1. Introduction
The
clustering of data is a fundamental task in unsupervised machine learning and exploratory data analysis. It has been the subject of countless studies over the last 50 years, with many definitions and algorithms being proposed, e.g., [
1,
2].
Persistent homology [
3,
4] is a powerful topological tool that provides multi-scale structural information about data and networks [
5,
6,
7,
8]. Given an increasing sequence of spaces (filtration), persistent homology tracks the formation of connected components (0-dimensional cycles), holes (1-dimensional cycles), cavities (2-dimensional cycles), and their higher-dimensional extensions. The information encoded in persistent homology is often represented by a
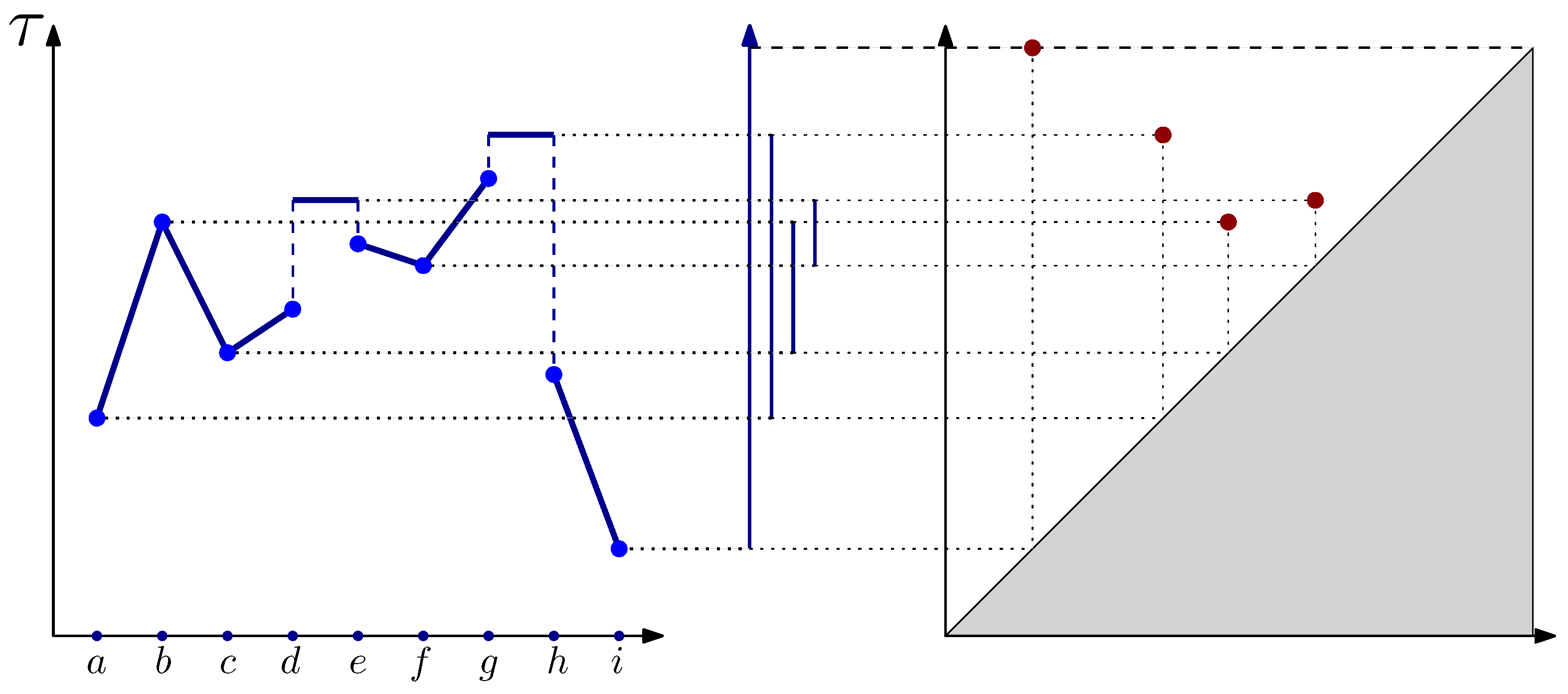
persistence diagram, which is a collection of points in
representing the birth and death of homology classes and providing an intuitive numerical representation for topological information (see
Figure 1).
The connection between clustering and 0-dimensional persistent homology is well established in various different scenarios. Specifically, the relationship with functoriality [
9,
10] has been investigated, as well as how to combine persistence with density-based methods [
11,
12]. An important motivating factor for connecting these methods is
stability. Namely, given small perturbations in the input data, persistent homology can provide guarantees on the number of the output clusters. One important drawback of this topological approach is that statistical tests for persistent homology and clustering based on persistence remain lacking.
Recently, for persistent homology in dimensions 1 and above (i.e., excluding connected components), persistent homology based on distance filtration has been experimentally shown to exhibit strong universal behavior [
13]. Suppose we are given as the input a point cloud generated by some unknown distribution. If we compute the distance-based persistent homology, under an appropriate transformation, the distribution of persistence values has been shown to be independent of the original point cloud distribution. This phenomenon has since been used to develop a statistical test to detect statistically significant homology classes. A key point in [
13] is that in order to obtain such universal behavior, the measure of persistence must be given by the value of death/birth, which makes the measure of persistence scale-invariant.
