Abstract
We present an empirical estimator for the squared Hellinger distance between two continuous distributions, which almost surely converges. We show that the divergence estimation problem can be solved directly using the empirical CDF and does not need the intermediate step of estimating the densities. We illustrate the proposed estimator on several one-dimensional probability distributions. Finally, we extend the estimator to a family of estimators for the family of -divergences, which almost surely converge as well, and discuss the uniqueness of this result. We demonstrate applications of the proposed Hellinger affinity estimators to approximately bounding the Neyman–Pearson regions.
1. Introduction
We present an empirical estimator for the squared Hellinger distance between two continuous distributions. The work is a direct extension of Perez-Cruz [1] where they provided an empirical KL divergence estimator. Their work is built upon previous works on divergence estimators such as [2,3,4,5,6]. Similar to their estimator, given two samples from two distributions, our estimator does not need to estimate the probability density functions explicitly before estimating the squared Hellinger distance between the two distributions, which makes it simple and fast. We show that the estimator converges to the true squared Hellinger distance almost surely as the sample size increases. We then extend our estimator to the family of -divergences, to which the squared Hellinger distance belongs. For each of the estimators, we can obtain a reverse estimator using the other direction of the two data samples, and we can also obtain a symmetric estimator by averaging the two one-sided estimators. We present several numerical examples to show the convergence of our estimators. Our newly proposed estimators can be used efficiently to approximate the adjacency of two data samples, leading to various applications in many fields of research.
2. Preliminaries on Divergences between Probability Distributions
Recall that the definition of squared Hellinger distance [7] is (for univariate continuous distributions):
It is symmetric and always bounded between 0 and 1.
Additionally, recall the definition of Kullback–Leibler divergence [8] is (for univariate continuous distributions):
KL divergence and the squared Hellinger distance both belong to a family of f-divergences, which are central to information theory and statistics. Compared with KL divergence, the squared Hellinger distance is symmetric, and Hellinger distance forms a bounded metric between 0 and 1 on the space of probability distributions. Hellinger distance is related to total variation distance as:
where total variation distance (TVD) is defined as:
The squared Hellinger distance is also closely related to KL divergence and can be bounded by:
It is also a known result that KL divergence is stronger than Hellinger distance in the sense that convergence in KL divergence implies convergence in Hellinger distance, which further implies convergence in total variation distances. Therefore, Hellinger distance represents a middle ground between KL divergence and total variation distance; it is weaker than KL divergence but stronger than total variation distance in terms of convergence. As shown before, Hellinger distance has close connections to the total variation distance, which is exactly what inference depends on (KL divergence does not admit a useful lower bound on the TVD). It has another attractive property compared with KL divergence, which is the fact that the squared Hellinger distance is always bounded between zero and one for probability distributions that may or may not have the same support, whereas the KL divergence becomes infinite for probability distributions of different supports. In fact, KL divergence can be unbounded for probability distributions supported on the real line. For example, consider P to be the standard Cauchy distribution and Q to be the standard normal distribution, then diverges to infinity. Hence, an empirical estimator for KL divergence does not provide meaningful estimates in such a case, while the squared Hellinger distance is always bounded. Due to these desirable properties, we focus mainly on the squared Hellinger distance in this work. The squared Hellinger distance is a member of the family of -divergences (up to a scaling factor), which are defined in Cichocki and Amari [9] for as,
The -divergence can also be related to TVD through the following inequalities, similar to squared Hellinger distance up to a scaling factor (see for example [10,11,12]),
3. Review of Empirical Sample-Based Kullback–Leibler Divergence Estimator of Continuous Distributions
Let be iid samples from P and Q in increasing order. Recall that the definition of the empirical CDFs of P and Q are, respectively,
where is a unit-step function with . The continuous piece-wise linear interpolation of the empirical CDF of P is denoted as . It is zero for any point smaller than a joint lower bound of the data samples from , and is one for anything greater than or equal to a joint upper bound of the data samples from ; everywhere in the middle, it is defined as:
where coefficients are set so that matches the values of at the sampled values . Similarly, we can define the interpolated empirical CDF for Q, denoted as . These empirical CDFs converge uniformly and are independent of the distribution of their CDFs.
Perez-Cruz [1] proposed an empirical KL estimator:
where for any denotes the left slope of at and denotes the left slope of at . Here, and are the samples from the P distribution. Ref. [1] showed that , almost surely. For this 1-D data setting, an experiment showing the convergence of their estimator is shown in Figure 1 where we plotted estimated values against increasing sample sizes, where are taken to be normal distributions and respectively.
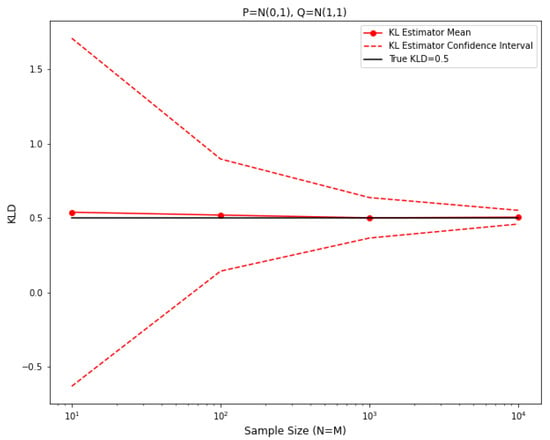
Figure 1.
