1. Introduction
Air pollution is closely linked to public health and climate issues. Understanding pollutant dispersion in urban environments is key for development of turbulence models capturing this phenomenon. Atmospheric boundary layer turbulence is a complex process of interacting coherent structures (spatial regions where flow properties are strongly correlated); thus, we seek to identify tools to detect and characterize coherent structures.
Robinson [
1] presented a review of major findings and challenges concerning coherent structures in turbulent boundary layers, specifically those developing over flat surfaces with zero pressure gradient and at relatively low Reynolds numbers (Re < 5000). A study by Kline et al. [
2] revealed the presence of near-wall low-speed “streaks” originating in the laminar sublayer. The dynamic sequence involving the generation, upward movement, and disintegration of these structures is widely referred to as the “bursting” process. Offen and Kline [
3] characterized this behavior as a “shear layer interface sandwiched between an upstream, high-speed sweep and a downstream, low-speed ejection”.
Bursts are essential contributors to momentum transfer over short durations due to their dominant role in producing turbulent kinetic energy within shear-driven flows. The study of burst-related phenomena generally focuses on three main areas: (i) techniques for detecting burst intervals, (ii) the formulation of appropriate scaling laws for burst duration, and (iii) exploring how bursts relate to coherent structures. An overview of research addressing these themes was provided by Metzger et al. [
4]. In [
5], Mahrt investigated intermittent turbulence bursts in the atmospheric boundary layer, emphasizing that higher-order statistics and event-based statistical analysis is needed to characterize non-Gaussian behavior of burst-dominated flows. Later, Mahrt focused on turbulence under stable and stratified conditions [
6] and noted that turbulence is patchy and intermittent, especially in strongly stratified conditions.
Renewal processes are important to our understanding of intermittent and burst-like transport phenomena. Higbie [
7] and Danckwerts [
8] showed that interfacial transfer cannot be understood purely from a static perspective; rather, stochastic and dynamic surface processes should be used (eddies rise to or fall from the interface, carrying new fluid volumes). Perlmutter [
9] introduced realistic eddy age/lifetime distributions into surface renewal models.
Katul et al. [
10] applied renewal theory to model passive scalar transport in turbulent flows. Paradisi and collaborators [
11,
12,
13] further incorporated renewal concepts to describe scalar dissipation, turbulent structure, and memory effects in stratified boundary layers. Cesari et al. [
14] and Luo et al. [
15] extended renewal-based models to environmental turbulence and wind energy applications, respectively, highlighting the model’s versatility across complex boundary-layer phenomena.
Using direct numerical simulations, Itano and Toh [
16] examined burst dynamics in turbulent channel flows and identified a traveling wave solution corresponding to a saddle point in the low-dimensional near-wall system, shedding light on the self-sustaining nature of wall turbulence. Similarly, Jiménez et al. [
17] employed direct numerical simulations to investigate near-wall turbulence in Couette and Poiseuille flows, revealing that intermittent bursting is primarily associated with vortex-dominated quiescent structures.
Kawahara and Kida [
18] discovered an exact time-periodic solution for Couette flow, offering a simplified model for the bursting process. The nonlinear growth and transition mechanisms in Couette flow were further explored by Cherubini and De Palma [
19], focusing on the evolution of optimal disturbances. Bomminayuni and Stoesser [
20] analyzed dominant turbulent events, such as sweeps and ejections, and their contributions to Reynolds stress, also quantifying turbulence anisotropy in rough-bed open-channel flows.
Quantitative insights into fluctuating velocity components were historically obtained through the development of conditional sampling methods, designed to enhance flow visualization by providing statistical context. Foundational contributions to this approach include the early work of Wallace [
21] and Willmarth [
22].
The quadrant method provides a useful framework for analyzing turbulent flows by transforming velocity time series into symbolic sequences, enabling the investigation of their information content. The streamwise and vertical velocity components are decomposed into their mean and fluctuating parts. The signs of the fluctuating streamwise and vertical components distinguish four distinct quadrants, each representing different turbulent events—outward interaction, corresponding to the upward motion of faster-than-average fluid; ejection, representing the upward motion of slower-than-average fluid; inward interaction, indicating the downward motion of slower-than-average fluid; and sweep, describing the downward motion of faster-than-average fluid.
From the standpoint of turbulent momentum exchange, ejection and sweep events are essential mechanisms that facilitate the mixing of slow-moving near-wall fluid with faster fluid from above. An extensive account of quadrant analysis and its applications is presented by Wallace [
23]. Further discussion on conditional sampling approaches, including variable-interval time averaging, can be found in Antonia et al. [
24].
Quadrant-based methods have been employed for various turbulent flows, including river hydraulics, the atmospheric boundary layer, and wind tunnel studies. For instance, Kirkbride et al. [
25] performed simultaneous measurements of vertical and streamwise velocities at multiple points above a gravel riverbed. By applying a simplified quadrant analysis, they categorized turbulence states and analyzed their transitions using a Markov chain model. Their results revealed the presence of large-scale structures.
Using a similar experimental setup, Buffin-Bélanger et al. [
26] corroborated the role of large-scale coherent structures in shaping river turbulence. They demonstrated that quadrant events frequently occur in cyclic or oscillatory groupings, likely driven by the passage of alternating high- and low-momentum fluid regions.
To further understand the spatiotemporal properties of such coherent structures, Roy et al. [
27] utilized an array of electromagnetic flow meters to characterize their scale, lifespan, and dynamics. Their statistical analysis of burst durations revealed that lab-scale observations align closely with the scaling behavior of natural river flows.
Field measurements have also identified coherent structures in atmospheric flows. Finnigan [
28] demonstrated that large-scale coherent structures dominate flow dynamics above plant canopies. Quadrant analysis showed that the sweep quadrant contributes most to momentum flux, as fast downward gusts penetrate lower boundary layer levels. In urban settings, Christen et al. [
29] used anemometers in a vertical grid across an urban canyon to study momentum and scalar transport. They found that sweep events dominate transport in the upper canyon, while ejection events follow sweeps in a cyclical pattern. Nelson et al. [
30] demonstrated that all four quadrants contribute to momentum transfer near the roof level within street canyons. They introduced the concept of a disorganized canopy layer, where the aerodynamic influence of individual buildings outweighs that of broader atmospheric flow structures.
Since direct turbulence measurements in urban environments are costly and complex, wind tunnel models are widely used [
31]. Kukačka et al. [
32] investigated flow and tracer gas concentration above an X-shaped street intersection, analyzing the dominant role of sweep events in impulse transfer. Nosek et al. [
33] applied quadrant analysis to study turbulence above a 3D street canyon, showing that:
Sweeps correlate with entrainment of clean air;
Ejections are associated with ventilation of polluted air;
Coherent structures passing over the canyon drive this process.
Kellnerová et al. [
34] examined the velocity field within a two-dimensional idealized street canyon using Particle Image Velocimetry. Their findings indicate that the street canyon vortex is frequently disturbed, a process which can significantly influence the efficiency of urban ventilation. Additionally, Di Bernardino et al. [
35] reported that the shear layer above the canyon roof exhibits a periodic flapping motion.
Conditional sampling techniques are commonly used for event detection in turbulent flows. This inspired our research into symbolic turbulence data analysis. A comprehensive review of symbolic analysis and its applications is provided by Daw et al. [
36]. The key step in symbolic analysis involves converting the original dataset into a sequence of symbols. For continuous datasets, this is typically achieved by partitioning the range of observed values into a finite number of discrete regions. Each data point is then replaced by the symbol corresponding to its respective region. This process, known as coarse graining or quantization, reduces high-resolution data to a lower-resolution representation.
Lehrman and Rechester [
37] developed a symbolic cycle extraction method for turbulent fluctuations in pipe flows. If simultaneous velocity component measurements are available, quadrant-based symbolization is a viable approach.
Daw et al. [
38] studied pressure fluctuations from air bubbles released through a nozzle into a water tank, aiming to detect periodic behavior in a two-phase fluid system under varying Reynolds numbers. They converted the time series into binary symbol sequences using the dataset median as a threshold and introduced a modified Shannon entropy, referred to as
normalized entropy, to evaluate the informational complexity of the symbolized data. To characterize the bubble formation process, they used word statistic histograms, where “words” represented smaller partitions of the symbolic sequence.
Using a comparable symbolic framework, Finney et al. [
39] analyzed heat release patterns across combustion engine cycles. Their results indicated that normalized entropy reaches a minimum at an optimal word length, beyond which the symbolic sequences either fail to encapsulate meaningful temporal structure (if too short) or become dominated by noise and limited sample size (if too long). This highlights the delicate balance between resolution and statistical reliability in symbolic analysis.
Keshavarzi et al. [
40] investigated the turbulent bursting process and its link to sediment transport using velocity measurements from an open water channel. By applying the quadrant method, they encoded instantaneous vertical and streamwise velocity components into discrete symbolic states. The sequence of transitions between these states was modeled using a first-order Markov chain.
Gheisi et al. [
41] expanded upon this approach by exploring the three-dimensional bursting process near the bed of a settling chamber. Using synchronized measurements of all three velocity components, they developed the
octant method, which symbolized the data according to the sign of velocity fluctuations along all three axes. Their analysis confirmed that a first-order Markov model was sufficient to capture the dominant dynamics of the bursting process. A similar Markov-based approach was employed by Jin et al. [
42], who simulated particle deposition near the wall by incorporating flow eddies, effectively modeling the impact of coherent structures on heavy particle trajectories.
In a wind tunnel study aimed at understanding the temporal organization of turbulence in urban-like environments, Kalmár-Nagy and Varga [
43] analyzed two-component velocity signals. Their methodology, closely followed in the present work, treated velocity fluctuations as a marked point process and used the quadrant method to construct symbolic sequences. Entropy analysis revealed that these sequences exhibited traits similar to noisy periodic signals, necessitating higher-order Markov chains to accurately capture the information content. Furthermore, performing quadrant analysis with rotated coordinate systems minimized entropy in the principal axes system of the velocity fluctuation cloud, suggesting a fundamental structure in turbulence dynamics. In this paper, we extend the analysis of the streamwise and vertical velocity components by including both measurements and simulations of street canyon flows, i.e., an idealized urban environment. The novelty of our work lies in the direct comparison between experimental and simulated symbolic sequences.
