
In Search of Dispersed Memories: Generative Diffusion Models Are Associative Memory Networks

Abstract
1. Introduction
2. Preliminaries
2.1. Associative Memory Networks
2.2. Generative Diffusion Models
3. The Equivalence between Diffusion Models and Modern Hopfield Networks
3.1. Variance-Exploding Models
3.2. The General Case
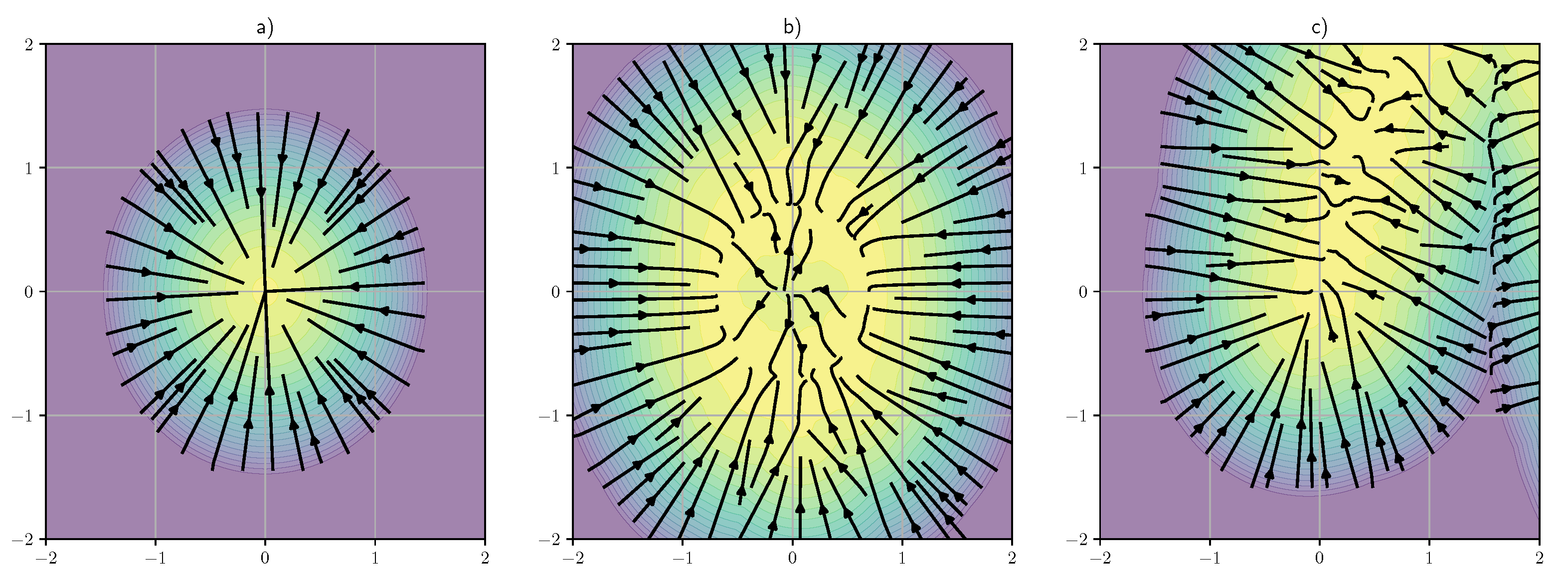
4. Encoding Memories by Denoising Neural State
5. Beyond Classical Associative Memories
5.1. Probabilistic Recall
5.2. Higher-Dimensional Memory Structures
6. A Theoretical Framework for Memory in Biological and Artificial Intelligent Systems
6.1. Semantic, Episodic, and Reconstructive Memory
6.2. Consolidation and Replays
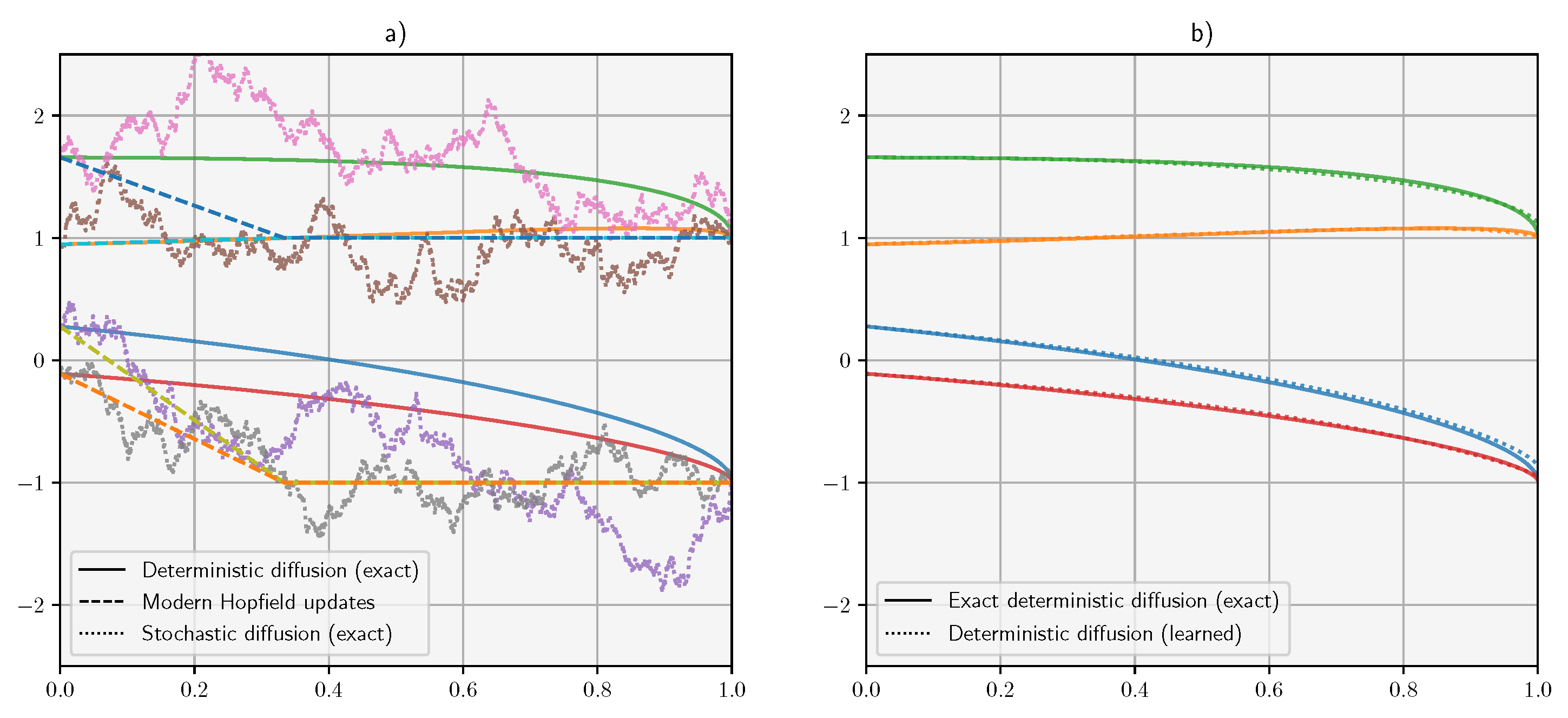
7. Experiments
8. Discussion
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Details of the Experiments
References
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef]
- Michel, A.N.; Farrell, J.A. Associative memories via artificial neural networks. IEEE Control Syst. Mag. 1990, 10, 6–17. [Google Scholar] [CrossRef]
- Graves, A.; Wayne, G.; Reynolds, M.; Harley, T.; Danihelka, I.; Grabska-Barwińska, A.; Colmenarejo, S.G.; Grefenstette, E.; Ramalho, T.; Agapiou, J.; et al. Hybrid computing using a neural network with dynamic external memory. Nature 2016, 538, 471–476. [Google Scholar] [CrossRef]
- Lopez-Paz, D.; Ranzato, M. Gradient episodic memory for continual learning. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, M.; Yang, T.; Rosing, T. Improved schemes for episodic memory-based lifelong learning. Adv. Neural Inf. Process. Syst. 2020, 33, 1023–1035. [Google Scholar]
- Kadam, S.; Vaidya, V. Review and analysis of zero, one and few shot learning approaches. In Intelligent Systems Design and Applications, Proceedings of the 18th International Conference on Intelligent Systems Design and Applications (ISDA 2018), Vellore, India, 6–8 December 2018; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Abu-Mostafa, Y.; Jacques, J.S. Information capacity of the Hopfield model. IEEE Trans. Inf. Theory 1985, 31, 461–464. [Google Scholar] [CrossRef]
- Sejnowski, T.J.; Tesauro, G. The Hebb rule for synaptic plasticity: Algorithms and implementations. In Neural Models of Plasticity; Elsevier: Amsterdam, The Netherlands, 1989; pp. 94–103. [Google Scholar]
- Krotov, D.; Hopfield, J.J. Dense associative memory for pattern recognition. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar] [CrossRef]
- Demircigil, M.; Heusel, J.; Löwe, M.; Upgang, S.; Vermet, F. On a model of associative memory with huge storage capacity. J. Stat. Phys. 2017, 168, 288–299. [Google Scholar] [CrossRef]
