1. Introduction
The rapid growth of computationally intensive applications has driven considerable research into efficient distributed computing frameworks. MapReduce [
1,
2] and its evolution Apache Spark [
3] have significant advantages in computational tasks dealing with massive datasets, where the amount of data can usually reach tens of terabytes. The MapReduce framework distributes computation tasks to multiple nodes, each storing a subset of the dataset. The computation process is decomposed into a set of “map” functions and “reduce” functions. Each map function processes a batch of data to generate intermediate values (IVs), which serve as inputs to the reduce functions. The overall process comprises three main phases: map, shuffle, and reduce phases. The nodes compute the map functions on their locally stored data, generate output IVs during the map phase, and exchange their computed IVs to ensure that each reduce function accesses to all necessary inputs during the map phase. In the reduce phase, all the nodes compute their assigned reduce functions using the gathered IVs.
Due to massive data exchange and limited communication bandwidth, the MapReduce-type system (MapReduce in short) often suffers from communication bottlenecks, i.e., the data shuffle phase consumes a significant portion of the overall task execution time. In order to reduce the communication overhead during the shuffling phase, Li et al. in [
4] proposed a CDC scheme which achieves an optimal tradeoff between the computation load and communication load under a given output function assignment. The CDC scheme has also been widely studied in the other distributed computing scenarios. For example, CDC has been combined with maximum distance separable (MDS) codes to handle matrix–vector multiplication tasks and mitigate the impact of stragglers [
5]. There are also many workers focusing on the stragglers in general functions [
6,
7], optimal resource allocation strategies [
8,
9], iterative computing and shuffling procedures [
10,
11], randomized file allocations [
12], and cases with random network connectivity [
13].
The CDC technique has been extended to wireless networks [
14,
15], where devices exchange information via wireless links. In such scenarios, owing to the decentralized nature of wireless networks, a central access point (AP) is typically required to facilitate data exchange, giving rise to uplink and downlink communication phases [
16,
17,
18]. In real-world scenarios, we usually consider multiple APs. For example, a large place like a university campus needs to deploy multiple APs to realize campus network coverage. Moreover, a multi-AP system is able to distribute the load to multiple repeaters, thus reducing the risk of a single point of failure and improving fault tolerance.
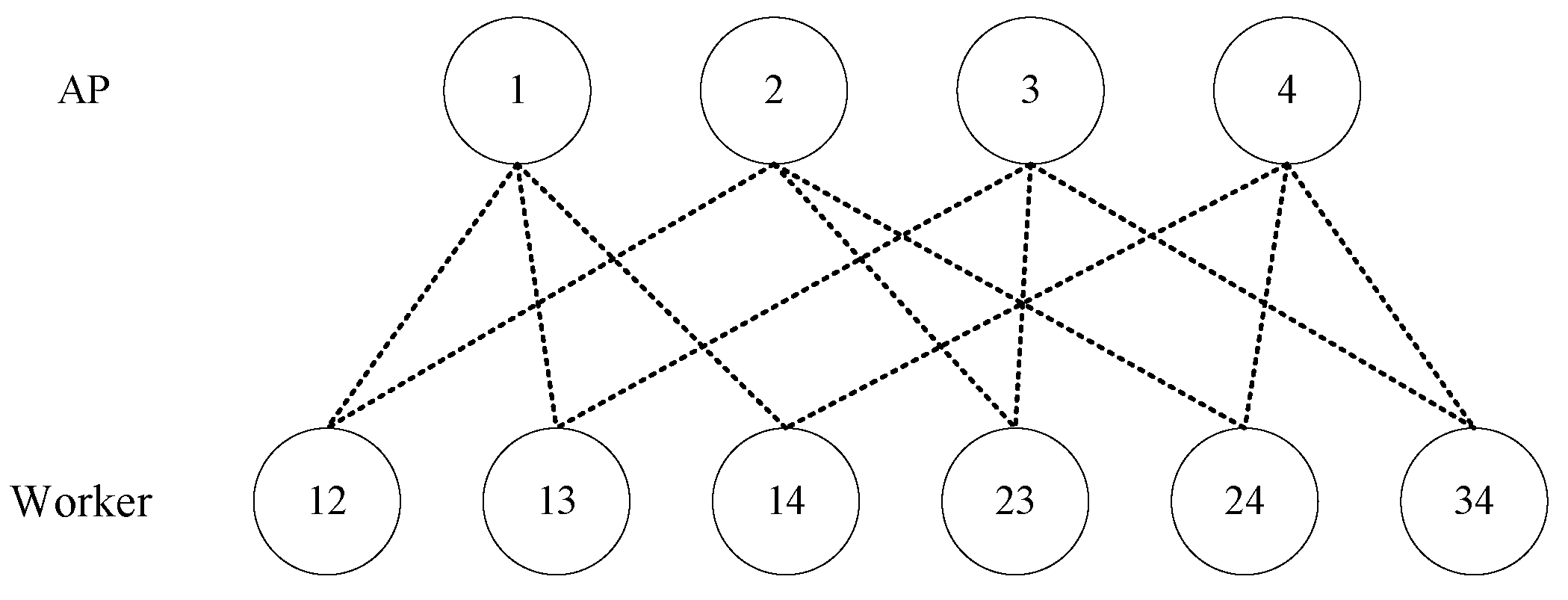
This paper considers the CDC problem in a wireless
-combination network [
