
Towards Efficient Federated Learning: Layer-Wise Pruning-Quantization Scheme and Coding Design


 ,
,  and
and
Abstract
1. Introduction
1.1. Background and Motivation
1.2. Related Work
1.3. Contribution and Organization
- •
- We propose FedLP-Q (the codes in this work are available at https://github.com/Zhuzzq/FedLP/tree/main/FedLP-Q), a joint pruning-quantization FL framework employing the layer-wise approach. FedLP-Q provides a simple but efficient paradigm to mitigate the communication loads and computation complexity in FL systems;
- •
- We develop two distinct FedLP-Q schemes for homogeneous and heterogeneous cases. The corresponding pruning strategies, quantization rules, and the coding designs are presented in detail. The theoretical analysis also shows the strengths of the coding scheme for FedLP-Q;
- •
- We carry out several experiments to evaluate the performance of FedLP-Q. The outcomes suggest that this layer-wise pruning-quantization mechanism significantly improves the system efficiency with controllable performance loss.
2. Preliminaries and FedLP-Q Framework
2.1. Basic FL
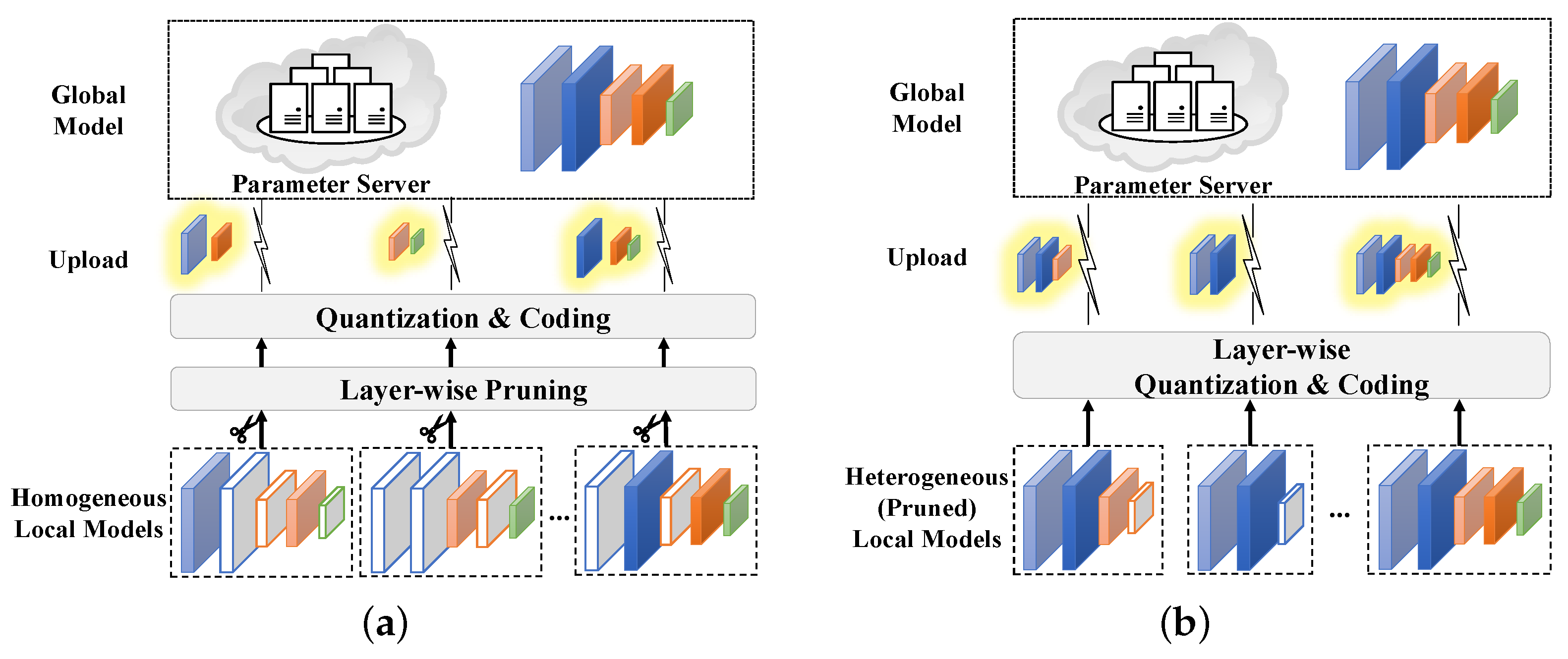
2.2. An Overview of the FedLP-Q Framework
3. FedLP-Q: Quantization-Coding Scheme for Layer-Wise Pruning
3.1. Pruning Phase
