
Reconstructing Sparse Multiplex Networks with Application to Covert Networks



Abstract
1. Introduction
2. Literature Review
- The sparsity of links in covert networks, i.e., the negatives (no links between nodes) significantly outnumber the positives, leads to challenges in inference and thus significantly affects the predictive performance of classical learning-based methods [31].
- It can infer the links that connect unobserved nodes of the network. This is hardly possible for methods built on structural similarities, such as Adamic–Adar index, Jaccard index, and Resource Allocation index [32], because the links to be inferred usually connect unobserved nodes that are isolated from the observed part of the network.
3. Methodology
3.1. Problem Description
3.2. Expectation–Maximization–Aggregation Framework
3.2.1. Expectation–Maximization
- E-step: updating by setting it to the posterior of given the current , which is used to construct the local ELBO on the log-likelihood.
- M-step: updating by maximizing the ELBO, i.e., solving for in
3.2.2. Network Generation Model
3.2.3. Full Algorithm for the EMA Framework
| Algorithm 1: EMA for multiplex network reconstruction |
| Input: Error tolerance , maximum number of iterations , number of unique nodes in the multiplex network , and partially observed topology . Output: Reconstructed complete topology for the multiplex network.
|
4. Datasets
4.1. Drug Trafficking Multiplex Network
4.2. Sicilian Mafia Multiplex Network
4.3. London Transportation Multiplex Network
4.4. C. elegans Multiplex Network
5. Experiments
5.1. Experiment Setup
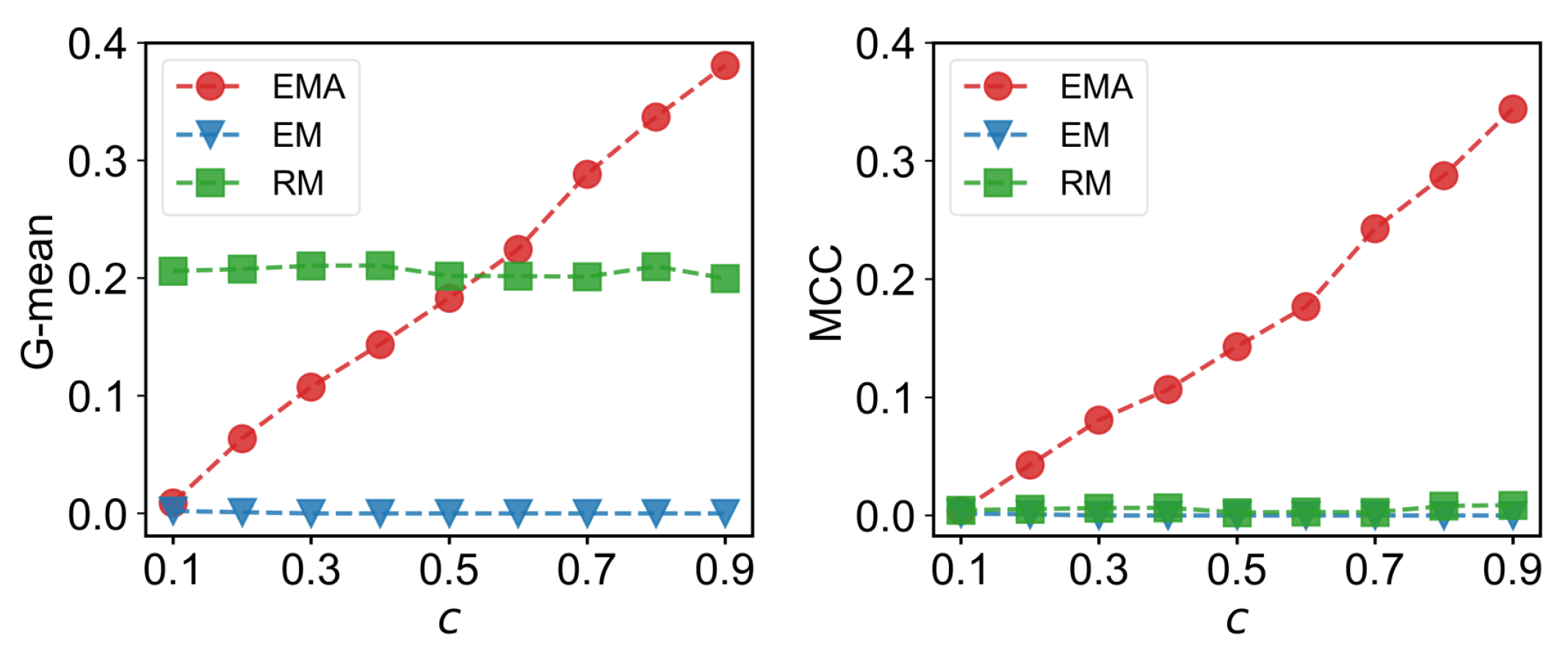
5.2. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Sets & Indices | |
| Indices of nodes | |
| ℓ | Index of layers |
| Set of layers | |
| , | Sets of nodes and links |
| Set of observed nodes | |
| Set of the observed topologies (by layer) of a multiplex network | |
| Set of complete topologies (by layer) of a multiplex network | |
| Variables & Parameters | |
| c | Fraction of observed nodes in a layer |
| Degree sequences | |
| Average degree | |
| m | Number of layers |
| Generic random variables | |
| Observed adjacency matrix (subnetwork) for layer ℓ | |
| Adjacency matrix (complete topology) for layer ℓ | |
| Adjacency matrix for the aggregate topology of a multiplex network | |
| , | Size of a connected component and size of the greatest connected component |
| Average size of connected components | |
| , | Convergence error and error tolerance |
| Probability of a link between node i and node j. | |
| Posterior distribution for the complete multiplex network | |
| Link density | |
| Model parameters | |
References
- Gao, J.; Bashan, A.; Shekhtman, L.; Havlin, S. Introduction to Networks of Networks; IOP Publishing Ltd.: Bristol, UK, 2022. [Google Scholar]
- Zhu, X.; Ma, J.; Su, X.; Tian, H.; Wang, W.; Cai, S. Information spreading on weighted multiplex social network. Complexity 2019, 2019, 5920187. [Google Scholar] [CrossRef]
- Solé-Ribalta, A.; Gómez, S.; Arenas, A. Congestion induced by the structure of multiplex networks. Phys. Rev. Lett. 2016, 116, 108701. [Google Scholar] [CrossRef]
- Kim, M.K.; Narasimhan, R. Exploring the multiplex architecture of supply networks. Int. J. Supply Chain Manag. 2019, 8, 45–64. [Google Scholar]
- Aleta, A.; Tuninetti, M.; Paolotti, D.; Moreno, Y.; Starnini, M. Link prediction in multiplex networks via triadic closure. Phys. Rev. Res. 2020, 2, 042029. [Google Scholar] [CrossRef]