However, in distance-based filtration, 0-dimensional persistent homology (tracking clusters) does not fit into this universality framework as the birth time of every 0-dimensional homology class is set to 0. To address this issue and enable the study of universality in the context of clustering, we introduce a new filtration approach, which we call k-cluster filtration. This is a novel non-local construction, where vertices only become ‘alive’ once they belong to a sufficiently large cluster. In other words, while traditional persistent homology considers every vertex as an individual cluster and tracks its evolution, k-cluster filtration only considers components with k or more vertices as ‘meaningful’ clusters.
We note that while the motivation for this new filtration method is to study distance-based filtrations, k-cluster filtration can be constructed over any weighted graph. It generally provides two key advantages over traditional filtration. Firstly, it results in ‘richer’ persistence diagrams, in the sense that components have non-trivial birth times. This improves our ability to compare between different features within the same diagram or across different diagrams. Secondly, k-cluster filtration provides a more ‘focused’ view of connected components by discarding those that are considered small (determined by application). In particular, it allows us to remove outliers from persistence diagrams.
This paper is organized as follows:
Section 2 provides essential background information about persistent homology;
Section 3 introduces
k-cluster filtration and presents some preliminary properties;
Section 4 provides an algorithm for computing the filtration function and its corresponding persistence diagram in a single pass;
Section 5 demonstrates some experimental results comparing our clustering method to some other approaches; and finally,
Section 6 discusses some probabilistic aspects of this filtration method by comparing it to known properties of random graphs and simplicial complexes.
2. Graph Filtration and Persistent Homology
We first introduce the required topological notions. As we focus on the special case of graphs and connected components (0-dimensional homology), we restrict our definitions to this case. For the general definition of homology, we refer the reader to [
14,
15].
Let
be an undirected graph. Our main object of study is
graph filtration, i.e., an increasing sequence of graphs. This can be constructed by defining a function
, with the restriction that if
, then
. This restriction ensures that the sublevel sets of
define a subgraph. The filtration
is then defined as
As we increase
t from 0 to
∞, we can track the connected components of
as they appear and merge, which are referred to as
births and
deaths, respectively. When two components merge, we use the ‘elder rule’ to determine that the component that was born last is the one that dies. Note that at least one component has an infinite death time in any graph filtration. We refer the reader to [
3] for an in-depth introduction to persistent homology.
These birth–death events can be tracked using an algebraic object called the 0-dimensional persistent homology group. Its most common visualization is a
persistence diagram, which is a collection of points in
where each point corresponds to a single connected component. The coordinates of a point encode its information, with the
x-coordinate representing the birth time and the
y-coordinate representing the death time. An example of a function on a line graph is shown in
Figure 1. Note that one component is infinite, which is denoted by the dashed line at the top of the diagram.
In a more general context, given the filtration of higher-dimensional objects (e.g., simplicial complexes), we can also study
k-dimensional persistent homology. This object tracks the formation of
k-dimensional cycles (various types of holes) and its definition is a natural extension of the 0-dimensional persistent homology we study here. However, this is beyond the scope of this paper and we refer the reader to [
3] for more information.
3. -Cluster Filtration
Let
be an undirected weighted graph. When computing 0-dimensional persistent homology, the filtration values are commonly taken to be
for all
and
for all
. We denote this filtration by
. In other words, we assume all vertices are present at time zero and that edges are gradually added according to the weight function
W. This has been common practice in almost all studies in the TDA literature, particularly in geometric settings where
W represents the distance between points, i.e., geometric graphs, which are the skeleton of two common constructions: the Čech and Vietoris–Rips complexes [
3]. While in many models, this choice of
seems reasonable, it has two significant drawbacks:
The produced persistence diagrams are degenerate as the birth time of every 0-cycle is , which significantly reduces the amount of information we can extract from the diagrams;
The generated persistence diagrams are superfluous in the sense that they contain a point for each vertex V, while obviously not all vertices contribute significant structural information.
In this paper, we propose a modification to standard graph filtration that will resolve both of these issues and lead to more concise and informative persistence diagrams.
We will first define the filtration values for the vertices. For every vertex and value
, we define
to be the number of vertices in the connected component of
that contains
v.Fix
, and define
The edge values are then defined as
Denoting the corresponding filtration by , note that . In other words, compared to , in , we delay the appearance of the vertices until the first time each vertex is contained in a component with at least k vertices (and adjust the edge appearance to be compatible). Effectively, the assignment of the new filtration values to the vertices introduces three changes to persistence diagrams:
All points that are linked to components smaller than k are removed;
Each birth time corresponds to an edge merging two components in , such that and ;
Each death time corresponds to an edge merging two components with at least k vertices each.
We call this filtration approach ‘k-cluster filtration’ to represent the fact that it tracks the formation and merging of clusters of at least k. The parameter k determines what we consider to be a sufficiently meaningful cluster. In , every vertex is considered to be a cluster but, statistically speaking, this is overkill. The chosen value of k should depend on the application, as well as the sample size.
We conclude this section by showing that k-cluster filtration decreases (in a set sense) as we increase k. This could be useful, for example, in the context of multi-parameter persistence, which we briefly mention later but leave for future work.
Lemma 1. Filtration decreases in k or equivalently: Proof. For any vertex
, if
, then
. From (
1), we therefore have that
. Using (
2), we have
for all
. □
4. Algorithm
In this section, we describe an efficient one-pass algorithm for computing the filtration function and persistence diagram at the same time. The time complexity of the algorithm is
, where
is the inverse Ackermann function [
16]. This is the same complexity as when computing 0-dimensional persistence diagrams if we were given the filtration function as input.