3.1.1. Homogeneity Case
3.1.2. Heterogeneity Case
3.2. Quantization and Coding Phase
3.2.1. Quantization Scheme
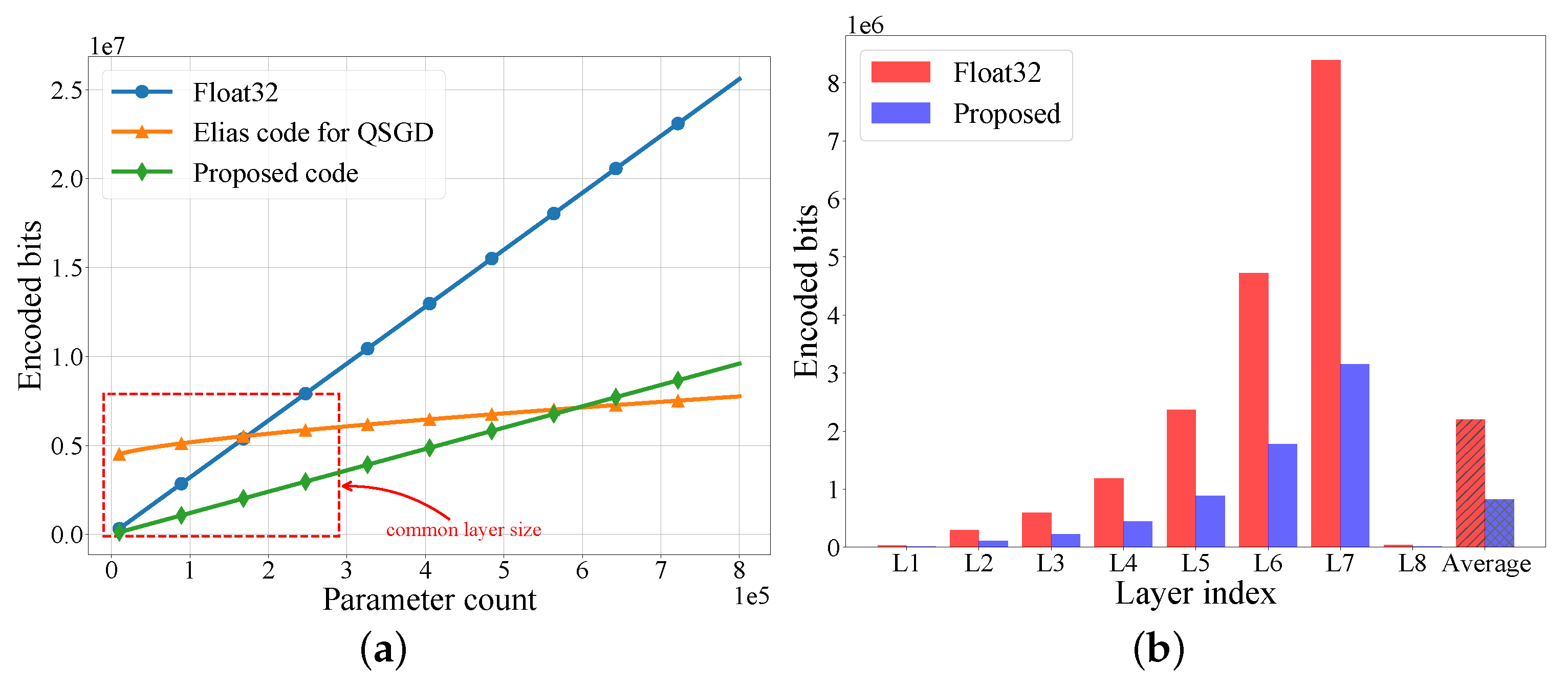
3.2.2. Coding Design
| Algorithm 1 Encoder for layer l | |
| Input:, ; | |
| 1: ; | ▹encode the header |
| 2: for do | |
| 3: ; | ▹ encode the interval index |
| 4: ; | ▹ encode the gradient sign |
| 5: end for | |
| Output: encoded message . |
| Algorithm 2 Decoder for layer l | |
| Input: received message ; Initialization: , , ; | |
| 1: ; | ▹decode the gradient norm |
| 2: ; | |
| 3: ; | ▹decode the quantization bit |
| 4: ; | |
| 5: while do | |
| 6: ; | ▹ decode the interval index |
| 7: ; | |
| 8: ; | ▹ decode the gradient sign |
| 9: ; ; | |
| 10: end while | |
| Output: decoded elements . |
3.2.3. Algorithm Formulation
| Algorithm 3 FedLP-Q | |
| Initialization: local models, pruning configures, etc. | |
| 1: for do | |
| 2: for participator client k in parallel do | ▹ client side |
| 3: Update ; | |
| 4: Calculate the accumulated gradients ; | |
| 5: Conduct layer-wise pruning: ; | |
| 6: Quantize the local gradients: ; | |
| 7: Carry out Algorithm 1 to encode the quantized gradients; | |
| 8: Upload local message to parameter server; | |
| 9: end for | |
