


Towards Identifying Objectivity in Short Informal Text


Abstract
1. Introduction
- This work originally formalizes objectivity detection as a distinct task tailored to the challenges of informal language. Meanwhile, we systematically analyze textual objectivity in platforms like social media and instant messaging.
- We propose a rule-based UVO (subject–predicate–object) quantification framework, which integrates syntactic analysis, tense detection via POS tagging with large-language-model-augmented triple extraction.
- Our two-stage framework synergizes OpenIE, LLMs, and fine-tuned pre-trained encoders. We mitigate hallucination risks inherent in LLMs by decoupling interpretable triple extraction from neural classification via rule-based and LLM voting while preserving input integrity.
- We rigorously evaluate our method across three benchmark datasets and achieve up to 6.97% accuracy improvements over baseline models. The insights revealed in our work provide actionable guidelines for domain-specific adaptation of objectivity detection systems.
2. Related Works
2.1. Early Objectivity Identification
2.2. Objectivity Identification via Artificial Intelligence
2.3. Objectivity in Informal Short Texts
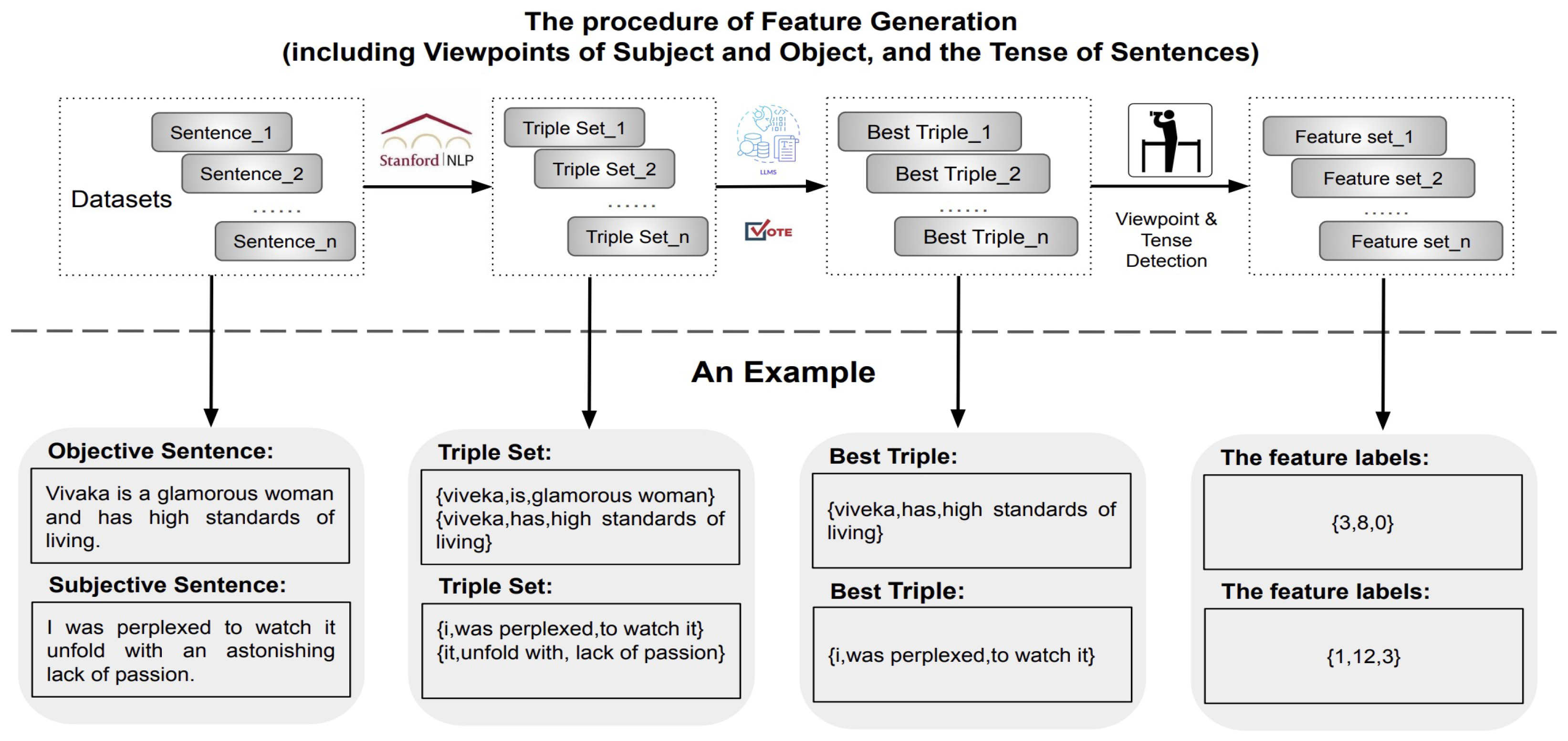
3. Feature Extraction and Quantification
3.1. Implementation Overview
3.2. The Detection of Viewpoints and Tense
3.3. Tense Detection
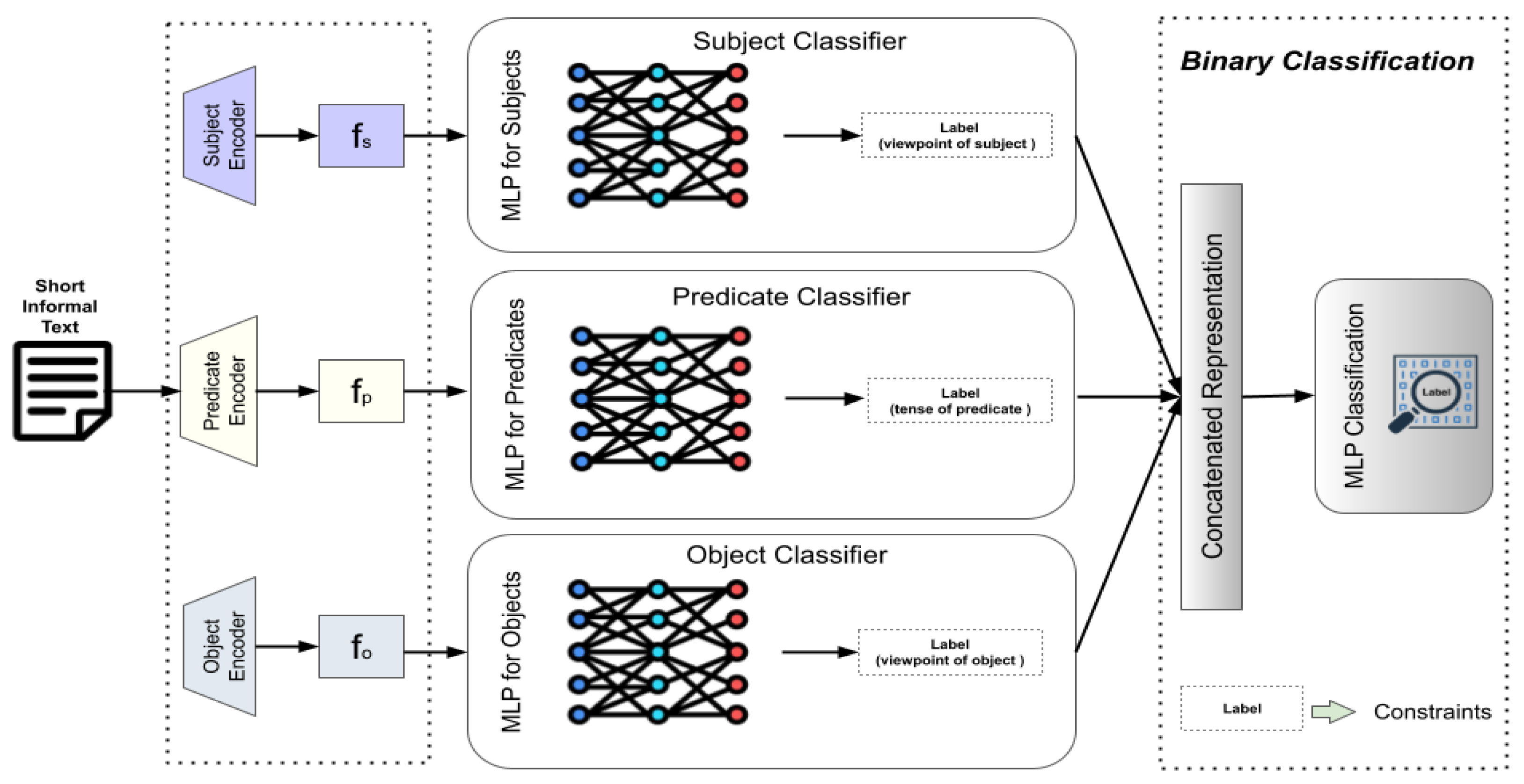
4. System Framework
4.1. Text Representation
4.2. Triple-Feature Learning
4.3. Binary Classification
5. Experimental Results
5.1. Experimental Configurations
- BERT, a bidirectional transformer-based model developed by Google, which is pre-trained using masked language modeling (MLM) and next sentence prediction (NSP) tasks. BERT can read an input sequence from two sides to capture deep contextual information, which allows it to be adaptable for our tasks.
- RoBERTa is developed by Facebook AI, which is an optimized variant of BERT. It removes the next sentence prediction (NSP) task, uses dynamic masking, and is trained on much larger datasets for more epochs than BERT.