Further contributions by Chowdhuri et al. [
44,
45,
46] provided detailed persistence-based analyses of velocity and temperature fluctuations in convective turbulence. Their work explored intermittent heat transport, Reynolds stress anisotropy, and temperature variability during gust front events, offering insights into the structure of atmospheric turbulence.
The paper is organized as follows.
Section 2 details the experimental and numerical setups, along with the signal acquisition and processing methodologies. In
Section 3, we explore statistical characteristics of velocity fluctuations, comparing the experimental observations with simulation results.
Section 4 introduces a quadrant-based symbolic encoding of both datasets and the marked point process used in the study.
Section 5 delves into word statistics derived from the symbolic sequences and quantifies their information content through normalized entropy. In
Section 6, we examine the Markovian properties of both the symbolic series and the quadrant-based marked point process. We also compare these datasets with surrogate sequences that mimic noisy periodic behavior and demonstrate how higher-order Markov models can replicate the symbolic data’s informational structure.
Section 7 focuses on the two-dimensional distribution of velocity fluctuations, and
Section 8 summarizes the key findings.
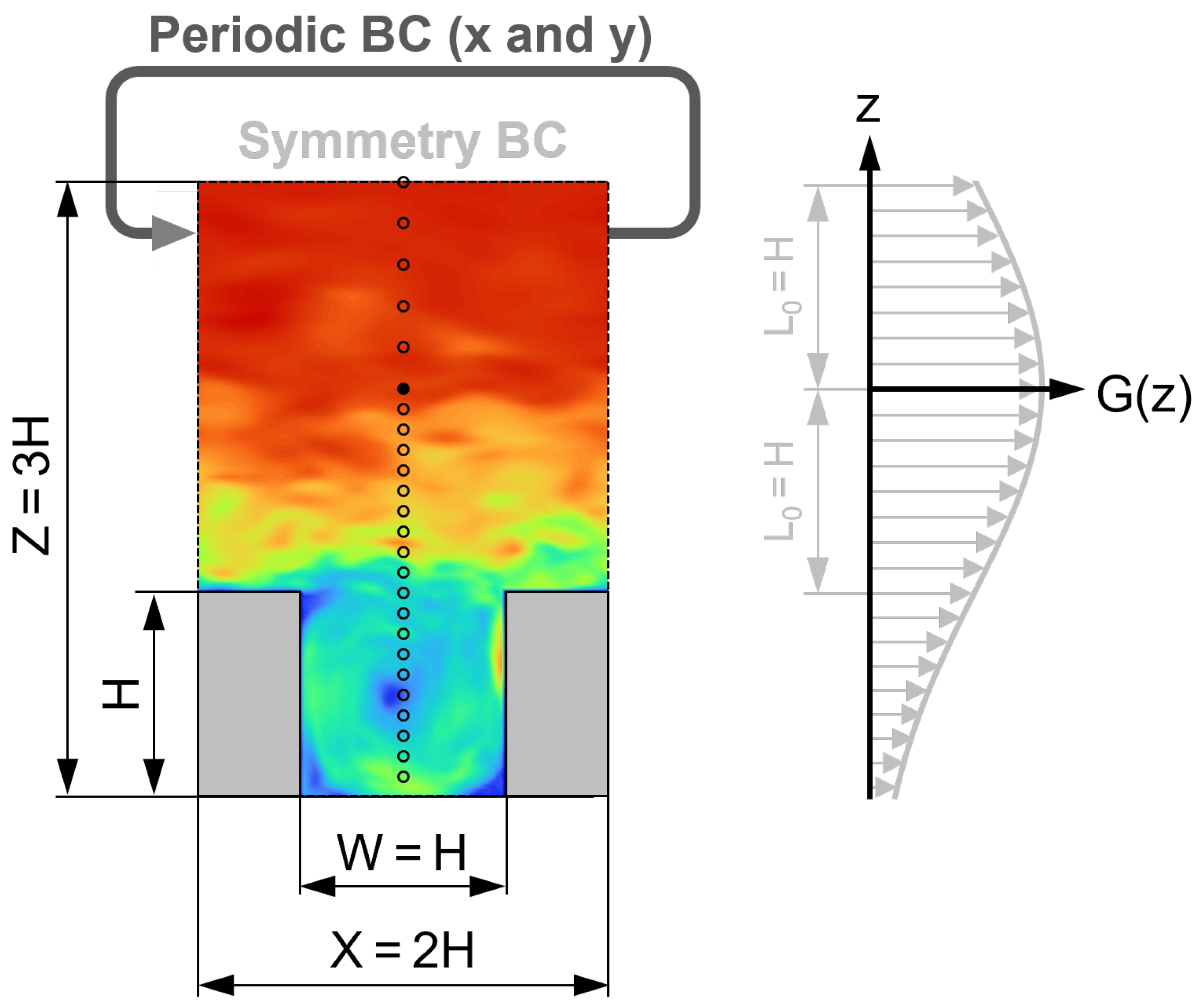
3. Descriptive Statistics of the Experimental and Simulation Data
The basic statistics of the measured and simulated velocity components
and
at different locations are given in
Table 2.
The mean value of the vertical velocity component
is close to
for all heights, meaning that the data represents fluctuations rather than persistent up/down motions.
Table 2 shows that the probability density histograms of
and
for both cases have mainly normal distribution (note that
Table 2 contains the excess kurtosis values). The skewness and kurtosis values are similar to those given in Czernuszenko et al. [
63]. Comparing the experiment and simulation the most significant difference can be seen at
, where the distribution of the simulated
is more skewed towards smaller values and “skinnier” than for the experimental data. The mean of the simulated
at
is lower than that of the experimental data. Furthermore, the range of the measured
is bigger and the corresponding distribution is less skewed than for the simulated vertical velocity component.
The fluctuating components of the streamwise and vertical velocity,
and
, respectively, are
where
and
, i.e., the time-averaged velocity components over an observation period
are given by
The velocity fluctuations
and
can be analyzed by identifying the location of their sign changes (note that the
and
switches are treated separately). These sign changes are called
events. The set of times
at which these events occur provides a so-called random point process [
64,
65,
66]. Other examples of random point processes are neuronal spike patterns (spike trains) and customer arrival times.
to express the duration of an event, i.e., the duration the system spends in state
,
,
or
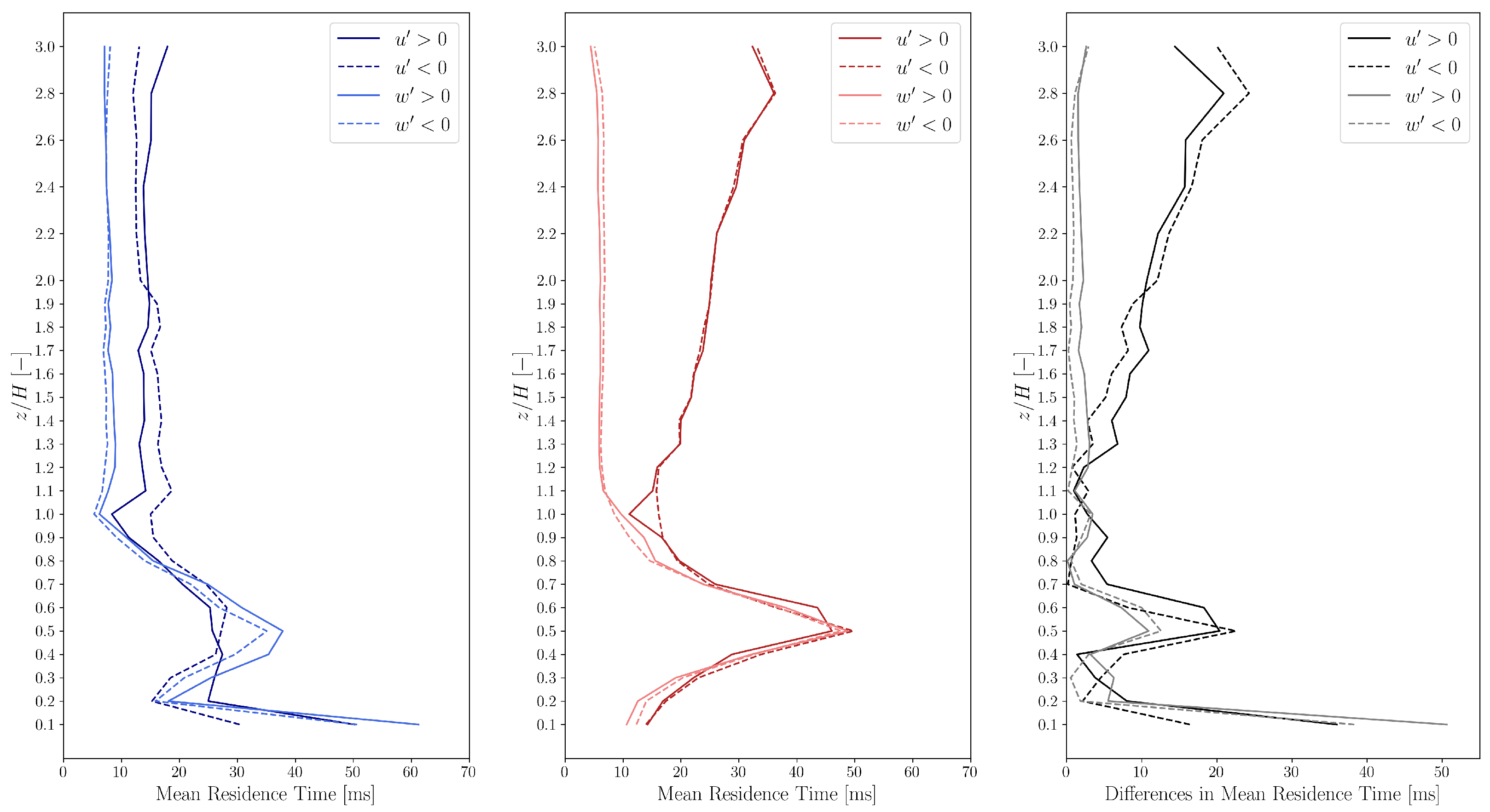
. The mean residence times
as a function of height are shown in
Figure 4.
The mean residence times are between 5 and 60 ms for both the experimental and simulation data. However, the simulation data show high discrepancies in the residence times of the horizontal fluctuations compared to the experimental results.