| 10: Carry out Algorithm 2 to decode the received messages; | ▹ server side |
| 11: Aggregate each layer by (3); | |
| 12: Download the global model: ; | ▹ client side |
| 13: end for | |
| Output: global model: . |
3.3. Theoretical Analysis
3.3.1. Impacts on Convergence
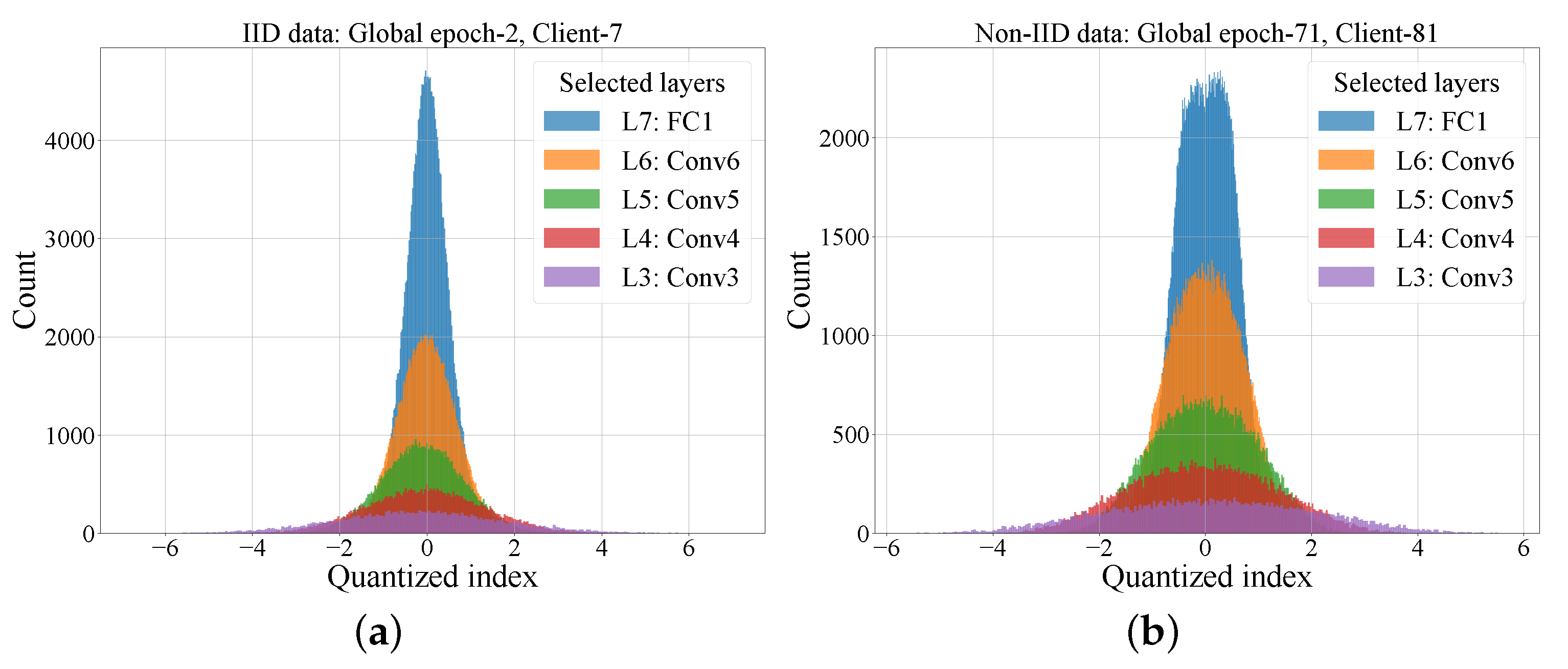
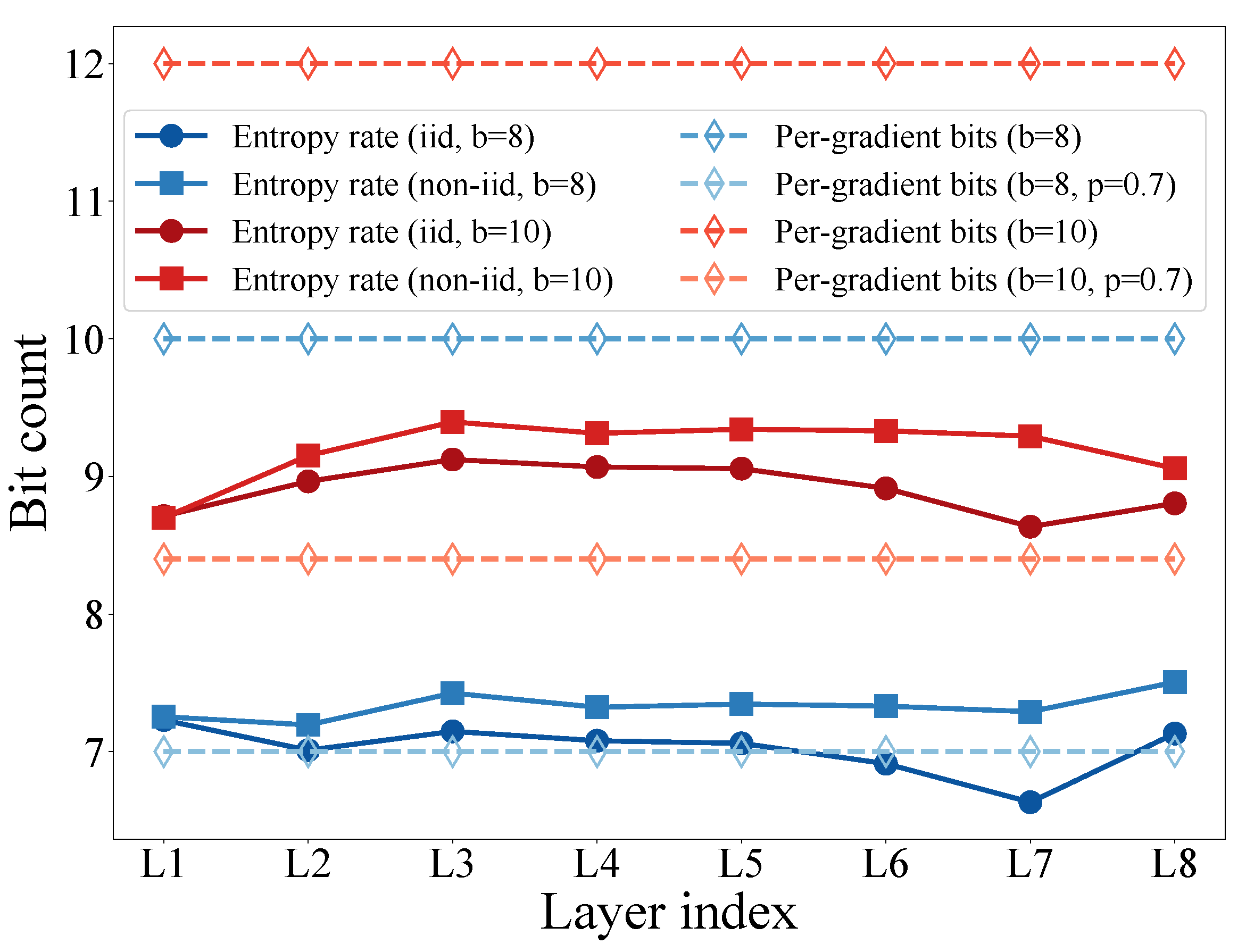
3.3.2. Coding Performance
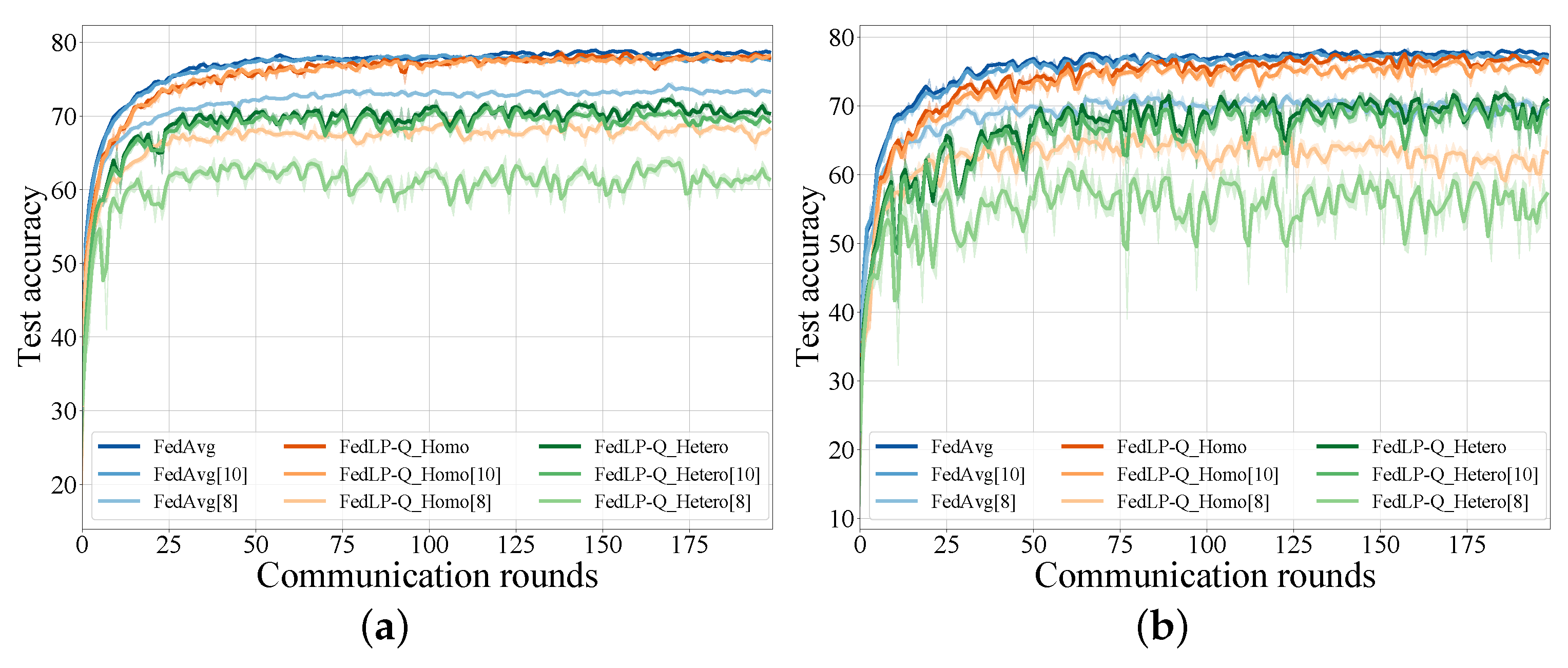
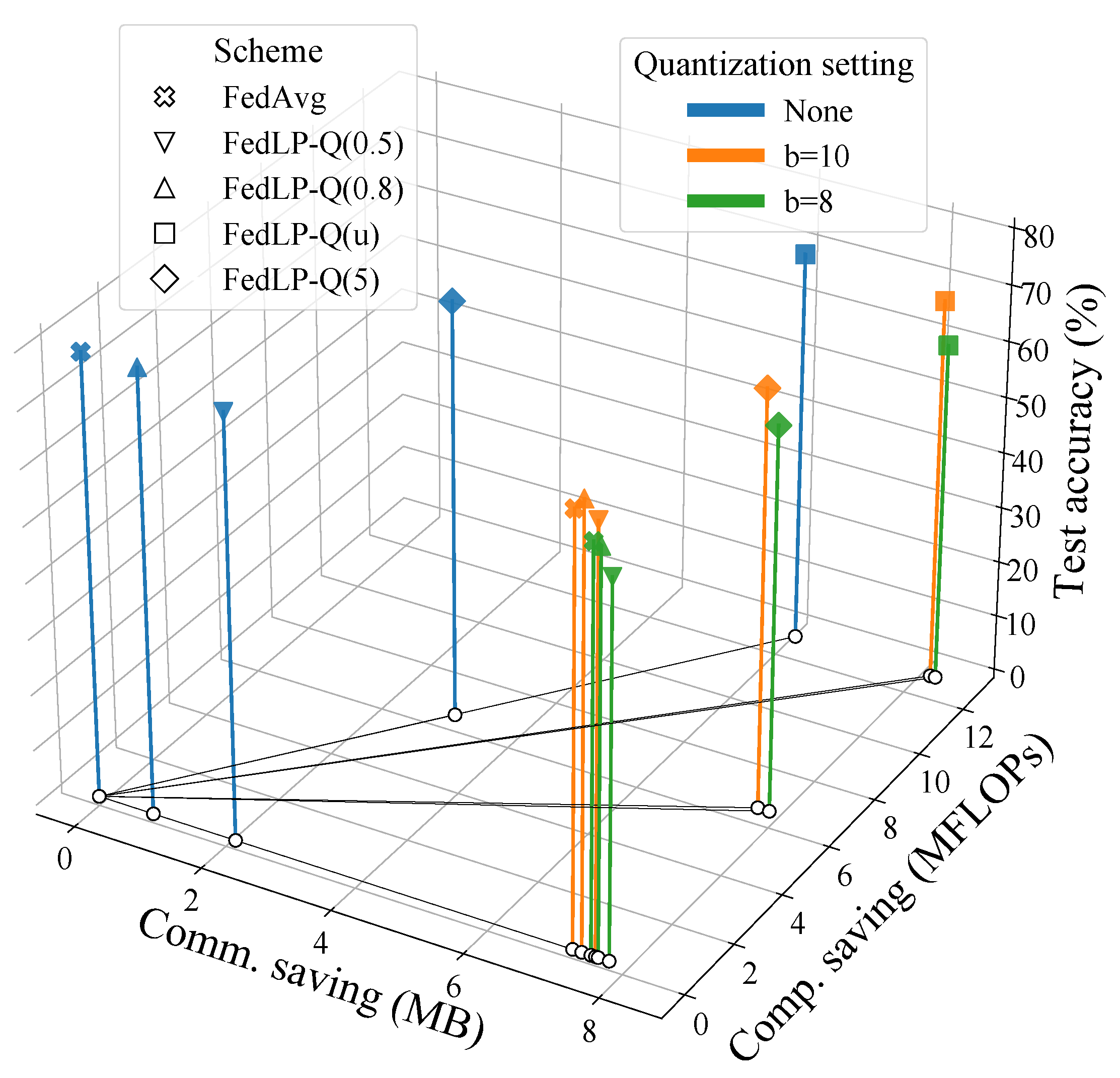
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FL | Federated Learning |
| iid | Independent and Identically Distributed |
| non-iid | Non-Independent and Non-Identically Distributed |
| FedAvg | Federated Averaging |
| QSGD | Quantized Stochastic Gradient Descent |
| FedLP | Federated Learning with Layer-wise Pruning |
| FedLP-Q | Federated Learning with Layer-wise Pruning and Quantization |
| Conv | Convolutional |
| FC | Fully Connected |
| FLOPs | Floating Point Operations |
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Letaief, K.B.; Chen, W.; Shi, Y.; Zhang, J.; Zhang, Y.J.A. The roadmap to 6G: AI empowered wireless networks. IEEE Commun. Mag. 2019, 57, 84–90. [Google Scholar] [CrossRef]
