

Differential Fairness: An Intersectional Framework for Fair AI †

 and
and
Abstract
1. Introduction
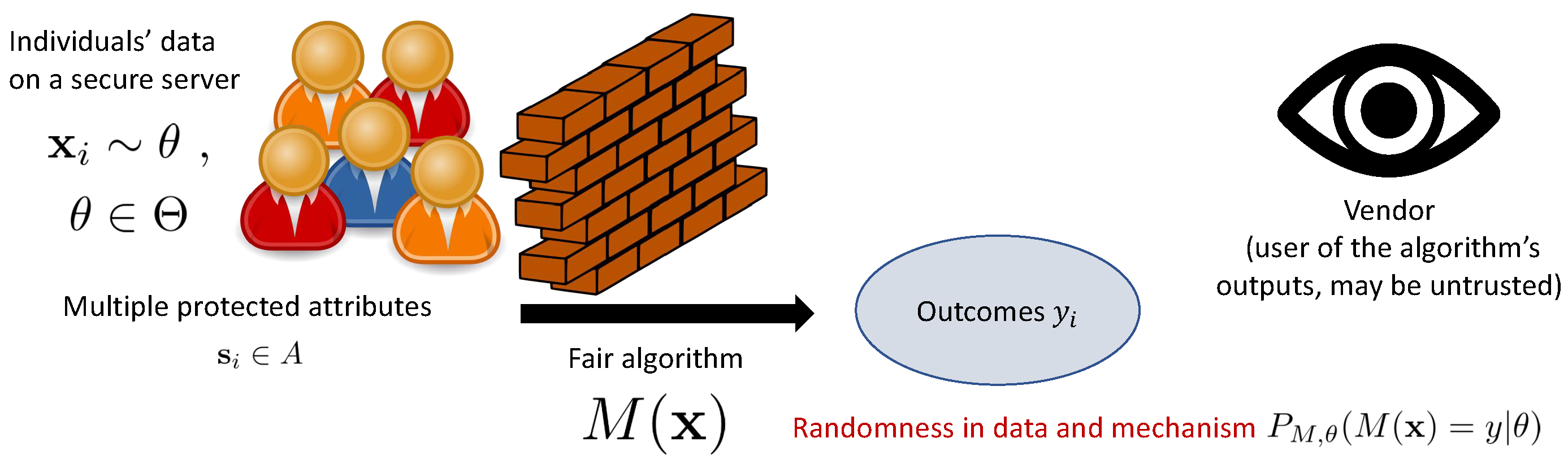
1.1. Differential Fairness: A Definition
1.2. Our Contribution
- A critical analysis of the consequences of intersectionality in the particular context of fairness for AI (Section 2);
- Three novel fairness metrics: differential fairness (DF), which aims to uphold intersectional fairness for AI and machine learning systems (Section 4), DF bias amplification, a slightly more conservative fairness definition than DF (Section 6), and differential fairness with confounders (DFC) (Section 7);
- Illustrative worked examples to aid with understanding (Section 5);
- Proofs of the desirable intersectionality, privacy, economic, and generalization properties of our metrics (Section 8);
- A simple learning algorithm which enforces our criteria using batch or deterministic gradient methods (Section 9.1);
- A practical and scalable learning algorithm that enforces our fairness criteria using stochastic gradient methods (Section 9.2);
- Extensive experiments on census, criminal recidivism, hospitalizations, and loan application data to demonstrate our methods’ practicality and benefits (Section 10).
- It operationalizes AI fairness in a manner that is more meaningful than previous definitions, in the sense that it can be interpreted in terms of economic and privacy guarantees, leveraging connections to differential privacy.
- It is the first AI fairness definition to implement the principles and values behind intersectionality, an important notion of fairness from the humanities and legal literature. As such, part of the significance of this work is philosophical, not only mathematical.
- It is a stepping stone toward the holistic, trans-disciplinary research endeavor that is necessary to adequately solve the real-world sociotechnical problem of AI fairness.
1.3. Limitations and Caveats
- Accounting for the Sociotechnical Context: Algorithmic systems do not generally exist in a vaccuum. They are deployed within the context of larger real-world sociotechnical systems. Our provable guarantees on the harms caused by an algorithmic system pertain to the direct impact of the system’s output, but not to the complicated interaction between that algorithm and its broader context, which can be difficult to account for [22].
- Mismatch Between Fairness Metrics and Real-World Fairness Harms: The measurement of fairness depends heavily on assumptions made when modeling the problem at hand, particularly when defining and measuring class labels that encode abstract constructs and are intended to act as proxies for decisions. For example, the COMPAS system defines its prediction target, recidivism, as a new misdemeanor or felony arrest within two years [4]. This assumption conflates arrests with crimes, thereby encoding systemic bias in policing into the class label itself [23]. Due to these types of issues, there is generally a gap in alignment between mathematical fairness metrics and the desired fairness construct regarding the real-world harms that they are intended to measure and prevent [23]. Whenever we interpret our mathematical guarantees on fairness-related harms due to an algorithm, it is important to recognize that the mathematical definition may not perfectly align with real-world harms.
- Countering Structural Oppression: Recently, Kong [30] critiqued fairness definitions based on multiple tuples of attributes [17,18,31] regarding the extent to which they implement intersectionality. It was argued that parity-based fairness does not place the proper emphasis on structural oppression, which is a core tenet of intersectionality, and may not go far enough to rectify such oppression. We broadly agree with this statement. However, as we argue here and in prior work [32], parity-based fairness is an important starting point toward addressing structural oppression which is appropriate for many applications. In particular, we try to explicitly incorporate the causal structure of interlocking structural oppression. We believe our definition can be extended to correct societal unfairness beyond the point of parity, as advocated by [30]. However, we leave this for future work.
- Stakeholder Interpretation: We have motivated our work via the interpretation that our fairness definition’s provable guarantees provide. We note, however, that it is not always straightforward to ensure that stakeholders correctly interpret the fairness properties of AI systems, particularly when they do not have technical backgrounds, and there is a growing body of research on this challenge and how best to address it [24,25,26]. Studying how stakeholders interpret and perceive differential fairness is beyond the scope of this paper, but is an important question for future research.
- Contextual Considerations: The impact of systems of oppression and privilege may vary contextually. For example, gender discrimination varies widely by area of study and this is a major factor in the choices women make in selecting college majors [33]. Similarly, in some contexts individuals from a particular race, gender, or sexual orientation may be able to “pass” as another, thus potentially avoiding discrimination, and in other contexts where their “passing” status is revealed, those individuals may suffer additional discrimination [34]. Our fairness framework does not presently consider these contextual factors.
- Knowledge of Protected Attributes: In order to compute (or enforce) our differential fairness criterion, we must observe the individuals’ protected attributes. This is not always possible in certain applications. For instance, social media users may not declare their gender, race, or other protected demographic information. Future work could address the extension of our methods to handle this scenario, e.g., via an imputation strategy.
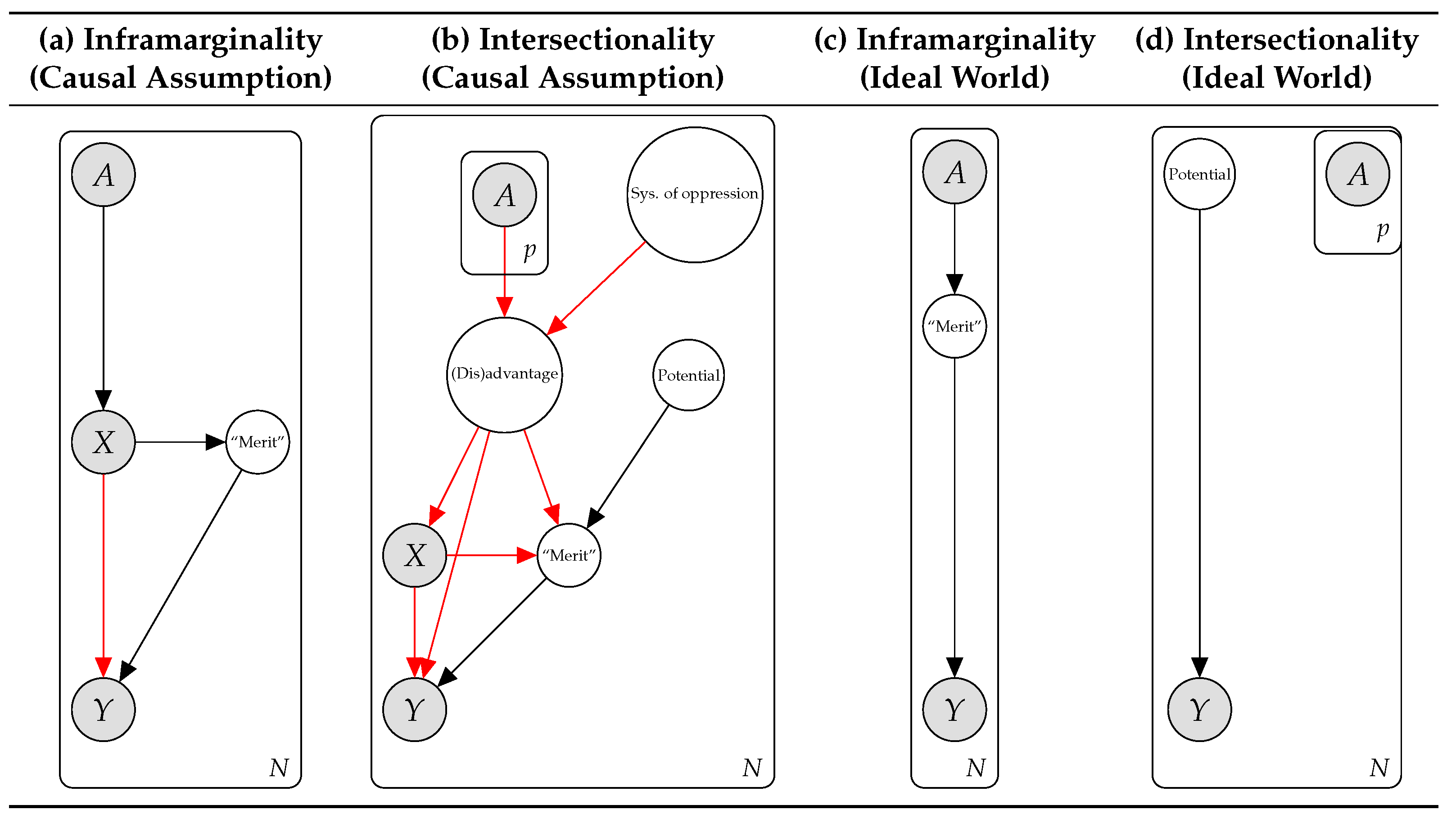
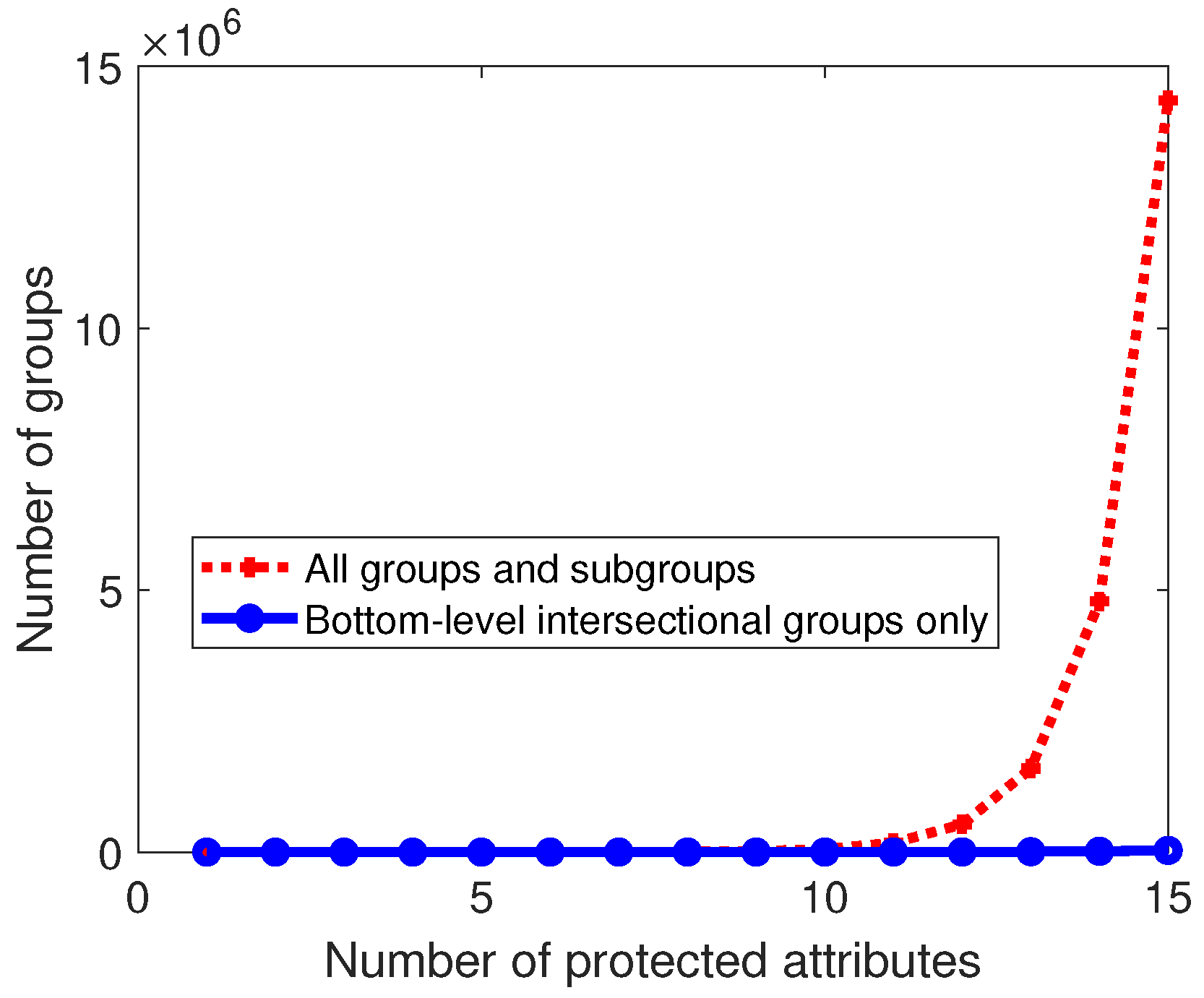
2. Intersectionality and Fairness in AI
“…that racism (and classism, homophobia, etc.) has made people physically, mentally, and spiritually ill and dampened their chance at a fair shot at higher education (and at life and living).”