In general, the values of for and are smaller than those for and for locations above the height of the building, showing that at these locations the fluctuation of the vertical velocity component is more rapid than that of the horizontal velocity component . However, close to the ground (only for the experimental data) and in the vortex core the values of for the measured and are larger than those for and .
The mean residence times of the vertical fluctuations show acceptable correspondence above roof height. Furthermore, the simulations yield mean residence times corresponding to the streamwise velocity substantially larger than the experimental observations, which can be attributed to the fact that the TWF control filters the streamwise velocity fluctuations above the frequency corresponding to the propulsion time scale ( s).
4. Statistics of “Quadrantified” Experimental and Simulation Data
The quadrant method distinguish four different states based on the signs of and , such as
Outward interaction (): ;
Ejection (): ;
Inward interaction (): ;
Sweep (): .
Note that as the mean of the vertical velocity components are close to zero (
) in all 25 gauging points (see
Figure 3), it can be stated that
and
are associated with upward motion and
and
are associated with downward motion at those specific locations. The visualization of the four quadrants is shown in
Figure 5.
We now apply the quadrant method to the experimental and CFD data. To the joint velocity fluctuation pair
, we assign a quadrant index according to
These 4 numbers can be thought as symbols/letters of the alphabet
with 4 letters. The joint velocity fluctuation time series is transformed to a sequence of time-symbol pairs
, denoting the occurrence of the distinct quadrant events at time
. This is a
marked point process, an extension of the simple point process described in
Section 3. In our quadrant-event model, outward interaction (
), ejection (
), inward interaction (
), and sweep (
) are the discrete events. The residence times
’s express the average duration that the system spends in a given quadrant.
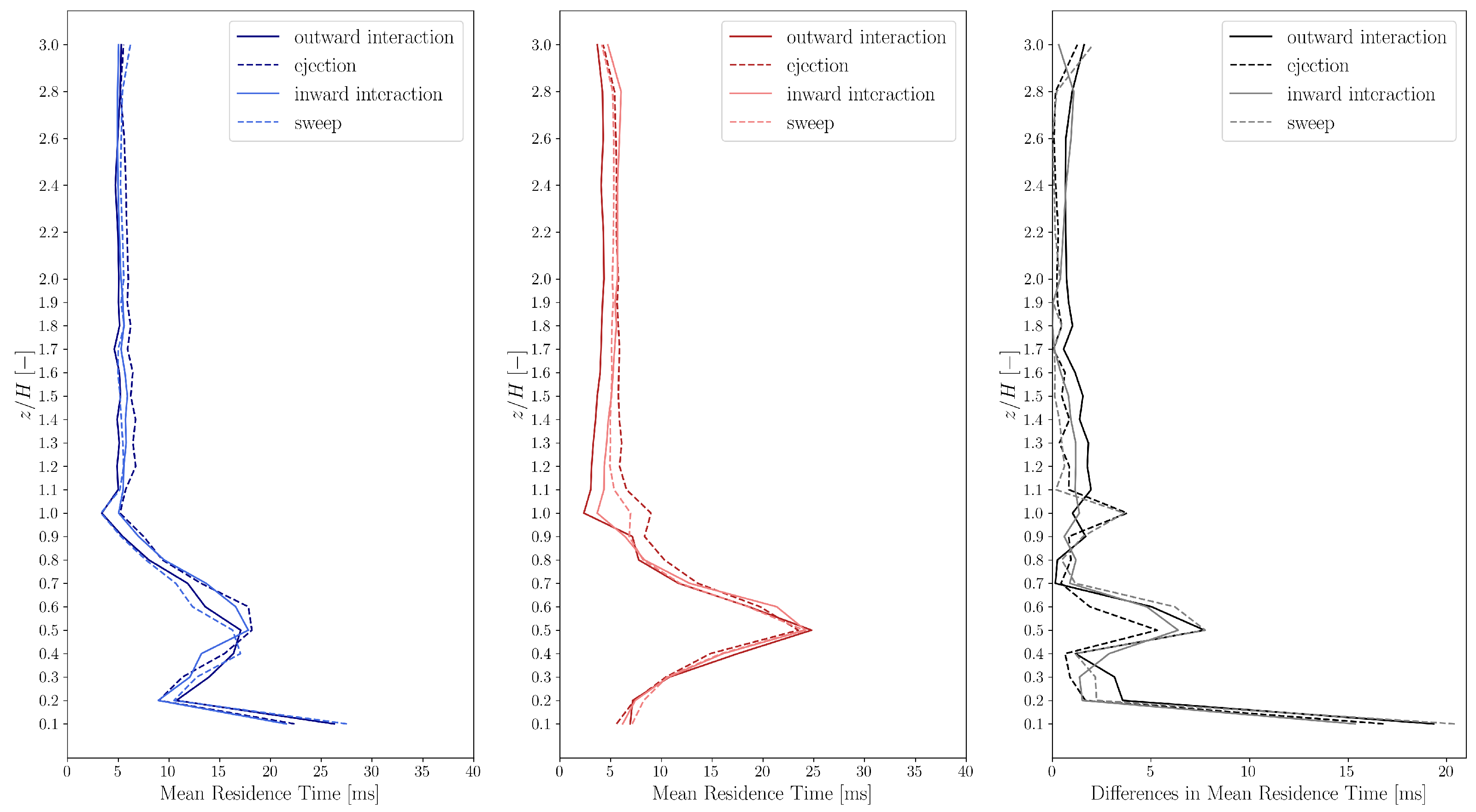
The comparison of the mean residence times for all 4 events are shown in
Figure 6. The mean residence time are 2 ms
ms for both cases. In case of the simulation, the mean residence time has a higher peak at
than for the experimental data, which can be explained by the fact that in the simulation the vortex core is substantially more enclosed than what was observed in the experiment. Corresponding evidence can be found in the concentration plots shown in Papp et al. [
53].
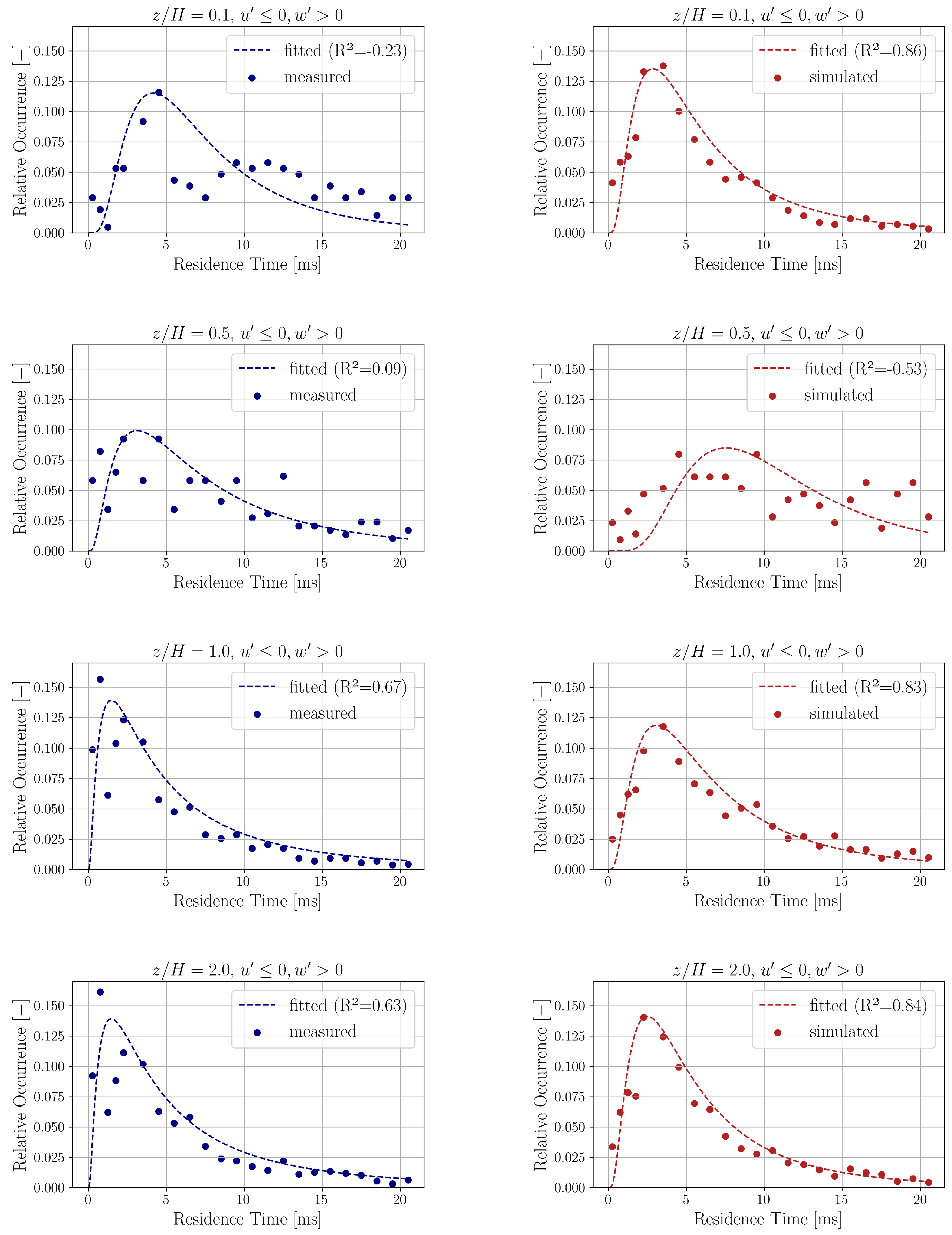
Figure 7 shows the distribution (relative occurrence) of ejection (
) residence times for both the experimental and simulation data at heights
and
. The relative occurrences of residence time intervals up to 20 ms are plotted. Bogard et al. [
67] reported that the time intervals between ejection events follow a distribution that is approximately exponential. However, several studies have shown that the durations between mean-level crossings in turbulent signals are better described by a lognormal distribution [
68,
69,
70,
71]. Based on this observation, we fit the following lognormal probability density function (PDF) to the distribution of relative occurrences of residence times
where
denotes the relative frequency associated with residence times
across the four quadrant event types (outward interaction, ejection, inward interaction, sweep), and
and
are the parameters of the lognormal distribution. The fitted values of these parameters are presented in
Table 3.
