
Differential Privacy Preservation for Continuous Release of Real-Time Location Data

Abstract
1. Introduction
- How to accurately estimate the data correlation. A prerequisite for the effective application of CLM is that the autocorrelation function of the data series is known or can be accurately estimated. However, the time series consisting of continuously observed location data is usually non-stationary, and its autocorrelation function changes over time, which makes it difficult to obtain accurate estimates based on time averaging.
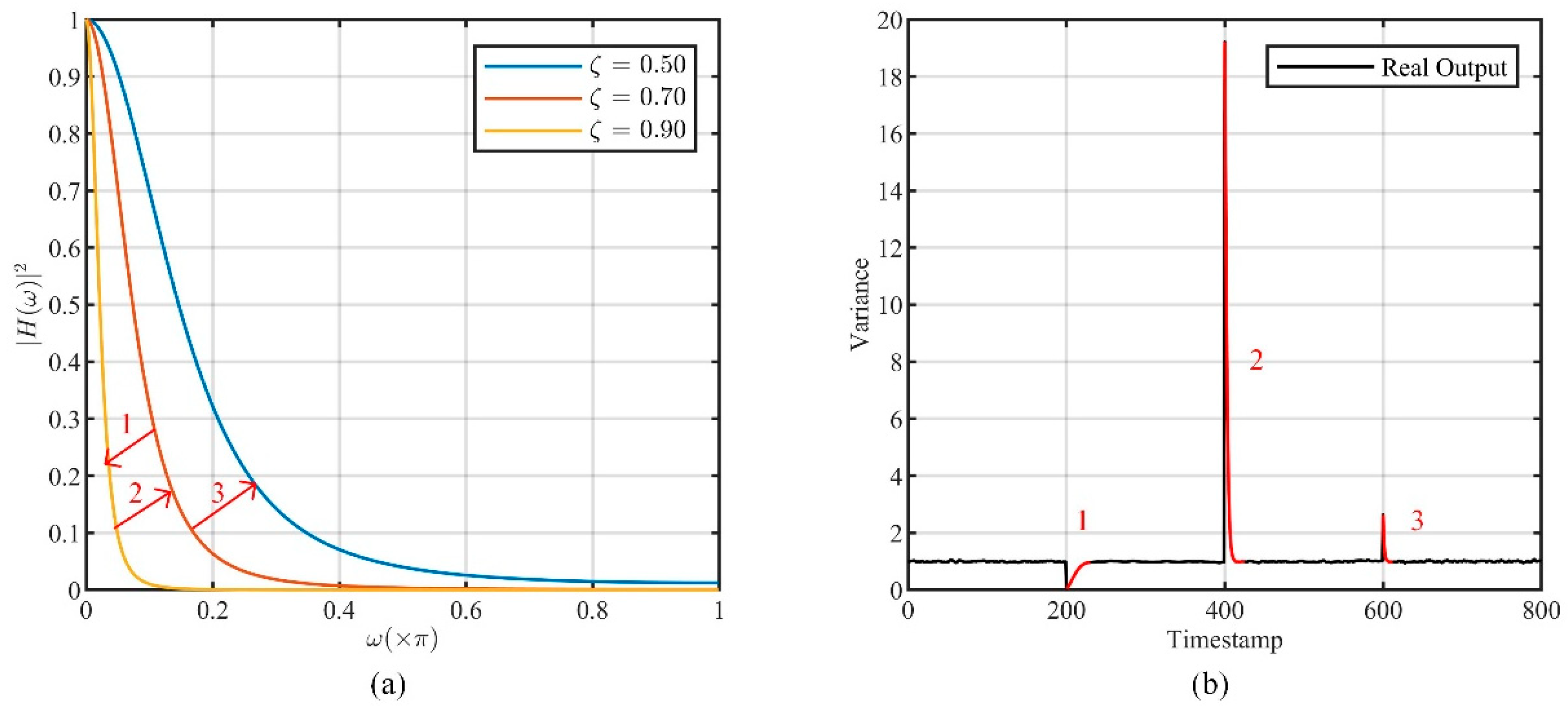
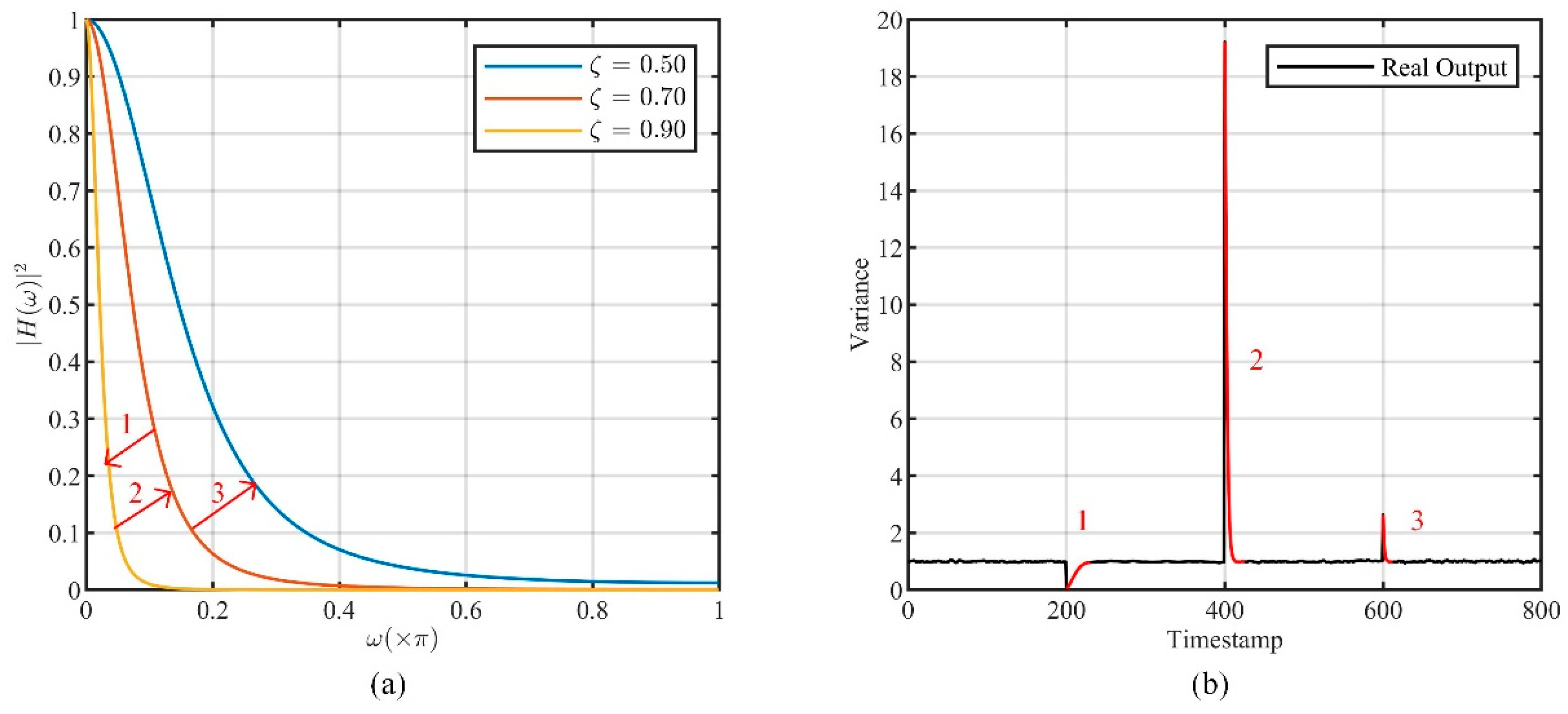
- How to make CLM dynamically track the time-varying data correlation. CLM based on the filter approach is performed by setting the filter parameters so that the steady-state response satisfies the given autocorrelation function. To track the time-varying data correlation, the CLM filter should be dynamically adjusted, which may cause the undesired transient response to be non-negligible, resulting in a deviation of the actual output from the target.
- A location data correlation estimation method based on the location increment is proposed, in which the problem of correlation estimation of a nonstationary location data series is converted into the problem of estimating real location increments. Thereby, the correlation of nonstationary location data can be accurately estimated in many practical scenarios.
- An adaptive adjustment model of the CLM filter (QCLM) and its effective implementation (QCLM-Lowpass) are proposed. The CLM filter is adjusted only at the necessary moments to reduce the generation of undesired transient responses, thus producing an output that satisfies series-indistinguishability as much as possible in time-varying environments.
- Extensive simulations and real data experiments validate the effectiveness of the proposed approaches, and the results show that the privacy scheme based on QCLM-Lowpass outperforms the other schemes compared in terms of data usability and the ability to resist the correlation-based attack.
2. Preliminaries
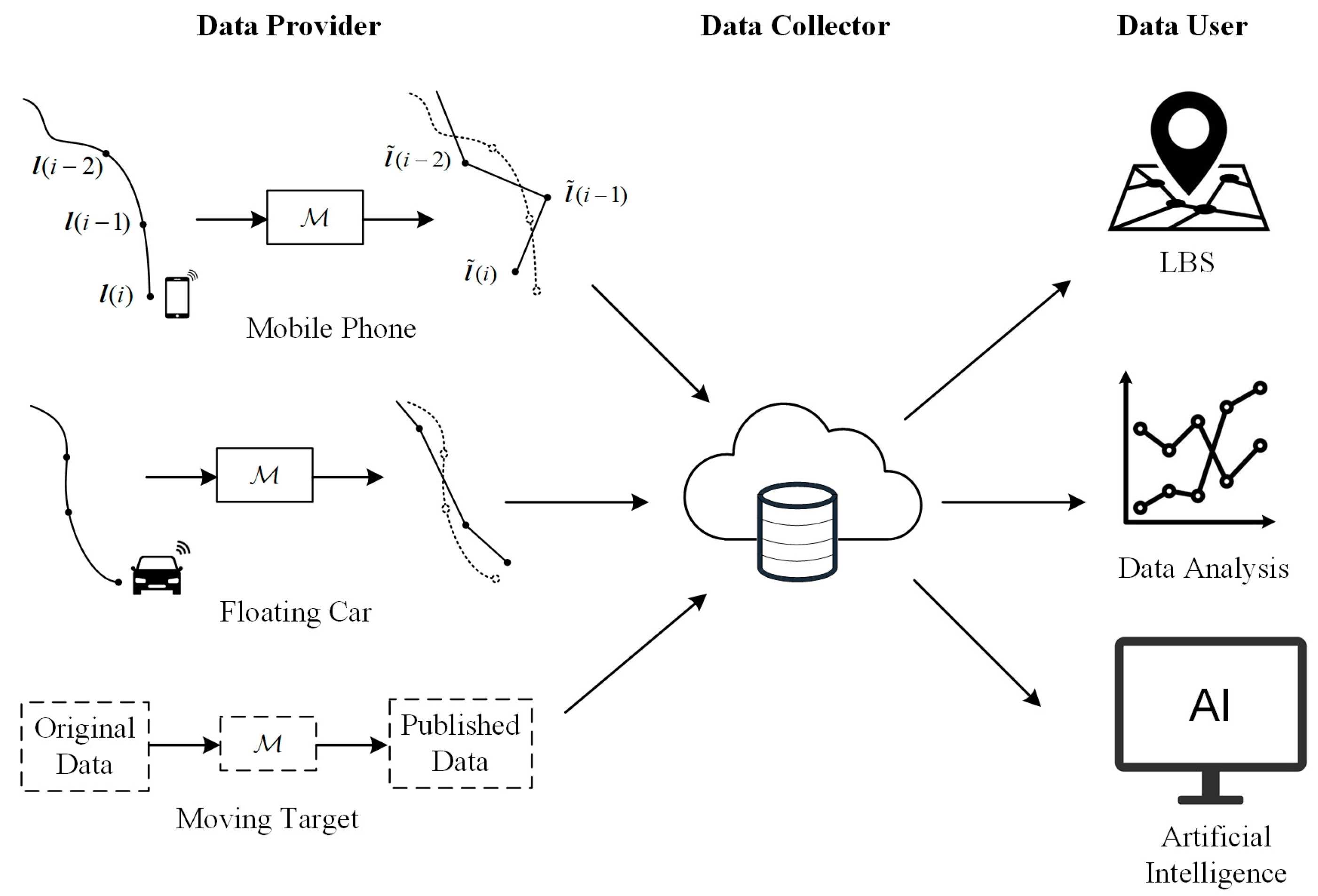
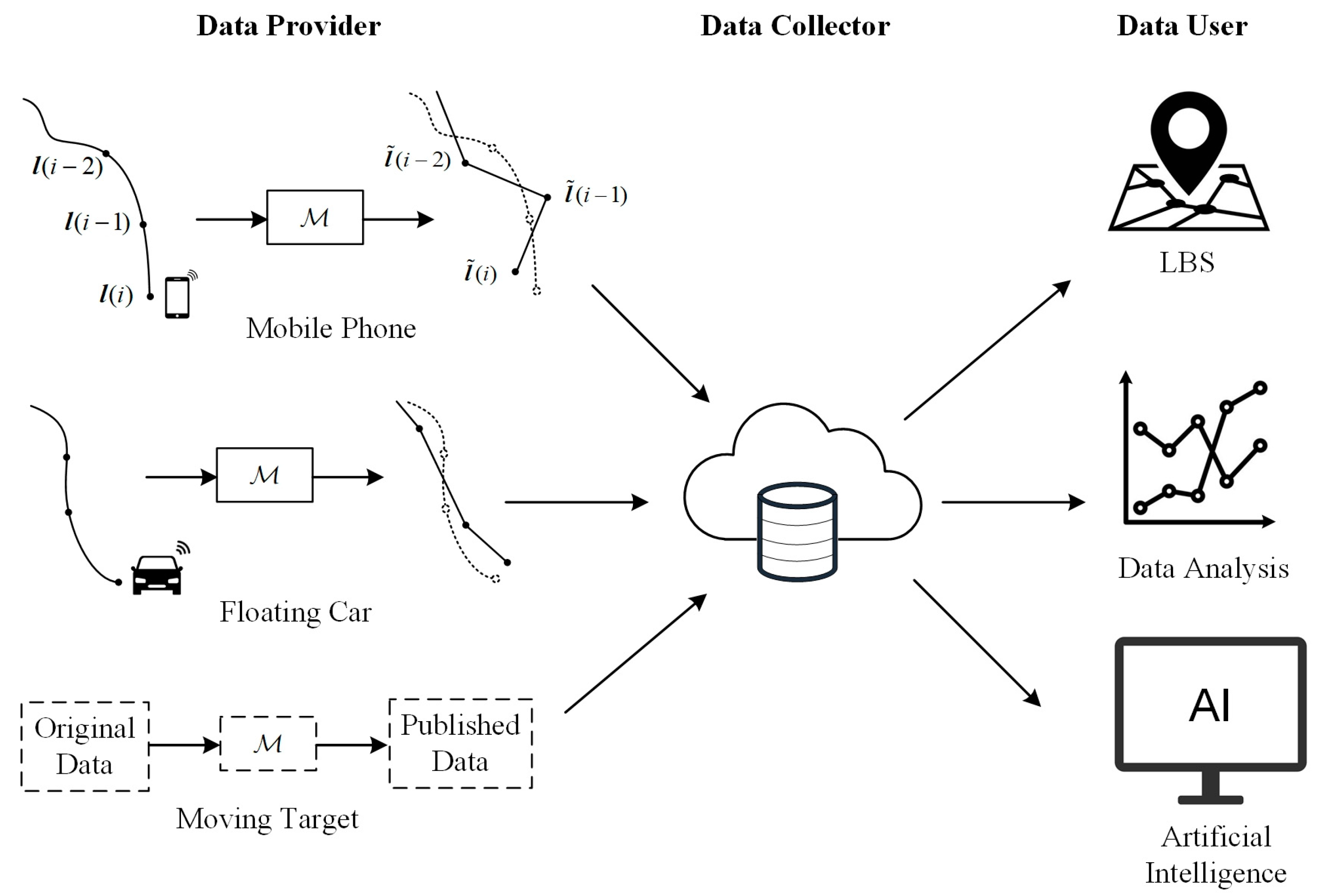
2.1. Continuous Real-Time Location Data Release Model
- The attacker cannot accurately infer the original location from at each moment.
- The attacker cannot accurately extrapolate the true location based on the historically published series .