- Krotov, D.; Hopfield, J. Large associative memory problem in neurobiology and machine learning. In Proceedings of the International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Friston, K.; Kilner, J.; Harrison, L. A free energy principle for the brain. J. Physiol. 2006, 100, 70–87. [Google Scholar] [CrossRef]
- Friston, K. The free-energy principle: A unified brain theory? Nat. Rev. Neurosci. 2010, 11, 127–138. [Google Scholar] [CrossRef]
- Ororbia, A.; Kifer, D. The neural coding framework for learning generative models. Nat. Commun. 2022, 13, 2064. [Google Scholar] [CrossRef]
- Jones, M.; Wilkinson, S. From Prediction to Imagination; Cambridge University Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Schacter, D.L.; Addis, D.R.; Buckner, R.L. Remembering the past to imagine the future: The prospective brain. Nat. Rev. Neurosci. 2007, 8, 657–661. [Google Scholar] [CrossRef]
- Kolodner, J.L. Reconstructive memory: A computer model. Cogn. Sci. 1983, 7, 281–328. [Google Scholar]
- Hemmer, P.; Steyvers, M. A Bayesian account of reconstructive memory. Top. Cogn. Sci. 2009, 1, 189–202. [Google Scholar] [CrossRef] [PubMed]
- Nash, R.A.; Wheeler, R.L.; Hope, L. On the persuadability of memory: Is changing people’s memories no more than changing their minds? Br. J. Psychol. 2015, 106, 308–326. [Google Scholar] [CrossRef]
- Buhry, L.; Azizi, A.H.; Cheng, S. Reactivation, replay, and preplay: How it might all fit together. Neural Plast. 2011, 2011, 203462. [Google Scholar] [CrossRef] [PubMed]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-Based Generative Modeling through Stochastic Differential Equations. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Kloeden, P.E.; Platen, E.; Kloeden, P.E.; Platen, E. Stochastic Differential Equations; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar]
- Krotov, D. A new frontier for Hopfield networks. Nat. Rev. Phys. 2023, 5, 366–367. [Google Scholar] [CrossRef]
- Ramsauer, H.; Schäfl, B.; Lehner, J.; Seidl, P.; Widrich, M.; Adler, T.; Gruber, L.; Holzleitner, M.; Pavlović, M.; Sandve, G.K.; et al. Hopfield networks is all you need. In Proceedings of the Internetional Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Fischer, A.; Igel, C. An introduction to restricted Boltzmann machines. In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications, Proceedings of the 17th Iberoamerican Congress, CIARP, Buenos Aires, Argentina, 3–6 September 2012; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Hyvärinen, A. Estimation of Non-Normalized Statistical Models by Score Matching. J. Mach. Learn. Res. 2005, 6, 695–709. [Google Scholar]
- Vincent, P. A connection between score matching and denoising autoencoders. Neural Comput. 2011, 23, 1661–1674. [Google Scholar] [CrossRef]
