
Encrypted Spiking Neural Networks Based on Adaptive Differential Privacy Mechanism


Abstract
1. Introduction
- The proposed ADPSNN can adaptively adjust the amount of Gaussian noise added to the gradient. Specifically, it adds more noise to gradients that are weakly correlated with the model output to protect model privacy. Meanwhile, less noise is added to gradients that are strongly correlated with the model output to maintain model performance. This provides a more accurate method for protecting the training data privacy in SNNs;
- The performance impact of IF and LIF neurons on ADPSNN is analyzed. On the CIFAR10 and CIFAR100 datasets, the performances of IF neurons are 1.25% and 0.7% higher than that of LIF neurons, respectively. It aims to help select the most suitable neuron model for different tasks and datasets, thus enhancing the applicability of the approach;
- Our method has been extensively tested on four datasets to validate the feasibility of ADPSNN. It effectively balances privacy protection and the practicality of sensitive data in SNNs. In terms of model accuracy, our approach is improved by 0.09% to 3.1% compared to other existing methods. Therefore, our method may be used in some privacy-preserving scenarios, such as image classification, healthcare, and intelligent driving.
2. Preliminaries and Background
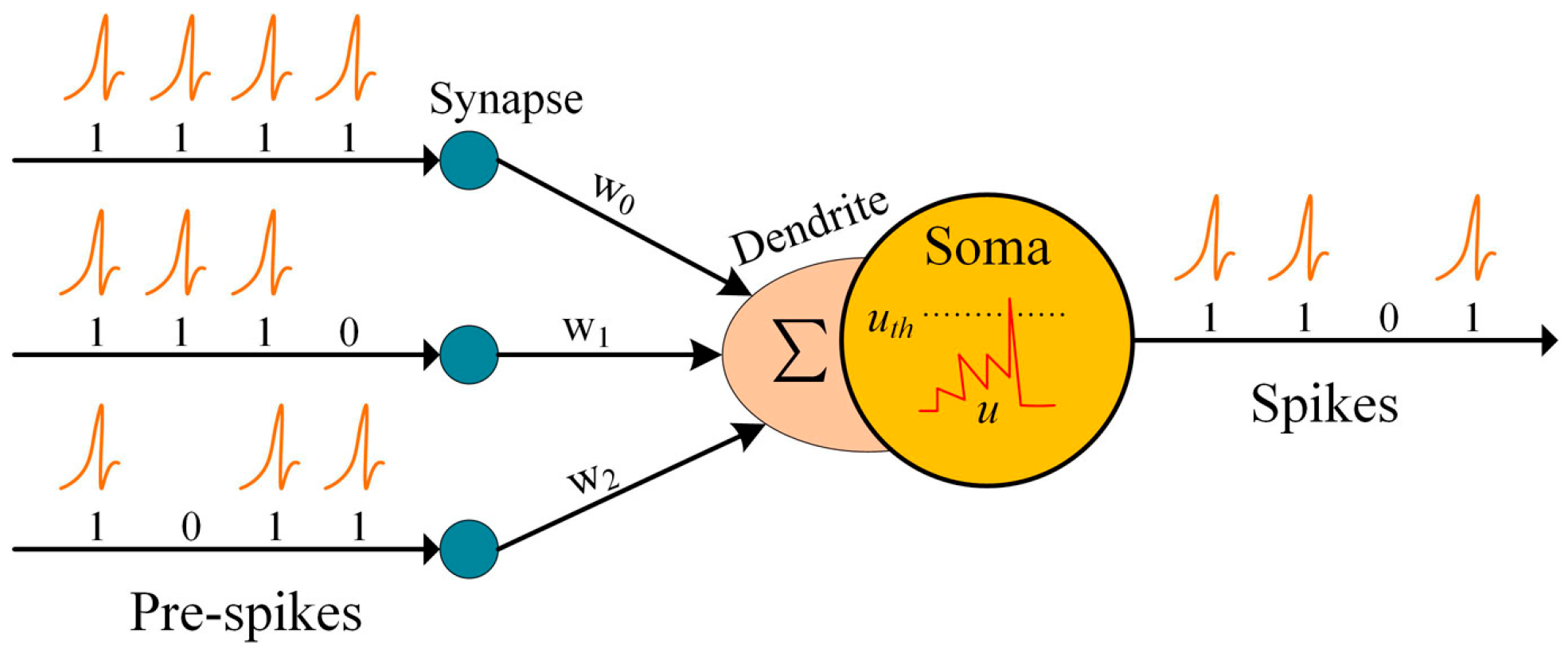
2.1. Spiking Neural Network
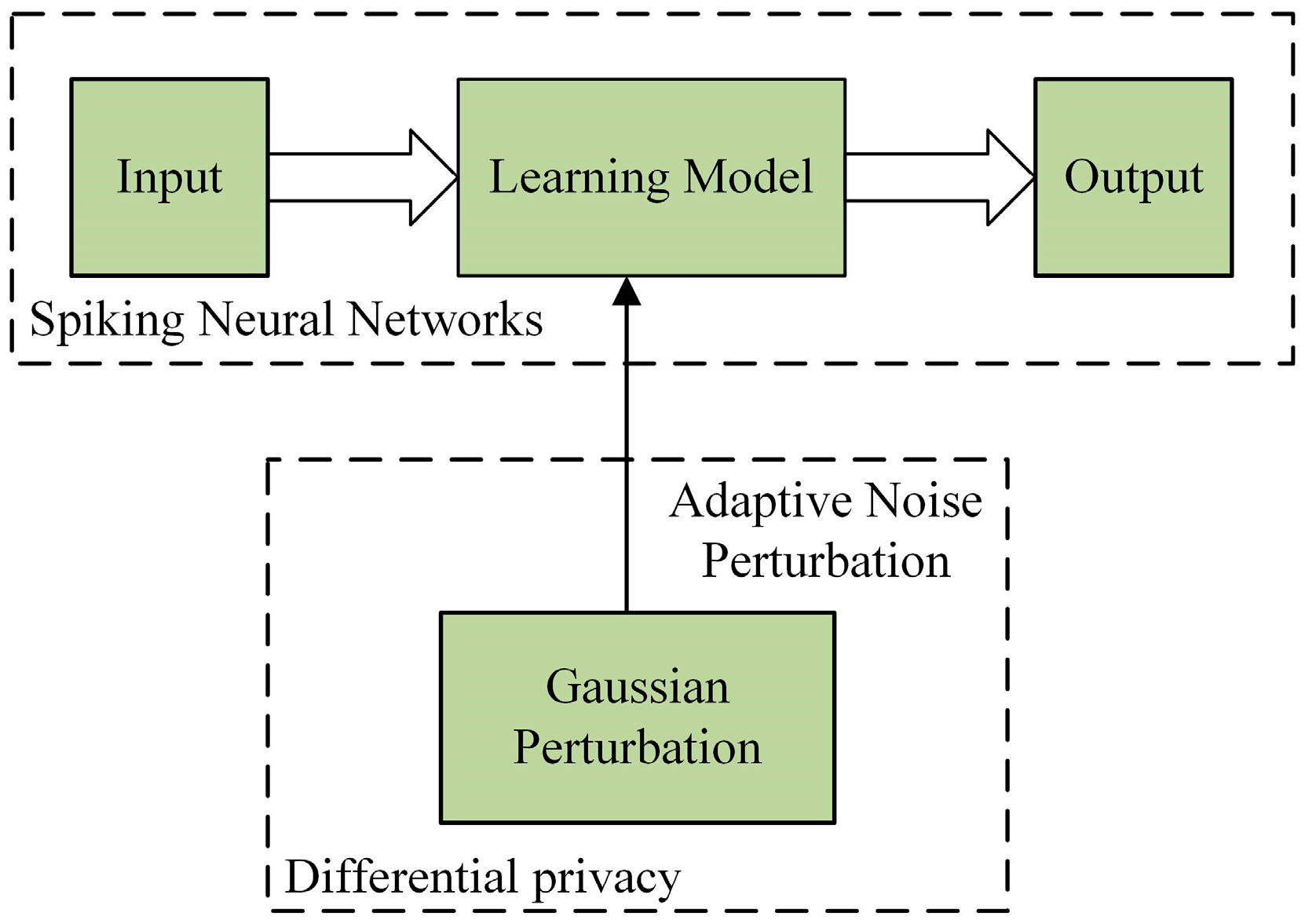
2.2. Differential Privacy
3. ADPSNN
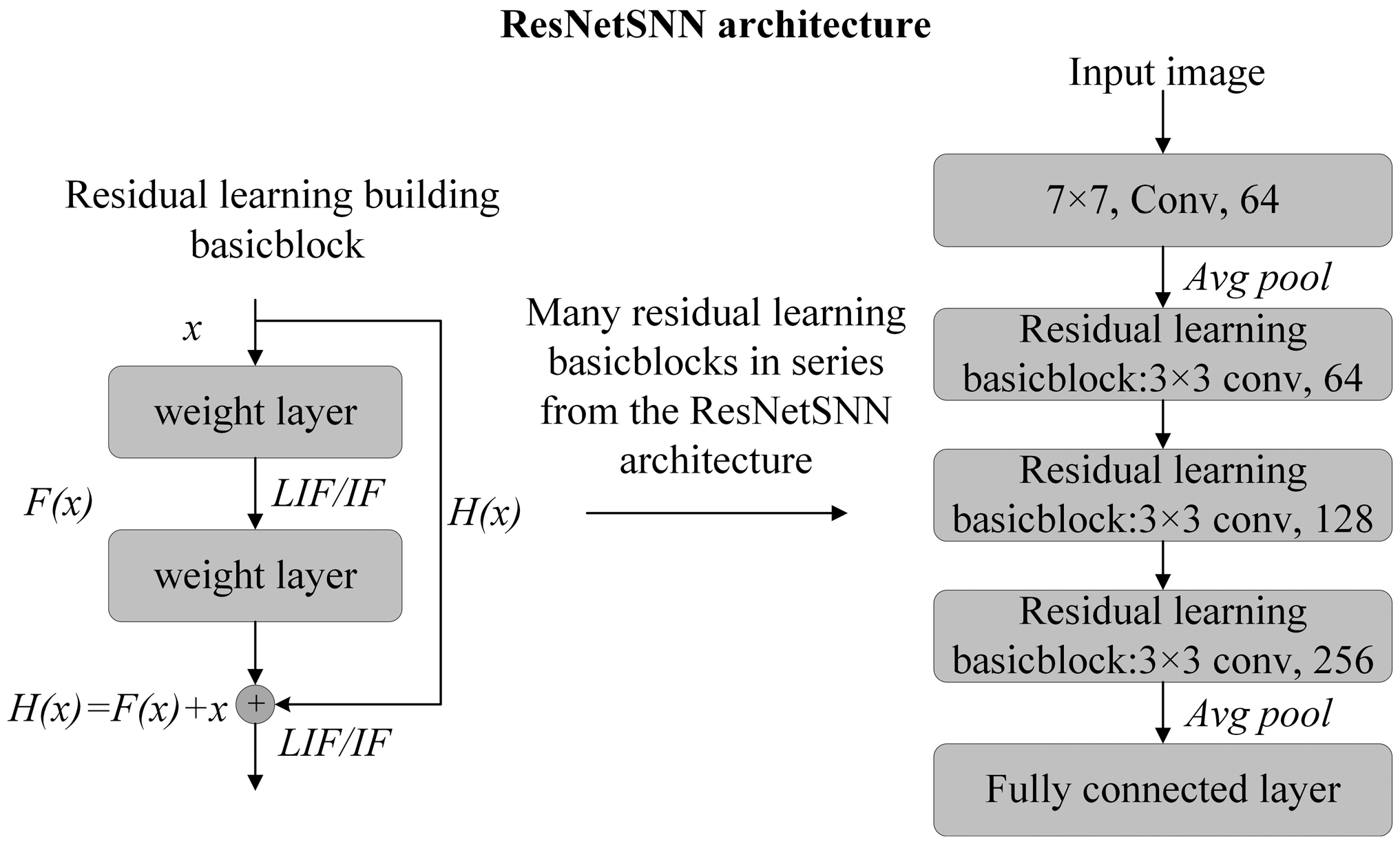
3.1. The ResNetSNN Architecture
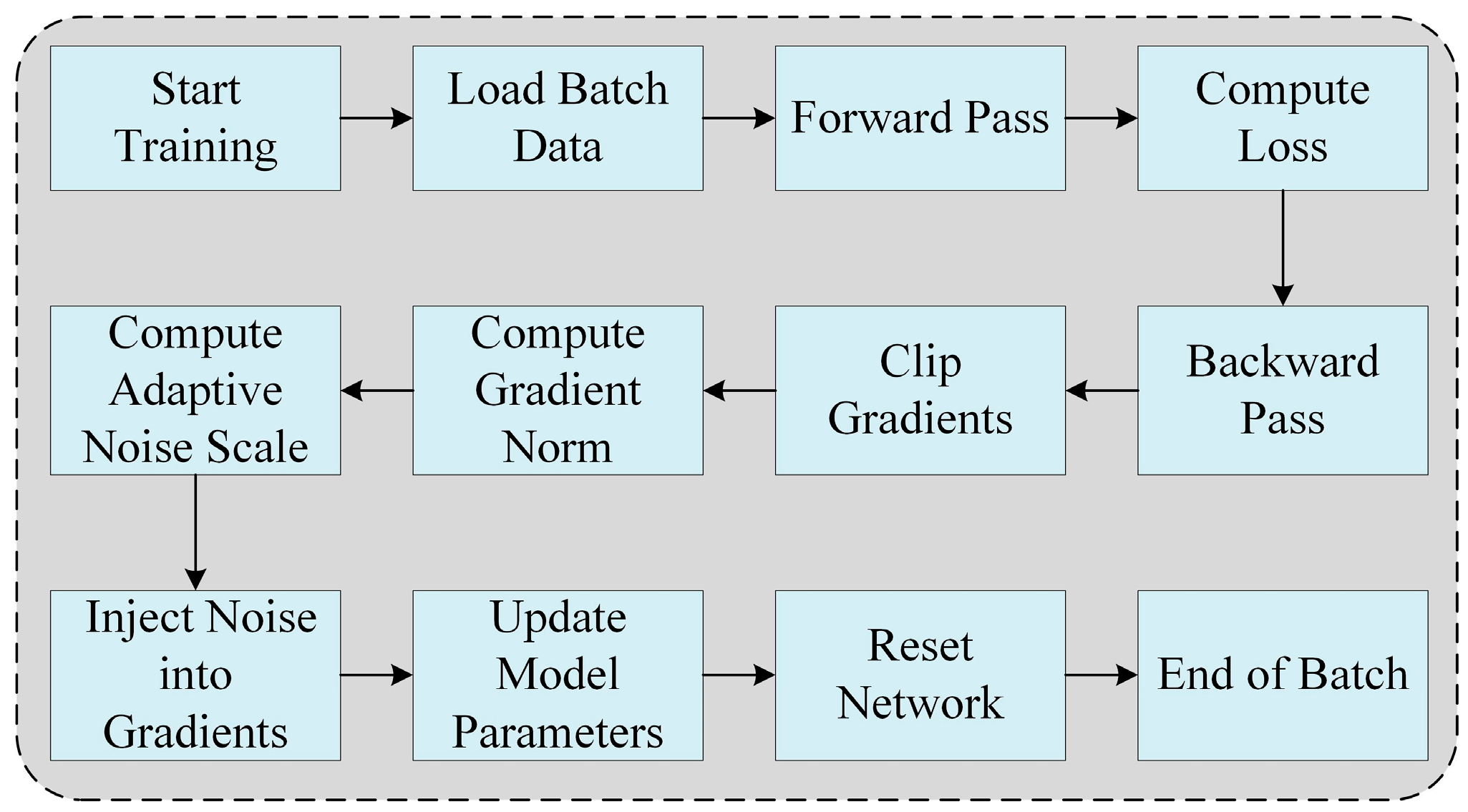
3.2. Gradient Perturbation for SNN
4. Experiments and Results
4.1. Datasets
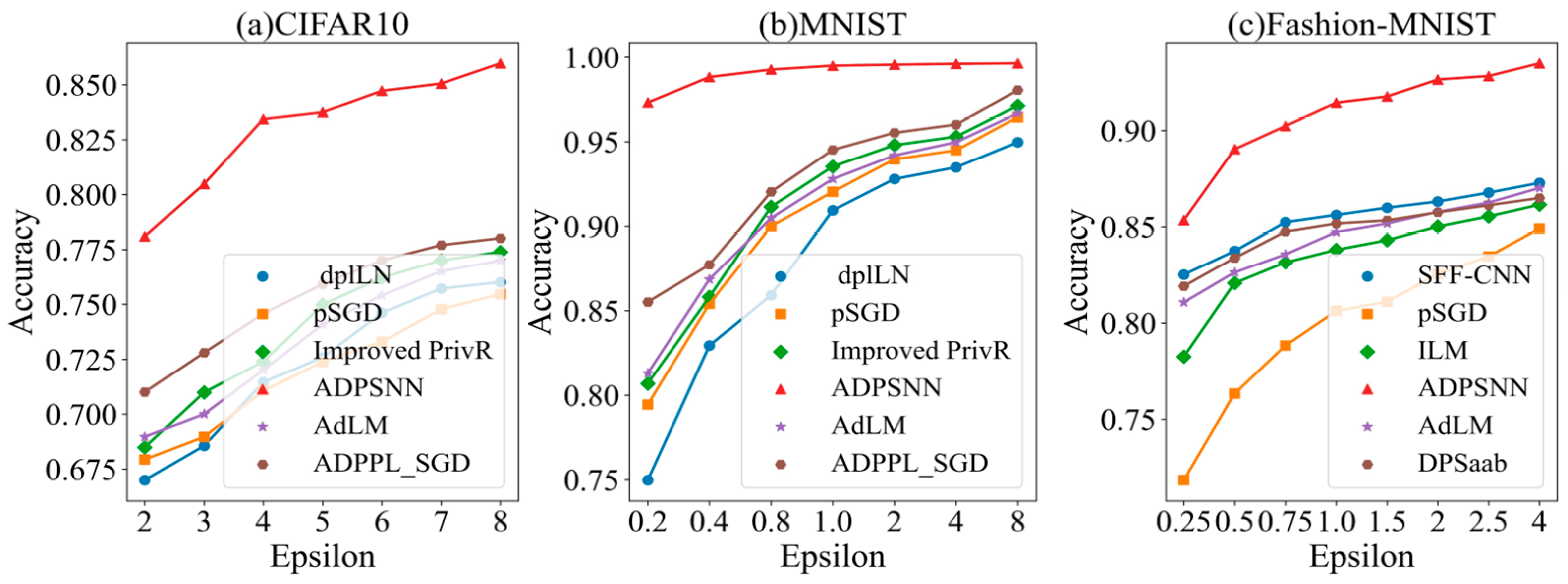
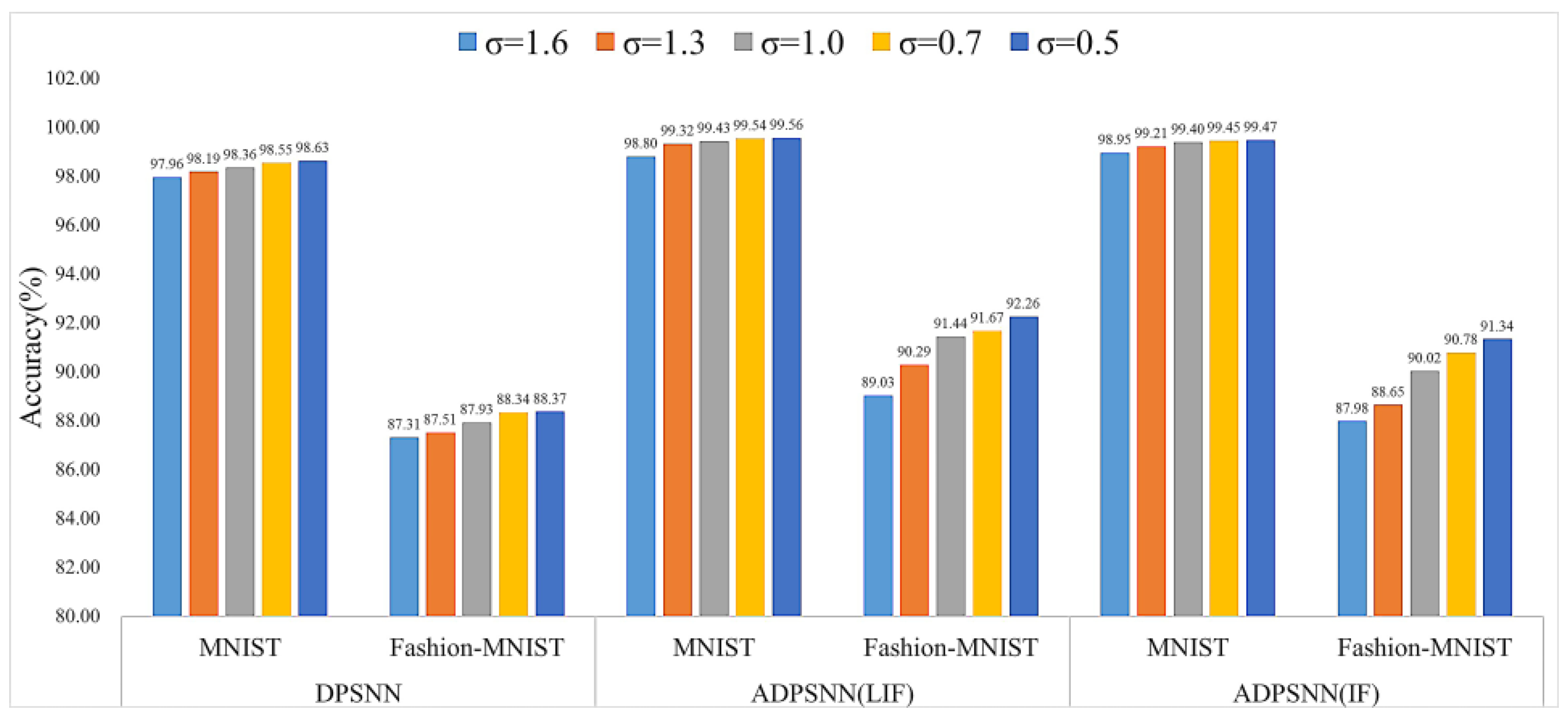
4.2. Experiments on Differentially Private Algorithms
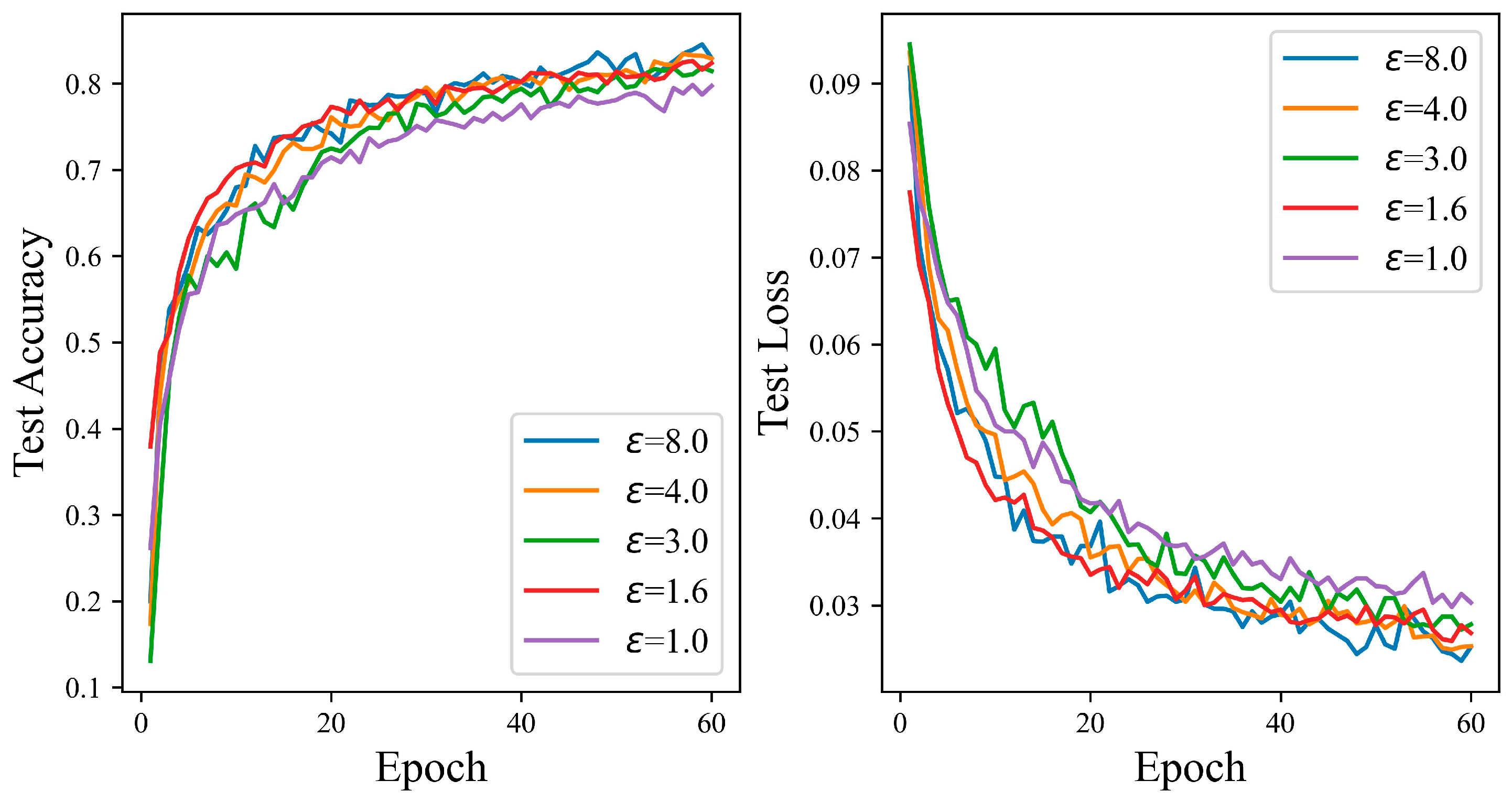
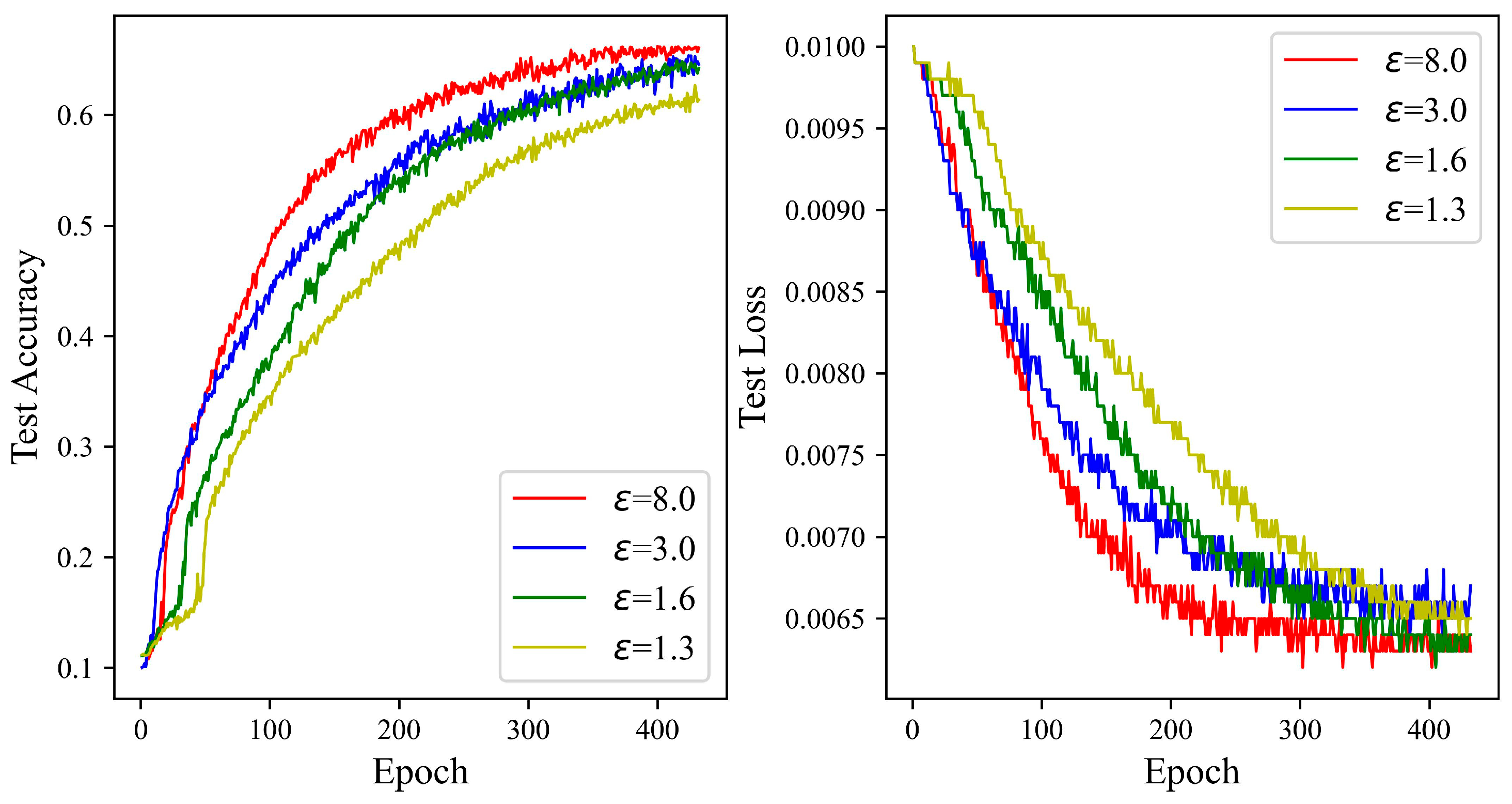
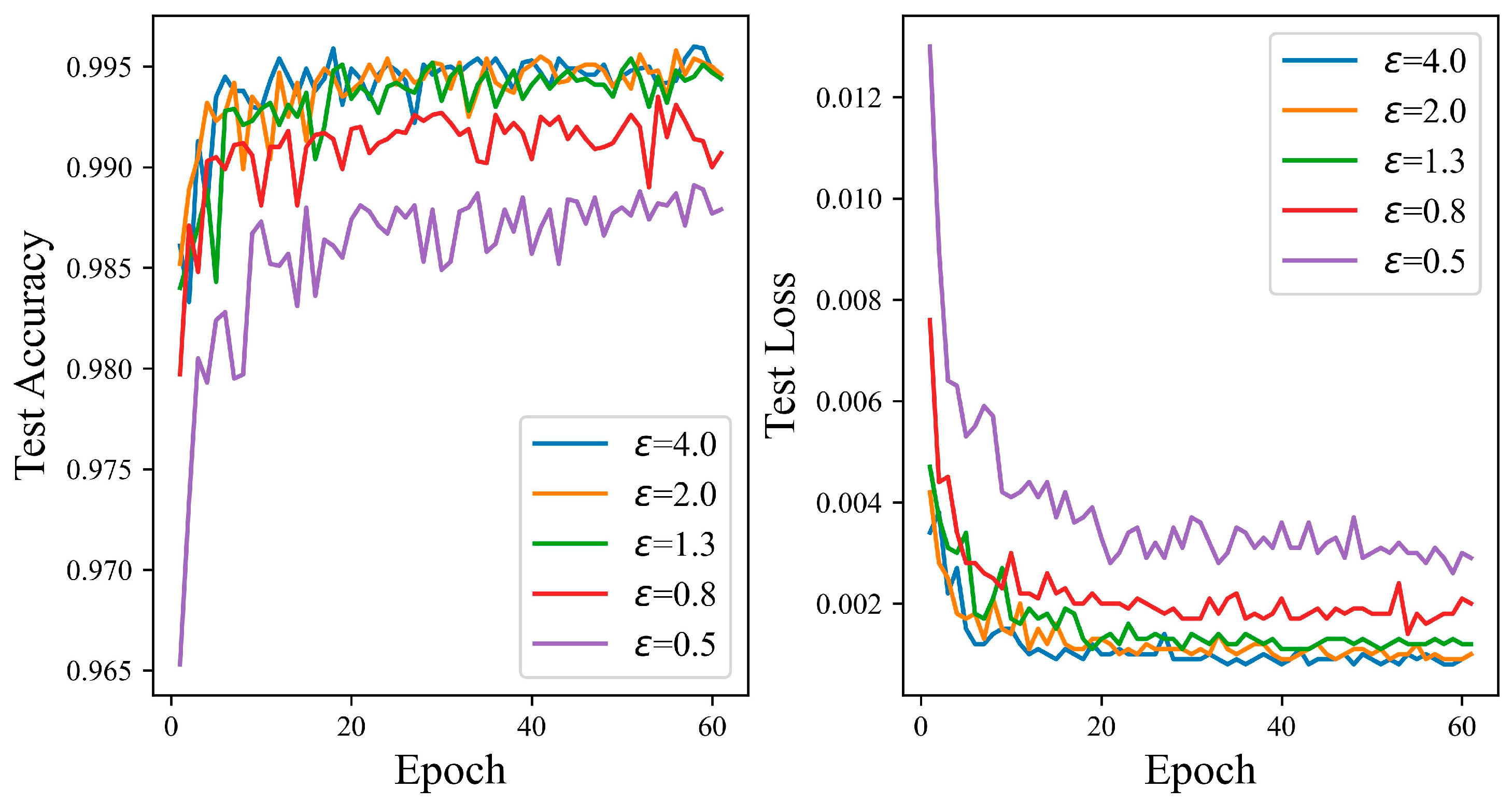
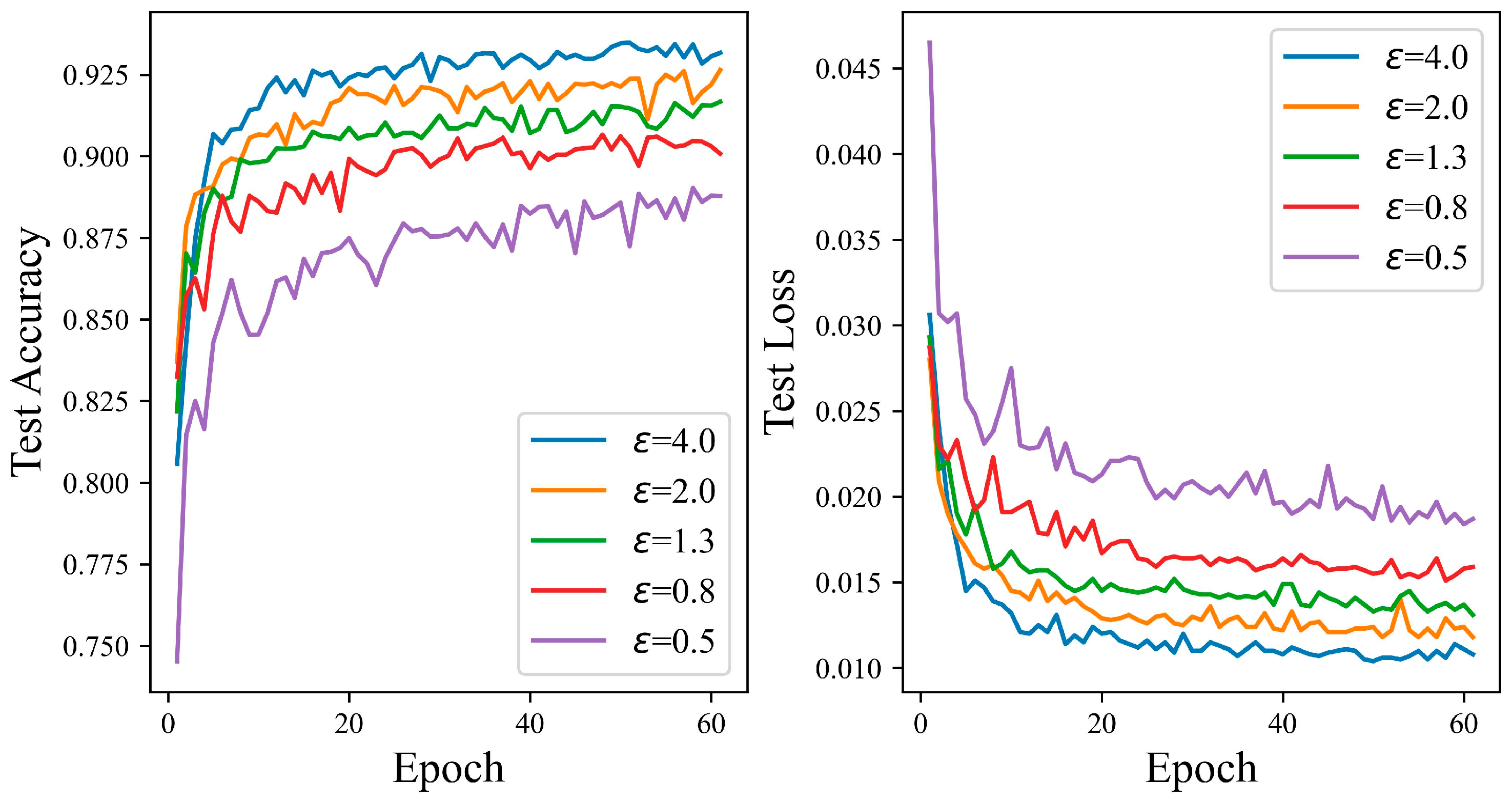