Empirical KLD estimator for two normal distributions.
It is worth mentioning that the major innovation and strength of these types of empirical estimators is the fact that there are no convergent density estimators required in the process of estimating the desired divergences. In fact, only the empirical CDF is used and the density model being used in the estimator is completely based on the slopes of the piecewise linear interpolation of the empirical CDF. This empirical density model is far from being convergent as we can see from the following figures in Figure 2, which shows the calculated slopes (in blue) for data samples from a normal distribution against the ground-truth normal densities (in red), plotted in log scale. Clearly, the empirical density model does not converge to the true densities.
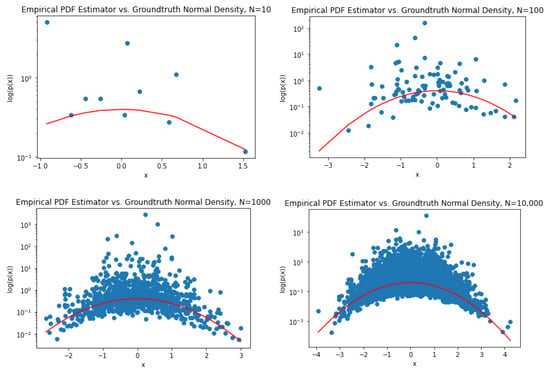
Figure 2.
Failure of empirical PDF estimator.
Perez-Cruz [1] also provided an empirical KL estimator for multivariate distribution samples. The estimator is based on a nearest-neighbor approach. For each sample in , where the dimension of the sample is d, let:
where are, respectively, the Euclidean distance to the k-th nearest neighbor of in and , and is the volume of the unit ball in . Ref. [1] continued to show that the random variable converges to an independent Gamma(k,k) random variable which has mean 1 and variance for each selected , where x is sampled from P. Therefore, they proposed the following estimator:
It was shown that, since and, consequently, converges to:
then almost surely.
4. Empirical Squared Hellinger Distance Estimator of Continuous Distributions
4.1. Estimator for 1D Data
Following Perez-Cruz [1], we have defined a similar estimator for Hellinger affinity using empirical CDFs. Let be iid samples from P and Q in increasing order. Recall that the definition of the empirical CDFs of P and Q are, respectively,
where is a unit-step function with . The continuous piece-wise linear interpolation of the empirical CDF of P (and Q) is denoted as (and , respectively). It is zero for anything smaller than a joint lower bound of the data samples from , and is one for anything greater than or equal to a joint upper bound of the data samples from ; everywhere in the middle, it is defined as:
where coefficients are set so that matches the values of at the sampled values . is defined similarly. These empirical CDFs converge uniformly and are independent of the distribution of their CDFs.
Our estimator for the squared Hellinger distance is based on estimating the Hellinger affinity, which is directly related to the quantity of interest by:
The new estimator for Hellinger affinity is
where for any denotes the left slope of at and, similarly, denotes the left slope of at .
We next claim and prove that converges to a scalar multiple of the true Hellinger affinity . To justify the use of this bias correction constant we need to prove that it results from terms we get from rewriting the estimator:
where and .
Notice that the first (square root) term in the sum converges almost surely to . We need to show that the above empirical sum converges almost surely to , where the constant is derived from the second term, using similar arguments as Perez-Cruz [1] through waiting time distributions between two consecutive samples from a uniform distribution between 0 and 1.
We outline the proof for the constant term below. Similar to Perez-Cruz [1], we know that, given , and is independent of P (similarly for Q). With this argument, the last expression for can be rewritten as (where )
The first sum converges almost surely to:
The second sum can be rewritten as:
The last expression converges almost surely to:
Notice here that is a density model but does not need to converge to for the above expression to converge to the desired constant.
Combining all previous results, we have shown that converges almost surely to:
Hence, we obtained the desired constant . The final estimator for squared Hellinger distance is .
Notice that Hellinger distance is a symmetric distance metric for any distributions P and Q, hence the estimator above is only one side of the story. Following exactly the same arguments, we can show that the opposite direction estimator,
also converges almost surely to , and since we can obtain a symmetric estimator of Hellinger affinity that converges almost surely to :
Therefore, we can construct a corresponding estimator for the squared Hellinger distance as:
which enjoys all of the properties shown above for the two estimators separately. Since the symmetric version uses more information from the two samples, it is supposed to be able to provide better estimates than the two single-sided estimators in terms of the rate of convergence.
4.2. Numerical Experiments
We show asymptotic convergence of the new estimator , and its symmetric version, to the true value as the data sample size grows in the below experiments. In each of the experiments, we took two distributions of the same family and compared the estimated squared Hellinger distance value against the ground truth value. We plotted mean estimated values for sample size (x-axis) used for each pair of distributions over 100 instances, and we also plotted the confidence interval of the estimates. For each experiment, the squared Hellinger distance estimators are plotted in red and blue, and the symmetric squared Hellinger distance estimator is plotted in purple. We also recall the fact that when are taken to be normal distributions , the squared Hellinger distance has an analytic form:
In the first experiment (Figure 3), are taken to be normal distributions and , respectively. In the second experiment are taken to be normal distributions and , respectively.
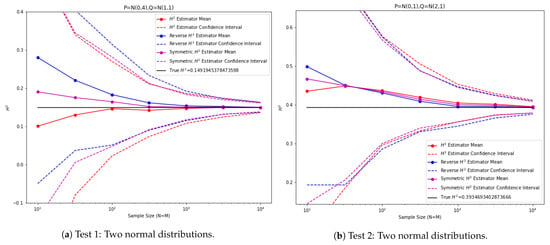
Figure 3.