- Raya, G.; Ambrogioni, L. Spontaneous symmetry breaking in generative diffusion models. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar] [CrossRef]
- Di Lollo, V. Temporal characteristics of iconic memory. Nature 1977, 267, 241–243. [Google Scholar] [CrossRef] [PubMed]
- Sakitt, B. Iconic memory. Psychol. Rev. 1976, 83, 257. [Google Scholar] [CrossRef] [PubMed]
- Graziano, M.; Sigman, M. The dynamics of sensory buffers: Geometric, spatial, and experience-dependent shaping of iconic memory. J. Vis. 2008, 8, 9. [Google Scholar] [CrossRef] [PubMed]
- Dalm, S.; van Gerven, M.; Ahmad, N. Effective Learning with Node Perturbation in Deep Neural Networks. arXiv 2023, arXiv:2310.00965. [Google Scholar]
- Hasselmo, M.E.; Cekic, M. Suppression of synaptic transmission may allow combination of associative feedback and self-organizing feedforward connections in the neocortex. Behav. Brain Res. 1996, 79, 153–161. [Google Scholar] [CrossRef] [PubMed]
- Hasselmo, M.E.; Linster, C.; Patil, M.; Ma, D.; Cekic, M. Noradrenergic suppression of synaptic transmission may influence cortical signal-to-noise ratio. J. Neurophysiol. 1997, 77, 3326–3339. [Google Scholar] [CrossRef] [PubMed]
- Hasselmo, M.E. Septal modulation of hippocampal dynamics: What is the function of the theta rhythm? In The Behavioral Neuroscience of the Septal Region; Springer: Berlin/Heidelberg, Germany, 2000; pp. 92–114. [Google Scholar]
- Nieuwenhuis, I.L.; Takashima, A. The role of the ventromedial prefrontal cortex in memory consolidation. Behav. Brain Res. 2011, 218, 325–334. [Google Scholar] [CrossRef]
- Tronel, S.; Feenstra, M.G.; Sara, S.J. Noradrenergic action in prefrontal cortex in the late stage of memory consolidation. Learn. Mem. 2004, 11, 453–458. [Google Scholar] [CrossRef]
- Benchenane, K.; Tiesinga, P.H.; Battaglia, F.P. Oscillations in the prefrontal cortex: A gateway to memory and attention. Curr. Opin. Neurobiol. 2011, 21, 475–485. [Google Scholar] [CrossRef]
- Comeaux, P.; Clark, K.; Noudoost, B. A recruitment through coherence theory of working memory. Prog. Neurobiol. 2023, 228, 102491. [Google Scholar] [CrossRef]
- Hancock, E.R.; Kittler, J. A Bayesian interpretation for the Hopfield network. In Proceedings of the IEEE International Conference on Neural Networks, San Francisco, CA, USA, 28 March–1 April 1993. [Google Scholar]
- Gupta, A.; Mendonca, R.; Liu, Y.; Abbeel, P.; Levine, S. Meta-reinforcement learning of structured exploration strategies. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Ambrogioni, L.; Ólafsdóttir, H.F. Rethinking the hippocampal cognitive map as a meta-learning computational module. Trends Cogn. Sci. 2023, 27, 702–712. [Google Scholar] [CrossRef]
