1. Introduction
Consider a time series
such as a text in natural language, a sequence of real numbers, or a sequence of vectors. Let
be the Shannon mutual information between two random variables separated by
n positions. By short-range dependence (SRD), we understand an asymptotic exponential bound for the decay of this dependence measure,
By long-range dependence (LRD), we understand any sort of decay of the dependence measure that does not fall under (
1). In particular, under LRD, we may have a power-law decay of the dependence measure,
which resembles a more standard definition of LRD for the autocorrelation function by Beran [
1], or we may have a stretched exponential decay thereof,
The SRD is characteristic of mixing Markov and hidden Markov processes ([
2], Theorem 1), which assume that the probability of the next token depends only on a finite number of preceding tokens or on a bounded memory. Hence, the observation of LRD for sufficiently large lags implies that the time series generation cannot be modeled by a mixing Markov process of a relatively small order or—via the data-processing inequality ([
3], Chapter 2.8)—by a mixing hidden Markov process with a small number of hidden states.
By contrast, it has often been expressed that texts in natural language exhibit LRD [
2,
4,
5,
6,
7,
8,
9,
10,
11]. Several empirical studies analyzing textual data at different linguistic levels, such as characters [
2,
4], words [
9], or punctuation [
11], have indicated that correlations in natural language persist over long distances. This persistent correlation suggests that dependencies in human language extend far beyond adjacent words or short phrases, spanning across entire paragraphs or even longer discourse structures.
The LRD should be put on par with other statistical effects signaling that natural language is not a finite-state hidden Markov process, a theoretical linguistic claim that dates back to [
12,
13,
14]. Let us write blocks of words
. A power-law growth of the block mutual information
is known as Hilberg’s law or as the neural scaling law [
15,
16,
17]. Another observation [
18] is a power-law logarithmic law of the maximal repetition length
where we denote the maximal repetition length
The long-range dependence (
2) or (
3), Hilberg’s law (
4), and the maximal repetition law (
5) have been all reported for natural language, whereas it can be mathematically proved that none of them is satisfied by finite-state hidden Markov processes [
19,
20].
The LRD, Hilberg’s law, and the maximal repetition law independently—and for different reasons—support the necessity of using complex memory architectures in contemporary large language models (LLMs). Neural networks designed for natural language processing must incorporate mechanisms capable of mimicking these laws. The older generation
n-gram models struggle with this requirement for reasons that can be analyzed mathematically. By contrast, it is has been unclear whether Transformers [
21], with their attention-based mechanisms, can leverage these extensive relationships. Understanding the nature of the LRD, Hilberg’s law, and the maximal repetition law in textual data may shed some light onto neural architectures that can progress on language modeling tasks.
Various smoothing techniques were proposed to discern LRD at the character or phoneme level [
2,
4,
6,
7]. Under no advanced estimation, the power-law decay of the Shannon mutual information between two characters dissolves into noise for lags up to 10 characters [
4]. By contrast, Lin and Tegmark [
2] considered sophisticated estimation techniques and reported the power-law decay of the Shannon mutual information between two characters for much larger lags.
Because of the arbitrariness of word forms relative to the semantic content of the text, we are not convinced that the results by Lin and Tegmark [
2] are not an artifact of their estimation method. For this reason, following the idea of Mikhaylovskiy and Churilov [
9], we have decided to seek the LRD on the level of words. We have supposed that pairs of words rather than pairs of characters better capture the long-range semantic coherence of the text. For this reason, we have expected that the LRD effect extends for a larger distance on the level of words than on the level of characters. Indeed, in the present study, we report a lower bound on the Shannon mutual information between two words that is salient for lags up to 1000 words, which is four decades of magnitude larger than the unsmoothed effect for characters.
A modest goal of this paper is to systematically explore a simple measure of dependence to check whether texts in natural language and those generated by large language models exhibit the LRD. Rather than directly investigating the Shannon mutual information, which is difficult to estimate for large alphabets and strongly dependent sources, we elect a measure of dependence called the cosine correlation. This object is related to the cosine similarity of two vectors and somewhat resembles the Pearson correlation. Formally, the cosine correlation between two random vectors
U and
V equals
where
is the expectation of random variable
X,
is the dot product, and
is the norm. By contrast, the cosine similarity of two non-random vectors
u and
v is
In order to compute the cosine correlation or the cosine similarity for actual word time series, we need a certain vector representation of words. As a practical vector representation of words, one may consider word2vec embeddings used in large language models [
22,
23]. Word embeddings capture semantic relationships between words by mapping them into continuous spaces, allowing for a more meaningful measure of similarity between distant words in a text. In particular, Mikhaylovskiy and Churilov [
9] observed an approximate power-law decay for the expected cosine similarity
of word embeddings.