- BART is a transformer model also developed by Facebook AI that combines BERT’s bidirectional encoding coupled with GPT’s autoregressive decoding. Its encoder–decoder architecture makes it versatile for both natural language comprehension and generation.
- T5, developed by Google, is a unified framework that can convert NLP tasks into a text-to-text problem. It uses a transformer-based encoder–decoder architecture to handle diverse tasks. Its text-to-text approach simplifies task design and has achieved strong performance across a variety of benchmarks.
- GPT-2, developed by OpenAI, is a large-scale transformer-based language model trained on a massive corpus of internet text in an unsupervised manner. Unlike encoder–decoder frameworks, GPT-2 uses a unidirectional decoder-only architecture, generating text by predicting the next word in a sequence.
5.2. The First Group Experiment
- Training Efficiency Improvement: In all datasets, the addition of UVO features consistently reduces the training loss as well as yields better training accuracy across all models, which suggests that these features help the models converge better and capture the structure of the data more effectively. In particular, the Bert + UVO model shows the largest reduction in training loss on the Movie dataset, which decreased by 36.69% compared with the base Bert model. Moreover, the Bert + UVO model demonstrated the highest increase in training accuracy percentage increment (6.65%) compared with the corresponding base model on the SST dataset. Notably, even for the GPT2 model—which generally shows higher training loss and lower accuracy compared to other models—the addition of UVO features reduces the training loss significantly across all datasets. For example, in the Movie dataset, the training loss decreased from 0.565 to 0.503, while training accuracy improved from 0.684 to 0.731, indicating better convergence due to the structural cues provided by UVO.
