1. Introduction
Classification algorithms are essential data mining techniques for real-world applications [
1]. They use a model based on the dataset’s contents to classify new objects or understand the existing class distribution [
2]. Classification has many applications, such as finding patterns in financial markets, automatically labelling large image collections, and supporting bank loan decisions [
3,
4]. It is also widely used in medical systems [
5]. Classification is a supervised data mining method that involves model building, testing, and predicting unknown values.
A classifier is a computational model or method that assigns input data examples to predefined classes. This supervised learning method uses labelled training data to teach the classifier how to predict or judge the class labels of future or unseen instances. A classifier can be defined as a function or mapping that assigns a feature vector representing an input instance x to one of the specified classes. A classifier can be expressed mathematically as , where X is the feature space or input domain and Y is the set of possible class labels or output domain. The function f maps an input instance x from X to its corresponding class label y in Y.
Multi-class classification is a type of classification that deals with many classes, but it seems it is less studied than binary classification, which only has two classes [
6]. Unlike binary classification, which separates normal and abnormal cases [
7], multi-class classification assigns examples to one of the known classes. However, multi-class problems can have a multitude of attributes that influence the classification outcome, making the task more complex and challenging. It is crucial to consider these attributes during model development to ensure accurate and reliable results [
8].
This contribution aims to introduce a new method of multi-class classification using interval modeling, which can handle the challenges of multi-class problems in the case of a large number of attributes. In this work, we concentrated on microarrays (used to measure the expression levels of large numbers of genes simultaneously or to genotype multiple regions of a genome) which are typical examples of high-dimensional datasets. However, the proposed models may be applied to other high-dimensional datasets. Technical solutions regarding the implementation of the algorithms allow to test the models on high-dimensional datasets. However, the quality of performance of the proposed models in the case of datasets other than microarrays are unpredictable.
The proposed ensemble classifier is a heterogeneous type, since it is based on diverse classification algorithms. As was stressed in [
9], known strong classifiers are tree-based ones (e.g., Random Forest [
10]), Support Vector Machines [
11,
12], or Multilayer Perceptrons/Deep Neural Networks [
13]. In that paper, the authors presented the results of a test performed on over 200 datasets and claimed that instead of optimizing the mentioned single models, it is better to build an ensemble classifier of the mentioned models. The comparative studies of classifiers give some indication which classifier to apply, e.g., Ref. [
14]—it is a suggestion which classifier is better on average over standard problems, but it seems that a definitive answer is not possible to be reached. In the situation of a lack of domain knowledge, it is reasonable to ensemble classifiers from different families rather than optimizing a specific type. In our approach as a base classifier, the simple and well-known k Nearest Neighbors (k-NN) classifier [
15] was also applied, which proved to work well in many applications. Scalability and interpretability are also the reason to use these simpler classifiers. Since the proposed approach of classification is a multi-class, we also compared our results with well-known decomposition techniques, such as one-versus-one (OVO) and one-versus-rest (OVR), which reduce the multi-class problem to multiple binary problems. The main reason of applying these methods is the fact that decomposition strategies prove to be profitable even when they are not required. This result also holds for k-NN [
16]. A comparison has since been made with the basic version of this algorithm (directly suitable for the multi-class case) as well as with the corresponding decomposiotion models. As a base classifier for decomposition, the k-NN classifier is applied. Moreover, Bagging [
17]—a well-known ensemble model—was considered to compare the results obtained by the proposed models.
The approach presented employs interval modeling to address uncertainty in the classification process [
18,
19,
20]. Intervals are generated from the predictions of component classifiers and then aggregated using interval-valued aggregation functions. The presented method assigns the decision class of an object by using interval order [
21,
22]. The paper also investigates how the choice of different interval-valued aggregation functions can affect the classifier performance. We conduct a comparative analysis of three ensemble classifier methodologies. Each of these methodologies employs interval modeling, with two of them additionally incorporating cross-entropy.
The Proposed Model trains a set of models on a dataset. Each model within a given group is individually trained on these data. This process is repeated for each group of models, resulting in a set of trained models ready for predictions. The Proposed Entropy Model differs from the Proposed Model in several ways. It introduces a cross-validation process using a repeated stratified K-fold, which splits the training data into different folds. For each model, it calculates the cross-entropy loss for each fold and stores these losses, then it selects the models based on their mean losses. Models with losses less than or equal to the average loss are chosen, while others are removed. The Proposed Entropy Groups Model introduces additional steps compared to the Proposed Entropy Model. It calculates the mean cross-entropy loss (
20) for each group of models. It then filters the groups based on their mean losses, keeping only those with a mean loss less than or equal to the average. If fewer than two groups remain after this filtering, it keeps the two groups with the lowest mean losses.
The obtained results show that interval modeling may be successfully applied in multi-class ensemble classification, outperforming the single classifiers’ performance. Furthermore, the performance of the evaluated ensemble classifier may be significantly enhanced by employing cross-entropy as a criterion to select the most effective component classifiers, which was proved using statistical tests.
The manuscript is organized as follows. In
Section 2, a brief literature review is provided concerning multi-class classification methods for high-dimensional datasets.
Section 3 provides basic concepts related to interval calculus and interval-valued aggregation functions.
Section 4 presents characteristic of microarray datasets applied in the experiments.
Section 5 and
Section 6 give information about the applied methodology and proposed models. In
Section 7, the results of the experiments are presented, while in
Section 8, a discussion on these results is provided.
2. Literature Review
The existing literature [
23,
24,
25] explores various techniques for performing multi-class classification tasks with many conditional attributes. One of the studies [
23] demonstrated that the support vector machine is an effective method for classifying multi-class breast cancer data with high dimensionality. The study compared the performance of Support Vector Machine with other methods, such as Naive Bayes, Random Forest, and multinomial Logistic Regression, and showed that the latter methods are prone to overfitting in this scenario. Another study [
24] developed a new learning algorithm called Latent-ISVM for achieving accurate multi-class image classification with very large datasets. The algorithm uses a latent variable model to capture the underlying structure of the images and a kernel function to map the images to a high-dimensional feature space. The study claims that Latent-ISVM can handle complex and diverse image data better than other methods. A third study [
25] presented a novel method called SEGEP (Sigmoid-based Ensemble Gene Expression Programming) for multi-class classification with high-dimensional and low-sample-size (HDLSS) data. The method integrates a flexible probability representation, an effective data splitting mechanism, and a unique sampling strategy to deal with output conflicts and improve binary classifiers. The study conducts experiments on several HDLSS datasets and shows that SEGEP outperforms other genetic programming methods for multi-class classification in this setting.
As can be noticed, diverse approaches have been taken to cope with the problem of multi-class classification. In our approach, we intended to use interval modeling, which was successfully applied in diverse areas of classification (cf. [
18,
19,
20]). To our knowledge, this is one of the first contributions in the field of multi-class classification which employs interval modeling. The Interval-Valued version of the decomposition OvO (one-versus-one) approach, proposed as an alternative strategy in [
26], is a notable academic contribution in the field of multi-class classification. In the proposed models, we do not use decomposition techniques.
Entropy is an important concept which may have diverse applications; one of them is using it in ensemble classification (cf. [
27,
28,
29]). In [
30], information entropy was used to measure the diversity of component classifiers. A novel algorithm, which utilizes the information entropy theory to assess classification outcomes, was introduced according to [
31]. It uses ensemble classification techniques, and the weight of each classifier is decided through the entropy of the result produced by an ensemble classifiers system. Weighted entropy was used in an ensemble model, which aims to automatically manage the strengths and weaknesses of each of its separate models [
32]. Entropy Convolutional Neural Network was used to estimate Ensemble Deep Learning [
33]. The proposed method in [
34] Entropy-based Hybrid Sampling Ensemble Learning (EHSEL) is used for imbalanced datasets. The method takes the distributions of the training data into consideration by the information entropy and as a result distinguishing the important samples in the undersampling procedure. In addition, the EHSEL is applied to three different kinds of basic classifiers to validate its robustness.
In this contribution, we propose and compare three ensemble classification models (based on interval modeling). In two out of three proposed models, cross-entropy (
20) (unlike the previously discussed works, a different type of entropy measure) is employed to choose the most promising component models in the ensemble classifier. It will be shown that the models with cross-entropy involved significantly outperform the model without cross-entropy.
3. Interval Modeling
This section will present fundamental concepts associated with interval-valued calculus and interval-valued aggregation functions.
3.1. Interval-Valued Fuzzy Sets
Early in the 1970s, Zadeh developed IVFS to express ambiguity and uncertainty in practical applications [
35]. They have since been applied in numerous areas, including decision making, recognizing patterns, and control systems [
36,
37,
38,
39].
The main distinguishing characteristic of IVFS is that each component of the universe of discourse is associated with an interval in which, according to epistemic interpretation, a given membership degree is placed, rather than a single membership degree [
40]. This range reflects the degree of ambiguity or confusion surrounding the element’s degree of membership. As an example, the degree of proximity of a given temperature to being classified as “hot” or “cold” can be modeled using an IVFS. An interval, for example [0.6, 0.9], can be used to reflect the degree of uncertainty associated with the temperature’s membership degree rather than designating a single membership degree, such as “0.7”, to express the temperature’s proximity to being “hot”.
Interval Calculus is a mathematical framework designed for studying and analyzing real number intervals. Let
be the set of all subintervals of the unit interval
, where each interval can be represented by a pair of numbers
, such that
. A partial classical order is a method for comparing two intervals based on their lower and upper bounds. The classical partial order in
is defined as follows:
The join and meet operations are defined as:
In terms of order
is a complete lattice (i.e., each subset of
has supremum and infimum in
, cf. [
35]). The values
and
represent the set’s lower and upper limits, respectively.
An interval-valued fuzzy set is defined as a function for , where denote fuzzy sets. denotes the collection of all intervals valued fuzzy sets in the universe X. In terms of the order ⪯, is a complete, bounded lattice.
Since the classically applied partial order between each pair of intervals is not linear (for example,
and
are incomparable with respect to the ⪯ order), diverse linear orders were also introduced for
(cf. [
21]). Well-known examples of linear orders are given below.
The Xu and Yager order
:
The first lexicographical order
:
The second lexicographical order
:
An example comparison will be performed using the linear orders Lex1, Lex2, Xu and Yager for the intervals and . Since , , there is a need to check the second condition in order to compare the intervals with the Xu and Yager Order., i.e., the width of each interval need to be established. These widths are . As a result, . Since , . Since , .
Diverse linear orders may yield diverse ordering of the intervals which are under consideration. However, some additional methods may be applied to decide about the order in the given applications (cf. [
20]). The comparison of orders in Lex1 and Lex2 is based on the interval lower or upper bounds, while the comparison in the case of Xu and Yager order relays on considering both bounds. The condition
is equivalent to
, namely the middle point representatives of each interval are compared, and if these values are equal, then in order to decide the order between intervals, the second option is to compare the width of the corresponding intervals. As a result, the Xu and Yager order seems to be more comprehensive in the analysis of the intervals to be compared. This is why, for the purpose of this contribution, this linear order was chosen to be applied in the algorithms studied. The Xu and Yager order proved to be more useful than Lex1 and Lex2 in some classification algorithms known from the literature (cf. [
20], Chapter 6), which also justifies its choice.
