

Design and Application of Deep Hash Embedding Algorithm with Fusion Entity Attribute Information

Abstract
1. Introduction
2. Introduction to Related Algorithms
2.1. The Introduction of One-Hot Encoding
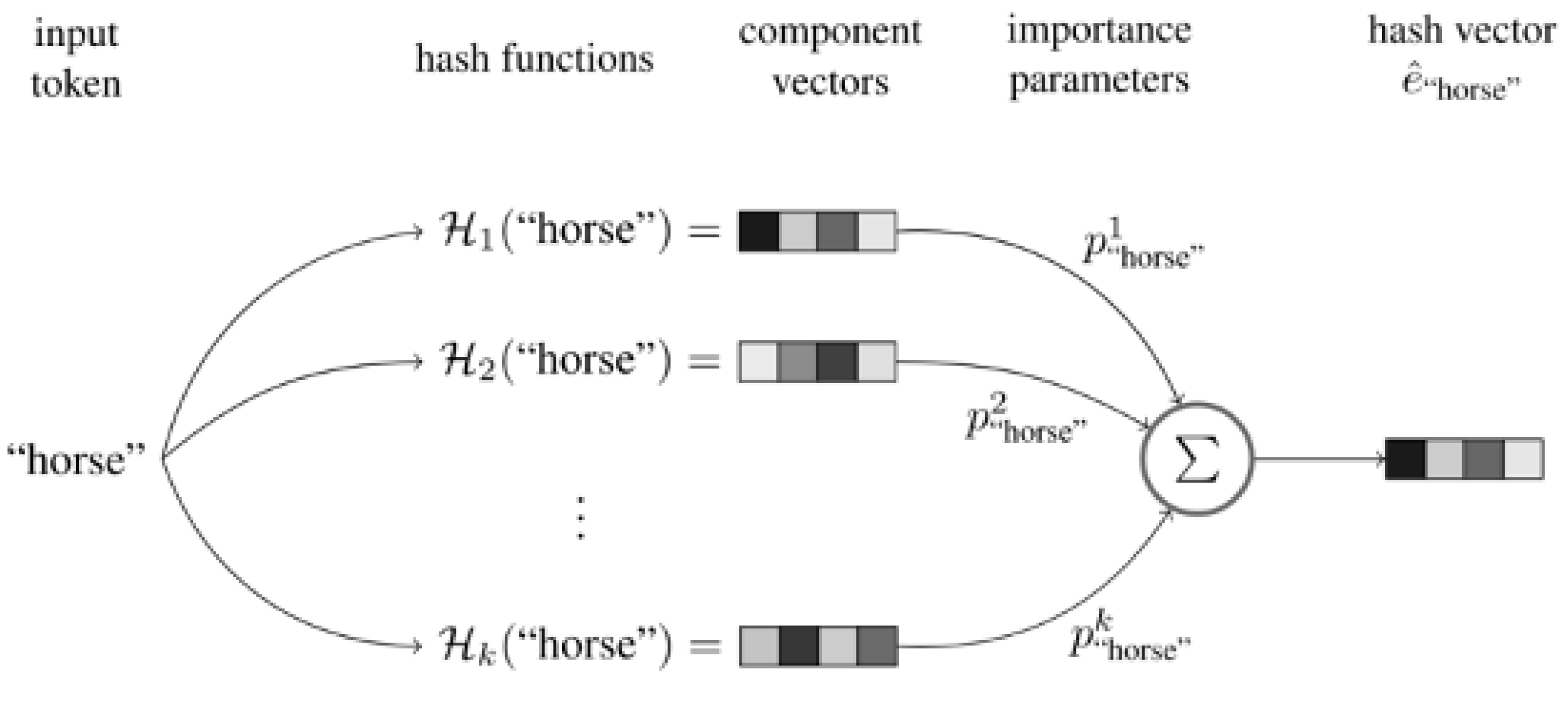
2.2. The Introduction of Hash Embedding Algorithms
3. Embedding Algorithm Based on a Deep Hash Fusion of Entity Information
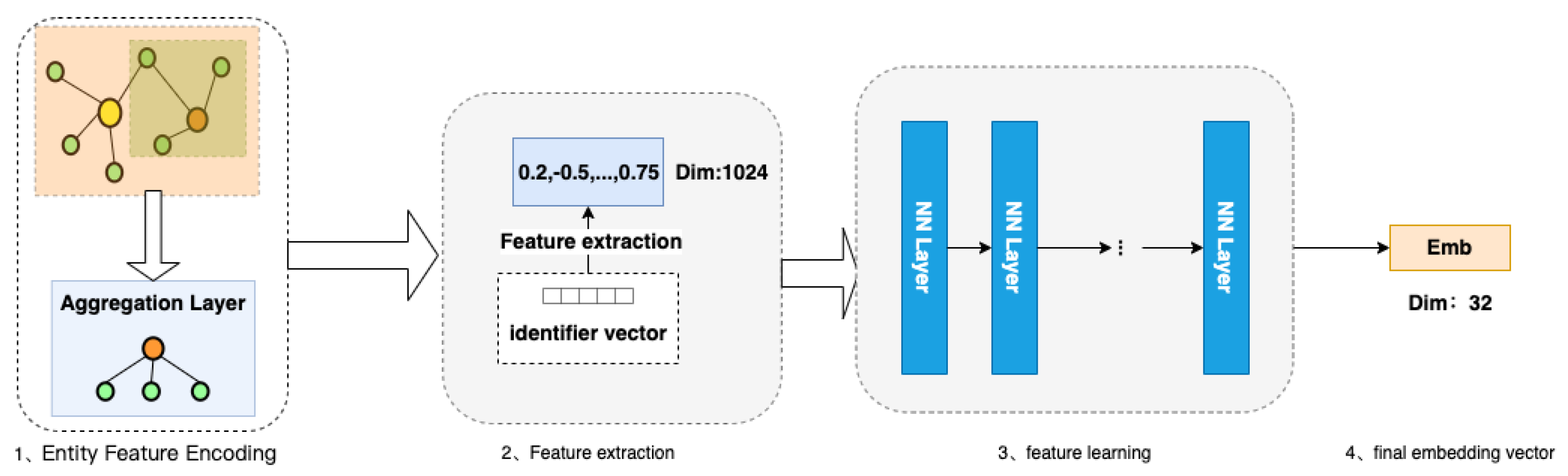
- Entity feature encoding: Firstly, the first part fuses and encodes all the features of the entity. The purpose is to express the features of additional information in the vector representation of the entity node. After encoding, a concatenated encoding of variable length is obtained.
- Feature extraction after encoding: In the second part of feature extraction, the variable length initial encoding of v is converted into k fixed hash values through k non-repetitive hash functions, and different entities can already be represented at this time.
