Abstract
In deep learning of classifiers, the cost function usually takes the form of a combination of SoftMax and CrossEntropy functions. The SoftMax unit transforms the scores predicted by the model network into assessments of the degree (probabilities) of an object’s membership to a given class. On the other hand, CrossEntropy measures the divergence of this prediction from the distribution of target scores. This work introduces the ISBE functionality, justifying the thesis about the redundancy of cross-entropy computation in deep learning of classifiers. Not only can we omit the calculation of entropy, but also, during back-propagation, there is no need to direct the error to the normalization unit for its backward transformation. Instead, the error is sent directly to the model’s network. Using examples of perceptron and convolutional networks as classifiers of images from the MNIST collection, it is observed for ISBE that results are not degraded with SoftMax only but also with other activation functions such as Sigmoid, Tanh, or their hard variants HardSigmoid and HardTanh. Moreover, savings in the total number of operations were observed within the forward and backward stages. The article is addressed to all deep learning enthusiasts but primarily to programmers and students interested in the design of deep models. For example, it illustrates in code snippets possible ways to implement ISBE functionality but also formally proves that the SoftMax trick only applies to the class of dilated SoftMax functions with relocations.
1. Introduction
A deep model is a kind of mental shortcut [1], broadly understood as a model created in deep learning of a certain artificial neural network , designed for a given application. What, then, is an artificial neural network [2], its deep learning [3,4], and what applications [5] are we interested in?
From a programmer’s perspective, an artificial neural network is a type of data processing algorithm [6], in which subsequent steps are carried out by configurable computational units, and the order of processing steps is determined by (dynamically created) computing graph. The computing graph is always directed and acyclic (DAG). Interestingly, even recurrent neural networks, such as the LSTM (Long Short-Term Memory) nets, which are trained using gradient methods, have DAG-type computational graphs defined.
At the training stage, each group of input data X, i.e., each group of training examples, technically each batch of training examples, first undergoes the inference (forward) phase on the current model, i.e., processing through the network at its current parameters W. As a result, network outputs are produced [7]. The result of the entire network with the functionality and joined set of parameters W is the result of combining the results of the activities for individual units with individual functionalities and with possible individual parameters , as well.
After the inference phase comes the model update phase, where the current model is modified (improved) according to the selected optimization procedure [8]. The model update phase begins with calculating the loss (cost) value defined by the chosen loss function as well as the inference outcome Y and the target result .
The loss Z depends (indirectly through Y) on all parameters W and what conditions the next step of the update phase is the determination of sensitivity of the loss function to their changes. The mathematical model of sensitivity is the gradient . Knowing this gradient, the optimizer will make the actual modification of W in a direction that also takes into account the values of gradients obtained for previous training batches.
Calculating the gradient with respect to parameters actually assigned to different computational units required the development of an efficient algorithm for its propagation in the opposite direction to inference [9,10].
Just as in the inference phase, each unit has its formula for processing data from input to output with parameters , so in the backward gradient propagation phase, it must have a formula for transforming the gradients assigned to its outputs into gradients assigned to its inputs and its parameters .
Based on such local rules of gradient backpropagation and the created computation graph, the backpropagation algorithm can determine the gradients of the cost function with respect to each parameter in the network. The computation graph is created during the inference phase and is essentially a stack of links between the arguments and results of calculations performed in successive units [10,11].
Deep learning is precisely a concert of these inference and update phases in the form of gradient propagation, calculated for randomly created groups of training examples. These phases, intertwined, operate on multidimensional, deep tensors (arrays) of data, processed with respect to network inputs, and on deep tensors of gradient data, processed with respect to losses, determined for the output data of the trained network.
Here, by a deep tensor, we mean a multidimensional data array that has many feature maps, i.e., its size along the feature axis is relatively large, e.g., 500, which means 500 scalar feature maps. We then say that at this point in the network, our data has a deep representation in a 500-dimensional space.
As for the applications we are interested in this work, the answer is those that have at least one requirement for classification [12]. An example could be crop detection from satellite images [13], building segmentation in aerial photos [14], but also text translation [15]. Classification is also related to voice command recognition [16], speaker recognition [17], segmentation of the audio track according to speakers [18], recognition of speaker emotions with visual support [19], but also classification of objects of interest along with their localization in the image [20].
It may be risky to say that after 2015, in all the aforementioned deep learning classifiers, the cost function takes the form of a composition of the function [21] and the function, i.e., cross-entropy [22]. The SoftMax unit normalizes the scores predicted by the classifier model for the input object into SoftMax scores that sum up to one, which can be treated as an estimation of the conditional probability distribution of classes. Meanwhile, cross-entropy measures the divergence of this estimation from the target probability distribution (class scores). In practice, the target score may be taken from a training set prepared manually by a so-called teacher [23] or may be calculated automatically by another model component, e.g., in the knowledge distillation technique [24].
For K classes and training examples, the function is defined for the raw score matrix as:
where the notation denotes any K-element set of indices—in this case, they are class labels.
The function on the matrix is defined by the formula:
When classifiers began using a separated implementation of the combination of the SoftMax normalization and the CrossEntropy loss, it quickly became evident in practice that its implementation had problems with scores close to zero, both in the inference phase and in the backward propagation of its gradient. In formulas of properties 1–3 in Theorem 1 of Section 2, we see from where the problem comes. Only the integration of CrossEntropy with normalization SoftMax eliminated these inconveniences. The integrated approach has the following form:
The integrated functionality of these two features has the following redundant mathematical notation:
This redundancy in notation was helpful in deriving the equation for the gradient backpropagation for the integrated loss function . Later, we will also use for such composition the name .
The structure of this paper is as follows:
- The second section is devoted to mathematics of the SoftMax trick. Its validity is proved in two ways:
- (a)
- Using gradient formulas for the composition of differentiable functions;
- (b)
- Using the concept of the Jacobian matrix and linear algebra calculus.
- In the third section titled ISBE Functionality, the conditions that a normalization unit must meet for its combination with a cross-entropy unit to have a gradient at the input equal to the difference in soft scores: are analyzed. Then the definition of ISBE functionality is introduced, which in the inference phase (I) normalizes the raw score to a soft score (S), and in the backward propagation phase (B) returns an error (E), equal to the difference in soft scores. It is also justified why, in the case of the normalization function, the ISBE functionality has, from the perspective of the learning process, the functionality of the integrated element CrossEntropy ∘ SoftMax.
- In the first subsection of the fourth section, using the example of the problem of recognizing handwritten digits and the standard MNIST(60K) image collection [25], numerous experiments show that in addition to the obvious savings in computational resources, in the case of five activations serving as normalization functions, the classifier’s effectiveness is not lower than that of the combination of the normalization SoftMax and Cross Entropy. This ISBE property was verified for the activation units SoftMax, Sigmoid, Hardsigmoid, and Tanh and Hardtanh. The second subsection of the fourth section reports on how ISBE behaves for a more demanding dataset CIFAR-10 and a more complex architecture VGG-16.
- The final fifth section contains conclusions.
- In Appendix A, the class of functions leading to the dilated SoftMax trick is fully characterized using concepts of dilation and relocation of function domain.
- In Appendix B the ISBE functionality is integrated with PyTorch class torch.autograd. Function.
The main contributions of this research are:
- Introducing ISBE functionality as simplification and, at the same time, extension of the functional combination of SoftMax with CrossEntropy.
- Verification of ISBE feasibility and efficiency on two datasets and three CNN architectures.
- Enhancement of theoretical background for the concept of SoftMax trick via its generalization and full characterization of normalization functions which exhibit this property.
Concluding this introduction, I would like to emphasize that this work is not intended to depreciate the concept of entropy in the context of machine learning. It has played and continues to play a key role as a loss function. Its form appears naturally in many data modeling tasks. For example, in the case of multi-class logistic regression, when computing optimal weights, maximizing the negative logarithm of the likelihood function directly leads to the cross-entropy function. In the context of modeling, cross-entropy will remain an important research tool. The context of the ISBE functionality concerns only the specific method of calculating the gradient of network parameters for the needs of SGD (Stochastic Gradient Descent) optimizers. Only this, nothing more.
2. Discrete Cross-Entropy and the SoftMax Trick Property
This section is devoted to the mathematics of the SoftMax trick. Its validity will be proved in two ways:
- Using gradient formulas for the composition of differentiable functions,
- Using the concept of Jacobian matrix and linear algebra calculus.
The discrete cross-entropy function of a target discrete probability distribution , relative to the calculated by the classifier the probability distribution , is defined by the formula:
The notation refers to a sequence of K indexes, such as or .
It appears that the gradient of the cross entropy with respect to y is not defined at the zero components:
where the operation ÷ for the expression , denotes the division of vector u components by the components of vector v, i.e., , .