3.2. Interval-Valued Aggregation Functions
Aggregation functions in
are applied to construct interval-valued aggregation functions in
. Aggregation function
(cf. [
41]) is increasing with respect to each variable:
and satisfies the boundary conditions
An aggregating function
A is called an averaging function if it satisfies the averaging property:
The most well-known aggregation function is the arithmetic mean:
Various other aggregation functions are available, particularly the quasi-arithmetic means [
41]. Analogously to the notion of an aggregation function in
, the notion of an interval-valued aggregation function
is defined, i.e.,
should fulfill the monotonicity condition (cf. (
7)) and boundary conditions with the intervals
and
. However, due to the diversity of orders, interval-valued aggregation functions with respect to diverse orders may be defined (cf. [
20]). The specifics of these relations are not the focus of the study, so the detailed information about the types of the orders is omitted here. The
convention is used to calculate the
,
,
, and
aggregations, which means that every division zero by zero within the calculations yields a value of zero. Let
for
. The list of applied in this research, interval-valued aggregation functions is the following:
In the proposed models, the aggregation functions that handle interval values are employed to amalgamate the intervals derived during the prediction phase. The application of these aggregations results in the formation of a consolidated interval, which offers a comprehensive depiction of the prediction.
To sum up, interval modeling is an effective tool for expressing ambiguity and uncertainty in practical applications. It is a useful tool for decision making, pattern recognition, as well as control systems because of the capability of handling imprecise and uncertain input more robustly than conventional fuzzy sets. Interval-valued membership degrees can be used to represent ambiguity and vagueness in a more flexible and nuanced manner, which can produce results that are more accurate and trustworthy [
42].
4. Microarray Datasets
Microarray datasets are a type of data collection produced by microarray technology, a method that allows for the simultaneous measurement of expression levels of thousands of genes. Microarrays are small glass slides or chips that are covered with a grid of tiny dots, each representing a unique gene or DNA sequence.
These datasets often include genes and can contain tens of thousands of data points. They are commonly used in bioinformatics and genomics research to study patterns of gene expression and to identify potential biomarkers for diseases or other biological processes.
There are several unique characteristics of microarray datasets:
They are typically high-dimensional and feature-rich, which can make them challenging to analyze and understand due to the difficulty in visualizing such large datasets and identifying patterns or trends.
Gene expression levels are frequently correlated because genes involved in the same biological processes are often co-regulated. This can make it difficult to determine the direct contribution of each gene to a specific phenotype or disease.
Microarray data can be noisy due to various sources of variability, including differences in sample preparation and labelling, the microarray technology itself, and errors in data collection and processing. This can make it challenging to identify strong patterns or trends in the data.
Despite these challenges, microarray datasets have been widely used in various research applications, such as studying gene expression, identifying biomarkers, and diagnosing diseases. They have also contributed to the development of personalized medicine approaches, where treatment plans are tailored to a patient’s unique genetic profile.
The following datasets (cf. [
43]), described in
Table 1, were applied in our experiments and are related to various medical specialities and research challenges. The identifiers for these datasets are provided in parentheses:
Identification of genetic subgroups in acute lymphoblastic leukaemia—Acute Lymphoblastic Leukaemia (ALL);
Human glioma—Brain Tumour (BTu);
Role of the chronic hepatitis C virus in the pathogenesis of HCV-associated hepatocellular carcinoma—Hepatitis C (HeC);
Transcription profiling of human heart samples with various causes of failure—Heart Failure Factors (HFF);
Study of genetic changes associated with skin psoriasis—Skin Psoriatic (SPs);
Profiling of critically ill children with sepsis, septic shock, and systemic inflammatory response syndrome (SIRS)—Septic Shock (SSh).
5. Details of Experiments and Methodology
The datasets applied in our experiments [
43] were already described in the section devoted to microarray datasets.
The general method applied in the proposed three versions of the model is using an ensemble of heterogeneous classifiers. As was already mentioned in the Introduction, according to the literature, the selected classifiers (Random Forest, Support Vector Machines, or Multilayer Perceptrons) are believed to have good performance in diverse areas. Instead of optimizing the hyperparameters of each one, it seems to be a good approach to create an ensemble of them [
14]. The implementation of the component classifiers was performed using scikit-learn library [
44,
45,
46,
47]. Moreover, a simple and well-known k-NN classifier was also involved as a component classifier to build the ensemble models. The hyperparameters of these models are the following. The first hyperparameter is interval order, which is default
, other possible options are
and
. The models’ hyperparameter refers to the selection of base models used in the ensemble. By default, this includes a variety of classifiers such as random forest with number of estimators set to {10, 50, 100}, multi-layer perceptron with hidden layer sizes set to {[100], [50, 50], [100, 50, 25]}, SVM with linear, polynomial, and radial basis function kernels, and k-NN with number of neighbors set to 1, 3, and 5, all using the Manhattan metric. The last hyperparameter is interval-valued aggregation, which can take on values from
to
, with
being the default, determines the method used to combine the predictions of the base models.
Further details of experiments are the following. The cross-validation (CV) strategy employed in this analysis utilizes a stratified train–test split [
48] for cross-validation. The dataset is divided into training (80%) and testing (20%) sets. This split is repeated five times with different seeds to enhance the model’s robustness and provide a reliable performance estimate. In the case of the Proposed Entropy Model and Proposed Entropy Groups Model, the additional nested stratified two-fold cross-validation is applied to optimize the selection of the models using cross-entropy loss. The procedure is repeated 10 times with different random seeds, each time to obtain a series of results and test multiple distributions of train and test data. The nested cross-validation is executed on train data. It is worth noting that the hyperparameter optimization is only performed on train data and final evaluation of the model is performed on test data.
The microarrays dataset usually contains a low number of objects and additionally in the case of multi-class dataset the classes can be unbalanced and have little representatives. To keep the reasonable number of instances in nested cross-validation and to ensure that all classes will be present, the train dataset contains 80% of the data. The choice to use only two-fold in nested cross-validation is also based on these circumstances. The repetition of cross-validations with different seeds provides the representative results.
To scale the features, we use the min–max scaler [
49]. This scaler transforms the features by scaling them to a given range, typically between 0 and 1.
5.1. The Role of Cross-Entropy Loss to Select Models
Cross-entropy is a measure of the difference between two probability distributions for a given random variable or set of events. It is built on the concept of entropy from information theory and it “is the average number of bits needed to encode data coming from a source with distribution p when we use model q” ([
50], p. 57). The concept of logistic loss, or log loss, is related to cross-entropy. Even though these measures have different origins, they calculate the same quantity in the context of classification algorithms. To achieve good performance in a classification task, currently, a large number of learning algorithms rely on minimizing the cross-entropy loss ([
51], p. 235) [
52].
The log loss [
53,
54] is a measure of uncertainty or disorder, which is essentially what entropy measures. By minimizing the log loss, the model is effectively minimizing the entropy of the predictions, which means it is selecting the models that provide the most information (or the least uncertainty). This is where the connection between log loss and cross-entropy [
52] becomes apparent: log loss is a form of cross-entropy. Cross-entropy is a measure of the difference between two probability distributions, and in this context, it is used to quantify the difference between the predicted and actual outcomes. Therefore, by minimizing log loss, we are effectively minimizing cross-entropy, leading to models that are more accurate and confident:
where [
54]:
N is the number of samples;
K is the number of classes (labels);
is the probability estimate for sample i belonging to class k;
Y reflects the true labels encoded as a 1-of-K binary indicator matrix;
is the binary indicator for whether sample i has label k.
The Proposed Entropy Model and Proposed Entropy Groups Model in the stage of fitting both use log loss to optimize the selection of models. Using the mentioned nested cross-validation, the strongest models, i.e., models with the lowest log loss, are recognized and kept in the models’ hyperparameters. The more details of this process are listed in
Section 6.2 and
Section 6.3.
5.2. Applied Metrics
Machine learning algorithms, known for their predictive and decision-making abilities, require evaluation metrics for effectiveness. Metrics such as accuracy [
55], recall [
56], precision [
57], and F1 score [
58] provide different perspectives on performance. Selecting the appropriate metric for a particular problem and evaluating a model’s performance can be aided by understanding these metrics. In our experiments, we used the following metrics: AUC [
59], accuracy, recall, balanced accuracy [
60], precision, and F1 score. Since we consider a multi-class problem, some of these metrics (recall, precision, and F1 score) are also available in specific types, such as micro, macro, and weighted.
We observed similar behavior between the results between the applied metrics, and this is why we only present the results for AUC, accuracy, and balanced accuracy (where accuracies were determined for the threshold value 0.5).
Accuracy [
55] is a simple and intuitive metric used in machine learning to evaluate model performance, particularly in classification tasks. It is calculated by dividing the number of correct predictions by the total predictions. The following formula is used for calculating multi-class accuracy:
where:
C—total number of classes;
i—each class’s index;
—true positives for class i;
—false positives for class i;
—false negatives for class i;
—true negatives for class i.
In multi-class classification, true positives are correct identifications of a class, false positives are incorrect attributions to a class, true negatives correctly identify non-membership, and false negatives incorrectly assume non-membership.
Balanced Accuracy [
60] is a metric for evaluating classification models, particularly useful when classes are unbalanced. It provides a more detailed view of performance than traditional accuracy by considering the balance of classes. It is the average of recall scores for each class, assessing each class’s performance separately. The following formula is used for calculating multi-class Balanced Accuracy:
The Receiver Operating Characteristic Area Under the Curve (ROC AUC) [
59] is a performance measurement for classification problems at various threshold settings. ROC is a probability curve, and AUC is an area under ROC curve which tells how much a model is capable of distinguishing between classes.
For multi-class ROC AUC, either One-vs-Rest [
61] (average ROC AUC for each class against all others) or One-vs-One [
62] (average pairwise ROC AUC scores for each pair of classes) is used. The choice depends on the specific problem and number of classes. In this contribution, the One-vs-One is used.
6. Implementation of Proposed Models
In this section, three versions of the proposed models will be described. Each of them is based on interval modeling and two of them are using additionally the concept of cross-entropy. The implementations of the proposed models are available at the repository [
63].
6.1. Fitting Process of the Proposed Model
The input of the ensemble model is a collection
, where each model group
consist of a collection of independent models. The procedure for fitting the models [
64] encompasses several stages
The ensemble model is a collection of independent models, grouped into distinct sets. Each model is trained individually on the data. The trained models, organized in their respective groups, form the ensemble model, which is used for constructing intervals.
6.2. Fitting Process of the Proposed Entropy Model
The input of the ensemble model is a collection
, where each model group
consist of a collection of independent models. The procedure for fitting the models [
65] encompasses several stages:
The enhanced ensemble model is composed of independent models, divided into groups. Each group undergoes an optimization process where the top-performing models are selected based on their mean cross-entropy loss from stratified two-fold cross-validation on training data. The final ensemble model is a compilation of these optimized groups. The cross-entropy loss serves as a key metric in this process, guiding the selection of models within each group to ensure the best performance.
6.3. Fitting Process of the Proposed Entropy Groups Model
The input of the ensemble model is a collection
, where each model group
consist of a collection of independent models. The procedure for fitting the models [
66] encompasses several stages:
As a result, the ensemble model consists of fitted independent models, divided into arbitrary groups. The cross-entropy loss is used here to optimize the selection of independent models in each group. Additionally, if some whole group is not optimal, i.e., it is lowering the overall performance of a classifier, it will be removed.
