
A Good View for Graph Contrastive Learning
Abstract
1. Introduction
- (1)
- What defines a good view?
- (2)
- What information should a good view include or exclude?
- (3)
- How can a good view be generated?
- We are the first, to the best of our knowledge, to formulate a definition for a “good view” in the context of graph contrastive learning, grounded in the theories of graph information bottleneck and structural entropy.
- Drawing on these theoretical insights, we introduce CtrlGCL as a method to actualize the concept of a good view for graph contrastive learning, employing coding tree representation learning.
- Our proposed methodology for constructing good views was comprehensively assessed across various benchmarks, encompassing unsupervised and semi-supervised learning scenarios. The results consistently showcase its superior performance compared to state-of-the-art methods, underscoring the efficacy of our approach.In this article, the initial section provides a comprehensive overview of the background and outlines our specific contributions. The subsequent section delves into the existing research on graph contrast learning and structural entropy. Following that, the third section elucidates our theory and delineates the instantiation of our model. Moving forward, the fourth and fifth sections expound upon the experimental setup and present the obtained results. Finally, the concluding section encapsulates the essence of our study, providing a succinct summary of our findings.
2. Related Work
2.1. Graph Contrastive Learning
2.2. Structural Entropy
3. Materials and Methods
3.1. Preliminaries
3.1.1. Graph Representation Learning
3.1.2. The Mutual Information Maximization
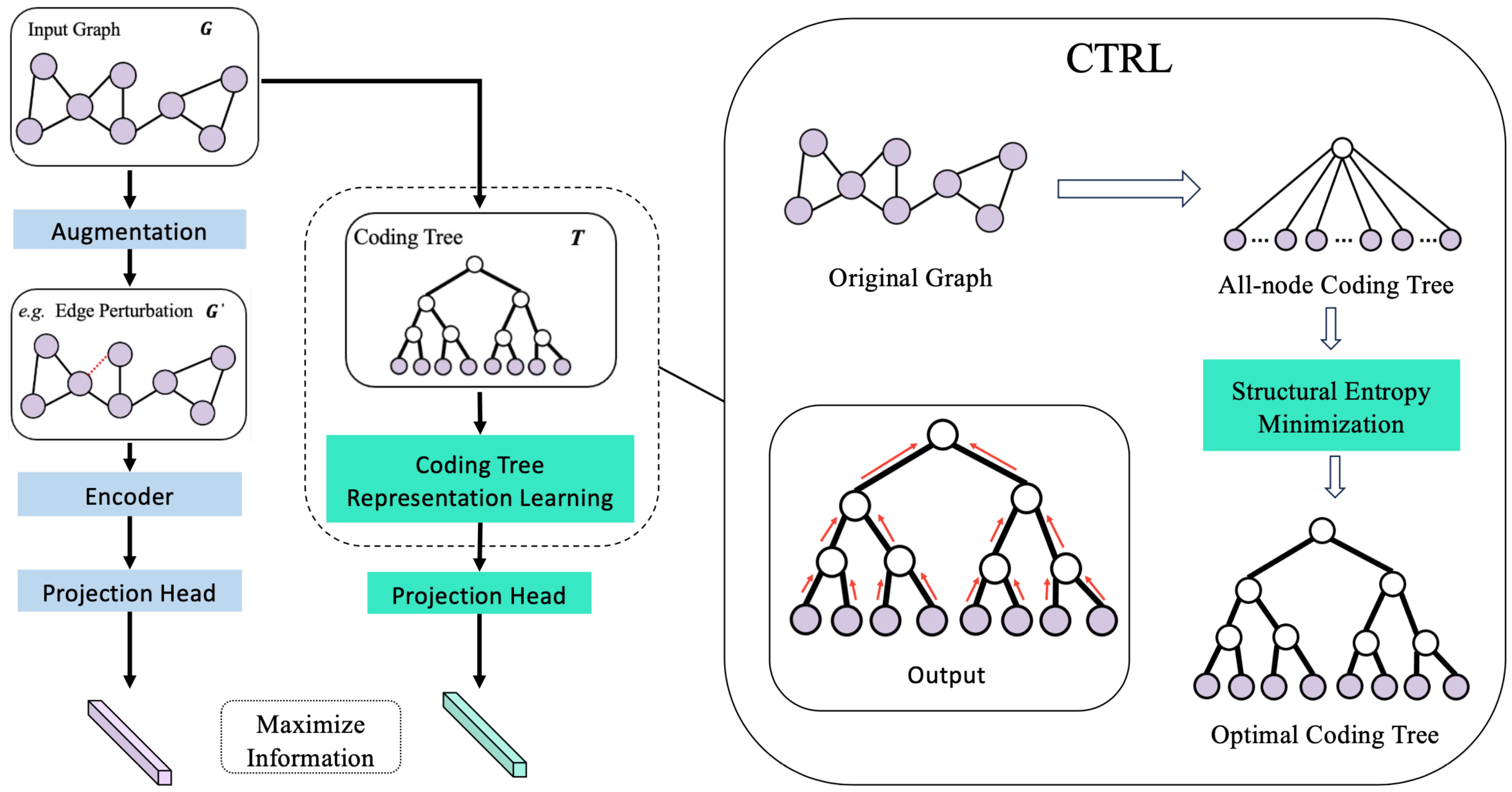
3.1.3. Methodology
3.2. The Essential Structure with Minimal Structural Uncertainty
An Instantiation of Essential Structure Decoding and Representation
| Algorithm 1 Coding tree with height k via structural entropy minimization. |
| Input: a graph , a positive integer Output: a coding tree T with height k
|
4. Experiment Setup
4.1. Datasets
4.2. Configuration
