1. Introduction
The use of proper symbolic encoding of information is a foundation of the mathematical theory of communication proposed by Shannon in 1948 [
1]. Daw et al. [
2] indicated that data analysis tools referred to as
symbolization or
symbolic time series analysis (STSA) involve the transformation of raw time series data into a series of discretized symbols that are processed to extract information about the generating process. Among others, Buhlmann [
3] and Schittenkopf et al. [
4] emphasized that a discretization strategy transforming real data time series into symbolic streams is an effective complexity reduction tool. However, there is no general rule for locating an optimal partition for actual data [
5], and therefore many symbolic encoding procedures have been proposed in the literature and the results are not homogenous [
2,
3,
6,
7,
8,
9,
10,
11,
12,
13].
The well-known concept of informational efficiency of capital markets, which is strictly connected with the Efficient Market Hypothesis (EMH) [
14], is closely related to the issue of information processing and depends on the representation of information by equity market participants. Specifically, the EMH defines an efficient market as one in which new information is quickly and correctly reflected in current security prices [
15]. The traditional taxonomy of information sets distinguishes between three forms of informational efficiency: (1) weak-form efficiency, (2) semi-strong-form efficiency, and (3) strong-form efficiency. Weak-form efficiency means that the information set includes only the history of prices or returns. Semi-strong-form efficiency denotes that the information set includes all publicly available information. The final one, strong-form efficiency, means that the information set includes all information known to any market participant (see, e.g., [
16]). Gulko [
17] emphasized that the idea of market efficiency is linked to the concept of entropy. The author proposed the so-called entropic market hypothesis, which states that the entropy maximization may be a basic property of efficient pricing.
In their seminal paper, Shannon [
1] documented that information content could be measured by entropy. Generally speaking, communication systems can be roughly classified into three main categories: discrete, continuous, and mixed. A typical case of a discrete system of communication is telegraphy, since both the message and the signal are a sequence of discrete symbols. In such a meaning, each discrete time series constitutes a discrete source of information that can be encoded with the use of symbols [
1]. The Shannon entropy definition is grounded on symbolic representation of the information with the respective estimated probabilities. According to the literature, the modified Shannon entropy approach based on symbolic encoding with thresholds is especially useful in assessing market (in)efficiency in terms of sequential regularity in financial time series during extreme event periods [
3].
Within turbulent periods, regularity in financial time series increases in terms of the existence of patterns in stock and index returns. For instance, Risso [
10] documented that market trends (both up and down) that are common during extreme event periods usually reduce the entropy of daily financial time series due to more frequent repeated patterns. Specifically, stock market crashes create declining trends in financial time series, which reduce the entropy but increase time series regularity. In general, the chances for price prediction rise within a crisis and economic downturns. To sum up, various methods based on entropy enable investors to evaluate the aforementioned problems (see, e.g., [
18] and the references therein).
The main research question of this study can be formulated as follows: which STSA method is the most effective one in entropy-based applications in financial markets, especially in the context of informational market efficiency? Therefore, the aim of this comprehensive research is to evaluate several methods based on the modified Shannon entropy and a symbolic representation of discrete time series in financial market analyses. In order to answer the research question, two turbulent periods are analyzed: (1) the COVID-19 pandemic outbreak and (2) the period of war in Ukraine. Fifteen selected European equity markets are investigated. As the analyzed sample periods are not long, the methods that allow for assessing market (in)efficiency within long-time periods (such as the Hurst exponent [
19]) are not appropriate in this case.
The added value of this study is derived from the novel methodological and empirical findings that have not been presented in the literature thus far. The contribution is twofold. First of all, to the authors’ knowledge, this is the first comprehensive piece of research that examines and compares a battery of symbolic encoding methods with thresholds in empirical analyses concerning the informational efficiency of financial markets. Moreover, after symbolization, the dynamic structure in real data is recognized by symbol sequences and symbol sequence histograms of relative frequencies, which provide a convenient way to observe possible patterns in time series. The findings document that the encoding method with two and quantile thresholds seems to be the most effective and precise procedure in assessing dynamic patterns in time series of stock market indices. Therefore, we can recommend the use of this STSA method for financial time series analyses.
