
The Typical Set and Entropy in Stochastic Systems with Arbitrary Phase Space Growth

{kind=link}
{kind=link}
{kind=link}
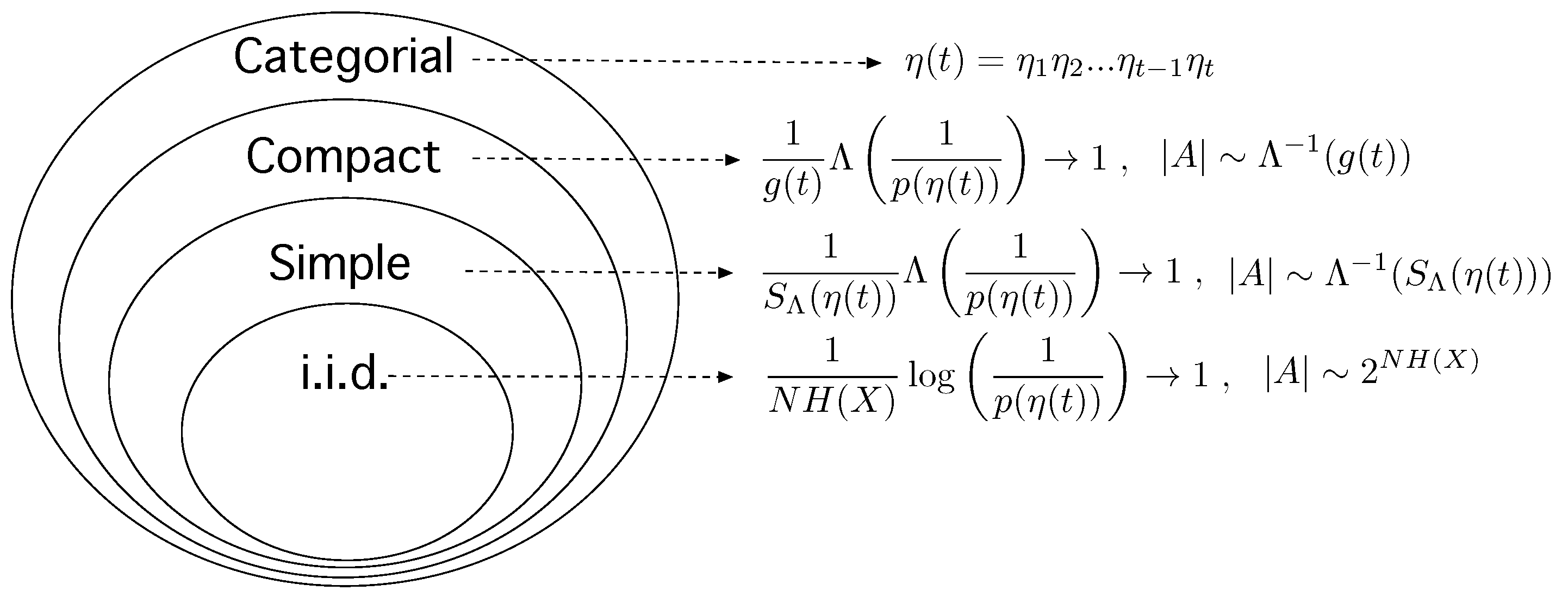{kind=link}
Abstract
1. Introduction
2. Results
2.1. Compact Stochastic Processes
2.2. The Typical Set and Generalized Entropies
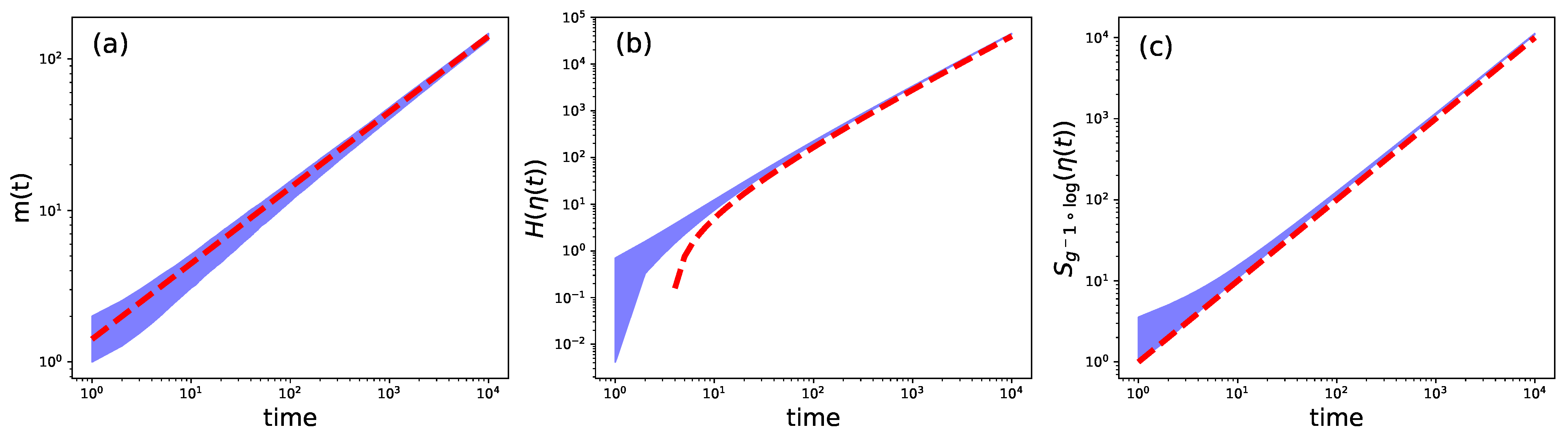
2.3. Example: A Path Dependent Process
3. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B. Compact Categorial Processes

Appendix B.1. Categorial Processes
Appendix B.2. Properties of Λ
Appendix C. Properties of the Generalized Entropies
- SK1 is a continuous function only depending on the probabilities .
- SK2 is maximized if , i.e., equiprobability.
- SK3If , then: , i.e., events with zero probability have no contribution to the entropy.
Appendix D. The Chinese Restaurant Process
Appendix D.1. Definition and Basics
Appendix D.2. Statistics of the CRPM
Appendix D.3. The Typical Set of the CRP
Appendix D.4. The Entropy of the CRP
Appendix D.5. A Different Compact Scale (Λ,G) for the CRP
References
- Morowitz, H.J. Energy Flow in Biology: Biological Organization as a Problem in Thermal Physics; Academic Press: London, UK, 1968. [Google Scholar]
- Bialek, W. Biophysics: Searching for Principles; Princeton University Press: Princeton, NJ, USA, 2012. [Google Scholar]
- Solé, R.; Goodwin, B. Signs of Life; Basic Books; Perseus Group: New York, NY, USA, 2000. [Google Scholar]
- Corominas-Murtra, B.; Seoane, L.; Solé, R. Zipf’s Law, unbounded complexity and open-ended evolution. J. R. Soc. Interface 2018, 15, 20180395. [Google Scholar] [CrossRef] [PubMed]
- Maynard Smith, J.; Szathmáry, E. The Major Transitions in Evolution; Freeman: Oxford, UK, 1995. [Google Scholar]
- Bonner, J.T. The Evolution of Complexity by Means of Natural Selection; Princeton University Press: Princeton, NJ, USA, 1988. [Google Scholar]
- Wolpert, L.; Jessell, T.; Lawrence, P.; Meyerowitz, E.; Robertson, E.; Smith, J. Principles of Development, 3rd ed.; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Schuster, P. How does complexity arise in evolution? In Evolution and Progress in Democracies. Theory and Decision Library; Götschl, J., Ed.; Springer: Dordrecht, The Netherlands, 1996; Volume 31. [Google Scholar]
- Bedau, M.A.; McCaskill, J.S.; Packard, N.H.; Rasmussen, S.; Adami, C.; Green, D.G.; Ikegami, T.; Kaneko, K.; Ray, T.S. Open Problems in Artificial Life. Artif. Life 2000, 6, 363–376. [Google Scholar] [CrossRef] [PubMed]
