1. Introduction
In our epoch, huge amounts of data are continuously stored and processed to extract relevant information. Artificial intelligence [
1] is increasingly being used with this goal in mind, but the results, although helpful in the short term, are opaque and do not directly provide insight on why given phenomena are actually occurring. Here, we address this problem in the context of time series [
2], a subject of crucial relevance in many scientific areas: from medical signals (ECG, EEG, MEG), to the functioning of mechanical devices, weather forecasts, and so on [
3].
The starting point is the representation of a time series as a sequence of ordinal patterns [
4], built without paying attention to the actual values of the recorded variable, but taking into account only the mutual ordering. This is the core of the approach introduced by Bandt and Pompe [
5], who proposed quantifying the complexity of a signal in terms of the so-called permutation entropy (PE). The first step consists of building a sequence of
m-dimensional vectors
out of a given scalar time series
by using the embedding approach proposed long ago by Takens [
6]. In the ordinal pattern context, Cao et al. [
7] proposed to build the vectors by assembling equispaced sampled variables,
, where the lag
L is any integer ⩾ 1. The vector
is then encoded as a symbolic sequence (permutation)
, henceforth also referred to as a word, where the integer
belongs, like the index
j, to the range
and corresponds to the rank, from the smallest to the largest, of
within
.
As a result, the initial time series is transformed into a sequence of words. The corresponding PE, evaluated as the Shannon entropy [
8] of the word frequencies, is typically used as an indicator of the underlying unpredictability. The resulting indicator has been implemented to address many different classes of signals and classify their complexity [
9], reveal changes in the dynamics [
7], identify elements of determinism [
10,
11,
12].
Interestingly, it has been shown that for large enough partition order
m, i.e., the length of the windows used for the encoding, the PE is a proxy of the Kolmogorov–Sinai entropy, though typically being an overestimate thereof [
13]. A strength of the method is that it does not require an explicit partitioning of the phase space, a task that is indeed unavoidably system-dependent and thus represents an additional burden. However, the implicit partitioning induced by the grouping of trajectories in different ordinal patterns also represents a weakness, since it washes out possibly relevant differences between equally coded trajectories. For a not-too-large
m, it might happen that hidden deterministic degrees of freedom are not resolved, or that a correlated noise induces pseudo-deterministic restrictions to the multiplicity of observable sequences. In order to shed light on those controversial effects, here we propose to complement the symbolic encoding with an inverse procedure to reconstruct a time series akin to the original one. The reliability of the method will directly confirm or disprove the correctness of the initial encoding.
The approach described and implemented in this paper is an elaboration of the method proposed by Small [
14] and further explored in [
15,
16]. A first difference is in the procedure we propose for the construction of a recurrent network that is as insensitive as possible to the presence of observational noise. The underlying idea is a careful selection of words whose probability can be determined in a statistically reliable way. This approach, implemented for the Hénon map [
17], can be seen as a process of hierarchical clustering [
18].
A second difference is the way time series are eventually reconstructed: suitably attributing weights to the words leads to a more accurate reconstruction. As a result, a simple protocol is defined, based on a Markov approximation. While we do not argue that this approach should replace standard methods like spectral analysis, or the identification of suitable sets of ordinary differential equations, we claim it to be a powerful tool that can profitably complement the existing methods.
The paper is organized as follows. The direct encoding in terms of symbolic sequences as well as the generation of an approximating Markov model is discussed in
Section 2. The inverse procedure, namely the reconstruction of the deterministic dynamics out of the Markov model, is the topic of
Section 3.
Section 4 describes the application of the method to the prototypical example of a time series generated by the Hénon map, also when it is contaminated by observational noise. Remaining open problems are outlined in the final
Section 5.