In the special case when the vector is calculated based on the vector according to the formula , the gradient of with respect to x has a particularly simple resultant formula. Its simplicity was the reason for the term SoftMax trick:
Some authors [26] also use the term SoftMax trick for that part of the proof showing that the derivative of the natural logarithm of the sum of functions equals to the function.
The SoftMax trick can be described as a theorem and proved in two ways: the elementary one and via the matrix calculus. The following theorem includes elementary properties of the cross-entropy function, optionally preceded by the normalization.
Theorem 1.
Let be the target probability distribution and be the predicted probability distribution. Then
- 1.
- For any .
- 2.
- 3.
- The range of covers the positive part of the real axis:
- 4.
- Let be the vector of raw scores, and be the target probability distribution. Then normalization followed by , is defined as followsContrary to only, exhibits the bounded gradient:
- (a)
- The Jacobian of equals to:
- (b)
- For any , where .
- (c)
- , where .
- (d)
- The range of covers the interval
Elementary proof of SoftCE properties.
□
Proof of SoftCE property using matrix calculus.
In matrix notation [27], the property of SoftMax trick has a longer proof, as we first need to calculate the Jacobian of the function [28].
If , then
The general formula is Therefore:
Hence, . From the chain rule
and the symmetry of Jacobian matrix , we obtain:
□
While looking at the above two proofs for the Theorem 1, a question can be raised: Is it only the function that has SoftMax trick property? The answer to this problem can be found in Appendix A. You can understand why the second proof using Jacobian matrix and matrix calculus has been presented here.
3. ISBE Functionality
The ISBE functionality is a proposed simplification of the cost function, combining the SoftMax normalization function with the cross-entropy function, hereafter abbreviated as . Its role is to punish those calculated probability distributions that significantly differ from the distributions of scores proposed by the teacher.
To understand this idea, let us extend the inference diagram for with the backward propagation part for the gradient. We consider this diagram in its separate version, omitting earlier descriptions for the diagram (1):
The meaning of variables and appearing in the above diagram (6):
The key formula here is . Its validity comes from the mentioned Theorem 1 which includes the proof for the Formula (4) associated with the SoftMax trick property.
The generalized form of this property is given in the Appendix A within the Theorem A1 which includes interesting observations on necessary and sufficient conditions for the SoftMax trick.
For instance, the Equation (A2) on the form of the Jacobian of the normalization unit is both a sufficient and necessary condition for its combination with the cross-entropy unit to ensure the equality (A3). Moreover, this condition implies that an activation function with a Jacobian of the SoftMax type is a SoftMax function with optional relocation.
Theorem A1 leads us to a seemingly pessimistic conclusion: it is not possible to seek further improvements by changing the activation and at the same time expect the SoftMax trick property to hold. Thus, the question arises: what will happen if, along with changing the activation unit, we change the cross-entropy unit to another or even omit it entirely?
In the ISBE approach, the aforementioned simplification of the cost function involves precisely omitting the cross-entropy operation in the inference stage and practically omitting all backward operations for this cost function. So what remains? The answer is also an opportunity to decode the acronym ISBE again:
- In the inference phase (I), we normalize the raw score X to , characterized as a soft score (S).
- In the backward propagation phase (B), we return an error (E) equal to the difference between the calculated soft score and the target score, i.e., .
Why can we do this and still consider that in the case of the SoftMax activation function, the value of the gradient transmitted to the network is identical: ?
The answer comes directly from the property , formulated in Equation (4), which as it was already mentioned, was proved in the Theorem 1 as the SoftMax trick property.
We thus have on the left the following diagram of data and gradient backpropagation through such a unit. On the right, we have its generalization to a ScoreNormalization unit instead of SoftMax unit.
Which activation functions should we reach for in order to test them in the ISBE technique?
- The SoftMax activation function should be the first candidate for comparison, as it theoretically guarantees behavior comparable to the system containing cross-entropy.
- Activations should be monotonic so that the largest value of the raw score remains the largest score in the soft score sequence.
- Soft scores should be within a limited range, e.g., as in the case of SoftMax and Sigmoid, or as for Tanh.
- The activation function should not map two close scores to distant scores. For example, normalizing a vector of scores by projecting onto a unit sphere in the p-th Minkowski norm meets all the above conditions. However, it is not stable around zero. Normalization maps, for example, two points distant by to points distant exactly by 2, thus changing their distance times, e.g., a million times, when . This operation is known in Pytorch library as normalize function.
The experiments conducted confirm the validity of the above recommendations. The Pytorch library functions SoftMax, sigmoid, tanh, hardsigmoid, hardtanh meet the above three conditions and provide effective classification at a level of effectiveness higher than , comparable to CrossEntropy ∘ SoftMax. In contrast, with the function normalize, the optimizer failed to converge on the same MNIST(60K) collection and with the same architectures.
What connects these good normalization functions , of which two are not even fully differentiable? Certainly, it is the Lipschitz condition occurring in a certain neighborhood of zero [29]:
Note that the Lipschitz condition meets the expectations of the fourth requirement on the above list of recommendations for ISBE. Moreover, we do not expect here that the constant c be less than one, i.e., that the function F has a narrowing character.
We also need a recommendation for teachers preparing class labels, which we represent as vectors blurred around the base vectors of axes :
- example blurring value , e.g., :
- when the range of activation values is other than the interval , we adjust the vector to the new range, e.g., for tanh the range is the interval and then the adjustment has the form:
Finally, let us take a look at the code for the main loop of the program implemented on the Pytorch platform.
- This is what the code looks like when loss_function is chosen as nn.CrossEntropyLoss:for (labels,images) in tgen:outputs = net(images)loss = loss_function(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()
- Now we introduce the ISBE option for SoftMax activation and replace the call for loss function by soft error calculation:for (labels,images) in tgen:outputs = net(images)soft_error = SoftMax(outputs) - labelsoptimizer.zero_grad()outputs.backward(soft_error)optimizer.step()
More options, including the definition of ISBE functionality, can be found in Appendix B. Of course, the above code snippets are only intended to illustrate how easy it is to add the functionality of ISBE to an existing application.
4. Experiments
What do we want to learn from the planned experiments? We already know from theory that in the case of the SoftMax activation, we cannot worsen the parameters of the classifier using cross-entropy, both in terms of success rate and learning time.
Therefore, we first want to verify whether theory aligns with practice, but also to check for which normalization functions the ISBE functionality does not degrade the model’s effectiveness compared to .
The learning time should be shorter than . Still, to be independent of the specific implementation, we will compare the percentage of the backpropagation time in the total time of inference and backpropagation:
From many quality metrics, for simplicity, we choose the success rate (also called accuracy), defined as the percentage of correctly classified elements from the test collection MNIST(10K)
We want to know how this value changes when we choose different architectures and different activations in the ISBE technique, as well as different options for aggregating cross-entropy over the elements of the training batch.
4.1. Experiments with MNIST Dataset
Firstly, we evaluate the efficiency of the ISBE idea on the standard MNIST(60K) image collection and the problem of their classification.
We have the following degrees of freedom in our experiments:
- Two architecture options
- Architecture consists of two convolutions and two linear units , of which the last one is a projection from the space of deep feature vectors of dimension 512 to the space of raw scores for each of the classes:as by STNN notation [30], for instance
- Architecture consists of two blocks, each with three convolutions—it is a purely convolutional network, except for the final projection:Note that the last convolution in each block has a p requirement for padding, i.e., filling the domain of the image with additional lines and rows so that the image resolution does not change.
- Three options for reducing the vector of losses in the CrossEntropyLoss element: none, mean, sum.
- Five options for activation functions used in the ISBE technique:
- SoftMax:
- Tanh:
- HardTanh:
- Sigmoid:
- HardSigmoid:
The results of the experiments, on the one hand, confirm our assumption that the conceptual Occam’s razor, i.e., the omission of the cross-entropy unit, results in time savings , and on the other hand, the results are surprisingly positive with an improvement in the metric of success rate in the case of hard activation functions and . It was observed that only the option of reduction by none behaves exactly according to theory, i.e., the success rate is identical to the model using normalization. Options mean and sum for the model with entropy are slightly better than the model with SoftMax.
The consistency of models in this case means that the number of images incorrectly classified out of 10 thousand is the same. The experiments did not check whether it concerns the same images. A slight improvement, in this case, meant that there were less than a few or a dozen errors, and the efficiency of the model above meant at most 40 errors per 10 thousand of test images.
4.1.1. Comparison of Time Complexity
We compare time complexity according to the metric given by the Formula (7).
