1. Introduction
Polar codes [
1] were the first channel coding method to achieve channel capacity with a low-complexity encoder and decoder. The CA-SCL [
2] decoding algorithm was proposed to improve the performance of polar codes compared to LDPC codes under finite code length.
SCL [
3] and CA-SCL are the most popular decoding algorithms for polar codes. However, there are two challenges in improving the throughput of SCL decoding: (1) Data dependence of successive cancellation in the decoding processes; the decoder can only decode bit by bit. (2) Path selection: usually, a metric sorter is used for path selection.
In this paper, we focus on path selection. Path selection selects the best L candidate paths from all candidate paths. Traditionally, the path metric (PM) is used for metric sorting, and L paths with the smallest path metric are selected as the surviving paths. In software simulation, metric sorting can be done using methods such as bubble sorting and quick sorting. In hardware implementation, it is necessary to consider the balance of hardware resources and latency.
The LLR-based path metric and pruned radix-2L sorting were proposed in [
4]. The LLR-based PM has some good properties that can reduce the complexity of sorting. If
L PMs are completely sorted, the
PMs after path extension are partially ordered, and there is no need to sort all the
PMs. Based on this property, pruned bitonic sorting and bubble sorting [
5] were proposed, both of which can reduce hardware complexity.
Focusing on reducing hardware complexity and latency, double thresholding sorting [
6], odd-even sorting [
7], pairwise metric sorting [
8], hybrid bucket sorting [
9], and other methods have been proposed, one after another. It is worth noting that the research proposes a non-sorting direct selection strategy that uses bitwise comparison of PMs to select surviving paths and lowers resource complexity and latency [
10]. However, all of the above methods come at a cost. Low resource consumption and delays will result in performance loss. When the list becomes larger (
), resource consumption and delay will increase sharply, which limits the throughput of the CA-SCL decoder. At the same time, for the polarization-adjusted convolutional (PAC) codes, the authors of [
11] proposed a local sorting method that picks only the best path at each state node, thereby greatly reducing the sorting latency.
Permutation entropy [
12] was proposed in 2002 to analyze the complexity of time series. Certainly, permutation entropy can be used to measure the chaotic degree of the PM sequence. By comparing the change in permutation entropy before and after extension, we can get a new measure of the complexity of path selection.
In recent years, neural networks have been applied to channel coding and decoding. In this paper, we exploit a neural network to perform path sorting and achieve a high-throughput SCL/CA-SCL decoder. The first neural sorting network was proposed in 1997 [
13]. It requires the time complexity of
, but the latency is still huge for a CA-SCL decoder. In 2020, Tim Kraska proposed an ML-enhanced sorting algorithm called Learned Sort [
14], which is based on learned index structures [
15]. The core of the algorithm is to train the cumulative distribution function (CDF) model
F over a small sample of data
A to predict the position of test data
x; the test set size is
M:
. In fact, it is impossible to train a perfect CDF model, so positional collisions will inevitably occur. Model establishment and collision handling methods will affect network performance and speed. This kind of neural network is usually used for processing big data, such as databases.
Inspired by neural network sorting methods, we have designed intelligent path selection (IPS) to replace the traditional path sorter. IPS is different from traditional sorters or neural sorting networks. Actually, IPS is not a sorter but a binary classifier. There is no need to sort from 1 to because all paths have been divided into good paths and bad ones.
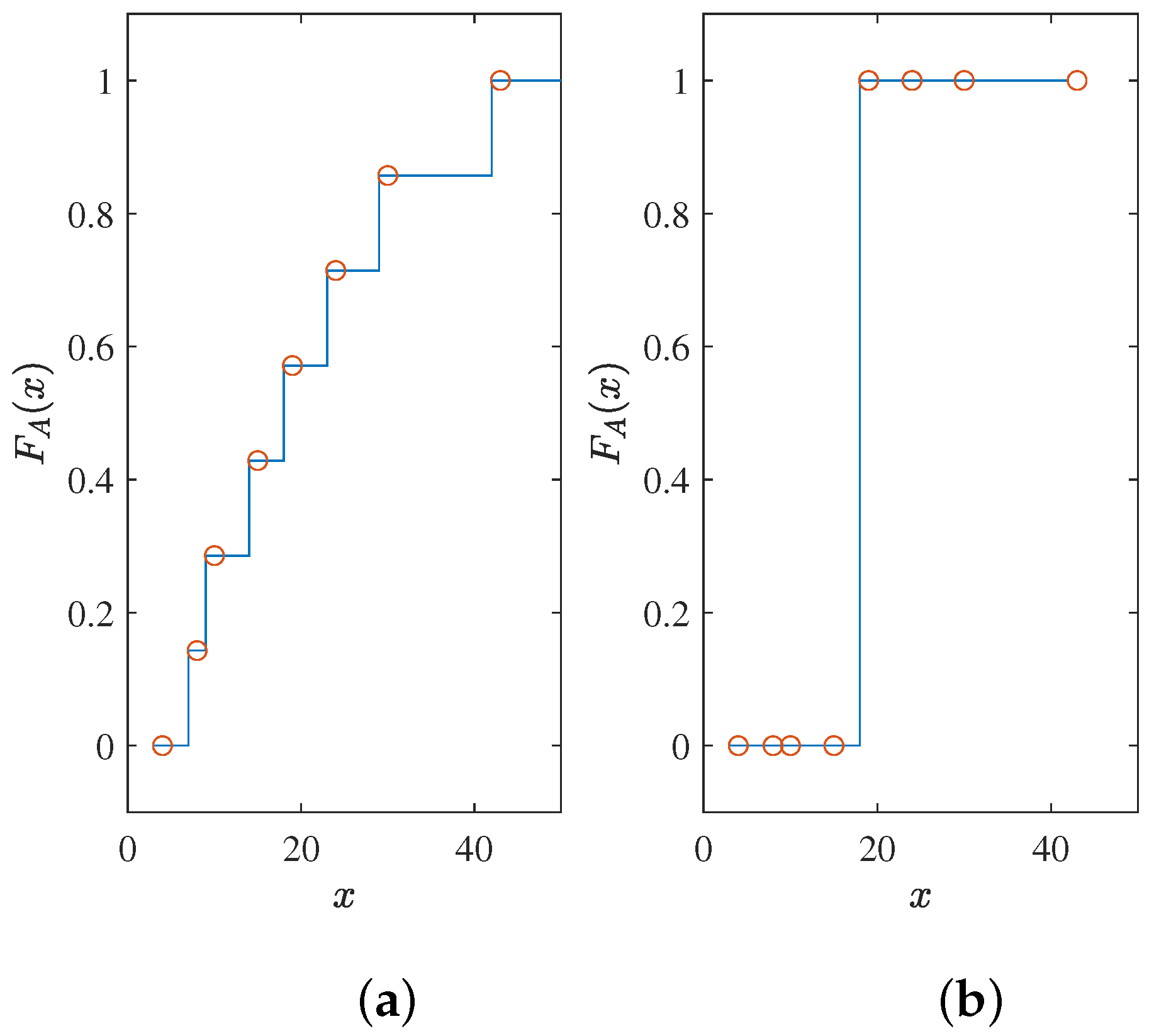
Here, we give an example. For an unordered array
A = [8, 10, 15, 24, 19, 4, 30, 43], the perfect CDF for its full sorting is a staircase function, and
Figure 1a is one of them. However, for the path selection of SCL, it only needs to be a step function, and one of the possibilities is
Figure 1b. The key to the problem is the position of the step. For a one-dimensional problem, it is an equivalent problem. If a suitable step position is obtained, the CDF is obtained. On the contrary, getting a CDF means that the suitable step position is known. For the path selection problem, a natural step position is the median. Knowing the median makes it easy to divide the data into two parts, larger and smaller. However, in SCL decoding, the arrays dynamically change, which is why we need a neural network to handle the problem. The neural network will give us a CDF or median that can adapt to dynamic arrays. In this study, we chose to train with a target output similar to the CDF.
