1. Introduction
In the past several decades, much attention has been given to
control problems, wherein the aim is to eliminate the influence of disturbance on the system.
control mainly focuses on designing a robust controller to regulate and stabilize the system. In practice, we should not only focus on the control performance, but also consider the optimization of the system [
1,
2]. Therefore, optimal
control problems will always be a hot research topic.
Adaptive dynamic programming (ADP), as one of the optimal control methods, has emerged as a powerful tool through which to deal with the optimal control problems of all kinds of dynamic systems [
3]. The ADP framework combines dynamic programming and neural network approximation, and it has strong learning and adaptive ability. In this sense, ADP has rapidly developed in the control community in recent years. Generally speaking, the core of controller designs mainly concentrates on solving a Hamilton–Jacobi–Bellman (HJB) equation for nonlinear systems or an algebraic Riccati equation for linear systems [
4]. Unfortunately, the HJB equation contains nonlinear, partial differential parts, which are difficult to solve directly [
5]. Therefore, many efforts have been made for finding approximate solutions to the HJB equation using iterative or learning methods. Regarding the case of iterative methods, the ADP can be classed into two categories: value iteration (VI) [
6,
7] and policy iteration (PI) [
8,
9]. Regarding the case of learning-based methods, neural network (NN) approximation is generally utilized to learn the optimal or suboptimal solutions to the HJB equation. The standard learning frameworks include the following: actor–critic NNs and only-critic NNs. However, the abovementioned pieces of literature require partial or full model information in the controller design loop. To avoid relying on system models, many data-driven or model-free methods have been developed for improving the existing ADP frameworks, that is, data-driven RL [
7], integral RL (IRL) [
10,
11], and system identification-based ADP methods [
12,
13,
14].
More recently, excellent development has been realized with the use of ADP for the robust controller designs of optimal
control problems [
15,
16,
17]. The main way through which to solve optimal
control problems is to model such problems as a two-player zero-sum game (min–max optimization problem), where the controller and the disturbance are viewed as players that try to find a controller to minimize the performance index function in worst-case disturbance conditions [
18,
19]. However, the disadvantage of zero-sum games is in judging the existence of the saddle point, which is generally difficult to judged. In order to overcome this issue, an indirect method motivated by [
20] was developed by formulating an optimal regulation for a nominal system with new designs of the cost/value function [
21]. For instance, Yang et al. proposed an event-triggered robust control strategy for nonlinear systems [
22] using the indirect method. Xue et al. studied a tracking control problem for partial continuous-time systems with uncertainties and constraints [
23] by transforming the robust control problem into an optimal regulation of nominal systems.
However, the existing results on
optimal control designs have two main characteristics: (1) their controller designs are based on the assumption that the complete or partial knowledge of the system dynamics are known in advance; however, (2) to address this issue, some system identification methods have been proposed, such as the identifier–critic- or identifier–actor–critic-based designs of
optimal control. However, it is generally required that the persistence of excitation (PE) condition must be satisfied to ensure the learning performance of the weight updating of neural networks, which is difficult to check online in practice [
18,
19,
23]. Therefore, how to weaken the PE condition is also the research motivation of this paper.
From the abovementioned observations and considerations, in this paper, we propose a novel online parameter estimation method based on an identifier–critic learning control framework for the optimal control of nonlinear systems that have unknown dynamics with relaxed PE conditions. The contributions of our work can be summarized as follows:
A new online identifier–critic learning control framework with a relaxed PE condition is proposed to address robust control for unknown continuous-time systems subject to unknown disturbances. To reconstruct the information of the system dynamics, neural networks combined with the linear regressor method are established to approximate the unknown system dynamics and disturbances.
The approach in this paper is different from the existing weight adaption laws [
18,
19,
23], where the PE condition is needed to ensure the learning performance of the NN’s weight parameters. However, such a condition is difficult to check online, and a general way through which to satisfy this condition is to add external noise to the controller, which may lead to the instability of the system. To overcome this issue, a Kreisselmeier regressor extension and mixing (KREM)-based weight adaption law is designed for identifier–critic NNs with new convergence conditions.
Weak PE properties of new convergence conditions are analyzed rigorously compared to traditional PE conditions. Moreover, the theoretical results indicate that the closed-loop system’s stability and the convergence of identifier–critic learning are guaranteed.