Second, the research hypothesis that the market informational efficiency measured by the modified Shannon entropy of daily index returns decreases during extreme event periods is assessed. To examine this hypothesis, changes in entropy values for the pre-turbulent and turbulent periods are estimated. The comparative results are homogenous for both pairs of the pre-event and event sub-periods and they confirm that there is no reason to reject the research hypothesis. The results support the evidence that stock market efficiency measured by entropy decreases during extreme events as the sequential regularity in time series increases in such cases. This conclusion is important for academics and practitioners and it is consistent with the existing literature which documents that turbulent periods are usually found to reduce the entropy of financial markets (e.g., [
18,
20,
21,
22,
23]).
The rest of this study is organized as follows.
Section 2 presents a brief literature review.
Section 3 describes the methodological background concerning symbolic encoding methods as well as the modified Shannon entropy approach based on symbolic representations of time series.
Section 4 contains real data descriptions.
Section 5 presents the experimental studies and compares empirical results on the European stock markets. The last section summarizes and discusses the main findings and indicates some further research directions. The paper is supplemented with three appendixes.
2. Brief Literature Review
The literature contains several studies that utilize entropy-based procedures with symbolic encoding in various applications in financial market analyses. However, the number of these studies is rather limited. For instance, Brida and Punzo [
5] constructed an artificial economy of the Italian macro-regions and focused on the STSA approach and the modified Shannon entropy to analyse the six-regime dynamics. Risso [
10] investigated the daily informational efficiency of five stock markets by using the local entropy and a symbolic time series analysis with one threshold. Mensi et al. [
24] evaluated the time-varying degree of the weak-form efficiency of the crude oil market using the modified Shannon entropy and the STSA approach. Sensoy et al. [
12] assessed the strength and direction of information flow between exchange rates and stock prices in emerging markets by the effective transfer entropy and symbolic encoding method with two thresholds. Risso [
11] applied a symbolic time series analysis with one threshold and the Shannon entropy in order to measure and rank the informational efficiency of twenty developed and emerging stock markets within the world. Mensi et al. [
25] examined two worldwide crude oil benchmarks and used the Shannon entropy based on the STSA procedure to rank the market-level efficiency. Oh et al. [
26] explored the degree of uncertainty in the return time series of several market indices based on the Shannon entropy, which incorporated the contribution of possible patterns. Ahn et al. [
6] used the Shannon entropy based on symbolic encoding with one threshold to analyse the effect of stock market uncertainty on economic fundamentals in China. Shternshis et al. [
13] proposed a computational methodology to estimate the Shannon entropy of high-frequency data to study the informational efficiency of Exchange Traded Funds (ETF). The authors considered symbolic encoding methods with one and two thresholds. Olbrys and Majewska [
9] applied two different STSA procedures with one threshold and the Shannon entropy to rank European stock markets’ informational (in)efficiency during the COVID-19 pandemic. In a recent paper, Brouty and Garcin [
27] determined the amount of information contained in the time series of price returns by using the Shannon entropy applied to symbolic representations of time series.
Another strand of the literature explores the topic of stock market efficiency during turbulent periods with the use of various entropy-based methods. For instance, Wang and Wang [
22] documented that the informational efficiency of the S&P 500 index substantially decreased during the COVID-19 extreme event. Ozkan [
21] investigated six developed equity markets during the COVID-19 pandemic outbreak and obtained that all markets deviate from market efficiency within this extreme event period. Ortiz-Cruz et al. [
20] indicated (based on the multi-scale Approximate Entropy procedure) that returns from crude oil markets were less uncertain during economic downturns. Olbrys and Majewska [
18] utilized a different approach, i.e., the Sample Entropy algorithm, to estimate the sequential regularity and entropy of the daily time series of 36 stock market indices within two extreme event periods: (1) the Global Financial Crisis in 2007–2009 and (2) the COVID-19 pandemic outbreak in 2020–2021. In general, the empirical results support the hypothesis that the regularity in financial time series usually increases, while the entropy and informational efficiency of stock markets usually decrease during various turbulence periods due to the existence of patterns in returns. In this context, Billio et al. [
28] proposed an entropy-based early warning indicator for systematic risk and documented the forecasting ability of entropy measures in predicting banking crises.