Empirical squared Hellinger estimator tests between 1D normal distributions.
In the third experiment (Figure 4), are taken to be normal distributions and , respectively. In the fourth experiment, are taken to be exponential distributions and , respectively.
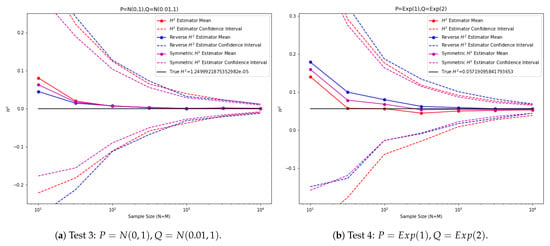
Figure 4.
Empirical squared Hellinger estimator tests between 1D distributions.
In the fifth experiment (Figure 5), are taken to be uniform distributions and , respectively. In the sixth experiment, are taken to be uniform distributions and , respectively. Notice that the squared Hellinger distance is well-defined for distributions of different support.
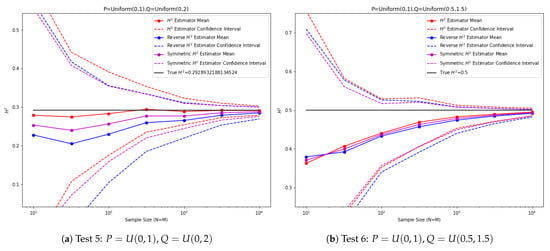
Figure 5.
Empirical squared Hellinger estimator tests between 1D distributions.
In the last two experiments (Figure 6), we considered two distributions from different distribution families. Here, is the standard Cauchy distribution. In the seventh experiment, and in the last experiment . The true squared Hellinger distances are computed using numerical integration.
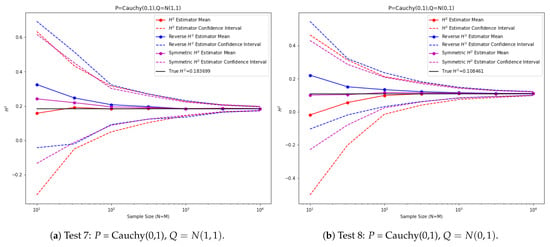
Figure 6.
Empirical squared Hellinger estimator tests between 1D Cauchy and normal distributions.
We can observe from the previous experiments that, depending on the distributions, either the estimator or the reverse direction estimator can turn out to be better, which is a consequence of our choice to take the left slope of the empirical CDF so the relative location of the two distributions will determine which estimator is more accurate. The symmetric squared Hellinger estimator provides a middle ground between the two one-sided estimators and it also exhibits smaller variances.
As mentioned before, the proposed estimator does not use the information of the underlying distribution and does not need to estimate the density first before estimating the squared Hellinger distance. As a comparison with an estimator that knows the distribution, we performed experiments with Gaussian distributions where we could use the sample mean and sample variance to estimate the distributions and then compute the squared Hellinger distance analytically using the estimated parameters. The estimator is constructed as follows,
where are sample estimates of mean and standard deviation from the two datasets. This estimator knows extra information about the data coming from Gaussian distributions.
However, as we can see from the plots in Figure 7, the proposed squared Hellinger distance estimator performs similarly to the estimator that knows the distribution family. In the first experiment, the two distributions are . In the second experiment, the two distributions are . For both plots, we plotted the proposed symmetric squared Hellinger distance estimator in red and the naive estimator using sampled parameters in blue. The upper bound and lower bound of each estimator, performed over 100 iterations, are plotted in dashed lines.
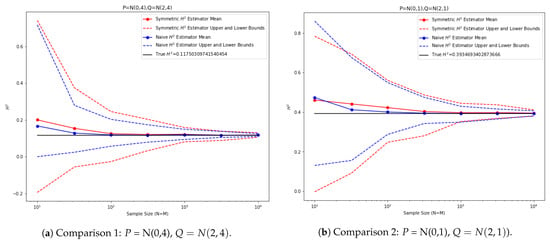
Figure 7.
Comparisons between empirical and naive estimators for 1D normal distributions.
Finally, we consider the setting in Test 8, where P is a standard Cauchy distribution and Q is a standard normal distribution, and we compare the behavior of the empirical squared Hellinger estimator with the empirical KL divergence estimator as in [1]. As mentioned in the discussion in Section 2, for this case, the KL divergence diverges to infinity while the squared Hellinger distance is bounded. With the same experiment setup, we plotted the resulting divergence estimates and confidence intervals for both KL divergence and squared Hellinger distance in Figure 8, where the ground truth value (approximated by numerical integration) is plotted in black and the ground truth value is infinity.
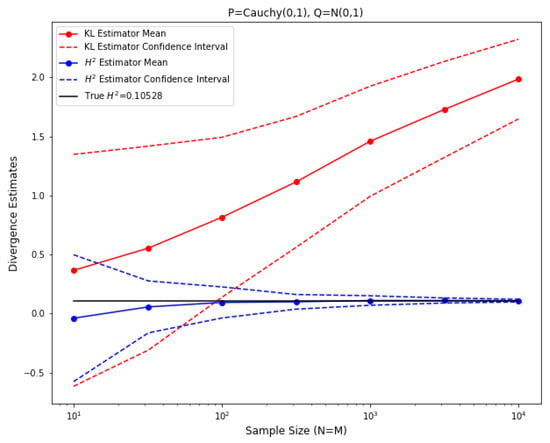
Figure 8.