19] which consists of
H numbers of APs and
computing workers. Each worker is connected to a distinct subset of
L numbers of APs through wireless links. The APs act as intermediate hubs, facilitating the exchange of IVs among workers over wireless channels. Each worker is assigned a subset of the input files, processes them locally to compute IVs, and then transmits some IVs to its connected APs. The APs aggregate and broadcast the received information to other workers, ensuring that all workers obtain the necessary IVs to compute their respective output functions. This multi-AP structure provides enhanced reliability and robustness in the face of AP or node failures. We are interested in the tradeoff between the communication load and computation load (defined as the average number of nodes processing each input file), and aim to improve the overall efficiency of the distributed computing system by exploiting computation resources at workers and creating additional opportunities for parallelism and multicast transmission.
In this paper, we first obtain a baseline scheme by using CPDA. Then, by novelly characterizing the scheme from the view point of linear algebra, the problem of designing a CDC scheme for combination network is equivalent to constructing a special matrix. Finally, using CPDA, we obtain an improved CDC scheme which has a lower communication load than that of the baseline scheme, for which the computation load does not increase.
Notations: We denote the set of positive integers by . For , the set is denoted as , and is used to represent the cardinality of a set or the length of a vector. Denote , i.e., is the collection of subsets of of size L.
2. System Model
We consider a
distributed coded computing system for a combination network, where there are
N input files
, each of which has
B bits,
H APs
without storage,
K workers, each of which can store at most
M files, and
K output functions
from
N files, each of which is arranged to one worker. Each worker is connected to a unique
L-subset of APs over the wireless channel. So
and the user set can be written as
. Each worker is connected to the other workers via these wireless channels through common APs. For instance,
Figure 1 shows a combination network with
and
. For each
, the output function
maps the
N input files into a streams of
U bits, i.e., we have
. The map function is defined as
. For each
, the map function maps the input file
into intermediate value (IV)
of
T bits. Similarly, for every
, we define the reduce function as
, which maps the
N IVs into a stream of
U bits. Consequently, the output function
is given by
as described in [
4,
18,
20]. Thus, a
distributed coded computing scheme for a combination network consists of the following three phases:
•Map Phase: Each worker stores M files, denoted by . We assume that each file is stored the same number of times. Based on its local stored files, worker can compute all the IVs .