2. Direct Encoding
As mentioned above, the lag L can, in general, be any strictly positive integer number, though it is surely inconvenient to assume it so large that the resulting words would be essentially indistinguishable from a random process (in the presence of chaos), a phenomenon also known as irrelevance. Here, since we deal with a discrete-time map, we set , a choice able to capture the nonlinearities, while minimizing the folding effects that tend to hide the underlying determinism.
Setting the partition order to a value
m, and assuming the input time series, or signal, to be sufficiently long, we identify all observed words and their probabilities from the respective frequencies along the signal itself. The words are then ranked according to their probability. Let
denote the probability of the
k-th most probable word
, i.e.,
. The words can be interpreted as the nodes of a network, and the original signal as a path on the network itself [
14]. The directed connections among the nodes are the transitions
, also known as edges or links, observed while scanning the time series. Even in the most stochastic system, there are at most
m different links departing from a given node
. This limit to diversity comes from the obvious requirement that, in the trajectory encoded as
, the last
values are, by construction, the same as the first
values of the next trajectory, encoded as
; their mutual ordering must be the same. Additionally, determinism and correlations further reduce the number of actual connections.
Irrespective of whether the original system is deterministic—and possibly chaotic—or stochastic, the path on the network is probabilistic. Our next goal is to generate sequences akin to the original one, under the approximation of a Markov process of unitary memory, i.e., a Markov chain. More accurate representations could be implemented, but since we want to test the meaningfulness of our whole approach, we define a procedure that is as simple as reasonably possible.
In order to produce a Markov process, it is necessary (and sufficient) to determine the rate
of the transition from each
to each
. The next step consists of simplifying the model by removing effectively improbable and therefore negligible transitions. The core motivation of this approach is the development of a reconstruction procedure that might also work in the presence of a weak observational noise (see, for example, [
19]), which leads to the appearance of several spurious low-probability nodes.
Deciding that the irrelevant nodes are those whose probability is smaller than some threshold is too naive an idea, since the supposedly relevant nodes are not necessarily arranged in a recurrent network. Hence, we propose to start ordering the transition frequencies, from the most to the least populated one, then scanning the list, and progressively including the items into a new list until the transitions produce a recurrent network that contains a single ergodic component. More precisely, since each transition is, by definition, a transition from a starting (S) to an arrival (A) node, two separate catalogs of S and A nodes are built; the procedure goes on until these two lists coincide. In fact, a minimal necessary condition for a network to be recurrent is that each node is both a potential starting and an arrival point of a network path. Since this condition is not sufficient to ensure the presence of a single ergodic component, it is necessary to check whether this is true; in all simulations, we have not found a single exception. In the end, we are at least sure that the associated stochastic process is well defined.
As a last step in the construction of a minimal Markov model, we renormalize the probabilities
and the frequencies
upon removing the excluded ones; henceforth, for the sake of simplicity, we keep the same notations. The transition probabilities can thus be estimated as
Let be the number of nodes that make up the recurrent network, and M the stochastic matrix describing it: . It is also convenient to define as the number of links, which corresponds to the number of nonzero elements of M.
3. Inverse Procedure
As already mentioned, even in low-dimensional chaos, the symbolic representation is an intrinsically stochastic process. The question is to what extent is it possible to retrieve the information content of the initial signal, thereby revealing its deterministic nature, if any. Pursuing this goal, we henceforth consider a sequence of words randomly generated according to the approximating Markov process defined above: for any n, , where the index k takes on an integer value between 1 and .
In the direct encoding, the same word is shared by trajectories exhibiting the same temporal pattern, regardless of the actual values of the recorded variable. Let be the set of all trajectories that are encoded as : . Whenever the dispersion within , i.e., the fluctuations among the components of the trajectories encoded by the same word , is sufficiently small, it looks plausible that a faithful copy of the original signal can be reproduced.
Let , where, for each , , represent the average sample trajectory encoded by the word . Similarly, let denote the standard deviation of the j-th component of the average trajectory.
