1. Introduction
Autonomous driving on a multi-agent system is a highly researched goal pursued in robotics.
Deliberative control techniques, which require precise recognition and knowledge of the surroundings and well-defined hierarchical structures, show an efficient performance in controlled environments; see [
1], where a broad review of path planning strategies is presented, including environment and robot interaction modeling. In contrast,
reactive control techniques, based on a robust stimulation–response behavior, yield a favorable execution on unknown environments [
2]. The location of the agents (mobile robots) about a global frame of reference, navigation in unknown environments, and the introduction of multiple robots in the same workspace make this a challenging problem to solve. Multiple mobile robots systems present new challenges compared to single vehicle control, such as the heterogeneity of the agents, mixed traffic, cooperative behaviors, collisions among vehicles, static obstacles, and even pedestrians [
3,
4].
Mobile robots are electro-mechanical devices that can move on the bi-dimensional plane, and this restriction leads to 3 degrees of freedom, which are its location and orientation coordinates. Mobile robots can be classified according to their grade of mobility and directional capabilities. Type (2, 0) or differential robots have two wheels with individual speeds and no directional actuator. Thus, differential mobile robots are underactuated systems subject to non-holonomic constraints, which hinders the design of the navigation controller. Although the navigation control of mobile robots is not new, novel applications and developments are studied, due to the recent technological advances and cost reduction in electronics, as well as more powerful, highly integrated but smaller computing devices [
5,
6]. In [
5], the application of multi-robot systems for harvester assisting purposes is presented such that a cooperative co-working set of robots must follow the farmer to help with weeding, harvesting, crop scouting, etc., rendering a human–machine collaboration system. Other applications for multi-agent systems and social robots navigation, such as delivery robots, warehouses, indoor service robots, surveillance robots, etc., are listed in [
7]. An interesting application is presented in [
8], where a multi-robot system is proposed for defect detection and location on large surface metal plates; it is pointed out that there are several trade-offs between the performance in terms of defect location accuracy and the number of robots, their navigation capabilities, and ability to keep a formation.
The implementation of multi-agent swarm systems usually involves the usage of several data acquisition devices, such as inertial sensors [
9], simultaneous localization and mapping (SLAM) [
10], onboard cameras for computer vision [
11], and relative radio positioning [
12], in order to provide data redundancy and diversity to model environmental conditions properly [
13]. There are even biomimetic sensors designed for navigation purposes in multi-robot systems; see [
14], where a micro lenses array is integrated to aperture and field diaphragms to emulate an insect compound eye and later is combined to SLAM techniques for the navigation of a set of outdoor light robots. In general, the amount of data processing is directly proportional to the number of agents in the system, increasing power consumption in onboard processing platform solutions. Centralized swarm navigation schemes usually share all their gathered data through all the agents in the system, making them utterly dependent on the communication system’s reliability [
15]. To overcome the burden of data required to create a map, in [
6], they propose using OpenStreetMaps, which are user-generated maps, publicly available, whose information is combined with lidar-based Naive-Valley-Path generation methodologies to render a local path that is free of obstacle collisions with other vehicles and pedestrians, thus combining deliberative and reactive techniques, providing a complete outdoor autonomous navigation system for unstructured environments. Another application of integrating deliberative and reactive techniques is found in [
16], where a navigation controller that uses SLAM, path-planning techniques and exteroceptive sensors is applied to small-scale vessels or surface vehicles.
On the other hand, some species in nature have developed effective ways to achieve evasion, following other members and shaping formation, yielding to behavior models of biological systems, such as schools of fish, flocks of birds, or crowd dynamics, which are examples of reactive control techniques, and can be used for its implementation on robotic systems, more specifically, unicycle differential robots. In these reactive models, the individual actions of each agent are defined toward the fulfillment of a global objective [
17,
18] so as to have the most number of animals in a reduced space or some species of birds that can make more complex formations toward a leader.
Some advances in the research of crowd dynamics allow, with a set of simple rules, to predict the agents’ behavior. For instance, in [
19], potential functions and panel methods are embedded into an algorithm to create a collision-free path for differential agents. The simplicity, ease of implementation, and low computational requirements make this modeling approach effective in robot navigation. However, potential functions may suffer from several problems, such as local minima traps, dead locks between close obstacles, oscillations in the presence of obstacles, and inside narrow passages.
Another kind of solution is obtained from observing the animal’s conduct when moving and interacting with each other, according to its goal. In [
20,
21], Helbing et al. (2000, 2005) analyzed crowd dynamics, describing a model of displacement behavior; if an individual wants to move to a desired point, it moves in the shortest path with the most comfortable speed; when an obstacle, like a wall or another individual appears, the individual starts evading it as soon as a comfort zone is invaded, i.e., a private space. This zone is preferred not to be invaded, so the individual tries to keep it clear.
There are other investigations, such as [
17], which set navigation rules with the purpose of the agents reaching geometric shape formations regarding the position of the other agents in a sort of coordinated behavior. In humans, for example, making a line or a circle implies knowing the location of everybody else in the group such that everyone sets their position on the formation.
More recently, reinforcement learning (RL) and deep reinforcement learning (DRL) techniques have been applied for the navigation of autonomous vehicles; [
4,
7] present surveys of advances on applying RL and DRL to problems such as obstacle avoidance, indoor navigation, multi-robot navigation, and social navigation, considering heterogeneous fleets, unmanned vehicles, aerial vehicles and ships, and possible interaction between agents and humans. They point out that the results highly depend of the degree of cooperation and shared information between the agents. Particular applications of RL to the case of groups of autonomous vehicles give rise to the so-called multi-agent reinforcement learning (MARL), which is a more distributed framework in which several agents simultaneously learn cooperative or competitive behaviors [
22]. This approach is being applied to mixed traffic problems and heterogeneous group of agents.
In this article, a decentralized control strategy is designed, allowing autonomous driving for a multi-agent system, using behavioral models to enable the trajectory tracking and collision avoidance of dynamic and static obstacles, based on the relative approaching velocity. A desired formation is simultaneously achieved by establishing some navigation restrictions, in this case, and without loss of generality, a circular formation. The objective of the research is then to use these models and to adapt them in a control strategy which allows a decentralized, autonomous navigation system.
