

Visualizing Quantum Circuit Probability: Estimating Quantum State Complexity for Quantum Program Synthesis



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. States and Complexities
2.1. The Statistical Emergence of Entropy
2.2. The Algorithmic Emergence of Universality
2.3. Relations to Circuit Complexity
- 1.
- Statistical complexity: Shannon entropy on an ensemble of states (given its probability distribution)
- 2.
- Computational complexity: Space-time scaling behavior of a program to generate the state (given a language)
- 3.
- Algorithmic complexity: Length of the program to generate the state (given a language)
3. Landscape of Circuits
3.1. Circuit Probability of States
3.2. Boolean Gate Sets
- For 1-input Boolean algebra, i.e., when , , , the total number of functions are . These functions are the .
- For 2-input Boolean algebra, i.e., when , , , the total number of functions are . These are denoted by .
- NOT(A) = NAND(A,A) = NOR(A,A),
- OR(A,B) = NAND(NAND(A,A),NAND(B,B)) = NOR(NOR(A,B),NOR(A,B))= NOT(AND(NOT(A),NOT(B))),
- AND(A,B) = NAND(NAND(A,B),NAND(A,B)) = NOR(NOR(A,A),NOR(B,B))= NOT(OR(NOT(A),NOT(B))).
3.3. Quantum Gate Sets
4. Implementation
4.1. Gate Sets
- 1.
- {CCX}—This set is universal for classical and reversible logic, provided both the initial states of and are provided. It is not practical to provide all initial states without knowing how to create one from the other. Since all gate-based quantum algorithms start from the all- state and prepare the required initial state via gates, we will not consider this set for our enumeration.
- 2.
- {X, CCX}—This set is universal for classical and reversible logic by starting from the all- state.
- 3.
- {X, H, CCX}—This set is weakly universal under encoding and ancilla assumptions for quantum logic. The encoding, while universal, might not preserve the computation resource complexity benefits of quantum (i.e., in the same way, classical computation can also encode all quantum computation using {NAND, Fanout}). Thus, we do not consider this set for our enumeration of the quantum case.
- 4.
- {H, S, CX}—The Clifford group is useful for quantum error correction. However, it is non-universal and can be efficiently simulated on classical logic [52]. The space of transforms on this set encoded error-correction codes and is, thus, useful to map.
- 5.
- {H, T}—This set is universal for single qubit quantum logic. However, we will consider the generalization to multi-qubit using an additional two-qubit gate in the set in the following case.
- 6.
- {H, T, CX}—This is universal for quantum logic.
- 7.
- {P(pi/4), RX(pi/2), CX}—The IBM native gate set is used to construct this gate set. The following relations establish the relation with the previous universal gate set: , , and, . We will consider additional constraints like device connectivity to apply this technique to real quantum processors.
4.2. Metrics for Evaluation
- Expressivity: refers to the extent to which the Hilbert space can be encoded by using an unbounded number of gates. It is not weighted by the probability as it is a characteristic of the encoding power of the gate set. We assign a 1 to a final state if it can be expressed as starting from the initial state and applying a sequence of gates from the gate set.
- Reachability: refers to a bounded form of expressibility. The length of the sequence of gates must be equal to or shorter than the specified bound. This corresponds to a physical implementation rather than the power of the gate set and characterizes the computational complexity and thereby the decoherence time of the processor.