In this way, the system’s complexity will be significantly reduced. Next, we designed a simple neural network for training: a universal neural network that can be adapted to different code lengths and code rates. Finally, we designed a threshold and a path selection matching strategy to match the network’s output and the SCL/CA-SCL decoder. The hardware structure of the fully connected neural network is designed to have highly parallel [
16] performance to maintain overall lower latency, and the pipelined structure [
17] reduces resource consumption and improves the utilization of hardware resources. The simulation results show that compared with the traditional sorting SCL/CA-SCL algorithm, IPS has little performance loss and low complexity. To conclude, the innovations of the proposed IPS are as follows:
We propose a framework that uses permutation entropy to measure the complexity of path selection. By comparing different path extension methods, the best path extension method can be determined. Treating path selection as a binary classification problem brings us new solutions.
We propose an intelligent path-selection method consisting of a neural network, a threshold, and a matching strategy, which reduces the latency of path selection. The simpler the network, the less the hardware resource complexity and latency.
The remainder of paper is as follows.
Section 2 gives a short introduction to polar codes and LLR-based SCL/CA-SCL.
Section 3 introduces the permutation entropy and the differences between various path extension schemes.
Section 4 shows the design of IPS, the neural network, and the matching strategy.
Section 5 provides the simulation results, and the conclusions are in
Section 6.
3. Path Selection and Permutation Entropy
In this section, we analyze the process of path selection in the SCL algorithm and establish a relationship with the permutation entropy.
3.1. Rethinking Path Selection
Among the L candidate paths maintained by the SCL algorithm, each path corresponds to a PM to represent the reliability of the path. In this paper, the smaller the PM, the more reliable the candidate path.
Assume that the PM metric of the -th bit is , After path extension, the PM extension (PME) values are . To find the most reliable L paths, the PME values are usually sorted to get , which satisfies . Keep the L smallest PME values as the new metric values: .
For software simulations, we generally do not care how sorting is done. However, hardware resource consumption and delay are crucial aspects that must be taken into account while designing hardware.
For the expansion from to , we discuss the following extension schemes.
Extension Scheme 1: Extend path
l to
and
, where the hard decision of
is zero and the hard decision of
is one.
In this way, it is easy to find the expanded original path after sorting.
Extension Scheme 2: Extend path
l to
and
, where the PM of
is smaller than that of
.
This is easy to extend, because
always remains the same.
Extension Scheme 3: Extend path
l to
l and
, where the PM of
l is smaller than
.
In this case, the entire PME remains unchanged for .
In hardware implementation, schemes 2 and 3 are both considered. Due to the potential size relationship ( or , the number of comparisons will be reduced.
Furthermore, not all PMEs require complete sorting. Partial path sorting simplifies the sorting operation and only needs to meet the condition of . This means that the number of comparisons can theoretically be reduced further.
In the next subsection, we explore a more idealized way of path selection by analyzing the permutation entropy.
3.2. Analysis Based on Permutation Entropy
Permutation entropy is used to describe the chaotic degree of a time series, which is calculated by the entropy based on the permutation patterns. A permutation pattern is defined as the order relationship among values of a time series.
3.2.1. Definition of Permutation Entropy
We use permutation entropy to define the chaotic degree of a sequence
. a vector composed of the
n-th subsequent values is constructed:
n is the order of permutation entropy. The permutation can be defined as:
, which satisfies
Obviously, there are a total of
permutation patterns
. For each
, we determine the relative frequency (# means number):
Definition 1. The permutation entropy is defined as (): Noting that
, a normalized permutation entropy can be defined as:
3.2.2. Permutation Entropy in Path Selection
In the SCL decoder, the size of the PM value is L and the size of the PM value after extension is .