- Ruíz-Mirazo, K.; Peretó, J.; Moreno, A. A universal definition of life: Autonomy and open-ended evolution. Orig. Life Evol. Biosph. 2004, 34, 323–346. [Google Scholar] [CrossRef] [PubMed]
- Ruíz-Mirazo, K.; Umérez, J.; Moreno, A. Enabling conditions for “open-ended” evolution. Biol. Philos. 2008, 23, 67–85. [Google Scholar] [CrossRef]
- Day, T. Computability, Gödel’s incompleteness theorem, and an inherent limit on the predictability of evolution. J. R. Soc. Interface 2012, 9, 624–639. [Google Scholar] [CrossRef] [PubMed]
- Packard, N.; Bedau, M.A.; Channon, A.; Ikegami, T.; Rasmussen, S.; Stanley, K.O.; Taylor, T. An Overview of Open-Ended Evolution: Editorial Introduction to the Open-Ended Evolution II Special Issue. Artif. Life 2019, 25, 93–103. [Google Scholar] [CrossRef]
- Pattee, H.H.; Sayama, H. Evolved Open-Endedness, Not Open-Ended Evolution. Artif. Life 2019, 25, 4–8. [Google Scholar] [CrossRef]
- Dietrich, J.E.; Hiiragi, T. Stochastic patterning in the mouse pre-implantation embryo. Development 2007, 134, 4219–4231. [Google Scholar] [CrossRef] [PubMed]
- Maitre, J.L.; Turlier, H.; Illukkumbura, R.; Eismann, B.; Niwayama, R.; Nédélec, F.; Hiiragi, T. Asymmetric division of contractile domains couples cell positioning and fate specification. Nature 2016, 536, 344–348. [Google Scholar] [CrossRef]
- Giammona, J.; Campàs, O. Physical constraints on early blastomere packings. PLoS Comput. Biol. 2021, 17, e1007994. [Google Scholar] [CrossRef] [PubMed]
- Tria, F.; Loreto, V.; Servedio, V.D.P.; Strogatz, S.H. The dynamics of correlated novelties. Sci. Rep. 2014, 4, 5890. [Google Scholar] [CrossRef]
- Loreto, V.; Servedio, V.D.P.; Strogatz, S.H.; Tria, F. Dynamics on expanding spaces: Modeling the emergence of novelties. Creat. Universality Lang. 2016, 59–83. [Google Scholar] [CrossRef]
- Iacopini, I.; Di Bona, G.; Ubaldi, E.; Loreto, V.; Latora, V. Interacting Discovery Processes on Complex Networks. Phys. Rev. Lett. 2020, 125, 248301. [Google Scholar] [CrossRef]
- Corominas-Murtra, B.; Hanel, R.; Thurner, S. Understanding scaling through history-dependent processes with collapsing sample space. Proc. Natl. Acad. Sci. USA 2015, 112, 5348–5353. [Google Scholar] [CrossRef] [PubMed]
- Corominas-Murtra, B.; Hanel, R.; Thurner, S. Sample space reducing cascading processes produce the full spectrum of scaling exponents. Sci. Rep. 2017, 7, 11223. [Google Scholar] [CrossRef]
- Fujii, K.; Berengut, J.C. Power-Law Intensity Distribution of γ-Decay Cascades: Nuclear Structure as a Scale-Free Random Network. Phys. Rev. Lett. 2021, 126, 102502. [Google Scholar] [CrossRef] [PubMed]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: New York, NY, USA, 2012. [Google Scholar]