4.3. Enumeration Procedure
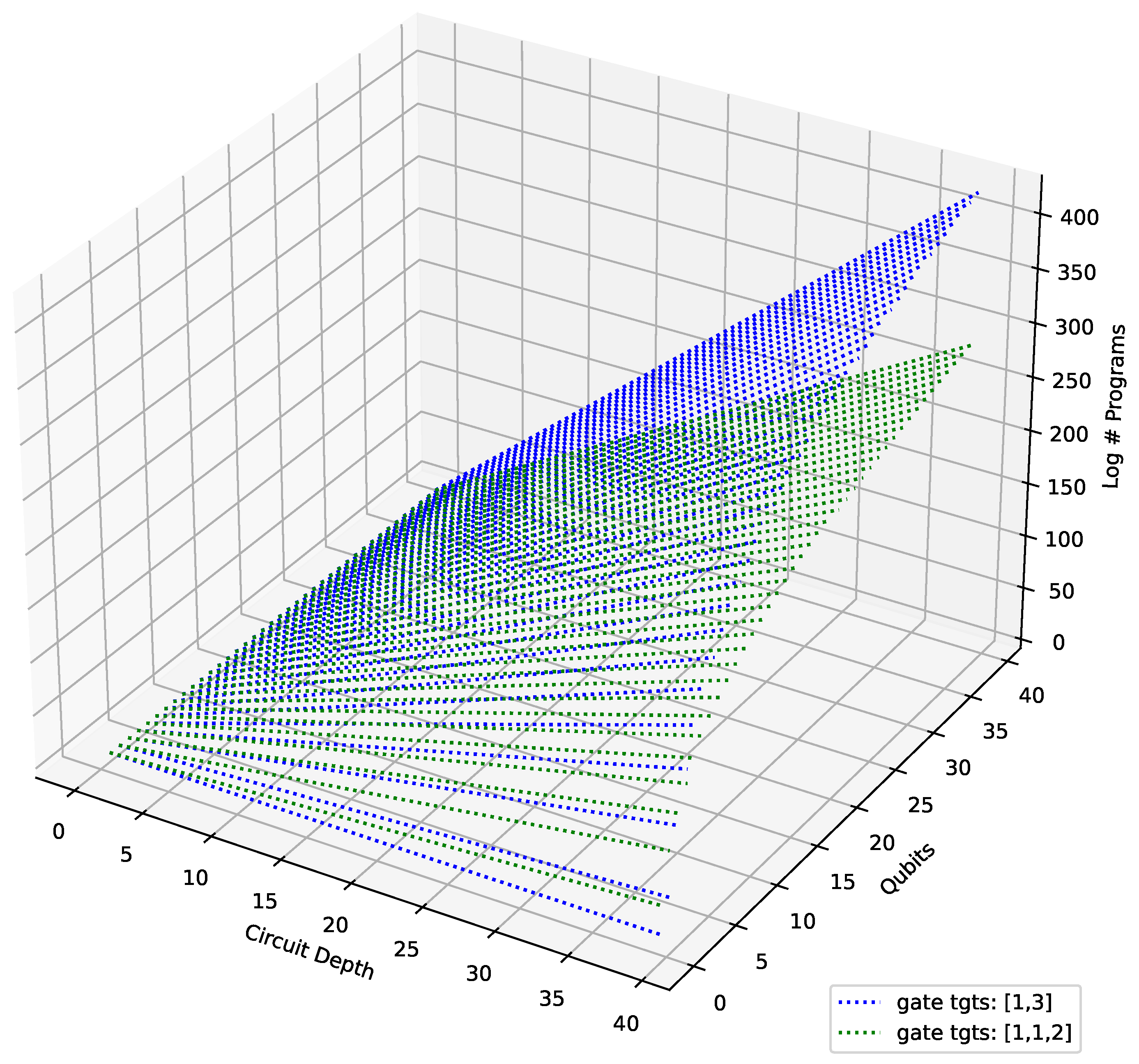
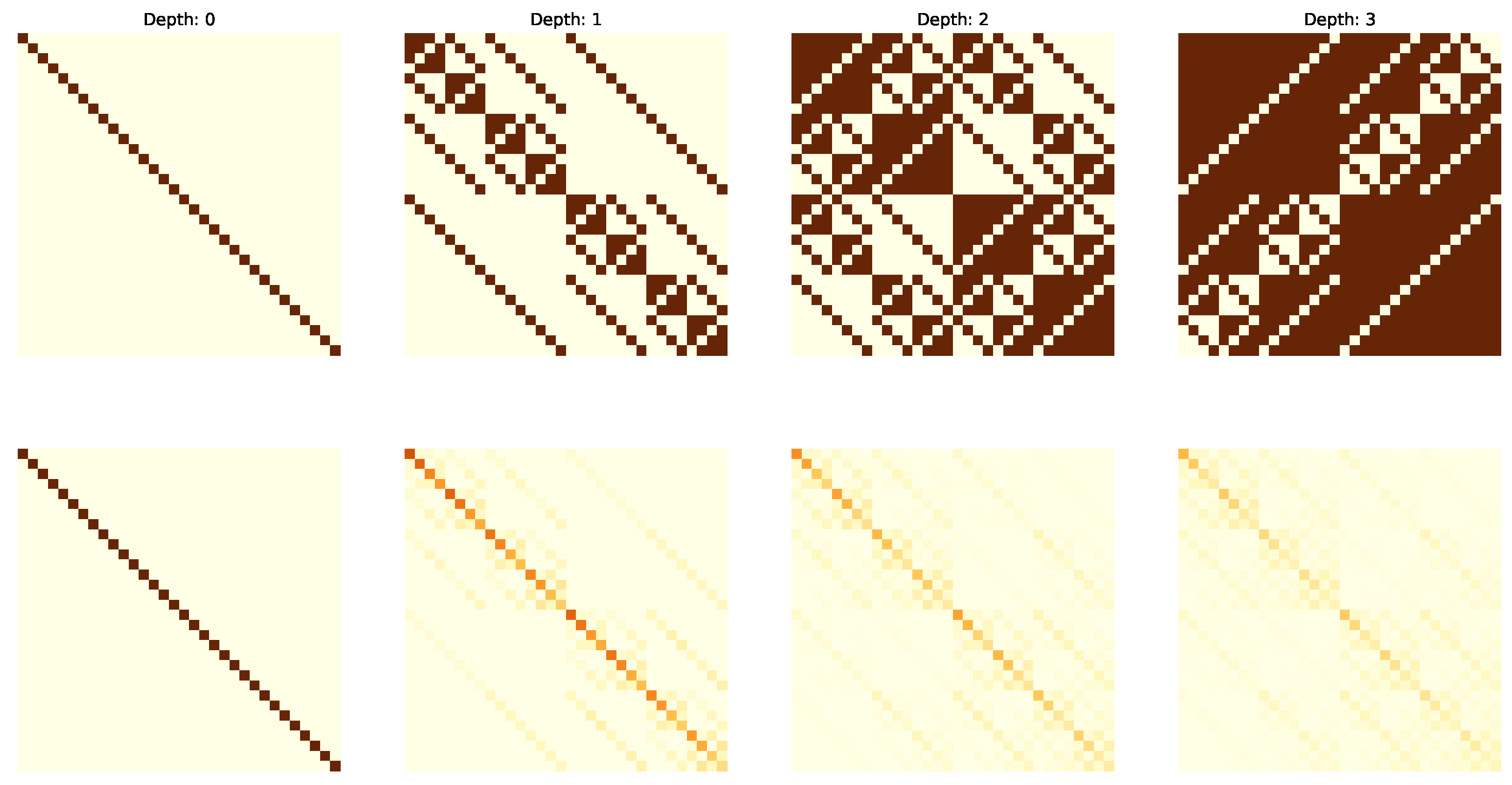
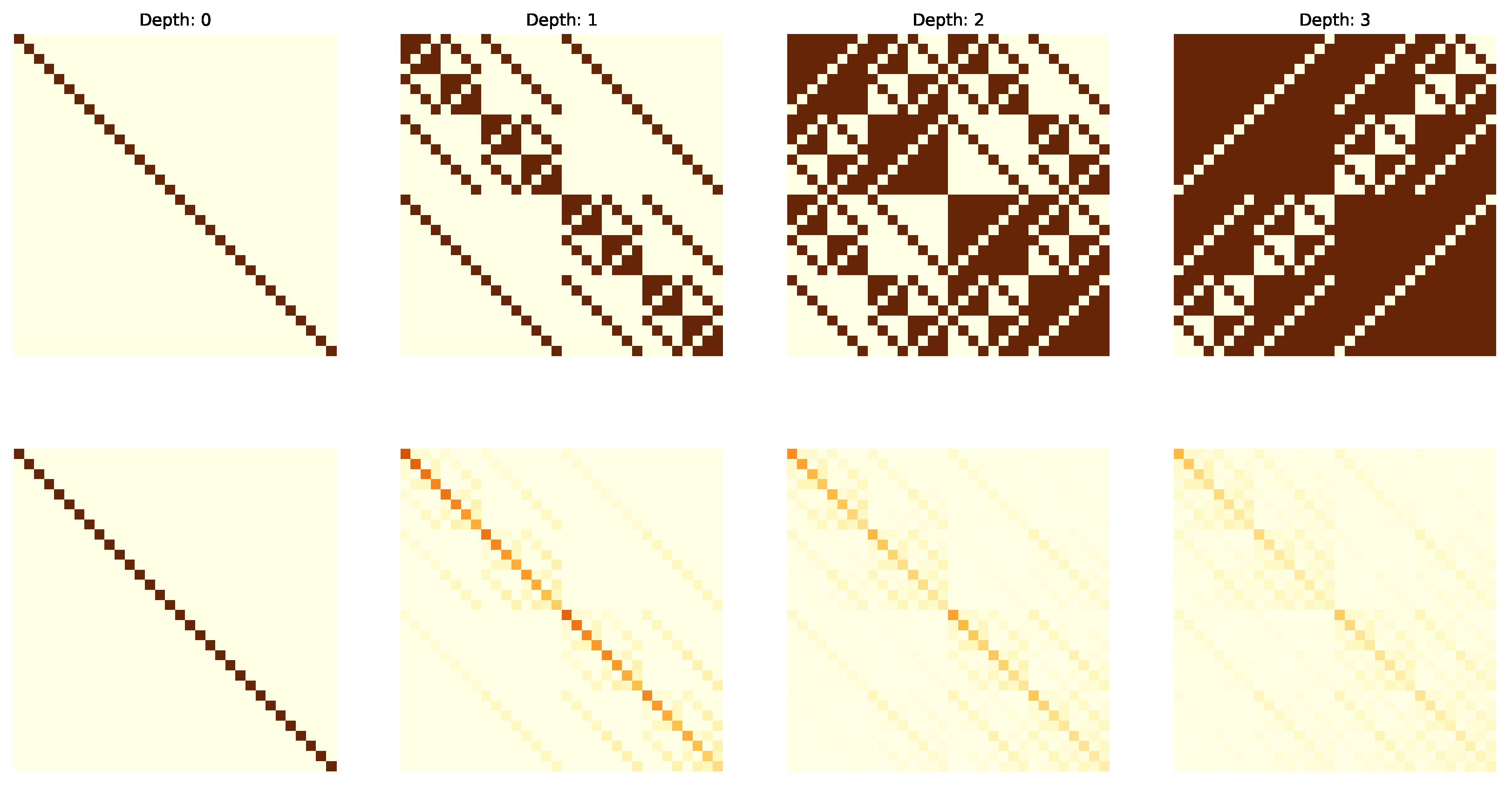
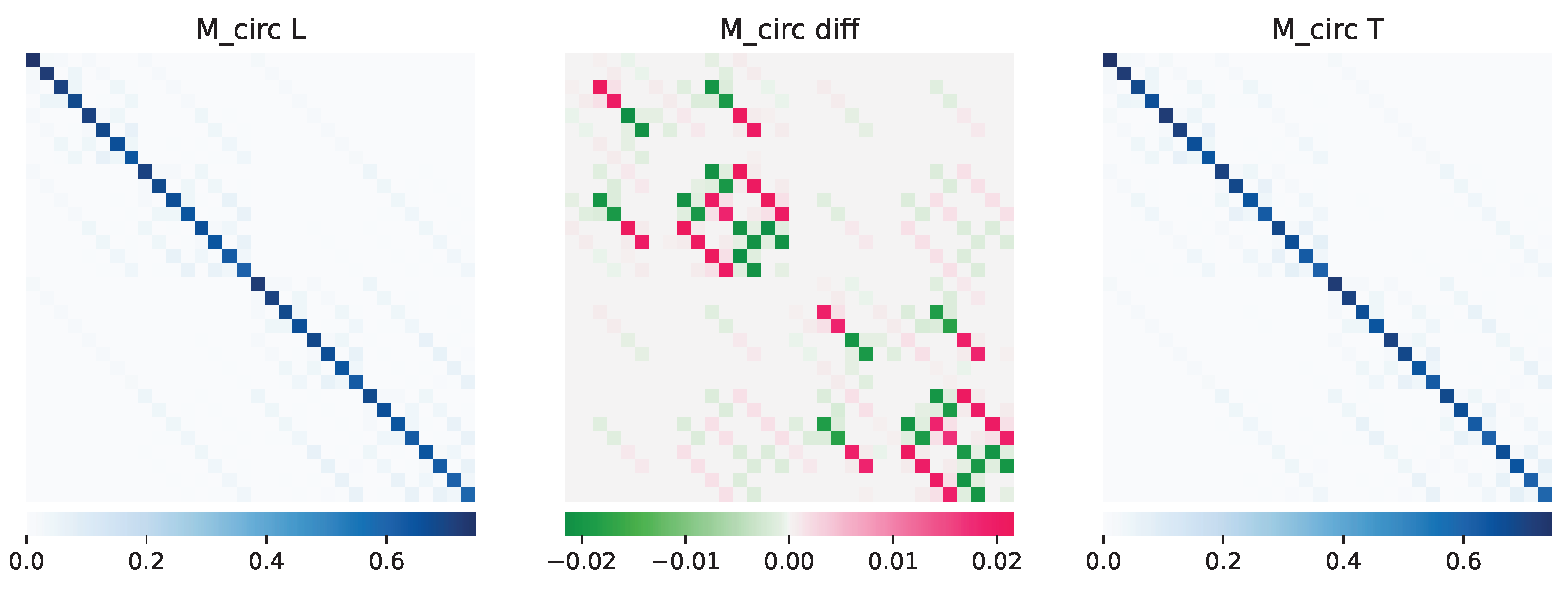
4.4. Results
4.5. Analysis and Discussion
5. Applications
5.1. Geometric Quantum Machine Learning
5.2. Novel Quantum Algorithm Synthesis
5.3. Quantum Artificial General Intelligence
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bertels, K.; Sarkar, A.; Ashraf, I. Quantum computing—From NISQ to PISQ. IEEE Micro 2021, 41, 24–32. [Google Scholar] [CrossRef]
- Bertels, K.; Sarkar, A.; Hubregtsen, T.; Serrao, M.; Mouedenne, A.A.; Yadav, A.; Krol, A.; Ashraf, I. Quantum computer architecture: Towards full-stack quantum accelerators. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 1–6. [Google Scholar]
- Preskill, J. Quantum computing in the NISQ era and beyond. Quantum 2018, 2, 79. [Google Scholar] [CrossRef]
