
Restart Mechanisms for the Successive-Cancellation List-Flip Decoding of Polar Codes


Abstract
1. Introduction
2. Background
2.1. Construction of Polar Codes
2.2. SC Decoding
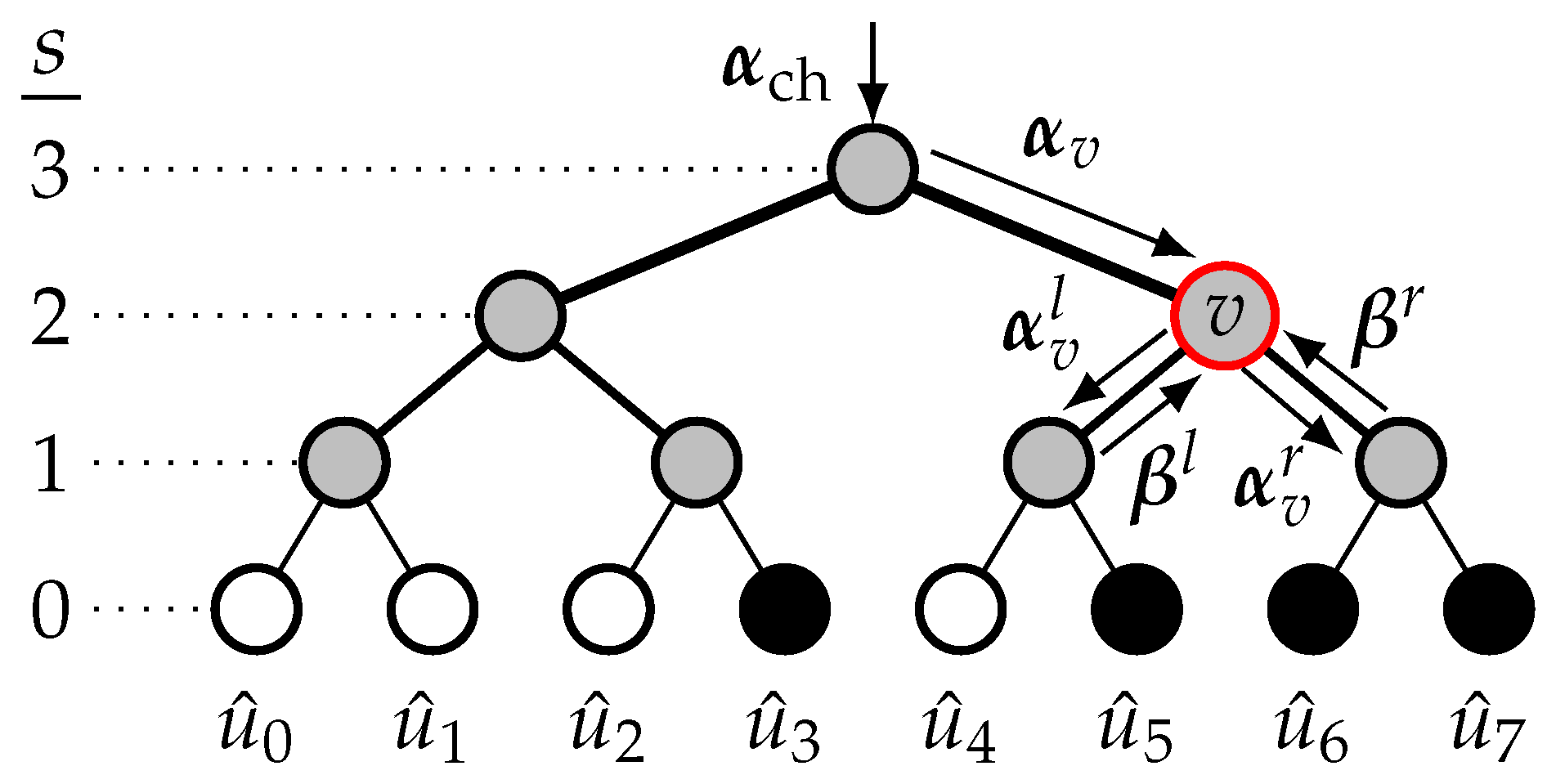
2.3. SCL Decoding
2.4. SCF Decoding
2.5. SCLF Decoding
2.6. Dynamic SCLF Decoding
3. Restart Mechanism for the List-Flip Decoder
3.1. Memory Requirements of List-Flip Algorithm