- Using neural networks for feature learning [25]: In the third part, we train a general deep neural network that inputs k different hash values encoded by each entity separately into the neural network, learns the inherent, implicit association between k features, and outputs the outputs in the desired dimension to obtain the embedding vector.
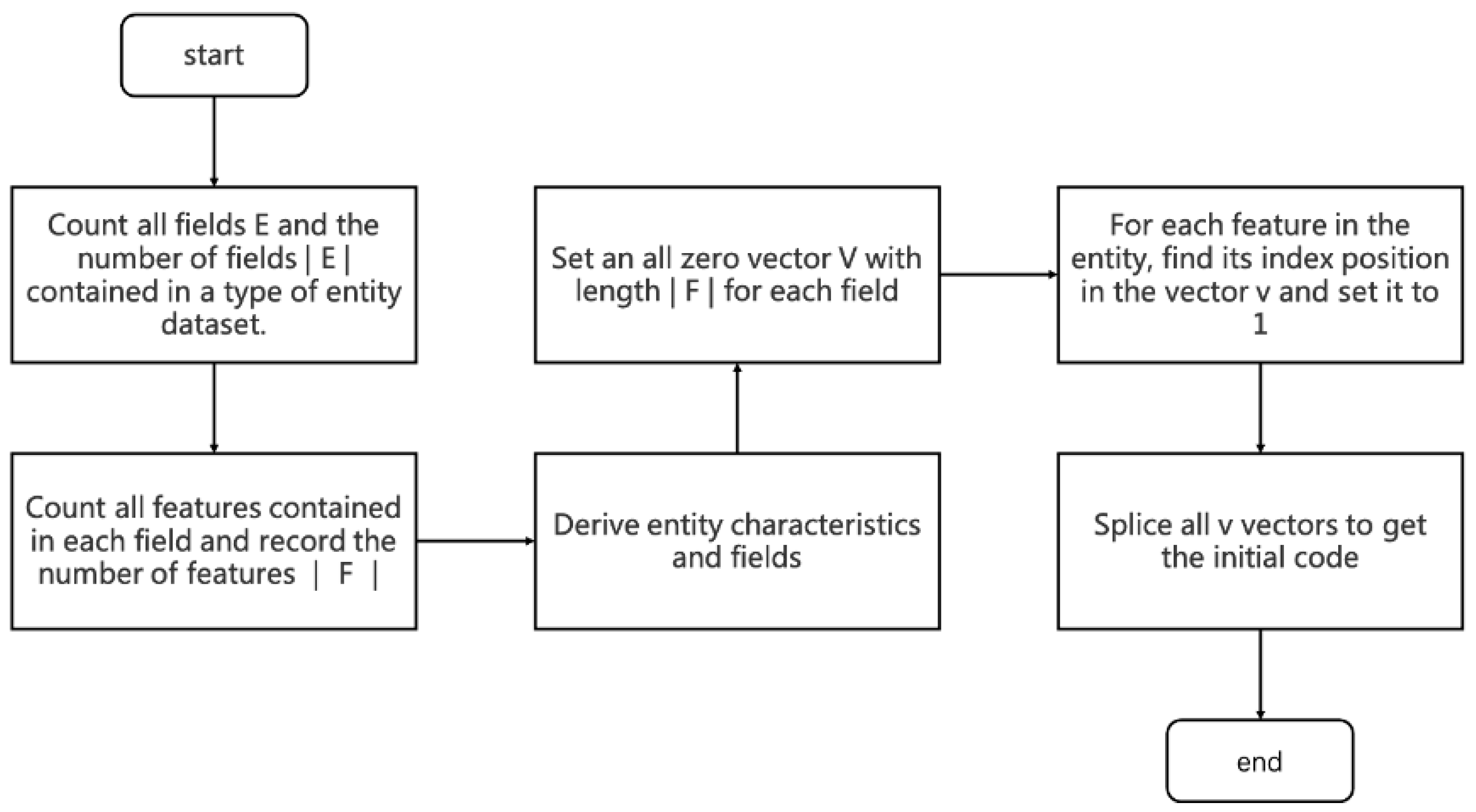
3.1. Entity Feature Encoding
3.2. Extract Features Using Hash Functions
3.3. Feature Learning
4. Experimental Simulation and Analysis
4.1. Experimental Setup and Dataset
4.2. Baseline Model
4.3. Parameter Setting
- FADH Model parameter settingsFor all datasets, the size of the embedded entity dimension was [32, 64, 128, 256, 1024] for the baseline algorithm model and the parameter model of the FADH algorithm in this paper. The number of training rounds was 1, and the initial learning rate of the neural network was 0.01. The learning rate was reduced by a minimum of 0.0001 after each training iteration. The network structure designed in this paper is shown in Table 3 below:Since the equal-width deep network had higher parameter utilization, the model effect was better. In this experiment, the neural network model was set as the input layer of 1024 dimensions, the middle hidden layer had six layers, the first three layers were all 1024 nodes, and the sixth hidden layer had the same number of nodes as the required dimension.
- Baseline model parameter settingsThe Node2vec model parameters were set. The depth of the random walk was 80, the number of random walks generated by each node was 10, and the localization parameter (the tendency of the random walk to stay close to the starting node or fan out) was set to 1. A higher value meant keeping the local state. The training neural network context window size was 10. The number of negative samples generated for each positive sample was 5.GraphSage and FastRP model parameters were set according to the parameters shown in the literature.