- Multiple protected attributes should be considered.
- All of the intersecting values of the protected attributes, e.g., Black women, should be protected by the definition.
- The definition should still also ensure that protection is provided on individual protected attribute values, e.g., women.
- The definition should ensure protection for minority groups, who are particularly affected by discrimination in society [36].
- The definition should ensure that systematic differences between the protected groups, assumed to be due to structural oppression, are rectified, rather than codified.
3. Related Work on Fairness
3.1. Models for Fairness
- The 80% rule: Our criterion is related to the 80% rule, also known as the four-fifths rule, a guideline for identifying unintentional discrimination in a legal setting which identifies disparate impact in cases where , for a favorable outcome , disadvantaged group , and best performing group [51]. This corresponds to testing that , in a version of Equation (2) where only the outcome is considered.
- Demographic Parity: Dwork et al. [7] defined (and criticized) the fairness notion of demographic parity, also known as statistical parity, which requires that for any outcome y and pairs of protected attribute values , (here assumed to be a single attribute). This can be relaxed, e.g., by requiring the total variation distance between the distributions to be less than . Differential fairness is closely related, as it also aims to match probabilities of outcomes but measures differences using ratios and allows for multiple protected attributes. The criticisms of [7] are mainly related to ways in which subgroups of the protected groups can be treated differently while maintaining demographic parity, which they call “subset targeting,” and which [17] term “fairness gerrymandering”. Differential fairness explicitly protects the intersection of multiple protected attributes, which can be used to mitigate some of these abuses.
- Equalized Odds: To address some of the limitations with demographic parity, Hardt et al. [8] propose to instead ensure that a classifier has equal error rates for each protected group. This fairness definition, called equalized odds, can loosely be understood as a notion of “demographic parity for error rates instead of outcomes.” Unlike demographic parity, equalized odds rewards accurate classification, and penalizes systems only performing well on the majority group. However, theoretical work has shown that equalized odds is typically incompatible with correctly calibrated probability estimates [52]. It is also a relatively weak notion of fairness from a civil rights perspective compared to demographic parity, as it does not ensure that outcomes are distributed equitably. Hardt et al. also propose a variant definition called equality of opportunity, which relaxes equalized odds to only apply to a “deserving” outcome. It is straightforward to extend differential fairness to a definition analogous to equalized odds, although we leave the exploration of this for future work. A more recent algorithm for enforcing equalized odds and equality of opportunity for kernel methods was proposed by [53].
- Individual Fairness (“Fairness Through Awareness”): The individual fairness definition, due to [7], mathematically enforces the principle that similar individuals should achieve similar outcomes under a classification algorithm. An advantage of this approach is that it preserves the privacy of the individuals, which can be important when the user of the classifications (the vendor), e.g., a banking corporation, cannot be trusted to act in a fair manner. However, this is difficult to implement in practice as one must define “similar” in a fair way. The individual fairness property also does not necessarily generalize beyond the training set. In this work, we take inspiration from Dwork et al.’s untrusted vendor scenario and the use of a privacy-preserving fairness definition to address it.
- Counterfactual Fairness: Kusner et al. [54] propose a causal definition of fairness. Under their counterfactual fairness definition, changing protected attributes A, while holding things which are not causally dependent on A constant, will not change the predicted distribution of outcomes. While theoretically appealing, there are difficulties in implementing this in practice. First, it requires an accurate causal model at the fine-grained individual level, while even obtaining a correct population-level causal model is generally very difficult. To implement it, we must solve a challenging causal inference problem over unobserved variables, which generally requires approximate inference algorithms. Finally, to achieve counterfactual fairness, the predictions (usually) cannot make direct use of any descendant of A in the causal model. This generally precludes using any of the observed features as inputs.
- Threshold Tests: Simoiu et al. [43] address infra-marginality by modeling risk probabilities for different subsets (i.e., attribute values) within each protected category and requiring algorithms to threshold these probabilities at the same points when determining outcomes. In contrast, based on intersectionality theory, our proposed differential fairness criterion specifies protected categories whose intersecting subsets should be treated equally, regardless of differences in risk across the subsets. Our definition is appropriate when the differences in risk are due to structural systems of oppression, i.e., the risk probabilities themselves are impacted by an unfair process. We also provide a bias amplification version of our metric, following [10], which is more in line with the infra-marginality perspective, namely that differences in probabilities of outcomes for different groups may be considered legitimate.
3.2. Subgroup Fairness and Multicalibration
4. Differential Fairness (DF)
4.1. Relationship to Privacy Definitions
- Differential Privacy: Like differential privacy [19,20], the differential fairness definition bounds ratios of probabilities of outcomes resulting from a mechanism. There are several important differences, however. When bounding these ratios, differential fairness considers different values of a set of protected attributes, rather than databases that differ in a single element. It posits a specified set of possible distributions which may generate the data, while differential privacy implicitly assumes that the data are independent [27]. Finally, since differential fairness considers randomness in data as well as in the mechanism, it can be satisfied with a deterministic mechanism, while differential privacy can only be satisfied with a randomized mechanism.
- Pufferfish: We have arrived at our criterion based on the 80% rule, but it can also be derived as an application of pufferfish [27], a generalization of differential privacy [20] which uses a variation of Equation (2) to hide the values of an arbitrary set of secrets. Different choices of the secrets and the data that the Pufferfish privacy-preserving mechanism operates on lead to both differential privacy and differential fairness.
4.2. Empirical DF Estimation
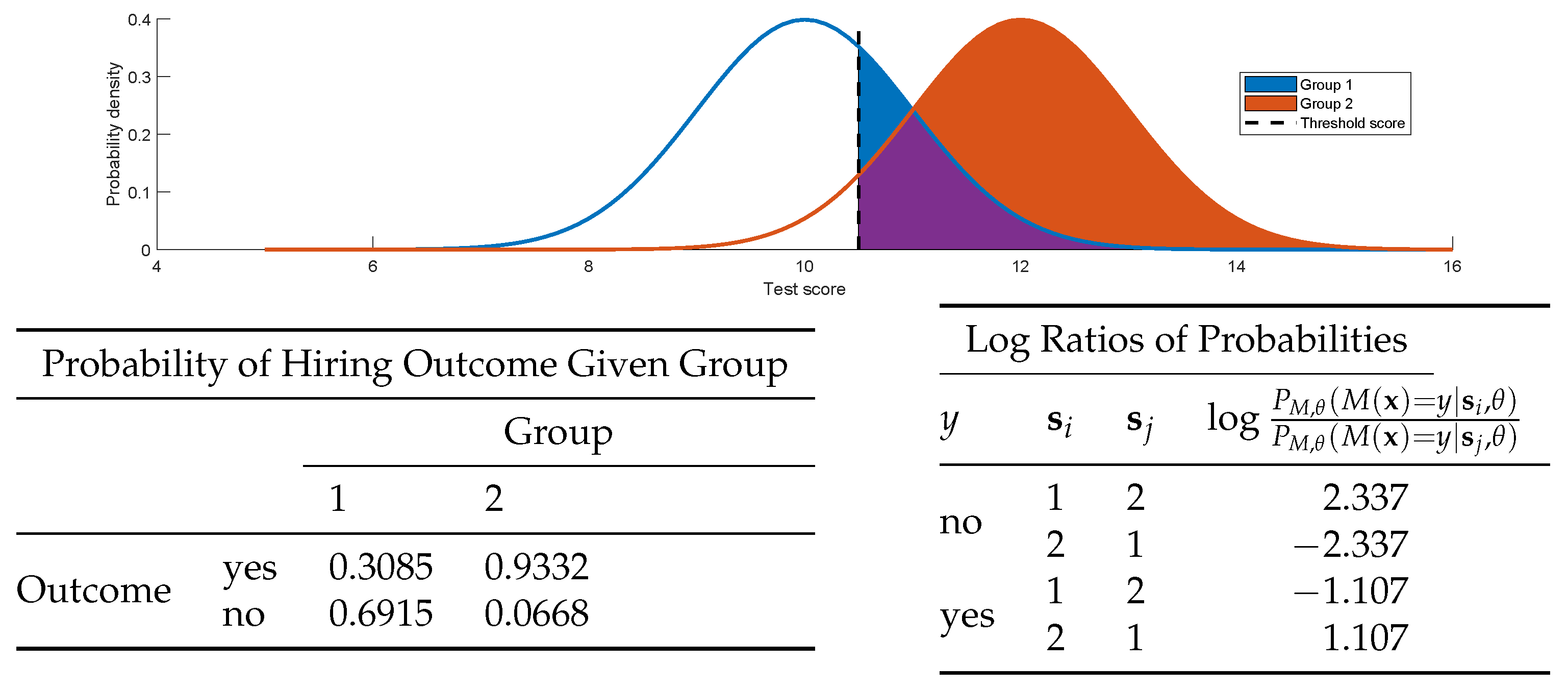
5. Illustrative Worked Examples
6. DF Bias Amplification Measure
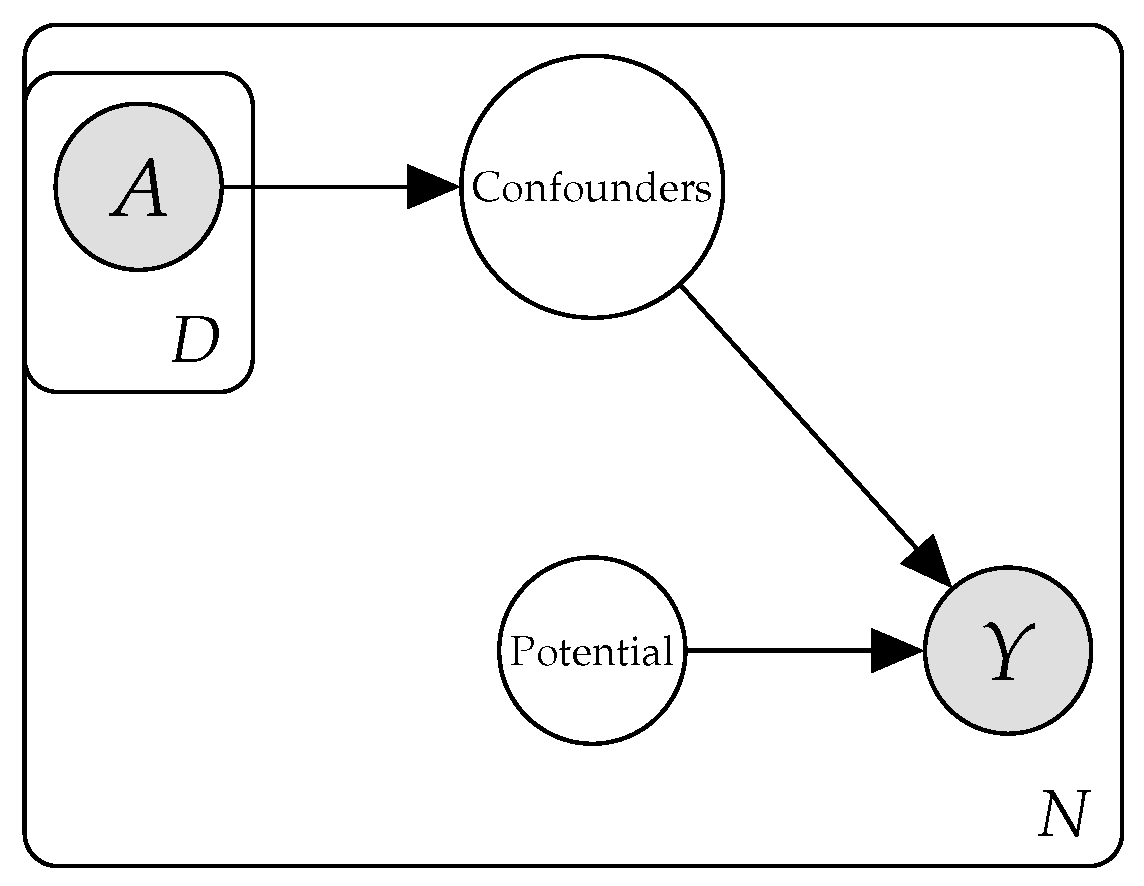
7. Dealing with Confounder Variables
8. Properties of Differential Fairness
8.1. Differential Fairness and Intersectionality
8.2. Privacy Interpretation
8.3. Economic Guarantees
8.4. Generalization Guarantees
9. Learning Algorithm
9.1. Batch Method
| Algorithm 1: Training Algorithm for Batch Differential Fair (BDF) Model |
Require: Train data Require: Tuning parameter Require: Learning step size schedule Require: Randomly initialize model parameters Output: BDF model
|
9.2. Stochastic Method
| Algorithm 2: Training Algorithm for Stochastic Differential Fair (SDF) Model |
Require: Train data Require: Tuning parameter Require: Constant learning step size schedule and Require: Randomly initialize model parameters and count parameters and Output: SDF model
|
| Algorithm 3: Practical Approach for Stochastic Differential Fair (SDF) Model |
Require: Train data Require: Tuning parameter Require: Constant learning step size and Require: Randomly initialize model parameters and count parameters and Output: SDF model
|
9.3. Convergence Analysis for Stochastic Method
10. Experiments and Results
10.1. Datasets
- COMPAS: The COMPAS dataset regarding a system that is used to predict criminal recidivism, and which has been criticized as potentially biased [4]. We used race and gender as protected attributes. Gender was coded as binary. Race originally had six values, but we merged “Asian” and “Native American” with “other,” as all three contained very few instances. We predict “actual recidivism,” which is binary, within a 2-year period for 7.22 K individuals.