In the context of time, Table 1 clearly shows that the total timeshare of backpropagation, obviously depending on the complexity of the architecture, affects the time savings of the ISBE technique compared to CrossEntropyLoss—Table 2. The absence of pluses in this table, i.e., the fact that all solutions based on ISBE are relatively faster in the learning phase, is an undeniable fact.

Table 1.
Comparison of the metric , i.e., the percentage share of backpropagation time in the total time with inference. The share of cross-entropy with three types of reduction is compared with five functions of soft normalization. The analysis was performed for architectures and .
Table 2.
Metric , i.e., the decrease in the percentage share of backpropagation time in the total time with inference. The analysis was performed for architectures and .
The greatest decrease in the share of backpropagation, over , occurs for the and activations. The smallest decrease in architecture is noted for the soft (soft) normalization function and its hard version . This decrease refers to cross-entropy without reduction, which is an aggregation of losses calculated for all training examples in a given group into one numerical value.
Inspired by the Theorem A1, which states that the relocation of the function preserves the SoftMax trick property, we also add data to the Table 1 for the network . This network differs from the network only because the normalization unit has a trained relocation parameter. In practice, we accomplish training with relocation for normalization by training with the relocation of the linear unit immediately preceding it. This is done by setting its parameter: bias = True.
As we can see, the general conclusion about the advantage of the ISBE technique in terms of time reduction for the model with the relocation of the normalization function is the same.
4.1.2. Comparison of Classifier Accuracy
Comparison of classifier accuracy and differences in this metric are contained in Table 3 and Table 4. The accuracy is computed according to the Formula (8).
Table 3.
In the table, the success rate of three classifiers based on cross-entropy with different aggregation options is compared with the success rate determined for five options of soft score normalization functions. The analysis was performed for architectures and .
Table 4.
Change in success rate between models with cross-entropy and models with soft score normalization function. The analysis was performed for architectures and .
The number of pluses on the side of ISBE clearly exceeds the number of minuses. The justification for this phenomenon requires separate research. Some light will be shed on this aspect by the analysis of learning curves—the variance in the final phase of learning is clearly lower. The learning process is more stable.
In Table 4, we observe that, with the exception of the function , which on several images of digits performed worse than the model with cross-entropy, the soft activations have an efficiency slightly or significantly better. However, we are talking about levels of tenths or hundredths of a percent here. The largest difference noted for the option SoftMax was 15-hundredths of a percent, meaning 15 more images correctly classified. Such differences are within the margin of statistical error.
The use of relocation for the normalization function does not provide a clear conclusion—for some models, there is a slight improvement; for others, there is a slight deterioration. It is true that the ISBE functionality with sigmoid activation achieved the best efficiency of , but this is only a matter of a few images.
Within the limits of statistical error, we can say that the ISBE functionality gives the same results in recognizing MNIST classes. Its advantages are:
- of decrease time in the total time,
- simplification of architecture, and therefore playing the philosophical role of Occam’s razor.
4.1.3. Visual Analysis
Further analysis of the results will be based on the visual comparison of learning curves.
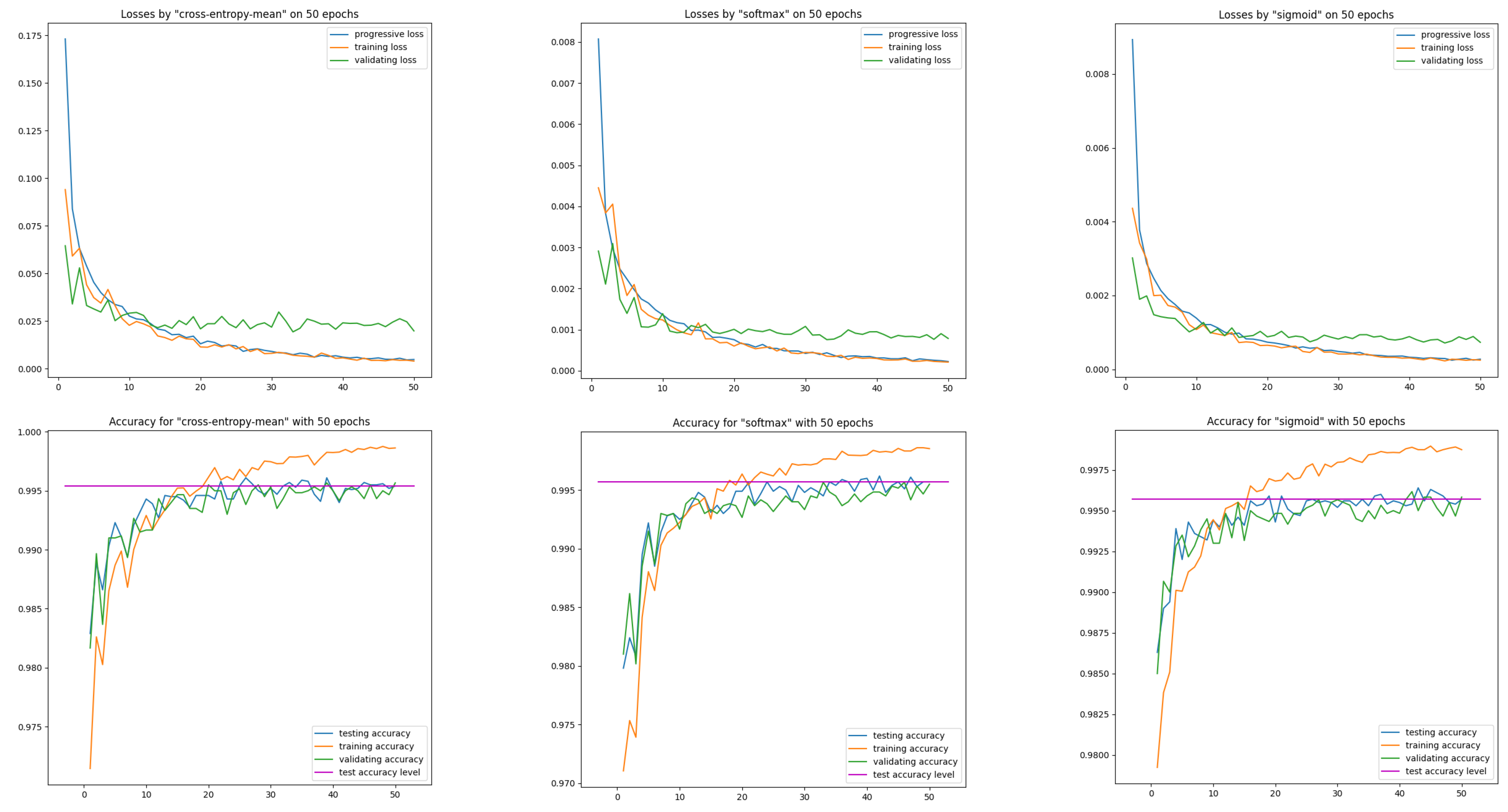
First, let us see on three models cross-entropy-mean, SoftMax, sigmoid their loss and efficiency curves obtained on training data MNIST(54K) and on data intended solely for model validation MNIST(6K). These two loss curves are calculated after each epoch. We supplement them with a loss curve calculated progressively after each batch of training data (see Figure 1).
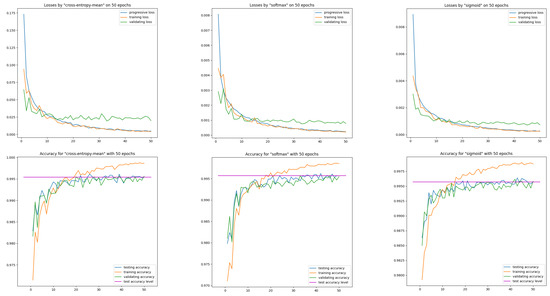
Figure 1.
Learning curves on training and validation data for the network and three models: cross-entropy-mean, SoftMax, sigmoid. The horizontal reference line represents the accuracy of test data computed after the last epoch.
Let us note the correct course of the train loss curve with respect to the progressive loss curve—both curves are close. The correct course is also for the validation loss curve—the validation curve from about epoch 30 is below the training curve, maintaining a significant distance. This effect was achieved only after applying a moderate input image augmentation procedure via random affine transformations in the pixel domain.
Correct behavior of learning curves was recorded both for the models with entropy and for models with the ISBE functionality. This also applies to classifier performance curves.
