
Spatio-Temporal Patterns of the SARS-CoV-2 Epidemic in Germany


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Methodological Basis
2.2. General Settings and Nomenclature
2.3. t-sne
2.4. UMAP and PCA
2.5. Correlation Matrix and Hierarchical Clustering
2.6. Multidimensional Scaling and Network Graphs
2.7. Spatial Heterogeneity
3. Results
3.1. German SARS-CoV-2 Epidemic Activity Geographically Clusters into East and West
3.1.1. Allowing for a Visual Exploration through Dimensionality Reduction
3.1.2. Canonical Correlation Analysis Provides Added Values to the Findings
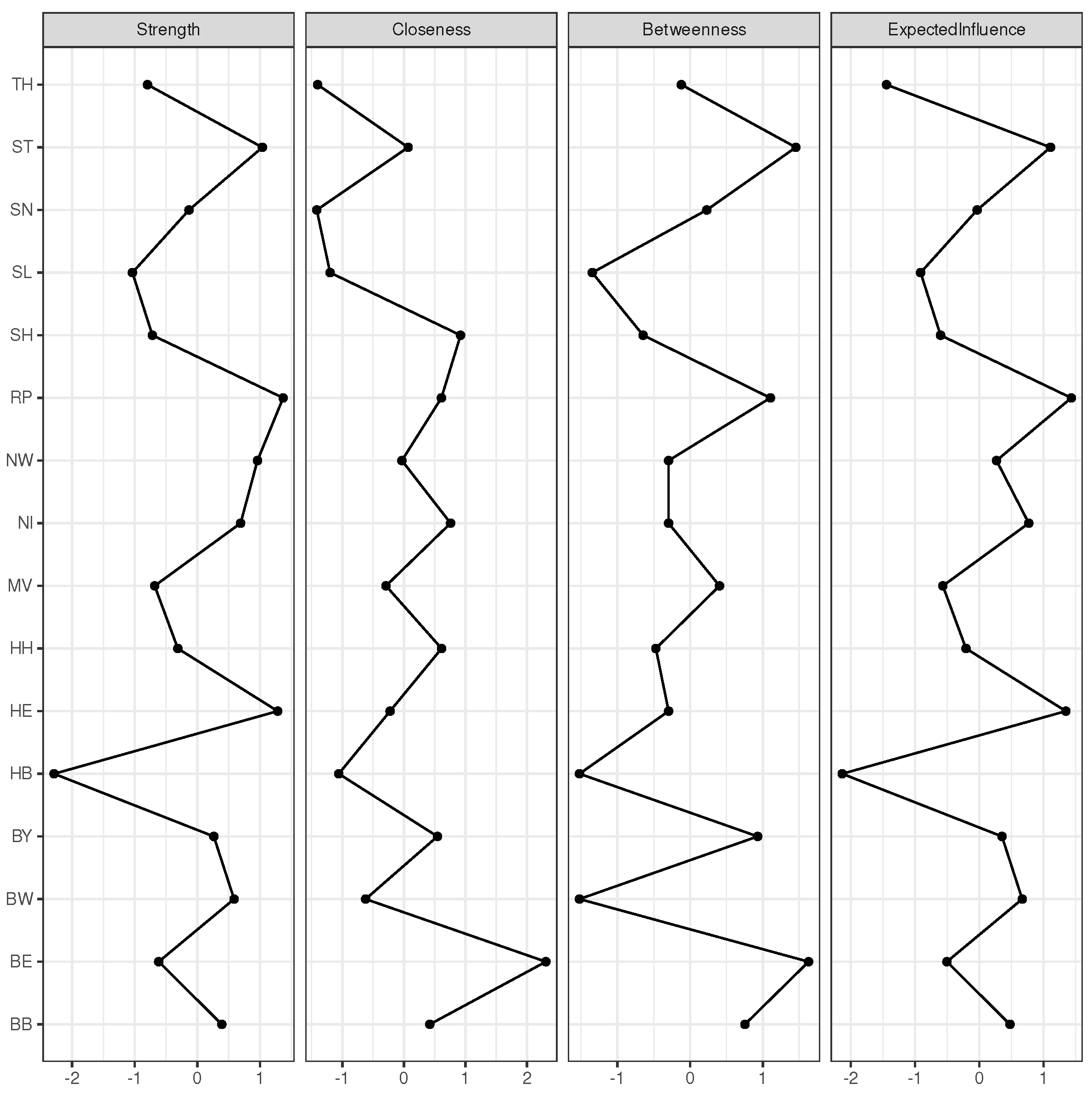
3.1.3. Consolidation of the Observed Clusters through Network Visualisation
3.2. Variability of County-Specific Fold Changes in Reproduction Numbers Correlates with Spatial Heterogeneity
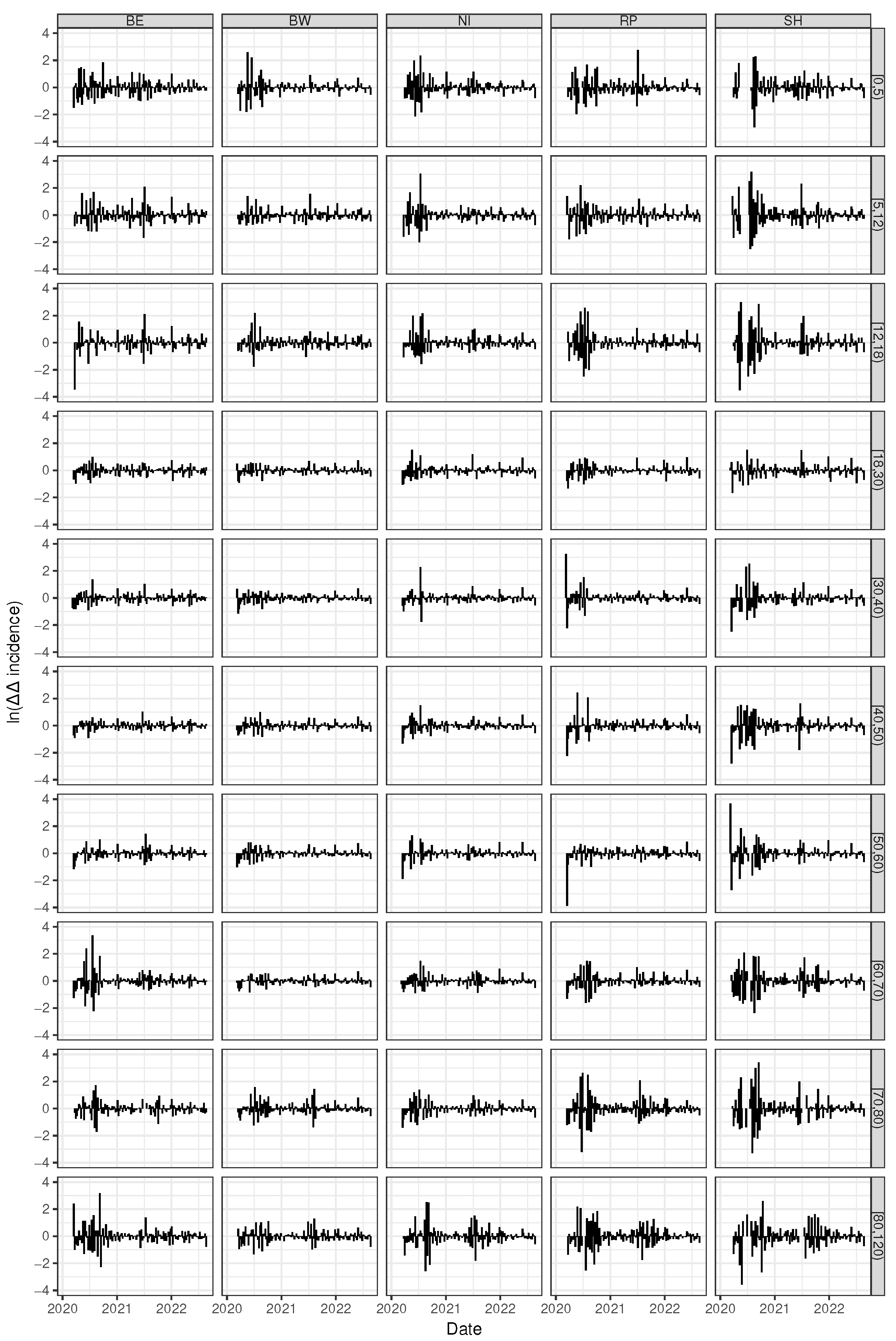
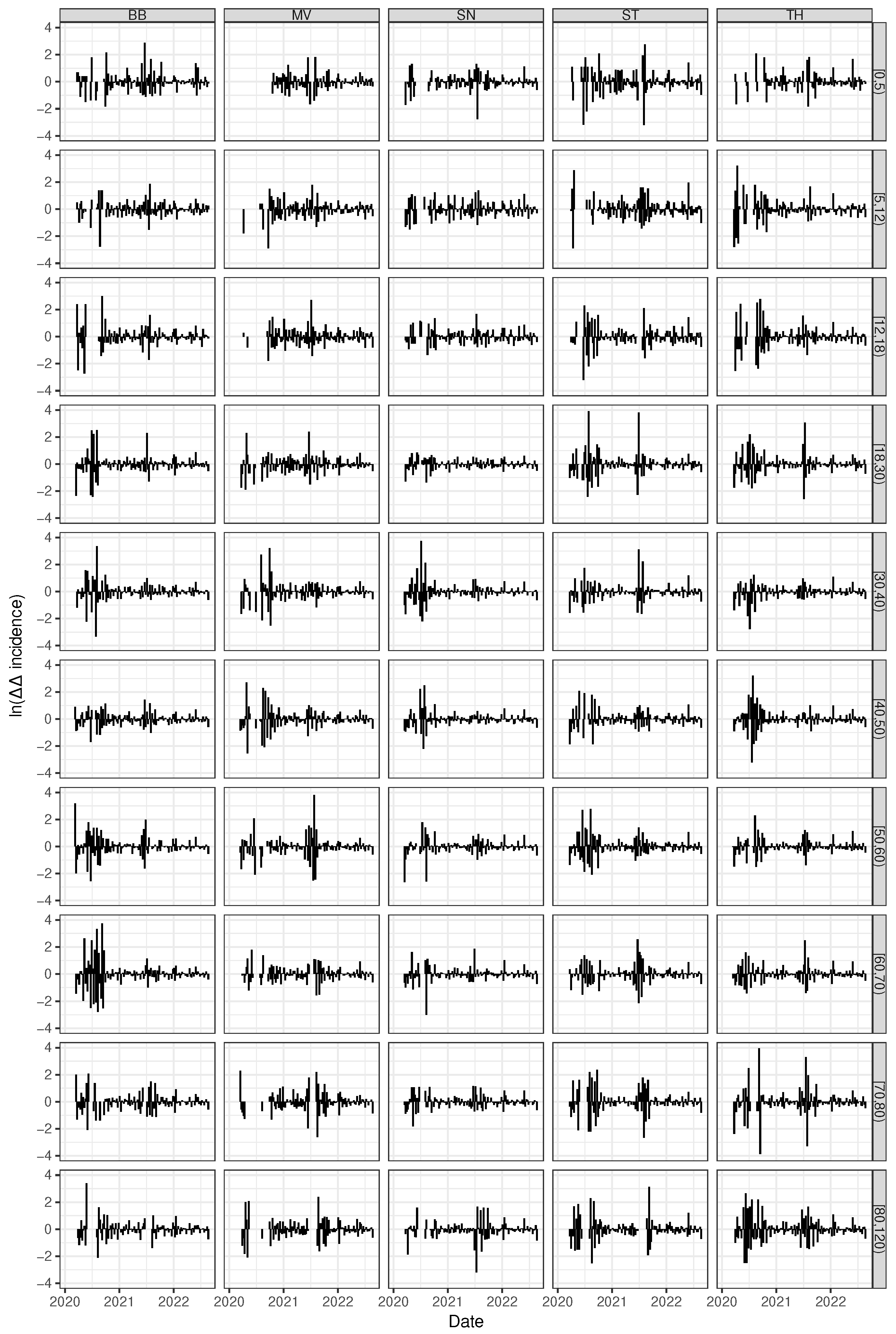
3.3. Spatial Homogeneity of Child Incidence but Increased Overall Heterogeneity in the East
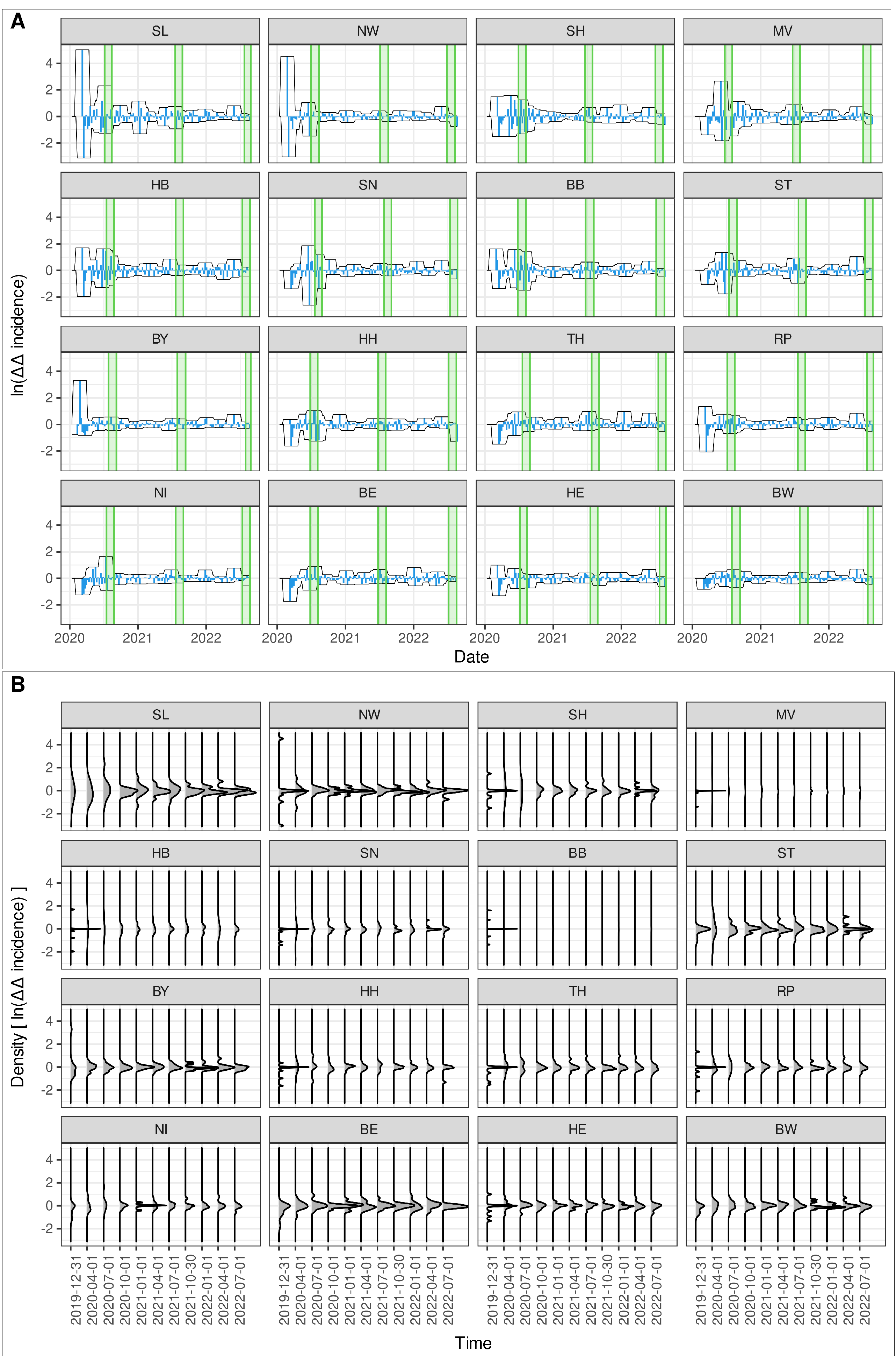
3.4. Decreasing Trend in Fold Changes in Reproduction Numbers
3.5. Pronounced Fold Changes in Reproduction Numbers for the Younger and the Elder Cohorts
3.6. Federal States Exhibit Dynamic Dissimilarities
4. Discussion
5. Conclusions
Supplementary Materials
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BB | Brandenburg |
| BE | Berlin |
| BW | Baden Württemberg (Baden-Wuerttemberg) |
| BY | Bayern (Bavaria) |
| HB | Hansestadt Bremen (Hanseatic City of Bremen) |
| HE | Hessen (Hesse) |
| HH | Hansestadt Hamburg (Hanseatic City of Hamburg) |
| MV | Mecklenburg-Vorpommern (Mecklenburg-Western Pomerania) |
| NI | Niedersachsen (Lower Saxony) |
| NW | Nord-Rhein-Westfalen (North Rhine-Westphalia) |
| RP | Rheinland-Pfalz (Rhineland-Palatinate) |
| SH | Schleswig-Holstein (Schleswig-Holstein) |
| SL | Saarland |
| SN | Sachsen (Saxony) |
| ST | Sachsen-Anhalt (Saxony-Anhalt) |