In ref. [
13], it was found that the
’s progressively decrease upon increasing the length
m; this is an indirect indication that the encoding provides an asymptotically unique representation of the dynamics, or equivalently that the underlying partition of the phase space is a generating one. However, the decrease in
upon increasing
m is true also for white-noise signals (once a set of
m randomly generated numbers are ranked, the fluctuation of the actual value of the set’s
k-th element decreases as
m is increased). Hence, it is not a priori obvious whether a given encoding can provide a sufficiently accurate description of the time series. In
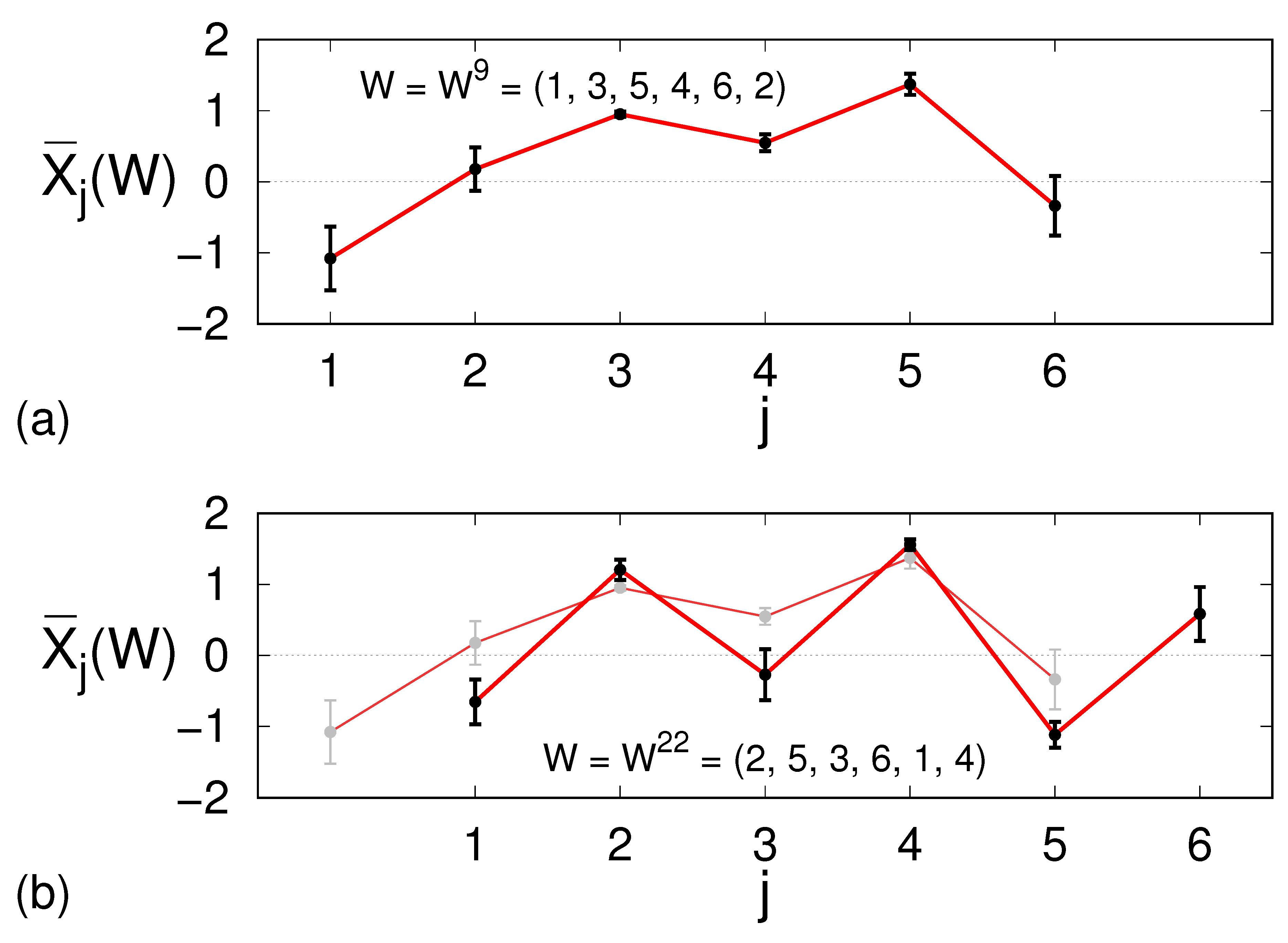
Figure 1a, for the Hénon map
with
and
, we show an instance of an average trajectory with
, namely the one corresponding to the word
, as well as the relative spreading.