4.3. Learning Protocols
4.4. The Compared Methods
- (1)
- A naive GCN without pre-training [7], which is directly trained with 10% labeled data from random initialization.
- (2)
- GAE [41], a predictive method based on edge-based reconstruction in the pre-training phase.
- (3)
- Infomax [6], a node-embedding method with global–local representation consistency.
- (4)
- ContextPred [19], a method using sub-structure information preserving.
- (5)
- GraphCL [7], the first graph contrastive learning method with data augmentations.
5. Results
5.1. Unsupervised Learning
5.2. Semi-Supervised Learning
5.3. Orthogonal to Graph Augmentations
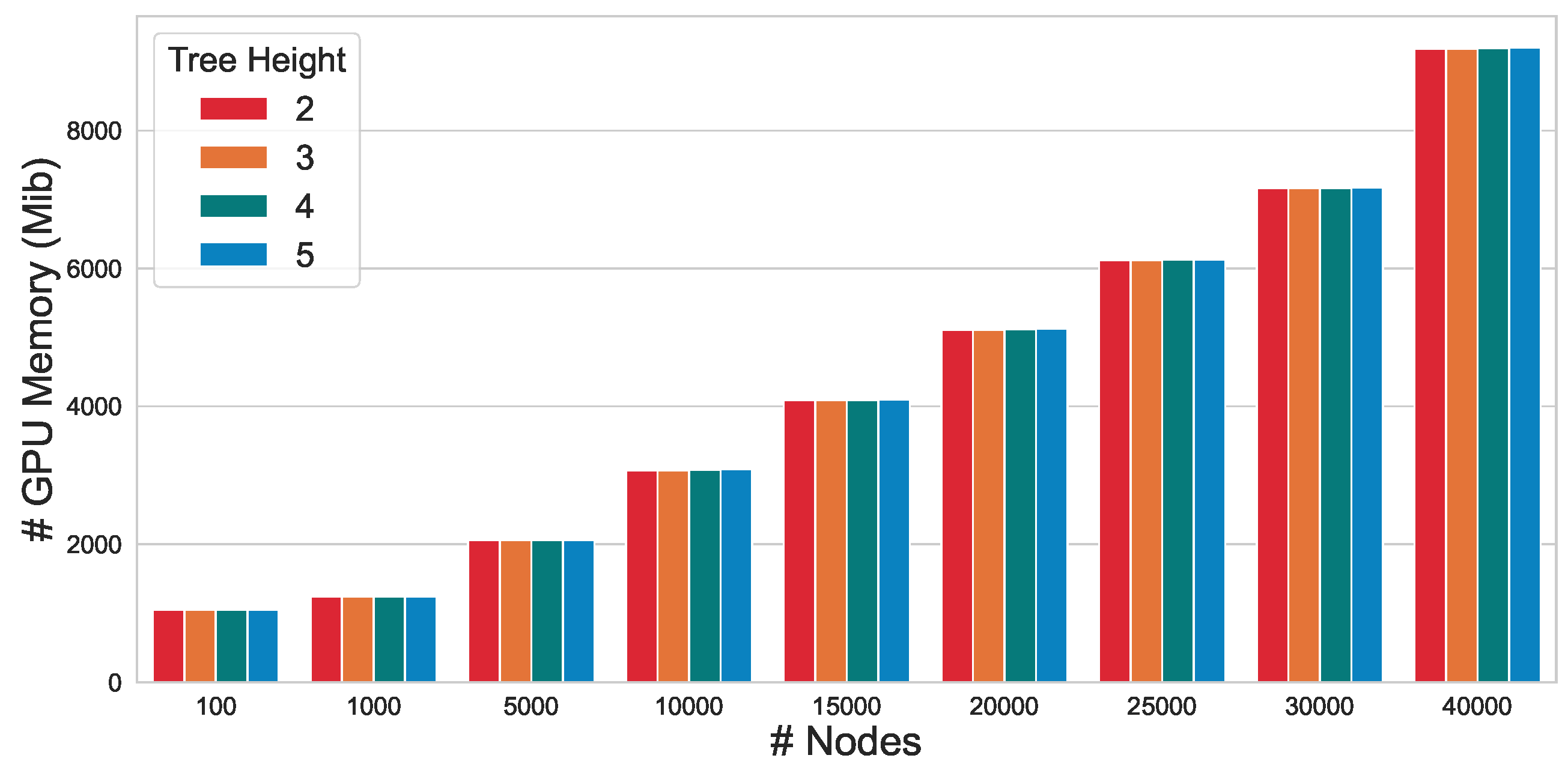
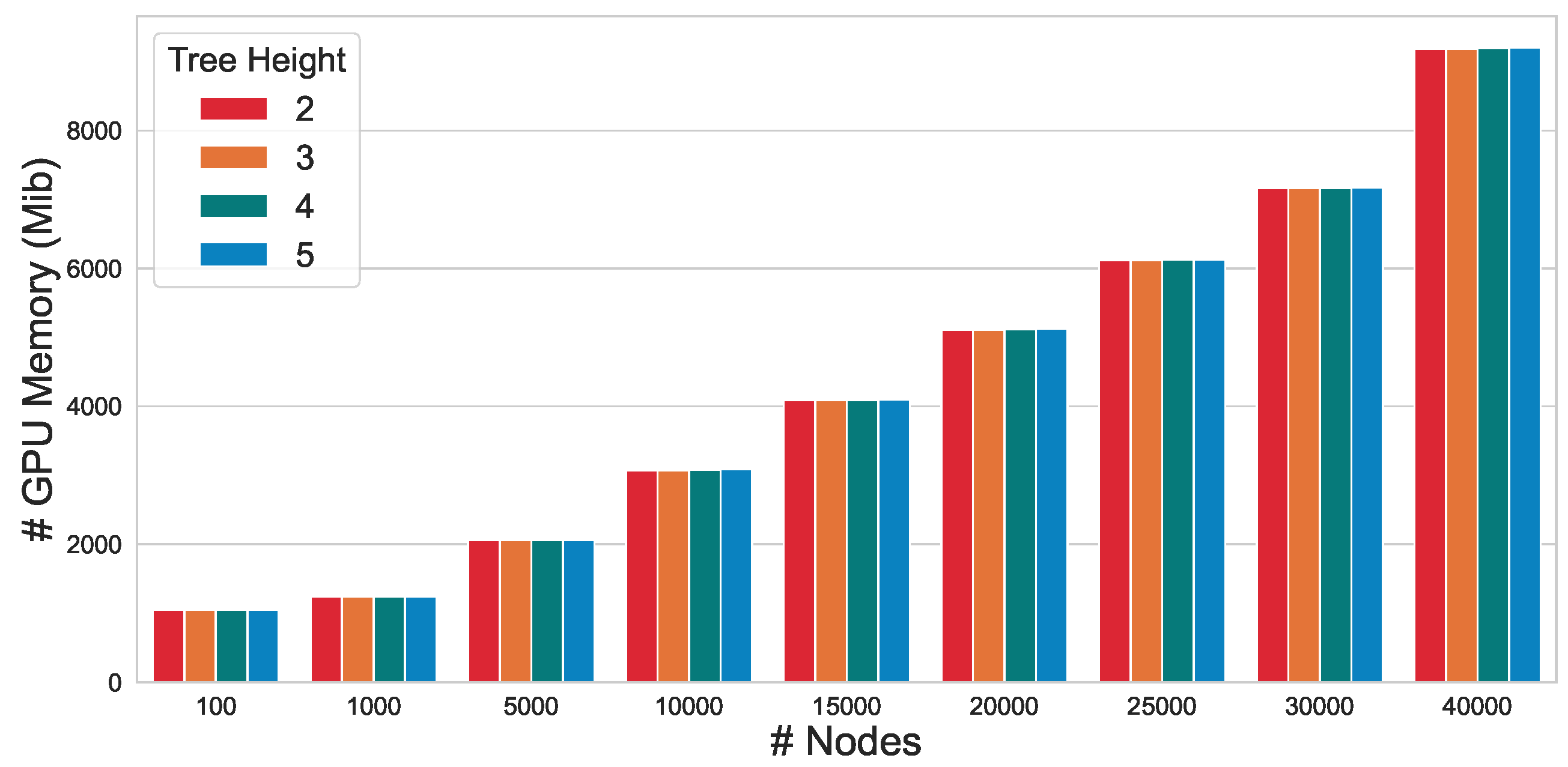
5.4. Memory Efficiency
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Rezaeifar, S.; Voloshynovskiy, S.; Asgari Jirhandeh, M.; Kinakh, V. Privacy-Preserving Image Template Sharing Using Contrastive Learning. Entropy 2022, 24, 643. [Google Scholar] [CrossRef]
- Gao, T.; Yao, X.; Chen, D. Simcse: Simple contrastive learning of sentence embeddings. arXiv 2021, arXiv:2104.08821. [Google Scholar]
- Albelwi, S. Survey on self-supervised learning: Auxiliary pretext tasks and contrastive learning methods in imaging. Entropy 2022, 24, 551. [Google Scholar] [CrossRef] [PubMed]
- Velickovic, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. ICLR 2019, 2, 4. [Google Scholar]
- You, Y.; Chen, T.; Sui, Y.; Chen, T.; Wang, Z.; Shen, Y. Graph contrastive learning with augmentations. Adv. Neural Inf. Process. Syst. 2020, 33, 5812–5823. [Google Scholar]
- Li, S.; Wang, X.; Zhang, A.; Wu, Y.; He, X.; Chua, T.S. Let Invariant Rationale Discovery Inspire Graph Contrastive Learning. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 13052–13065. [Google Scholar]
- Tian, Y.; Sun, C.; Poole, B.; Krishnan, D.; Schmid, C.; Isola, P. What makes for good views for contrastive learning? Adv. Neural Inf. Process. Syst. 2020, 33, 6827–6839. [Google Scholar]
- Suresh, S.; Li, P.; Hao, C.; Neville, J. Adversarial graph augmentation to improve graph contrastive learning. Adv. Neural Inf. Process. Syst. 2021, 34, 15920–15933. [Google Scholar]