- Ash, R.B. Information Theory; Dover Publications: New York, NY, USA, 2012. [Google Scholar]
- Pathria, R.K. Statistical Mechanics; Oxford University Press: Oxford, UK, 2002. [Google Scholar]
- Pitowsky, I. Typicality and the Role of the Lebesgue Measure in Statistical Mechanics. In Probability in Physics; Ben-Menahem, Y., Hemmo, M., Eds.; Springer: Berlin, Germany, 2012; pp. 41–58. [Google Scholar]
- Lebowitz, J.L. Macroscopic Laws, Microscopic Dynamics, Time’s Arrow and Boltzmann’s Entropy. Physica A 1993, 194, 1–27. [Google Scholar] [CrossRef]
- Ledoux, M. The Concentration of Measure Phenomenon; American Mathematical Society: Providence, RI, USA, 2005. [Google Scholar]
- Battermann, R. The Devil in the Details: Asymptotic Reasoning in Explanation, Reduction, and Emergence; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Frigg, R. Typicality and the Approach to Equilibrium in Boltzmannian Statistical Mechanics. Philos. Sci. 2009, 76, 997–1008. [Google Scholar] [CrossRef]
- Kač, M. A history-dependent random sequence defined by Ulam. Adv. Appl. Math. 1989, 10, 270–277. [Google Scholar] [CrossRef]
- Pitman, J. Combinatorial Stochastic Processes; Springer: Berlin, Germany, 2006. [Google Scholar]
- Clifford, P.; Stirzaker, D. History-dependent random processes. Proc. R. Soc. Lond. A 2008, 464, 1105–1124. [Google Scholar] [CrossRef]
- Biró, T.; Néda, Z. Unidirectional random growth with resetting. Phys. A Stat. Mech. Its Appl. 2018, 499, 335–361. [Google Scholar] [CrossRef]
- Jensen, H.J.; Pazuki, R.H.; Pruessner, G.; Tempesta, P. Statistical mechanics of exploding phase spaces: Ontic open systems. J. Phys. A Math. Theor. 2018, 51, 375002. [Google Scholar] [CrossRef]
- Korbel, J.; Lindner, S.D.; Hanel, R.; Thurner, S. Thermodynamics of structure-forming systems. Nat. Commun. 2021, 12, 1127. [Google Scholar] [CrossRef]
- Gray, R.M.; Davisson, L.D. Source coding theorems without the ergodic assumption. IEEE Trans. Inform. Theory 1974, 20, 502–516. [Google Scholar] [CrossRef]
- Visweswariah, K.; Kulkarni, S.R.; Verdu, S. Universal coding of nonstationary sources. IEEE Trans. Inf. Theory 2000, 46, 1633–1637. [Google Scholar] [CrossRef]
- Vu, V.Q.; Yu, B.; Kass, R.E. Information in the Non-Stationary Case. Neural Comput. 2009, 21, 688–703. [Google Scholar] [CrossRef] [PubMed]