2.2. Privacy Theories
2.2.1. Differential Privacy
2.2.2. Geo-Indistinguishability
2.2.3. Series-Indistinguishability
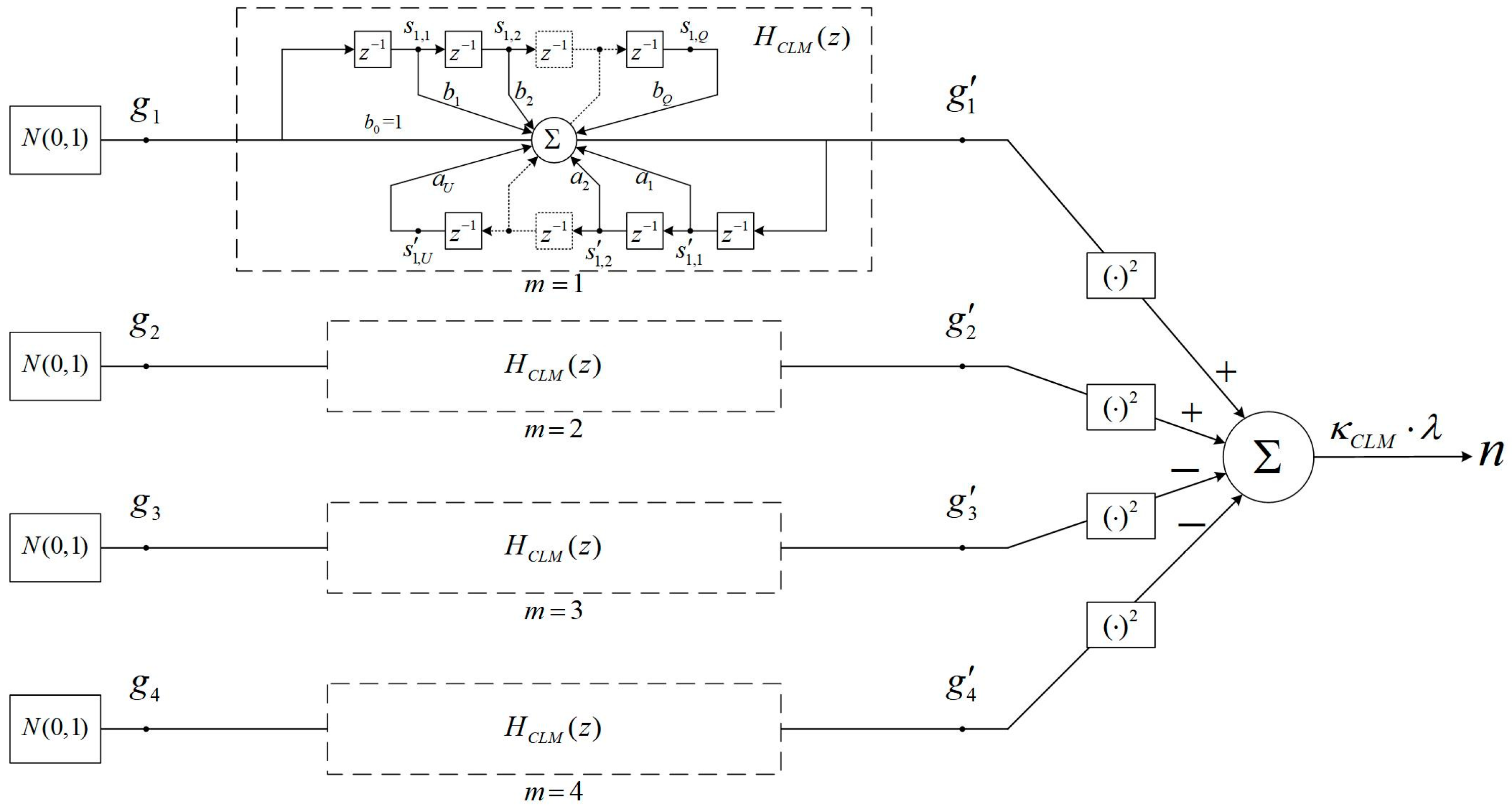
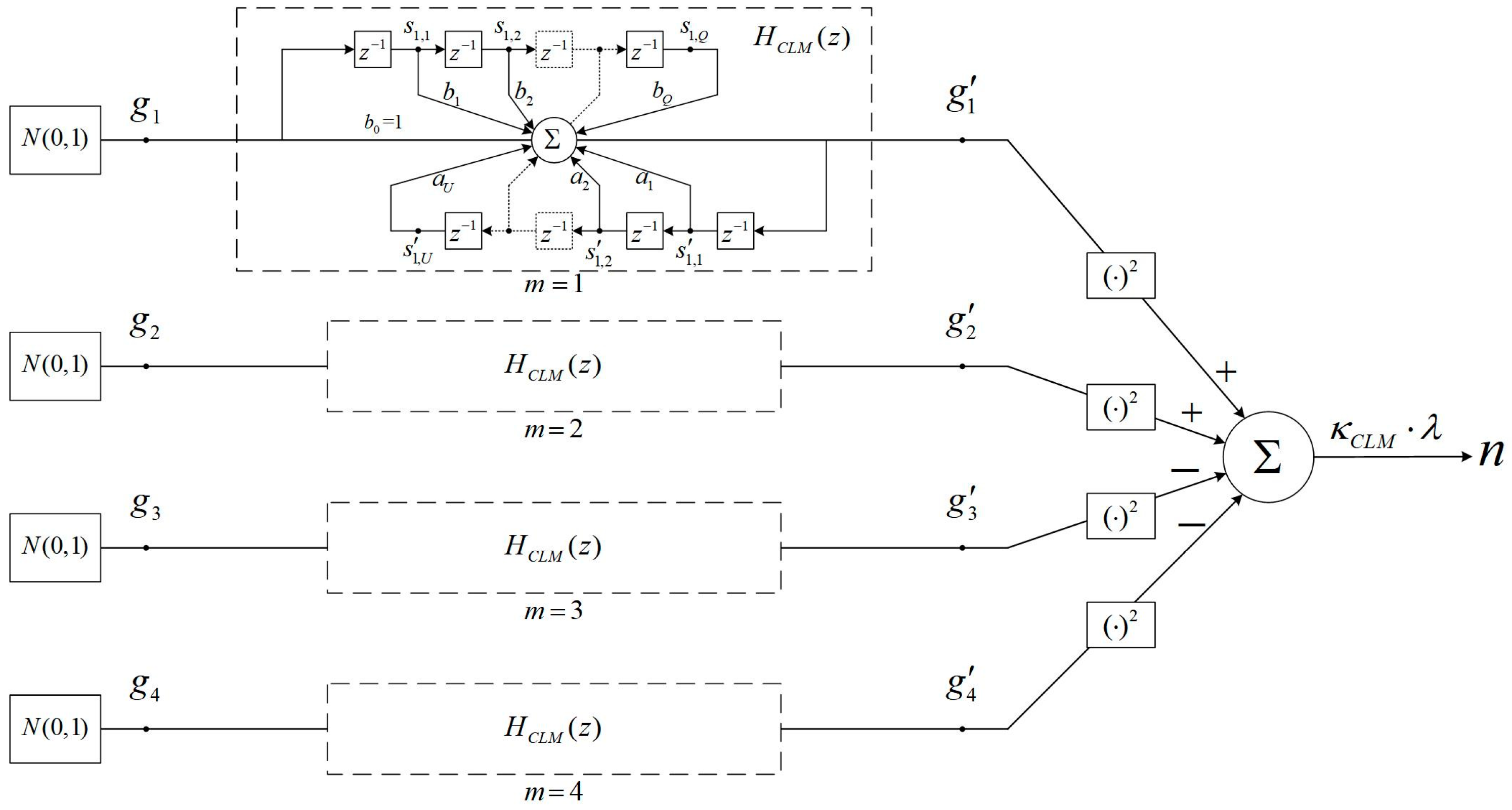
2.2.4. Correlated Laplace Mechanism
- Generate four Gaussian distributed random numbers independently, , , where denotes the timestamp. Thereby, four Gaussian noise series are generated over time, denoted as . Each of them satisfies the same autocorrelation function , but are independent from each other.
- Generate the Laplace distributed random number , which can be calculated as follows:Thereby, the correlated Laplace noise series can be generated over time, where the autocorrelation function of the Laplace and Gaussian noise series, and , satisfy the following equation:
| Algorithm 1. CLM: | |
| 1 | Generate four i.i.d random numbers, |
| Set | |
| 2 | Calculate four correlated Gaussian noise, |
| 3 | Update the input state matrix S, |
| 4 | Update the output state matrix S′, |
| 5 | Calculate the noise |
| 6 | return n |
2.3. Privacy Protection Goals
- At each release moment, if the privacy mechanism satisfies -geo-indistinguishability as defined in Equation (12), then the attacker cannot easily and accurately infer the original location from the published location :where is a location near with a Euclidean distance .
- As for the original and perturbed location series, , if they are series-indistinguishable, then the attacker cannot easily use data correlation to accurately infer from . This requires that their autocorrelation function matrices, , satisfy the following condition:where denotes the Hadamard division (element-wise division), and are defined as follows:
3. Problems of Dynamic Correlated Laplace Mechanism
3.1. Dynamic Correlated Laplace Mechanism
| Algorithm 2. DCLM: | |
| Input: the autocorrelation function vector | |
| Output: the Laplace noise | |
| 1 | Calculate the CLM filter’s estimated parameter vector according to ; |
| 2 | Update the CLM filter’s parameter vector, |
| 3 | Calculate the gain coefficient according to ; |
| 4 | Update the parameters of the CLM filter |
| 5 | Generate the Laplace noise ; |
| 6 | return n; |
3.2. Problems of DCLM in Continuous Location Data Release
3.2.1. Correlation Estimation
3.2.2. Transient Response in Dynamic Adjustment
4. Methodology
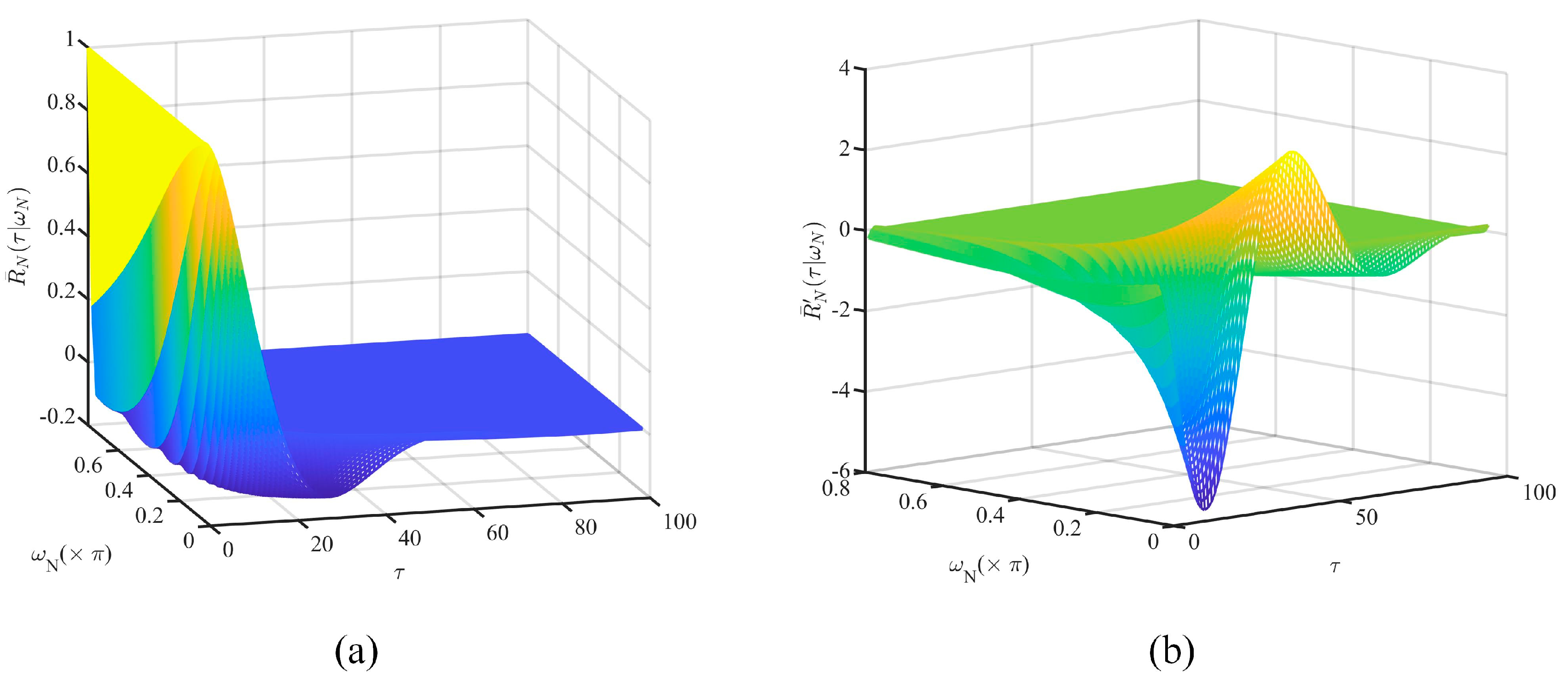
- Location data correlation estimation based on the location increment. The autocorrelation function of the location data is expressed in terms of true location increments. Thus, if the location increment series satisfies stationary conditions, the location data correlation can be calculated indirectly using the estimated location increments.
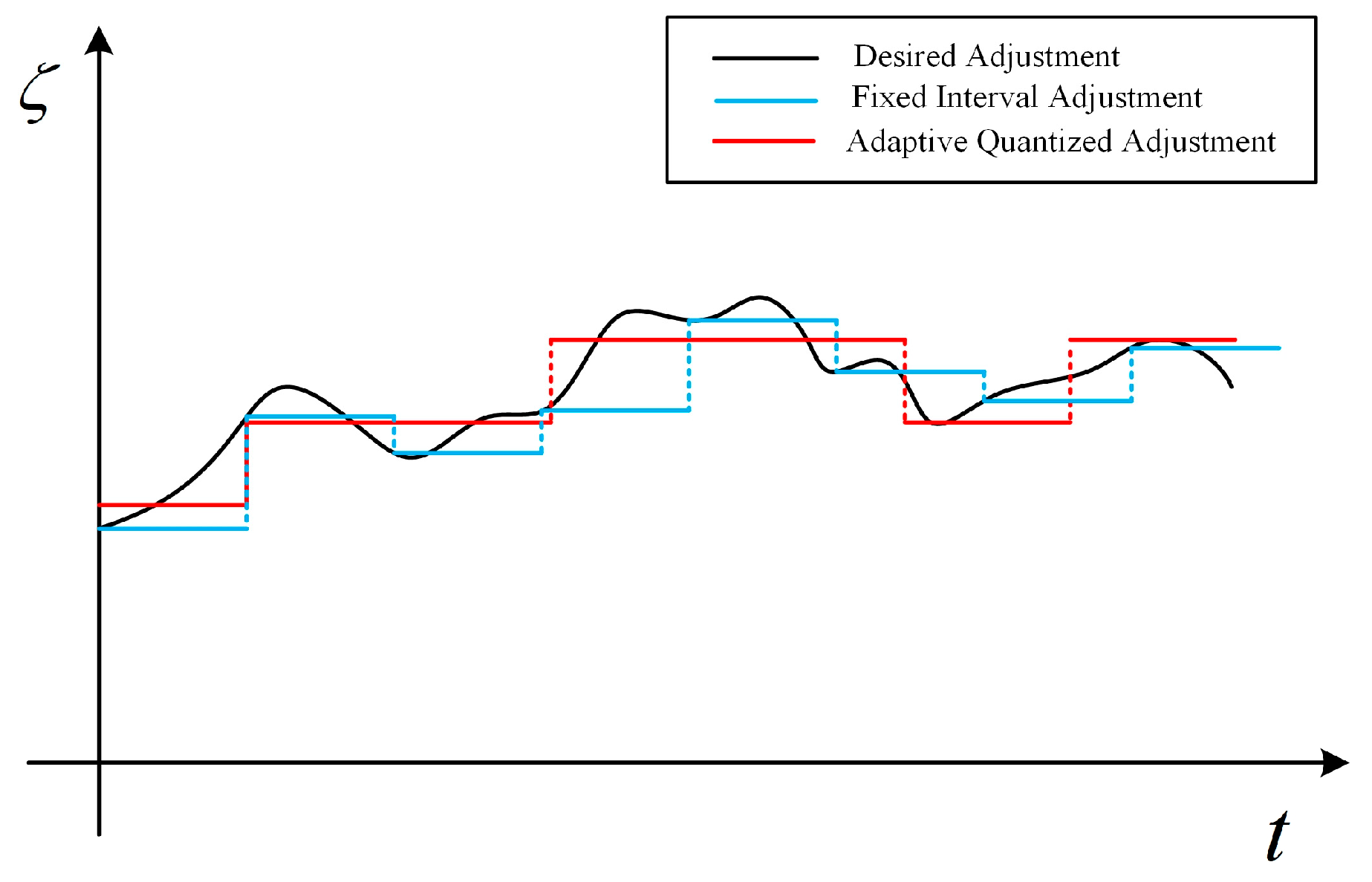
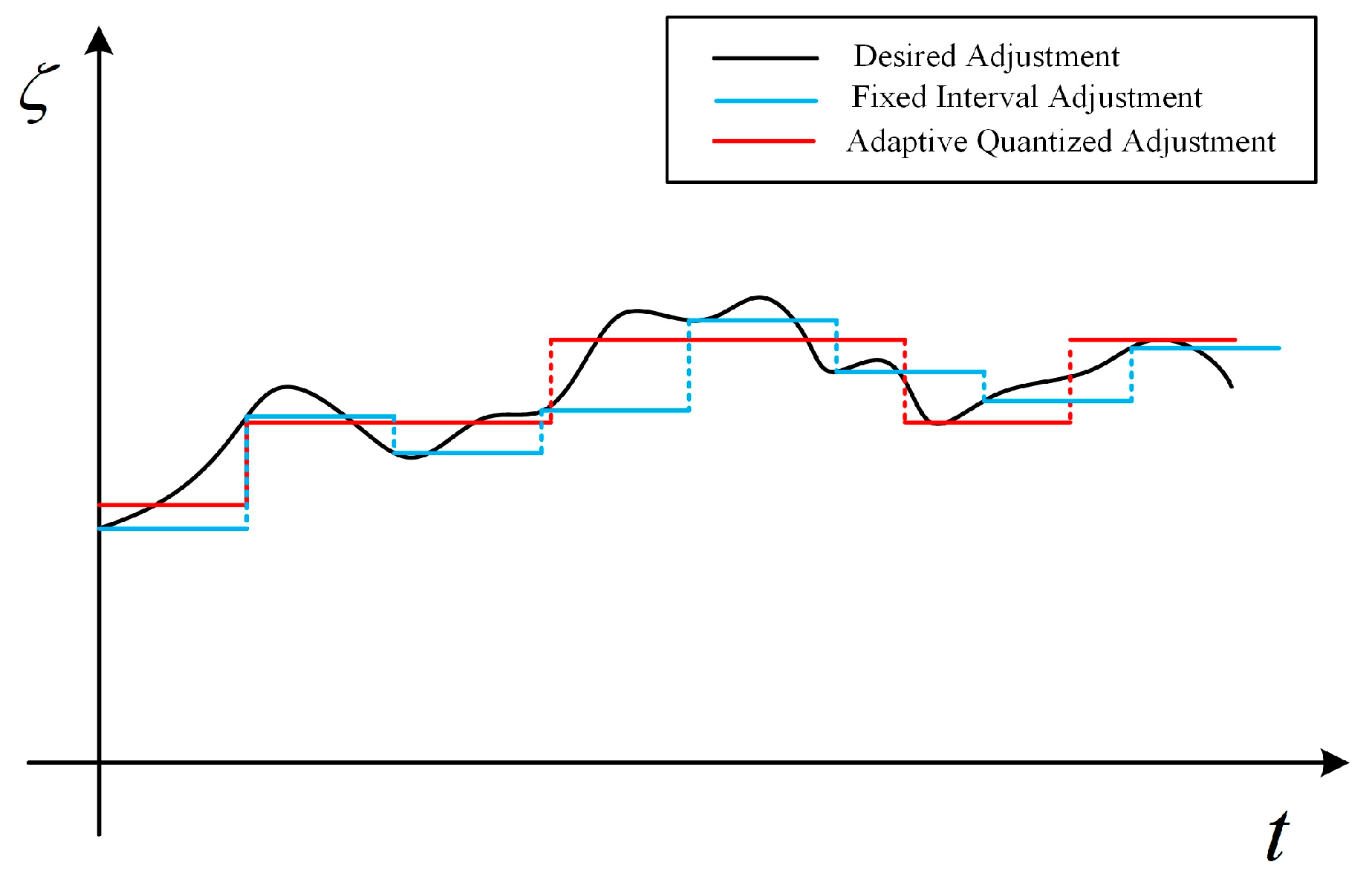
- Quantized Correlated Laplace Mechanism (QCLM). On the one hand, the CLM filter should remain unchanged to suppress the transient response; on the other hand, it needs to be adjusted to track the time-varying data correlation. To balance these two requirements, this paper proposes an adaptive adjustment method based on parameter quantization. It adjusts the CLM filter only at the necessary moments, so that series-indistinguishability can be satisfied as much as possible.