- Better Generalization on Testing Phase: For all the base pre-trained models, UVO features can help them to achieve both better testing loss and accuracy, which reflects the better generalization capabilities of UVO triple features. This improvement signifies that the UVO-added base models are not overfitting to the training data but learning meaningful patterns that transfer well to the test data. For example, the above-mentioned Bert + UVO model on the Movie dataset also can reduce the testing loss by 1.1% and enhance the testing accuracy by 0.8% under the promise of effective training progress. It is noteworthy that the most significant reduction in testing loss (i.e., 16.18%) is from the UVO-added Bert model on the SST dataset compared with the Bert-only, and the UVO-added Bert model also produces the best testing accuracy improvement (i.e., 4.03%) while tested on the SST dataset. In addition, GPT2 models also exhibit consistent improvements in generalization: on the SST dataset, testing loss decreased from 0.538 to 0.460 and test accuracy increased from 0.784 to 0.811 with UVO. A similar trend is observed on the Twitter dataset, where testing accuracy rose from 0.808 to 0.811 and testing loss slightly reduced, demonstrating that GPT2 also benefits from UVO in learning transferable patterns.
- Efficient Objectivity Identification: UVO features consistently improve the Obj-F1 score across all datasets and models, demonstrating that the inclusion of the triple features helps all the base models handle objective information better by focusing on syntactic roles (viewpoints of subjects, tenses of predicates, and viewpoints of objects). For instance, the T5 + UVO model achieves an Obj-F1 of 0.956 on the Movie dataset and 0.926 on the Twitter dataset. Similarly, GPT2 + UVO shows marked improvement over the baseline GPT2 in Obj-F1 scores: from 0.727 to 0.735 (+0.8%) on Movie, from 0.873 to 0.896 (+2.3%) on SST, and from 0.880 to 0.894 (+1.4%) on Twitter, reinforcing the conclusion that UVO helps even relatively weaker baselines like GPT2 to better capture objectivity.
5.3. The Ablation Study
- In the Movie dataset, the viewpoint of subjects (i.e., U) can supply better improvement to the performance in terms of five metrics across all of the base pre-trained models compared with the other two features—the tense of predicates and the viewpoint of objects (i.e., Bert + U achieves the best performance—0.095 training loss, 0.97 training accuracy, 0.102 testing loss, 0.968 testing accuracy, and 0.966 F1 score in objective). Such a phenomenon reflects that the viewpoint of object (O) and the tense of predicate (V) might be less influential than the subject’s perspective in movie reviews. While the viewpoint of objects and the tense of movie reviews are important, they are secondary to how the reviewer personally feels and expresses those feelings. Since the subject’s expression of opinion is critical in movie reviews, its viewpoint allows the model to focus more on this subjective lens, which is key for improving generalization in objectivity detection.
- It is observable from the results yielded from the SST dataset that the tense of predicates (i.e., V) promotes the base models with the relatively best performance in perspectives of all five metrics compared with the viewpoints of subjects and objects. That means, in the SST dataset, the tense of predicates is a major clue in determining whether the content is a personal opinion or a more neutral statement of fact. More insightful, since SST data consists of shorter texts, and other contextual information is sparse, the verbs carry a significant proportion of the determination in helping the model to identify objectivity.
- For the Twitter dataset, various pre-trained base models yield relatively unstable performance compared with the experiment results on the other two datasets. However, the viewpoint of subjects (U) still plays the most important role in distinguishing objective texts. Specifically, the different performance of fine-tuning pre-trained models on the Twitter dataset when applying the U, V, or O constraints reflects their architectural differences and varying pretraining objectives. Models like RoBERTa excel in short-text, informal settings like Twitter due to their fine-tuned contextual embeddings, yet BART performs better at tasks involving sequence structure (e.g., tense or object viewpoint detection). It is crucial to understand the differences between models or datasets to detect objectivity in short informal text.
- In the Movie dataset, combinations of two features—especially U+V and U+O—tend to slightly improve performance compared to using a single constraint. For example, BERT with U+O achieves 0.098 Tr-Loss, 0.969 Tr-Acc, 0.118 Te-Loss, 0.964 Te-Acc, and 0.966 Obj-F1, nearly matching the best single-feature result (BERT+U). This suggests that while subject viewpoint (U) is dominant, integrating it with either tense (V) or object viewpoint (O) can reinforce semantic grounding. However, the marginal improvement indicates that most of the predictive strength still lies in the subject’s viewpoint, highlighting the expressive nature of movie reviews.