- Boashash, B.; Azemi, G.; O’Toole, J. Time-frequence processing of nonstationary signals: Advanced TFD design to aid diagnosis with highlights from medical applications. IEEE Signal Process. Mag. 2013, 30, 108–119. [Google Scholar] [CrossRef]
- Granero-Belinchón, C.; Roux, S.G.; Garnier, N.B. Information Theory for Non-Stationary Processes with Stationary Increments. Entropy 2019, 21, 1223. [Google Scholar] [CrossRef]
- Abe, S. Axioms and uniqueness theorem for Tsallis entropy. Phys. Lett. A 2000, 271, 74–79. [Google Scholar] [CrossRef]
- Hanel, R.; Thurner, S. A comprehensive classification of complex statistical systems and an axiomatic derivation of their entropy and distribution functions. Europhys. Lett. 2011, 93, 20006. [Google Scholar] [CrossRef]
- Enciso, A.; Tempesta, P. Uniqueness and characterization theorems for generalized entropies. J. Stat. Mech. Theory Exp. 2017, 12, 123101. [Google Scholar] [CrossRef]
- Tempesta, P. Beyond the Shannon–Khinchin formulation: The composability axiom and the universal-group entropy. Ann. Phys. 2016, 365, 180–197. [Google Scholar] [CrossRef]
- Tempesta, P. Formal groups and Z-entropies. Proc. R. Soc. Lond. A 2016, 472, 20160143. [Google Scholar] [CrossRef]
- Thurner, S.; Corominas-Murtra, B.; Hanel, R. The three faces of entropy for complex systems—Information, thermodynamics and the maxent principle. Phys. Rev. E 2017, 96, 032124. [Google Scholar] [CrossRef] [PubMed]
- Jizba, P.; Korbel, J. When Shannon and Khinchin meet Shore and Johnson: Equivalence of information theory and statistical inference axiomatics. Phys. Rev. E 2020, 101, 042126. [Google Scholar] [CrossRef]
- Korbel, J.; Jizba, P. Maximum Entropy Principle in Statistical Inference: Case for Non-Shannonian Entropies. Phys. Rev. Lett. 2019, 122, 120601. [Google Scholar]
- Jizba, P.; Korbel, J. On the Uniqueness Theorem for Pseudo-Additive Entropies. Entropy 2017, 19, 605. [Google Scholar] [CrossRef]
- Hanel, R.; Thurner, S. When do generalized entropies apply? How phase space volume determines entropy. Europhys. Lett. 2011, 96, 50003. [Google Scholar] [CrossRef]
- Jensen, H.J.; Tempesta, P. Group entropies: From phase space geometry to entropy functionals via group theory. Entropy 2018, 20, 804. [Google Scholar] [CrossRef]
- Korbel, J.; Hanel, R.; Thurner, S. Classification of complex systems by their sample-space scaling exponents. New J. Phys. 2018, 20, 093007. [Google Scholar] [CrossRef]
- Korbel, J.; Hanel, R.; Thurner, S. Information geometry of scaling expansions of non-exponentially growing configuration spaces. Eur. Phys. J. Spec. Top. 2020, 229, 787–807. [Google Scholar] [CrossRef]