4.1. Location Data Correlation Estimation Based on The Location Increment
4.2. Quantized Correlated Laplace Mechanism
4.2.1. Adaptive Adjustment Based on Parameter Quantization
- It is difficult to determine the appropriate adjustment time. The CLM filter needs to be adjusted in time when the correlation of the output noise series does not match that of the original data. However, the time-varying data correlation is unpredictable, which makes it difficult to set the adjustment time interval in advance.
- It is difficult to compute the appropriate parameters of the CLM filter. To reduce the effects of estimation errors or transient changes of data, it is necessary to determine the final adjustment based on the correlation estimate over a period of time. However, the computation of the filter parameters is non-linear, which makes it difficult to solve for the optimized results.
- Calculated the estimated parameter vector according to the autocorrelation function vector ;
- Identify the corresponding subspace , and set .
- For any subspace , it should be guaranteed that the actual privacy strength does not change significantly when replacing with ;
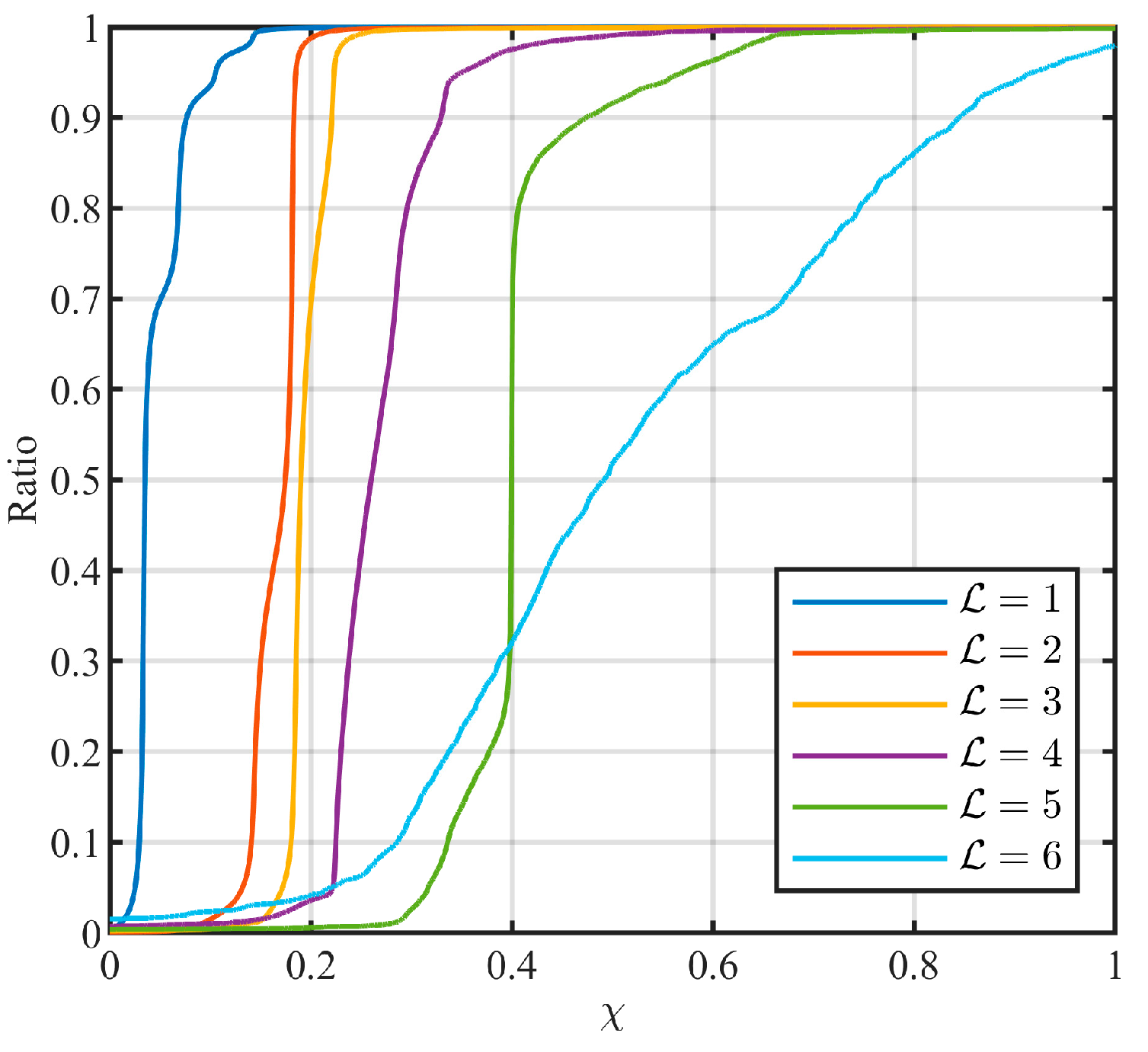
- It is not trivial to determine . The larger the value of , the smaller the quantization error, but it causes the CLM filter to change more frequently. Conversely, a smaller introduces a larger quantization error, but it allows the CLM filter to remain unchanged for a longer period of time.
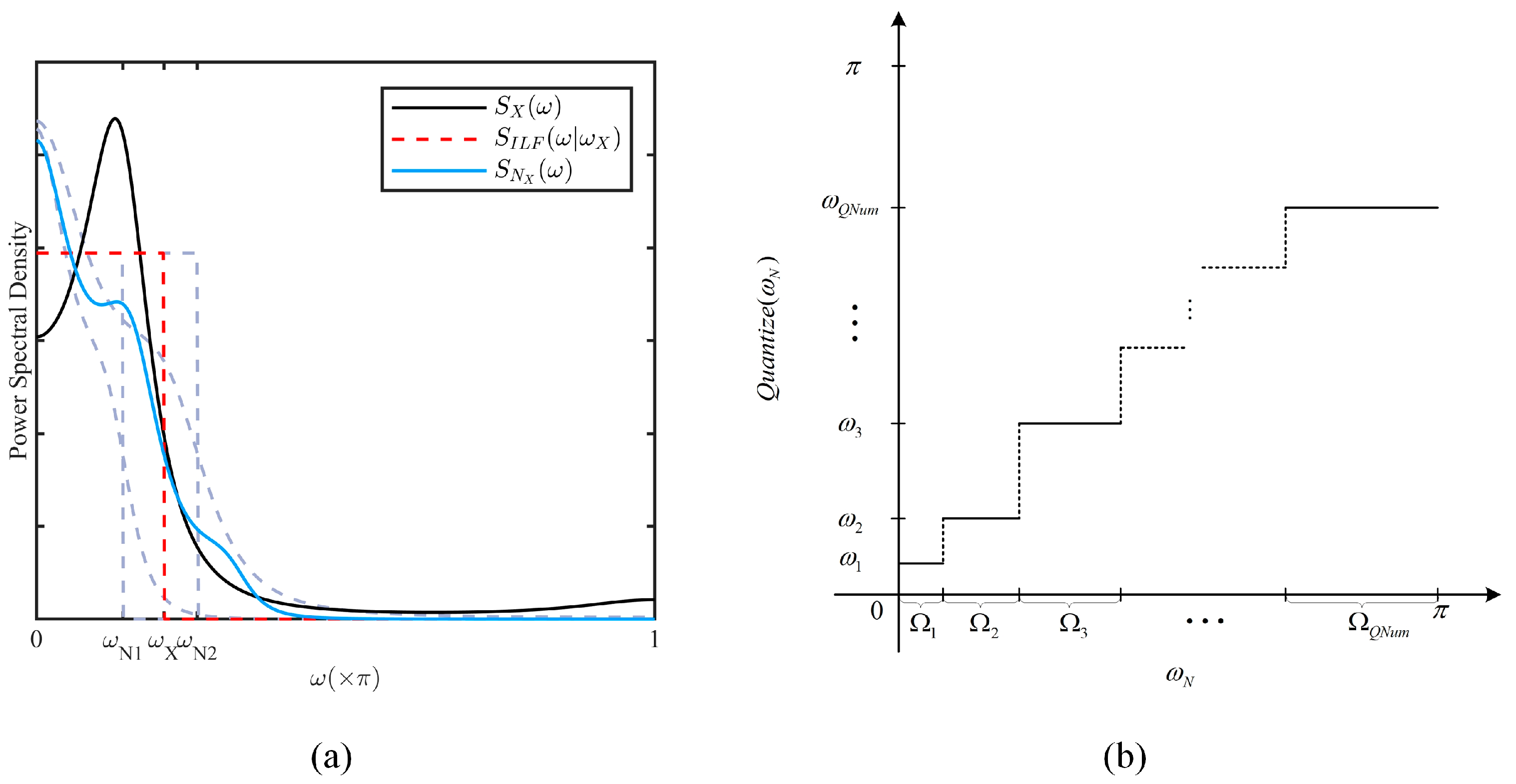
4.2.2. QCLM Based on Lowpass Characteristic
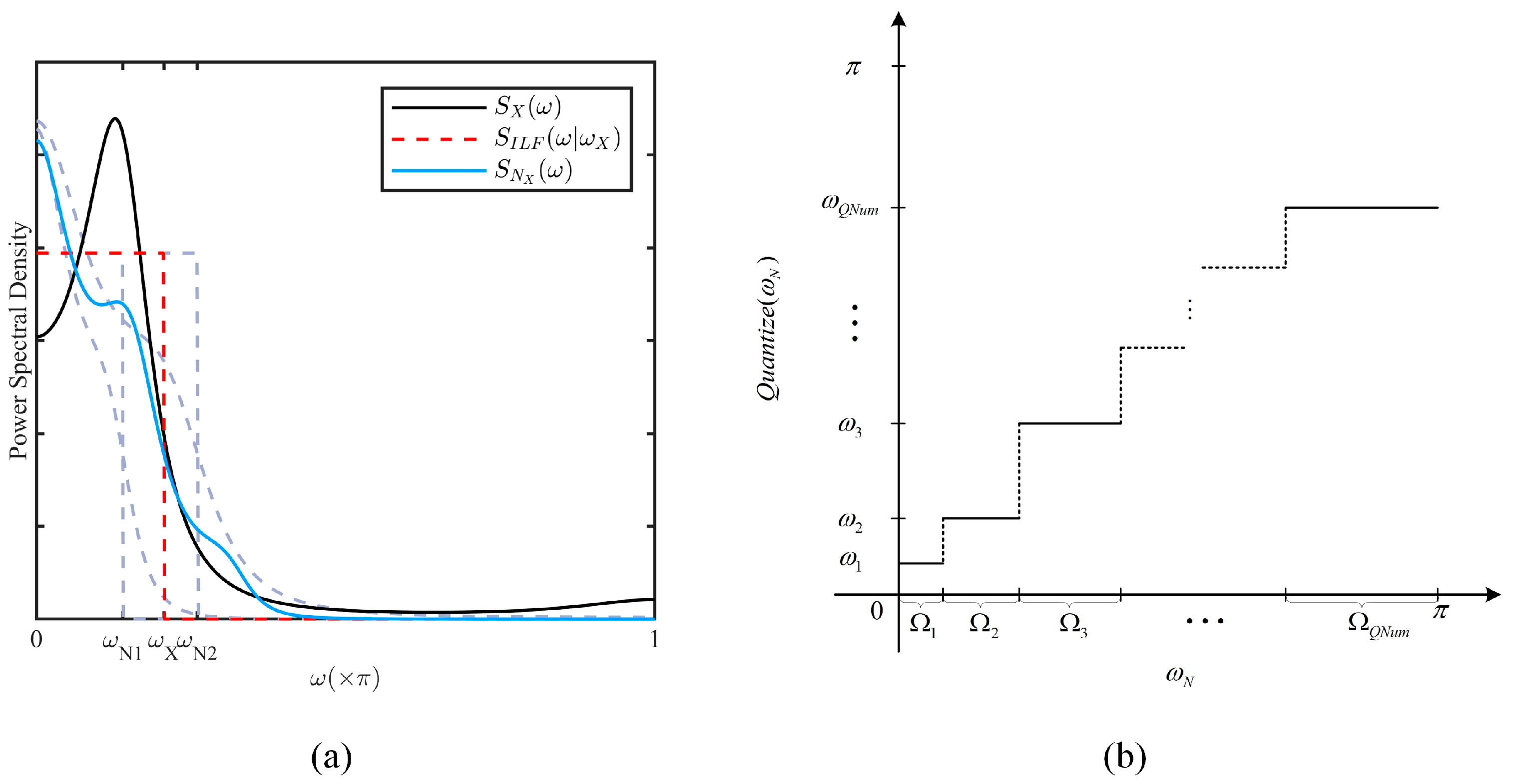
- Estimate the power spectrum from the autocorrelation function vector and calculate its lowpass cutoff frequency .
- Identify the corresponding subinterval , and set , from which can be determined.
4.2.3. Feasibility Analysis of QCLM-Lowpass
- At the release moment , the Laplace noise are generated independently by , and then the perturbed location can be obtained .
- During the continuous location data release, the CLM filters in are separately adjusted by QCLM-Lowpass, so that the autocorrelation functions of ,, and , satisfy the following condition:Here, we analyze whether can satisfy the privacy goals presented in Section 2.3.
- a.
- The requirement of geo-indistinguishability.
- b.
- The requirement of series-indistinguishability.
- c.
- The analysis of quantization errors.