- You, Y.; Chen, T.; Shen, Y.; Wang, Z. Graph contrastive learning automated. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 12121–12132. [Google Scholar]
- Feng, S.; Jing, B.; Zhu, Y.; Tong, H. Adversarial graph contrastive learning with information regularization. In Proceedings of the the ACM Web Conference 2022, Virtual, 25–29 April 2022; pp. 1362–1371. [Google Scholar]
- Wu, T.; Ren, H.; Li, P.; Leskovec, J. Graph information bottleneck. Adv. Neural Inf. Process. Syst. 2020, 33, 20437–20448. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Brooks, F.P., Jr. Three great challenges for half-century-old computer science. J. ACM 2003, 50, 25–26. [Google Scholar] [CrossRef]
- Li, A.; Pan, Y. Structural information and dynamical complexity of networks. IEEE Trans. Inf. Theory 2016, 62, 3290–3339. [Google Scholar] [CrossRef]
- You, Y.; Chen, T.; Wang, Z.; Shen, Y. Bringing your own view: Graph contrastive learning without prefabricated data augmentations. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Lyon, France, 25–29 April 2022; pp. 1300–1309. [Google Scholar]
- Guo, Q.; Liao, Y.; Li, Z.; Liang, S. Multi-Modal Representation via Contrastive Learning with Attention Bottleneck Fusion and Attentive Statistics Features. Entropy 2023, 25, 1421. [Google Scholar] [CrossRef]
- Hu, W.; Liu, B.; Gomes, J.; Zitnik, M.; Liang, P.; Pande, V.; Leskovec, J. Strategies For Pre-training Graph Neural Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Sun, F.Y.; Hoffman, J.; Verma, V.; Tang, J. InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Li, W.; Zhu, E.; Wang, S.; Guo, X. Graph Clustering with High-Order Contrastive Learning. Entropy 2023, 25, 1432. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.; Liang, J.; Liu, D.; Wang, F. Contrastive Graph Structure Learning via Information Bottleneck for Recommendation. Adv. Neural Inf. Process. Syst. 2022, 35, 20407–20420. [Google Scholar]
- Cai, X.; Huang, C.; Xia, L.; Ren, X. LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Mowshowitz, A.; Dehmer, M. Entropy and the complexity of graphs revisited. Entropy 2012, 14, 559–570. [Google Scholar] [CrossRef]
