1. Introduction
We consider a distributed machine learning setting, in which a central entity, referred to as the
main node, possesses a large amount of data on which it wants to run a machine learning algorithm. To speed up the computations, the main node distributes the computation tasks to several
worker machines. The workers compute smaller tasks in parallel and send back their results to the main node, which then aggregates the partial results to obtain the desired result of the large computation. A naive distribution of the tasks to the workers suffers from the presence of
stragglers, that is, slow or unresponsive workers [
1,
2].
The negative effect of stragglers can be mitigated by assigning redundant computations to the workers and ignoring the responses of the slowest ones [
3,
4]. However, in gradient descent algorithms, assigning redundant tasks to the workers can be avoided when a (good) estimate of the gradient loss function is sufficient. On a high level, gradient descent is an iterative algorithm requiring the main node to compute the gradient of a loss function at every iteration based on the current model. Simply ignoring the stragglers is equivalent to stochastic gradient descent (SGD) [
5,
6], which advocates computing an estimate of the gradient of the loss function at every iteration [
2,
7]. As a result, SGD trades off the time spent per iteration with the total number of iterations for convergence, or until a desired result is reached.
The authors of [
8] show that for distributed SGD algorithms, it is faster for the main node to assign tasks to all the workers but wait for only a small subset to return their results. In the strategy proposed in [
8], called
adaptive k-sync, in order to improve the convergence speed, the main node increases the number of workers it waits for as the algorithm evolves in iterations. Despite reducing the runtime of the algorithm, i.e., the total time needed to reach the desired result, this strategy requires the main node to transmit the current model to all available workers and pay for all computational resources while only using the computations of the fastest ones. This concern is particularly relevant in scenarios where computational resources are rented from external providers, making unused or inefficiently utilized resources financially costly [
9]. It is equally important when training on resource-constrained edge devices, where communication and computation capabilities are severely limited [
10,
11].
In this work, we take into account the cost of employing workers and transferring the current model to the workers. In contrast to [
8], we propose a communication- and computation-efficient scheme that distributes tasks only to the fastest workers and waits for the completion of all their computations. However, in practice, the main node does not know in advance which workers are the fastest. For this purpose, we introduce the use of a stochastic multi-armed bandit (MAB) framework to learn the speed of the workers while efficiently assigning them computational tasks.
Stochastic MABs, introduced in [
12], are iterative algorithms designed to maximize the gain of a user gambling with multiple slot machines, termed “armed bandits”. At each iteration, the user is allowed to pull one arm from the available set of armed bandits. Each arm pull yields a random reward following a known distribution with an unknown mean. The user wants to design a strategy to learn the expected reward of the arms while maximizing the accumulated rewards. Stochastic combinatorial MABs (CMABs) were introduced in [
13] and model the behavior when a user seeks to find a combination of arms that reveals the best overall expected reward.
Following the literature on distributed computing [
3,
14], we model the response times of the workers by independent and exponentially distributed random variables. We additionally assume that the workers are heterogeneous, i.e., have different mean response times. To apply MABs to distributed computing, we model the rewards by the response times. Our goal here is to use MABs to minimize the expected response time; hence, we would like to minimize the average reward, instead of maximizing it. Under this model, we show that compared to adaptive
k-sync, using an MAB to learn the mean response times of the workers on the fly cuts the average cost (reflected by the total number of ‘worker employments’) but comes at the expense of significantly increasing the total runtime of the algorithm.
1.1. Related Work
1.1.1. Distributed Gradient Descent
Assigning redundant tasks to the workers and running distributed gradient descent is known as gradient coding [
4,
9,
15,
16,
17,
18]. Approximate gradient coding is introduced to reduce the required redundancy and run SGD in the presence of stragglers [
19,
20,
21,
22,
23,
24,
25]. The schemes in [
17,
18] use redundancy but no coding to avoid encoding/decoding overheads. However, assigning redundant computations to the workers increases the computation time spent per worker and may slow down the overall computation process. Thus, Refs. [
2,
7,
8] advocate for running distributed SGD without redundant task assignment to the workers.
In [
7], the convergence speed of the algorithm was analyzed in terms of the wall-clock time rather than the number of iterations. It was assumed that the main node waits for
k out of
n workers and ignores the rest. Gradually increasing
k, i.e., gradually decreasing the number of tolerated stragglers as the algorithm evolves, is shown to increase the convergence speed of the algorithm [
8]. In this work, we consider a similar analysis to the one in [
8]; however, instead of assigning tasks to all the workers and ignoring the stragglers, the main node only employs (assigns tasks to) the required number of workers. To learn the speed of the workers and choose the fastest ones, we use ideas from the literature on MABs.
1.1.2. MABs
Since their introduction in [
12], MABs have been extensively studied for decision-making under uncertainty. An MAB strategy is evaluated by its
regret, defined as the difference between the actual cumulative reward and the one that could be achieved should the user know the expected reward of the arms a priori. Refs. [
26,
27] introduced the use of upper confidence bounds (UCBs) based on previous rewards to decide which arm to pull at each iteration. Those schemes are said to be asymptotically optimal since the increase of their regret becomes negligible as the number of iterations goes to infinity.