The fitted lognormal curves are also shown in
Figure 7 with their coefficient of determination [
72]
where
values are the calculated relative occurrence values of residence time
and
is the mean of the relative occurrence values
’s. The predicted relative occurrence values
are obtained from the fitted lognormal model described in Equation (
8). It is important to note that the coefficient of determination
can occasionally be negative. This occurs when the mean value
provides a better fit to the data than the nonlinear model predictions
, as indicated by Equation (
9).
The distributions for the other quadrants are qualitatively similar to the ones shown in
Figure 7 for ejection. The relative occurrence results show fairly good qualitative agreement between the experimental and simulation data in all analyzed measurement points.
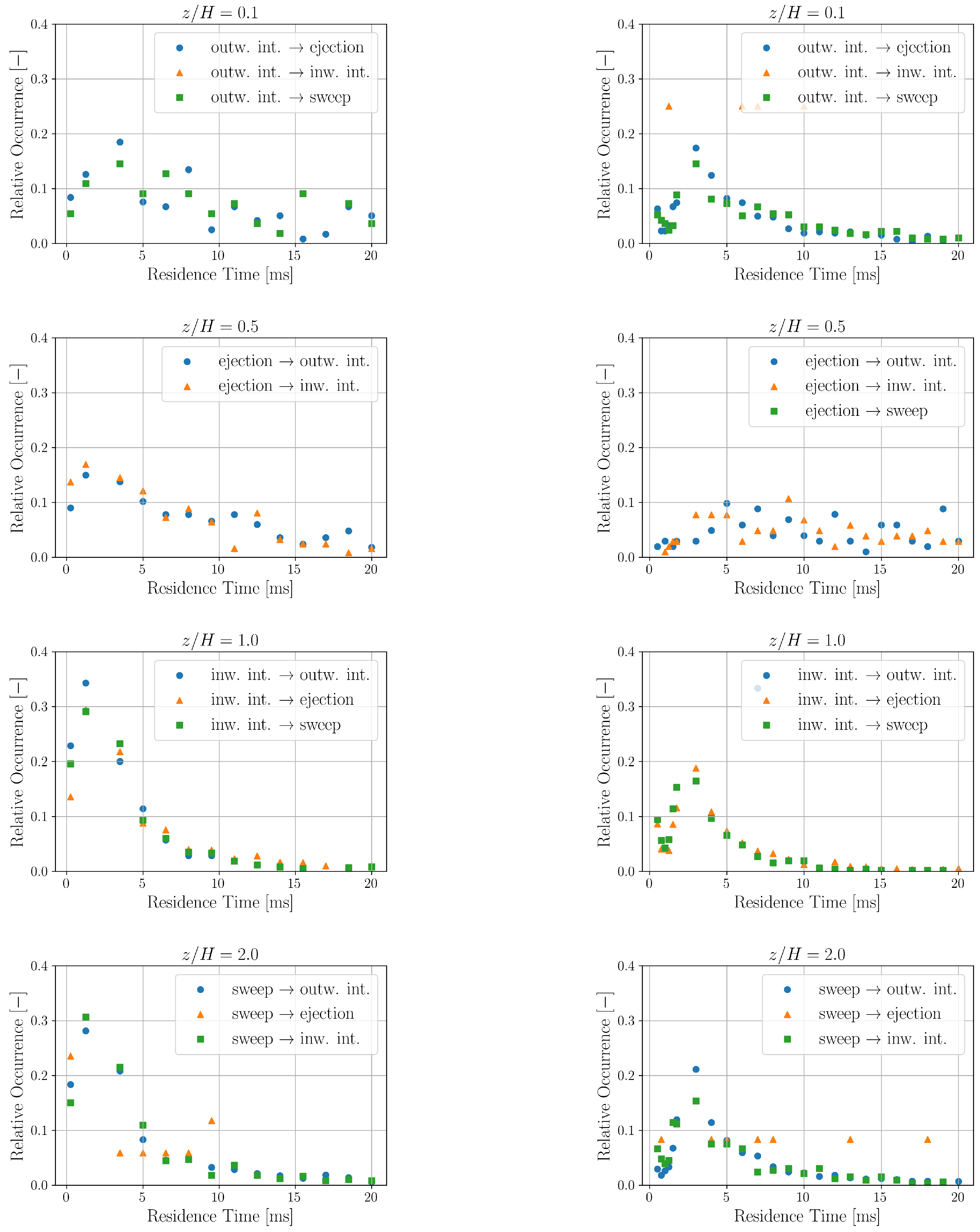
The relative occurrences of residence times for a quadrant transitioning to another specific quadrant is shown in
Figure 8. The residence time distributions corresponding to one quadrant transitioning to another specific quadrant obtained here are comparable with the ones obtained in [
43].
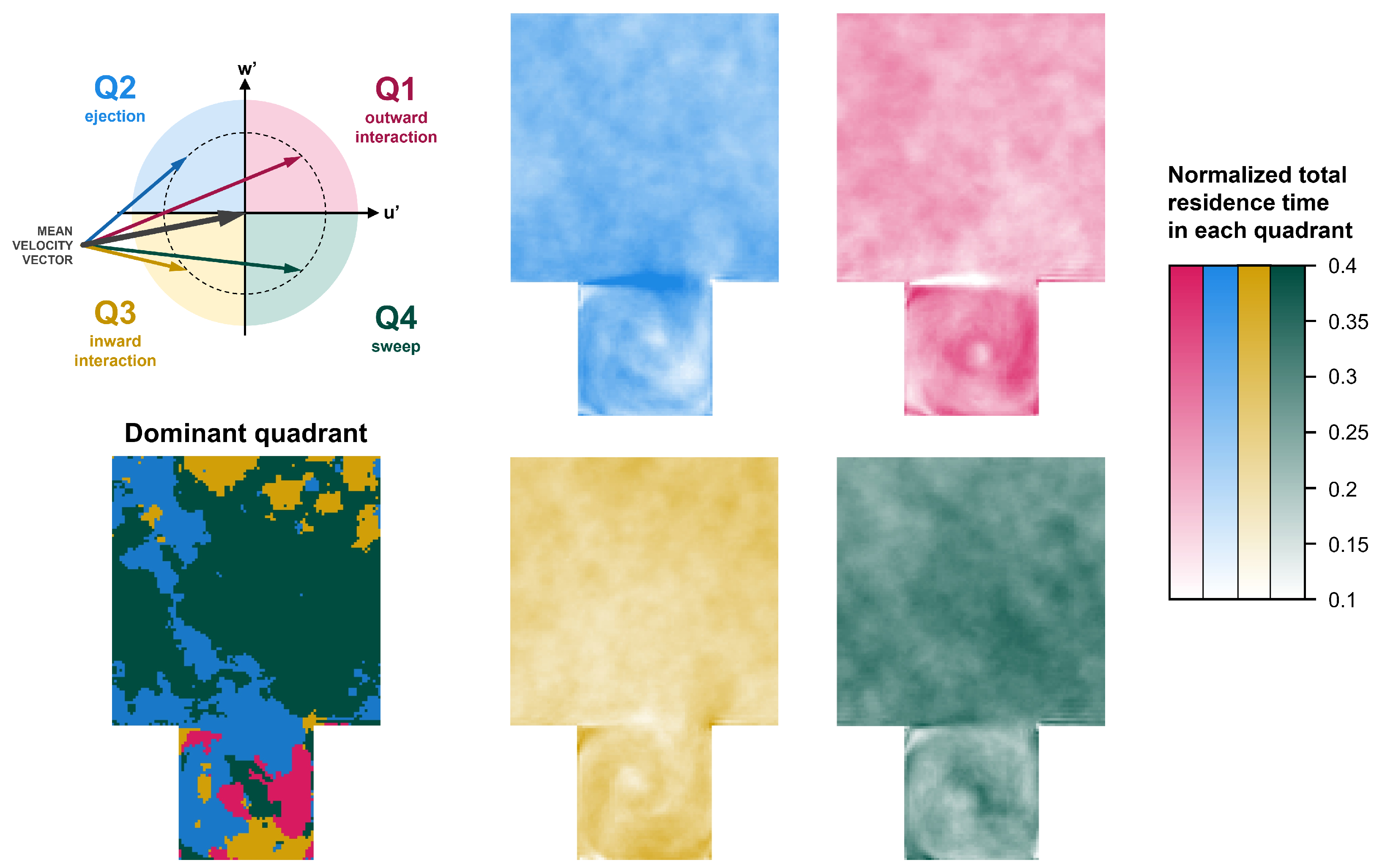
Finally, let us utilize the fine spatial resolution of the CFD simulations to gain further insight into the flow field.
Figure 9 shows the quadrant statistics based on the CFD simulations, averaged in time and in the spanwise direction, i.e., over the length of the street canyon. The presence of the shear layer at roof height is clearly visible in the quadrant statistics: at
, the normalized total residence time (probability) corresponding to
(ejection) peaks at a value of above 0.4. Correspondingly, the probabilities of the other quadrants must decrease locally. Interestingly,
(outward interaction) shows a probability below 0.1 in the shear layer. This, combined with the fact that the mean vertical velocity is around zero in the shear layer (
, see
Figure 3), means that while downward motion (
) is equally distributed over
(inward interaction) and
(sweep), upward motion (
) dominantly happens in
(ejection). In other words, air parcels (or transported pollutants) are likely to escape the canyon when the streamwise velocity component in the shear layer is lower than its time-average.
Furthermore, let us observe the path of a fluid parcel through the clockwise-rotating canyon vortex. Importantly, due to the fact that the mean velocity vector can significantly deviate from the positive x direction below roof height, the meaning of the quadrants must be assessed with special attention. Around the 3 o’clock position in the downward-moving fluid (, ), is dominant (to the detriment of ), meaning that the most probable state of the current velocity vector is of a smaller magnitude than the mean velocity vector, and it is pointing outwards. Further ahead, around the 6 o’clock position, i.e., in the street-level backflow (, ), is dominant, and in the upward-moving fluid (, ) around the 9 o’clock position, the most probable quadrants are and , respectively. These findings indicate that outward drift is the most likely state in these regions too.