- Raychaudhury, C.; Ray, S.; Ghosh, J.; Roy, A.; Basak, S. Discrimination of isomeric structures using information theoretic topological indices. J. Comput. Chem. 1984, 5, 581–588. [Google Scholar] [CrossRef]
- Bianconi, G. Entropy of network ensembles. Phys. Rev. E 2009, 79, 036114. [Google Scholar] [CrossRef] [PubMed]
- Dehmer, M. Information processing in complex networks: Graph entropy and information functionals. Appl. Math. Comput. 2008, 201, 82–94. [Google Scholar] [CrossRef]
- Braunstein, S.L.; Ghosh, S.; Severini, S. The Laplacian of a graph as a density matrix: A basic combinatorial approach to separability of mixed states. Ann. Comb. 2006, 10, 291–317. [Google Scholar] [CrossRef]
- Li, A.L.; Yin, X.; Xu, B.; Wang, D.; Han, J.; Wei, Y.; Deng, Y.; Xiong, Y.; Zhang, Z. Decoding topologically associating domains with ultra-low resolution Hi-C data by graph structural entropy. Nat. Commun. 2018, 9, 3265. [Google Scholar] [CrossRef]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1263–1272. [Google Scholar]
- Ma, Y.; Tang, J. Deep Learning on Graphs; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Shannon, C. The lattice theory of information. Trans. IRE Prof. Group Inf. Theory 1953, 1, 105–107. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Morris, C.; Kriege, N.M.; Bause, F.; Kersting, K.; Mutzel, P.; Neumann, M. TUDataset: A collection of benchmark datasets for learning with graphs. arXiv 2020, arXiv:2007.08663. [Google Scholar]
- Shervashidze, N.; Vishwanathan, S.; Petri, T.; Mehlhorn, K.; Borgwardt, K. Efficient graphlet kernels for large graph comparison. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Clearwater Beach, FL, USA, 16–18 April 2009; pp. 488–495. [Google Scholar]
- Shervashidze, N.; Schweitzer, P.; Van Leeuwen, E.J.; Mehlhorn, K.; Borgwardt, K.M. Weisfeiler-lehman graph kernels. J. Mach. Learn. Res. 2011, 12, 2539–2561. [Google Scholar]