•
Shuffle Phase: Each worker
is assigned to compute an output function
, where
. In order to obtain all the IVs
, the worker needs to request its required IVs from the other workers through their common APs. So, the communication process consists of two phases: uplink and downlink steps. Before the transmission begins, each worker encodes the IVs
as
using a randomized Gaussian encoding scheme. We assume that the transmission strategy is one-shot linear, i.e., each transmitted coded IV in a transmission could be decoded by any required worker and its local IVs. At each time slot
s, in the uplink step, we denote the signal sent from the worker
by
which satisfies the power constraint
. Here, the worker can be silent, i.e., not send any data. Then, each AP
receives the following signal:
where
and
denote the channel coefficients from worker
k to AP
h and the additive white Gaussian noise, respectively. We assume that
is chosen from
if worker
k is connected to AP
h; otherwise,
. Additionally,
follows a normal distribution
if worker
k is connected to AP
h; otherwise,
.
In the downlink step, each AP sends the received coded signal from its connected workers. The goal of the communication is to obtain all the IVs required by each worker , who is arranged to compute the output function .
Specifically, each worker
receives the following signal from its connected APs
where
is also the additive white Gaussian noise, and if
h is connected to
k, then
follows a normal distribution with
; otherwise,
. We can omit the additive noise terms
and
. This assumption is valid under the condition that the transmit power is sufficiently large to ensure a high signal-to-noise ratio (SNR).
•Reduce Phase: After receiving all the signals sent down by the AP, each worker can decode all its required IVs and compute the arranged output function .
Definition 1. The following two types of loads are used as criteria for evaluating the merits of a distributed coded computing scheme for combination network:
Computation load is defined as the total number of mapped files across the K workers, normalized by N, i.e., ;
Communication load consists of the uplink load , where is the length of the message received by the AP h in the uplink phase, i.e., the total normalized number of bits received by the H APs in the uplink process, and the downlink load where is the length of the message sent by AP h in the downlink phase, i.e., the total normalized number of bits sent by the H APs in the downlink process.
The authors in [
21] introduced the CPDA to realize a coded caching scheme for a combination network. In this paper, we will use it to construct our schemes.
Definition 2 (CPDA). For any positive integers H, N, Z and L with and , let , an array over is called a CPDA if it satisfies the following conditions:
- C1.
The symbol "∗" appears Z times in each column;
- C2.
Each occurs at least once in the array;
- C3.
For any two distinct entries and satisfying , then ;
- C4.
For any , the labels of all columns containing symbol s have a nonempty intersection.
Let us take the following example to further illustrate the concept of CPDA.
Example 1. When 4 and 2, let us consider the following array.Clearly each column has exactly 2 stars, and each integer occurs at least once in . So the conditions C1–2 hold. Let us consider the conditions C3–4. When 1, we can obtain the following subarray:Clearly, the entriesTherefore, the above two symbols 1 satisfy condition C3. The column labels corresponding to each integer 1 are , , and . Clearly, , which satisfy condition C4. Similarly, we can obtain the subarrays which only contain integers 2, 3, and 4, respectively and show that the conditions C3–4 hold. So, is a CPDA. There are many constructions of CPDAs in [
21,
22,
23,
24]. Here, we list some results which we will use in this paper as follows:
Lemma 1 ([
21])
. For any positive integers H, L, and t satisfying and , there exists a , , CPDA. Lemma 2 ([
22])
. For any positive integers satisfying , , , and , there exists a CPDA. 3. Main Results
In this section, the baseline scheme is introduced. Then, we characterize the CDC scheme from the view point of a coefficient matrix, thereby obtaining an optimized CDC scheme for the combination network. Finally, we use CPDA to derive the required coefficient matrix, which significantly simplifies the system design and enhances its performance. In addition, we demonstrate that the proposed scheme achieves a lower transmission load than the baseline scheme.
When each output function is computed by exactly one worker, the authors in [
25] showed that the CDC problem is equivalent to the coded caching problem for device-to-device (D2D) networks. In addition, the authors in [
26] proposed that a coded caching scheme for a shared link can be used to generate a coded caching scheme for a D2D network. Using the same method in [
26], we can generate a CDC scheme for a combination network based on the CPDA and obtain the following result.
