1. Introduction
High-speed railways have become a crucial mode of transportation in modern society, offering advantages such as time efficiency and convenience for passengers. The stability and safety of high-speed trains are paramount, considering their high-speed nature. The suspension system plays a pivotal role in maintaining this stability, consisting of key components like coil springs, air springs, and hydraulic dampers. Any malfunction in these components poses a potential threat to the safe operation of the train and the wellbeing of passengers. Therefore, monitoring the health of critical components in the suspension system of high-speed trains holds significant importance [
1]. Ensuring the continuous and accurate diagnosis of faults in these components is essential for maintaining the safety and reliability of high-speed train operations.
Various methodologies exist for diagnosing faults in high-speed train components, encompassing expert knowledge-based, model-based, and data-driven approaches [
2,
3]. Among these, deep learning, a subset of data-driven techniques, has gained prominence for its capabilities in extracting intricate features from data [
4,
5]. Noteworthy architectures such as stacked autoencoders, deep belief networks, and convolutional neural networks are commonly employed in fault diagnosis. These models serve either as feature extractors or as end-to-end structures, showcasing advantages in adaptive feature extraction and comprehensive fault analysis [
6,
7]. Recent studies have explored fault diagnosis methods for high-speed train components, including traction systems [
5], running gears [
8], bogies [
9], and yaw dampers [
10]. Additionally, hybrid models integrating physical and data-driven approaches have been proposed for fault detection in axle bearings [
11]. Despite their successes, these approaches face challenges, particularly in the need for substantial labeled data. The limited availability of fault samples poses a significant constraint on the practical application of deep learning models for fault diagnosis in high-speed train components. Overcoming this limitation and effectively handling the scarcity of labeled data remain critical aspects for further advancing the field of high-speed train fault diagnosis.
Few-shot learning emerges as a promising solution for addressing the challenges of data scarcity in fault diagnosis, especially in scenarios where obtaining abundant labeled data is impractical. This approach involves training models to recognize new fault classes with minimal labeled examples, making it adaptable to situations with limited data availability. Few-shot learning’s effectiveness extends beyond traditional machine learning limitations, finding applications in various domains where data is scarce. In the context of fault diagnosis, few-shot learning becomes particularly relevant by requiring only a small number of labeled samples for each fault class. This adaptability is crucial in overcoming challenges associated with acquiring extensive labeled data, a common constraint in fault diagnosis applications. Few-shot learning’s ability to generalize from limited examples makes it well-suited for the dynamic and diverse nature of fault patterns in high-speed train components. The efficacy of few-shot learning in fault diagnosis is demonstrated through diverse strategies, including data augmentation-based methods, meta-learning approaches, distance metric-based techniques, and migration learning-based methods. These methodologies within the few-shot learning framework contribute to enhancing fault diagnosis accuracy, especially in the presence of limited labeled data. The efficacy of few-shot learning in fault diagnosis is demonstrated through diverse strategies. Snell et al. [
12] introduce a simple yet effective approach for few-shot learning by learning prototype representations of each class in a metric space. Finn et al. [
13] propose Model-Agnostic Meta-Learning method for few-shot learning, which is compatible with any model trained with gradient descent and applicable to a variety of different learning problems. Ren et al. [
14] extend Prototypical Networks to incorporate unlabeled examples within each episode, demonstrating improved predictions akin to semi-supervised algorithms. Liu et al. [
15] propose Transductive Propagation Network (TPN) for transductive inference in few-shot learning, addressing the low-data problem by learning to propagate labels from labeled instances to unlabeled test instances. Notably, transductive inference is a flavor of few-shot learning that has gained attention for its ability to leverage unlabeled data for better generalization. This characteristic is particularly advantageous in fault diagnosis, where labeled data is often limited, and the inclusion of unlabeled data can significantly improve model performance. As the field progresses, the application of few-shot learning principles is expected to play a pivotal role in advancing fault diagnosis capabilities, providing effective solutions for real-world scenarios characterized by data scarcity.