- Yanardag, P.; Vishwanathan, S. Deep graph kernels. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1365–1374. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Adhikari, B.; Zhang, Y.; Ramakrishnan, N.; Prakash, B.A. Sub2vec: Feature learning for subgraphs. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Melbourne, VIC, Australia, 3–6 June 2018; pp. 170–182. [Google Scholar]
- Annamalai, N.; Mahinthan, C.; Rajasekar, V.; Lihui, C.; Yang, L.; Jaiswal, S. graph2vec: Learning Distributed Representations of Graphs. In Proceedings of the 13th International Workshop on Mining and Learning with Graphs (MLG), Halifax, NS, Canada, 14 August 2017. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational Graph Auto-Encoders. arXiv 2016, arXiv:1611.07308v1. [Google Scholar]
- Yin, Y.; Wang, Q.; Huang, S.; Xiong, H.; Zhang, X. AutoGCL: Automated graph contrastive learning via learnable view generators. Proc. AAAI Conf. Artif. Intell. 2022, 36, 8892–8900. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Fan, R.E.; Chang, K.W.; Hsieh, C.J.; Wang, X.R.; Lin, C.J. LIBLINEAR: A library for large linear classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful are Graph Neural Networks? In Proceedings of the ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Erdos, P.; Rényi, A. On the evolution of random graphs. Publ. Math. Inst. Hung. Acad. Sci 1960, 5, 17–60. [Google Scholar]
- Baek, J.; Kang, M.; Hwang, S.J. Accurate Learning of Graph Representations with Graph Multiset Pooling. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]


{kind=link}
{kind=link}
| Dataset | #Graphs | #Classes | Avg. #Nodes | Avg. #Edges |
|---|---|---|---|---|
| REDDIT-BINARY | 2000 | 2 | 429.63 | 497.75 |
| COLLAB | 5000 | 3 | 74.49 | 2457.78 |
| REDDIT-MULTI-5K | 4999 | 5 | 508.52 | 594.87 |
| IMDB-MULTI | 1500 | 3 | 13.00 | 65.94 |
| IMDB-BINARY | 1000 | 2 | 19.77 | 96.53 |
| GITHUB | 12,725 | 2 | 113.79 | 234.64 |
| MUTAG | 188 | 2 | 17.93 | 19.79 |
| NCI1 | 4110 | 2 | 29.87 | 32.30 |
| DD | 1178 | 2 | 284.32 | 715.66 |
| PROTEINS | 1113 | 2 | 39.06 | 72.82 |
| NCI1 | PROTEINS | DD | MUTAG | COLLAB | RED-B | RED-M5K | IMDB-B | A.R. | |
|---|---|---|---|---|---|---|---|---|---|
