Square Root Statistics of Density Matrices and Their Applications



{kind=link}
{kind=link}
Abstract
1. Introduction and Main Results
1.1. Square Root Spectrum and Applications
1.2. Description of Bures–Hall Ensemble
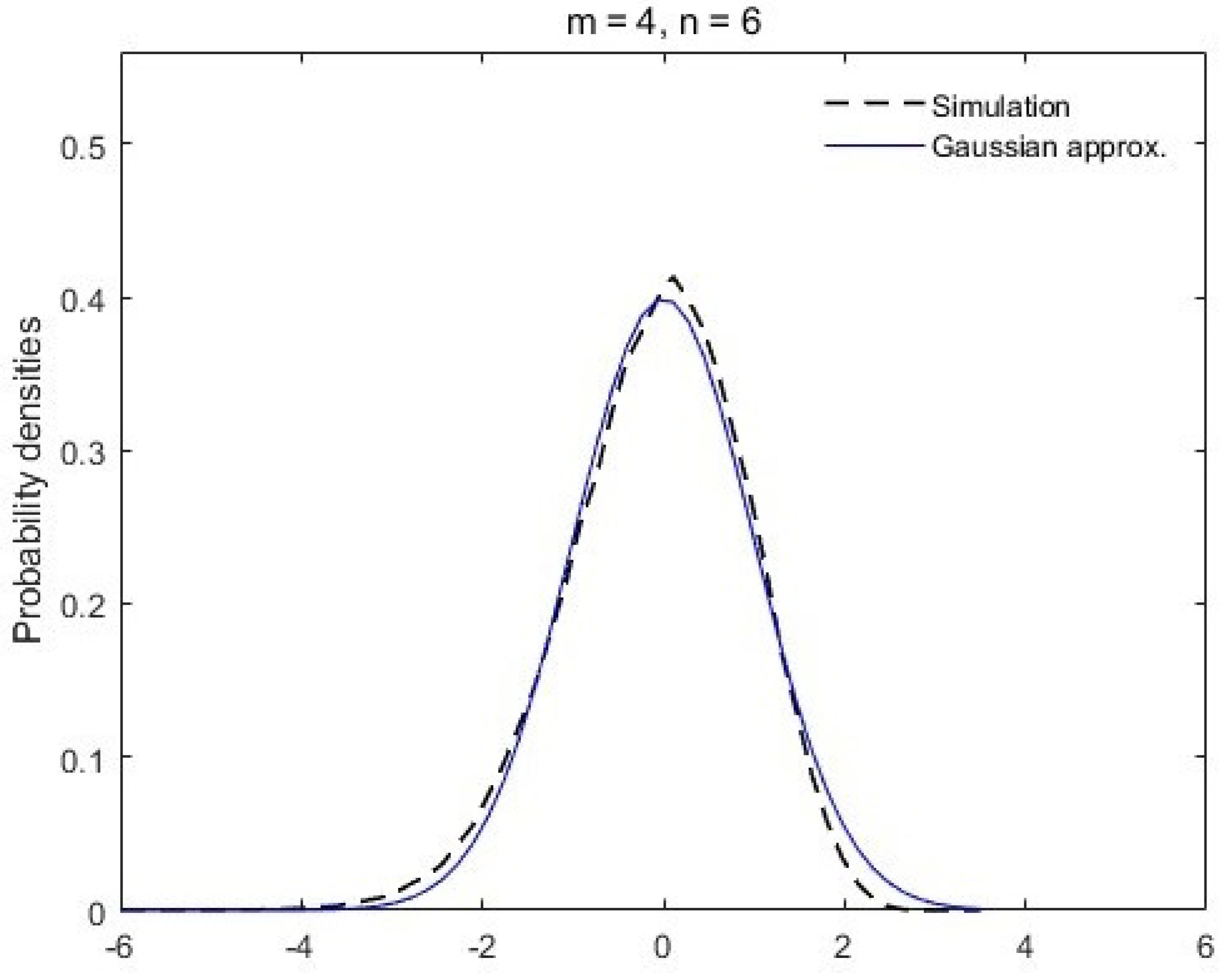
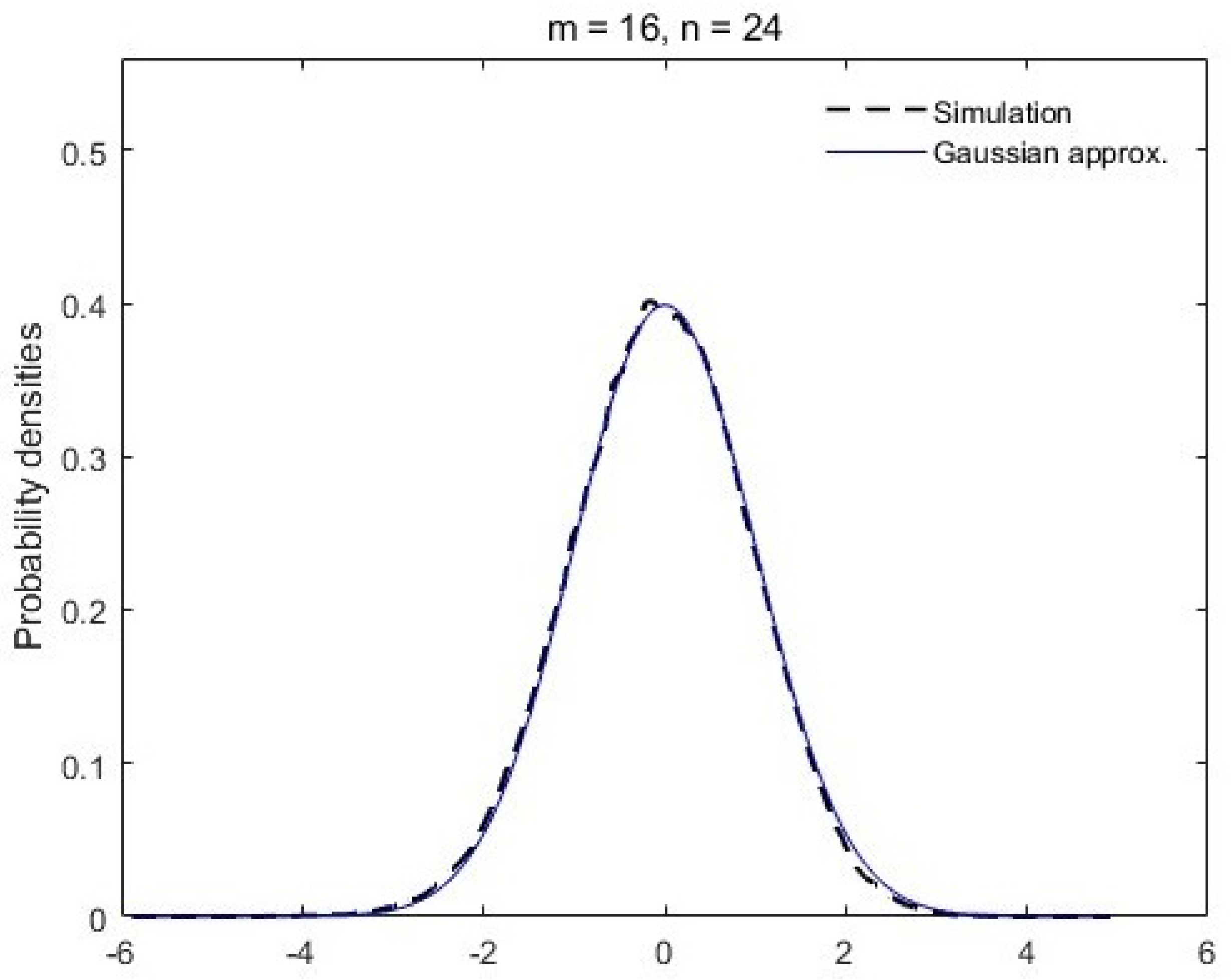
1.3. Main Results
2. Moments Computation
2.1. Ensemble Conversion
2.2. Calculation of the First Moment
2.3. Calculation of the Second Moment
2.3.1. Calculation of
2.3.2. Calculation of and
2.3.3. Calculation of
3. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Page, D.N. Average entropy of a subsystem. Phys. Rev. Lett. 1993, 71, 1291–1294. [Google Scholar] [CrossRef] [PubMed]
- Lubkin, E. Entropy of an n-system from its correlation with ak-reservoir. J. Math. Phys. 1978, 19, 1028–1031. [Google Scholar] [CrossRef]
- Yao, H.; Qi, X.L. Entanglement entropy and entanglement spectrum of the Kitaev model. Phys. Rev. Lett. 2010, 105, 080501. [Google Scholar] [CrossRef] [PubMed]
- Vidal, G.; Werner, R.F. Computable measure of entanglement. Phys. Rev. A 2002, 65, 032314. [Google Scholar] [CrossRef]
- Dahlsten, O.C.; Lupo, C.; Mancini, S.; Serafini, A. Entanglement typicality. Phys. Rev. A 2014, 47, 363001. [Google Scholar] [CrossRef]
- Laha, A.; Kumar, S. Random density matrices: Analytical results for mean fidelity and variance of squared Bures distance. Phys. Rev. E 2023, 107, 034206. [Google Scholar] [CrossRef] [PubMed]