4.3. Experiments on Different Privacy Levels
4.4. Experiments on Different SNN Algorithms
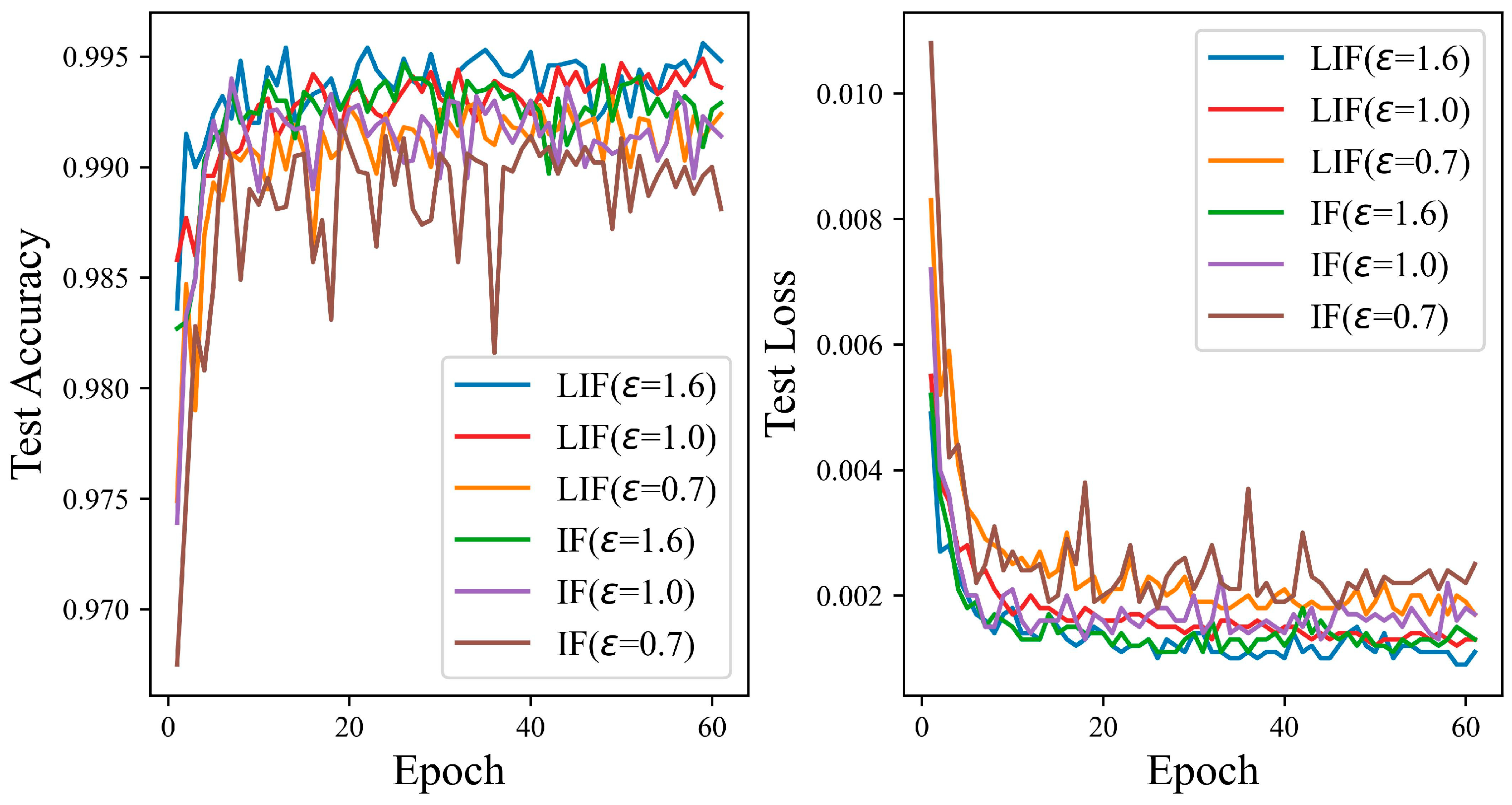
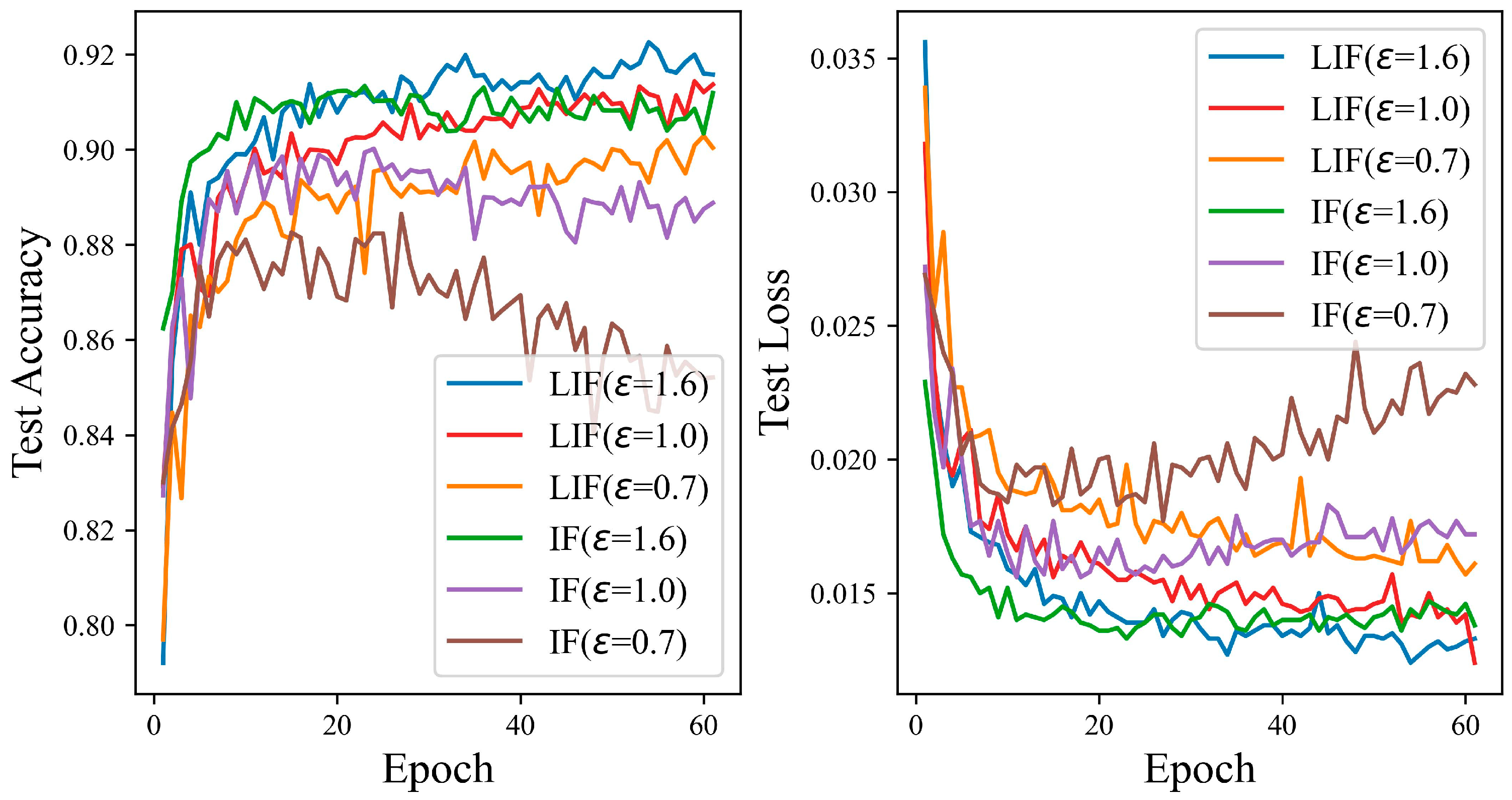
4.5. Experiments on the LIF and IF Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Nie, F.; Gao, Q.; Gao, X.; Han, J.; Shao, L. Flexible Unsupervised Feature Extraction for Image Classification. Neural Netw. 2019, 115, 65–71. [Google Scholar]
- Li, Y.; Guo, Z.; Wang, L.; Xu, L. TBC-MI: Suppressing Noise Labels by Maximizing Cleaning Samples for Robust Image Classification. Inf. Process. Manag. 2024, 61, 103801. [Google Scholar]
- Liu, J.; Qin, S.; Su, M.; Luo, Y.; Zhang, S.; Wang, Y.; Yang, S. Traffic Signal Control Using Reinforcement Learning Based on the Teacher-student Framework. Expert Syst. Appl. 2023, 228, 120458. [Google Scholar]
- Liu, J.; Qin, S.; Su, M.; Luo, Y.; Wang, Y.; Yang, S. Multiple Intersections Traffic Signal Control Based on Cooperative Multi-agent Reinforcement Learning. Inf. Sci. 2023, 647, 119484. [Google Scholar]
- Song, Y.; Guo, L.; Man, M.; Wu, Y. The Spiking Neural Network Based on FMRI for Speech Recognition. Pattern Recognit. 2024, 155, 110672. [Google Scholar]
- Liu, J.; Qin, S.; Luo, Y.; Wang, Y.; Yang, S. Intelligent Traffic Light Control by Exploring Strategies in an Optimised Space of Deep Q-Learning. IEEE Trans. Veh. Technol. 2022, 71, 5960–5970. [Google Scholar]
- Liu, J.; Sun, T.; Luo, Y.; Yang, S.; Cao, Y.; Zhai, J. Echo State Network Optimization using Binary Grey Wolf Algorithm. Neurocomputing 2020, 385, 310–318. [Google Scholar]
- Fu, Q.; Dong, H. An Ensemble Unsupervised Spiking Neural Network for Objective Recognition. Neurocomputing 2021, 419, 47–58. [Google Scholar]
- Xian, R.; Xiong, X.; Peng, H.; Wang, J.; de Arellano Marrero, A.R.; Yang, Q. Feature Fusion Method Based on Spiking Neural Convolutional Network for Edge Detection. Pattern Recognit. 2024, 147, 110112–110120. [Google Scholar]