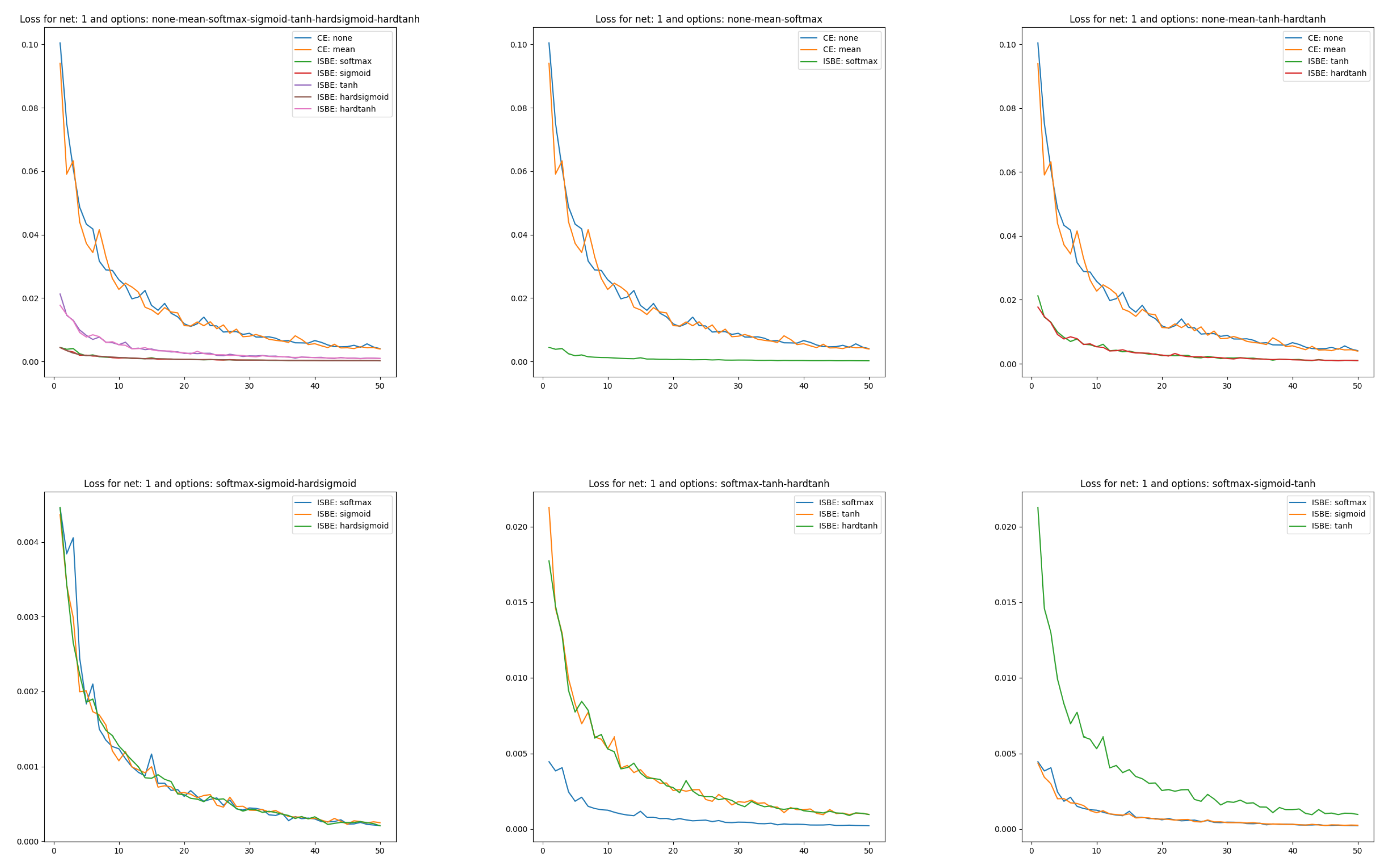
- Curves of loss functions can appear together as long as the type of function is identical, which entails a similar range of variability for loss function values. One might wonder what measure of loss to adopt in the case of ISBE since this technique, in fact, does not calculate loss values. We opt for a natural choice of mean square error for errors in soft scores:where is the batch size.For such defined measures, it turns out that only the option of reduction by summing has a different range of variability, and therefore it is not on the Figure 2.
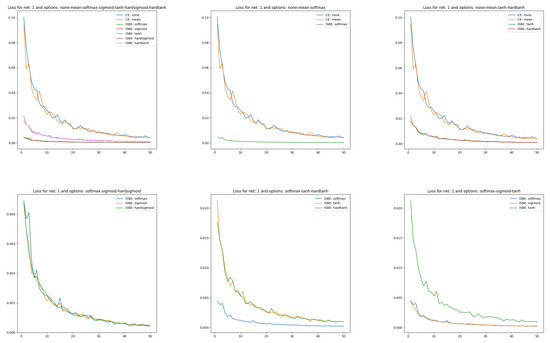 Figure 2. Loss charts of learning in comparisons of CE versus ISBE options. In the first row: (1) all options for loss functions and soft score functions; (2) CE none, CE mean versus SoftMax; (3): CE none, CE mean versus tanh, hardtanh. In the second row: (1) SoftMax versus sigmoid, hardsigmoid; (2) SoftMax versus tanh, hardtanh; (3) SoftMax versus sigmoid, tanh.
Figure 2. Loss charts of learning in comparisons of CE versus ISBE options. In the first row: (1) all options for loss functions and soft score functions; (2) CE none, CE mean versus SoftMax; (3): CE none, CE mean versus tanh, hardtanh. In the second row: (1) SoftMax versus sigmoid, hardsigmoid; (2) SoftMax versus tanh, hardtanh; (3) SoftMax versus sigmoid, tanh. - In the case of classifier accuracy, a common percentage scale does not exclude placing all eight curves for each considered architecture. However, due to the low transparency of such a figure, it is also worth juxtaposing different groups of curves of the dependency . The accuracy of the classifier MNIST(60K) is calculated on the test set MNIST(10K).
Sets of curves, which we visualize separately for architectures , are:
- All options for loss functions (3) and soft score functions (5),
- CE none, CE mean, CE sum versus SoftMax,
- CE none, CE mean, CE sum versus tanh, hardtanh,
- SoftMax versus sigmoid, hardsigmoid,
- SoftMax versus tanh, hardtanh,
- SoftMax versus sigmoid, tanh.
Due to space constraints, we show learning curves and classifier effectiveness graphs only for architecture in Figure 2 and Figure 3.
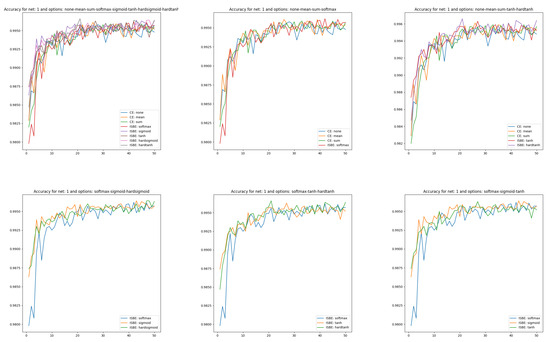
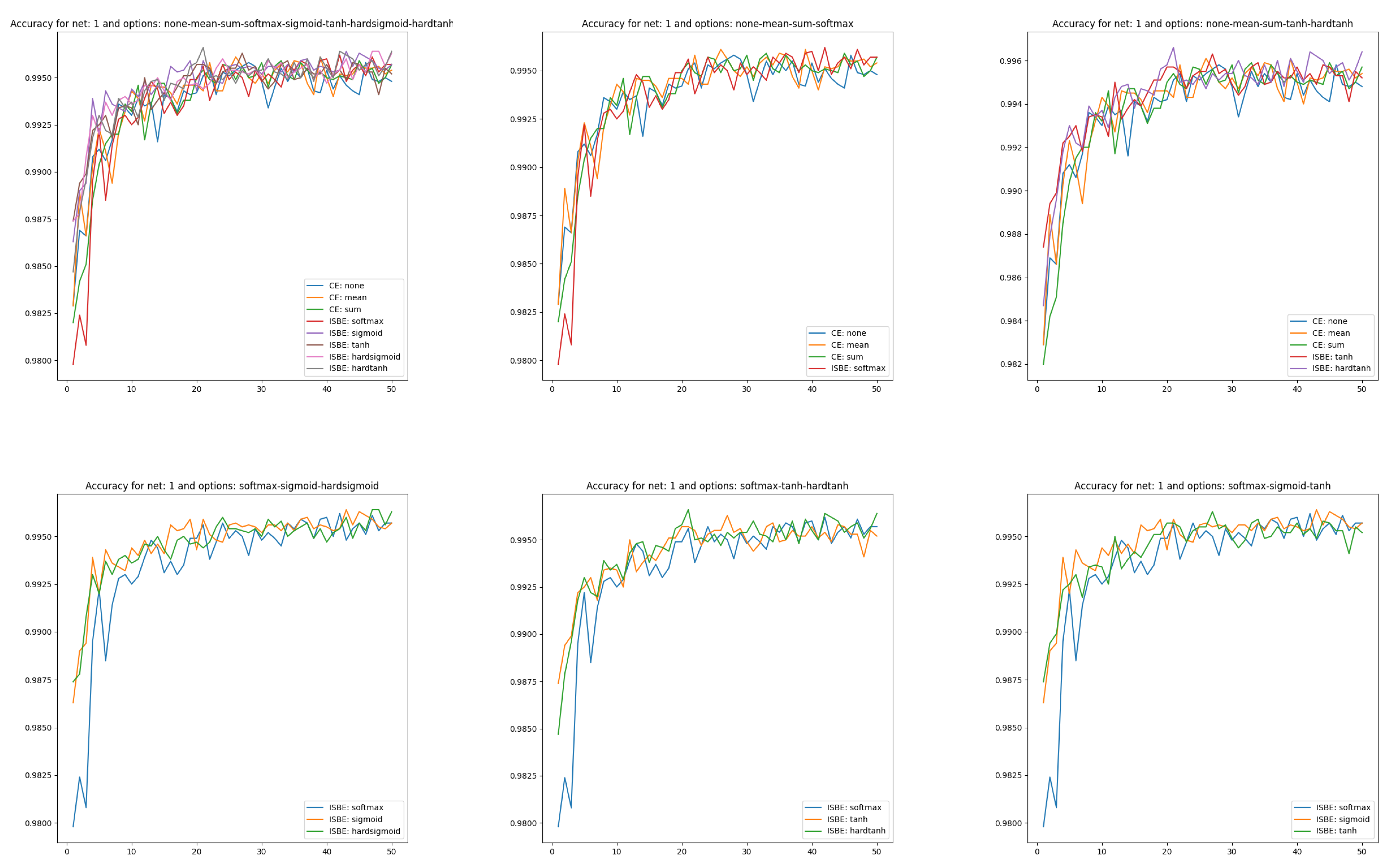
Figure 3.