The relatively small
values encourage us to interpret, for example,
as the value
of a synthetic time series to be associated to the word
. There is, however, a problem. As apparent in
Figure 1b, where the average trajectories
are displayed for two consecutive words, we can see that the last five values of the first averaged trajectory do not coincide with the first five of the following one. A reasonable way to cope with this uncertainty is to define the synthetic value
as the average over all possible expected values as
Furthermore, mimicking the evaluation of the sample mean of a non-homoscedastic set of samples, an improved reconstruction rule reads
where the previous rule corresponds to
. In this last expression, one would set
if the samples were normally distributed. As this is typically not the case for the situation at hand, we opted for the less strict value
. Some tests (see the discussion below on the PE values) showed that the use of the reciprocal standard deviations (
) instead of the reciprocal variances (
) as weights indeed provides a good compromise.
Finally, it is important to note that, once the Markov transition matrix
M is given, the proposed decoding procedure unavoidably yields a finite number
of points in the original phase space. Provided that all terms of the sum in the numerator of Equation (
2) are different from one another, the “density”
turns out to be equal to the number of possible
m-tuples
,
, …,
that are generated by the Markov process (here
n can be any number), or equivalently, the number of possible
m-tuples
, where
,
.
Altogether,
can be obtained as follows. Let
be a Boolean matrix whose elements
are equal to 1 if the transition
exists, or equal to 0 if it is forbidden. If
,
. Considering
, an
m-tuple
exists if
It is then straightforward to show that
We expect that, the larger the
m, the more densely the
points fill the phase space (see, for example, the values reported in the rightmost column of
Table 1 below).
