1. Introduction
Accurate representation of asset returns is one of the key topics in finance. Based on the theoretical results from [
1,
2], standard approaches to asset pricing have largely focused on the first and second moments. Stochastic volatility (SV) models, discussed, for example, by [
3], are among the cornerstone models in modern financial econometrics. In their simplest form, SV models represent asset returns via normal distribution with persistent volatility and a mean that is either constant or a linear function of explanatory variables. Such models capture the first two moments of asset returns in a simple and elegant manner, being supported empirically and theoretically, as discussed in [
4].
While we acknowledge the importance of the first two moments in asset pricing, we also recognize the potential benefits of including skewness when modeling returns. Due to its ability to capture the likely direction of returns, models with time-varying skewness may be more suitable for forecasting periods with a higher concentration of same sign returns, leading to better detection of both overperformance and underperformance periods. Ref. [
5] is one key example of the empirical benefits of adding such feature for modeling cross-sectional stock momentum. While the momentum factor is known for delivering good mean–variance compensation, it is also subject to a long period of negative performance. By capturing such prolonged periods of likely negative returns via dynamic skewness, ref. [
5] improves the performance of the stock momentum factor compared to traditional approaches that neglect skewness.
However, including dynamic skewness in traditional financial econometric models can be costly. While allowing for asymmetry may lead to a better representation of some financial time series, it may not be a vital feature, and its inclusion risks overparameterization. Therefore, we wish to include dynamic skewness only when required by the data and remove such a feature if it is not necessary.
This paper expands stochastic volatility models by allowing dynamic skewness without having to impose it. We replace the traditional hypothesis of Gaussian errors with a skew-normal distribution. Such a change preserves the usual features for the first two moments of SV models but allows for dynamic skewness. Since the inclusion of time-varying asymmetry may not always be necessary, we consider a sparsity-inducing scheme for its parameters. In particular, we consider a random-walk evolution for the asymmetry. When the standard deviation of the dynamic process is shrunk to zero, our model results in an SV model with constant skewness. Additionally, if the level of skewness is shrunk to zero, we recover a traditional SV model. By combining prior information with the likelihood of the model, our proposed approach automatically chooses between dynamic, static, or no skewness.
We consider two empirical applications. In our first application, we model Brazil and US bonds, obtaining three main results. First, our proposed model indicates that bond yield changes for both countries, better represented by including time-varying skewness, resulting in out-of-sample improvements for forecasting the direction of future yields when compared to generalized autoregressive score (GAS) models. Second, the recovered skewness is associated with interest rate cycles of monetary easing and tightening. Third, inflation and unemployment partially explain the recovered skewness, linking it to central banks’ mandates. In a second application, we model the carry factor for currency returns. Our model indicates not only the lack of dynamics, but also no skewness at all for it after accounting for volatility. Therefore, similar to the crash mitigation via volatility scaling proposed in [
6], the carry factor also experiences reduced crashes once dynamic volatility is considered, without requiring the inclusion of skewness.
This paper intersects and contributes to multiple areas. First, it contributes to the stochastic volatility literature by expanding the static skewness model of [
7] to the dynamic case while also extending the sparsity-inducing scheme of [
8] by allowing for dynamic skewness to shrink towards the static case. Second, it contributes to the toolbox of methods for recovering dynamic skewness. Ref. [
9] relies on option data, while [
10] uses rolling windows. Both approaches have limitations. While theoretically sound, option-based approaches require tradeable options with a large collection of strikes, high liquidity, and continuous expiration dates. Such requirements are hard to meet in many applications, especially for emerging markets such as in our Brazilian bond applications. Rolling window-based approaches artificially introduce dynamics into skewness by changing the sample period continually. Such changes come at the cost of outliers playing a large role in estimation, in addition to a trade-off based on window size, which affects the precision of the estimate and the speed at which the dynamics change. Third, it contributes to the interest rate literature by showing that inflation and unemployment partially explain skewness, linking it to central banks’ mandates, and expanding the traditional mean and variance analysis of papers such as [
11,
12]. Fourth, it contributes to the debate of whether the carry factor presents dynamic skewness after accounting for heteroskedasticity, as discussed in [
13,
14], by claiming that skewness is unlikely to be dynamic and, in fact, is more likely to be zero after accounting for SV effects.
The paper is organized as follows. It starts by describing traditional SV models and moves on to our proposal with time-varying skewness in
Section 2.
Section 3 discusses the sparsity-inducing framework.
Section 4 shows our Hmailtonian Monte Carlo (HMC) approach to simulate from the joint posterior.
Section 5 presents the bond yield forecasting application while
Section 6 shows the carry factor application.
Section 7 concludes.
2. SV Model with Time-Varying Skewness
A traditional stochastic volatility model is defined in Equations (
1)–(
5). Equation (
1) represents asset returns with a mean of zero and dynamic volatility of
. Equation (
2) indicates persistent log-volatility with level
and persistence
, having initial values given by the stationary distribution shown in Equation (
3). In its simplest form, both measure and state equations have Gaussian errors as represented in Equations (
4) and (
5).
In order to introduce asymmetry into the model, we replace the normal variable,
in Equation (
4) with a skew-normal random variable,
. We utilize the skew-normal density representation described in [
15,
16] as shown in Equation (
6), where
and
represent standard normal density and distribution function, respectively.