We begin with the (standard) terminology and data structures. For simplicity, we assume that the weights of the edges are unique and that the vertices have a lexicographical order. We first define the filtration function, which determines the total ordering of the vertices. Initially, undefined filtration function values are assumed to be ∞. If the function value is the same or undefined for two vertices, the order is determined via lexicographical ordering. It is then straightforward to check this is a total ordering.
Remark 1. In the case of a total ordering, we can choose a representative 0-dimensional persistent homology class. Notably, in total ordering, a unique vertex is the earliest generator for a homology class (i.e., cluster), which we denote as a canonical representative of the persistent component.
To track components as we proceed incrementally through the filtration approach, we use the union-find data structure, which supports two operations:
returns the canonical representative for the connected component containing v;
merges the connected components containing u and v into one component, including updating the root.
We augment the data structure by keeping track of two additional records:
To track the size of the component, we store the size at the root (i.e., the canonical representative) of each component, updating it each time a merge occurs. To access a connected component, recall that union-find data structures can be implemented as rooted trees. For each vertex, we store a list of children in the tree. To recover the list of vertices in the component, we perform a depth-first search of the tree, starting from the root (although any other traversal method could be used). All update operations have
cost (cf., [
16]).
Note that when , the filtration value of each vertex is 0; so, the problem reduces to finding the minimum spanning tree of a weighted graph. Hence, we assume that . Initially, we set the filtration functions for all vertices and for all edges and assume that the edges are sorted by increasing weight. Note that if this is not the case, this step will become a bottleneck, with a cost of . Thus, we begin with a forest where each component is a single vertex, i.e., all components are initially born at 0.
We proceed as in the case of standard 0-dimensional persistence, by adding edges incrementally. As all components are present at time 0, we are only concerned with merges. The problem is reduced to updating birth times as we proceed by keeping track of ’active’ components, i.e., those larger than k. We omit points in persistence diagrams that are on the diagonal (death = birth), although these may be included with some additional bookkeeping.
Assume we are adding the edge . If e is internal to a connected component (i.e., ), then it does not affect the 0-persistence. Otherwise, it connects the two components denoted as . There are a few cases to consider:
The full procedure is given in Algorithm 1. Note that we only compute the filtration of the vertices as the correct edge values can then be computed using Equation (
2).
Proof of Correctness. We first argue that the function is correctly computed. This follows directly from the fact that the algorithm explicitly tests that the components contain at least k vertices. The fact that the corresponding persistence diagram is correctly computed is a consequence of the following result. □
Lemma 2. The minimum spanning tree for is the minimum spanning tree for any k.
Proof. The key observation is that until a component contains k vertices, any spanning tree is a minimum spanning tree as all edges are assigned the value of when the component becomes active. The values of the remaining edges do not change and so remain in the MST. □
The equivalence of the MST and persistence diagram [
17] then implies the correctness of the algorithm.
Proof of Running Time. The analysis of the merging is covered verbatim in the standard analysis of union-find data structures [
16]. As described above, updating the sizes of the components and the lists of children in the merges are
operations. All that remains to prove is the cost of updating the function
. We observe that each vertex is only updated once. This has a total cost of
, while the edges can be updated at a cost of
each. However, if we only want to obtain a persistence diagram (and not the actual graph filtration), we do not need to update the edges since we perform a single pass. Therefore, the overall running time is
. □
Extracting the Clusters. To obtain clusters, we can use the algorithm in [
12]. This algorithm extracts the
ℓ-most persistent clusters by only performing merges when the resulting persistence is less than a given threshold. This threshold can be chosen such that there are only
ℓ points above the threshold in the diagram. Finally, we note that cluster extraction can be performed on an MST rather than a full graph.
| Algorithm 1 The one-pass algorithm |
- 1:
- 2:
- 3:
Initialize union-find data structure: for all - 4:
- 5:
for do - 6:
if then - 7:
- 8:
if then - 9:
if then - 10:
for do - 11:
- 12:
end for - 13:
end if - 14:
if then - 15:
for do - 16:
- 17:
end for - 18:
end if - 19:
if then - 20:
- 21:
- 22:
- 23:
end if - 24:
end if - 25:
- 26:
end if - 27:
end for - 28:
return
|
5. Experiments and Applications
In this section, we probe the behavior of
k-cluster persistence through a sequence of experiments. Using several synthetic datasets, we study the dependence on the parameter
k and experimentally show that this filtration approach follows the universality laws discovered in [
13]. Next, we demonstrate how
k-cluster persistence can be used for clustering by taking advantage of universality to automatically determine the number of ’statistically significant’ clusters. Finally, we show how our new clustering method works in more exotic spaces, specifically tree structures. The results presented here are a preliminary investigation into this construction and we expect to continue with more applications in future work.
Remark 2. Note that in all persistence diagrams presented in the figures, the axes are modified to birth vs. death/birth (rather than birth vs. death).