- Hwang, S.; Kung, J. One-Spike SNN: Single-Spike Phase Coding with Base Manipulation for ANN-to-SNN Conversion Loss Minimization. IEEE Trans. Emerg. Top. Comput. 2024, 13, 162–172. [Google Scholar]
- Dwork, C.; Mcsherry, F.; Nissim, K.; Smith, A. Calibrating Noise to Sensitivity in Private Data Analysis. In Theory of Cryptography, Proceedings of the Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, 4–7 March 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Ribero, M.; Henderson, J.; Williamson, S.; Vikalo, H. Federating Recommendations Using Differentially Private Prototypes. Pattern Recognit. 2022, 129, 108746. [Google Scholar] [CrossRef]
- Tang, X.; Panda, A.; Sehwag, V.; Mittal, P. Differentially Private Image Classification by Learning Priors from Random Processes. In NIPS’23, Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Curran Associates Inc.: Red Hook, NY, USA, 2024; pp. 1–23. [Google Scholar]
- Wang, Y.; Nedić, A.N. Differentially-private Distributed Algorithms for Aggregative Games with Guaranteed Convergence. IEEE Trans. Autom. Control. 2024, 69, 5168–5183. [Google Scholar] [CrossRef]
- Guan, J.; Sharma, A.; Tian, C.; Lahlou, S. On the Privacy Risks of Spiking Neural Networks: A Membership Inference Analysis. arXiv 2025, arXiv:2502.13191. [Google Scholar]
- Wang, J.; Zhao, D.; Shen, G.; Zhang, Q.; Zeng, Y. DPSNN: A Differentially Private Spiking Neural Network with Temporal Enhanced Pooling. arXiv 2022, arXiv:2205.12718. [Google Scholar]
- Kim, Y.; Panda, P. PrivateSNN: Privacy-Preserving Spiking Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; pp. 1192–1200. [Google Scholar]
- Luo, X.; Fu, Q.; Qin, S.; Wang, K. Encrypted-SNN: A Privacy-Preserving Method for Converting Artificial Neural Networks to Spiking Neural Networks. In Neural Information Processing, Proceedings of the 30th International Conference, ICONIP 2023, Changsha, China, 20–23 November 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 519–530. [Google Scholar]
