


Broadcast Channel Cooperative Gain: An Operational Interpretation of Partial Information Decomposition


.png)
{kind=link}
Abstract
1. Introduction
- The common (or redundancy) information in X and Y, regarding T;
- The unique information in X, but not in Y, regarding T;
- The unique information in Y, but not in X, regarding T;
- The synergistic information (or complementary) information in X and Y, regarding T, which only becomes useful when combined, but is useless otherwise.
2. Partial Information Decomposition
2.1. A Few Examples
- 1.
- Common information dominant: X is a uniformly distributed Bernoulli random variable and . It is clear that . In this case, the common information should be one, since X and Y are exactly identical. The other components should all be 0, since there is no unique information in either X or Y regarding T, and there is no synergistic information when combining X and Y.
- 2.
- Synergistic information dominant: X and Y are uniformly distributed Bernoulli random variables independent of each other, and , where ⊕ is the XOR operation. Here, the synergistic information should be 1, and the other components should be 0. This is because X or Y alone do not reveal any information regarding T, and since they are completely independent, they do not share any common information either, but their combination reveals the full information on T.
- 3.
- Component-wise decomposition: and , where are all uniformly-distributed Bernoulli random variables, mutually independent of each other. Let . Clearly, in this case, the common information is still 0, but the two kinds of unique information are both 1, and the synergistic information is also 1.
2.2. Partial Information Decomposition
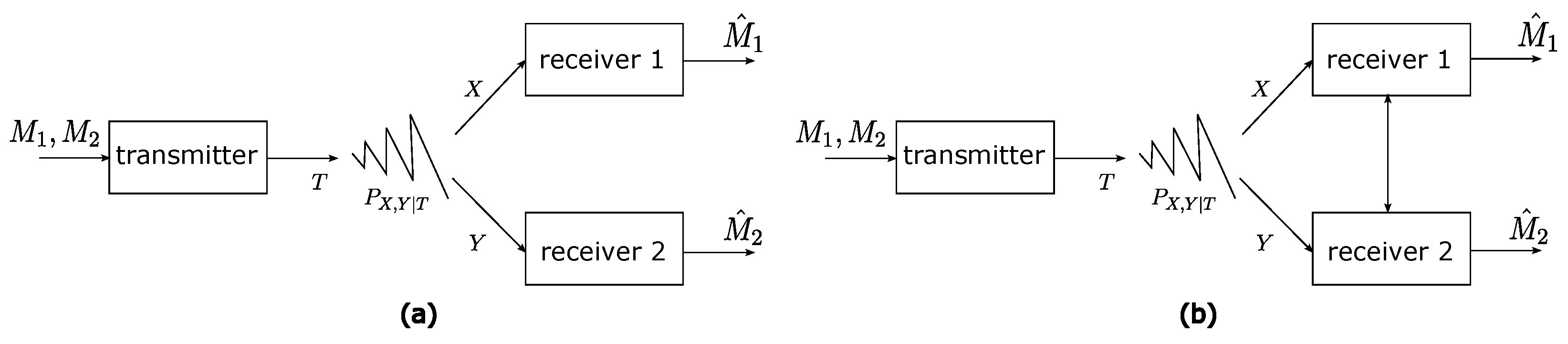
3. Broadcast Channels
- Two message sets:
- An encoding functionwhich assigns to each pair of messages a length-n input sequence .
- Two decoding functions:where is the estimate of message by receiver 1, and is the estimate of message by receiver 2.
4. Main Result: An Operational Interpretation of PID
4.1. PID via Sato’s Outer Bound
4.2. Gaussian MIMO Broadcast Channel and Gaussian PID
4.3. Revisiting the Examples
- 1.
- Common information dominant: Here, the two receivers both know the transmitted signal completely, and therefore, there is no difference even if they are allowed to cooperate, and the cooperative gain is 0.
- 2.
- Synergistic information dominant: Clearly, here, T is a uniformly distributed Bernoulli random variable. When the two receivers are not allowed to cooperate, they cannot decode anything because the channel is completely noisy, and similarly for the channel . When the receivers are allowed to cooperate, then from X and Y, we can completely recover T—i.e., the channel becomes noiseless. Therefore, the full information in T can be decoded. The cooperative gain is then one, matching the synergistic information.
- 3.