We assume that the original sequence
before extension is unordered (order-3 permutation entropy for analysis):
The
after
Extension Scheme 1 is obviously unordered:
However, after
Extension Scheme 2, the situation becomes different. Permutation
never appears. The maximum permutation entropy becomes
Extension Scheme 3 is similar to
Extension Scheme 1 but more ordered than
Extension Scheme 1:
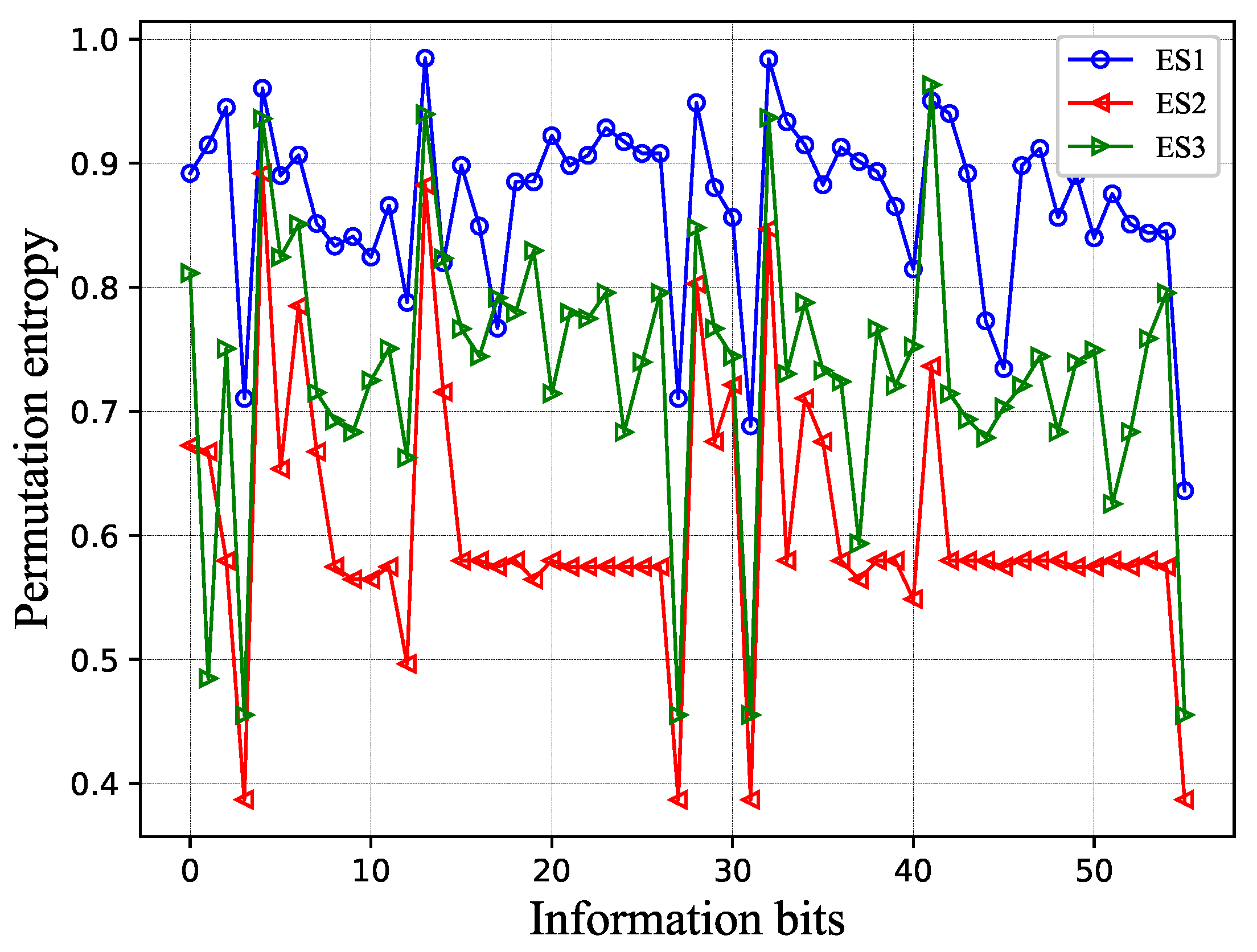
Figure 2 shows the PME permutation entropy under the same codeword and noise conditions. The horizontal axis has the information bits (only if fully extended to
L paths), and the vertical axis has the order-3 permutation entropy. The logarithm is in base 2. From this result, we can find many interesting conclusions. (1) As in the previous analysis, in most cases,
. (2) Some specific information bits have high permutation entropy, and some specific information bits have low permutation entropy. This means that, for a specific set of information bits, sorting algorithms with different complexities can be used to reduce the overall complexity of the algorithm.
3.2.3. Ideal-Path-Selection Method
The traditional sorting method, whether it involves complete sorting or a partial sorting, will get
, which is
. The new PM values are completely ordered:
However, the paths in the list do not actually need to be sorted. Due to the existence of noise, the PM value cannot fully represent the reliability of the path. Every surviving path has the potential to be the correct path. This can be reflected in the CA-SCL algorithm, which selects the path that passes the CRC check instead of the path with the smallest PM. Thus, it is not necessary to sort the surviving path every time, and this leads to the following corollary.
Corollary 1. The ideal path selection can be viewed as a binary classification, where all paths are classified as more reliable and less reliable. Assuming that the goes through the ideal path selection, then it should satisfyKeep the L smallest PME values as the new metric value ; the permutation entropy of PM should satisfy The ideal path selection can be represented using the system model of
Figure 3, where the input is
and the output is
.
is the label of the PME;
means this is a more reliable path and needs to be kept. On the contrary,
means discard it.
Before the extension, the path metric has the same complexity, . After different path selections, different permutation entropies are obtained. Obviously, the larger , the lower the complexity of path selection.
Finding such a function is almost impossible, but luckily, we can approximate this function using neural network methods. In the next section, we go into the details of the design and use of the neural network.
4. Intelligent-Path-Selection-Aided Decoding Algorithm
In this section, we design a general path-selection neural network. We describe the overall IPS structure in the first subsection and explain each detail in the following subsections.
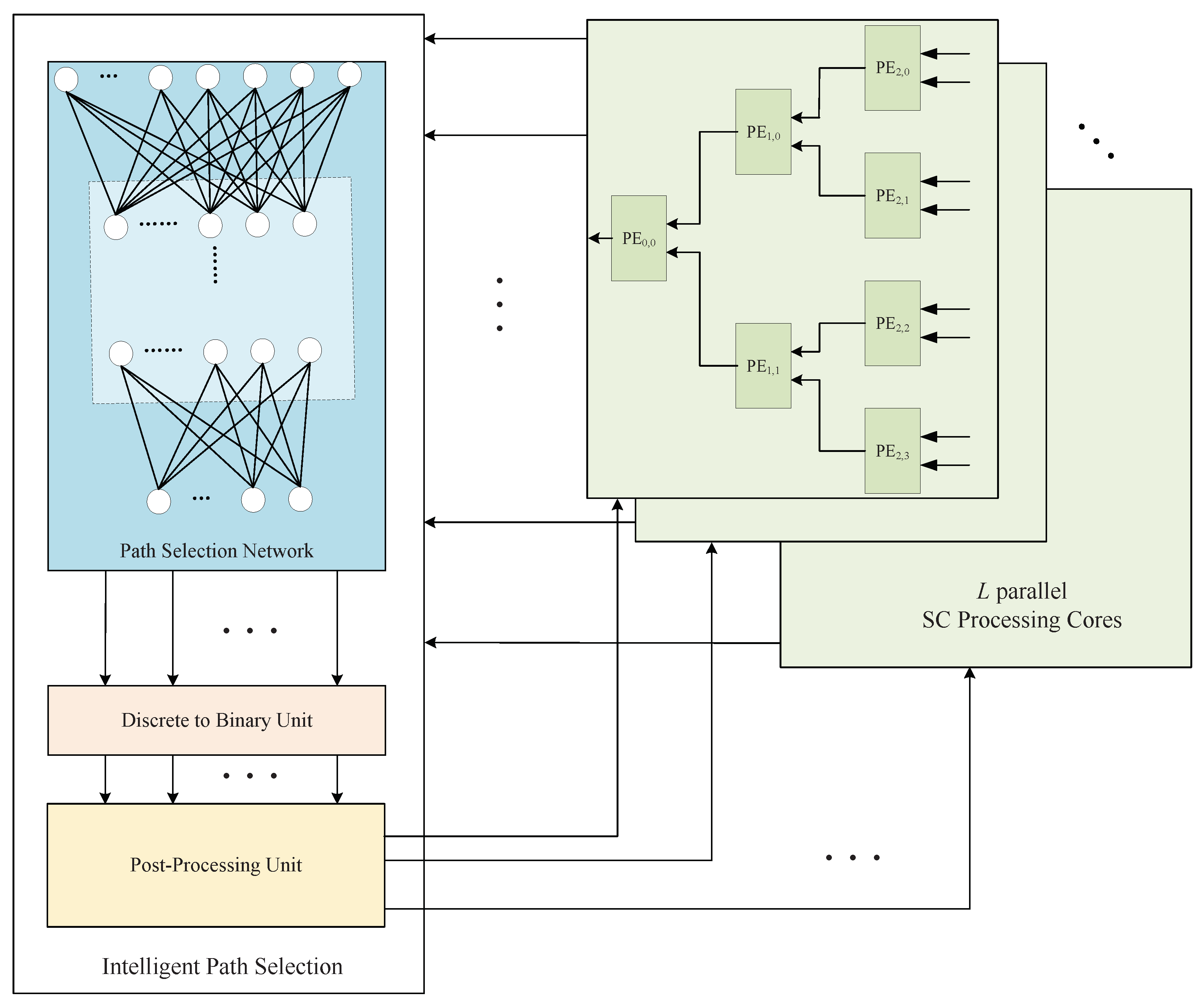
4.1. Intelligent-Path-Selection-Aided Decoder’s Structure
The intelligent path selection input is PMEs, and the output is L PMs. We designed the following intelligent path-selection architecture to accomplish these functions.
