1. Introduction
In molecular biology and population genetics, the biological evolution of biopolymers and viruses is usually described using concepts such as quasispecies [
1], the fitness landscape [
2], the error threshold [
3], etc. These concepts first appeared and were applied in the context of RNA models [
4], where a genotype-to-phenotype mapping was investigated. A typical application of such a framework to experimental data can be seen in Ref. [
5], where Kimura’s neutral theory [
6], genotype–phenotype mapping [
4], and fitness landscapes [
2] were utilized.
Quasispecies are usually defined as a population of macromolecular species with closely interrelated sequences, dominated by one or several degenerate master copies [
1]. This is a useful concept, which, as we shall see below, is closely related to a quasi-equilibrium state that can be defined more-rigorously using the tools of statistical physics. Roughly speaking, quasi-equilibrium states are formed by random genetic drift acting on neutral or nearly neutral mutations, rather than by positive selection for advantageous traits, in agreement with the neutral theory [
6]. In terms of statistical physics, quasi-equilibrium states represent a micro-canonical-type ensemble, with the negative logarithm of fitness playing the role of energy [
7,
8]
Although the quasi-equilibrium states are relatively stable and their macroscopic parameters change continuously, sudden discontinuous changes may also occur, leading to a phase transition. One example of the phase transition is the so-called error threshold, a point at which the mutation rate of the replicating molecules surpasses a critical threshold [
3]. Below this threshold, the population can maintain a certain level of genetic information, and natural selection can effectively act to preserve functional sequences. Above the threshold, the error rate becomes too high, leading to a loss of information due to the accumulation of deleterious mutations, and the population enters a state of error catastrophe. These phase transitions were recently discussed in Ref. [
9], where the authors pointed out the benefit of using simple physical models. In this article, we shall perform a statistical analysis of the quasi-equilibrium states and the phase transitions between such states by following the temporal dynamics of the macroscopic parameters, such as the total entropy and average Hamming distance, using the tools of statistical physics.
Numerous efforts have been made to formulate a systematic physical description of biological evolution starting from the early part of the 20th Century (see Ref. [
10]). It was widely believed that the laws of biology, particularly those of evolutionary biology, can be somehow derived from the laws of physics, especially statistical physics. Notable attempts to develop a physical theory of biology include renowned works such as Schrödinger’s
What Is Life? The Physical Aspect of the Living Cell [
11] and Fisher’s
The Genetical Theory of Natural Selection [
12]. Some approaches involved utilizing well-known physical effects, e.g., resonance [
13], to describe evolution, and there was even an attempt to apply the formalism of quantum mechanics [
14]. However, until recently, clear connections between physical or thermodynamic quantities and observable biological parameters had not been established, despite the practice of measuring parameters like enthalpy, entropy, and Gibbs free energy for microorganisms [
15,
16,
17].
The situation began to change at the beginning of the 21st Century, when Sella and Hirsh [
7] identified the effective population size with inverse temperature, and a few years later, Barton and Coe [
18] identified the volume of allele frequency space with entropy, while Pan and Deem [
19] used Shannon’s entropy to measure diversity and selection pressure for H3N2 influenza sequences. Another important work was by Jones and collaborators [
20], who modeled viral evolution using a grand-canonical-type ensemble. All of these results marked a paradigm shift in the phenomenological description of biological evolution, but if one wishes to derive the description from first principles, the starting point should not be the identification of macroscopic parameters, but the specification of a statistical ensemble, i.e., a probability distribution over sequences. Then, for example, the entropy would have to be defined as the Shannon entropy of the distribution and the inverse temperature as a Lagrange multiplier, which imposes a constraint on the average energy-like quantity (e.g., logarithmic fitness).
The first-principles approach was recently employed in Ref. [
21], where a fully statistical description of biological evolution (modeled as multilevel learning [
22]) was developed using a theory of machine learning (established earlier in Refs. [
8,
23]). The primary new thermodynamic concept that accompanies learning, and consequently biological evolution, is that, in addition to the increase in entropy (according to the second law of thermodynamics), the entropy of a learning system may also decrease (according to the second law of learning [
8,
23]). As we shall argue, this is precisely what happens in biological systems: entropy increases in the so-called quasi-equilibrium states and decreases after phase transitions. This finding further strengthens the idea that biological evolution can be effectively modeled through learning dynamics, opening up possibilities for investigating various biological phenomena using the framework provided by the theory of learning. Indeed, numerous non-trivial emergent physical phenomena, including quantum mechanics [
8,
24] and gravity [
8,
25], as well as critical phenomena such as phase transitions [
23] or scale invariance [
26], have already been derived from learning dynamics. This paper, along with Refs. [
21,
22], can be regarded as a step toward modeling emergent biological phenomena within the same mathematical framework of learning theory [
23].
The major transitions in evolution, a concept in evolutionary biology popularized by Smith and Szathmary in their book
The Major Transitions in Evolution [
27,
28], can be correlated with learning phase transitions as proposed in Ref. [
21]. Specifically, the “origin-of-life” phase transition has been demonstrated to represent a shift from a grand-canonical ensemble of molecules to a grand-canonical ensemble of organisms. However, in line with the theory of learning [
23], learning phase transitions are much more common, and it is not immediately clear how to consistently identify and describe them in the biological context. (See, however, Refs. [
29,
30] for other attempts to describe transitions in biological evolution as thermodynamic phase transitions.) For instance, in biological evolution, can the formation of new genetic variants (or formation of new levels [
22]) be interpreted as a learning phase transition, or what one might call a “minor transition in evolution”? This paper addresses these minor transitions by analyzing the dynamics of macroscopic quantities such as the entropy of sequences, denoted as
S (defined as the Shannon entropy), and the Hamming distance between sequences, denoted as
H (averaged over all pairs of sequences in a given ensemble). It is shown that these minor transitions occur when both the entropy and the Hamming distances undergo a sudden, discontinuous jump. The term
phase transition comes from statistical physics and can be related to a discontinuous change of a statistical ensemble described, for example, by free energy. In biology, and particularly in genetics, such a term is not widely used. A more-familiar term is the so-called “selective sweep”, which occurs when an advantageous mutation gets fixed (along with some other nearby genes on the same allele, which is known as “hitchhiking” [
31]). Though selective sweep is an example of a phase transition, there are more general phase transitions that shall be discussed in the paper.
To illustrate the procedure, we performed the statistical analysis of ensembles of sequences from SARS-CoV-2 datasets. The main reason for using the SARS-CoV-2 datasets is that the datasets contain an unprecedented amount of data collected during a sufficiently long period of time, which allows us to observe and analyze a number of quasi-equilibrium states and phase transitions. Furthermore, the preformed analysis revealed the possibility of using the procedure for developing an early warning system for pandemics, which by itself may have an independent value.
The paper is organized as follows. In
Section 2, we describe the datasets and define statistical ensembles. In
Section 3 and
Section 4, we approximate, respectively, the total Shannon entropy of the system and the average Hamming distances for the statistical ensembles. In
Section 5, we identify and analyze the quasi-equilibrium states and phase transitions between them. In
Section 6, we discuss the main results of the paper.
2. Statistical Ensembles
A statistical ensemble is typically defined as a probability distribution over configuration space (or phase space). In the context of biological evolution, the relevant configuration space is the space of genomes, known as the genotype space. Individual points in the genotype space represent genome sequences, drawn from an alphabet of four characters or nucleobases: adenine (A), cytosine (C), guanine (G), and thymine (T). Considering sequences of a fixed length K and each site having one of four states, there are distinct points (or states) in the relevant genotype space. Not all of these states are equally probable, and to define a probability distribution, one can either model it analytically or extract it from experimental data. In this paper, we employed the experimental approach to study the statistical properties of an evolving biological system, such as the coronavirus.
For the numerical analysis, genome sequence data were extracted from the NCBI Virus SARS-CoV-2 Data Hub, GenBank [
32,
33]. Specifically, we selected complete genomes collected in the United Kingdom, retaining only those with fewer than 1% ambiguous characters—ensuring relatively clean sequences. These sequences were then grouped into statistical ensembles representing different months starting from March 2020, as the first two months of the pandemic (January and February 2020) had too few sequences. Genome sequences from all other months were randomly selected (ranging from at least 1500 to at most 2000 sequences) and aligned using the FFT-NS-2 method implemented in MAFFT [
34,
35]. After alignment, the probabilities of the nucleobases A, T, G, and C were calculated for each site
i, i.e.,
with the appropriate normalization
. These probabilities were then used to replace any absent nucleobases (i.e., gaps or ambiguous characters) with randomly selected nucleobases. Alternatively, we could have introduced an additional “character” for insertions and deletions, but our analysis indicated that this did not significantly modify the macroscopic statistical properties of the ensembles.
For each statistical ensemble or, equivalently, for each probability distribution,
, over sequences
, two relevant macroscopic quantities were computed: the total Shannon entropy of the sequences:
and the average Hamming distance between the sequences (see
Section 3):
where the Hamming distance between individual sequences is defined as (see
Section 4)
and
is similar to the Kronecker delta function. In addition, we calculated the average Hamming distances from individual sequences, i.e., the average distance to all other sequences in the ensemble. The fractional part of this distribution, as discussed in
Section 4, contains some nontrivial information about the ensembles or, more precisely, about the network of neutral mutations [
36,
37,
38].
One of the main objectives in our studies was the analysis of the temporal dynamics of the statistical ensembles, described by the macroscopic quantities
S and
H, over extended periods of time. This allowed us to identify the so-called quasi-equilibrium states (usually lasting a few months) during which an approximate linear dependence holds:
Phase transitions between quasi-equilibrium states occur when the parameters
a and
b change discontinuously (see
Section 5).
3. Entropy
For starters, consider an ensemble of sequences with the average single-site Shannon entropy defined as
The above equation involves averaging over both: an ensemble of N sequences (the inner summation) and over K sites with non-zero entropy (the outer summation). We will refer to the sites with non-zero entropy as “active” sites and the sites with zero entropy (i.e., with a unique nucleobase) as “passive” sites. In what follows, passive sites will be excluded from the analysis since they do not contribute to the statistical properties of the system.
The single-site entropy (
7) can be fairly accurately estimated by analyzing a finite number of sequences, or samples, from the ensemble. Unfortunately, the analysis breaks down if we attempt the same “brute-force” approach to calculate the total entropy of the system, of all active sites (
2). The problem arises because the number of possible states grows exponentially with the number of sites
K, and if the number of sequences is fixed (due to computational constraints, e.g.,
), then we cannot reliably estimate a probability distribution for more than
sites.
To overcome these computational constraints, we first calculated the entropies for only a few consecutive sites
and, then, extrapolated to
. In fact, it is more convenient to extrapolate the entropy per site
, which usually scales as a decaying exponential, i.e.,
for constants
A,
B, and
C, which may vary between ensembles, but are assumed to be fixed within a given ensemble. The average entropy per site can be estimated as
where the averaging is over both:
N samples (the inner summation) and
choices of consecutive sites (the outer summation).