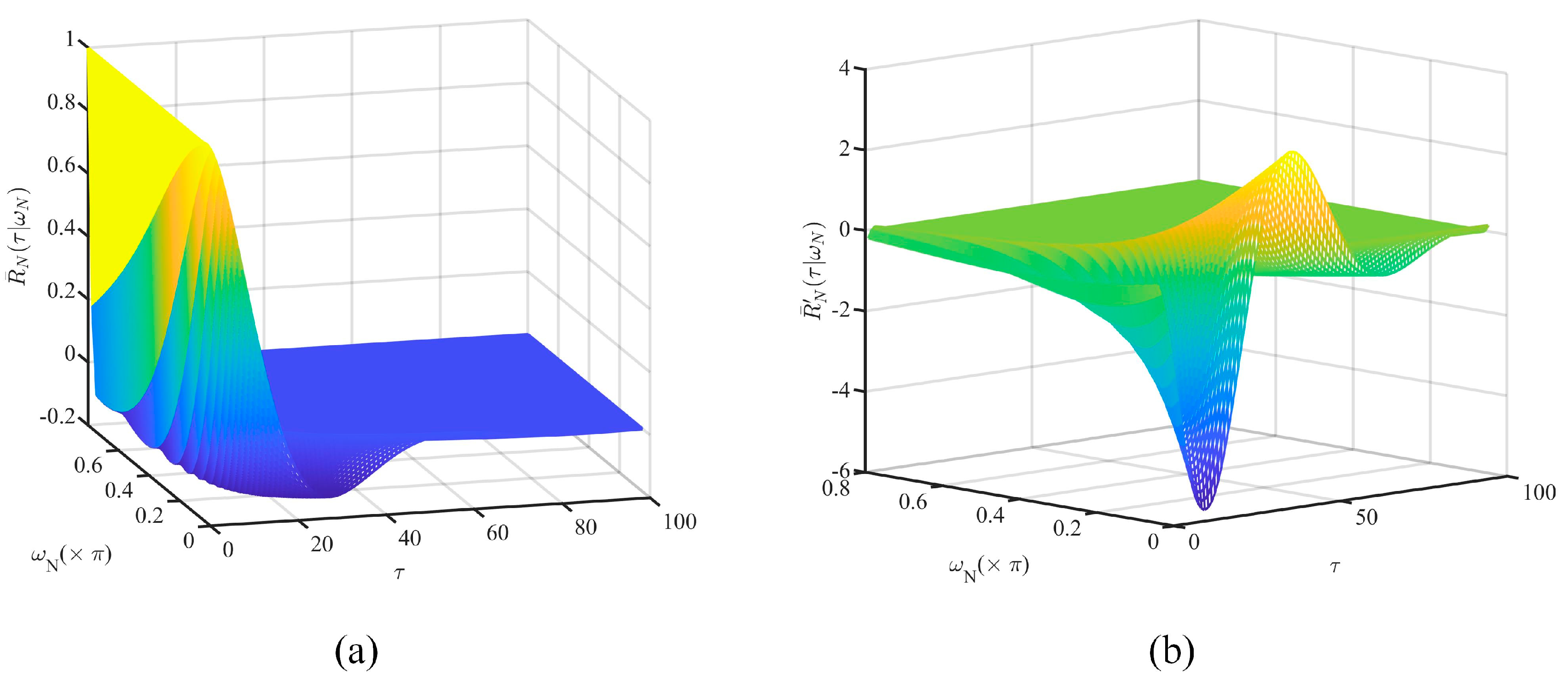
- is bounded with respect to .
- is not linearly related to and shows a tendency to decay to 0 as , increase.
4.3. Algorithmic Implementation
4.3.1. Quasi-Stationary State Identification
4.3.2. CLM Filter Design
4.3.3. Quantization Scheme
4.3.4. Level Identification
4.3.5. Gain Coefficients
4.3.6. Implementation of QCLM-Lowpass
| Algorithm 3. QCLM-Lowpass: | |
| Input: the autocorrelation function vector | |
| Output: the Laplace noise | |
| 1 | Calculate the feature parameter according to ; |
| 2 | Calculate the estimated level according to , |
| 3 | Update , |
| 4 | if then |
| 5 | Keep the actual level unchanged ; |
| 6 | Update the index ; |
| 7 | Set the gain coefficient ; |
| 8 | Update the gain coefficient of CLM |
| 9 | elseif and then |
| 10 | Calculate the actual level ; |
| 11 | Calculate the parameter vector ; |
| 12 | Calculate the gain coefficient vector ; |
| 13 | Set , and the gain coefficient |