As shown in
Figure 4, the input PMEs can be recalculated by the network to obtain the new path reliability metrics
. The larger
is, the more reliable the path. Next, a threshold divides the paths into good paths (
) and bad paths (
). Up till now, we have completed the binary classification process and picked out the most reliable paths. However, there is the small drawback that the number of the most reliable paths is not always equal to
L, which sometimes results in wasted resources. Thus, we designed a post-processing unit such that the number of IPS outputs is always
L.
It is worth noting that training does not need to be done online. After the network has been trained, the parameters are put into the SCL/CA-SCL decoder. Therefore, the complexity of the training does not affect the latency of the decoding. However, complex networks are not conducive to hardware implementation. Thus, for the network structure, the simpler the better.
4.2. Path-Selection Neural Network
4.2.1. Data Preparation
For input vector , PME values are sorted . If , label vector is defined as ; else, . Thus, the sum of label vector is L.
4.2.2. Neural Network Model
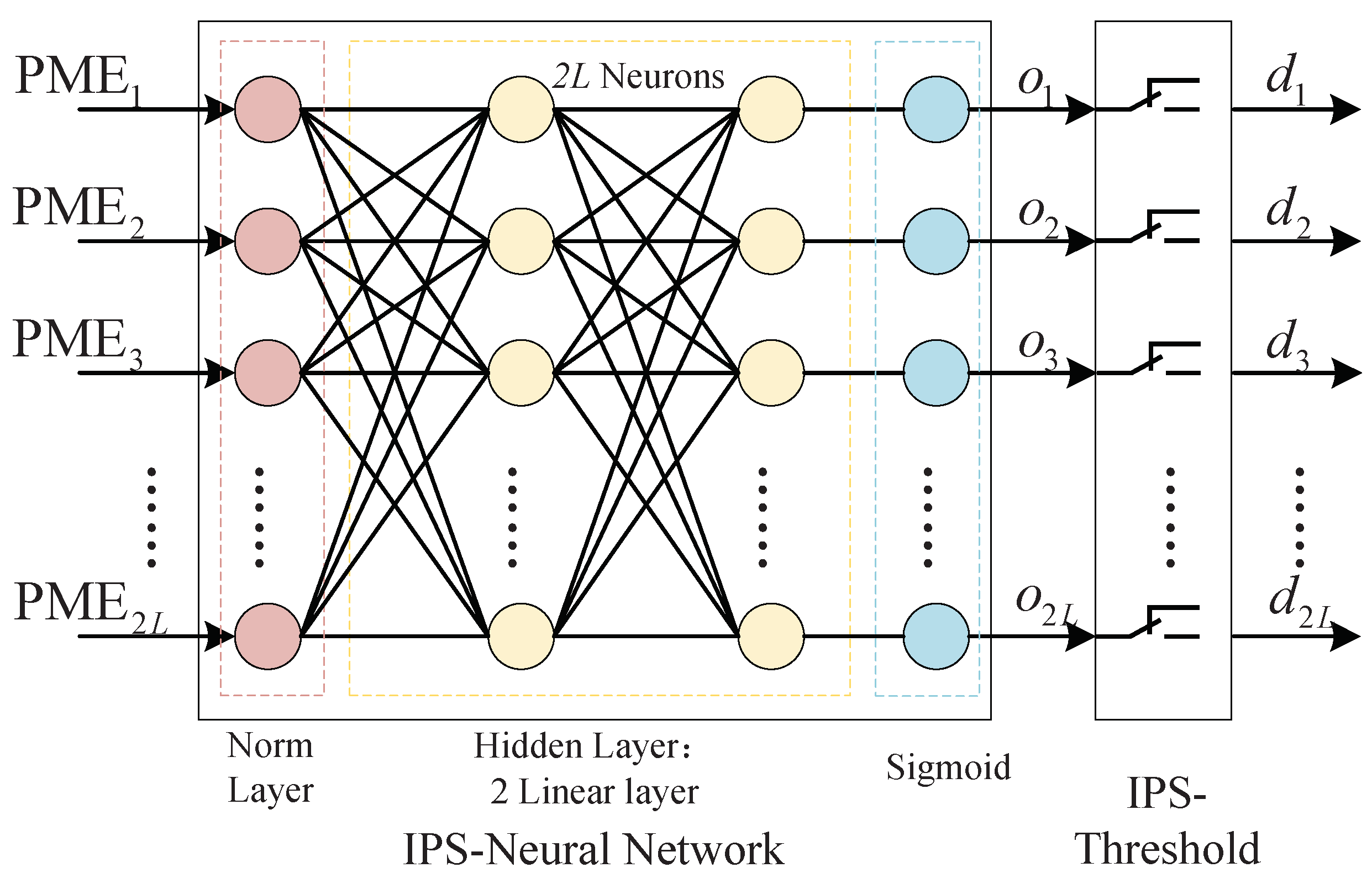
We use a simple neural network as the basic component of IPS (IPS-NN), including a normalization layer, two linear layers, and a sigmoid layer. Each layer of the network has
neurons.
Figure 5 shows the IPS neural network model.
The binary cross entropy (BCE) is considered as the loss function:
where
is
l-th output of the IPS-NN.
The IPS threshold is a simple switch structure used to convert the network’s output discrete value
into a binary value
.
where
T is the threshold value. Obviously,
means that the metric value of this path is small, and it is a potential successful decoding path (good path); otherwise, it is a bad path.