In
Section 2, the specifications of the control proposal are described, while in
Section 3, the Lyapunov’s stability test is applied on the closed-loop system, for the non-collision case, to obtain stability conditions to be satisfied by the control gains. In
Section 4, the development of an experimental platform is shown.
Section 5 compares the simulation and experimental results.
Section 6 gives the conclusions of this work.
3. Stability Analysis for the Non-Collision Case
The avoidance collision force term represents repulsive forces for dynamic and static obstacles, depending on the relative approaching velocity. Therefore, such forces depend on each possible scenario that the agent may encounter, and thus the stability analysis is carried out for the free collision case. From the simulation and experimental tests, it is concluded that the proper tuning of repulsive forces will not affect convergence to the desired position as far as there is not an obstacle inside the comfort zone, generating a conflict for the agent being in its desired position.
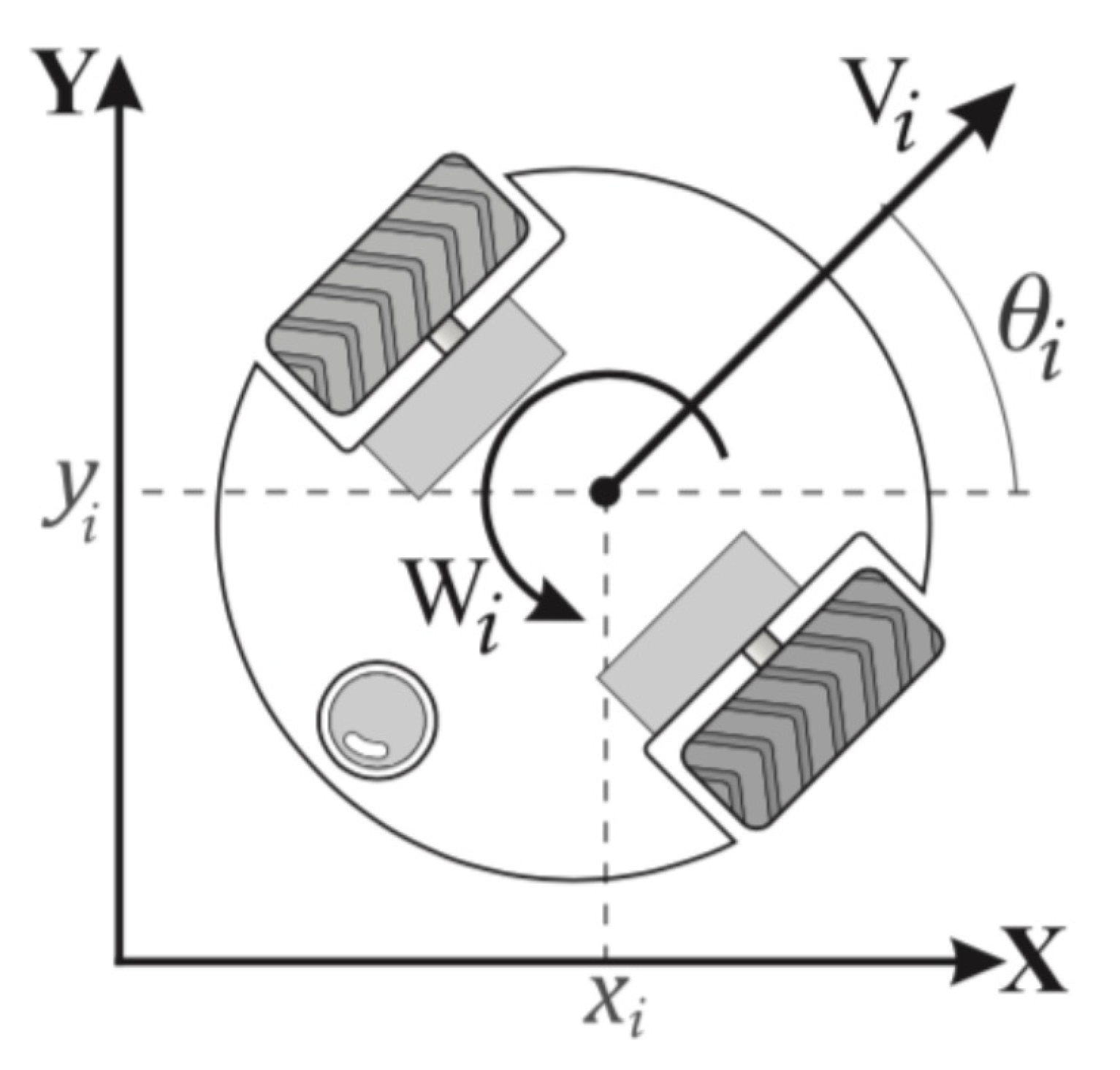
Using Lyapunov’s stability test, setting
for the collision-free case and taking into consideration the values of interest
and their desired references
, the next state variables are defined:
The closed loop for the
i-th agent is given by
With
as angular velocity reference and
Using the Lyapunov candidate function
, the time derivate of
is
In order to prove
, we can upper bound it considering the algebraic properties
and
. Furthermore, it is worth mentioning that the motors produce a maximal velocity and acceleration, which are positive and bounded, regardless of its spin direction. So, it results in
,
and
,
. Replacing the bounds of the trigonometrical functions in (
15) given by
,
,
and considering the worst-case operation scenario, the function can be written as
According to (
7), the best-case scenario is when agent
i is in a circular formation, i.e.,
, yielding to
. The worst-case scenario is
, which means the agent
i is outside the circumference and
. These considerations lead to the next list of conditions, which accomplish
:
Under the conditions given in (
17), the closed-loop system is asymptotically stable only when
as
,
,
and
. Nevertheless, when
, there are unvanishing terms, which makes
and only retrieves practical stability, known as uniformly ultimately bounded (UUB) stability.
To perform stability analysis considering possible collisions with dynamic and static obstacles, each different reaction force for each possible situation during the navigation of the agent should be properly modeled, which is a cumbersome task. Nevertheless, simulation and experimental tests showed that tuning the reaction forces for dynamic obstacles would also work for static obstacles since for the last ones, the relative approaching velocity is smaller than that of dynamic obstacles, thus requiring less aggressive evasion actions. Then,
in expression (
3) are tuned so the repulsive forces can produce a quick response to avoid collisions with dynamic obstacles; the same tuning is used for static obstacles, while maintaining the system’s stability, assuming bounded and differentiable perturbations.