| 14 | Update the parameters of CLM |
| 15 | else |
| 16 | Keep the actual level unchanged ; |
| 17 | end if |
| 18 | Update , |
| 19 | Generate the Laplace noise |
| 20 | return n |
5. Experimental Evaluation
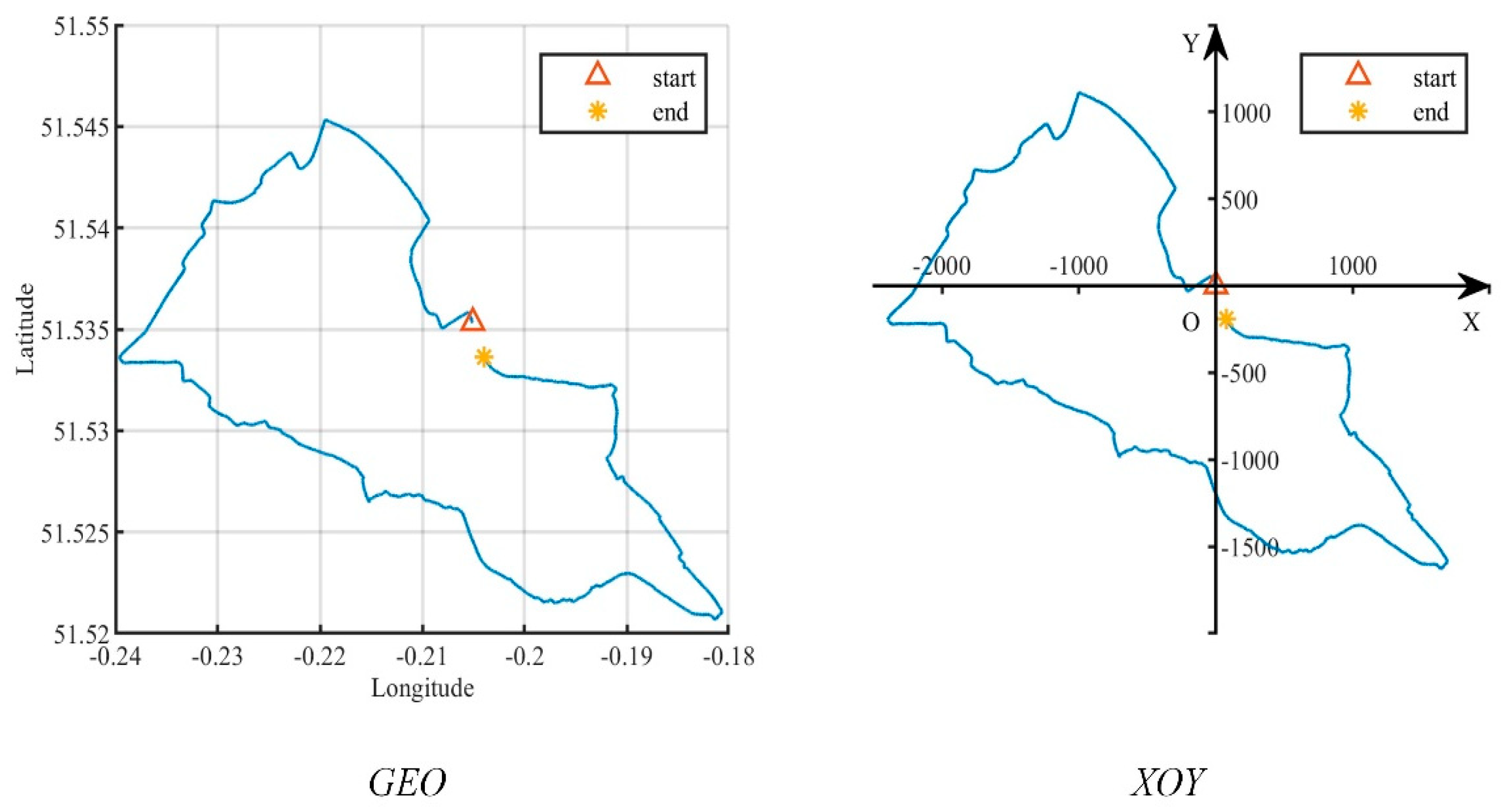
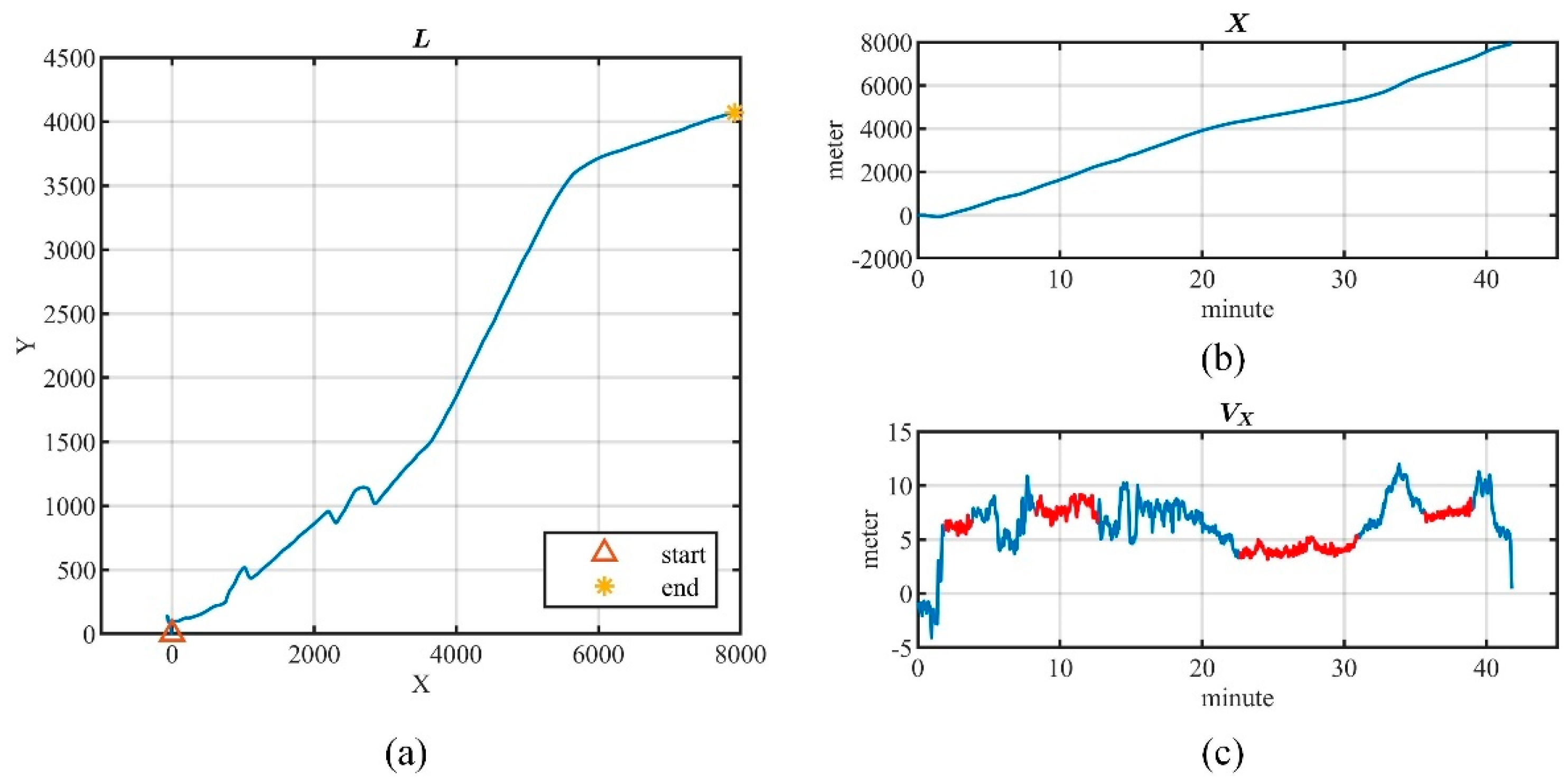
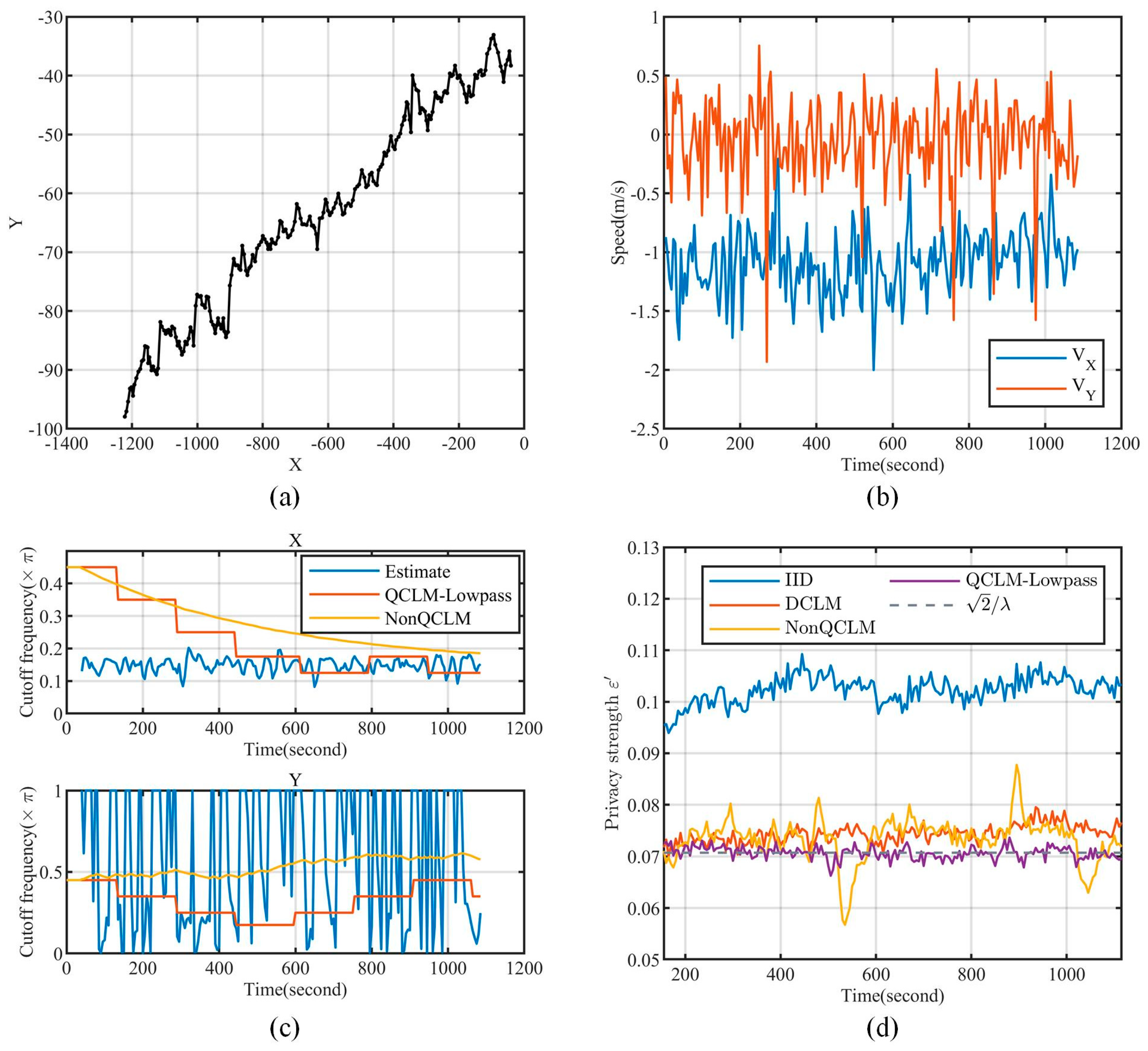
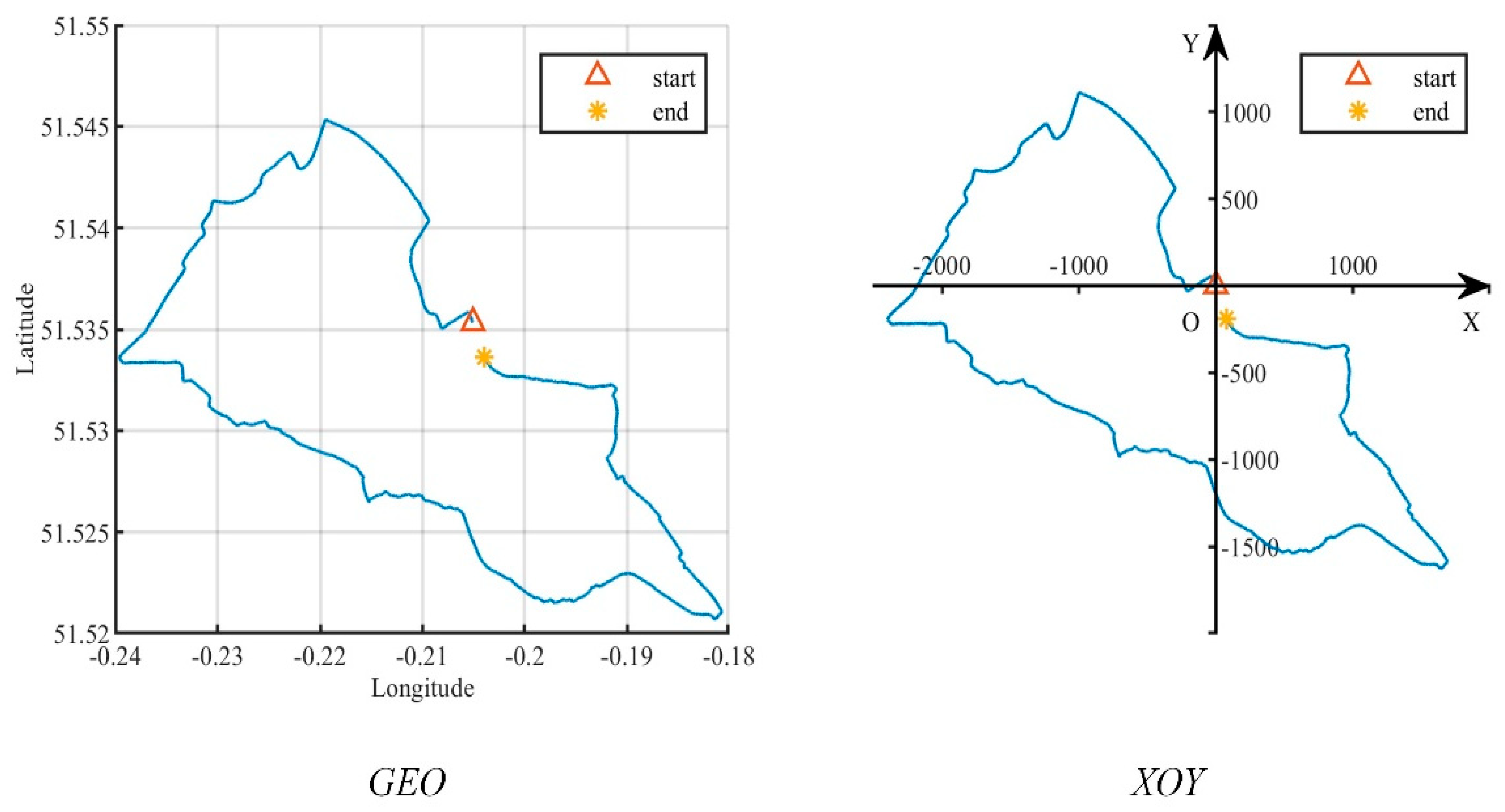
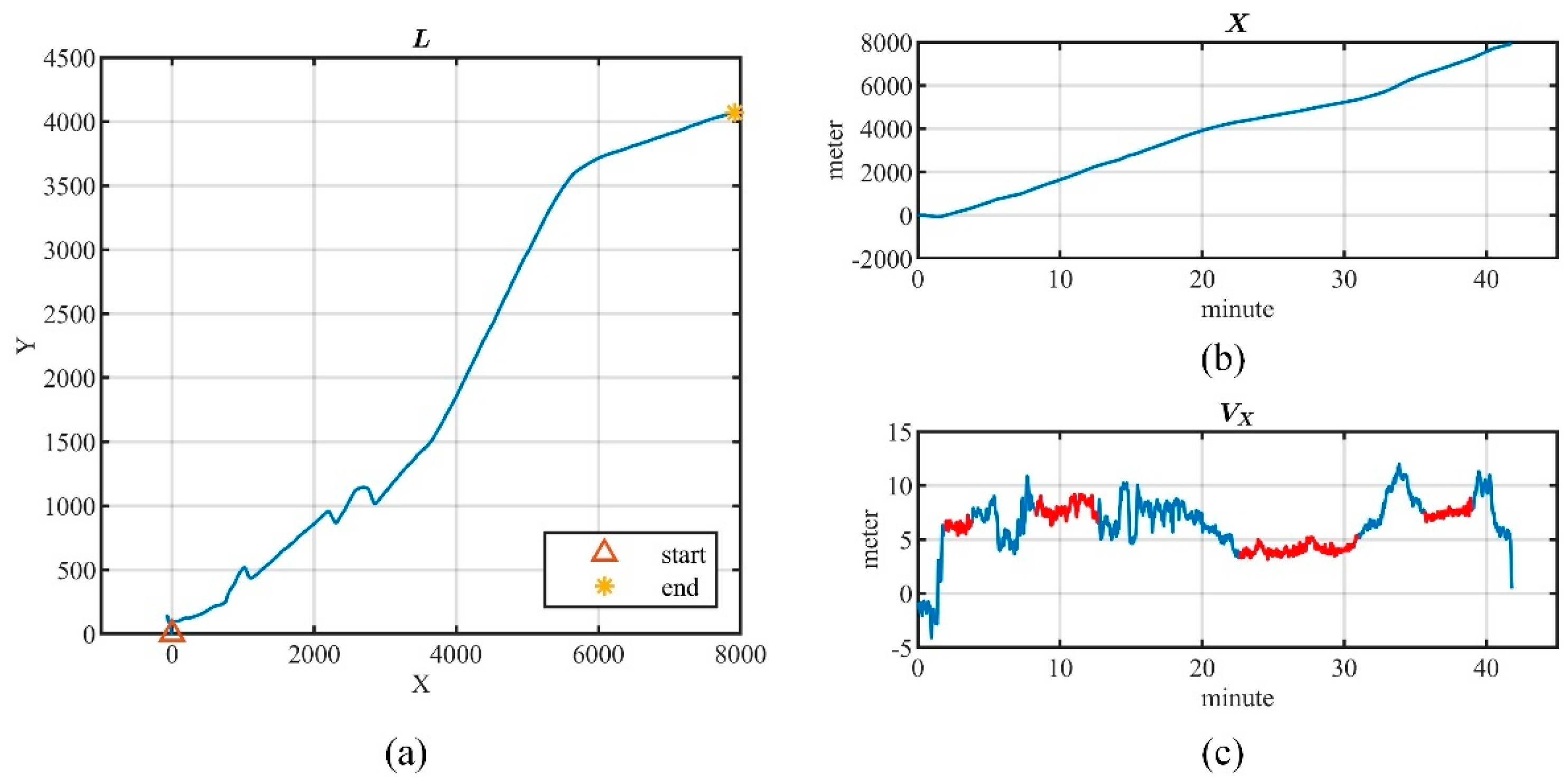
5.1. Experimental Datasets
5.1.1. Real Datasets
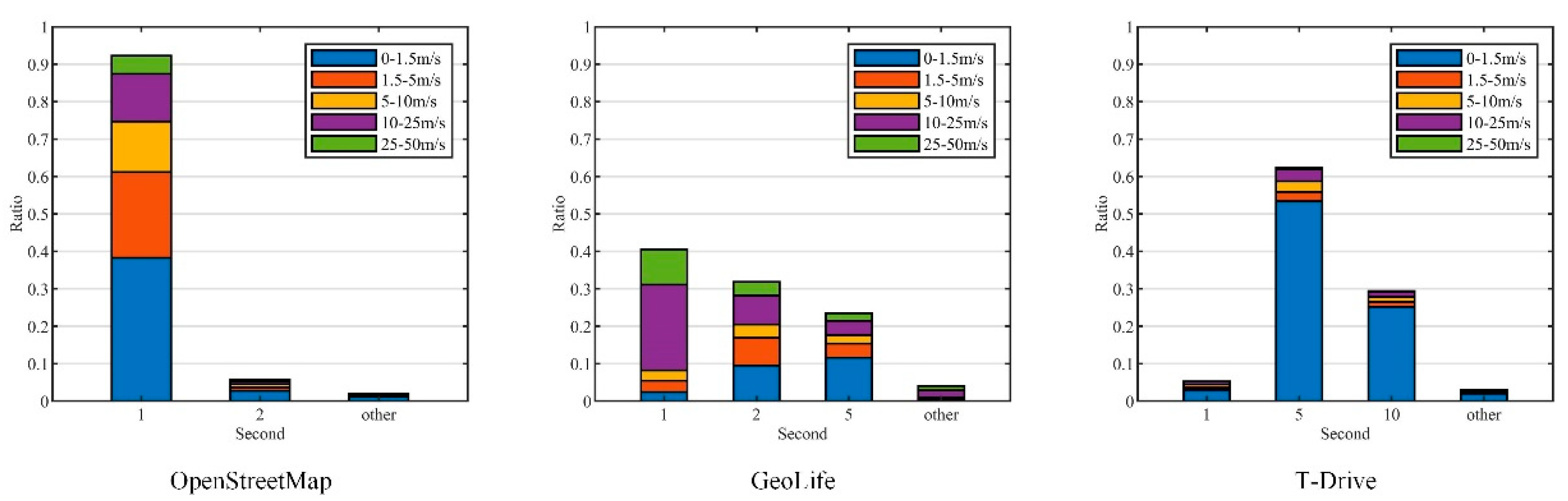
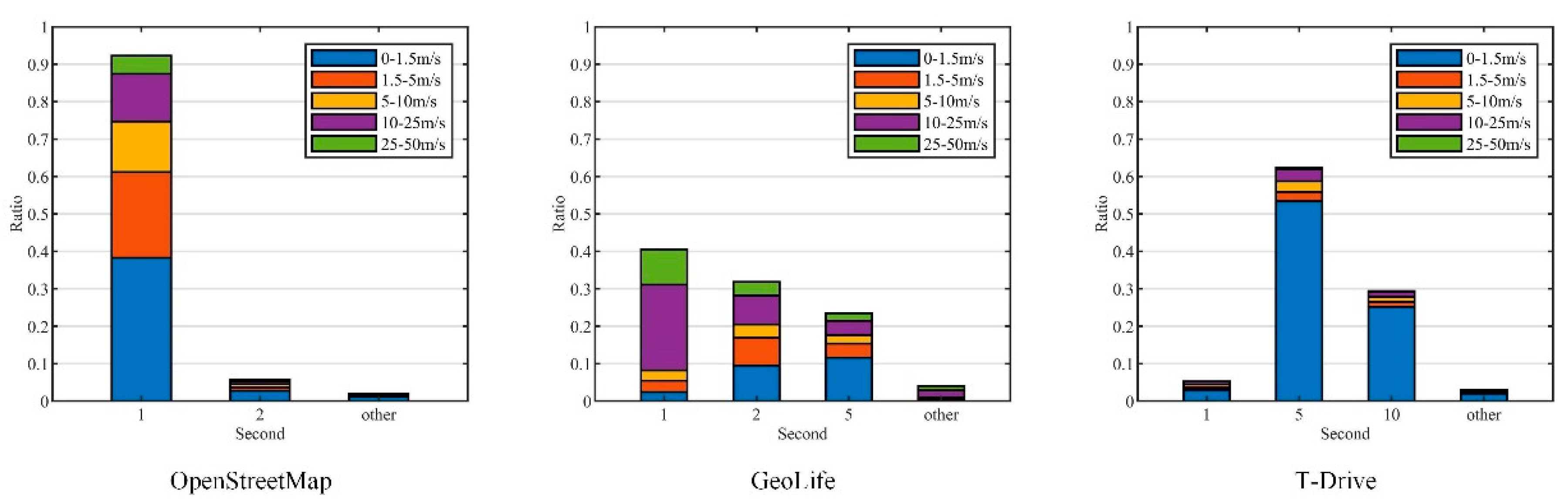
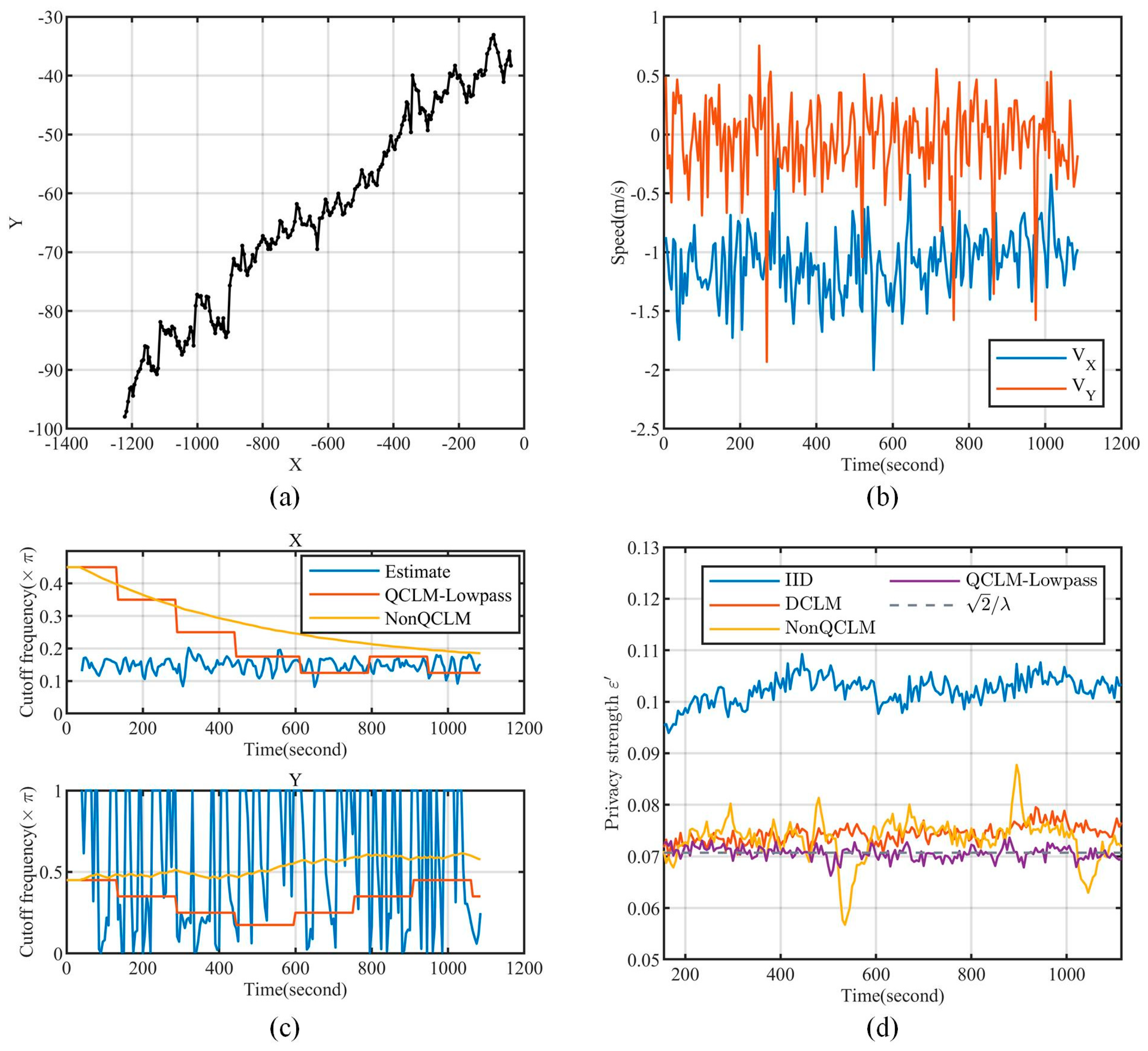
- OpenStreetMap(OSM) (https://www.openstreetmap.org/traces, accessed on 17 July 2022). It is a collaborative online mapping project that allows users to share their trajectories. We downloaded 406,399 trajectories with more than locations between May 2016 and May 2022, including location data with high-frequency sampling (less than 1 s) and high accuracy (less than 1 m).