Accuracy charts of learning in comparisons of CE versus ISBE options. In the first row: (1) all options for loss functions and soft score functions; (2) CE none, CE mean versus SoftMax; (3): CE none, CE mean versus tanh, hardtanh. In the second row: (1) SoftMax versus sigmoid, hardsigmoid; (2) SoftMax versus tanh, hardtanh; (3) SoftMax versus sigmoid, tanh.
In Figure 2 we can clearly observe four clusters of models:
- CrossEntropyLoss based with reduction option sum (as out of common range it was not shown),
- CrossEntropyLoss based with reduction options none, and mean,
- ISBE based with normalizations to range including functionsand ,
- ISBE based with normalizations to range including functions and .
Within a cluster, the loss curves behave very similarly. Interestingly, the loss curves in ISBE-based clusters tend to the same value greater than zero. In contrast, cross-entropy-based curves also tend to the same limit. However it is clearly greater than ISBE one.
Now, we will pay more attention to test learning curves. We generate test learning curves on the full set of test data MNIST(10K). After each epoch, one point is scored towards the test learning curve. We will show these curves in several comparative contexts.
Accuracy charts of learning (see Figure 3) were obtained to compare cross entropy (CE) performances versus ISBE performance. We have:
- Comparison of CE versus soft options:
- all options for loss functions and soft score functions
- CE none, CE mean versus SoftMax,
- CE none, CE mean versus tanh, hardtanh.
- Comparison of SoftMax versus other soft options:
- SoftMax versus sigmoid, hardsigmoid,
- SoftMax versus tanh, hardtanh,
- SoftMax versus sigmoid, tanh.
In the case of classifier accuracy curves, the variances in the clusters described above are smaller than in the union of clusters. Close to the final epochs, all curves tend to be chaotic within the range of .
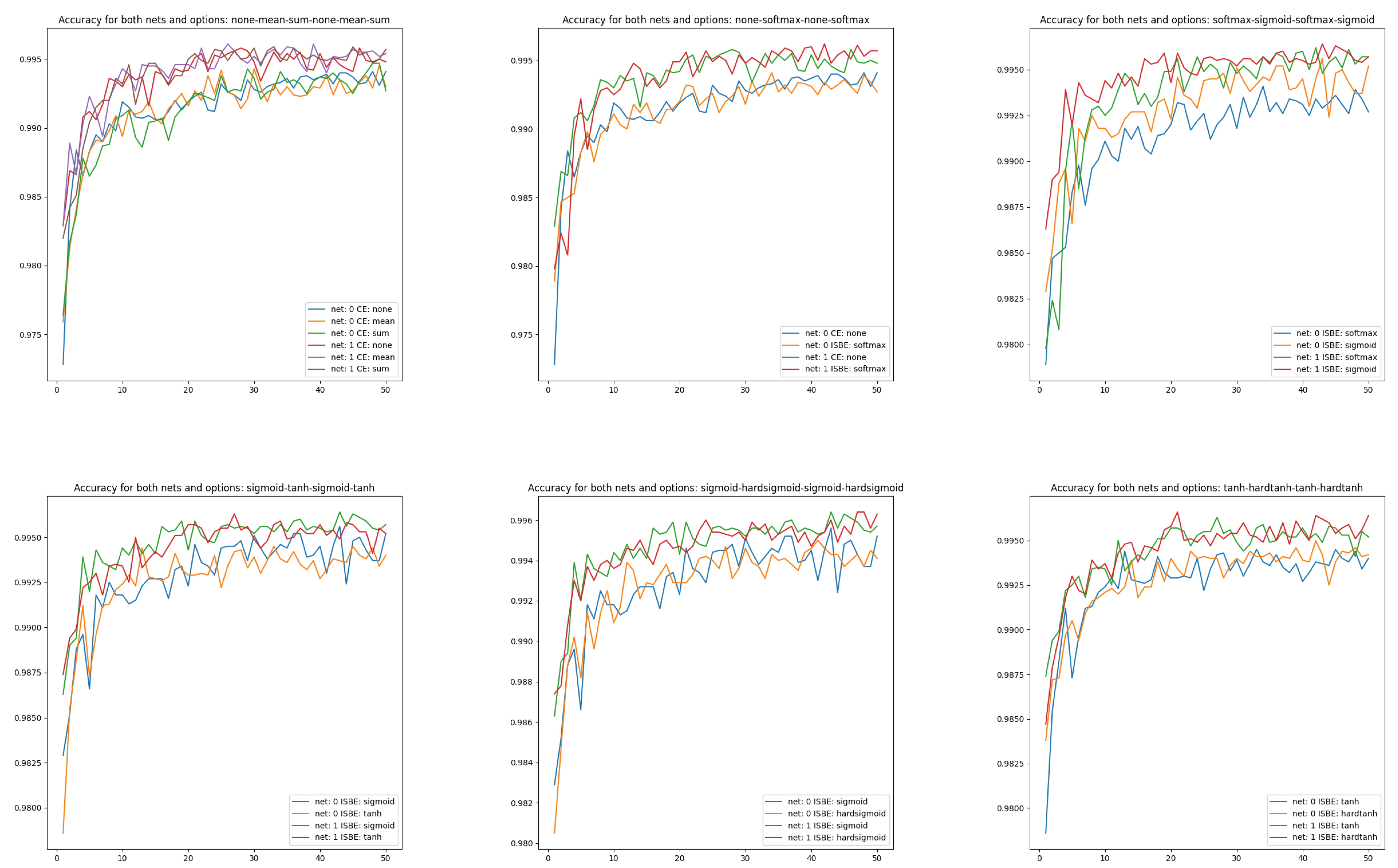
Visualizing the effectiveness of classifiers for different architectures of different complexities, although more obvious, also has research value (see Figure 4):
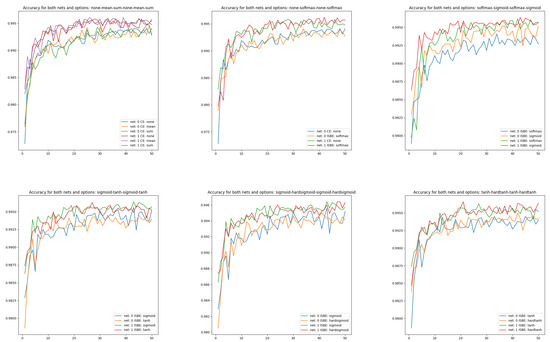
Figure 4.
Accuracy charts of learning in comparisons of CE versus ISBE options and architecture versus . In the first row: (1) CE none, CE mean, CE sum; (2) CE none, SoftMax; (3): SoftMax, sigmoid. In the second row: (1) sigmoid, tanh; (2) sigmoid, hardsigmoid; (3) tanh, hardtanh.