5. Word Statistics and Entropy
Following the approach described by Daw et al. [
36], symbolic sequences
S, composed of individual symbols
, are transformed into sequences of words of fixed length
L. This transformation is accomplished by sliding a window of length
L across the original sequence.
In formal terms, the sequence
S is transformed into a multiset of words
as follows:
The word list has elements and is a multiset, i.e., it can contain identical words multiple times. We denote with the set of unique words in (obtained by removing duplicate words ), with cardinality denoted by .
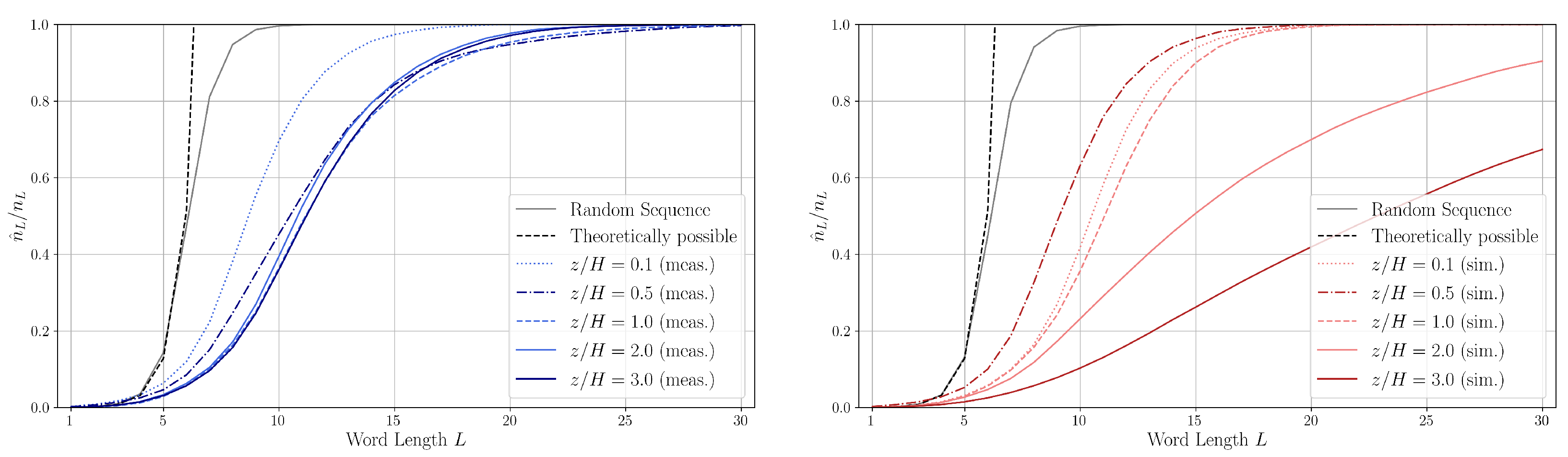
In
Figure 10, the normalized quantities (dimensionless word number)
are shown for different heights. For word lengths approximately
, the number of unique words
in the measured series is approximately the half of the length
of the measured word lists. This is different for the simulation data, especially for heights
and
in the simulation data. We attribute this to the driving force being applied at height
and the slip symmetry boundary condition at
.
For comparison, the dimensionless word number for both infinite (theoretically possible) and finite random sequences is also shown in
Figure 10. One can see that the dimensionless word number curve of the measurement at
, i.e., close to the ground in the canyon, is in-between the curve of the random sequence and the sequences corresponding to the other measurement heights. The random sequence represents a fully disordered, uncorrelated flow; hence, the data above
may show the presence of coherent structures.
A comparison of the symbolic sequences up to word length reveals that the number of unique words increases at a nearly identical rate for both measured and randomly generated sequences. However, beyond , the number of unique words in the random sequences grows significantly faster. Due to the finite length of the sequences (an infinite sequence is also shown for comparison), the growth of unique words is naturally bounded by the total number of possible words . This saturation occurs at L = 9–10 for the random sequence, between L = 16–30 for the measured sequence and around L = 20–50 for the simulated sequences.
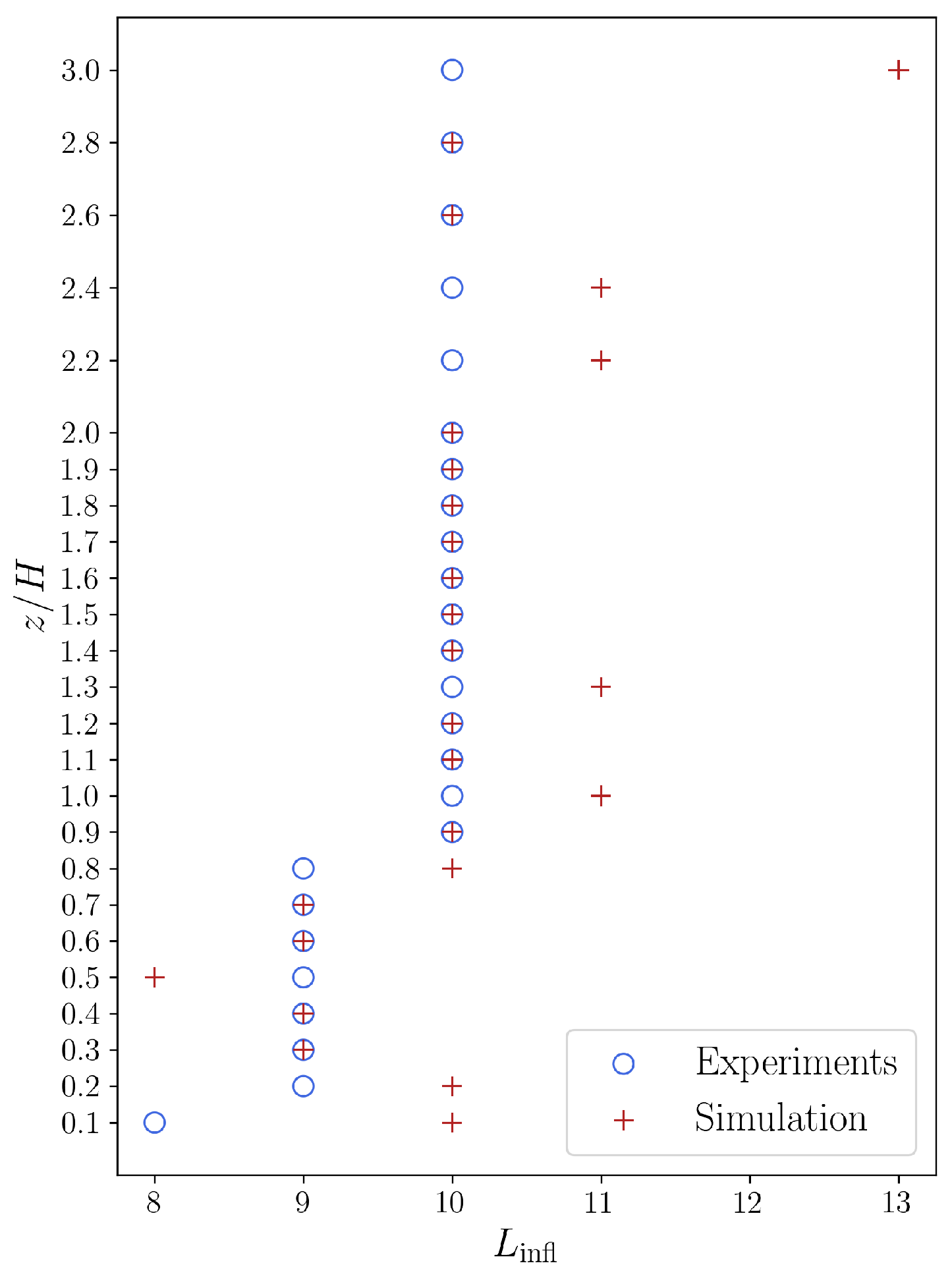
Figure 11 shows at which word length value
L is the inflection point of the experimental and dimensionless word number curves. We can state that the inflection points for the experimental and simulation sequences show a good agreement setting aside a few “jumps” in the inflection points of the simulation sequences. We believe the shift of inflection point outside the canyon means that the symbolic sequence—exhibiting a more ordered flow—is diverging from the reference random sequence, i.e., the number of unique symbolic words increases more slowly with the word length.
The lower number of unique words in the measured sequence, relative to the random counterpart, is attributable to the recurrence of specific words, indicating that some word patterns appear with higher frequency. For instance, the relative frequency distribution of words of length
is illustrated in
Figure 12,
Figure 13,
Figure 14 and
Figure 15.
