
An Automated Decision Support System for Portfolio Allocation Based on Mutual Information and Financial Criteria



Abstract
1. Introduction
- We develop a knowledge-based financial management system to solve cardinality-constrained portfolio optimization problems. This expert system is built upon two interconnected modules. On the one hand, a multi-criteria decision analysis technique called TODIM handles the cardinality constraint. On the other hand, the DISH-XX algorithm is extended with an ensemble of constraint-handling techniques and a gradient-based mutation.
- This study introduces two portfolio selection models where the objective function to maximize is a modified version of the Sharpe ratio under some real-world constraints. The first instance considers cardinality, box, and budget constraints. The second one introduces a set of risk budgeting constraints to provide explicit control of risk.
- When running the TODIM procedure for the preliminary ranking, we use three complementary financial criteria, namely the peripherality measure based on mutual information, the momentum measure, and the upside-to-downside beta ratio.
- To set up the relative preference weights of the three criteria, an equally weighted method and an entropy-based method are adopted.
- An extensive experimental analysis is conducted considering the two most significant indices of the American and European stock markets, namely the S&P 500 and the STOXX Europe 600.
- The empirical part validates the profitability of our investment strategy considering several ex post performance metrics and compares the two portfolio models described above against some alternatives that pre-select the stocks using the criteria individually, as well as the market benchmark.
2. Related Works
2.1. From DE to DISH-XX
2.2. Information Theory in Portfolio Optimization
3. Portfolio Models
3.1. Investment Strategy Setup
3.2. First Proposed Model
- Budget. Since all available capital needs to be invested at each investment window, the following holds:
- Cardinality. The portfolio includes exactly K assets, where . To model the inclusion or exclusion of the ith asset in the portfolio, a binary variable is introduced asfor , where , and the cardinality constraint can be written asThen, denotes the set of active portfolio weights, with .
- Box. A balanced portfolio should avoid extreme positions and foster diversification. Hence, maximum and minimum limits for portfolio weights are imposed, expressed bywhere and are the lower and upper bounds for the weight of the ith asset, respectively, with to exclude short sales.
3.3. Risk Budgeting Approach
3.4. Proposed Risk Budgeting Formulation for the Second Portfolio Model
4. Multi-Criteria Decision Analysis Module
4.1. TODIM Generalities
- Constructing the multi-criteria decision-making matrix between criteria and alternatives. Given m alternatives and s criteria , the decision matrix is expressed aswhere is the performance evaluation of under criterion .
- Determining the criteria weights. In this step, the criteria weighting vector , which satisfies and , needs to be determined. This vector defines the relative preference degree of the procedure toward the s criteria. Two weighting schemes are analyzed in this paper. The first assigns the same weight to each criterion to avoid any prior preference for a specific criterion in the TODIM structure. The second one utilizes the entropy weight method [59]. The contribution of the alternative to the criterion is calculated asNext, the entropy value for the jth criterion is given bywhere denotes the total contribution of all alternatives to criterion . If , it follows that . After obtaining the entropy values, the entropy weight is
- Binning and normalizing criteria matrix. The third step transforms the raw criteria matrix A into a different matrix, , by binning each element into 10 bins. Specifically, if a criterion is considered a benefit, a value of 10 is assigned to the alternatives in the top for that criterion. Conversely, if the criterion is a cost, a value of 10 is assigned to the alternatives in the bottom . Then, to make the scores comparable, a normalization procedure is used to obtain the normalized values .
- Computing alternative comparisons. Through the normalized scores, the alternatives can be compared based on their overall scores across the criteria. For criterion , the criteria score of alternative against alternative is defined as in [60]where is the objective weight of criterion ; are the two risk parameters of the value function in the domain of gains and losses; and is the loss aversion coefficient in the loss domain.After calculating the dominance degree with respect to criterion between any two alternatives and using Equation (13), the final comparison score concerning each criterion is
- Determining the final ranking between alternatives. In the last step, the rank of each alternative is obtained asThe procedure then concludes with the normalization of the final ranks. These range between 0 and 1, with the most preferred alternative having a value of 1 and the least preferred having a value of 0.
4.2. Application of TODIM to Investable Universe
5. Optimization Module
5.1. DISH-XX Algorithm
- Initialization. At iteration , the algorithm commences with the initialization of a random population consisting of solutions. During this step, additional parameters are configured: the final population size (), the maximum number of objective function evaluations (), and two parameters utilized in the mutation operator ( and ). Moreover, two external archives are introduced: the first, denoted as A, stores solutions that have been improved by the corresponding trial vectors; the second, , contains the most promising solutions. Based on the prescriptions given in [25], two historical memory arrays of size H, and , are defined component-wise asandwhich will be used to define the values for the scaling factor F and the crossover rate .
- Mutation. For each generation , the mutation operator used in DISH-XX is the current-to--w/1 strategy. Let be the ratio between the current number of objective function evaluations and . The mutation vector for each individual p is then generated as follows:where is one of the best solutions in the archive , with ; is randomly selected from the current population and from . It is worth noting that . The scaling factor is generated from a Cauchy distribution with location parameter randomly selected from the historical memory array and a scale parameter value of . If the generated value is non-positive, it is drawn again, and, if it is greater than 1, it is set to 1. In addition, to bound its value in the exploration phase, we set whenever and . The weighted scaling factor depends on and as follows:This mutation strategy combines a greedy approach in the first difference and an exploratory factor in the second difference.
- Double Crossover. The DISH-XX algorithm employs a double crossover mechanism. The first crossover is the standard binomial crossover as in [36], which combines the mutation vector with the target vector to produce a temporary trial vector . This process is based on the crossover rate value , which is randomly generated using a normal distribution with a mean value , randomly selected from the memory array , and a standard deviation value of . The value is then bounded between 0 and 1, with values outside this range truncated to the nearest bound. Similarly to the scaling factor, the crossover rate depends on as follows:The second crossover involves the archive of historically best-found solutions , enhancing the diversity and exploration capabilities of the algorithm. Using the same value of the first crossover, the trial vector is generated component-wise as follows:where is a uniformly distributed random number, is a randomly chosen index in , and is a solution randomly selected from .
- Selection. The selection process in DISH-XX is based on the comparison of the trial vector and the target vector . The objective function values of both vectors are evaluated, and the one with the better fitness value is selected for the next generation. This ensures that the population evolves toward better solutions over time.
- Adaptation of Control Parameters. DISH-XX incorporates adaptive mechanisms for control parameters, such as the scaling factor and the crossover rate. These parameters are adjusted based on the success history of previous generations, allowing the algorithm to dynamically adapt to the problem landscape and enhance its performance. After each generation, one cell in both memory arrays is updated. DISH-XX uses an index k to track which cell will be updated. The index is initialized to 1, so, after the first generation, the first memory cell is updated. The index is incremented by one after each update, and, when it exceeds the value of H, it resets to 1. There is one exception to this update process: the last cell in both arrays is never updated and retains a value of 0.9 for both control parameters. Let and be arrays storing successful and , respectively. A pair is considered successful if it generates a trial vector that outperforms the target vector . The size of and is a random number between 0 (indicating that no trial vector is better than the target) and (indicating that all trial vectors are better than their targets). Consequently, the value stored in the kth cell of the memory arrays after a given generation isandwhere is the weighted Lehmer mean of the corresponding control parameter and and is defined asfor . The weights are computed as the Euclidean distance between the trial vector and the the individual ; specifically,This weighting scheme encourages exploitation while aiming to prevent the premature convergence of the algorithm to local optima.
- Decrease in the Population Size. The population size dynamically reduces during the execution of the algorithm to allocate more time for exploration in the later stages of optimization. Specifically, at the end of each generation, the population size is updated using the following formula:
- Population and Archive Management. The archive of historically best-found solutions is maintained throughout the optimization process. The archive is periodically updated with the best solutions available, ensuring that it remains relevant and effective. The population and the archive A adjust their sizes in response to changes in (25) by removing the worst-ranking individuals.