3.2. Generalized Restart Mechanism
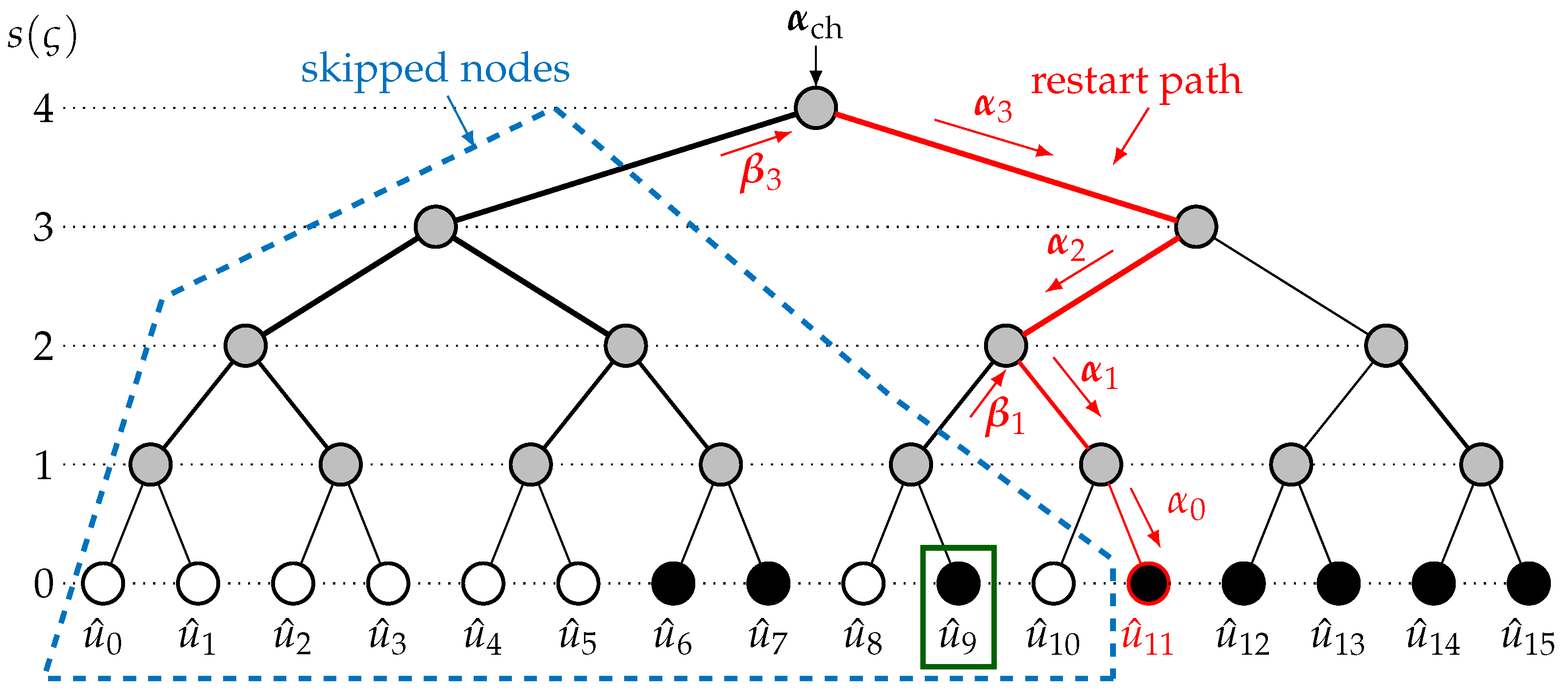
3.3. Limited Location Restart Mechanism
3.4. Example of the LLRM
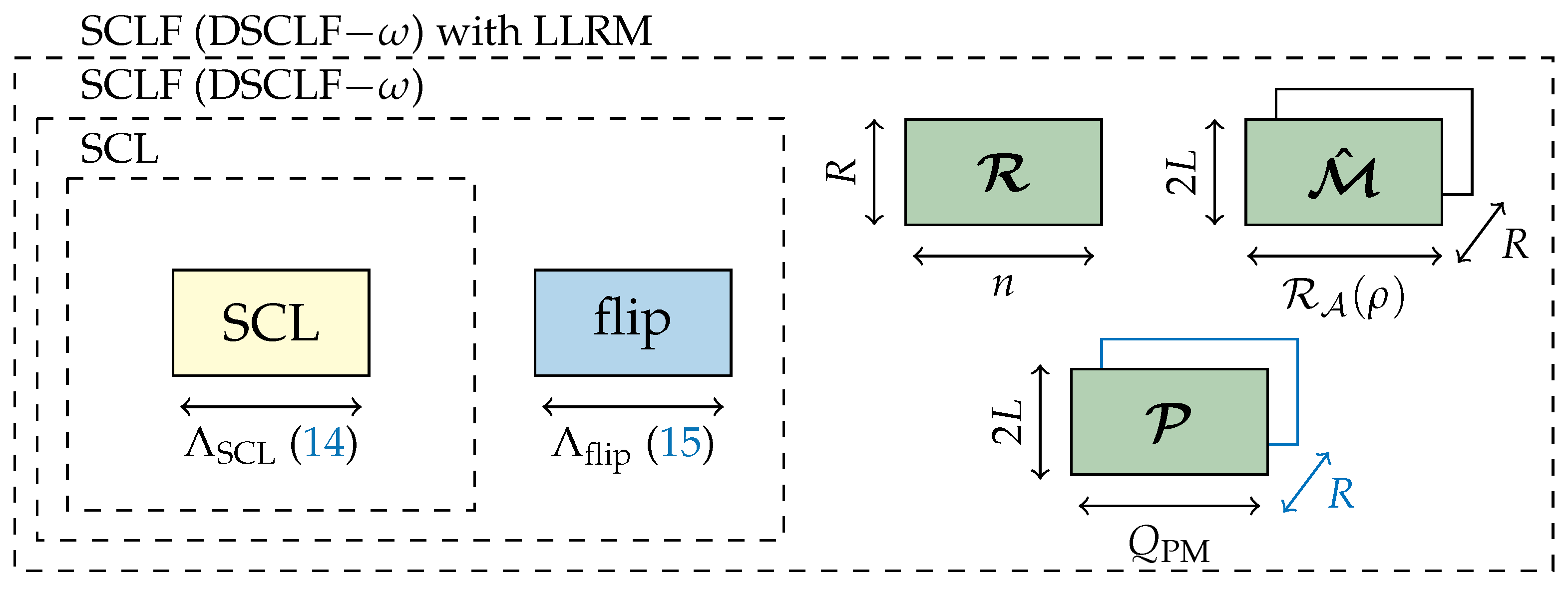
3.5. Memory Model
- the set of restart locations ;
- the path metric information on each restart location ;
- the partial message candidate on each restart location .