6.4. Process of Predicting Decision Classes Using the Proposed Models
The input of the ensemble model is a collection , where each model group consist of a collection of independent models; the interval-valued aggregation , the interval order o. The prediction procedure is carried out through the following stages:
Create empty collection of intervals ;
For each model group in :
- (a)
Create empty collection of soft labels for each decision class c;
- (b)
For each model M in model group :
Compute model M soft labels for each decision class c on test data and append it to ;
If soft labels values are outside unit interval , then normalize it using the function;
- (c)
For each decision class c, create intervals and append it to .
For each class c aggregate its corresponding intervals from using ;
Sort the intervals using order o;
Return the class c, the corresponding interval of which is the highest in the term of order o.
Soft labels indicate the degree of membership of the data to the given classes, while hard labels indicate the belonging only to one, concrete class. Soft labels represent the extent to which data associate with various classes, whereas hard labels denote the data’s affiliation with a single, specific class.
6.5. Process of Predicting Decision Class Membership of Proposed Models
The input of the ensemble model is a collection , where each model group consist of a collection of independent models, the interval-valued aggregation , and the interval order o. The prediction procedure is carried out through the following stages:
Create empty collection of intervals ;
For each model group in ModelGroups:
- (a)
Create empty collection of soft labels for each decision class c;
- (b)
For each model M in model group :
Compute model M soft labels for each decision class c on test data and append it to ;
If soft labels values are outside unit interval , then normalize it using the function.
- (c)
For each decision class c, create intervals and append it to .
For each class c, aggregate its corresponding intervals from using ;
For each class c, compute its membership degree by averaging the lower and upper bound of an interval assigned to c;
If membership degrees of all decision classes are not sum to value 1, then normalize them;
Return the membership degrees for all decision classes.
In
Table 2, the comparison of the considered models is presented.
7. Results
In the following tables, we use several abbreviations to refer to different machine learning models and methods. Here is a brief introduction to these abbreviations:
POM_eGRP—Proposed Model Entropy Groups;
POM_ENT—Proposed Model Entropy;
POM_ALG—Proposed Model;
SVC—Support Vector Classification;
RND_FST—Random Forest;
MLP—Multilayer Perceptron;
BAGGING—Bagging;
7NN_MUL—Seven Nearest Neighbors;
7NN_OVR—Seven Nearest Neighbors; (One-vs-Rest);
7NN_OVO—Seven Nearest Neighbors (One-vs-One);
5NN_MUL—Five Nearest Neighbors
5NN_OVR—Five Nearest Neighbors (One-vs-Rest);
5NN_OVO—Five Nearest Neighbors (One-vs-One);
3NN_MUL—Three Nearest Neighbors;
3NN_OVR—Three Nearest Neighbors (One-vs-Rest);
3NN_OVO—Three Nearest Neighbors (One-vs-One);
1NN_MUL—One Nearest Neighbor;
1NN_OVR—One Nearest Neighbor (One-vs-Rest);
1NN_OVO—One Nearest Neighbor (One-vs-One).
The results are presented in descending order with respect to the ROC AUC measure. We decided to analyze the results with respect to this measure, since it is related to diverse thresholds, unlike accuracy or balanced accuracy, which is determined with respect to a given threshold. It is natural that results for accuracy may have lower values comparing to AUC ROC—the considered threshold (here 0.5) may not be optimal. On the other hand, balanced accuracy results may have lower values than those of accuracy due to the imbalance problem which occur in the considered datasets.
Some of the results in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 are highlighted. Light gray color denotes the highest three results of the models which are used as comparative models, i.e., these are all component models used to create an ensemble model (Random Forest, MLP, SVM, and k-NN with diverse values of k); additionally. this is a well-known ensemble model, which is Bagging and OVO and OVA versions of suitable k-NN models. Light green, light blue, and light red colors denote the highest three results of the proposed models, with corresponding versions. The results for the same aggregation function, applied as a hyperparameter of the model, are highlighted in the same color.
The results for the proposed models will be analyzed for a given hyperparameter value, which is an aggregation function, as is highlighted in light green, light blue, and light red colors in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8.
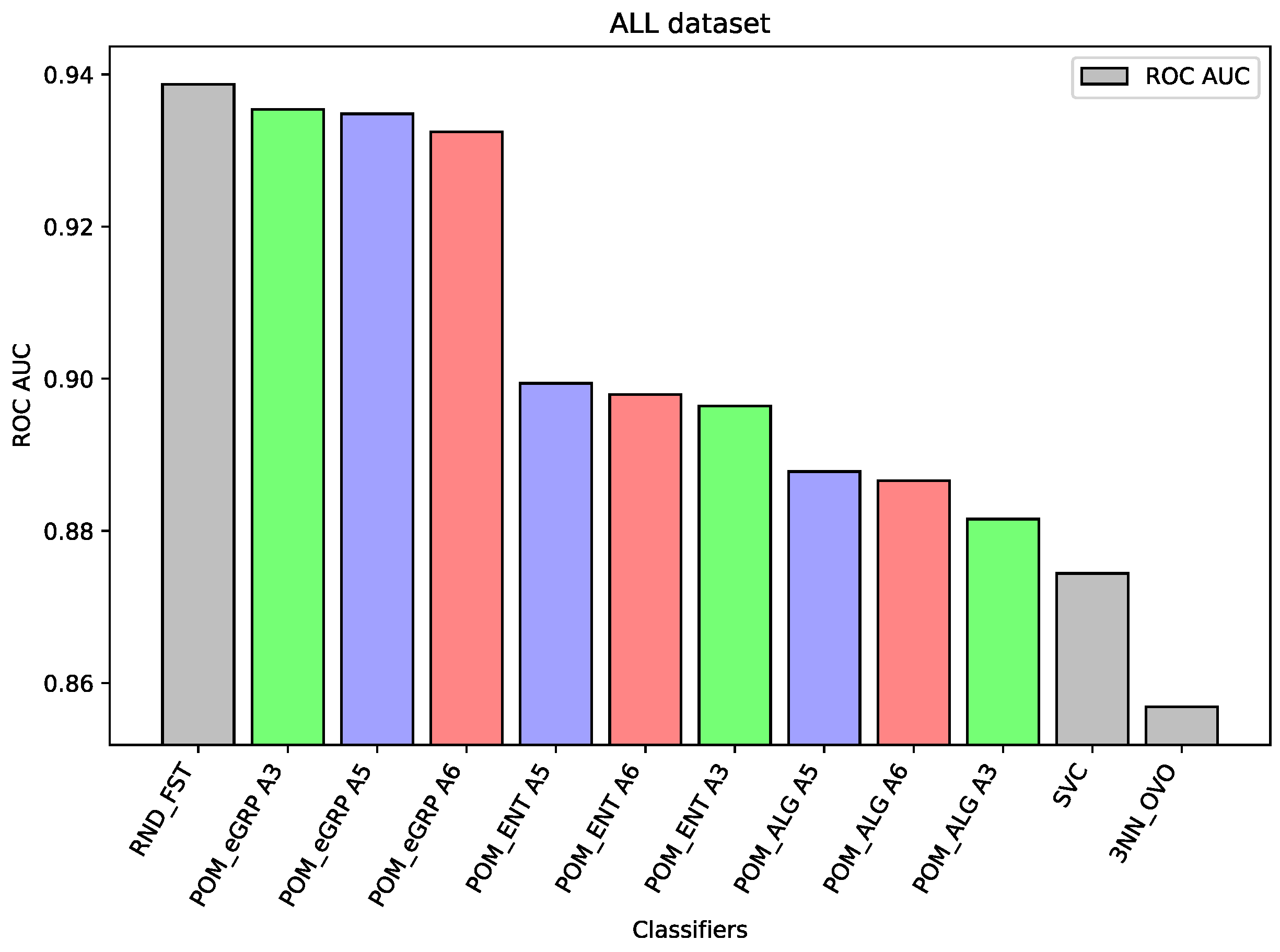
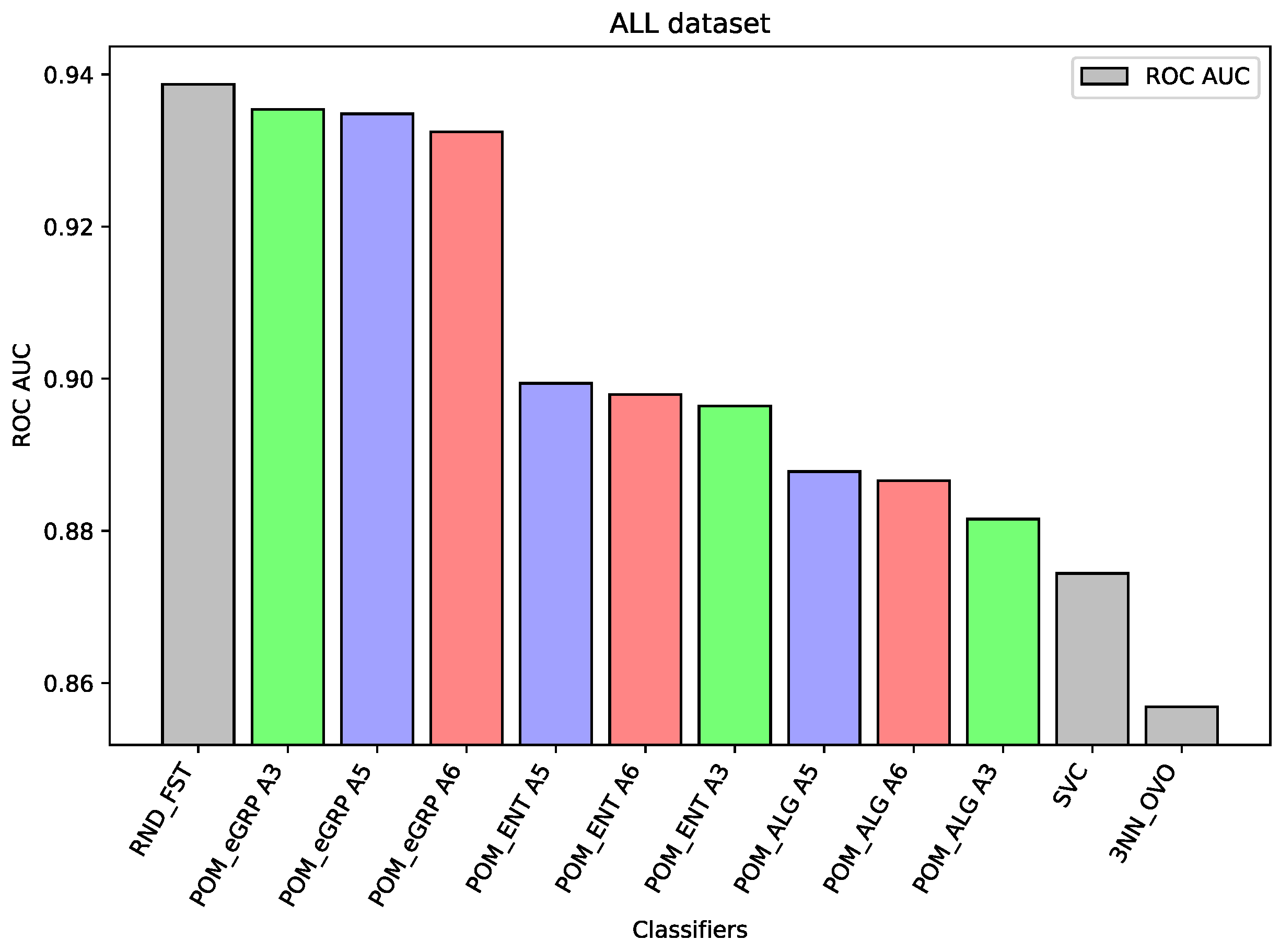
For the dataset ALL, Random Forest was the best-performing classifier. The Proposed Model Entropy Groups has very similar results to Random Forest, but it is several percentage points better than the Proposed Model Entropy, and in turn, it is also better than the Proposed Model (without the concept of cross-entropy).