- Letaief, K.B.; Shi, Y.; Lu, J.; Lu, J. Edge artificial intelligence for 6G: Vision, enabling technologies, and applications. IEEE J. Sel. Areas Commun. 2021, 40, 5–36. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, M.; Wong, K.K.; Poor, H.V.; Cui, S. Federated learning for 6G: Applications, challenges, and opportunities. Engineering 2022, 8, 33–41. [Google Scholar] [CrossRef]
- Wan, S.; Lu, J.; Fan, P.; Shao, Y.; Peng, C.; Chuai, J. How global observation works in Federated Learning: Integrating vertical training into Horizontal Federated Learning. IEEE Internet Things J. 2023, 10, 9482–9497. [Google Scholar] [CrossRef]
- Zhu, Z.; Wan, S.; Fan, P.; Letaief, K.B. Federated multiagent actor–critic learning for age sensitive mobile-edge computing. IEEE Internet Things J. 2021, 9, 1053–1067. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Zhu, Z.; Fan, P.; Peng, C.; Letaief, K.B. ISFL: Federated Learning for Non-i.i.d. Data with Local Importance Sampling. arXiv 2022, arXiv:2210.02119v2. [Google Scholar]
- Chen, M.; Mao, B.; Ma, T. Efficient and robust asynchronous federated learning with stragglers. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Caldas, S.; Konečny, J.; McMahan, H.B.; Talwalkar, A. Expanding the reach of federated learning by reducing client resource requirements. arXiv 2018, arXiv:1812.07210. [Google Scholar]