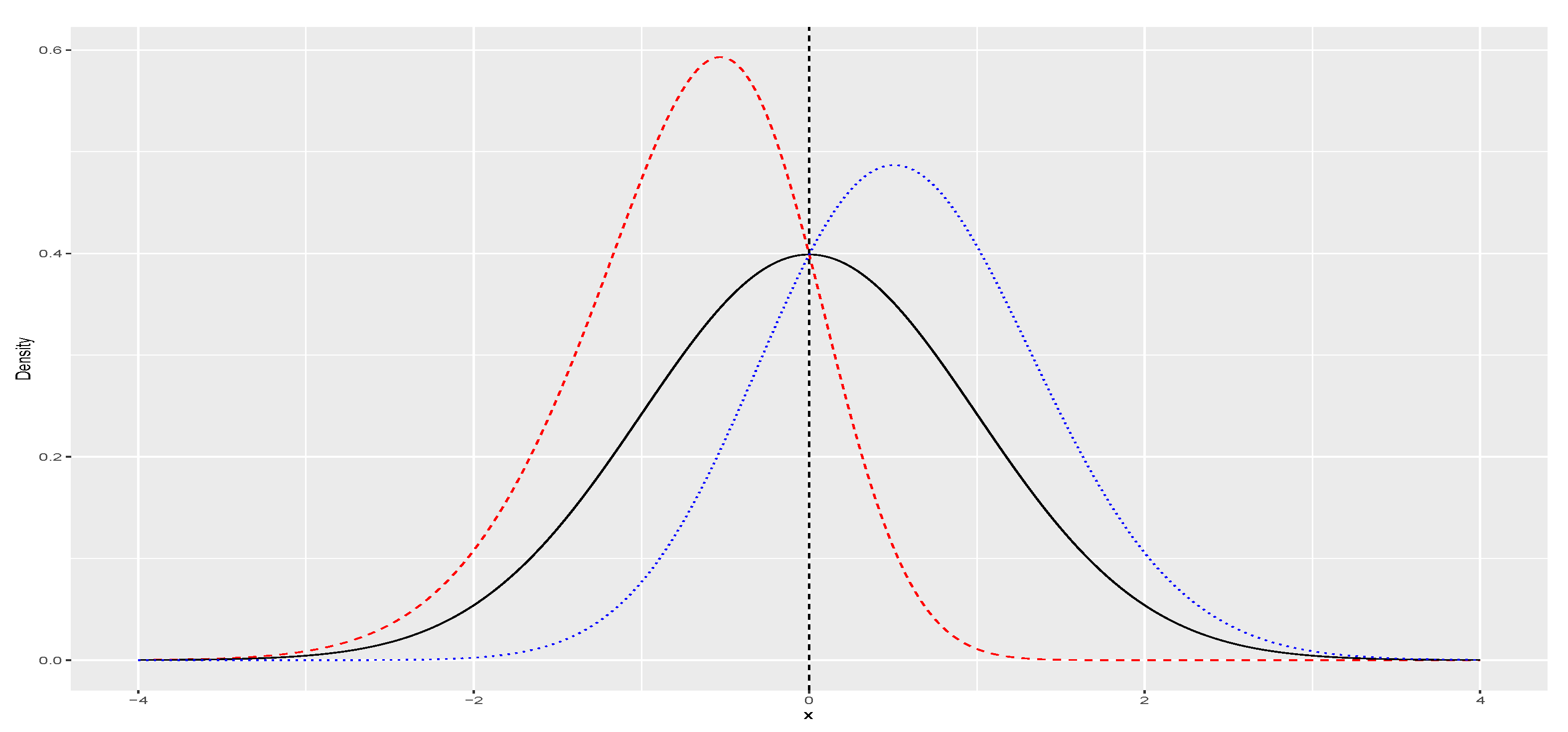
controls the degree of asymmetry in the distribution, as depicted in
Figure 1. Specifically, for
, the skew-normal reduces to standard normal distribution. Additionally, we can introduce location (
) and scale (
) parameters to the skew-normal, denoting
as
, with its density presented in Equation (
7).
Appendix A describes the relationships between
,
, and
in terms of mean, variance, and skewness.
We allow for the possibility of dynamic skewness by replacing static
with
, which evolves according to a random walk starting at
as represented by Equations (
8) and (
9). Therefore, we modify our observation equation by enabling both volatility and skewness to vary with time, changing the observation equation to Equation (
11). While Equation (
1) implies that
follows a symmetric distribution, Equation (
11) indicates that
comes from a potentially skewed distribution. Therefore, our model can be viewed as an extension of the stochastic volatility models with static skewness proposed in [
7,
8,
17].
Since
, Equation (
1) implies that
follows a normal distribution with a location of zero and a scale of
. By replacing
with
, Equation (
11) implies that
follows a skew-normal distribution with a location of zero, a scale of
, and skewness parameter
.
We are not the first to consider models with dynamic skewness. For instance, refs. [
18,
19] introduced GAS models which induce time-varying skewness through the score of conditional density. More recently, refs. [
5,
20] used GAS models to model Bitcoin returns and manage momentum-based portfolios. However, unlike our proposal, GAS models are suitable for including time-varying higher moments within a GARCH-like framework, while our proposal is designed for SV models.
3. Sparsity-Inducing Approach
The inclusion of asymmetry may improve the representation of time series by capturing periods with a higher concentration of returns exhibiting the same sign, as demonstrated, for instance, in [
5,
16,
21]. However, it may not always be necessary as it involves estimating additional parameters. To mitigate the risk of overparametrization, our aim is to incorporate time-varying skewness only when required by the data. One possible approach involves estimating multiple models with different skewness specifications and then selecting a model using the Bayes factor. Ref. [
22] provides a comprehensive review of using Bayes factors for model selection. However, recovering Bayes factors can be a challenging problem, as highlighted in [
23]. We propose a sparsity-inducing method that conveniently performs model selection without the need to estimate multiple models and entirely avoids the use of Bayes factors.
In the non-Bayesian literature, shrinkage is based on maximizing the likelihood of a model subject to a penalty function with the LASSO of [
24] being the most commonly employed approach. From a Bayesian perspective, shrinkage problems can be framed as a penalization of the log-likelihood through a log-prior. In fact, the posterior mode of a linear model with Double Exponential prior having a location of zero and a scale of
equals the point estimate of the LASSO with penalty
, as shown in [
25]. Therefore, to shrink both
and
towards zero, we utilize Double Exponential priors for both parameters, as illustrated in Equations (
12) and (
13).
Our proposal is consistent with the concept of sparsity in dynamic models, a principle also utilized in [
26,
27,
28,
29]. Our approach is considered sparsity-inducing in the sense that both the random walk variance and initial state for the skewness parameter are shrunk towards zero. Equation (
9) governs the dynamics of the asymmetry parameter. When
approaches zero,
becomes static and assumes the value of its initial point,
. Furthermore, if the initial point is also zero, the model reduces to the vanilla SV model. Hence, by inducing sparsity for both
and
, we can encompass all three cases of interest.
To the best of our knowledge, we are the first to introduce sparsity in the dynamic skewness framework. The closest paper to ours is [
8], which uses the spike and slab prior of [
30] to estimate the posterior probability of inclusion of static skewness.
4. Remaining Priors and Posterior Inference
Our modeling approach involves the following unknown quantities:
. Our goal is to estimate the joint posterior distribution
, which, according to Bayes’ rule, can be calculated as
is the likelihood component being characterized by our proposed sampling model. We consider independent components for each member of
.
and
follow Gaussian distributions,
has inverse gamma distribution while
and
have double exponential distribution, as discussed previously. The exact values for the prior parameters are described in
Appendix B and
Appendix C.
After defining and , we must recover . However, does not have an analytical solution. Moreover, due to the high dimensionality of , grid-based integration methods are computationally infeasible. Thus, we employ to Markov Chain Monte Carlo (MCMC) methods to sample from . In this paper, we use a particular MCMC method, known as HMC, instead of the more traditional Random–Walk Metropolis Hastings (RWMH).