The remainder of this article is organized as follows. In
Section 2, some preliminaries are introduced and the optimal robust control problem of nonlinear continuous-time systems is given. Then, a system identifier design with a relaxed PE condition is constructed in
Section 3.
Section 4 gives the critic NN design for robust control under a relaxed PE condition. Theoretical analyses of the weak PE properties under new convergence conditions and the stability of the closed-loop systems are given in
Section 5. The simulation results are provided in
Section 6. Some conclusions are summarized in
Section 7.
3. System Identifier Design with Relaxed PE Condition
In this section, an NN-based identifier is utilized to reconstruct the unknown system dynamics in (
1). The KREM technique is introduced to adjust the identifier weights under relaxed PE conditions. We assume that the unknown system dynamics
,
, and
in (
1) are continuous functions defined on compact sets. The NN-based identifier is designed as follows:
where
,
and
are the ideal NN weights;
,
and
are the basis functions; and
,
and
are the reconstruction errors. Then, according to the Weierstrass theorem and the statements in [
10], the approximation errors
,
, and
can be shown to approach zero as the number of NN neurons
,
, and
increases to infinity.
Before proceeding, it is essential to establish the following underlying assumption.
Assumption 1. - (1)
The basis functions , and are bounded, that is, , , , respectively.
- (2)
The reconstruction errors , and are bounded, that is, , , , respectively.
Using (
10)–(
12), the system (
1) can be rewritten as
where
is the augmented weight matrix with
, and
is the augmented regressor vector.
is the model approximation error.
Note that
and
are unknown. Therefore, we define the filtered variables
and
as
where
is the filter coefficient. From Equations (
13) and (
14), we can deduce that
where
denotes the filtered version of
as
. Clearly, (
15) is a linear regression equation (LRE), where
and
can be calculated from (
14). In the following, we describe how the KREM technique is applied to estimate
by using the measured information
and
.
To approximate the unknown weights
in (
15) such that the estimated weights
converge to their true values under a relaxed PE condition, we aim to construct an extended LRE (E-LRE) based on (
15). We define the matrices
and
as follows:
where
with
,
is a forgetting factor. From (
16), we can derive its solution as
Note that it can be verified that
and
are bounded for any given bounded
and
x due to the appropriate choice of
. Thus, an E-LRE is obtained
where
.
To construct an identifier weight error dynamics that achieves better convergence properties, we define the variables
,
, and
as follows:
Then Equation (
18) becomes
Note that for any square matrix
, we have
, even if
M is not full rank. Thus,
. Moreover,
is a scalar diagonal matrix, where (
20) can be decoupled into a series of scalar LREs:
where
and
indicate the
ith row and
jth column of
and
, respectively.
Then, the estimation algorithm for the unknown identifier NN weights can be designed based on (
21) as follows:
where
presents the adaptive learning gain.
The convergence of identifier (
22) can be given as follows.
Theorem 1. Consider the system (13) with the online update law (22); if , then - (i)
for , the estimator error converges to zero exponentially;
- (ii)
for , the estimator error converges to a compact set around zero.
Proof. If
, according to Definition 1 we have
. Defining the estimation error
,
,
. Due to (
21) and (
22), the identifier weight error dynamics can be obtained
Considering the Lyapunov function
, the derivation of
can be calculated as
In fact, when
, (
24) can be rewritten as
where
. According to the Lyapunov theorem, the weight estimation error
exponentially converges to zero.
When
, (
24) can be further presented as
According to Assumption 1,
is bounded, denoted as
. Then,
According to the extended Lyapunov theorem, the estimation error
uniformly ultimately converges to a compact set
. □
Remark 1. In [12], the update law for the unknown weight was designed based on (18), while the PE condition (i.e., ) was required to ensure convergence. However, satisfying the PE condition is generally challenging. In Theorem 1, we provide a new convergence condition . Notably, this new condition is significantly superior to the conventional PE condition for two reasons. (1) We theoretically prove that is much weaker than , as detailed in Section 5. (2) is directly related to the determinant of the matrix . Therefore, checking online becomes feasible by calculating the determinant of . In contrast, assessing the standard PE condition directly online is not possible [18,19,23]. Based on the above analysis, the unknown information
,
, and
can be estimated using (
13) and (
22). This allows for the reconstruction of the completely unknown system dynamics. In order to obtain the optimal
control pair, the critic NN will be introduced to learn the solution of the HJB equation in the subsequent section.