- Termination. The algorithm iterates through the above steps until a termination criterion is met. Common termination criteria include reaching a maximum number of generations, achieving a satisfactory fitness level, or observing no significant improvement over a predefined number of iterations.
5.2. Dealing with Budget and Box Constraints
- ;
- ;
- .
5.3. Dealing with Risk Budgeting Constraints
5.3.1. Controlling the -Level
5.3.2. Gradient-Based Mutation
5.4. The Proposed DISH-XX- Algorithm
6. Experimental Analysis
6.1. Data Set Description and Experimental Setup
6.2. Criteria Used for the Screening of Assets
6.2.1. Eigenvector Centrality Measure Based on Mutual Information
6.2.2. Momentum Measure
6.2.3. Upside-to-Downside Beta Ratio
6.3. Ex Post Performance Metrics
6.4. Compared Strategies and Benchmark Portfolios
- ModSharpe-Equi-TODIMK: the portfolio model (16) that maximizes the modified Sharpe ratio with cardinality K and using the equal weighting method.
- ModSharpe-Entr-TODIMK: the portfolio model (16) that maximizes the modified Sharpe ratio with cardinality K and using the entropy weighting method.
- ModSharpe-RB-Equi-TODIMK,ν: the proposed risk budgeting portfolio model (17) with cardinality K, risk parity deviation , and adopting the equal weighting method.
- ModSharpe-RB-Entr-TODIMK,ν: the proposed risk budgeting portfolio model (17) with cardinality K, risk parity deviation , and adopting the entropy weighting method.
- BenchEW: the equally weighted portfolio constructed using all assets in the investable universe.
- BenchMI,K: an equally weighted strategy that adopts a preliminary stock-picking technique only based on the mutual information criterion for each of the three choices for K.
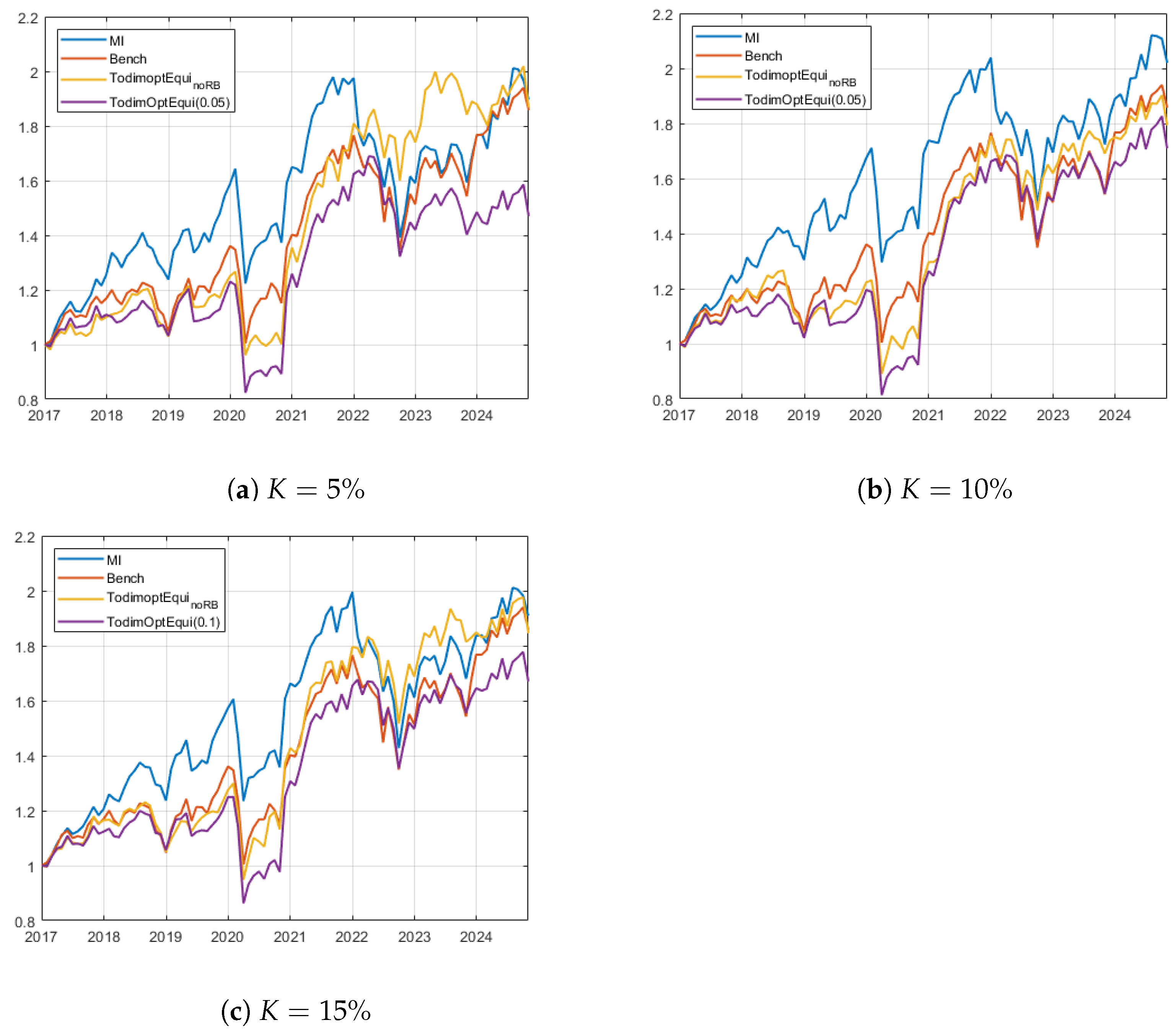
6.5. Discussion of the Ex Post Investment Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Risk Parity and Risk Budgeting
Appendix A.1. Details of Risk Parity
Appendix A.2. Non-Convexity of the Proposed Risk Budgeting Formulation
Appendix B. Pseudocode of DISH-XX-εg
| Algorithm A1 DISH-XX- |
|
Appendix C. Assessment of the Algorithm’s Efficiency


Appendix D. Statistical Significance of Differences Among the Sharpe Ratios of Portfolios

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BenchEW | BenchMI,5% | BenchMI,10% | BenchMI,15% | Equi-NoRB5% | Equi-NoRB10% | Equi-NoRB15% | Entr-NoRB5% | Entr-NoRB10% | Entr-NoRB15% | |
| BenchMI,5% | 0.4094 | |||||||||
| BenchMI,10% | 0.2394 | 0.9758 | ||||||||
| BenchMI,15% | 0.0665 | 0.6023 | 0.3479 | |||||||
| Equi-NoRB5% | 0.1915 | 0.6093 | 0.5634 | 0.7518 | ||||||
| Equi-NoRB10% | 0.3769 | 0.9258 | 0.9178 | 0.8843 | 0.3474 | |||||
| Equi-NoRB15% | 0.6828 | 0.6943 | 0.6488 | 0.4919 | 0.1680 | 0.3219 | ||||
| Entr-NoRB5% | 0.3074 | 0.8718 | 0.8818 | 0.9383 | 0.5559 | 0.9123 | 0.4594 | |||
| Entr-NoRB10% | 0.7013 | 0.7608 | 0.7198 | 0.5759 | 0.1880 | 0.4649 | 0.9903 | 0.2569 | ||
| Entr-NoRB15% | 0.5504 | 0.2644 | 0.1585 | 0.0995 | 0.1680 | |||||
| Equi-RB5%,0.01 | 0.1910 | 0.6478 | 0.5794 | 0.8238 | 0.7603 | 0.5949 | 0.2639 | 0.7608 | 0.3404 | |
| Equi-RB5%,0.05 | 0.1910 | 0.6483 | 0.5749 | 0.8208 | 0.7583 | 0.5859 | 0.2564 | 0.7588 | 0.3354 | |
| Equi-RB5%,0.10 | 0.1935 | 0.6448 | 0.5784 | 0.8223 | 0.7433 | 0.5934 | 0.2539 | 0.7553 | 0.3334 | |
| Equi-RB10%,0.01 | 0.3634 | 0.9818 | 0.9683 | 0.7818 | 0.2964 | 0.8713 | 0.4799 | 0.8388 | 0.5664 | 0.0575 |
| Equi-RB10%,0.05 | 0.3579 | 0.9743 | 0.9583 | 0.7973 | 0.3074 | 0.8853 | 0.4674 | 0.8548 | 0.5544 | 0.0580 |
| Equi-RB10%,0.10 | 0.3719 | 0.9858 | 0.9868 | 0.7763 | 0.2819 | 0.8513 | 0.4899 | 0.8323 | 0.5754 | 0.0600 |
| Equi-RB15%,0.01 | 0.2514 | 0.9793 | 0.9633 | 0.6853 | 0.3414 | 0.8348 | 0.5019 | 0.7893 | 0.6128 | |
| Equi-RB15%,0.05 | 0.2514 | 0.9848 | 0.9663 | 0.6838 | 0.3394 | 0.8338 | 0.4974 | 0.7888 | 0.6103 | |
| Equi-RB15%,0.10 | 0.2584 | 0.9778 | 0.9573 | 0.6828 | 0.3349 | 0.8283 | 0.5029 | 0.7838 | 0.6168 | |
| Entr-RB5%,0.01 | 0.4014 | 0.9773 | 0.9788 | 0.7748 | 0.3944 | 0.8633 | 0.6063 | 0.6648 | 0.5584 | |
| Entr-RB5%,0.05 | 0.3964 | 0.9848 | 0.9853 | 0.7828 | 0.4034 | 0.8763 | 0.5959 | 0.6838 | 0.5469 | |
| Entr-RB5%,0.10 | 0.4114 | 0.9678 | 0.9628 | 0.7648 | 0.3819 | 0.8503 | 0.6168 | 0.6368 | 0.5694 | |
| Entr-RB10%,0.01 | 0.4254 | 0.9418 | 0.9203 | 0.7233 | 0.3229 | 0.7533 | 0.6668 | 0.5779 | 0.5544 | |
| Entr-RB10%,0.05 | 0.4214 | 0.9468 | 0.9243 | 0.7293 | 0.3264 | 0.7593 | 0.6593 | 0.5839 | 0.5464 | |
| Entr-RB10%,0.10 | 0.4289 | 0.9448 | 0.9198 | 0.7253 | 0.3239 | 0.7508 | 0.6643 | 0.5779 | 0.5474 | |
| Entr-RB15%,0.01 | 0.6988 | 0.6088 | 0.5154 | 0.3649 | 0.1310 | 0.3604 | 0.8828 | 0.2089 | 0.8828 | 0.1100 |
| Entr-RB15%,0.05 | 0.7093 | 0.6033 | 0.5129 | 0.3604 | 0.1270 | 0.3544 | 0.8758 | 0.2024 | 0.8743 | 0.1125 |
| Entr-RB15%,0.10 | 0.7198 | 0.5994 | 0.5034 | 0.3549 | 0.1270 | 0.3479 | 0.8658 | 0.1980 | 0.8568 | 0.1175 |