- Leymann, F.; Barzen, J. The bitter truth about gate-based quantum algorithms in the NISQ era. Quantum Sci. Technol. 2020, 5, 044007. [Google Scholar] [CrossRef]
- Shi, Y.; Gokhale, P.; Murali, P.; Baker, J.M.; Duckering, C.; Ding, Y.; Brown, N.C.; Chamberland, C.; Javadi-Abhari, A.; Cross, A.W.; et al. Resource-efficient quantum computing by breaking abstractions. Proc. IEEE 2020, 108, 1353–1370. [Google Scholar] [CrossRef]
- Landauer, R. Irreversibility and heat generation in the computing process. IBM J. Res. Dev. 1961, 5, 183–191. [Google Scholar] [CrossRef]
- Bennett, C.H. Logical reversibility of computation. IBM J. Res. Dev. 1973, 17, 525–532. [Google Scholar] [CrossRef]
- Fredkin, E.; Toffoli, T. Conservative logic. Int. J. Theor. Phys. 1982, 21, 219–253. [Google Scholar] [CrossRef]
- Lloyd, S. Ultimate physical limits to computation. Nature 2000, 406, 1047–1054. [Google Scholar] [CrossRef]
- Markov, I.L. Limits on fundamental limits to computation. Nature 2014, 512, 147–154. [Google Scholar] [CrossRef]
- Wolfram, S. A New Kind of Science; Wolfram Media: Champaign, IL, USA, 2002; Volume 5. [Google Scholar]
- Deutsch, D. Constructor theory. Synthese 2013, 190, 4331–4359. [Google Scholar] [CrossRef]
- Biamonte, J.; Bergholm, V. Tensor networks in a nutshell. arXiv 2017, arXiv:1708.00006. [Google Scholar]
- Hardy, L. Quantum theory from five reasonable axioms. arXiv 2001, arXiv:quant-ph/0101012. [Google Scholar]
- Schmidhuber, J. Algorithmic theories of everything. arXiv 2000, arXiv:quant-ph/0011122. [Google Scholar]
- Müller, M.P. Law without law: From observer states to physics via algorithmic information theory. Quantum 2020, 4, 301. [Google Scholar] [CrossRef]
- Toffoli, T. Action, or the fungibility of computation. In Feynman and Computation; CRC Press: Boca Raton, FL, USA, 2018; pp. 349–392. [Google Scholar]
- Lloyd, S.; Dreyer, O. The universal path integral. Quantum Inf. Process. 2016, 15, 959–967. [Google Scholar] [CrossRef]
- Solomonoff, R.J. A Preliminary Report on a General Theory of Inductive Inference; Zator Company: Cambridge, MA, USA, 1960. [Google Scholar]
- Deutsch, D.E. Quantum computational networks. Proc. R. Soc. Lond. A Math. Phys. Sci. 1989, 425, 73–90. [Google Scholar]
- Maziero, J. Random Sampling of Quantum States: A Survey of Methods: And Some Issues Regarding the Overparametrized Method. Braz. J. Phys. 2015, 45, 575–583. [Google Scholar] [CrossRef]
- Jordan, S. Quantum Algorithm Zoo. Available online: https://quantumalgorithmzoo.org/ (accessed on 25 April 2023).