- For SST, the dual-feature combinations V+O and U+V perform slightly better than single features for some models. For instance, RoBERTa with V+O yields a Te-Acc of 0.824 and Obj-F1 of 0.903, higher than U or O alone. This reinforces the earlier observation that verb tense (V) carries the most semantic weight in the SST dataset, and when enhanced with object viewpoint (O), the contextual understanding is deepened. Since SST texts are short and less informative, having both predicate tense and object perspectives can aid in identifying subtle subjectivity markers.>
- In Twitter, U+V and U+O combinations generally outperform other pairs or single features. For example, T5 with U+O achieves 0.821 Tr-Acc and 0.915 Obj-F1, higher than V+O. These results imply that in short and informal texts like tweets, integrating subject viewpoint (U) with an additional semantic constraint (V or O) enhances model robustness. However, due to noise and structural variation in tweets, improvements remain dataset- and model-dependent.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Laureate, C.D.P.; Buntine, W.; Linger, H. A systematic review of the use of topic models for short text social media analysis. Artif. Intell. Rev. 2023, 56, 14223–14255. [Google Scholar] [CrossRef]
- Tommasel, A.; Godoy, D. Short-text feature construction and selection in social media data: A survey. Artif. Intell. Rev. 2018, 49, 301–338. [Google Scholar] [CrossRef]
- Wuraola, I.; Dethlefs, N.; Marciniak, D. Understanding Slang with LLMs: Modelling Cross-Cultural Nuances through Paraphrasing. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 15525–15531. [Google Scholar]
- Liu, J.; Tian, X.; Tong, H.; Xie, C.; Ruan, T.; Cong, L.; Wu, B.; Wang, H. Enhancing Chinese abbreviation prediction with LLM generation and contrastive evaluation. Inf. Process. Manag. 2024, 61, 103768. [Google Scholar] [CrossRef]
- Qiu, Z.; Qiu, K.; Lyu, H.; Xiong, W.; Luo, J. Semantics Preserving Emoji Recommendation with Large Language Models. In Proceedings of the 2024 IEEE International Conference on Big Data (BigData), Washington, DC, USA, 15–18 December 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 7131–7140. [Google Scholar]
- Yadav, A.; Garg, T.; Klemen, M.; Ulcar, M.; Agarwal, B.; Robnik-Sikonja, M. From Translation to Generative LLMs: Classification of Code-Mixed Affective Tasks. IEEE Trans. Affect. Comput. 2025. [Google Scholar] [CrossRef]
- Kamath, G.; Schuster, S.; Vajjala, S.; Reddy, S. Scope ambiguities in large language models. Trans. Assoc. Comput. Linguist. 2024, 12, 738–754. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Sachdeva, B.; Rathee, H.; Tiwari, N. Role of social media in causing and mitigating disasters. Int. J. Resil. Fire Saf. Disasters 2021, 1, 52–58. [Google Scholar]
- Fersini, E.; Messina, E.; Pozzi, F.A. Expressive signals in social media languages to improve polarity detection. Inf. Process. Manag. 2016, 52, 20–35. [Google Scholar] [CrossRef]
- Lawrie, D.; Mayfield, J.; Oard, D.W.; Yang, E.; Nair, S.; Galuščáková, P. HC3: A suite of test collections for CLIR evaluation over informal text. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taipei, Taiwan, 23–27 July 2023; pp. 2880–2889. [Google Scholar]
- Alhussain, A.I.; Azmi, A.M. Automatic story generation: A survey of approaches. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Chenlo, J.M.; Losada, D.E. An empirical study of sentence features for subjectivity and polarity classification. Inf. Sci. 2014, 280, 275–288. [Google Scholar] [CrossRef]
- Wankhade, M.; Rao, A.C.S.; Kulkarni, C. A survey on sentiment analysis methods, applications, and challenges. Artif. Intell. Rev. 2022, 55, 5731–5780. [Google Scholar] [CrossRef]
- Küçük, D.; Can, F. Stance detection: A survey. ACM Comput. Surv. 2020, 53, 1–37. [Google Scholar] [CrossRef]
- Bekoulis, G.; Papagiannopoulou, C.; Deligiannis, N. A review on fact extraction and verification. ACM Comput. Surv. 2021, 55, 1–35. [Google Scholar] [CrossRef]
- Miao, Z.; Li, Y.; Wang, X.; Tan, W.C. Snippext: Semi-supervised opinion mining with augmented data. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 617–628. [Google Scholar]
- Biber, D. Variation Across Speech and Writing; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar]