| 0.4444 | 1.0000 | 1.0000 | 1.0000 | 0.4321 | 1.0000 | 0.6240 | 1.0000 | 0.6522 | 0.0000 | |
| 0.5556 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.3760 | 0.0000 | 0.3478 | 1.0000 | |
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.5679 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| Equi-RB5%,0.01 | Equi-RB5%,0.05 | Equi-RB5%,0.10 | Equi-RB10%,0.01 | Equi-RB10%,0.05 | Equi-RB10%,0.10 | Equi-RB15%,0.01 | Equi-RB15%,0.05 | Equi-RB15%,0.10 | ||
| BenchMI,5% | ||||||||||
| BenchMI,10% | ||||||||||
| BenchMI,15% | ||||||||||
| Equi-NoRB5% | ||||||||||
| Equi-NoRB10% | ||||||||||
| Equi-NoRB15% | ||||||||||
| Entr-NoRB5% | ||||||||||
| Entr-NoRB10% | ||||||||||
| Entr-NoRB15% | ||||||||||
| Equi-RB5%,0.01 | ||||||||||
| Equi-RB5%,0.05 | 0.8633 | |||||||||
| Equi-RB5%,0.10 | 0.9353 | 0.9768 | ||||||||
| Equi-RB10%,0.01 | 0.1985 | 0.1910 | 0.1895 | |||||||
| Equi-RB10%,0.05 | 0.2159 | 0.2119 | 0.2104 | 0.3524 | ||||||
| Equi-RB10%,0.10 | 0.1850 | 0.1815 | 0.1775 | 0.5739 | 0.2729 | |||||
| Equi-RB15%,0.01 | 0.3134 | 0.3164 | 0.3149 | 0.8973 | 0.8738 | 0.9283 | ||||
| Equi-RB15%,0.05 | 0.3164 | 0.3184 | 0.3199 | 0.9053 | 0.8818 | 0.9353 | 0.8453 | |||
| Equi-RB15%,0.10 | 0.3044 | 0.3014 | 0.3069 | 0.8838 | 0.8573 | 0.9108 | 0.7473 | 0.7063 | ||
| Entr-RB5%,0.01 | 0.4429 | 0.4414 | 0.4374 | 0.9418 | 0.9278 | 0.9528 | 0.9968 | 0.9988 | 0.9853 | |
| Entr-RB5%,0.05 | 0.4494 | 0.4489 | 0.4484 | 0.9513 | 0.9338 | 0.9673 | 0.9853 | 0.9853 | 0.9753 | |
| Entr-RB5%,0.10 | 0.4309 | 0.4279 | 0.4274 | 0.9203 | 0.9008 | 0.9363 | 0.9863 | 0.9843 | 0.9938 | |
| Entr-RB10%,0.01 | 0.3829 | 0.3744 | 0.3784 | 0.8063 | 0.7888 | 0.8238 | 0.8853 | 0.8773 | 0.8938 | |
| Entr-RB10%,0.05 | 0.3889 | 0.3869 | 0.3869 | 0.8158 | 0.7978 | 0.8323 | 0.8978 | 0.8903 | 0.9088 | |
| Entr-RB10%,0.10 | 0.3804 | 0.3754 | 0.3774 | 0.8013 | 0.7853 | 0.8173 | 0.8848 | 0.8813 | 0.8908 | |
| Entr-RB15%,0.01 | 0.1090 | 0.1100 | 0.1075 | 0.2459 | 0.2379 | 0.2584 | 0.2674 | 0.2664 | 0.2674 | |
| Entr-RB15%,0.05 | 0.1085 | 0.1065 | 0.1055 | 0.2389 | 0.2324 | 0.2539 | 0.2604 | 0.2544 | 0.2594 | |
| Entr-RB15%,0.10 | 0.1065 | 0.1055 | 0.1060 | 0.2349 | 0.2299 | 0.2479 | 0.2509 | 0.2494 | 0.2489 | |
| 0.5931 | 0.5931 | 0.5931 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | ||
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| 0.4069 | 0.4069 | 0.4069 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Entr-RB5%,0.01 | Entr-RB5%,0.05 | Entr-RB5%,0.10 | Entr-RB10%,0.01 | Entr-RB10%,0.05 | Entr-RB10%,0.10 | Entr-RB15%,0.01 | Entr-RB15%,0.05 | Entr-RB15%,0.10 | ||
| BenchMI,5% | ||||||||||
| BenchMI,10% | ||||||||||
| BenchMI,15% | ||||||||||
| Equi-NoRB5% | ||||||||||
| Equi-NoRB10% | ||||||||||
| Equi-NoRB15% | ||||||||||
| Entr-NoRB5% | ||||||||||
| Entr-NoRB10% | ||||||||||
| Entr-NoRB15% | ||||||||||
| Equi-RB5%,0.01 | ||||||||||
| Equi-RB5%,0.05 | ||||||||||
| Equi-RB5%,0.10 | ||||||||||
| Equi-RB10%,0.01 | ||||||||||
| Equi-RB10%,0.05 | ||||||||||
| Equi-RB10%,0.10 | ||||||||||
| Equi-RB15%,0.01 | ||||||||||
| Equi-RB15%,0.05 | ||||||||||
| Equi-RB15%,0.10 | ||||||||||
| Entr-RB5%,0.01 | ||||||||||
| Entr-RB5%,0.05 | 0.5784 | |||||||||
| Entr-RB5%,0.10 | 0.6583 | 0.5294 | ||||||||
| Entr-RB10%,0.01 | 0.8238 | 0.7973 | 0.8568 | |||||||
| Entr-RB10%,0.05 | 0.8373 | 0.8103 | 0.8643 | 0.6548 | ||||||
| Entr-RB10%,0.10 | 0.8153 | 0.7948 | 0.8523 | 0.9558 | 0.7328 | |||||
| Entr-RB15%,0.01 | 0.1935 | 0.1865 | 0.2124 | |||||||
| Entr-RB15%,0.05 | 0.1825 | 0.1785 | 0.1995 | 0.4324 | ||||||
| Entr-RB15%,0.10 | 0.1775 | 0.1750 | 0.1960 | 0.2064 | 0.5064 | |||||
| 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.2963 | 0.2778 | 0.2778 | ||
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.6741 | 0.7222 | 0.7222 | ||
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0296 | 0.0000 | 0.0000 | ||
| BenchEW | BenchMI,5% | BenchMI,10% | BenchMI,15% | Equi-NoRB5% | Equi-NoRB10% | Equi-NoRB15% | Entr-NoRB5% | Entr-NoRB10% | Entr-NoRB15% | |
| BenchMI,5% | 0.9568 | |||||||||
| BenchMI,10% | 0.6213 | 0.4944 | ||||||||
| BenchMI,15% | 0.7688 | 0.7833 | 0.5334 | |||||||
| Equi-NoRB5% | 0.9823 | 0.9403 | 0.6898 | 0.7998 | ||||||
| Equi-NoRB10% | 0.8613 | 0.8463 | 0.5959 | 0.7188 | 0.8678 | |||||
| Equi-NoRB15% | 0.9423 | 0.9293 | 0.6873 | 0.7923 | 0.9778 | 0.8448 | ||||
| Entr-NoRB5% | 0.0645 | 0.1220 | ||||||||
| Entr-NoRB10% | 0.2994 | 0.4014 | 0.2039 | 0.2629 | 0.2399 | 0.2574 | 0.2089 | 0.0825 | ||
| Entr-NoRB15% | 0.1115 | 0.3034 | 0.1540 | 0.1830 | 0.1710 | 0.0935 | 0.3109 | 0.6698 | ||
| Equi-RB5%,0.01 | 0.1990 | 0.3114 | 0.1535 | 0.1700 | 0.1100 | 0.2119 | 0.1415 | 0.1630 | 0.7458 | 0.9348 |
| Equi-RB5%,0.05 | 0.2059 | 0.3144 | 0.1580 | 0.1730 | 0.1145 | 0.2154 | 0.1475 | 0.1485 | 0.7638 | 0.9143 |