The paper by Mikhaylovskiy and Churilov [
9] lacked, however, the following important theoretical insight. As a novel result of this paper, we demonstrate that the cosine correlation
, rather than the expected cosine similarity
, provides a lower bound for the Shannon mutual information
. Applying the Pinsker inequality [
24,
25], we obtain the bound
This approach provides an efficient alternative to direct statistical estimation of mutual information, which is often impractical due to the sparse nature of natural language data. In particular, a slower than exponential decay of the cosine correlation implies LRD. Thus, a time series with a power-law or stretched exponential decay of the cosine correlation is not a Markov process or a hidden Markov process.
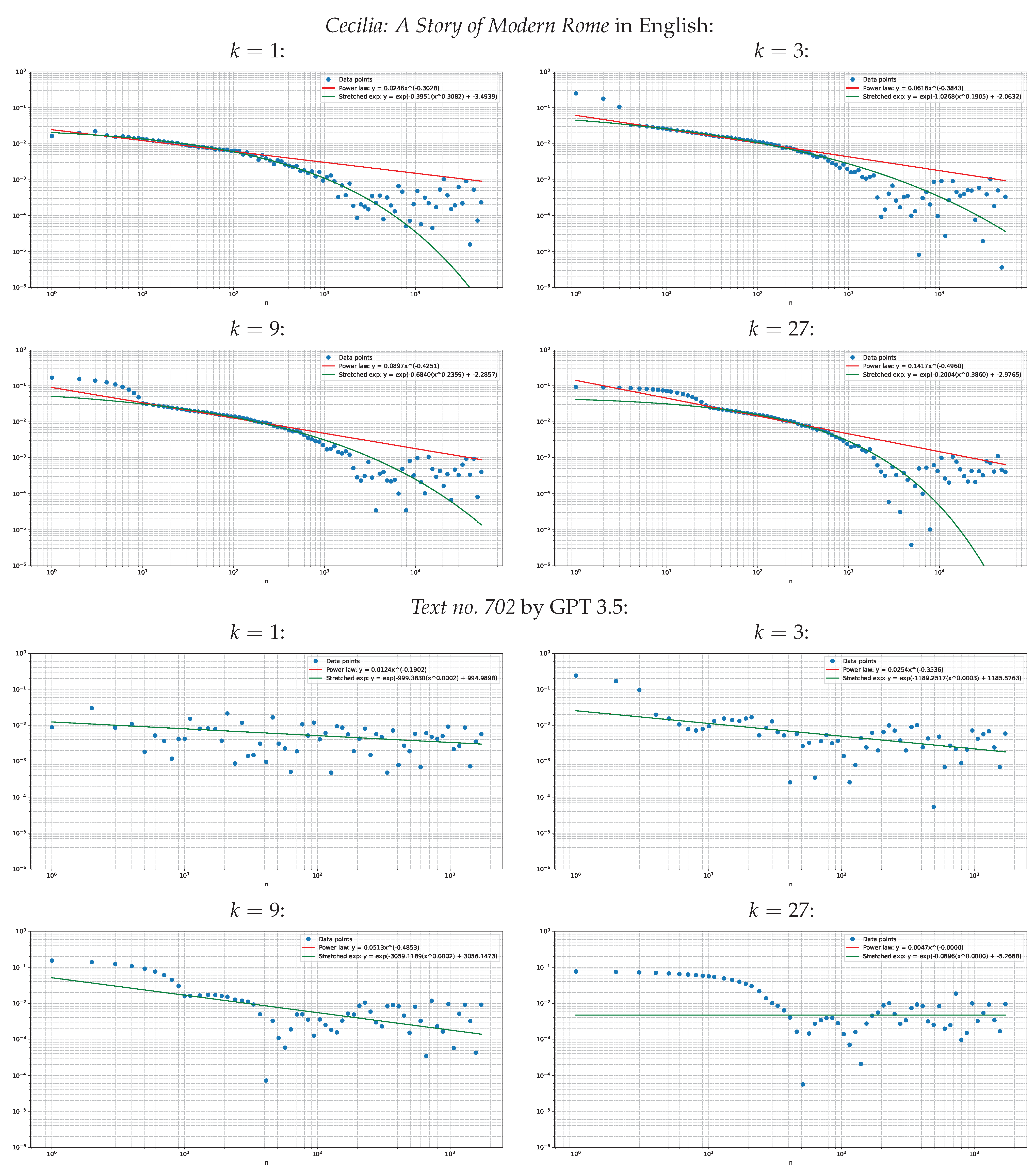
Indeed, on the experimental side, we observe a stretched exponential decay of the cosine correlation, which is clearly visible roughly for lags up to 1000 words—but only for natural texts. By contrast, artificial texts do not exhibit this trend in a systematic way. Our source of natural texts is the Standardized Project Gutenberg Corpus [
26], a diverse collection of literary texts that offers a representative sample of human language usage. Our source of artificial texts is the Human vs. LLM Text Corpus [
27]. To investigate the effect of semantic correlations, we also consider the cosine correlation between moving sums of neighboring embeddings, a technique that we call pooling. Curiously, pooling does not make the stretched exponential decay substantially slower. The lack of a prominent LRD signal was already noticed for the previous generation of language models by Takahashi and Tanaka-Ishii [
6,
7].
Our observation of the slow decay of the cosine correlation in general confirms the prior results of Mikhaylovskiy and Churilov [
9] and supports the hypothesis of LRD. We notice that Mikhaylovskiy and Churilov [
9] did not try to fit the stretched exponential decay to their data and their power-law model was not visually very good. Both theoretical and experimental findings of this paper contribute to the growing body of statistical evidence proving that natural language is not a finite-state hidden Markov process.
