



Will You Become the Next Troll? A Computational Mechanics Approach to the Contagion of Trolling Behavior



Abstract
1. Introduction
2. Trolling as a Dynamic Communication Process
Predictive State Models
3. Methods
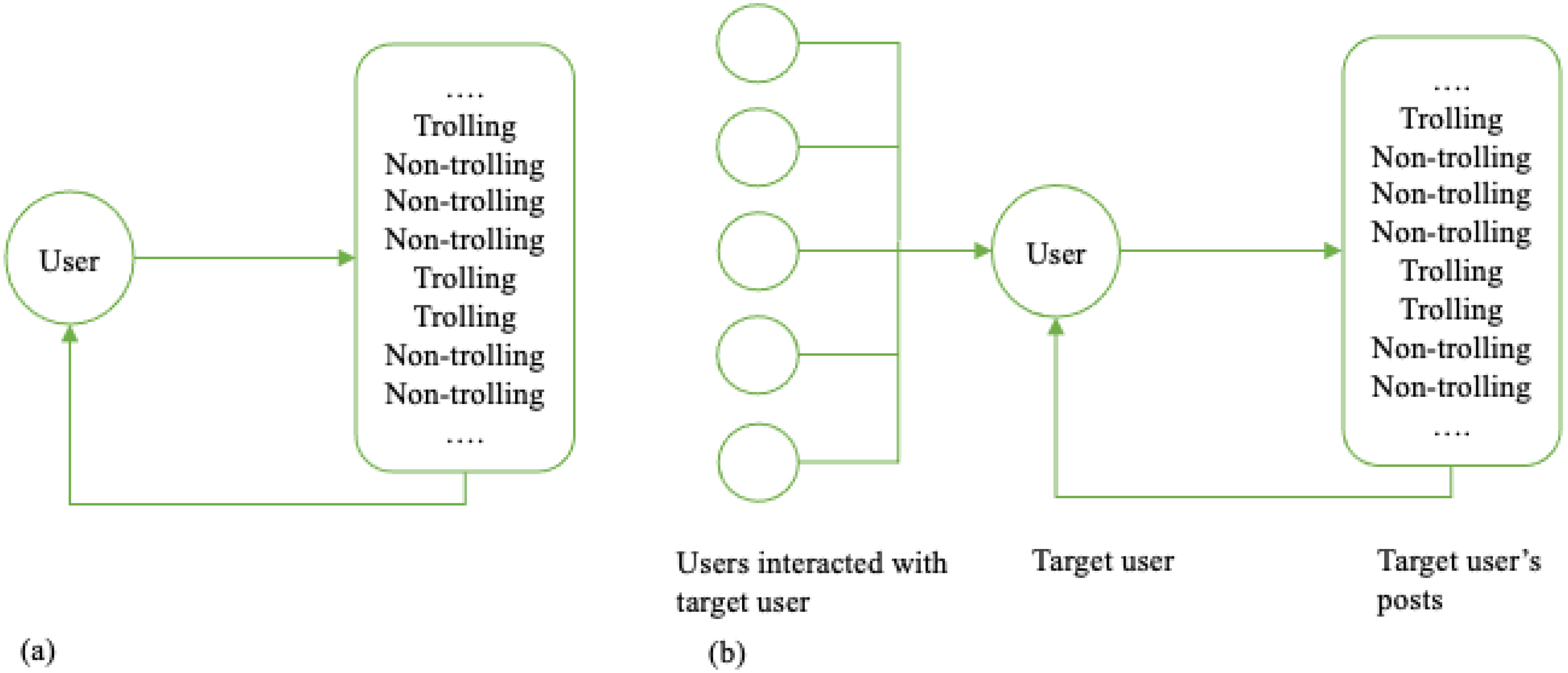
3.1. Data Collection
3.2. Data Annotation and Classification
3.3. Predictive State Model Building