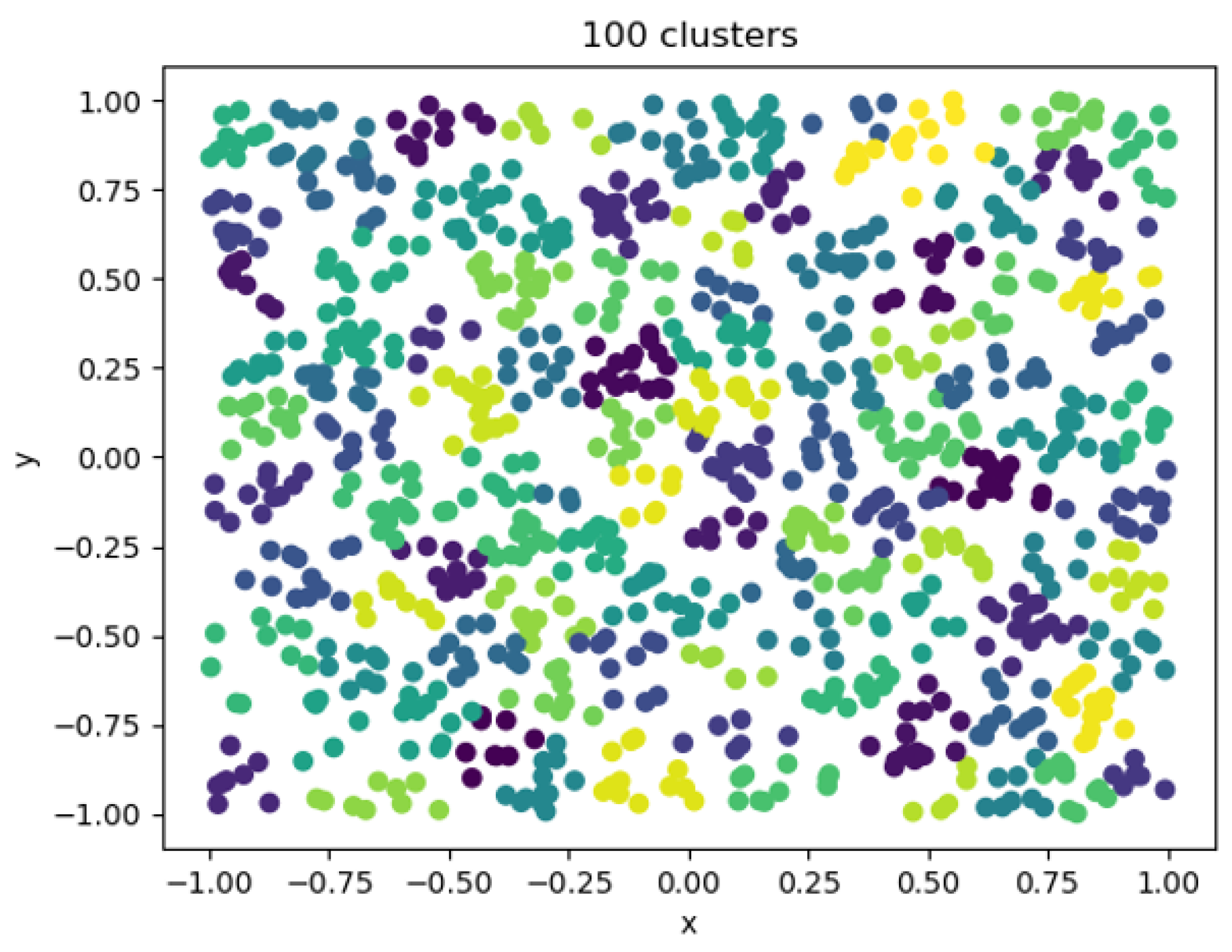
4.4. Data Visualization
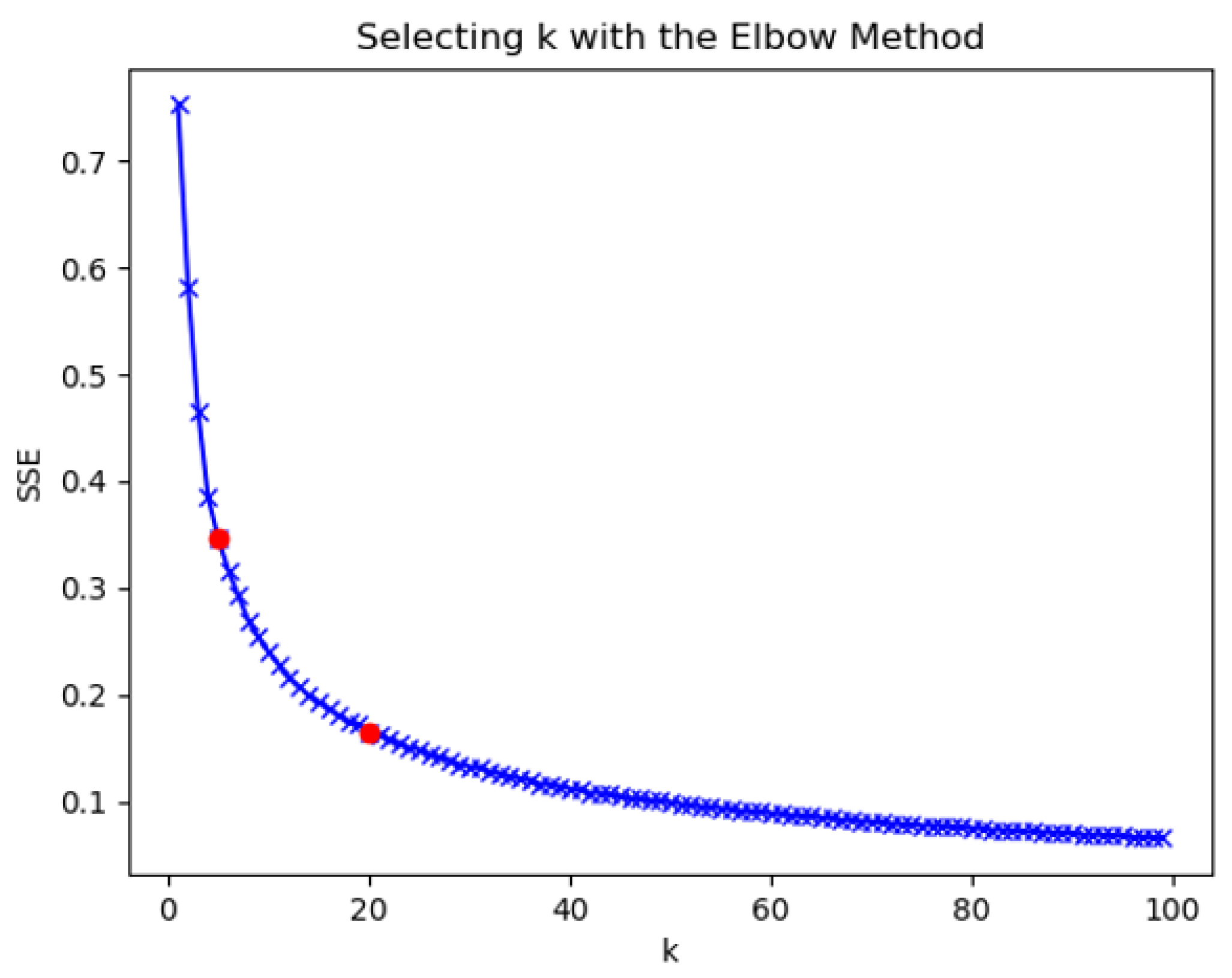
- When the clustering coefficient was from 1 to 5, the sum of squares of errors decreased rapidly, indicating that the number of clusters was quickly optimized to find the optimal number of clusters within this interval.
- When the clustering coefficient was 5 to 20, the rate of decline of the clustering coefficient slowed down, and the most likely interval of the number of clusters was most likely to be close to the actual situation.
- When the clustering coefficient was 20 to 100, as the clustering coefficient increased, the decrease of the sum of squared error was the slowest. The rise in the number of clusters exceeded the actual number of clusters represented by the data. The division of the number of clusters directly affected the performance of downstream.
