1. Introduction
The landscape of modern machine learning has been shaped by exponential growth in computational power, particularly through advances in GPU technology and frameworks like PyTorch. While Moore’s law continues to drive hardware improvements, and CUDA algorithms have revolutionized our ability to process vast amounts of internet data, we pose the following question: can we achieve superior performance through mathematically efficient representations of multivariate functions rather than raw computational power?
In this paper, we introduce Kolmogorov-generalized additive models (K-GAM), a novel neural network architecture whose additive structure enables simplified training and accelerated inference through a marked reduction in parameters compared to traditional approaches. K-GAMs leverage Kolmogorov’s superposition theorem by utilizing a composition of two key components, namely, a universal Köppen embedding (functioning as a space-filling curve), followed by a trainable outer function, . Unlike the original iterative look-up table approach proposed by Köppen and Sprecher, which faces NP-hard computational challenges, we implement the outer function using a ReLU neural network that can be efficiently trained using standard optimization techniques.
A fundamental challenge in machine learning lies in effectively handling high-dimensional input–output relationships. This challenge manifests itself in two distinct but related tasks. First, one task is to construct a “look-up” table (dictionary) for the fast search and retrieval of input–output examples. This is an encoding and can be thought of as a data compression problem. Second, and perhaps more importantly, we must develop prediction rules that can generalize beyond these examples to handle arbitrary inputs.
More formally, we seek to find a good predictor function
that maps an input
x to its output prediction
y. In practice, the input
x is typically a high-dimensional vector:
Given a training dataset
of example input–output pairs, our goal is to train a model, i.e., to find the function
f. The key question is as follows:
how do we represent a multivariate function so as to obtain a desirable f?We demonstrate that Transformer architectures can be decomposed into two fundamental operations: a particular form of embedding followed by kernel smoothing. Hence, K-GAM models are natural competitors to Transformers. The significance of this connection becomes clear when we consider that Transformers have largely supplanted alternative architectures across a wide range of applications. Previous work in this direction—[
1,
2]—demonstrated the potential of Köppen-based approaches only for
image reconstruction tasks. Our analysis extends this framework to encompass A wider spectrum of machine learning problems.
The rest of this paper is outlined as follows.
Section 2 discusses the Kolmogorov superposition theorem.
Section 3 introduces Kolmogorov-generalized additive models (K-GAMs).
Section 4 describes Transformer architectures as kernel smoothers.
Section 5 provides an application of GAM-Kolmogorov embeddings to the iris dataset.
Section 6 concludes with directions for future research.
2. Kolmogorov Superposition Theorem (KST)
Kolmogorov demonstrated that any real-valued continuous function
where
defined on
can be represented as a convolution of two single-variable functions:
where
are continuous single-variable functions defined on the
d-dimensional unit cube
. Kolmogorov further showed that the
functions can be decomposed into sums of single-variable functions:
This result is known as the Kolmogorov representation theorem [
3] and is often written in the following form:
Kolmogorov originally defined the inner functions as , , using the following property . Then, for any integer , let be a family of mutually disjoint d-dimensional cubes . The diameter of each cube approaches zero as , and every point of a unit cube belongs to at least cubes for each k. Unfortunately, this derivation is not constructive and does not provide a practical algorithm for constructing the inner functions .
Our goal is to show that it applies directly to the problems of machine learning. Furthermore, we interpret the architecture as a statistical model that allows us to draw on uncertainty quantification and approximation bounds. To understand the power of this representation from a machine learning perspective, we can think of
as features. Note that the number of features is then
for the
d-dimensional input. This representation is also remarkable in the sense that
can be viewed as an embedding, which is
independent of
f. For details, see
Section 3.
2.1. Kolmogorov–Arnold Networks
A significant development has been the emergence of Kolmogorov–Arnold networks (KANs). The key innovation of KANs is their use of learnable functions rather than weights on the network edges. This replaces traditional linear weights with univariate functions, typically parametrized by splines, enhancing both representational capacity and interpretability. Ref. [
4] established the first practical connection between KST and neural networks by showing that any KAN can be constructed as a three-layer MLP. Polson and Sokolov proposed Bayesian KAN networks.
Recently, Refs. [
5,
6] considered KST in the form of a sum of functions, represented as a two-layer model:
More explicitly,
Ref. [
7] presented a significant theorem regarding the approximation of generalized bandlimited multivariate functions using deep ReLU networks. The key finding is that deep ReLU networks can approximate generalized bandlimited functions without suffering from the curse of dimensionality. The paper utilizes an extension of Carathéodory’s theorem to infinite-dimensional spaces, which is crucial for the approximation of bandlimited functions. As a result, this paper provides a theoretical foundation for the effectiveness of deep learning in high-dimensional problems, especially for a class of functions relevant to many scientific computing applications.
One can think of KAN networks as NNs in which functions
are estimated at the nodes, rather than weights. This makes them very flexible. A natural choice involves the use of splines for
; Ref. [
8] proposed the application of KSNs (Kolmogorov spline networks).
Another advantage is that they can be trained using fast, high-dimensional algorithms such as the Newton–Kaczmarz algorithm [
9]. The authors showed that KAN is not only a superposition of functions but also a special case of a tree of discrete Urysohn operators:
This insight leads to a fast, scalable algorithm that avoids backpropagation, is applicable to any GAM model, and uses a projection descent method with a Newton–Kaczmarz scheme.
Recent research has explored various functional classes for the outer functions, including Wan-KAN [
10], SineKAN [
11], and functional combinations [
12]. Ref. [
13] demonstrated that KAN networks can outperform traditional MLPs, while [
14] proved their optimality in terms of approximation errors. Ref. [
15] discussed the Bayesian interpretation of the Kolmogorov–Arnold representation. KAN networks are widely trained with gradient descent. Ref. [
9] proposed a Newton–Kaczmarz scheme. Bayesian methods are also available [
16] and offer the potential for fewer parameters and more efficient inference. There are also optimal posterior concentration results [
17].