- Udochukwu, O.; He, Y. A rule-based approach to implicit emotion detection in text. In Proceedings of the Natural Language Processing and Information Systems: 20th International Conference on Applications of Natural Language to Information Systems, NLDB 2015, Passau, Germany, 17–19 June 2015; Proceedings 20. Springer: Berlin/Heidelberg, Germany, 2015; pp. 197–203. [Google Scholar]
- Abirami, M.; Uma, M.; Prakash, M. Sentiment analysis of informal text using a Rule based Model. J. Chem. Pharm. Sci. 2016, 9, 2854–2858. [Google Scholar]
- Androutsopoulos, J. From variation to heteroglossia in the study of computer-mediated discourse. In Digital Discourse: Language in the New Media; Oxford University Press: Oxford, UK, 2011; pp. 277–298. [Google Scholar]
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 216–225. [Google Scholar]
- Zhuang, W.; Zeng, Q.; Zhang, Y.; Liu, C.; Fan, W. What makes user-generated content more helpful on social media platforms? Insights from creator interactivity perspective. Inf. Process. Manag. 2023, 60, 103201. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, W.; Wang, Y. Hot Technology Analysis Method Based on Text Mining and Social Networks. In Proceedings of the 2023 4th International Conference on Machine Learning and Computer Application, Hangzhou, China, 27–29 October 2023; pp. 161–167. [Google Scholar]
- Guo, Z.; Schlichtkrull, M.; Vlachos, A. A survey on automated fact-checking. Trans. Assoc. Comput. Linguist. 2022, 10, 178–206. [Google Scholar] [CrossRef]
- Soprano, M.; Roitero, K.; La Barbera, D.; Ceolin, D.; Spina, D.; Demartini, G.; Mizzaro, S. Cognitive Biases in Fact-Checking and Their Countermeasures: A Review. Inf. Process. Manag. 2024, 61, 103672. [Google Scholar] [CrossRef]
- Augenstein, I.; Baldwin, T.; Cha, M.; Chakraborty, T.; Ciampaglia, G.L.; Corney, D.; DiResta, R.; Ferrara, E.; Hale, S.; Halevy, A.; et al. Factuality challenges in the era of large language models and opportunities for fact-checking. Nat. Mach. Intell. 2024, 6, 852–863. [Google Scholar] [CrossRef]
- Liu, B.; Li, C.; Zhou, W.; Ji, F.; Duan, Y.; Chen, H. An attention-based deep relevance model for few-shot document filtering. ACM Trans. Inf. Syst. 2020, 39, 1–35. [Google Scholar] [CrossRef]
- Liu, K.; Wang, Z.; Yang, Y.; Huang, C.; Niu, M.; Lu, Q. Hierarchical Diachronic Embedding of Knowledge Graph Combined with Fragmentary Information Filtering. In Proceedings of the International Conference on Artificial Neural Networks, Heraklion, Greece, 26–29 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 435–446. [Google Scholar]
- Fields, J.; Chovanec, K.; Madiraju, P. A survey of text classification with transformers: How wide? How large? How long? How accurate? How expensive? How safe? IEEE Access 2024, 12, 6518–6531. [Google Scholar] [CrossRef]
- Taha, K.; Yoo, P.D.; Yeun, C.; Homouz, D.; Taha, A. A comprehensive survey of text classification techniques and their research applications: Observational and experimental insights. Comput. Sci. Rev. 2024, 54, 100664. [Google Scholar] [CrossRef]
- Ren, F.; Zhang, L.; Zhao, X.; Yin, S.; Liu, S.; Li, B. A simple but effective bidirectional framework for relational triple extraction. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 824–832. [Google Scholar]
- Rosso, P.; Yang, D.; Cudré-Mauroux, P. Beyond triplets: Hyper-relational knowledge graph embedding for link prediction. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1885–1896. [Google Scholar]
- Zhao, Y.; Zhou, H.; Zhang, A.; Xie, R.; Li, Q.; Zhuang, F. Connecting embeddings based on multiplex relational graph attention networks for knowledge graph entity typing. IEEE Trans. Knowl. Data Eng. 2022, 35, 4608–4620. [Google Scholar] [CrossRef]
- Li, P.; Wang, X.; Liang, H.; Zhang, S.; Zhang, Y.; Jiang, Y.; Tang, Y. A fuzzy semantic representation and reasoning model for multiple associative predicates in knowledge graph. Inf. Sci. 2022, 599, 208–230. [Google Scholar] [CrossRef]
- González, W.J. Semantics of science and theory of reference: An analysis of the role of language in basic science and applied science. In Language and Scientific Research; Springer: Berlin/Heidelberg, Germany, 2021; pp. 41–91. [Google Scholar]
- Rodrigo-Ginés, F.J.; Carrillo-de Albornoz, J.; Plaza, L. A systematic review on media bias detection: What is media bias, how it is expressed, and how to detect it. Expert Syst. Appl. 2024, 237, 121641. [Google Scholar] [CrossRef]