4. A Prototypical Example: Hénon Map
To test the performance of the method, we applied it to a time series of
points generated by the Hénon map described by Equation (
1) and using three different values of
m:
,
,
. In addition, we analyzed, with
, the Hénon map perturbed by observational noise: a perturbed time series is obtained by adding to each value
a realization of a continuous random variable uniformly distributed in the range
, thus having a standard deviation
.
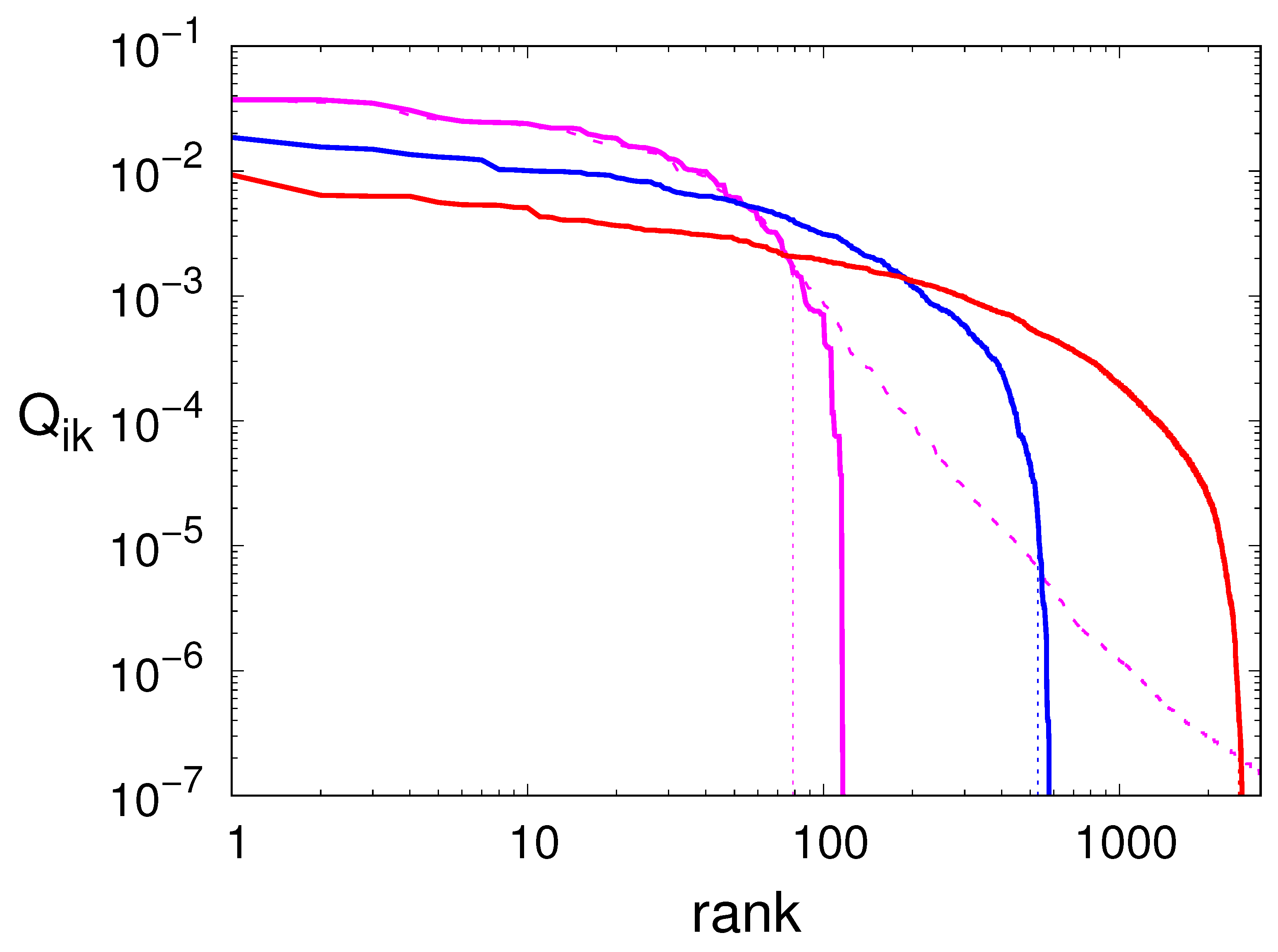
In
Figure 2, we plot the frequencies
of all transitions for the deterministic model, ranked in decreasing order (see the solid curves). The vertical logarithmic scale reveals a large dispersion of the actual values, which cover several decades. This upholds the argument that it should be legitimate to neglect the least probable transitions. The horizontal logarithmic scale, instead, reveals an exponential growth with
m of the number of transitions: a manifestation of the topological entropy of this dynamical system.
The procedure discussed in the previous section shows that, in the case
, the smallest recurrent network involves
nodes out of 65 observed while scanning a time series of
points, and
transitions out of 120 observed ones (see
Table 1). The vertical dotted line in
Figure 2 shows the location of the critical point which represents the border of the interval of “acceptable” transitions. The fraction of discarded transitions is therefore about 21%, whereas the discarded mass is just 2.5%: a very small number indeed. The reported numbers reveal the sparsity of the stochastic matrices used in the Markov approximations. Notice also that the fraction of nodes used for the reconstruction of the signal tends to grow for increasing
m, indicating that more of them become essential.
Next, we let the associated Markov process evolve so as to generate a sequence
of synthetic words, which are afterwards decoded to generate the corresponding
sequence according to Equation (
2).