4.2.3. IPS-NN Configuration and Results
We trained IPS-NN with
. The detailed hyperparameters for training are shown in
Table 1.
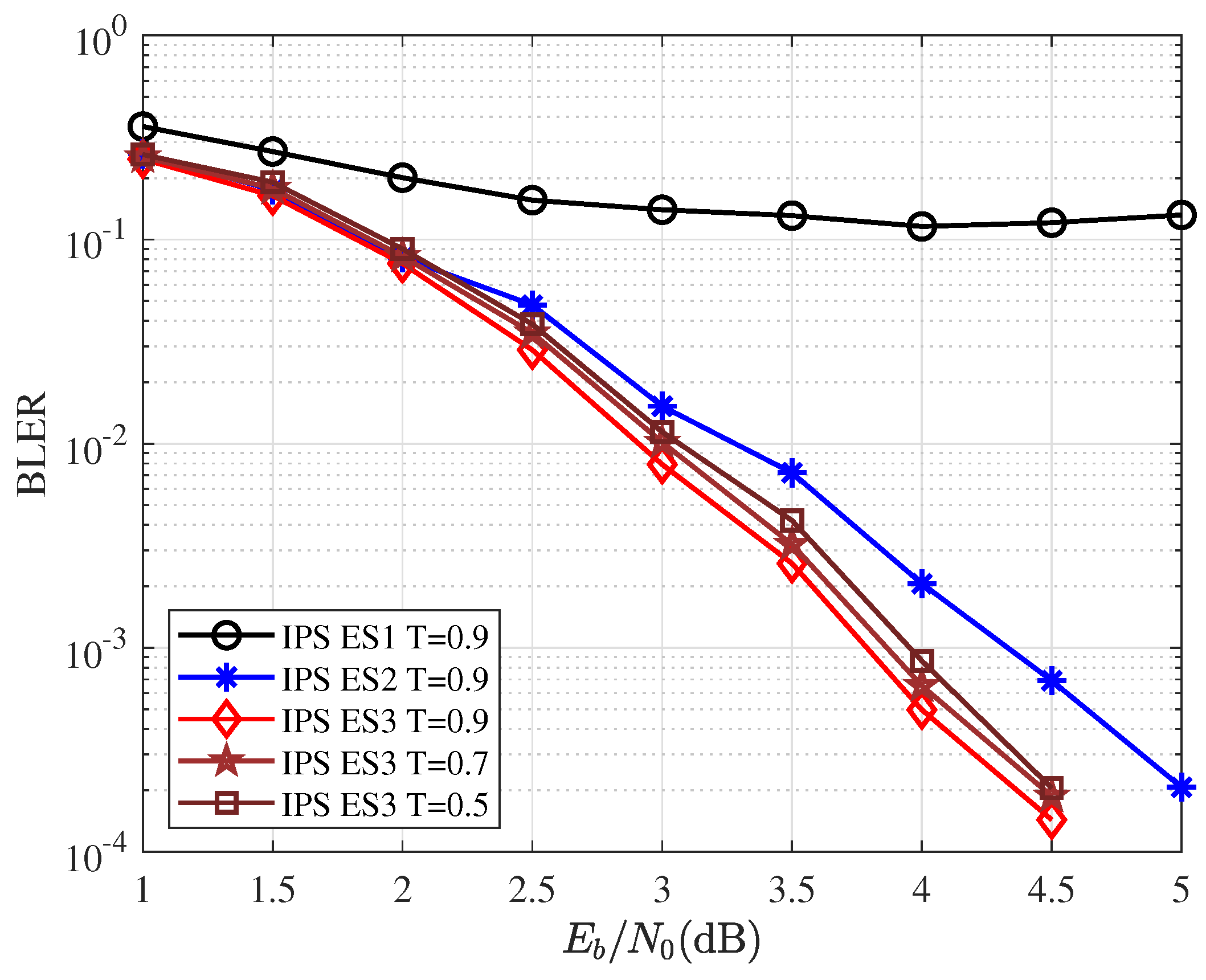
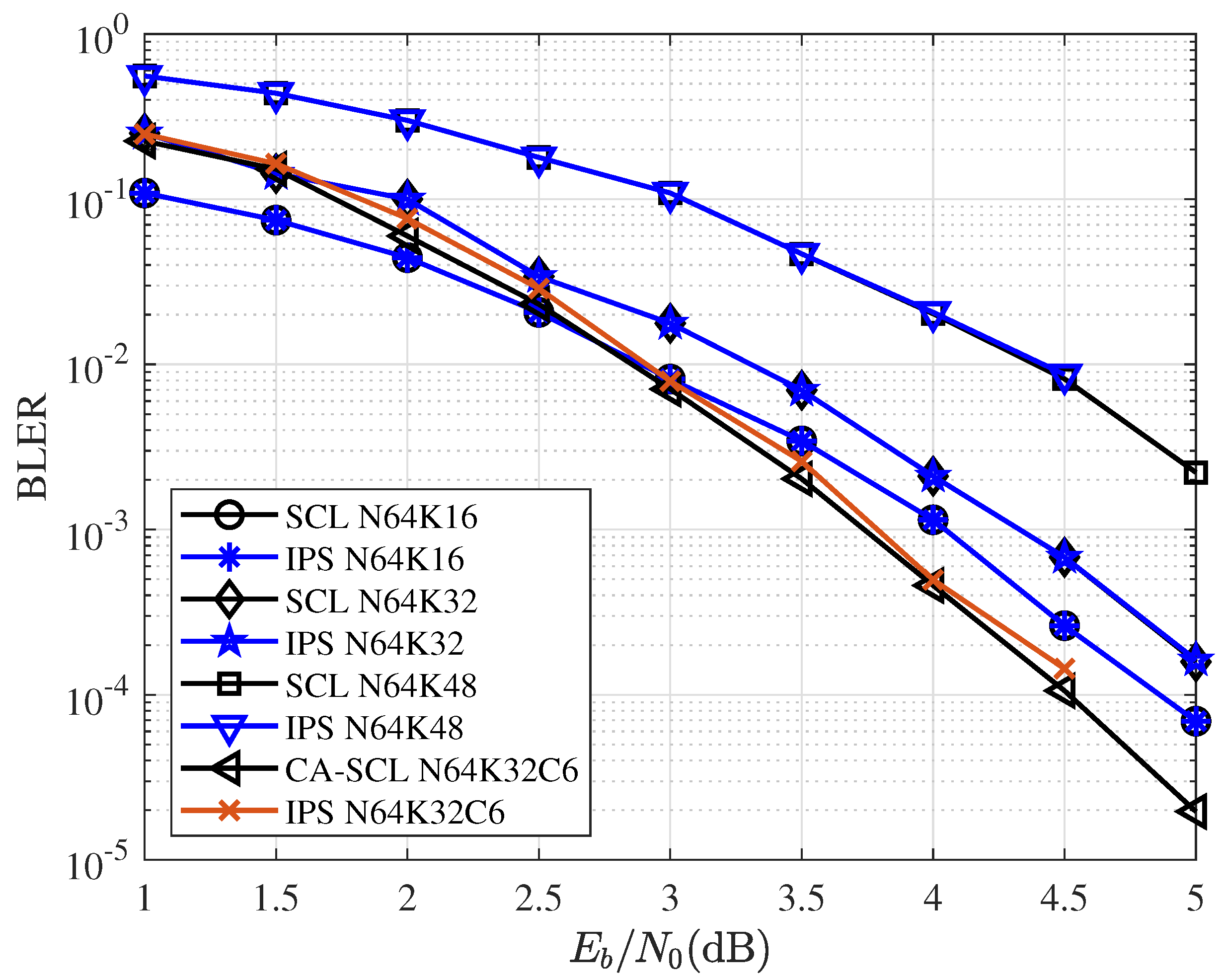
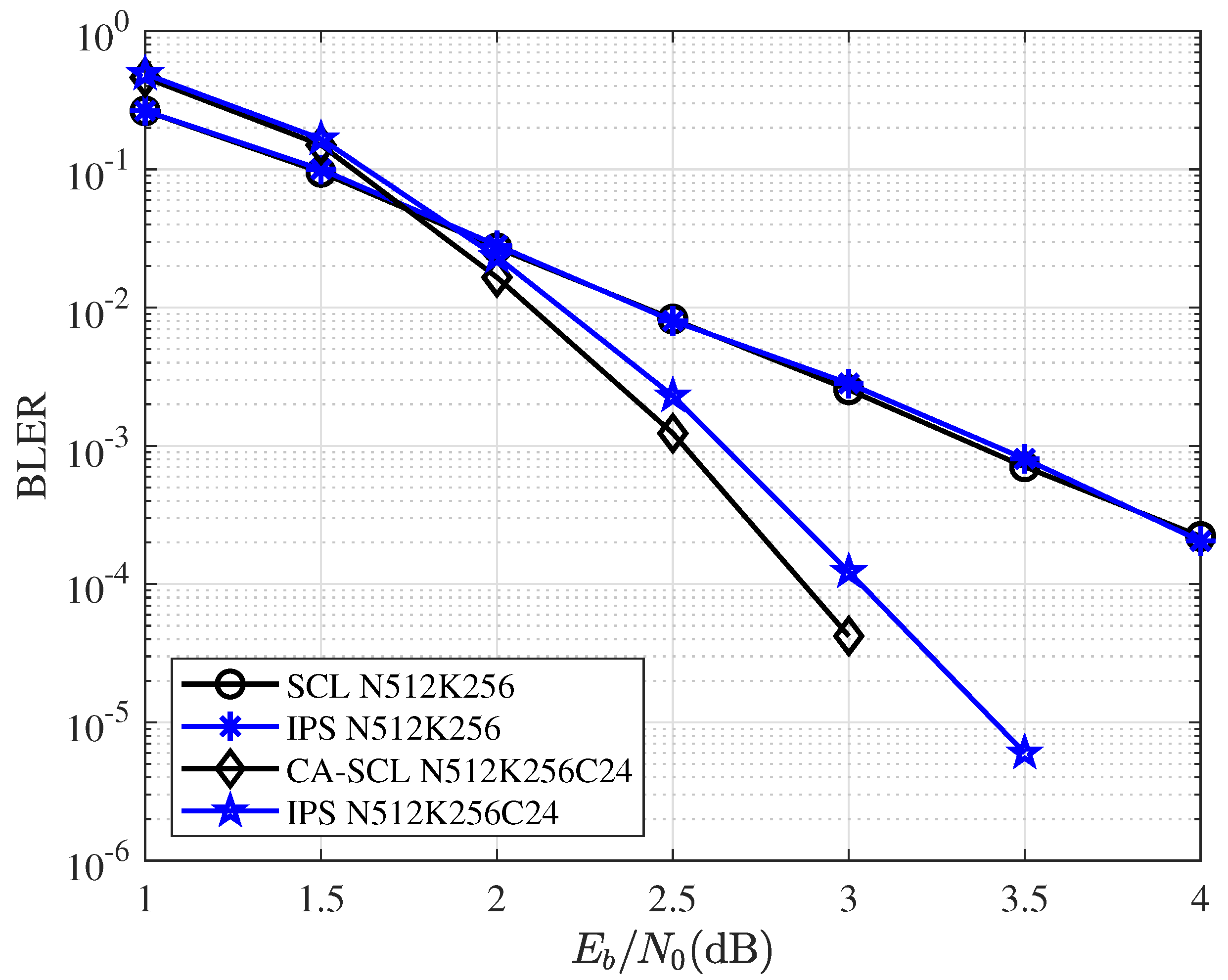
Definition 2. The accuracy of the neural network is defined as:S is test data set and is the size of the test data set. is the IPS output vector. is an indicator function that takes value one if the argument is true and zero otherwise. We consider each element in the vector as the standard of accuracy, rather than the entire vector. Even if the output vector is not exactly equal to the label, as long as the correct path is included, this vector is valid for the SCL algorithm. The IPS-NN network was implemented using the Pytorch framework. For the test set, the IPS-NN achieved an accuracy of 98.3%. However, this accuracy rate cannot completely determine the performance of the entire decoder. What is important is the performance of the entire CA-SCL decoder after replacing metric sorting with IPS.
4.3. Post-Processing Unit
In the previous section, we proposed IPS-NN and IPS-Threshold. It is worth noting that the output value of IPS is . We expect the sum of to be L, but in fact, the sum of is related to the network output and threshold. We need to perform post-processing operations on the network’s output.