Recent advancements in few-shot learning for fault diagnosis have yielded diverse methodologies tailored to mitigate the challenges of limited data availability. These approaches encompass various strategies, including meta-learning frameworks [
16,
17], which address data scarcity by leveraging innovative decomposition methods and model-agnostic meta-learning strategies integrated with specialized frameworks. Additionally, Ref. [
18] introduces a multimodal few-shot learning framework adept at handling unbalanced data in industrial bearing fault diagnosis, while Cen et al. [
19] propose an anomaly detection model for industrial motors that utilizes reinforcement and ensemble learning under few-shot feature conditions. Moreover, methods like meta-transfer learning [
20], customized meta-learning frameworks [
21], and efficient two-stage learning frameworks [
22] offer innovative solutions to address domain-shift challenges and enhance feature invariance to data shifts, ultimately improving fault diagnosis performance. These studies collectively underscore the versatility and efficacy of few-shot learning techniques in fault diagnosis applications.
In this context, although previous research has explored the application of few-shot learning in fault diagnosis, it has largely overlooked the uncertainty of samples from unknown distributions in fault diagnosis tasks. This uncertainty can lead to misdiagnosis of faults and result in serious consequences. Additionally, the lack of targeted regularization methods, such as signal-specific data augmentation techniques, to address the overfitting problem in few-shot learning for fault diagnosis tasks has also constrained the performance of models. This paper introduces a novel few-shot learning approach, denoted as Sensor-Perturbation Injection and Meta-Confidence Learning (SPI-MCL), designed for diagnosing high-speed train faults. The methodology involves mapping input data from various tasks to a shared feature space using one-dimensional convolutional neural networks. Each query sample in each class is then assigned a distinct confidence score based on a distance metric formula in this feature space. Subsequently, weighted averages of confidence scores are computed to update class prototypes, thereby enhancing fault classification. Given the non-overlapping nature of training and test classes, the classification of unknown samples in the test set may be unreliable. To mitigate this concern, we introduce sensor-wise data perturbation and model perturbations during the meta-learning process to bolster the reliability of output confidence scores. The designed sensor-wise perturbation can generate different perturbation modes for each sensor and accommodate multichannel scenarios in high-speed train fault diagnosis, where monitoring signals from different sensors exhibit varying distributions and characteristics. This injection of randomness facilitates better learning of confidence measures, consequently improving fault classification accuracy. Our key contributions encompass:
- (1)
Proposing a novel approach for fault diagnosis based on meta confidence learning.
- (2)
Enhancing fault detection performance through the injection of sensor-wise perturbations.
- (3)
Validating the effectiveness of the proposed method on a high-speed train fault diagnosis dataset.
2. Method
This section provides a detailed description of the proposed SPI-MCL method, which is designed for high-speed train fault diagnosis. The methodology employs a neural network model, and involves two main techniques: meta-confidence learning (in
Section 2.2) for learning confidence scores and updating prototypes, and sensor-wise perturbations (in
Section 2.3) to enhance the model’s capability for extracting features from nonlinear signals. The overall framework of the proposed method is presented in
Section 2.4.
2.1. Few-Shot Classification and Prototype-Based Method
The detection task for fault types with limited labeled data can be seen as a few-shot classification problem, a scenario frequently encountered in fault diagnosis applications. In the realm of few-shot classification, particularly relevant to fault detection, the task is often termed K-way N-shot classification. Here, K represents the number of fault classes, and N denotes the limited number of labeled samples available per fault class for training. In practical terms, this can be likened to the scenario where each fault class has a sparse set of exemplar samples for model learning.
The setup involves a support set () and a query set (). The support set includes K classes, each with N samples, denoted as . The query set, used for evaluating the model’s performance, also comprises K classes, but with M samples per class, represented as . In the context of fault detection, this aligns with the practical challenge of learning from a small number of labeled samples for each fault type in the training set and subsequently validating the model on a similarly limited dataset.
A notable approach in few-shot learning, particularly relevant to fault diagnosis, is the Prototype-based method [
12]. This method addresses the challenge by learning a prototype
for each fault class, where
represents the set of labeled samples with
k class, and
represents learnable parameters. In the fault diagnosis context, the prototype can be conceptualized as a representative reference or average feature set of the support samples within a given fault class. The classification of samples in the query set is then determined based on the distance metric between the prototype and the query sample. This methodology is well-suited for fault detection scenarios where learning from a limited number of labeled samples is a common challenge, enabling effective generalization and discrimination among fault classes in the presence of sparse training data.