| Equi-RB5%,0.10 | 0.2034 | 0.3114 | 0.1525 | 0.1705 | 0.1075 | 0.2089 | 0.1425 | 0.1575 | 0.7503 | 0.9293 |
| Equi-RB10%,0.01 | 0.3914 | 0.5784 | 0.3249 | 0.3844 | 0.4699 | 0.5069 | 0.4094 | 0.5529 | 0.2809 | |
| Equi-RB10%,0.05 | 0.4099 | 0.5919 | 0.3329 | 0.3949 | 0.4854 | 0.5364 | 0.4304 | 0.5249 | 0.2589 | |
| Equi-RB10%,0.10 | 0.3969 | 0.5804 | 0.3284 | 0.3889 | 0.4744 | 0.5114 | 0.4104 | 0.5404 | 0.2659 | |
| Equi-RB15%,0.01 | 0.3459 | 0.5484 | 0.3154 | 0.3799 | 0.4654 | 0.4934 | 0.2954 | 0.6028 | 0.2634 | |
| Equi-RB15%,0.05 | 0.3469 | 0.5504 | 0.3169 | 0.3819 | 0.4629 | 0.4914 | 0.2924 | 0.6033 | 0.2619 | |
| Equi-RB15%,0.10 | 0.3594 | 0.5589 | 0.3259 | 0.3889 | 0.4769 | 0.5119 | 0.3084 | 0.5809 | 0.2449 | |
| Entr-RB5%,0.01 | 0.1335 | 0.0565 | 0.0510 | 0.8658 | 0.1265 | 0.3034 | ||||
| Entr-RB5%,0.05 | 0.1310 | 0.0555 | 0.8448 | 0.1180 | 0.2939 | |||||
| Entr-RB5%,0.10 | 0.1320 | 0.0550 | 0.8478 | 0.1185 | 0.2924 | |||||
| Entr-RB10%,0.01 | 0.1005 | 0.2669 | 0.1210 | 0.1435 | 0.1470 | 0.1315 | 0.0930 | 0.2644 | 0.4269 | 0.7913 |
| Entr-RB10%,0.05 | 0.0995 | 0.2644 | 0.1185 | 0.1410 | 0.1410 | 0.1290 | 0.0905 | 0.2699 | 0.4154 | 0.7813 |
| Entr-RB10%,0.10 | 0.1010 | 0.2644 | 0.1185 | 0.1410 | 0.1435 | 0.1260 | 0.0900 | 0.2679 | 0.4254 | 0.7743 |
| Entr-RB15%,0.01 | 0.1095 | 0.3064 | 0.1420 | 0.1685 | 0.1820 | 0.1785 | 0.1095 | 0.1915 | 0.6678 | 0.9873 |
| Entr-RB15%,0.05 | 0.1095 | 0.3049 | 0.1405 | 0.1695 | 0.1805 | 0.1775 | 0.1095 | 0.1935 | 0.6668 | 0.9883 |
| Entr-RB15%,0.10 | 0.1140 | 0.3134 | 0.1440 | 0.1750 | 0.1900 | 0.1900 | 0.1165 | 0.1720 | 0.7003 | 0.9453 |
| 0.4444 | 0.4631 | 0.0000 | 0.3703 | 0.6351 | 0.6351 | 0.4444 | 0.1852 | 0.3704 | 0.6351 | |
| 0.5556 | 0.5369 | 1.0000 | 0.6297 | 0.3649 | 0.3649 | 0.5556 | 0.0000 | 0.2963 | 0.0000 | |
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.8148 | 0.3333 | 0.3649 | |
| Equi-RB5%,0.01 | Equi-RB5%,0.05 | Equi-RB5%,0.10 | Equi-RB10%,0.01 | Equi-RB10%,0.05 | Equi-RB10%,0.10 | Equi-RB15%,0.01 | Equi-RB15%,0.05 | Equi-RB15%,0.10 | ||
| BenchMI,5% | ||||||||||
| BenchMI,10% | ||||||||||
| BenchMI,15% | ||||||||||
| Equi-NoRB5% | ||||||||||
| Equi-NoRB10% | ||||||||||
| Equi-NoRB15% | ||||||||||
| Entr-NoRB5% | ||||||||||
| Entr-NoRB10% | ||||||||||
| Entr-NoRB15% | ||||||||||
| Equi-RB5%,0.01 | ||||||||||
| Equi-RB5%,0.05 | 0.2959 | |||||||||
| Equi-RB5%,0.10 | 0.8273 | 0.6783 | ||||||||
| Equi-RB10%,0.01 | 0.1015 | 0.1090 | 0.1100 | |||||||
| Equi-RB10%,0.05 | 0.0895 | 0.0975 | 0.0915 | |||||||
| Equi-RB10%,0.10 | 0.1000 | 0.1090 | 0.1030 | 0.6078 | 0.4554 | |||||
| Equi-RB15%,0.01 | 0.2299 | 0.2414 | 0.2354 | 0.8818 | 0.7778 | 0.8298 | ||||
| Equi-RB15%,0.05 | 0.2259 | 0.2389 | 0.2334 | 0.8933 | 0.7848 | 0.8408 | 0.8873 | |||
| Equi-RB15%,0.10 | 0.2114 | 0.2284 | 0.2214 | 0.9563 | 0.8598 | 0.9183 | 0.1545 | 0.1685 | ||
| Entr-RB5%,0.01 | ||||||||||
| Entr-RB5%,0.05 | ||||||||||
| Entr-RB5%,0.10 | ||||||||||
| Entr-RB10%,0.01 | 0.6448 | 0.6178 | 0.6413 | 0.0525 | 0.0510 | |||||
| Entr-RB10%,0.05 | 0.6293 | 0.5979 | 0.6273 | |||||||
| Entr-RB10%,0.10 | 0.6343 | 0.6068 | 0.6298 | |||||||
| Entr-RB15%,0.01 | 0.9043 | 0.8698 | 0.8958 | 0.0865 | 0.0750 | 0.0800 | 0.1100 | 0.1085 | 0.1015 | |
| Entr-RB15%,0.05 | 0.9033 | 0.8743 | 0.8978 | 0.0870 | 0.0735 | 0.0790 | 0.1080 | 0.1055 | 0.0995 | |
| Entr-RB15%,0.10 | 0.9438 | 0.9153 | 0.9353 | 0.1020 | 0.0875 | 0.0960 | 0.1280 | 0.1265 | 0.1180 | |
| 0.5291 | 0.5291 | 0.5291 | 0.3704 | 0.2778 | 0.3704 | 0.4938 | 0.4938 | 0.2778 | ||
| 0.0476 | 0.1217 | 0.0476 | 0.4444 | 0.5741 | 0.4815 | 0.4074 | 0.4074 | 0.5741 | ||
| 0.4233 | 0.3492 | 0.4233 | 0.1852 | 0.1481 | 0.1481 | 0.0988 | 0.0988 | 0.1481 | ||
| Entr-RB5%,0.01 | Entr-RB5%,0.05 | Entr-RB5%,0.10 | Entr-RB10%,0.01 | Entr-RB10%,0.05 | Entr-RB10%,0.10 | Entr-RB15%,0.01 | Entr-RB15%,0.05 | Entr-RB15%,0.10 | ||
| BenchMI,5% | ||||||||||
| BenchMI,10% | ||||||||||
| BenchMI,15% | ||||||||||
| Equi-NoRB5% | ||||||||||
| Equi-NoRB10% | ||||||||||
| Equi-NoRB15% | ||||||||||
| Entr-NoRB5% | ||||||||||
| Entr-NoRB10% | ||||||||||
| Entr-NoRB15% | ||||||||||
| Equi-RB5%,0.01 | ||||||||||
| Equi-RB5%,0.05 | ||||||||||
| Equi-RB5%,0.10 | ||||||||||
| Equi-RB10%,0.01 | ||||||||||
| Equi-RB10%,0.05 | ||||||||||
| Equi-RB10%,0.10 | ||||||||||
| Equi-RB15%,0.01 | ||||||||||
| Equi-RB15%,0.05 | ||||||||||
| Equi-RB15%,0.10 | ||||||||||
| Entr-RB5%,0.01 | ||||||||||
| Entr-RB5%,0.05 | 0.3854 | |||||||||
| Entr-RB5%,0.10 | 0.7443 | 0.7783 | ||||||||
| Entr-RB10%,0.01 | 0.0710 | 0.0630 | 0.0635 | |||||||
| Entr-RB10%,0.05 | 0.0815 | 0.0675 | 0.0685 | 0.5289 | ||||||
| Entr-RB10%,0.10 | 0.0830 | 0.0700 | 0.0695 | 0.7128 | 0.9618 | |||||
| Entr-RB15%,0.01 | 0.0670 | 0.0600 | 0.0580 | 0.4659 | 0.4424 | 0.4554 | ||||
| Entr-RB15%,0.05 | 0.0660 | 0.0590 | 0.0585 | 0.4684 | 0.4444 | 0.4599 | 0.9243 | |||