Both HMC and RWMH are MCMC methods. Thus, both methods generate a proposed value for unknown quantities
on each Markov chain iteration i in order to approximate
. We denote the sequence of
by
. In our applications, we run our HMC scheme for 30,000 iterations with the first 15,000 being used as burn-in draws. HMC and RWMH differ in their approach to generating
from
. RWMH generates
as a random walk from the previously sampled
. In contrast, HMC enhances the process by using guided proposals based on the gradient of the log posterior. This guidance helps direct the Markov chain toward regions of higher posterior density while also sampling tail areas properly, as discussed in [
31,
32]. Specifically, HMC generates proposals by solving the following Hamiltonian equations:
where
represents the Hamilton function. In the context of this paper,
. Additionally,
is the gradient of the log posterior density. Due to
, ref. [
31] claims that HMC generates guided proposals. We refer readers to [
31,
32] for a thorough review of HMC methods.
We choose HMC over RWMH for two main reasons. First, due to its more refined method to generate
, HMC requires several iterations less than RWMH. This difference becomes even bigger if
is high-dimensional which is the case in this paper. Second, the software Stan verison 1.2, introduced in [
33], offers convenient implementation of HMC. In our study, we utilize Stan in conjunction with R through the rStan package introduced in [
34] (The codes and data for this project are available on the first author’s GitHub page,
github.com/igorfbmartins, shortly after publication).
5. Empirical Application: Bond Yields
The bond market is one of the largest in the world being key for investors and policymakers. Most papers focus on the first two moments, e.g., refs. [
11,
12,
35,
36]. Our paper focuses on the much less explored third moment. Skewness captures the likely direction of returns allowing for an interest rate investor to improve their forecast about the sign of future yields. Such feature is explored in the literature in at least three ways. First, ref. [
5] highlights the role of skewness in forecasting crashes in momentum portfolios. Second, works [
37,
38] highlight that even monetary ’surprises,’ such as the differences between actual policy rates announced by the Federal Open Market Committee (FOMC) and expectations from professional forecasters, can be partially predicted by the option-implied skewness of the 10-year US bond. Third, ref. [
17] demonstrates that allowing for skewness improves value-at-risk evaluation for multiple assets.
In our first application, we model the monthly yield changes in fixed 1-year maturity for both American and Brazilian bonds. We sample from the joint posterior via the HMC scheme presented in
Section 3 by combining the likelihood implied by our proposed model in
Section 2 and the priors described in
Appendix B. In both cases, skewness is likely to be time-varying. It is associated with cycles of monetary easing and tightening. It is partially explained by the central bank’s mandate and provides valuable information regarding the future direction of yield changes.
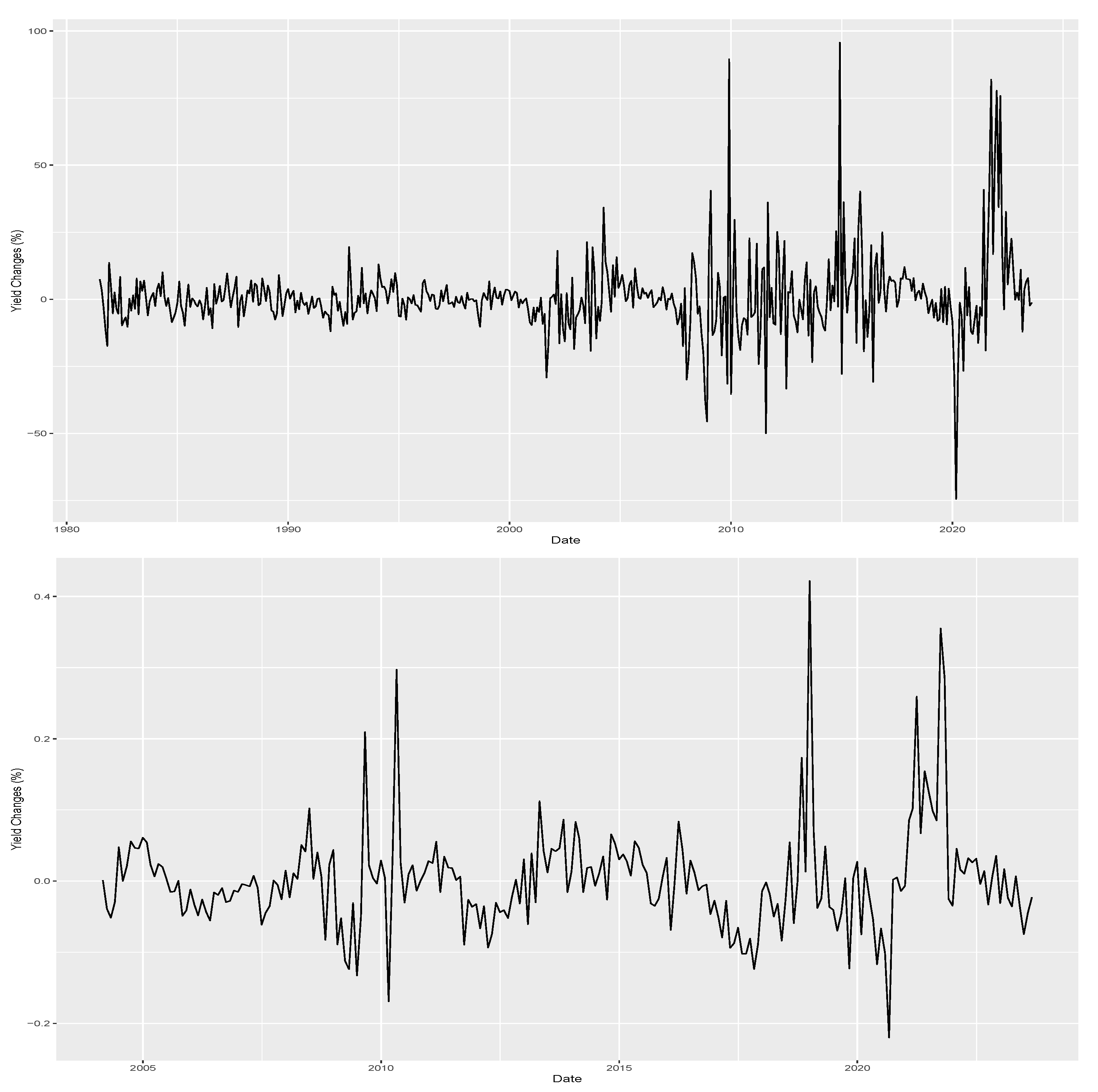
The sample of US bonds comes from the updated dataset of [
39] made available by the Federal Reserve Board starting on July 1981 and lasting until August 2023. The sample of Brazilian bonds is based on the DI interest rate contracts available on the Brazilian stock and future exchange B3. The DI contracts are interpolated to form 1-year fixed maturity bonds using the same Nelson–Siegel procedure described in [
39] resulting in a sample starting in February 2004 and ending in August 2023.