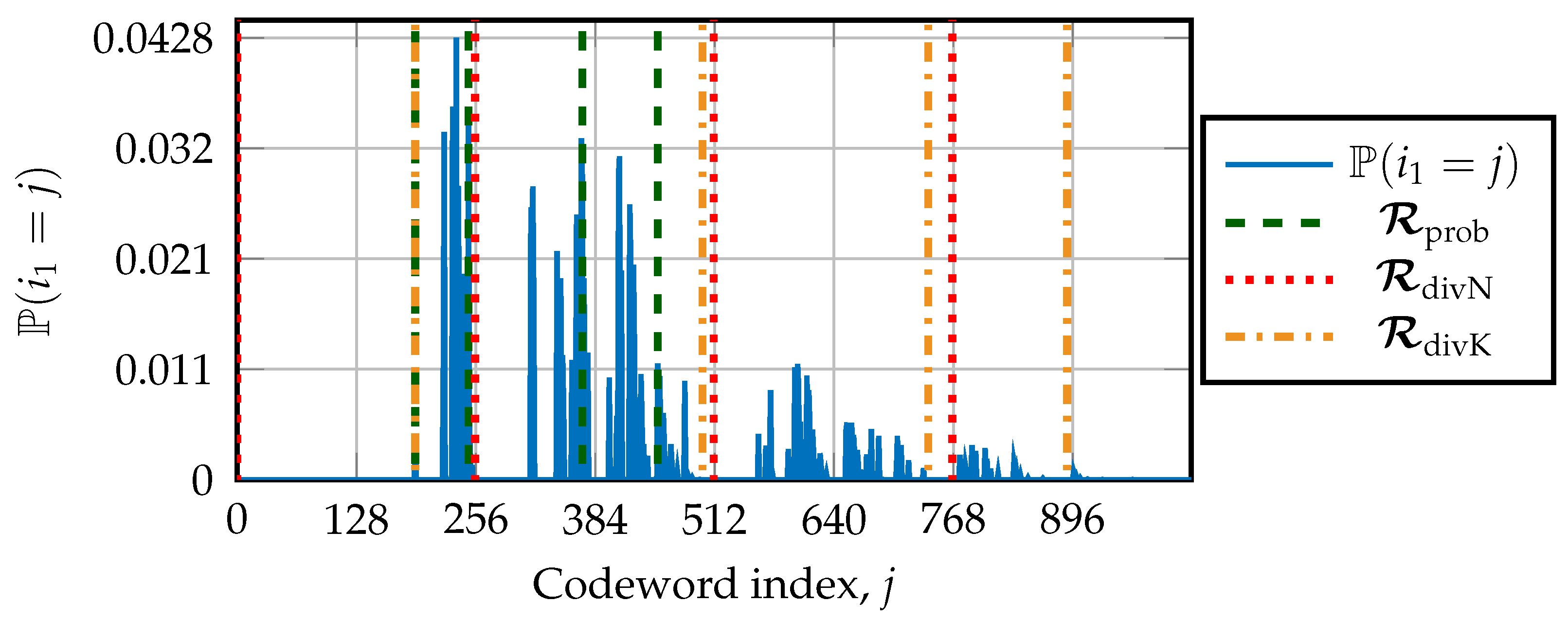
4. Obtaining the Restart Locations
4.1. Structural Design
4.2. Design Based on the First Path-Flipping Location
| Algorithm 1 Obtaining the distribution of the first path-flipping candidates occurring in SCLF by simulation | |
| 1: procedure Distr_Bit_Flip_SCLF() | |
| 2: for do | |
| 3: | ▹ Initialize |
| 4: | ▹ Initialize counter |
| 5: end for | |
| 6: | ▹ Total number of additional trials performed |
| 7: for do | |
| 8: Polar_Encoding | |
| 9: | ▹ Channel LLRs for the decoding |
| 10: | ▹ : Set of flipping locations in SCLF, t: Number of additional trials performed |
| 11: if then | ▹ Initial trial has failed |
| 12: | ▹ Update the total number of additional trials |
| 13: for do | |
| 14: | |
| 15: | ▹ Extract first bit-flipping |
| 16: | ▹ Increase by 1 the occurence |
| 17: end for | |
| 18: end if | |
| 19: end for | |
| 20: for do | |
| 21: | ▹ Estimate the probability-mass function |
| 22: end for | |
| 23: return the distribution | |
| 24: end procedure | |