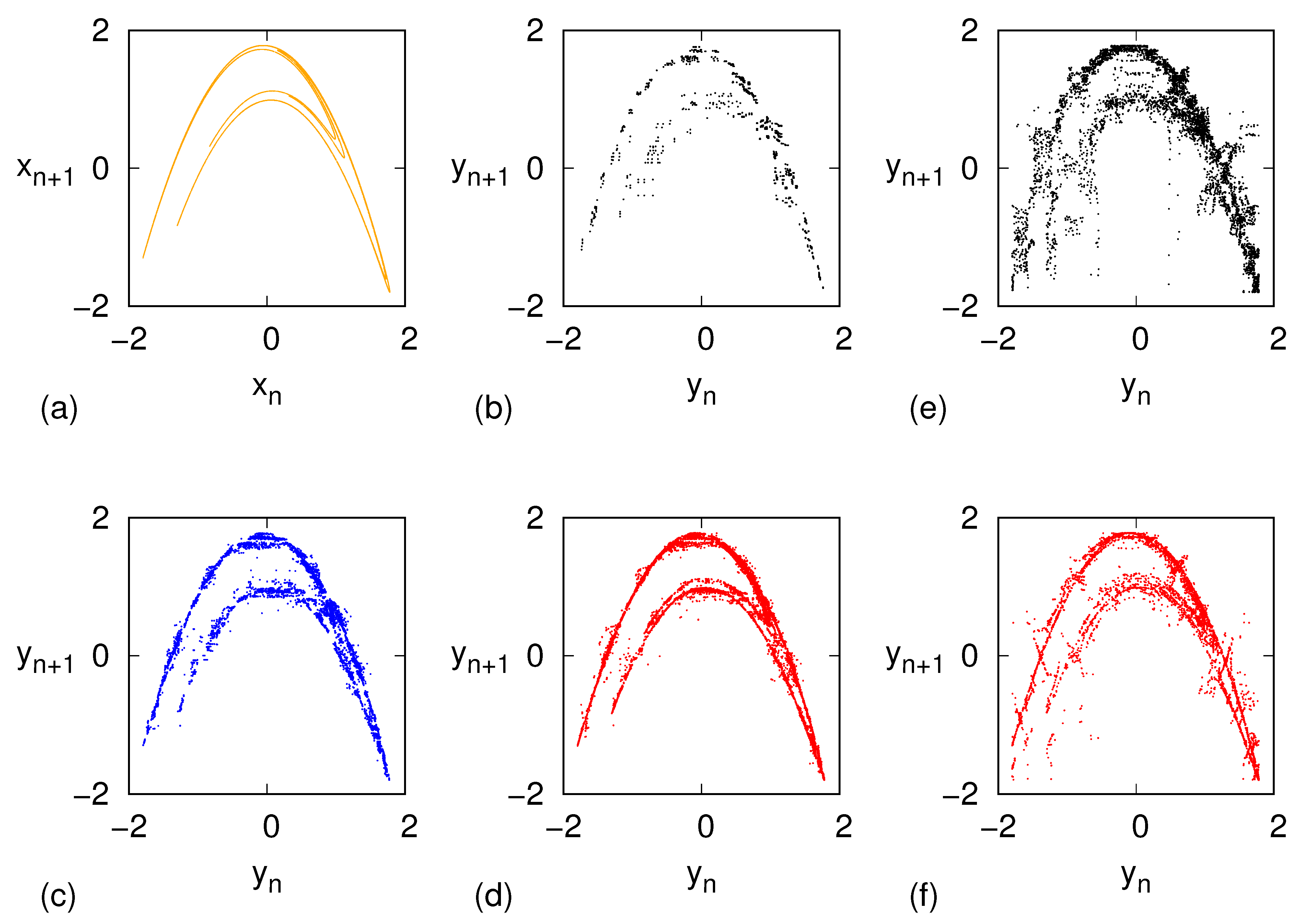
Figure 3 shows the phase-space evolution of the original model (panel a) along with the ones resulting from our inverse procedure for the three values of
m considered (panels b–d).