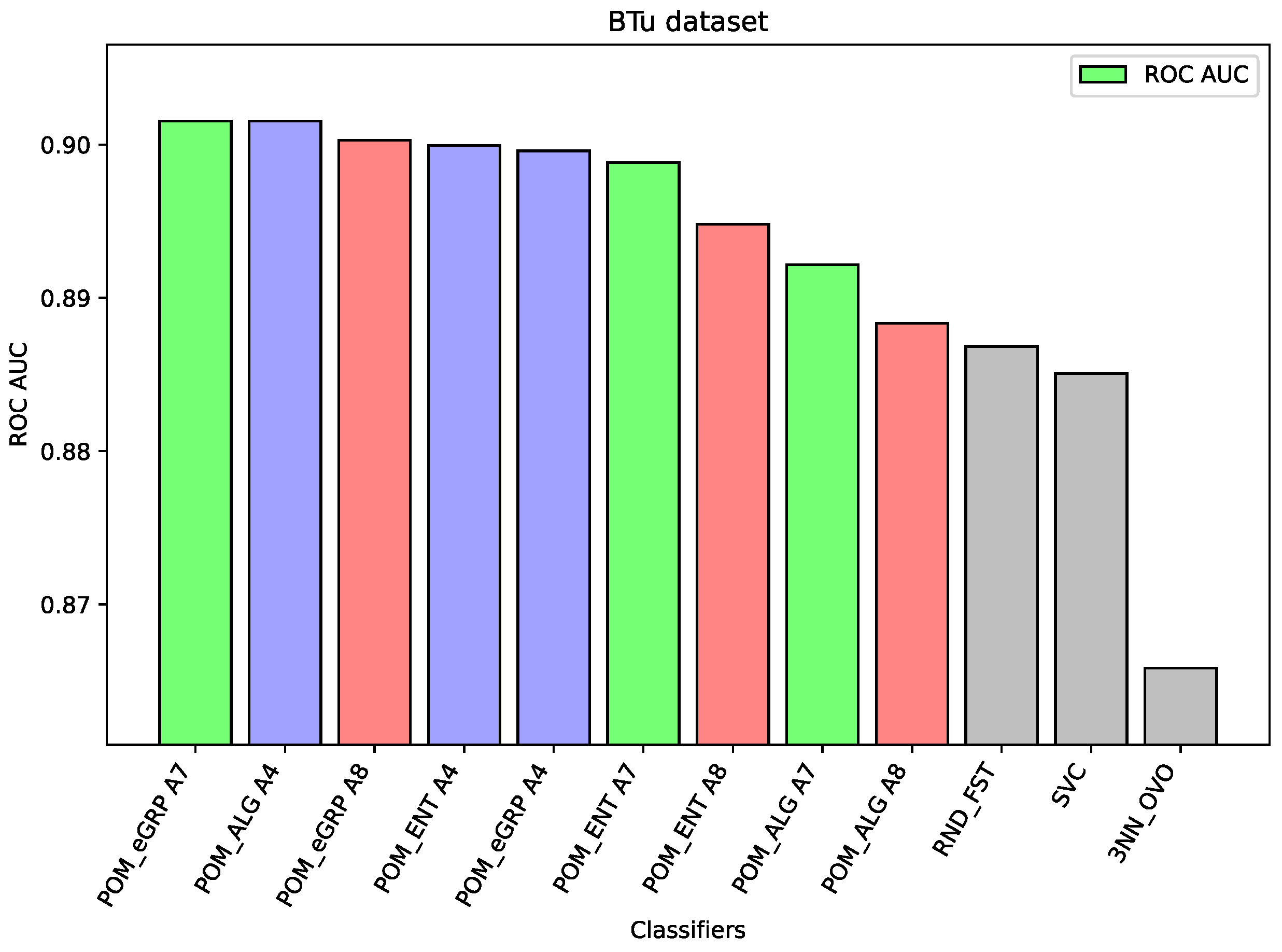
For the dataset Btu, all versions of the considered models obtained better results than the component models or the models applied as comparative ones. However, the difference between the best result which belongs to the Proposed Model Entropy Groups (with the aggregation ) and ex aequo for the Proposed Model (with the aggregation ) is only slightly better than the best results for other models, i.e., Random Forest.
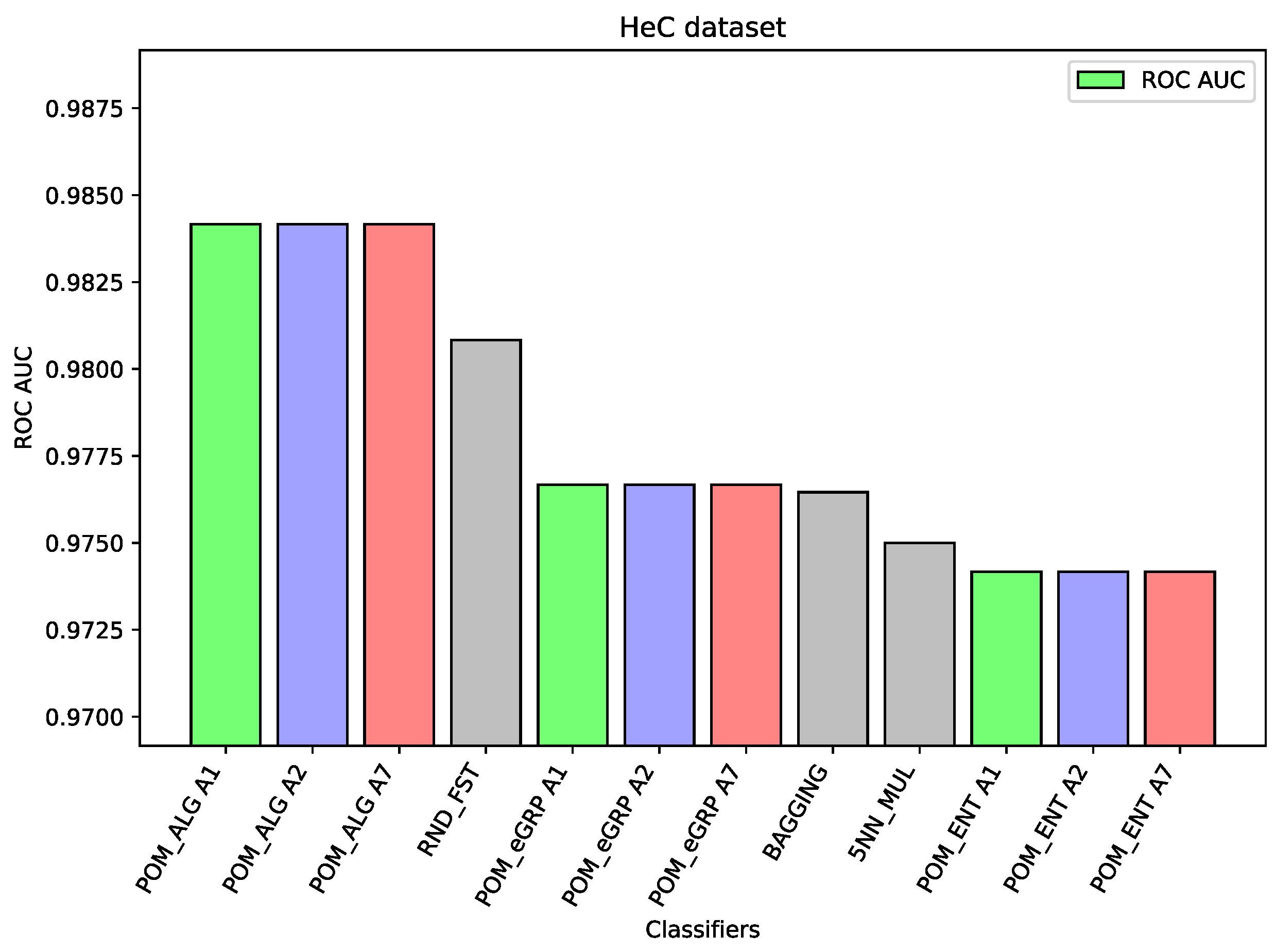
For the dataset HeC, there are only slight differences (about one percentage point between the best result of the Proposed Model and the best results of the comparative models) between the considered three models and the best comparative models, i.e., Random Forest and Bagging. This time, the Proposed Model gave slightly better results than the proposed models with the applied cross-entropy.