4.5. Algorithm Performance
- A single feature was calculated by relative clustering distance.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Weinberger, K.; Dasgupta, A.; Langford, J.; Smola, A.; Attenberg, J. Feature hashing for large scale multitask learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 1113–1120. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Uchida, S.; Yoshikawa, T.; Furuhashi, T. Application of Output Embedding on Word2Vec. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toyama, Japan, 5–8 December 2020; pp. 3377–3381. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Yao, T.; Zhai, Z.; Gao, B. Text Classification Model Based on fastText. In Proceedings of the International Conference on Artificial Intelligence and Information Systems (ICAIIS), Dalian, China, 20–22 March 2020; pp. 154–157. [Google Scholar]
- Barkan, O.; Koenigstein, N. Item2vec: Neural item embedding for collaborative filtering. In Proceedings of the IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Vietri sul Mare, Italy, 13–16 September 2016; pp. 1–6. [Google Scholar]
- Barkan, O.; Caciularu, A.; Katz, O.; Koenigstein, N. Attentive Item2vec: Neural Attentive User Representations. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (ICAIIS), Barcelona, Spain, 4–8 May 2020; pp. 3377–3381. [Google Scholar]
- Covington, P.; Adams, J.; Sargin, E. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 191–198. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Shah, H. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Kang, W.C.; Cheng, D.Z.; Yao, T.; Yi, X.; Chen, T.; Hong, L.; Chi, E.H. Learning to embed categorical features without embedding tables for recommendation. arXiv 2020, arXiv:2010.10784. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Voulme 30. [Google Scholar]
- Chen, H.; Sultan, S.F.; Tian, Y.; Chen, M.; Skiena, S. Fast and accurate network embeddings via very sparse random projection. ACM Int. Conf. Inf. Knowl. Manag. 2019, 66, 399–408. [Google Scholar]
- Achlioptas, D. Database-friendly random projections: Johnson-Lindenstrauss with binary coins. J. Comput. Syst. Sci. 2003, 66, 671–687. [Google Scholar] [CrossRef]
- Argerich, L.; Zaffaroni, J.T.; Cano, M.J. Hash2vec, feature hashing for word embeddings. arXiv 2016, arXiv:1608.08940. [Google Scholar]
- Svenstrup, D.T.; Hansen, J.; Winther, O. Hash embeddings for efficient word representations. Adv. Neural Inf. Process. Syst. 2017, 30, 4928–4936. [Google Scholar]
- Luo, X.; Wang, H.; Wu, D.; Chen, C.; Deng, M.; Huang, J.; Hua, X.S. A survey on deep hashing methods. ACM Trans. Knowl. Discov. Data (TKDD) 2020. [Google Scholar] [CrossRef]
- Yan, B.; Wang, P.; Liu, J.; Lin, W.; Lee, K.C.; Xu, J.; Zheng, B. Binary code based hash embedding for web-scale applications. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual Event, QLD, Australia, 1–5 November 2021; pp. 3563–3567. [Google Scholar]
- Al-Ansari, K. Survey on Word Embedding Techniques in Natural Language Processing. 2020. Available online: https://www.researchgate.net/publication/343686323_Survey_on_Word_Embedding_Techniques_in_Natural_Language_Processing (accessed on 28 November 2022).
- Deng, Y. Recommender systems based on graph embedding techniques: A comprehensive review. arXiv 2021, arXiv:2109.09587. [Google Scholar] [CrossRef]
- Song, T.; Luo, J.; Huang, L. Rot-pro: Modeling transitivity by projection in knowledge graph embedding. Adv. Neural Inf. Process. Syst. 2021, 34, 24695–24706. [Google Scholar]
- Shi, H.M.; Mudigere, D.; Naumov, M.; Yang, J. Compositional embeddings using complementary partitions for memory-efficient recommendation systems. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 165–175. [Google Scholar]
- Qiao, Y.; Yang, X.; Wu, E. The research of BP neural network based on one-hot encoding and principle component analysis in determining the therapeutic effect of diabetes mellitus. Iop Conf. Ser. Earth Environ. Sci. Iop Publ. 2019, 267, 042178. [Google Scholar] [CrossRef]