4. Real Data Description
This section describes the real datasets that have been used in empirical research. In order to ensure the coherence and comparability of empirical findings, both datasets include daily observations of the main stock market indices for the same fifteen European countries that have been chosen in the context of the Russian invasion of Ukraine. These countries are France, the United Kingdom, Germany, Finland, Norway, Turkey and the so-called ‘Bucharest 9’ (NATO Eastern flank states, i.e., Poland, Hungary, Czechia, Romania, Bulgaria, Lithuania, Estonia, Latvia and Slovakia). The choice of the selected countries can be justified as follows: (1) France, the United Kingdom, Germany and Turkey have taken an active part in diplomatic efforts concerning the Russian–Ukrainian conflict, (2) Finland and Norway border Russia and (3) all members of the so-called ‘Bucharest 9’ NATO Eastern flank states were either part of the former Soviet Union (USSR) or members of the defunct Soviet-led Warsaw Pact.
4.1. The COVID-19 Pandemic Outbreak
The first four-year sample comprises the two-year pre-COVID-19 pandemic period (from January 2018 to December 2019) and the two-year COVID-19 pandemic period (from January 2020 to December 2021). Since there is no unanimity in determining the COVID-19 pandemic period among researchers, in this study it is assumed that this period comprised two years (2020–2021), since on 30 January 2020, the COVID-19 outbreak was declared as a Public Health Emergency of International Concern by the World Health Organization (WHO), while on 11 March 2020, the WHO officially declared the COVID-19 outbreak to be a global pandemic [
32].
Table 1 includes brief information about the analyzed indices in the order of decreasing value of market capitalization (in EUR billion) on 31 December 2020, as well as the summarized statistics for the daily logarithmic rates of return within the entire first sample period and two investigated sub-periods.
4.2. The War in Ukraine
The second two-year sample comprises the one year pre-war period in Ukraine (from 24 February 2021 to 23 February 2022) and a one-year war period in Ukraine (from 24 February 2022 to 24 February 2023). Analogous to
Table 1, the subsequent
Table 2 presents brief information about the analyzed indices in the same order and the summarized statistics for the daily logarithmic rates of return within the entire second sample period and two investigated sub-periods.
5. Empirical Experiments
This section presents various empirical experiments concerning symbolic encoding with thresholds and entropy-based comparative analyses in the context of sequential regularity in financial time series. The selected fifteen European stock markets are investigated within the turbulent periods including the COVID-19 pandemic outbreak and the war in Ukraine.
Computations were conducted with a dedicated program. To perform the calculations and generate graphs, the Jupyter Notebook—a web-based interactive computing platform—and the pandas, numpy, math, matplotlib and itertools libraries were used. Jupyter (formerly known as IPython Notebook) allows to create documents that include the code and visualizations, while the libraries enable users to process data and generate graphs efficiently.
The findings of real data experiments document that the modified Shannon entropy based on the encoding method with two and quantile thresholds seems to be the most effective explicit procedure in assessing the dynamic patterns in the time series of stock market indices. This method evaluates extreme returns during turbulent periods much more appropriately than other methods, and the empirical results are especially homogenous for all investigated equity markets within all analyzed sub-periods.
5.1. Symbolic Dynamic Patterns in Financial Time Series
As mentioned in
Section 3.3, direct identification of symbolic dynamic patterns in time series consists of two steps. The first step encompasses symbolic encoding with one or two thresholds based on Definition 1 or Definition 2, respectively. The next step is the construction of symbol sequences (words). Each possible sequence is represented in terms of a unique identifier (code) given by a natural number.
Table 3 reports the number of all possible sequences (words) in the case of both definitions.
Table 4 exemplifies the assigned codes of all possible sequences in the case of the alphabet
(
) and the
length of a code sequence (
natural numbers). Sequence No. 8 (i.e.,
) is marked in bold as the one most frequently observed (see
Table 5 and
Table 6). Moreover, the sequence codes reported in
Table 4 are visible in
Figure 1 and
Figure 2 (
Section 5.2) and
Figure A2 and
Figure A3 (
Appendix B).