- Liu, S.; Yu, G.; Yin, R.; Yuan, J. Adaptive network pruning for wireless federated learning. IEEE Wirel. Commun. Lett. 2021, 10, 1572–1576. [Google Scholar] [CrossRef]
- Wen, D.; Jeon, K.J.; Huang, K. Federated Dropout—A Simple Approach for Enabling Federated Learning on Resource Constrained Devices. IEEE Wirel. Commun. Lett. 2022, 11, 923–927. [Google Scholar] [CrossRef]
- Cheng, G.; Charles, Z.; Garrett, Z.; Rush, K. Does Federated Dropout Actually Work? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3387–3395. [Google Scholar]
- Horvath, S.; Laskaridis, S.; Almeida, M.; Leontiadis, I.; Venieris, S.; Lane, N. Fjord: Fair and accurate federated learning under heterogeneous targets with ordered dropout. Adv. Neural Inf. Process. Syst. 2021, 34, 12876–12889. [Google Scholar]
- Chen, Y.; Chen, Z.; Wu, P.; Yu, H. FedOBD: Opportunistic Block Dropout for Efficiently Training Large-scale Neural Networks through Federated Learning. arXiv 2022, arXiv:2208.05174. [Google Scholar]
- Zhu, Z.; Shi, Y.; Luo, J.; Wang, F.; Peng, C.; Fan, P.; Letaief, K.B. FedLP: Layer-wise Pruning Mechanism for Communication-Computation Efficient Federated Learning. arXiv 2023, arXiv:2303.06360. [Google Scholar]