3.4. Measurements
3.4.1. Predictable Information
3.4.2. Predictive Complexity
3.4.3. Remaining Uncertainty
3.4.4. Number of States
3.4.5. Maximum History Length
4. Results
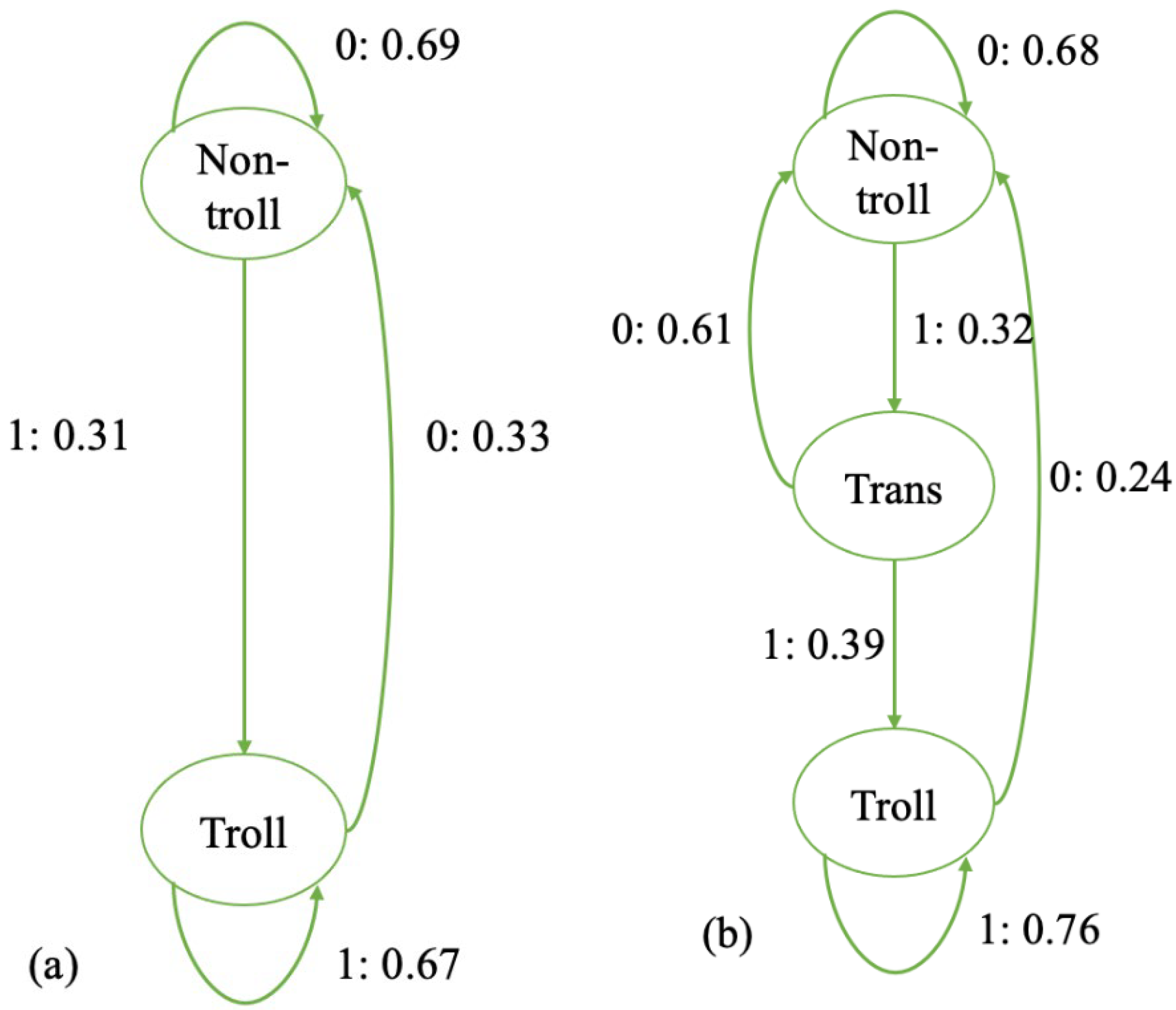
4.1. Self-Driven Models
4.2. Social-Induced Models
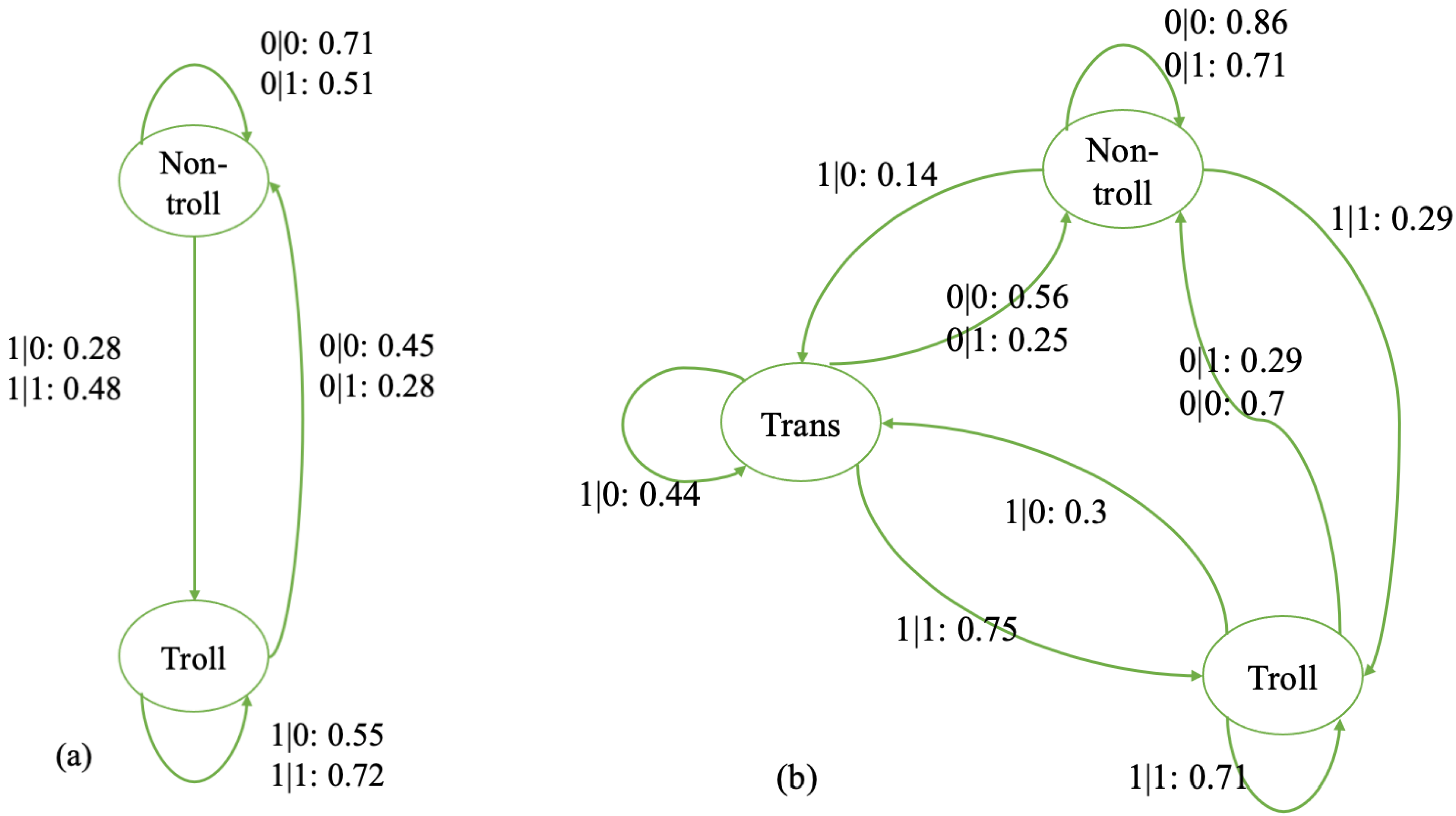
4.3. Self-Driven vs. Social-Induced Models
4.4. Average Machines
5. Discussion
Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Statista. Share of Adult Internet Users in the United States Who Have Personally Experienced Online Harassment as of March 2023. 2024. Available online: https://www.statista.com/statistics/1497946/us-internet-online-harassment-severe/ (accessed on 25 April 2025).