- Zhu, H.; Hayashi, M.; Chen, L. Axiomatic and operational connections between the l1-norm of coherence and negativity. Phys. Rev. A 2018, 97, 022342. [Google Scholar] [CrossRef]
- Jozsa, R. Fidelity for Mixed Quantum States. J. Mod. Opt. 1994, 41, 2315–2323. [Google Scholar] [CrossRef]
- Akemann, G.; Baik, J.; Di Francesco, P. (Eds.) The Oxford Handbook of Random Matrix Theory; Oxford University Press: Oxford, UK, 2011. [Google Scholar] [CrossRef]
- Bengtsson, I.; Zyczkowski, K. Geometry of Quantum States: An Introduction to Quantum Entanglement; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar] [CrossRef]
- Sarkar, A.; Kumar, S. Bures–Hall ensemble: Spectral densities and average entropies. J. Phys. A Math. Theor. 2019, 52, 295203. [Google Scholar] [CrossRef]
- Hall, M.J. Random quantum correlations and density operator distributions. Phys. Lett. A 1998, 242, 123–129. [Google Scholar] [CrossRef]
- Zyczkowski, K.; Sommers, H.J. Induced measures in the space of mixed quantum states. J. Phys. A Math. Gen. 2001, 34, 7111. [Google Scholar] [CrossRef]
- Sommers, H.J.; Zyczkowski, K. Bures volume of the set of mixed quantum states. J. Phys. A Math. Gen. 2003, 36, 10083. [Google Scholar] [CrossRef]
- Wei, L. Exact variance of von Neumann entanglement entropy over the Bures-Hall measure. Phys. Rev. E 2020, 102, 062128. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Wei, L. Second-order statistics of fermionic Gaussian states. J. Phys. A Math. Theor. 2022, 55, 105201. [Google Scholar] [CrossRef]