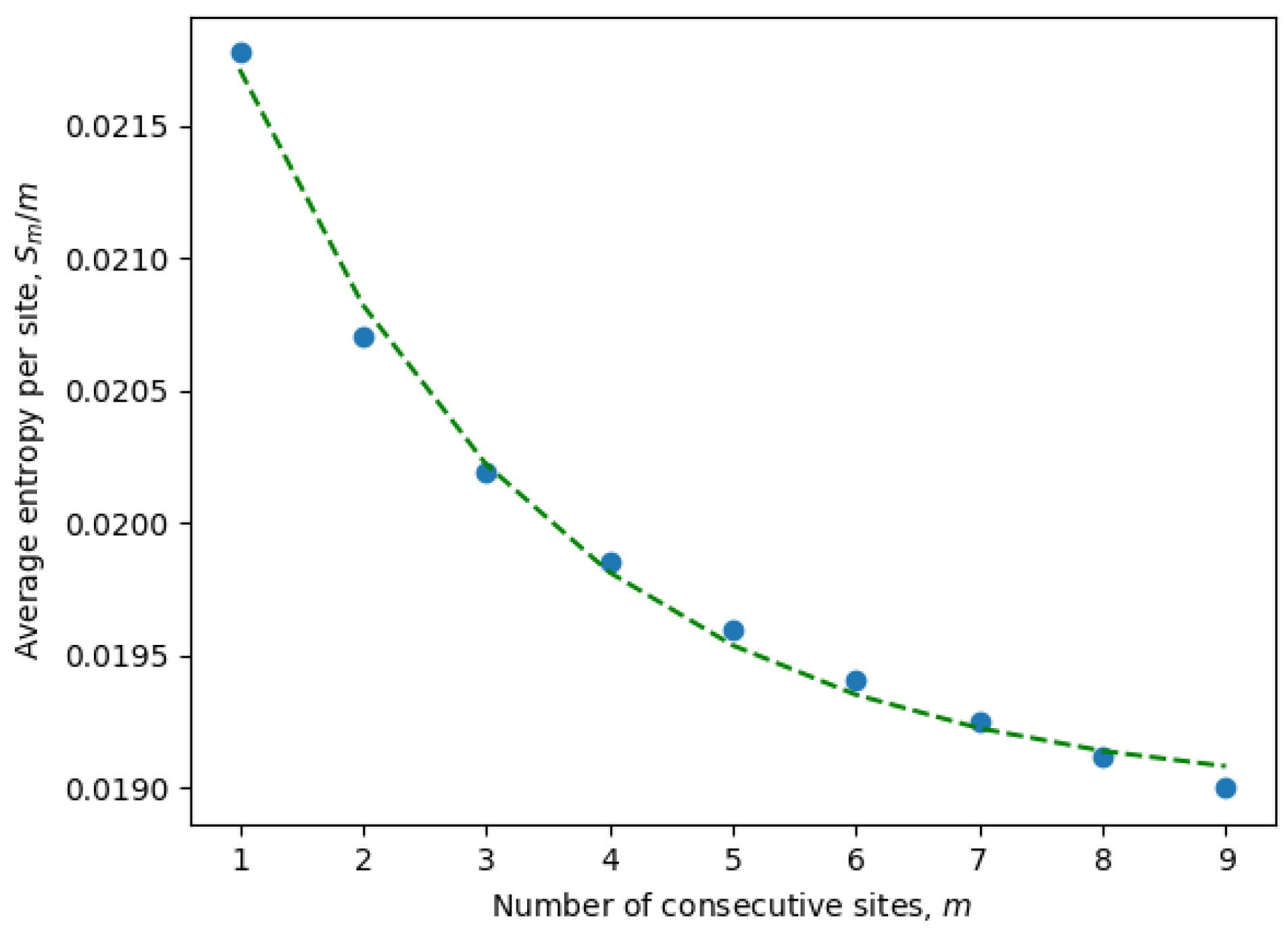
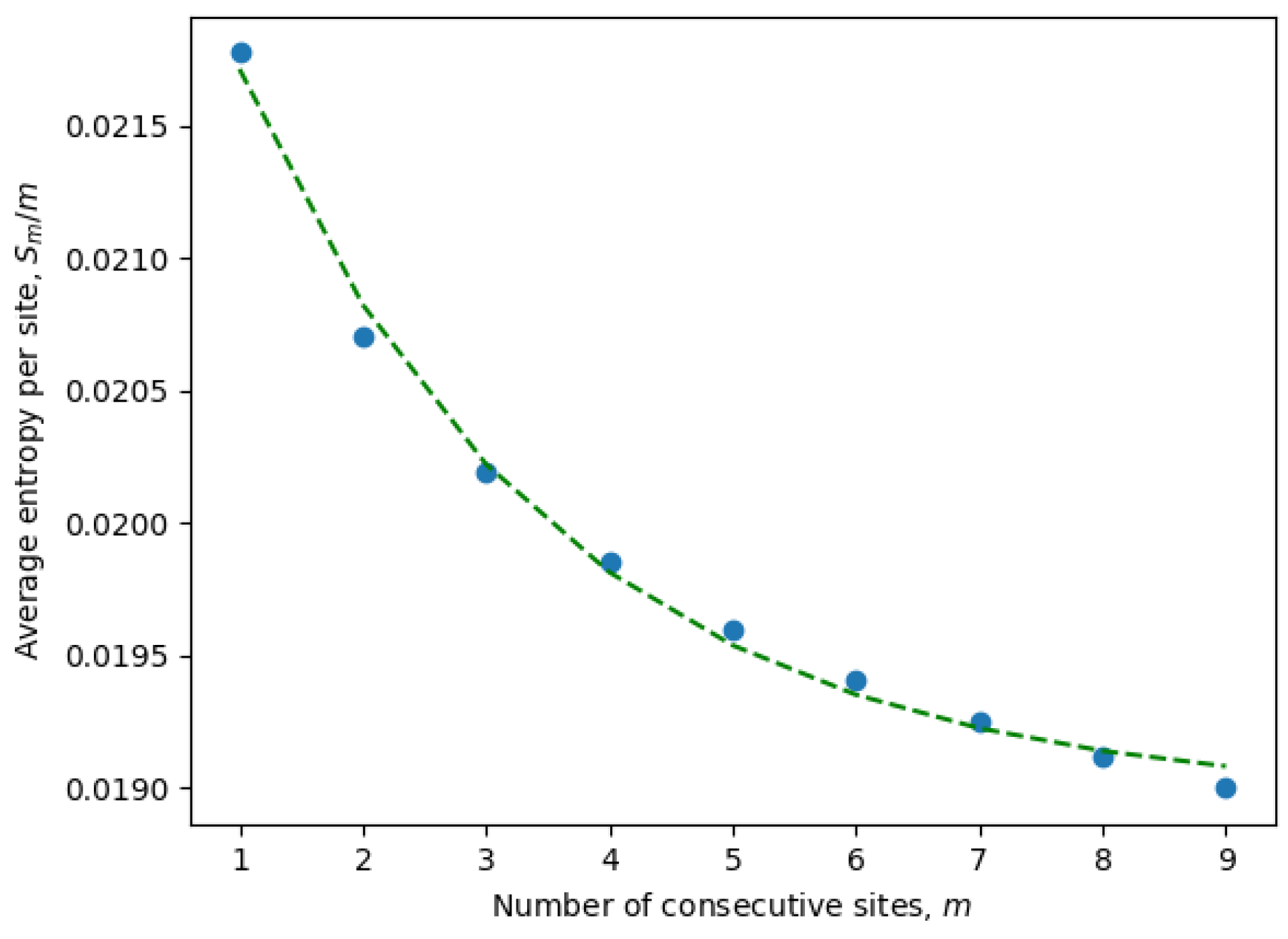
It is important to emphasize once again that the entropy is calculated for only active consecutive sites (after eliminating passive sites with zero entropy). These are the only sites contributing to the statistical properties of the system and, at the same time, may include non-trivial correlations between neighboring sites. Indeed, it is well known that local correlations in the sequences are much stronger than non-local correlations. For example, three consecutive nucleotides (a trinucleotide) encode a single amino acid, and because of that, there are stronger correlations between sites at distances of order three or less. This phenomena can be observed in
Figure 1, where the parameters of an exponential fit of Equation (
8) are estimated by considering different numbers of consecutive sites (
9). In
Table 1, we have compiled the parameters from Equation (
8) for all ensembles corresponding to different months. It is evident that the exponential decay rate
B is approximately on the order of
, in accordance with our expectations.
Essentially the same analysis was performed for all ensembles (i.e., all months), and then, the total entropy of each ensemble was calculated:
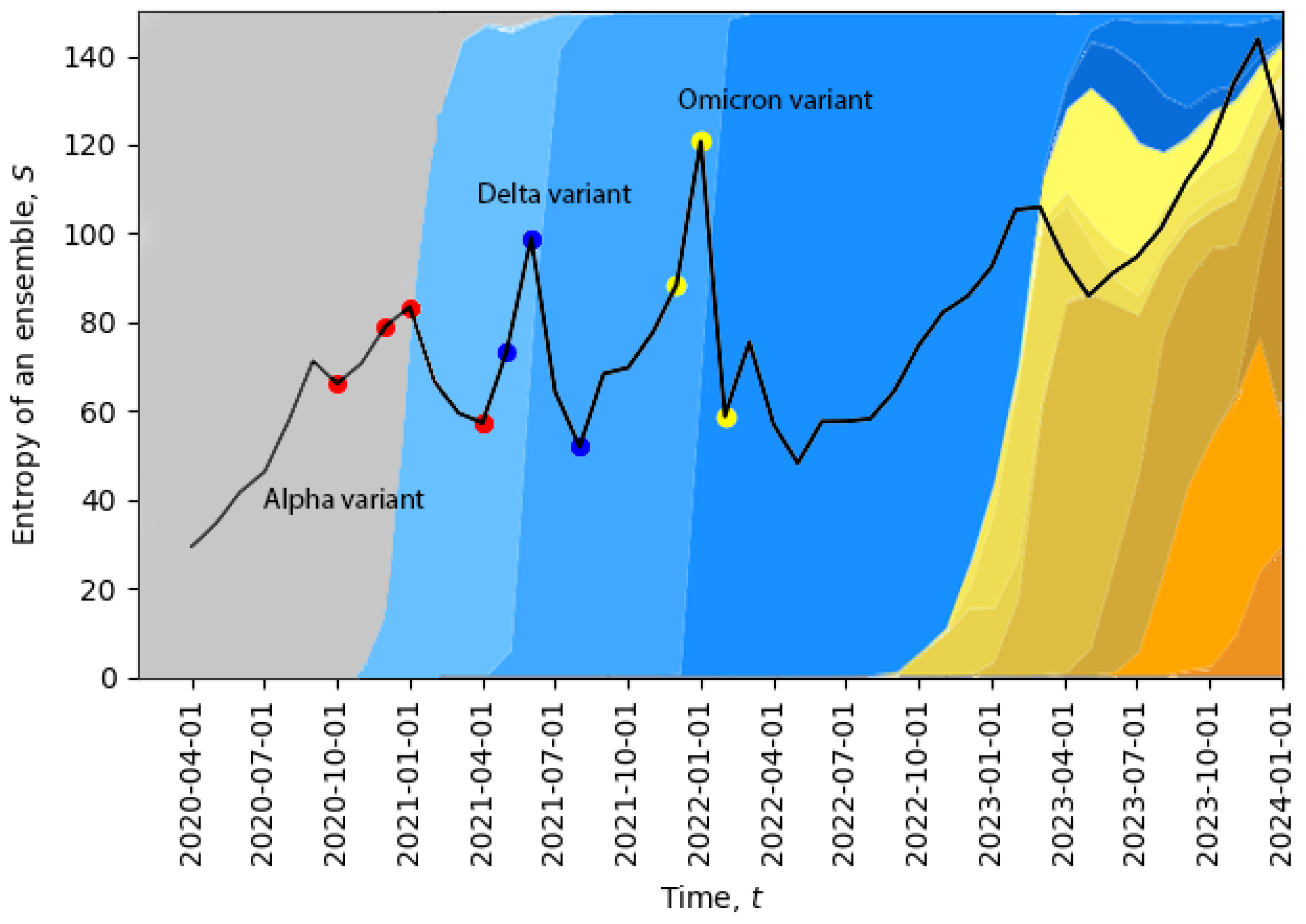
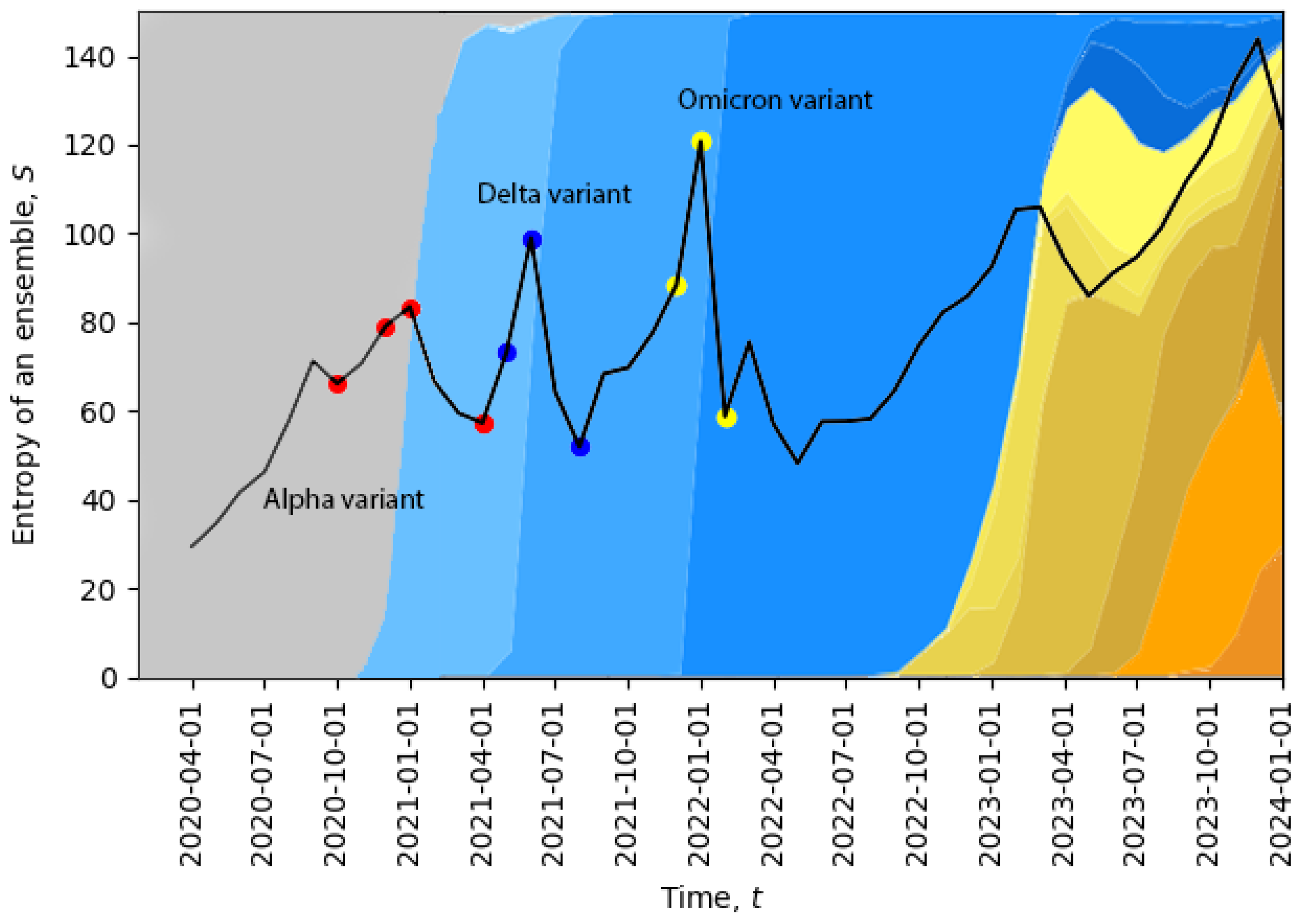
In
Figure 2, we plot the evolution of the total entropy (
10) as a function of time. The growth of the total entropy indicates that the virus spreads across the space of neutral mutations, or what we call the neutral network. This high-entropy state corresponds to a higher diversity of genomes, allowing for a larger volume of genotype space to be explored for possible positive mutations (i.e., mutations to states with higher fitness). The entropy growth accelerates further when the positive mutation is found, and then, the system quickly undergoes a phase transition. After this transition, the entropy drops, corresponding to a new variant replacing the old one and in agreement with the second law of learning [
21,
23]. In
Figure 2, we can already identify four phase transitions in December 2020, May 2021, December 2021, and November 2023, and additional phase transitions will be identified in
Section 5. Note that the peak in November 2023 suggests that the system might be currently undergoing a phase transition.