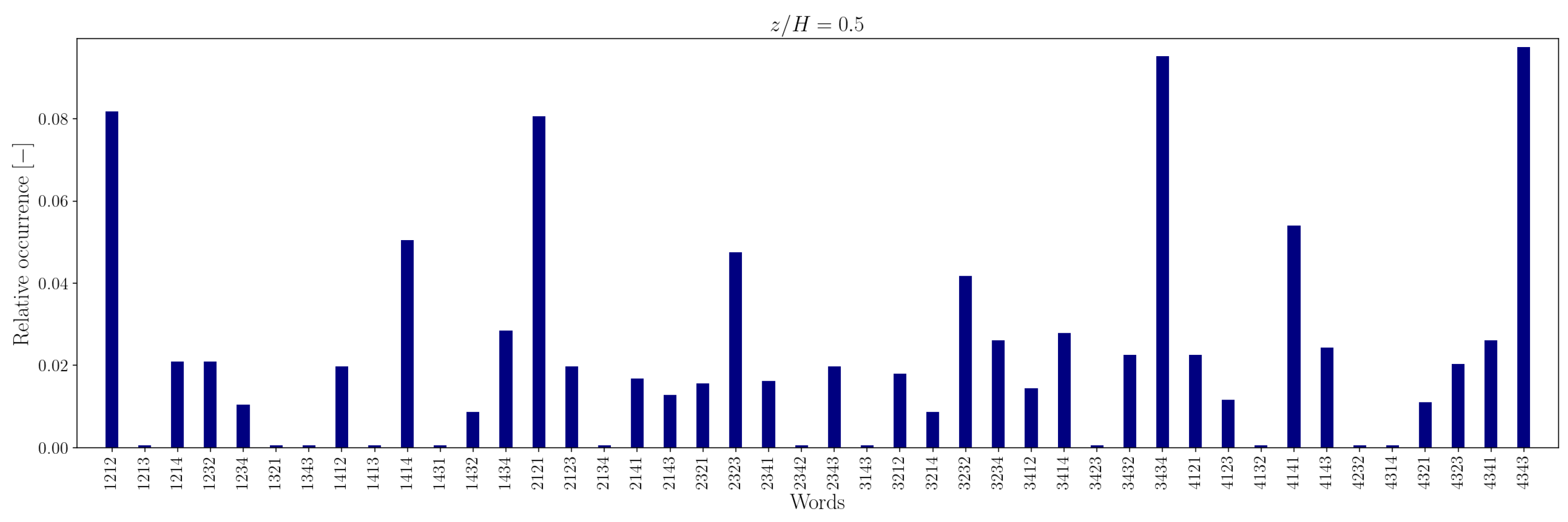
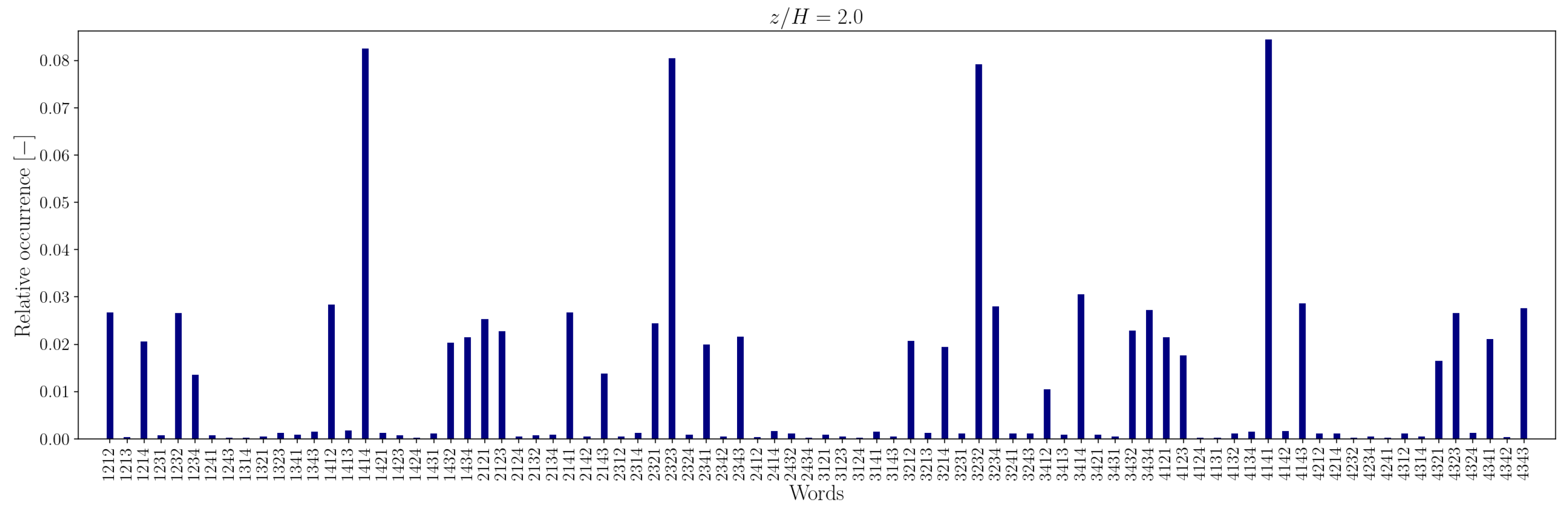
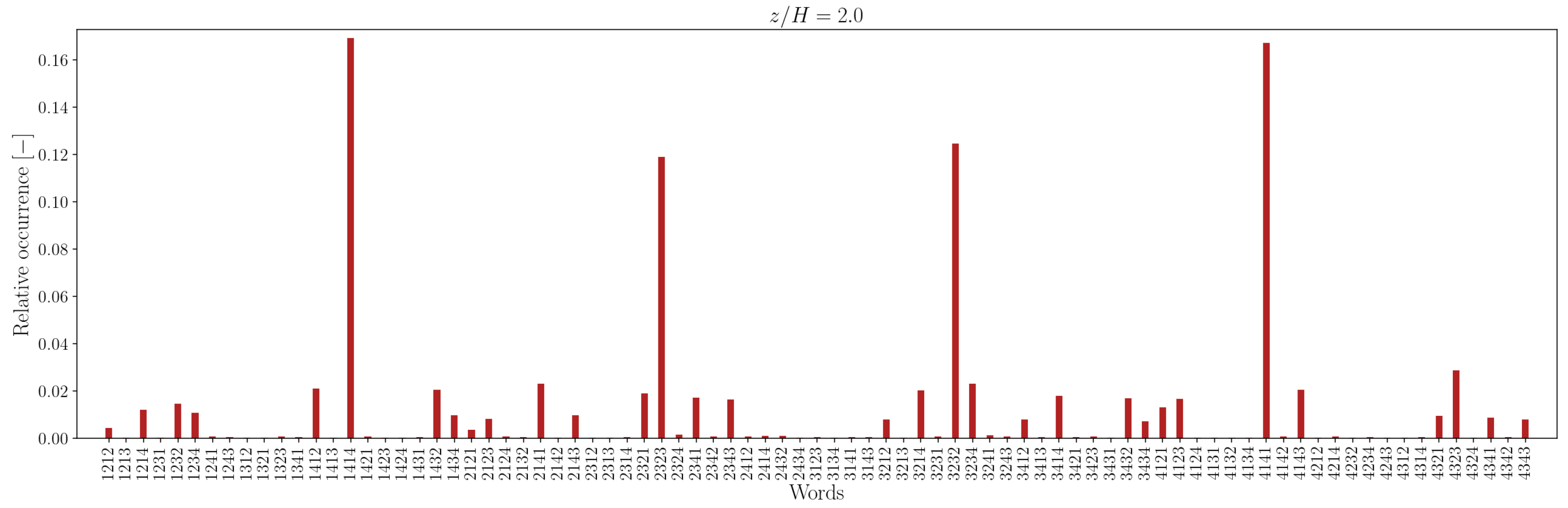
In the canyon at , the four most common words are 1212/2121 and 3434/4343 in the experimental sequence and 1432/3214 and 4321/2143 in the simulation sequence. Outside the canyon, for both experimental and simulation data, the four most common words are 1414/4141 and 2323/3232.
At longer word lengths, the most frequently observed words are in which symbol pairs 12/21 and 34/43 (within the canyon) and 14/41 and 23/32 (outside the canyon) follow one another. These alternating patterns indicate that pairs of outward interaction–ejection events () and inward interaction–sweep events () commonly follow one another inside the canyon, possibly due to the influence of the no-slip boundary condition at the canyon bottom.
In contrast, outside the canyon, the repetition of symbol pairs and suggests a tendency for outward interaction–sweep and ejection–inward interaction pairs to alternate. This behavior implies that the reduced quadrantified signal often becomes trapped in cycles involving rapid switching between two dominant turbulent event states.
Note that moving away from the bottom of the canyon, the most common unique words represent almost
of the word list. The word frequency distributions show a somewhat central symmetry that suggests a self-similar (multi-fractal) nature of the data [
73].
We characterize the degree of regularity and information content within the measured reduced symbolic sequences using the normalized entropy
, a modified form of Shannon entropy as introduced by Finney et al. [
39]. For a given word length
L, it is defined as:
where
represents the relative frequency of the word
in the word list
. Notably, this formulation parallels the concept used in Kolmogorov–Sinai entropy for evaluating the information rate in dynamical systems. A review on entropy in various fields of science is given in [
74].
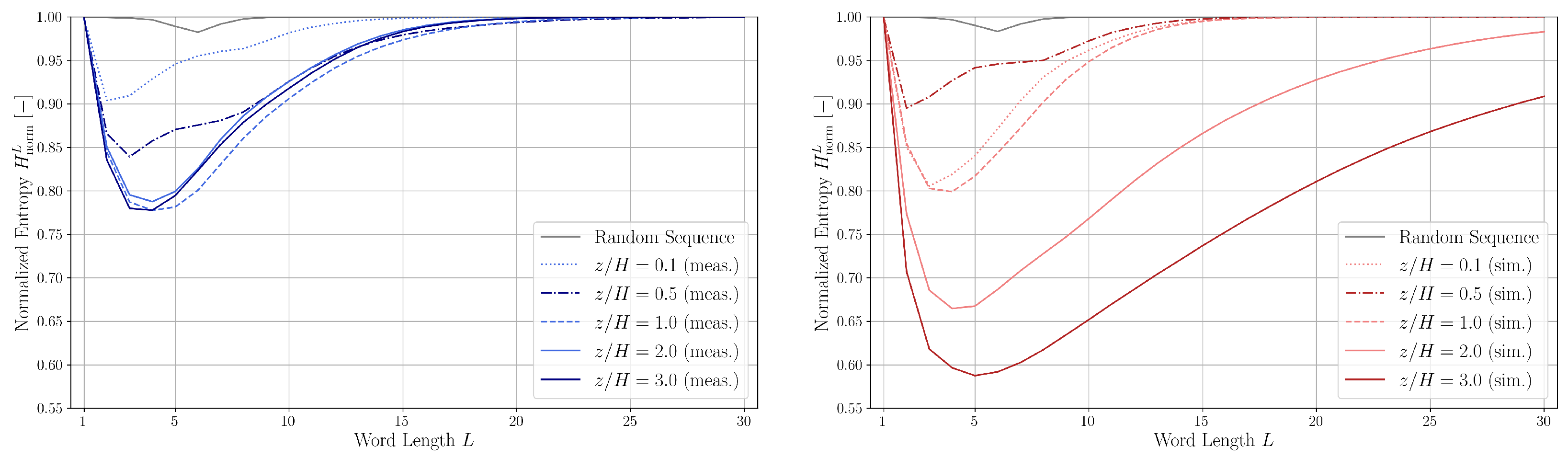
The normalized entropy values for various word lengths and heights are plotted in
Figure 16.
The entropy curves exhibit trends consistent with those reported by Finney et al. [
39]: a significant decrease in entropy occurs for the shortest word lengths, reaching a minimum around
L = 2–5, followed by a gradual approach toward
at larger
L.