| TH | Thüringen (Thuringia) |
| Counties | Land-/Stadtkreise (rural/urban districts), local administrative districts (subdivisions of the federal states) in Germany |
| DE | Deutschland (Germany) |
| EW | East/West, used to label the categorical variable with values Eastern and Western Germany, where East comprises the federal states BB, MV, SN, ST, TH. |
| Western Germany accounts for the remaining federal states. | |
| FS, Fed. State | Bundesland (federal state) |
| agegrp | age group or age class |
| RKI | Robert Koch Institute (Federal Government’s Public Health Institute of Germany) |
| MDS | Multidimensional Scaling |
| PCA | Principal Component Analysis |
References
- Wang, C.; Horby, P.W.; Hayden, F.G.; Gao, G.F. A novel coronavirus outbreak of global health concern. Lancet 2020, 395, 470–473. [Google Scholar] [CrossRef] [PubMed]
- Kissler, S.M.; Tedijanto, C.; Goldstein, E.; Grad, Y.H.; Lipsitch, M. Projecting the transmission dynamics of SARS-CoV-2 through the postpandemic period. Science 2020, 368, 860–868. [Google Scholar] [CrossRef] [PubMed]
- Abu El Kheir-Mataria, W.; El-Fawal, H.; Chun, S. Global health governance performance during COVID-19, what needs to be changed? A Delphi survey study. Global Health 2023, 19, 24. [Google Scholar] [CrossRef] [PubMed]
- Brainard, J. Scientists are drowning in COVID-19 papers. Can new tools keep them afloat? Sci. Mag. News 2020, 13, 1126. [Google Scholar] [CrossRef]
- Ahmad, S.J.; Degiannis, K.; Borucki, J.; Pouwels, S.; Rawaf, D.L.; Head, M.; Li, C.H.; Archid, R.; Ahmed, A.R.; Lala, A.; et al. The most influential COVID-19 articles: A systematic review. New Microbes New Infect. 2023, 52, 101094. [Google Scholar] [CrossRef]
- Maier, C.; Ankermann, T. Studienrückrufe: Fake News in Fachzeitschriften. Dtsch. Arztebl. Int. 2022, 119, A-116. [Google Scholar]