5.1. Simulated Point Clouds
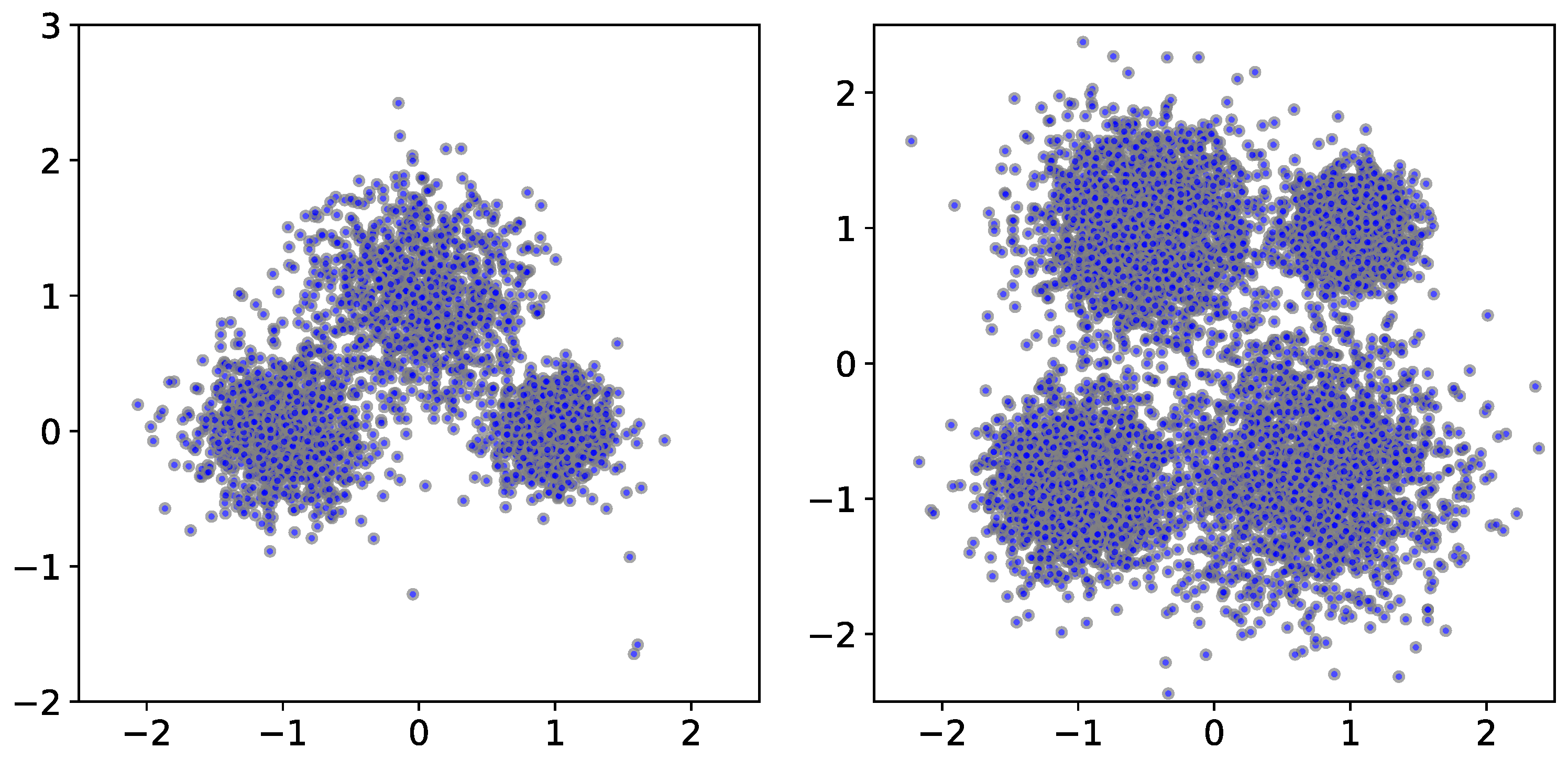
We start by generating point clouds from a mixture of Gaussians, resulting in several clusters of points (
Figure 2). We first show the effect of the parameter
k on the filtration function and the corresponding persistence diagrams. For the two point clouds in
Figure 2, we show the resulting persistence diagrams for the
k-cluster filtration functions in
Figure 3. Notice that the correct number of persistent clusters is evident, especially for
and 50. An important phenomenon that is evident in the figures is that higher values of
k filter out more of the ‘noise’.
To place the behavior of the persistence diagrams into further context, we compare the
k-cluster filtration method to a related construction from the applied topology literature, which has been suggested for dealing with outliers in clustering (and higher homological dimensions):
k-degree Vietoris–Rips filtration [
18]. Given a weighted graph
, we define the
k-degree filtration function
as follows: for every vertex
, we take
to be its
k-nearest neighbor distance. The values of the edges are then determined as in (
2). The
k-degree filtration approach has been used in the context of multi-parameter persistence, with bifiltration induced by decreasing
k and increasing the edge weight (commonly, Euclidean distance). In this paper, we do not explore multi-parameter settings. Rather, we focus the properties of persistence diagrams for fixed values of
k. We make two observations before investigating the differences:
The k-degree filtration function is determined completely by the local neighborhood of a vertex, i.e., its immediate neighbors in the graph. The same is not true for k-cluster filtration;
For a fixed value of k, we have for all . In other words, the value of the k-cluster function is less than or equal to the value of the -degree function. This follows from the fact that if a vertex has neighbors, then it is part of a cluster with at least k vertices.