| Avg. #Nodes | 29.87 | 39.06 | 284.32 | 17.93 | 74.49 | 429.63 | 508.52 | 19.77 | |
| Avg. #Edges | 32.30 | 72.82 | 715.66 | 19.79 | 2457.78 | 497.75 | 594.87 | 86.53 | |
| GL | - | - | - | 81.66 ± 2.11 | - | 77.34 ± 0.18 | 41.01 ± 0.17 | 65.87 ± 0.98 | 8.3 |
| WL | 80.01 ± 0.50 | 72.92 ± 0.56 | - | 80.72 ± 3.00 | - | 68.82 ± 0.41 | 46.06 ± 0.21 | 72.30 ± 3.44 | 6.7 |
| DGK | 80.31 ± 0.46 | 73.30 ± 0.82 | - | 87.44 ± 2.72 | - | 78.04 ± 0.39 | 41.27 ± 0.18 | 66.96 ± 0.56 | 5.7 |
| node2vec | 54.89 ± 1.61 | 57.49 ± 3.57 | - | 72.63 ± 10.20 | - | - | - | - | 9.3 |
| sub2vec | 52.84 ± 1.47 | 53.03 ± 5.55 | - | 61.05 ± 15.80 | - | 71.48 ± 0.41 | 36.69 ± 0.42 | 55.26 ± 1.54 | 10 |
| graph2vec | 73.22 ± 1.81 | 73.30 ± 2.05 | - | 83.15 ± 9.25 | - | 75.78 ± 1.03 | 47.86 ± 0.26 | 71.10 ± 0.54 | 7.0 |
| InfoGraph | 76.20 ± 1.06 | 74.44 ± 0.31 | 72.85 ± 1.78 | 89.01 ± 1.13 | 70.65 ± 1.13 | 82.50 ± 1.42 | 53.46 ± 1.03 | 73.03 ± 0.87 | 4.3 |
| GraphCL | 77.87 ± 0.41 | 74.39 ± 0.45 | 78.62 ± 0.40 | 86.80 ± 1.34 | 71.36 ± 1.15 | 89.53 ± 0.84 | 55.99 ± 0.28 | 71.14 ± 0.44 | 4.0 |
| CtrlGCL-G | 79.00 ± 0.72* | 75.79 ± 0.27 | 78.15 ± 0.56 | 90.21 ± 0.66 * | 70.73 ± 0.65 | 89.85 ± 0.56 | 55.27 ± 0.32 | 72.30 ± 0.24 | 2.9 |
| CtrlGCL-T | 74.92 ± 0.53 | 76.01 ± 0.42 * | 77.34 ± 1.03 | 88.50 ± 1.30 | 74.12 ± 0.47 * | 88.67 ± 0.60 | 52.26 ± 0.69 | 73.58 ± 0.44 * | 3.4 |
| CtrlGCL-H | 78.86 ± 0.38 | 75.85 ± 0.46 | 78.76 ± 0.57 * | 90.17 ± 0.97 | 71.44 ± 0.45 | 90.21 ± 0.65 * | 56.13 ± 0.30 * | 72.78 ± 0.64 | 2.0 |
| NCI1 | PROTEINS | DD | COLLAB | RED-B | RED-M5K | GITHUB | A.R. | |
|---|---|---|---|---|---|---|---|---|
| No Pre-Train | 73.72 ± 0.24 | 70.40 ± 1.51 | 73.56 ± 0.41 | 73.71 ± 0.27 | 86.63 ± 0.27 | 51.33 ± 0.44 | 60.87 ± 0.17 | 7.0 |
| GAE | 74.36 ± 0.24 | 70.51 ± 0.17 | 74.54 ± 0.68 | 75.09 ± 0.19 | 87.69 ± 0.40 | 53.58 ± 0.13 | 63.89 ± 0.52 | 5.0 |
| Infomax | 74.86 ± 0.26 | 72.27 ± 0.40 | 75.78 ± 0.34 | 73.76 ± 0.29 | 88.66 ± 0.95 | 53.61 ± 0.31 | 65.21 ± 0.88 | 4.0 |
| ContextPred | 73.00 ± 0.30 | 70.23 ± 0.63 | 74.66 ± 0.51 | 73.69 ± 0.37 | 84.76 ± 0.52 | 51.23 ± 0.84 | 62.35 ± 0.73 | 7.3 |