- Tran, C.; Shin, W.Y.; Spitz, A.; Gertz, M. DeepNC: Deep generative network completion. arXiv 2019, arXiv:1907.07381. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Barzel, B.; Barabási, A.L. Universal resilience patterns in complex networks. Nature 2016, 530, 307–312. [Google Scholar] [CrossRef]
- Liu, X.; Li, D.; Ma, M.; Szymanski, B.K.; Stanley, H.E.; Gao, J. Network resilience. Phys. Rep. 2022, 971, 1–108. [Google Scholar]
- Xu, J.; Chen, H. The topology of dark networks. Commun. ACM 2008, 51, 58–65. [Google Scholar] [CrossRef]
- Hosseinkhani, J.; Chuprat, S.; Taherdoost, H. Discovering criminal networks by Web structure mining. In Proceedings of the 2012 7th International Conference on Computing and Convergence Technology (ICCCT), Seoul, Republic of Korea, 3–5 December 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1074–1079. [Google Scholar]
- Pourhabibi, T.; Ong, K.L.; Kam, B.H.; Boo, Y.L. DarkNetExplorer (DNE): Exploring dark multi-layer networks beyond the resolution limit. Decis. Support Syst. 2021, 146, 113537. [Google Scholar] [CrossRef]
- Martínez, V.; Berzal, F.; Cubero, J.C. A survey of link prediction in complex networks. ACM Comput. Surv. (CSUR) 2016, 49, 1–33. [Google Scholar] [CrossRef]
- Abdolhosseini-Qomi, A.M.; Jafari, S.H.; Taghizadeh, A.; Yazdani, N.; Asadpour, M.; Rahgozar, M. Link prediction in real-world multiplex networks via layer reconstruction method. R. Soc. Open Sci. 2020, 7, 191928. [Google Scholar] [CrossRef]
- Berlusconi, G.; Calderoni, F.; Parolini, N.; Verani, M.; Piccardi, C. Link prediction in criminal networks: A tool for criminal intelligence analysis. PLoS ONE 2016, 11, e0154244. [Google Scholar]
- Calderoni, F.; Catanese, S.; De Meo, P.; Ficara, A.; Fiumara, G. Robust link prediction in criminal networks: A case study of the Sicilian Mafia. Expert Syst. Appl. 2020, 161, 113666. [Google Scholar] [CrossRef]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. A Stat. Mech. Its Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef]
- Herlau, T.; Schmidt, M.N.; Mørup, M. Infinite-degree-corrected stochastic block model. Phys. Rev. E 2014, 90, 032819. [Google Scholar] [CrossRef]
- Williamson, S.A. Nonparametric network models for link prediction. J. Mach. Learn. Res. 2016, 17, 7102–7121. [Google Scholar]
- Stanley, N.; Bonacci, T.; Kwitt, R.; Niethammer, M.; Mucha, P.J. Stochastic block models with multiple continuous attributes. Appl. Netw. Sci. 2019, 4, 1–22. [Google Scholar] [CrossRef]
- Wu, M.; Li, Z.; Shao, C.; He, S. Quantifying multiple social relationships based on a multiplex stochastic block model. Front. Inf. Technol. Electron. Eng. 2021, 22, 1458–1462. [Google Scholar] [CrossRef]
- Kim, M.; Leskovec, J. The network completion problem: Inferring missing nodes and edges in networks. In Proceedings of the 2011 SIAM International Conference on Data Mining, Mesa, AZ, USA, 28–30 April 2011; SIAM: Philadelphia, PA, USA, 2011; pp. 47–58. [Google Scholar]
- Wu, M.; Chen, J.; He, S.; Sun, Y.; Havlin, S.; Gao, J. Discrimination reveals reconstructability of multiplex networks from partial observations. Commun. Phys. 2022, 5, 163. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Chen, Y. Link prediction based on graph neural networks. Adv. Neural Inf. Process. Syst. 2018, 31. Available online: https://proceedings.neurips.cc/paper/2018/hash/53f0d7c537d99b3824f0f99d62ea2428-Abstract.html (accessed on 7 January 2023).