- Moshruba, A.; Snyder, S.; Poursiami, H.; Parsa, M. On the Privacy-Preserving Properties of Spiking Neural Networks with Unique Surrogate Gradients and Quantization Levels. arXiv 2025, arXiv:2502.18623. [Google Scholar]
- Chen, J.; Park, S.; Simeone, O. Agreeing to Stop: Reliable Latency-Adaptive Decision Making via Ensembles of Spiking Neural Networks. Entropy 2024, 26, 126. [Google Scholar] [CrossRef]
- Han, B.; Fu, Q.; Zhang, X. Towards Privacy-Preserving Federated Neuromorphic Learning via Spiking Neuron Models. Electronics 2023, 12, 3984. [Google Scholar] [CrossRef]
- Lopuhaä-Zwakenberg, M.; Goseling, J. Mechanisms for Robust Local Differential Privacy. Entropy 2024, 26, 233. [Google Scholar] [CrossRef]
- Garipova, Y.; Yonekura, S.; Kuniyoshi, Y. Noise and Dynamical Synapses as Optimization Tools for Spiking Neural Networks. Entropy 2025, 27, 219. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, T.; Jiang, C.; Liu, J.; Zhang, H. Chaotic loss-based spiking neural network for privacy-preserving bullying detection in public places. Appl. Soft Comput. 2025, 169, 112643. [Google Scholar] [CrossRef]
- Yadav, S.; Pundhir, A.; Goyal, T.; Raman, B.; Kumar, S. Differentially Private Spiking Variational Autoencoder. In Pattern Recognition, Proceedings of the 27th International Conference, ICPR 2024, Kolkata, India, 1–5 December 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 96–112. [Google Scholar]
- Eshraghian, J.K.; Ward, M.; Neftci, E.O.; Wang, X.; Lenz, G.; Dwivedi, G.; Bennamoun, M.; Jeong, D.S.; Lu, W. Training Spiking Neural Networks Using Lessons from Deep Learning. Proc. IEEE 2023, 111, 1016–1054. [Google Scholar]
- Fang, W.; Chen, Y.; Ding, J.; Yu, Z.; Masquelier, T.; Chen, D.; Huang, L.; Zhou, H.; Li, G.; Tian, Y. SpikingJelly: An Open-source Machine Learning Infrastructure Platform for Spike-based intelligence. Sci. Adv. 2023, 9, eadi1480–eadi1497. [Google Scholar] [PubMed]
- Roy, K.; Jaiswal, A.; Panda, P. Towards Spike-based Machine Intelligence with Neuromorphic Computing. Nature 2019, 575, 607–617. [Google Scholar] [CrossRef]