4. Critic NN Design for Control under Relaxed PE Condition
In this section, the performance index will be approximated via a critic NN to obtain the optimal
control pair. The KREM algorithm will be continually utilized to design the update law of critic NN under the relaxed PE condition. Firstly, based on the above identifier, the system (
1) can be represented as
where
,
and
are the estimated values of
,
and
, respectively.
denotes the identifier error. And, the Hamiltonian (
5) can be further written as
Then, the HJI Equation (
6) becomes
Therefore, based on (
30), the
control pair
for the estimated system (
28) can be expressed as follows:
Since the HJI Equation (
30) is a nonlinear PDE, similar to (
6), we utilize a critic NN to estimate
and its gradient
as follows:
where
is the unknown constant weight.
represents the independent basis function with
.
l is the number of neurons. The approximation error is presented as
with
. Note that as the number of independent basis functions increases, both the approximation errors and their gradients can approach zero.
Before proceeding, the following assumption is needed.
Assumption 2. - (1)
The ideal critic NN’s weight is bounded, that is, .
- (2)
The basis functions and its gradients are bounded, that is, , .
- (3)
The approximator reconstruction error and its gradients are bounded, that is, , .
Since the ideal critic NN weights
are unknown, take
as the estimated value of
and
as the estimated value of
V, where the practical critic NN is given by
The estimated
control pair
and
can be obtained as
To online estimate the unknown weights of the critic NN using KREM technology, we aim to construct a linear equation according to (
30) and (
34) as
where
is a bounded residual HJI equation error. Let
and
, where a linear equation is obtained as follows:
Similar to the previous section, we define the filtered regressor matrix
and the vector
as follows:
where
and
is the forgetting factor. Then, the solution of (
40) can be deduced as
From (
39) and (
41), an E-LRE related to
and
is obtained
where
is bounded. To estimate the unknown parameter
in (
42) under a relaxed PE condition, define the variables
,
, and
as
Then Equation (
42) becomes
Note that
. Since
is a scalar matrix, a series of scalar LREs is obtained as
where
,
and
indicate the
rows of
,
, and
, respectively.
Driven by the parameter error based on (
45), the critic unknown weight
is designed as
where
presents the adaptive learning gain.
The convergence condition for the proposed critic NN adaptive law is provided in Theorem 2.
Theorem 2. For adaptive law (46) of critic NN with the regressor matrix in (44); if , then - (i)
for , the estimator error converges to zero exponentially;
- (ii)
for , the estimator error converges to a compact set around zero;
Proof. Defining the estimation error , . The proofs presented in Theorem 1 can be extended to establish similar results in the current context. Note that the Lyapunov function here is chosen as . □
Remark 2. According to Theorem 2, a new convergence condition for the estimation error of the critic neural network weights, denoted as , is provided. This condition does not rely on the conventional parameter estimation (PE) condition, i.e., . In this paper, the additional exploration signal is not required to guarantee . Instead, the satisfaction of can be achieved by adjusting the forgetting factor . It is worth noting that the new convergence condition is associated with the matrix , and it can be verified online by calculating the determinant of . The proof of the weak PE property for the new convergence condition will be presented in the following section.
Remark 3. The convergence analysis of and are provided in Theorem 1 and Theorem 2, respectively. In fact, we can derive the convergence of and using simple matrix operations, which will be omitted in this paper.
Till now, the identifier–critic learning-based framework for optimal control under the relaxed PE condition is given. For clarity, the design details of the proposed method are shown in Algorithm 1, which can be considered the pseudocode for the simulation part.
