1. Introduction
High-resolution multispectral (HRMS) imaging is essential for various domains [
1,
2,
3,
4,
5,
6], including environmental surveillance [
7,
8] and urban development [
9,
10]. However, due to constraints in satellite sensor technology, acquired data often consist of low-resolution multispectral (LRMS) images and high-resolution panchromatic (PAN) images [
11,
12,
13,
14]. To overcome this limitation, pansharpening techniques are employed to synthesize HRMS images by integrating the spectral richness of LRMS images with the fine spatial details of PAN images, thereby improving both spectral and spatial fidelity. From an information-theoretic perspective, the goal of pansharpening is to maximize the mutual information between PAN and LRMS sources while minimizing information loss and redundancy in the fused result. The quality of fusion can be interpreted through entropy-based metrics that evaluate information preservation and distortion.
In the early development of pansharpening, traditional methodologies dominated, including component substitution (CS) [
15,
16], multiresolution analysis (MRA)-based approaches [
17,
18], and model-driven techniques [
19,
20,
21]. CS methods fused spatial details from high-resolution PAN images into corresponding LRMS images, while MRA-based strategies employed multi-scale fusion to capture hierarchical features. In contrast, model-based approaches formulated pansharpening as an inverse problem: the LRMS image was treated as a spatially degraded version of the HRMS image, whereas the PAN image was its spectrally degraded counterpart. The HRMS image was then reconstructed by solving this degradation model. However, the ill-posed nature of this formulation introduced significant challenges. To mitigate these issues, constraints based on sparsity, low-rank structures [
22,
23], and total variation [
24] were incorporated to regularize the solution space, improving fidelity. While these methods proved effective in certain scenarios, their reliance on handcrafted features limited adaptability. Moreover, their inability to automatically capture complex spectral–spatial dependencies constrained their performance, particularly in handling fine-grained structures and high-frequency details.
Deep neural networks (DNNs), leveraging their nonlinear mapping capabilities and advanced feature extraction mechanisms, have emerged as the predominant approach in the pansharpening domain [
25,
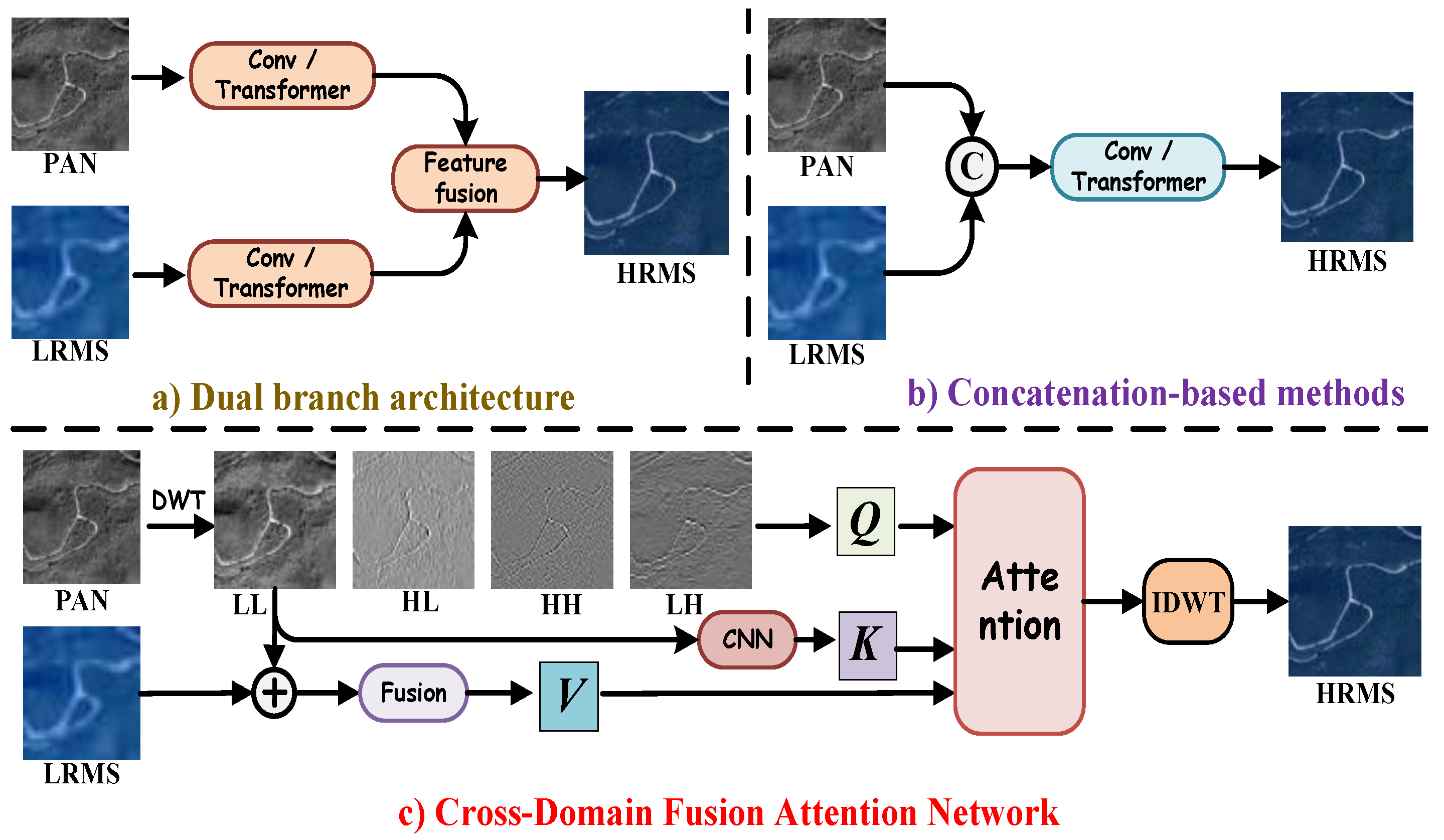
26]. Within dual-branch architectures (
Figure 1a), Zhang et al. [
27] employed multiple CNNs to extract complementary features from LRMS and PAN images. By effectively integrating the high spatial resolution of PAN images with the rich spectral information of LRMS images, this approach enhances fusion performance. In contrast, concatenation-based methods (
Figure 1b) adopt a different strategy. Ozcelik et al. [
28] introduced PCGAN, a generative adversarial network (GAN)-based framework that conceptualizes pansharpening as a colorization process applied to the PAN image. This method enhances spatial fidelity while preserving spectral consistency. To further enhance fusion quality, Lu et al. [
29] introduced the multi-scale self-attention network (MSAN), which combines a feature extraction branch with a self-attention mechanism. This approach allows for the dynamic incorporation of detailed spectral information, enhancing the effectiveness of pansharpening. More recently, Quan et al. [
30] introduced a dual-parallel Transformer designed to enhance semantic reconstruction, effectively capturing both spatial and spectral dependencies for higher-quality fused remote sensing images. However, despite their advantages, both CNN-based and Transformer-based architectures exhibit a fundamental limitation: their tendency to prioritize low-frequency information. This issue primarily arises due to the direct fusion of spatial features, which fails to adequately disentangle high-frequency textures from background structures. As a result, generated images often suffer from blurred textures and a loss of fine-grained details, compromising the overall sharpness and structural integrity of the output. Moreover, these methods often fail to explicitly quantify or control the information flow across modalities. Without an information-theoretic constraint or awareness, such models may lead to spectral distortion or loss of high-frequency spatial entropy during fusion.