Early theoretical groundwork for adaptive learning in KANs was laid by [
18], who introduced the concept of counter-propagation networks, where outer functions self-organize in response to input–output pairs
. Theoretical understanding has continued to advance, with [
19] showing that Kolmogorov networks with two hidden layers can precisely represent continuous, discontinuous, and unbounded multivariate functions, depending on the activation function choice in the second layer. Ref. [
20] extended this to three-layer networks for discontinuous functions.
2.2. Inner and Outer Functions
The theorem has seen several refinements over time. Ref. [
21] made a crucial advancement by proving that the inner functions could be Hölder continuous. Ref. [
22] later strengthened this result, showing that these functions could be Lipschitz continuous, although this required modifications to both the outer and inner functions.
We focus on the Kolmogorov–Sprecher formulation, as modified by [
23,
24,
25]. The first representation is as follows:
We will call this the Kq-GAM model to indicate the fact that there are
q univariate outer functions. Ref. [
7] provided an iterative algorithm to find
based on the original Köppen formulation.
The second (and most parsimonious) representation is one in which there is only one univariate outer function! This expresses any multivariate continuous function as follows:
Ref. [
25] defines the
term.
We will refer to this as the K-GAM model in our ML implementation. Bryant discussed the choice of offset . Note that the complexity reduction is that there is only one outer function that depends on f. The caveat involves finding a computation algorithm to compute g in polynomial time.
Here, the inner functions
are constructed as sums of translated versions of a single univariate function
, known as the Köppen function. The Köppen function is monotone, Hölder continuous with smoothness parameters, and has fractal-like properties. Recent work by [
26] provides a modern construction of the Köppen function and establishes theoretical approximation results with ReLU networks. Ref. [
27] extended these theoretical results and showed that a function with a smaller number of parameters can be used. The author used
-adic representation, where
The structure of
differs fundamentally from the approaches used in traditional neural networks, which rely on hyperplanes (as in ReLU networks) or decision trees. In
, a slice in any given univariate direction cuts the regions defined by the embedding in half.
The inner functions,
, partition the input space into distinct regions, and the outer function,
g, must be constructed to provide the correct output values across the regions that the inner function defines. The outer function,
g, can be determined via a computationally intensive process of averaging. For each input configuration, the inner functions,
, generate a unique encoding, and
g must map this encoding to the appropriate value of
. This creates a dictionary-like structure that associates each region with its corresponding output value. Köppen made significant contributions by correcting Sprecher’s original proof of this construction process, with improvements to the computational algorithm later suggested by [
28,
29]. Braun further enhanced the understanding by providing precise definitions of the shift parameters
and characterizing the topological structure induced by
.
A fundamental trade-off in KST exists between function smoothness and dimensionality. The inner functions, , can be chosen from two different function spaces, with each offering distinct advantages. The first option is to use functions from , but this limits the network’s ability to handle higher dimensions effectively. The second option is to relax the smoothness requirement to Hölder-continuous functions (), which satisfy the inequality . These functions are less smooth, but this “roughness” enables better approximation in higher dimensions.
2.3. Ridge and Projection Pursuit Regression
To understand the significance of this trade-off, we consider ridge functions, which represent a fundamental building block in multivariate analysis. Since our ultimate goal is to model arbitrary multivariate functions
f, we need a way to reduce dimensionality while preserving the ability to capture nonlinear relationships. Ridge functions accomplish this by representing one of the simplest forms of nonlinear multivariate functions, requiring only a single linear projection and a univariate nonlinear transformation. Formally, a ridge function
takes the form
, where
g is a univariate function and
. The non-zero vector
w is called the direction. The term “ridge” reflects a key geometric property, that is, the function remains constant along any direction orthogonal to
w. Specifically, for any direction
u, such that
, we have the following:
This structural simplicity makes ridge functions particularly useful as building blocks for high-dimensional approximation. Ref. [
30] provides bounds on the approximation error when a function with a finite spectral norm is approximated by ridge functions.
Ridge functions play a central role in high-dimensional statistical analysis. For example, projection pursuit regression approximates input–output relations using a linear combination of ridge functions [
31,
32,
33]:
where both the directions,
, and functions,
, are variables, and
denotes one-dimensional projections of the input vector. The vector
is a projection of the input vector
x onto a one-dimensional space, and
denotes a feature calculated from the data. Ref. [
34] used nonlinear functions of linear combinations, laying important groundwork for deep learning.
3. Kolmogorov-Generalized Additive Models (K-GAMs)
We take a different approach. Rather than using learnable functions as network node activations, we directly use the KST representation. This is a two-layer network with a non-differentiable inner function. The network’s architecture can be expressed as follows:
where the inner layer performs an embedding from
to
via the following;
Here,
is a
p-adic expansion with
and
, with
.
3.1. Köppen Function
The Köppen function
straightforwardly computes and provides the basis for the inner architecture of the network. The function
is defined through a recursive limit:
where each
has the following representation:
and
is defined recursively as follows:
Here, the sets
are defined as follows.
is a uniform grid, with step size
, defined by the following:
There are
different points
on each grid
where each point is as follows:
.
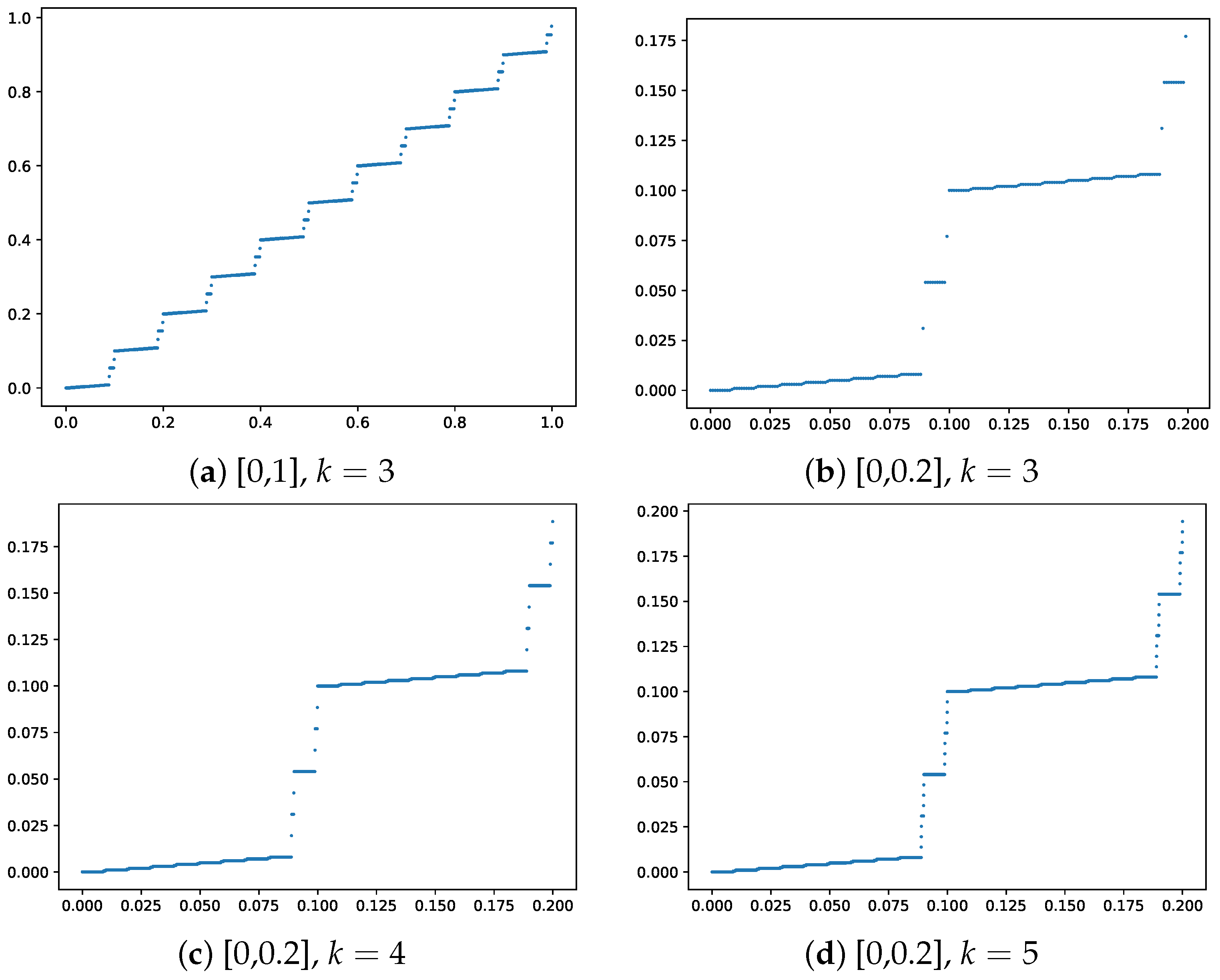
To illustrate, we show how the iterates update.
Figure 1 shows the plot of the Köppen function
for
on intervals
and
(top row). The bottom row shows a “zoomed in” view of the function for
and
on the intervals
. The function has a fractal-like structure, with the number of discontinuities increasing with
k. The Köppen function is a key component of the KST representation, providing a topological embedding of the input space that is independent of the target function
f. This embedding is crucial for the network’s ability to capture complex multivariate relationships. Ref. [
28] provided a detailed algorithm for computing the Köppen function and its properties. The author also provided a good, intuitive understanding of the function and its properties.
The most striking aspect of KST is that it leads to a generalized additive model (GAM) with fixed features that are independent of the target function f. These features, determined by the Köppen function, provide universal topological information about the input space, effectively implementing a k-nearest neighbors structure that is inherent to the representation. The outer function, g, is then responsible for learning the relationship between these features and the target function f. This separation of feature engineering and learning is a key advantage of K-GAM networks, enabling efficient training and inference.
Theorem 1 (K-GAM)
. Any function and dataset can be represented as a GAM with feature engineering (topological information) given by features in the hidden layer:where ψ is a single activation function common to all nodes, known as the Köppen function, and g is a single outer function. Proof. We can take the Köppen–Sprecher representation for
and apply it
N times to each output–input pair
and obtain a representation for
. For example, for the K-GAM model and
g-outer function, we have the following:
where
and
.
Now, for a dataset
where
, we apply this representation to each data point:
where we define
.
Ref. [
7] proved that the outer function
g can be approximated by a ReLU network to arbitrary precision. Therefore, we can replace
g with a single ReLU network:
where
K is the number of neurons. We see that any function,
f, and its corresponding dataset can be represented as a GAM with features engineered through the Köppen function
. □
Ref. [
35] further developed this insight into a specialized two-layer ReLU network architecture. Specifically, the authors introduced a class of functions called Kolmogorov–Lipschitz continuous, where the outer function in the KST representation is Lipschitz continuous. Then they demonstrated that KL continuous functions can be approximated using a ReLU neural network with two hidden layers, achieving a dimension-independent approximation rate, and they introduced LKB-splines, created by using linear B-splines to replace the outer function in the KST representation.
As in [
36], we can decompose with Lipschitz continuous functions. Note, the number of outer functions grows with the input dimension,
d, not with the dataset size. The outer function,
g, is shared across all terms, making this a true GAM representation with universal feature engineering provided by the inner Köppen function
.
In a similar vein to [
4], we show how this functional representation can be used to define a statistical model for applications in machine learning tasks [
37,
38]. We propose the following model:
where
K denotes the number of neurons in the outer function’s architecture. The parameters
can be learned using
-minimization and SGD. This architecture employs only two univariate activation functions, that is, a learned ReLU network for the outer layer and the Köppen function for the inner layer, which can be computed independently of
f.
Note
A crucial aspect of KST-based architectures is their relationship to p-adic expansions and embeddings. This connection, first explored by [
39] and recently advanced by [
40], builds upon the foundational work of [
41] on cellular neural networks in the 1980s, which included cellular automata as special cases.
For any input
x, its p-adic expansion can be written as follows:
where
serves as the base of the expansion and
denotes the digits in this representation. This expansion provides a natural embedding of the input space into a higher-dimensional representation, resembling contemporary kernel embedding techniques in deep learning [
15,
37,
38].