- Dong, J.; Roth, A.; Su, W.J. Gaussian Differential Privacy. J. R. Stat. Soc. Series B. Stat. Methodol. 2022, 84, 3–37. [Google Scholar]
- Kim, Y.; Li, Y.; Park, H.; Venkatesha, Y.; Hambitzer, A.; Panda, P. Exploring Temporal Information Dynamics in Spiking Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 8308–8316. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Gong, M.; Pan, K.; Xie, Y.; Qin, A.K.; Tang, Z. Preserving Differential Privacy in Deep Neural Networks with Relevance-based Adaptive Noise Imposition. Neural Netw. 2020, 125, 131–141. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; Brendan McMahan, H.; Mironov, I.; Talwar, K.; Zhang, L. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Gong, M.; Pan, K.; Xie, Y. Differential Privacy Preservation in Regression Analysis Based on Relevance. Knowl.-Based Syst. 2019, 173, 140–149. [Google Scholar]
- Phan, N.H.; Wu, X.; Dou, D. Preserving Differential Privacy in Convolutional Deep Belief Networks. Mach. Learn. 2017, 106, 1681–1704. [Google Scholar]
- Li, D.; Wang, J.; Li, Q.; Hu, Y.; Li, X. A Privacy Preservation Framework for Feedforward-Designed Convolutional Neural Networks. Neural Netw. 2022, 155, 14–27. [Google Scholar] [CrossRef]
- Saranirad, V.; Dora, S.; McGinnity, T.M.; Coyle, D. CDNA-SNN: A New Spiking Neural Network for Pattern Classification Using Neuronal Assemblies. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 2274–2287. [Google Scholar]
- Diehl, P.U.; Cook, M. Unsupervised Learning of Digit Recognition using Spike-Timing-Dependent Plasticity. Front. Comput. Neurosci. 2015, 9, 99. [Google Scholar]
- Mostafa, H.; Pedroni, B.U.; Sheik, S.; Cauwenberghs, G. Fast Classification Using Sparsely Active Spiking Networks. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Srinivasan, G.; Roy, K. ReStoCNet: Residual Stochastic Binary Convolutional Spiking Neural Network for Memory-Efficient Neuromorphic Computing. Front. Neurosci. 2019, 13, 189. [Google Scholar]