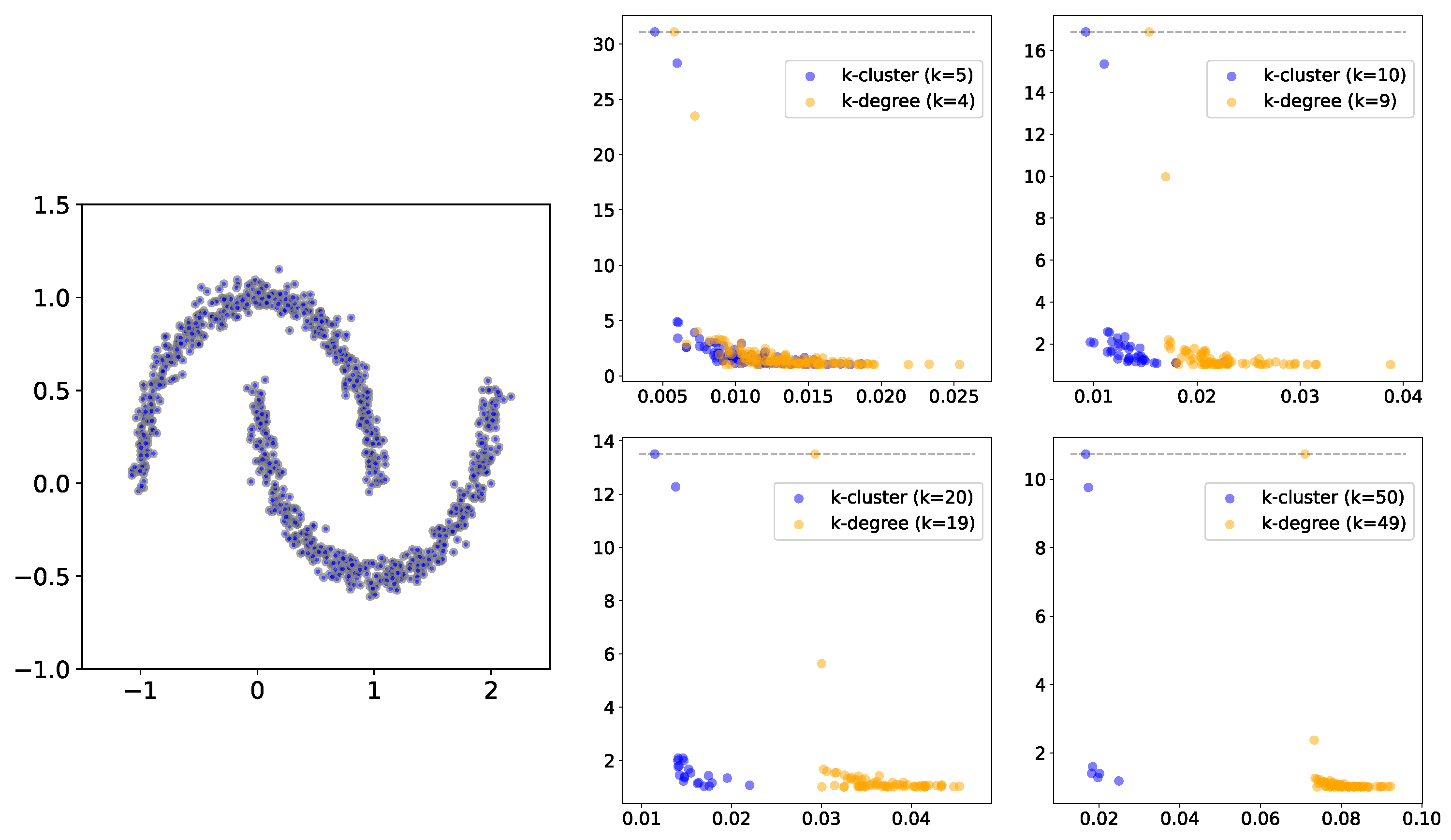
In
Figure 4, we show the persistence diagrams (i.e., birth vs. death/birth) for two non-convex clusters for both the
k-degree and
k-cluster filtration methods, using different values of
k. In this example, especially for larger
k values, the persistent clusters are much more prominent in
k-cluster filtration compared to
k-degree filtration. This may be explained by the fact that a much larger radius is needed to obtain the required number of neighbors. In
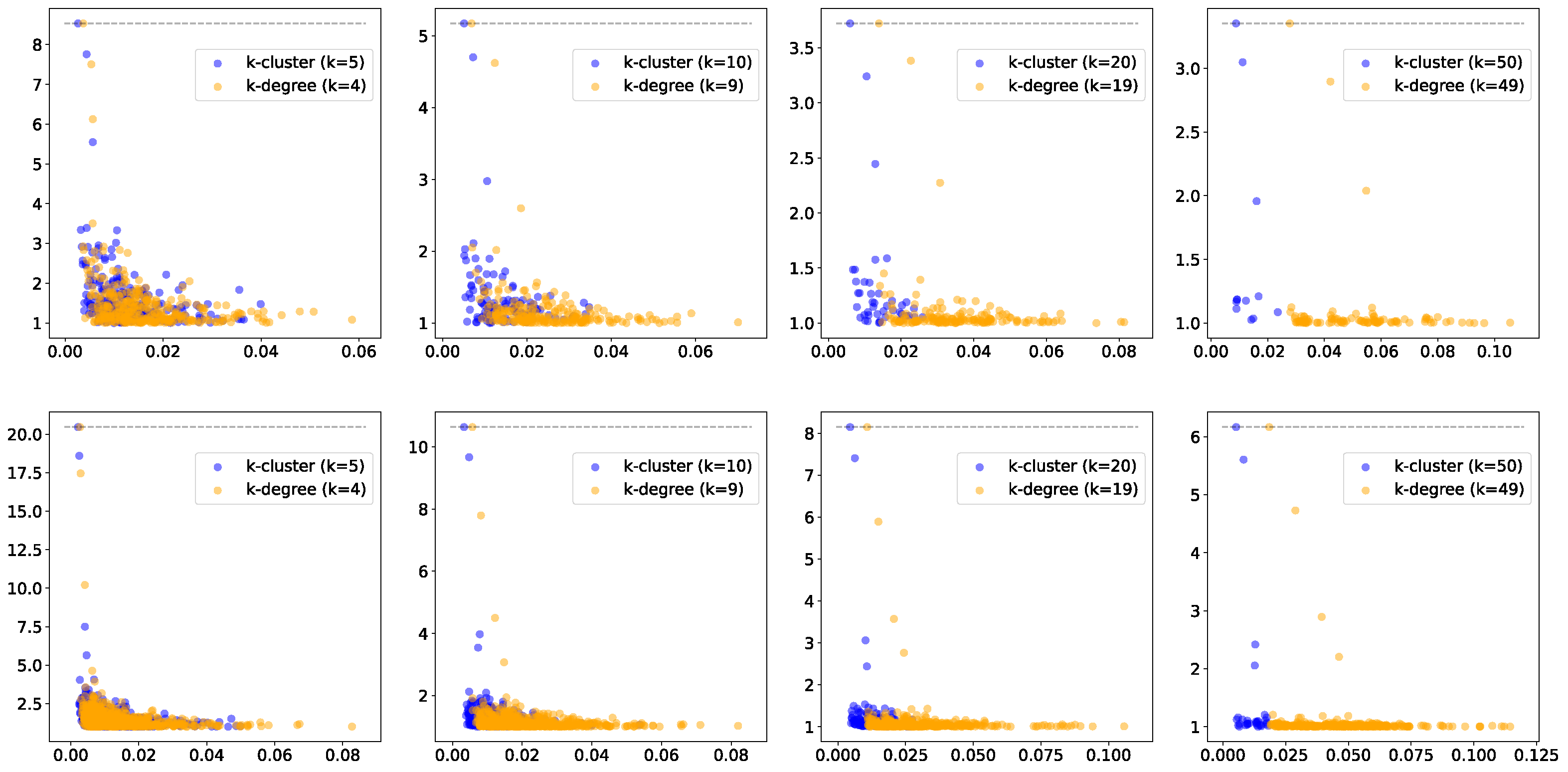
Figure 5, we show the same comparison for persistence diagrams for 3 and 4 groups, where the difference between the two methods is less clear. However,
Figure 6 highlights an additional difference between the behaviors of the two filtration approaches. In this figure, we compare persistence (death/birth) for the second most persistent cluster, using a wide range of
k values. In the left and center plots, the second most persistent clusters correspond to true clusters in the data. We observe that the persistence value decays much more slowly for
k-cluster filtration, i.e., the true cluster remains more persistent for increasing values of
k. The plot on the right presents the same comparison but for uniformly distributed random points. In this case, the second most persistent cluster is construction noise, i.e., not a real cluster in the data. Although
k-cluster filtration still decays more slowly, it is at a comparable rate to that of
k-filtration. Hence, we can conclude that persistent clusters show more stable behavior over ranges of
k for
k-cluster filtration compared to
k-degree filtration.
5.2. Universality
In [
13], we published a comprehensive experimental work showing that the distribution of persistence values is universal. We consider persistence diagrams as finite collections of points in
:
. For each point
, we consider the multiplicative persistence value
. Our goal is to study the distributions of
-values across entire diagrams.
Our results in [
13] are divided into two main parts. Given a point cloud of size
n, we compute the persistence diagrams for Čech and Vietoris–Rips filtrations. In
weak universality, we consider the empirical measure
and we conjecture that for IID samples, we have
where
d is the dimension of the point cloud,
i is the degree of homology, and
is the filtration type, i.e., Čech or Vietoris–Rips. In other words, the limiting distributions for the
-values depend on