- Spector, L. Automatic Quantum Computer Programming: A Genetic Programming Approach; Springer Science & Business Media: New York, NY, USA, 2004; Volume 7. [Google Scholar]
- Quetschlich, N.; Burgholzer, L.; Wille, R. Towards an Automated Framework for Realizing Quantum Computing Solutions. arXiv 2022, arXiv:2210.14928. [Google Scholar]
- Sarkar, A. Automated Quantum Software Engineering: Why? what? how? arXiv 2022, arXiv:2212.00619. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- MetaGolfScript—Esolang. Available online: https://esolangs.org/wiki/MetaGolfScript (accessed on 25 April 2023).
- Jiang, M.; Luo, S.; Fu, S. Channel-state duality. Phys. Rev. A 2013, 87, 022310. [Google Scholar] [CrossRef]
- Complexity Zoo. Available online: https://complexityzoo.net/Complexity_Zoo (accessed on 25 April 2023).
- Kolmogorov, A.N. Three approaches to the definition of the concept “quantity of information”. Probl. Peredachi Informatsii 1965, 1, 3–11. [Google Scholar]
- Allender, E. Circuit Complexity, Kolmogorov Complexity, and Prospects for Lower Bounds. In Proceedings of the 10th International Workshop on Descriptional Complexity of Formal Systems, DCFS 2008, Charlottetown, PE, Canada, 16–18 July 2008; pp. 7–13. [Google Scholar]
- Grunwald, P.; Vitányi, P. Shannon information and Kolmogorov complexity. arXiv 2004, arXiv:cs/0410002. [Google Scholar]
- Fortnow, L. Kolmogorov complexity and computational complexity. In Complexity of Computations and Proofs; Quaderni di Matematica; Aracne: Rome, Italy, 2004; Volume 13. [Google Scholar]
- Sarkar, A.; Al-Ars, Z.; Bertels, K. Quantum circuit design for universal distribution using a superposition of classical automata. arXiv 2020, arXiv:2006.00987. [Google Scholar]
- Zenil, H.; Badillo, L.; Hernández-Orozco, S.; Hernández-Quiroz, F. Coding-theorem like behaviour and emergence of the universal distribution from resource-bounded algorithmic probability. Int. J. Parallel Emergent Distrib. Syst. 2019, 34, 161–180. [Google Scholar] [CrossRef]
- Solomonoff, R.J. A formal theory of inductive inference. Part I. Inf. Control 1964, 7, 1–22. [Google Scholar] [CrossRef]
- Sarkar, A. Applications of Quantum Computation and Algorithmic Information for Causal Modeling in Genomics and Reinforcement Learning. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 2022. [Google Scholar]
- Soler-Toscano, F.; Zenil, H.; Delahaye, J.P.; Gauvrit, N. Calculating Kolmogorov complexity from the output frequency distributions of small Turing machines. PLoS ONE 2014, 9, e96223. [Google Scholar] [CrossRef]
- Delahaye, J.P.; Zenil, H. Numerical evaluation of algorithmic complexity for short strings: A glance into the innermost structure of randomness. Appl. Math. Comput. 2012, 219, 63–77. [Google Scholar] [CrossRef]
- Wernick, W. Complete Sets of Logical Functions; New York University: New York, NY, USA, 1941. [Google Scholar]
- Sheffer, H.M. A set of five independent postulates for Boolean algebras, with application to logical constants. Trans. Am. Math. Soc. 1913, 14, 481–488. [Google Scholar] [CrossRef]
- Shi, Y. Both Toffoli and controlled-NOT need little help to do universal quantum computation. arXiv 2002, arXiv:quant-ph/0205115. [Google Scholar]