- Zhang, W.; Li, P. Temporal Spike Sequence Learning via Backpropagation for Deep Spiking Neural Networks. In NIPS’20, Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Curran Associates Inc.: Red Hook, NY, USA, 2020; pp. 12022–12033. [Google Scholar]
- Rueckauer, B.; Liu, S.C. Conversion of Analog to Spiking Neural Networks using Sparse Temporal Coding. In Proceedings of the2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Chen, T.; Wang, L.; Li, J.; Duan, S.; Huang, T. Improving Spiking Neural Network with Frequency Adaptation for Image Classification. IEEE Trans. Cogn. Dev. Syst. 2023, 16, 864–876. [Google Scholar]
- Han, B.; Roy, K. Deep Spiking Neural Network: Energy Efficiency Through Time based Coding. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 388–404. [Google Scholar]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going Deeper in Spiking Neural Networks: VGG and Residual Architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef]
- Rathi, N.; Srinivasan, G.; Panda, P.; Roy, K. Enabling Deep Spiking Neural Networks with Hybrid Conversion and Spike Timing Dependent Backpropagation. arXiv 2020, arXiv:2005.01807. [Google Scholar]
- Lee, C.; Sarwar, S.S.; Panda, P.; Srinivasan, G.; Roy, K. Enabling Spike-Based Backpropagation for Training Deep Neural Network Architectures. Front. Neurosci. 2020, 14, 119. [Google Scholar]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Xie, Y.; Shi, L. Direct Training for Spiking Neural Networks: Faster, Larger, Better. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 1311–1318. [Google Scholar]
- Zhang, Y.; Wang, Z.; Zhu, J.; Yang, Y.; Rao, M.; Song, W.; Zhuo, Y.; Zhang, X.; Cui, M.; Shen, L.; et al. Brain-inspired Computing with Memristors: Challenges in Devices, Circuits, and Systems. Appl. Phys. Rev. 2020, 7, 011308. [Google Scholar]
- Rathi, N.; Roy, K. DIET-SNN: Direct Input Encoding with Leakage and Threshold Optimization in Deep Spiking Neural Networks. arXiv 2020, arXiv:2008.03658. [Google Scholar]