- Alistarh, D.; Grubic, D.; Li, J.; Tomioka, R.; Vojnovic, M. QSGD: Communication-efficient SGD via gradient quantization and encoding. Adv. Neural Inf. Process. Syst. 2017, 30, 1707–1718. [Google Scholar]
- Hönig, R.; Zhao, Y.; Mullins, R. DAdaQuant: Doubly-adaptive quantization for communication-efficient Federated Learning. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 8852–8866. [Google Scholar]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K.B. Hierarchical federated learning with quantization: Convergence analysis and system design. IEEE Trans. Wirel. Commun. 2022, 22, 2–18. [Google Scholar] [CrossRef]
- Amiri, M.M.; Gunduz, D.; Kulkarni, S.R.; Poor, H.V. Federated learning with quantized global model updates. arXiv 2020, arXiv:2006.10672. [Google Scholar]
- Shlezinger, N.; Chen, M.; Eldar, Y.C.; Poor, H.V.; Cui, S. UVeQFed: Universal vector quantization for federated learning. IEEE Trans. Signal Process. 2020, 69, 500–514. [Google Scholar] [CrossRef]
- Reisizadeh, A.; Mokhtari, A.; Hassani, H.; Jadbabaie, A.; Pedarsani, R. Fedpaq: A communication-efficient federated learning method with periodic averaging and quantization. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Online, 26–28 August 2020; pp. 2021–2031. [Google Scholar]