- Aharonov, D. A simple proof that Toffoli and Hadamard are quantum universal. arXiv 2003, arXiv:quant-ph/0301040. [Google Scholar]
- Nielsen, M.A.; Dowling, M.R.; Gu, M.; Doherty, A.C. Quantum computation as geometry. Science 2006, 311, 1133–1135. [Google Scholar] [CrossRef] [PubMed]
- Lloyd, S. Almost any quantum logic gate is universal. Phys. Rev. Lett. 1995, 75, 346. [Google Scholar] [CrossRef] [PubMed]
- Shende, V.V.; Bullock, S.S.; Markov, I.L. Synthesis of quantum logic circuits. In Proceedings of the 2005 Asia and South Pacific Design Automation Conference, Shanghai, China, 18–21 January 2005; pp. 272–275. [Google Scholar]
- Vitányi, P.M. Quantum Kolmogorov complexity based on classical descriptions. IEEE Trans. Inf. Theory 2001, 47, 2464–2479. [Google Scholar] [CrossRef]
- Berthiaume, A.; Van Dam, W.; Laplante, S. Quantum kolmogorov complexity. J. Comput. Syst. Sci. 2001, 63, 201–221. [Google Scholar] [CrossRef]
- Mora, C.E.; Briegel, H.J.; Kraus, B. Quantum Kolmogorov complexity and its applications. Int. J. Quantum Inf. 2007, 5, 729–750. [Google Scholar] [CrossRef]
- Dawson, C.M.; Nielsen, M.A. The solovay-kitaev algorithm. arXiv 2005, arXiv:quant-ph/0505030. [Google Scholar] [CrossRef]
- Barenco, A.; Bennett, C.H.; Cleve, R.; DiVincenzo, D.P.; Margolus, N.; Shor, P.; Sleator, T.; Smolin, J.A.; Weinfurter, H. Elementary gates for quantum computation. Phys. Rev. A 1995, 52, 3457. [Google Scholar] [CrossRef]
- Gottesman, D. The Heisenberg representation of quantum computers. arXiv 1998, arXiv:quant-ph/9807006. [Google Scholar]
- Bandić, M.; Almudever, C.G.; Feld, S. Interaction graph-based profiling of quantum benchmarks for improving quantum circuit mapping techniques. arXiv 2022, arXiv:2212.06640. [Google Scholar]
- Renou, M.O.; Trillo, D.; Weilenmann, M.; Le, T.P.; Tavakoli, A.; Gisin, N.; Acín, A.; Navascués, M. Quantum theory based on real numbers can be experimentally falsified. Nature 2021, 600, 625–629. [Google Scholar] [CrossRef] [PubMed]
- Demey, L. Metalogic, metalanguage and logical geometry. Log. Anal. 2019, 62, 453–478. [Google Scholar]
- Zenil, H. A Computable Piece of Uncomputable Art whose Expansion May Explain the Universe in Software Space. arXiv 2021, arXiv:2109.08523. [Google Scholar]
- Brown, A.R.; Susskind, L. Second law of quantum complexity. Phys. Rev. D 2018, 97, 086015. [Google Scholar] [CrossRef]
- Haferkamp, J.; Faist, P.; Kothakonda, N.B.; Eisert, J.; Yunger Halpern, N. Linear growth of quantum circuit complexity. Nat. Phys. 2022, 18, 528–532. [Google Scholar] [CrossRef]
- Halpern, N.Y.; Kothakonda, N.B.; Haferkamp, J.; Munson, A.; Eisert, J.; Faist, P. Resource theory of quantum uncomplexity. Phys. Rev. A 2022, 106, 062417. [Google Scholar] [CrossRef]
- Selby, J.H.; Scandolo, C.M.; Coecke, B. Reconstructing quantum theory from diagrammatic postulates. Quantum 2021, 5, 445. [Google Scholar] [CrossRef]
- Pratt, V.R. Linear logic for generalized quantum mechanics. In Proceedings of the Workshop on Physics and Computation, Dallas, TX, USA, 2–4 October 1992. [Google Scholar]
- Nielsen, M.A.; Dowling, M.R.; Gu, M.; Doherty, A.C. Optimal control, geometry, and quantum computing. Phys. Rev. A 2006, 73, 062323. [Google Scholar] [CrossRef]