The temporal dynamics of the total entropy of
Figure 2 can be compared with data representing the appearance of different variants of the virus. In
Figure 2, the percentage of cases relative to different virus variants from Ref. [
39] was added in the background. The four red dots represent: the first case of the Alpha variant in the U.K., 5% of all cases, 50% of all cases, 95% of all cases; the three dark blue dots represent: the Delta variant, 5% of all cases, 50% of all cases, 95% of all cases; and the three yellow dots represent: the Omicron variant, 5% of all cases, 50% of all cases, 95% of all cases. Evidently, the replacement of the old variant with a new one is a phase transition, which is accompanied by a sudden increase in the total entropy, and after the phase transition, the total entropy drops, as expected. For example, when the Delta variant started to displace the older Alpha variant or when the Omicron variant started to displace the Delta variant, we clearly see sharp peaks of the total entropy. On the far right part of the figure, the entropy gradually increases for a long period of time along with the appearance of multiple new variants, which may indicate a multi-level quasi-equilibrium state, to be discussed below in
Section 5.
4. Hamming Distance
A natural measure of distances in the genotype space is the Hamming distance, which is also a common metric for comparing sequences of letters. In our case, these sequences consist of nucleobases A, T, G, and C, and the Hamming distance between such sequences is defined as the number of sites with different nucleobases (see Equation (