- Yue, K.; Jin, R.; Wong, C.W.; Dai, H. Communication-efficient federated learning via predictive coding. IEEE J. Sel. Top. Signal Process. 2022, 16, 369–380. [Google Scholar] [CrossRef]
- Prakash, P.; Ding, J.; Chen, R.; Qin, X.; Shu, M.; Cui, Q.; Guo, Y.; Pan, M. IoT Device Friendly and Communication-Efficient Federated Learning via Joint Model Pruning and Quantization. IEEE Internet Things J. 2022, 9, 13638–13650. [Google Scholar] [CrossRef]
- Elias, P. Universal codeword sets and representations of the integers. IEEE Trans. Inf. Theory 1975, 21, 194–203. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| N | The number of distributed clients. |
| Local training epoch. | |
| Distributed local datasets. | |
| The set of participation clients at t-th global epoch. | |
| K | The number of participation clients. |
| The global model. | |
| Local models. | |
| Aggregation weights for each client. | |
| The accumulated gradient of client k in t-th global epoch. |
| Schemes | Test Accuracy % (iid/Non-iid) | #Param ↘ | MFLOPs ↘ | ||
|---|---|---|---|---|---|
| No Quant | b = 10 | b = 8 | |||
| FedAvg | 78.8/75.3 | 76.2/74.9 | 71.7/68.5 | / | / |
| FedLP-Q(0.2) | 73.4/68.2 | 71.5/66.8 | 56.6/50.4 | 40.0% | / |
| FedLP-Q(0.5) | 75.5/73.5 | 75.4/72.5 | 66.7/62.0 | 25.0% | / |
| FedLP-Q(0.8) | 78.9/77.3 | 78.3/76.2 | 71.3/66.9 | 10.0% | / |