| Algorithm 2 Design of with the distribution of the first path-flipping location | |
| 1: procedure Design_Restart_with_PMF() | |
| 2: | |
| 3: | |
| 4: for do | |
| 5: | |
| 6: if then | ▹ Divide equally with resp. to |
| 7: | |
| 8: | ▹ Next restart location |
| 9: end if | |
| 10: if then | |
| 11: return | ▹ Already R restart locations in |
| 12: end if | |
| 13: end for | |
| 14: end procedure | |
4.3. Simulation Setup and Results
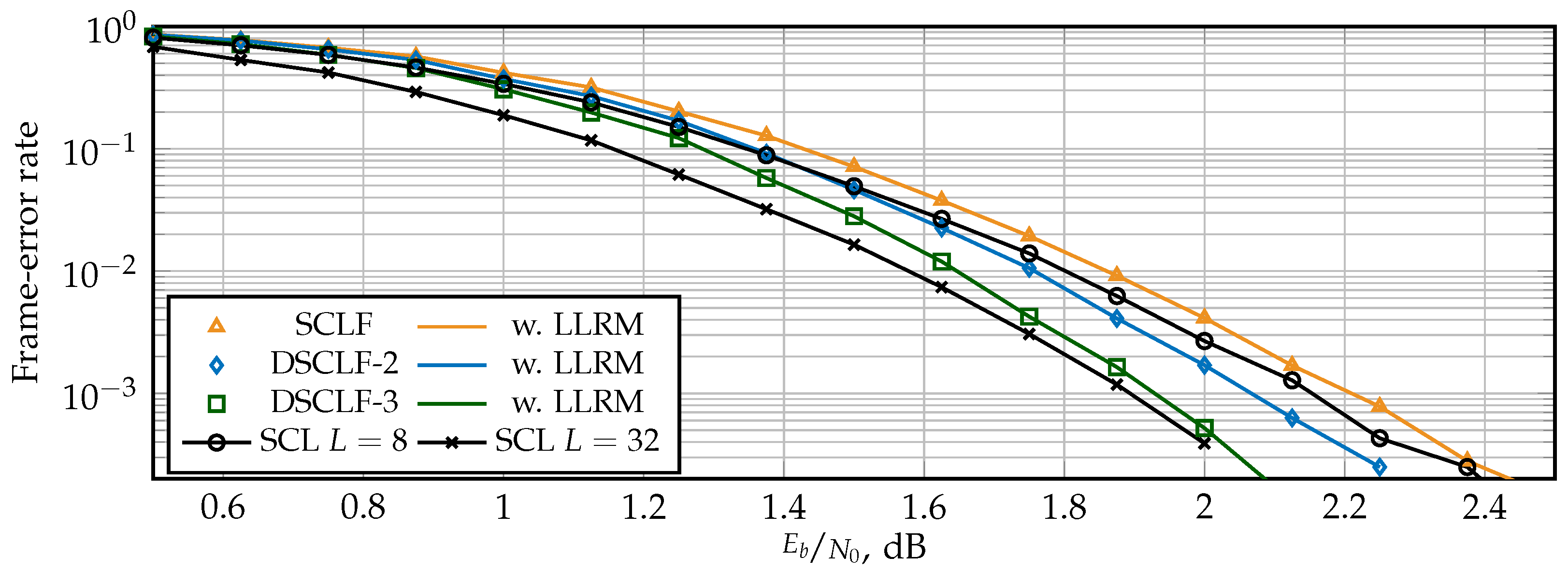
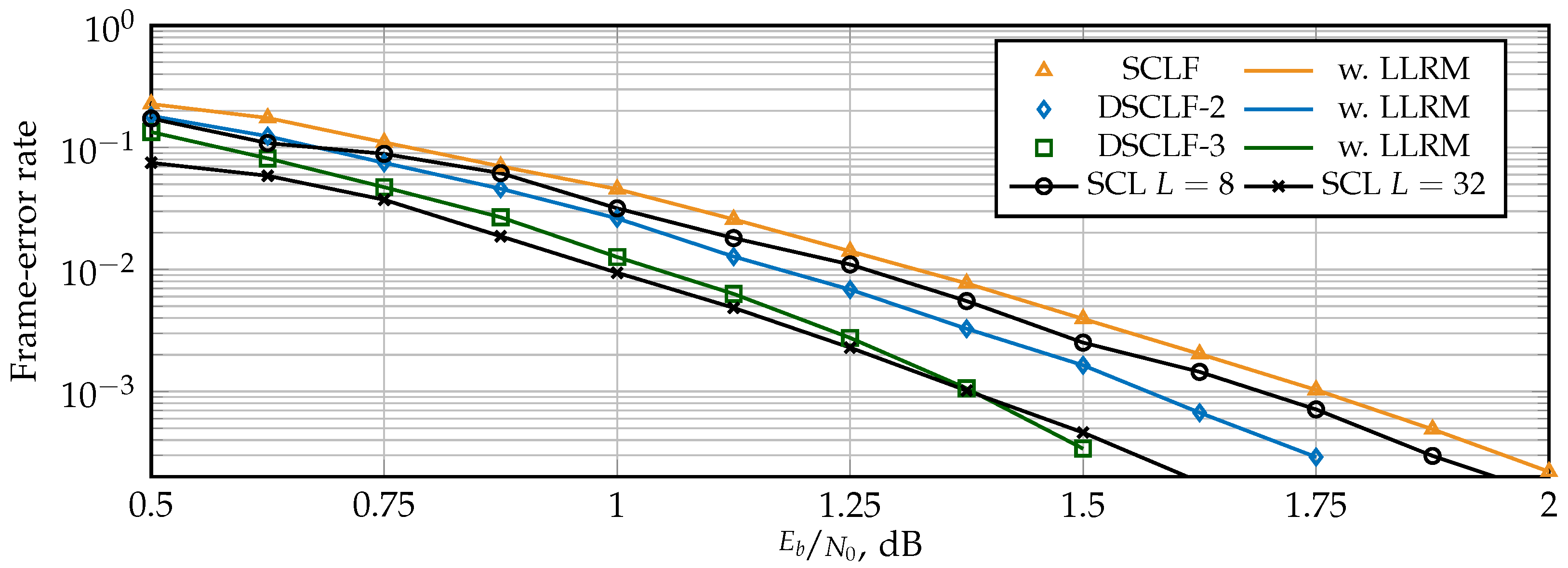
5. Simulation Results
5.1. Error-Correction Performance
5.2. Memory Estimations
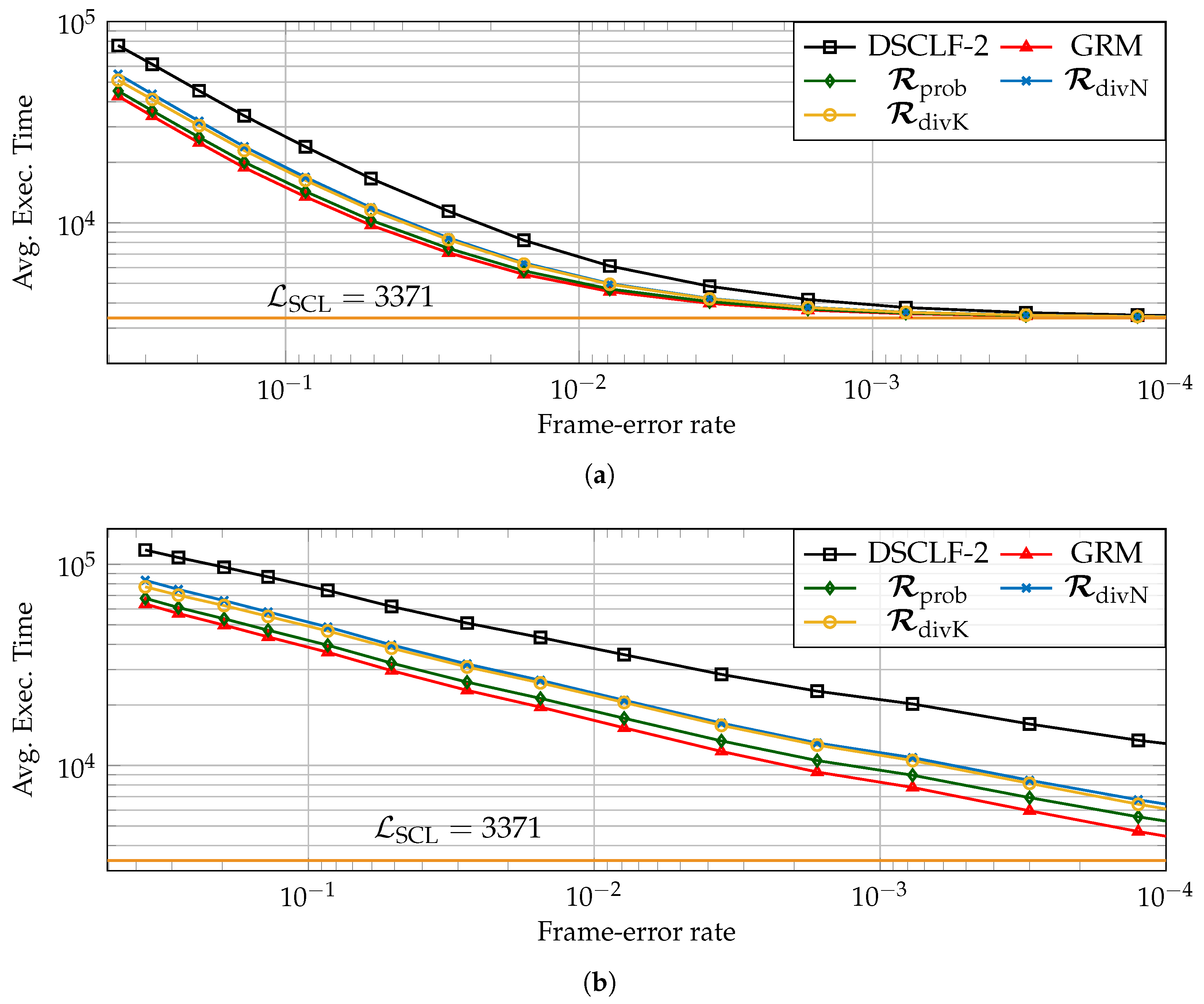
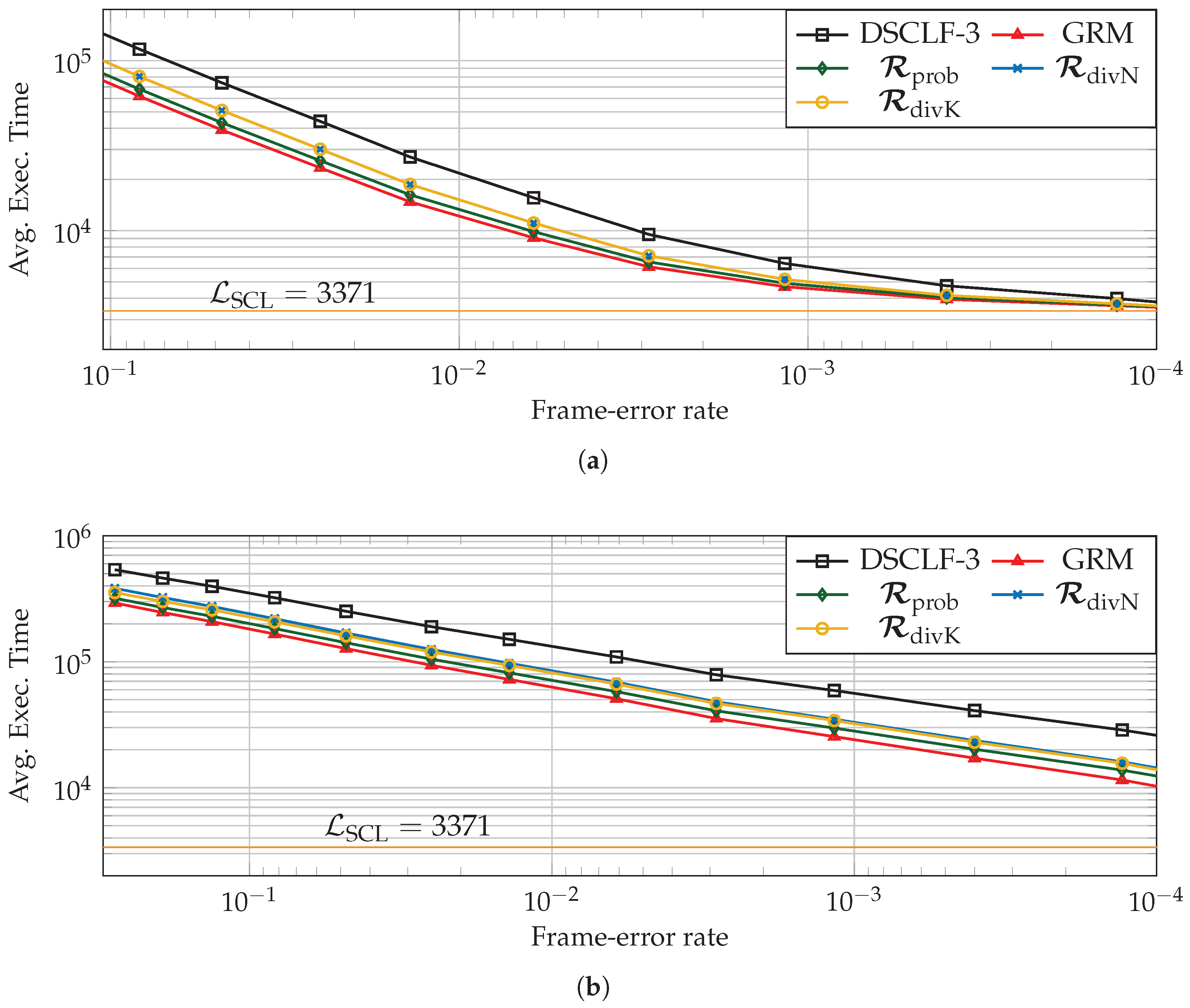
5.3. Average Execution Time Reduction Induced by the LLRM
 ), the reduction brought by the LLRM is estimated for various code lengths, code rates, and various restart locations designed according to simulations (
), the reduction brought by the LLRM is estimated for various code lengths, code rates, and various restart locations designed according to simulations ( ) or designed according to code properties such as (