- Adult: The Adult 1994 U.S. census income data from the UCI ML-repository [72] consists of 14 attributes regarding work, relationships, and demographics for individuals, who are labeled according to whether their income exceeds USD 50,000/year (Predicted income used for consequential decisions such as housing approval may result in digital redlining [1].) pre-split into a training set of 32.56 K and a test set of 16.28 K instances. We considered race, gender, and nationality as the protected attributes. Gender was coded as binary. As most instances have U.S. nationality, we treat nationality as binary also between U.S. and “other.” The race attribute originally had five values, but we merged the “Native American” with “other,” as both contained very few instances.
- HHP: This is a medium-sized dataset which is derived from the Heritage Health Prize (HHP) milestone 1 challenge (https://www.kaggle.com/c/hhp accessed on 10 April 2023). The dataset contains information for 171.07 K patients over a 3-year period. Our goal is to predict whether the Charlson Index, an estimation of patient mortality, is greater than zero. Following Song et al. [73], we consider age and gender as the protected attributes, where there are nine possible age values and two possible gender values.
- HMDA: This is the largest dataset in our study, which is derived from the loan application register form for the Home Mortgage Disclosure Act (HMDA) [74]. The HMDA is a federal act approved in 1975 which requires mortgage lenders to keep records of information regarding their lending practices to create greater transparency and borrower protections in the residential mortgage market (https://www.ffiec.gov/hmda/ accessed on 10 April 2023). The downstream task is to predict whether the loan application is approved. We used