Comparison of empirical estimator against empirical estimator, .
As we can observe from Figure 8, while the empirical squared Hellinger estimator converges to the ground truth value quickly, the empirical KL divergence estimator cannot converge to some value due to the fact that the ground truth value is infinity. This justifies the desirability of considering the squared Hellinger distance, which is always bounded.
4.3. Estimator for Vectorial Data
Utilizing the results proved for the vectorial data case in [1], we propose the following estimator for squared Hellinger distance in multivariate cases (for a chosen k). Similar to the definitions in [1], let the kNN density estimator be defined as:
where are, respectively, the Euclidean distance to the k-th nearest neighbor of in and . Let:
since are independent Gamma(k,k) random variables that are also independent from , we conclude that converges almost surely to:
So, converges almost surely to the true Hellinger affinity up to a constant multiplier, similar to the 1D case. Therefore, we propose the following estimator for squared Hellinger distance, which converges almost surely to the true squared Hellinger distance:
Similar to the 1D case, we can extend this estimator to a symmetric version that also shares the desired convergence properties:
4.4. Numerical Experiments for Vectorial Data
Similar to the experiment setting in Section 4.2, we show the convergence of the proposed estimators in Section 4.3. Sample size (plotted on the x-axis) is used for each pair of distributions. The analytical formula for the squared Hellinger distance for two multivariate Gaussians is:
In the experiment in Figure 9, we picked 2D normal distributions P and Q with . For the proposed k-nearest neighbor estimator, we picked . The performance of the proposed estimators and a comparison with the naive estimator are plotted below. The naive estimator estimates the mean and covariance based on the data samples and estimates the squared Hellinger distance based on the analytic formula:
From these results we can observe that, similar to the 1D cases, the symmetric estimator seems to perform the best and is comparable to the naive estimator in terms of convergence.
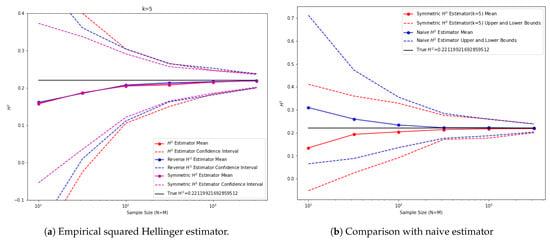
Figure 9.
Vectorial squared Hellinger estimator () tests on 2D normal distributions.
In general, a larger k leads to a smaller variance in the proposed estimator for multivariate data. To balance the convergence rate with computational cost, we can select k to be around 4 to 6 which converges faster than a smaller k and is also easy to compute. This behavior is shown in Figure 10, where we compared the performance of the proposed estimator using for the same experiment setting as above.
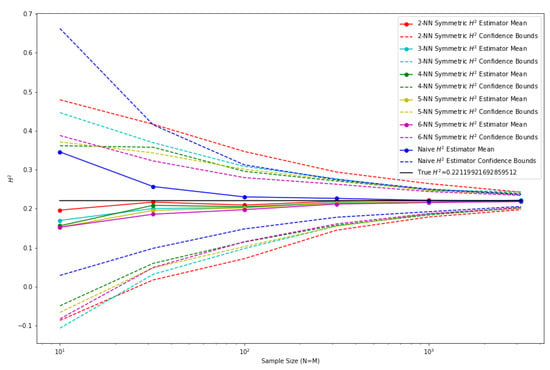
Figure 10.
Comparison of kNN-based squared Hellinger distance estimators.
Another test we conducted was to check if the squared Hellinger distance estimate behavior in a non-asymptotic sense is similar for two pairs of concentric Gaussians that have the same squared Hellinger distance. For this experiment, we picked the first pair of Gaussians to be and , and the second pair of Gaussians to be and . The squared Hellinger distance between each pair of Gaussians is 0.2 and, since these two pairs correspond to a single coordinate transformation on the sample space, we expect similar behavior of the estimator in terms of convergence on both pairs. The result is shown in Figure 11. As expected, the empirical estimator for vectorial data has very similar convergence behavior for each of the two pairs of Gaussians to the same ground-truth value.
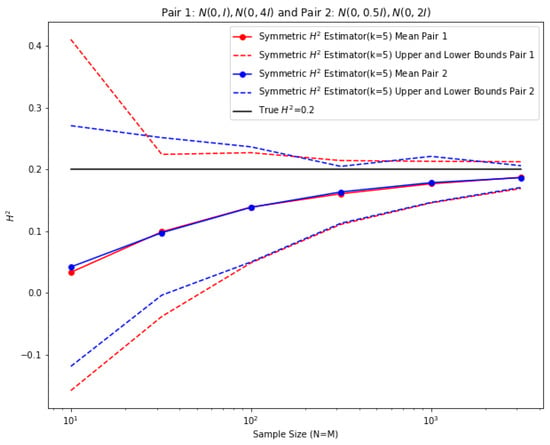
Figure 11.
Two pairs of concentric Gaussians with invariant squared Hellinger distance.