- Wang, Y.; Liu, H.; Zhang, M.; Luo, X.; Qu, H. A Universal ANN-to-SNN Framework for Achieving High Accuracy and Low Latency Deep Spiking Neural Networks. Neural Netw. 2024, 174, 106244. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Parameter | Value/Description |
|---|---|---|
| Hardware | GPU | NVIDIA RTX 3090 (24GB VRAM) |
| CPU | 13th Gen Intel(R) Core(TM) i5-13600K 3.50 GHz | |
| RAM | 32 GB | |
| Storage | SSD | |
| Software | Python | 3.9 |
| Torch | 2.3.1 | |
| SpikingJelly | 0.0.0.0.14 | |
| Torchvision | 0.18.0 | |
| TensorBoard | 2.18.0 | |
| Optimizer | Adam | |
| Threshold | 10 | |
| Reset Potential | 0.0 | |
| Time Constant | 2 | |
| Surrogate Function | ATan | |
| Delta | 1.0 × 10−5 |
| Approaches | Neuron Model | Input Coding | Learning Rule | Accuracy (%) | Timesteps |
|---|---|---|---|---|---|
| 2 FC [39] | LIF | Rate | STDP | 95.00 | 700 |
| 784FC-600FC-10FC [40] | IF | Temporal | Backprop | 96.98 | 167 |
| 36C3-2P-128FC-10FC [41] | LIF | Rate | Stochastic STDP | 66.23 | 100 |
| 15C5-P2-40C5-P2-300FC [42] | LIF | Encoding layer | Backprop | 99.53 | 5 |
| LeNet-5 [43] | IF | Temporal | ANN-to-SNN | 98.53 | - |
| [16] | LIF | Temporal | DPSNN | 98.63 | - |
| [44] | LIF | - | Backprop | 99.52 | - |
| [38] | LIF | - | Backprop | 98.91 | 300 |
| ConvNet [19] | LIF | Temporal | Backprop | 99.22 (±0.02) | 25 |
| VGG16 [18] | - | - | ANN-to-SNN | 99.47 | |
| ADPSNN (This work) | LIF | Poisson | Backprop | 99.56 | 8 |
| ADPSNN (This work) | IF | Poisson | Backprop | 99.47 | 8 |
| Approaches | Neuron Model | Input Coding | Learning Rule | Accuracy (%) | Timesteps |
|---|---|---|---|---|---|
| VGG16 [45] | IF | Temporal | ANN-to-SNN | 93.63 | 2048 |
| VGG16 [46] | IF | Rate | ANN-to-SNN | 91.55 | 1000 |
| VGG16 [47] | LIF | Rate | Hybrid | 92.02 | 200 |
| VGG9 [48] | IF | Rate | Backprop | 90.45 | 100 |
| 256C3-2P-1024 FC-10FC [40] | LIF | Rate | Stochastic STDP | 98.54 | 100 |
| CIFARNet [49] | - | Encoding layer | Backprop | 90.53 | 12 |