ethnicity, race, and gender as protected attributes, where ethnicity and gender were coded as binary. The race attribute originally had five values such as “American-Indian/Alaska-Native,” “Asian,” “Black/African-American,” “Native-Hawaiian or Other Pacific-Islander,” and “White.” we merged “American-Indian/Alaska-Native,” “Asian,” and “Native-Hawaiian or Other Pacific-Islander” to the same category as “other” since all three contained very few instances. Note that we filtered out individuals who did not declare information, i.e., incomplete or missing, related to the protected and/or other attributes. After pre-processing, the HMDA data consist of 30 attributes regarding loan type, property type, loan purpose, etc., for 2.33 M individuals.
10.2. Fair Learning Algorithms
10.2.1. Experimental Settings
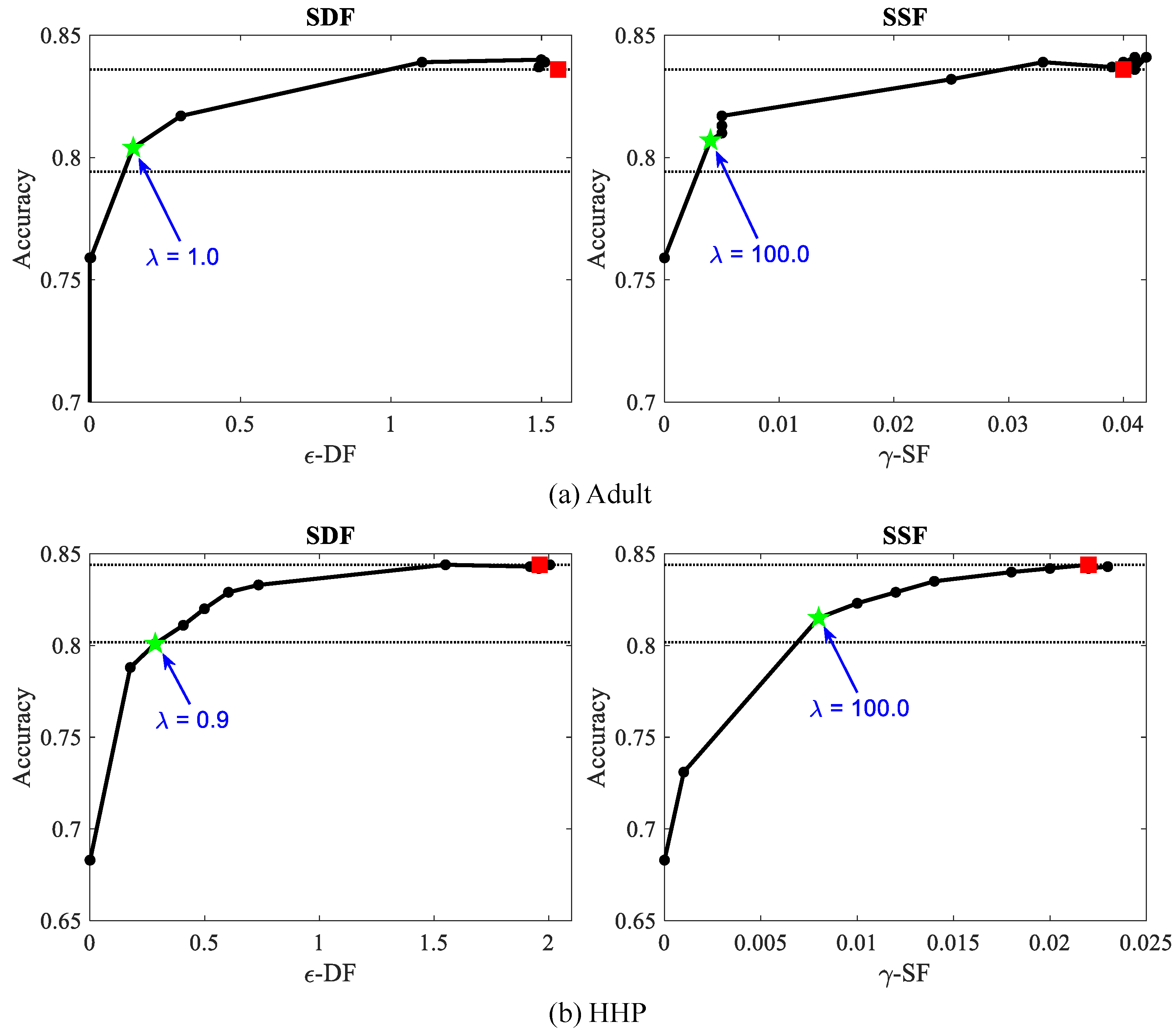
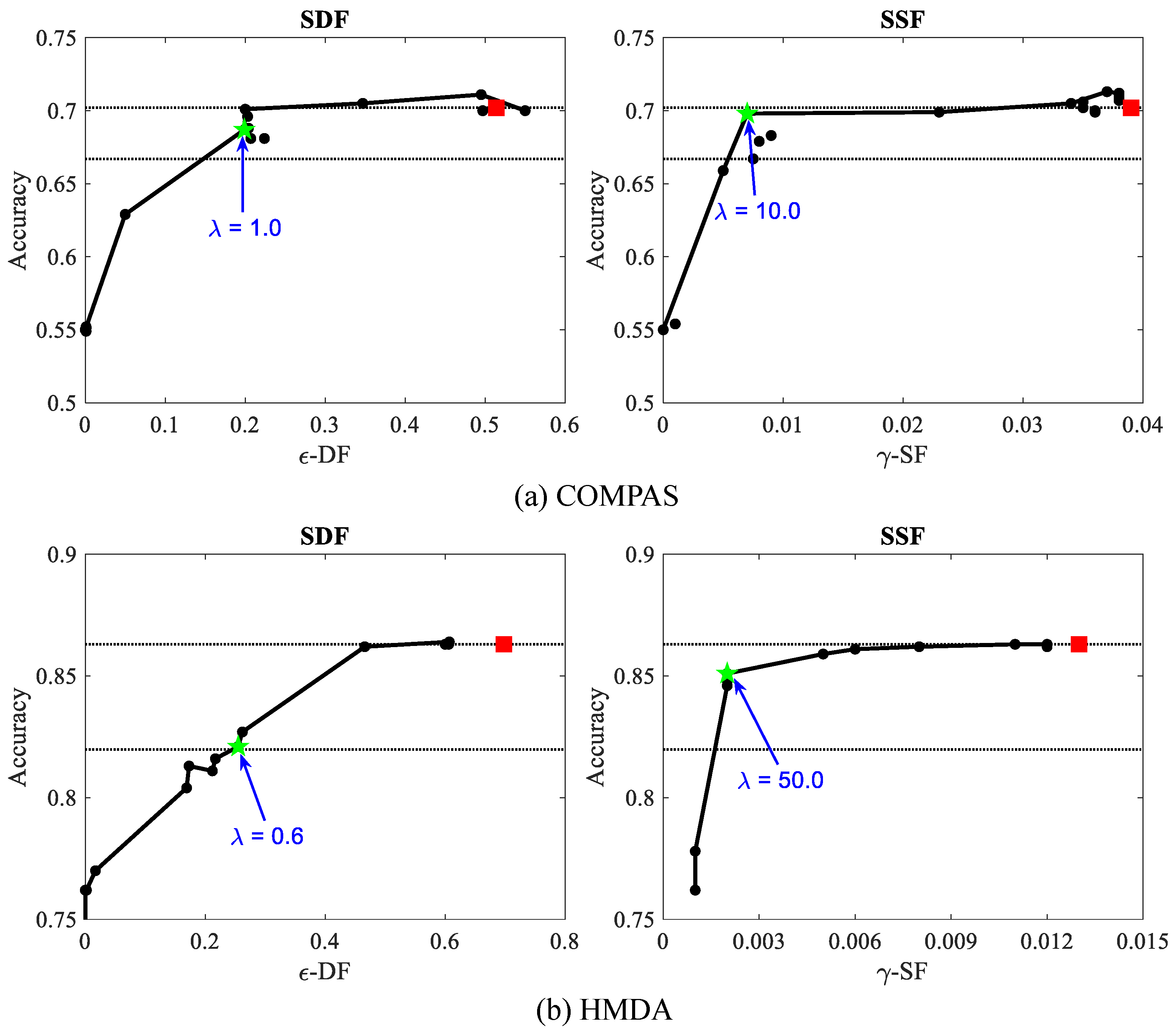
10.2.2. Fairness and Accuracy Trade-Off
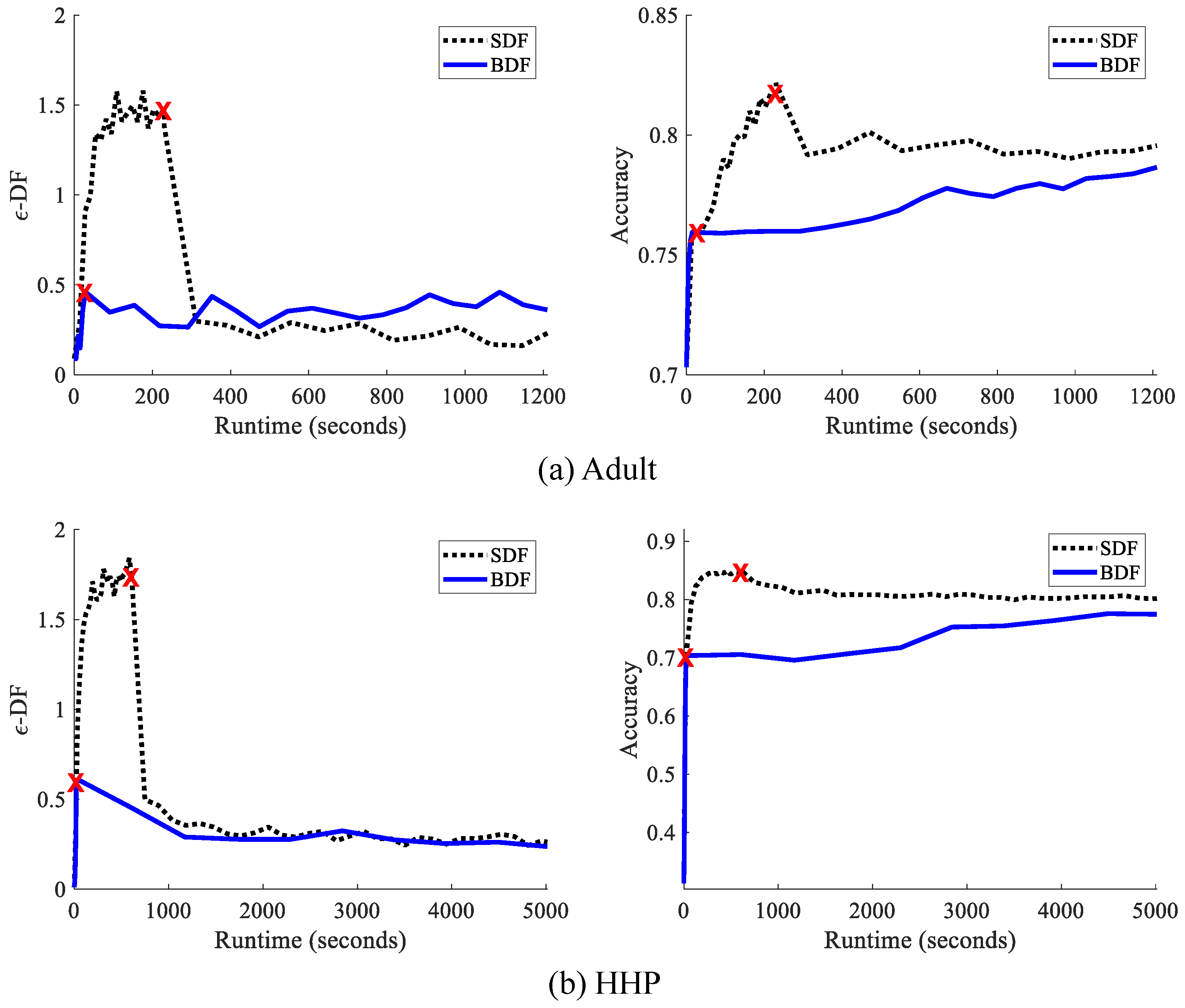
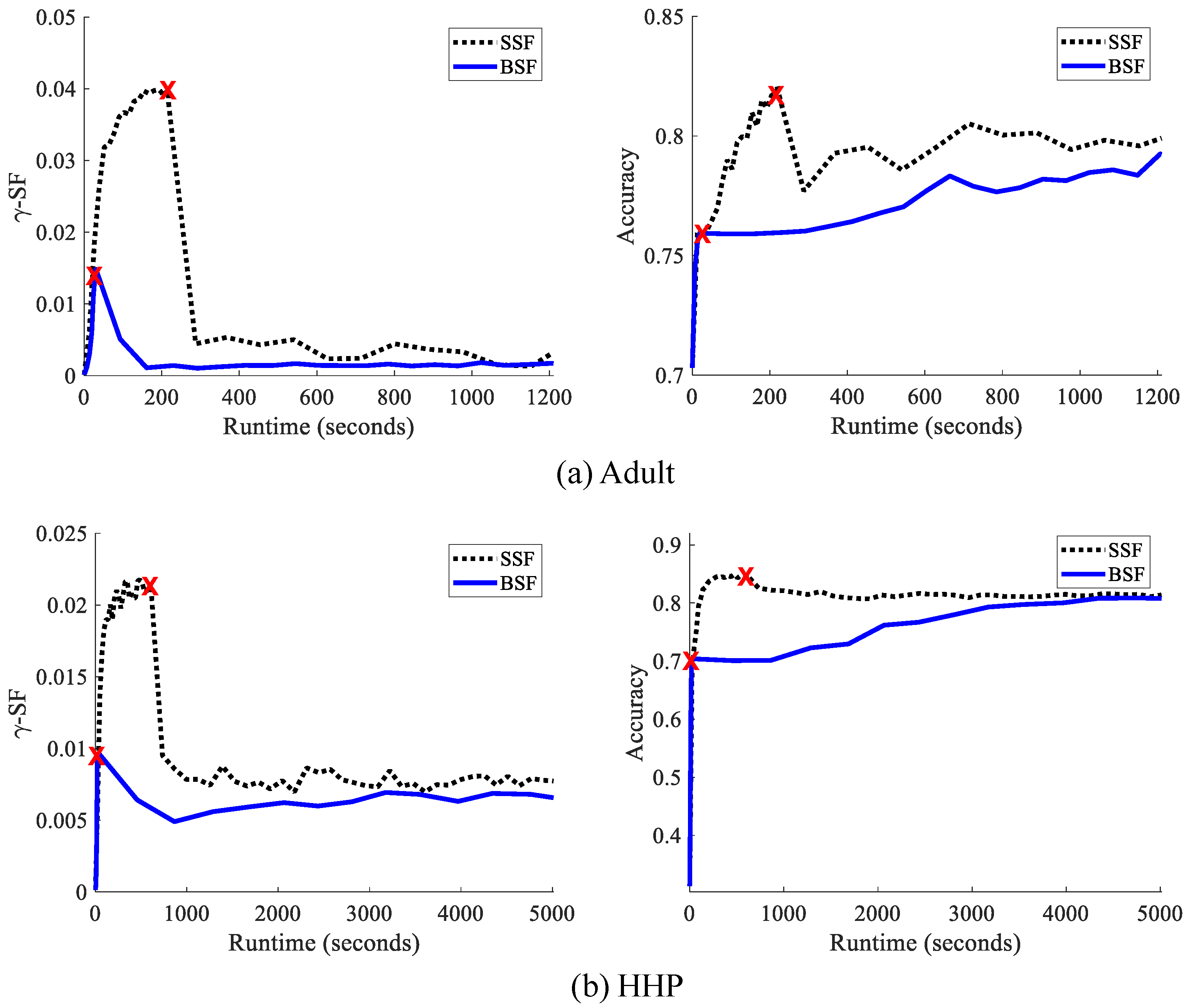
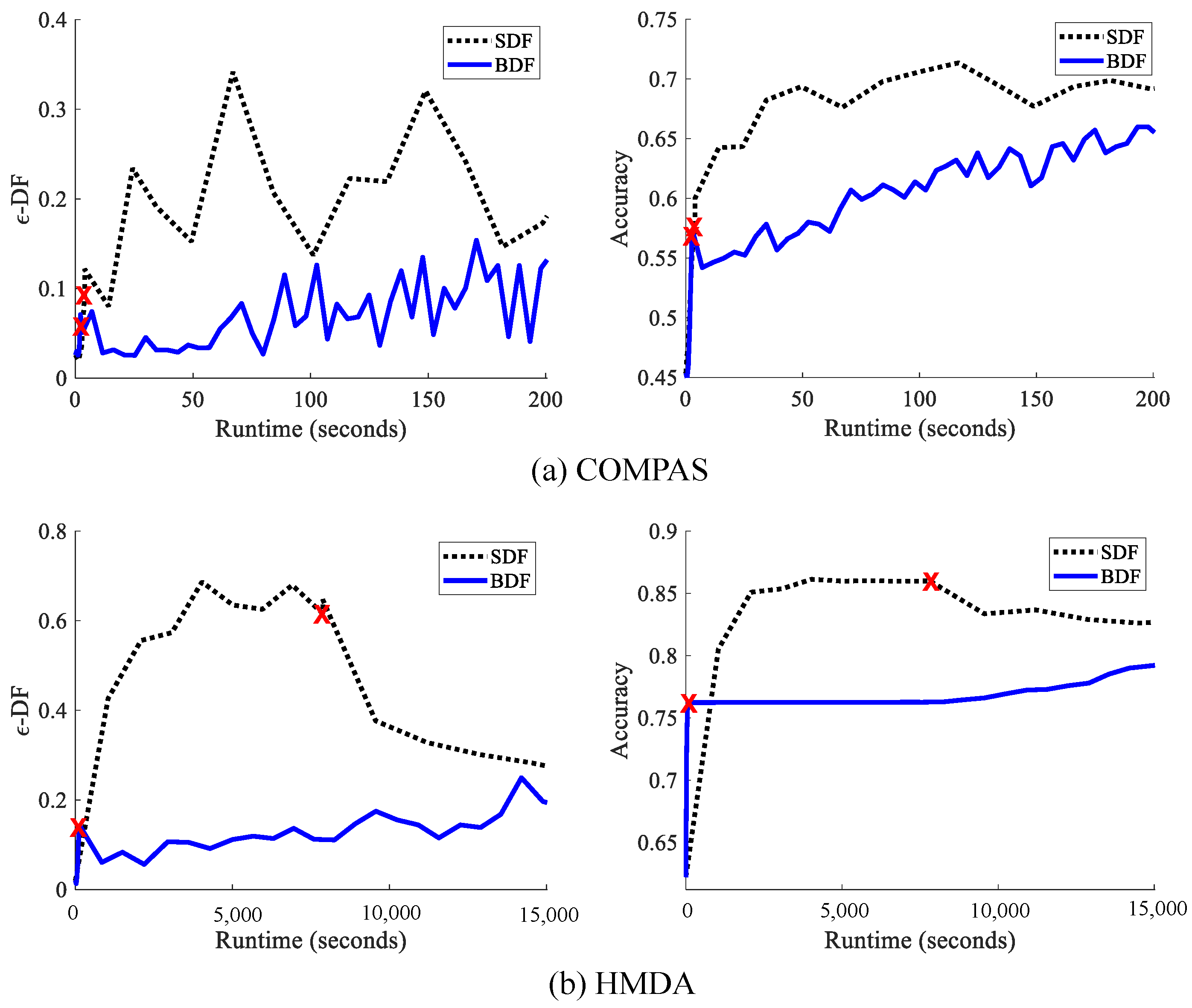
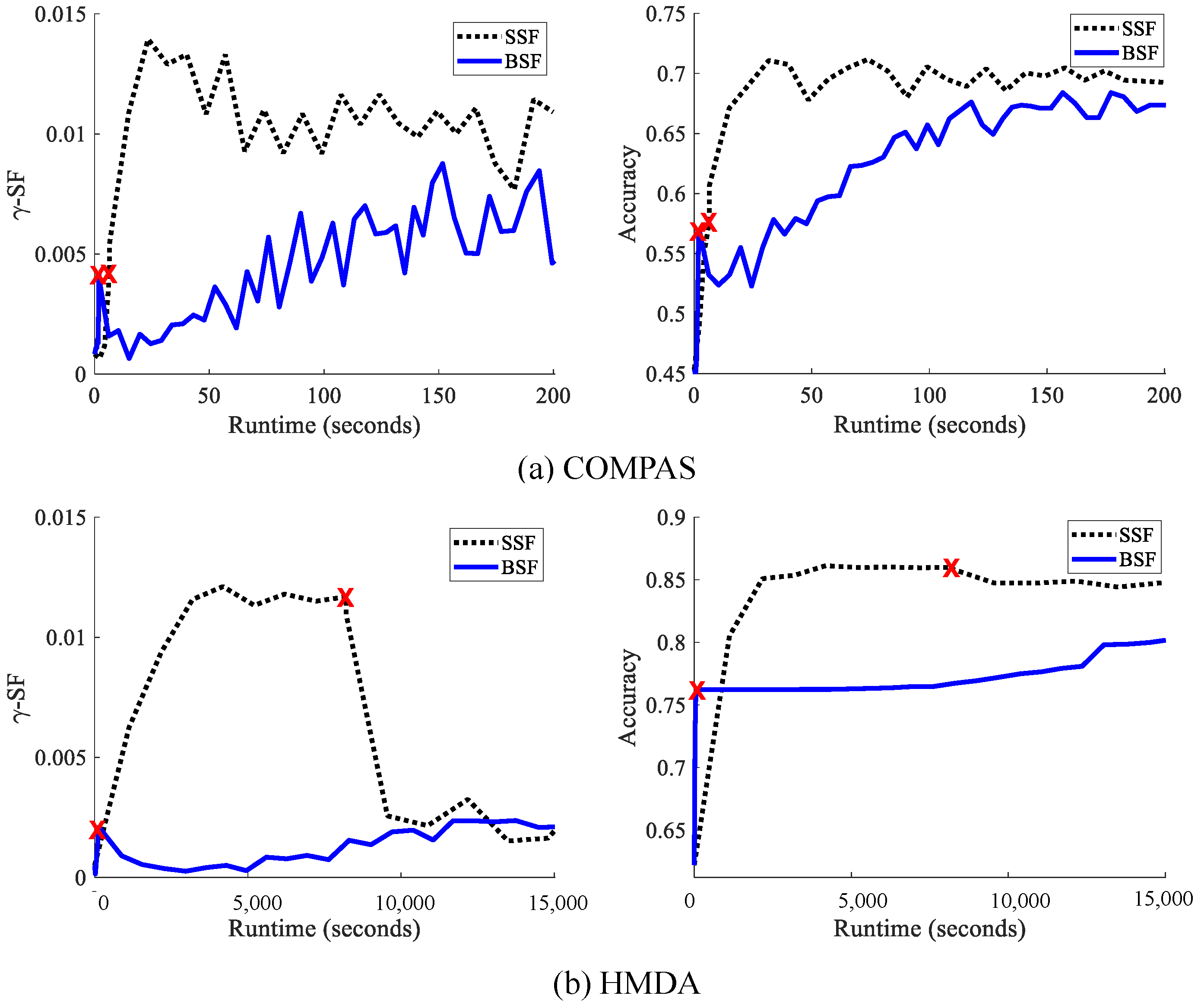
10.2.3. Comparative Analysis for Batch and Stochastic Methods
10.2.4. Performance for Fair Classifiers
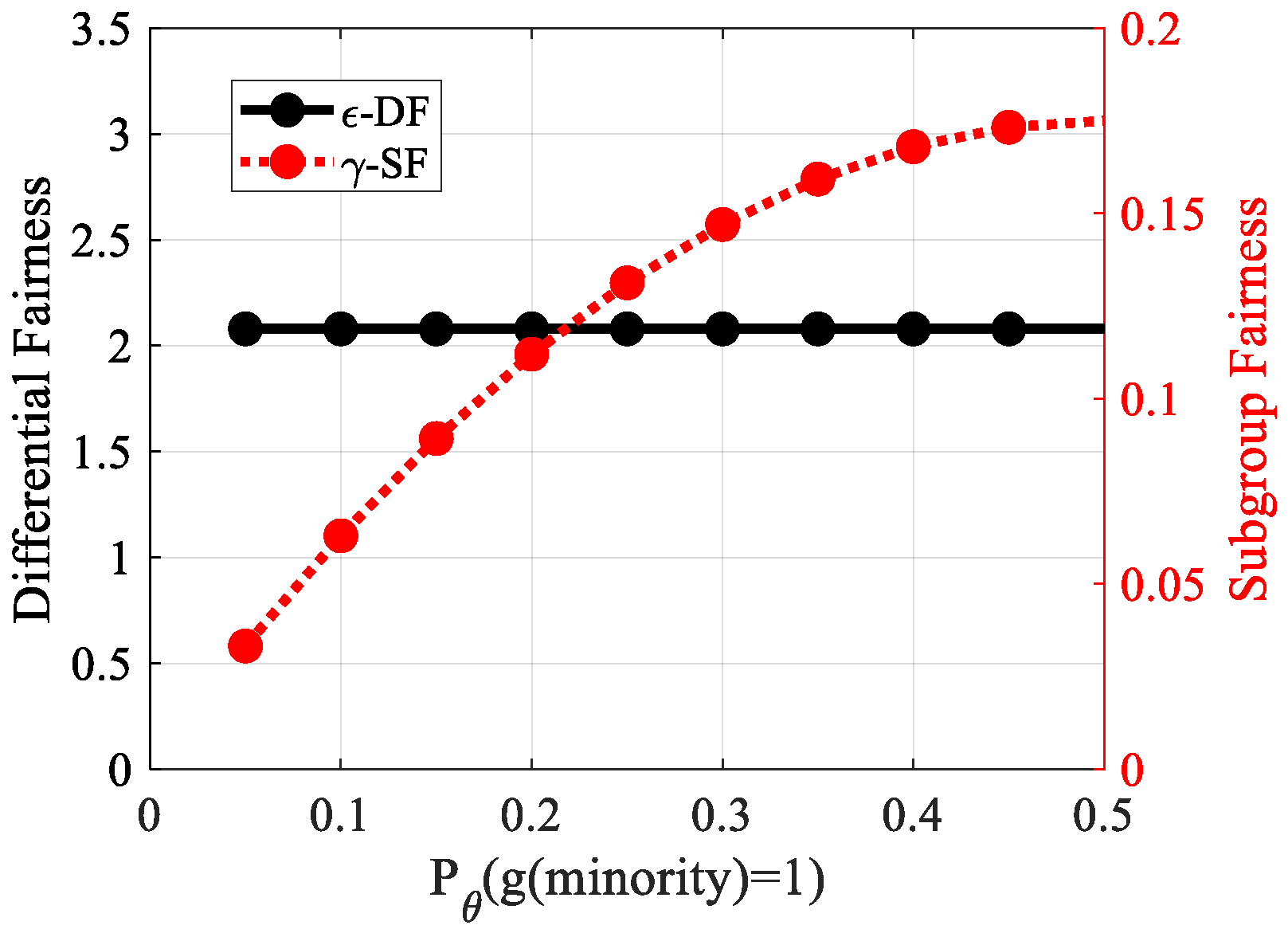
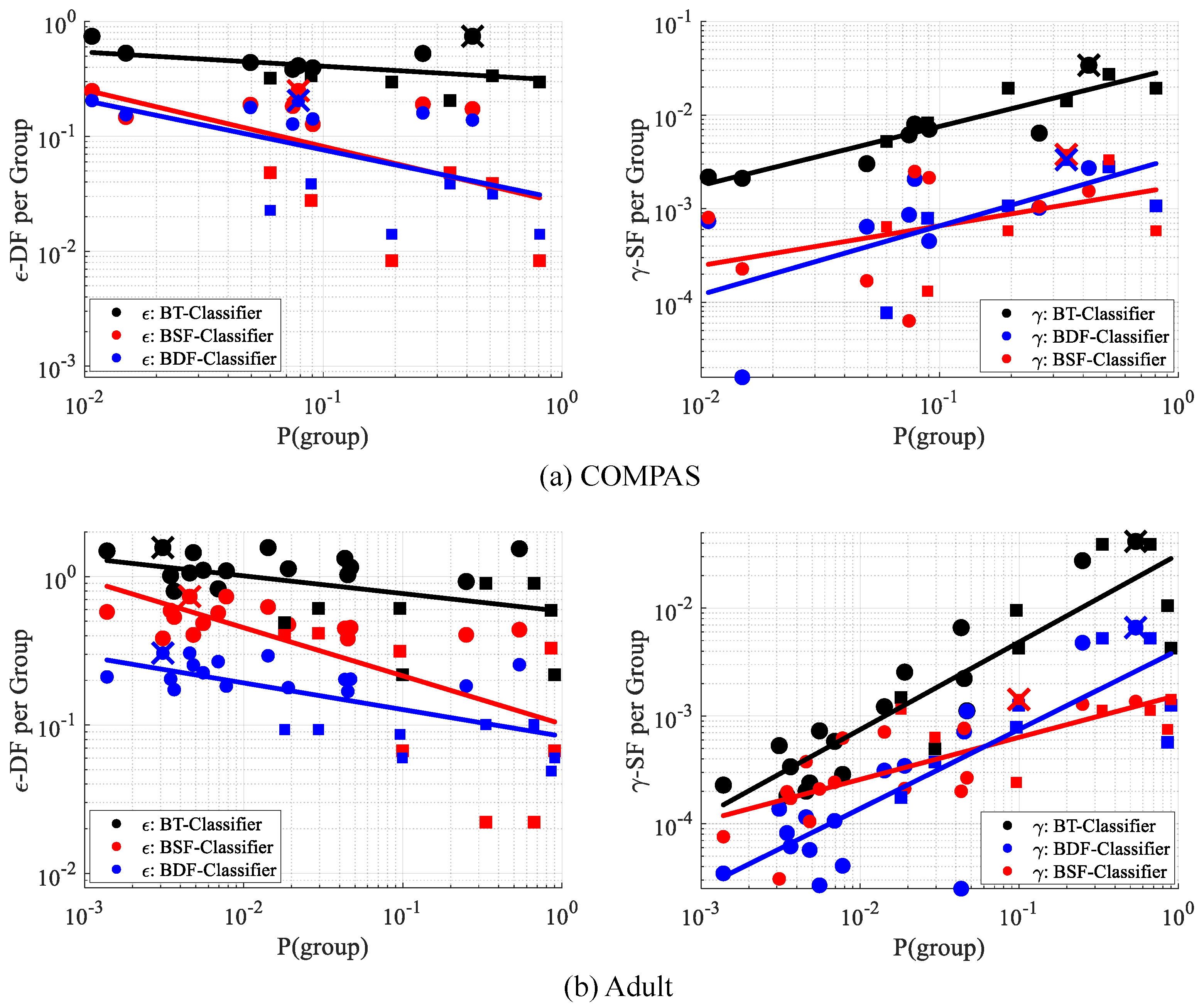
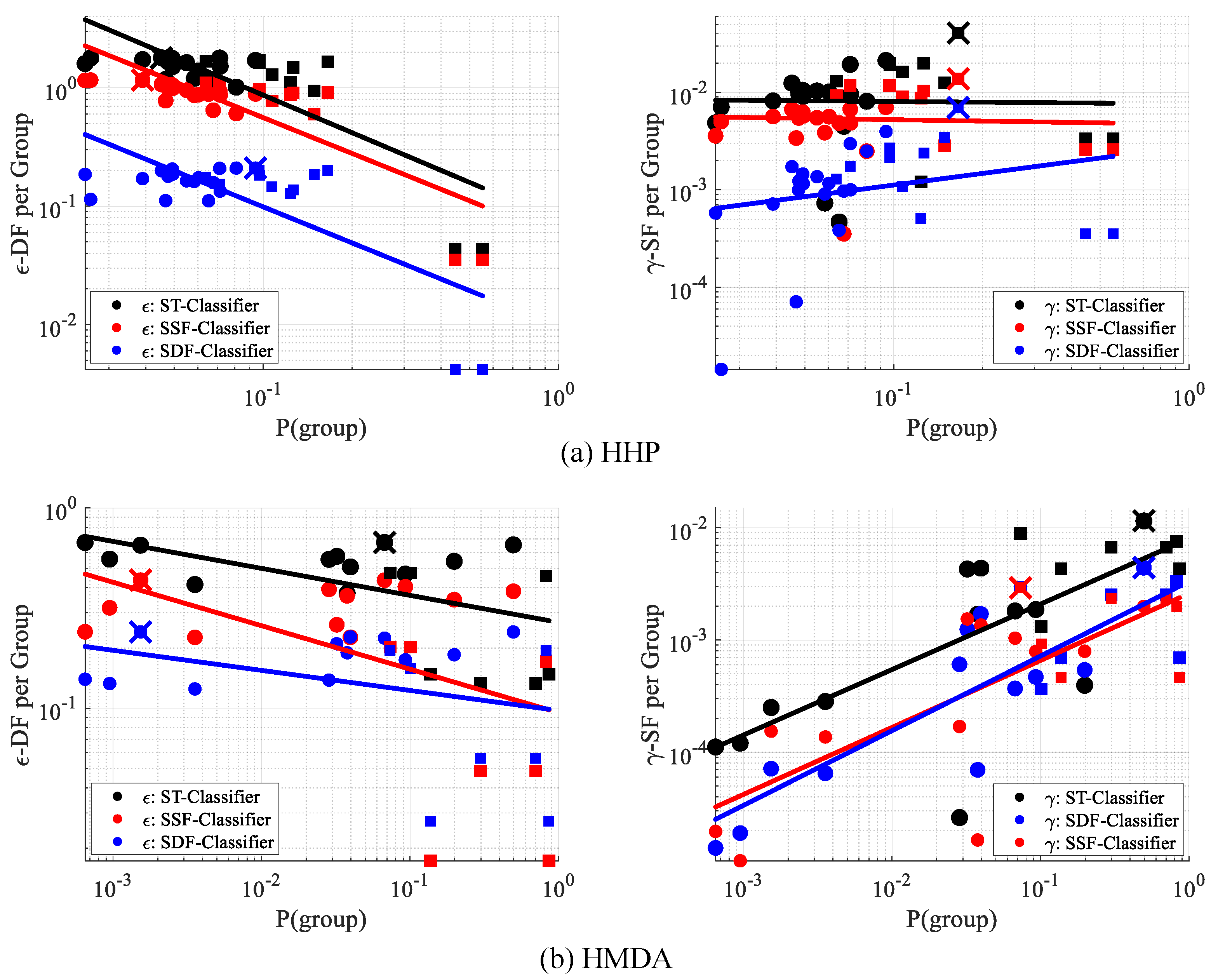
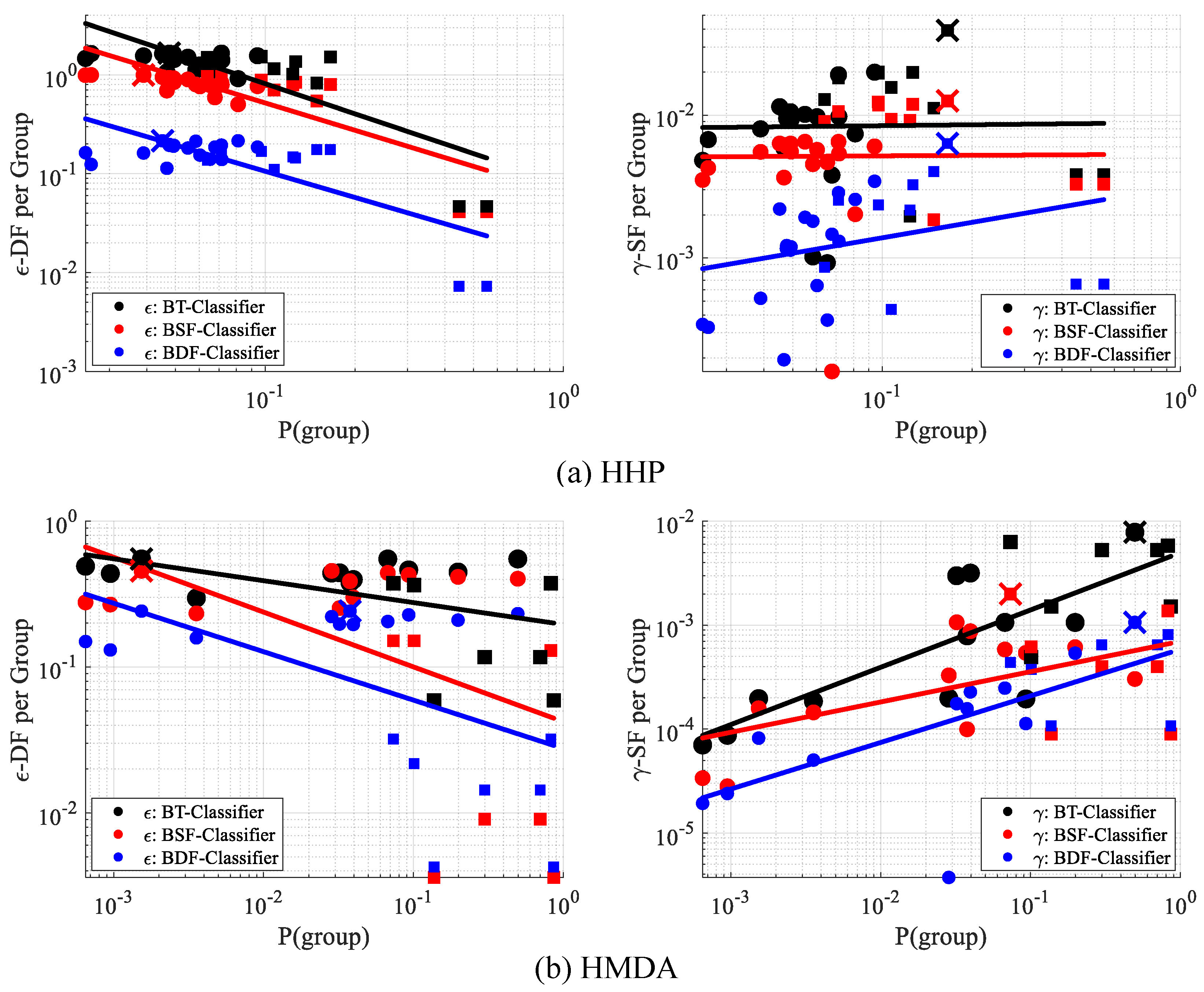
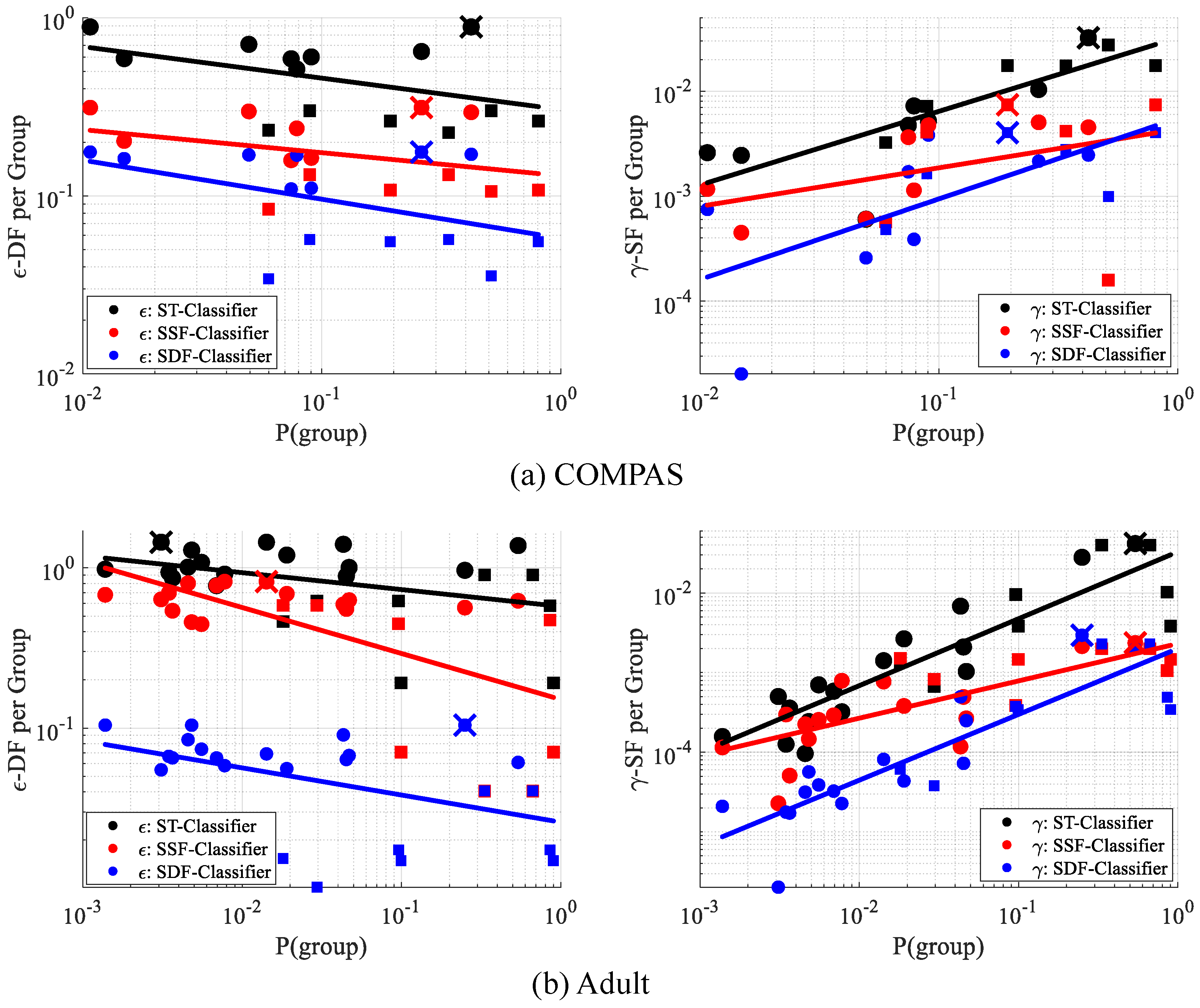
10.3. Inequity of Fairness Measures
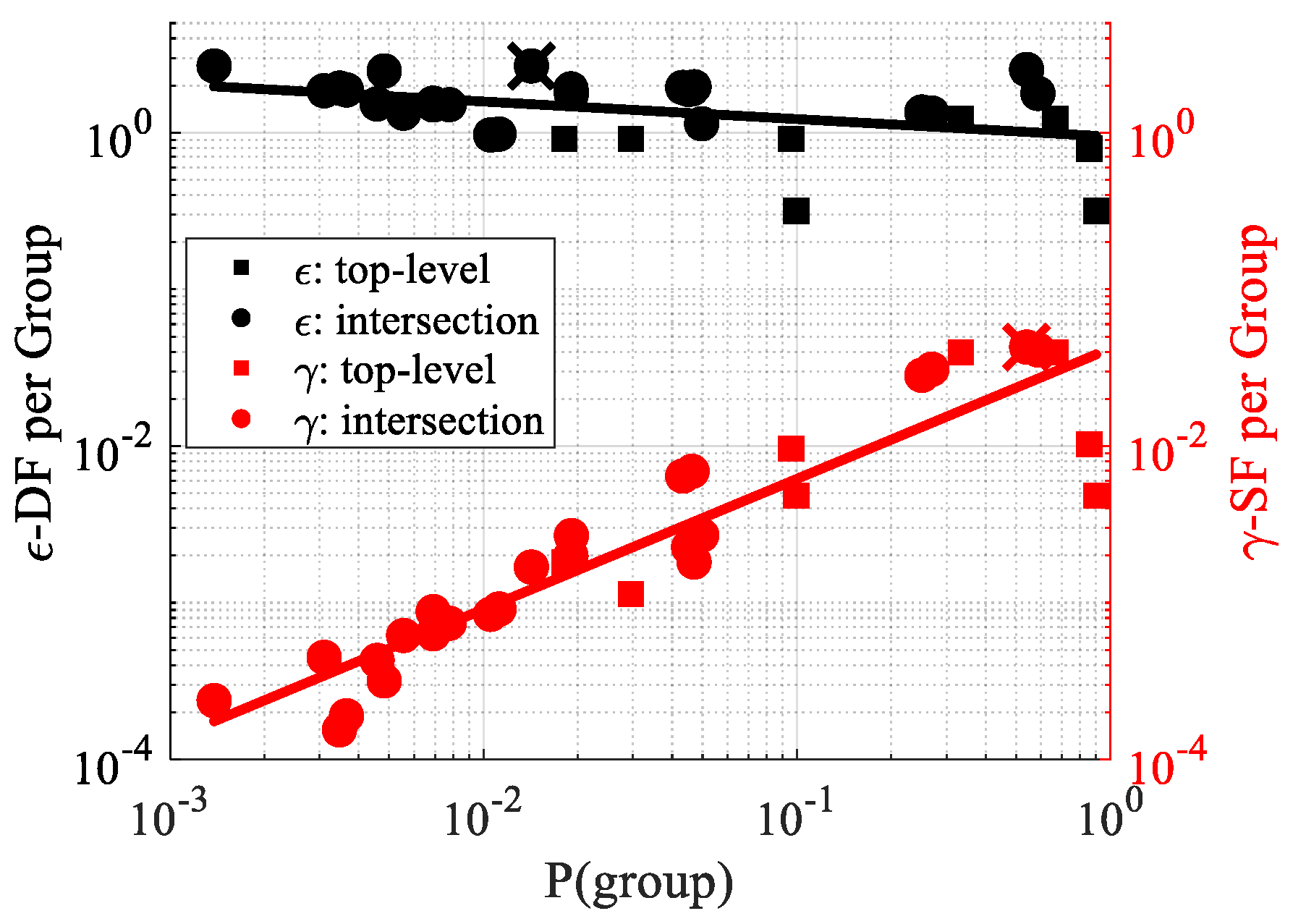
10.4. Evaluation of Intersectionality Property
11. Discussion
12. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Additional Experimental Results
Appendix A.1. Fairness and Accuracy Trade-Off

Appendix A.2. Comparative Analysis for Batch and Stochastic Methods


Appendix A.3. Performance for Fair Classifiers