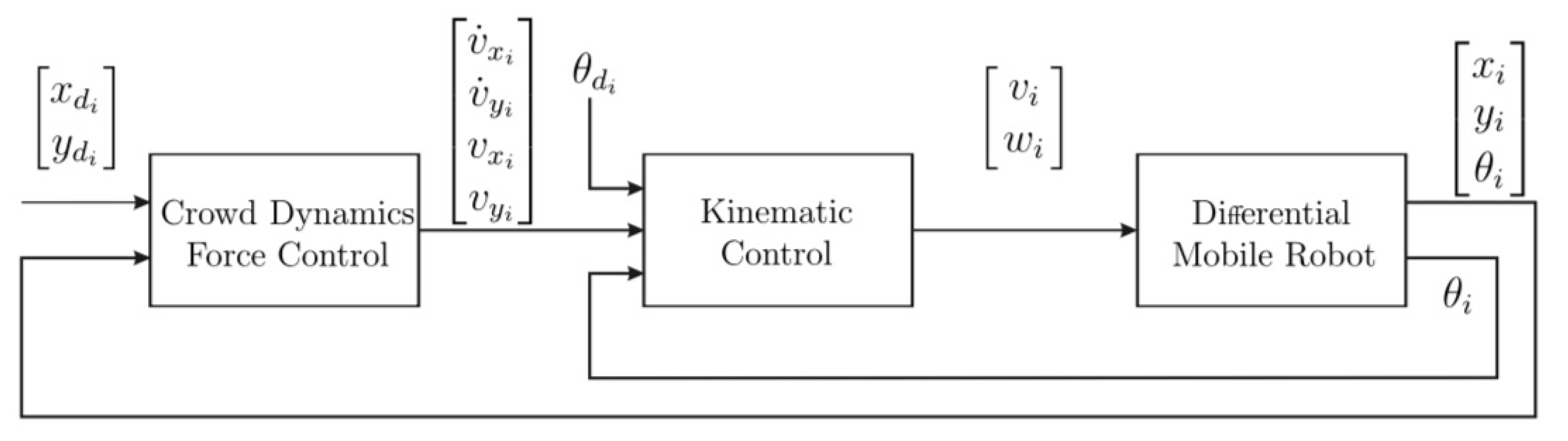
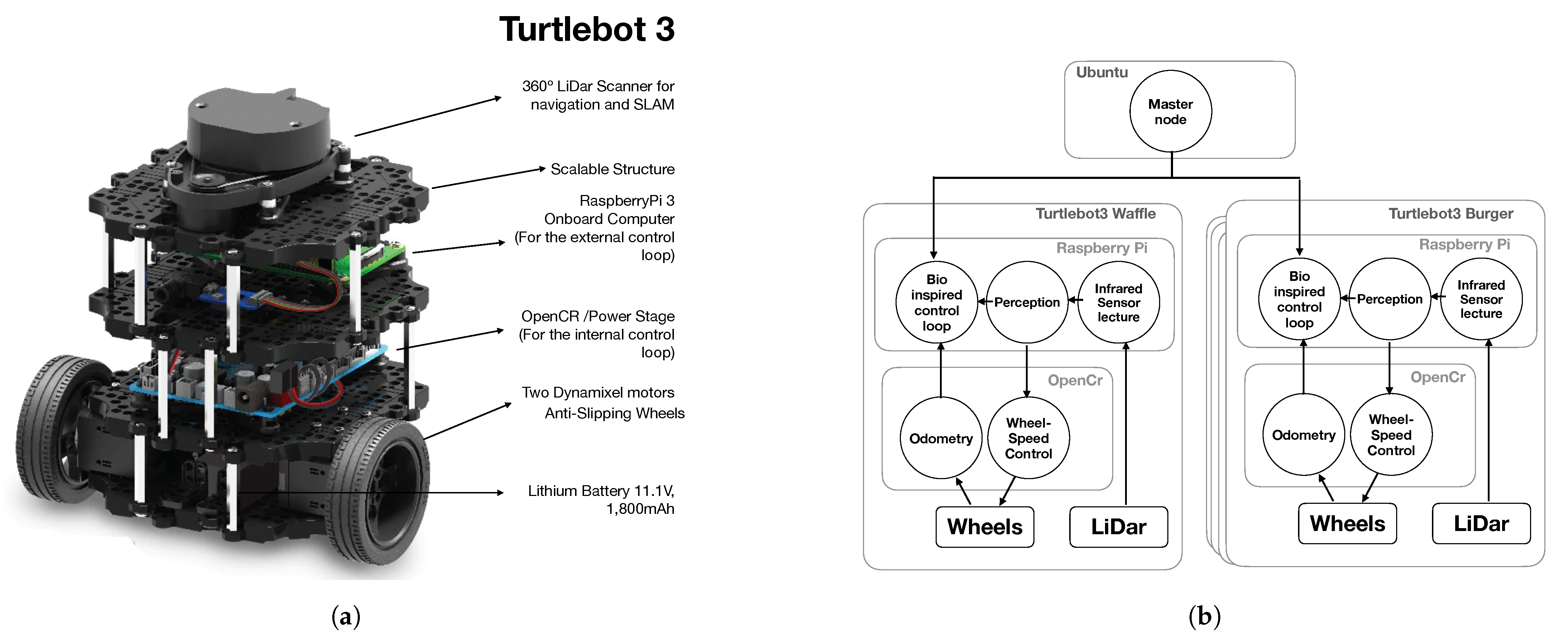
4. Experimental Platform Considerations
In order to prove the proposed control law, a MATLAB
® [
25] simulation and a physical implementation are prepared. During experimentation, four Turtlebot3 Burger
® and one Turtlebot3 Waffle Pi
® are used, giving a total of 5 agents, individually controlled using ROS in an onboard Raspberry Pi
®, where the external control law is deployed, computing the control inputs
,
for each agent, delivered to the onboard OpenCR
® power stage card through serial protocol. The description of the hardware and the programmed nodes in ROS is available in
Figure 3.
The initial position of each robot, on the same inertial global frame, is given, so each agent, using odometry, can compute its position on each given time. The used algorithms to obtain parameters needed in the control loop are described next.