What is more novel is that our findings may support the view that natural language cannot be either generated by Transformer-based large language models—in view of no systematic decay trend of the cosine correlation for the Human vs. LLM Text Corpus. As mentioned, the LRD, Hilberg’s law, and the maximal repetition law independently substantiate the necessity of sophisticated memory architectures in modern computational linguistic applications. These results open avenues for further research into the theoretical underpinnings of language structure, potentially informing the development of more effective models for language understanding and generation.
2. Theory
Similarly as Mikhaylovskiy and Churilov [
9] but differently than Li [
4], Lin and Tegmark [
2], and Takahashi and Tanaka-Ishii [
6,
7], we will seek for LRD on the level of words rather than on the level of characters or phonemes. The Shannon mutual information between words is difficult to estimate for large alphabets and strongly dependent sources. Thus, we consider its lower bound defined via the cosine correlation of word2vec embeddings [
22,
23].
Let
denote the expectation of a real random variable
X. Let
be the natural logarithm of
x and let
be the Shannon entropy of a discrete random variable
X, where
is the probability density of
X with respect to a reference measure ([
3], Chapters 2.1 and 8.1). The Shannon mutual information between variables
X and
Y ([
3], Chapters 2.4 and 8.5) equals
By contrast, the Pearson correlation between real random variables
X and
Y is defined as
where we denote the covariance
and the variance
. By the Cauchy–Schwarz inequality, we have
.
We will introduce an analog of the Pearson correlation coefficient for vectors, which we call the cosine correlation. First, let us recall three standard concepts. For vectors
and
, we consider the dot product
the norm
, and the cosine similarity
By the Cauchy–Schwarz inequality, we have
.
Now, we consider something less standard. For vector random variables
U and
V, we define the cosine correlation
If
U and
V are discrete and we denote the difference of measures
then we may write
We observe that if random variables
U and
V are unidimensional, then
with probability 1 and
. Similarly,
if
is constant with probability 1 or if
U and
V are independent.
To build some more intuitions, let us notice the following three facts. First of all, the cosine correlation between two copies of a random vector lies in the unit interval.
Proof. Let us write
. We have
Hence, the claim follows. □
Second, the cosine correlation satisfies a version of the Cauchy–Schwarz inequality.