- Hanel, R.; Thurner, S. Generalized (c,d)-entropy and aging random walks. Entropy 2013, 15, 5324–5337. [Google Scholar] [CrossRef]
- Nicholson, S.B.; Alaghemandi, M.; Green, J.R. Learning the mechanisms of chemical disequilibria. J. Chem. Phys. 2016, 145, 084112. [Google Scholar] [CrossRef] [PubMed]
- Balogh, S.G.; Palla, G.; Pollner, P.; Czégel, D. Generalized entropies, density of states, and non-extensivity. Sci. Rep. 2020, 10, 15516. [Google Scholar] [CrossRef] [PubMed]
- Gardiner, C.W. Handbook of Stochastic Methods for Physics, Chemistry and the Natural Sciences; Springer: Berlin, Germany, 1983. [Google Scholar]
- Feller, W. An Introduction to Probability Theory and Its Applications; Wiley: New York, NY, USA, 1991; Volumes 1 and 2. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Khinchin, A. Mathematical Foundations of Information Theory; Dover: New York, NY, USA, 1957. [Google Scholar]
- Bassetti, B.; Zarei, M.; Cosentino Lagomarsino, M.; Bianconi, G. Statistical mechanics of the “Chinese restaurant process”: Lack of self-averaging, anomalous finite-size effects, and condensation. Phys. Rev. E 2009, 80, 066118. [Google Scholar] [CrossRef]
- Abramowitz, M.; Stegun, I. Handbook of Mathematical Functions. National Bureau of Standards; Applied Mathematics Series 55; U.S. Government Printing Office: Washington, DC, USA, 1964. [Google Scholar]
- Abe, S.; Martínez, S.; Pennini, F.; Plastino, A. Nonextensive thermodynamic relations. Phys. Lett. A 2001, 281, 126–130. [Google Scholar] [CrossRef]
- Abe, S. Temperature of nonextensive systems: Tsallis entropy as Clausius entropy. Phys. A Stat. Mech. Its Appl. 2006, 368, 430–434. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hanel, R.; Corominas-Murtra, B. The Typical Set and Entropy in Stochastic Systems with Arbitrary Phase Space Growth. Entropy 2023, 25, 350. https://doi.org/10.3390/e25020350
Hanel R, Corominas-Murtra B. The Typical Set and Entropy in Stochastic Systems with Arbitrary Phase Space Growth. Entropy. 2023; 25(2):350. https://doi.org/10.3390/e25020350
Chicago/Turabian StyleHanel, Rudolf, and Bernat Corominas-Murtra. 2023. "The Typical Set and Entropy in Stochastic Systems with Arbitrary Phase Space Growth" Entropy 25, no. 2: 350. https://doi.org/10.3390/e25020350
APA StyleHanel, R., & Corominas-Murtra, B. (2023). The Typical Set and Entropy in Stochastic Systems with Arbitrary Phase Space Growth. Entropy, 25(2), 350. https://doi.org/10.3390/e25020350