4.1. Trajectory Reference Generation
The function in (
18) retrieves a lemniscate figure, and it can be computed to obtain the reference position, velocity and acceleration of each agent
:
Here, are the length and width of the lemniscate, R is the formation circle radius, N is the number of agents, the sub-index i refers to the i-th agent, and is the temporary exchange rate.
The trajectory reference has a duration d, where if , the function and its time derivatives are computed. If , the last computed value on is used in order to obtain the final position coordinates of the trajectory, with reference velocity equal to zero.
Once the references are obtained, the expressions in (
19)–(
21) are used to obtain
:
4.2. Perception
The agent’s comfort zone consists of a continuous area around the agent. This area can be set as several shapes, which matches the surrounding obstacles. For simplicity, for the analysis performed in this work, it is chosen to be circular, assuming that potential obstacles in the surrounding space of the reactive behavior of the robot should conform to the circular-shaped area, as shown in a wide variety of cases in nature, e.g., in agriculture, as the robotic solution proposed in [
5].
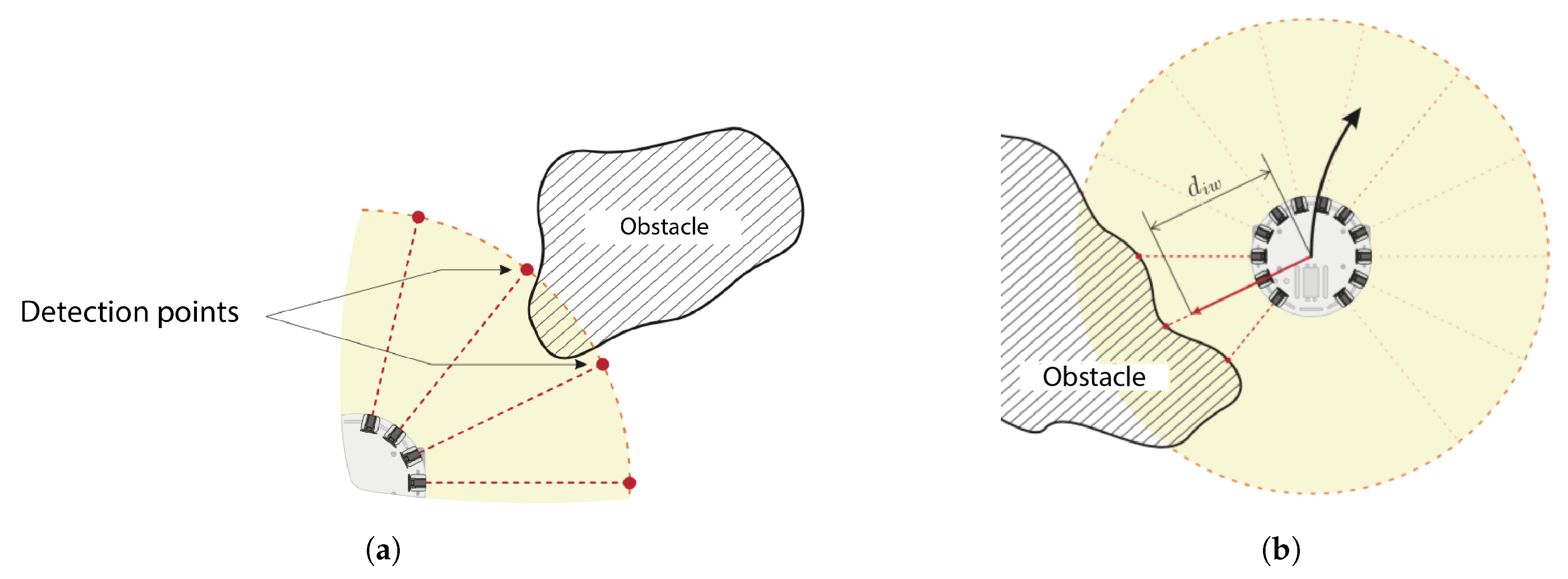
To measure the distance
from the agent
i to the agent
j, and the angle
about the agent
i’s translational axis, where agent
j is located, it is necessary to implement the comfort zone properly. An infrared sensor emits a beam of light, which, when reflected on an object’s surface, enables measurement of the distance from where it is located. Setting multiple infrared sensors around the agent is impractical due to the poor retrieved resolution due to the number of beams on the circumference, which is limited to the available space. This can be observed in
Figure 4a, where an obstacle is not detected despite being in the comfort zone. A lidar system allows increasing the resolution, spinning an infrared beam to cover all the circumference. The LDS-01, used in this work, has a
resolution, scilicet, emits a beam each 0.0174 [rad] [
26]. This is a 360-beam configuration around the agent and improves the environment perception, as many beams are now reflected in a single object.
In this event, the shortest registered distance is set as
, while
is set as the average angle of all the triggered beam lights. When there are multiple beams activated, but these are not consecutive, it is considered to be multiple-obstacle detection, as shown in
Figure 4b.
4.3. Position and Velocity Estimation of the Other Agents
For computing collision avoidance function
given by (
3) and used in (
5), the position and velocity of the
j-th agent are needed. These are denoted as
and
, and in order to compute them, the decentralized estimation algorithm starts from these suppositions:
Each agent knows its own position regarding a global reference frame.
All the obstacles detected in a radio detection are considered agents.
The comfort zone of the agent j is assumed to be the same radius as agent i.