| FedLP-Q(1) | 64.4/60.3 | 64.1/59.2 | 53.6/49.4 | 84.6% | 51.2% |
| FedLP-Q(3) | 66.8/62.0 | 66.1/61.7 | 58.4/53.9 | 79.6% | 32.3% |
| FedLP-Q(u) | 70.1/66.5 | 68.3/65.4 | 60.7/55.7 | 71.1% | 34.5% |
| FedLP-Q(5) | 74.6/73.1 | 74.4/72.1 | 68.6/64.5 | 35.6% | 17.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Z.; Shi, Y.; Xin, G.; Peng, C.; Fan, P.; Letaief, K.B. Towards Efficient Federated Learning: Layer-Wise Pruning-Quantization Scheme and Coding Design. Entropy 2023, 25, 1205. https://doi.org/10.3390/e25081205
Zhu Z, Shi Y, Xin G, Peng C, Fan P, Letaief KB. Towards Efficient Federated Learning: Layer-Wise Pruning-Quantization Scheme and Coding Design. Entropy. 2023; 25(8):1205. https://doi.org/10.3390/e25081205
Chicago/Turabian StyleZhu, Zheqi, Yuchen Shi, Gangtao Xin, Chenghui Peng, Pingyi Fan, and Khaled B. Letaief. 2023. "Towards Efficient Federated Learning: Layer-Wise Pruning-Quantization Scheme and Coding Design" Entropy 25, no. 8: 1205. https://doi.org/10.3390/e25081205
APA StyleZhu, Z., Shi, Y., Xin, G., Peng, C., Fan, P., & Letaief, K. B. (2023). Towards Efficient Federated Learning: Layer-Wise Pruning-Quantization Scheme and Coding Design. Entropy, 25(8), 1205. https://doi.org/10.3390/e25081205