2.2. Meta-Confidence Learning with Transductive Inference
The prototype-based method has shown its effectiveness in many related tasks. However, the original prototype-based method does not consider the uncertainties of prediction on an unseen task, which may cause serious consequences, especially in fault diagnosis tasks. In fault diagnosis scenarios, where faults may exhibit similar characteristics leading to confusion or where fault features vary, addressing prediction uncertainties becomes crucial for reliable diagnosis. Meta-confidence learning [
23] provides a feasible solution with transductive inference. The method leverages the unlabeled examples for refining prototypes by updating them according to the confidence score [
14]. The concept behind meta-learning is that the information gain obtained from learned instances should prove valuable for analyzing future instances.
The method is described as follows: First, the initial prototype for each class
is computed as
. Subsequently, for each step
, and for each query example
, the confidence score
is determined, representing the probability of it belonging to each class
k, according to the equation:
where
d denotes the Euclidean distance and
represents the prototype updated up to step
.
The prototypes of class
k are then updated based on the confidence scores (or soft labels)
for all
, given by the following:
which represents the weighted average. It is noted that the confidence of the support examples is invariably 1, given their observed class labels. The process is iteratively repeated until
. The confidence scores reflect the model’s certainty in its predictions, crucial for distinguishing between similar faults or handling variations in fault characteristics.
Specifically, the distance metric
is meta-learned, where it is defined as the Euclidean distance with normalization and instance-wise or pair-wise metric scaling, denoted as
and
, respectively:
for all
, where
are the
l-dimensional feature vector generated by the network model from two data samples. The normalization ensures that the confidence is primarily determined by metric scaling. To obtain the optimal scaling function
for transduction, the query likelihoods after
T transduction steps are computed first, followed by the optimization of
, the parameter of the scaling function
, through minimizing the instance-wise loss for
:
Regarding , a convolutional neural network with fully-connected layers can be utilized, which takes either the feature map of an instance or the concatenated feature map of a pair of instances as input. The meta-learning of distance metrics allows the model to adapt to variations in fault characteristics and similarities, ensuring reliable diagnosis in diverse fault scenarios.
In few-shot classification, to enhance the robustness and generalization capability of the model to the samples, a feasible approach is to inject perturbations into the samples. By introducing various types of perturbations, the model can better adapt to different data distributions and features during the training process, thus improving its ability to recognize unseen samples. Additionally, perturbation injection helps prevent the model from overfitting to the training data, facilitating the model to better capture the underlying features among samples in few-shot learning tasks. In [
23], both data perturbation and model perturbation are utilized to output more reliable and consistent confidence.
In this section, we proposed sensor-wise perturbations into the fault detection process. By adding sensor-wise perturbations to the monitoring data, the model can better adapt to different data distributions and features during the training process, thus improving its ability to recognize unseen samples. The introduction of sensor-wise perturbations during training induces controlled entropy in the model’s decision boundaries, allowing it to learn more nuanced and robust representations of the input data. This approach enables it to effectively capture intricate patterns in the data for fault diagnosis tasks.