- Component-wise decomposition: Here, T has three uniformly distributed Bernoulli random variable components, mutually independent of each other. In the channel , the first component is noiseless, and the second component is completely noisy. This is similarly the case for . When the receivers are not allowed to cooperate, the sum rate on the channel is two. However, when the channels are allowed to cooperate, the last component in T becomes useful (noiseless), and the total communication rate becomes three. Therefore the cooperative gain is , equal to the synergistic information.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wibral, M.; Priesemann, V.; Kay, J.W.; Lizier, J.T.; Phillips, W.A. Partial information decomposition as a unified approach to the specification of neural goal functions. Brain Cogn. 2017, 112, 25–38. [Google Scholar] [CrossRef] [PubMed]
- Feldman, A.K.; Venkatesh, P.; Weber, D.J.; Grover, P. Information-theoretic tools to understand distributed source coding in neuroscience. IEEE J. Sel. Areas Inf. Theory 2024, 5, 509–519. [Google Scholar] [CrossRef]
- Wibral, M.; Finn, C.; Wollstadt, P.; Lizier, J.T.; Priesemann, V. Quantifying information modification in developing neural networks via partial information decomposition. Entropy 2017, 19, 494. [Google Scholar] [CrossRef]
- Ehrlich, D.A.; Schneider, A.C.; Priesemann, V.; Wibral, M.; Makkeh, A. A measure of the complexity of neural representations based on partial information decomposition. Trans. Mach. Learn. Res. 2023, 5, 2835–8856. [Google Scholar]
- Timme, N.; Alford, W.; Flecker, B.; Beggs, J.M. Synergy, redundancy, and multivariate information measures: An experimentalist’s perspective. J. Comput. Neurosci. 2014, 36, 119–140. [Google Scholar] [CrossRef]
- Stramaglia, S.; Cortes, J.M.; Marinazzo, D. Synergy and redundancy in the Granger causal analysis of dynamical networks. New J. Phys. 2014, 16, 105003. [Google Scholar] [CrossRef]
- Timme, N.M.; Ito, S.; Myroshnychenko, M.; Nigam, S.; Shimono, M.; Yeh, F.C.; Hottowy, P.; Litke, A.M.; Beggs, J.M. High-degree neurons feed cortical computations. PLoS Comput. Biol. 2016, 12, e1004858. [Google Scholar] [CrossRef]
- Liang, P.P.; Cheng, Y.; Fan, X.; Ling, C.K.; Nie, S.; Chen, R.; Deng, Z.; Allen, N.; Auerbach, R.; Mahmood, F.; et al. Quantifying & modeling multimodal interactions: An information decomposition framework. Adv. Neural Inf. Process. Syst. 2024, 36, 27351–27393. [Google Scholar]
- Liang, P.P.; Zadeh, A.; Morency, L.P. Foundations & trends in multimodal machine learning: Principles, challenges, and open questions. ACM Comput. Surv. 2024, 56, 1–42. [Google Scholar]
- Liang, P.P.; Deng, Z.; Ma, M.Q.; Zou, J.Y.; Morency, L.P.; Salakhutdinov, R. Factorized contrastive learning: Going beyond multi-view redundancy. Adv. Neural Inf. Process. Syst. 2024, 36, 32971–32998. [Google Scholar]
- Williams, P.L.; Beer, R.D. Nonnegative decomposition of multivariate information. arXiv 2010, arXiv:1004.2515. [Google Scholar]
- Schneidman, E.; Bialek, W.; Berry, M.J. Synergy, redundancy, and independence in population codes. J. Neurosci. 2003, 23, 11539–11553. [Google Scholar] [CrossRef] [PubMed]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying unique information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J. Shared information—New insights and problems in decomposing information in complex systems. In Proceedings of the European Conference on Complex Systems 2012, Agadir, Morocco, 5–6 November 2012; pp. 251–269. [Google Scholar]
- Griffith, V.; Koch, C. Quantifying synergistic mutual information. In Guided Self-Organization: Inception; Springer: Berlin/Heidelberg, Germany, 2014; pp. 159–190. [Google Scholar]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. E—Stat. Nonlinear Soft Matter Phys. 2013, 87, 012130. [Google Scholar] [CrossRef]
- Olbrich, E.; Bertschinger, N.; Rauh, J. Information decomposition and synergy. Entropy 2015, 17, 3501–3517. [Google Scholar] [CrossRef]
- Porta, A.; Bari, V.; De Maria, B.; Takahashi, A.C.; Guzzetti, S.; Colombo, R.; Catai, A.M.; Raimondi, F.; Faes, L. Quantifying net synergy/redundancy of spontaneous variability regulation via predictability and transfer entropy decomposition frameworks. IEEE Trans. Biomed. Eng. 2017, 64, 2628–2638. [Google Scholar]
- Lizier, J.T.; Bertschinger, N.; Jost, J.; Wibral, M. Information decomposition of target effects from multi-source interactions: Perspectives on previous, current and future work. Entropy 2018, 20, 307. [Google Scholar] [CrossRef]