| CIFARNet [50] | - | Encoding layer | Backprop | 91.41 | 5 |
| VGG16 [51] | - | Encoding layer | Hybrid | 92.70 | 5 |
| PrivateSNN [17] | LIF | - | ANN-to-SNN | 89.30 | - |
| ConvNet [19] | LIF | Temporal | Backprop | 78.99 (±0.33) | 25 |
| ResNet18 [15] | LIF | Latency | ANN-to-SNN | 88.20 | 4 |
| ResNet18 [10] | - | - | ANN-to-SNN | 94.91 | 16 |
| VGG16 [52] | - | - | ANN-to-SNN | 95.14 | 6 |
| ResNet18 [52] | - | - | ANN-to-SNN | 94.57 | 6 |
| Encrypted-SNN [18] | - | - | ANN-to-SNN | 88.10 | - |
| ADPSNN (This work) | LIF | Poisson | Backprop | 89.42 | 8 |
| ADPSNN (This work) | IF | Poisson | Backprop | 90.67 | 8 |
| Approaches | Neuron Model | Input Coding | Learning Rule | Accuracy (%) | Timesteps |
|---|---|---|---|---|---|
| VGG16 [46] | IF | Rate | ANN-to-SNN | 62.7 | 1000 |
| PrivateSNN [17] | LIF | - | ANN-to-SNN | 62.3 | - |
| Encrypted-SNN [18] | - | - | ANN-to-SNN | 63.0 | - |
| ResNet18 [10] | - | - | ANN-to-SNN | 68.1 | 16 |
| ResNet18 [15] | LIF | Latency | ANN-to-SNN | 63.9 | 4 |
| ADPSNN(LIF) (This work) | LIF | Poisson | Backprop | 65.4 | 8 |
| ADPSNN(IF) (This work) | IF | Poisson | Backprop | 66.1 | 8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, X.; Fu, Q.; Liu, J.; Luo, Y.; Qin, S.; Ouyang, X. Encrypted Spiking Neural Networks Based on Adaptive Differential Privacy Mechanism. Entropy 2025, 27, 333. https://doi.org/10.3390/e27040333
Luo X, Fu Q, Liu J, Luo Y, Qin S, Ouyang X. Encrypted Spiking Neural Networks Based on Adaptive Differential Privacy Mechanism. Entropy. 2025; 27(4):333. https://doi.org/10.3390/e27040333
Chicago/Turabian StyleLuo, Xiwen, Qiang Fu, Junxiu Liu, Yuling Luo, Sheng Qin, and Xue Ouyang. 2025. "Encrypted Spiking Neural Networks Based on Adaptive Differential Privacy Mechanism" Entropy 27, no. 4: 333. https://doi.org/10.3390/e27040333
APA StyleLuo, X., Fu, Q., Liu, J., Luo, Y., Qin, S., & Ouyang, X. (2025). Encrypted Spiking Neural Networks Based on Adaptive Differential Privacy Mechanism. Entropy, 27(4), 333. https://doi.org/10.3390/e27040333