| Entr-RB15%,0.10 | 0.0575 | 0.0530 | 0.0530 | 0.3994 | 0.3714 | 0.3824 | 0.0880 | |||
| 0.1481 | 0.1587 | 0.1587 | 0.2469 | 0.2469 | 0.4444 | 0.4762 | 0.4762 | 0.4233 | ||
| 0.0148 | 0.0000 | 0.0000 | 0.0864 | 0.0494 | 0.0000 | 0.0688 | 0.0688 | 0.1640 | ||
| 0.8370 | 0.8413 | 0.8413 | 0.6666 | 0.7037 | 0.5556 | 0.4550 | 0.4550 | 0.4127 | ||
References
- Morel, C. Stock selection using a multi-factor model: Empirical evidence from the French stock market. Eur. J. Financ. 2001, 7, 312–334. [Google Scholar] [CrossRef]
- De Franco, C. Stock picking in the US market and the effect of passive investments. J. Asset Manag. 2021, 22, 1–10. [Google Scholar] [CrossRef]
- Breitung, C. Automated stock picking using random forests. J. Empir. Financ. 2023, 72, 532–556. [Google Scholar] [CrossRef]
- Wolff, D.; Echterling, F. Stock picking with machine learning. J. Forecast. 2023, 43, 81–102. [Google Scholar] [CrossRef]
- Albadvi, A.; Chaharsooghi, S.K.; Esfahianipour, A. Decision making in stock trading: An application of PROMETHEE. Eur. J. Oper. Res. 2007, 177, 673–683. [Google Scholar] [CrossRef]
- Vetschera, R.; De Almeida, A.T. A PROMETHEE-based approach to portfolio selection problems. Comput. Oper. Res. 2012, 39, 1010–1020. [Google Scholar] [CrossRef]
- Tavana, M.; Keramatpour, M.; Santos-Arteaga, F.J.; Ghorbaniane, E. A fuzzy hybrid project portfolio selection method using data envelopment analysis, TOPSIS and integer programming. Expert Syst. Appl. 2015, 42, 8432–8444. [Google Scholar] [CrossRef]
- Vásquez, J.A.; Escobar, J.W.; Manotas, D.F. AHP–TOPSIS methodology for stock portfolio investments. Risks 2021, 10, 4. [Google Scholar] [CrossRef]
- Ho, W.R.J.; Tsai, C.L.; Tzeng, G.H.; Fang, S.K. Combined DEMATEL technique with a novel MCDM model for exploring portfolio selection based on CAPM. Expert Syst. Appl. 2011, 38, 16–25. [Google Scholar]
- Pätäri, E.; Karell, V.; Luukka, P.; Yeomans, J.S. Comparison of the multicriteria decision-making methods for equity portfolio selection: The US evidence. Eur. J. Oper. Res. 2018, 265, 655–672. [Google Scholar] [CrossRef]
- Jing, D.; Imeni, M.; Edalatpanah, S.A.; Alburaikan, A.; Khalifa, H.A.E.-W. Optimal selection of stock portfolios using multi-criteria decision-making methods. Mathematics 2023, 11, 415. [Google Scholar] [CrossRef]
- Gomes, L.F.A.M.; Lima, M.M.P.P. TODIM: Basics and application to multicriteria ranking of projects with environmental impacts. Found. Comput. Decis. Sci. 1991, 16, 113–127. [Google Scholar]
- Kahneman, D.; Tversky, A. Prospect theory: An analysis of decision under risk. Econometrica 1979, 47, 263–291. [Google Scholar] [CrossRef]
- Alali, F.; Tolga, A.C. Portfolio allocation with the TODIM method. Expert Syst. Appl. 2019, 124, 341–348. [Google Scholar] [CrossRef]
- Wu, Q.; Liu, X.; Qin, J.; Zhou, L.; Mardani, A.; Deveci, M. An integrated generalized TODIM model for portfolio selection based on financial performance of firms. Knowl.-Based Syst. 2022, 249, 108794. [Google Scholar] [CrossRef]
- Markowitz, H.M. Portfolio selection. J. Financ. 1952, 7, 77–91. [Google Scholar]
- Maillard, S.; Roncalli, T.; Teïletche, J. The properties of equally weighted risk contribution portfolios. J. Portf. Manag. 2010, 36, 60–70. [Google Scholar] [CrossRef]
- Fabozzi, F.A.; Simonian, J.; Fabozzi, F.J. Risk parity: The democratization of risk in asset allocation. J. Portf. Manag. 2021, 47, 41–50. [Google Scholar] [CrossRef]
- Feng, Y.; Palomar, D.P. SCRIP: Successive convex optimization methods for risk parity portfolio design. IEEE Trans. Signal Process. 2015, 63, 5285–5300. [Google Scholar] [CrossRef]
- Bai, X.; Scheinberg, K.; Tutuncu, R. Least-squares approach to risk parity in portfolio selection. Quant. Financ. 2016, 16, 357–376. [Google Scholar] [CrossRef]
- Feng, Y.; Palomar, D.P. Portfolio optimization with asset selection and risk parity control. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shangai, China, 20–25 March 2016; pp. 1–8. [Google Scholar]
- Kaucic, M. Equity portfolio management with cardinality constraints and risk parity control using multi objective particle swarm optimization. Comput. Oper. Res. 2019, 109, 300–316. [Google Scholar] [CrossRef]
- Qian, E. On the financial interpretation of risk contribution: Risk budgets do add up. J. Investig. Manag. 2006, 4, 41–51. [Google Scholar] [CrossRef]
- Bruder, B.; Roncalli, T. Managing risk exposures using the risk budgeting approach. SSRN. 2012. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2009778 (accessed on 10 March 2025).
- Viktorin, A.; Senkerik, R.; Pluhacek, M.; Kadavy, T.; Zamuda, A. DISH-XX solving CEC2020 single objective bound constrained numerical optimization benchmark. In Proceedings of the 2020 IEEE International Conference on Evolutionary Computation, Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Banerjee, A.K.; Pradham, H.K.; Sensoy, A.; Fabozzi, F.; Mahapatra, B. Robust portfolio optimization with fuzzy TODIM, genetic algorithm and multi-criteria constraints. Ann. Oper. Res. 2024, 337, 1–22. [Google Scholar] [CrossRef]