5.1.2. Data Preprocessing
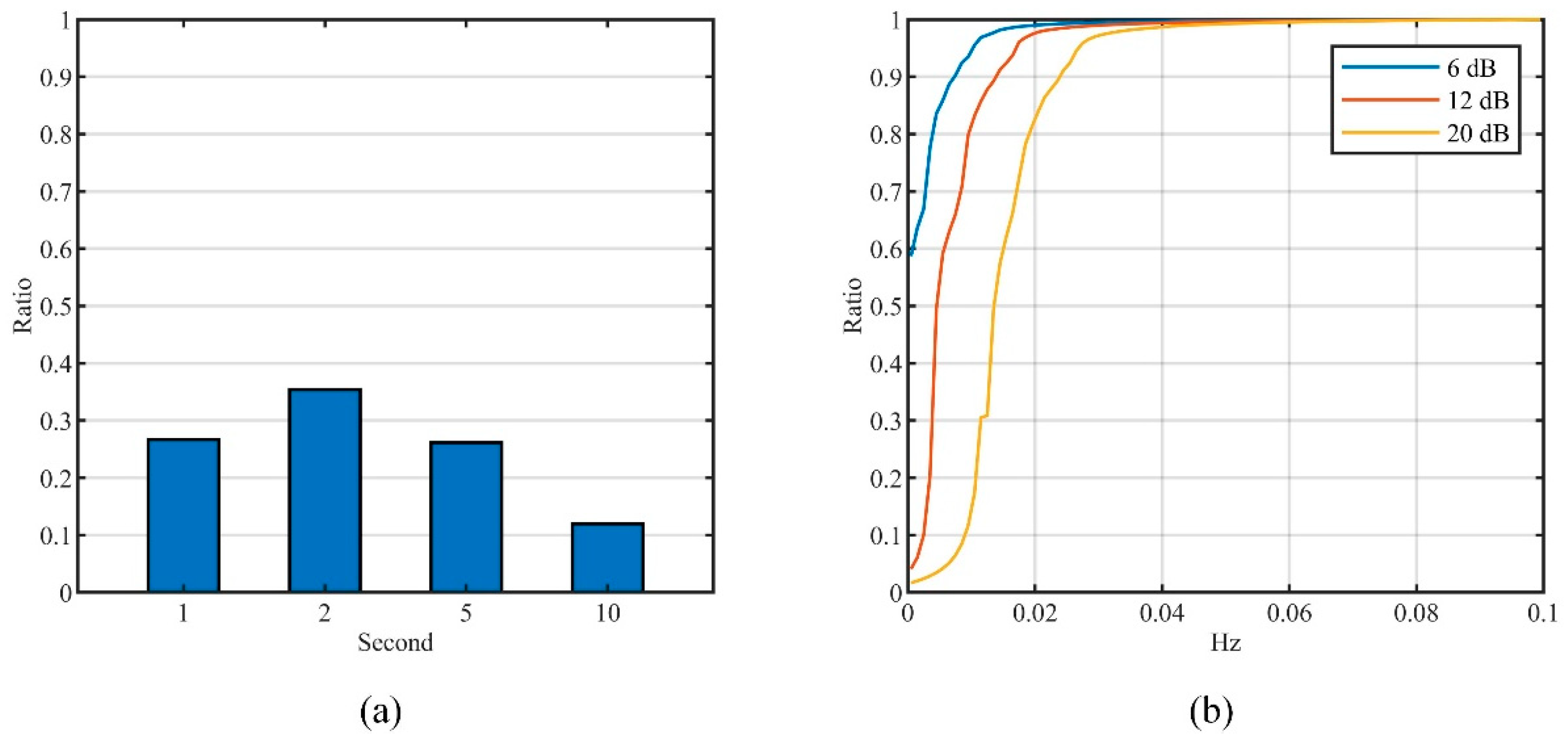
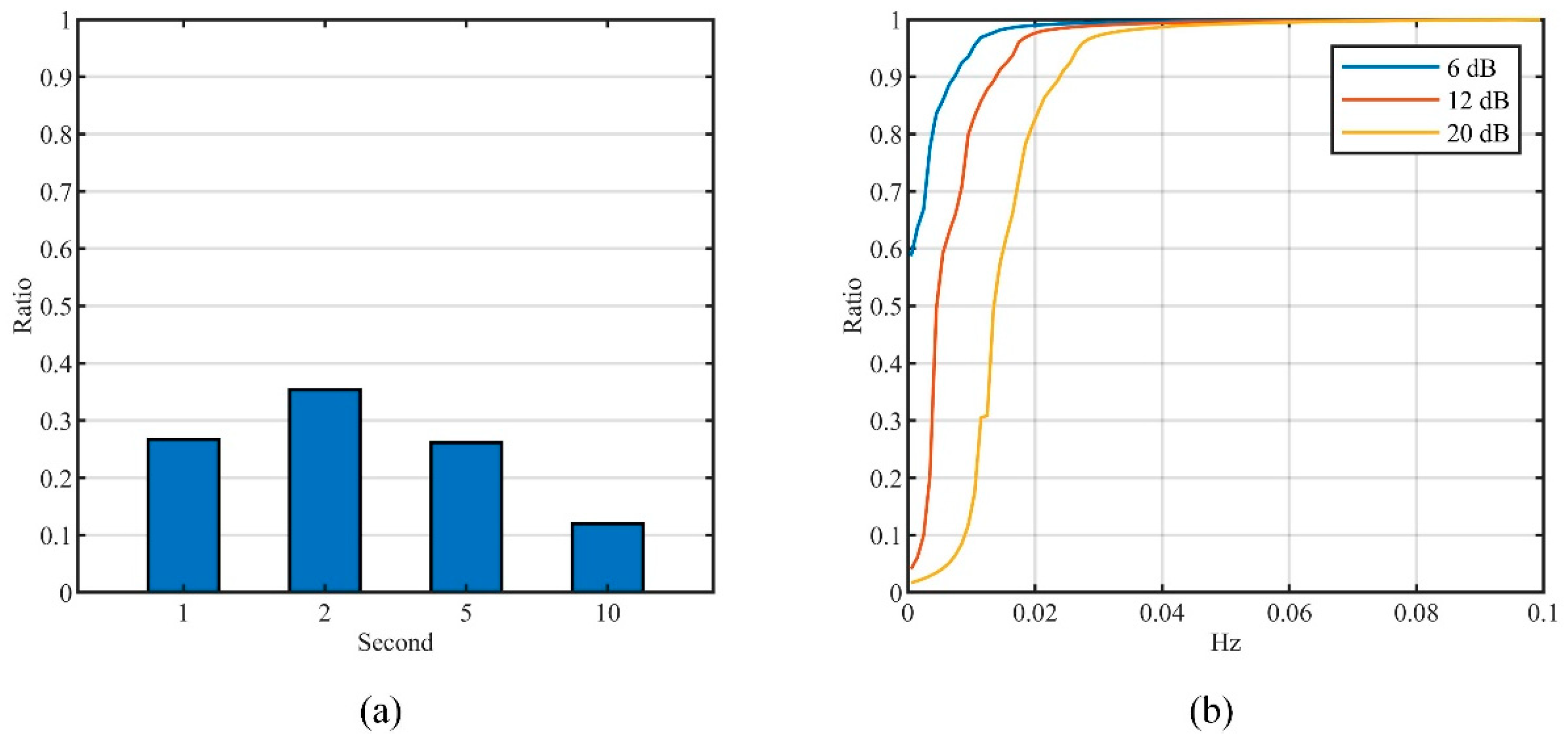
5.1.3. Stationary Analysis
5.1.4. Power Spectrum Characterization
5.2. Experimental Configurations
5.2.1. Competitors
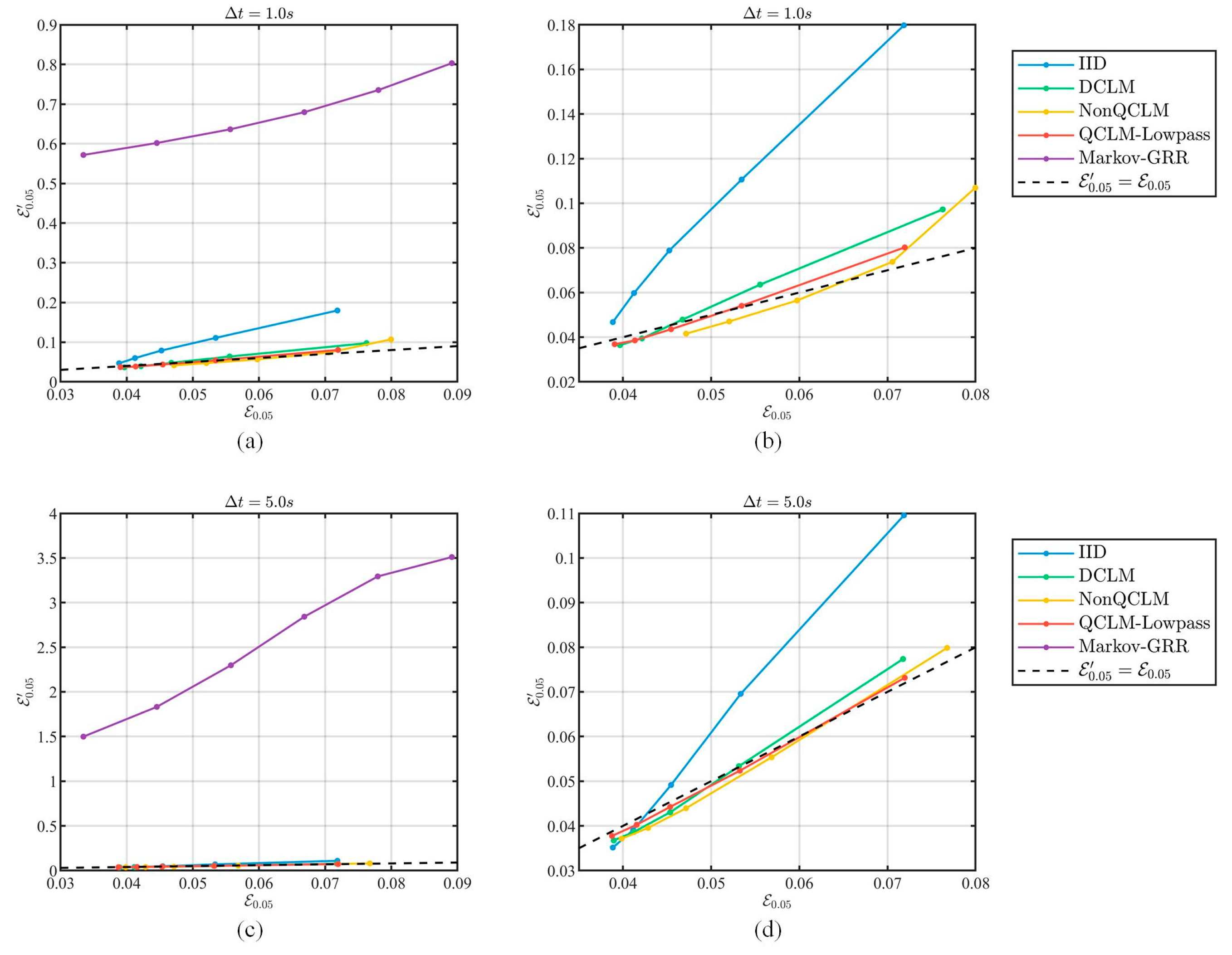
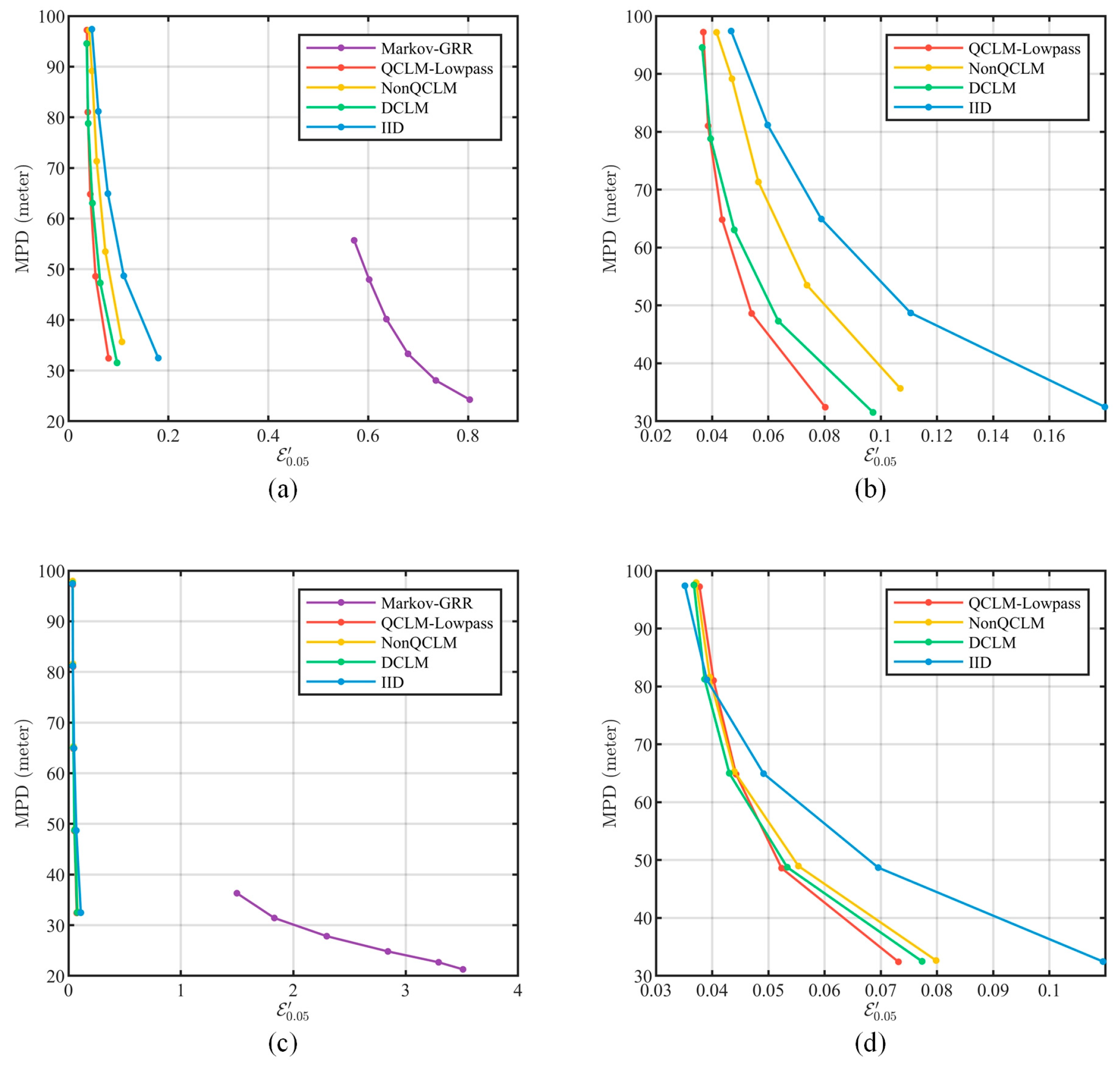
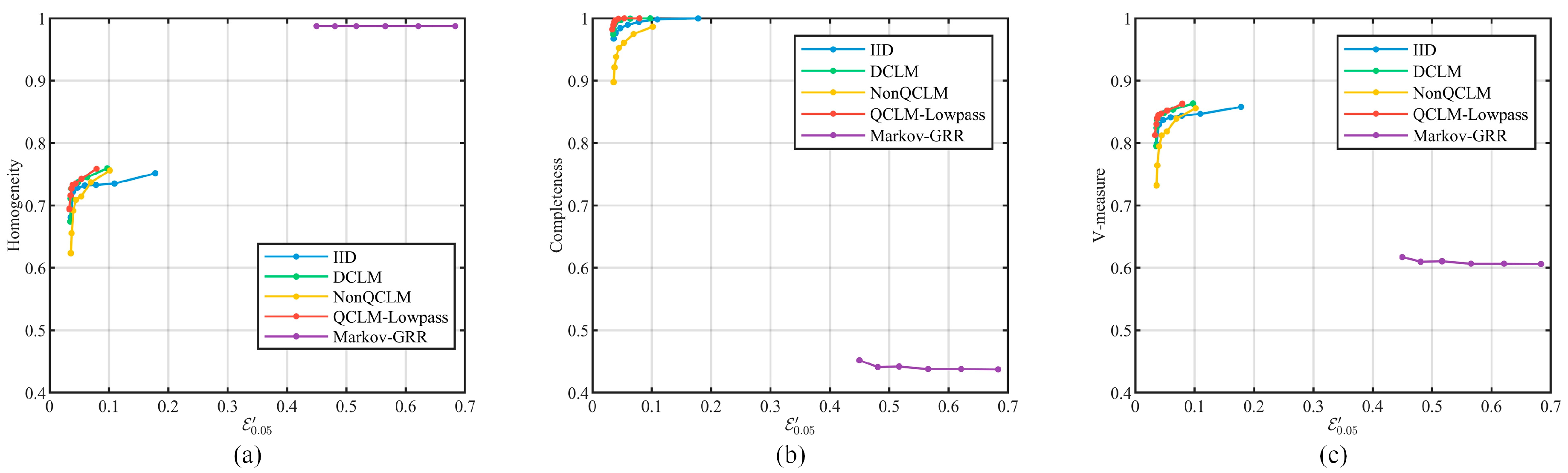
- IID. This is the classical Laplace mechanism that adds independently and identically distributed Laplace noise to the data series, which is used as the basic reference in this paper.
- DCLM. Recall from Section 3.1 that this scheme calculates the CLM filter parameter directly based on the estimated data correlation, and thus dynamically adjusts the filter. In the experiments, the adjustment step is set as .
- NonQCLM. In contrast to QCLM-Lowpass, this scheme dynamically adjusts the noise power spectrum cutoff frequency instead of quantizing it, with the adjustment step being set as in experiments.
- Markov-GRR, which was proposed in [17]. The setup is described in Section 5.4.