) or designed according to code properties such as ( ) and (
) and ( ). In order to compute it, the chosen architectural execution-time model is from [17]. Moreover, the number of processing elements, having an impact on the average execution time of decoders, is as in [23,25]. Moreover, the latency of SCL is estimated as in [15], i.e., one clock cycle is added whenever the SCL encounters an information bit.
). In order to compute it, the chosen architectural execution-time model is from [17]. Moreover, the number of processing elements, having an impact on the average execution time of decoders, is as in [23,25]. Moreover, the latency of SCL is estimated as in [15], i.e., one clock cycle is added whenever the SCL encounters an information bit. ).
).6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AWGN | additive white Gaussian noise |
| BPS | binary phase-shift keying |
| CA | CRC-aided |
| CRC | cyclic redundancy check |
| DSCF | dynamic successive-cancellation flip |
| DSCLF | dynamic successive-cancellation list flip |
| eMBB | enhanced mobile broadband |
| FER | frame-error rate |
| GRM | generalized restart mechanism |
| LLR | log-likelihood ratio |
| LLRM | limited location restart mechanism |
| PM | path metric |
| PMF | probability-mass function |
| PS | partial sum |
| PSCLF | successive-cancellation list flip |
| RHS | right-hand side |
| SC | successive cancellation |
| SCL | successive-cancellation list |
| SCLF | successive-cancellation list flip |
| SCF | successive-cancellation flip |
| SCF | simplified restart mechanism |
| SNR | signal-to-noise ratio |
References
- Arıkan, E. Channel Polarization: A Method for Constructing Capacity-Achieving Codes for Symmetric Binary-Input Memoryless Channels. IEEE Trans. Inf. Theory 2009, 55, 3051–3073. [Google Scholar] [CrossRef]
- 3GPP. Multiplexing and Channel Coding. Technical Report TS 38.212; Release 16.5. 2018. Available online: https://www.etsi.org/deliver/etsi_ts/138200_138299/138212/16.05.00_60/ts_138212v160500p.pdf (accessed on 9 March 2025).