- Wiebe, J.; Bruce, R.; O’Hara, T.P. Development and use of a gold-standard data set for subjectivity classifications. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics, College Park, MD, USA, 20–26 June 1999; pp. 246–253. [Google Scholar]
- Riloff, E.; Wiebe, J. Learning extraction patterns for subjective expressions. In Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, Sapporo, Japan, 11–12 July 2003; pp. 105–112. [Google Scholar]
- Wiebe, J.; Wilson, T.; Bruce, R.; Bell, M.; Martin, M. Learning subjective language. Comput. Linguist. 2004, 30, 277–308. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Liu, B.; Hu, M.; Cheng, J. Opinion observer: Analyzing and comparing opinions on the web. In Proceedings of the 14th International Conference on World Wide Web, Chiba, Japan, 10–14 May 2005; pp. 342–351. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Hu, H.; Liao, M.; Zhang, C.; Jing, Y. Text classification based recurrent neural network. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 652–655. [Google Scholar]
- Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Lewis, M. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Radford, A. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 27 May 2025).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Qasim, R.; Bangyal, W.H.; Alqarni, M.A.; Ali Almazroi, A. A Fine-Tuned BERT-Based Transfer Learning Approach for Text Classification. J. Healthc. Eng. 2022, 2022, 3498123. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Sun, X.; Li, X.; Li, J.; Wu, F.; Guo, S.; Zhang, T.; Wang, G. Text classification via large language models. arXiv 2023, arXiv:2305.08377. [Google Scholar]
- Tang, L.; Shalyminov, I.; Wong, A.W.m.; Burnsky, J.; Vincent, J.W.; Yang, Y.; Singh, S.; Feng, S.; Song, H.; Su, H.; et al. Tofueval: Evaluating hallucinations of llms on topic-focused dialogue summarization. arXiv 2024, arXiv:2402.13249. [Google Scholar]
- Laurenzi, E.; Mathys, A.; Martin, A. An LLM-Aided Enterprise Knowledge Graph (EKG) Engineering Process. Proc. AAAI Symp. Ser. 2024, 3, 148–156. [Google Scholar] [CrossRef]
- Zhang, K.; Choi, Y.; Song, Z.; He, T.; Wang, W.Y.; Li, L. Hire a linguist!: Learning endangered languages in LLMs with in-context linguistic descriptions. In Proceedings of the Findings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 15654–15669. [Google Scholar]
- Guo, R.; Xu, W.; Ritter, A. Meta-Tuning LLMs to Leverage Lexical Knowledge for Generalizable Language Style Understanding. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; pp. 13708–13731. [Google Scholar]
- Smith, G.; Fleisig, E.; Bossi, M.; Rustagi, I.; Yin, X. Standard Language Ideology in AI-Generated Language. arXiv 2024, arXiv:2406.08726. [Google Scholar]
- Song, G.; Ye, Y.; Du, X.; Huang, X.; Bie, S. Short text classification: A survey. J. Multimed. 2014, 9, 635–643. [Google Scholar] [CrossRef]
- Chen, M.; Jin, X.; Shen, D. Short text classification improved by learning multi-granularity topics. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Verdonck, T.; Baesens, B.; Óskarsdóttir, M.; van den Broucke, S. Special issue on feature engineering editorial. Mach. Learn. 2024, 113, 3917–3928. [Google Scholar] [CrossRef]
- Nayak, T.; Majumder, N.; Goyal, P.; Poria, S. Deep neural approaches to relation triplets extraction: A comprehensive survey. Cogn. Comput. 2021, 13, 1215–1232. [Google Scholar] [CrossRef]
- Zhang, C.; Gupta, A.; Kauten, C.; Deokar, A.V.; Qin, X. Detecting Fake News for Reducing Misinformation Risks Using Analytics Approaches. Eur. J. Oper. Res. 2019, 279, 1036–1052. [Google Scholar] [CrossRef]
- UzZaman, N.; Llorens, H.; Derczynski, L.; Allen, J.; Verhagen, M.; Pustejovsky, J. SemEval-2013 Task 1: TempEval-3: Evaluating Time Expressions, Events, and Temporal Relations. In Proceedings of the Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013), Atlanta, GA, USA, 13–14 June 2013; Manandhar, S., Yuret, D., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 1–9. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]

{kind=link}
{kind=link}
| text:{text} |
| triples:{triples} |
| Goal: Choose the best subject-predicate-object triples from the text. |