- Velásquez, N.; Leahy, R.; Restrepo, N.J.; Lupu, Y.; Sear, R.; Gabriel, N.; Jha, O.K.; Goldberg, B.; Johnson, N.F. Online hate network spreads malicious COVID-19 content outside the control of individual social media platforms. Sci. Rep. 2021, 11, 11549. [Google Scholar] [CrossRef] [PubMed]
- Shin, J. Morality and Internet Behavior: A study of the Internet Troll and its relation with morality on the Internet. In Proceedings of the Society for Information Technology & Teacher Education International Conference, Las Vegas, NV, USA, 3 March 2008; Association for the Advancement of Computing in Education (AACE): Waynesville, NC, USA, 2008. [Google Scholar]
- Herring, S.; Job-Sluder, K.; Scheckler, R.; Barab, S. Searching for safety online: Managing “trolling” in a feminist forum. Inf. Soc. 2002, 18, 371–384. [Google Scholar] [CrossRef]
- Engelin, M.; De Silva, F. Troll detection: A comparative study in detecting troll farms on Twitter using cluster analysis. Bachelor Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2016. [Google Scholar]
- Coles, B.A.; West, M. Trolling the trolls: Online forum users constructions of the nature and properties of trolling. Comput. Hum. Behav. 2016, 60, 233–244. [Google Scholar] [CrossRef]
- Hardaker, C. Trolling in asynchronous computer-mediated communication: From user discussions to academic definitions. J. Politeness Res. 2010, 6, 215–242. [Google Scholar] [CrossRef]
- Lökk, A.; Hallman, J. Viability of Sentiment Analysis for Troll Detection on Twitter: A Comparative Study Between the Naive Bayes and Maximum Entropy Algorithms. 2016. Available online: https://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-186443 (accessed on 10 March 2025).
- Cook, C.; Conijn, R.; Schaafsma, J.; Antheunis, M. For whom the gamer trolls: A study of trolling interactions in the online gaming context. J. Comput.-Mediat. Commun. 2019, 24, 293–318. [Google Scholar] [CrossRef]
- Poole, M.S. Generalization in process theories of communication. Commun. Methods Meas. 2007, 1, 181–190. [Google Scholar] [CrossRef]
- Shalizi, C.R.; Crutchfield, J.P. Computational mechanics: Pattern and prediction, structure and simplicity. J. Stat. Phys. 2001, 104, 817–879. [Google Scholar] [CrossRef]
- Ellis, D.G.; Fisher, B.A. Phases of conflict in small group development: A Markov analysis. Hum. Commun. Res. 1975, 1, 195–212. [Google Scholar] [CrossRef]
- Fisher, B.A.; Drecksel, G.L. A cyclical model of developing relationships: A study of relational control interaction. Commun. Monogr. 1983, 50, 66–78. [Google Scholar] [CrossRef]
- Cappella, J.N. Talk-silence sequences in informal conversations I. Hum. Commun. Res. 1979, 6, 3–17. [Google Scholar] [CrossRef]
- Thomas, M.; Joy, A.T. Elements of Information Theory; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Fogel, A. Dynamic systems research on interindividual communication: The transformation of meaning-making. J. Dev. Process. 2006, 1, 7–30. [Google Scholar]
- Komaç, G.; Çağıltay, K. An overview of trolling behavior in online spaces and gaming context. In Proceedings of the 2019 1st International Informatics and Software Engineering Conference (UBMYK), Ankara, Turkey, 6–7 November 2019; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Clarke, I. Functional linguistic variation in Twitter trolling. Int. J. Speech Lang. Law 2019, 26, 57–84. [Google Scholar] [CrossRef]
- Breeze, M. The Problems with Anonymous Trolls and Accountability in the Digital Age. 2012. Available online: https://thenextweb.com/insider/2012/10/27/the-problems-with-anonymous-trolls-and-accountability-in-the-digital-age/ (accessed on 10 March 2025).