The wavelet-domain transform [
31,
32,
33] has emerged as a powerful framework for pansharpening, offering significant advantages over spatial-domain fusion methods. By enabling multi-scale image analysis, it effectively mitigates the inherent trade-offs between spectral and spatial information representation. Huang et al. [
31] introduced a wavelet-based super-resolution CNN, which operates directly in the wavelet domain, leveraging wavelet coefficients to preserve high-frequency details and enhance spatial resolution. However, CNNs inherently prioritize low-frequency features, making them less effective at preserving high-frequency details [
34], which ultimately degrades fusion quality. In contrast, the Wavelet Pyramid Recurrent Structure-Preserving Attention Network [
32] adopted a distinct strategy, independently processing low- and high-frequency components to retain structural integrity while refining fine details. However, conventional wavelet transforms combined with Transformers fail to simultaneously capture and integrate information across different frequency bands and the unique spectral channels of remote sensing images. Huang et al. [
33] utilized wavelet transform to achieve precise frequency separation, generating frequency queries, spatial keys, and fusion values that are based on the physical significance of the different features, thereby enhancing the capture of targeted frequency-domain information.
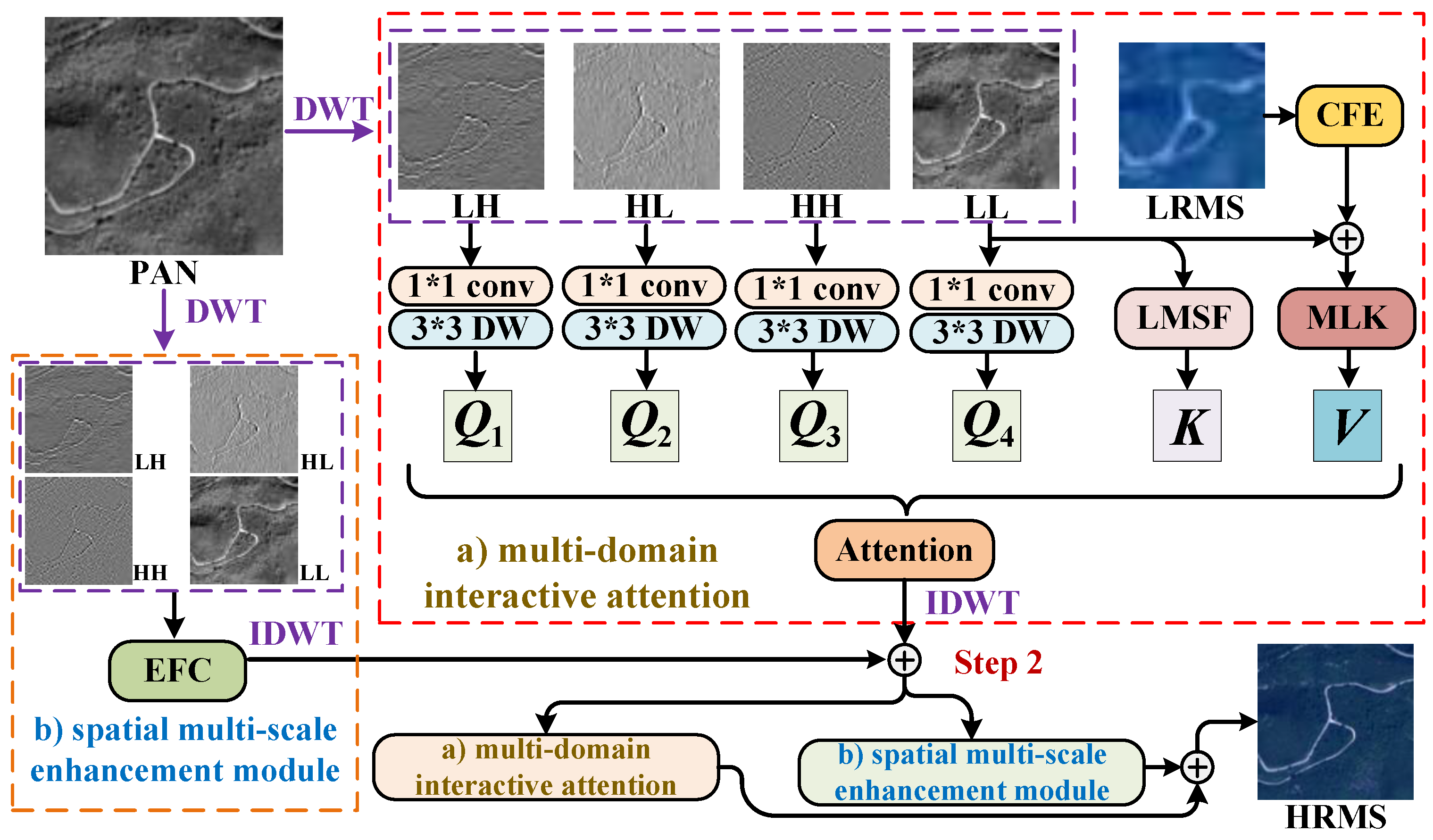
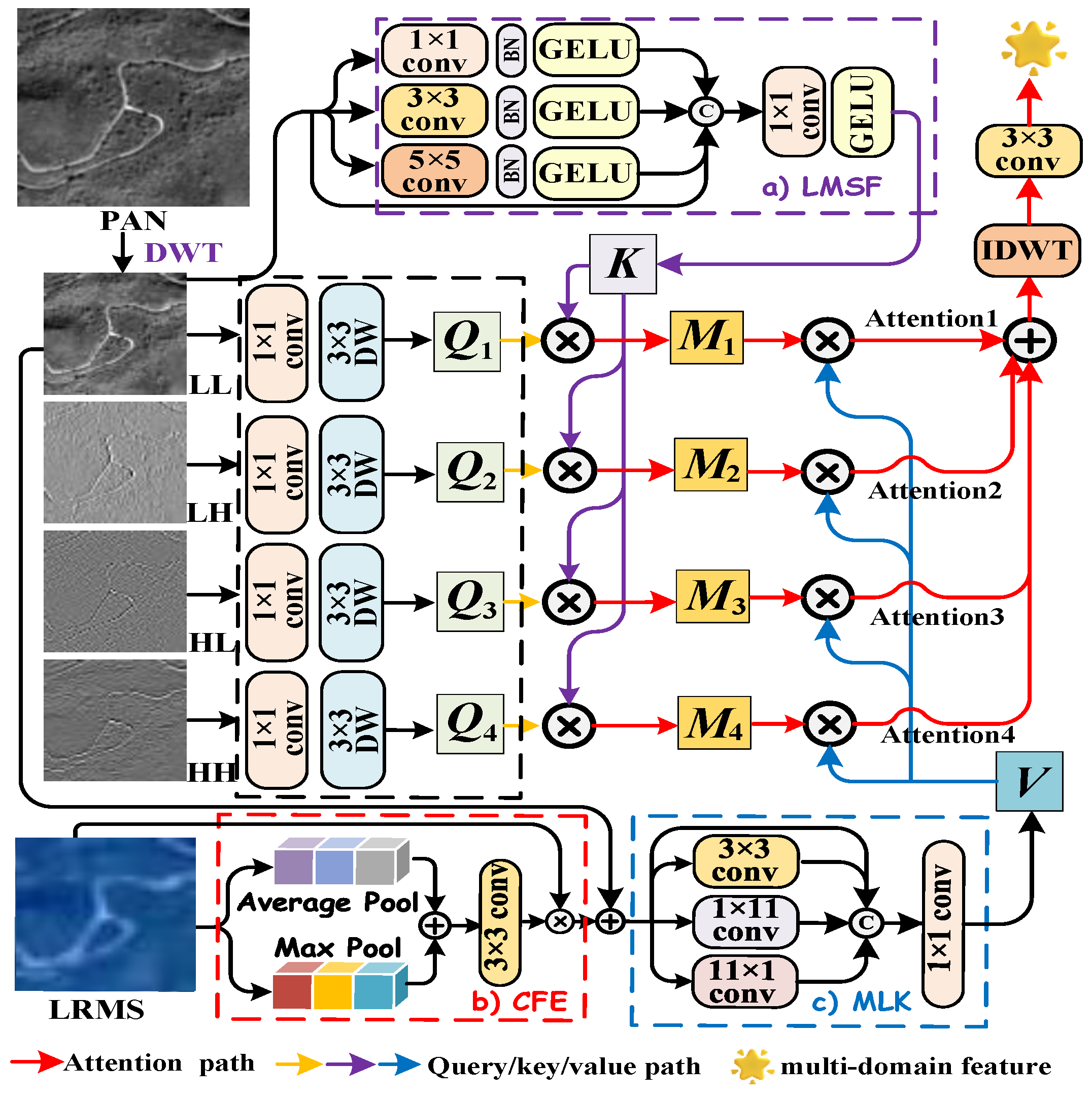
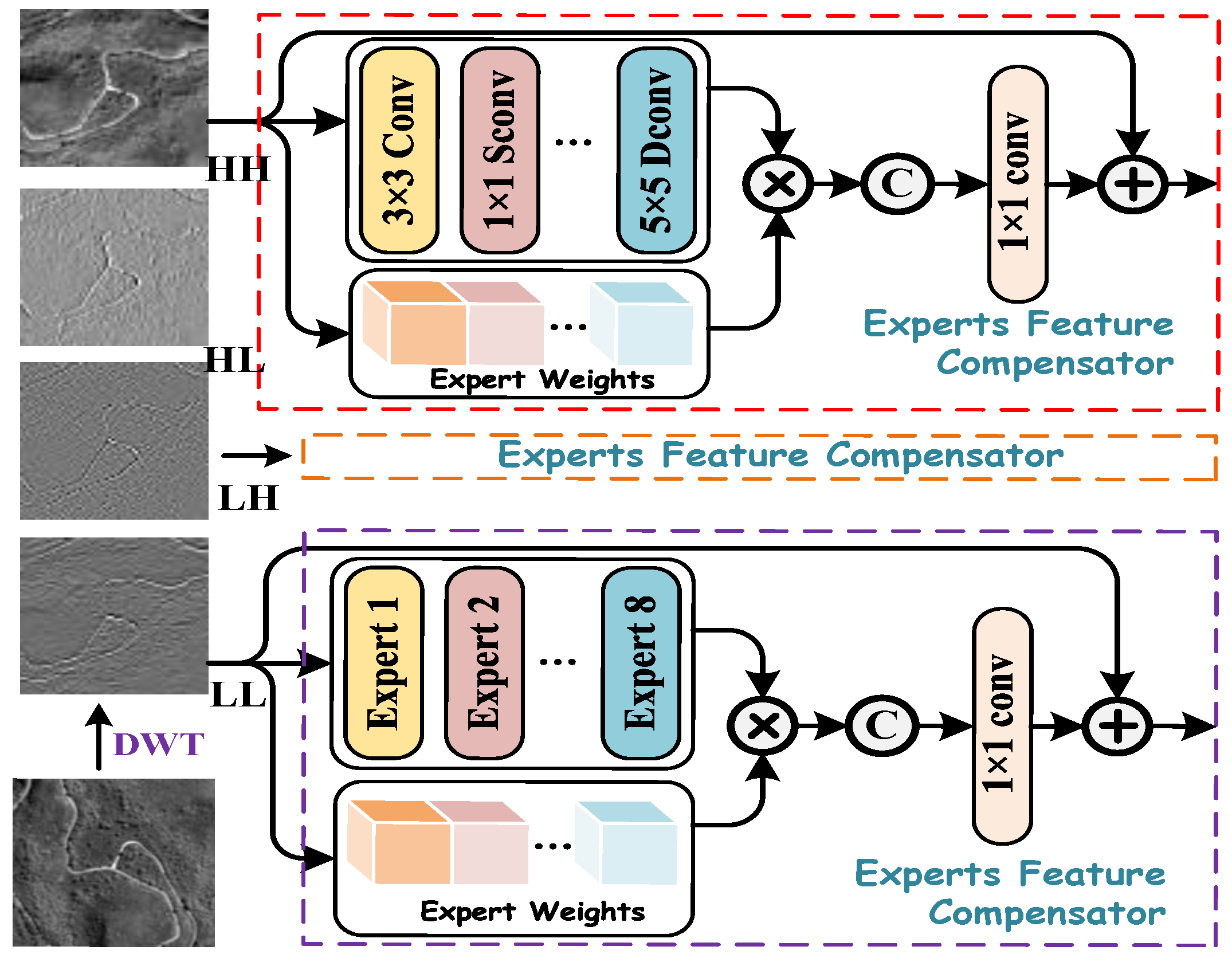
Inspired by the need for entropy-aware and information-preserving fusion mechanisms, and building upon recent wavelet-domain advances, we propose a novel Cross-Domain Fusion Attention Network (CDFAN), illustrated in