- Perrier, E.; Tao, D.; Ferrie, C. Quantum geometric machine learning for quantum circuits and control. New J. Phys. 2020, 22, 103056. [Google Scholar] [CrossRef]
- General, I.J. Principle of maximum caliber and quantum physics. Phys. Rev. E 2018, 98, 012110. [Google Scholar] [CrossRef]
- Shor, P.W. The Early Days of Quantum Computation. arXiv 2022, arXiv:2208.09964. [Google Scholar]
- Lehman, J.; Stanley, K.O. Efficiently evolving programs through the search for novelty. In Proceedings of the 12th Annual Conference on Genetic and Evolutionary Computation, Portland, OR, USA, 7–11 July 2010; pp. 837–844. [Google Scholar]
- Lehman, J.; Gordon, J.; Jain, S.; Ndousse, K.; Yeh, C.; Stanley, K.O. Evolution through Large Models. arXiv 2022, arXiv:2206.08896. [Google Scholar]
- Hutter, M. Universal Artificial Intelligence: Sequential Decisions Based on Algorithmic Probability; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Catt, E.; Hutter, M. A gentle introduction to quantum computing algorithms with applications to universal prediction. arXiv 2020, arXiv:2005.03137. [Google Scholar]
- Sarkar, A.; Al-Ars, Z.; Bertels, K. QKSA: Quantum Knowledge Seeking Agent. In Proceedings of the Artificial General Intelligence: 15th International Conference, AGI 2022, Seattle, WA, USA, 19–22 August 2022; pp. 384–393. [Google Scholar]
- Lavin, A.; Zenil, H.; Paige, B.; Krakauer, D.; Gottschlich, J.; Mattson, T.; Anandkumar, A.; Choudry, S.; Rocki, K.; Baydin, A.G.; et al. Simulation intelligence: Towards a new generation of scientific methods. arXiv 2021, arXiv:2112.03235. [Google Scholar]
- Sarkar, A.; Al-Ars, Z.; Bertels, K. Estimating algorithmic information using quantum computing for genomics applications. Appl. Sci. 2021, 11, 2696. [Google Scholar] [CrossRef]
- Chiribella, G.; Ebler, D. Quantum speedup in the identification of cause–effect relations. Nat. Commun. 2019, 10, 1472. [Google Scholar] [CrossRef]
- Acharya, T.; Kundu, A.; Sarkar, A. Quantum Accelerated Causal Tomography: Circuit Considerations Towards Applications. arXiv 2022, arXiv:2209.02016. [Google Scholar]
- Wittek, P.; Gogolin, C. Quantum enhanced inference in Markov logic networks. Sci. Rep. 2017, 7, 45672. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bach, B.G.; Kundu, A.; Acharya, T.; Sarkar, A. Visualizing Quantum Circuit Probability: Estimating Quantum State Complexity for Quantum Program Synthesis. Entropy 2023, 25, 763. https://doi.org/10.3390/e25050763
Bach BG, Kundu A, Acharya T, Sarkar A. Visualizing Quantum Circuit Probability: Estimating Quantum State Complexity for Quantum Program Synthesis. Entropy. 2023; 25(5):763. https://doi.org/10.3390/e25050763
Chicago/Turabian StyleBach, Bao Gia, Akash Kundu, Tamal Acharya, and Aritra Sarkar. 2023. "Visualizing Quantum Circuit Probability: Estimating Quantum State Complexity for Quantum Program Synthesis" Entropy 25, no. 5: 763. https://doi.org/10.3390/e25050763
APA StyleBach, B. G., Kundu, A., Acharya, T., & Sarkar, A. (2023). Visualizing Quantum Circuit Probability: Estimating Quantum State Complexity for Quantum Program Synthesis. Entropy, 25(5), 763. https://doi.org/10.3390/e25050763