- CE none, CE mean, CE sum from versus CE none, CE mean, CE sum from ,
- CE none, SoftMax from versus CE none, SoftMax from ,
- SoftMax, sigmoid from versus SoftMax, sigmoid from ,
- sigmoid, tanh from versus sigmoid, tanh from ,
- sigmoid, hardsigmoid from versus sigmoid, hardsigmoid from ,
- tanh, hardtanh from versus tanh, hardtanh from .
Figure 4 shows the better performance of compared to . Moreover, we can observe slightly more stable behavior for ISBN-based curves than for cross-entropy-based.
4.2. Experiments with CIFAR-10 Dataset
In this subsection, the CIFAR-10—the more demanding than MNIST dataset is considered in the context of ISBE functionality. Moreover, the VGG feature extractor with more than 14 M parameters, i.e., more than 10 times larger model than , is joined to make further tests. In Figure 5, we can compare sample images from MNIST dataset and CIFAR-10 dataset. What is immediately observed is the background of objects classified—the uniform black for MNIST and the natural scene in case of CIFAR-10. It is the main reason that despite the almost perfect fit achieved by VGG-16 on the training set CIFAR-10 of 50 thousand images,the best results on the independent testing dataset of 10 thousand images are near . The best results known w CIFAR-10 for all architectures attempted so far are near —about one percent more than the record achieved by human beings.

Figure 5.
Comparing sample images from MNIST and CIFAR-10 datasets. CIFAR-10 classes: plane, car, bird, cat, deer, dog, frog, horse, ship, truck.
The architecture VGG-16 was presented by Simonyan and Zisserman in their seminal paper [31], Very Deep Convolutional Networks for Large-Scale Image Recognition. VGG-16 model now serves the community as the universal image feature extractor. Its structure has the following sequential form:
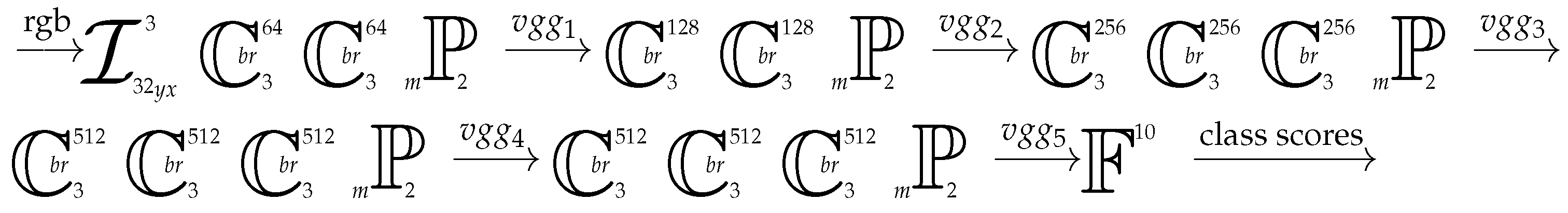
Like for the two architectures tested for MNIST, the optimizer used for model updates is still AdaM with exponential decay of learning rate with respect to epochs. However, now the initial learning rate is , not .
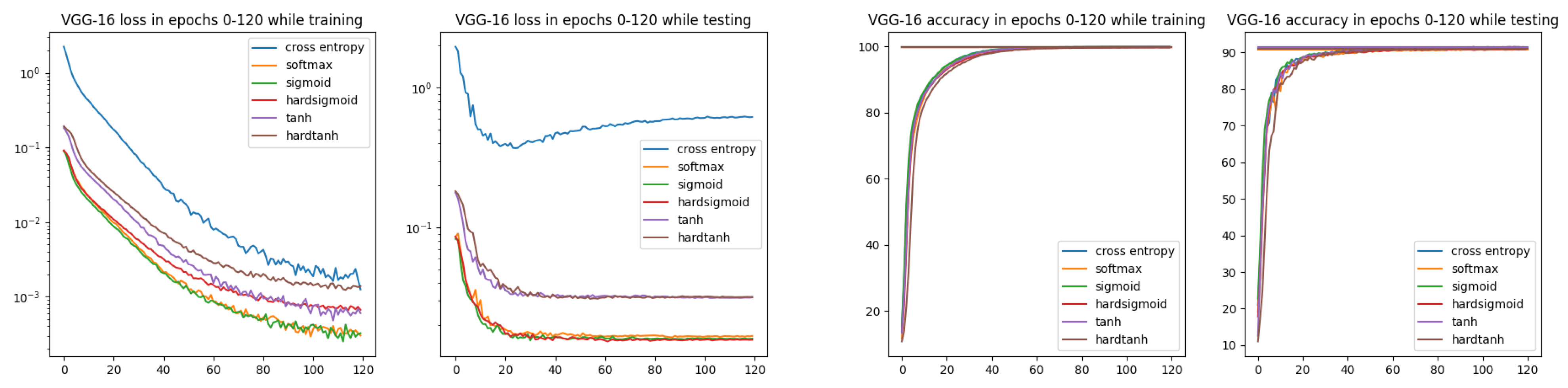
In Figure 6, we can observe better convergence for all ISBE options than for the cross-entropy. Moreover, during testing, the loss value for CE is slowly increasing, starting at about epoch 30, while for all ISBE options, it is stabilizing on the fixed level.
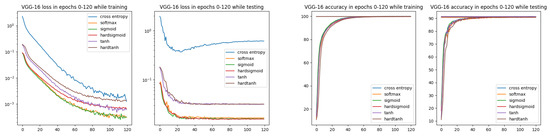
Figure 6.
Loss and accuracy charts for VGG-16 architecture and CIFAR-10 dataset. In the loss chart for training, we can observe better convergence for all ISBE options than for cross-entropy.
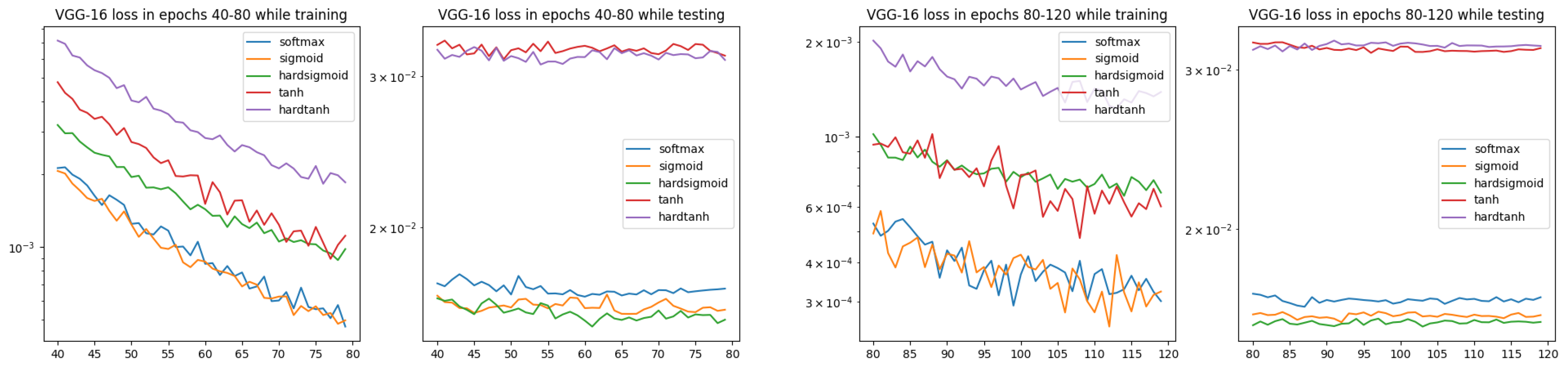
From the results presented in Figure 7, it is visible that in the training and testing stages, there are different clusterings for ISBE options:
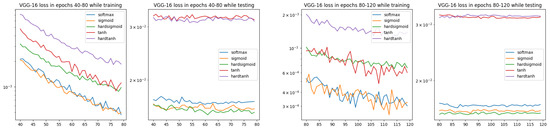
Figure 7.
Loss charts for VGG-16 architecture and CIFAR-10 dataset within epochs 40–80 and 80–120 (only ISBE options are shown). During testing, we can observe two clusters for convergence: the cluster and the cluster.
- In training, there are three groups of ISBE options: {hardtanh}, {tanh, hardsigmoid}, {sigmoid, SoftMax}.
- In testing there are two groups: {tanh, hardtanh} and {SoftMax, sigmoid, hardsigmoid}.
The significant gap between tanh, hardtanh and other ISBE options can be explained by different ranges for the first group and for the second one, i.e., versus . It is not fully clear why in the training stage hardtanh is separate to tanh.