| Algorithm 1 Identifier–critic learning-based optimal control algorithm |
- 1:
Initialization - 2:
Initialize system parameters: , Q, R and running time T; - 3:
Set the identifier and critic filter operators: and ; - 4:
Set the basis functions of identifier and critic NNs: and ; - 5:
Initialize and set the filter operator parameters: , , , , and ; - 6:
Initialize identifier NNs parameters: , ; - 7:
Initialize critic NNs parameters: , ; - 8:
Initialize the control pair by and ; - 9:
while
do - 10:
Calculate the filter processing of the identifier NNs by ; - 11:
Calculate the dynamic regressor extension (DRE) of the identifier NNs by ; - 12:
Calculate the regressor “mixing” of the identifier NNs by ; - 13:
Update the weight parameters of the identifier NNs by ;
- 14:
Compute the approximated HJB equation by ; - 15:
Calculate the dynamic regressor extension (DRE) of the critic NNs by ; - 16:
Calculate the regressor “mixing” of the critic NNs by ; - 17:
Update the weight parameters of the critic NNs by ;
- 18:
Update the control pair by and ; - 19:
Update the system states x by ; - 20:
end while
|
5. Stability and Convergence Analysis
In this section, we present the main results, which include the theoretical analysis of weak PE properties under new convergence conditions proposed in Theorem 1 and Theorem 2. Furthermore, we provide a stability result for the closed-loop system under the proposed online learning optimal control method.
To facilitate the analysis, the following assumption is made.
Assumption 3. The system dynamics in (1) satisfy , and , where , and . 5.1. Weak PE Properties of New Convergence Conditions
As shown in Theorem 1, Theorem 2 and Remark 3, the convergence of and is established without the restrictive PE condition, i.e., and . These new convergence conditions can be easily checked online, as mentioned in Remark 1 and Remark 2. Furthermore, we will analyze the superiority of the new convergence conditions compared to the conventional PE condition from a theoretical standpoint.
Theorem 3. Consider the system (13) with the online identifier NN adaptive law (22) and critic NN adaptive law (46), - (i)
The convergence condition of estimation error in Theorem 1, that is, , is weaker than in the following precise sense - (ii)
The convergence condition of estimation error in Theorem 2, that is, , is weaker than in the following precise sense
Proof. For
, suppose that
in (
13) is PE, indicating that
[
25]. From Definition 1, we have
Moreover, since
with
, the following inequality holds
Furthermore, for
, we also have
From (
17), (
52) and (
53), we conclude that
Hence, the matrix
in (
16) is positive definite, that is,
,
. Considering that the determinant of a matrix is equal to the product of all its eigenvalues, that is,
, we obtain
. Thus, (
47) is true.
The proof of (
48) is established by the following:
For (ii), the proof process can be referred to in (i). This finishes the proof. □
5.2. Stability and Convergence Analysis
The stability result for the closed-loop system under the proposed online learning optimal control method will be presented in the following theorem.
Theorem 4. Let Assumptions 1 and 2 hold. Considering system (1) with the identifier weight tuning law given by (22), the control pair are computed by (36) and (37), respectively. The critic NN weight tuning laws are updated by (46). If and , then the closed-loop system, system identifier estimation error , and critic estimation error are uniformly ultimately bounded (UUB). Moreover, the approximated control pair given by (36) and (37) are close to the optimal control pair and within a small region and , that is, and , where and are positive constants. Proof. We consider the Lyapunov function as follows:
where
,
,
and
are positive constants.
By applying matrix operations, we can obtain the following:
According to Definition 1,
and
imply that
and
. Substituting (
19), (
43), and using Young’s inequality
with
, we have
where
,
.
For
and
,
Since
, and
, (
60) can be rewritten as
where
is a bounded variable.
Recall that
and
, thus
Since
. Hence, the last term of (
56) can be given as
where
and
are bounded variables. Consequently, we substitute (
58), (
59), and (
61)–(
63) into (
56); thus, we have
We choose the parameters
,
,
,
and
, fulfilling the following conditions
Then, (
64) can be further presented as
where
,
,
,
,
and
are positive constants
Thus,
is negative if
which implies that the NN weight estimation errors
,
and the system state
x are all UUB.
Lastly, the error between the proposed
control pair and the ideal one are written as
which further implies the following fact
where
and
are constants determined by the identifier NN estimation error
and the critic NN estimation error
. It proves that the approximate
control pair can converge to a set around the optimal solution.
This completes the proof. □
6. Numerical Simulation
This section aims to verify the effectiveness of the proposed KREM-based IC learning approach for optimal robust control. We consider the following NCT system [
12]
where
,
,
.
We choose the regressor of identifier NN as
with the unknown identifier weight matrix given by
The activation function in (
33) for the critic NN is selected as
The ideal critic NN weights were
.