4)). The measure is well defined for sequences with no ambiguous characters, but to generalize this measure to all aligned sequences and, thus, define statistical ensembles in the genotype space, we substituted ambiguous characters with random characters drawn from a marginal probability distribution for the corresponding site (see
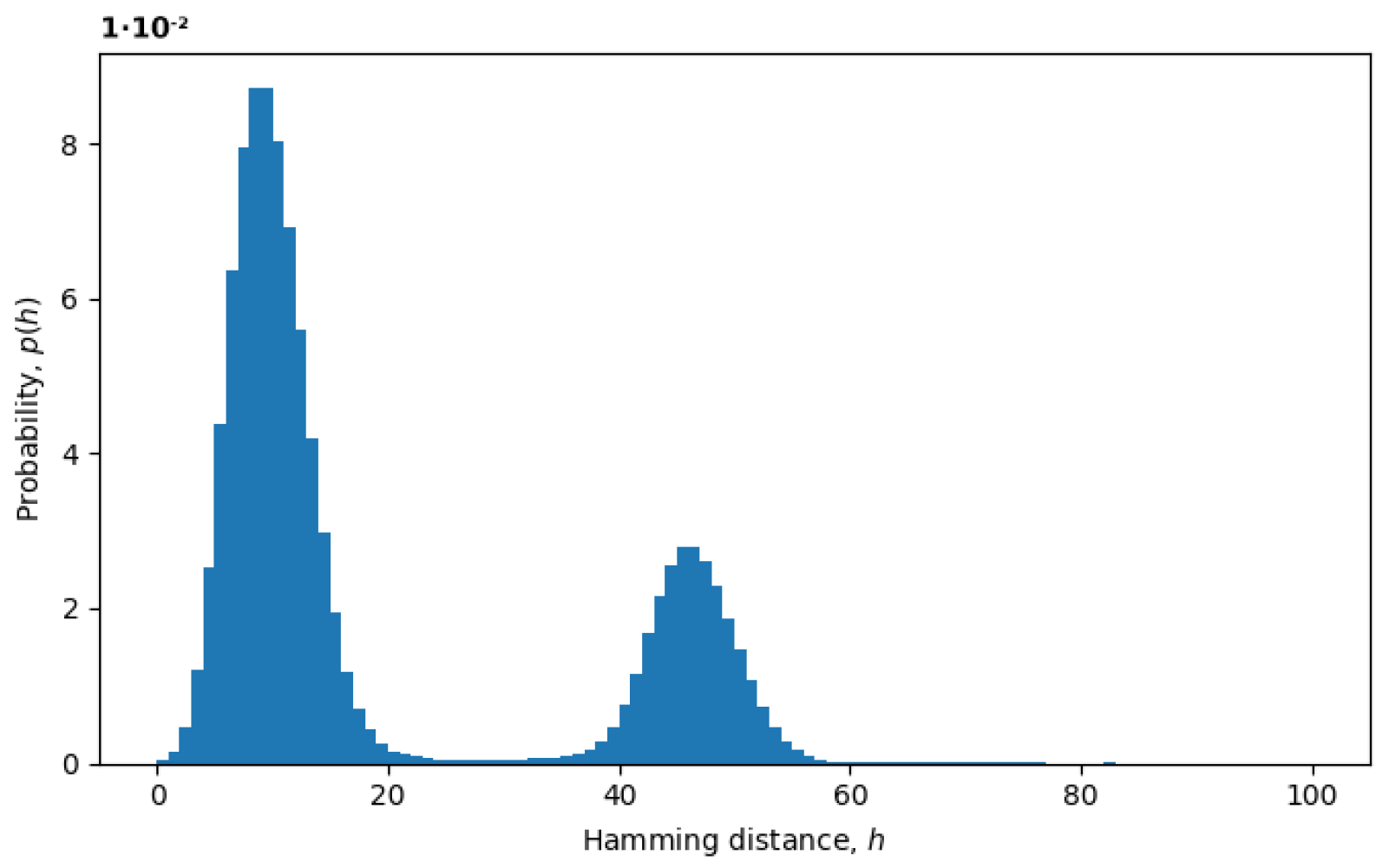
Section 2). In
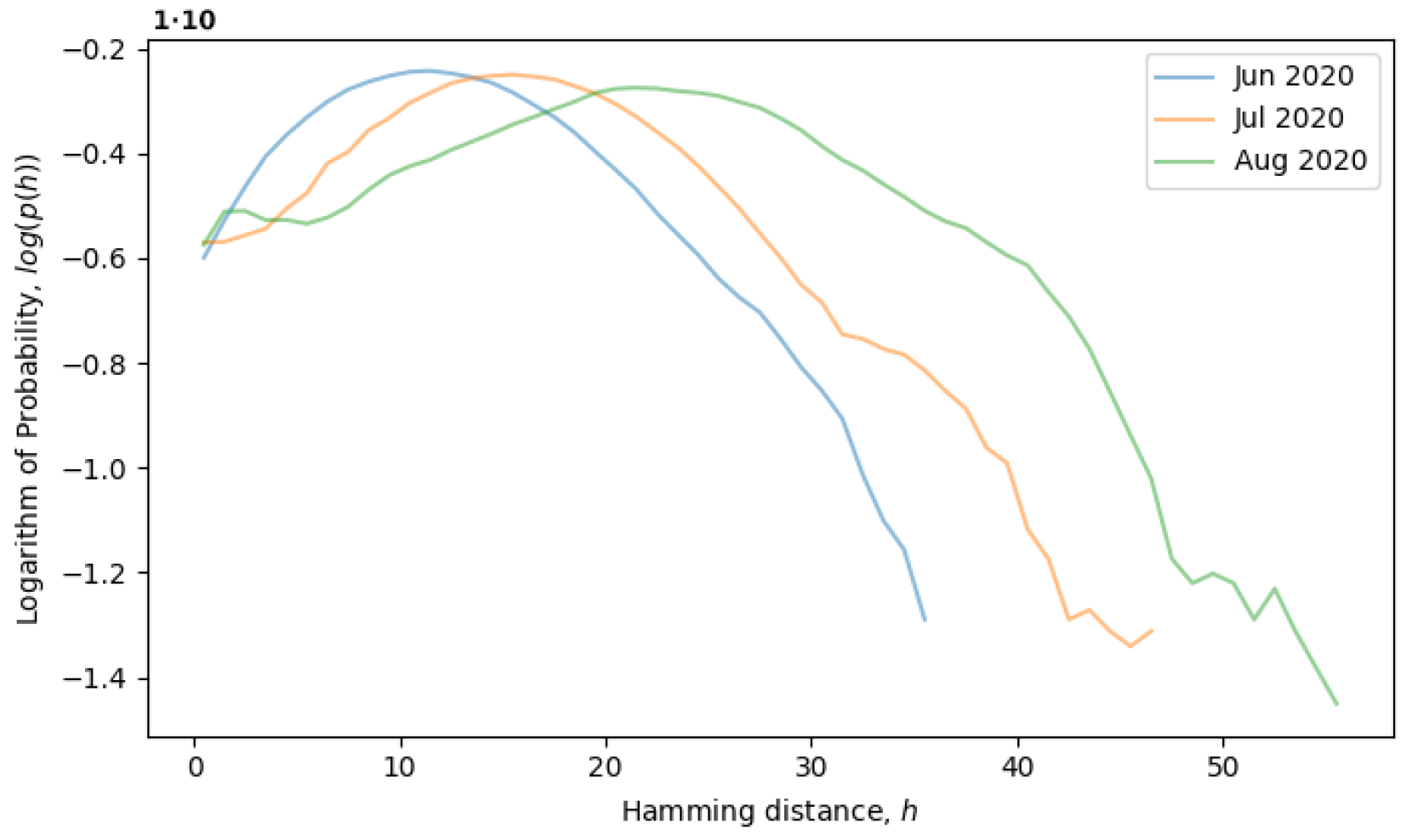
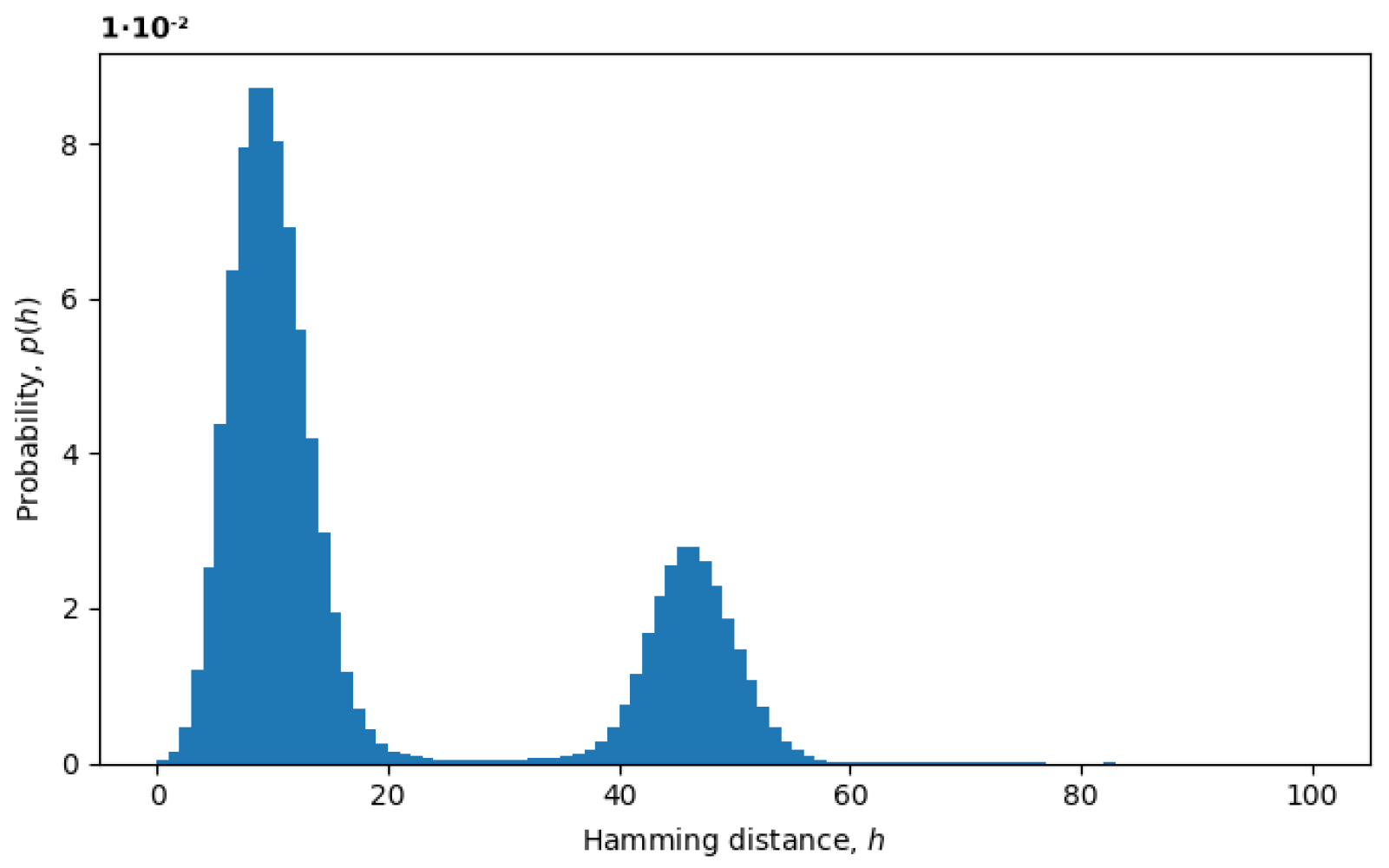
Figure 3, we plot an example of the probability distribution of Hamming distances
between random pairs of sequences, where the Hamming distances
are treated as random variables. The two peaks represent the presence of at least two variants in the virus populations, as discussed below.
Assuming that the evolving system is in a local equilibrium state, individual sequences might undergo mutations, but the overall distribution of sequences
, as well as the distribution of Hamming distances
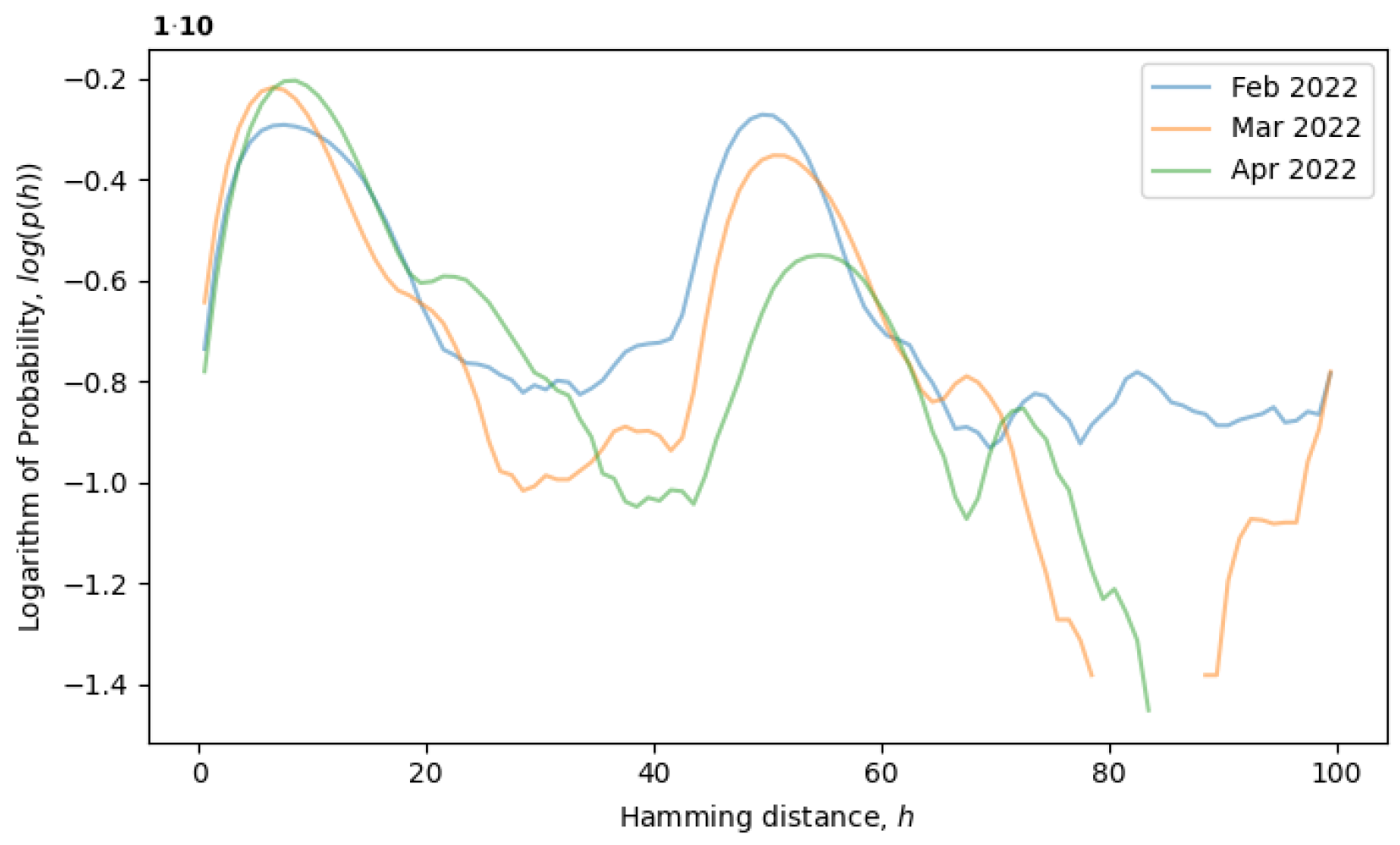
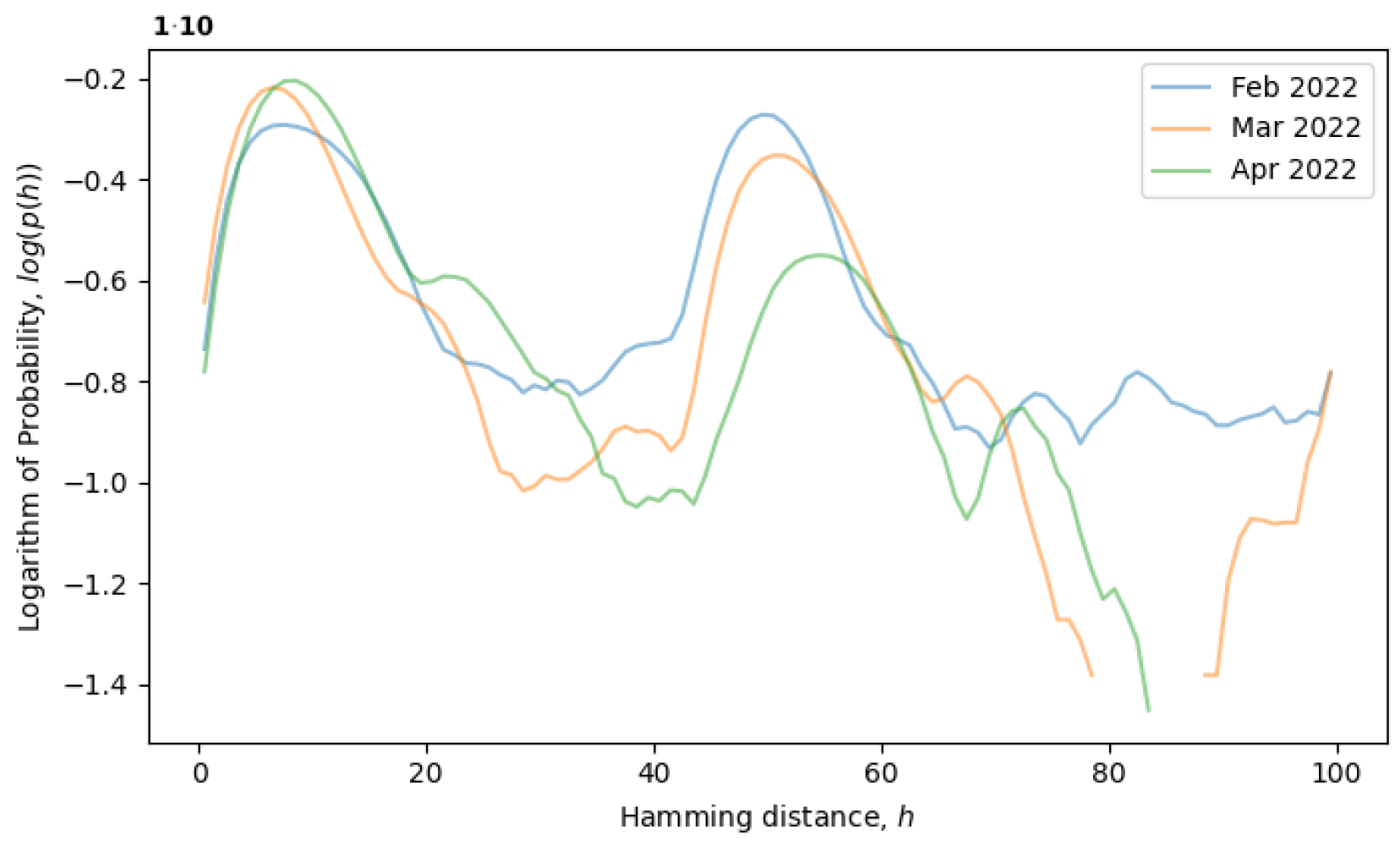
would remain constant. For example, the formation of a local equilibrium state after a phase transition can be observed in
Figure 4. From February to April 2022, the rightmost peak consistently decreases (a remnant of the old phase), while the leftmost peak steadily increases (describing the new phase). Note that the logarithm of the distribution is plotted in
Figure 4, as opposed to
Figure 3, providing more information for distributions with exponential tails, like exponential or normal distributions.