5.2.2. Evaluation Metrics
5.2.3. Filtering Attack
5.3. Validity Analysis of QCLM-Lowpass
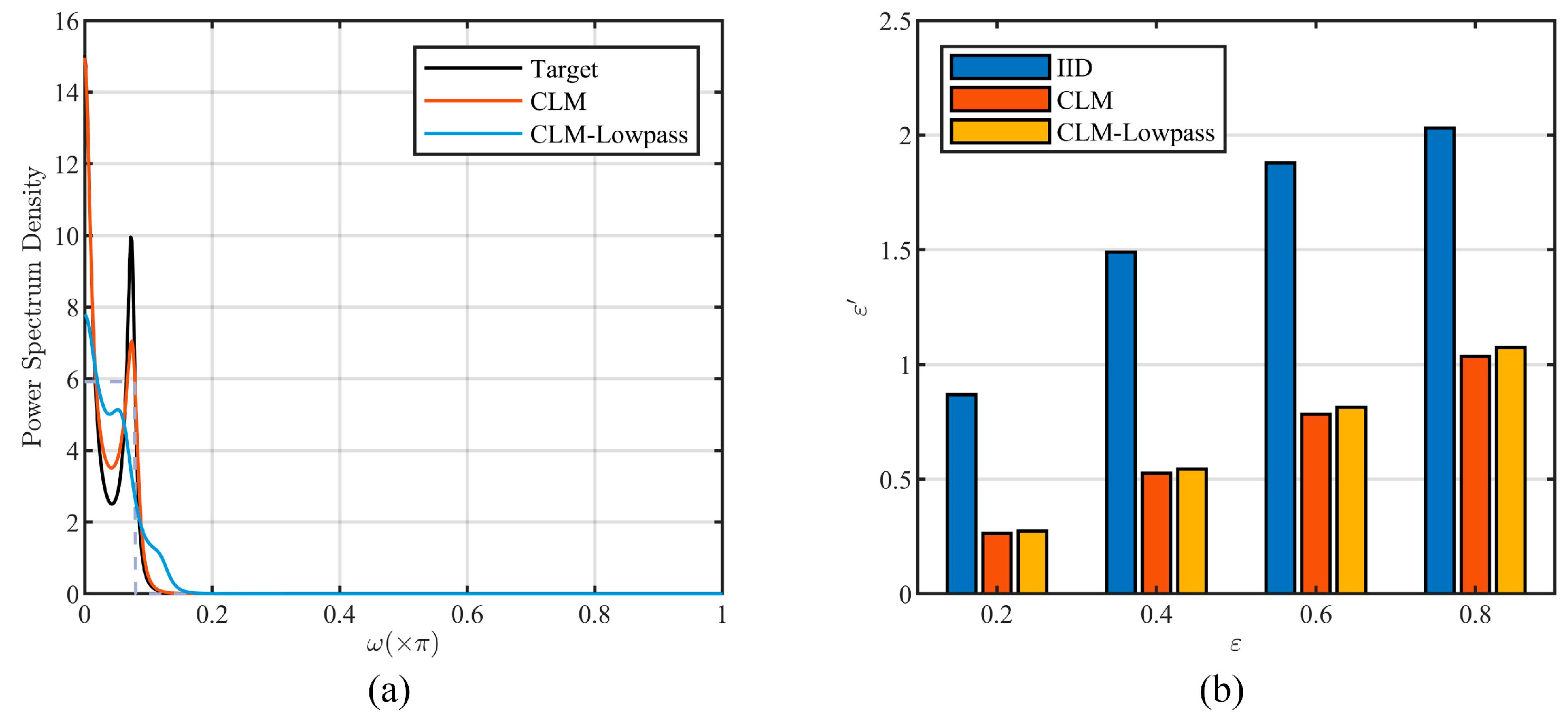
5.3.1. Effectiveness of CLM-Lowpass
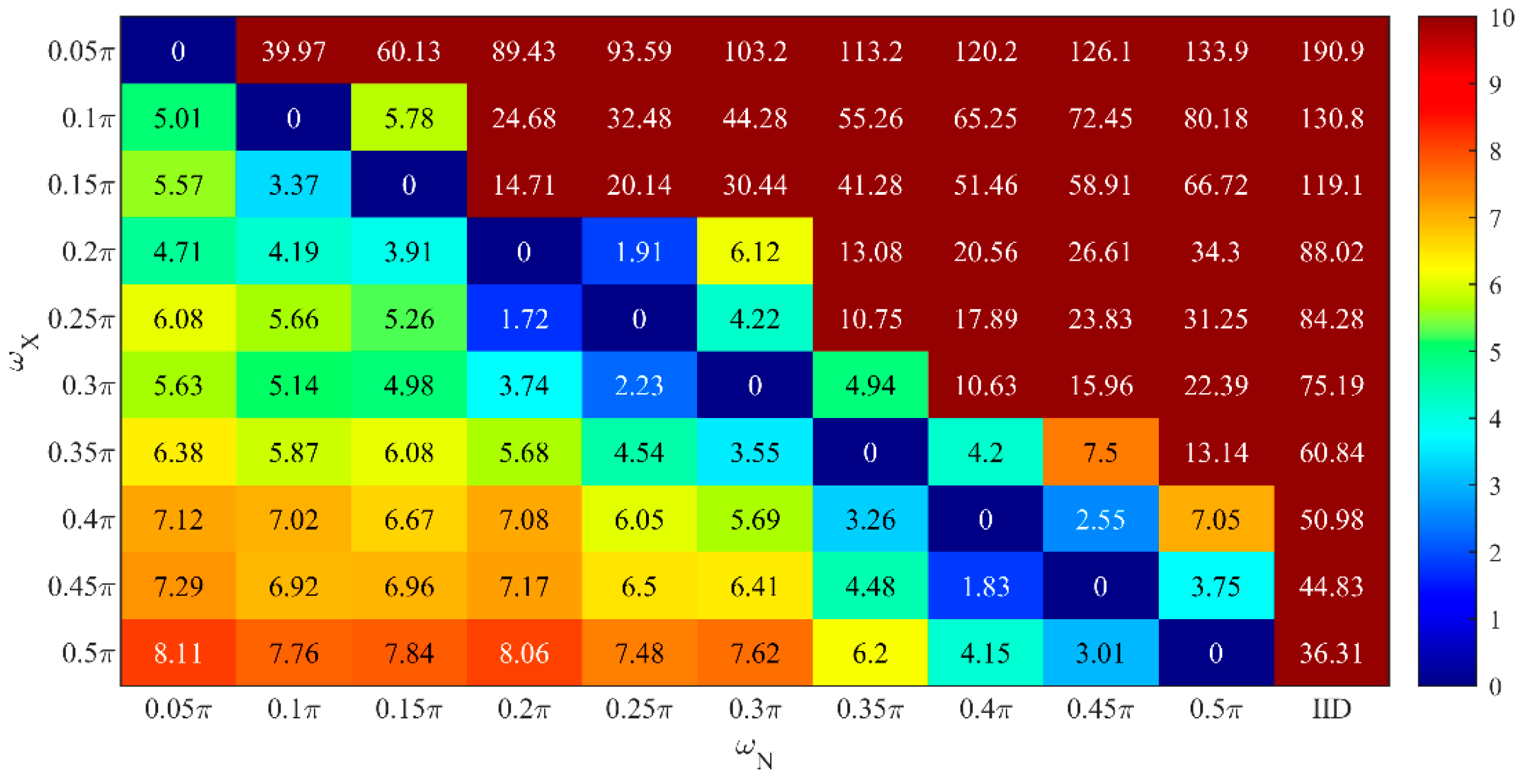
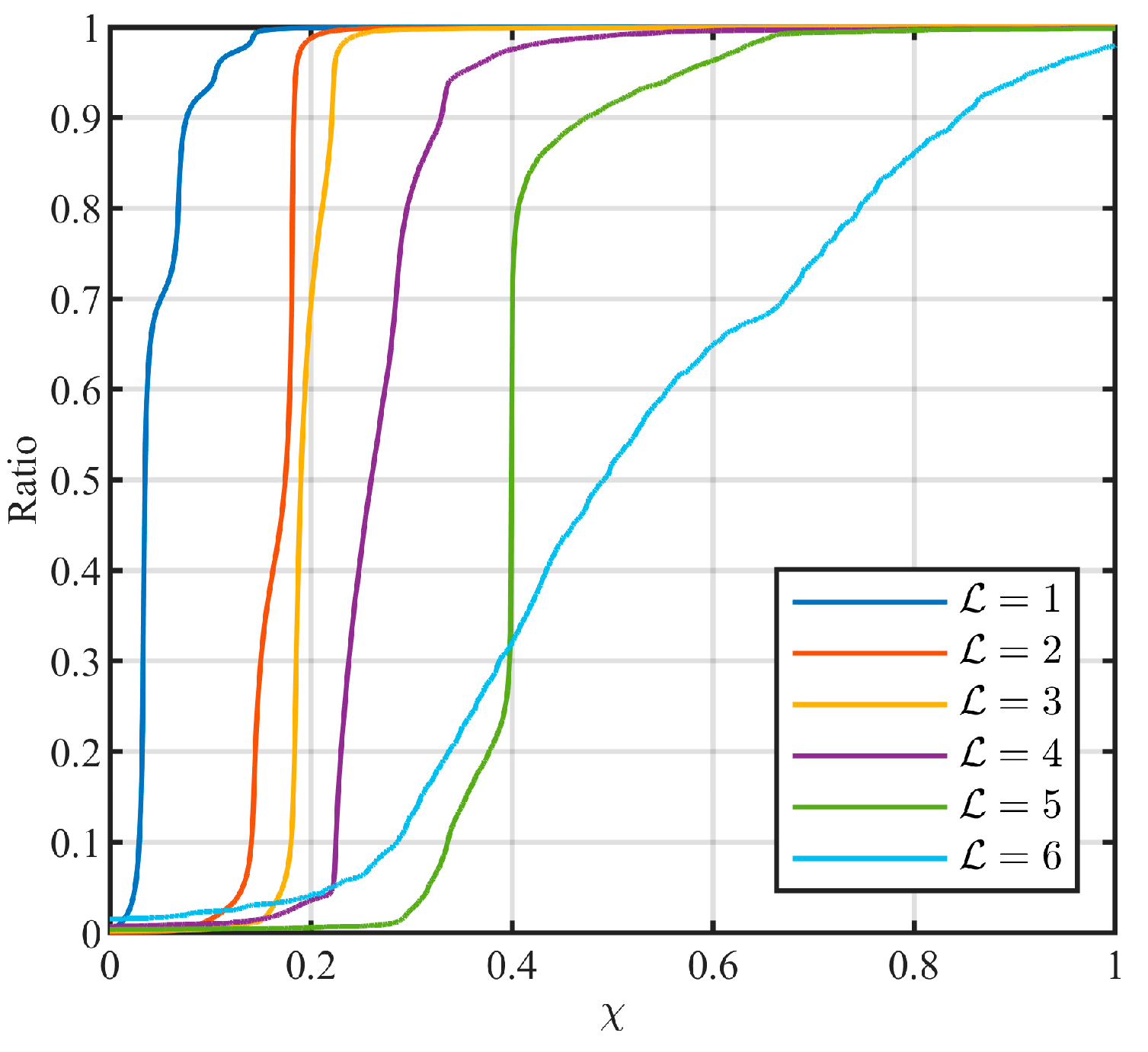
5.3.2. Effectiveness of Parameter Quantization
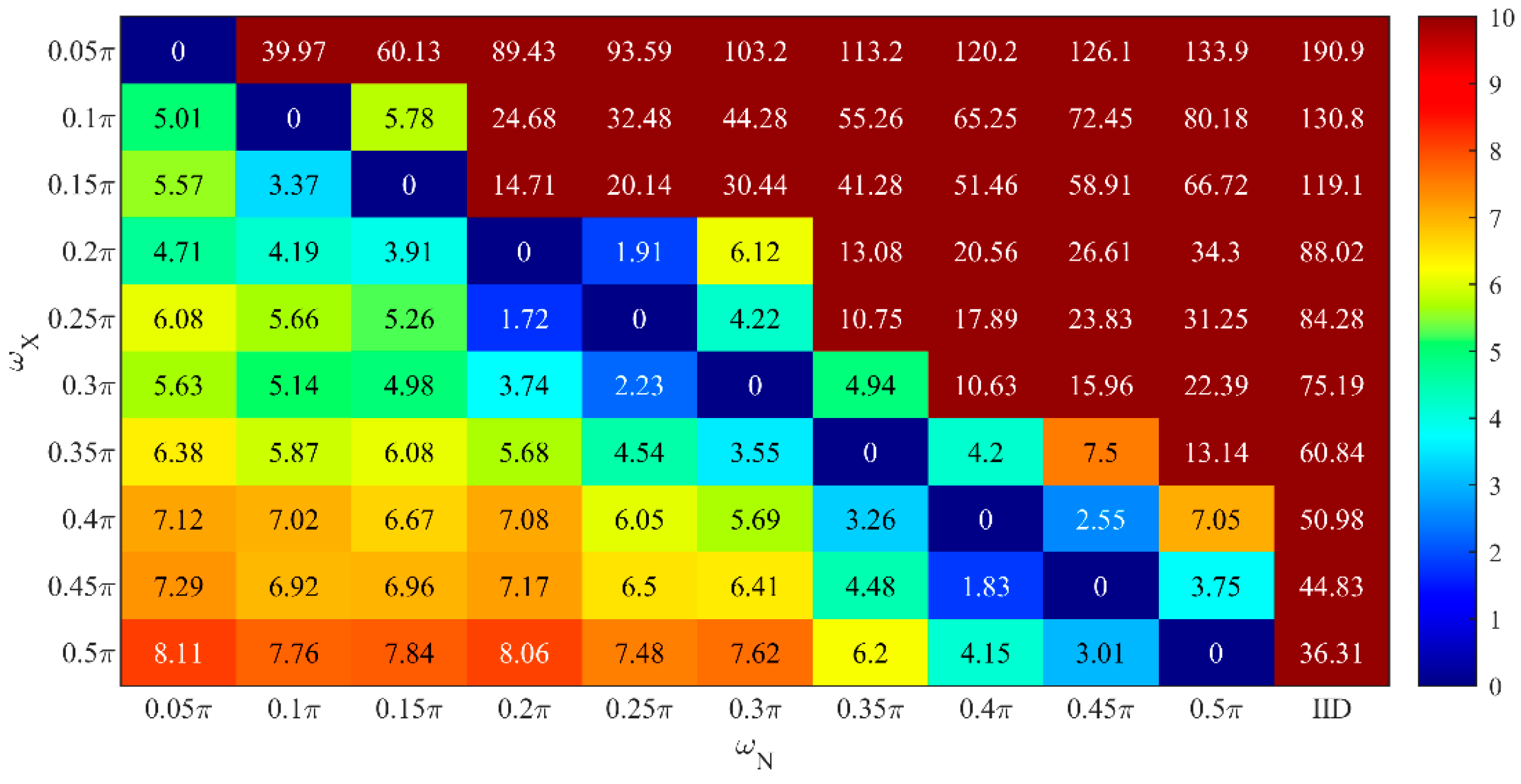
5.3.3. Feature Parameter in Level Identification
5.3.4. The Effectiveness of QCLM-Lowpass for Continuous Location Data Publishing
5.4. Performance Evaluation
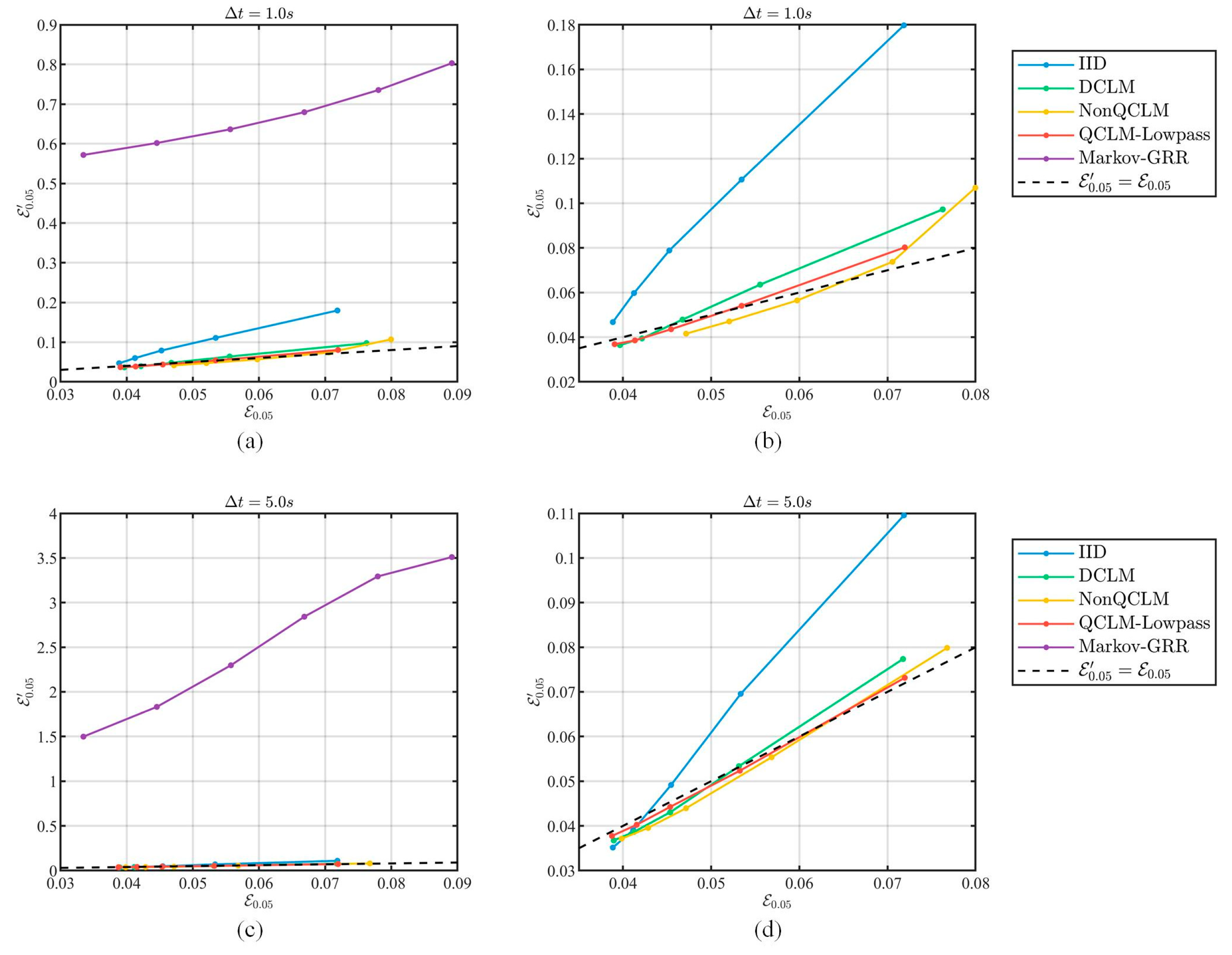
- For privacy performance, this paper focuses on the ability to resist correlation-based attacks, which was evaluated by comparing the change in privacy strength before and after the filtering attack.