- Gao, M.; Jiao, P.; Lu, R.; Wu, H.; Wang, Y.; Zhao, Z. Inductive link prediction via interactive learning across relations in multiplex networks. IEEE Trans. Comput. Soc. Syst. 2022. Early Access. [Google Scholar] [CrossRef]
- Baycik, N.O.; Sharkey, T.C.; Rainwater, C.E. Interdicting layered physical and information flow networks. IISE Trans. 2018, 50, 316–331. [Google Scholar] [CrossRef]
- Kosmas, D.; Sharkey, T.C.; Mitchell, J.E.; Maass, K.L.; Martin, L. Interdicting restructuring networks with applications in illicit trafficking. arXiv 2020, arXiv:2011.07093. [Google Scholar] [CrossRef]
- Shen, Y.; Sharkey, T.C.; Szymanski, B.K.; Wallace, W.A. Interdicting interdependent contraband smuggling, money and money laundering networks. Socio-Econ. Plan. Sci. 2021, 78, 101068. [Google Scholar] [CrossRef]
- Ficara, A.; Fiumara, G.; De Meo, P.; Catanese, S. Multilayer network analysis: The identification of key actors in a Sicilian Mafia operation. In International Conference on Future Access Enablers of Ubiquitous and Intelligent Infrastructures; Springer: Cham, Switzerland, 2021; pp. 120–134. [Google Scholar]
- Traganitis, P.A.; Shen, Y.; Giannakis, G.B. Topology inference of multilayer networks. In Proceedings of the 2017 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Atlanta, GA, USA, 1–4 May 2017; pp. 898–903. [Google Scholar]
- Chen, C.; Tong, H.; Xie, L.; Ying, L.; He, Q. Cross-dependency inference in multi-layered networks: A collaborative filtering perspective. ACM Trans. Knowl. Discov. Data (TKDD) 2017, 11, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Aggarwal, C.; Derr, T. Distance-wise prototypical graph neural network in node imbalance classification. arXiv 2021, arXiv:2110.12035. [Google Scholar]
- Liben-Nowell, D.; Kleinberg, J. The link prediction problem for social networks. In Proceedings of the Twelfth International Conference on Information and Knowledge Management, Orleans, LA, USA, 3–8 November 2003; pp. 556–559. [Google Scholar]
- Agreste, S.; Catanese, S.; De Meo, P.; Ferrara, E.; Fiumara, G. Network structure and resilience of Mafia syndicates. Inf. Sci. 2016, 351, 30–47. [Google Scholar] [CrossRef]
- Smith, C.M.; Papachristos, A.V. Trust thy crooked neighbor: Multiplexity in Chicago organized crime networks. Am. Sociol. Rev. 2016, 81, 644–667. [Google Scholar] [CrossRef]
- Malm, A.; Bichler, G. Using friends for money: The positional importance of money-launderers in organized crime. Trends Organ. Crime 2013, 16, 365–381. [Google Scholar] [CrossRef]
- Kleemans, E.R.; Van de Bunt, H.G. The social embeddedness of organized crime. Transnatl. Organ. Crime 1999, 5, 19–36. [Google Scholar]
- Duijn, P.A.; Kashirin, V.; Sloot, P.M. The relative ineffectiveness of criminal network disruption. Sci. Rep. 2014, 4, 4238. [Google Scholar] [CrossRef] [PubMed]
- Krebs, V. Mapping networks of terrorist cells. Connections 2002, 24, 43–52. [Google Scholar]
- Malm, A.; Bichler, G.; Van De Walle, S. Comparing the ties that bind criminal networks: Is blood thicker than water? Secur. J. 2010, 23, 52–74. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–22. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational inference: A review for statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef]
- Bender, E.A.; Canfield, E.R. The asymptotic number of labeled graphs with given degree sequences. J. Comb. Theory Ser. A 1978, 24, 296–307. [Google Scholar] [CrossRef]
- Newman, M. Networks; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Cavallaro, L.; Ficara, A.; De Meo, P.; Fiumara, G.; Catanese, S.; Bagdasar, O.; Song, W.; Liotta, A. Disrupting resilient criminal networks through data analysis: The case of Sicilian Mafia. PLoS ONE 2020, 15, e0236476. [Google Scholar] [CrossRef]
- De Domenico, M.; Solé-Ribalta, A.; Gómez, S.; Arenas, A. Navigability of interconnected networks under random failures. Proc. Natl. Acad. