2.1. Cross-Distribution of Works Based on Genetic Algorithms
When constructing the cross-distribution model for works, it is necessary to maximize the overlap of reviewed works between every pair of experts while ensuring that the number of works assigned to each expert and the degree of overlap remain relatively balanced. From an information-theoretic standpoint, the cross-distribution scheme can be viewed as a process of maximizing the information entropy of review coverage while maintaining controlled overlap among reviewers. Entropy, a fundamental concept in information theory, quantifies the uncertainty or diversity of a system. In this context, a higher entropy value in the review distribution implies greater diversity in reviewer combinations across submissions, which enhances the robustness of evaluation and mitigates the bias caused by reviewer-specific tendencies. Mathematically, the entropy
H of the distribution of submissions among reviewers can be expressed as:
where
denotes the probability that reviewer
i reviews submission
k, derived from the binary matrix
. Maximizing this entropy, subject to workload balance and overlap constraints, helps ensure an optimal review assignment that captures a broad spectrum of perspectives.
Based on these requirements, we developed a cross-distribution model for works and employed a genetic algorithm to solve for the optimal distribution scheme.
2.1.1. Model for Cross-Distribution of Works
Let
m be the total number of participating teams in the competition, where each team is allowed to submit only one entry. The entries are numbered from 1 to
m. The competition is evaluated by
n judges, each identified by a unique number from 1 to
n. Each entry is assessed by a subset of
t judges who provide their scores. The cross-distribution model for entries is established as follows:
where
or 1, with
indicating that the
k-th entry is reviewed by the
i-th judge; otherwise,
.
and
represent the maximum and minimum number of reviews assigned to judge
i, respectively.
denotes the number of entries assigned to both judges
i and
j.
represents the constraint on the number of entries reviewed by judge
i. By adjusting the values of
and
, the workload among judges can be balanced as evenly as possible.
ensures that each entry is reviewed by exactly
t judges.
denotes the number of entries assigned to both judges
i and
j, expressed as
. Here,
or 1, where
indicates that judge
i reviews entry
k. If
, then
, meaning that entry
k is reviewed by both judges
i and
j; otherwise,
.
2.1.2. Genetic Algorithm Based Cross-Distribution Scheme Solution for Works
We employ a genetic algorithm to solve the work crossover distribution problem. The workflow of the Algorithm 1 is as follows:
| Algorithm 1: Cross-Distribution Algorithm-Based on Genetic Algorithm |
![Entropy 27 00591 i001]() |
2.2. Score Adjustment Model
In current peer review processes, ranking methods based on standardized scores (Z-scores) are commonly employed. These methods rest on the assumption that the distribution of academic quality is consistent across the sets of submissions evaluated by different reviewers. However, in large-scale innovation competitions, each submission is typically reviewed by only a small number of experts, and there is limited overlap between the works assessed by any two reviewers. Consequently, each expert evaluates only a small subset of the total submissions, and the assumption of a uniform distribution of academic quality may no longer hold. This limitation calls for the development of alternative evaluation models.
In this section, we focus on the review process for large-scale innovation competitions and propose a modified Z-score model, building upon the conventional standardization approach. Furthermore, considering that the final ranking of first-prize submissions in the second stage of evaluation is achieved through expert consensus, we leverage this information to develop the Z-score Pro model. To assess the effectiveness of the proposed methods, we also introduce four evaluation metrics.
2.2.1. Z-Score Model
Z-score, also known as the standard score or zero-mean normalization, is a widely used statistical tool for representing the distance or deviation of an observation or data point from the mean. Expressed in units of standard deviation, it reflects how far a given score deviates from the average in a relative and standardized manner.
To compute a Z-score, the difference between the raw data point and the mean is divided by the standard deviation. This calculation yields a Z-score that quantifies the distance of a specific score from the mean, measured in standard deviation units. The specific procedure is as follows:
- (1)
For a given reviewer, let the assigned scores be represented by a set of n samples: .
- (2)
The sample mean of the scores given by this reviewer is calculated as:
- (3)
The sample standard deviation of the reviewer’s scores is given by:
- (4)
The Z-score is then computed as:
In Equation (
6), the constants 50 and 10 control the mean and amplitude of the standardized scores, respectively. Since this standardization formula is predefined and adopted in the original problem, we do not further discuss the rationale behind the selection of these specific values. To ensure the comparability between our proposed model and the original standardization method, we retain the use of these two constants in the subsequent modeling process.
The final score of submissions that participate only in the first-stage review is calculated as the average of the standardized scores assigned by five reviewers. Submissions are then ranked based on this average. For submissions that undergo both the first and second stages of review, the final score consists of two parts: (1) the average of the standardized scores from the first-stage review, and (2) the sum of three standardized scores derived from the raw scores given by three reviewers in the second-stage review, after appropriate adjustments. The final ranking for these submissions is determined based on the combined score from both stages.
2.2.2. Modified Z-Score Model
In scoring systems, entropy can be used to measure the dispersion and uncertainty of the score distributions across submissions. Before standardization, raw scores typically exhibit varying ranges and biases among reviewers. The Z-score model implicitly reduces entropy by normalizing scores to a common distribution, which facilitates comparability but may lead to information loss—especially when outlier scores reflect meaningful expert judgments.
Given a set of scores
,
, …,
from a reviewer, the normalized Shannon entropy is given by:
where
is the empirical probability of score level
j. High entropy indicates high diversity in scoring, while low entropy suggests convergence or bias. By comparing entropy levels before and after normalization, we can quantify the extent to which the standardization process simplifies (or distorts) the underlying evaluation signal.
To objectively determine which scores qualify as extreme and require adjustment, we apply the interquartile range (IQR) method. Specifically, any score that falls below or above , where , is identified as an outlier. This statistical rule ensures that the adjustment process is data-driven and minimizes subjective threshold selection.
However, the traditional Z-score method has several limitations. First, the calculation of Z-scores requires knowledge of the population mean and variance, which are often difficult to obtain in real-world analysis and data mining scenarios. In most cases, the sample mean and standard deviation are used as substitutes. Second, the Z-score method assumes certain characteristics of the data distribution, with normal distribution being the most favorable condition for its application. Third, the Z-score transformation removes the original meaning of the data. The Z-scores of items A and B are no longer directly related to their original scores. As a result, Z-scores are only useful for relative comparison between data points, while the actual values must be recovered to interpret the real-world meaning. Moreover, both the mean and standard deviation are sensitive to outliers, which may distort the standardized results and compromise the balance of feature scaling. To address these issues, we propose a modified Z-score method that reduces the sensitivity to outliers and minimizes potential distortions.
To overcome the sensitivity of the traditional Z-score method to the mean and standard deviation, and to prevent large deviations caused by outliers, we propose a modified Z-score method. The general form of the modified Z-score method is defined as:
where
represents the sample score,
is the median of all sample observations, and
(Median Absolute Deviation) is defined as:
The standard deviation is based on the sum of squared distances from the mean, making it highly sensitive to outliers. For example, a large sample value within the dataset directly affects the standard deviation. In contrast, remains unaffected by such extreme values, offering better robustness.
In this paper, the formula for the modified Z-score model is specified as:
2.2.3. Z-Score Pro Model
The modified Z-score method reduces the influence of outliers on the results, but it is essentially the same as the traditional standard score model. Both methods use statistical measures from the sample data to fit the original scores, aiming to approximate a reasonable distribution. This approach is quite reasonable for general cases; however, when applied to large-scale innovation competitions, it overlooks an important factor—the range (or “extreme values”). The size of the range is non-linearly related to the creativity of the submissions. Therefore, by incorporating the ranking of first-prize submissions, which was determined through expert consensus, we propose an improvement to the modified Z-score method, leading to the introduction of the Z-score Pro model.
In this study, the second stage of review involves three experts evaluating the submissions. The standardized scores are calculated for each submission, and necessary adjustments are made for those with large ranges. Then, the average of the five experts’ standardized scores from the first stage and the three experts’ standardized scores from the second stage are summed. The final ranking is determined based on this total score, as follows:
- (1)
For submissions with small ranges that were not re-evaluated, the total score is:
where
represents the final total score,
is the average of the first stage standardized scores for submission
i from five experts, and
represents the standardized score for submission
i given by the
q-th expert in the second stage.
- (2)
For submissions with large ranges that were re-evaluated, the total score is:
where
represents the final total score,
is the average of the first stage standardized scores for submission
i, and
represents the re-evaluated score for submission
i from the
q-th expert in the second stage.
The total score using the modified Z-score method is calculated by summing the average of the first stage standardized Z-scores from five experts, and the standardized Z-scores from three experts in the second stage, as follows:
where
represents the total score using the modified Z-score method,
is the average of the first stage standardized Z-scores for submission
i, and
represents the standardized Z-score for submission
i given by the
q-th expert in the second stage.
For the first-prize submissions, the rankings are determined by expert consensus and considered as precise data. Using data from 27 first-prize submissions, the impact of the range on the rankings is considered, and a quadratic function fitting is applied to improve the model. The procedure is as follows:
- (1)
Compute the difference:
where
C represents the difference between the adjusted score (
) and the modified Z-score-based score (
).
- (2)
To capture the non-linear effect of score range
R on this deviation, we performed a curve fitting procedure using multiple candidate models, including linear, logarithmic, exponential, and polynomial functions. Among them, the quadratic function exhibited the best balance between fit accuracy and interpretability. Specifically, it achieved the highest
value (0.87) and showed clear parabolic characteristics in the residual distribution, whereas other forms either underfit the data or produced unstable coefficients. Therefore, we fit the deviation
C to a quadratic function of the range
R, yielding the parameters
m,
n, and
o:
The calculated values are , , and . This quadratic form reflects the observation that extremely low or high ranges have non-proportional effects on ranking bias, aligning with the empirical distribution of creative submission scores.
- (3)
The formula for calculating the Z-score Pro score is:
where
is the Z-score Pro score,
is the sample score,
is the median of all sample observations,
is the Median Absolute Deviation, and
is the range of submission
i.
- (4)
The final total score using the Z-score Pro method is calculated by summing the average of the Z-score Pro scores from five experts in the first stage and the Z-score Pro scores from three experts in the second stage, as follows:
where
represents the final total score using the Z-score Pro method,
is the average of the Z-score Pro scores from five experts in the first-stage, and
represents the Z-score Pro score for submission
i given by the
q-th expert in the second stage.
The Z-score Pro model relies on standardized scores derived from the mean and standard deviation of each evaluator’s score set. A constant value of 50 is used in the model because it is specifically designed for a 0–100 scoring range. If different scoring scales are used, the scores can be normalized to the [0, 100] interval through a standard normalization process, enabling the model to remain applicable across various evaluation settings.
2.2.4. Evaluation Metrics
To reflect the relative advantages of each method, this study designs four evaluation metrics based on information-theoretic principles. In decision-making and evaluation systems, the core ideas of information theory can be employed to quantify uncertainty, divergence, and consistency among outcomes. Especially in contexts involving rankings or judgments, analyzing the informational differences between various ranking results allows for a more objective and nuanced assessment of how a given ranking deviates from a reference standard.
Given that the scores in the second stage were obtained after experts’ careful deliberation and reassessment, they are regarded as accurate and reliable. Therefore, in designing the evaluation metrics, we focus exclusively on the degree of deviation from these standard results, rather than assessing the methods in isolation.
- (1)
Overlap Degree: The number of instances where the subjective and objective rankings match is called the overlap degree, denoted as C.
- (2)
Disorder Degree: The sum of the absolute differences between the subjective and objective rankings is called the disorder degree. Denoted as
D, it is calculated as:
where
represents the subjective ranking of submission
i, and
represents the objective ranking of submission
i.
- (3)
Divergence Degree: The Divergence degree between the two rankings is defined as:
where
and
represent the rankings of submission
i in the two different ranking methods.
- (4)
Award Change Degree: This refers to the number of submissions that were awarded under the original scheme but would not be awarded under the new scheme.
To examine whether the proposed evaluation metrics—Overlap Degree, Disorder Degree, Divergence Degree, and Award Change Degree—can effectively reflect the rationality and stability of final rankings, we conducted a correlation analysis using a reference ranking constructed through the Borda count method based on consensus scores.For each experimental run, we calculated the Kendall’s Tau distance between the model-generated ranking and the reference ranking, treating it as an indicator of ranking deviation in
Table 1.
The results show strong correlations between the evaluation metrics and ranking deviation. Specifically, higher overlap and lower disorder or divergence tend to indicate a closer alignment with the reference ranking. This validates the effectiveness of these metrics in assessing the fairness and rationality of the evaluation outcome.
2.3. A Range-Based Programmable Model Based on BP Neural Network
The defining feature of innovation-oriented competitions lies in their emphasis on creativity and the absence of standard answers. Due to the high complexity of the problems posed in such competitions, participants are generally required to propose innovative solutions to make partial progress within the competition timeframe. However, the extent of innovation demonstrated by a given submission, as well as its potential for future research, is often subject to divergent opinions. Even face-to-face discussions among experts may fail to reach consensus, as evaluators tend to hold differing perspectives. This divergence is further exacerbated by graduate students’ limited ability to articulate their work clearly and the varying evaluation criteria adopted by different judges. As a result, substantial discrepancies frequently emerge in the scores assigned to the same project by different experts.
The range, defined as the difference between the highest and lowest scores assigned to a single submission within the same evaluation stage, is a typical characteristic of large-scale innovation competitions. Submissions with large scoring ranges are often found at the upper or lower ends of the overall score spectrum. To explore the relationship between score range and innovativeness, and to identify truly innovative works among those with significant scoring discrepancies, this study introduces a programmable range model based on a BP neural network. The model is designed to address ranking optimization problems based on expert scoring data and is particularly well-suited for scenarios in which submissions in the middle-score range exhibit substantial score variability or lack evaluative consensus.
2.3.1. Requirements for Constructing the Programmable Range Model
The development of the programmable range model is guided by two key requirements. First, the model should be capable of categorizing submissions based on expert scores from the initial evaluation stage. Specifically, it should be able to identify submissions with large scoring ranges and classify them accordingly. Second, the model must enable programmable processing of these categorized high-range submissions, such that adjustments can be made to their scores based on a consistent set of principles.
The overall modeling approach involves training a neural network using data obtained from the second-stage expert reassessment. By learning the relationship between standardized scores and reassessed scores in the second stage, the model captures how scores assigned by outlier experts relate to both the mean standardized score and the final reassessed score. This learned relationship is then applied to adjust the outlier expert scores from the first evaluation stage in a systematic and automated manner.
2.3.2. The Programmable Range Model
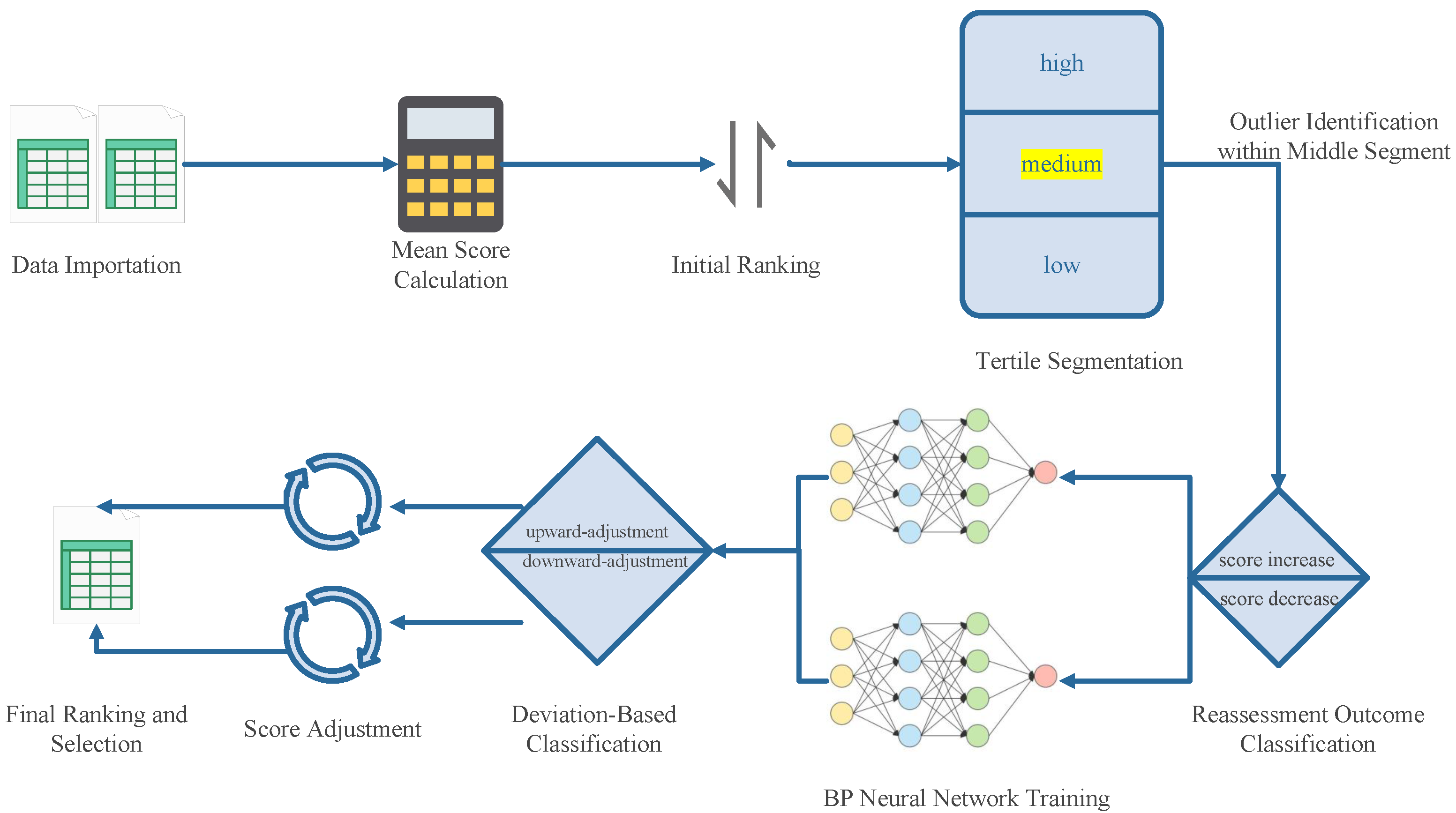
The flowchart of the Programmable Range Model is shown in
Figure 1, and the specific steps are as follows:
Step 1: Data Importation: Load the expert scoring data, including standardized or raw scores, along with corresponding identifiers for works and reviewers.