- The Lancet Infectious Diseases. The COVID-19 infodemic. Lancet Infect. Dis. 2020, 20, 875. [Google Scholar] [CrossRef]
- Green, J.; Edgerton, J.; Naftel, D.; Shoub, K.; Cranmer, S.J. Elusive consensus: Polarization in elite communication on the COVID-19 pandemic. Sci. Adv. 2020, 6, eabc2717. [Google Scholar] [CrossRef]
- Nachtwey, P.; Walther, E. Survival of the fittest in the pandemic age: Introducing disease-related social Darwinism. PLoS ONE 2023, 18, e0281072. [Google Scholar] [CrossRef]
- Geana, M.V.; Rabb, N.; Sloman, S. Walking the party line: The growing role of political ideology in shaping health behavior in the United States. SSM—Popul. Health 2021, 16, 100950. [Google Scholar] [CrossRef]
- Richter, C.; Wächter, M.; Reinecke, J.; Salheiser, A.; Quent, M.; Wjst, M. Politische Raumkultur als Verstärker der Corona-Pandemie? Einflussfaktoren auf die regionale Inzidenzentwicklung in Deutschland in der ersten und zweiten Pandemiewelle 2020. ZRex—Z. Rechtsextremismusforsch. 2021, 1, 191–211. [Google Scholar] [CrossRef]
- Qamar, A.I.; Gronwald, L.; Timmesfeld, N.; Diebner, H.H. Local socio-structural predictors of COVID-19 incidence in Germany. Front. Public Health 2022, 10, 970092. [Google Scholar] [CrossRef]
- Lippold, D.; Kergaßner, A.; Burkhardt, C.; Kergaßner, M.; Loos, J.; Nistler, S.; Steinmann, P.; Budday, D.; Budday, S. Spatiotemporal modeling of first and second wave outbreak dynamics of COVID-19 in Germany. Biomech. Model. Mechanobiol. 2022, 21, 119–133. [Google Scholar] [CrossRef]
- Hatipoglu, V. Forecasting of COVID-19 Fatality in the USA: Comparison of Artificial Neural Network-Based Models. Bull. Malays. Math. Sci. Soc. 2023, 46, 143. [Google Scholar] [CrossRef]
- Enserink, M.; Kupferschmidt, K. With COVID-19, modeling takes on life and death importance. Science 2020, 367, 1414–1415. [Google Scholar] [CrossRef]