| GraphCL | 74.63 ± 0.25 | 74.17 ± 0.34 | 76.17 ± 1.37 | 74.23 ± 0.21 | 89.11 ± 0.19 | 52.55 ± 0.45 | 65.81 ± 0.79 | 3.3 |
| CtrlGCL-G | 74.72 ± 0.26 | 74.65 ± 0.54 | 76.33 ± 0.43 | 74.26 ± 0.27 | 89.40 ± 0.23 | 52.93 ± 0.37 | 65.92 ± 0.64 | 2.1 |
| CtrlGCL-T | 71.80 ± 0.35 | 73.31 ± 0.47 | 75.63 ± 0.58 | 73.36 ± 0.35 | 88.70 ± 0.15 | 52.11 ± 0.34 | 65.39 ± 0.58 | 5.6 |
| CtrlGCL-H | 75.09 ± 0.22 | 73.85 ± 0.53 | 75.82 ± 0.65 | 75.18 ± 0.22 | 89.35 ± 0.27 | 53.73 ± 0.28 | 66.01 ± 0.66 | 1.7 |
| View1 | View2 | NCI1 | PROTEINS | DD | MUTAG | COLLAB | RED-B | RED-M5K | IMDB-B | IMDB-M | A.A. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AD-GCL-FIX | 69.57 ± 0.51 | 73.59 ± 0.65 | 74.49 ± 0.52 | 89.25 ± 1.45 | 73.71 ± 0.27 | 85.52 ± 0.79 | 53.00 ± 0.82 | 71.57 ± 1.01 | 49.04 ± 0.53 | 71.05 | |
| CtrlGCL-G | AD-GCL-Fix | 69.93 ± 0.73 | 73.76 ± 0.57 | 74.62 ± 0.43 | 89.63 ± 1.54 | 73.77 ± 0.56 | 85.75 ± 0.67 | 53.88 ± 0.63 | 71.76 ± 0.57 | 49.44 ± 0.98 | 71.39 |
| CtrlGCL-T | 69.78 ± 0.32 | 74.61 ± 0.81 | 75.55 ± 0.51 | 88.20 ± 1.20 | 73.97 ± 0.55 | 86.73 ± 0.55 | 53.52 ± 0.31 | 72.32 ± 0.49 | 50.83 ± 0.34 | 71.72 | |
| CtrlGCL-H | 70.38 ± 0.76 | 74.57 ± 0.50 | 75.84 ± 0.64 | 89.89 ± 0.69 | 75.03 ± 0.36 | 87.74 ± 0.39 | 54.29 ± 0.54 | 72.28 ± 1.40 | 50.03 ± 0.81 | 72.23 | |
| JOAO | 78.07 ± 0.47 | 74.55 ± 0.41 | 77.32 ± 0.54 | 87.35 ± 1.02 | 69.50 ± 0.36 | 85.29 ± 1.35 | 55.74 ± 0.63 | 70.21 ± 3.08 | 74.75 | ||
| CtrlGCL-G | JOAO | 75.99 ± 0.59 | 74.95 ± 0.42 | 77.70 ± 0.85 | 87.12 ± 2.46 | 69.58 ± 0.27 | 86.57 ± 1.22 | 54.69 ± 0.73 | 71.46 ± 0.17 | 74.88 | |
| CtrlGCL-T | 73.32 ± 0.37 | 75.44 ± 0.54 | 76.29 ± 0.55 | 85.13 ± 1.79 | 72.82 ± 0.35 | 86.09 ± 0.94 | 54.63 ± 0.64 | 71.74 ± 1.26 | 74.43 | ||
| CtrlGCL-H | 76.19 ± 0.77 | 75.18 ± 0.63 | 78.27 ± 1.32 | 87.70 ± 1.31 | 71.80 ± 0.33 | 86.79 ± 1.31 | 56.17 ± 0.67 | 71.66 ± 0.42 | 75.47 | ||
| JOAOv2 | 78.36 ± 0.53 | 74.07 ± 1.10 | 77.40 ± 1.15 | 87.67 ± 0.79 | 69.33 ± 0.34 | 86.42 ± 1.45 | 56.03 ± 0.27 | 70.83 ± 0.25 | 75.01 | ||