Figure 1c. The architecture comprises two synergistic modules: the Multi-Domain Interactive Attention (MDIA) and the Spatial Multi-Scale Enhancement (SMCE) module. The MDIA module first applies discrete wavelet transform (DWT) to the PAN image, explicitly decomposing it into four frequency sub-bands that serve as wavelet-domain queries. The low-frequency sub-band, which retains the core spatial structure, is separately processed via a Local Multiscale Spatial Feature Extraction (LMSF) module to form spatial-domain keys. Simultaneously, the LRMS image undergoes enhancement through a Channel Feature Enhancement (CFE) module and is further processed by a multi-scale large-kernel convolution (MLK) module to generate multi-domain values. These query–key–value triplets, drawn from both the spatial and wavelet domains, are fused using a cross-domain attention mechanism that enables entropy-aware interaction and frequency-specific representation learning. In parallel, the SMCE module again applies DWT to the PAN image, followed by an Expert Feature Compensator (EFC), which dynamically adjusts the contribution of multi-scale features using adaptive weighting. This module integrates convolutional operations at different scales to robustly capture both global contextual cues and fine-grained textures, enhancing spatial representational capacity. Notably, our work is partly inspired by the SFIIN framework [
35], which introduced a dual-branch architecture that fuses spatial and frequency information using Fourier decomposition. However, our method diverges fundamentally by operating in the wavelet domain and incorporating a cross-domain attention mechanism, rather than relying on global Fourier representations and conventional convolution-based fusion. The explicit construction of wavelet-domain queries and spatial-domain keys, along with adaptive multi-scale enhancement through EFC, distinguishes our approach and enhances its ability to capture localized frequency textures while maintaining entropy structure.
Our contributions can be summarized as follows.
We introduce a novel MDIA mechanism that leverages DWT to achieve explicit frequency separation. By processing frequency sub-bands as wavelet-domain queries and integrating spatial-domain keys and multi-domain values, the model effectively captures frequency-specific information, leading to enhanced spatial–spectral representation.
We propose the EFC branch, which employs an adaptive feature weighting mechanism to dynamically balance global contextual awareness and fine-grained spatial detail preservation. By integrating multi-scale convolutional operations, the EFC enhances hierarchical spatial feature fusion, improving the model’s ability to capture fine-grained structures in high-resolution remote sensing images.
Experiments conducted on three distinct pansharpening datasets showcase the superiority of our approach compared to state-of-the-art (SOTA) methods, resulting in improved visual quality and superior quantitative metrics.
4. Experiments and Evaluation
This section outlines the experimental framework used to assess the efficacy of the proposed CDFAN method, leveraging remote sensing imagery from three satellite platforms: WorldView-3 (WV-3), WorldView-2 (WV-2), and GaoFen-2 (GF-2).