The next algorithm is executed:
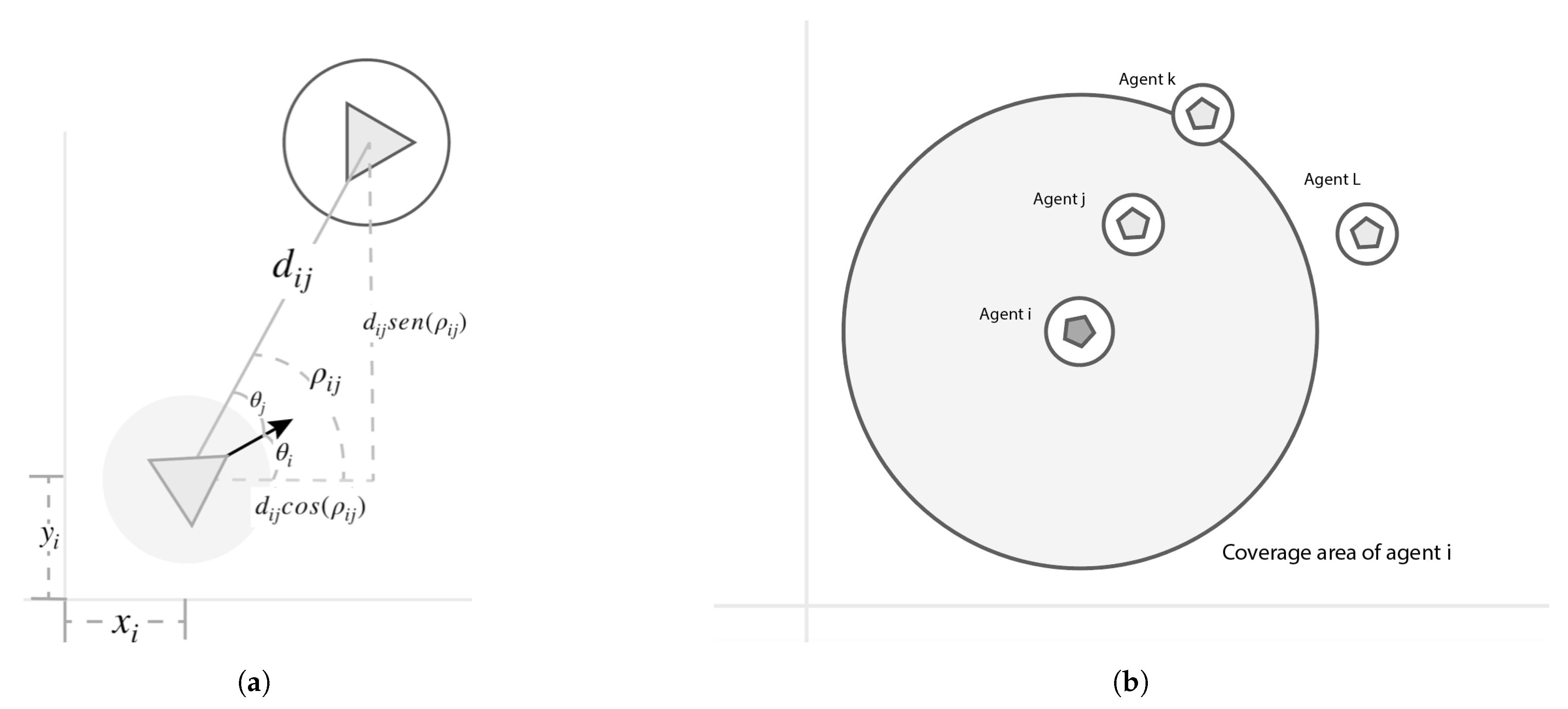
Agent i determines with its sensors the vector to the agent j, which is composed by the distance , and the angle from the global x axis frame, denoted as .
To obtain the angle, the orientation of the agent i in its inertial frame and the angle of the agent j detected by the sensor, denoted as , are needed.
While
increases, the value of
decreases, as shown in
Figure 5a. This yields the value
given by
Agent
j’s position on the global reference frame is obtained by
The geometric center is computed by
where is the number of agents detected by the i-th agent. The fact that is possible must be remarked, due to these reasons:
If the agent j is out of the sensor coverage area of the agent i;
If agent k is behind the agent j, agent i will not be detected.
Note: This only applies for the experimentation platform. In simulation, all variables are available, which disables the scenario depicted in Figure 5b. Finally, to determine the velocity of agent
j, the distance
is compared with the distance on the previous execution step, denoted as
. The expression (
25) obtains the velocity of agent
j:
To obtain the velocity on its axis components and to evaluate the tangential velocity
, the next functions are evaluated:
5. Simulation and Experimental Results
At simulation, comparison studies for the case of trajectory tracking and collision avoidance were carried out, considering other techniques proposed in the literature, such as potential repulsive fields, and the geometric obstacle avoidance control method (GOACM), obtaining similar performance; however, there is not a completely similar strategy that integrates formation, trajectory tracking, and collision avoidance of dynamic and static obstacles, for which full comparison of our proposed strategy could be done. Then, for the sake of space and considering that such comparison studies do not represent a fair layout, such results are not presented here.
The experimental configuration consists of a set of
agents, which has to follow a lemniscate trajectory given by (
18), with the parameters on
Table 1 and an execution period of
[s]. Considering the stability conditions given by (
17), the upper bound for the control actions is chosen according to the specification of the TurtleBot 3. This is
[m/s] and
[rad/s], [
26], and the tuning of the control gains is shown in
Table 2. Lastly, the initial conditions of each agent are shown in
Table 3.
Simulation and experimental results are presented under the same conditions of desired trajectory and tuning gains for comparison purposes. It is essential to emphasize that simulations are an ideal case. At the same time, during experiments, odometry and lidar measurements are used to determine each agent’s location and distance to possible obstacle collision. For the sake of space, only results that involve trajectory tracking, a desired circular formation and possible collisions between agents, i.e., dynamic obstacles, are presented. Since the proposed avoidance collision strategy is based on the relative approaching velocity, it is clear that more aggressive evasion actions are required for dynamic obstacles than for static ones because for dynamic obstacles the relative approaching velocity is higher than that of the proper agent, while for a static obstacle, the approaching velocity corresponds to that of the agent. Collision avoidance among agents is present at the transient, between 0 and 8 s, both in the simulation and experimental results because the initial position of the agents imply possible collisions while trying to get into their assigned position at the formation. Nevertheless, several cases considering static obstacles were tested both by simulation and experiments, showing good obstacle avoidance.
First, the simulation results are shown.