- Li, J.; Si, Y.; Xu, T.; Jiang, S. Deep convolutional neural network based ECG classification system using information fusion and one-hot encoding techniques. Math. Probl. Eng. 2018, 2018, 7354081. [Google Scholar] [CrossRef]
- Li, F.; Yan, B.; Long, Q.; Wang, P.; Lin, W.; Xu, J.; Zheng, B. Explicit Semantic Cross Feature Learning via Pre-trained Graph Neural Networks for CTR Prediction. arXiv 2021, arXiv:2105.07752. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol Definition | Meaning Description |
|---|---|
| s | Feature word |
| e | Embedding vector |
| V | Feature value (representation of feature word) |
| W | Embedding table: one-hot coding with all feature words |
| N | number of datasets |
| k | number of hash functions |
| n | the size of the vocabulary |
| d | Embedded dimension |
| m | Size of the hash table (usually m < n) |
| H: V → [m] | Hash function: map feature words to 1, 2, 3, …, m |
| Dataset | Total | Genre | Actor | User | Ratings |
|---|---|---|---|---|---|
| hetrec2011-movielens-2k-v2 | 10,197 | 20 | 95,321 | 2113 | 855,598 |
| Input | Hidden Layer 1 | Hidden Layer 2 | Hidden Layer 3 | Hidden Layer 4 | Hidden Layer 5 | Hidden Layer 6 | Output Layer | |
|---|---|---|---|---|---|---|---|---|
| 1 | 1024 | 1024 | 1024 | 1024 | 32 | 32 | 32 | 1 |
| 2 | 1024 | 1024 | 1024 | 1024 | 64 | 64 | 64 | 1 |
| 3 | 1024 | 1024 | 1024 | 1024 | 128 | 128 | 128 | 1 |
| 4 | 1024 | 1024 | 1024 | 1024 | 256 | 256 | 256 | 1 |
| 5 | 1024 | 1024 | 1024 | 1024 | 1024 | 1024 | 1024 | 1 |
| Movie Title | 2-D Vector | |
|---|---|---|
| Scream | 0.21266807615756989 | 0.5888321399688721 |
| Tommy Boy | 0.9140979647636414 | 0.7566967606544495 |
| Alien | 0.9574490785598755 | 0.41326817870140076 |
| …… | ||
| She’s So Lovely | 0.7865368723869324 | 0.10100453346967697 |
| U.S. Marshals | 0.0719037652015686 | 0.07177785784006119 |
| …… | ||
| A Night at the Roxbury | 0.5604234933853149 | 0.8568414449691772 |
| Node2vec | GraphSage | FastRP | FADH | |
|---|---|---|---|---|
| Titanic | Revolutionary Road | Top Gun | Ladder 49 | Ghost |
| Top Gun | Casablanca | Mighty Joe Young | Revolutionary Road | |
| Ghost | Revolutionary Road | Revolutionary Road | Ladder 49 | |
| Firestorm | Ghost | Casablanca | Firestorm | |
| Ladder 49 | Firestorm | Top Gun | Top Gun | |
| The Shawshank Redemption | The Green Mile | Fight Club | Fight Club | A Clockwork Orange |
| One Flew Over the Cuckoo’s Nest | The Silence of the Lambs | One Flew Over the Cuckoo’s Nest | The Silence of the Lambs | |
| Fight Club | The Sixth Sense | The Green Mile | The Green Mile | |
| A Clockwork Orange | Mr. Smith Goes to Washington | The Sixth Sense | Fight Club | |
| Forrest Gump | The Green Mile | The Bridge on the River Kwai | One Flew Over the Cuckoo’s Nest |
| Dimension | 32 | 64 | 128 | 256 | 1024 | |
| FADH | time/s memory/MB | 10,431 6.3 | 10,600 11.2 | 10,833 21.1 | 13,092 40.6 | 40,319 158.4 |
| Node2vec | time/s memory/MB | 14,773 8.2 | 17,483 13.4 | 20,849 24.5 | 32,531 51.1 | 74,773 169 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Chen, H.; Zhang, Z. Design and Application of Deep Hash Embedding Algorithm with Fusion Entity Attribute Information. Entropy 2023, 25, 361. https://doi.org/10.3390/e25020361
Huang X, Chen H, Zhang Z. Design and Application of Deep Hash Embedding Algorithm with Fusion Entity Attribute Information. Entropy. 2023; 25(2):361. https://doi.org/10.3390/e25020361
Chicago/Turabian StyleHuang, Xiaoli, Haibo Chen, and Zheng Zhang. 2023. "Design and Application of Deep Hash Embedding Algorithm with Fusion Entity Attribute Information" Entropy 25, no. 2: 361. https://doi.org/10.3390/e25020361
APA StyleHuang, X., Chen, H., & Zhang, Z. (2023). Design and Application of Deep Hash Embedding Algorithm with Fusion Entity Attribute Information. Entropy, 25(2), 361. https://doi.org/10.3390/e25020361