- Giordano, G.; Blanchini, F.; Bruno, R.; Colaneri, P.; Di Filippo, A.; Di Matteo, A.; Colaneri, M. Modelling the COVID-19 epidemic and implementation of population-wide interventions in Italy. Nat. Med. 2020, 26, 855–860. [Google Scholar] [CrossRef]
- Schlickeiser, R.; Kröger, M. Analytical Modeling of the Temporal Evolution of Epidemics Outbreaks Accounting for Vaccinations. Physics 2021, 3, 386–426. [Google Scholar] [CrossRef]
- Webb, G. A COVID-19 Epidemic Model Predicting the Effectiveness of Vaccination in the US. Infect. Dis. Rep. 2021, 13, 654–667. [Google Scholar] [CrossRef]
- Maier, B.; Wiedermann, M.; Burdinski, A.; Klamser, P.; Jenny, M.; Betsch, C.; Brockmann, D. Germany’s fourth COVID-19 wave was mainly driven by the unvaccinated. Commun. Med. 2022, 2, 116. [Google Scholar] [CrossRef]
- Ramamoorthi, P.; Muthukrishnan, S. Dynamics of COVID-19 spreading model with social media public health awareness diffusion over multiplex networks: Analysis and control. Int. J. Mod. Phys. C 2021, 32, 2150060. [Google Scholar] [CrossRef]
- Ruck, D.J.; Bentley, R.A.; Borycz, J. Early warning of vulnerable counties in a pandemic using socio-economic variables. Econ. Hum. Biol. 2021, 41, 100988. [Google Scholar] [CrossRef] [PubMed]
- Fliess, M.; Join, C.; d’Onofrio, A. Feedback control of social distancing for COVID-19 via elementary formulae. IFAC-PapersOnLine 2022, 55, 439–444. [Google Scholar] [CrossRef]
- Diebner, H.H.; Timmesfeld, N. Exploring COVID-19 Daily Records of Diagnosed Cases and Fatalities Based on Simple Nonparametric Methods. Infect. Dis. Rep. 2021, 13, 302–328. [Google Scholar] [CrossRef] [PubMed]
- Diebner, H.H. Phase Shift Between Age-Specific COVID-19 Incidence Curves Points to a Potential Epidemic Driver Function of Kids and Juveniles in Germany. medRxiv 2021. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2023. [Google Scholar]
- Robert Koch-Institut. SurvStat@RKI 2.0. 2022. Available online: https://www.rki.de/EN/Content/infections/epidemiology/SurvStat/survstat_node.html (accessed on 1 September 2022).