In this numerical example, several other parameters are set as follows: the initial values of the system states are and . and . The filter coefficients are , , , , . It is important to note that in this simulation, there is no need to add noise to the control input to ensure the PE condition. This condition is often necessary for many existing ADP-based control methods to ensure that and .
For comparison, we consider the Kreisselmeier’s Regressor Extension (KRE) based identifier-critic network framework [
12] for the system (
66).
Figure 2 and
Figure 3 display the convergence of the identifier NN weights and the critic NN weights, respectively, under our KREM-based optimal robust control method and the KRE-based control method [
12]. As illustrated in
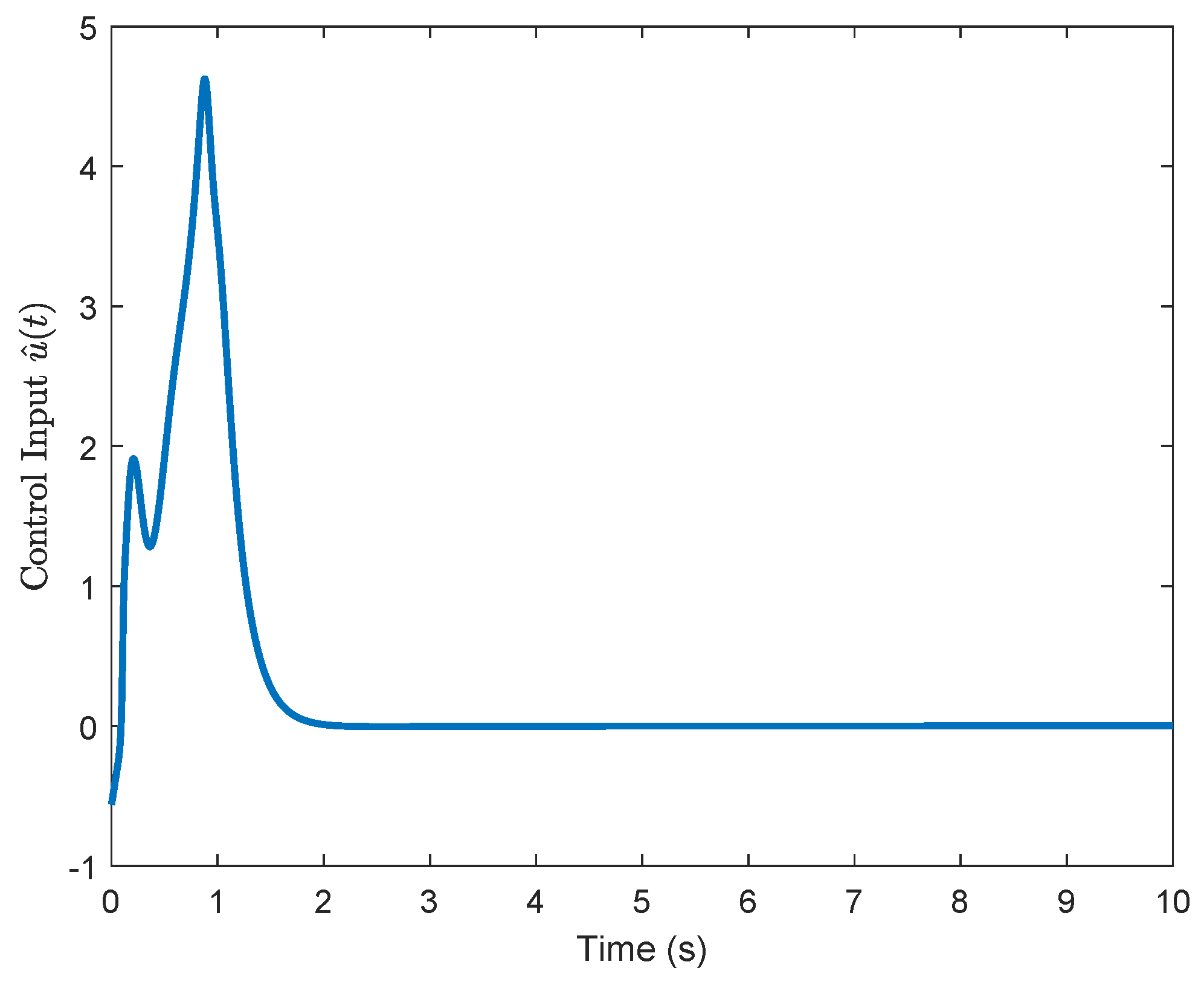
Figure 2, the KREM-based ADP method proposed in this paper exhibits faster convergence compared to the KRE-based ADP method. Furthermore, it