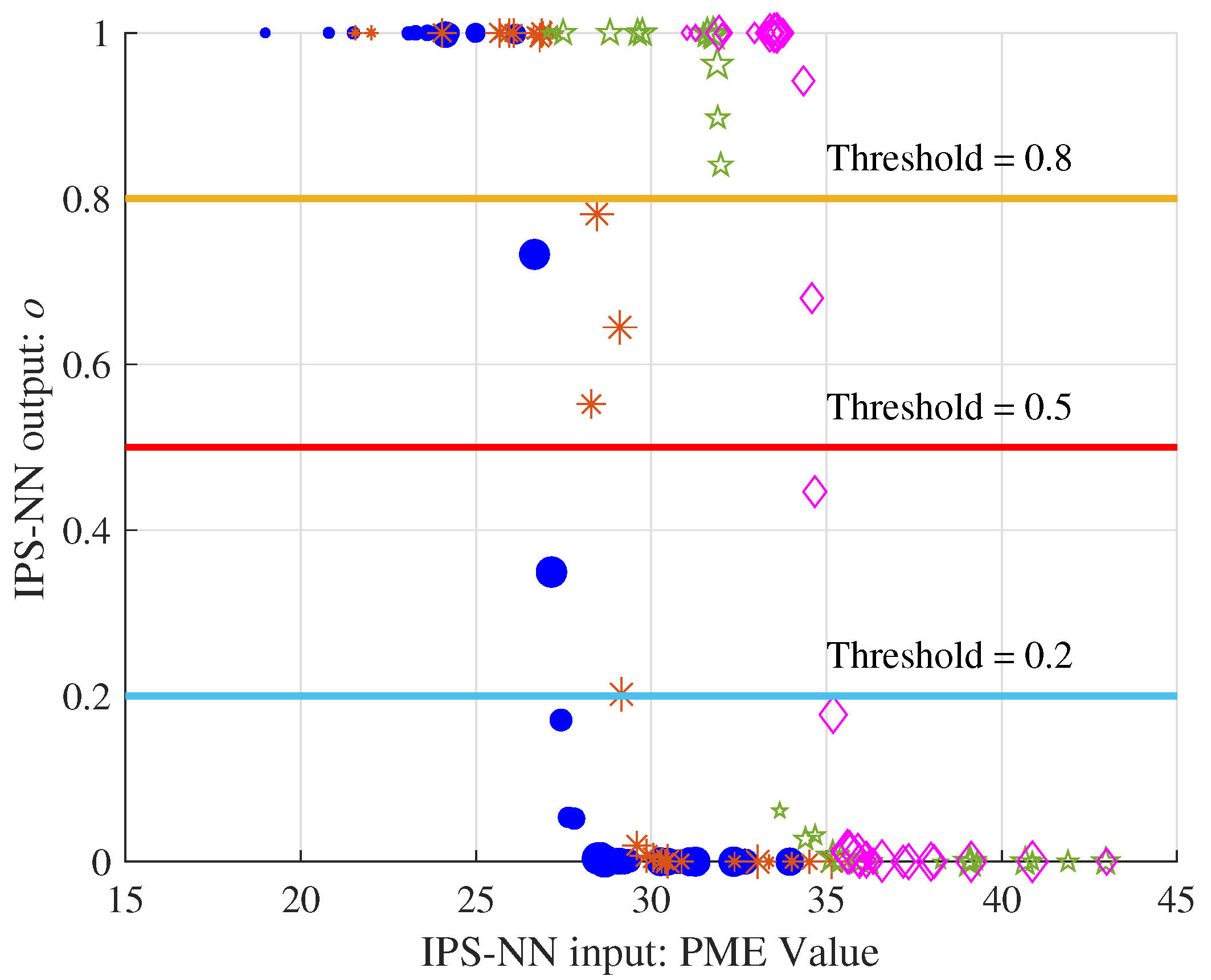
Figure 6 shows four sets of PME values selected in the decoding process with
. The size of the shape represents the order the input PME value. After IPS-NN, four sets of output values in the range
are obtained.
We can observe two phenomena: (1) The same PME value has different outputs in different sets, which shows that the IPS-NN can well adapt to the PME value of the entire set. In decoding the different bits, the PM value continues to increase, and the network is applicable. (2) The number of IPS output is related to the threshold value; the larger the threshold, the smaller the output .
We denote the sum of as . In order to solve the effect of the threshold on the output results, there are two solutions: (1) Using a variable threshold, use the dichotomy method to find the threshold value of when . (2) Add a compensation strategy to make the decoder output L paths when . Method 1 has good performance but increases the complexity of each decoding stage. Method 2 has some performance losses, but it is not sensitive to the decoding threshold and can have a larger threshold range. In this paper, we use method 2 and propose a simple matching strategy to make the decoder work smoothly. The matching strategy is intended to be compatible with conventional SCL/CA-SCL decoders and does not need to provide additional performance. Our network chooses the best paths, even if they are smaller than the size of the list. However, there is only one correct path, and it is most likely in the path we have chosen.
Strategy 1.(Discard Matching Strategy): When , a simple discarding matching strategy is adopted. If , discard some good path; if , discard some decoding path. A detailed description of the discard matching strategy is given in Algorithm 1.
If , we simply discard the good paths larger than L. If , we supplement the unselected paths at the front of the list with the candidate paths. Obviously, the performance of this strategy is related to the extension scheme. We can set a larger threshold to ensure in most cases, and the performance of the matching strategy is determined by the extension scheme.