- Donath, J.S. Identity and deception in the virtual community. In Communities Cyberspace; Routledge: Abingdon-on-Thames, UK, 2002; pp. 37–68. [Google Scholar]
- Bergstrom, K. “Don’t feed the troll”: Shutting down debate about community expectations on Reddit.com. First Monday 2011, 16, 8. [Google Scholar] [CrossRef]
- Merritt, E. An analysis of the Discourse of Internet Trolling: A Case Study of Reddit.com. Bachelor’s thesis, Mount Holyoke College, South Hadley, MA, USA, 2012. [Google Scholar]
- Nevin, A.D. Cyber-Psychopathy: Examining the Relationship Between Dark E-Personality and Online Misconduct. Master’s Thesis, The University of Western Ontario, London, ON, Canada, 2015. [Google Scholar]
- Cook, C.L. Between a troll and a hard place: The demand framework’s answer to one of gaming’s biggest problems. Media Commun. 2019, 7, 176–185. [Google Scholar] [CrossRef]
- Fichman, P.; Sanfilippo, M.R. Online Trolling and Its Perpetrators: Under the Cyberbridge; Rowman & Littlefield: Lanham, MD, USA, 2016. [Google Scholar]
- Cheng, J.; Bernstein, M.; Danescu-Niculescu-Mizil, C.; Leskovec, J. Anyone can become a troll: Causes of trolling behavior in online discussions. In Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing, Portland, ON, USA, 25 February–1 March 2017. [Google Scholar]
- Buckels, E.E.; Trapnell, P.D.; Paulhus, D.L. Trolls just want to have fun. Personal. Individ. Differ. 2014, 67, 97–102. [Google Scholar] [CrossRef]
- Craker, N.; March, E. The dark side of Facebook®: The Dark Tetrad, negative social potency, and trolling behaviours. Personal. Individ. Differ. 2016, 102, 79–84. [Google Scholar] [CrossRef]
- Raine, A. Annotation: The role of prefrontal deficits, low autonomic arousal, and early health factors in the development of antisocial and aggressive behavior in children. J. Child Psychol. Psychiatry 2002, 43, 417–434. [Google Scholar] [CrossRef]
- Cinelli, M.; Pelicon, A.; Mozetič, I.; Quattrociocchi, W.; Novak, P.K.; Zollo, F. Dynamics of online hate and misinformation. Sci. Rep. 2021, 11, 22083. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Information theory and statistics. Elem. Inf. Theory 1991, 1, 279–335. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Entropy per unit time as a metric invariant of automorphisms. Dokl. Russ. Acad. Sci. 1959, 124, 754–755. [Google Scholar]
- Sinai, Y. Kolmogorov-sinai entropy. Scholarpedia 2009, 4, 2034. [Google Scholar] [CrossRef]
- Shannon, C.E. Prediction and entropy of printed English. Bell Syst. Tech. J. 1951, 30, 50–64. [Google Scholar] [CrossRef]
- Crutchfield, J.P. The calculi of emergence: Computation, dynamics and induction. Phys. D Nonlinear Phenom. 1994, 75, 11–54. [Google Scholar] [CrossRef]
- Crutchfield, J.P. The origins of computational mechanics: A brief intellectual history and several clarifications. arXiv 2017, arXiv:1710.06832. [Google Scholar]
- Crutchfield, J.P.; Young, K. Inferring statistical complexity. Phys. Rev. Lett. 1989, 63, 105. [Google Scholar] [CrossRef]
- Darmon, D. Statistical Methods for Analyzing Time Series Data Drawn from Complex Social Systems. Ph.D. Thesis, University of Maryland, College Park, MD, USA, 2015. [Google Scholar]