In [
28], the regret of a UCB algorithm is bounded for a finite number of iterations. Subsequent research aims to improve on this by introducing variants of UCBs, e.g., KL-UCB [
29,
30], which is based on Kullback–Leibler (KL)-divergence. While most of the works assume a finite support for the reward, MABs with unbounded rewards were studied in [
29,
30,
31,
32], where in the latter, the variance factor is assumed to be known. In the class of CMABs, the user is allowed to pull multiple arms with different characteristics at each iteration. The authors of [
13] extended the asymptotically efficient allocation rules of [
26] to a CMAB scenario. General frameworks for the CMAB with bounded reward functions are investigated in [
33,
34,
35,
36]. The analysis in [
37,
38] for linear reward functions with finite support is an extension of the classical UCB strategy and is most closely related to our work.
1.2. Contributions and Outline
Our main contribution is the design of a computation-efficient and communication-efficient distributed learning algorithm through the use of the MAB framework. We apply MAB algorithms from the literature and adapt them to our distributed computing setting. We show that the resulting distributed learning algorithm outperforms state-of-the-art algorithms in terms of computation and communication costs. The costs are measured in terms of the number of ‘worker employments’, whether the results of the corresponding computations carried out by the workers are used by the main node or not. On the other hand, the proposed algorithm requires a longer runtime due to learning the speed of the workers. Parts of the results in this paper were previously presented in [
39].
The rest of the paper is organized as follows. After a description of the system model in
Section 2, in
Section 3, we introduce a round-based CMAB model based on lower confidence bounds (LCBs) to reduce the cost of distributed gradient descent. Our cost-efficient policy increases the number of employed workers as the algorithm evolves. In
Section 4, we introduce and theoretically analyze an LCB that is particularly suited to exponential distributions and requires low computational complexity at the main node. To improve the performance of our CMAB, we investigate in
Section 5 an LCB that is based on KL-divergence, and generalizes to all bounded reward distributions and those belonging to the canonical exponential family. This comes at the expense of a higher computational complexity for the main node. In
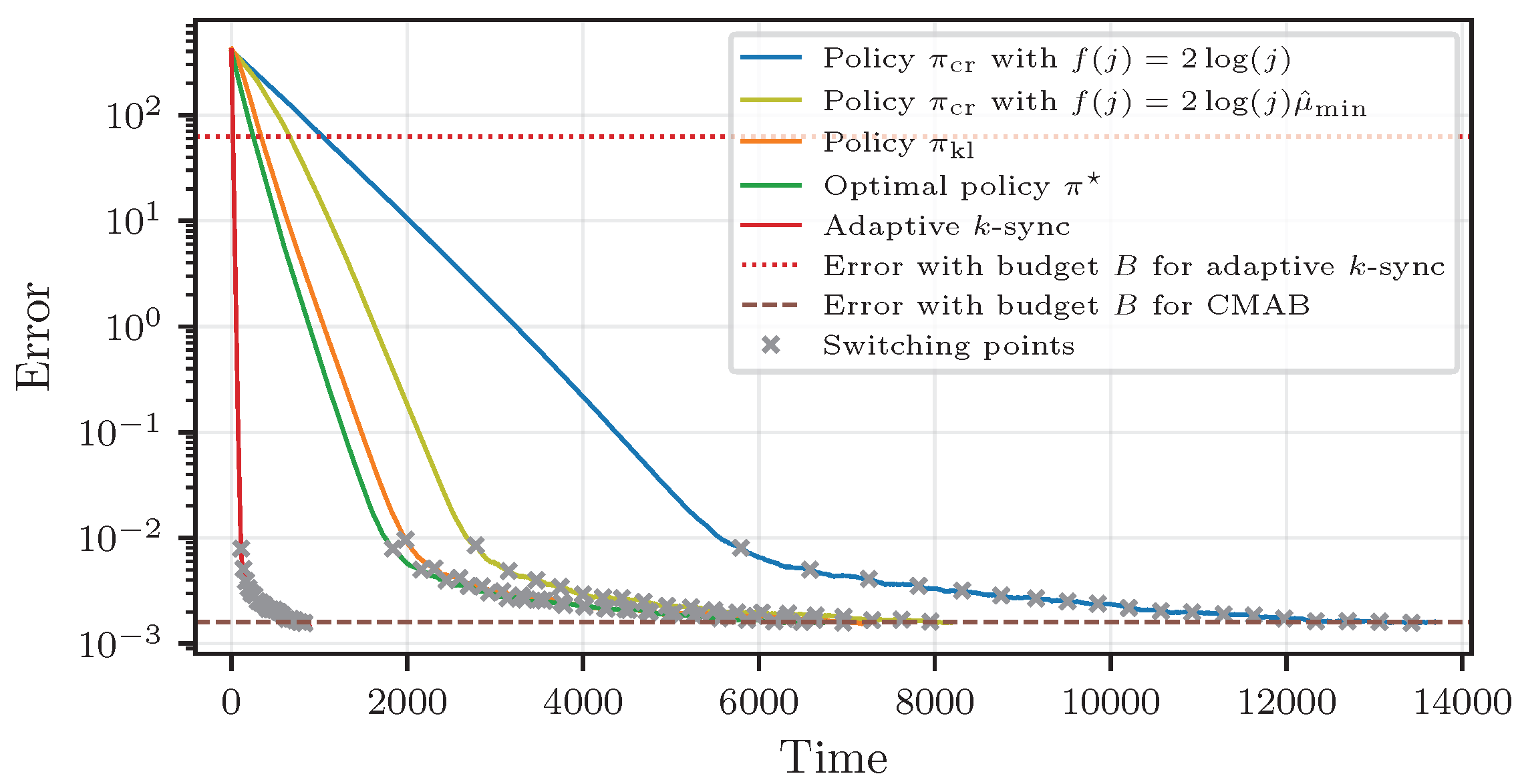
Section 6, we provide simulation results for linear regression to underline our theoretical findings.