In addition to using the discard matching strategy, different strategies, such as random selection, can also be used. These strategies will affect the performance of the decoder to a certain extent.
| Algorithm 1 Discard matching strategy. |
Input: Current extended path , IPS output
Output: L survival paths PM
1:
2: for do
3: if then
4:
5:
6: end if
7: end for
8: if then
9: for do
10: if then
11:
12:
13: end if
14: end for
15: end if |
4.4. Hardware Design for IPS-NN
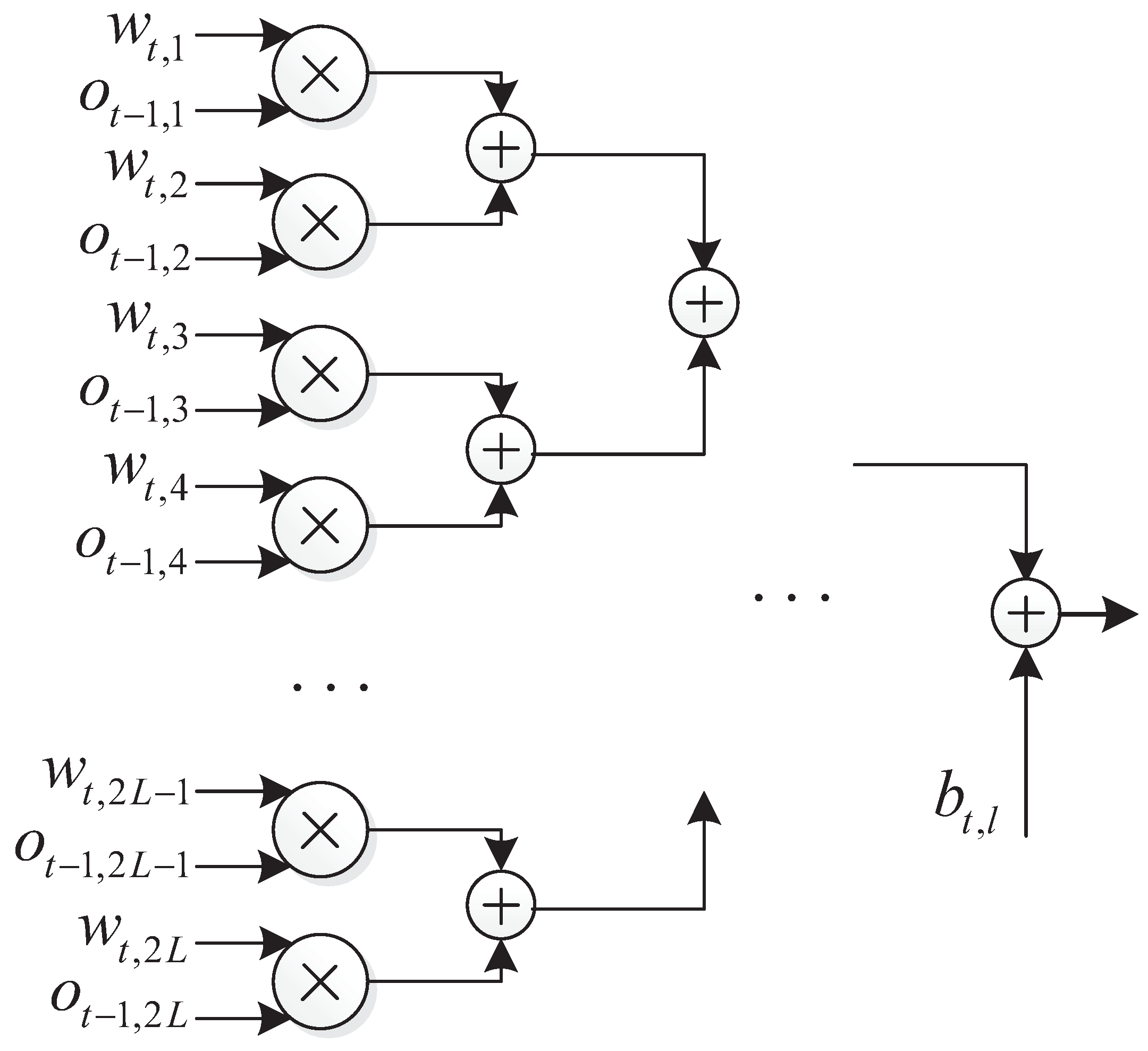
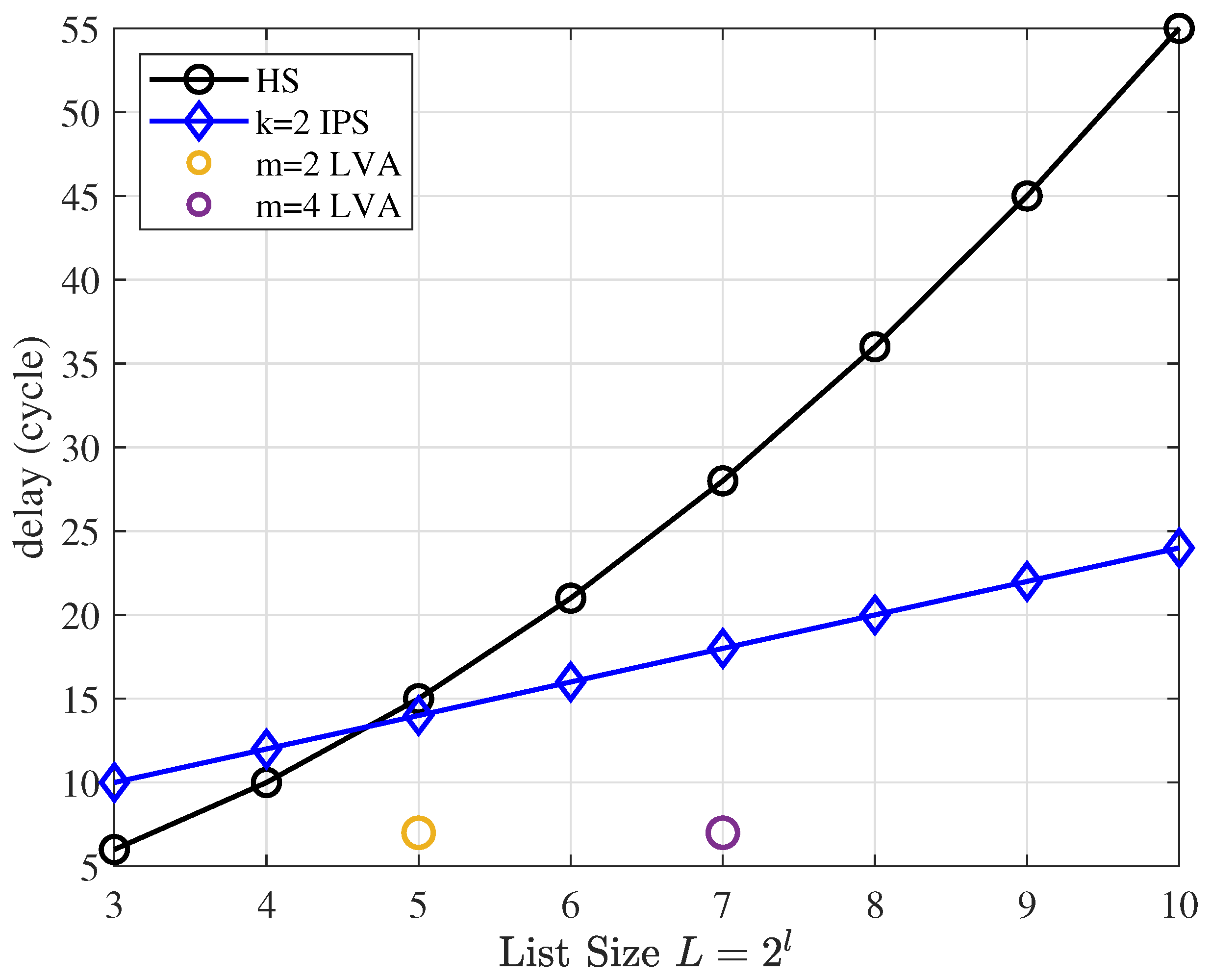
In this subsection, we provide a basic parallel NN structure for more convenient representation of latency. In the simulation, the norm layer was not necessary, and its removal does not affect performance. As for the sigmoid function, it can be implemented using ROM as a look-up table. The key to the latency is the design of the hidden layer.
The design of the hidden layers is based on two basic principles. (1) Parallelism: the nodes of the same layer depend only on the previous layer and can be computed simultaneously. (2) Pipelined operation, as each hidden layer depends only on the output of the previous layer; therefore, hardware resources can be reused to achieve pipelined operation. Therefore, we only need to design for one hidden layer node.
The output of the
l-th node at the
t-th hidden layer is
where
is the activation function, which can be implemented using a look-up table. One parallel structure of this hidden nodes is as
Figure 7.
In the structure, multiplication can be performed in parallel, and the time consumed by addition is
. Thus, the time consumption for a single hidden layer is
It is worth noting that, unlike the compare-and-swap (CAS) used for the traditional sorter, the NN implementation relies on adders and multipliers. With the same structure, the data-bit width also affects the throughput of the hardware.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}