Theorem 1 (Baseline scheme)
. Given a g- CPDA with and , there exists a baseline coded distributed computing scheme for a -combination network, with a computation load of and uplink and downlink communication loads of Proof. We use the star positions in
to assign the files to each worker as follows. When
, worker
k stores file
. So worker
k stores the following files:
In the map phase, the set of IVs computed locally by worker
k is
According to Definition 1, the computation load is .
Recall that each worker
is assigned to compute the output function
. From (
5), worker
k contains the required IVs in
and needs the other required IVs in
, each of which should be transmitted by the other workers.
Now, we will use the integers in
to design the transmission strategy in the shuffle phase. For each integer
, we assume that
s occurs exactly
g times in
. That is,
Denote the set of workers associated with
s as
and their respective connected AP sets as
By the condition C4 of Definition 2, there exists at least one integer, say
, satisfying
Recall that in the map phase, each worker can encode the IV
into
using a random Gaussian coding scheme, where
has a size of
t bits. To facilitate efficient transmission, each IV
in
is divided into
equal-sized packets. That is,
where
denotes the packet of
intended for worker
.
In the shuffle phase, each worker
transmits the following encoded information of length
bits to the AP
where
represents the sub-slot within time slot
s allocated to worker
for transmitting its encoded data. Upon receiving the message
where the coefficient
is the channel coefficient between worker
k and AP
and is chosen from
under the independent and identically distributed condition, the AP
broadcasts it to all workers in
. Consequently, each worker
receives the message
In the reduce phase, each worker
needs to compute the output function
. By Condition C3 of Definition 2 and Equation (
5), each worker
already possesses all IVs in
except
. Therefore, each worker
can decode its desired IV
from
. After time slot
s, each worker
obtains the IV
. After all
S time slots, each worker
obtains all the missing IVs
, which are required to compute the output function
. With all the necessary IVs, each worker
proceeds to compute
and completes the reduce phase.
Now, let us consider the communication load. By Definition 1, the uplink and downlink loads are
Then, the proof is completed. □
3.1. Main Idea
In this subsection, we characterize the CDC scheme under the combination network from a matrix perspective. Our task is to compute output functions, where each worker owns a portion of the input file denoted as .
Map Phase: For each mapped file
, worker
k computes the IV
for all
K output functions. Consequently, the set of IVs available at worker
is given by
The computation load in the map phase is given by
Shuffle Phase: The shuffle phase consists of two processes: (1) workers upload IVs to the AP via wireless channels, and (2) the AP broadcasts the received IVs to the connected workers. Before transmitting the information, each worker encodes the IV
into
using a random Gaussian coding scheme. During time slot
s, a set of workers
uploads IVs to AP
. Assuming that the signal sent by worker
at time slot
s is denoted as
, the signal received by AP
can be expressed as
where
is the channel coefficient matrix for time slot
s, and
is the transmit signal vector for time slot
s. To design
, we define
as the encoding coefficients for worker
. Then,
where
is the coefficient matrix for time slot
s, and
is the vector of encoded IVs. Thus, the message received by AP
is
By designing the coefficient matrix , we can control the IVs uploaded by workers to AP , completing the uplink process.
Next, we describe the downlink process. In time slot
s, AP
broadcasts the received message
to its connected workers. Each worker
then receives
Using the IVs it already possesses, worker can decode the required information from .
After
S time slots, all
K workers acquire the missing IVs required for the reduce function. Specifically, each worker
obtains
By combining their own IVs , each worker now possesses all the necessary information to compute the output function.
Since the messages in both the uplink and downlink processes are , and assuming each IV has a size of t bits, the communication load per time slot is t bits. According to Definition 1, the total uplink and downlink communication loads are
Reduce Phase: After the shuffle phase, each worker computes the output function using all the IVs they possess.
Theorem 2. Given an CPDA with , there exists a coded distributed computing scheme under a combination network, with a computation load of and its uplink and downlink communication loads given by Proof. We use a CPDA to design both the input file assignment and the coefficient matrix for the shuffle phase.