- Sharpe, W.F. Mutual funds performance. J. Bus. 1966, 39, 119–138. [Google Scholar] [CrossRef]
- Israelsen, C. A refinement to the Sharpe ratio and information ratio. J. Asset Manag. 2005, 5, 423–427. [Google Scholar] [CrossRef]
- Kaucic, M.; Piccotto, F.; Sbaiz, G.; Valentinuz, G. A hybrid level-based learning swarm algorithm with mutation operator for solving large-scale cardinality-constrained portfolio optimisation problems. Inf. Sci. 2023, 634, 321–339. [Google Scholar] [CrossRef]
- Costa, G.; Kwon, R. Generalized risk parity portfolio optimization: An ADMM approach. J. Glob. Optim. 2020, 78, 207–238. [Google Scholar] [CrossRef]
- Kalayci, C.B.; Ertenlice, O.; Akbay, M.A. A comprehensive review of deterministic models and applications for mean-variance portfolio optimization. Expert Syst. Appl. 2019, 125, 345–368. [Google Scholar] [CrossRef]
- Erwin, K.; Engelbrecht, A. Meta-heuristics for portfolio optimization. Soft Comput. 2023, 27, 19045–19073. [Google Scholar] [CrossRef]
- Khan, A.T.; Cao, X.; Brajevic, I.; Stanimirovic, P.S.; Katsikis, V.N.; Li, S. A non-linear activated beetle antennae search: A novel technique for non-convex tax-aware portfolio optimization problem. Expert Syst. Appl. 2022, 197, 116631. [Google Scholar] [CrossRef]
- Cao, X.; Francis, A.; Pu, X.; Zhang, Z.; Katsikis, V.N.; Stanimirovic, P.S.; Brajevic, I.; Li, S. A novel recurrent neural network based online portfolio analysis for high frequency trading. Expert Syst. Appl. 2023, 233, 120934. [Google Scholar] [CrossRef]
- Cao, X.; Yang, S.; Stanimirovic, P.S.; Katsikis, V.N. Artificial neural dynamics for portfolio allocation: An Optimization perspective. IEEE Trans. Syst. Man Cybern. Syst. 2025, 55, 1960–1971. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Krink, T.; Paterlini, S. Multiobjective optimization using differential evolution for real-world portfolio optimization. Comput. Manag. Sci. 2011, 8, 157–179. [Google Scholar] [CrossRef]
- Vijayalakshmi Pai, G.A.; Michel, T. Metaheuristic optimization of risk budgeted global asset allocation portfolios. In Proceedings of the 2011 World Congress on Information and Communication Technologies, Mumbai, India, 11–14 December 2011; pp. 154–159. [Google Scholar]
- Meghwani, S.S.; Thakur, M. Multi-criteria algorithms for portfolio optimization under practical constraints. Swarm Evol. Comput. 2017, 37, 104–125. [Google Scholar] [CrossRef]
- Chootinan, P.; Chen, A. Constraint handling in genetic algorithms using a gradient-based repair method. Comp. Oper. Res. 2006, 33, 2263–2281. [Google Scholar] [CrossRef]
- Takahama, T.; Sakai, S. Constrained optimization by the ε-constrained differential evolution with gradient-based mutation and feasible elites. In Proceedings of the 2006 IEEE International Conference on Evolutionary Computation, Vancouver, BC, Canada, 16–21 July 2006; pp. 1–8. [Google Scholar]
- Sharma, C.; Habib, A. Mutual information based stock networks and portfolio selection for intraday traders using high frequency data: An Indian market case study. PLoS ONE 2019, 14, e0221910. [Google Scholar] [CrossRef]
- Das, S.; Mullick, S.S.; Suganthan, P.N. Recent advances in differential evolution—An updated survey. Swarm Evolut. Comput. 2016, 27, 1–30. [Google Scholar] [CrossRef]
- Chang, J.; Sanderson, A.C. JADE: Adaptive differential evolution with optional external archive. IEEE Trans. Evol. Comput. 2009, 13, 945–958. [Google Scholar]
- Tanabe, R.; Fukunaga, A.S. Success-history based parameter adaptation for differential evolution. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation (CEC), Cancun, Mexico, 20–23 June 2013; pp. 71–78. [Google Scholar]
- Tanabe, R.; Fukunaga, A.S. Improving the search performance of SHADE using linear population size reduction. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; pp. 1658–1665. [Google Scholar]
- Viktorin, A.; Senkerik, R.; Pluhacek, M.; Kadavy, T.; Zamuda, A. Distance based parameter adaptation for success-history based differential evolution. Swarm Evolut. Comput. 2019, 50, 100462. [Google Scholar] [CrossRef]
- Philippatos, G.C.; Wilson, C.J. Entropy, market risk, and the selection of efficient portfolios. Appl. Econ. 1972, 4, 209–220. [Google Scholar] [CrossRef]
- Mercurio, P.J.; Wu, Y.; Xie, H. An entropy-based approach to portfolio optimization. Entropy 2020, 22, 332. [Google Scholar] [CrossRef]
- Novais, R.G.; Wanke, P.; Antunes, J.; Tan, Y. Portfolio optimization with a mean-entropy-mutual information model. Entropy 2022, 24, 369. [Google Scholar] [CrossRef] [PubMed]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E Stat. Nonlin. Soft Matter Phys. 2004, 69, 6. [Google Scholar] [CrossRef] [PubMed]