3.2. Inference
An important property of an algorithm is how many parameters exist in the evaluation of the network, the so-called inference problem. The K-GAM network is notable for its relatively sparse parameterization.
Consider the class that corresponds to kernel estimators of the following form:
We call
an
-atom if
. For such estimators, there exists an M-term approximation of
f:
with
C independent of dimension
d. While general approximations suffer from the curse of dimensionality with error
[
42], where r denotes isotropic smoothness, certain restrictions yield dimension-independent bounds. For instance, when
is in the
-Fourier class, the error becomes
independent of
d [
43].
The class of functions that we consider can be represented as
-combinations of
-atoms. For
, we will use superpositions of functions. For example, with
and Gaussian atoms
, see [
44]. Let
, where
k is an orthant indicator. Then the resultant approximation is also of order
, independent of
d.
This framework naturally extends to incorporate dimension-reduction techniques like partial least squares (PLS). Given the input–output pairs
, we can construct models of the following form:
where
provides dimension reduction and
g is a learnable transformation.
A more general class is found by the superposition of
functions, each monotone for a different orthant. Then, the condition
manifests as a derivative condition:
This characterizes the space of functions with bounded mixed derivatives, which naturally leads to
-Hölder-smooth functions. For such
-Hölder-continuous functions, the network typically requires
parameters (see [
45] for further results on additive models and approximation properties in high dimensions).
Kolmogorov spline networks, designed for differentiable functions with bounded derivatives, satisfy the stronger property:
with the number of parameters given by
. This compares favorably to both the
approximation rate and the
parameter count of the general one-layer-hidden feed-forward networks [
8].
Deep ReLU networks, using
activation, create separating hyperplanes across
L layers, unlike cylinder sets (a.k.a. trees), which are a special case. Ref. [
46] showed that energy-norm-based sparse grids and Kolmogorov approximation schemes have bounds that are independent of
d.
Ref. [
47] showed that efficient approximation schemes can be developed by the use of superpositions. Every continuous function of several variables can be represented by the superposition of functions with only two variables. Ref. [
20] considered discontinuous functions.
As Kolmogorov might have said—there are no true multivariate problems, only superpositions of univariate affine ones!
3.3. Kernel Smoothing: Interpolation
The theory of kernel methods was developed by Fredholm in the context of integral equations [
48]. The idea is to represent a function as a linear combination of basis functions, which are called kernels.
Here, the unknown function,
, is represented as a linear combination of kernels,
, with unknown coefficients,
. The kernels are known, and the coefficients are unknown. The coefficients are found by solving the integral equation. The first work in this area was done by Abel [
49], who considered equations of the form above.
Nowadays, we call those equations Volterra integral equations of the first kind. Integral equations typically arise in inverse problems. Their significance extends beyond their historical origins, as kernel methods have become instrumental in addressing one of the fundamental challenges in modern mathematics, that is, the curse of dimensionality.
Bartlett [
50,
51] proposed the use of kernels to estimate the regression function. The idea is to estimate the regression function,
, at point
x by averaging the values of the response variable,
, at points
that are close to
x. The kernel is used to define the weights.
The regression function is estimated as follows:
where the kernel weights are normalized.
Both Nadaraya [
50] and Watson [
51] considered the symmetric kernel
, where
is the Euclidean norm. The most popular kernel of that sort is the Gaussian kernel:
Alternatively, the two-norm can be replaced by the inner product:
.
Later, Ref. [
52] proposed using kernels to estimate the density function. The idea is to estimate the density function
at point
x by averaging the values of the kernel
at points
that are close to
x. This idea was applied in many contexts by statisticians [
53,
54], machine learners [
55], and engineers [
56]. K-GAM builds upon these foundations.
Kernel methods are supported by numerous generalization bounds, which often take the form of inequalities that describe the performance limits of kernel-based estimators. A particularly important example is the Bayes risk for
k-nearest neighbors (
k-NN), which can be expressed in a kernel framework as follows:
k-NN classifiers have been proven to converge to an error rate that is bounded in relation to the Bayes error rate, with the exact relationship depending on the number of classes. For binary classification, the asymptotic error rate of
k-NN is, at most,
, where
is the Bayes error rate. This theoretical bound suggests potential for improvement in practice. Cover and Hart proved that interpolated k-NN schemes are consistent estimators, meaning that their performance improves with the increasing sample size.
3.4. Training Rates
Consider the non-parametric condition regression,
where
. We wish to estimate
where
. From a classical risk perspective, we define the following:
where
denotes the
-norm.
Under standard assumptions, we have an optimal minimax rate of for -Hölder-smooth functions f. This rate depends on the dimension d, which can be problematic in high-dimensional settings. By restricting the class of functions, better rates can be obtained, including ones that do not depend on d. In this sense, we avoid the curse of dimensionality. Common approaches include considering the class of linear superpositions (a.k.a. ridge functions) and projection pursuit models.
Another asymptotic result comes from a posterior concentration property. Here,
is constructed as a regularized MAP (maximum a posteriori) estimator, which solves the optimization problem:
where
is a regularization term. Under appropriate conditions, the ensuing posterior distribution
can be shown to concentrate around the true function at the minimax rate (up to a
factor).
A key result in the deep learning literature provides convergence rates for deep neural networks. Given a training dataset of input–output pairs
from the model
, where
f is a deep learner (i.e., superposition of functions)
where each
is a
-smooth Hölder function with
variables, we have the following condition:
Then, the estimator has an optimal rate:
This result can be applied to various function classes, including generalized additive models of the following form:
where
,
and
. In this case,
, and assuming
h is Lipschitz, we obtain an optimal rate of
, which is independent of
d.
Ref. [
57] shows that deep ReLU networks also have an optimal rate of
for certain function classes. For 3-times differentiable (e.g., cubic B-splines ), Ref. [
58] found a rate of
. Ref. [
8] found a rate
for Kolmogorov spline networks.
Finally, it is worth noting the relationship between expected risk and empirical risk. The expected risk,
R, is typically bounded by the empirical risk plus a term of order
:
where
is the minimizer of the expected risk. However, in the case of interpolation, where the model perfectly fits the training data, the empirical risk term becomes zero, leaving only the
term.
