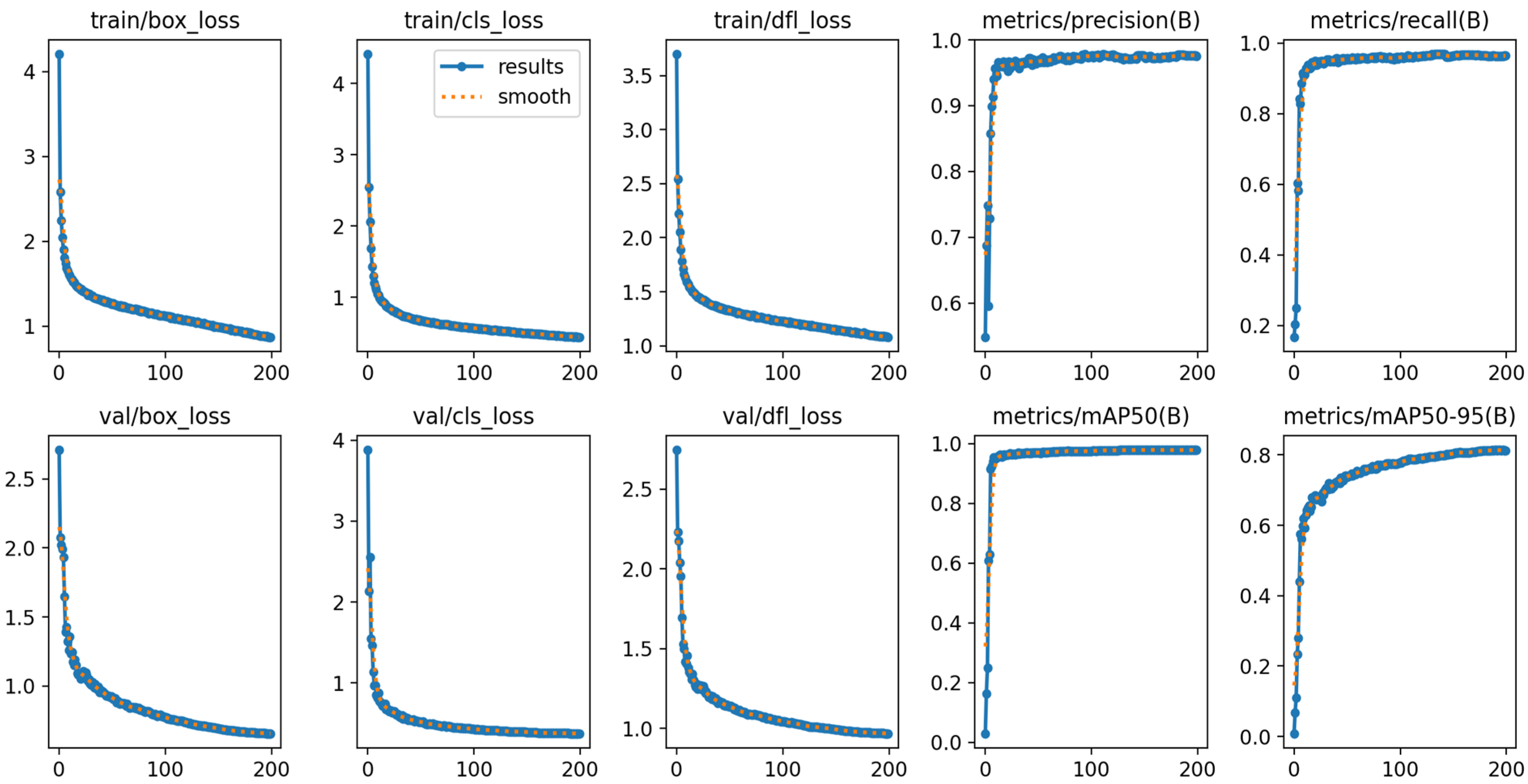
3.4. Ablation Experiment
3.5. Comparative Experiment
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, J.; Hu, M.; Dong, J.; Lu, X. Summary of insulator defect detection based on deep learning. Electr. Power Syst. Res. 2023, 224, 109688. [Google Scholar] [CrossRef]
- Liu, S.; Xiao, J.; Hu, X.; Pan, L.; Liu, L.; Long, F. Defect insulator detection method based on deep learning. In Proceedings of the 2022 IEEE 17th Conference on Industrial Electronics and Applications (ICIEA), Chengdu, China, 16–19 December 2022; pp. 1622–1627. [Google Scholar]
- Wang, X.; Feng, J.; Qin, Y. An Improved Multi-objective artificial hummingbird algorithm for capacity allocation of Supercapacitor energy storage systems in urban rail transit. J. Bionic Eng. 2025, 22, 866–883. [Google Scholar] [CrossRef]
- Wang, X.; Deng, C.; Qin, B. Working condition recognition based on lightweight network and knowledge distillation for rotary kilns. J. Electron. Meas. Instrum. 2023, 37, 149–159. [Google Scholar]
- Kong, C.; Chen, B.; Li, H.; Wang, S.; Rocha, A.; Kwong, S. Detect and Locate: Exposing Face Manipulation by Semantic- and Noise-level Telltales. arXiv 2022, arXiv:2107.05821. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhou, Y.; Ren, X.; Zhi, H.; Zhang, J.; Chen, H. YOLO-HMC: An Improved Method for PCB Surface Defect Detection. IEEE Trans. Instrum. Meas. 2024, 73, 2001611. [Google Scholar] [CrossRef]
- Chen, J.; Wen, Y.; Nanehkaran, Y.A.; Zhang, D.; Zeb, A. Multiscale attention networks for pavement defect detection. IEEE Trans. Instrum. Meas. 2023, 72, 2522012. [Google Scholar] [CrossRef]
- Wang, C.; Wei, X.; Jiang, X. An automated defect detection method for optimizing industrial quality inspection. Eng. Appl. Artif. Intell. 2024, 127, 107387. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, D.; Huang, X.; Li, C. Insulator defect detection with deep learning: A survey. IET Gener. Transm. Distrib. 2023, 17, 3541–3558. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision–ECCV 2016 In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. Part 1. pp. 14, 21–37. [Google Scholar]
- Miao, X.; Liu, X.; Chen, J.; Zhuang, S.; Fan, J.; Jiang, H. Insulator detection in aerial images for transmission line inspection using single shot multibox detector. IEEE Access 2019, 7, 9945–9956. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–23 June 2023; pp. 7464–7475. [Google Scholar]