- Tal, I.; Vardy, A. List decoding of polar codes. IEEE Trans. Inf. Theory 2015, 61, 2213–2226. [Google Scholar] [CrossRef]
- Afisiadis, O.; Balatsoukas-Stimming, A.; Burg, A. A low-complexity improved successive cancellation decoder for polar codes. In Proceedings of the 2014 48th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 2–5 November 2014; pp. 2116–2120. [Google Scholar] [CrossRef]
- Chandesris, L.; Savin, V.; Declercq, D. Dynamic-SCFlip Decoding of Polar Codes. IEEE Trans. Commun. 2018, 66, 2333–2345. [Google Scholar] [CrossRef]
- Yu, Y.; Pan, Z.; Liu, N.; You, X. Successive Cancellation List Bit-flip Decoder for Polar Codes. In Proceedings of the 2018 10th International Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 18–20 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Cheng, F.; Liu, A.; Zhang, Y.; Ren, J. Bit-Flip Algorithm for Successive Cancellation List Decoder of Polar Codes. IEEE Access 2019, 7, 58346–58352. [Google Scholar] [CrossRef]
- Pan, Y.H.; Wang, C.H.; Ueng, Y.L. Generalized SCL-Flip Decoding of Polar Codes. In Proceedings of the IEEE Global Telecommunications Conference (GLOBECOM), Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Shen, Y.; Balatsoukas-Stimming, A.; You, X.; Zhang, C.; Burg, A.P. Dynamic SCL Decoder With Path-Flipping for 5G Polar Codes. IEEE Wireless Commun. Lett. 2022, 11, 391–395. [Google Scholar] [CrossRef]
- Lv, H.; Yin, H.; Yang, Z.; Wang, Y.; Dai, J. Adaptive List Flip Decoder for Polar Codes with High-Order Error Correction Capability and a Simplified Flip Metric. Entropy 2022, 24, 1806. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Zhou, L.; Li, Z.; Gao, W.; Ji, R.; Zhu, J.; Liu, Z. Deep Learning-Assisted Adaptive Dynamic-SCLF Decoding of Polar Codes. IEEE Trans. Cogn. Commun. Netw. 2024, 10, 836–851. [Google Scholar] [CrossRef]
- Ivanov, F.; Morishnik, V.; Krouk, E. Improved generalized successive cancellation list flip decoder of polar codes with fast decoding of special nodes. J. Commun. Netw. 2021, 23, 417–432. [Google Scholar] [CrossRef]
- Doan, N.; Hashemi, S.; Gross, W. Fast Successive-Cancellation List Flip Decoding of Polar Codes. IEEE Access 2022, 10, 5568–5584. [Google Scholar] [CrossRef]
- Wang, Y.; Qiu, S.; Chen, L.; Wang, Q.; Zhang, Y.; Liu, C.; Xing, Z. A Low-Latency Successive Cancellation Hybrid Decoder for Convolutional Polar Codes. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 5105–5109. [Google Scholar] [CrossRef]
- Pillet, C.; Sagitov, I.; Domer, G.; Giard, P. Partitioned Successive-Cancellation List Flip Decoding of Polar Codes. In Proceedings of the 2024 IEEE Workshop on Signal Processing Systems (SiPS), Cambridge, MA, USA, 4–6 November 2024; pp. 19–24. [Google Scholar] [CrossRef]
- Sagitov, I.; Pillet, C.; Balatsoukas-Stimming, A.; Giard, P. Successive-Cancellation Flip Decoding of Polar Code with a Simplified Restart Mechanism. In Proceedings of the 2023 IEEE Wireless Communications and Networking Conference (WCNC), Glasgow, Scotland, 26–29 March 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Sagitov, I.; Pillet, C.; Balatsoukas-Stimming, A.; Giard, P. Generalized Restart Mechanism for Successive-Cancellation Flip Decoding of Polar Codes. J. Signal Process. Syst. 2025. [Google Scholar] [CrossRef]
- Tal, I.; Vardy, A. How to Construct Polar Codes. IEEE Trans. Inf. Theory 2013, 59, 6562–6582. [Google Scholar] [CrossRef]
- Alamdar-Yazdi, A.; Kschischang, F.R. A Simplified Successive-Cancellation Decoder for Polar Codes. IEEE Commun. Lett. 2011, 15, 1378–1380. [Google Scholar] [CrossRef]
- Leroux, C.; Tal, I.; Vardy, A.; Gross, W.J. Hardware architectures for successive cancellation decoding of polar codes. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 1665–1668. [Google Scholar] [CrossRef]