4. Transformers as Kernel Smoothing
The fundamental connection between K-GAMs and Transformers becomes clear when we decompose Transformer architectures into their core operations, that is, embedding and kernel smoothing. This decomposition reveals why K-GAMs serve as natural competitors to Transformers, as both architectures leverage these same fundamental principles, albeit through different mechanisms. In both architectures, the embedding phase transforms raw inputs into a higher-dimensional space, where relationships can be more easily captured, while the smoothing phase aggregates information across this embedded space to produce outputs.
Transformers have become a main building block for various natural language processing (NLP) tasks and have been extended to other domains as well due to their effectiveness. The Transformer architecture is primarily designed to handle sequential data, making it well-suited for tasks such as machine translation, language modeling, text generation, and more.
The Transformer approach to embedding begins by converting input tokens into vectors in a high-dimensional space, augmented with positional information to preserve sequential structure. K-GAMs, in contrast, employ the Köppen function to transform inputs into a universal embedding space. This difference in embedding strategy reflects a fundamental trade-off, that is, Transformers learn task-specific embeddings that can adapt to particular domains, while K-GAMs leverage a universal embedding that can theoretically capture any continuous function.
Next, we will discuss the role of kernel smoothing in Transformers. Ref. [
59] first introduced kernel smoothing for sequence-to-sequence learning through what became known as the attention mechanism. This approach estimates the probability of the next word in the sequence using a so-called context vector
, which is a weighted average of the vectors from the input sequence
:
where
denotes the weights. The weights are defined by a kernel function, specifically a normalized exponential (softmax):
When used for self-supervised learning, this attention mechanism is called self-attention. When a sequence is mapped to a matrix
M, it is called multi-head attention.
This formulation mirrors the structure of traditional kernel smoothing methods, with the key innovation being that, rather than using a fixed similarity measure like Euclidean distance, the energy function is learned through a neural network. This neural network adaptively measures the similarity between the last generated element of the output sequence and the j-th element of the input sequence , allowing the model to learn context-dependent attention patterns.
Both architectures use these phases to reduce the dimensionality of the learning problem while preserving the ability to capture complex relationships. The key difference lies in how they implement these phases; Transformers learn both the embedding and smoothing operations, while K-GAMs use a fixed, universal embedding (Köppen function) followed by learned smoothing.
The main advantage of using smoothing techniques is that they are parallelizable. This is the key draw of Transformers. Current language models such as BERT, GPT, and T5 rely on the Transformer approach. Further, Transformers have also been applied to computer vision and other domains. Their ability to capture long-range dependencies and their scalability have made them powerful tools for a wide range of applications. See Ref. [
60] for further details.
5. Application
5.1. Simulated Data
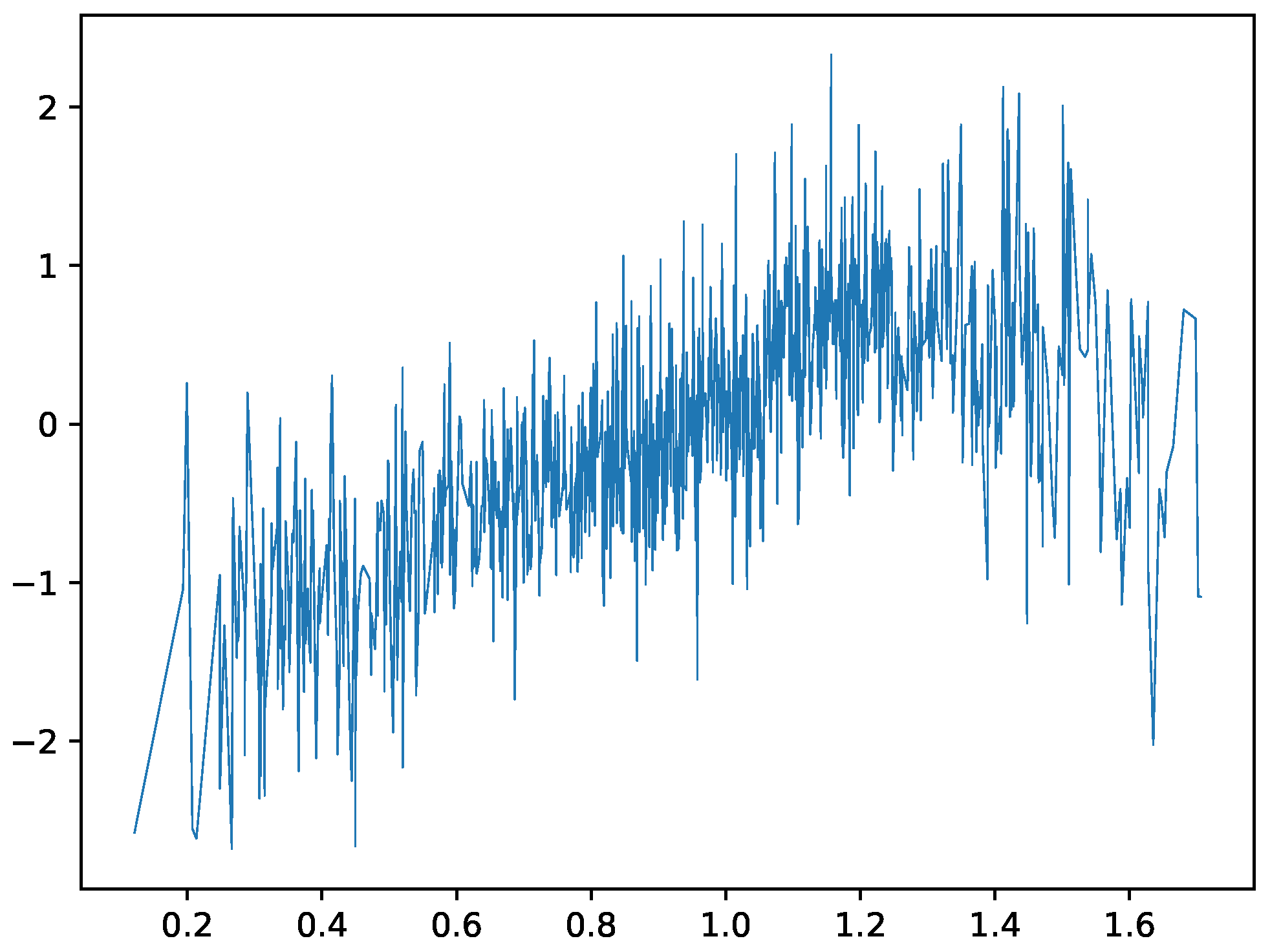
We also apply the K-GAM architecture to a simulated dataset to evaluate its performance on data with known structures and relationships. The dataset contains 100 observations generated from the following function:
The goal is to predict the function
based on the input
x. The dataset is often used as a benchmark dataset for regression algorithms due to its diverse mix of relationships (linear, quadratic, nonlinear, Gaussian random noise) between the input features and the target function. The plot of
(no noise) vs.