- Crutchfield, J.P. Between order and chaos. Nat. Phys. 2012, 8, 17–24. [Google Scholar] [CrossRef]
- Barnett, N.; Crutchfield, J.P. Computational Mechanics of Input–Output Processes: Structured Transformations and the ϵ-Transducer. J. Stat. Phys. 2015, 161, 404–451. [Google Scholar] [CrossRef]
- Levy, D.A.; Nail, P.R. Contagion: A theoretical and empirical review and reconceptualization. Genet. Soc. Gen. Psychol. Monogr. 1993, 119, 233–284. [Google Scholar]
- Tsvetkova, M.; Macy, M. The social contagion of antisocial behavior. Sociol. Sci. 2015, 2, 36–49. [Google Scholar] [CrossRef]
- Eisenberg, D.; Golberstein, E.; Whitlock, J.L.; Downs, M.F. Social contagion of mental health: Evidence from college roommates. Health Econ. 2013, 22, 965–986. [Google Scholar] [CrossRef] [PubMed]
- Hatfield, E.; Cacioppo, J.T.; Rapson, R.L. Emotional contagion. Curr. Dir. Psychol. Sci. 1993, 2, 96–100. [Google Scholar] [CrossRef]
- Wood, W. Attitude change: Persuasion and social influence. Annu. Rev. Psychol. 2000, 51, 539–570. [Google Scholar] [CrossRef]
- Wheeler, L. Toward a theory of behavioral contagion. Psychol. Rev. 1966, 73, 179. [Google Scholar] [CrossRef]
- Young, H.P. Innovation diffusion in heterogeneous populations: Contagion, social influence, and social learning. Am. Econ. Rev. 2009, 99, 1899–1924. [Google Scholar] [CrossRef]
- Herrando, C.; Constantinides, E. Emotional contagion: A brief overview and future directions. Front. Psychol. 2021, 12, 712606. [Google Scholar] [CrossRef]
- Ekman, P.; Levenson, R.W.; Friesen, W.V. Autonomic nervous system activity distinguishes among emotions. Science 1983, 221, 1208–1210. [Google Scholar] [CrossRef]
- Kramer, A.D.; Guillory, J.E.; Hancock, J.T. Experimental evidence of massive-scale emotional contagion through social networks. Proc. Natl. Acad. Sci. USA 2014, 111, 8788–8790. [Google Scholar] [CrossRef]
- Huesmann, L.R.; Eron, L.D. Cognitive processes and the persistence of aggressive behavior. Aggress. Behav. 1984, 10, 243–251. [Google Scholar] [CrossRef]
- Hilvert-Bruce, Z.; Neill, J.T. I’m just trolling: The role of normative beliefs in aggressive behaviour in online gaming. Comput. Hum. Behav. 2020, 102, 303–311. [Google Scholar] [CrossRef]
- Beres, N.A.; Frommel, J.; Reid, E.; Mandryk, R.L.; Klarkowski, M. Don’t you know that you’re toxic: Normalization of toxicity in online gaming. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021. [Google Scholar]
- Shen, C.; Sun, Q.; Kim, T.; Wolff, G.; Ratan, R.; Williams, D. Viral vitriol: Predictors and contagion of online toxicity in World of Tanks. Comput. Hum. Behav. 2020, 108, 106343. [Google Scholar] [CrossRef]
- Sipser, M. Introduction to the Theory of Computation. ACM Sigact News 1996, 27, 27–29. [Google Scholar] [CrossRef]
- Statista. Most Popular Social Networks Worldwide as of January 2023, Ranked by Number of Monthly Actuve Users. 2023. Available online: https://www.statista.com/statistics/272014/global-social-networks-ranked-by-number-of-users/ (accessed on 14 February 2023).
- Reddit. Reddit Policy. 2021. Available online: https://www.reddithelp.com/hc/en-us/categories/360003246511-Privacy-Security (accessed on 2 September 2021).