but are independent of the probability distributions generating the point clouds.
In
strong universality, we present a much more powerful and surprising conjecture. Here, we define
(the values of
A and
B are specified in [
13]) and the empirical measure
Our conjecture is that for wide class of random point clouds (including non-IID and real data), we have
where
is a unique universal limit. Furthermore, we conjecture that
might be the left-skewed Gumbel distribution.
Originally, the results in [
13] were irrelevant for the 0-th persistence diagrams of random point clouds as the birth times were all zero. However, once we replace standard filtration with
k-cluster filtration, we obtain new persistence diagrams with non-trivial birth times that we can study. In
Figure 7, we demonstrate both weak and strong universality properties for
k-cluster persistent homology. We generated IID point clouds across different dimensions and with different distributions (uniform in a box, exponential, normal). The results show that both weak and strong universality hold in these cases as well. We note that for weak universality, the limiting distribution depends on both
d (the dimension of the point cloud) and
k (the minimum cluster size).
5.3. Clustering
As mentioned in the introduction, a key motivation for this work was to apply
k-cluster filtration to clustering. To obtain clustering from a 0-dimensional persistence diagram, we use the algorithm proposed in [
12]. Roughly speaking, given a threshold
, the algorithm extracts all clusters that are at least
-persistent. We note that the original measure for persistence in [
12] was given by
; however, the change to use
in the algorithm is trivial.
Statistical Testing. An important consequence of the universality results presented in
Section 5.2 is that the limiting distribution (after normalization) appears to be a known distribution, i.e., the left-skewed Gumbel. We can thus perform statistical testing on the number of clusters, as in [
13]. The null hypothesis denoted by
is that the
i-th most persistent cluster is due to noise. Assuming that the universality conjectures hold, the null hypothesis is given in terms of the
ℓ-values as
where
represents the
i-th most persistent cluster in terms of death/birth. The corresponding
p-value is given by
Note that since we are testing sorted values, we must use multiple hypothesis testing corrections. In the experiments we describe below, we use the Bonferroni correction.