- Federal Statistical Office of Germany. German Census Data. 2022. Available online: www.destatis.de (accessed on 2 November 2022).
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Hinton, G.; Roweis, S. Stochastic Neighbor Embedding. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2002; Volume 15, pp. 833–840. [Google Scholar]
- Krijthe, J.H. Rtsne: T-Distributed Stochastic Neighbor Embedding Using Barnes-Hut Implementation, R Package Version 0.16. 2015. Available online: https://github.com/jkrijthe/Rtsne (accessed on 25 July 2023).
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Konopka, T. umap: Uniform Manifold Approximation and Projection, R package version 0.2.10.0. 2023. Available online: https://github.com/tkonopka/umap (accessed on 25 July 2023).
- Revelle, W. psych: Procedures for Psychological, Psychometric, and Personality Research, R package version 2.3.3; Northwestern University: Evanston, IL, USA, 2023. [Google Scholar]
- Wei, T.; Simko, V. R Package ‘corrplot’: Visualization of a Correlation Matrix (Version 0.92). 2021. Available online: https://github.com/taiyun/corrplot (accessed on 25 July 2023).
- Mair, P.; Groenen, P.J.F.; de Leeuw, J. More on Multidimensional Scaling and Unfolding in R: Smacof Version 2. J. Stat. Softw. 2022, 102, 1–47. [Google Scholar] [CrossRef]
- Epskamp, S.; Cramer, A.O.J.; Waldorp, L.J.; Schmittmann, V.D.; Borsboom, D. qgraph: Network Visualizations of Relationships in Psychometric Data. J. Stat. Softw. 2012, 48, 1–18. [Google Scholar] [CrossRef]
- Tuomisto, H. A consistent terminology for quantifying species diversity? Yes, it does exist. Oecologia 2010, 164, 853–860. [Google Scholar] [CrossRef]
- Diebner, H.H.; Kather, A.; Roeder, I.; de With, K. Mathematical basis for the assessment of antibiotic resistance and administrative counter-strategies. PLoS ONE 2020, 15, e0238692. [Google Scholar] [CrossRef]