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HHP Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|
| Models | BDF-Classifier | BSF-Classifier | BPR-Classifier | BT-Classifier | ||||
| Tuning Parameter | 0.100 | 0.100 | 50.000 | 10.000 | 70.000 | 0.010 | X | |
| Performance Measures | Accuracy ↑ | 0.801 | 0.810 | 0.800 | 0.818 | 0.835 | 0.816 | 0.848 |
| F1 Score ↑ | 0.590 | 0.610 | 0.650 | 0.640 | 0.700 | 0.660 | 0.730 | |
| ROC AUC ↑ | 0.777 | 0.792 | 0.848 | 0.847 | 0.868 | 0.842 | 0.885 | |
| Fairness Measures | -DF ↓ | 0.215 | 0.277 | 1.232 | 0.996 | 1.594 | 1.450 | 1.654 |
| -SF ↓ | 0.003 | 0.004 | 0.017 | 0.007 | 0.012 | 0.021 | 0.020 | |
| -Rule ↑ | 61.610 | 60.628 | 53.809 | 55.060 | 50.281 | 62.128 | 51.122 | |
| Bias Amp-DF ↓ | −1.245 | −1.183 | −0.228 | −0.464 | 0.134 | −0.010 | 0.194 | |
| Bias Amp-SF ↓ | −0.010 | −0.009 | 0.004 | −0.006 | −0.001 | 0.008 | 0.007 | |
| HMDA Dataset | ||||||||
| Models | BDF-Classifier | BSF-Classifier | BPR-Classifier | BT-Classifier | ||||
| Tuning Parameter | 0.070 | 0.100 | 1.000 | 5.000 | 70.000 | 0.001 | X | |
| Performance Measures | Accuracy ↑ | 0.800 | 0.803 | 0.856 | 0.812 | 0.825 | 0.839 | 0.849 |
| F1 Score ↑ | 0.870 | 0.870 | 0.900 | 0.880 | 0.880 | 0.890 | 0.900 | |
| ROC AUC ↑ | 0.888 | 0.895 | 0.924 | 0.898 | 0.898 | 0.910 | 0.916 | |
| Fairness Measures | -DF ↓ | 0.242 | 0.375 | 0.605 | 0.457 | 0.390 | 0.537 | 0.553 |
| -SF ↓ | 0.001 | 0.002 | 0.009 | 0.001 | 0.003 | 0.006 | 0.008 | |
| -Rule ↑ | 70.528 | 71.846 | 65.888 | 69.342 | 67.231 | 71.642 | 66.122 | |
| Bias Amp-DF ↓ | −0.419 | −0.286 | −0.056 | −0.204 | −0.271 | −0.124 | −0.108 | |
| Bias Amp-SF ↓ | −0.008 | −0.007 | 0.000 | −0.008 | −0.006 | −0.003 | −0.001 | |
| COMPAS Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|
| Models | SDF-Classifier | SSF-Classifier | SPR-Classifier | ST-Classifier | ||||