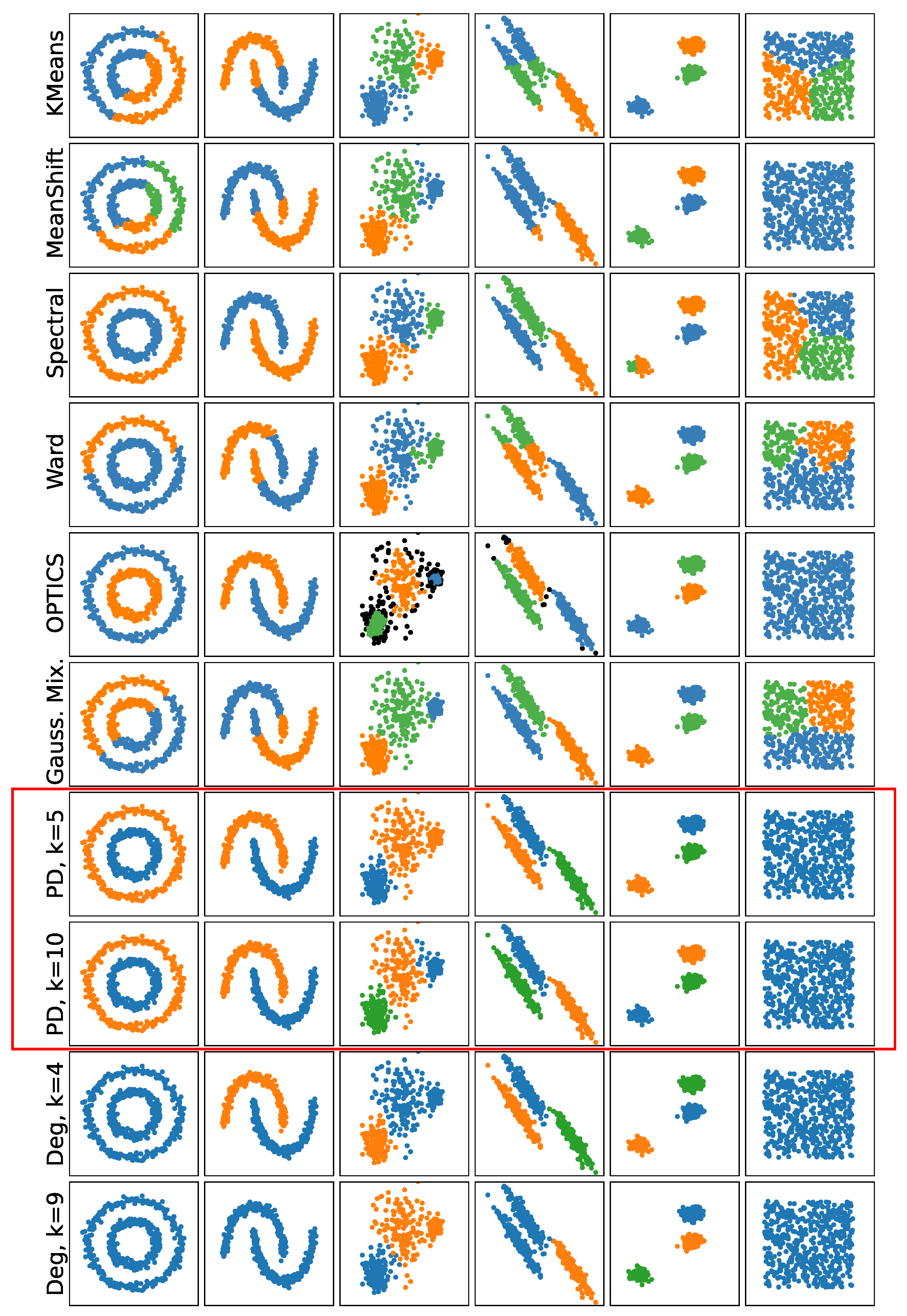
In
Figure 8, we compare
k-cluster filtration and
k-degree filtration using persistence-based clustering from [
12] and other common algorithms for clustering. For the other approaches, we use the standard implementations found in [
19], which have associated techniques for choosing the number of clusters. In the cases of
k-cluster filtration and
k-degree filtration, the numbers of clusters are chosen using the statistical testing described above. Note that since the numbers of points in the standard examples are quite small, we limit
k to 5 and 10. The best result is for
k-cluster filtration with
(
fails to identify one of the clusters in the third example). On the other hand,
k-degree filtration performs well but the additional ‘noise’ points in the diagram mean that some clusters are not identified as significant.