- Kennel, M.; Shlens, J.; Abarbanel, H.; Chichilnisky, E. Estimating entropy rates with Bayesian confidence intervals. Neural Comput. 2005, 17, 1531–1576. [Google Scholar] [CrossRef]
- Berger, U.; Fritz, C.; Kauermann, G. Schulschließungen Oder Schulöffnung Mit Testpflicht? Epidemiologisch-Statistische Aspekte Sprechen für Schulöffnungen Mit Verpflichtenden Tests; Report CODAG Bericht Nr. 14 vom 30.04.2021; Ludwig Maximilian University of Munich: Munich, Germany, 2021. [Google Scholar]
- Goodman-Bacon, A.; Marcus, J. Using Difference-in-Differences to Identify Causal Effects of COVID-19 Policies. Surv. Res. Methods 2020, 14, 153–158. [Google Scholar] [CrossRef]
- Herby, J.; Jonung, L.; Hanke, S.H. A Literature Review and Meta-Analysis of the Effects of Lockdowns on COVID-19 Mortality; Technical Report; Institute for Applied Economics, Global Health, and the Study of Business Enterprise at the Johns Hopkins University: Baltimore, MD, USA, 2022. [Google Scholar]
- Korencak, M.; Sivalingam, S.; Sahu, A.; Dressen, D.; Schmidt, A.; Brand, F.; Krawitz, P.; Hart, L.; Maria Eis-Hübinger, A.; Buness, A.; et al. Reconstruction of the origin of the first major SARS-CoV-2 outbreak in Germany. Comput. Struct. Biotechnol. J. 2022, 20, 2292–2296. [Google Scholar] [CrossRef]
- Böhmer, M.M.; Buchholz, U.; Corman, V.M.; Hoch, M.; Katz, K.; Marosevic, D.V.; Böhm, S.; Woudenberg, T.; Ackermann, N.; Konrad, R.; et al. Investigation of a COVID-19 outbreak in Germany resulting from a single travel-associated primary case: A case series. Lancet Infect. Dis. 2020, 20, 920–928. [Google Scholar] [CrossRef]
- Häussler, B. Pandemie-Meldewesen: Deutschland im Corona-Blindflug. ÄrzteZeitung Online, 15 January 2021. Available online: https://www.aerztezeitung.de/Politik/Deutschland-im-Corona-Blindflug-416280.html (accessed on 25 July 2023).