- Balatsoukas-Stimming, A.; Parizi, M.; Burg, A. LLR-Based Successive Cancellation List Decoding of Polar Codes. IEEE Trans. Signal Process. 2015, 63, 5165–5179. [Google Scholar] [CrossRef]
- Sarkis, G.; Giard, P.; Vardy, A.; Thibeault, C.; Gross, W.J. Fast Polar Decoders: Algorithm and Implementation. IEEE J. Sel. Areas Commun. 2014, 32, 946–957. [Google Scholar] [CrossRef]
- Ercan, F.; Tonnellier, T.; Doan, N.; Gross, W.J. Practical Dynamic SC-Flip Polar Decoders: Algorithm and Implementation. IEEE Trans. Signal Process. 2020, 68, 5441–5456. [Google Scholar] [CrossRef]
- Xiyue, X.; Meilin, H.; Rui, G. Flexible Restart Mechanism for Successive Cancellation Flip Decoding of Polar Codes. IEEE Commun. Lett. 2024, 28, 2459–2463. [Google Scholar] [CrossRef]
- Giard, P.; Balatsoukas-Stimming, A.; Müller, T.C.; Bonetti, A.; Thibeault, C.; Gross, W.J.; Flatresse, P.; Burg, A. PolarBear: A 28-nm FD-SOI ASIC for Decoding of Polar Codes. IEEE J. Emerg. Sel. Top. Circuits Syst. 2017, 7, 616–629. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | ||||||||
|---|---|---|---|---|---|---|---|---|
| bits | % | % | % | % | ||||
| 1024 | 1 | 30 | 32,270 | ¼ | 1.8 | 5.5 | 2.1 | 235.0 |
| ½ | 7.7 | 10.3 | 6.1 | 875.1 | ||||
| ¾ | 4.6 | 15.0 | 12.0 | 1921.5 | ||||
| 1024 | 2 | 50 | 33,110 | ¼ | 2.2 | 5.5 | 2.1 | |
| ½ | 2.2 | 10.0 | 6.0 | |||||
| ¾ | 2.7 | 14.7 | 11.7 | |||||
| 1024 | 3 | 300 | 42,860 | ¼ | 1.5 | 4.2 | 1.6 | |
| ½ | 1.4 | 7.7 | 4.6 | |||||
| ¾ | 1.8 | 11.3 | 11.7 | |||||
| 512 | 3 | 300 | 21,682 | ¼ | 1.7 | 3.9 | 1.7 | 83.1 |
| ½ | 2.4 | 6.8 | 4.2 | 290.7 | ||||
| ¾ | 1.8 | 9.8 | 7.6 | 623.8 | ||||
| 2048 | 3 | 300 | 75,504 | ¼ | 1.5 | 4.4 | 1.6 | 374.0 |
| ½ | 1.6 | 8.5 | 4.9 | 1442.1 | ||||
| ¾ | 1.1 | 12.5 | 13.0 | 3204.5 | ||||
| N | (%) | (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dB | (%) | (%) | ||||||||||
| 1024 | 1 | 30 | ¼ | 1.34 | 18.5 | 16.9 | 12.3 | 14.3 | 51.9 | 47.4 | 34.6 | 40.1 |
| ½ | 1.87 | 12.8 | 9.9 | 7.9 | 8.1 | 35.8 | 27.7 | 22.1 | 22.7 | |||
| ¾ | 3.03 | 10.4 | 7.8 | 7.1 | 5.9 | 28.3 | 21.0 | 19.1 | 16.1 | |||
| 1024 | 2 | 50 | ¼ | 1.21 | 25.4 | 23.1 | 18.2 | 18.9 | 56.7 | 51.7 | 40.7 | 42.1 |
| ½ | 1.78 | 19.1 | 14.8 | 12.5 | 12.2 | 36.0 | 27.9 | 23.5 | 22.9 | |||
| ¾ | 3.00 | 9.8 | 7.0 | 5.8 | 5.1 | 23.1 | 16.5 | 13.7 | 12.0 | |||
| 1024 | 3 | 300 | ¼ | 1.06 | 45.5 | 41.7 | 31.0 | 33.2 | 52.0 | 47.6 | 35.4 | 37.9 |
| ½ | 1.66 | 27.8 | 22.2 | 16.7 | 17.2 | 32.2 | 25.7 | 19.3 | 19.9 | |||
| ¾ | 2.86 | 15.3 | 11.7 | 7.1 | 7.5 | 18.7 | 14.3 | 8.7 | 9.2 | |||
| 512 | 3 | 300 | ¼ | 1.39 | 47.3 | 43.3 | 34.4 | 35.5 | 55.7 | 51.0 | 40.5 | 41.9 |
| ½ | 1.92 | 30.8 | 28.1 | 20.0 | 20.3 | 35.5 | 32.4 | 23.1 | 23.4 | |||
| ¾ | 3.08 | 14.5 | 11.5 | 6.6 | 6.8 | 18.2 | 14.4 | 8.2 | 8.5 | |||
| 2048 | 3 | 300 | ¼ | 0.84 | 44.1 | 38.0 | 31.8 | 26.7 | 55.2 | 47.6 | 39.8 | 33.4 |
| ½ | 1.49 | 27.8 | 21.8 | 17.2 | 17.7 | 33.7 | 26.5 | 20.8 | 21.5 | |||
| ¾ | 2.73 | 12.5 | 8.9 | 4.7 | 4.8 | 15.5 | 11.0 | 5.8 | 6.0 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pillet, C.; Sagitov, I.; Balatsoukas-Stimming, A.; Giard, P. Restart Mechanisms for the Successive-Cancellation List-Flip Decoding of Polar Codes. Entropy 2025, 27, 309. https://doi.org/10.3390/e27030309
Pillet C, Sagitov I, Balatsoukas-Stimming A, Giard P. Restart Mechanisms for the Successive-Cancellation List-Flip Decoding of Polar Codes. Entropy. 2025; 27(3):309. https://doi.org/10.3390/e27030309
Chicago/Turabian StylePillet, Charles, Ilshat Sagitov, Alexios Balatsoukas-Stimming, and Pascal Giard. 2025. "Restart Mechanisms for the Successive-Cancellation List-Flip Decoding of Polar Codes" Entropy 27, no. 3: 309. https://doi.org/10.3390/e27030309
APA StylePillet, C., Sagitov, I., Balatsoukas-Stimming, A., & Giard, P. (2025). Restart Mechanisms for the Successive-Cancellation List-Flip Decoding of Polar Codes. Entropy, 27(3), 309. https://doi.org/10.3390/e27030309