Figure 5 presents the MS and PAN images for use in the experiment. To simulate realistic low-resolution data, we apply downsampling techniques to the original high-resolution imagery, as prescribed by Wald et al. [
49]. This downsampling ensures a comprehensive evaluation of the fusion model’s ability to restore information from low-resolution inputs. The three datasets are further split into non-overlapping subsets for training and testing, and the detailed properties of these datasets are summarized in
Table 1.
4.1. Quality Metrics and Cutting-Edge Competitors
To thoroughly assess the quantitative performance of all the competing approaches, we utilize six well-established evaluation metrics, peak signal-to-noise ratio (PSNR), structural similarity (SSIM), spectral angle mapper (SAM), and erreur relative globale admensionnelle de synthese (ERGSA) [
50], along with universal image quality indices for 4-band (Q4) and 8-band (Q8) images [
51]. In addition to traditional quality metrics, we incorporate entropy-aware indicators such as the QNR [
52],
[
53], and
[
54] to assess the degree of information distortion across the spatial and spectral domains, especially in the absence of ground-truth reference images. These metrics serve as information-theoretic tools to quantify mutual information preservation and redundancy reduction.
The comparative study involves three model-based techniques—GSA [
55], SFIM [
56], and [
57]—alongside eight advanced deep learning-based methods: PanFormer [
58], CTINN [
59], LightNet [
60], SFIIN [
35], MutInf [
61], MDCUN [
62], LGTEUN [
46], SSDBPN [
63], BiMPan [
64], and PAPS [
65].
4.2. Experimental Setup
To guarantee uniformity and replicability across all experiments, we performed our computations using Python 3.7 alongside PyTorch 1.9.0, leveraging a computational platform equipped with NVIDIA GeForce RTX 3090 GPUs. For the deep learning-based pansharpening approach, the training configuration was established as follows: a batch size of 4 was adopted, with the GF-2 and WV-2 datasets undergoing 500 training epochs, while the WV-3 dataset was trained for 140 epochs. The starting learning rate was configured at , subject to a decay factor of 0.85 applied at intervals of 100 epochs.
4.3. Synthetic Data Experiments
In this section, we present the outcomes generated by all the evaluated methods across the three chosen datasets, namely, the WV-3, WV-2, and GF-2 datasets. The optimal values are marked in red, while the second-best values are indicated in blue.
4.3.1. Quantitative Analysis
The CDFAN approach demonstrates exceptional performance across all major evaluation metrics on the WorldView-3 dataset, as summarized in
Table 2. It achieves a notable PSNR of 32.5080, surpassing the second-place method, BiMPan, by 0.2230, highlighting CDFAN’s superior capacity for preserving critical information content and reducing cross-domain redundancy, ultimately leading to higher image quality. Additionally, CDFAN shows a marked improvement in the ERGAS metric, registering a value of 2.5389, which is 21.36% better than the PAPS method (2.6127). This emphasizes the effectiveness of SCTA not only in preserving image fidelity but also in providing a more accurate and computationally efficient reconstruction, making it particularly suitable for high-precision tasks that require optimization.
On the WorldView-2 dataset, CDFAN consistently outperforms competing methods, as evidenced by the results in
Table 3. It secures the highest PSNR of 42.7719, exceeding LGTEUN by 0.1475 and PAPS by 0.1403, which underscores CDFAN’s superior ability to preserve image fidelity. Furthermore, CDFAN leads the SSIM metric with a score of 0.9789, indicating that it consistently maintains a high degree of structural similarity in the reconstructed images. CDFAN also excels in the SAM metric with a notably low score of 1.1747, improving by 16.87% over BiMPan (1.2433), thus demonstrating its proficiency in preserving angular fidelity and minimizing distortion in pixel vectors.
On the GaoFen-2 dataset, CDFAN proves to be the dominant method, leading almost every evaluation metric, as detailed in
Table 4. It achieves the highest PSNR score of 46.8108, outperforming the second-best LGTEUN by a significant 0.9744, indicating its exceptional capability to maximize information fidelity and maintain entropy consistency, producing high-quality and perceptually faithful reconstructions. In terms of SSIM, CDFAN maintains its dominance with a score of 0.9868, outperforming BiMPan (0.9822) by 0.0046, further confirming its ability to preserve image structure. Additionally, CDFAN leads the Q4 metric with a value of 0.9117, surpassing BiMPan (0.8928) by 0.0189, thus highlighting its superior performance in image quantization and quality evaluation.
In conclusion, CDFAN stands out as the clear leader across all datasets, consistently demonstrating its exceptional ability to preserve image quality, structural integrity, and computational efficiency. With top scores in PSNR, SSIM, and ERGAS on the WorldView-3 and WorldView-2 datasets, and leading results in PSNR and SSIM on GaoFen-2, CDFAN proves to be the most reliable and effective method for remote sensing image reconstruction, offering both high-quality results and computational efficiency across a wide range of benchmark datasets.