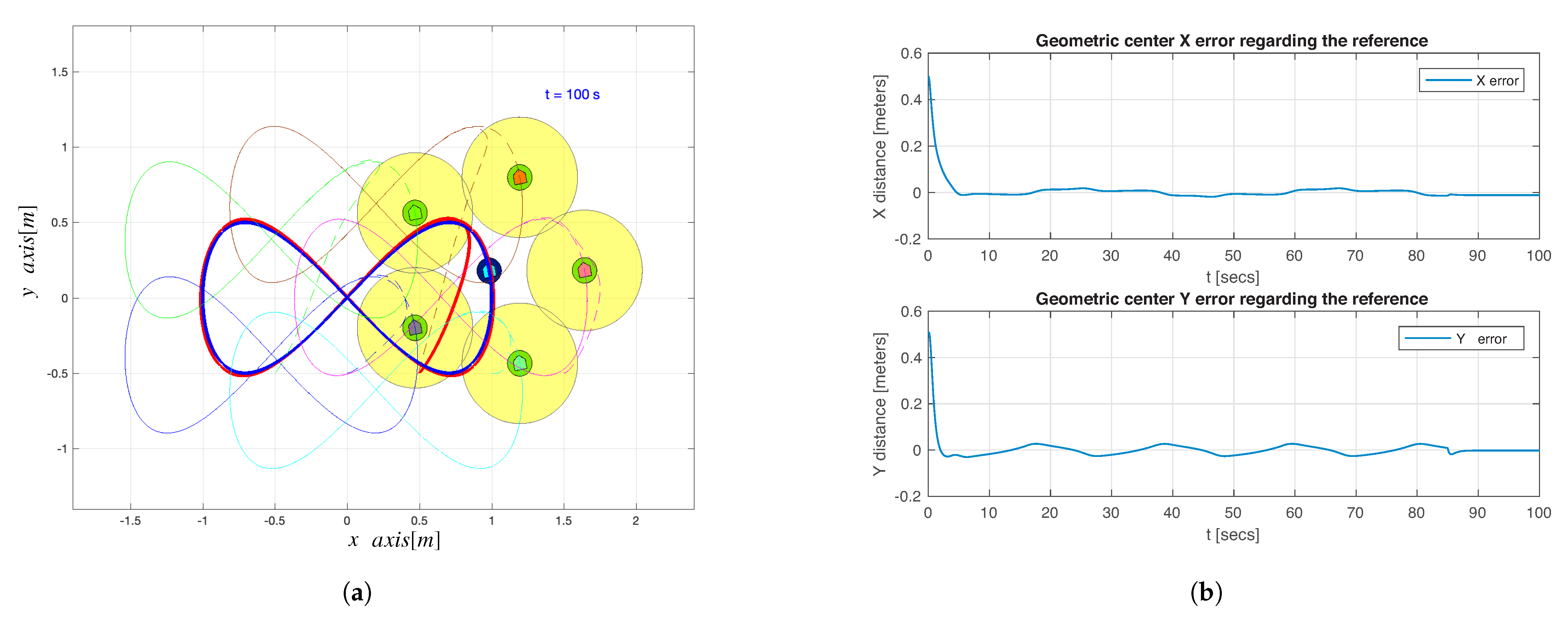
Figure 6a shows the geometric center position of the whole system, compared with the ideal group formation reference. A better convergence is exhibited in sections where the curvature radio is prominent.
Figure 6b shows the correspondent convergence error, and it can be deduced that for
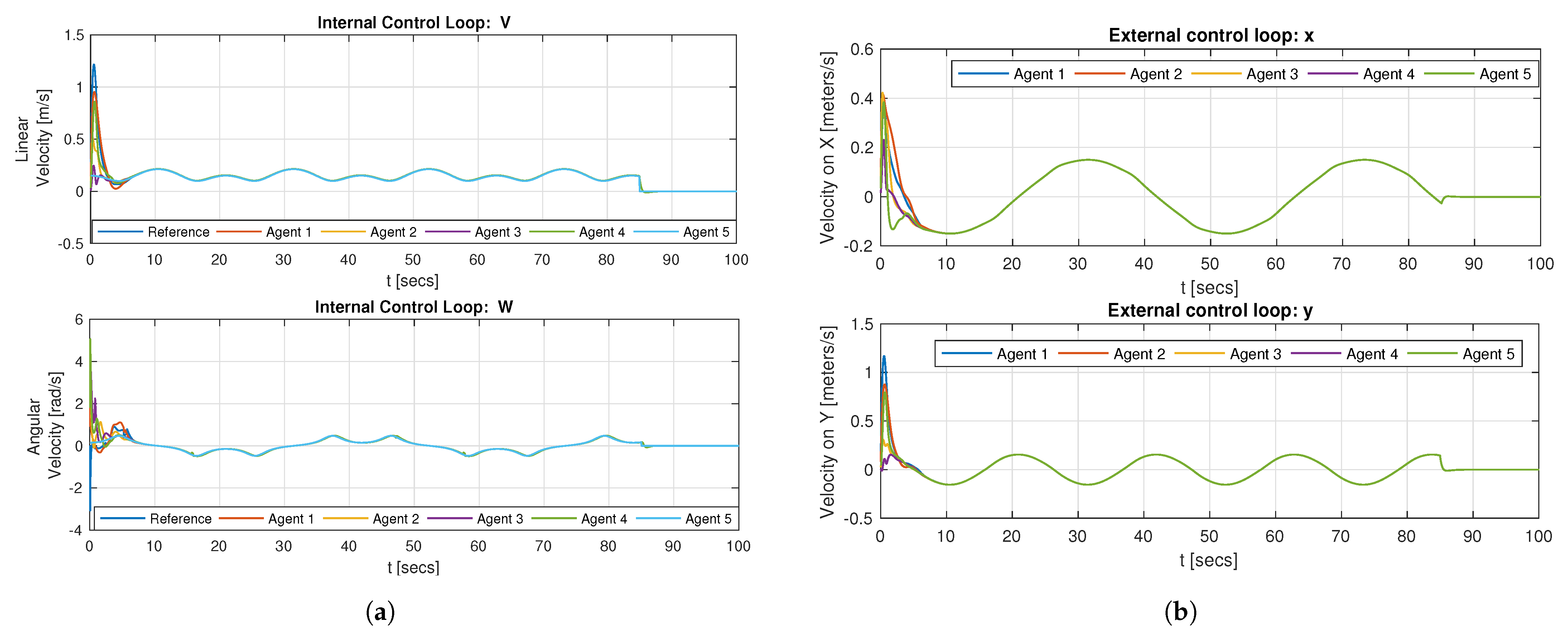
[s], the geometric center position converges to a standstill position. All the agents converge to the same external and internal control loop action, as shown in
Figure 7a,b, thus moving in a synchronized way, while tracking the desired lemniscate trajectory.