Step 2: Mean Score Calculation: For each work, calculate the average standardized score across all experts, which serves as the basis for initial ranking.
Step 3: Initial Ranking: Rank all works based on their average scores in descending order.
Step 4: Tertile Segmentation: Divide the ranked works into three segments: high, middle, and low. The proportion of each segment can be customized, e.g., top 15% as high, middle 50% as medium, and bottom 35% as low.
Step 5: Outlier Identification within Middle Segment: For each work in the middle segment, compute the score range (maximum minus minimum expert score). Define a range threshold and identify works with as range-outlier candidates for further reevaluation.
Step 6: Reassessment Outcome Classification: Categorize range-outlier candidates into two groups based on changes in their reassessed scores: score increase and score decrease.
Step 7: BP Neural Network Training: For each of the two categories (upward and downward adjustment), a separate BP neural network is trained. The independent variables include the five standardized scores provided by the experts and their mean, while the dependent variable is the re-evaluated score obtained from the second-round review. This design aims to capture the latent non-linear mapping between expert judgments and revised outcomes.
To examine the adjustment mechanism in middle-segment works with inconsistent evaluations, the data is imported into MATLAB’s Neural Network Toolbox. The dataset is randomly split into 70% for training, 15% for validation, and 15% for testing. The number of neurons in the hidden layer is set to 10, a value determined empirically through iterative testing and validation performance. This configuration ensures sufficient model capacity without overfitting, which is crucial given the moderate size of the reassessment dataset.
The training algorithm employed is the Quantized Conjugate Gradient (QCG) method, selected for its robustness and efficiency in handling regression tasks with relatively small sample sizes. The tanh activation function is used in the hidden layer to provide smooth, non-linear transformations, while a linear activation function is applied in the output layer to accommodate the continuous nature of the scoring outcome. This architecture enables the network to approximate the re-evaluation function effectively while maintaining stability and generalizability.
Step 8: Deviation-Based Classification: For each range-outlier candidate, calculate the absolute deviation of each expert’s score from the mean . Identify the expert with the largest deviation. If this expert’s score is higher than the mean, the work is classified as a downward-adjustment case; otherwise, it is classified as an upward-adjustment case.
Step 9: Score Adjustment: Use the trained BP neural networks to adjust the most deviant expert score for each candidate. Apply the score-decrease network to downward-adjustment cases and the score-increase network to upward-adjustment cases to generate revised scores.
Step 10: Final Ranking and Selection: Re-rank all works based on their adjusted scores and select a subset for advancement to the next evaluation stage according to predefined criteria.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}