| Tuning Parameter | 1.000 | 1.000 | 70.000 | 10.000 | 70.000 | 0.010 | X | |
| Performance Measures | Accuracy ↑ | 0.671 | 0.667 | 0.670 | 0.660 | 0.674 | 0.669 | 0.683 |
| F1 Score ↑ | 0.600 | 0.600 | 0.590 | 0.600 | 0.600 | 0.610 | 0.630 | |
| ROC AUC ↑ | 0.704 | 0.698 | 0.694 | 0.694 | 0.703 | 0.706 | 0.713 | |
| Fairness Measures | -DF ↓ | 0.176 | 0.343 | 0.374 | 0.313 | 0.517 | 0.676 | 0.888 |
| -SF ↓ | 0.004 | 0.014 | 0.020 | 0.005 | 0.012 | 0.029 | 0.032 | |
| -Rule ↑ | 63.064 | 62.953 | 64.306 | 61.885 | 62.727 | 64.684 | 61.680 | |
| Bias Amp-DF ↓ | −0.362 | −0.195 | −0.164 | −0.225 | −0.021 | 0.138 | 0.350 | |
| Bias Amp-SF ↓ | −0.016 | −0.006 | 0.000 | −0.015 | −0.008 | 0.009 | 0.012 | |
| Adult Dataset | ||||||||
| Models | SDF-Classifier | SSF-Classifier | SPR-Classifier | ST-Classifier | ||||
| Tuning Parameter | 1.000 | 1.000 | 25.000 | 100.000 | 1000.000 | 0.100 | X | |
| Performance Measures | Accuracy ↑ | 0.803 | 0.808 | 0.810 | 0.802 | 0.811 | 0.815 | 0.832 |
| F1 Score ↑ | 0.390 | 0.440 | 0.420 | 0.410 | 0.390 | 0.480 | 0.600 | |
| ROC AUC ↑ | 0.821 | 0.844 | 0.861 | 0.843 | 0.871 | 0.858 | 0.885 | |
| Fairness Measures | -DF ↓ | 0.104 | 0.259 | 0.648 | 0.821 | 1.028 | 1.268 | 1.446 |
| -SF ↓ | 0.003 | 0.012 | 0.023 | 0.002 | 0.017 | 0.028 | 0.042 | |
| -Rule ↑ | 59.896 | 58.054 | 52.147 | 59.036 | 50.220 | 59.616 | 46.052 | |
| Bias Amp-DF ↓ | −1.276 | −1.121 | −0.732 | −0.559 | −0.352 | −0.112 | 0.066 | |
| Bias Amp-SF ↓ | −0.030 | −0.021 | −0.010 | −0.031 | −0.016 | −0.555 | 0.009 | |


References
- Barocas, S.; Selbst, A. Big data’s disparate impact. Calif. Law Rev. 2016, 104, 671. [Google Scholar] [CrossRef]
- Munoz, C.; Smith, M.; Patil, D. Big Data: A Report on Algorithmic Systems, Opportunity, and Civil Rights; Executive Office of the President: Washington, DC, USA, 2016.