2.3. Sensor-Wise Perturbation
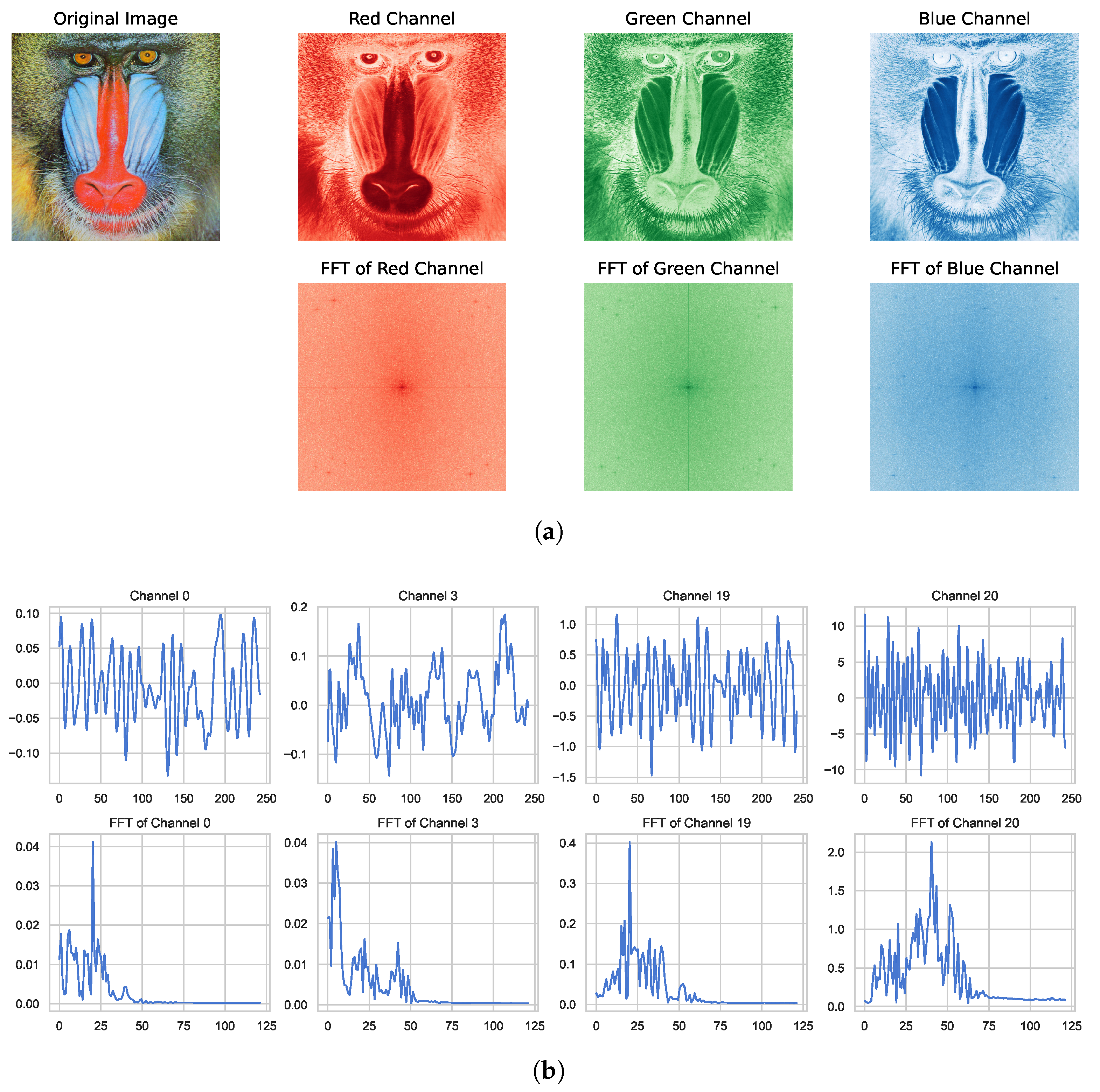
The motivation behind sensor-wise perturbation is based on the following considerations. Unlike image data and other similar formats, multi-sensor monitoring signals possess their own characteristics. For typical natural image data, the three color channels commonly exhibit the same range and similar distribution. Therefore, perturbations and data augmentation techniques for image data typically treat the entire image data without distinguishing between channels. However, for sensor monitoring signals, data from different sensors usually have different ranges and distributions, especially for coupled mechanical systems. For instance, low-frequency vibrations at one monitoring point may induce high-frequency responses at another monitoring point, resulting in inconsistent distributions of key modal identification features across different monitoring channels. Here,
Figure 1 demonstrates the similarities and differences between different channels of image data and the vibration monitoring data addressed in this paper. The proposed sensor-wise perturbation in this section specifically addresses the perturbation techniques related to the characteristics of sensor monitoring signals, aiming to enhance the distribution of data in scenarios of limited sample learning.