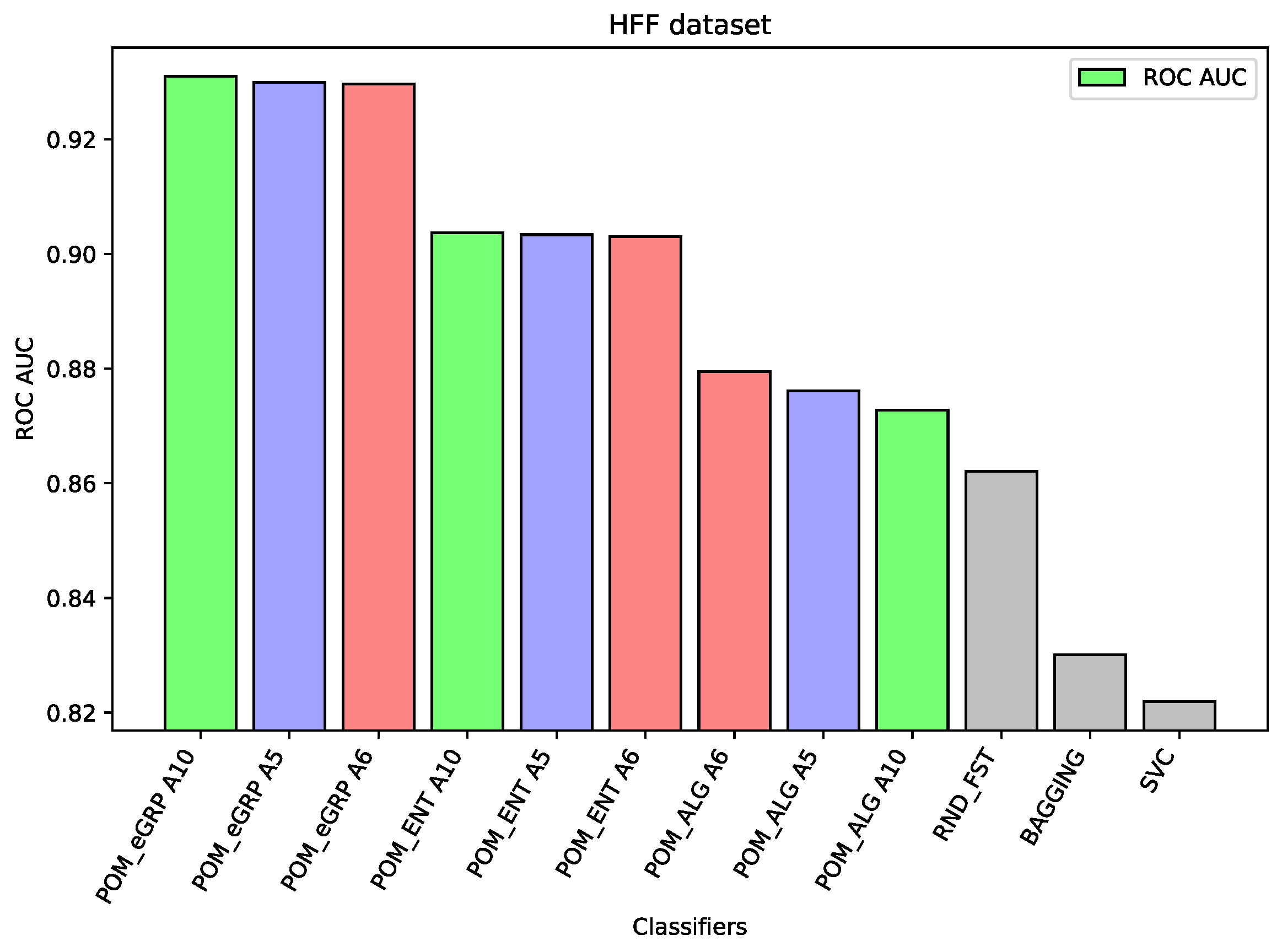
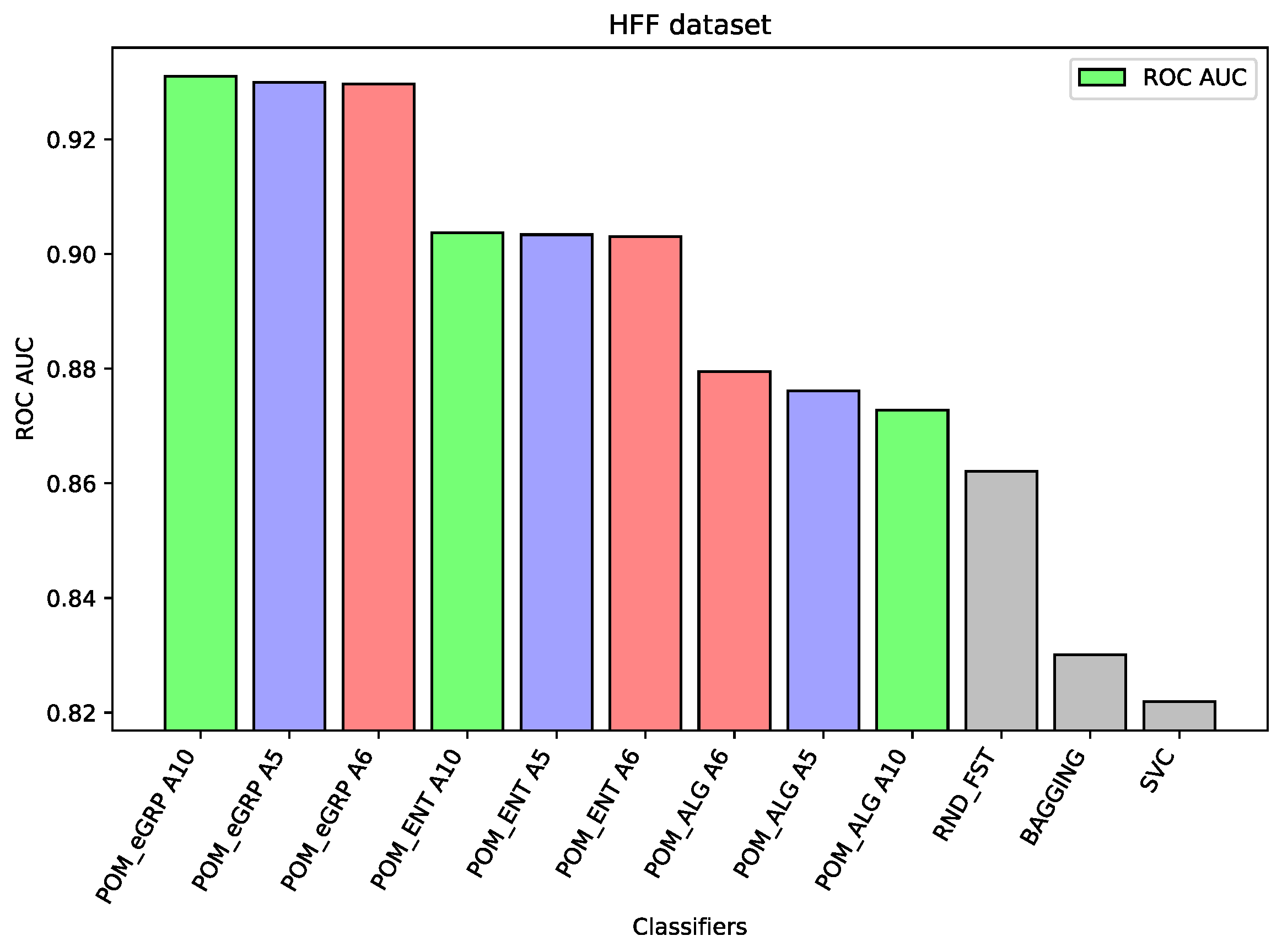
For the dataset HFF, The Proposed Model Entropy Groups has the best results—seven percentage points better than Random Forest (the best comparative model), about three percentage points better than Proposed Model Entropy; moreover, it is also better than Proposed Model (without the concept of cross-entropy). In the case of this dataset, the differences between the results of the proposed models and other comparative models are the most significant.
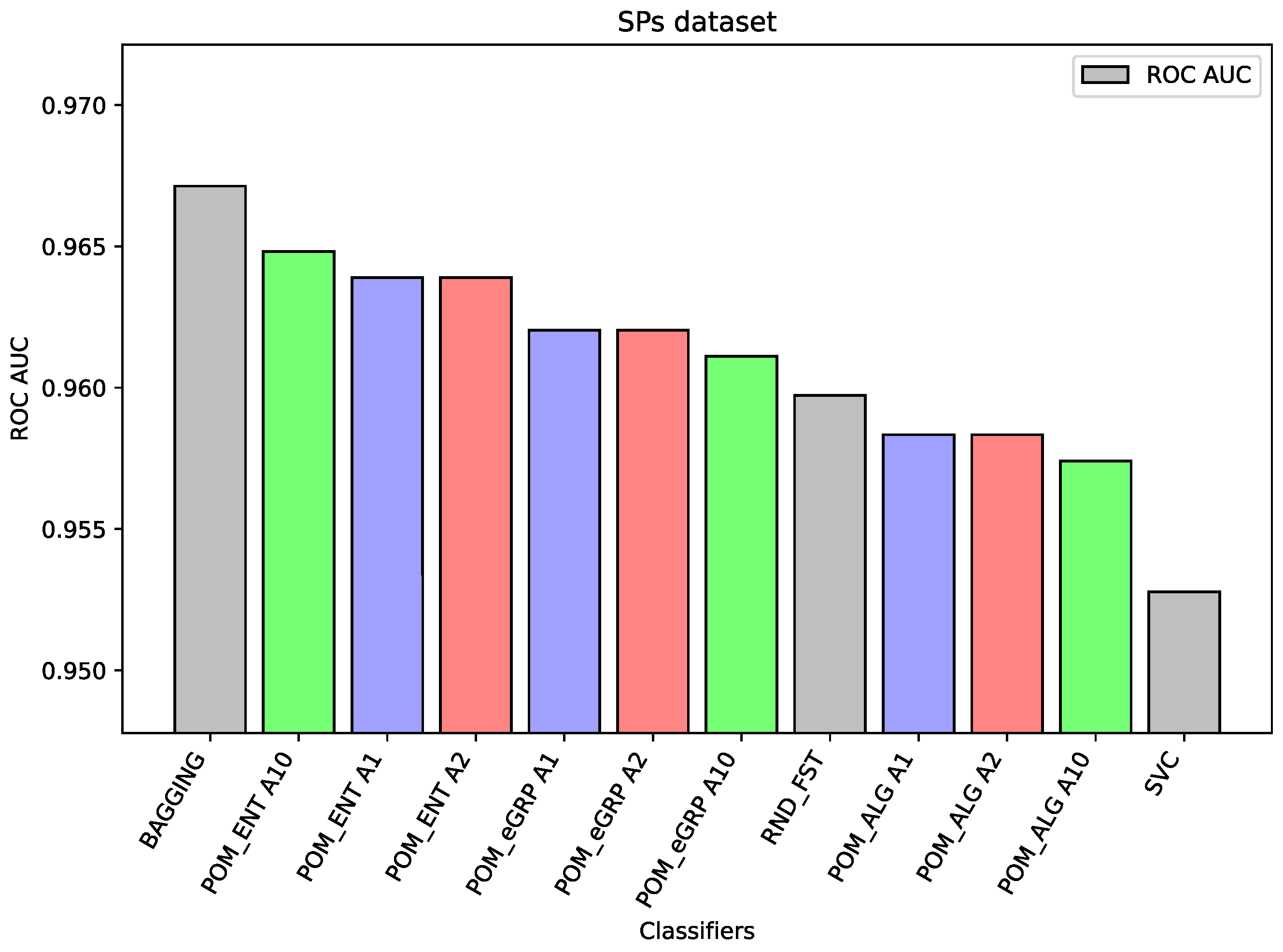
For the dataset SPs, there are only slight differences (third decimal place between the best result of the proposed models and the best results of the comparative model Random Forest and Bagging and also between the proposed models). However, the best performance was obtained for the Bagging model and the proposed models with cross-entropy had better performance than the Proposed Model (without cross-entropy).