| Requirements 1: The output format should be: (subject, predicate, object). |
| Requirements 2: Do not rephrase the triples. |
| Requirements 3: Avoid excessive introduction or background description. |
| Tenses | POS Schemes | Example | Labels |
|---|---|---|---|
| Future Perfect Continuous | “MD” + “VB” + “VBN” + “VBG” | I will have been doing | 1 |
| Future Perfect | “MD” + “VB” + “VBN” | I will have done | 2 |
| Future Continuous | “MD” + “VB” + “VBG” | I will be doing | 3 |
| Future Simple | “MD” | I will do | 4 |
| Present Perfect Continuous | “VBD” + “VBN” + “VBG” | I have been doing | 5 |
| Present Perfect | “VBD” + “VBN” + “VBG” | I have done | 6 |
| Present Continuous | “VBD” + “VBN” | I am doing | 7 |
| Present Simple | “VBD” | I do | 8 |
| Past Perfect Continuous | “VBP”/“VBZ” + “VBN” + “VBG” | I had been doing | 9 |
| Past Perfect | “VBP”/“VBZ” + “VBN” | I had done | 10 |
| Past Continuous | “VBP”/“VBZ” + “VBG” | I was doing | 11 |
| Past Simple | “VBP”/“VBZ” | I did | 12 |
| Datasets | Methods | Tr-Loss | Tr-Acc | Te-Loss | Te-Acc | Obj-F1 |
|---|---|---|---|---|---|---|
| Movie | RoBERTa | 0.136 | 0.953 | 0.139 | 0.955 | 0.954 |
| RoBERTa + UVO | 0.101 | 0.966 | 0.129 | 0.963 | 0.962 | |
| Bert | 0.101 | 0.972 | 0.130 | 0.958 | 0.954 | |
| Bert + UVO | 0.086 | 0.975 | 0.117 | 0.965 | 0.963 | |
| Bart | 0.181 | 0.933 | 0.133 | 0.956 | 0.954 | |
| Bart + UVO | 0.167 | 0.934 | 0.121 | 0.961 | 0.961 | |
| T5 | 0.181 | 0.940 | 0.122 | 0.960 | 0.956 | |
| T5 + UVO | 0.152 | 0.946 | 0.119 | 0.960 | 0.956 | |
| GPT2 | 0.565 | 0.684 | 0.566 | 0.702 | 0.727 | |
| GPT2 + UVO | 0.503 | 0.731 | 0.565 | 0.705 | 0.735 | |
| SST | RoBERTa | 0.536 | 0.765 | 0.518 | 0.803 | 0.889 |
| RoBERTa + UVO | 0.498 | 0.809 | 0.486 | 0.812 | 0.898 | |
| Bert | 0.520 | 0.769 | 0.554 | 0.786 | 0.879 | |
| Bert + UVO | 0.450 | 0.816 | 0.464 | 0.817 | 0.898 | |
| Bart | 0.528 | 0.792 | 0.554 | 0.801 | 0.890 | |
| Bart + UVO | 0.511 | 0.792 | 0.491 | 0.815 | 0.897 | |
| T5 | 0.575 | 0.707 | 0.551 | 0.739 | 0.834 | |
| T5 + UVO | 0.461 | 0.809 | 0.499 | 0.809 | 0.893 | |
| GPT2 | 0.497 | 0.808 | 0.538 | 0.784 | 0.879 | |
| GPT2 + UVO | 0.478 | 0.820 | 0.493 | 0.811 | 0.896 | |
| RoBERTa | 0.344 | 0.874 | 0.353 | 0.871 | 0.921 | |
| RoBERTa + UVO | 0.282 | 0.887 | 0.318 | 0.872 | 0.922 | |
| Bert | 0.328 | 0.875 | 0.395 | 0.867 | 0.919 | |
| Bert + UVO | 0.252 | 0.902 | 0.343 | 0.866 | 0.919 | |
| Bart | 0.436 | 0.801 | 0.401 | 0.848 | 0.905 | |
| Bart + UVO | 0.359 | 0.840 | 0.334 | 0.863 | 0.916 | |
| T5 | 0.372 | 0.850 | 0.335 | 0.864 | 0.920 | |
| T5 + UVO | 0.329 | 0.860 | 0.302 | 0.874 | 0.926 | |
| GPT2 | 0.471 | 0.806 | 0.492 | 0.808 | 0.880 | |
| GPT2 + UVO | 0.440 | 0.817 | 0.460 | 0.811 | 0.894 |
| Datasets | Models | Constraints | Tr-Loss | Tr-Acc | Te-Loss | Te-Acc | Obj-F1 | ||
|---|---|---|---|---|---|---|---|---|---|
| U | V | O | |||||||
| Movie | RoBERTa | ✓ | 0.131 | 0.959 | 0.127 | 0.963 | 0.961 | ||
| ✓ | 0.136 | 0.957 | 0.118 | 0.961 | 0.961 | ||||
| ✓ | 0.142 | 0.951 | 0.130 | 0.958 | 0.957 | ||||
| Bert | ✓ | 0.095 | 0.970 | 0.102 | 0.968 | 0.966 | |||
| ✓ | 0.108 | 0.969 | 0.139 | 0.953 | 0.952 | ||||
| ✓ | 0.104 | 0.970 | 0.112 | 0.963 | 0.962 | ||||
| BART | ✓ | 0.190 | 0.932 | 0.156 | 0.949 | 0.948 | |||
| ✓ | 0.220 | 0.920 | 0.181 | 0.939 | 0.939 | ||||
| ✓ | 0.194 | 0.934 | 0.153 | 0.947 | 0.946 | ||||
| T5 | ✓ | 0.174 | 0.946 | 0.135 | 0.958 | 0.954 | |||
| ✓ | 0.213 | 0.926 | 0.148 | 0.949 | 0.944 | ||||
| ✓ | 0.184 | 0.939 | 0.130 | 0.955 | 0.951 | ||||
| GPT2 | ✓ | 0.502 | 0.731 | 0.585 | 0.687 | 0.735 | |||
| ✓ | 0.505 | 0.733 | 0.619 | 0.676 | 0.719 | ||||
| ✓ | 0.504 | 0.729 | 0.601 | 0.684 | 0.727 | ||||
| SST | RoBERTa | ✓ | 0.548 | 0.765 | 0.524 | 0.808 | 0.893 | ||
| ✓ | 0.523 | 0.796 | 0.490 | 0.822 | 0.902 | ||||
| ✓ | 0.539 | 0.773 | 0.519 | 0.805 | 0.890 | ||||
| Bert | ✓ | 0.557 | 0.764 | 0.534 | 0.800 | 0.890 | |||
| ✓ | 0.528 | 0.781 | 0.514 | 0.806 | 0.891 | ||||
| ✓ | 0.543 | 0.767 | 0.528 | 0.789 | 0.881 | ||||
| BART | ✓ | 0.537 | 0.774 | 0.545 | 0.814 | 0.897 | |||
| ✓ | 0.515 | 0.797 | 0.494 | 0.827 | 0.905 | ||||
| ✓ | 0.518 | 0.796 | 0.529 | 0.813 | 0.897 | ||||
| T5 | ✓ | 0.665 | 0.603 | 0.584 | 0.693 | 0.780 | |||
| ✓ | 0.521 | 0.766 | 0.506 | 0.800 | 0.887 | ||||
| ✓ | 0.526 | 0.760 | 0.516 | 0.798 | 0.886 | ||||
| GPT2 | ✓ | 0.498 | 0.806 | 0.507 | 0.802 | 0.891 | |||