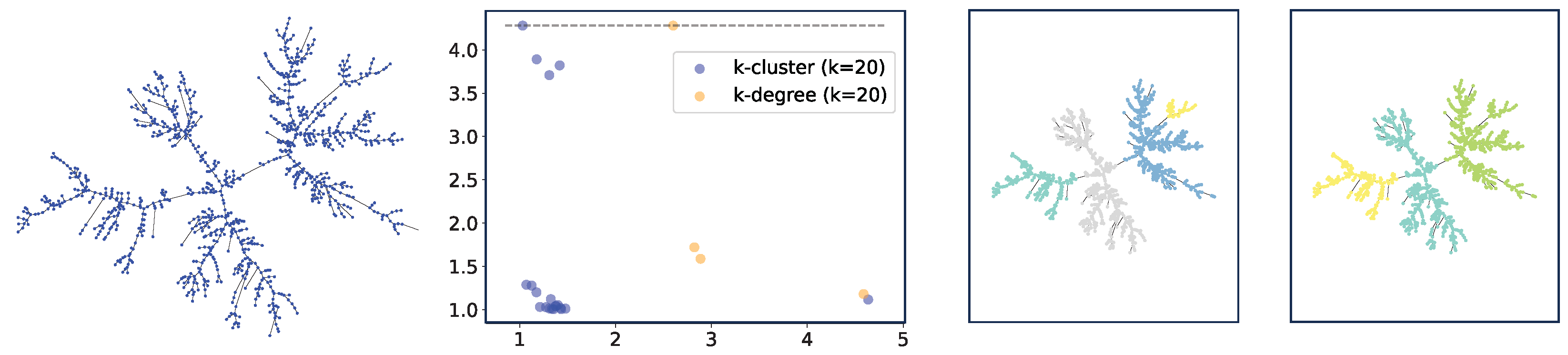
Clustering on Trees. As a second example, we describe clustering on weighted trees. We generate a uniform random tree on
n vertices and assign uniformly distributed random weights on the edges (between 0 and 1). We show an example in
Figure 9. The method seems to capture a certain structure of the tree, although we leave further investigation of this structure as future work.
Note that in the tree case, it is often impossible to use
k-degree filtration as the trees have vertices with degrees that are smaller than
k, which will never be included in filtration, whereas for
k-cluster filtration, all nodes are included as long as the underlying graph is connected (or all components have at least
k vertices). We note that it is possible to use alternative definitions for
k-degree filtration by embedding the trees into metric spaces (i.e., using graph metrics induced by the weights). However, this is similar to studying complete graphs induced by the metrics, which is somewhat different from studying the graphs directly. We demonstrate this method in the rightmost plot of
Figure 9.
6. Probabilistic Analysis
In this section, we revisit some fundamental results for random graphs and random simplicial complexes and show that analogous statements hold for our new
k-cluster filtration approach. We provide the main statements, while the proofs are available in the
Appendix A,
Appendix B and
Appendix C. As real data are random, we view these statements (and their future expansions) as an integral part of the analysis of
k-cluster persistence, within the context of topological data analysis.
6.1. Connectivity
We consider two models here. In the
random graph, we have
n vertices and each edge is placed independently with probability
p. In the
random geometric graph, we take a homogeneous Poisson process
on the
d-dimensional flat torus, with rate
n. Edges are then placed between vertices that are less than
r apart. In both models, connectivity results are tied to the expected degree. For the
model, we define
, while for the
model, we take
. Then, in [
20,
21], the following was proved.
Theorem 1. Let be either or . Then A key element in proving connectivity (for either model) is to show that around , the random graph consists of a single giant component, a few isolated vertices, and nothing else. Thus, connectivity is achieved when the last isolated vertices become connected.
Our goal in this section is to analyze connectivity in the and models using our new k-cluster filtration method. Note that for a fixed value of n, we can view both models as filtrations over the complete graphs. For the model, the weights of the edges are independent random variables that are uniformly distributed in . For the model, the weight of an edge is given by the distance between the corresponding points in the torus. We define and as the random filtrations generated by changing the filtration function to . Our goal here is to explore the phase transitions for k-cluster connectivity. As opposed to connectivity in the original random graphs, these results differ between the models.
Theorem 2. For the filtered graph, we havefor any , such that . For the model, proving the connectivity is a much more challenging task and beyond the scope of this paper. However, the following statement is relatively straightforward to prove.
Proposition 1. Let be the number of connected components of size k in . Then,for any , such that . From this lemma, we conclude that when , the graph has components of size k, which implies that is not connected. On the other hand, when , we have for all fixed , which indicates that should be connected. This leads to the following conjecture.
Conjecture 3. For the filtered graph, we have Note that both phase transitions occur before those for the original graph models. This is due to the fact that for , k-cluster filtration does not allow any isolated vertices. Also note that when taking , both results coincide with Theorem 1.
6.2. Limiting Persistence Diagrams
In [
22], it is shown that for stationary point processes, persistence diagrams have non-random limits (in the vague convergences of measures). A similar statement holds for
k-cluster persistence diagrams.
Let
be the
k-cluster persistence diagram for point cloud
. We define the discrete measure on
as
Let
. The following is an analog of Theorem 1.5 in [
22].
Theorem 4. Assume that is a stationary point process in , with all finite moments. For any k, there exists a deterministic measure , such thatwhere the limit is in the sense of vague convergence. Furthermore, if is ergodic, then almost surely 6.3. Maximal Cycles
In [
23], the largest cycles in persistence diagrams are studied. In particular, the behavior of the largest
-value:
arising from a homogeneous Poisson process
is studied. Let
be the largest
-value in the
i-th persistent homology. The main result in [
23] then states that, with high probability,
where
are constants, and
For k-cluster persistence, we show that the largest -value has a completely different scaling.
Theorem 5. Let be a homogeneous Poisson process in the flat torus, with rate n. Let denote the maximum π-value in the k-cluster persistence diagram (excluding the infinite cluster). Then, for every , we have Remark 3. We observe that the largest π-value in k-cluster persistence is significantly larger than that in i-dimensional homology. The main reason for this can be explained as follows. In [23], our upper bound for is an iso-perimetric inequality, which implies that large π-values require large connected components. However, the π-values in k-cluster persistence only require clusters of size k to be formed; thus, they can be generated by much smaller connected components.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}