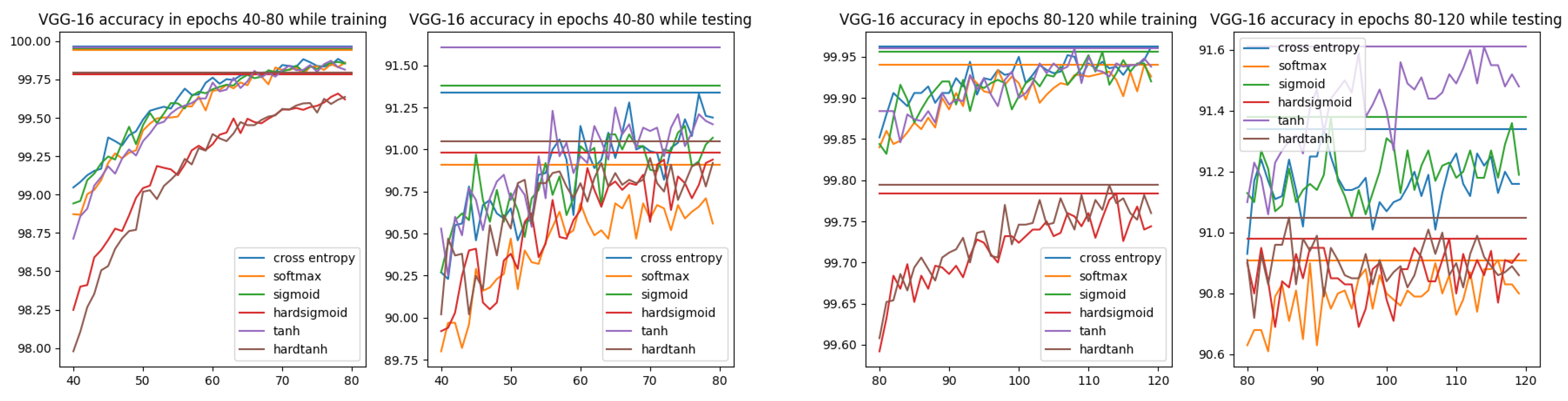
In Figure 8, the accuracy for cross-entropy and all ISBE options can be compared. It is observed that hard versions are inferior to others. However, while testing, a slight advantage is achieved by the hyperbolic tangent tanh.
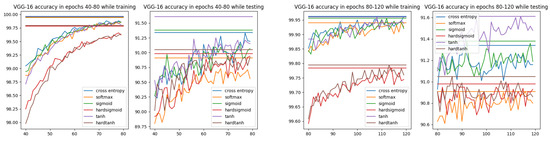
Figure 8.
Accuracy charts for VGG-16 architecture and CIFAR-10 dataset within epochs 40–80 and 80–120. Each horizontal line denotes the maximum accuracy for the option of the same color.
Ultimately, we have bad news on time savings when using autograd interface. Contrary to MNIST experiments where ISBE functionality was implemented by the direct replacement of CE loss in the main learning loop, the CIFAR-10 experiments were using the definition of ISBE_func class being the extension to torch.autograd.Function class. It seems that the general mechanism of interfacing to C++ used by PyTorch in this case, is less efficient than for cross_entropy function. This is perhaps the reason that functionality with fewer operations takes slightly more time while the same functionality without explicit use of autograd mechanism gives always time savings up to .
5. Conclusions
Cross-entropy CE as a loss function owes much to normalization performed by the SoftMax activation function. In the backward gradient backpropagation phase, only this activation, through perfect linearization, can prevent the explosion or suppression of the gradient originating from CE. What we call the SoftMax trick, as a mathematical phenomenon, is explained by the theory presented in the second section and its extension in Appendix A. There is proof that such linearization can only be realized by a function with a Jacobian identical to that of the SoftMax function. In turn, such a Jacobian can only be derived for the dilated and relocated versions of the SoftMax function.
For further research, there remain practical aspects of a more general Theorem A1 implying that dilated and relocated versions of SoftMax are the only ones having the property of dilated SoftMax trick. However, it is quite intuitive that the dilation vector could be used to deal with class unbalanced datasets.
Should we, therefore, celebrate this unique relationship between activation and cost function? In this work, we have shown that it is rather beneficial to use the final effect of the action of this pair, namely the linear value equal to , which can be calculated without their participation. This is exactly what the ISBE functionality does—it calculates the soft score vector in the forward step to return in the backward step its error from the target score.
To determine the normalized score, the ISBE functionality can use not only the SoftMax function, as it is not necessary to meet the unity condition, i.e., to ensure a probability distribution as scores of the trained classifier. At least four other activation functions sigmoid, tanh and their hard versions HardSigmoid and HardTanh perform no worse. The choice of these final activations was rather a matter of chance, so researchers face further questions. How do we normalize raw scores and appropriately represent (encode) class labels in relation to this normalization to not degrade the classifier’s results? What properties should such normalization functions have? Experiments suggest that meeting the Lipschitz condition in the vicinity of zero may be one of these properties.
The theoretical considerations presented prove that the ISBE functionality in the process of deep model learning correctly simulates the behavior of the CrossEntropy unit preceded by the SoftMax normalization.
The experiments showed that the ISBE functionality saves the time of forward and backward stages up to , and the effectiveness of the classifier model remains unchanged within the margin of statistical error. Obviously, those gains are strongly dependent on datasets and network architectures.
In turn, a more complex case of integrating ISBE functionality with AD tools (AutoGrad) of a given platform can be solved for PyTorch by copying the proven code from Appendix B. However, as we described in the section on experiments with CIFAR-10, the time savings were consumed by this kind of interfacing to autograd system.
Funding
This research received no external funding.
Data Availability Statement
Data and their references are contained within the article.
Acknowledgments
Let me express my thanks to the anonymous reviewers, whose insightful and valuable comments encouraged me to make few modifications and extensions to the original version of this article.
Conflicts of Interest
The author declares no conflicts of interest.
Appendix A. Functions Giving the SoftMax Trick for Cross-Entropy
While looking on the two proofs for the Theorem 1 an interesting question arises: is it only the function that has SoftMax trick property? It seems possible that there are others, as for any differentiable function , the starting point for reasoning is the same:
The following theorem fully characterizes functions that have the dilated SoftMax trick property.
Theorem A1
(On the properties of the SoftMax trick).
For a differentiable function , the following three properties are equivalent:
- 1.
- F is a generalized SoftMax function if there exist a reference point and a dilation vector , such that for every :where ⊙ operation is the component-wise multiplication.
- 2.
- F has a dilated SoftMax-type Jacobian, if there exists dilation vector , such that for every :where
- 3.
- F possesses the dilated SoftMax trick property, if for every target vector and its Jacobian matrix satisfies the following equation:
Proof of Theorem A1.
We prove the implications in the following order: ,
- Proof of implication :If the Jacobian of the function F is of the dilated SoftMax type, then for :
- Proof of implication : Denote the axis unit vector j by . Then . Substitute into property (A3) the target score vector . ThenTherefore . Swapping i with j we obtain: .Thus,
- Proof of implication :If , thenThe general formula is Therefore:Hence,
- Proof of implication :If and then the diagonal of the Jacobian matrix gives us differential Equations [32], from which we can determine the general form of the function ,Now we calculate the partial derivatives . If , thenFor , the result is the same:Therefore, for any , we have K equalities: , . This means that vector fields for each pair of functions and are identical.Integrating these fields yields the same function up to a constant : . Consequently, , , and therefore . From the unity condition, we can now determine the value of :
□
Note that the above theorem excludes the functions Sigmoid, Tanh and HardSigmoid, HardTanh from the group of functions for which we can apply the SoftMax trick. Namely, in the vector version, all these functions, none of them can be considered as the special form of the generalized SoftMax function. It is obvious fact, but to give a formal reason, we observe that all those functions operate on each component of vector x independently, i.e., the result depends only on argument . In the generalized SoftMax function, depends on all arguments .
Appendix B. ISBE Functionality in PyTorch
Appendix B.1. Testing Soft Options-Direct Way
ISBE functionality can be introduced to our training procedures in many ways.
- The simplest way of replacing the call of the cross-entropy function is by calling and, after, subtracting target hot vectors or their soften versions, calling the backward for the net output:for (labels,images) in tgen:outputs = net(images)soft_error = SoftMax(outputs) - labelsoptimizer.zero_grad()outputs.backward(soft_error)optimizer.step()
- If we want to test more options and compare them with cross-entropy, the loop code will extend a bit:for (labels,images) in tgen:outputs = net(images)if no_cross_entropy:if soft_option=="SoftMax":soft_error = SoftMax(outputs) - labelsif soft_option=="tanh":soft_error = tanh(outputs) - (2.*labels-1.)elif soft_option=="hardtanh":soft_error = hardtanh(outputs) - (2.*labels-1.)elif # …# next optionsoptimizer.zero_grad()outputs.backward(soft_error)else:loss = loss_function(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()
- If we prefer to have a visually shorter loop, then by introducing the variable soft_function and extending the class DataProvider with matching target labels for a given soft option, we finally obtain a compact form:for (labels,images) in tgen:outputs = net(images)if no_cross_entropy:soft_error = soft_function(outputs) - labelsoptimizer.zero_grad()outputs.backward(soft_error)else:loss = loss_function(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()
- However, if we want to register ISBE functionality as torch.autograd.Function then we have to follow the instruction of PyTorch on this kind registration. The effect is described in the next subsection.