4.3.2. Qualitative Analysis
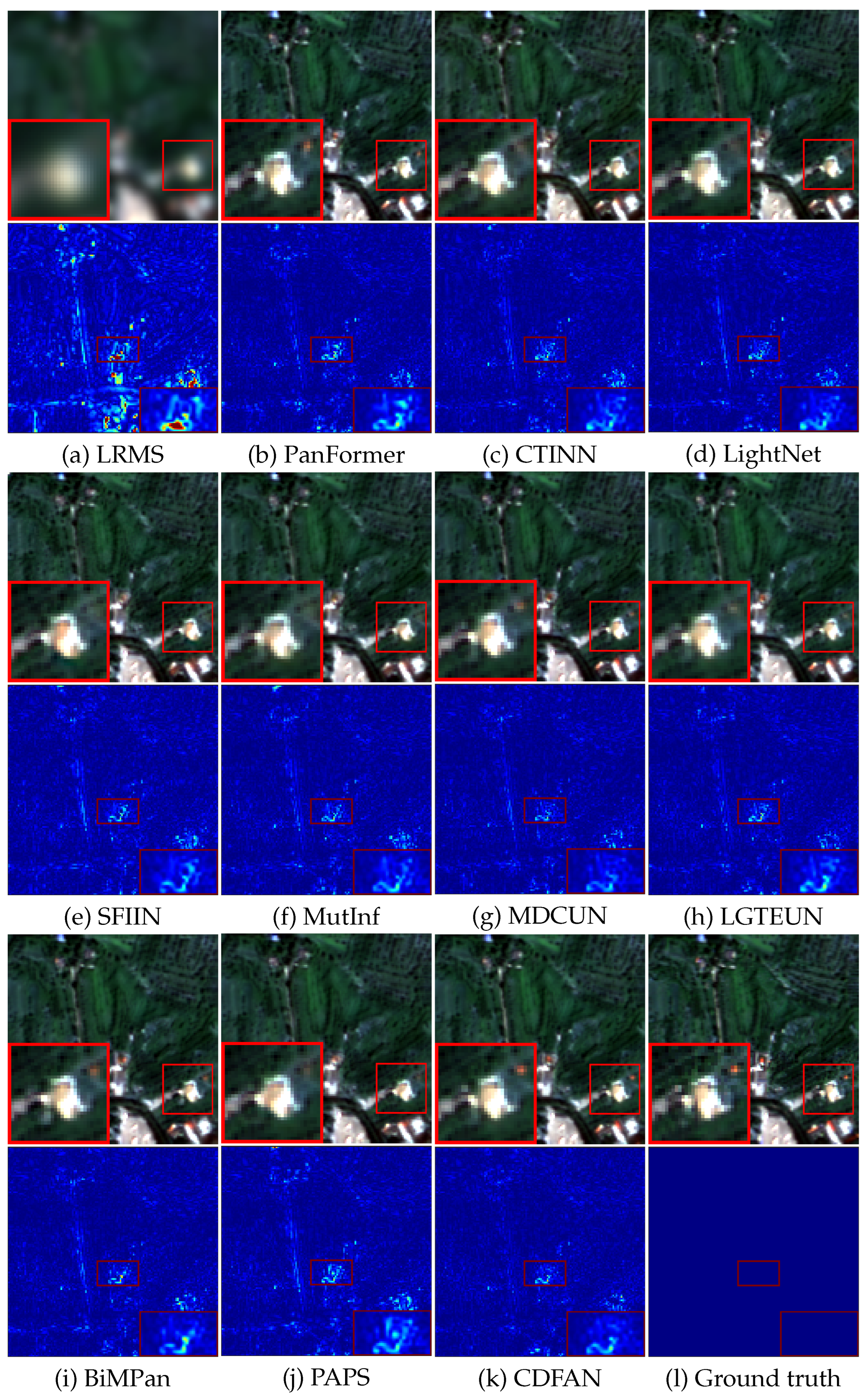
For visual evaluation,
Figure 6 presents representative examples and corresponding error maps recovered from the GF-2 dataset. As observed in the figure, all models yield relatively satisfactory results. However, upon closer inspection of the zoomed-in thumbnails, it becomes apparent that nearly all the comparative methods struggle to effectively reconstruct the rooftop area in the upper-right corner, particularly failing to recover the original red pseudo-color. While BiMPan and MDCUN partially restore the red rooftop, their results remain dimmer. In contrast, CDFAN delivers clearer results with fewer artifacts, especially in the zoomed-in region, where it more accurately recovers the red rooftop. The error maps, particularly in the magnified areas, reveal that our method tends to produce smoother, more blue-toned results, in contrast to competing methods that integrate HRMS with noticeable defects and noise. Overall, the experimental results demonstrate that our method surpasses other holographic reconstruction approaches. Moreover, the smoother error maps observed in CDFAN’s outputs reflect its capacity to minimize information distortion and preserve entropy structure across spatial scales, leading to better texture fidelity and detail preservation. This superiority is mainly attributed to the comprehensive extraction of both local-global and deeper features enabled by the MDIA and SMCE modules, which significantly enhance the final reconstruction quality.
For the WV-3 dataset, as shown in
Figure 7, it is evident that model-based techniques fail to perform adequately, as their generated results are plagued by abnormal pixels and excessive distortion. On the other hand, all deep learning-based competitors can roughly capture spatial details from the PAN image. However, while other algorithms struggle to restore the bright rooftop colors clearly, the proposed method achieves the most accurate restoration. The error maps, particularly in the magnified regions, indicate that our method tends to generate smoother and more blue-toned results, highlighting the flaws of other methods that fuse HRMSs with more defects and scattered points. In general, the experimental results confirm the superiority of our method over other pansharpening approaches. This advantage arises from the comprehensive extraction of both local-global and deeper features facilitated by the CDFAN and MAC modules, which contribute to the refined quality of the final outcomes. Moreover, visual inspections across multiple samples reveal no noticeable artifacts introduced by the wavelet decomposition, indicating that our MDIA design effectively mitigates potential side effects of DWT.
4.4. Effectiveness of CDFAN in Mitigating Entropy Degradation
To further evaluate the entropy-preserving capability of CDFAN under full-resolution settings, we report three information-theoretic metrics—
,
, and QNR—in
Table 5. These metrics quantify the spectral distortion, spatial distortion, and overall fusion quality, respectively, without requiring reference ground-truth HRMS images. In the absence of reference images, we process the full-resolution input directly through a model that was trained on downsampled datasets, producing pansharpened outputs. The PAN images used have dimensions of
, while the LRMS images are
. On the WorldView-3 dataset in
Table 5, CDFAN achieves the highest QNR score (0.9539) and the second-best scores in both
(0.0289) and
(0.0293), indicating its strong ability to preserve entropy structure during fusion. On the GaoFen-2 dataset, CDFAN outperforms all competitors with
and matches the best QNR score (0.8121) alongside BiMPan. The low values of
and
suggest that the proposed network maintains a favorable balance between spatial and spectral fidelity, while its high QNR reflects the model’s superior joint fusion performance. Notably, although BiMPan also achieves competitive QNR, it suffers from higher spectral distortion on WorldView-3 (
) and spatial degradation on GaoFen-2 (
). In contrast, CDFAN demonstrates more consistent performance across datasets and domains, reinforcing its advantage as an entropy-aware fusion framework capable of minimizing information loss and redundancy.