5. Empirical -Divergence Estimator of Continuous Distributions
5.1. Estimator for 1D Data
We generalized the results obtained before to a family of -divergences to which the squared Hellinger distance belongs. Following Cichoki and Amari [9], we define an -divergence between two probability distributions as:
We want to obtain an empirical estimator similar to that in Section 3 that uses only the empirical CDFs of P and Q and estimates this quantity directly for any . Notice that for , , which corresponds to the squared Hellinger distance.
Notice that we can rewrite the -divergence above as:
Clearly, we are interested in the last quantity, so we only need to have an estimator for that term that converges almost surely.
For this purpose, let us define an estimator:
Notice that, in the general cases, the -divergence is not symmetric.
Following similar procedures as in Section 3, we can rewrite the estimator as:
This sum converges almost surely to (since the exponential waiting distributions are independent of the data distribution):
Following the same arguments as in Section 3, we can show that the proposed estimator converges almost surely to:
where we define the constants .
Therefore, we know that the estimator
converges almost surely to the true -divergence value, .
Although the -divergence is not symmetric, it has the property that
So, given the same two sample data sets, we can get another estimator for the same quantity based on , where we are estimating based on the sampling distribution from Q instead of P. Since converges to the same divergence value, we can again create a symmetric estimator based on averaging these two estimators and it is expected to perform similarly if not better. Lastly, notice that, when , we obtain and , which corresponds to the squared Hellinger estimator we have seen in Section 3, scaled by 4.
5.2. Numerical Experiments
We show asymptotic convergence of the new estimator , and its symmetric version, to the true -divergence value as the data sample size grows in the below experiments. In each of the below experiments, we took two distributions of the same family and compared the estimated -divergence value against the ground truth value. Mean estimated values for sample size (plotted on the x-axis) used for each pair of distributions over 100 instances and we also plotted the confidence interval of the estimates. For each experiment, the -divergence estimators are plotted in red and blue, and the symmetric -divergence estimator is plotted in purple.
In the first experiment, are taken to be normal distributions and , respectively, and . In the second experiment, are taken to be normal distributions and , respectively, and . The results are plotted in Figure 12. Notice that for two normal distributions , we have an analytical formula for the -divergence:
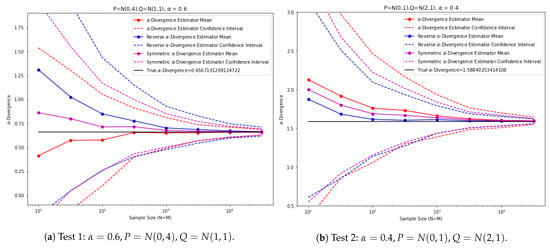
Figure 12.
-divergence estimator tests on 1D normal distributions.
Again, we provide a comparison with an estimator that knows the distribution family. We performed experiments with Gaussian distributions where we could use the sample mean and sample variance to estimate the distributions and then compute the -divergences analytically using the estimated parameters. The estimator is constructed as follows:
where are sample estimates of mean and standard deviation from the two datasets. This estimator knows extra information about the data coming from Gaussian distributions. However, as we can see from the plots in Figure 13, the proposed -divergence estimator performs similarly to the estimator that knows the distribution family.
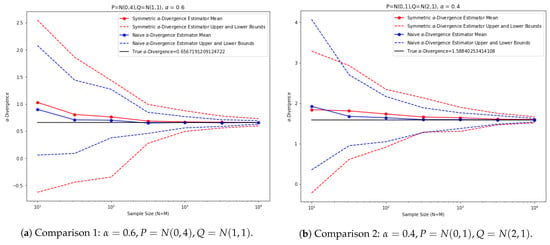
Figure 13.
Comparisons between empirical and naive estimators for 1D normal distributions.
In the first experiment, the two distributions are and . In the second experiment, the two distributions are and . For both plots, we plotted the proposed symmetric -divergence estimator in red and the naive estimator using sampled parameters in blue. The upper bound and lower bound of each estimator, performed over 100 iterations, are plotted in dashed lines.
5.3. Estimator for Vectorial Data
Similarly to Section 4.3, we propose -divergence estimators for samples from multivariate distributions. For this purpose, let us define:
Using similar arguments, we can show that this estimator converges almost surely to:
Therefore, we propose the following estimator for -divergences, which converges almost surely:
Similarly, we can extend this estimator to a symmetric version, for any fixed k:
As a remark, for the vectorial case, the above kNN density-based empirical estimator for -divergences (and the squared Hellinger distance in Section 4.3 as a special case) agree with the estimators proposed in [13], although the proof of convergence differs. Nonetheless, the univariate estimators we proposed in Section 4.1 and Section 5.1 are different from trivial reductions of the kNN-based estimators in Section 4.3 and Section 5.3 when taking and .
6. Limitation of the Proposed Methodologies and Uniqueness of the -Divergences
6.1. Failure of a Similar Estimator for Total Variation Distance
As we have shown so far, by using the trick of waiting time distributions, we can bias-correct an empirical mean type estimator to produce an almost-sure convergence estimator for KL divergence, squared Hellinger distance, and in general the -divergences. However, the same kind of trick does not work for other f-divergences that have an f-function without certain desired properties such as for KL divergence or for Hellinger affinity, which we shall discuss in more detail later. As a simple demonstration, consider the Total Variation Distance (TVD), which, for two continuous distributions P and Q, is defined as:
Notice that the TVD is always bounded between 0 and 1.