| CtrlGCL-G | JOAOv2 | 77.81 ± 0.73 | 75.22 ± 0.94 | 77.84 ± 0.84 | 87.82 ± 2.17 | 69.34 ± 0.31 | 87.97 ± 0.80 | 56.11 ± 0.33 | 71.68 ± 0.74 | 75.47 | |
| CtrlGCL-T | 77.37 ± 0.31 | 75.94 ± 0.88 | 77.67 ± 0.48 | 86.77 ± 1.08 | 72.76 ± 0.27 | 87.32 ± 0.60 | 55.49 ± 0.32 | 72.52 ± 0.79 | 75.73 | ||
| CtrlGCL-H | 78.04 ± 0.19 | 75.25 ± 0.41 | 78.37 ± 1.26 | 88.53 ± 2.45 | 70.18 ± 0.34 | 87.98 ± 0.29 | 56.15 ± 0.29 | 72.50 ± 0.94 | 75.87 | ||
| AutoGCL | 82.00 ± 0.29 | 75.80 ± 0.36 | 77.57 ± 0.60 | 88.64 ± 1.08 | 70.12 ± 0.68 | 88.58 ± 1.49 | 56.75 ± 0.18 | 73.30 ± 0.40 | 76.60 | ||
| CtrlGCL-G | AutoGCL | 81.77 ± 0.32 | 75.63 ± 0.77 | 77.94 ± 0.85 | 88.84 ± 1.34 | 71.98 ± 0.83 | 88.75 ± 1.03 | 56.93 ± 0.28 | 73.87 ± 0.68 | 76.93 | |
| CtrlGCL-T | 81.04 ± 0.41 | 76.43 ± 0.67 | 78.29 ± 0.59 | 88.63 ± 1.29 | 72.49 ± 0.47 | 89.59 ± 1.48 | 57.27 ± 0.75 | 73.95 ± 0.87 | 77.21 | ||
| CtrlGCL-H | 81.84 ± 0.53 | 76.38 ± 0.54 | 78.31 ± 1.37 | 89.03 ± 1.01 | 72.68 ± 0.23 | 89.88 ± 1.21 | 57.43 ± 0.37 | 73.94 ± 0.99 | 77.44 | ||
| RGCL | 78.14 ± 1.08 | 75.03 ± 0.43 | 78.86 ± 0.48 | 87.66 ± 1.01 | 70.92 ± 0.65 | 90.34 ± 0.58 | 56.38 ± 0.40 | 71.85 ± 0.84 | 76.15 | ||
| CtrlGCL-G | RGCL | 79.28 ± 0.94 | 75.28 ± 0.72 | 79.45 ± 0.63 | 88.87 ± 1.46 | 72.73 ± 0.55 | 90.47 ± 0.77 | 56.58 ± 0.41 | 72.19 ± 0.67 | 76.86 | |
| CtrlGCL-T | 78.95 ± 1.53 | 75.87 ± 0.45 | 79.12 ± 0.88 | 87.50 ± 1.75 | 73.11 ± 0.24 | 90.90 ± 0.62 | 56.82 ± 0.29 | 72.75 ± 0.66 | 76.88 | ||
| CtrlGCL-H | 79.42 ± 0.82 | 76.21 ± 0.46 | 79.54 ± 1.14 | 88.79 ± 1.87 | 73.14 ± 0.37 | 90.75 ± 0.84 | 57.28 ± 0.42 | 72.61 ± 0.94 | 77.22 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Li, S. A Good View for Graph Contrastive Learning. Entropy 2024, 26, 208. https://doi.org/10.3390/e26030208
Chen X, Li S. A Good View for Graph Contrastive Learning. Entropy. 2024; 26(3):208. https://doi.org/10.3390/e26030208
Chicago/Turabian StyleChen, Xueyuan, and Shangzhe Li. 2024. "A Good View for Graph Contrastive Learning" Entropy 26, no. 3: 208. https://doi.org/10.3390/e26030208
APA StyleChen, X., & Li, S. (2024). A Good View for Graph Contrastive Learning. Entropy, 26(3), 208. https://doi.org/10.3390/e26030208