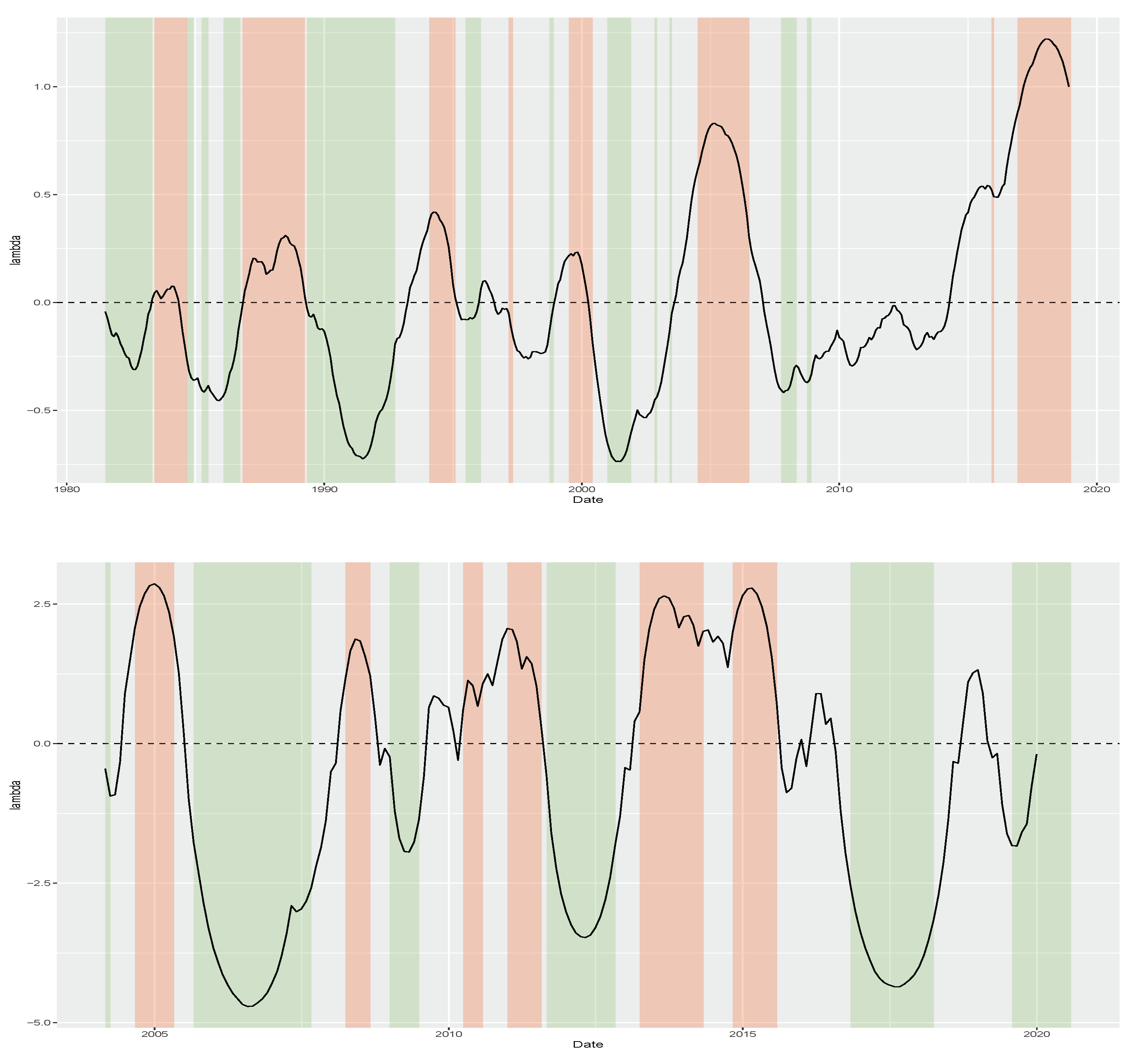
Figure 2 plots both time series of monthly yield changes. Notably, both series fluctuate around zero with volatility clusters. Both series hint at the possibility of skewness. For example, the US series presents a persistent and negative yield change period in early 1990 and early 2000. In the Brazilian series, the negative and persistent yield changes are even clearer, with the period from August 2016 to March 2018 being one example.
Some might express concern that the guidance provided by central banks regarding future rates entirely dictates yield changes. However, such concerns are unlikely to be substantial for several reasons. First, if central bank communication were the sole determinant of yields for 1-year fixed maturity bonds, yields would instantly adjust to incorporate the information from newly announced paths and persist at that level until subsequent announcements, in line with the efficient market hypothesis. Second, current yields not only reflect the anticipated average future short rate over a bond’s lifespan, but also encompass a term premium component. As demonstrated, for instance, in [
40,
41], this term premium component is likely to be time-varying. Consequently, yields are expected to fluctuate over time even after accounting for the expected future short rate. Third, while central bank communication indeed aids in forecasting future yields, it is by no means the sole source of information, as exemplified in [
42].
We apply our proposed model to both US and Brazilian bonds with the priors presented in
Appendix B. To account for the Brazilian time series being shorter than the American, the estimation sample comes closer to the present than the American. Precisely, we consider an estimation period which lasts up to December 2018 for the US and up to December 2019 to the Brazilian case.