demonstrates element-wise monotonicity, thus preventing oscillations and peaking in the learning curve. The trajectories of the approximate control input
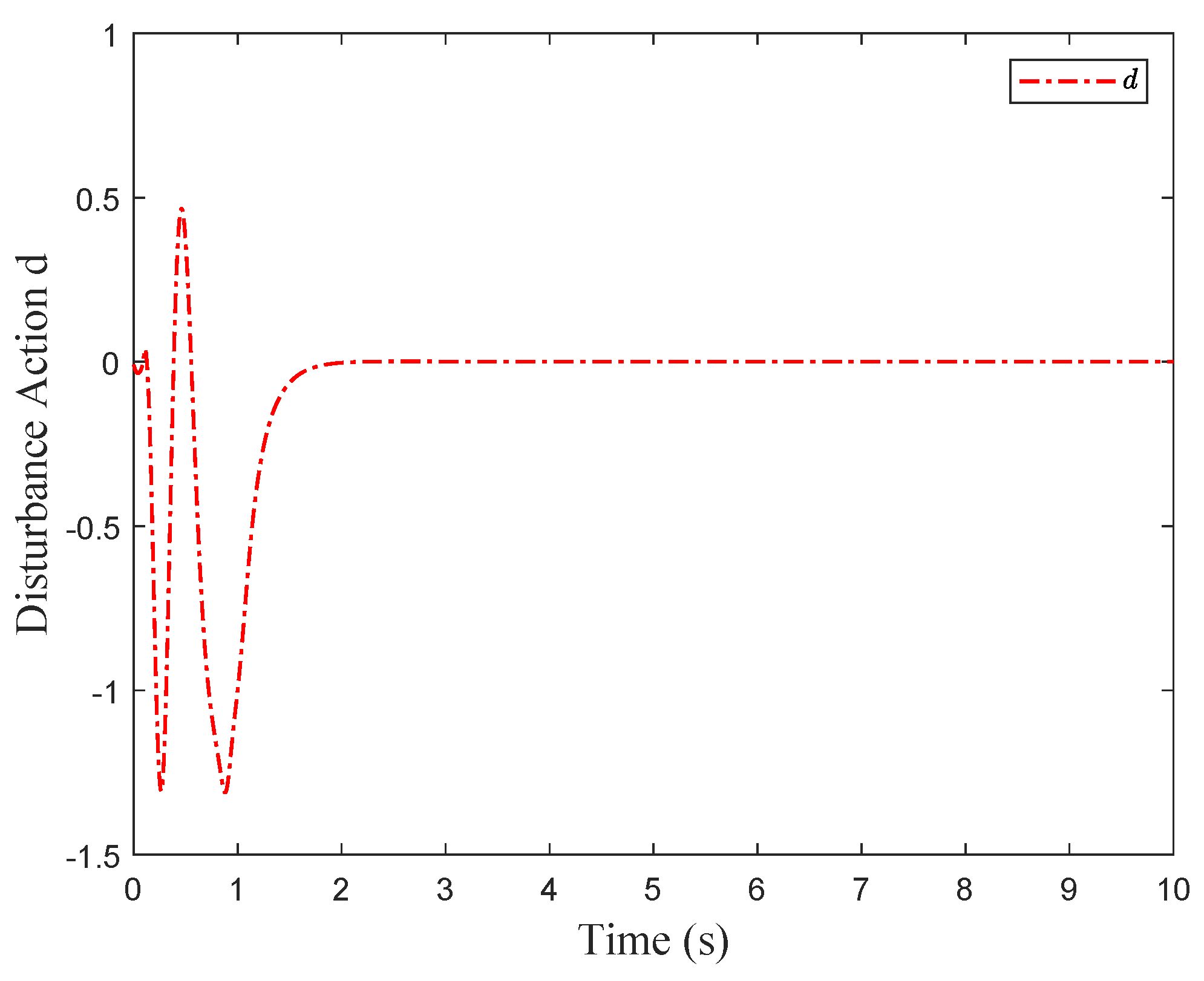
and the estimated disturbance
are presented in
Figure 4 and
Figure 5, respectively. By applying the optimal
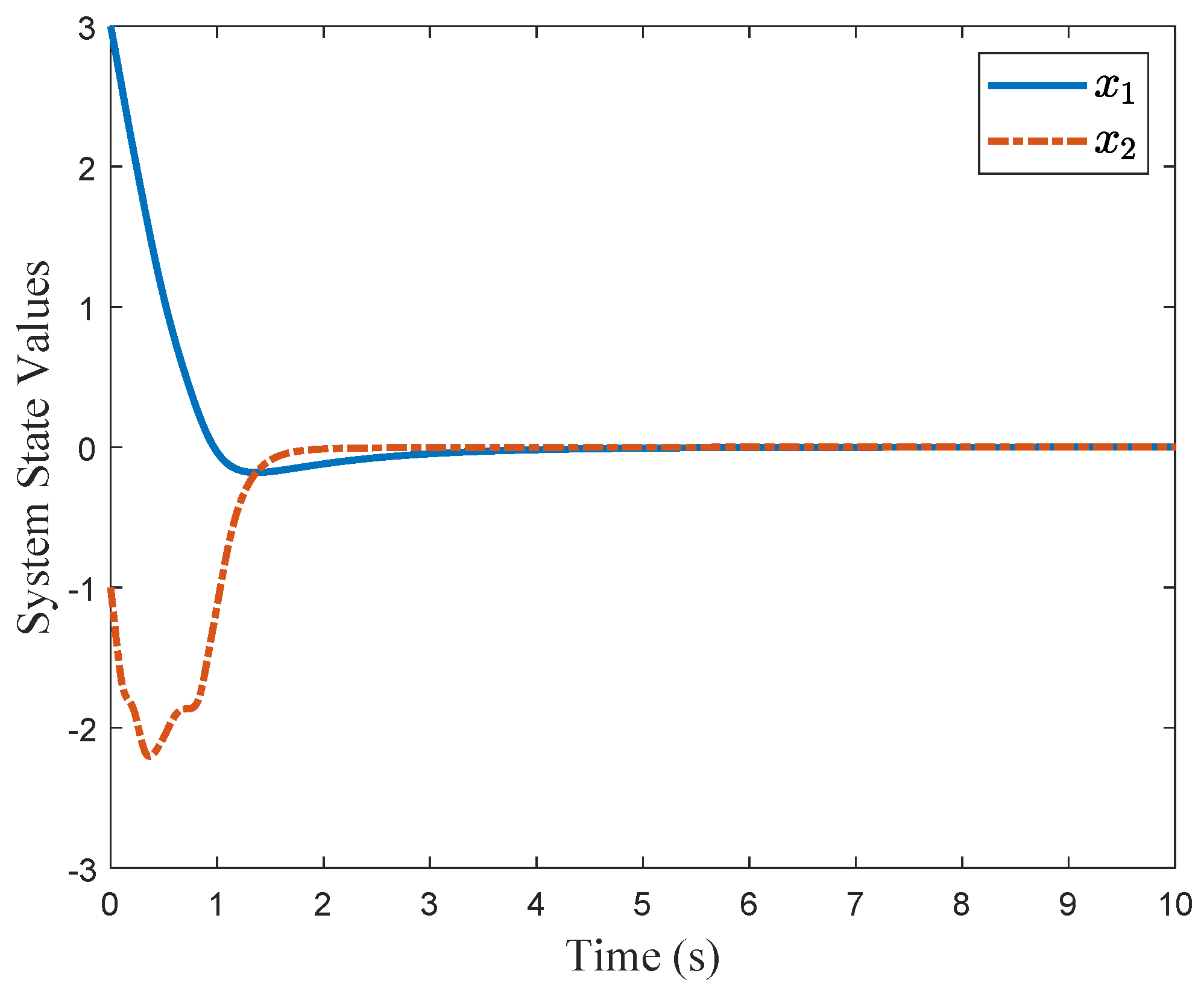
control pair, the system states are stabilized, as depicted in
Figure 6.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}