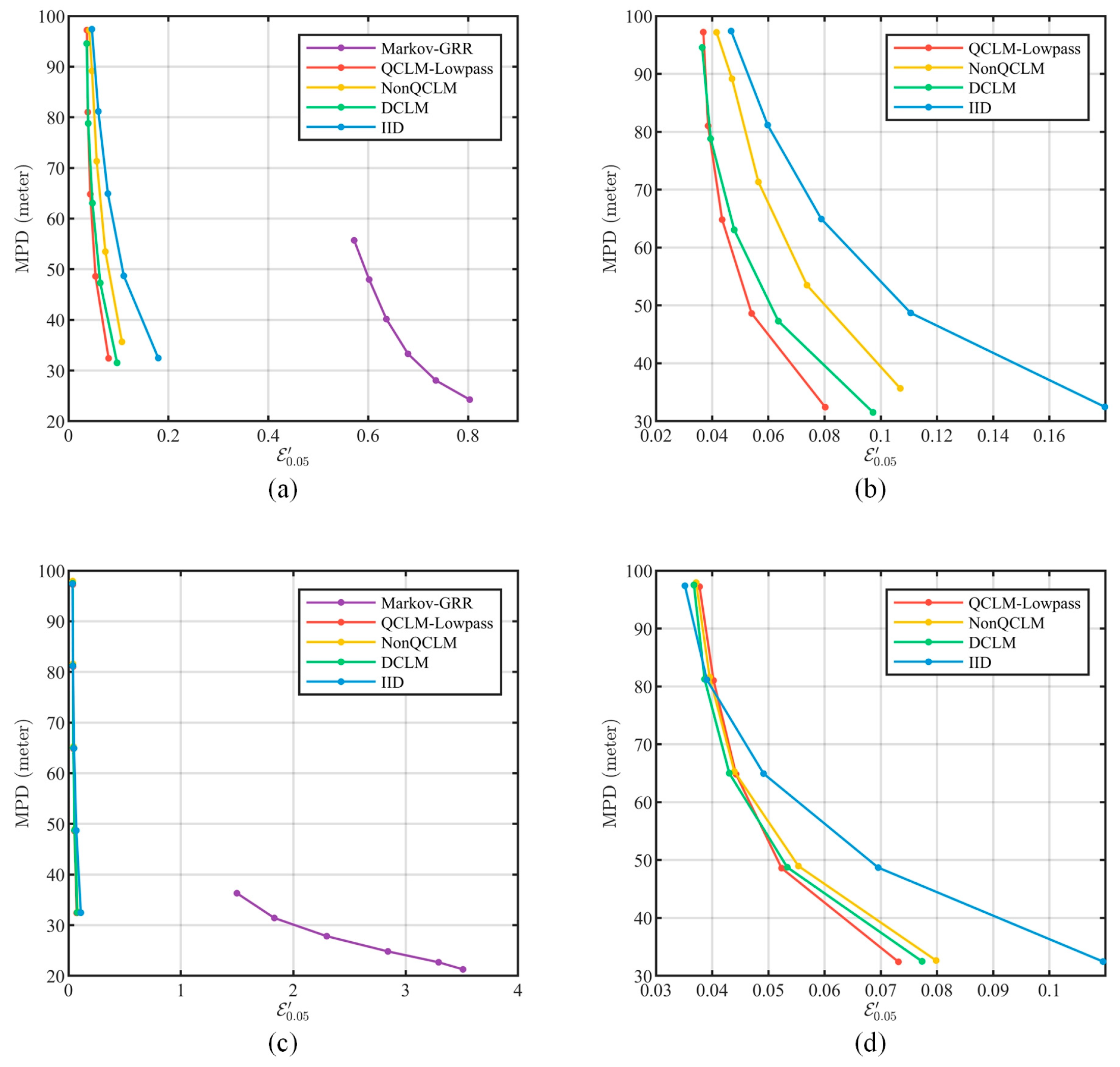
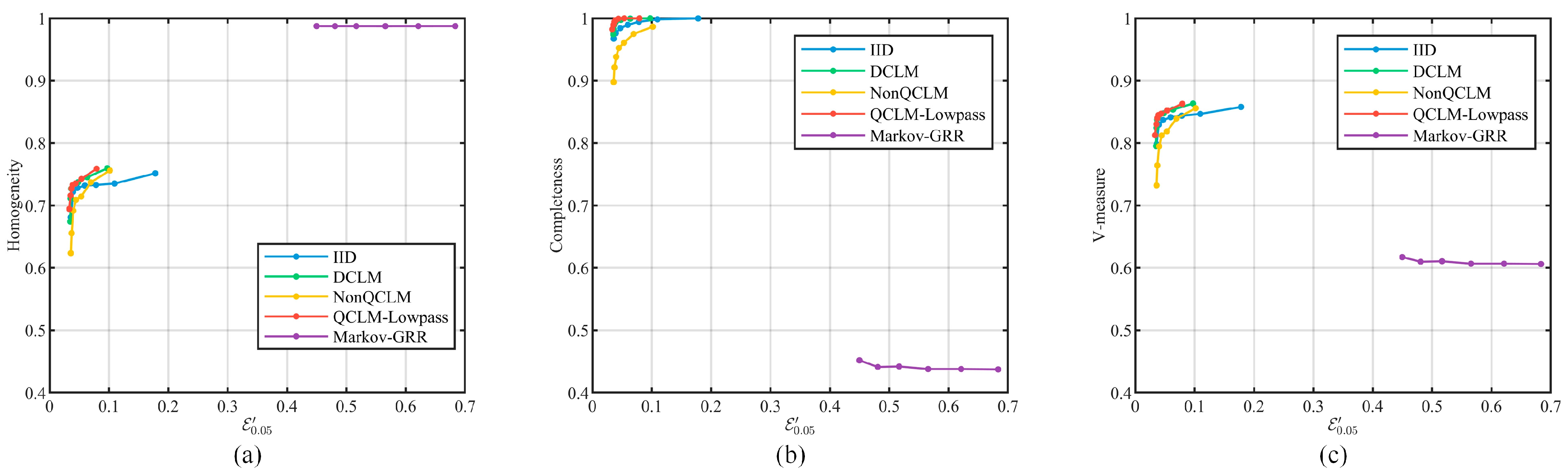
- For data availability, this paper evaluated the ability to balance privacy protection and data availability by comparing the data availability at the same level of privacy strength under the filtering attack.
5.4.1. Privacy Evaluation
5.4.2. Usability Evaluation
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, S.; Sinnott, R.O. Protecting Personal Trajectories of Social Media Users through Differential Privacy. Comput. Secur. 2017, 67, 142–163. [Google Scholar] [CrossRef]
- Katsomallos, M.; Tzompanaki, K.; Kotzinos, D. Privacy, Space and Time: A Survey on Privacy-Preserving Continuous Data Publishing. J. Spat. Inf. Sci. 2019, 19, 57–103. [Google Scholar] [CrossRef]
- Jiang, H.; Li, J.; Zhao, P.; Zeng, F.; Xiao, Z.; Iyengar, A. Location Privacy-Preserving Mechanisms in Location-Based Services: A Comprehensive Survey. ACM Comput. Surv. 2022, 54, 1–36. [Google Scholar] [CrossRef]
- Chatzikokolakis, K.; ElSalamouny, E.; Palamidessi, C.; Anna, P. Methods for Location Privacy: A Comparative Overview. Found. Trends Priv. Secur. 2017, 1, 199–257. [Google Scholar]
- Dwork, C. Differential Privacy. In Automata, Languages and Programming; Bugliesi, M., Preneel, B., Sassone, V., Wegener, I., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4052, pp. 1–12. ISBN 978-3-540-35907-4. [Google Scholar]
- Zhao, X.; Pi, D.; Chen, J. Novel Trajectory Privacy-Preserving Method Based on Clustering Using Differential Privacy. Expert Syst. Appl. 2020, 149, 113241. [Google Scholar] [CrossRef]
- Kim, J.W.; Edemacu, K.; Kim, J.S.; Chung, Y.D.; Jang, B. A Survey of Differential Privacy-Based Techniques and Their Applicability to Location-Based Services. Comput. Secur. 2021, 111, 102464. [Google Scholar] [CrossRef]
- Ma, T.; Song, F. A Trajectory Privacy Protection Method Based on Random Sampling Differential Privacy. ISPRS Int. J. Geo-Inf. 2021, 10, 454. [Google Scholar] [CrossRef]
- Kasiviswanathan, S.P.; Lee, H.K.; Nissim, K.; Raskhodnikova, S.; Smith, A. What Can We Learn Privately? SIAM J. Comput. 2011, 40, 793–826. [Google Scholar] [CrossRef]
- Andrés, M.E.; Bordenabe, N.E.; Chatzikokolakis, K.; Palamidessi, C. Geo-Indistinguishability: Differential Privacy for Location-Based Systems. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, Berlin, Germany, 4–8 November 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 901–914. [Google Scholar] [CrossRef]
- Cao, Y.; Yoshikawa, M.; Xiao, Y.; Xiong, L. Quantifying Differential Privacy in Continuous Data Release Under Temporal Correlations. IEEE Trans. Knowl. Data Eng. 2019, 31, 1281–1295. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Xu, Z.; Jia, S.; Xia, Y.; Zhang, X. Why Current Differential Privacy Schemes Are Inapplicable for Correlated Data Publishing? World Wide Web 2021, 24, 1–23. [Google Scholar] [CrossRef]
- Jiang, K.; Shao, D.; Bressan, S.; Kister, T.; Tan, K.-L. Publishing Trajectories with Differential Privacy Guarantees. In Proceedings of the 25th International Conference on Scientific and Statistical Database Management, Baltimore, MD, USA, 29–31 July 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 1–12. [Google Scholar] [CrossRef]
- Chatzikokolakis, K.; Palamidessi, C.; Stronati, M. A Predictive Differentially-Private Mechanism for Mobility Traces. In Privacy Enhancing Technologies; De Cristofaro, E., Murdoch, S.J., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8555, pp. 21–41. ISBN 978-3-319-08505-0. [Google Scholar]
- Al-Dhubhani, R.; Cazalas, J.M. An Adaptive Geo-Indistinguishability Mechanism for Continuous LBS Queries. Wirel. Netw. 2018, 24, 3221–3239. [Google Scholar] [CrossRef]
- Xiao, Y.; Xiong, L. Protecting Locations with Differential Privacy under Temporal Correlations. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security—CCS ’15, Denver, CO, USA, 12–16 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1298–1309. [Google Scholar] [CrossRef]
- Xiong, X.; Liu, S.; Li, D.; Wang, J.; Niu, X. Locally Differentially Private Continuous Location Sharing with Randomized Response. Int. J. Distrib. Sens. Netw. 2019, 15. [Google Scholar] [CrossRef]
- Wang, H.; Xu, Z. CTS-DP: Publishing Correlated Time-Series Data via Differential Privacy. Knowl. Based Syst. 2017, 122, 167–179. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating Noise to Sensitivity in Private Data Analysis. In Theory of Cryptography; Halevi, S., Rabin, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Elnagar, A.; Gupta, K. Motion Prediction of Moving Objects Based on Autoregressive Model. IEEE Trans. Syst. Man Cybern. Part Syst. Hum. 1998, 28, 803–810. [Google Scholar] [CrossRef]
- Zaidi, Z.R.; Mark, B.L. Mobility Tracking Based on Autoregressive Models. IEEE Trans. Mob. Comput. 2011, 10, 32–43. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, L.; Xie, X.; Ma, W.-Y. Mining Interesting Locations and Travel Sequences from GPS Trajectories. In Proceedings of the 18th international conference on World Wide Web—WWW ’09, Madrid, Spain, 20–24 April 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 791–800. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, Q.; Chen, Y.; Xie, X.; Ma, W.-Y. Understanding Mobility Based on GPS Data. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Republic of Korea, 21–24 September 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 312–321. [Google Scholar] [CrossRef]
- Zheng, Y.; Xie, X.; Ma, W.-Y. GeoLife: A Collaborative Social Networking Service among User, Location and Trajectory. IEEE Data Eng. Bull. 2010, 33, 32–39. [Google Scholar]
- Yuan, J.; Zheng, Y.; Xie, X.; Sun, G. Driving with Knowledge from the Physical World. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’11, San Diego, CA, USA, 21–24 August 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 316–324. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Zhang, C.; Xie, W.; Xie, X.; Sun, G.; Huang, Y. T-Drive: Driving Directions Based on Taxi Trajectories. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems—GIS ’10, San Jose, CA, USA, 2–5 November 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 99–108. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; AAAI Press: Portland, OR, USA, 1996; Volume 96, pp. 226–231. [Google Scholar]
- Rosenberg, A.; Hirschberg, J. V-Measure: A Conditional Entropy-Based External Cluster Evaluation Measure. In Proceedings of the Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; Eisner, J., Ed.; Association for Computational Linguistics: Prague, Czech Republic, 2007; pp. 410–420. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Definition |
|---|---|
| a location data in XOY at time | |
| the time interval for data release | |
| the time of i-th data release | |
| the simplified representation of in time discretization | |
| the location data series up to I-th data release | |
| the autocorrelation function matrix of , | |
| the perturbation noise added to at time | |
| the noise series up to I-th data release | |
| the perturbed location data at time | |
| the perturbed location data series up to I-th data release | |
| the autocorrelation function matrix of , | |
| the location increment at time , | |
| the modulus and azimuth of | |
| the location increment series up to I-th data release |
| CLM | ||
| Attributes | ||
| integer | the order of zeros and poles of the CLM filter | |
| vector | are coefficients of the numerator of , where | |
| vector | are coefficients of the denominator of , where | |
| real | : the gain coefficient; : the scale of Laplace distribution | |
| matrix | the input state of four CLM filters, and each row corresponds to one filter | |
| matrix | the output state of four CLM filters and each row corresponds to one filter | |
| vector | are the input of four CLM filters | |
| vector | are the output of four CLM filters | |
| Methods | ||
| : Set ; Set : zeros matrix, : zeros matrix. | ||
| : Generate four i.i.d random numbers . | ||
| : Update . | ||
| : Update . | ||
| : Generate the Laplace distributed noise . | ||
| QCLM-Lowpass | ||
| Attributes | ||
| matrix | the parameter vectors at different levels, defined in Section 4.3.2 | |
| matrix | the gain coefficients in different level shifts, defined in Section 4.3.5 | |
| vector | the gain coefficient vector | |
| integer | the index of the gain coefficient vector | |
| vector | is the estimated level change, defined in Section 4.3.4 | |
| integer | denote the estimated and actual level of the CLM filter | |
| Methods | ||
| : Set ; Set : zeros vector, and ; Set , and the index ; Initialize the member ; | ||
| : Determine the estimated level according to the feature parameter , defined in Section 4.3.4. | ||
| : Adjust the CLM filter based on the autocorrelation function vector , and generate the Laplace noise . | ||
| λ | 20 | 30 | 40 | 50 | 60 | |
|---|---|---|---|---|---|---|
| IID | 150.17 | 107.02 | 74.25 | 44.85 | 20.33 | |
| DCLM | 27.54 | 14.40 | 2.35 | −6.41 | −8.07 | |
| NonQCLM | 33.77 | 4.54 | −5.52 | −9.61 | −11.88 | |
| QCLM-Lowpass | 11.54 | 1.12 | −4.18 | −6.77 | −5.63 | |
| IID | 52.47 | 30.37 | 8.14 | −5.10 | −9.52 | |
| DCLM | 7.80 | 0.38 | −5.07 | −6.30 | −5.65 | |
| NonQCLM | 4.04 | −2.64 | −6.79 | −7.70 | −6.78 | |
| QCLM-Lowpass | 1.67 | −1.69 | −2.42 | −3.13 | −2.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, L.; Xu, Z. Differential Privacy Preservation for Continuous Release of Real-Time Location Data. Entropy 2024, 26, 138. https://doi.org/10.3390/e26020138
Mao L, Xu Z. Differential Privacy Preservation for Continuous Release of Real-Time Location Data. Entropy. 2024; 26(2):138. https://doi.org/10.3390/e26020138
Chicago/Turabian StyleMao, Lihui, and Zhengquan Xu. 2024. "Differential Privacy Preservation for Continuous Release of Real-Time Location Data" Entropy 26, no. 2: 138. https://doi.org/10.3390/e26020138
APA StyleMao, L., & Xu, Z. (2024). Differential Privacy Preservation for Continuous Release of Real-Time Location Data. Entropy, 26(2), 138. https://doi.org/10.3390/e26020138