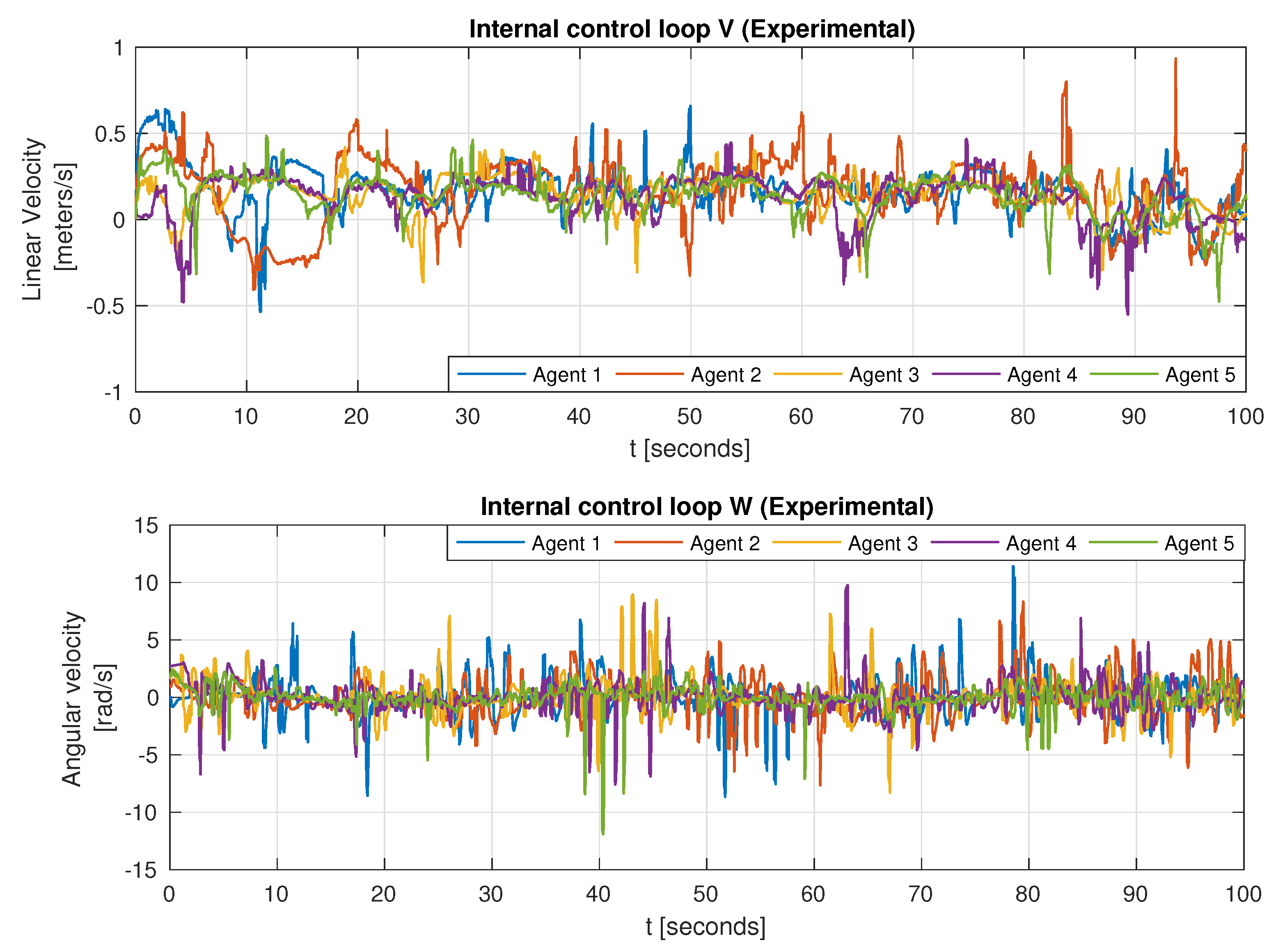
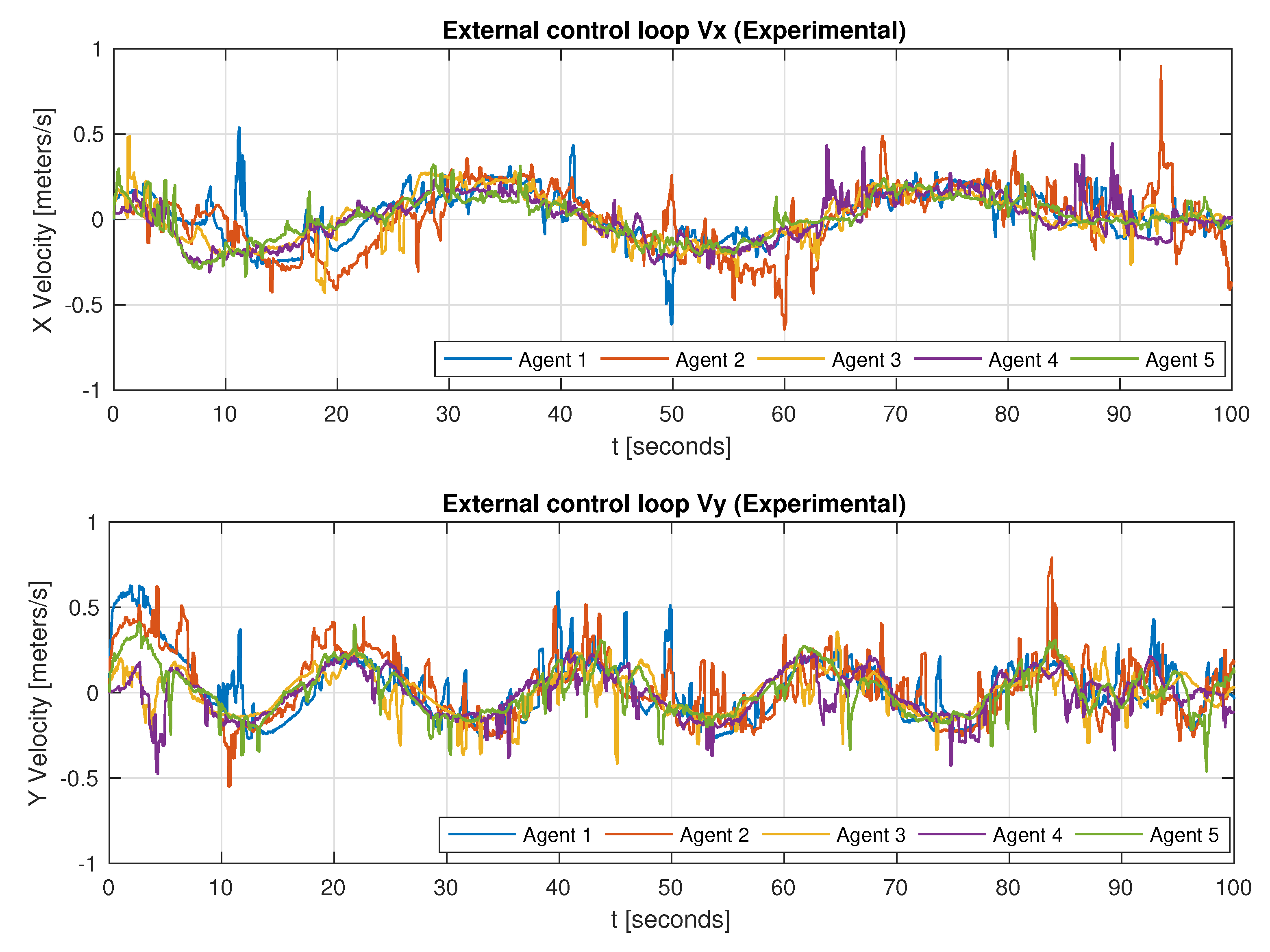
As for the experimental setup, technical difficulties and limitations are evident in
Figure 8 and
Figure 9, where noise and abrupt changes are present. This is because of the lidar measurements and poor odometry location.