The specific steps of sensor-wise perturbation can be described as follows: Firstly, for a monitoring signal
x with
C channels, perform fast Fourier transform (FFT) on all channels to obtain
X. Then, compute the sensor-wise perturbation threshold based on the amplitude spectrum
, where
,
, and
is a scale factor for tuning the perturbation threshold. Subsequently, apply random perturbation to the parts of the amplitude spectrum that exceed the threshold, where
,
,
denotes the standard deviation of the amplitude spectrum for channel
c, and
is a scale factor for tuning the noise level. Regarding the perturbations mentioned above, parameter
controls how many frequency components will be perturbed, while parameter
controls the intensity of the perturbation. Finally, perform inverse transform on the perturbed spectrum to obtain the perturbed signal, and superimpose Gaussian white noise
to simulate the noise characteristics of real monitoring signals. Equation (
6) shows the detailed steps of sensor-wise perturbation.
The advantage of sensor-wise perturbation lies in its ability to introduce variation to vibration-like signals. By perturbing the main frequency components of the signal based on the frequency characteristics of different sensor channels, sensor-wise perturbation ensures that these perturbations are reflected in the time domain while maintaining consistency in the spectral features. Such perturbation enhances the fit of the sample distribution for models trained with limited data, thereby improving the generalization capability of the model.
Figure 2 provides an illustrative example of sensor-wise perturbation applied to a vibration signal, which can be seen to introduce variation in the signal while preserving its spectral features. The introduction of sensor-wise perturbations aligns with the intrinsic characteristics of fault diagnosis tasks. By perturbing the data at the sensor level, the model becomes more adept at capturing subtle variations in sensor readings that may indicate fault conditions. Furthermore, the channel-wise nature of the perturbations ensures that the model learns to differentiate between various sensor channels, enhancing its ability to pinpoint the source of anomalies. The introduction of data perturbations enhances the uncertainty in the model’s predictions, enabling it to focus on regions of the feature space with higher information gain and adapt to varying data distributions. This approach aligns with the requirements of fault diagnosis applications, where precise identification of sensor-specific deviations is crucial for accurate diagnosis and maintenance decisions.
2.4. Overall Framework
The overall framework of the proposed method is depicted in
Figure 3. The monitoring signal samples are divided into a support set and a query set based on whether they have labels for the components’ conditions (normal or fault) in an episode, which represents a training cycle. The input samples are fed into the model through two pipelines to generate confidence scores. One pipeline involves feeding the original samples into the neural network without any model perturbation, while the other pipeline introduces model perturbation by randomly dropping the last residual block in the residual network and sensor-wise perturbation by adding sensor-wise perturbation to the entire data in the episode. The confidence scores from these two pipelines are then combined as inputs to the soft k-means algorithm for updating prototypes. The initial prototypes for both pipelines are derived by averaging the embeddings of the support set, which are then used to compute confidence scores for each space and class. Then, the prototypes for each space are updated using the ensemble confidence scores obtained from various spaces and queries. This updating process is repeated T times, with each update incorporating an averaged confidence. Finally, inference is performed based on
.
4. Conclusions and Future Work
This paper proposes a few-shot learning-based fault detection method for high-speed train suspension systems to address the challenge of limited fault samples in real-world scenarios. Leveraging few-shot learning principles and meta-confidence learning, the designed approach enhances the model’s robustness and generalization capability by incorporating sensor-wise perturbation. This perturbation method augments the main components of monitoring signals based on their characteristics, strengthening the model’s ability to learn sample distributions and generalize under limited data conditions. Experimental validation on both high-speed train fault datasets and publicly available benchmark bearing datasets, along with comparisons with other few-shot learning methods, demonstrate the effectiveness and superiority of the proposed approach. Furthermore, discussions and analyses on the effects of different perturbations and experiments on high-way settings during training provide guidance for practical applications. The proposed method achieves high accuracy in fault detection under limited sample conditions and is easily extendable to fault diagnosis problems in other domains.
Our future research includes exploring additional techniques to enhance the robustness of the proposed method under complex and dynamic operating conditions, as well as extending its applicability to diverse domains beyond high-speed train fault diagnosis. This may involve investigating advanced data augmentation strategies, exploring advanced information gain techniques in the presence of sensor-wise perturbations, and adapting the method to varying environmental conditions to ensure its effectiveness across a wide range of practical scenarios.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}