Higher entropy values indicate greater disorder and randomness, whereas lower entropy suggests more correlated, deterministic behavior, the dip of entropy suggest the presence of structured patterns or intermittency. For the random sequence, remains close to 1 across all word lengths, reflecting the absence of meaningful structure. The small dip near is attributed to the finite length of the random dataset.
The smallest entropy value is obtained at for the measurement data and at for the simulation data. The entropies of the experimental and simulation sequences at show good agreement; at , the flow is more disordered in the simulation data, and at and , one can again see the effect of driving force and slip symmetry boundary condition the makes the flow more ordered than under real-world conditions.
6. Surrogate Series
In
Section 5, we compare the normalized entropy
derived from symbolic analysis of measured and simulated velocity fluctuation data, as well as from a random sequence. To assess the variation of entropy as a function of word length across different types of symbolic sequences, we generated the following artificial sequences, all having the same length as the measured dataset:
Noisy periodic sequence: A periodic symbolic pattern constructed by repeating the block , with a subset of symbols randomly replaced at a controlled rate. Replacements are constrained to differ from both the preceding and following symbols.
Markov chain-generated sequences: Symbolic sequences generated using Markov models of orders up to five, constructed from transition probabilities estimated from both measured and simulated data.
To construct these Markov-based surrogate sequences, we define transition probabilities between quadrant states. Transitions between the four quadrants are categorized as follows:
stable (remaining in the same quadrant),
cross (transitions such as 1↔3, 2↔4), and
marginal (transitions such as 1↔2, 3↔4). Kalmár-Nagy and Varga [
43] observed that stable transitions have the highest probability. This finding is in agreement with earlier observations by Keshavarzi et al. [
75,
76], who identified similar patterns of transition preference near different types of boundaries, including plain beds, ripple beds, and obstacles such as bridge piers.
When the time stamps of events are discarded from the marked point process, the result is a sequence of symbolic words of length L, each composed of four-symbol combinations . A key constraint on these sequences is that no two adjacent symbols are identical, i.e., .
If the symbolic sequence arises from a Markovian process, transitions between symbols can be characterized by transition probabilities
(denoted simply as
). Under this assumption, the symbolic quadrant sequence
S forms a first-order Markov chain with the transition probability matrix:
where
denotes the probability of transitioning from quadrant
i to quadrant
j. For our quadrant-based symbolic process, self-transitions are not permitted, so the diagonal elements
are all zero. These stable movements instead correspond to the residence times spent within each state.
To generalize the size of the transition matrix for a Markov model of order
m, we consider an alphabet
A of
symbols. The number of valid symbolic words of length
L, where adjacent symbols differ, is given by:
In our case with
, this evaluates to
.
The elements of the transition probability matrix
for a Markov chain of order
are defined as follows:
This expression specifies the conditional probability that a symbol follows the prefix sequence within a valid word .
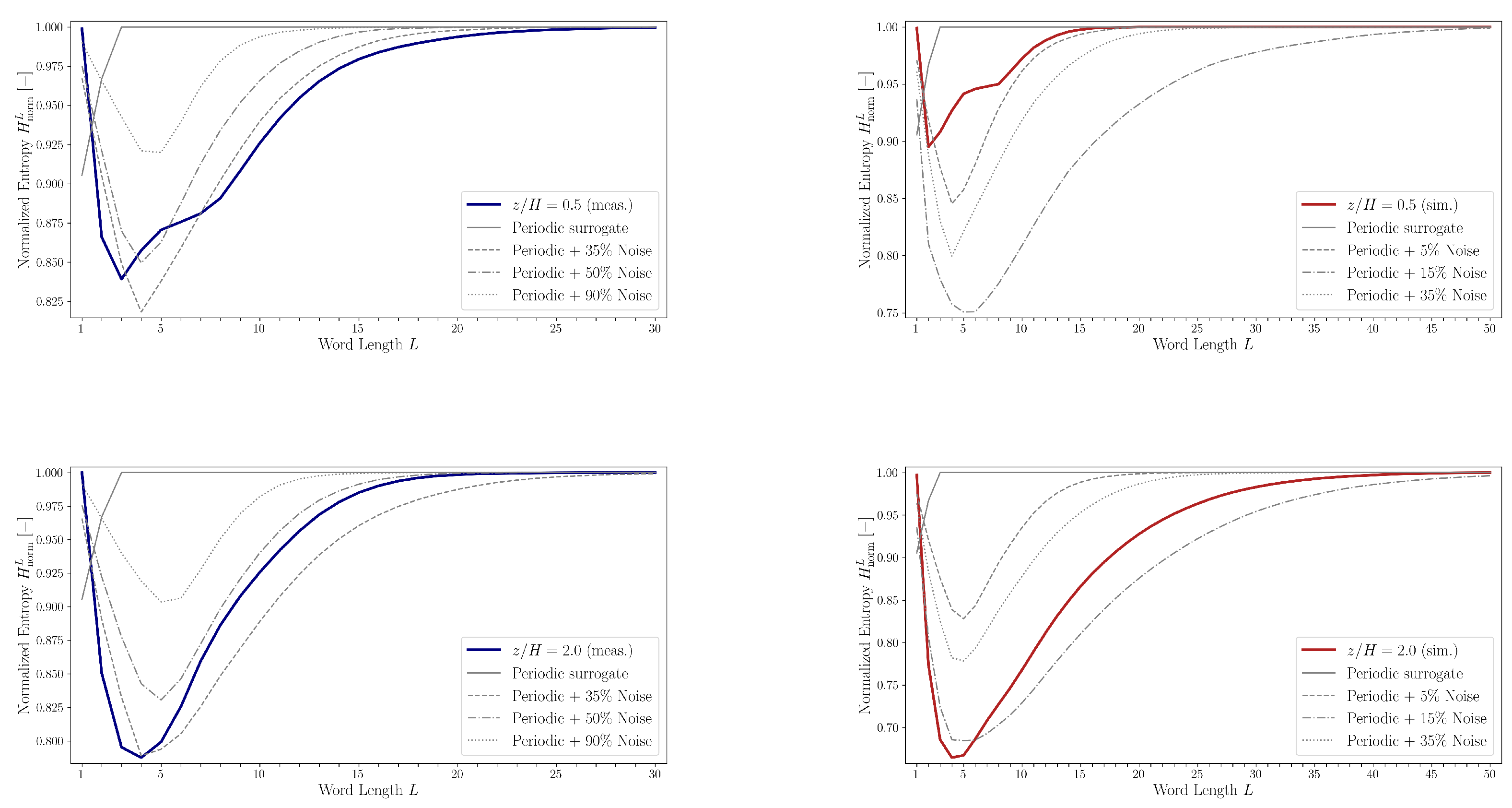
Figure 17 presents a comparison of normalized entropy values
as a function of word length
L for both the measured and artificially generated noisy periodic sequences. For the purely periodic sequence,
remains close to 1 across nearly all word lengths. This behavior is attributed to the nearly uniform distribution of words in the partitioned word list
, which mimics the properties of a random sequence where all unique words have approximately equal probability of occurrence.
Entropy curves for several noisy periodic sequences, derived by corrupting the base periodic pattern with noise levels of 35%, 50%, and 90% (relative to the length of the measured sequence) and 5%, 15%, and 35% (relative to the length of the simulated sequence), are also shown in
Figure 17. These entropy profiles exhibit characteristics similar to those observed in measured and simulated data: they are unimodal and gradually converge toward
. Additionally, the location of the entropy minimum shifts to higher word lengths with increasing noise. However, the entropy minima for the experimental and simulated datasets tend to occur at shorter word lengths compared to those of the noisy periodic sequences.
The transition probability matrices
were computed up to order
(see Equation (
14)) using experimental and simulation data at heights
and
. These matrices were then used to generate surrogate symbolic sequences. The corresponding normalized entropy values
for both the original and the surrogate sequences are compared in
Figure 18.
In general, surrogate sequences generated using fifth-order Markov models provide the closest match to the entropy curves of the measured and simulated data. An exception arises at in the experimental dataset, where the characteristic dip in the entropy curve is not replicated even by the fifth-order Markov chain. This discrepancy suggests that the symbolic quadrant sequence possesses a level of temporal correlation or structural complexity that exceeds what can be captured by a fifth-order Markov process.
Such behavior points to the influence of temporally coherent structures within the flow field, and supports the interpretation that the quadrant series retains memory effects over longer word lengths, indicative of organized turbulence phenomena.