Table 1 presents the posterior summaries for the parameters of both time series. The values of
indicate high persistence in the log-scale which is reflected in
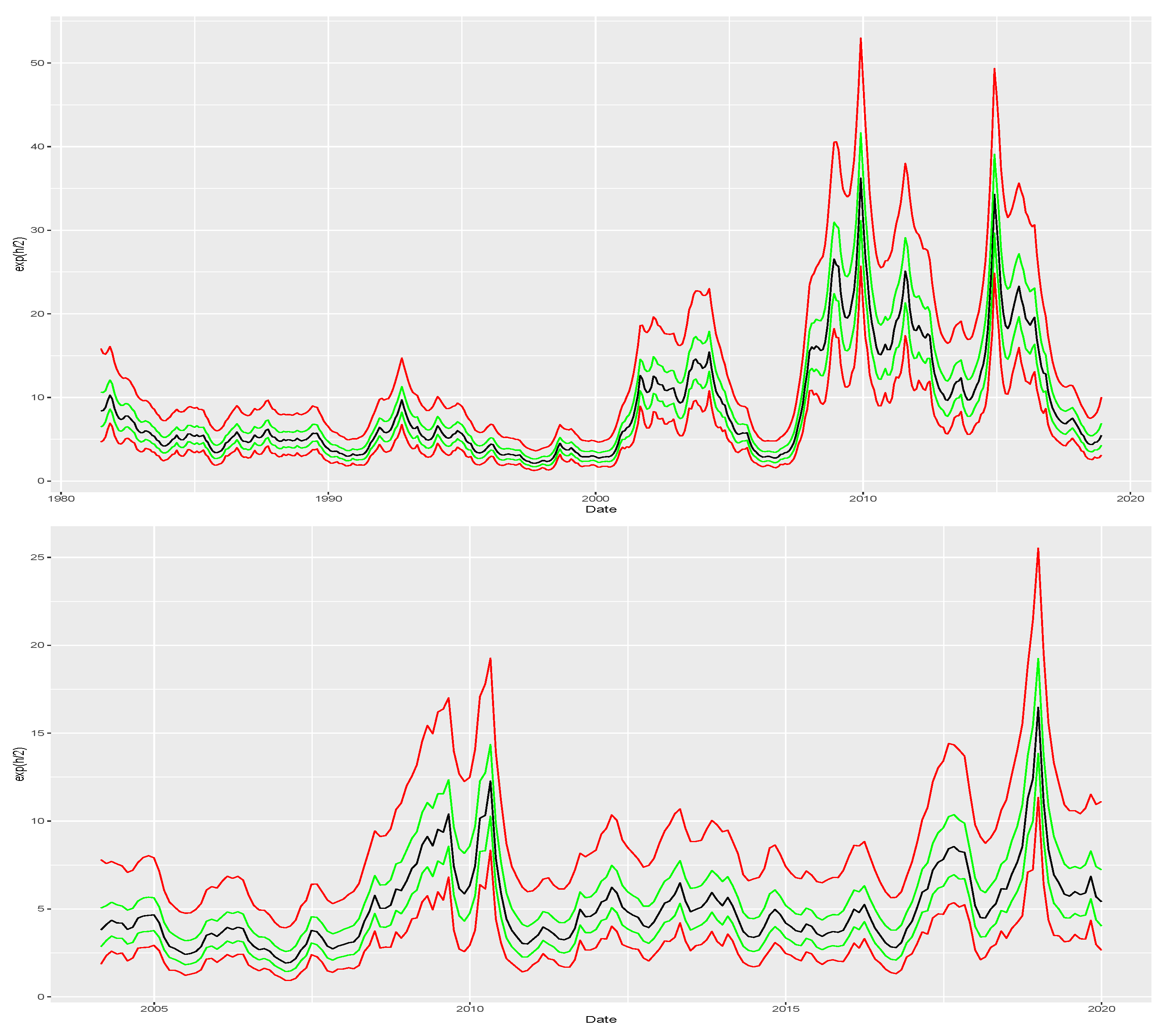
Figure 3 that plots posterior summaries of
. In both cases, our approach captures the surges in volatility indicated in
Figure 2. For instance, in the US series, our model captures spikes in volatility during the early 2000s and the financial crisis of 2008. Similarly, the Brazilian time series shows a volatility spike in 2008, which our model also captures. Additionally, both series are likely to have a dynamic skewness as shown by the posterior summaries of
with the Brazilian bonds having a bigger range of variation for
than bonds from the US. This evidence is supported by the posterior summaries of
in
Figure 4 as well.
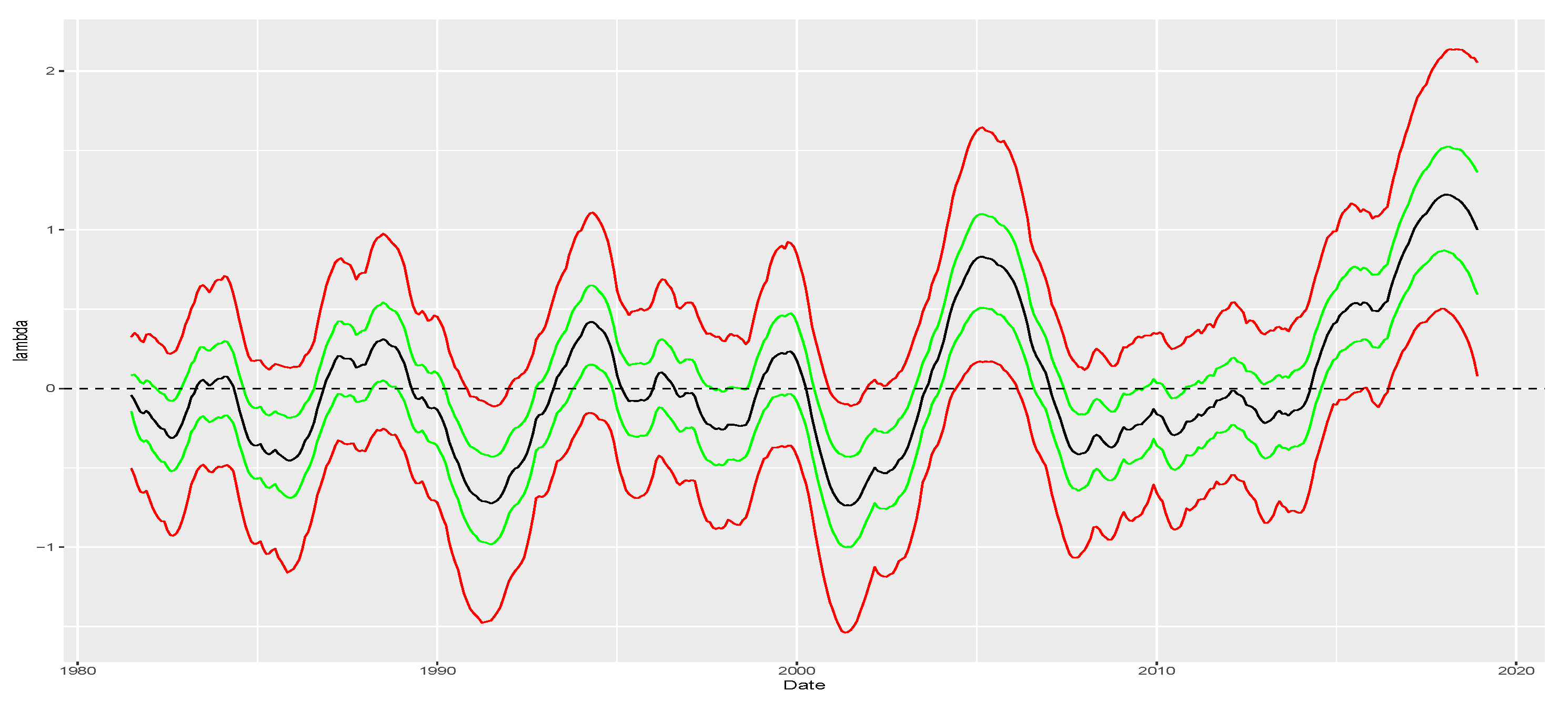