Section 8 concludes the paper.
2. System Model and Preliminaries
Notations. Vectors and matrices are denoted in bold lower and upper case letters, e.g., and , respectively. For integers , with , the set is denoted by , and . Sub-gamma distributions are expressed by shape and rate , i.e., , and sub-Gaussian distributions by variance , i.e., . The identity function is 1 if z is true, and 0 otherwise. Throughout the paper, we use the terms arm and worker interchangeably.
We denote by a data matrix with m samples, where each sample , , corresponds to the ℓ-th row of . Let be the vector containing the labels for every sample . The goal is to find a model that minimizes an additively separable loss function , i.e., to find .
We consider a distributed learning model, where a main node possesses the large dataset
, and a set of
n workers available for outsourcing the computations needed to run the minimization. We assume that the dataset
is stored on a shared memory, and can be accessed by all
n workers. The main node employs a distributed variant of the iterative stochastic gradient descent (SGD) algorithm. At each iteration
j, the main node employs some number of workers, indexed by
, to run the necessary computations. More precisely, each worker
will perform the following actions: (i) The worker receives the model
from the main node; (ii) it samples a random subset (batch)
of
, and
of
consisting of
samples (for ease of analysis, we assume that
b divides
m, which can be satisfied by adding all-zero rows to
and corresponding zero labels to
). The size of the subset is constant and fixed throughout the training process; (iii) worker
computes a
partial gradient estimate
based on
and
, as well as the model
, and returns the gradient estimate to the main node. The main node waits for
responsive workers and updates the model
as follows:
where
denotes the learning rate, and by
we denote the set of indices of all samples in
. According to [
7,
40], fixing the value of
and running
j iterations of gradient descent with a mini-batch size of
results in an expected deviation from the optimal loss
, bounded as follows. This result holds under the standard assumptions detailed in [
7,
40], i.e., a Lipschitz-continuous gradient with bounds on the first and second moments of the objective function, characterized by
L and
, respectively, strong convexity with parameter
c, the stochastic gradient being an unbiased estimate, and a sufficiently small learning rate
:
As the number of iterations goes to infinity, the influence of the transient behavior vanishes, and what remains is the contribution of the error floor.
As shown in [
7], algorithms that fix
k throughout the process exhibit a trade-off between the time spent per iteration, the final error achieved by the algorithm, and the number of iterations required to reach that error. The authors show that a careful choice of
k can reduce the total runtime. However,
k need not be fixed throughout the process. Hence, in [
8,
41,
42], the authors study a family of algorithms that change the value of
k as the algorithm progresses in the number of iterations, further reducing the total runtime. The main drawback of all those works is that they employ
n workers at each iteration and only use the computation results of
of them. Thus, resulting in a waste of worker employment. In this work, we tackle the same distributed learning problem, but with a budget constraint
B, measured by the total number of worker employments. Algorithms of [
7,
8,
41,
42] exhaust the budget in
iterations, as they employ
n workers per iteration. On the contrary, we achieve a larger number of iterations by employing the necessary number
k of workers at each iteration and using all their results. We impose the constraint of
for a certain parameter
, i.e., we restrict the number of workers that can be employed in parallel. The main challenge is to choose the fastest
k workers at all iterations to reduce the runtime of the algorithm.
3. CMAB for Distributed Learning
We focus on the interplay between communication/computation costs and the runtime of the algorithm. For a given desired value of the loss to be achieved (cf. (
2), parametrized by a value
), we study the runtime of algorithms constrained by the total number of workers employed. The number of workers employed serves as a proxy for the total communication and computation costs incurred. Our design choices (in terms of increasing
k) stem from the optimization provided in [
8], where the runtime was optimized as a function of
k while neglecting the associated costs. We use a combinatorial multi-armed bandit framework to learn the response times of the workers while using them to run the machine learning algorithm.
We group the iterations into
b rounds, such that at iterations within round
, the main node employs
workers and waits for all of them to respond, i.e.,
. As in [
8], we let each round
r run for a predetermined number of iterations. The number of iterations per round is chosen based on the underlying machine learning algorithm to optimize the convergence behavior.More precisely, at a switching iteration
, the algorithm advances to round
. Algorithms for convergence diagnostics can be used to determine the best possible switching times. For example, the authors of [
8,
42] used Pflug’s diagnostics [
43] to measure the state of convergence by comparing the statistics of consecutive gradients. Improved measures were studied in [
44] and can be directly applied to this setting. Furthermore, established early stopping tools apply; however, studying them is not the focus of this work. We define
, i.e., the algorithm starts in round one, and
is the last iteration, i.e., the algorithm ends in round
b. The total budget
B is defined as
, which gives the total number of worker employments. We use the number of worker employments as a measure of the algorithm’s efficiency, as it directly impacts both computation and communication costs. The goal of this work is to reach the best possible performance with the fewest employments while reducing the total runtime. Since the number of iterations per round is chosen based on the underlying machine learning algorithm,
best arm identification techniques, such as those studied in [
45], are not adequate for this setting. Identifying the best arm in a certain round may require a larger number of iterations, thus delaying the algorithm.