- Sohan, M.; Sai Ram, T.; Reddy, R.; Venkata, C. A review on yolov8 and its advancements. In International Conference on Data Intelligence and Cognitive Informatics; Springer: Singapore, 2024; pp. 529–545. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Zhao, W.; Xu, M.; Cheng, X.; Zhao, Z. An insulator in transmission lines recognition and fault detection model based on improved faster RCNN. IEEE Trans. Instrum. Meas. 2021, 70, 5016408. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN[C]. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Stefenon, S.F.; Singh, G.; Souza, B.J.; Freire, R.Z.; Yow, K.C. Optimized hybrid YOLOu-Quasi-ProtoPNet for insulators classification. IET Gener. Transm. Distrib. 2023, 17, 3501. [Google Scholar] [CrossRef]
- Tao, W.; Weibin, W.; Li, Y.; Beimin, X.; Weiwei, Y.; Hongyu, W. Lightweight YOLOV3 insulator defect detection method. Comput. Eng. 2019, 45, 275–280. [Google Scholar]
- Li, J.; Liu, L.; Niu, Y.; Li, L.; Peng, Y. YOLOv3 insulator string recognition method incorporating attention. High Volt. Appar. 2022, 58, 67–74. [Google Scholar]
- Xiao, C.; Pan, R.; Li, C.; Huang, J. Research on Improved YOLOv5s Insulator Defect Detection Technology. Electron. Meas. Technol. 2022, 45, 137–144. [Google Scholar]
- Wang, Y.; Feng, T.; Sun, N.; Yang, C.; Yu, H.; Cui, H. A defective detection method for power insulators integrating attention and multi-scale features. High Volt. Technol. 2024, 50, 1933–1942. [Google Scholar]
- Zou, H.; Chen, J.; Chai, Y.; Yang, Q. Detection method for insulators and their self-explosion defects in foggy scenarios based on improved YOLOv7. Foreign Electron. Meas. Technol. 2023, 42, 1–11. [Google Scholar]
- Jia, X.; Wu, X.; Zhao, B. Lightweight detection network DE-YOLO for insulator self-explosion defects. J. Electron. Meas. Instrum. 2023, 37, 28–35. [Google Scholar]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance problems in object detection: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3388–3415. [Google Scholar] [CrossRef] [PubMed]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic snake convolution based on topological geometric constraints for tubular structure segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6070–6079. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 July 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Ge, Z. Yolox: Exceeding Yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- InsulatorData. InsulatorDataSet. [EB/OL]. (26 January 2018). Available online: https://github.com/InsulatorData/InsulatorDataSet (accessed on 20 January 2025).