In this research, three different numbers () are utilized as the length of a code sequence. The amount of all calculations is large; thus, only selected results are displayed in this paper. The remaining empirical findings are available upon request.
Table 5 and
Table 6 document that dynamic patterns of symbolic encoding with two thresholds (Definition 2, Method 1: the 5% and 95% sample quantiles) for sequences of length
and
within the pre-event and event periods are homogenous for all fifteen analyzed stock market indices. The results reported in these tables confirm that the sequences
(
) and
(
) are the most frequently observed. These sequences mean that, respectively, three or four successive daily stock index returns are not extremely high or low, but they lie between the sample quantile thresholds, i.e.,
and
(Definition 2). The percentage numbers of sequences
(
) and
(
) vary between
and
(
Table 5) and between
and
(
Table 6). The empirical findings for the
sequence (
) are illustrated by the appropriate histograms of relative frequencies for selected indices in
Figure A1,
Figure A2,
Figure A3 and
Figure A4 (
Appendix B). Moreover, the additional comparative results for
and the sequence
are reported in
Table A1 (
Appendix A).
5.2. Symbol–Sequence Histograms
As pointed out in
Section 3.3, a dynamic structure in real data can be expressed by the relative frequency of each possible symbol sequence. The observed dynamics can be illustrated by a
k-histogram of relative frequencies. Therefore, in this subsection, selected histograms are presented. For comparison,
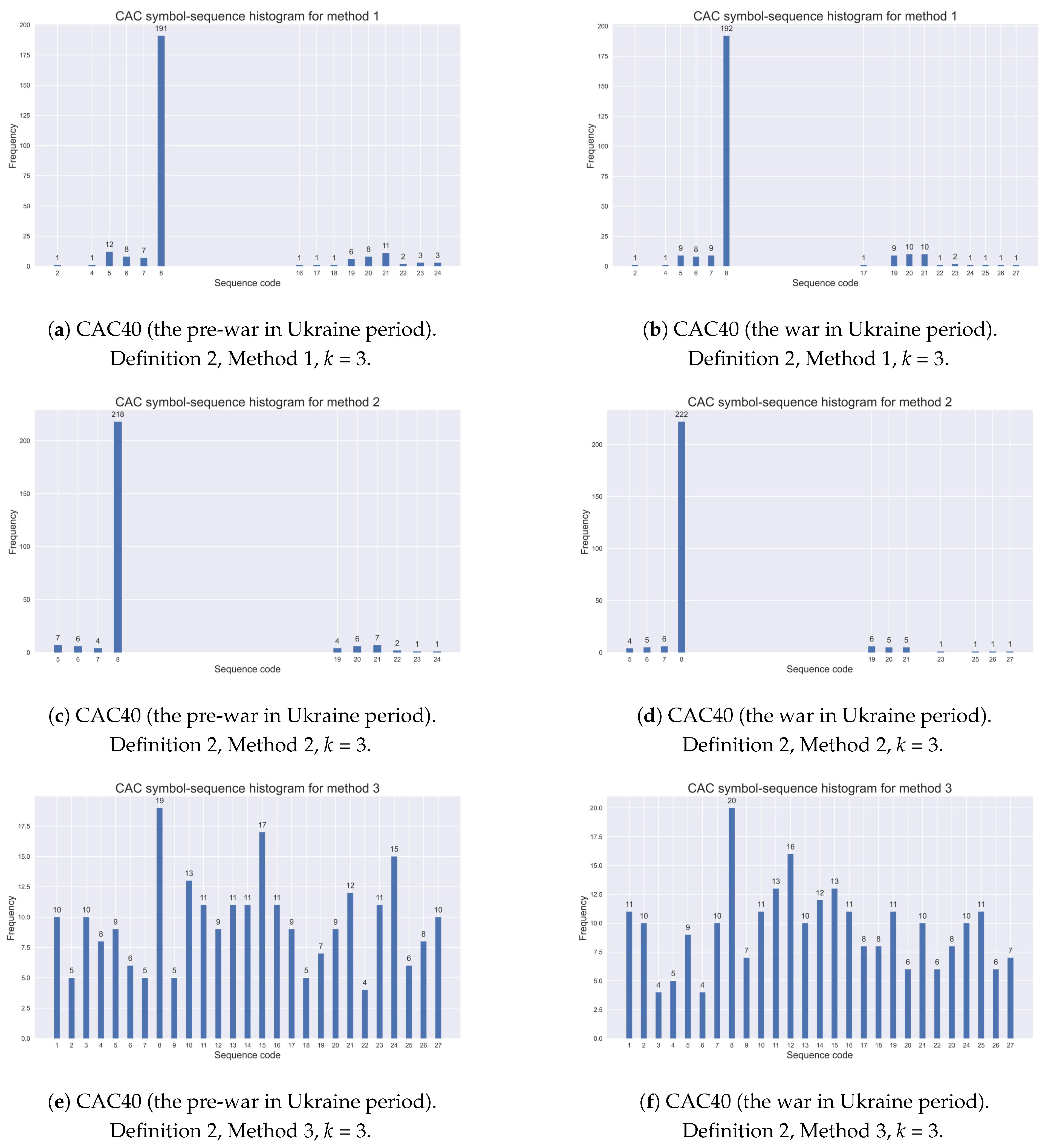
Figure 1 shows symbol–sequence histograms (
) based on Definition 2 and three different STSA methods with two thresholds for the CAC40 (France) index, within the pre-COVID-19 and COVID-19 periods, respectively. Furthermore,
Figure 2 exemplifies the appropriate histograms for the same index within the pre-war and war periods in Ukraine.
The evidence shows that Method 1 with two and quantile thresholds specifies extreme returns during turbulent periods more accurately than the other two encoding methods with two thresholds. Method 2 (with two and quantile thresholds) is too restrictive, while Method 3 (with sample tertiles as the thresholds) collects index returns similarly to the methods with one threshold, given by Definition 1. This observation was commented on in the previous subsection.
The additional
Figure A1,
Figure A2,
Figure A3 and
Figure A4 (