Following the literature on distributed computing [
3,
9,
14,
46], we assume exponentially distributed response times of the workers; that is, the response time
of worker
i in iteration
j, resulting from the sum of communication and computation delays, follows an exponential distribution with rate
and mean
, i.e.,
. The minimum rate of all the workers is
. The goal is to assign tasks only to the
r fastest workers. The assumption of exponentially distributed response times is motivated by its wide use in the literature of distributed computing and storage. However, we note that the theoretical guarantees we will provide hold, with slight modifications, for a much larger class of distributions that exhibit the properties of sub-Gaussian distributions on the left tail, and those of sub-gamma distributions on the right tail. This holds for many heavy-tailed distributions, e.g., the Weibull or the log-normal distribution for certain parameters.
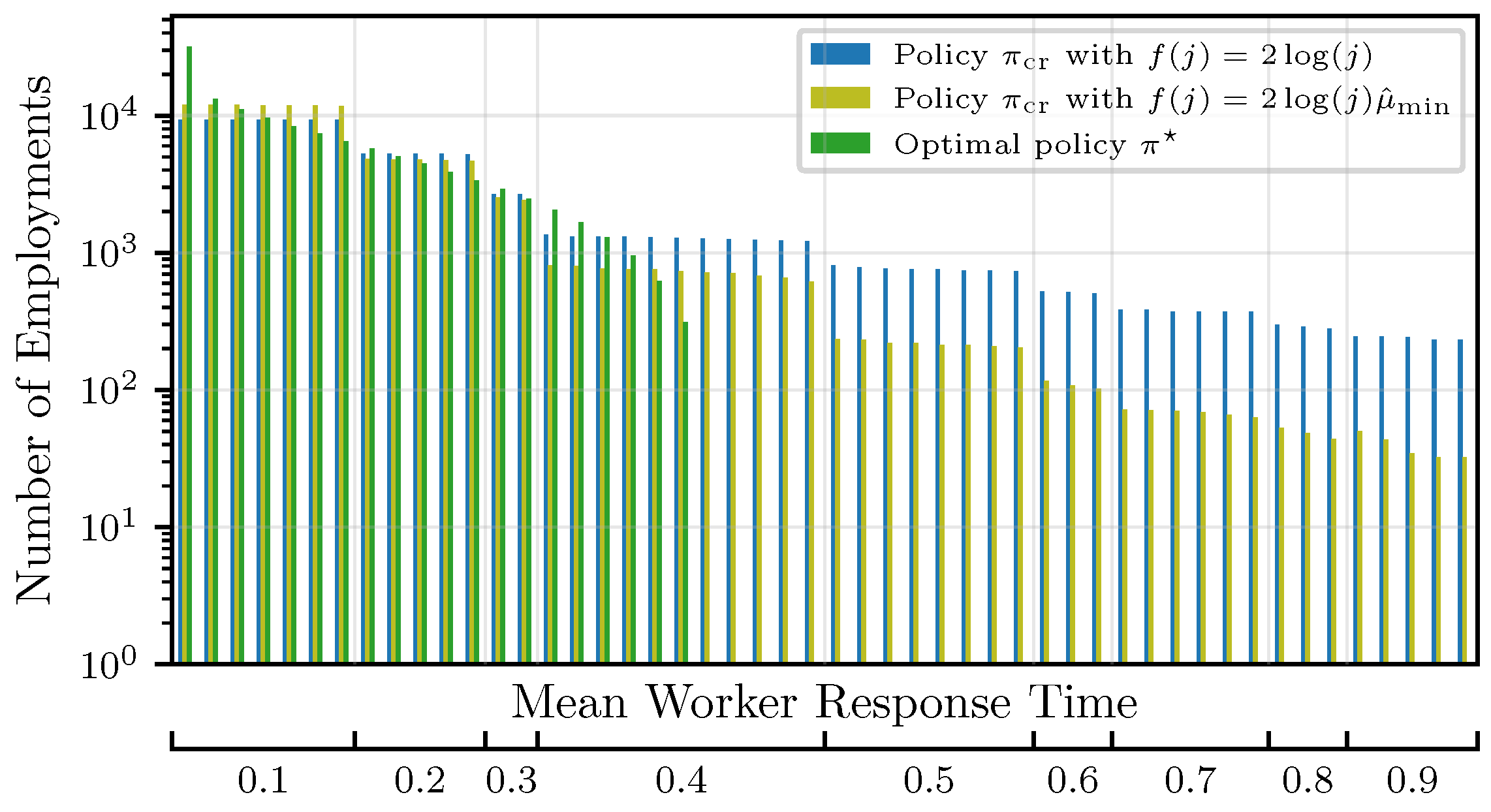
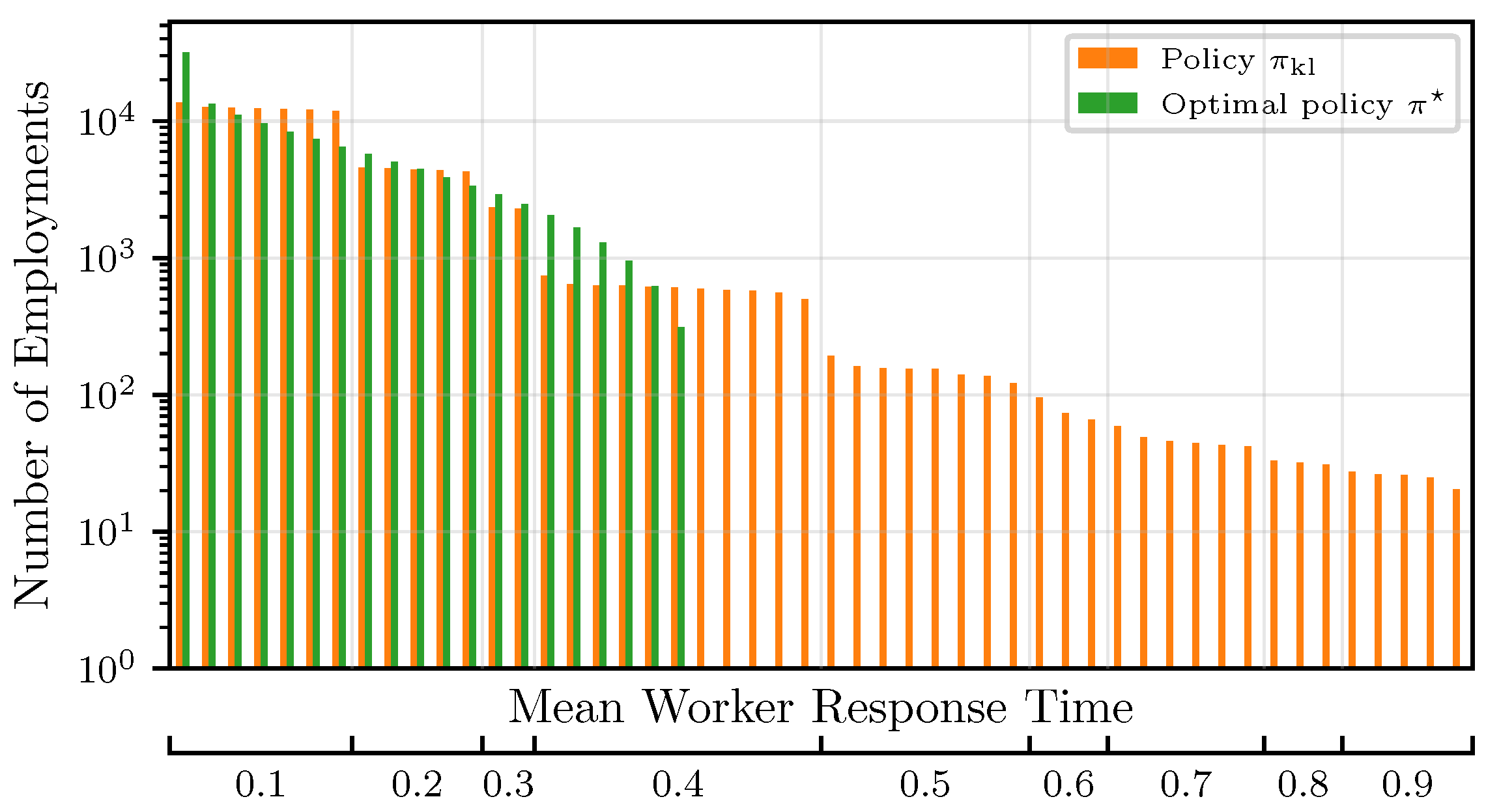
We denote by policy a decision process that chooses the r expected fastest workers. The optimal policy assumes knowledge of the and chooses r workers with the smallest . Rather than fixing a certain value of r throughout the training process, it can be shown that starting with small values of r and gradually increasing the number of concurrently employed workers is beneficial for the algorithm’s convergence, with respect to both time and efficiency, as measured by the number of worker employments. Hence, we choose this policy as a baseline. However, in practice, the s are unknown in the beginning. Thus, our objective is twofold. First, we want to find confident estimates of the mean response times to correctly identify (explore) the fastest workers, and second, we want to leverage (exploit) this knowledge to employ the fastest workers as much as possible, rather than investing in unresponsive/straggling workers.
To trade off this exploration–exploitation dilemma, we utilize the MAB framework, where each arm corresponds to a different worker, and r arms are pulled at each iteration. A superarm with is the set of indices of the arms pulled at iteration j, and is the optimal choice containing the indices of the r workers with the smallest means.