Appendix B.2. ISBE Functionality with Automatic Differentiation
In order to make ISBE_func callable in both inference and backpropagation stage we have to define three static methods in extension of class torch.autograd.Function:
class ISBE_func(torch.autograd.Function):
@staticmethod
def forward(...)
<body of forward>
@staticmethod
def setup_context(...)
<body of setup_context>
@staticmethod
def backward(...)
<body of backward>
The whole job is performed in the body of forward static method. Other two methods simply switch tensors:
- Body of forward:def forward(raw_scores, labels,options=dict(soft=’SoftMax’, num_classes=10, eps=1e-8)):K = options[’num_classes’]eps = options[’eps’]; soft_option = options[’soft’]one_hots = torch.nn.functional.one_hot(\labels, num_classes=K)*(1-K*eps)+eps)if soft_option==’SoftMax’:soft_scores = torch.nn.functional.SoftMax(raw_scores,dim=1)target_scores = one_hotselif soft_option==’sigmoid’:soft_scores = torch.nn.functional.sigmoid(raw_scores)target_scores = one_hotselif soft_option==’hardsigmoid’:soft_scores = torch.nn.functional.hardsigmoid(raw_scores)target_scores = one_hotselif soft_option==’tanh’:soft_scores = torch.nn.functional.tanh(raw_scores)target_scores = 2.*one_hots-1.elif soft_option==’hardtanh’:soft_scores = torch.nn.functional.hardtanh(raw_scores)target_scores = 2.*one_hots-1.soft_scores.requires_grad = Falsesoft_errors = soft_scores - target_scoresmse_soft = torch.mean(soft_errors**2)return mse_soft, soft_errors, soft_scores
- Body of setup_context:def setup_context(ctx, inputs, output):raw_scores, labels, options = inputsmse_soft, soft_errors, soft_scores = outputctx.set_materialize_grads(False)ctx.soft_errors = soft_errors
- Body of backward:def backward(ctx, grad_mse, grad_errors, grad_scores):return ctx.soft_errors, None, None
We cannot directly call the forward static function. We have to use apply method.
def isbe_func_(raw_scores, labels,
options=dict(soft=’SoftMax’, num_classes=10, eps=1e-8)):
return ISBE_func.apply(raw_scores, labels, options)
We could also simplify the use of options if there is a global object ‘ex’ which includes its reference:
isbe_func = lambda raw_scores,labels:\
isbe_func_(raw_scores, labels, options=ex.loss_options)[0]
Instead of a method backward on PyTorch tensor we could use its wrapper isbe_backward:
isbe_backward = lambda soft_error: soft_error.backward()
Finally we can also hide the options for the F.cross_entropy function:
tones_ = torch.ones(ex.batch_size).to(ex.device)
cross_entropy_func = lambda x,t:\
F.cross_entropy(x,t,reduction=ex.loss_options[’reduction’],
label_smoothing=ex.loss_options[’label_smoothing’])
ce_backward = lambda loss: loss.backward(tones_[:loss.size(0)])\
if ex.loss_options[’reduction’]==’none’ else loss.backward()
References
- Schmidhuber, J. Annotated History of Modern AI and Deep Learning. arXiv 2022, arXiv:2212.11279. [Google Scholar]
- Rosenblatt, F. The Perceptron: A Probabilistic Model For Information Storage and Organization in the Brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [PubMed]
- Amari, S.I. A theory of adaptive pattern classifier. IEEE Trans. Electron. Comput. 1967, EC-16, 279–307. [Google Scholar] [CrossRef]
- Golden, R.M. Mathematical Methods for Neural Network Analysis and Design; The MIT Press: Cambridge, MA, USA, 1996. [Google Scholar]
- Fergus, P.; Chalmers, C. Applied Deep Learning—Tools, Techniques, and Implementation; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Hinton, G. How to Represent Part-Whole Hierarchies in a Neural Network. Neural Comput. 2023, 35, 413–452. [Google Scholar] [CrossRef] [PubMed]
- MacKay, D.J.C. Information Theory, Inference, and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Werbos, P.J. Applications of advances in: Nonlinear sensitivity analysis. In System Modeling and Optimization; Drenick, R., Kozin, F., Eds.; Springer: Berlin/Heidelberg, Germany, 1982. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Representations by Back-propagating Errors. In Neurocomputing: Foundations of Research; MIT Press: Cambridge, MA, USA, 1988. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in: PyTorch. In Proceedings of the 31st Conference on Neural Information Processing Systems NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Sahin, H.M.; Miftahushudur, T.; Grieve, B.; Yin, H. Segmentation of weeds and crops using multispectral imaging and CRF-enhanced U-Net. Comput. Electron. Agric. 2023, 211, 107956. [Google Scholar] [CrossRef]
- Yan, G.; Jing, H.; Li, H.; Guo, H.; He, S. Enhancing Building Segmentation in Remote Sensing Images: Advanced Multi-Scale Boundary Refinement with MBR-HRNet. Remote Sens. 2023, 15, 3766. [Google Scholar] [CrossRef]
- Min, B.; Ross, H.; Sulem, E.; Veyseh, A.P.B.; Nguyen, T.H.; Sainz, O.; Agirre, E.; Heinz, I.; Roth, D. Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey. arXiv 2021, arXiv:2111.01243. [Google Scholar] [CrossRef]
- Majumdar, S.; Ginsburg, B. MatchboxNet: 1D Time-Channel Separable Convolutional Neural Network Architecture for Speech Commands Recognition. arXiv 2020, arXiv:2004.08531v2. [Google Scholar]
- Chung, J.S.; Nagrani, A.; Zisserman, A. VoxCeleb2: Deep Speaker Recognition. arXiv 2018, arXiv:1806.05622. [Google Scholar]
- Han, J.; Landini, F.; Rohdin, J.; Diez, M.; Burget, L.; Cao, Y.; Lu, H.; Cernocky, J. DiaCorrect: Error Correction Back-end For Speaker Diarization. arXiv 2023, arXiv:2309.08377. [Google Scholar]
- Chang, X.; Skarbek, W. Multi-Modal Residual Perceptron Network for Audio-Video Emotion Recognition. Sensors 2021, 21, 5452. [Google Scholar] [CrossRef]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2023, arXiv:2305.09972. [Google Scholar]
- Bridle, J.S. Probabilistic Interpretation of Feedforward Classification Network Outputs, with Relationships to Statistical Pattern Recognition; Soulié, F.F., Hérault, J., Eds.; Neurocomputing. NATO ASI Series; Springer: Berlin/Heidelberg, Germany, 1990; Volume 68, pp. 227–236. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Mohri, M.; Rostazadeh, A.; Talwalkar, A. Foundations of Machine Learning; The MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Cho, J.H.; Hariharan, B. On the Efficacy of Knowledge Distillation. arXiv 2019, arXiv:1910.01348. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C.J.C. THE MNIST DATABASE of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 11 November 2013).
- Bendersky, E. The SoftMax Function and Its Derivative. Available online: https://eli.thegreenplace.net/2016/the-softmax-function-and-its-derivative/ (accessed on 11 November 2013).
- Golub, G.H.; Van Loan, C.F. Matrix Computations, 3rd ed.; Johns Hopkins University Press: Baltimore, MD, USA, 1996. [Google Scholar]
- Liu, S.; Leiva, V.; Zhuang, D.; Ma, T.; Figueroa-Zúñiga, J.I. Matrix differential calculus with applications in the multivariate linear model and its diagnostics. J. Multivar. Anal. 2022, 188, 104849. [Google Scholar] [CrossRef]
- Gao, B.; Lacra, P. On the Properties of the SoftMax Function with Application in Game Theory and Reinforcement Learning. arXiv 2018, arXiv:1704.00805. [Google Scholar]
- Skarbek, W. Symbolic Tensor Neural Networks for Digital Media—From Tensor Processing via BNF Graph Rules to CREAMS Applications. Fundam. Inform. 2019, 168, 89–184. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Riley, K.F.; Hobson, M.P.; Bence, S.J. Mathematical Methods for Physics and Engineering; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).