Before the computation task begins, the input file assigned to each worker
is
In the map phase, each worker maps the input file it owns into
K IVs
. Thus, the IVs at worker
are
Since each worker is allocated Z input files, the computation load according to Definition 1 is
Before the shuffle phase, each worker encodes the IV into using a random Gaussian coding scheme, where has a size of t bits. In the shuffle phase, we consider an integer in the CPDA , and suppose s occurs g times in . Let . The set of workers involved in time slot s is , and the APs connected to all workers in are denoted as . An arbitrary AP is selected to handle the uplink and downlink communication in time slot s.
In time slot
s, we design the message received by AP
as
From (
13) and (
18), we need to design the coefficient matrix
such that
Since
, by (
17), worker
does not possess the IV
. Thus,
, and (
19) can be written as
By linear algebra, i.e., given the row vector
, we can always obtain a non-zero column vector
of
such that the
ith coordinate is zero. So, we can always obtain the coefficient matrix
in (
20).
In the uplink phase, each worker
transmits the encoded information
to AP
. In the downlink phase, AP
broadcasts
to all workers in
. From Condition
of Definition 2 and Equation (
17), each worker
already possesses all IVs in
except
. Thus, each worker
can decode its desired IV
from
. After
S time slots, all
K workers obtain the missing IVs necessary for computing the reduce function.
Since the size of each IV
is
t bits, the communication load per time slot is
t bits. The total uplink and downlink communication loads are
In the reduce phase, each worker computes the output function . Since , worker k utilizes the IVs of all N files for the -th output function. After the shuffle phase, each worker is given the IVs needed to compute . Therefore, all workers can compute their assigned output functions. □
3.2. Performance Evaluation
In this subsection, let us consider the performance of the proposed schemes by applying the CPDA in Lemmas 1 and 2 to Theorems 1 and 2, respectively. The resulting schemes are summarized in
Table 1 and
Table 2 respectively. In the following, let us consider the computation load and communication load of these schemes.
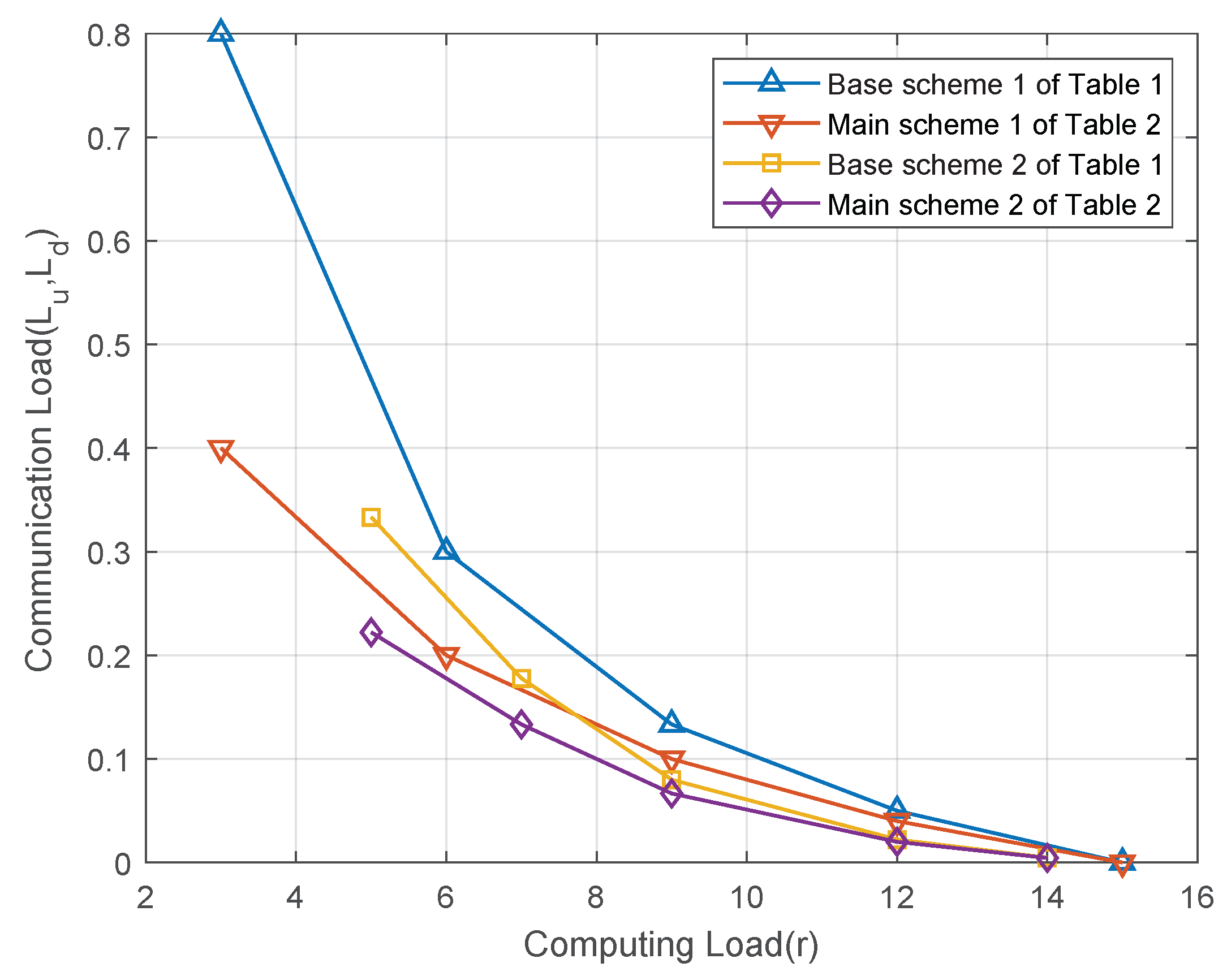