- Fleiss, J.L.; Levin, B.; Paik, M.C. The measurement of interrater agreement. Stat. Methods Rates Proportions 1981, 2, 22–23. [Google Scholar]
- Sun, Q.; Wojcieszak, M.; Davidson, S. Over-Time Trends in Incivility on Social Media: Evidence From Political, Non-Political, and Mixed Sub-Reddits Over Eleven Years. Front. Political Sci. 2021, 3, 130. [Google Scholar] [CrossRef]
- Sun, Q.; Shen, C. Who would respond to A troll? A social network analysis of reactions to trolls in online communities. Comput. Hum. Behav. 2021, 121, 106786. [Google Scholar] [CrossRef]
- Davidson, S.; Sun, Q.; Wojcieszak, M. Developing a New Classifier for Automated Identification of Incivility in Social Media. In Proceedings of the Fourth Workshop on Online Abuse and Harms, Online, 20 November 2020. [Google Scholar]
- Crutchfield, J.P.; Ellison, C.J.; Mahoney, J.R. Time’s barbed arrow: Irreversibility, crypticity, and stored information. Phys. Rev. Lett. 2009, 103, 094101. [Google Scholar] [CrossRef]
- Darmon, D.; Sylvester, J.; Girvan, M.; Rand, W. Predictability of user behavior in social media: Bottom-up v. In top-down modeling. In Proceedings of the 2013 International Conference on Social Computing, Washington, DC, USA, 8–14 September 2013; IEEE: New York, NY, USA, 2013. [Google Scholar]
- Hilbert, M.; Darmon, D. How complexity and uncertainty grew with algorithmic trading. Entropy 2020, 22, 499. [Google Scholar] [CrossRef]
- Hilbert, M.; Darmon, D. Large-scale communication is more complex and unpredictable with automated bots. J. Commun. 2020, 70, 670–692. [Google Scholar] [CrossRef]
- Grassberger, P. Toward a quantitative theory of self-generated complexity. Int. J. Theor. Phys. 1986, 25, 907–938. [Google Scholar] [CrossRef]
- Crutchfield, J.P.; Feldman, D.P. Statistical complexity of simple one-dimensional spin systems. Phys. Rev. E 1997, 55, R1239. [Google Scholar] [CrossRef]
- Bialek, W.; Nemenman, I.; Tishby, N. Predictability, complexity, and learning. Neural Comput. 2001, 13, 2409–2463. [Google Scholar] [CrossRef] [PubMed]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Munkres, J. Algorithms for the assignment and transportation problems. J. Soc. Ind. Appl. Math. 1957, 5, 32–38. [Google Scholar] [CrossRef]
- Ybarra, M.L.; Mitchell, K.J.; Wolak, J.; Finkelhor, D. Examining characteristics and associated distress related to Internet harassment: Findings from the Second Youth Internet Safety Survey. Pediatrics 2006, 118, e1169–e1177. [Google Scholar] [CrossRef] [PubMed]
- Suler, J. The online disinhibition effect. Cyberpsychol. Behav. 2004, 7, 321–326. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Effect | F | ||
|---|---|---|---|
| Number of States | 17.973 | *** | |
| 3.539 | |||
| Number of States | 0.003 | ||
| 1.878 | |||
| Number of States | 20.198 | *** | |
| 8.405 | ** |
| Effect | F | ||
|---|---|---|---|
| Number of States | 61.016 | *** | |
| 19.442 | *** | ||
| Number of States | 21.853 | *** | |
| 5.265 | * | ||
| Number of States | 79.270 | *** | |
| 28.973 | *** |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Q.; Hilbert, M. Will You Become the Next Troll? A Computational Mechanics Approach to the Contagion of Trolling Behavior. Entropy 2025, 27, 542. https://doi.org/10.3390/e27050542
Sun Q, Hilbert M. Will You Become the Next Troll? A Computational Mechanics Approach to the Contagion of Trolling Behavior. Entropy. 2025; 27(5):542. https://doi.org/10.3390/e27050542
Chicago/Turabian StyleSun, Qiusi, and Martin Hilbert. 2025. "Will You Become the Next Troll? A Computational Mechanics Approach to the Contagion of Trolling Behavior" Entropy 27, no. 5: 542. https://doi.org/10.3390/e27050542
APA StyleSun, Q., & Hilbert, M. (2025). Will You Become the Next Troll? A Computational Mechanics Approach to the Contagion of Trolling Behavior. Entropy, 27(5), 542. https://doi.org/10.3390/e27050542