- Roediger, H.L.; McDermott, K.B. Creating false memories: Remembering words not presented in lists. J. Exp. Psychol. Learn. Mem. Cogn. 1995, 21, 803. [Google Scholar] [CrossRef]
- Ólafsdóttir, H.F.; Bush, D.; Caswell, B. The role of hippocampal replay in memory and planning. Curr. Biol. 2018, 28, R37–R50. [Google Scholar] [CrossRef]
- Güçlü, U.; van Gerven, M.A.J. Deep neural networks reveal a gradient in the complexity of neural representations across the ventral stream. J. Neurosci. 2015, 35, 10005–10014. [Google Scholar] [CrossRef]
- Rao, R.P.N.; Ballard, D.H. Predictive coding in the visual cortex: A functional interpretation of some extra-classical receptive-field effects. Nat. Neurosci. 1999, 2, 79–87. [Google Scholar] [CrossRef]
- Spratling, M.W. A review of predictive coding algorithms. Brain Cogn. 2017, 112, 92–97. [Google Scholar] [CrossRef] [PubMed]
- Millidge, B.; Seth, A.; Buckley, C.L. Predictive coding: A theoretical and experimental review. arXiv 2021, arXiv:2107.12979. [Google Scholar]
- Stachenfeld, K.L.; Botvinick, M.M.; Gershman, S.J. The hippocampus as a predictive map. Nat. Neurosci. 2017, 20, 1643–1653. [Google Scholar] [CrossRef]
- Barron, H.C.; Auksztulewicz, R.; Friston, K. Prediction and memory: A predictive coding account. Prog. Neurobiol. 2020, 192, 101821. [Google Scholar] [CrossRef] [PubMed]
- Salvatori, T.; Song, Y.; Hong, Y.; Sha, L.; Frieder, S.; Xu, Z.; Bogacz, R.; Lukasiewicz, T. Associative memories via predictive coding. Adv. Neural Inf. Process. Syst. 2021, 34, 3874–3886. [Google Scholar] [PubMed]


{kind=link}
{kind=link}
{kind=link}
| Denoising Task | Number of Patterns | Diffusion Model | Classic Hopfield | True Patterns |
|---|---|---|---|---|
| 10 | 0.995 | 0.732 | 0.893 | |
| 20 | 0.991 | 0.704 | 0.822 | |
| 30 | 0.991 | 0.715 | 0.81 | |
| Completion task | ||||
| 10 | 0.996 | 0.741 | 0.897 | |
| 20 | 0.991 | 0.707 | 0.838 | |
| 30 | 0.989 | 0.700 | 0.795 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ambrogioni, L. In Search of Dispersed Memories: Generative Diffusion Models Are Associative Memory Networks. Entropy 2024, 26, 381. https://doi.org/10.3390/e26050381
Ambrogioni L. In Search of Dispersed Memories: Generative Diffusion Models Are Associative Memory Networks. Entropy. 2024; 26(5):381. https://doi.org/10.3390/e26050381
Chicago/Turabian StyleAmbrogioni, Luca. 2024. "In Search of Dispersed Memories: Generative Diffusion Models Are Associative Memory Networks" Entropy 26, no. 5: 381. https://doi.org/10.3390/e26050381
APA StyleAmbrogioni, L. (2024). In Search of Dispersed Memories: Generative Diffusion Models Are Associative Memory Networks. Entropy, 26(5), 381. https://doi.org/10.3390/e26050381