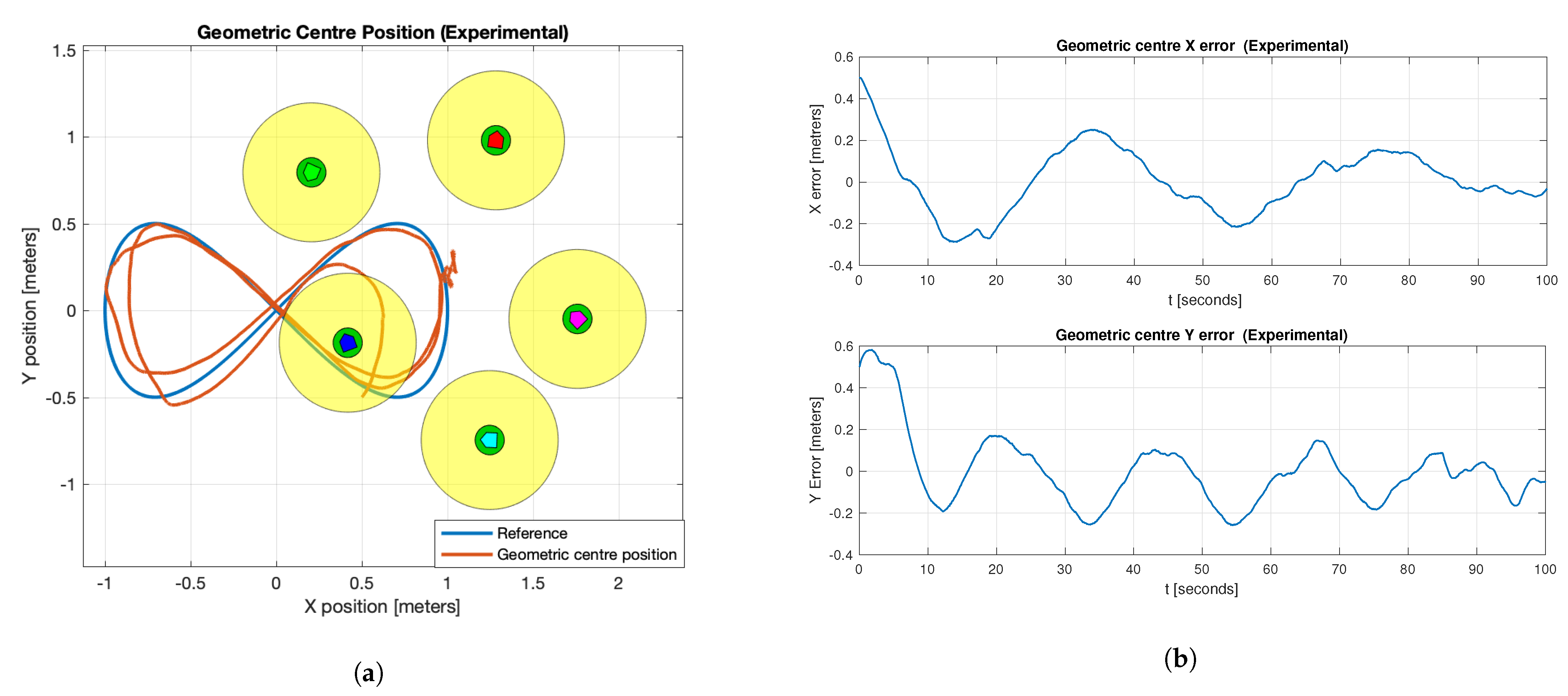
Nevertheless, the group tries to follow the lemniscate trajectory reference while generating the circular formation pattern as exhibited in
Figure 10a. This can also be noted in the tracking errors in
Figure 10b; for
[s], the desired trajectory stops, but since there are position errors of each agent concerning the circular formation, the agent keeps moving to fit into the circumference, but at the end, the circular formation is achieved as shown in the experiment snapshot of
Figure 11.
6. Conclusions
The proposed control law, which aims to generate a desired formation during path tracking, shows satisfactory performance in simulation and acceptable performance in the experimental setup, taking into account the technical limitations of the experimental platform. Better acquisition of the environment data, achieving recognition between the agents in the system, and other localization mechanisms, such as sensor data fusion and filtering, would be reflected in an improvement of the controller behavior.
The proposed controller can be seen as a dynamic extension of the standard kinematic control because of the incorporation of the force-driven model, which allows obstacle avoidance, trajectory tracking, and enforcing the formation. This dynamic force model can be further modified to include some other goals related to the synchronization of the agents, enclosing, escorting, etc. The proposed controller is decentralized and highly relies on the perception capacities of each agent, but it could be easily implemented based on communication systems such that each agent shares its location and event information of detected obstacles. The overall multi-agent systems would enhance its performance and possible applications, such as harvesting, bodyguard formation, terrain coverage and a possible extension into flying vehicles.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}