In general, the presence of multiple peaks corresponds to different characteristic scales, such as the mean distance within a cluster, the mean distance between clusters, the mean distances between clusters of clusters, etc. If the additional peaks remain fixed over extended periods of time, then this would indicate that the evolving system has developed new scales (or levels) and can, thus, be described as a multi-level learning system [
21,
22]. There may also be more fine-grained details of the quasi-equilibrium states that are not captured by the analysis of the total entropy or average Hamming distances, but can be extracted only by considering the spectral properties of the neutral network, i.e., the network of neutral mutations. We leave the analysis of the spectral properties for future research.
Returning to the concept of simple single-level equilibrium states, characterized by a single primary peak (or scale) in the distribution of Hamming distances, if the primary peak is fixed, as in
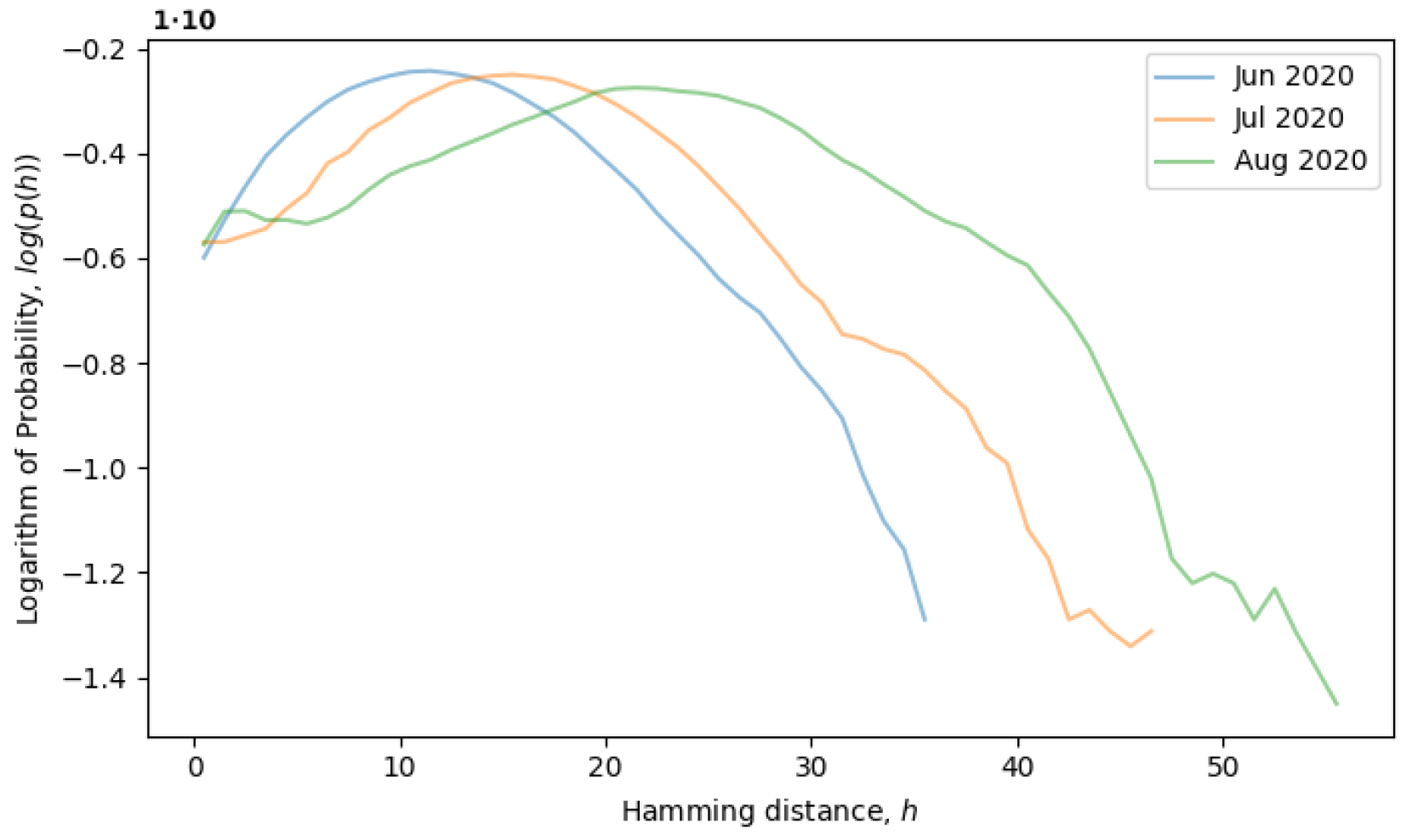
Figure 4, then the local genotype space has already been explored, and the system is in a local equilibrium state. However, the general tendency of the system is to explore the genotype space through neutral mutations, in which case, the peak should move to larger scales, i.e., to the right. In
Figure 5, the system is observed from June till August of 2020, during which time, the local neutral network is explored and what we call a quasi-equilibrium state is established.
Given the probability distribution
, we can calculate the average Hamming distance (
3):
Roughly speaking, H tells us about the dispersion of the sequence distribution or the divergence between different genomes. More precisely, it is a combination of multiple effects, dependent on both inter-cluster distances and the average distance within each cluster. Therefore, a large H can be a sign of multiple clusters existing at the same time, for example during phase transitions between quasi-equilibrium states or, possibly, in a multi-level quasi-equilibrium state.
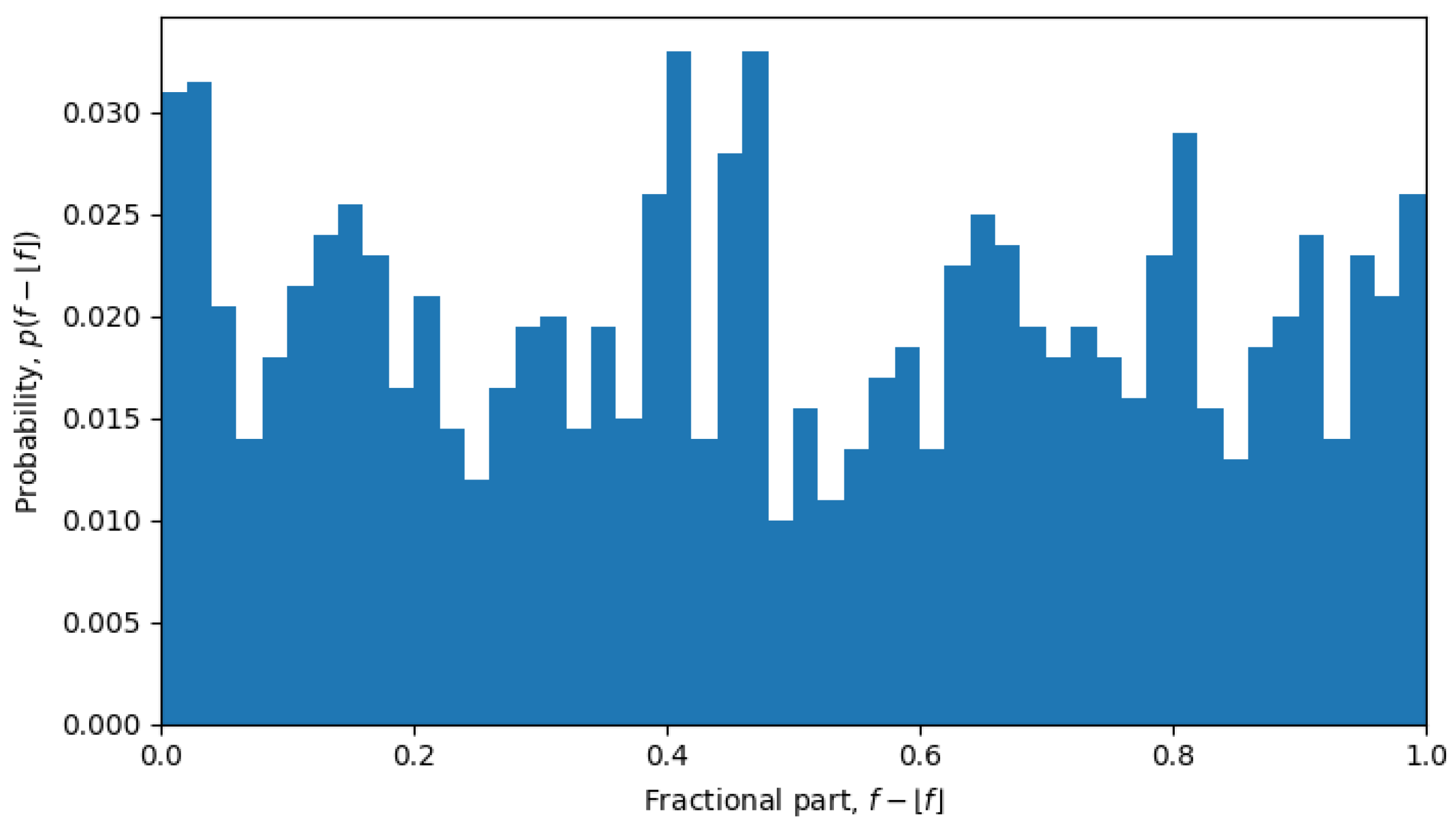
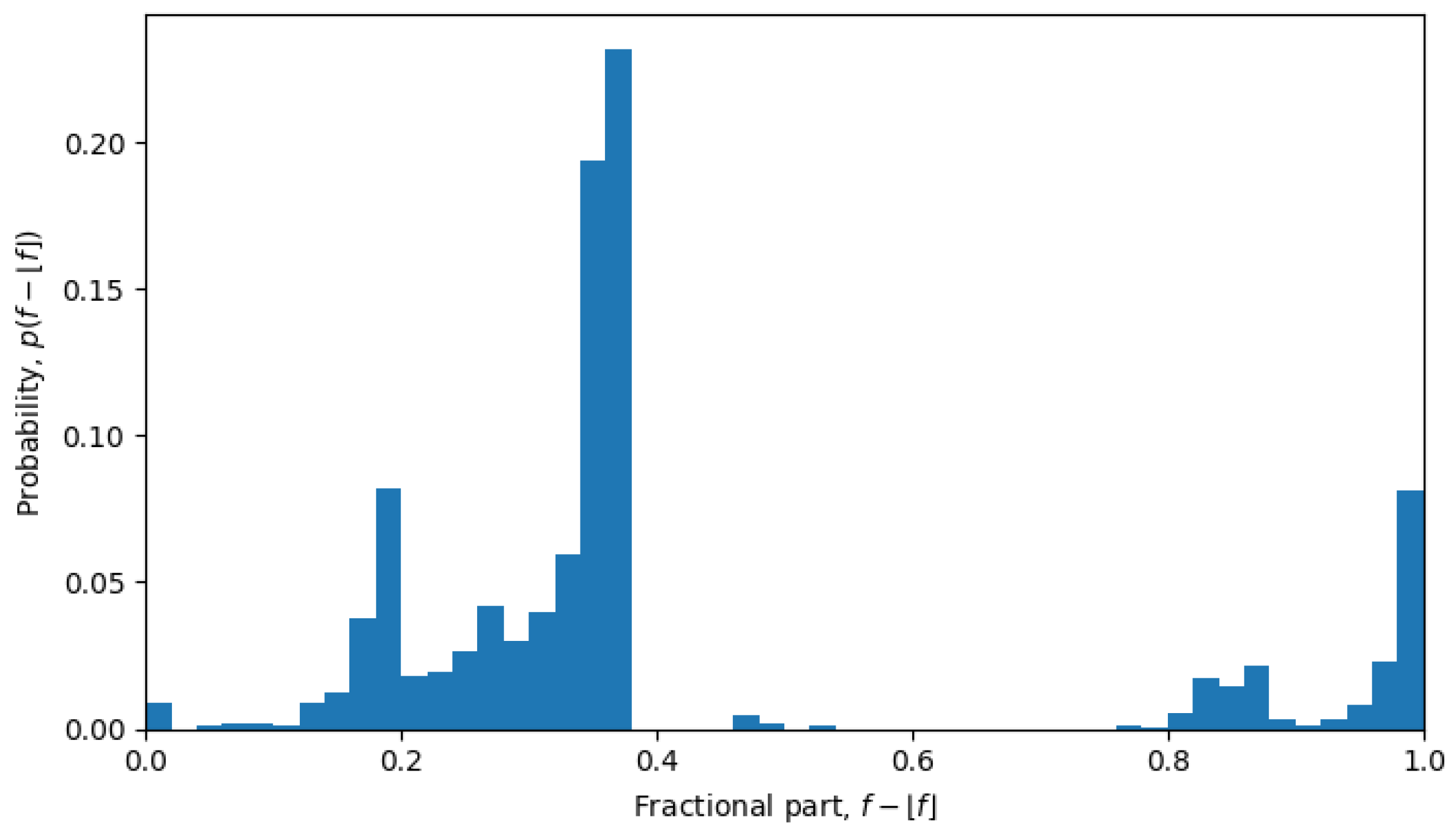
Another interesting property of the ensembles can be observed in the distribution of the fractional parts of single-sequence average Hamming distances. In other words, if we define the average Hamming distance from a given sequence
, i.e.,
and, then, consider its fractional part
as a random variable, the corresponding probability distribution
has a rather peculiar form. Indeed, if the space of neutral mutations were filled uniformly, we would also expect to see a uniform distribution of the fractional parts, i.e.,
, which is exactly what was observed during phase transitions, but not in the quasi-equilibrium states.