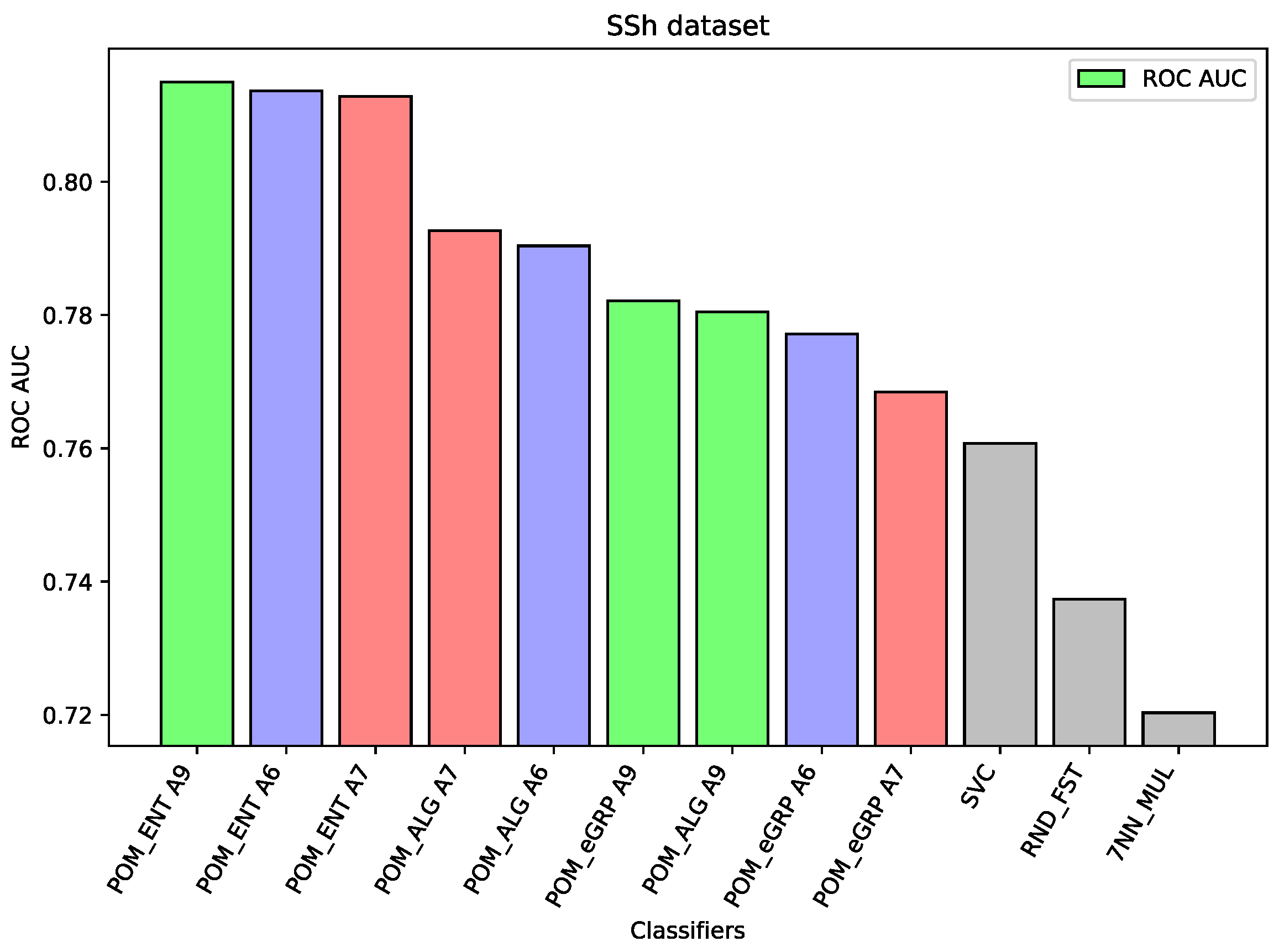
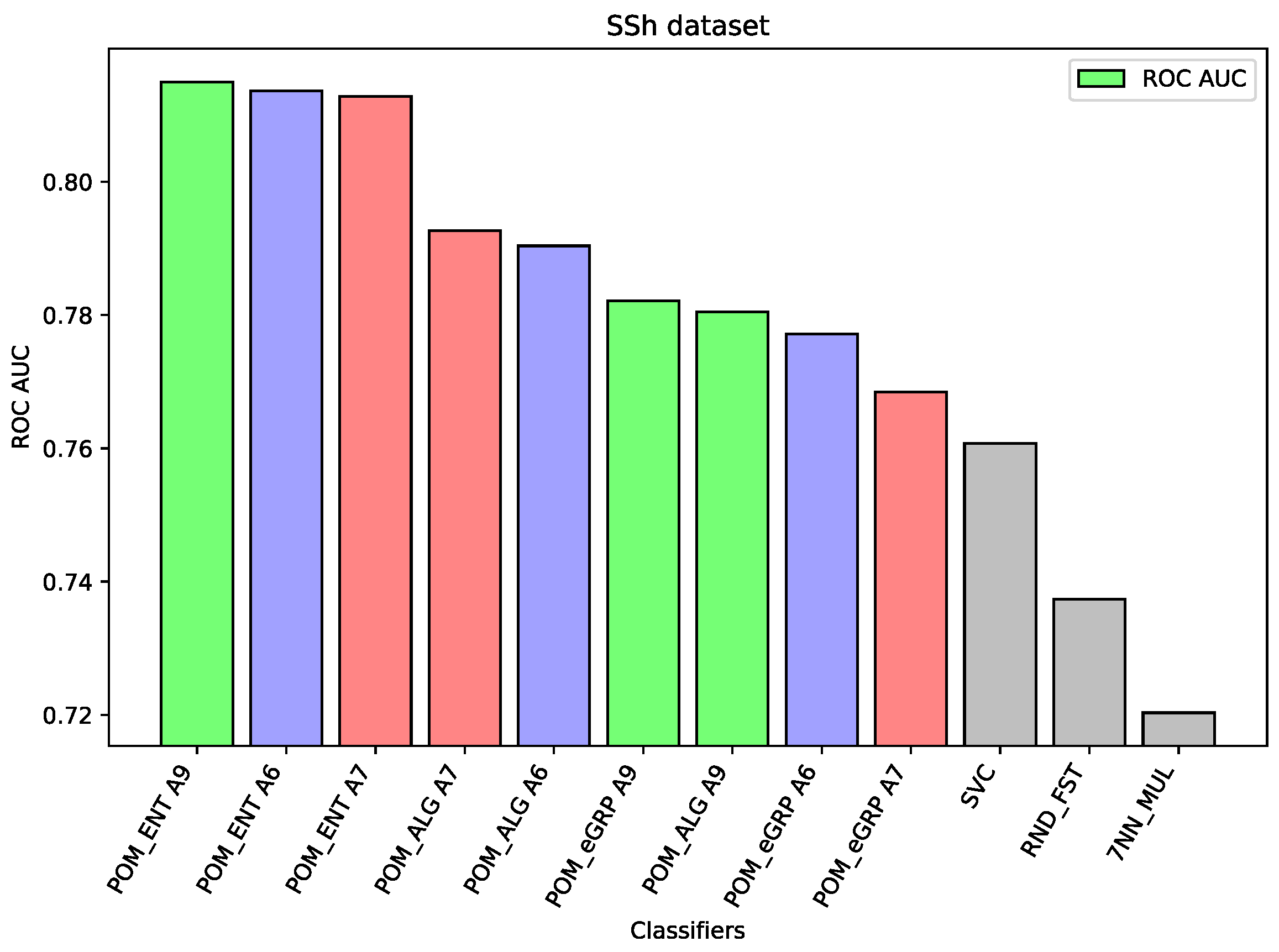
For the dataset SSh, the Proposed Model Entropy has the best results—five percentage points better than Support Vector Machine (the best comparative model) and about two percentage points better than Proposed Model. In the case of this dataset, the differences between the results of the proposed models and other comparative models are significant. Moreover, among the three proposed models the Proposed Model Entropy has the best results, the Proposed Model Entropy Groups has the worst results. All results of the proposed models are better than those of the comparative models.
8. Discussion
Regarding the interval-valued aggregation function which was applied here as a hyperparameter, we may notice that the choice of the aggregation to obtain the best performance of the classifier depends on the dataset (diverse aggregation functions yield the best results in each dataset). It confirms that it is right to include diverse aggregations in the proposed models.
Regarding the choice of the model, for most of the datasets, the best results were obtained by the Proposed Model Entropy Groups, but there are also datasets for which the Proposed Model Entropy gave the best results. However, the cross-entropy applied to choose the best component classifiers seems undoubtedly a good choice to improve the classification results.
Analyzing the results on each dataset, we may notice that if the component classifiers such as Random Forest, MLP, or SVC have relatively weak results, as in the case of the dataset HFF (cf.
Figure 1) or the dataset SSh (cf.
Figure 2), then all the proposed ensemble models obtain much better results than the component models or other comparative models. In the case of the HFF dataset, the Proposed Model Entropy Group obtained the best result 0.931 ROC AUC, while the highest result for the component models belong to Random Forest, i.e., 0.862 ROC AUC. Moreover, in the case of this dataset, we may observe a clear dependence between the three considered models—the best results (regardless of the interval-valued aggregation function applied) were obtained by the Proposed Model Entropy Group, then by Proposed Model Entropy, and finally by the Proposed Model. In the case of the SSh dataset, the Proposed Model Entropy obtained the highest result, which is 0.815 ROC AUC, while the highest result for the component models belong to SVC, i.e., 0.761 ROC AUC. Moreover, in the case of this dataset, we may observe a clear dominant model among the three considered models—the best results (regardless the interval-valued aggregation function applied) were obtained by the Proposed Model Entropy.
In the case of the ALL dataset (cf.
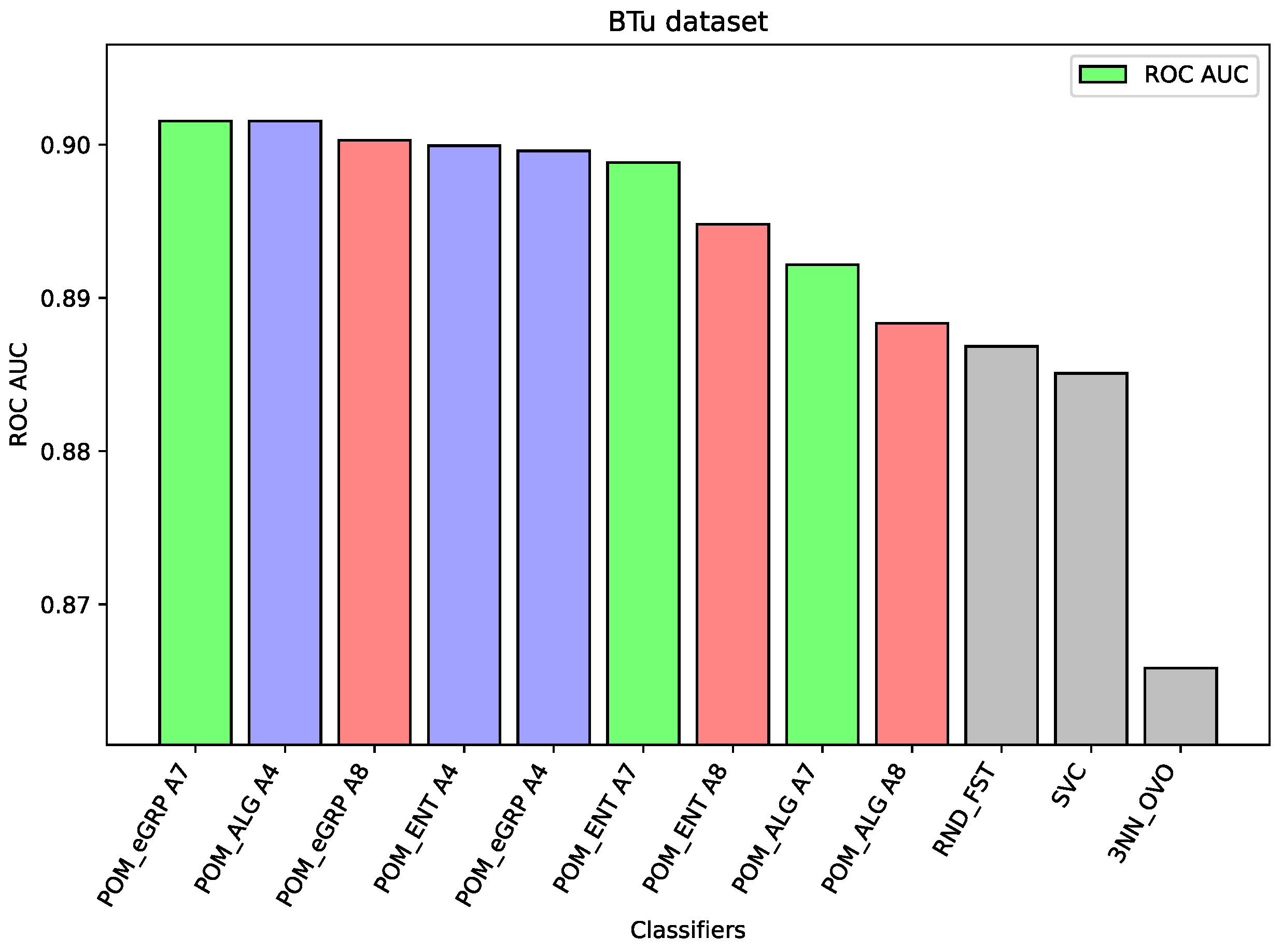
Figure 3), the component classifier which is Random Forest was strong enough to obtain an ROC AUC value of 0.939. As a result, ensemble models were weaker, and it proves the well-known thesis that creating ensembles makes sense in the case of the weak performance of single-component classifiers. A similar situation is in the case of the BTu dataset (cf.