- Klement, R.J. Systems Thinking about SARS-CoV-2. Front. Public Health 2020, 8, 585229. [Google Scholar] [CrossRef]
- Müller, B. Zur Modellierung der Corona-Pandemie—Eine Streitschrift. Monitor Versorgungsforsch. 2021, 14, 68–79. [Google Scholar] [CrossRef]
- Emery, F. (Ed.) Systems Thinking; Penguin Books: Harmondsworth, UK, 1969. [Google Scholar]
- Haken, H. Information and Self-Organization—A Macroscopic Approach to Complex System; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar] [CrossRef]
- Diebner, H.H. Bilder sind komplexe Systeme und deren Interpretationen noch viel komplexer—Über die Verwandtschaft von Hermeneutik und Systemtheorie. In The Picture’s Image: Wissenschaftliche Visualisierung als Komposit; Hinterwaldner, I., Buschhaus, M., Eds.; Fink-Verlag: Munich, Germany, 2006; pp. 282–299. [Google Scholar]
- Diebner, H.H. Performative Science—Transgressions from Scientific to Artistic Practices and Reverse. In Complexity and Synergetics; Müller, S.C., Plath, P.J., Radons, G., Fuchs, A., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 373–381. [Google Scholar] [CrossRef]
- Seo, M.; Chang, H. Context of Discovery and Context of Justification. In Encyclopedia of Science Education; Gunstone, R., Ed.; Springer: Dordrecht, The Netherlands, 2015; pp. 229–232. [Google Scholar] [CrossRef]
- Heath, A.; Hunink, M.G.M.; Krijkamp, E.; Pechlivanoglou, P. Prioritisation and design of clinical trials. Eur. J. Epidemiol. 2021, 36, 1111–1121. [Google Scholar] [CrossRef]
- Muller, S.M. Masks, Mechanisms and COVID-19: The Limitations of Randomized Trials in Pandemic Policymaking. Hist. Philos. Life Sci. 2021, 43, 43. [Google Scholar] [CrossRef]
- Hippich, M.; Holthaus, L.; Assfalg, R.; Zapardiel-Gonzalo, J.; Kapfelsperger, H.; Heigermoser, M.; Haupt, F.; Ewald, D.A.; Welzhofer, T.C.; Marcus, B.A.; et al. A Public Health Antibody Screening Indicates a 6-Fold Higher SARS-CoV-2 Exposure Rate than Reported Cases in Children. Clin. Adv. 2021, 2, 149–163.e4. [Google Scholar] [CrossRef]
- Brinkmann, F.; Diebner, H.H.; Matenar, C.; Schlegtendal, A.; Spiecker, J.; Eitner, L.; Timmesfeld, N.; Maier, C.; Lücke, T. Longitudinal Rise in Seroprevalence of SARS-CoV-2 Infections in Children in Western Germany–A Blind Spot in Epidemiology? Infect. Dis. Rep. 2021, 13, 957–964. [Google Scholar] [CrossRef] [PubMed]
- Brinkmann, F.; Schlegtendal, A.; Hoffmann, A.; Theile, K.; Hippert, F.; Strodka, R.; Timmesfeld, N.; Diebner, H.H.; Lücke, T.; Maier, C. SARS-CoV-2 Infections Among Children and Adolescents with Acute Infections in the Ruhr Region. Dtsch. Arztebl. Int. 2021, 118, 363–364. [Google Scholar] [CrossRef] [PubMed]
- Brinkmann, F.; Diebner, H.H.; Matenar, C.; Schlegtendal, A.; Eitner, L.; Timmesfeld, N.; Maier, C.; Lücke, T. Seroconversion rate and socio-economic and ethnic risk factors for SARS-CoV-2 infection in children in a population-based cohort, Germany, June 2020 to February 2021. Euro Surveill. 2022, 27, 2101028. [Google Scholar] [CrossRef]
- Ott, R.; Achenbach, P.; Ewald, D.A.; Friedl, N.; Gemulla, G.; Hubmann, M.; Kordonouri, O.; Loff, A.; Marquardt, E.; Sifft, P.; et al. SARS-CoV-2 seroprevalence in preschool and school-age children. Dtsch. Arztebl. Int. 2022, 119, 765–770. [Google Scholar] [CrossRef] [PubMed]