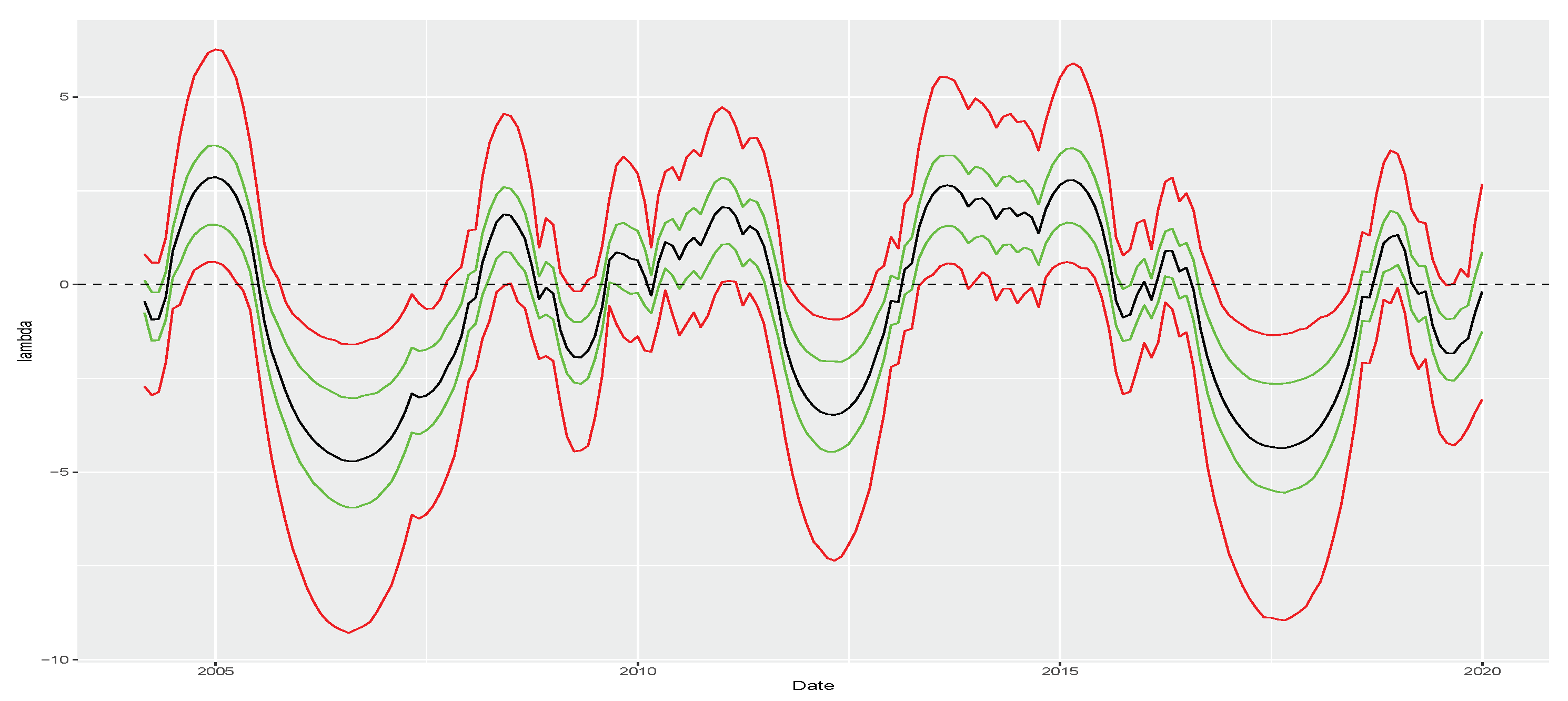
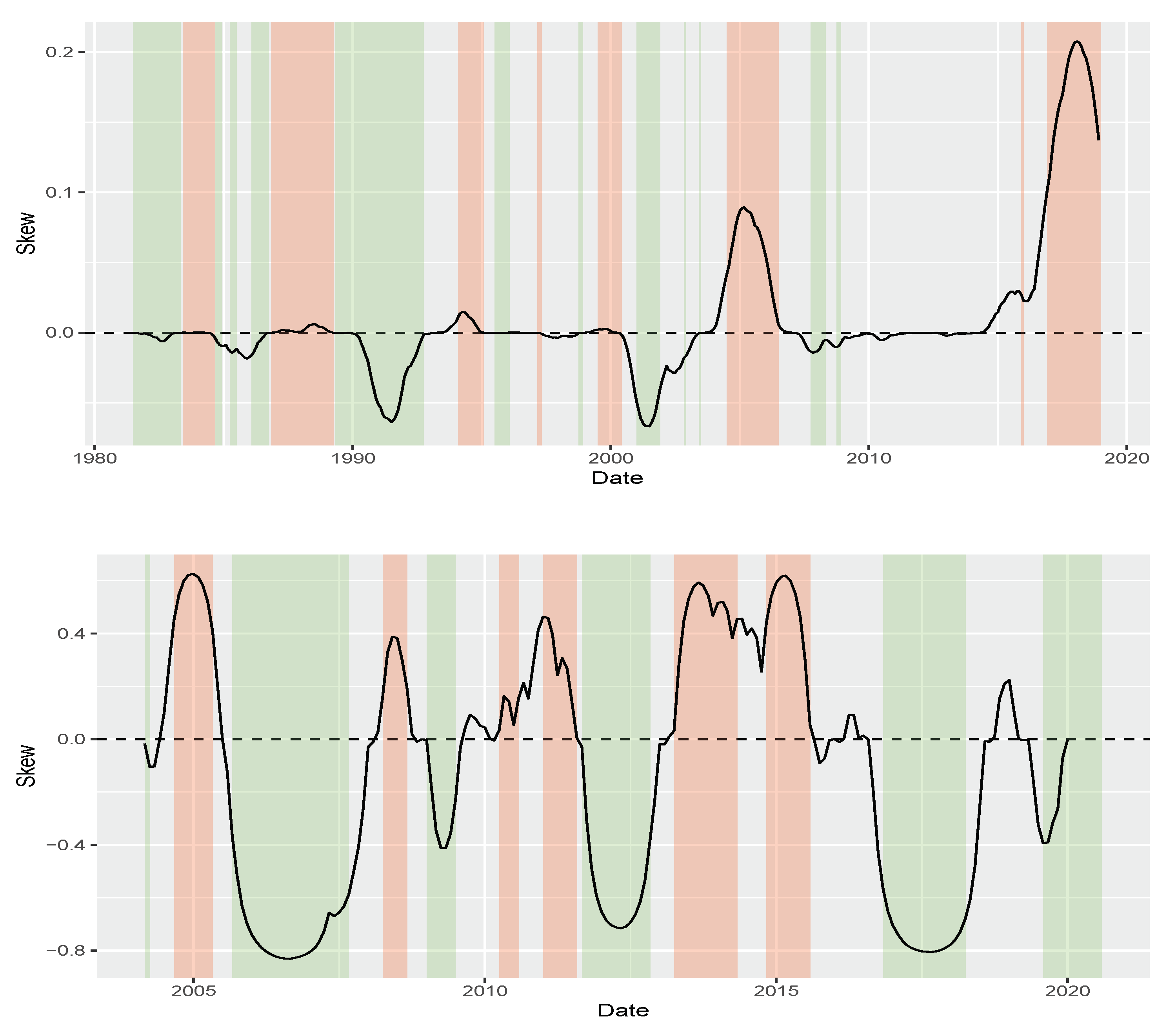
Figure 5 plots the posterior mean of
alongside monetary easing–tightening cycles. The green shaded areas represent periods of monetary easing characterized by interest rate cuts implemented by the countries’ central banks. Conversely, the red shaded areas represent periods of monetary tightening marked by interest rate hikes. Our approach identifies negative skewness in yield changes during easing periods and large positive skewness when a central bank is hiking interest rates. The monetary policy cycles for the US are based on the FED effective fund rate, while for the Brazilian case, they are derived from the target rate policy decisions of each meeting (Brazilian target policy rate is available at
https://www.bcb.gov.br/controleinflacao/historicotaxasjuros (accessed on 28 November 2023)).