For all workers, indexed with
i, we maintain a counter
for the number of times this worker has been employed until iteration
j, i.e.,
, and a counter
for the sum of its response times, i.e.,
. The LCB of a worker is a measure based on the empirical mean
and the number of samples
chosen such that the true mean
is unlikely to be smaller. As the number of samples grows, the LCB of worker
i approaches
. A policy
is then a rule to compute and update the LCBs of the
n workers, such that at iteration
, the
r workers with the smallest LCBs are pulled. The choice of the confidence bounds significantly affects the performance of the model and will be analyzed in
Section 4 and
Section 5. A summary of the CMAB policy and the steps executed by the workers is given in Algorithm 1.
| Algorithm 1 Combinatorial multi-armed bandit policy |
- 1:
Initialize: : and - 2:
for do ▹ Run (combinatorial) MAB with n arms pulling r at a time - 3:
for do - 4:
calculate - 5:
Choose , i.e., r workers with the minimum where - 6:
Every worker computes a gradient estimate and sends it to the main node - 7:
: Observe response time - 8:
: Update statistics, i.e., , - 9:
Update model according to ( 1) - 10:
end for - 11:
end for
|
Remark 1. Instead of using a CMAB policy, one could consider the following non-combinatorial strategy. At every round, one arm is declared to be the best and is removed from the MAB policy in future rounds. That is, at round r, arms are pulled deterministically, and an MAB policy is used on the remaining arms to determine the next best arm. While this strategy simplifies the analysis, it could result in a linear increase in the regret. The number of iterations per round is decided based on the performance of the machine learning algorithm. This number can be small and may not be sufficient to determine the best arm with high probability. Thus, making the non-combinatorial MAB more likely to commit to sub-optimal arms.
In contrast to most works on MABs, we minimize an unbounded objective, i.e., the overall computation time at iteration j. This corresponds to waiting for the slowest worker. The expected response time of a superarm is then defined as and can be calculated according to Proposition 1.
Proposition 1. The mean of the maximum of independently distributed exponential random variables with different means, indexed by a set , i.e., , , is given as follows:with denoting the power set of . Proposition 2. The variance of the maximum of independently distributed exponential random variables with different means, indexed by a set , i.e., , , is given as follows:with denoting the power set of . Proof. The proof follows similar lines to that of Proposition 1 and is omitted for brevity. □
The suboptimality gap of a chosen (super-)arm describes the expected difference in time compared to the optimal choice.
Definition 1. For a superarm , and for , defined as the set of indices of the r slowest workers, we define the following superarm suboptimality gaps: For , and , denote the indices of the fastest worker in and , respectively. Then, we define the suboptimality gap for the employed
arms as follows: Let denote the set of all superarms with cardinality r. We define the minimum suboptimality gap for all
the arms as follows: Example 1. For mean worker computation times given by , we obtain the following:
Definition 2. We define the regret of a policy π run until iteration j as the expected difference in the runtime of the policy π compared to the optimal policy , i.e., Definition 2 quantifies the overhead in total time spent by
to learn the average speeds of the workers and will be analyzed in
Section 4 and
Section 5 for two different policies, i.e., choices of LCBs. In Theorem 1, we provide a runtime guarantee of an algorithm using a CMAB for distributed learning as a function of the regret
and the number of iterations
j.
Theorem 1. Given a desired , the time until policy π reaches iteration j is bounded from above as follows:with probabilityThe mean and variance can be calculated according to Propositions 1 and 2. The theorem bounds the runtime required by a policy to reach a certain iteration j as a function of the time it takes an optimal policy to reach iteration j (determined by the response time of the optimal arms at each round r), and the regret of the policy that is executed. The regret quantifies the gap to the optimal policy. To give a complete performance analysis, in Proposition 3, we provide a handle on the expected deviation from the optimal loss as a function of the number of iterations j. Combining the results of Theorem 1 and Proposition 3, we obtain a measure on the expected deviation from the optimal loss with respect to time. Proposition 3 is a consequence of the convergence characteristics of the underlying machine learning algorithm, showing the expected deviation from the optimal loss reached at a certain iteration j.
Proposition 3. The expected deviation from the optimal loss at iteration j in round r of an algorithm using CMAB for distributed learning can be bounded by as in (2) for and , where , and for ,with , and . Proof. The statement holds because, at each round
r, the algorithm follows the convergence behavior of an algorithm with a mini-batch of fixed size
. For algorithms with a fixed mini-batch size, we only need the number of iterations run to bound the expected deviation from the optimal loss. However, in round
and iteration
j, the algorithm has advanced differently than with a constant mini-batch of size
. Thus, we need to recursively compute the equivalent number of iterations
that have to be run for a fixed mini-batch of size
to finally apply (
2).
Therefore, we have to compute
, which denotes the iteration for a fixed batch size
with the same error as for a batch size of
at the end of the previous round
, denoted by
. To calculate
, the following condition must hold:
. This can be repeated recursively, until we can use
. For round
, the problem is trivial. Alternatively, one could also use the derivation in [
40], Equation (4.15), and recursively bound the expected deviation from the optimal loss in round
r based on the expected deviation at the end of the previous round
, i.e, use
instead of
. □
In this section, the LCBs are treated as a black box. In
Section 4 and
Section 5, we present two different LCB policies along with their respective performance guarantees.
Remark 2. The explained policies can be seen as an SGD algorithm, which gradually increases the mini-batch size. In the machine learning literature, this is one of the approaches considered to optimize convergence. Alternatively, one could also use b workers with a larger learning rate from the start and gradually decrease the learning rate to trade off the error floor in (2) against runtime. For the variable learning rate approach, one can use a slightly adapted version of our policies, where is fixed. If the goal is to reach a particular error floor, our simulations show that the latter approach achieves this target faster than the former. This, however, only holds under the assumption that the chosen learning rate in (1) is sufficiently small, i.e., the scaled learning rate at the beginning of the algorithm still leads to convergence. However, if one seeks to optimize the convergence speed at the expense of reaching a slightly higher error floor, simulations show that decaying the learning rate is slower because the learning rate is limited to ensure convergence.