- Noble, S. Algorithms of Oppression: How Search Engines Reinforce Racism; NYU Press: New York, NY, USA, 2018. [Google Scholar]
- Angwin, J.; Larson, J.; Mattu, S.; Kirchner, L. Machine bias: There’s software used across the country to predict future criminals. and it’s biased against blacks. ProPublica 2016. Available online: https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing (accessed on 4 April 2023).
- Buolamwini, J.; Gebru, T. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the Conference on Fairness, Accountability, and Transparency, New York, NY, USA, 23–24 February 2018. [Google Scholar]
- Bolukbasi, T.; Chang, K.W.; Zou, J.; Saligrama, V.; Kalai, A. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. In Proceedings of the Advances in NeurIPS, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Dwork, C.; Hardt, M.; Pitassi, T.; Reingold, O.; Zemel, R. Fairness through awareness. In Proceedings of the Innovations in Theoretical Computer Science (ITCS), Cambridge, MA USA, 8–10 January 2012; pp. 214–226. [Google Scholar]
- Hardt, M.; Price, E.; Srebro, N. Equality of opportunity in supervised learning. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Barcelona, Spain, 5–10 December 2016; pp. 3315–3323. [Google Scholar]
- Berk, R.; Heidari, H.; Jabbari, S.; Joseph, M.; Kearns, M.; Morgenstern, J.; Neel, S.; Roth, A. A convex framework for fair regression. In Proceedings of the FAT/ML Workshop, Halifax, NS, Canada, 14 August 2017. [Google Scholar]
- Zhao, J.; Wang, T.; Yatskar, M.; Ordonez, V.; Chang, K.W. Men also like shopping: Reducing gender bias amplification using corpus-level constraints. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- Islam, R.; Keya, K.; Zeng, Z.; Pan, S.; Foulds, J. Debiasing Career Recommendations with Neural Fair Collaborative Filtering. In Proceedings of the Web Conference, Ljubljana, Slovenia, 19–23 April 2021. [Google Scholar]
- Keya, K.N.; Islam, R.; Pan, S.; Stockwell, I.; Foulds, J.R. Equitable Allocation of Healthcare Resources with Fair Survival Models. In Proceedings of the 2021 SIAM International Conference on Data Mining (SIAM), Virtual, 29 April–1 May 2021. [Google Scholar]
- Campolo, A.; Sanfilippo, M.; Whittaker, M.; Crawford, A.S.K.; Barocas, S. AI Now 2017 Symposium Report; AI Now: New York, NY, UCA, 2017. [Google Scholar]
- Mitchell, S.; Potash, E.; Barocas, S. Prediction-Based Decisions and Fairness: A Catalogue of Choices, Assumptions, and Definitions. arXiv 2018, arXiv:1811.07867. [Google Scholar]
- Keyes, O.; Hutson, J.; Durbin, M. A Mulching Proposal: Analysing and Improving an Algorithmic System for Turning the Elderly into High-Nutrient Slurry. In Proceedings of the Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; ACM: New York, NY, USA, 2019. [Google Scholar]
- Crenshaw, K. Demarginalizing the intersection of race and sex: A black feminist critique of antidiscrimination doctrine, feminist theory and antiracist politics. Univ. Chic. Leg. Forum 1989, 1989, 139–167. [Google Scholar]
- Kearns, M.; Neel, S.; Roth, A.; Wu, Z. Preventing Fairness Gerrymandering: Auditing and Learning for Subgroup Fairness. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 2569–2577. [Google Scholar]
- Hebert-Johnson, U.; Kim, M.; Reingold, O.; Rothblum, G. Multicalibration: Calibration for the (Computationally-Identifiable) Masses. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 1944–1953. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Third Theory of Cryptography, New York, NY, USA, 4–7 March 2006; pp. 265–284. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Theor. Comput. Sci. 2013, 9, 211–407. [Google Scholar]
- Mironov, I. Rényi differential privacy. In Proceedings of the 2017 IEEE 30th Computer Security Foundations symposium (CSF), Santa Barbara, CA, USA, 21–25 August 2017; pp. 263–275. [Google Scholar]
- Selbst, A.D.; Boyd, D.; Friedler, S.A.; Venkatasubramanian, S.; Vertesi, J. Fairness and abstraction in sociotechnical systems. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 59–68. [Google Scholar]
- Jacobs, A.Z.; Wallach, H. Measurement and Fairness. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual Event, 3–10 March 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 375–385. [Google Scholar] [CrossRef]
- Cheng, H.F.; Wang, R.; Zhang, Z.; O’Connell, F.; Gray, T.; Harper, F.M.; Zhu, H. Explaining decision-making algorithms through UI: Strategies to help non-expert stakeholders. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–12. [Google Scholar]
- Van Berkel, N.; Goncalves, J.; Russo, D.; Hosio, S.; Skov, M.B. Effect of information presentation on fairness perceptions of machine learning predictors. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–13. [Google Scholar]
- Wang, R.; Harper, F.M.; Zhu, H. Factors influencing perceived fairness in algorithmic decision-making: Algorithm outcomes, development procedures, and individual differences. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–14. [Google Scholar]
- Kifer, D.; Machanavajjhala, A. Pufferfish: A framework for mathematical privacy definitions. TODS 2014, 39, 3. [Google Scholar] [CrossRef]
- Green, B.; Chen, Y. Algorithmic risk assessments can alter human decision-making processes in high-stakes government contexts. Proc. ACM Hum.-Comput. Interact. 2021, 5, 1–33. [Google Scholar] [CrossRef]
- Green, B. The flaws of policies requiring human oversight of government algorithms. Comput. Law Secur. Rev. 2022, 45, 105681. [Google Scholar] [CrossRef]
- Kong, Y. Are “Intersectionally Fair” AI Algorithms Really Fair to Women of Color? A Philosophical Analysis. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 485–494. [Google Scholar] [CrossRef]
- Foulds, J.R.; Islam, R.; Keya, K.N.; Pan, S. An intersectional definition of fairness. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 1918–1921. [Google Scholar]
- Foulds, J.; Pan, S. Are Parity-Based Notions of AI Fairness Desirable? Bull. IEEE Tech. Comm. Data Eng. 2020, 43, 51–73. [Google Scholar]
- Ganley, C.M.; George, C.E.; Cimpian, J.R.; Makowski, M.B. Gender equity in college majors: Looking beyond the STEM/Non-STEM dichotomy for answers regarding female participation. Am. Educ. Res. J. 2018, 55, 453–487. [Google Scholar] [CrossRef]
- Piper, A. Passing for white, passing for black. Transition 1992, 58, 4–32. [Google Scholar] [CrossRef]
- Truth, S. Ain’t I a Woman? Speech delivered at Women’s Rights Convention: Akron, OH, USA, 1851. [Google Scholar]
- Collins, P.H. Black Feminist thought: Knowledge, Consciousness, and the Politics of Empowerment; Routledge: London, UK, 2002. [Google Scholar]
- Combahee River Collective. A Black Feminist Statement. In Capitalist Patriarchy and the Case for Socialist Feminism; Eisenstein, Z., Ed.; Monthly Review Press: New York, NY, USA, 1978. [Google Scholar]
- Hooks, B. Ain’t I a Woman: Black Women and Feminism; South End Press: Boston, MA, USA, 1981. [Google Scholar]
- Lorde, A. Age, race, class, and sex: Women redefining difference. In Sister Outsider; Ten Speed Press: Berkeley, CA, USA, 1984; pp. 114–124. [Google Scholar]
- Yang, F.; Cisse, M.; Koyejo, O.O. Fairness with Overlapping Groups; a Probabilistic Perspective. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual, 6–12 December 2020. [Google Scholar]
- La Cava, W.; Lett, E.; Wan, G. Proportional Multicalibration. arXiv 2022, arXiv:2209.14613. [Google Scholar]
- Lett, E.; La Cava, W. Translating Intersectionality to Fair Machine Learning in Health Sciences. SocArXiv 2023. [Google Scholar] [CrossRef]
- Simoiu, C.; Corbett-Davies, S.; Goel, S. The problem of infra-marginality in outcome tests for discrimination. Ann. Appl. Stat. 2017, 11, 1193–1216. [Google Scholar] [CrossRef]
- Davis, A. Are Prisons Obsolete? Seven Stories Press: New York, NY, USA, 2011. [Google Scholar]
- Wald, J.; Losen, D. Defining and redirecting a school-to-prison pipeline. New Dir. Youth Dev. 2003, 2003, 9–15. [Google Scholar] [CrossRef]
- Verschelden, C. Bandwidth Recovery: Helping Students Reclaim Cognitive Resources Lost to Poverty, Racism, and Social Marginalization; Stylus: Sterling, VA, USA, 2017. [Google Scholar]
- Alexander, M. The New Jim Crow: Mass Incarceration in the Age of Colorblindness; T. N. P.: New York, NY, USA, 2012. [Google Scholar]
- Grant, J.; Mottet, L.; Tanis, J.; Harrison, J.; Herman, J.; Keisling, M. Injustice at Every Turn: A Report of the National Transgender Discrimination Survey; National Center for Transgender Equality: Washington, DC, USA, 2011. [Google Scholar]
- Berk, R.; Heidari, H.; Jabbari, S.; Kearns, M.; Roth, A. Fairness in Criminal Justice Risk Assessments: The State of the Art. Sociol. Methods Res. 2018, 1050, 28. [Google Scholar] [CrossRef]
- Dastin, J. Amazon Scraps Secret AI Recruiting Tool That Showed Bias against Women. Reuters 2018. Available online: https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G (accessed on 4 April 2023).