Figure 2 illustrates the relationship between the computation load and the communication load for the schemes in
Table 1 and
Table 2. Let us consider the distributed computing system with
computing nodes and
output functions under the
-combination network. As shown in
Figure 2, when the same class of CPDA is used, the main scheme of Theorem 2 achieves a lower communication load than the base scheme of Theorem 1 for the same computation load. This improvement results from the main scheme’s more efficient utilization of the multicast gain, which reduces the communication load.
3.3. Example for Achievable Scheme
We consider a combinatorial network with , , where and . The tasks to be computed by the 3 workers are , , and , respectively. The workers are denoted as , and the input files are denoted as . Before starting the task, the input files are assigned as follows: to worker 12, to worker 13, and to worker 23.
3.3.1. Map Phase
In the map phase, each worker maps each assigned file into 3 IVs. Specifically:
Worker 12 owns but lacks .
Worker 13 owns but lacks .
Worker 23 owns but lacks .
3.3.2. Shuffle Phase
After the map phase, the shuffle phase begins, where workers exchange IVs via the APs. Each worker encodes the IVs into using a randomized Gaussian coding scheme to ensure reliable transmission over the wireless channel.
Time Slot 1: Workers 12 and 13 send and to AP 1 simultaneously. AP 1 receives the message , completing the uplink process. AP 1 then broadcasts to workers 12 and 13, who receive and , respectively.
Time Slot 2: Workers 12 and 23 send and to AP 2 simultaneously. After the uplink and downlink phases, workers 12 and 23 receive and , respectively.
Time Slot 3: Workers 13 and 23 send and to AP 3 simultaneously. After the uplink and downlink phases, workers 13 and 23 receive and , respectively.
3.3.3. Reduce Phase
In the reduce phase, each worker decodes the missing IVs:
Worker 12 solves and from and using its own and .
Worker 13 solves and from and using its own and .
Worker 23 solves and from and using its own and .
After obtaining all the required IVs, each worker computes its assigned output function.
In this example, the computation load is . Assuming each IV has a size of t bits, the uplink and downlink loads are calculated as .





{kind=link}
{kind=link}