If the asymmetry of yield changes is connected to interest rate cycles, then drivers of the monetary policy should help explain skewness. We test this hypothesis by regressing the posterior mean of
, denoted
, into inflation and unemployment as represented by Equation (
14). Both variables are reasonable ex-ante since central banks have mandates of price stability and full employment.
Table 2 indicates that unemployment levels partially explain the asymmetry in yield changes for both countries. The negative sign of
is reasonable since central banks typically address high unemployment levels by implementing interest rate cuts to encourage consumption, and, as shown in
Figure 5, easing cycles are associated with negative skewness on yield changes. Moreover, in the case of Brazil, inflation is likely to also influence this asymmetry. The positive sign of
aligns with central banks’ tendency to counter inflation surges by raising interest rates. As illustrated in
Figure 5, this is associated with higher values of skewness. Regarding the US, although inflation posed challenges in the late 1970s and early 1980s, for most of our estimation sample, the American economy did not face significant inflationary pressures. Consequently, yields did not react substantially to inflation. Therefore, the nearly zero effect of
is justifiable.
We also evaluate the out-of-sample performance of our proposed model. If skewness is informative about the likely direction of changes in bond yields, then
should agree with
. We verify this claim within an increasing window framework, where the initial window corresponds to the estimation sample. For each window, we execute our HMC procedure and obtain
.
Table 3 presents our findings. For US bonds, we observe that
matches
in 66.1% of cases, with an average change of 20.6% when correctly forecasted and only 8.7% when incorrect. Similarly, in the case of Brazilian bonds,
aligns with
in 72.7% of instances. Moreover, the average magnitude of correctly predicted yield changes is 8.2%, while it is only 2.4% when the prediction is incorrect. Therefore, out-of-sample analysis supports our assertion that dynamic skewness in bond yield changes serves as a predictive variable for future yield changes. Furthermore, we compare our results with skewness-based forecasts using GAS models via the implementation of [
43] (check
https://cran.r-project.org/web/packages/GAS/ (accessed on 28 November 2023)). While our proposal demonstrates similar performance to those of GAS models in the US case, it outperforms GAS in the Brazilian case. Thus, for our dataset, our proposed model not only predicts the future direction of yield changes, but also shows improvements over GAS models.
6. Empirical Application: Carry Factor
In addition to the bond yield application detailed in
Section 5, we explore application in the currency market. According to [
44], two factors—dollar factor and carry—account for the cross-section of currency returns. Our focus is on the latter factor, which captures interest rate differentials between countries. It involves taking long positions on countries with high interest rate differentials relative to the US and short positions on countries with the smallest differentials. While our emphasis is on the FX markets, ref. [
45] argues that carry-based factors can effectively explain the cross-section of various asset classes, including commodities and equities. For this analysis, we consider and update a sample of the carry factor described in [
44] (readers can check out Lustig’s carry factor on gsb-faculty.stanford.edu/hanno-lustig/files/2022/05/CurrencyPortfolios.xls), presented in
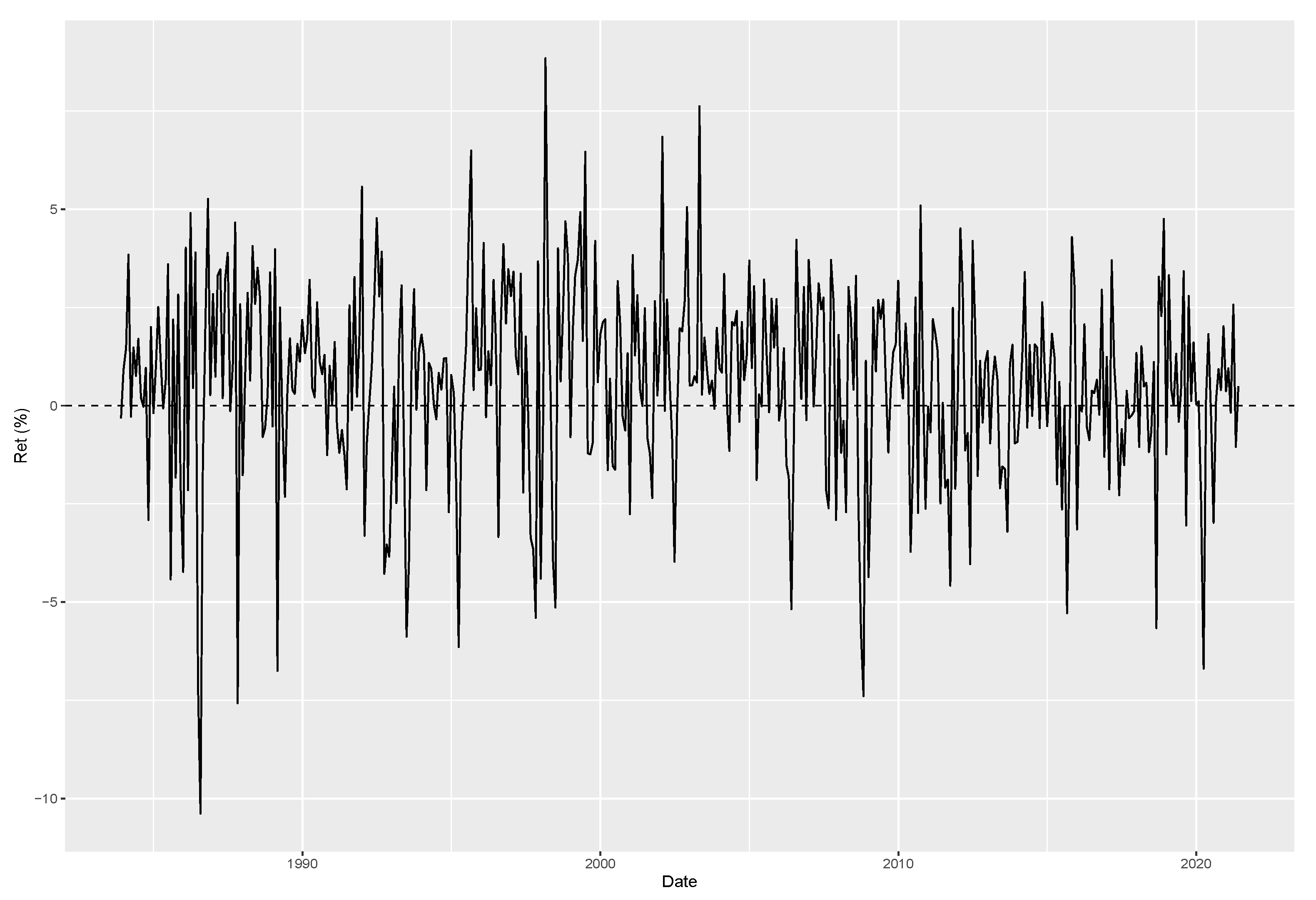
Figure 6, which starts on November 1983 and lasts up to May 2021.