| ✓ | 0.486 | 0.814 | 0.480 | 0.816 | 0.899 | ||||
| ✓ | 0.492 | 0.811 | 0.487 | 0.803 | 0.891 | ||||
| RoBERTa | ✓ | 0.317 | 0.877 | 0.321 | 0.873 | 0.923 | |||
| ✓ | 0.349 | 0.859 | 0.323 | 0.868 | 0.921 | ||||
| ✓ | 0.360 | 0.858 | 0.350 | 0.863 | 0.917 | ||||
| Bert | ✓ | 0.304 | 0.889 | 0.346 | 0.868 | 0.919 | |||
| ✓ | 0.331 | 0.877 | 0.347 | 0.860 | 0.915 | ||||
| ✓ | 0.360 | 0.860 | 0.364 | 0.858 | 0.914 | ||||
| BART | ✓ | 0.409 | 0.806 | 0.356 | 0.856 | 0.910 | |||
| ✓ | 0.399 | 0.820 | 0.362 | 0.855 | 0.913 | ||||
| ✓ | 0.450 | 0.779 | 0.395 | 0.834 | 0.896 | ||||
| T5 | ✓ | 0.393 | 0.836 | 0.350 | 0.853 | 0.913 | |||
| ✓ | 0.414 | 0.815 | 0.366 | 0.852 | 0.909 | ||||
| ✓ | 0.404 | 0.826 | 0.339 | 0.862 | 0.917 | ||||
| GPT2 | ✓ | 0.440 | 0.819 | 0.455 | 0.823 | 0.902 | |||
| ✓ | 0.446 | 0.810 | 0.453 | 0.816 | 0.897 | ||||
| ✓ | 0.462 | 0.814 | 0.466 | 0.808 | 0.891 | ||||
| Datasets | Models | Constraints | Tr-Loss | Tr-Acc | Te-Loss | Te-Acc | Obj-F1 | ||
|---|---|---|---|---|---|---|---|---|---|
| U | V | O | |||||||
| Movie | RoBERTa | ✓ | ✓ | 0.125 | 0.957 | 0.122 | 0.963 | 0.964 | |
| ✓ | ✓ | 0.138 | 0.949 | 0.133 | 0.954 | 0.957 | |||
| ✓ | ✓ | 0.152 | 0.943 | 0.135 | 0.953 | 0.956 | |||
| Bert | ✓ | ✓ | 0.099 | 0.970 | 0.097 | 0.969 | 0.970 | ||
| ✓ | ✓ | 0.096 | 0.972 | 0.116 | 0.961 | 0.964 | |||
| ✓ | ✓ | 0.098 | 0.969 | 0.118 | 0.964 | 0.966 | |||
| BART | ✓ | ✓ | 0.169 | 0.935 | 0.135 | 0.955 | 0.955 | ||
| ✓ | ✓ | 0.179 | 0.930 | 0.123 | 0.956 | 0.959 | |||
| ✓ | ✓ | 0.173 | 0.934 | 0.138 | 0.951 | 0.952 | |||
| T5 | ✓ | ✓ | 0.159 | 0.945 | 0.119 | 0.964 | 0.962 | ||
| ✓ | ✓ | 0.157 | 0.945 | 0.114 | 0.962 | 0.959 | |||
| ✓ | ✓ | 0.160 | 0.946 | 0.121 | 0.960 | 0.957 | |||
| GPT2 | ✓ | ✓ | 0.505 | 0.729 | 0.583 | 0.688 | 0.670 | ||
| ✓ | ✓ | 0.507 | 0.727 | 0.615 | 0.674 | 0.627 | |||
| ✓ | ✓ | 0.505 | 0.722 | 0.598 | 0.673 | 0.652 | |||
| SST | RoBERTa | ✓ | ✓ | 0.503 | 0.806 | 0.478 | 0.820 | 0.900 | |
| ✓ | ✓ | 0.518 | 0.793 | 0.497 | 0.810 | 0.896 | |||
| ✓ | ✓ | 0.496 | 0.803 | 0.475 | 0.824 | 0.903 | |||
| Bert | ✓ | ✓ | 0.497 | 0.795 | 0.504 | 0.802 | 0.889 | ||
| ✓ | ✓ | 0.488 | 0.789 | 0.525 | 0.798 | 0.886 | |||
| ✓ | ✓ | 0.455 | 0.807 | 0.470 | 0.811 | 0.894 | |||
| BART | ✓ | ✓ | 0.522 | 0.780 | 0.511 | 0.818 | 0.900 | ||
| ✓ | ✓ | 0.526 | 0.774 | 0.539 | 0.803 | 0.889 | |||
| ✓ | ✓ | 0.508 | 0.798 | 0.515 | 0.802 | 0.889 | |||
| T5 | ✓ | ✓ | 0.471 | 0.807 | 0.482 | 0.812 | 0.895 | ||
| ✓ | ✓ | 0.466 | 0.810 | 0.491 | 0.812 | 0.895 | |||
| ✓ | ✓ | 0.461 | 0.811 | 0.483 | 0.813 | 0.896 | |||
| GPT2 | ✓ | ✓ | 0.493 | 0.811 | 0.496 | 0.805 | 0.892 | ||
| ✓ | ✓ | 0.493 | 0.810 | 0.496 | 0.804 | 0.892 | |||
| ✓ | ✓ | 0.494 | 0.809 | 0.482 | 0.815 | 0.897 | |||
| RoBERTa | ✓ | ✓ | 0.296 | 0.883 | 0.302 | 0.878 | 0.927 | ||
| ✓ | ✓ | 0.304 | 0.878 | 0.315 | 0.877 | 0.925 | |||
| ✓ | ✓ | 0.335 | 0.857 | 0.344 | 0.861 | 0.915 | |||
| Bert | ✓ | ✓ | 0.267 | 0.894 | 0.336 | 0.869 | 0.920 | ||
| ✓ | ✓ | 0.297 | 0.880 | 0.355 | 0.858 | 0.913 | |||
| ✓ | ✓ | 0.294 | 0.879 | 0.323 | 0.876 | 0.925 | |||
| BART | ✓ | ✓ | 0.364 | 0.844 | 0.309 | 0.878 | 0.927 | ||
| ✓ | ✓ | 0.397 | 0.813 | 0.329 | 0.863 | 0.916 | |||
| ✓ | ✓ | 0.360 | 0.847 | 0.309 | 0.874 | 0.925 | |||
| T5 | ✓ | ✓ | 0.359 | 0.846 | 0.318 | 0.869 | 0.923 | ||
| ✓ | ✓ | 0.385 | 0.821 | 0.335 | 0.862 | 0.918 | |||
| ✓ | ✓ | 0.334 | 0.862 | 0.314 | 0.871 | 0.925 | |||
| GPT2 | ✓ | ✓ | 0.465 | 0.808 | 0.453 | 0.819 | 0.899 | ||
| ✓ | ✓ | 0.463 | 0.809 | 0.461 | 0.813 | 0.895 | |||
| ✓ | ✓ | 0.468 | 0.807 | 0.451 | 0.814 | 0.895 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Zhao, C.; Zhang, Z.; Huang, Y. Towards Identifying Objectivity in Short Informal Text. Entropy 2025, 27, 583. https://doi.org/10.3390/e27060583
Zhang C, Zhao C, Zhang Z, Huang Y. Towards Identifying Objectivity in Short Informal Text. Entropy. 2025; 27(6):583. https://doi.org/10.3390/e27060583
Chicago/Turabian StyleZhang, Chaowei, Cheng Zhao, Zewei Zhang, and Yuchao Huang. 2025. "Towards Identifying Objectivity in Short Informal Text" Entropy 27, no. 6: 583. https://doi.org/10.3390/e27060583
APA StyleZhang, C., Zhao, C., Zhang, Z., & Huang, Y. (2025). Towards Identifying Objectivity in Short Informal Text. Entropy, 27(6), 583. https://doi.org/10.3390/e27060583