The large-scale deterministic character of the model is already captured for the lowest depth
, where the finiteness of the points is clearly visible as
. However, upon increasing
m,
increases rapidly and tinier details are progressively resolved, as revealed by panels c,d in
Figure 3. Remarkably, the first level of the fractal structure of the Hénon map is clearly visible for
.
For the sake of comparison,
Figure 3 also shows the results of a reconstruction procedure akin to the one used in ref. [
15], for the cases
(panel e) and
(panel f) as follows. Let
be the node visited at the
n-th step of the random walk generated by the stochastic matrix
M, i.e.,
. Then
is set as the first element of a randomly chosen trajectory, with replacement, among those that belong to
. The improvement of the present approach is visually apparent.
More quantitatively,
Table 2 reports the values of the PE computed, for each of the three
m values, on the pristine Hénon time series as well as on time series generated via the two reconstruction methods, namely the present approach and the protocol, described above, modeled on ref. [
15]. The values produced by the present approach are very close to the original ones, while the older protocol yields significantly larger PE values. The reason is that the generation of a “new"
x value as the average of the last component over all possible
m-tuples encoded by the same word preserves the mutual ordering (among the last
m components), while this is not guaranteed if the new variable is selected randomly among all possible values.
Finally, we analyze the noise-perturbed case with
. The dashed line in
Figure 2 shows that many more links appear in the presence of an observational noise characterized by
. Actually, their number is more than 50 times larger than in the deterministic case (see
Table 1). In spite of this huge variation, the Markov network obtained by implementing the method proposed in the previous section contains exactly the same number of nodes and links (see again
Table 1). The efficacy of the “filtering effect” is confirmed by
Table 2 where we see that, while the PE of the noisy signal is significantly larger than that of the deterministic one, the PE of the Markov model is in line with the value of the pristine time series.
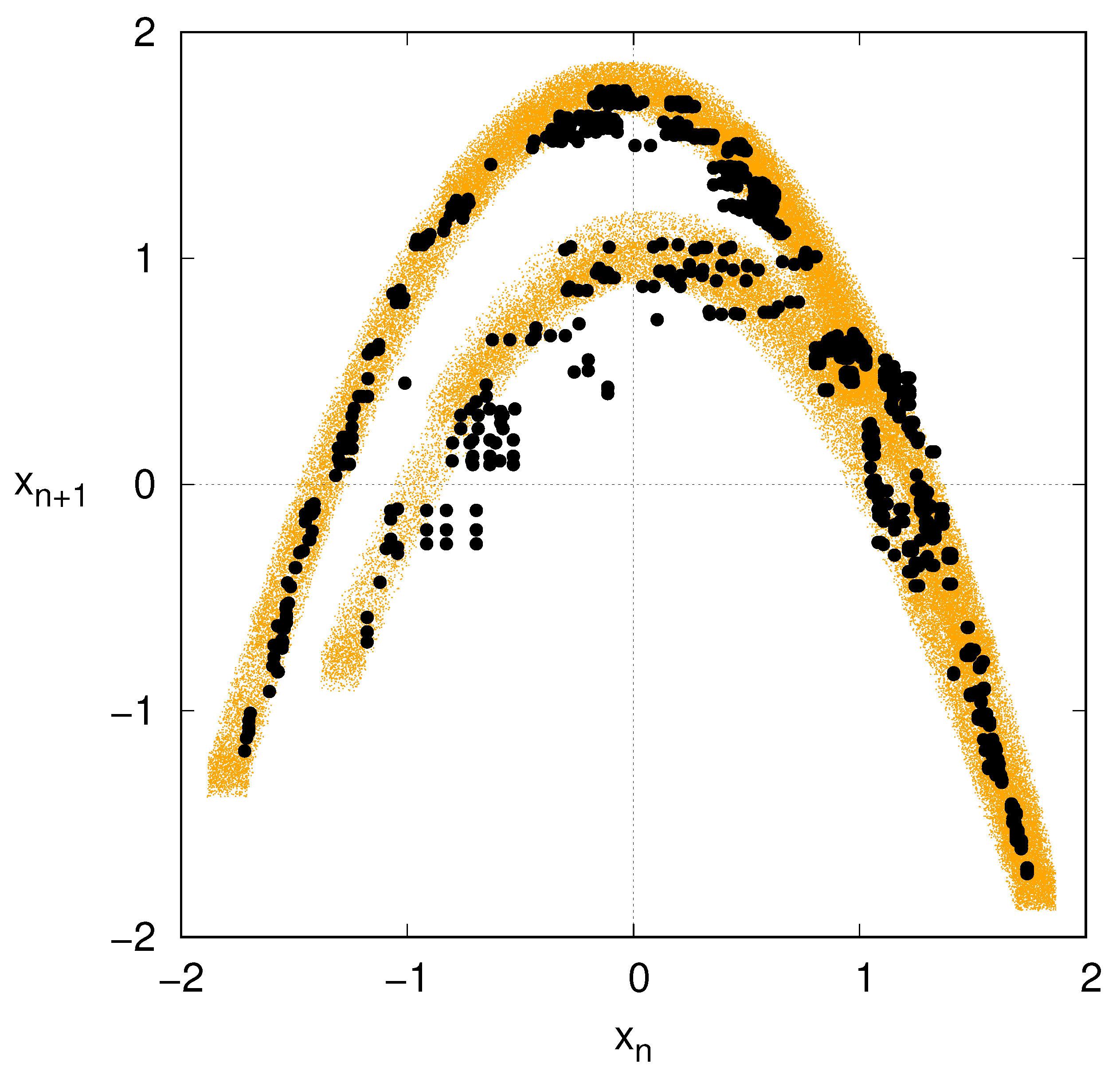