- Bera, A.K.; Park, S.Y. Optimal portfolio diversification using the maximum entropy principle. Econom. Rev. 2008, 27, 484–512. [Google Scholar] [CrossRef]
- Usta, I.; Kantar, Y.M. Mean-variance-skewness-entropy measures: A multi-objective approach for portfolio selection. Entropy 2011, 13, 117–133. [Google Scholar] [CrossRef]
- Song, R.; Chan, Y. A new adaptive entropy portfolio selection model. Entropy 2020, 22, 951. [Google Scholar] [CrossRef]
- Pozzi, F.; Di Matteo, T.; Aste, T. Spread of risk across financial markets: Better to invest in the peripheries. Sci. Rep. 2013, 3, 1665. [Google Scholar] [CrossRef]
- Peralta, G.; Zareei, A. A network approach to portfolio selection. J. Empir. Financ. 2016, 38, 157–180. [Google Scholar] [CrossRef]
- Clemente, G.P.; Grassi, R.; Hitaj, A. Asset allocation: New evidence through network approaches. Ann. Oper. Res. 2019, 299, 61–80. [Google Scholar] [CrossRef]
- Guo, X.; Zhang, H.; Tian, T. Development of stock correlation networks using mutual information and financial big data. PLoS ONE 2018, 13, e0195941. [Google Scholar] [CrossRef]
- Zhao, D.; Li, C.; Wang, J.; Yuan, J. Comprehensive evaluation of national electric power development based on cloud model and entropy method and TOPSIS: A case study in 11 countries. J. Clean. Prod. 2020, 277, 123190. [Google Scholar] [CrossRef]
- Llamazares, B. An analysis of the generalized TODIM method. Eur. J. Oper. Res. 2018, 269, 1041–1049. [Google Scholar] [CrossRef]
- Gurrola-Ramos, J.; Hernàndez-Aguirre, A.; Dalmau-Cedeño, O. COLSHADE for real-world single-objective constrained optimization problems. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, Scotland, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Tang, H.; Lee, J. Adaptive initialization LSHADE algorithm enhanced with gradient-based repair for real-world constrained optimization. Knowl.-Based Syst. 2022, 246, 108696. [Google Scholar] [CrossRef]
- Kaucic, M.; Piccotto, F.; Sbaiz, G. A constrained swarm optimization algorithm for large-scale long-run investments using Sharpe ratio-based performance measures. Comp. Manag. Sci. 2024, 21, 6. [Google Scholar] [CrossRef]
- Guy, A. Upside and downside beta portfolio construction: A different approach to risk measurement and portfolio construction. Risk Gov. Control Financ. Mark. Inst. 2015, 5, 243–251. [Google Scholar] [CrossRef]
- DeMiguel, V.; Garlappi, L.; Uppal, R. Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy? Rev. Financ. Stud. 2009, 22, 1915–1953. [Google Scholar] [CrossRef]
- Fisher, J.D.; D’Alessandro, J. Portfolio upside and downside risk—Both matter! J. Port. Manag. 2021, 47, 158–171. [Google Scholar] [CrossRef]
- Martin, P.G.; McCann, B.B. The Investor’s Guide to Fidelity Funds, 2nd ed.; Venture Catalyst, Inc.: Redmond, WA, USA, 1998. [Google Scholar]
- Sortino, F.A.; Satchell, S. Managing Downside Risk in Financial Markets: Theory, Practice and Implementation; Butterworth Heinemann: Oxford, UK, 2001. [Google Scholar]
- Keating, C.; Shadwick, W.F. A universal performance measure. J. Perf. Meas. 2002, 6, 59–84. [Google Scholar]
- Ledoit, O.; Wolf, M. Robust performance hypothesis testing with the Sharpe ratio. J. Empir. Financ. 2008, 15, 850–859. [Google Scholar] [CrossRef]
- Storey, J.D. A direct approach to false discovery rates. J. R. Stat. Soc. B 2002, 64, 479–498. [Google Scholar] [CrossRef]
- Ardia, D.; Boudt, K. The peer performance ratios of hedge funds. J. Bank. Financ. 2018, 87, 351–368. [Google Scholar] [CrossRef]
- Beck, A. Introduction to Nonlinear Optimization: Theory, Algorithms, and Applications with MATLAB, 1st ed.; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2014. [Google Scholar]
- Olorunda, O.; Engelbrecht, A.P. Measuring exploration/exploitation in particle swarms using swarm diversity. In Proceedings of the 2008 IEEE International Conference on Evolutionary Computation, Hong Kong, China, 1–8 June 2008; pp. 1128–1134. [Google Scholar]


| Data Set | n | Time Window | Estimation Window (Months) | Ex Post Months |
|---|---|---|---|---|
| S&P 500 (US) | 470 stocks | 31/12/2014–31/10/2024 | 24 | 94 |
| STOXX Europe 600 (EU) | 535 stocks | 31/12/2014–31/10/2024 | 24 | 94 |
| US Data Set | ||||||||
|---|---|---|---|---|---|---|---|---|
| Configuration | CAGR | SR | SSRout | Ωout | σout (×100) | maxDD | UI | |
| K = 5% | MSR-Equi-TODIM | 0.08 | 0.15 | 0.21 | 1.49 | 5.00 | 0.35 | 0.14 |
| MSR-RB-Equi-TODIM0.01 | 0.08 | 0.16 | 0.23 | 1.53 | 4.94 | 0.30 | 0.12 | |
| MSR-RB-Equi-TODIM0.05 | 0.08 | 0.16 | 0.23 | 1.53 | 4.94 | 0.30 | 0.12 | |
| MSR-RB-Equi-TODIM0.1 | 0.08 | 0.16 | 0.23 | 1.53 | 4.95 | 0.30 | 0.12 | |
| MSR-Entr-TODIM | 0.10 | 0.18 | 0.22 | 1.61 | 4.99 | 0.33 | 0.13 | |
| MSR-RB-Entr-TODIM0.01 | 0.10 | 0.19 | 0.25 | 1.64 | 5.03 | 0.34 | 0.13 | |