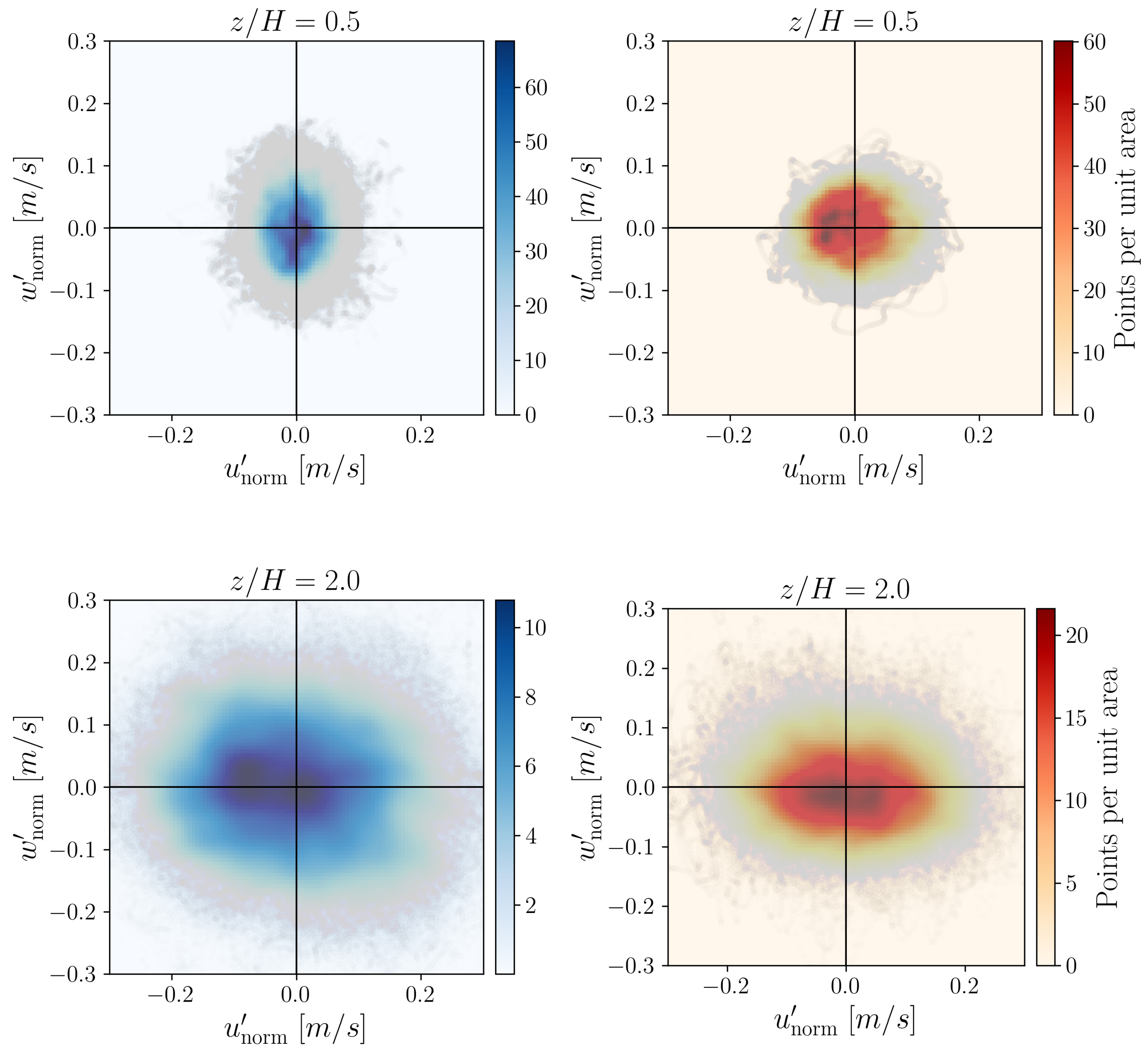
7. 2D Distributions of Velocity Fluctuations
Figure 19 shows the velocity fluctuation pairs
normalized with the free stream velocity
m/s colored by the probability density distribution of the fluctuation pairs at heights
and
. The probability distributions were calculated by the Gaussian kernel-density estimation utilizing a
grid over the point cloud range. The probability distributions of the point clouds are colored by point density.
Comparing the probability distribution in
Figure 19 to the relative occurrence of words in
Figure 12,
Figure 13,
Figure 14 and
Figure 15, one can see that for
, the “horizontal” transitions
and
are really more frequent at height
in the experimental data. However, for larger heights like
, the transitions
and
happen more. This means that while the fluctuations may display isotropy at some point, at the investigated heights, there is a preferential orientation of the velocity fluctuations. A comparable pattern of anisotropy was reported in open-channel flow over a rough bed by [
20].
Note that at
the distribution of the simulation data shows a remarkably flat ellipse compared to the experimental result. This also highlights that there is a noticeable deficit in the vertical fluctuations above roof height, a finding consistent with the results shown in
Figure 3, and is a shortcoming of the applied model (also shown in
Figure 20).
For all velocity fluctuation pairs
the moment of inertia matrices,
determines the principal axis (dashed straight lines in
Figure 20) of the point clouds. The angles between the
axis and the principal axis relative to
are
and
for the experimental data and
and
for the simulation data. Obviously, the calculated angles for both cases are different, showing the difference between a vortex core at
in the CFD model and the measurement, as well as the effect of driving force at
.
From the inertia matrices, the radii of gyration
were determined, too, for each measurement and simulation height (represented by the dashed circles in
Figure 20). The radii of gyration values show better agreement for the experimental and simulation data.
Since the proper partitioning for the use of symbolic dynamics is still an open question [
77], we also investigated the influence of coordinate rotation on the entropy. We considered the coordinate system
generated from the original
system by a counterclockwise rotation by angle
as
For a given rotation angle
, the rotation (
16) is applied to each pair of normalized velocity fluctuations
. The resulting rotated fluctuation components
are then classified into symbolic sequences through quadrant analysis, yielding the series
.
Using this procedure, the normalized entropy
(see Equation (
11)) was computed as a function of the rotation angle
.
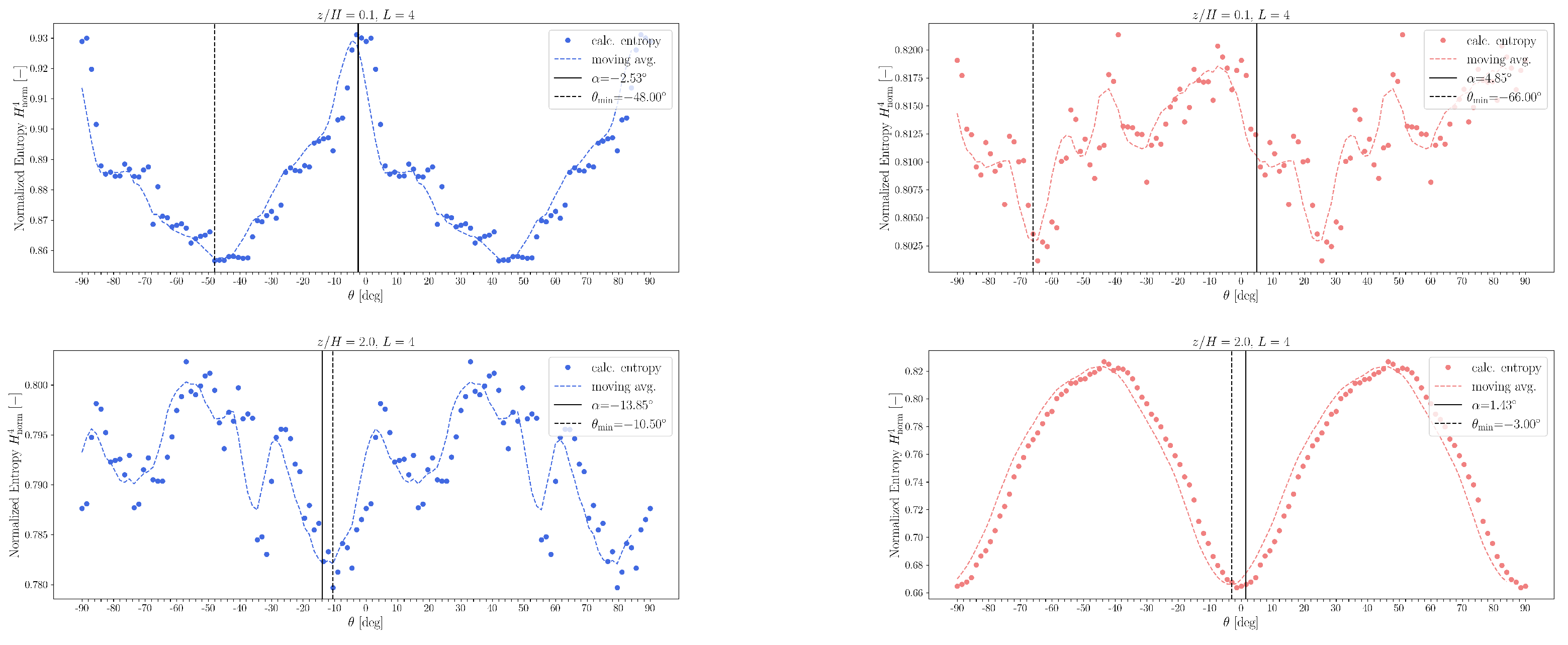
Figure 21 displays the resulting entropy profiles for measurement heights
and
, with angular resolution
.
As expected, the function
exhibits
-periodicity because a
rotation simply permutes the quadrant labels. Kalmár-Nagy and Varga [
43] observed that the locations of entropy extrema with respect to
are invariant under changes in word length. They further reported that the rotation angle
, corresponding to the minimum of the smoothed entropy curve (indicated by vertical dashed lines), tends to align closely with the principal axis directions (marked by vertical solid lines). However, in our case, this holds only outside the canyon region.
The hypothesis of Kalmár-Nagy and Varga was that the observed entropy minimum results from the most frequent transitions. In the original coordinate system, these transitions primarily cross the
axis. However, transitions more frequently align with the principal axis, so when the system is rotated accordingly, the number of transitions increases, leading to lower entropy values. This interpretation, however, does not hold at height
, as evident from
Figure 21.
8. Conclusions
We analyzed and compared time series data from wind tunnel measurement and CFD simulation of flows over street canyons through the use of the quadrant method, calculating entropies, Markov matrices and generating surrogate series.
We studied the idea that coherent structures in the atmospheric boundary layer manifest as “almost periodic temporal patterns”, characterized by the imperfect repetition of specific turbulent events or states. The time series of fluctuating velocities were converted into symbolic sequences using the quadrant method and treated as marked point processes. Analysis of the residence times—defined as the duration spent in each quadrant state—revealed distributions consistent with a lognormal form. To evaluate the information content of the symbolic sequences, normalized entropy was calculated across a range of word lengths. The resulting entropy profiles and the number of unique symbolic words were then compared to those derived from random sequences. Interestingly, artificially generated noisy periodic sequences produced entropy trends that qualitatively matched those of the experimental data.
Furthermore, surrogate sequences were created using Markov processes (orders 1 through 5). These surrogates reproduced entropy distributions close to those of the measured and simulated series, supporting the suitability of higher-order Markov models for characterizing the observed symbolic dynamics. Analysis of symbolic word histograms indicated that much of the information content in both measured and simulated sequences arises from the elevated frequency of words composed of alternating pairs of symbols.
Our investigation showed that simulation results are in qualitative agreement with measurements in several aspects, including the general trends observed in the residence time distributions of quadrants, the inflection points of dimensionless word number curves, as well as word frequencies. The vortex structures within the canyon, as the 2D distributions of the velocity fluctuations show, are well captured, demonstrating the capability of the model to reproduce the dominant flow patterns. It should be noted that some discrepancies exist, such as the differences in the mean residence time of the states above roof level () and in the entropy minima. Another discrepancy is the underestimation of the vertical velocity fluctuation () magnitude, but it is a known imperfection of the simulation model used in this work. Note that an important advantage of the CFD model used in the present work is that it provides a valuable tool for analyzing the entire flow field across the computational domain, offering insight beyond the discrete measurement points.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}