Proof. Let us write
and
. By the Cauchy–Schwarz inequalities
for random scalars
X and
Y and
for real numbers
, we obtain
Hence, the claim follows (
17). □
Third, we will show that cosine correlation provides a lower bound for mutual information .
Proof. Let us recall the Pinsker inequality
for two discrete probability distributions
p and
q [
24,
25]. By the Pinsker inequality (
22), the Cauchy–Schwarz inequality
, and identity (
16), we obtain
Hence, the claim follows. □
We note in passing that the Pinsker inequality can be modified as the Bretagnolle–Huber bound
for probability distributions
p and
q [
28,
29]. Respectively, we obtain
This bound is weaker than (
21) since
.
Let
be the text in natural language treated as a word time series. Let
be an arbitrary vector representation of word
w, such as word2vec embeddings [
22,
23], and let
. In particular, since embeddings
are functions of words
, by the data-processing inequality ([
3], Chapter 2.8) and by the cosine correlation bound (
21), we obtain
Wrapping up, a slow decay of cosine correlation
implies a slow decay of mutual information
. Since
is damped exponentially for any mixing Markov or hidden Markov process
by Theorem 1 of Lin and Tegmark [
2], observing a power-law or a stretched exponential decay of cosine correlation
is enough to demonstrate that process
is not a mixing Markov or hidden Markov process.
The framework that we have constructed in this section has its prior in the literature. We remark that Mikhaylovskiy and Churilov [
9] investigated estimates of expectation
rather than cosine correlation
. That approach required estimation and subtraction of the asymptotic constant term. Mikhaylovskiy and Churilov [
9] observed an approximate power-law decay but they did not mention the cosine correlation bound (
21) in their discussion explicitly.
4. Conclusions
In this paper, we have provided an empirical support for the claim that texts in natural language exhibit long-range dependence (LRD), understood as a slower than exponential decay of the two-point mutual information. Similar claims have been reiterated in the literature [
2,
4,
5,
6,
7,
8,
9,
10,
11] but we hope that we have provided more direct and convincing evidence.
First, as a theoretical result, we have shown that the squared cosine correlation lower bounds the Shannon mutual information between two vectors. Under this bound, a power-law or a stretched exponential decay of the cosine correlation implies the LRD. In particular, the vector time series which exhibits such a slow decay of the cosine correlation cannot be not a mixing Markov or hidden Markov process by Theorem 1 of Lin and Tegmark [
2].
Second, using the Standardized Project Gutenberg Corpus [
26] and vector representations of words taken from the NLPL repository [
23], we have shown experimentally that the estimates of the cosine correlation of word embeddings follow a stretched exponential decay. This decay extends for lags up to 1000 words without any smoothing, which is four decades of magnitude larger than the unsmoothed, presumably LRD, effect for characters [
4].
Third, the stability of this decay suggests that the LRD is a fundamental property of natural language, rather than an artifact of specific preprocessing methods or statistical estimation techniques. The observation of the slow decay of the cosine correlation for natural texts not only supports the hypothesis of LRD but also reaffirms the prior results of Mikhaylovskiy and Churilov [
9], who reported a rough power-law decay of the expected cosine similarity of word embeddings.
Fourth, like Takahashi and Tanaka-Ishii [
6,
7], we have observed the LRD only for natural data. We stress that, as we were able to observe, artificial data do not exhibit the LRD in a systematic fashion. Our source of artificial texts was the Human vs. LLM Text Corpus [
27]. We admit that texts in this corpus may be too short to draw firm conclusions and further research on longer LLM-generated texts is necessary to confirm our early claim.
As we have mentioned in the introduction, non-Markovianity effects such as the LRD, Hilberg’s law [
15,
16,
17], and the maximal repetition law [
18] may have implications for understanding the limitations and capabilities of contemporary language models. The presence of such effects in natural texts in contrast to texts generated by language models highlights the indispensability of complex memory mechanisms, potentially showing that state-of-the-art architectures such as Transformers [
21] are insufficient.
Future research might explore whether novel architectures could capture quantitative linguistic constraints such as the LRD more effectively [
32]. Further studies may also explore alternative embeddings or dependence measures and their impact on the stability of the LRD measures such as the stretched exponential decay parameters. Investigating other linguistic corpora, text genres, and languages could also provide valuable insights into the universality of these findings.







{kind=link}