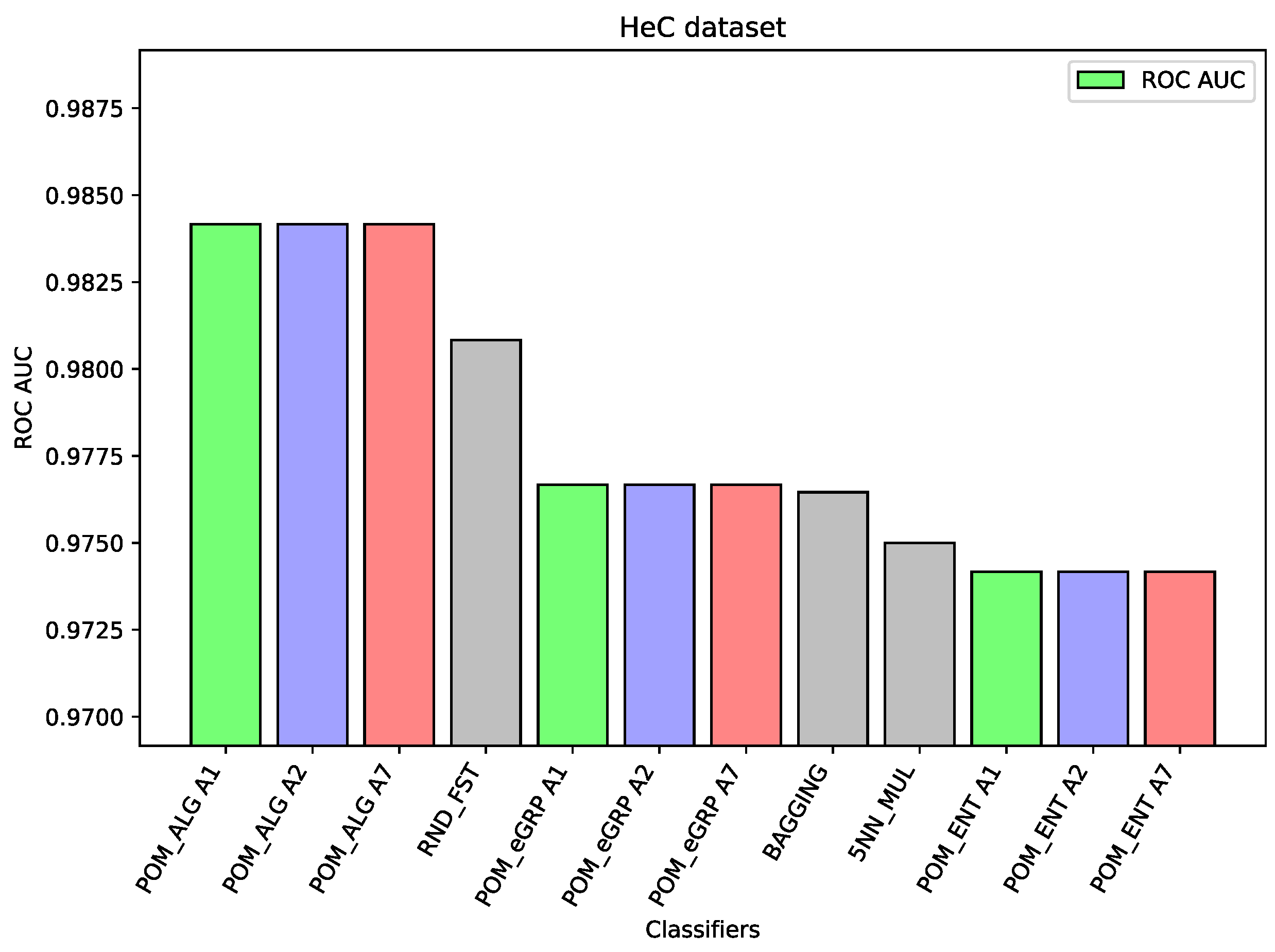
Figure 4). On this dataset, the proposed ensemble models had better performance than the component models, but the difference was small. The ROC AUC result for Random Forest is 0.887 or 0.885 for SVC, which may be considered a high value, so the ensemble models were only able to improve these results slightly. Again, analogous behavior may be observed for the dataset HeC (cf.
Figure 5), where the best component model ROC AUC result belongs to Random Forest 0.981 and the Proposed Model was only able to improve it to the value 0.984. Similarly, on the dataset SPs (cf.
Figure 6), the differences between the proposed models and the best comparative models are very small—for most of the cases, this is the difference in the third decimal place. The best value of the proposed model is 0.965 ROC AUC and the best value of the component model belongs to Random Forest, i.e., 0.960 ROC AUC (which is a very high value).
The following
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6 present the performance of the selected models—the best three results of each proposed model and the best three results of the comparative models (as highlighted in light green, light blue, light red, and light gray colors in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8).
Following the results of the non-parametric Kruskal–Wallis test [
67] using a 0.05 significance level and Dunn’s Multiple Comparison test with Bonferroni correction [
68], we can further discuss the performance of the models (with the use of AUC measure). In
Table 9,
Table 10 and
Table 11, the results of the Kruskal–Wallis test and Dunn’s Multiple Comparison test with Bonferroni correction [
68] are presented. Each of compared groups consist of 10 values AUC, obtained for 10 interval-valued aggregation functions and each model. The results indicate that there is a statistically significant difference in the AUC values across the three proposed models POM_ALG, POM_ENT, and POM_eGRP. This is evident as the
p-value of the Kruskal–Wallis test is less than 0.05 for each dataset, suggesting that there exists at least one pair of models which has a significant difference in results. Upon applying Dunn’s test with Bonferroni corrections as a post hoc test, it was observed that for most of the considered datasets, the performance of a model with the cross-entropy involved (POM_ENT or POM_eGRP) is significantly better than the performance of the model POM_ALG. The exception is the HeC dataset where POM_ALG obtained the best results. In
Table 9,
Table 10 and
Table 11 the
p-values, i.e., the significant differences, are in bold (concrete values of AUC are presented in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8). The most clear situation is in the case of the HFF dataset, where there are significant difference between each pair of the considered models POM_ALG, POM_ENT, and POM_eGRP. According to
Table 6 (where the AUC results for the HFF dataset are provided), the best performing model is POM_eGRP, then POM_ENT, and finally POM_ALG. The obtained results indicate that the incorporation of cross-entropy in the models in most of the cases enhances their performance. However, there is no clear tendency to suggest which of the models POM_ENT or POM_eGRP could be considered a better solution. The performance varies across different datasets. In some datasets, POM_eGRP outperforms POM_ENT, while in others, the reverse is true. This suggests that the choice between POM_ENT and POM_eGRP may depend on the specific characteristics of the dataset. Further research could be conducted to investigate the factors that influence the performance of POM_ENT and POM_eGRP on different datasets, which could provide insights into the conditions under which each model is most effective. This could potentially lead to the development of more robust and versatile models for interval-valued classification.
9. Conclusions
To sum up, in this research, the problem of using interval modeling and cross-entropy in ensemble heterogeneous classification was applied. Interval modeling proved to be a useful tool in improving classification results for high-dimensional datasets such as microarrays compared to the results of component classifiers, Multilayer Perceptron, Support Vector Classification, and Random Forest, which usually provide good performance for diverse problems. Applying cross-entropy to choose the best component classifier for the ensemble was even able to improve these results. Two models with the cross-entropy involved were analyzed. In the case of most of the considered datasets, the differences between the proposed model (using interval modeling) and at least one of the models with the cross-entropy (applied to choose the best components in the ensemble) are statistically significant.
In future work, other approaches of using interval modeling and applying the concept of cross-entropy is planned for other problems of classification, such as numerous missing values in datasets or coping with imbalanced datasets. Moreover, for the presented models, it is important to adjust the considered ensemble models to the case of other types of entropy, for example Tsallis, Renyi, Shannon, Kolmogorov-Sinai, or approximate entropy (cf. [
69,
70,
71,
72,
73,
74]). The applied entropy measure may have an influence on the overall results of the considered models.
Author Contributions
Conceptualization, U.B., W.G., M.M. and A.W.; methodology, U.B., A.W., W.G. and M.M.; software, A.W. and W.G.; validation, A.W., M.M. and W.G.; formal analysis, U.B., A.W. and M.M.; investigation, U.B., A.W., M.M. and W.G.; resources, A.W. and W.G.; data curation, A.W. and W.G.; writing—original draft preparation, U.B., A.W. and M.M.; writing—review and editing, U.B., A.W., M.M. and W.G.; visualization, A.W.; supervision, U.B., A.W., M.M. and W.G.; project administration, U.B., M.M., W.G. and A.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data utilized in this study can be made accessible upon request from the corresponding author, who will provide it in accordance with their current status.