We considered paired distributions in two different families in 1D, namely normal distributions and exponential distributions. For different choices of parameters, we plotted the performance of a biased estimator using the empirical CDFs against the true TVD value. For every parameter setting, we looked at the case where and averaged over 100 instances. The estimator is defined as:
Specifically, for the normal distributions, we fixed and varied from 0 to 5. For the exponential distributions, we fixed and varied from 0.1 to 7. This generated a range of true TVD values that are spaced between 0 and 1 for each distribution family. Figure 14 plots the biased estimator values (on the y-axis) against true TVD values (on the x-axis) for pairs of normal distributions in blue and pairs of exponential distributions in red. The confidence intervals are also plotted. We observe that, for the same true TVD values, the biased estimator produced different values for different distribution families, where the relationship looks nonlinear and depends on the distribution family itself. This is an indication that the proposed estimator cannot be uniformly corrected with a simple additive and/or multiplicative constant as we performed for squared Hellinger distance (and in general -divergences) and [1] for KL divergences. Therefore, we conclude that, so far, the proposed methodologies work for KL divergence, squared Hellinger distance, and in general -divergences only, but cannot be extended to the general f-divergences in a straightforward way.
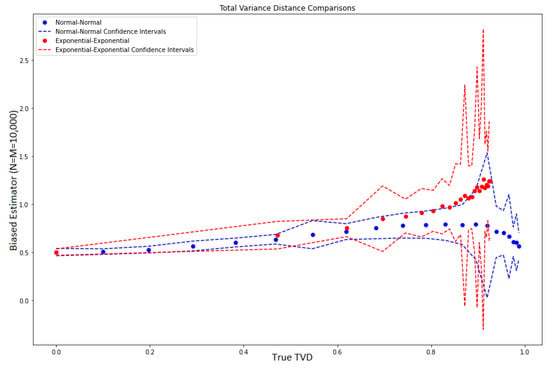
Figure 14.
Raw empirical TVD estimator.
6.2. Uniqueness of -Divergences
We provide a more detailed explanation as to why the -divergences are the unique family of f-divergences that can be estimated using our type of estimator based on waiting time random variable transformations. Take the vectorial case for example, where we construct kNN empirical density estimates for the probability densities ; for an estimator that is based on these estimates to work for an f-divergence, we would require the f-divergence to be computable through an affinity term as an integration of the form or up to some constant terms, and we require that the affinity generating functions f satisfy a functional form that can be separated as either or for some functions g and h. This restriction is made because, as we have seen for KL or -divergence estimators, we rely on the independence property of the waiting time random variables, hence we can separate the empirical sums into three terms which converge separately and show the estimator to converge asymptotically up to additive or multiplicative bias constants. Let us examine these two types of restrictions on f.
For f to satisfy , we can see that f is equivalent to g and h in the sense that they differ by a constant. Differentiating the previous equation with respect to x and setting we would get:
where is a constant. The unique family of solutions to this condition is up to some additive constants. This obviously corresponds to KL divergence and reverse KL divergence when integrated against P and Q, respectively.
For the other case where , let us consider differentiating both sides with respect to x; this gives:
Taking log on both sides and let :
Now take the derivative with respect to x again and set , we get:
where is a constant. The unique family of solutions satisfying the last condition is and hence is a general solution up to some additive constant. Without loss of generality, we can see that this corresponds uniquely to the affinity term of interest of the family of alpha divergences where , and up to some constant terms.
Since KL and reverse KL divergence are limits of the -divergences at two endpoints, we can conclude that the unique family of f-divergences that can be estimated based on the proposed estimators using waiting time random variables are the -divergences. There is an interesting connection, pointed out by Amari [14], that states that -divergence is the unique intersection between f-divergences and decomposable Bregman divergences on the space on positive measures. Notice that if restricted to the space of probability measures then the intersection reduces to only the KL divergences. Although the result does not directly connect to the uniqueness of -divergences being estimable through our proposed methodologies, the proof technique that justifies the functional forms of the -divergence being the unique f-divergence that allows a decomposition into the Bregman divergence dual functions up to some nonlinear coordinate transformation is very similar to what we carried out above and reaches the same conclusion—that the function f must take on a power function form that corresponds to an -divergence and at the limit of becomes logarithm functions that correspond to KL and reverse KL divergences.
7. Applications
The proposed estimator finds interesting applications in statistical estimation theory, clustering algorithms, visualization/embedding algorithms, and possibly online learning algorithms. We next describe a few such examples.
7.1. Bounding the Neyman–Pearson Region by Hellinger Affinity
We show that the Neyman–Pearson region contains one convex region determined by the Hellinger affinity, which is contained in another. These inclusion relations generalize the classical inequalities between total variation and Hellinger distance. Deploying our estimator for Hellinger affinity , we can approximately bound the Neyman–Pearson region.
Our results (see Appendix A for more details) show that, with two distributions , and with (which can be chosen so that in standard case), the Neyman–Pearson region for type I () and type II () errors satisfies the following relation with the total variation distance for optimal choice of event :
and can hence be bounded by the following inequalities where is the Hellinger affinity:
Hence, by substituting our symmetric estimator for the Hellinger affinity term , we can approximately bound the Neyman–Pearson region given two samples from distributions p and q,
If we are dealing with multivariate distributions, then the appropriate multivariate Hellinger affinity estimator from Section 4.3 can be used to approximately bound the Neyman–Pearson region. As a remark, we observe that there is no provable general relationship between Kullback–Leibler divergence or the rest of the -divergences (besides Hellinger distance) with the Neyman–Pearson regions.
7.2. Estimating Eigenvalues of the Matrix Pencil for Inference in the Family of Concentric Gaussians
Consider two multivariate distributions from the concentric Gaussian family , where . It can be shown that any meaningful statistical inference function on the two covariance matrices should satisfy , where is the diagonal matrix with diagonal entries being the eigenvalues of the matrix ; see Appendix C for more details.
Since is diagonal and I is simply the identity matrix, we can write . Hence, any inference we can make on the two concentric Gaussians will depend only on sufficient statistics, which are the eigenvalues . In the case of Hellinger affinity (and in general affinities for -divergences), we can write it as , where is the affinity calculated based on two univariate Gaussian distributions and . For example, we have analytic formulas for the affinity term of the -divergence family between such univariate Gaussian distributions:
Then, we have, for the d-dimensional multivariate concentric Gaussians,
Now, given d distinct values of , the affinity values can be used to determine the eigenvalues . Since our proposed estimator for vectorial -affinities converges up to a multiplicative constant, we can use the estimated values for -affinities corresponding to d different values of to estimate the eigenvalues by solving a system of d equations. The estimated values can be then used for any inference problems on these two probability distributions and they are sufficient for inference. This significantly reduces the noise in estimating the entire covariance matrices when the data come from high dimensions where we could have an over-parametrization problem.
7.3. Stock Clustering and Visualization
We next describe a simple application to stock segmentation in a portfolio allocation setting. Consider N stocks with T historic dates. Let denote the returns of each stock on each date. Let denote the random variable standing for the returns of each stock, which is composed of data . To cluster this universe of stocks into K distinct groups, we can first use the Hellinger distance estimator for a pair of stocks . Since the estimator is symmetric, we would arrive at a symmetric distance matrix denoted by . It is also possible to combine the Hellinger distance with a correlation distance metric through some transformations. After obtaining the distance matrix (or an affinity matrix by subtracting it from 1), we can deploy any desired clustering algorithm on it. The result would be K clusters of stocks that are grouped by similarity in the chosen distance sense. We can also add another step, which is to repair the distance matrix before clustering. There is the possibility that the distance matrix estimated using the proposed estimator does not exactly correspond to a metric, which means some groups of stocks may violate the triangle law in a metric. We can apply a simple sparse metric repair algorithm, see, for example, [15]. The resulting clustering can be helpful for portfolio allocation strategies since we can build sub-strategies inside each cluster and merge them together.
Another example using the same distance matrix constructed from sample data is in visualization algorithms such as FATE [16], which allow for the input of a precomputed distance/affinity matrix specifying the dataset. The visualization algorithm uses the input distance to compute embeddings in lower dimensions that preserve the local/global structures of the dataset and can be useful in many subsequent applications. Here, our estimator can also serve to compute the input distance matrix on sample data from N entities using the Hellinger distance or -divergences as the distance metric. This could also be used in conjunction with a metric repair algorithm to adjust for the biases and errors in empirical estimators.
7.4. Other Applications
Lastly, we suspect that the proposed estimator can find interesting applications in UCB-type algorithms in multi-armed bandit frameworks, where the estimated pairwise Hellinger distances/-divergences for sample distributions from different arms can be used to eliminate arms that fall outside of the confidence region balls around the top arms historically. We leave these open problems as future works.
8. Conclusions
We have proposed an estimator for the Hellinger affinity, and hence the squared Hellinger distance, between samples from two distributions based solely on the empirical CDF without the need to estimate the densities themselves. We have proven its almost-sure convergence to the true squared Hellinger distance and have constructed a symmetric version of this estimator. We showed the convergence behavior using several experiments where we observed that the symmetric estimator constructed from averaging the two one-sided estimators for the squared Hellinger distance turned out to be a favorable choice due to accuracy in general and smaller variances. We then extended the estimator to a family of -divergences, where similar properties hold up to small modifications. For each choice of , we also showed how to construct a symmetric version of the estimator. We also extended respective estimators to work with multivariate data in higher dimensions using k-nearest-neighbor-based estimators. Numerical examples are given to show the convergence of our proposed estimators. We conclude that the -divergence family is the unique f-divergences that can be estimated consistently using the proposed methodologies. Our proposed estimators can be applied to approximately bounding the Neyman–Pearson region of a statistical test, among many other applications.
Author Contributions
Methodology, R.D.; Formal analysis, R.D.; Writing—original draft, R.D.; Writing—review & editing, A.M.; Visualization, R.D.; Supervision, A.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Shannon Entropy Estimator for 1D and Vectorial Data
Another simple extension of the methodologies in this work provides us with a convergent estimator for the Shannon entropy defined as:
Here given 1D data samples from distribution P, we propose the following estimator:
where are as defined in Section 4.1. It can be shown that:
This suggests that where is the Euler-Mascheroni constant. Hence we conclude that converges almost surely to , the true Shannon entropy of P.
Similarly, for vectorial data in d-dimensions, we define the estimator based on the k-nearest neighbor for a fixed k:
where is as defined in Section 4.3. By a similar argument, we show that:
Since the integral evaluates to , we conclude that converges almost surely to .
On a related note, a class of estimators of the Rényi and Tsallis entropies for multidimensional densities has been studied in [17], which is also based on computing the k-nearest neighbor distances from empirical samples.