- Forrester, P.J.; Kieburg, M. Relating the Bures Measure to the Cauchy Two-Matrix Model. Comm. Math. Phys. 2016, 342, 151–187. [Google Scholar] [CrossRef]
- Prudnikov, A.; Brychkov, Y.; Marichev, O. Integrals and Series. Volume 3: More Special Functions; Gordon and Breach: New York, NY, USA, 1989. [Google Scholar]
- Wei, L. Proof of Sarkar–Kumar’s conjectures on average entanglement entropies over the Bures–Hall ensemble. J. Phys. A Math. Theor. 2020, 53, 235203. [Google Scholar] [CrossRef]
- Bertola, M.; Gekhtman, M.; Szmigielski, J. Cauchy–Laguerre Two-Matrix Model and the Meijer-G Random Point Field. Commun. Math. Phys. 2014, 326, 111–144. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, L.; Huang, Y.; Osborn, J.C.; Wei, L. Square Root Statistics of Density Matrices and Their Applications. Entropy 2024, 26, 68. https://doi.org/10.3390/e26010068
Ye L, Huang Y, Osborn JC, Wei L. Square Root Statistics of Density Matrices and Their Applications. Entropy. 2024; 26(1):68. https://doi.org/10.3390/e26010068
Chicago/Turabian StyleYe, Lyuzhou, Youyi Huang, James C. Osborn, and Lu Wei. 2024. "Square Root Statistics of Density Matrices and Their Applications" Entropy 26, no. 1: 68. https://doi.org/10.3390/e26010068
APA StyleYe, L., Huang, Y., Osborn, J. C., & Wei, L. (2024). Square Root Statistics of Density Matrices and Their Applications. Entropy, 26(1), 68. https://doi.org/10.3390/e26010068