- Equal Employment Opportunity Commission. Guidelines on Employee Selection Procedures. In C.F.R. 29.1607; Office of the Federal Register: Washington, DC, USA, 1978. [Google Scholar]
- Pleiss, G.; Raghavan, M.; Wu, F.; Kleinberg, J.; Weinberger, K. On fairness and calibration. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5684–5693. [Google Scholar]
- Donini, M.; Oneto, L.; Ben-David, S.; Shawe-Taylor, J.S.; Pontil, M. Empirical risk minimization under fairness constraints. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 3–8 December 2018; pp. 2791–2801. [Google Scholar]
- Kusner, M.; Loftus, J.; Russell, C.; Silva, R. Counterfactual fairness. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Jagielski, M.; Kearns, M.; Mao, J.; Oprea, A.; Roth, A.; Sharifi-Malvajerdi, S.; Ullman, J. Differentially private fair learning. arXiv 2018, arXiv:1812.02696. [Google Scholar]
- Foulds, J.; Islam, R.; Keya, K.N.; Pan, S. Bayesian Modeling of Intersectional Fairness: The Variance of Bias. In Proceedings of the 2020 SIAM International Conference on Data Mining, Cincinnati, OH, USA, 5–9 May 2020; pp. 424–432. [Google Scholar]
- Charig, C.; Webb, D.; Payne, S.; Wickham, J. Comparison of treatment of renal calculi by open surgery, percutaneous nephrolithotomy, and extracorporeal shockwave lithotripsy. Br. Med. J. 1986, 292, 879–882. [Google Scholar] [CrossRef]
- Julious, S.; Mullee, M. Confounding and Simpson’s paradox. Br. Med. J. 1994, 309, 1480–1481. [Google Scholar] [CrossRef] [PubMed]
- Bickel, P.J.; Hammel, E.A.; O’Connell, J.W. Sex Bias in Graduate Admissions: Data from Berkeley: Measuring bias is harder than is usually assumed, and the evidence is sometimes contrary to expectation. Science 1975, 187, 398–404. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the Advances in Neural Information Processing Systems (Autodiff Workshop), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Cappé, O.; Moulines, E. On-line expectation–maximization algorithm for latent data models. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2009, 71, 593–613. [Google Scholar] [CrossRef]
- Hoffman, M.; Bach, F.R.; Blei, D.M. Online learning for latent Dirichlet allocation. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 856–864. [Google Scholar]
- Hoffman, M.D.; Blei, D.M.; Wang, C.; Paisley, J. Stochastic variational inference. J. Mach. Learn. Res. 2013, 14, 1303–1347. [Google Scholar]
- Mimno, D.; Hoffman, M.D.; Blei, D.M. Sparse stochastic inference for latent Dirichlet allocation. In Proceedings of the 29th International Conference on Machine Learning, Edinburgh, Scotland, 26 June–1 July 2012; pp. 1515–1522. [Google Scholar]
- Foulds, J.; Boyles, L.; DuBois, C.; Smyth, P.; Welling, M. Stochastic collapsed variational Bayesian inference for latent Dirichlet allocation. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 446–454. [Google Scholar]
- Islam, R.; Foulds, J. Scalable Collapsed Inference for High-Dimensional Topic Models. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 2836–2845. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Statist. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Andrieu, C.; Moulines, É.; Priouret, P. Stability of stochastic approximation under verifiable conditions. SIAM J. Control Optim. 2005, 44, 283–312. [Google Scholar] [CrossRef]
- Bao, M.; Zhou, A.; Zottola, S.; Brubach, B.; Desmarais, S.; Horowitz, A.; Lum, K.; Venkatasubramanian, S. It’s COMPASlicated: The Messy Relationship between RAI Datasets and Algorithmic Fairness Benchmarks. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1 (NeurIPS Datasets and Benchmarks 2021), Virtual, 6–14 December 2021. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2017; Available online: http://archive.ics.uci.edu/ml (accessed on 10 April 2023).
- Song, J.; Kalluri, P.; Grover, A.; Zhao, S.; Ermon, S. Learning controllable fair representations. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Naha, Japan, 16–18 April 2019; pp. 2164–2173. [Google Scholar]
- ProPublica/Investigative Reporters and Editors. Home Mortgage Disclosure Act. 2015. Available online: https://www.consumerfinance.gov/data-research/hmda/ (accessed on 10 April 2023).
- Zafar, M.; Valera, I.; Rodriguez, M.; Gummadi, K. Fairness constraints: Mechanisms for fair classification. In Proceedings of the AISTATS, Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. (NeurIPS) 2019, 32, 8026–8037. [Google Scholar]
- Lorenz, M. Methods of measuring the concentration of wealth. Publ. Am. Stat. Assoc. 1905, 9, 209–219. [Google Scholar] [CrossRef]
- Agarwal, A.; Beygelzimer, A.; Dudík, M.; Langford, J.; Wallach, H. A reductions approach to fair classification. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 60–69. [Google Scholar]
- Fioretto, F.; Van Hentenryck, P.; Mak, T.W.; Tran, C.; Baldo, F.; Lombardi, M. Lagrangian Duality for Constrained Deep Learning. In Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases, ECML PKDD 2020, Ghent, Belgium, 14–18 September 2020; Springer Science and Business Media Deutschland GmbH: Berlin/Heidelberg, Germany, 2021; pp. 118–135. [Google Scholar]
- Tran, C.; Fioretto, F.; Van Hentenryck, P. Differentially Private and Fair Deep Learning: A Lagrangian Dual Approach. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 9932–9939. [Google Scholar]
- Foulds, J.R.; Pan, S. (Eds.) Bulletin of the IEEE Technical Committee on Data Engineering; IEEE Computer Society: Washington, DC, USA, 2020; Volume 43. [Google Scholar]












| Probability of Being Admitted to University X | ||||
|---|---|---|---|---|
| Gender | ||||
| A | B | Overall | ||
| Race | 1 | |||
| 2 | ||||
| Overall | ||||
| Abbreviation | Definition | Description |
|---|---|---|
| BT | Batch Typical (vanilla) model | Train deep learning classifier with batch method without any fairness interventions |
| BPR | Batch -Rule model | Train deep learning classifier with batch method that enforces -Rule criteria |
| BSF | Batch Subgroup Fair model | Train deep learning classifier with batch method that enforces -SF criteria |
| BDF | Batch Differential Fair model | Train deep learning classifier with batch method that enforces proposed -DF criteria |
| ST | Stochastic Typical (vanilla) model | Train deep learning classifier with stochastic method without any fairness interventions |
| SPR | Stochastic -Rule model | Train deep learning classifier with stochastic method that enforces -Rule criteria |
| SSF | Stochastic Subgroup Fair model | Train deep learning classifier with stochastic method that enforces -SF criteria |
| SDF | Stochastic Differential Fair model | Train deep learning classifier with stochastic method that enforces proposed -DF criteria |
| COMPAS Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|
| Models | BDF-Classifier | BSF-Classifier | BPR-Classifier | BT-Classifier | ||||
| Tuning Parameter | 0.800 | 5.000 | 50.000 | 25.000 | 100.000 | 0.010 | X | |
| Performance Measures | Accuracy ↑ | 0.672 | 0.674 | 0.665 | 0.660 | 0.667 | 0.674 | 0.671 |
| F1 Score ↑ | 0.560 | 0.580 | 0.580 | 0.560 | 0.580 | 0.620 | 0.630 | |
| ROC AUC ↑ | 0.700 | 0.698 | 0.687 | 0.701 | 0.701 | 0.700 | 0.686 | |
| Fairness Measures | -DF ↓ | 0.205 | 0.252 | 0.308 | 0.249 | 0.303 | 0.630 | 0.743 |
| -SF ↓ | 0.003 | 0.016 | 0.019 | 0.003 | 0.012 | 0.035 | 0.034 | |
| -Rule ↑ | 66.027 | 65.278 | 64.276 | 63.853 | 62.296 | 63.096 | 60.062 | |
| Bias Amp-DF ↓ | −0.333 | −0.286 | −0.230 | −0.289 | −0.235 | 0.092 | 0.205 | |
| Bias Amp-SF ↓ | −0.017 | −0.004 | −0.001 | −0.017 | −0.008 | 0.015 | 0.014 | |
| Adult Dataset | ||||||||
| Models | BDF-Classifier | BSF-Classifier | BPR-Classifier | BT-Classifier | ||||
| Tuning Parameter | 0.100 | 0.100 | 10.000 | 10.000 | 25.000 | 0.001 | X | |
| Performance Measures | Accuracy ↑ | 0.795 | 0.802 | 0.802 | 0.798 | 0.818 | 0.827 | 0.831 |
| F1 Score ↑ | 0.380 | 0.440 | 0.420 | 0.420 | 0.500 | 0.580 | 0.600 | |
| ROC AUC ↑ | 0.836 | 0.847 | 0.860 | 0.835 | 0.876 | 0.876 | 0.883 | |
| Fairness Measures | -DF ↓ | 0.305 | 0.442 | 1.194 | 0.733 | 1.355 | 1.362 | 1.591 |
| -SF ↓ | 0.007 | 0.011 | 0.031 | 0.001 | 0.030 | 0.033 | 0.042 | |
| -Rule ↑ | 55.590 | 54.855 | 46.988 | 58.112 | 47.128 | 54.071 | 45.019 | |
| Bias Amp-DF ↓ | −1.075 | −0.938 | −0.186 | −0.647 | −0.025 | −0.018 | 0.211 | |
| Bias Amp-SF ↓ | −0.026 | −0.022 | −0.002 | −0.032 | −0.003 | 0.000 | 0.009 | |
| HHP Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|
| Models | SDF-Classifier | SSF-Classifier | SPR-Classifier | ST-Classifier | ||||
| Tuning Parameter | 0.900 | 0.900 | 1000.000 | 100.000 | 500.000 | 0.100 | X | |
| Performance Measures | Accuracy ↑ | 0.801 | 0.801 | 0.832 | 0.813 | 0.829 | 0.818 | 0.843 |
| F1 Score ↑ | 0.580 | 0.580 | 0.680 | 0.620 | 0.660 | 0.650 | 0.720 | |
| ROC AUC ↑ | 0.796 | 0.803 | 0.859 | 0.870 | 0.887 | 0.873 | 0.895 | |
| Fairness Measures | -DF ↓ | 0.210 | 0.229 | 0.762 | 1.164 | 1.444 | 1.688 | 1.791 |
| -SF ↓ | 0.004 | 0.005 | 0.013 | 0.007 | 0.010 | 0.022 | 0.022 | |
| -Rule ↑ | 61.507 | 61.292 | 56.183 | 53.678 | 51.169 | 61.720 | 49.860 | |
| Bias Amp-DF ↓ | −1.250 | −1.231 | −0.698 | −0.296 | −0.016 | 0.228 | 0.331 | |
| Bias Amp-SF ↓ | −0.009 | −0.008 | 0.000 | −0.006 | −0.003 | 0.009 | 0.009 | |
| HMDA Dataset | ||||||||
| Models | SDF-Classifier | SSF-Classifier | SPR-Classifier | ST-Classifier | ||||
| Tuning Parameter | 0.600 | 0.600 | 1.000 | 50.000 | 1000.000 | 0.010 | X | |
| Performance Measures | Accuracy ↑ | 0.819 | 0.821 | 0.848 | 0.851 | 0.858 | 0.858 | 0.863 |
| F1 Score ↑ | 0.890 | 0.890 | 0.900 | 0.900 | 0.910 | 0.910 | 0.910 | |
| ROC AUC ↑ | 0.903 | 0.903 | 0.917 | 0.921 | 0.927 | 0.926 | 0.931 | |
| Fairness Measures | -DF ↓ | 0.240 | 0.296 | 0.417 | 0.436 | 0.549 | 0.554 | 0.673 |
| -SF ↓ | 0.004 | 0.005 | 0.007 | 0.002 | 0.005 | 0.008 | 0.011 | |
| -Rule ↑ | 71.018 | 69.938 | 66.822 | 70.260 | 64.643 | 71.256 | 62.045 | |
| Bias Amp-DF ↓ | −0.421 | −0.365 | −0.244 | −0.225 | −0.112 | −0.107 | 0.012 | |
| Bias Amp-SF ↓ | −0.005 | −0.004 | −0.002 | −0.007 | −0.004 | −0.001 | 0.002 | |
| Gini Coefficient (G) | ||||
|---|---|---|---|---|
| Dataset | ||||
| COMPAS | 0.151 | 0.376 | 0.135 | 0.343 |
| Adult | 0.099 | 0.256 | 0.126 | 0.257 |
| HHP | 0.113 | 0.311 | 0.105 | 0.305 |
| HMDA | 0.073 | 0.423 | 0.094 | 0.358 |
| COMPAS Dataset | HHP Dataset | ||||||
|---|---|---|---|---|---|---|---|
| Protected Attributes | -DF | -SF | Protected Attributes | -DF | -SF | ||
| race | 0.1003 | 0.0070 | gender | 0.0505 | 0.0039 | ||
| gender | 0.9255 | 0.0656 | age | 2.0724 | 0.0469 | ||
| race, gender | 1.3156 | 0.0604 | gender, age | 2.2505 | 0.0241 | ||
| Adult Dataset | HMDA Dataset | ||||||
| Protected Attributes | -DF | -SF | Protected Attributes | -DF | -SF | ||
| nationality | 0.2177 | 0.0045 | ethnicity | 0.1846 | 0.0056 | ||
| race | 0.9188 | 0.0128 | race | 0.6067 | 0.0126 | ||
| gender | 1.0266 | 0.0434 | gender | 0.1702 | 0.0088 | ||
| gender, nationality | 1.1511 | 0.0431 | gender, ethnicity | 0.3221 | 0.0118 | ||
| race, nationality | 1.1534 | 0.0163 | race, ethnicity | 0.6911 | 0.0167 | ||
| race, gender | 1.7511 | 0.0451 | race, gender | 0.6855 | 0.0137 | ||
| race, gender, nationality | 1.9751 | 0.0455 | race, gender, ethnicity | 0.8498 | 0.0163 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, R.; Keya, K.N.; Pan, S.; Sarwate, A.D.; Foulds, J.R. Differential Fairness: An Intersectional Framework for Fair AI. Entropy 2023, 25, 660. https://doi.org/10.3390/e25040660
Islam R, Keya KN, Pan S, Sarwate AD, Foulds JR. Differential Fairness: An Intersectional Framework for Fair AI. Entropy. 2023; 25(4):660. https://doi.org/10.3390/e25040660
Chicago/Turabian StyleIslam, Rashidul, Kamrun Naher Keya, Shimei Pan, Anand D. Sarwate, and James R. Foulds. 2023. "Differential Fairness: An Intersectional Framework for Fair AI" Entropy 25, no. 4: 660. https://doi.org/10.3390/e25040660
APA StyleIslam, R., Keya, K. N., Pan, S., Sarwate, A. D., & Foulds, J. R. (2023). Differential Fairness: An Intersectional Framework for Fair AI. Entropy, 25(4), 660. https://doi.org/10.3390/e25040660