We are not the first to study the skewness of carry returns. For example, refs. [
10,
13] identify a time-varying crash risk on the carry factor. This risk materializes in some occasions leading to large negative returns to the carry factor and skewing its distribution to the left. Conversely, ref. [
14] uses out-of-the-money currency options hedging against large crashes and shows that carry remains profitable, indicating a small role for tail risk on currency returns. Additionally, ref. [
14] presents evidence in favor of time varying volatility for carry returns and that the largest negative return of its sample, October 2008, occurs in a period of high volatility. Our model is well suited to evaluate such claims. Ref. [
14] is not an isolated case. Ref. [
6] provides another example of tail risk mitigation in tradeable factors after accounting for volatility without skewness playing a major role.
We consider the prior specification shown in
Appendix C and sample from the posterior using the HMC scheme described in
Section 4.
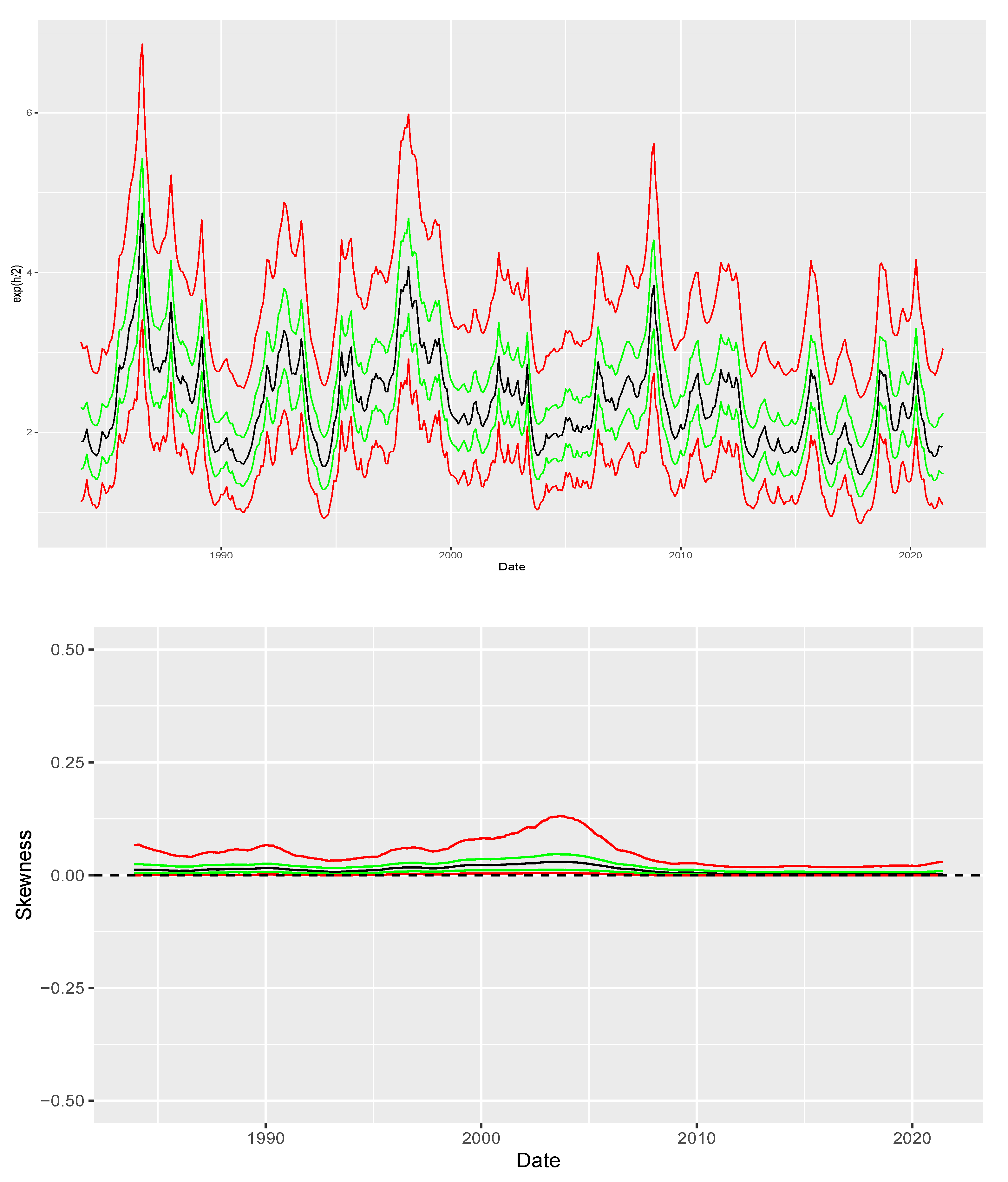
Figure 7 plots the posterior mean (black), interquartile range (green) and q05-q95 interval (red) for both
and
which are shown at the top and bottom panel, respectively. The top panel corroborates the evidence of time-varying volatility with a surge in volatility around October 2008 similarly to the description in [
14]. The bottom panel indicates that it is likely that there is no skewness at all after accounting for stochastic volatility.
Additionally, we assess the performance of the carry factor during periods of high volatility compared to low volatility. We say that volatility is high if it is above the average volatility recovered for the full sample and we say it is low otherwise.
Table 4 reports the results of our analysis. The average return for the carry factor is the same in both environments. However, crash indicators such as the return on the fifth percentile and minimum return exhibit significant improvements. Therefore, in combination with the results shown in
Figure 7, our results indicate that after accounting for volatility, it is unlikely that skewness plays a large role in affecting the returns of the carry factor.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}