Appendix B. Hellinger Affinity and Neyman–Pearson Region
Following [18], we define the squared Hellinger distance and Hellinger affinity as:
Then the Type I and Type II errors for any event E used as a test for distribution by q, are given by
and we have the inequality for any non-negative :
This is because , and , where is the complement of event E. Combining these results gives the aforementioned inequality, which can be seen as a generalization of the classic case when , see Chapter 13 of [18]. For an optimal , an event for which this holds with equality (for example when is the support of ), we have:
and is the point on the Neyman–Pearson boundary with supporting line . Since the Neyman–Pearson region is convex, the family of f-divergences , where say , obtains a complete description of the Neyman–Pearson region.
Additionally, we can relate the Neyman–Pearson region to the Hellinger distance by using the Hellinger affinity. It is convenient to compute
where the first term is from the conservation of probability. Then we use this to simplify the chain of inequalities:
and
(where we used the Cauchy-Schwarz inequality) to the chain of inequalities:
We obtain then for the Neyman–Pearson boundary the upper and lower bounds in terms of the Hellinger affinity:
This bound has the gigantic advantage of also bounding the Neyman–Pearson region for joint distributions, such as the result of i.i.d. samples. There is no general relationship between Kullback–Leibler divergence and Neyman–Pearson regions since, say, for the Bernoulli family we can have a sequence of pairs such that but .
Appendix C. Sufficient Information Eigenvalues for Inference between Concentric Gaussians
Let . For any meaningful statistical inference function on we require
where X is a coordinate transformation. Writing the QR decomposition for and let R be chosen so that (where Q is unitary), which is equivalent to the Cholesky factorization . Define then we have
We choose Q so that it is the eigenvectors of the Hermitian matrix . So we have the diagonal matrix where the diagonal elements are eigenvalues of . Then we obtain,
References
- Perez-Cruz, F. Kullback–Leibler divergence estimation of continuous distributions. In Proceedings of the IEEE International Symposium on Information Theory, Toronto, ON, Canada, 6–11 July 2008; pp. 1666–1670. [Google Scholar]
- Lee, Y.K.; Park, B.U. Estimation of Kullback–Leibler divergence by local likelihood. Ann. Inst. Stat. Math. 2006, 58, 327–340. [Google Scholar] [CrossRef]
- Anderson, N.; Hall, P.; Titterington, D. Two-sample test statistics for measuring discrepancies between two multivariate probability density functions using kernel-based density estimates. J. Multivar. Anal. 1994, 50, 41–54. [Google Scholar] [CrossRef]
- Nguyen, X.; Wainwright, M.J.; Jordan, M.I. Nonparametric estimation of the likelihood ratio and divergence functionals. In Proceedings of the IEEE International Symposium on Information Theory, Nice, France, 24–29 June 2007. [Google Scholar]
- Wang, Q.; Kulkarni, S.; Verdú, S. Divergence estimation of continuous distributions based on data-dependent partitions. IEEE Trans. Inf. Theory 2005, 51, 3064–3074. [Google Scholar] [CrossRef]
- Wang, Q.; Kulkarni, S.; Verdú, S. A nearest-neighbor approach to estimating divergence between continuous random vectors. In Proceedings of the IEEE International Symposium on Information Theory, Seattle, WA, USA, 9–14 July 2006; pp. 242–246. [Google Scholar]
- Yang, G.L.; Le Cam, L. Asymptotics in Statistics: Some Basic Concepts; Springer: Berlin, Germany, 2000. [Google Scholar]
- Kulllback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Cichocki, A.; Amari, S. Families of alpha- beta- and gamma- divergences: Flexible and robust measures of similarities. Entropy 2010, 12, 1532–1568. [Google Scholar] [CrossRef]
- Binette, O. A note on reverse Pinsker inequalities. IEEE Trans. Inf. Theory 2019, 65, 4094–4096. [Google Scholar] [CrossRef]
- Sason, I.; Verdú, S. f-divergence inequalities. IEEE Trans. Inf. Theory 2016, 62, 5973–6006. [Google Scholar] [CrossRef]
- Gilardoni, G.L. On Pinsker’s type inequalities and Csiszar’s f-divergences, Part I: Second and Fourth-Order Inequalities. arXiv 2006, arXiv:cs/0603097. [Google Scholar]
- Poczos, B.; Schneider, J. On the Estimation of α-Divergences. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 609–617. [Google Scholar]
- Amari, S. α-Divergence is unique, belonging to both f-divergence and Bregman divergence classes. IEEE Trans. Inf. Theory 2009, 55, 4925–4931. [Google Scholar] [CrossRef]
- Gilberg, A.; Jain, L. If it ain’t broke, don’t fix it: Sparse metric repair. In Proceedings of the 55th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 3–6 October 2017; pp. 612–619. [Google Scholar]
- Ding, R. Visualizing Structures in Financial Time-Series Datasets through Affinity-Based Diffusion Transition Embedding. J. Financ. Data Sci. 2023, 5, 111–131. [Google Scholar] [CrossRef]
- Leonenko, N.N.; Pronzato, L.; Savani, V. A class of Rényi information estimators for multidimensional densities. Ann. Stat. 2008, 36, 2153–2182. [Google Scholar] [CrossRef]
- Lehmann, E.L.; Romano, J.P. Testing Statistical Hypotheses; Springer: New York, NY, USA, 2005. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).