y (noise) is shown in
Figure 2.
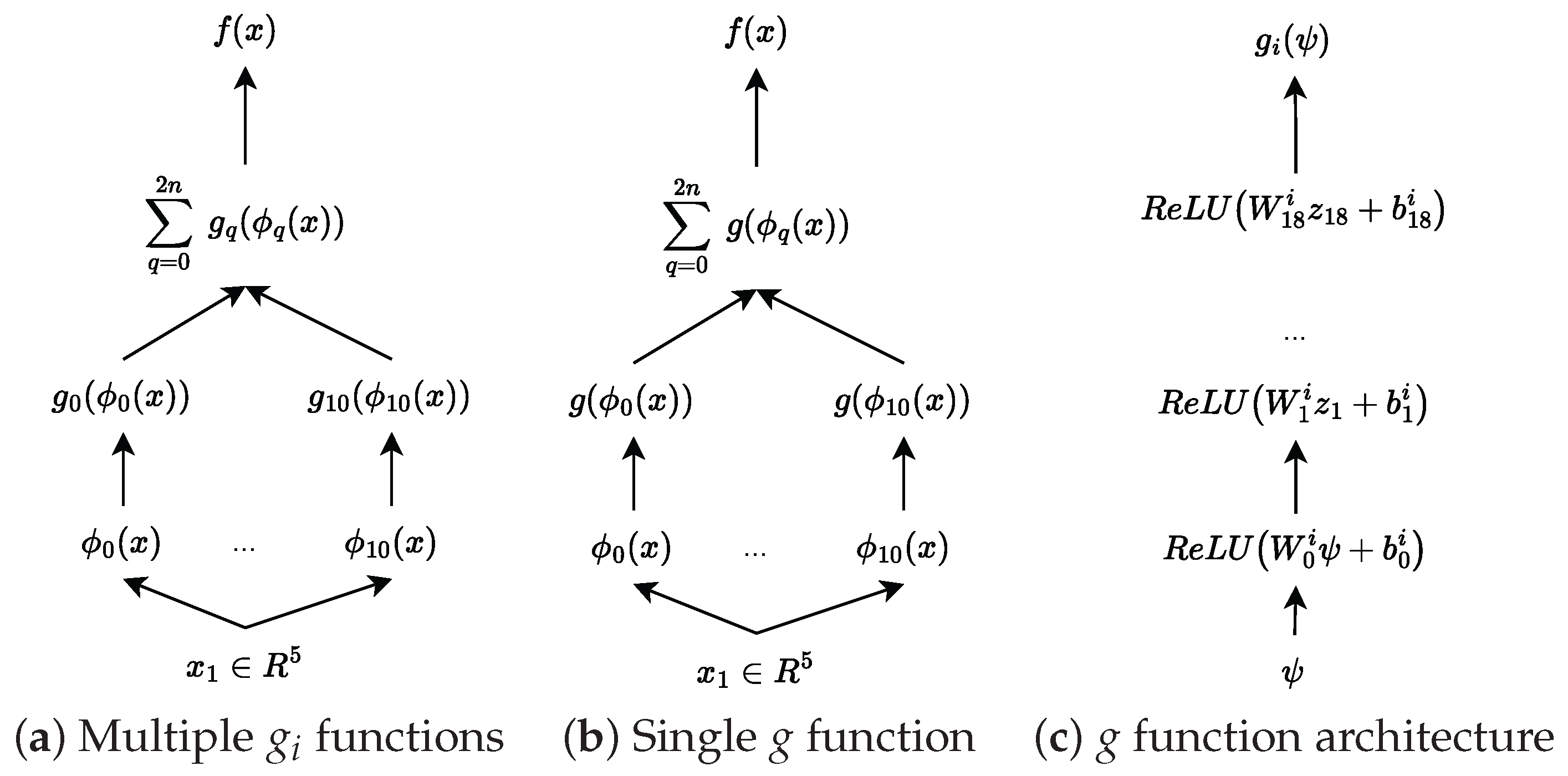
We use the Köppen function to transform the five-dimensional input into a set of 11 features (
). We then learn the outer function
g using a ReLU network. To thoroughly investigate the model’s capabilities, we implement two distinct approaches to learning the outer function. The first approach uses different
g functions for each feature, following the original KST formulation. This allows each function to specialize in capturing specific patterns, but it might be more difficult to train and has more parameters. The second approach uses a single
g function for all features, as proposed by [
61], providing a more unified and parameter-efficient representation.
Figure 3 illustrates these architectural choices in detail, showing how the information flows through each version of the model. For the first model with multiple
functions, the dimensions of each
are as follows:
and for
,
. Exemplary outer functions are shown in
Figure 4.
The next architecture, which uses only one function,
g, for all features, maintains a similar structure to the multiple-
g function approach. The only difference is in the dimensionality of the inner layers—we increase the width from 16 to 200. This increased capacity allows the single function to learn more complex patterns and compensate for the constraint of using just one function instead of multiple specialized ones. The behavior of this unified outer function is shown in
Figure 5, where we can observe how it adapts to handle multiple feature transformations simultaneously.