| MSR-RB-Entr-TODIM0.05 | 0.10 | 0.19 | 0.25 | 1.63 | 5.03 | 0.34 | 0.13 | |
| MSR-RB-Entr-TODIM0.1 | 0.11 | 0.19 | 0.25 | 1.64 | 5.02 | 0.33 | 0.13 | |
| BenchMI | 0.09 | 0.19 | 0.27 | 1.62 | 4.50 | 0.20 | 0.06 | |
| K = 10% | MSR-Equi-TODIM | 0.09 | 0.18 | 0.23 | 1.60 | 4.49 | 0.29 | 0.12 |
| MSR-RB-Equi-TODIM0.01 | 0.10 | 0.19 | 0.25 | 1.61 | 4.64 | 0.27 | 0.10 | |
| MSR-RB-Equi-TODIM0.05 | 0.10 | 0.19 | 0.24 | 1.61 | 4.64 | 0.27 | 0.10 | |
| MSR-RB-Equi-TODIM0.1 | 0.10 | 0.19 | 0.25 | 1.62 | 4.64 | 0.27 | 0.10 | |
| MSR-Entr-TODIM | 0.12 | 0.22 | 0.27 | 1.79 | 4.97 | 0.34 | 0.15 | |
| MSR-RB-Entr-TODIM0.01 | 0.11 | 0.20 | 0.25 | 1.68 | 4.99 | 0.34 | 0.14 | |
| MSR-RB-Entr-TODIM0.05 | 0.11 | 0.20 | 0.25 | 1.67 | 4.99 | 0.34 | 0.14 | |
| MSR-RB-Entr-TODIM0.1 | 0.11 | 0.20 | 0.25 | 1.67 | 4.99 | 0.34 | 0.14 | |
| BenchMI | 0.09 | 0.19 | 0.27 | 1.65 | 4.54 | 0.19 | 0.06 | |
| K = 15% | MSR-Equi-TODIM | 0.12 | 0.22 | 0.29 | 1.76 | 4.91 | 0.33 | 0.12 |
| MSR-RB-Equi-TODIM0.01 | 0.10 | 0.19 | 0.25 | 1.64 | 4.71 | 0.25 | 0.09 | |
| MSR-RB-Equi-TODIM0.05 | 0.10 | 0.19 | 0.25 | 1.64 | 4.70 | 0.25 | 0.09 | |
| MSR-RB-Equi-TODIM0.1 | 0.10 | 0.19 | 0.25 | 1.64 | 4.70 | 0.25 | 0.09 | |
| MSR-Entr-TODIM | 0.16 | 0.28 | 0.34 | 2.05 | 4.92 | 0.28 | 0.10 | |
| MSR-RB-Entr-TODIM0.01 | 0.12 | 0.23 | 0.28 | 1.80 | 4.82 | 0.30 | 0.11 | |
| MSR-RB-Entr-TODIM0.05 | 0.12 | 0.23 | 0.28 | 1.81 | 4.81 | 0.30 | 0.11 | |
| MSR-RB-Entr-TODIM0.1 | 0.12 | 0.23 | 0.28 | 1.81 | 4.81 | 0.30 | 0.11 | |
| BenchMI | 0.09 | 0.17 | 0.25 | 1.58 | 4.65 | 0.22 | 0.06 | |
| BenchEW | 0.14 | 0.24 | 0.33 | 1.89 | 5.06 | 0.25 | 0.06 | |
| EU Data Set | ||||||||
|---|---|---|---|---|---|---|---|---|
| Configuration | CAGR | SR | SSRout | Ωout | σout (×100) | maxDD | UI | |
| K = 5% | MSR-Equi-TODIM | 0.08 | 0.16 | 0.23 | 1.58 | 4.93 | 0.24 | 0.07 |
| MSR-RB-Equi-TODIM0.01 | 0.05 | 0.10 | 0.13 | 1.37 | 5.69 | 0.33 | 0.11 | |
| MSR-RB-Equi-TODIM0.05 | 0.05 | 0.10 | 0.13 | 1.38 | 5.68 | 0.33 | 0.11 | |
| MSR-RB-Equi-TODIM0.1 | 0.05 | 0.10 | 0.13 | 1.37 | 5.66 | 0.33 | 0.11 | |
| MSR-Entr-TODIM | 0.02 | 0.06 | 0.08 | 1.20 | 5.97 | 0.43 | 0.15 | |
| MSR-RB-Entr-TODIM0.01 | 0.02 | 0.05 | 0.07 | 1.19 | 6.43 | 0.43 | 0.15 | |
| MSR-RB-Entr-TODIM0.05 | 0.02 | 0.05 | 0.07 | 1.19 | 6.43 | 0.43 | 0.15 | |
| MSR-RB-Entr-TODIM0.1 | 0.02 | 0.05 | 0.07 | 1.19 | 6.40 | 0.43 | 0.15 | |
| BenchMI | 0.09 | 0.17 | 0.23 | 1.54 | 4.79 | 0.30 | 0.10 | |
| K = 10% | MSR-Equi-TODIM | 0.08 | 0.15 | 0.21 | 1.55 | 4.79 | 0.30 | 0.08 |
| MSR-RB-Equi-TODIM0.01 | 0.07 | 0.13 | 0.16 | 1.50 | 5.45 | 0.32 | 0.09 | |
| MSR-RB-Equi-TODIM0.05 | 0.07 | 0.13 | 0.16 | 1.51 | 5.44 | 0.32 | 0.09 | |
| MSR-RB-Equi-TODIM0.1 | 0.07 | 0.13 | 0.16 | 1.51 | 5.43 | 0.32 | 0.09 | |
| MSR-Entr-TODIM | 0.06 | 0.11 | 0.13 | 1.37 | 5.35 | 0.39 | 0.13 | |
| MSR-RB-Entr-TODIM0.01 | 0.04 | 0.09 | 0.11 | 1.32 | 6.09 | 0.40 | 0.12 | |
| MSR-RB-Entr-TODIM0.05 | 0.04 | 0.09 | 0.11 | 1.32 | 6.08 | 0.39 | 0.12 | |
| MSR-RB-Entr-TODIM0.1 | 0.04 | 0.09 | 0.11 | 1.32 | 6.08 | 0.40 | 0.12 | |
| BenchMI | 0.09 | 0.19 | 0.25 | 1.65 | 4.63 | 0.26 | 0.09 | |
| K = 15% | MSR-Equi-TODIM | 0.08 | 0.16 | 0.22 | 1.58 | 4.84 | 0.27 | 0.07 |
| MSR-RB-Equi-TODIM0.01 | 0.07 | 0.13 | 0.16 | 1.49 | 5.28 | 0.31 | 0.08 | |
| MSR-RB-Equi-TODIM0.05 | 0.07 | 0.13 | 0.16 | 1.49 | 5.28 | 0.31 | 0.08 | |
| MSR-RB-Equi-TODIM0.1 | 0.07 | 0.13 | 0.16 | 1.49 | 5.26 | 0.31 | 0.08 | |
| MSR-Entr-TODIM | 0.05 | 0.10 | 0.12 | 1.33 | 5.38 | 0.37 | 0.11 | |
| MSR-RB-Entr-TODIM0.01 | 0.05 | 0.10 | 0.11 | 1.34 | 5.81 | 0.36 | 0.10 | |
| MSR-RB-Entr-TODIM0.05 | 0.05 | 0.10 | 0.11 | 1.34 | 5.81 | 0.36 | 0.10 | |
| MSR-RB-Entr-TODIM0.1 | 0.05 | 0.10 | 0.11 | 1.35 | 5.81 | 0.36 | 0.10 | |
| BenchMI | 0.09 | 0.18 | 0.23 | 1.60 | 4.52 | 0.28 | 0.09 | |
| BenchEW | 0.08 | 0.16 | 0.22 | 1.54 | 4.80 | 0.26 | 0.08 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaucic, M.; Pelessoni, R.; Piccotto, F. An Automated Decision Support System for Portfolio Allocation Based on Mutual Information and Financial Criteria. Entropy 2025, 27, 480. https://doi.org/10.3390/e27050480
Kaucic M, Pelessoni R, Piccotto F. An Automated Decision Support System for Portfolio Allocation Based on Mutual Information and Financial Criteria. Entropy. 2025; 27(5):480. https://doi.org/10.3390/e27050480
Chicago/Turabian StyleKaucic, Massimiliano, Renato Pelessoni, and Filippo Piccotto. 2025. "An Automated Decision Support System for Portfolio Allocation Based on Mutual Information and Financial Criteria" Entropy 27, no. 5: 480. https://doi.org/10.3390/e27050480
APA StyleKaucic, M., Pelessoni, R., & Piccotto, F. (2025). An Automated Decision Support System for Portfolio Allocation Based on Mutual Information and Financial Criteria. Entropy, 27(5), 480. https://doi.org/10.3390/e27050480