Figure 8 presents a visual comparison of the full-resolution outputs, using a representative GF-2 example. Among the deep learning-based methods, LightNet struggles with spectral fidelity, showing a significant loss of detail. Other methods, including CTINN, SFIIN, MDCUN, and PAPS, demonstrate slight improvements; however, their results are affected by blurred rooftop edges, particularly in the road areas. These results provide strong quantitative evidence that CDFAN effectively addresses the entropy degradation problem often observed in traditional spatial-domain fusion approaches.
4.5. Ablation Experiments and Discussion
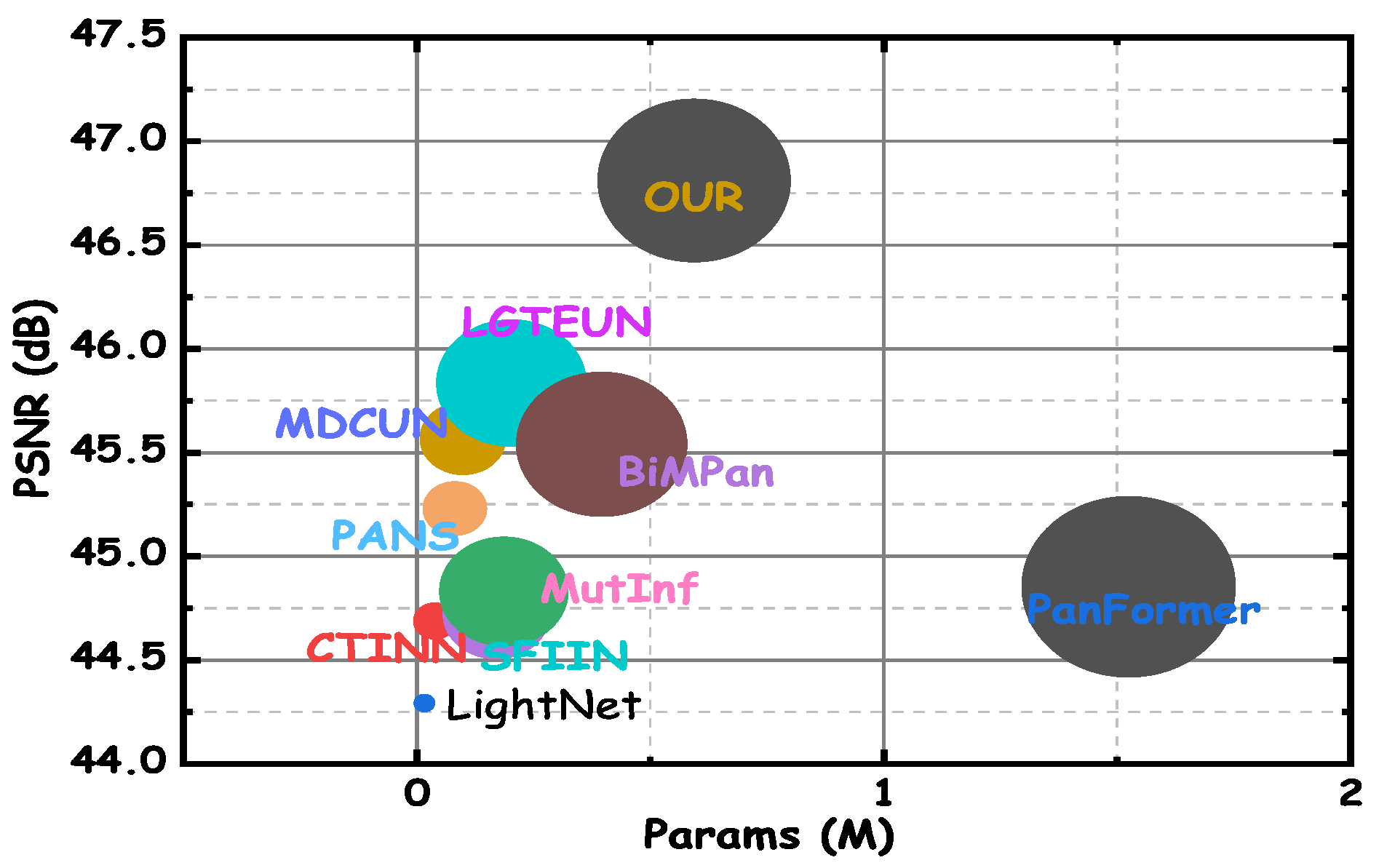
4.5.1. Computational Efficiency Analysis
Figure 9 shows the balance between computational cost and performance for all algorithms, with CDFAN achieving substantial performance improvements despite requiring additional computational resources due to advanced modules like MDIA, SMCE, and DWT. The ablation study in
Table 6 demonstrates that each module enhances performance without significantly increasing the number of parameters. For example, when MDIA is used alone (index 1), the model achieves a PSNR of 45.0148 with 0.2754 million parameters. Adding SMCE (index 2) and DWT (index 3) increases the PSNR to 45.8971 with only a modest increase in parameters to 0.2927 million. The final model, including all modules (index 4), achieves the highest PSNR of 46.8108, with a slight increase in parameters to 0.2988 million. These results confirm that while the inclusion of advanced processing mechanisms increases the computational cost, the performance gains—especially in terms of PSNR, SSIM, and SAM—justify the added computational load, making CDFAN a highly effective solution for high-resolution remote sensing applications.