- Quax, R.; Har-Shemesh, O.; Sloot, P.M. Quantifying synergistic information using intermediate stochastic variables. Entropy 2017, 19, 85. [Google Scholar] [CrossRef]
- Barrett, A.B. Exploration of synergistic and redundant information sharing in static and dynamical Gaussian systems. Phys. Rev. E 2015, 91, 052802. [Google Scholar] [CrossRef]
- Chatterjee, P.; Pal, N.R. Construction of synergy networks from gene expression data related to disease. Gene 2016, 590, 250–262. [Google Scholar] [CrossRef]
- Rauh, J.; Banerjee, P.K.; Olbrich, E.; Jost, J.; Bertschinger, N. On extractable shared information. Entropy 2017, 19, 328. [Google Scholar] [CrossRef]
- Ince, R.A. Measuring multivariate redundant information with pointwise common change in surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef]
- Finn, C.; Lizier, J.T. Pointwise partial information decompositionusing the specificity and ambiguity lattices. Entropy 2018, 20, 297. [Google Scholar] [CrossRef] [PubMed]
- James, R.G.; Emenheiser, J.; Crutchfield, J.P. Unique information via dependency constraints. J. Phys. A Math. Theor. 2018, 52, 014002. [Google Scholar] [CrossRef]
- Varley, T.F. Generalized decomposition of multivariate information. PLoS ONE 2024, 19, e0297128. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Kolchinsky, A. A novel approach to the partial information decomposition. Entropy 2022, 24, 403. [Google Scholar] [CrossRef]
- Cover, T. Broadcast channels. IEEE Trans. Inf. Theory 1972, 18, 2–14. [Google Scholar] [CrossRef]
- Cover, T. An achievable rate region for the broadcast channel. IEEE Trans. Inf. Theory 1975, 21, 399–404. [Google Scholar] [CrossRef]
- Weingarten, H.; Steinberg, Y.; Shamai, S.S. The capacity region of the Gaussian multiple-input multiple-output broadcast channel. IEEE Trans. Inf. Theory 2006, 52, 3936–3964. [Google Scholar] [CrossRef]
- El Gamal, A.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Sato, H. An outer bound to the capacity region of broadcast channels (Corresp.). IEEE Trans. Inf. Theory 1978, 24, 374–377. [Google Scholar] [CrossRef]
- Geng, Y.; Nair, C. The capacity region of the two-receiver Gaussian vector broadcast channel with private and common messages. IEEE Trans. Inf. Theory 2014, 60, 2087–2104. [Google Scholar] [CrossRef]
- Tian, C. Latent capacity region: A case study on symmetric broadcast with common messages. IEEE Trans. Inf. Theory 2011, 57, 3273–3285. [Google Scholar] [CrossRef]
- Gacs, P.; Korner, J. Common information is far less than mutual information. Probl. Control Inf. Theory 1973, 2, 149–162. [Google Scholar]
- Wyner, A. The common information of two dependent random variables. IEEE Trans. Inf. Theory 1975, 21, 163–179. [Google Scholar] [CrossRef]
- Yu, W.; Cioffi, J.M. Sum capacity of Gaussian vector broadcast channels. IEEE Trans. Inf. Theory 2004, 50, 1875–1892. [Google Scholar] [CrossRef]
- Costa, M. Writing on dirty paper (corresp.). IEEE Trans. Inf. Theory 1983, 29, 439–441. [Google Scholar] [CrossRef]
- Venkatesh, P.; Bennett, C.; Gale, S.; Ramirez, T.; Heller, G.; Durand, S.; Olsen, S.; Mihalas, S. Gaussian partial information decomposition: Bias correction and application to high-dimensional data. Adv. Neural Inf. Process. Syst. 2024, 36, 74602–74635. [Google Scholar]
- Dabora, R.; Servetto, S.D. Broadcast channels with cooperating decoders. IEEE Trans. Inf. Theory 2006, 52, 5438–5454. [Google Scholar] [CrossRef]
- Liese, F.; Vajda, I. On divergences and informations in statistics and information theory. IEEE Trans. Inf. Theory 2006, 52, 4394–4412. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, C.; Shamai, S. Broadcast Channel Cooperative Gain: An Operational Interpretation of Partial Information Decomposition. Entropy 2025, 27, 310. https://doi.org/10.3390/e27030310
Tian C, Shamai S. Broadcast Channel Cooperative Gain: An Operational Interpretation of Partial Information Decomposition. Entropy. 2025; 27(3):310. https://doi.org/10.3390/e27030310
Chicago/Turabian StyleTian, Chao, and Shlomo Shamai (Shitz). 2025. "Broadcast Channel Cooperative Gain: An Operational Interpretation of Partial Information Decomposition" Entropy 27, no. 3: 310. https://doi.org/10.3390/e27030310
APA StyleTian, C., & Shamai, S. (2025). Broadcast Channel Cooperative Gain: An Operational Interpretation of Partial Information Decomposition. Entropy, 27(3), 310. https://doi.org/10.3390/e27030310