5.2. Iris Data
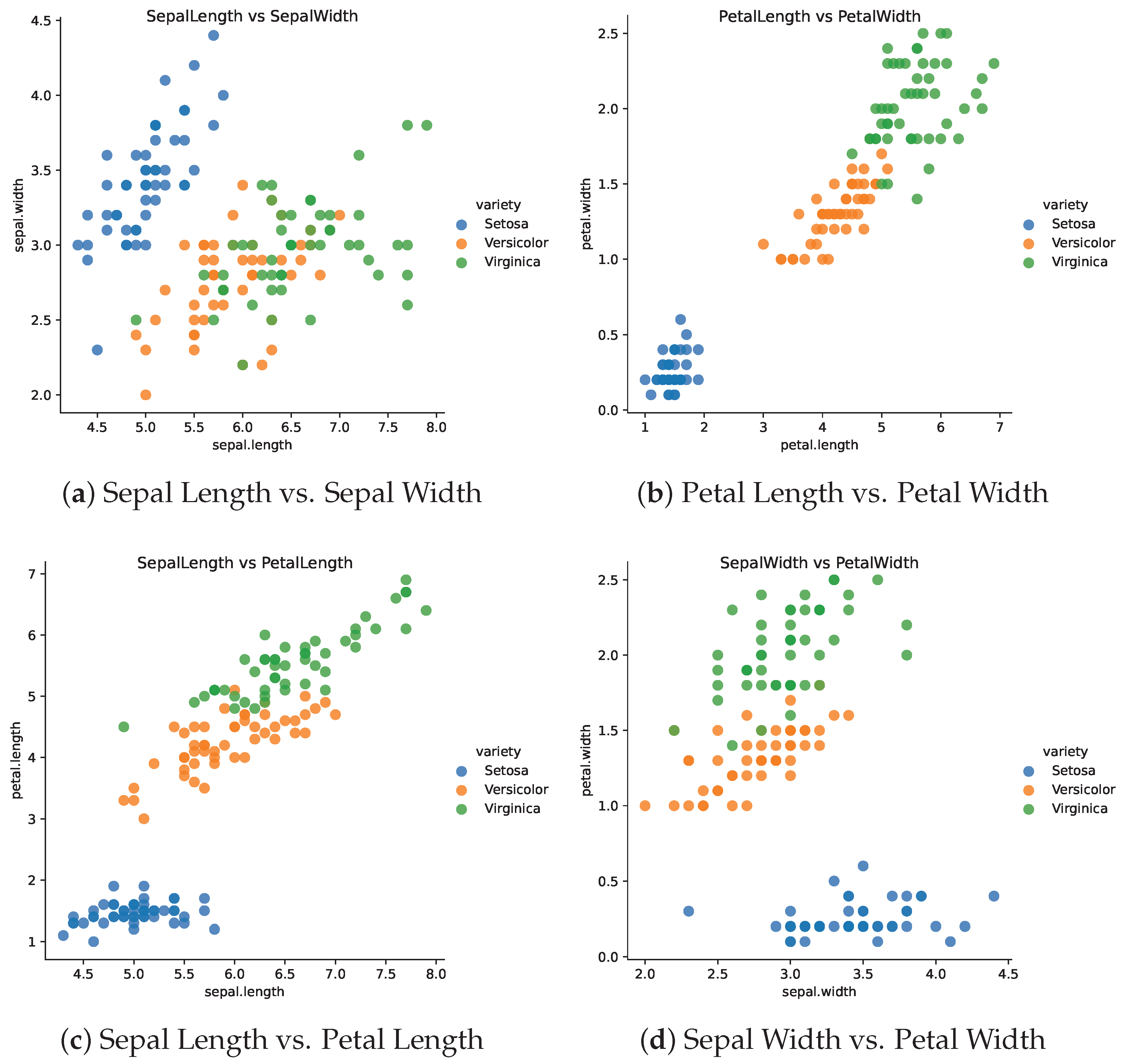
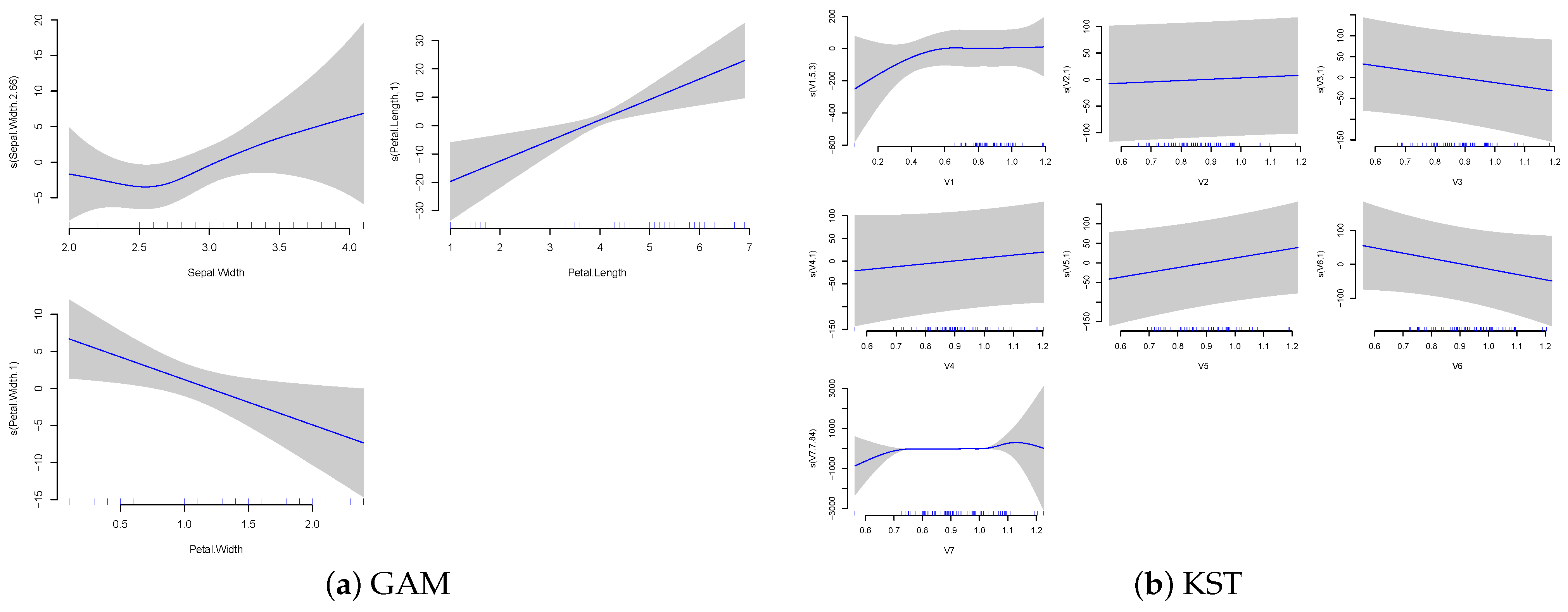
We apply the KST architecture to an iris dataset. The iris dataset is a classic dataset in machine learning and statistics. It contains 150 observations of iris flowers. Each observation contains four features, namely, sepal length, sepal width, petal length, and petal width. The goal is to predict the species of the iris flower based on these features. The dataset contains three classes of iris flowers, namely, setosa, versicolor, and virginica. The dataset is often used as a benchmark dataset for classification algorithms. The dataset has five variables, which include four characteristics of the iris flower and the species of the flower.