- Head, J.R.; Andrejko, K.L.; Remais, J.V. Model-based assessment of SARS-CoV-2 Delta variant transmission dynamics within partially vaccinated K-12 school populations. Lancet Reg. Health Am. 2022, 5, 100133. [Google Scholar] [CrossRef]
- Sombetzki, M.; Lücker, P.; Ehmke, M.; Bock, S.; Littmann, M.; Reisinger, E.C.; Hoffmann, W.; Kästner, A. Impact of Changes in Infection Control Measures on the Dynamics of COVID-19 Infections in Schools and Pre-schools. Front. Public Health 2021, 9, 780039. [Google Scholar] [CrossRef]
- Nachtwey, O.; Schäfer, R.; Frei, N. Politische Soziologie der Corona-Proteste. SocArXiv 2020. [Google Scholar] [CrossRef]
- Nachtwey, O.; Frei, N.; Markwardt, N. “Querdenken”: Die erste wirklich postmoderne Bewegung. Oliver Nachtwey und Nadine Frei, im Interview mit Nils Markwardt. Philosophie Magazin Online, 14 January 2021. [Google Scholar]
- Wachtler, B.; Hoebel, J. Soziale Ungleichheit und COVID-19: Sozialepidemiologische Perspektiven auf die Pandemie. Gesundheitswesen 2020, 82, 670–675. [Google Scholar] [CrossRef]
- Hoebel, J.; Michalski, N.; Wachtler, B.; Diercke, M.; Neuhauser, H.; Wieler, L.H.; Hövener, C. Socioeconomic Differences in the Risk of Infection During the Second SARS-CoV-2 Wave in Germany. Dtsch. Arztebl. Int. 2021, 118, 269–270. [Google Scholar] [CrossRef]
- Maftei, A.; Petroi, C.E. “I’m luckier than everybody else!”: Optimistic bias, COVID-19 conspiracy beliefs, vaccination status, and the link with the time spent online, anticipated regret, and the perceived threat. Front. Public Health 2022, 10, 1019298. [Google Scholar] [CrossRef]
- BMJ Expert Media Panel. School Testing Plans Risk Spreading COVID-19 More Widely, Warn Experts. 2021. Available online: https://www.bmj.com/company/newsroom/school-testing-plans-risk-spreading-covid-19-more-widely-warn-experts/ (accessed on 25 November 2021).
- Fuhrmann, J.; Barbarossa, M.V. The significance of case detection ratios for predictions on the outcome of an epidemic—A message from mathematical modelers. Arch. Public Health 2020, 78, 63. [Google Scholar] [CrossRef]
- Zhao, S.; Musa, S.S.; Lin, Q.; Ran, J.; Yang, G.; Wang, W.; Lou, Y.; Yang, L.; Gao, D.; He, D.; et al. Estimating the Unreported Number of Novel Coronavirus (2019-nCoV) Cases in China in the First Half of January 2020: A Data-Driven Modelling Analysis of the Early Outbreak. J. Clin. Med. 2020, 9, 388. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diebner, H.H. Spatio-Temporal Patterns of the SARS-CoV-2 Epidemic in Germany. Entropy 2023, 25, 1137. https://doi.org/10.3390/e25081137
Diebner HH. Spatio-Temporal Patterns of the SARS-CoV-2 Epidemic in Germany. Entropy. 2023; 25(8):1137. https://doi.org/10.3390/e25081137
Chicago/Turabian StyleDiebner, Hans H. 2023. "Spatio-Temporal Patterns of the SARS-CoV-2 Epidemic in Germany" Entropy 25, no. 8: 1137. https://doi.org/10.3390/e25081137
APA StyleDiebner, H. H. (2023). Spatio-Temporal Patterns of the SARS-CoV-2 Epidemic in Germany. Entropy, 25(8), 1137. https://doi.org/10.3390/e25081137