Appendix B) further express comparative analyses of symbol–sequence histograms based on Definition 2 and Method 1 with two thresholds (5% and 95%) within two pairs of turbulent periods: (1) the pre-COVID-19 and the COVID-19 pandemic periods and (2) the pre-war and war periods in Ukraine.
5.3. The Modified Shannon Entropy Comparative Results: The COVID-19 Pandemic Outbreak
In this subsection, the comparative entropy results during the pre-COVID-19 and COVID-19 periods for the fifteen analyzed stock market indices are presented and discussed.
Table 7 includes the findings for the modified Shannon entropy based on three different methods of symbolic encoding with one threshold given by Definition 1 (for sequences of length
). The columns entitled ‘Change’ report changes in the Shannon entropy before and during the COVID-19 pandemic period. The down arrows show an entropy decrease, while the up arrows illustrate an entropy increase. As one can observe, the results are rather mixed and heterogenous, and they are not in line with expectations, since the literature documents that the market informational efficiency measured by entropy of index returns usually decreases during extreme event periods [
18,
20,
21,
22,
23]. Therefore, there is no reason to recommend the use of encoding methods with one threshold for financial time series analyses within extreme event periods.
Table 8 contains the empirical results for the modified Shannon entropy based on three different methods of symbolic encoding with two threshold given by Definition 2 (for sequences of length
). It is evident that the modified Shannon entropy values given by Definition 4 depend on the choice of the encoding procedure. This is rather obvious since the lower entropy values determined by Definition 4 are directly connected to a higher level of regularity in time series, expressed by symbol sequences. Conversely, higher entropy values represent a lower level of regularity. Therefore, the entropy values obtained from Method 2 are the lowest, while the results from Method 3 are the highest. These results are associated with the demonstration graphs presented in
Figure 1 and
Figure 2 (
Section 5.2). It is worthwhile noting that the results are homogenous for all investigated stock market indices.
5.4. Modified Shannon Entropy Comparative Results: The War in Ukraine
Similarly to the previous subsection, this subsection describes and discusses the modified Shannon entropy comparative results during the pre-war and war periods in Ukraine for the fifteen analyzed stock market indices. The general conclusions are very similar.