Figure 6 shows the scatter plots of the iris dataset.
We calculate the mean
of the sepal length column and use a binary variable
as the output. We use the other three flower characteristics,
, as input variables. We use a classical GAM model to fit the data and compare it to KST-GAN. The classical generalized additive model is given by the following:
where
are smooth functions of the input features. The KST-GAN model is given by the following:
where
is the Köppen transformation function (in
Appendix A) of the input features
We use
and
to transform the input features into a set of seven features. We then learn the outer function
g using a classical GAN approach. We use the
mgcv package in R to fit the GAM model. This package uses a penalized likelihood approach to fit the model [
62].
Table 1 compares the performances of the GAM and KST-GAM models. We also include a classical logistic regression model for comparison. The KST-GAM model has a higher AIC and BIC compared to the GAM model. The KST-GAM model has a comparable RMSE.
Table 2 and
Table 3 show the confusion matrices for the GAM and KST GAM models, respectively. The KST GAM model has a lower accuracy compared to the GAM model.
Figure 7 shows the original features plotted against those fitted by the GAM function for both original inputs and the KST-transformed inputs.
Overall, the iris example demonstrates the inability of the GAM model to capture the complex relationships between the transformed features and the target variable.
The comparison between traditional GAM and K-GAM approaches in
Figure 7 shows some notable differences. The GAM plots show slightly smoother relationships between individual features and the output. For instance, petal width and petal length show particularly strong linear relationships with the target variable. In comparison, the K-GAM architecture seems to capture different aspects of the feature relationships. Notably, while one of the features retains a largely linear relationship, the other two features encode more complicated relationships. This difference demonstrates the effect of the Köppen function’s mapping.
Next, the simulated data study explores how K-GAM handles data with known structures, as well as the differences between using multiple outer functions and a single shared outer function within the K-GAM framework. The comparison between multiple
functions (
Figure 4) and a single
g function (
Figure 5) demonstrates the architectural flexibility of the approach. The single
g function variant shows a highly variable pattern across its input range, showing that the increased dimension compensates for the reduced flexibility of having a single function by developing more complex internal representations. The ability to choose between multiple specialized functions or a single shared function provides a useful degree of freedom in the model’s design.
5.3. Image Processing
A number of authors have proposed the use of Kolmogorov networks for image processing tasks (for example, see Refs. [
1,
2]). More recently, functional KANs were proposed in [
12].
Figure 8 shows the error outputs for the MNIST dataset. Equivalent rates for the MNIST dataset can be found in [
63].
Functional KAN methods have been shown to be effective for image processing tasks and have been shown to be promising in other tasks. Ref. [
8] provided theoretical results for Kolmogorov networks applied to image segmentation tasks. Another alternative is deep partial least squares (DPLS) networks—a type of Kolmogorov network that uses partial least squares regression to learn the network weights [
64].
6. Discussion
At its core, our work reinforces Kolmogorov’s profound insight, that is, there are no true multivariate problems, only superpositions of univariate affine ones. This principle guides our approach to efficiently decomposing complex multivariate functions into simpler univariate components through the Köppen transformation. The results demonstrate that while K-GAM can effectively model both real (iris) and simulated data, the internal representations it learns may be more complex than traditional GAM approaches. The approach appears particularly effective at capturing nonlinear patterns, although the interpretability of individual feature effects becomes more challenging due to the Köppen function transformation. Importantly, the K-GAM approach requires significantly fewer parameters compared to standard GAMs, as it leverages a shared embedding space through the Köppen function and can capture nonlinear relationships without requiring explicit interaction terms. However, most of the research since 2010 has been about increasing the depth of the networks and not about the width of the networks. The K-GAM approach is a step forward in the direction of increasing the width of the networks. The difference is that the Kolmogorov architecture is based on non-smooth functions, while the deep learning architecture is based on the composition of smooth functions. As shown by [
65], it is impossible to obtain a universal approximation using a two-layer architecture with smooth functions.
Our findings suggest several promising directions for future research across both theoretical and practical domains. One priority involves the enhancement of the scalability of KST-based approaches, along with the characterization of the function classes for which K-GAM performs optimally over existing alternatives. Given K-GAM’s parameter efficiency, exploring Bayesian learning methods could provide principled approaches to uncertainty quantification and model regularization. An important optimization for K-GAM would be a specialized optimization algorithm capable of handling the discontinuities inherent in the Köppen function and the development of an efficient training algorithm specifically designed for high-dimensional problems.
These findings suggest that K-GAM networks represent a promising direction for efficient function approximation, particularly in scenarios where traditional deep learning approaches may be computationally intractable or parameter-inefficient. The combination of theoretical guarantees from Kolmogorov’s superposition theorem with modern machine learning techniques opens new avenues for both theoretical research and practical applications.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}