Optimally, one would combine both approaches by starting with the maximum possible learning rate, gradually increasing the number of workers per iteration until reaching b, and then decreasing the learning rate to reach the best error floor.
5. KL-Based Policy
The authors of [
29] proposed using a KL-divergence-based confidence bound for MABs to improve the regret compared to classical UCB-based algorithms. Due to the use of KL-divergence, this scheme is applicable to reward distributions that have bounded support or belong to the canonical exponential family. Motivated by this, we extend this model to a CMAB for distributed machine learning, and define a policy
that calculates LCBs according to the following:
where
. This confidence bound, i.e., the minimum value for
q, can be calculated using the Newton procedure for root finding by solving
, and is thus computationally heavy for the main node. For exponential distributions with probability density function
p parametrized by means
and
q, respectively, the KL-divergence is given by
. Its derivative can be calculated as
. With this at hand, the
Newton update is denoted as follows:
Note that must not be equal to . In case , the first update step would be undefined since would be 0. In addition, should be chosen smaller than , e.g., . For this policy , we give the worst-case regret in Theorem 3. To ease the notation, we write .
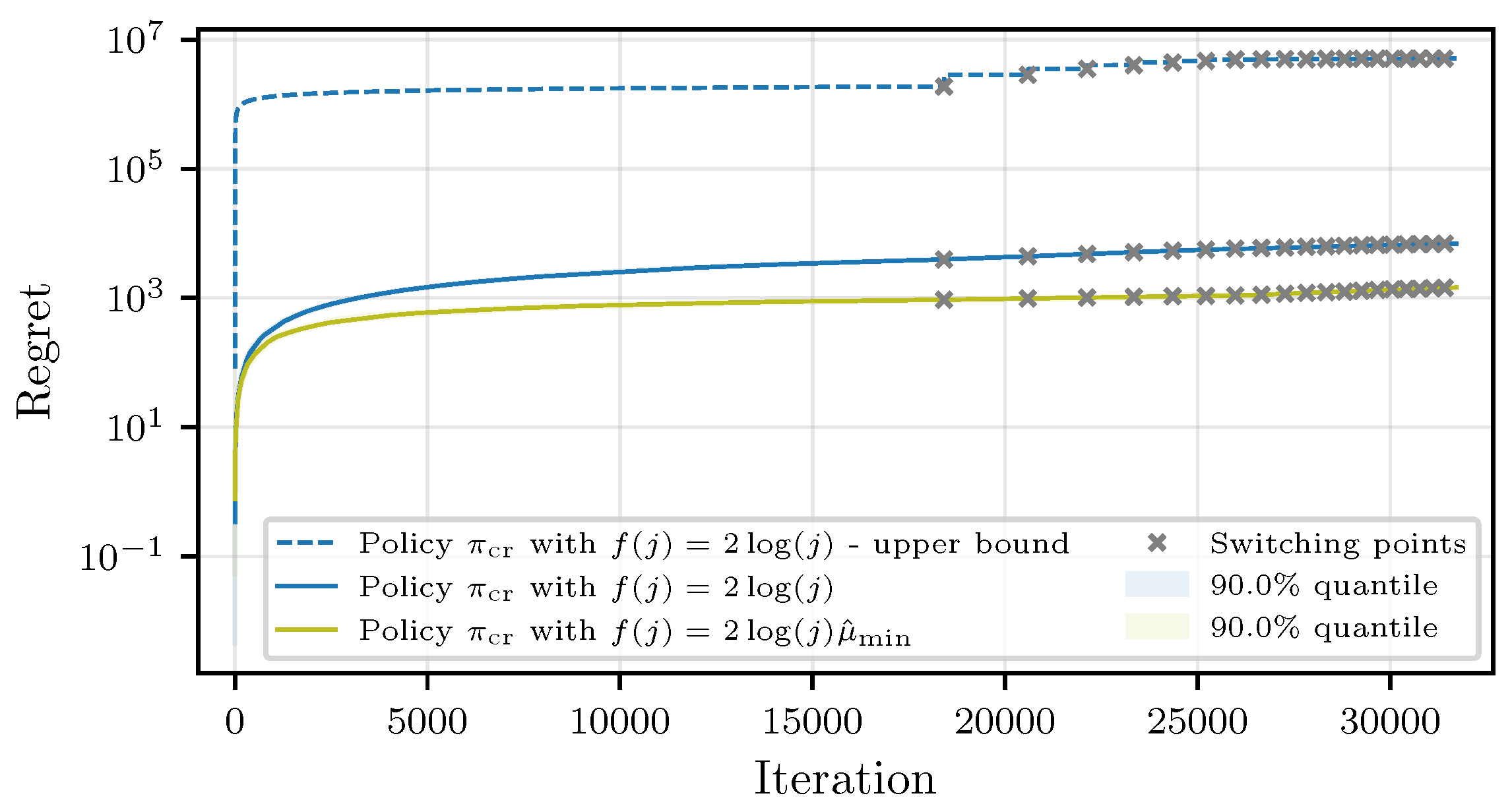
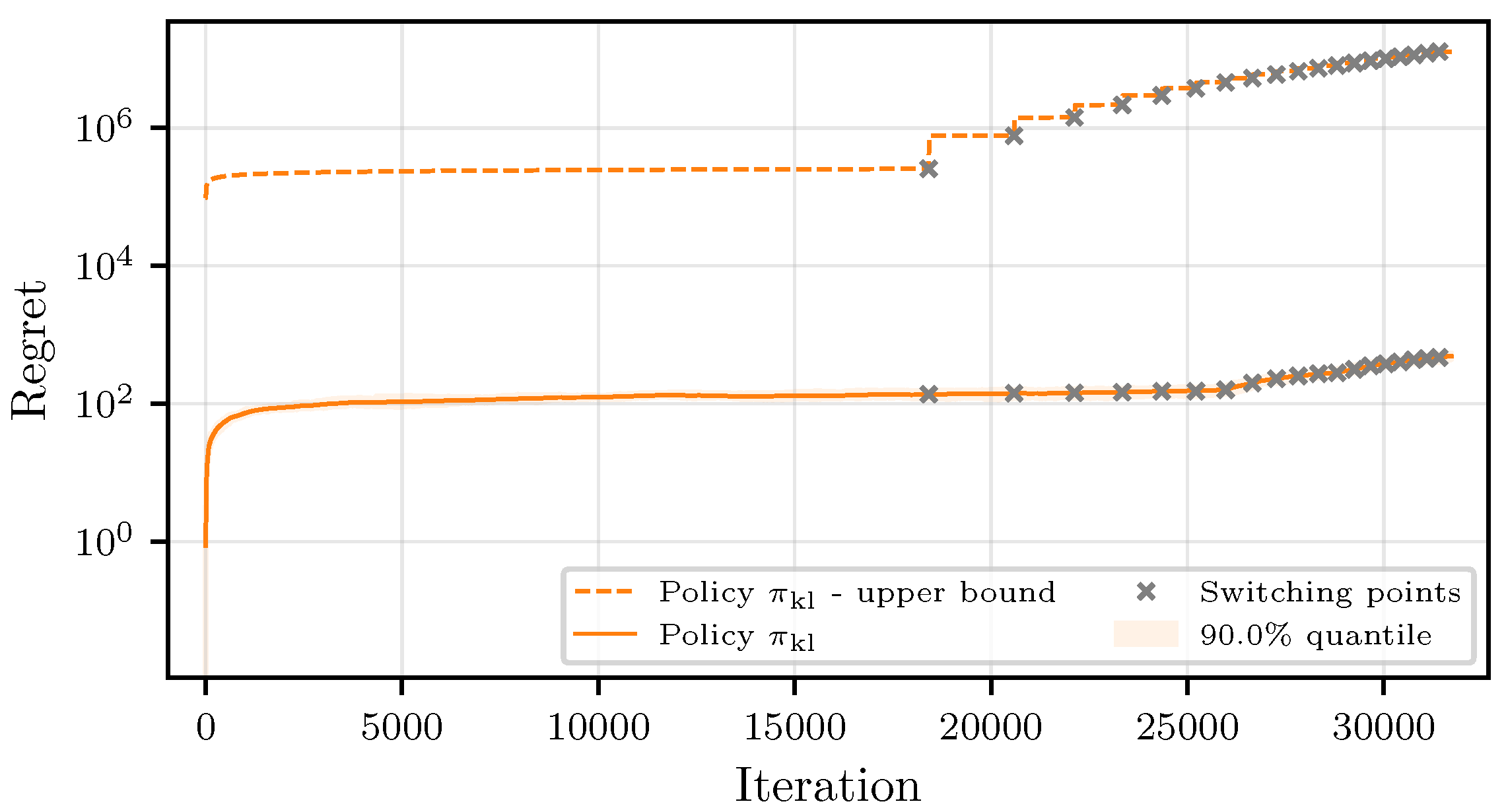
Theorem 3. Let the response times of the workers be sampled from a finitely supported distribution or a distribution belonging to the canonical exponential family. Then, the regret of the CMAB policy , with the gradually increasing superarm size and arms chosen based on a KL-based