Acknowledgments
The authors are very grateful to the reviewers for their valuable comments which helped to improve the final version of the paper. This work was partially supported by the Center for Innovation and Transfer of Natural Sciences and Engineering Knowledge in Rzeszów.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zaki, M.J.; Meira, J.W. Data Mining and Machine Learning: Fundamental Concepts and Algorithms; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Kotsiantis, S.; Zaharakis, I.; Pintelas, P. Machine learning: A review of classification and combining techniques. Artif. Intell. Rev. 2006, 26, 159–190. [Google Scholar] [CrossRef]
- Hamid, A.; Ahmed, T. Developing Prediction Model of Loan Risk in Banks Using Data Mining. Mach. Learn. Appl. Int. J. 2016, 3, 1–9. [Google Scholar] [CrossRef]
- Li, Y.; Crandall, D.J.; Huttenlocher, D.P. Landmark classification in large-scale image collections. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1957–1964. [Google Scholar]
- Xing, W.; Bei, Y. Medical Health Big Data Classification Based on KNN Classification Algorithm. IEEE Access 2019, 8, 28808–28819. [Google Scholar] [CrossRef]
- Kolo, B. Binary and Multiclass Classification; Weatherford Press: Weatherford, OK, USA, 2011. [Google Scholar]
- Buyya, R.; Hernandez, S.; Kovvur, R.; Sarma, T. Computational Intelligence and Data Analytics: Proceedings of ICCIDA 2022; Lecture Notes on Data Engineering and Communications Technologies; Springer Nature: Singapore, 2022. [Google Scholar]
- Jain, P.; Kapoor, A. Active learning for large multi-class problems. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 762–769. [Google Scholar] [CrossRef]
- Large, J.; Lines, J.; Bagnall, A. A probabilistic classifier ensemble weighting scheme based on cross-validated accuracy estimates. Data Min. Knowl. Discov. 2019, 33, 1674–1709. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Murty, M.N.; Raghava, R. Support Vector Machines and Perceptrons: Learning, Optimization, Classification, and Application to Social Networks; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Vang-Mata, R. Multilayer Perceptrons: Theory and Applications; Computer science, technology and applications; Nova Science Publishers: New York, NY, USA, 2020. [Google Scholar]
- Fernandez-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Ma, G.; Lu, J.; Liu, F.; Fang, Z.; Zhang, G. Multiclass Classification with Fuzzy-Feature Observations: Theory and Algorithms. IEEE Trans. Cybern. 2024, 54, 1048–1061. [Google Scholar] [CrossRef] [PubMed]
- Galar, M.; Fernández, A.; Barrenechea, E.; Bustince, H.; Herrera, F. An overview of ensemble methods for binary classifiers in multi-class problems: Experimental study on one-vs-one and one-vs-all schemes. Pattern Recognit. 2011, 44, 1761–1776. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Dyczkowski, K. Intelligent Medical Decision Support System Based on Imperfect Information: The Case of Ovarian Tumor Diagnosis; Studies in Computational Intelligence; Springer International Publishing: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Pękala, B. Uncertainty Data in Interval-Valued Fuzzy Set Theory: Properties, Algorithms and Applications; Studies in Fuzziness and Soft Computing; Springer International Publishing: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Bentkowska, U. Interval-Valued Methods in Classifications and Decisions; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Bustince, H.; Fernandez, J.; Kolesárová, A.; Mesiar, R. Generation of linear orders for intervals by means of aggregation functions. Fuzzy Sets Syst. 2013, 220, 69–77. [Google Scholar] [CrossRef]
- Bhunia, A.; Karmakar, S. A Comparative study of different order relations of intervals. Reliab. Comput. 2012, 16, 38–72. [Google Scholar]
- Abdullah, M.N.; Yap, B.W.; Sapri, N.N.F.F.; Wan Yaacob, W.F. Multi-class Classification for Breast Cancer with High Dimensional Microarray Data Using Machine Learning Classifier. In Lecture Notes on Data Engineering and Communications Technologies, Proceedings of the International Conference on Data Science and Emerging Technologies, Virtual, 20–21 December 2022; Springer Nature: Singapore, 2023; pp. 329–342. [Google Scholar]
- Do, T.N.; Poulet, F. Latent-lSVM classification of very high-dimensional and large-scale multi-class datasets. Concurr. Comput. Pract. Exp. 2017, 31, e4224. [Google Scholar] [CrossRef]
- Wei, T.; Liu, W.L.; Zhong, J.; Gong, Y.J. Multiclass Classification on High Dimension and Low Sample Size Data Using Genetic Programming. IEEE Trans. Emerg. Top. Comput. 2022, 10, 704–718. [Google Scholar] [CrossRef]
- Elkano, M.; Galar, M.; Sanz, J.; Lucca, G.; Bustince, H. IVOVO: A new interval-valued one-vs-one approach for multi-class classification problems. In Proceedings of the 2017 Joint 17th World Congress of International Fuzzy Systems Association and 9th International Conference on Soft Computing and Intelligent Systems (IFSA-SCIS), Otsu, Japan, 27–30 June 2017; pp. 1–6. [Google Scholar]
- Ren, F.; Li, Y.; Hu, M. Multi-classifier Ensemble Based on Dynamic Weights. Multimed. Tools Appl. 2018, 77, 21083–21107. [Google Scholar] [CrossRef]
- Susan, S.; Kumar, A.; Jain, A. Evaluating Heterogeneous Ensembles with Boosting Meta-Learner. In Inventive Communication and Computational Technologies; Springer: Berlin/Heidelberg, Germany, 2020; pp. 699–710. [Google Scholar] [CrossRef]
- Özgür, A.; Nar, F.; Erdem, H. Sparsity-driven weighted ensemble classifier. Int. J. Comput. Intell. Syst. 2018, 11, 962. [Google Scholar] [CrossRef]
- Zhou, X.; Zou, J.; Fu, X.; Guo, L.; Ju, C.; Chen, J. Creating Ensemble Classifiers with Information Entropy Diversity Measure. Secur. Commun. Netw. 2021, 2021, 9953509. [Google Scholar] [CrossRef]
- Wang, J.; Xu, S.; Duan, B.; Liu, C.; Liang, J. An Ensemble Classification Algorithm Based on Information Entropy for Data Streams. arXiv 2017, arXiv:1708.03496. [Google Scholar] [CrossRef]
- Ramakrishna, M.T.; Venkatesan, V.K.; Izonin, I.; Havryliuk, M.; Bhat, C.R. Homogeneous Adaboost Ensemble Machine Learning Algorithms with Reduced Entropy on Balanced Data. Entropy 2023, 25, 245. [Google Scholar] [CrossRef]
- Lavanya, S.R.; Mallika, R. An Ensemble Deep Learning Classifier of Entropy Convolutional Neural Network and Divergence Weight Bidirectional LSTM for Efficient Disease Prediction. Int. J. Syst. Assur. Eng. Manag. 2022, 21083–21107. [Google Scholar] [CrossRef]
- Li, D.; Chi, Z.; Wang, B.; Wang, Z.; Yang, H.; Du, W. Entropy-based hybrid sampling ensemble learning for imbalanced data. Int. J. Intell. Syst. 2021, 36, 3039–3067. [Google Scholar]
- Zadeh, L. The concept of a linguistic variable and its application to approximate reasoning—I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Chen, S.; Chen, S. A prioritized information fusion method for handling fuzzy decision-making problems. Appl. Intell. 2005, 22, 219–232. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. Internal-valued fuzzy sets, possibility theory and imprecise probability. In Proceedings of the 4th Conference of the European Society for Fuzzy Logic and Technology and 11èmes Rencontres Francophones sur la Logique Floue et ses Applications (Eusflat-LFA 2005), Barcelona, Spain, 7–9 September 2005; pp. 314–319. [Google Scholar]
- Xu, Z.; Yager, R. Some geometric aggregation operators based on intuitionistic fuzzy sets. Int. J. Gen. Syst. 2006, 35, 417–433. [Google Scholar] [CrossRef]
- Zeng, W.; Yin, Q. Similarity Measure of Interval-Valued Fuzzy Sets and Application to Pattern Recognition. In Proceedings of the 2008 Fifth International Conference on Fuzzy Systems and Knowledge Discovery, Jinan, China, 18–20 October 2008; Volume 1, pp. 535–539. [Google Scholar]
- Zadeh, L. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Beliakov, G.; Bustince, H.; Calvo, T. A Practical Guide to Averaging Functions; Springer: Berlin/Heidelberg, Germany, 2016; Volume 329. [Google Scholar]
- Lertworaprachaya, Y.; Yang, Y.; John, R. Interval-valued fuzzy decision trees with optimal neighbourhood perimeter. Appl. Soft Comput. 2014, 24, 851–866. [Google Scholar] [CrossRef]
- Janusz, A. Algorithms for Similarity Relation Learning from High Dimensional Data. Ph.D. Thesis, Computer Science and Mechanics, Faculty of Mathematics, University of Warsaw, Warsaw, Poland, 2014. [Google Scholar]
- RandomForestClassifier. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html (accessed on 29 January 2024).
- SVM. Available online: https://scikit-learn.org/stable/modules/svm.html (accessed on 29 January 2024).
- MLPClassifier. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html (accessed on 29 January 2024).
- BaggingClassifier. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingClassifier.html (accessed on 29 January 2024).
- train_test_split. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html (accessed on 29 January 2024).
- MinMaxScaler. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html (accessed on 29 January 2024).
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-Entropy Loss Functions: Theoretical Analysis and Applications. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; Proceedings of Machine Learning Research, PMLR. Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J., Eds.; Volume 202, pp. 23803–23828. [Google Scholar]
- Log Loss. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.log_loss.html (accessed on 29 January 2024).
- Multi-Class Log Loss. Available online: https://scikit-learn.org/stable/modules/model_evaluation.html#log-loss (accessed on 29 January 2024).
- Accuracy. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html (accessed on 29 January 2024).
- Recall. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.recall_score.html (accessed on 29 January 2024).
- Precision. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_score.html (accessed on 29 January 2024).
- F1 Score. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html (accessed on 29 January 2024).
- ROC AUC. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html (accessed on 29 January 2024).
- Balanced Accuracy. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.balanced_accuracy_score.html (accessed on 29 January 2024).
- One Vs Rest. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.multiclass.OneVsRestClassifier.html (accessed on 29 January 2024).
- One Vs One. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.multiclass.OneVsOneClassifier.html (accessed on 29 January 2024).
- Proposed Models. Available online: https://github.com/AleksanderW/EntropyEnsembleIntervalModel (accessed on 29 January 2024).
- Proposed Model Algorithm. Available online: https://is.gd/tTzldX (accessed on 29 January 2024).
- Proposed Entropy Model Algorithm. Available online: https://is.gd/iGXRQC (accessed on 29 January 2024).
- Proposed Entropy Groups Model Algorithm. Available online: https://is.gd/doM8OW (accessed on 29 January 2024).
- Kruskal–Wallis H-Test. Available online: https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.kruskal.html (accessed on 29 January 2024).
- Dunn’s Test. Available online: https://scikit-posthocs.readthedocs.io/en/latest/generated/scikit_posthocs.posthoc_dunn.html (accessed on 29 January 2024).
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Kolmogorov, A. Entropy per unit time as a metric invariant of automorphism. Dokl. Russ. Acad. Sci. 1959, 124, 754–755. [Google Scholar]
- Sinai, Y. On the Notion of Entropy of a Dynamical System. Dokl. Russ. Acad. Sci. 1959, 124, 768–771. [Google Scholar]
- Rényi, A. On measures of information and entropy. In Proceedings of the Fourth Berkeley Symposium on Mathematics, Statistics and Probability 1960, Berkeley, CA, USA, 20 June–30 July 1961; Statistical Laboratory of the University of California: Berkeley, CA, USA; pp. 547–561. [Google Scholar]
- Rioul, O. This is it: A Primer on Shannon’s Entropy and Information. Inf. Theory Prog. Math. Phys. 2021, 78, 49–86. [Google Scholar]
- Delgado-Bonal, A.; Marshak, A. Approximate Entropy and Sample Entropy: A Comprehensive Tutorial. Entropy 2019, 21, 541. [Google Scholar] [CrossRef] [PubMed]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}