A last comparison is made in
Figure 4, which displays the phase portrait of the noise-perturbed Hénon map, and the related reconstruction via Markov approximation with
. While the customary Hénon map profile is blurred by the presence of the additive, observational noise, the reconstructed attractor is more defined, indeed resembling the noiseless case of
Figure 3b.
The Markov approximation therefore seems to act as a nonlinear filter that enables us to reconstruct the noiseless dynamics, at least as far as the noise is sufficiently small.
5. Conclusions and Open Issues
In this paper, we have revisited the method proposed in ref. [
15], for the reconstruction of irregular signals, with the goal of making it more robust to the presence of observational noise. Although the outlined application to the Hénon map is very promising, several issues should be further tested. In this paper, having studied a discrete-time map, we have everywhere assumed
, but if one decided to deal with continuous-time signals, it might be more convenient to consider a short sampling time accompanied by a larger
L value. This way, one could better reproduce the continuity of the original signal, although difficulties may be expected in the reconstruction of the underlying Markov approximation (see, e.g., the necessity of implementing algorithms to check for constrained random walks [
15]).
Another question is the choice of the window length
m. In a strictly deterministic system, it is, in principle, convenient to increase
m as much as possible, since the size of the “cells” that encode the different words progressively decreases. A limitation is imposed only by the computational load. However, in the presence of noise, a cell size smaller than the noise amplitude does not imply an improved accuracy. In practice, it does not make sense to consider windows that are too long. How can an optimal
m value be identified? Possibly useful information might come from the principal component analysis [
22], which can provide a more accurate identification of the cell size, by distinguishing the uncertainty along different directions. Additional help can come from the implementation of appropriate indicators quantifying the degree of predictability (see, for example, ref. [
23]).





{kind=link}
{kind=link}
{kind=link}
{kind=link}