confidence bound with , , and can be upper-bounded as follows:where ϵ is a parameter that can be freely chosen, and we have the following:with such that . Similar to Theorem 2, the dominating factors of the regret in Theorem 3 depend logarithmically on the number of iterations and linearly on the worst-case suboptimality gap across all superarms up until the round r that corresponds to iteration j. The KL terms reflect the difficulty of the problem of identifying the best possible superarm, dominated by the superarm that is closest to the optimal choice.
Remark 3. The main goal of Theorems 2 and 3 is to show that the expected computation time of such algorithms is bounded, and to study the qualitative behavior of the round-based exploration strategy of the proposed algorithms. The performance for practical applications is expected to be significantly better. Results from [47,48,49] could be used to prove possibly tighter regret bounds, which will be left for future work. Remark 4. Regret lower bounds for non-combinatorial stochastic bandits were established in [26], and later extended to linear and contextual bandits in [50,51], respectively. In the combinatorial setting, lower bounds under general reward functions were studied in [52], revealing the added complexity introduced by combinatorial action spaces. In non-combinatorial problems, the KL-UCB algorithm of [29] is known to match the lower bound of [26] in specific cases. While our algorithm builds on a variant of KL-UCB, the round-dependent structure of our combinatorial bandit setting introduces additional challenges for proving optimality guarantees. Deriving regret lower bounds in such settings remains an open problem. 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}