4.5.2. Effectiveness of the DWT Decomposition
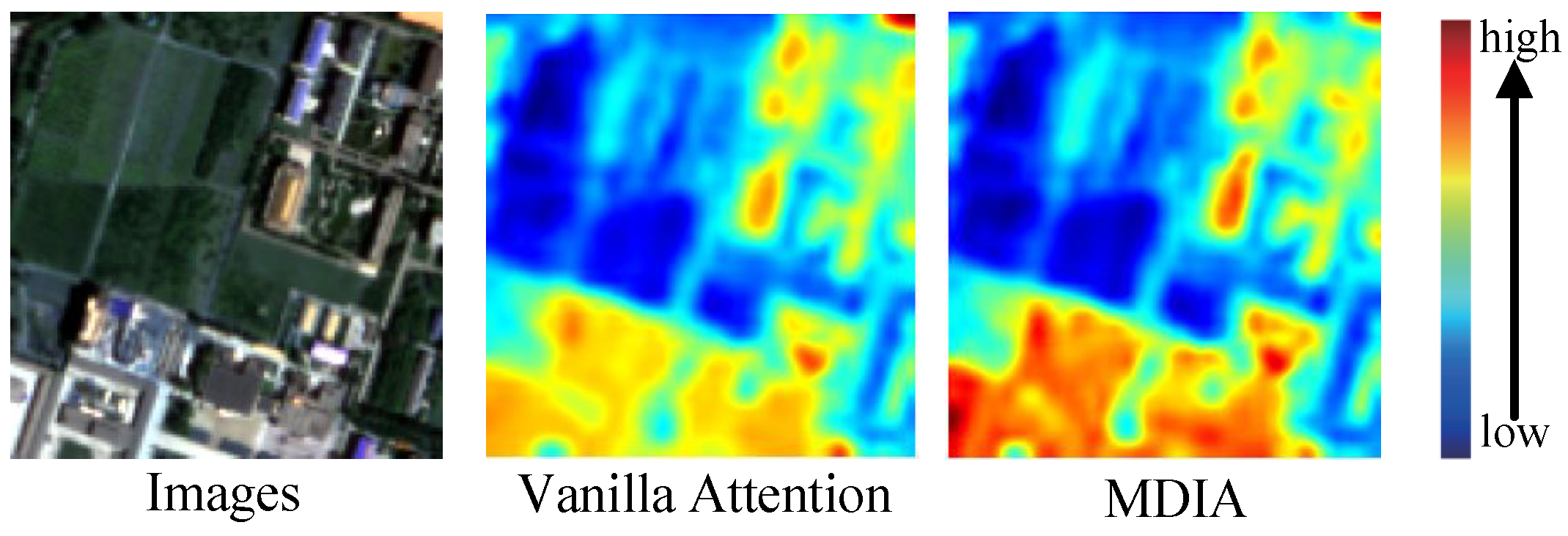
To address the concern regarding potential artifacts or detail loss introduced by DWT, we conducted an ablation study to evaluate its actual impact within our framework. As shown in
Table 6, removing DWT from the pipeline (index 3) results in a noticeable drop in performance metrics: the PSNR decreases from 46.8108 to 45.8971, and SAM increases from 1.2490 to 1.4354, suggesting increased spectral distortion and reduced spatial fidelity. While it is true that traditional DWT-based models may introduce artifacts due to the coarse decomposition of frequency components, our integration of DWT into the MDIA module mitigates this issue by guiding the attention mechanism toward high-frequency components. As shown in the attention heatmaps (
Figure 10), MDIA with DWT more effectively highlights critical spatial features—such as rooftops and edges—compared to vanilla attention. These results demonstrate that, in the context of our model design, DWT not only avoids generating noticeable artifacts but also contributes significantly to preserving fine-grained textures and enhancing feature localization.
4.5.3. Effectiveness of MDIA
To evaluate the specific contribution of the MDIA module, we conducted both qualitative and quantitative comparisons. As shown in
Table 6, removing MDIA (index 2) leads to a noticeable performance drop. Specifically, the PSNR decreases from 46.8108 to 43.5478, while the SAM increases from 1.2490 to 1.7154, indicating increased spectral distortion and a loss of fine-grained details. The absence of MDIA also results in blurred textures, particularly in areas with high structural complexity, such as rooftops, as demonstrated in
Figure 10 (case 1). This focused attention helps to preserve important high-frequency features, improving the fusion of spatial and spectral information. Overall, these results confirm that MDIA is vital for maintaining the high image fidelity of the fused output, improving both visual quality and performance metrics by enhancing the model’s ability to focus on relevant image features.
4.5.4. Effectiveness of SMCE
To further examine the effectiveness of SMCE, we isolate its core component—Expert Feature Compensator (EFC)—and evaluate different convolutional configurations to substitute the EFC. Initially, the EFC used a set of multi-scale convolutions. However, to optimize the fusion process, we replaced this with combinations of 3 × 3, 3 × 3, and 5 × 5, and 3 × 3, 5 × 5, and 7 × 7 convolutions, as shown in
Table 7. The results in
Table 7 demonstrate that as we incorporate larger kernel sizes and more combinations, the model’s performance improves. When only the 3 × 3 kernel is used (index 1), the PSNR reaches 45.5014. By adding a 5 × 5 kernel (index 2), the performance slightly improves to 45.5789, indicating the positive effect of using multiple kernel sizes for better feature extraction. The combination of 3 × 3, 5 × 5, and 7 × 7 kernels (index 3) yields an even better PSNR of 45.6185, suggesting that a broader range of spatial features are captured with these multi-scale convolutions. Finally, when the full EFC module is included (index 4), which uses all the previous configurations with the EFC mechanism, the PSNR reaches its highest value of 46.8108. This demonstrates that the EFC with these multi-scale convolutions significantly contributes to the performance improvement by better compensating for fine spatial details.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}