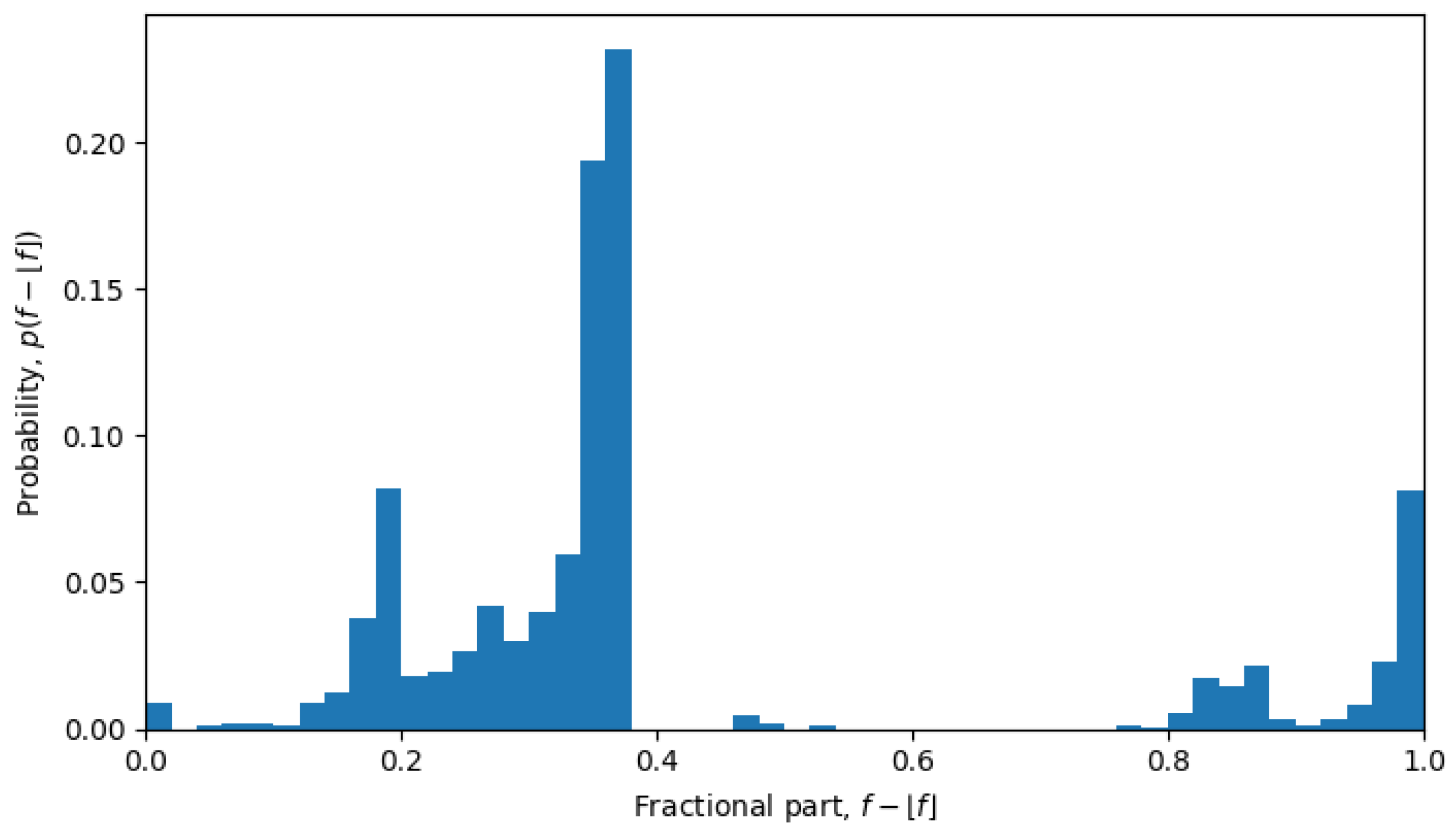
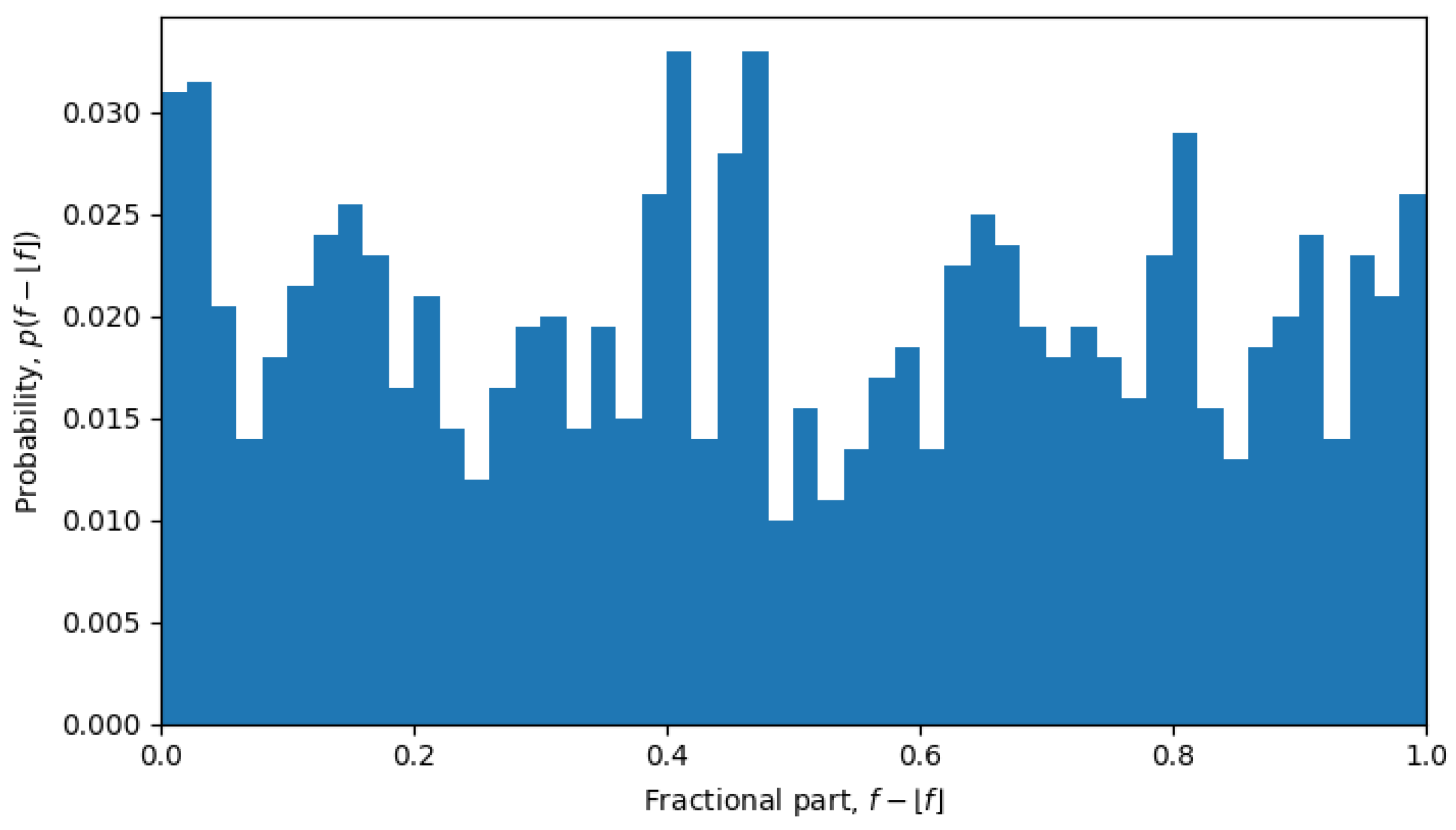
For example, in October 2023, the system was undergoing a phase transition, and the distribution is nearly uniform (see
Figure 6), but in April 2022, the system is in a quasi-equilibrium state, and the distribution has a very sharp peak (see
Figure 7), i.e., one value (or a few values) of the fractional part dominates over other values. The peaked distribution indicates that there is a central sequence
, and most of the shortest Hamming distances between sequences
and
go through that sequence, i.e.,
then the fractional part of all the average Hamming distances is approximately the same:
for all
. This may be expected in a single-level quasi-equilibrium state with one or few central sequences, but not as much during phase transitions between quasi-equilibrium states or in a multi-level quasi-equilibrium state.