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Yang, S.; Xiao, W.; Zhang, M.; Guo, S.; Zhao, J.; Shen, F. Image data augmentation for deep learning: A survey. arXiv 2022, arXiv:2204.08610. [Google Scholar]
- Qin, B.; Zeng, Y.; Wang, X.; Peng, J.; Li, T.; Wang, T.; Qin, Y. Lightweight DB-YOLO Facemask Intelligent Detection and Android Application Based on Bidirectional Weighted Feature Fusion. Electronics 2023, 12, 4936. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Environment | Environment Configuration |
|---|---|
| Frame | PyTorch 1.8 |
| Language | Python 3.8 |
| Operating system | Windows 10 |
| Processor | Intel(R)Xeon(R)CPU E5-2680 v4, Intel, Santa Clara, CA, USA @2.4 GHz |
| GPU | 24G NVIDIA Tesla M40, NVIDIA, Santa Clara, CA, USA |
| Methods | Data Augmentation | D2f_DySnake | EMA | BIFPN | EIOU | mAP50 |
|---|---|---|---|---|---|---|
| 1 | 94.7% | |||||
| 2 | √ | 97.8% | ||||
| 3 | √ | √ | 98.0% | |||
| 4 | √ | √ | √ | 98.3% | ||
| 5 | √ | √ | √ | √ | 98.5% | |
| 6 | √ | √ | √ | √ | √ | 98.6% |
| Name | Params | Size | Precision | Recall | mAP50 | mAP50:95 | ms |
|---|---|---|---|---|---|---|---|
| YOLOv3-Tiny | 11.5 M | 23.2 M | 98.2% | 94.9% | 97.1% | 82.0% | 4.1 ms |
| YOLOv5n | 2.39 M | 5.02 M | 97.5% | 96.4% | 97.8% | 81.2% | 3.9 ms |
| YOLOv5s | 8.69 M | 17.6 M | 98.0% | 96.3% | 97.9% | 82.4% | 4.0 ms |
| YOLOv6 | 4.03 M | 8.28 M | 97.7% | 96.6% | 97.6% | 81.0% | 3.8 ms |
| YOLOv8n | 2.87 M | 5.97 M | 98.3% | 97.2% | 97.8% | 89.8% | 4.0 ms |
| YOLOv8s | 10.65 M | 22.5 M | 99.2% | 97.5% | 98.4% | 90.6% | 4.2 ms |
| Ours | 3.05 M | 6.40 M | 99.2% | 97.7% | 98.6% | 89.5% | 4.1 ms |
| Name | Params | Size | Precision | Recall | mAP50 | mAP50:95 | FLOPS |
|---|---|---|---|---|---|---|---|
| YOLOv5s | 2.5 M | 17.6 M | 62.0% | 63.6% | 68.3% | 35.2% | 7.2 |
| YOLOv8n | 3.01 M | 5.97 M | 71.1% | 61.9% | 68.3% | 35.2% | 8.2 |
| Yolov8s | 11.65 M | 22.5 M | 64.0% | 65.4% | 71.1% | 38.3% | 28 |
| Ours | 3.12 M | 6.19 M | 71.2% | 69.9% | 76.7% | 42.0% | 8.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, Y.; Zeng, Y.; Wang, X. Insulator Defect Detection in Complex Environments Based on Improved YOLOv8. Entropy 2025, 27, 633. https://doi.org/10.3390/e27060633
Qin Y, Zeng Y, Wang X. Insulator Defect Detection in Complex Environments Based on Improved YOLOv8. Entropy. 2025; 27(6):633. https://doi.org/10.3390/e27060633
Chicago/Turabian StyleQin, Yuxin, Ying Zeng, and Xin Wang. 2025. "Insulator Defect Detection in Complex Environments Based on Improved YOLOv8" Entropy 27, no. 6: 633. https://doi.org/10.3390/e27060633
APA StyleQin, Y., Zeng, Y., & Wang, X. (2025). Insulator Defect Detection in Complex Environments Based on Improved YOLOv8. Entropy, 27(6), 633. https://doi.org/10.3390/e27060633