Firstly, the results reported in
Table 9 (the modified Shannon entropy based on three different methods of symbolic encoding with one threshold given by Definition 1,
) are diverse and ambiguous, and they are not in line with expectations. Hence, we cannot advocate the use of STSA methods with one threshold in financial time series analyses within turbulent periods.
Secondly, the findings displayed in
Table 10 (the modified Shannon entropy based on three different methods of symbolic encoding with two thresholds given by Definition 2,
) are much better compared to those in
Table 9, specifically for Method 1 (with two
and
quantile thresholds). In the case of this method, the pronounced decrease in the modified Shannon entropy for all investigated stock markets is visible in the fourth column (‘Change’) in
Table 10. The obtained results are much more homogenous compared to those in
Table 9, especially for Method 1 (the fourth column). The up arrows are rare and they are visible only in the case of three markets (i.e., the U.K., Poland and Estonia). Hence, we can recommend the use of Method 1 with two
and
quantile thresholds in assessing stock market efficiency.
It is important to note that the obtained results decidedly support the research hypothesis. Therefore, we can assert that the recommendation of the use of the STSA method with two and quantile thresholds is well founded.
Furthermore, additional comparative findings of Method 1 (the
and
sample quantiles) for sequences of length
and
within the pre-event and event periods for the fifteen analyzed stock market indices are reported in
Table A4 and
Table A5 (
Appendix C). The obtained results indicate that the choice of the sequence length
k is a minor issue as the results for
and
are very similar to those for
. However, the visualization of the results by
k-histograms is much more difficult for
and
, as the total number of possible sequences is large (see
Table 3).
6. Conclusions
The purpose of this empirical study was to investigate and compare various methods based on the symbolic representation of discrete time series and the modified Shannon entropy in assessing stock market informational efficiency in terms of sequential regularity in financial time series. Fifteen European stock markets within two extreme event periods (i.e., the COVID-19 pandemic outbreak and the war in Ukraine) were analyzed. The markets were selected in the context of the Russian invasion of Ukraine. To capture the sequential dynamics in daily time series of equity market indices, changes in the Shannon entropy values before and during the particular extreme event were calculated and compared. The research hypothesis that the stock market efficiency measured by entropy usually decreases during turbulent periods was examined with the use of six different variants of STSA methods.
The research contribution of our paper to the discussion concerning stock market informational efficiency is twofold. Firstly, the most pronounced and consistent empirical results were obtained with the use of the STSA method with two thresholds (the and sample quantiles). This method was the best and most unambiguous in assessing the stock market efficiency measured by the modified Shannon entropy. Moreover, the empirical findings confirmed no reason to reject the proposed research hypothesis, since the entropy of stock market indices visibly decreased during both turbulent periods. This well-justified observation is consistent with the existing literature, and it is the second important contribution of our study.
The obtained comparative findings were especially unambiguous within the pre-COVID-19 and COVID-19 sub-periods. This evidence is rather obvious. It is worth recalling that the European stock markets were affected by the COVID-19 pandemic outbreak at the same time and to a similar extent, as opposed to the influence of the war in Ukraine.
It is worth mentioning that our research relates to the literature concerning the weak form of market informational efficiency, since the used information sets include only the history of index returns. Stock market index returns contain the influence of public information and, during various extreme event periods, all public information is especially important for investors and determines investment decisions. Among others, Lim and Brooks [
15] emphasized that the empirical findings of market efficiency are rather heterogenous, as the EMH remains an elusive concept. Generally speaking, the topic is interesting and valid for academics and practitioners, and the recommended STSA method might be used as a useful tool in systems that support investment decisions.
The potential limitations of our research are mainly related to the choice of the investigated European stock markets. However, these limitations are not very significant as this choice is well justified (see
Section 4) and the obtained empirical findings are homogenous.
Since the topic of stock market informational efficiency measured by entropy is strictly connected to the problem of market dynamics and volatility, a promising direction for further research could be an extensive assessment of STSA methods that incorporate volatility estimates (e.g., [
4]). The motivation for such research can be, for instance, the study conducted by Gradojevic and Caric [
33]. The authors emphasize that although volatility and entropy are related measures of market risk and uncertainty, entropy can be more useful in predictive modeling.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