5. Quasi-Equilibrium States
During phase transitions, a system is transferred from one quasi-equilibrium state to another, which is accompanied by discontinuous change in the statistical ensembles, which can often be observed as a discontinuous change of macroscopic parameters. In our analysis, the two main macroscopic parameters are the total Shannon entropy
S (see
Section 3) and the average Hamming distance
H (see
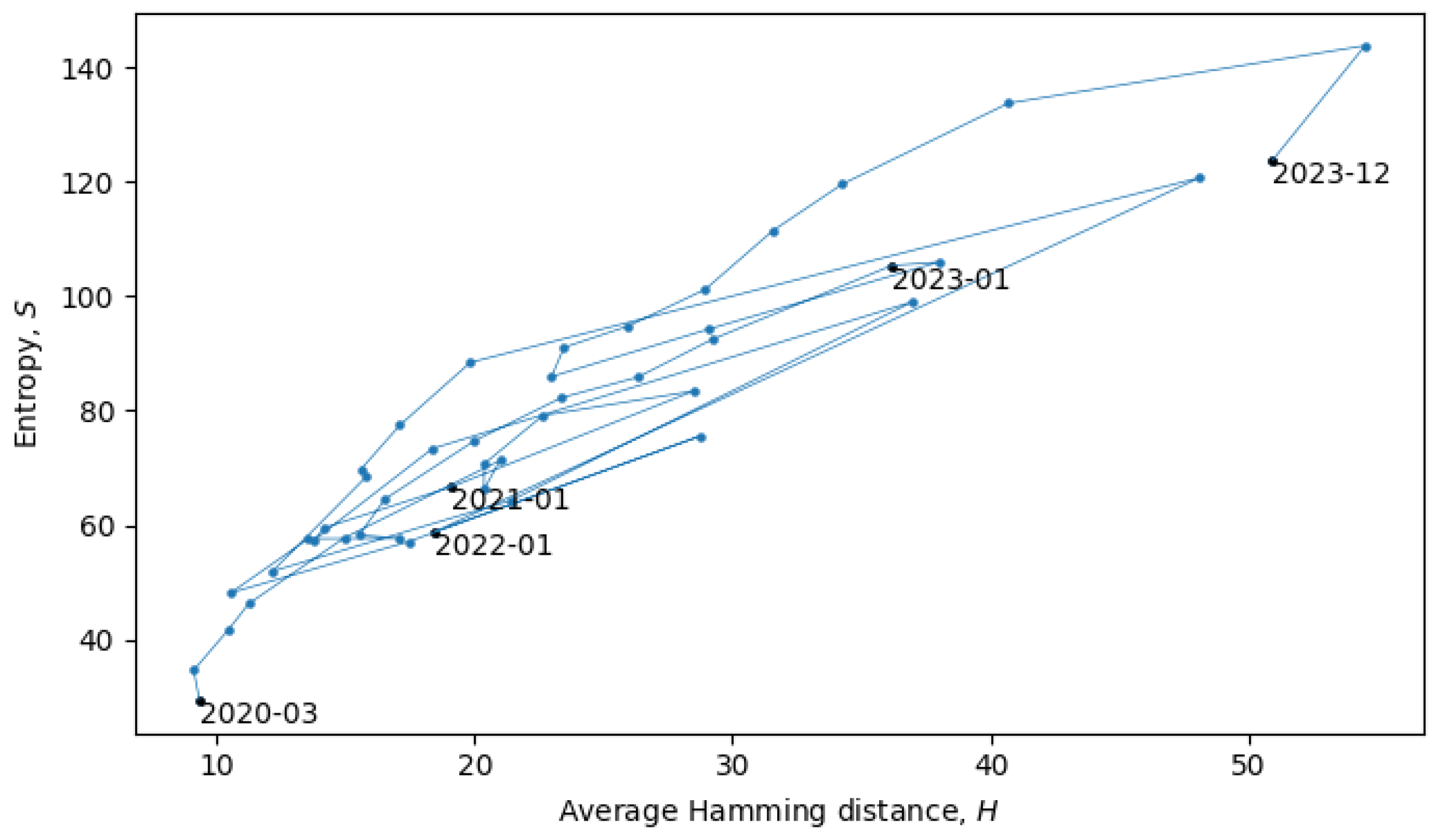
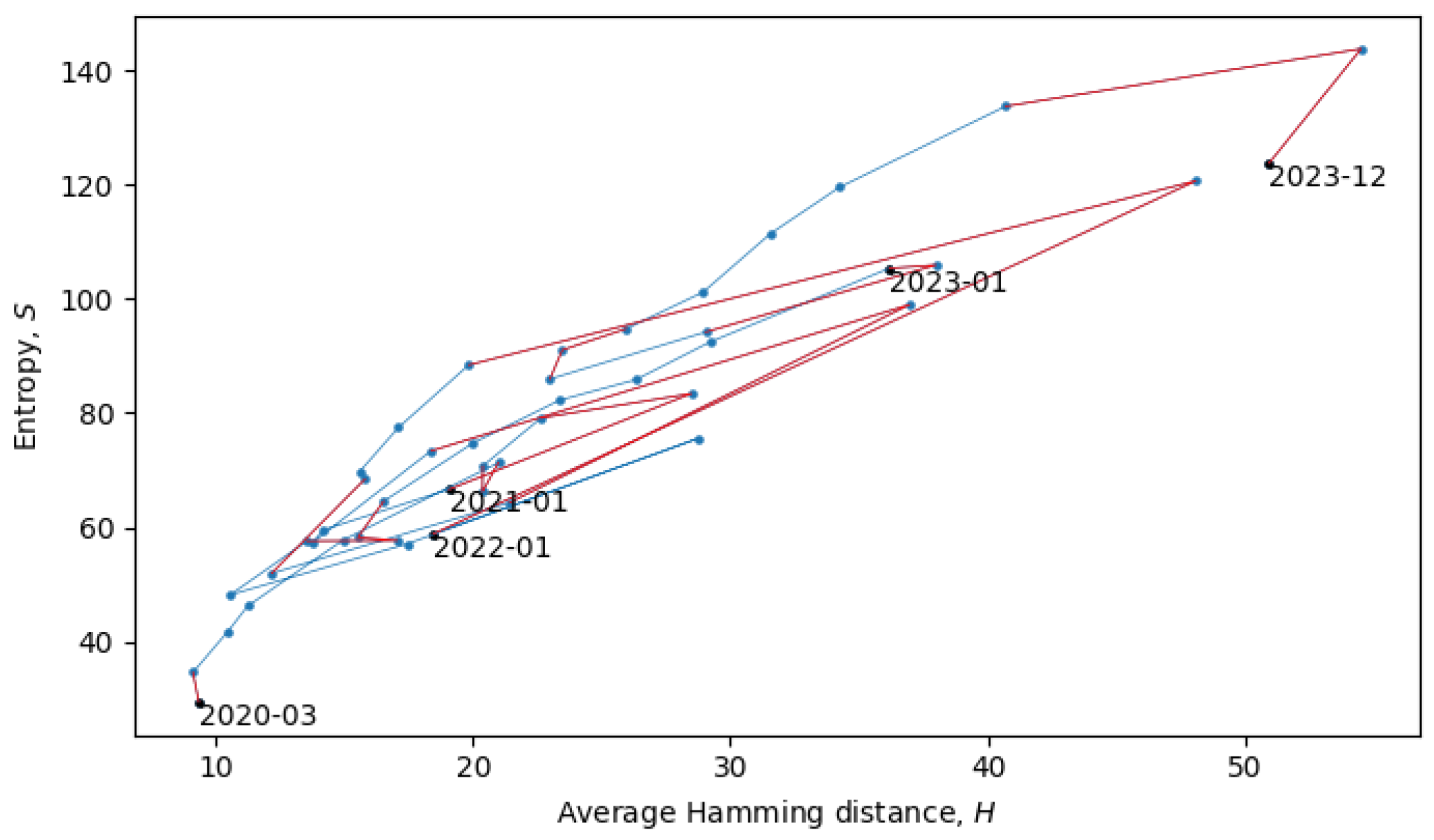
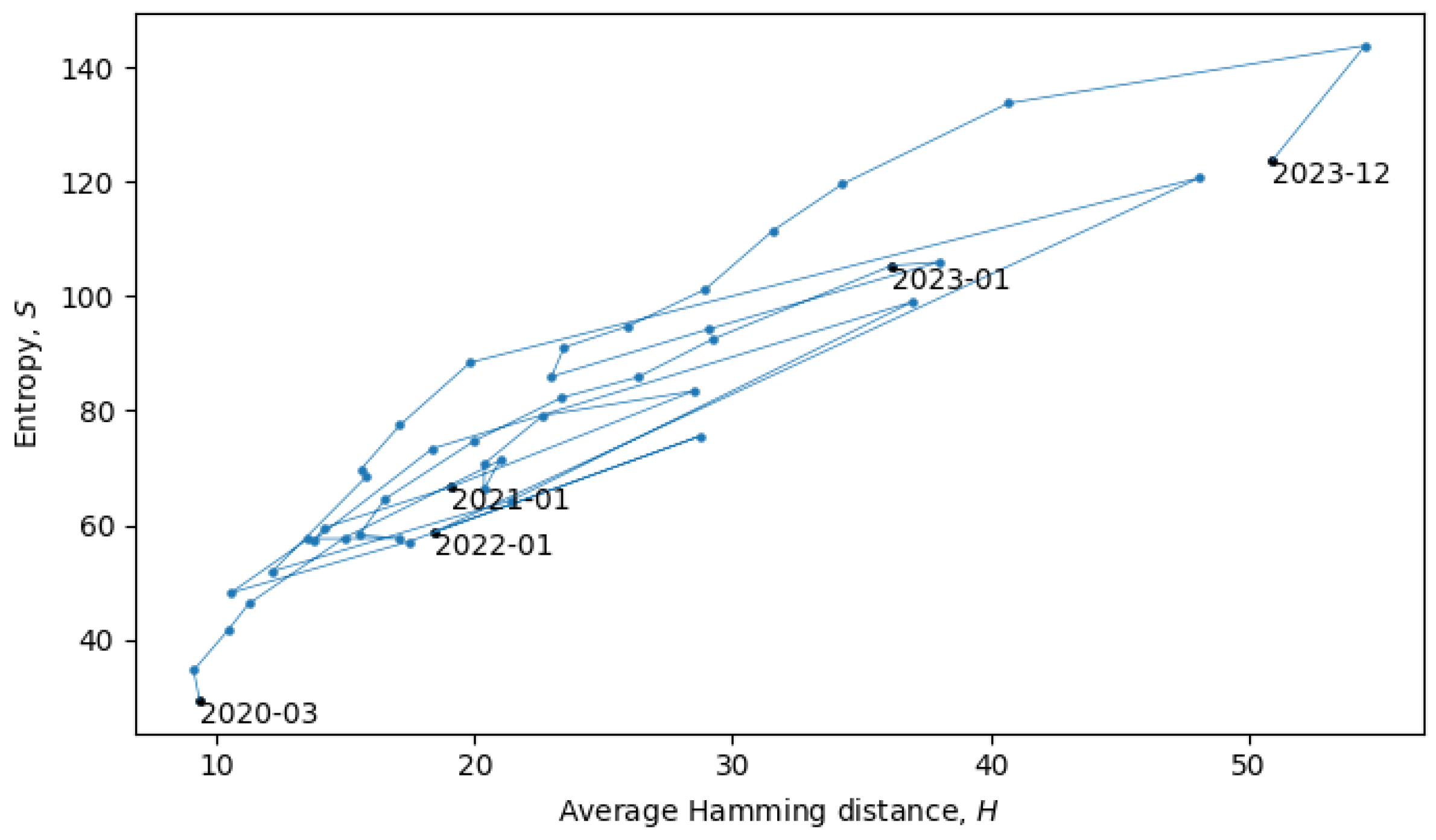
Section 4). In the scatter plot in
Figure 8, each point represents a single month in the evolution of coronaviruses and consecutive months are connected by lines. In what follows, we will describe a procedure for grouping the consecutive points into a quasi-equilibrium state, which can be described by a joint probability distribution
.
When the system is in a quasi-equilibrium state (i.e., between phase transitions), both
S and
H can change more or less continuously, but an approximately linear dependence between them remains fixed. In a Gaussian limit, such distributions are given by
with variances
. There may also be non-Gaussianities, the analysis of which is beyond the scope of this paper. In relation to the coronavirus data, we identified eight quasi-equilibrium states, whose parameters are summarized in
Table 2.
Note that the identification of the quasi-equilibrium states depends on the considered time scales. For example, by considering a larger time scale, we could have grouped together all of the data in
Figure 8 into a single statistical ensemble described by parameters
,
,
,
, and
, but then, we would not be able to identify the more fine-grained details of the “minor transitions in evolution” discussed here.
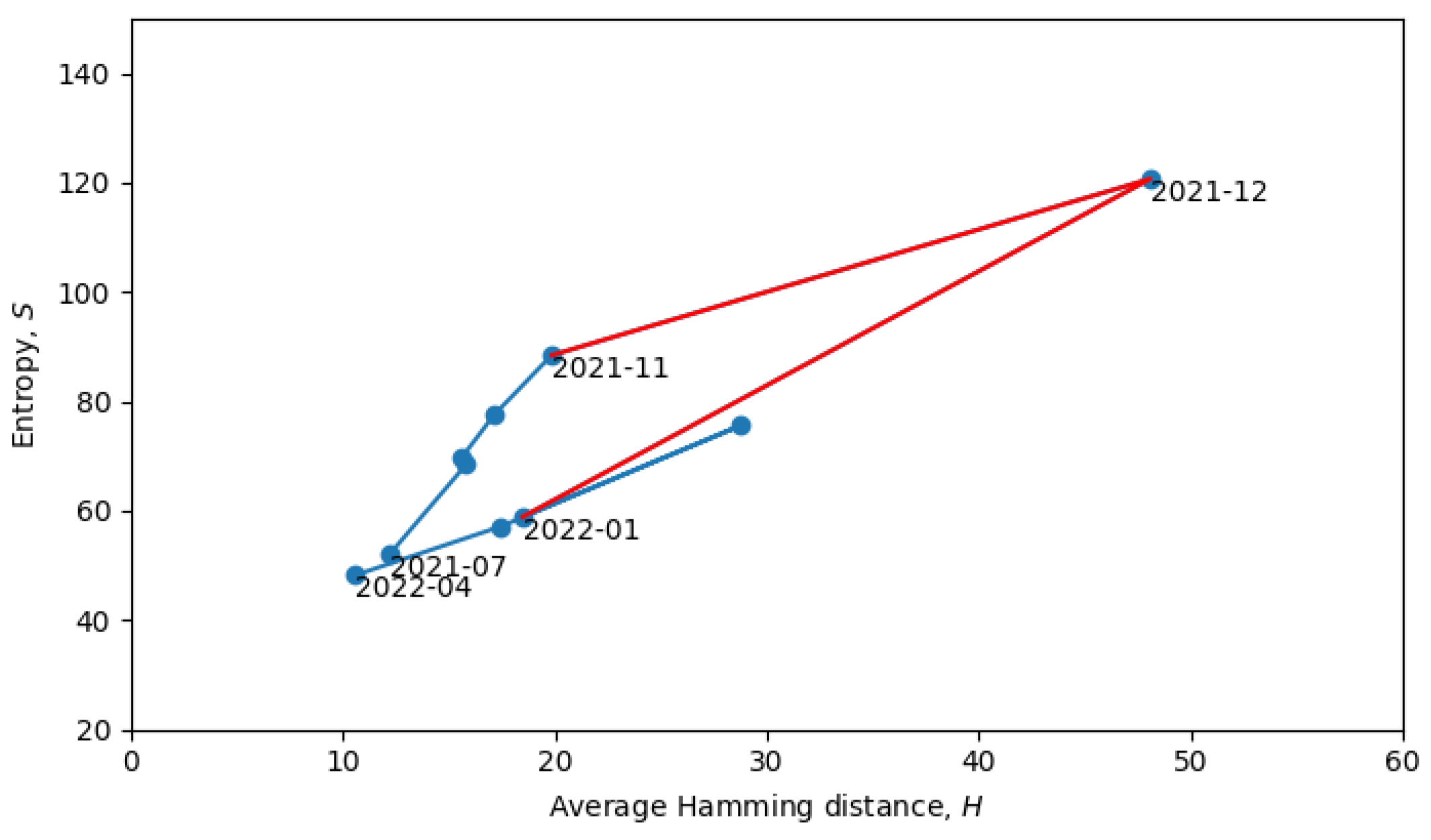
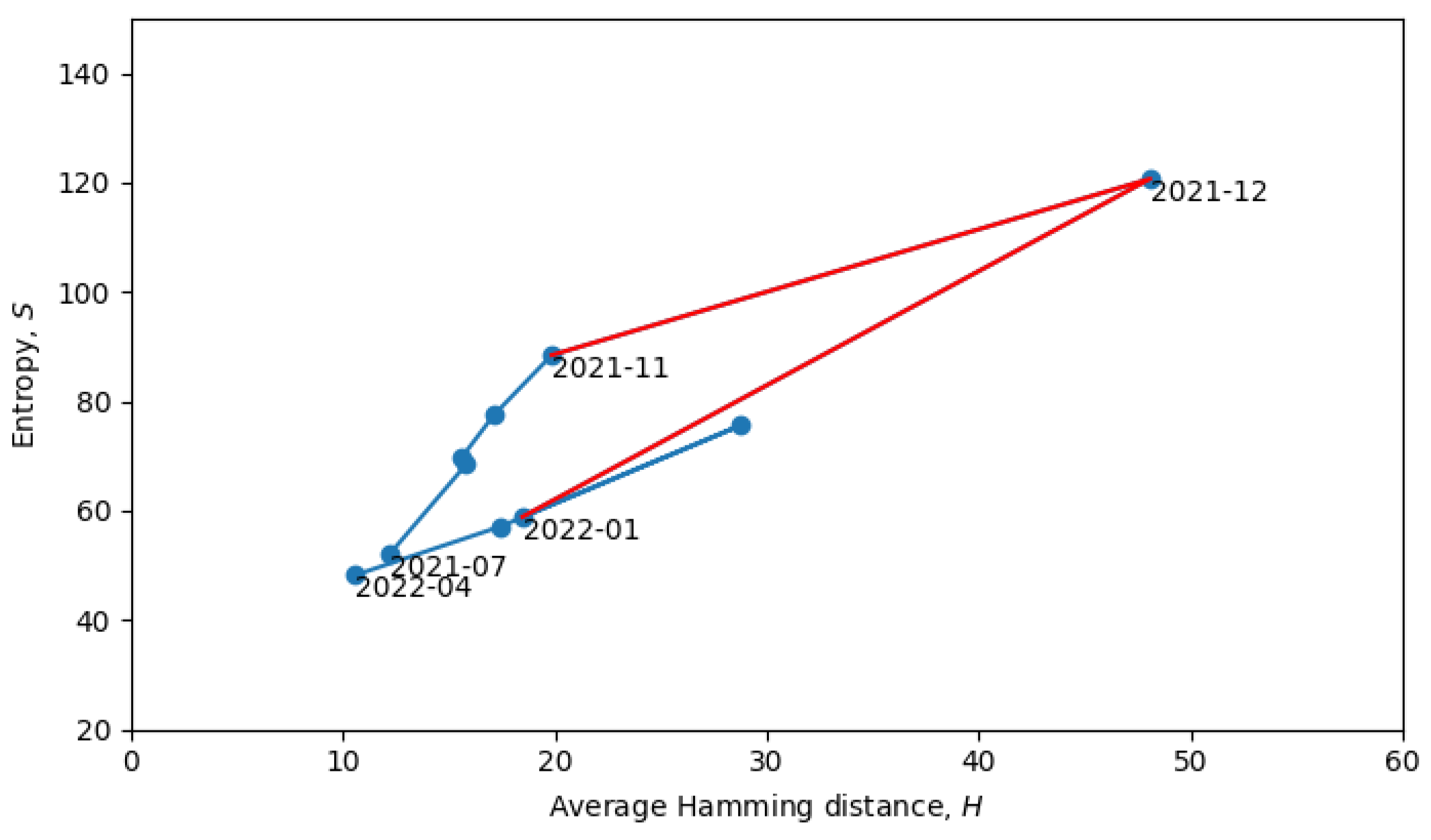
Returning to the phase transitions between quasi-equilibrium states, consider the period from July 2021 to April 2022, as plotted in
Figure 9.
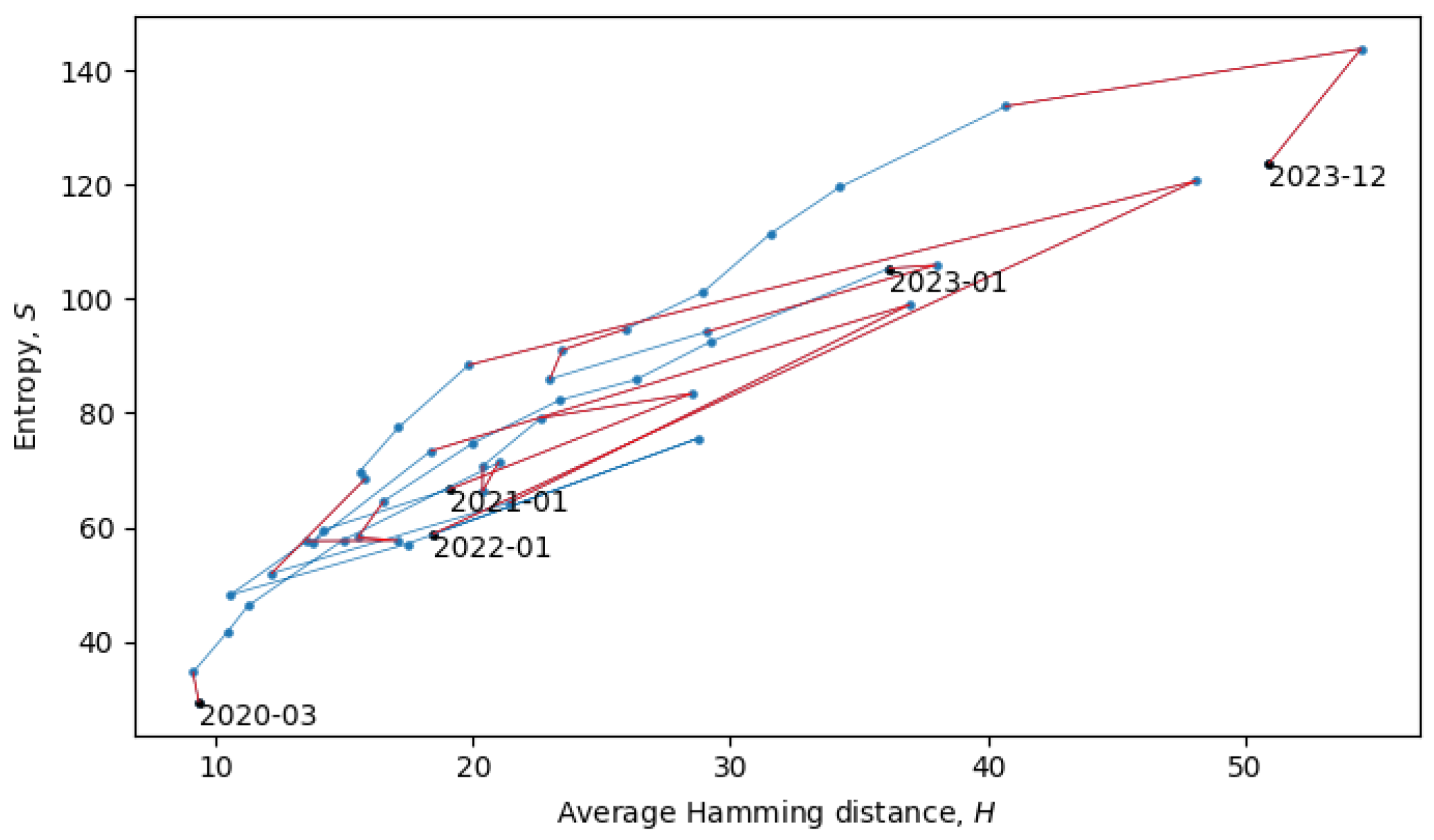
The two connected blue lines represent the two quasi-equilibrium states, and the red line indicates a single phase transition that occurred around December 2021. Other phase transitions (and quasi-equilibrium states) can be seen in
Figure 10, which is the same as
Figure 8, but with quasi-equilibrium states marked in blue and phase transitions marked in red. It appears that the system has recently undergone a phase transition and is currently transitioning to a new quasi-equilibrium state, the statistical properties of which are still to be revealed.
6. Conclusions
The evolution of any biological system can be analyzed either microscopically (e.g., by tracking individual mutations) or macroscopically (e.g., by monitoring the dynamics of macroscopic or thermodynamic parameters). In this paper, we primarily focused on the macroscopic modeling of the total Shannon entropy (see
Section 3) and average Hamming distance (see
Section 4) to study the evolution of the coronavirus using publicly available data from the United Kingdom between March 2020 and December 2023. In particular, we identified the so-called quasi-equilibrium states, when an approximate linear dependence between the total Shannon entropy and the average Hamming distance holds, and phase transitions between such states, when the linear dependence breaks down (see
Section 5).
The quasi-equilibrium state in the early pandemic corresponds to the prevalence of a single variant. However, in the late pandemic, the quasi-equilibrium states can acquire additional scales (or levels) and simultaneously describe multiple variants, forming what we call a multi-level quasi-equilibrium state. The numerical analysis suggests that the system is about to complete a phase transition to a new (and perhaps multi-level) quasi-equilibrium state, whose statistical properties are yet to be uncovered (see
Section 5).
In a quasi-equilibrium state, an evolving system constantly undergoes neutral mutations, exploring the neutral network. However, these mutations do not significantly increase or decrease its fitness. For the coronavirus, this typically lasts for a period of a few months until the virus undergoes an adaptive mutation that increases its fitness, providing it with an advantage over the old variants. This is a phase transition, during which, a statistical ensemble of viruses (and the corresponding macroscopic parameters such as the Shannon entropy and Hamming distance) changes discontinuously, which allowed us to consistently identify and study such phase transitions.
The performed studies open a gateway for modeling evolutionary dynamics in terms of macroscopic parameters, which need not be confined to only the Shannon entropy and Hamming distances. As was discussed in the paper, for each quasi-equilibrium state, there is a network of neutral mutations, and the statistical properties of the network can be analyzed using either numerical or analytical tools such as partition functions, perturbative calculations, spectral methods, etc. For example, some of the quasi-equilibrium states contain central sequences, which is evident from the analysis of the single-sequence average Hamming distances (see
Section 4), but in general, much more statistical and spectral information about the neutral networks remains to be uncovered.
Furthermore, the conducted analysis revealed the potential utility of statistical methods in establishing an early warning system for pandemics, offering an independent value for humanity. The argument put forth suggests that a discontinuous change in the average Hamming distance or total Shannon entropy serves as a robust early indicator of a phase transition. While this concept makes sense, there might be an even more-effective approach to detecting potentially perilous phase transitions. For instance, even if the total entropy remains continuous, but experiences rapid growth, the effective space of possible mutations expands rapidly, thereby increasing the probability of an adaptive mutation. Utilizing the spectrum of the neutral network could enable predictions regarding when such mutations and subsequent phase transitions might occur. However, for making accurate predictions, additional spectral and statistical analyses are required, which we defer to future research.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}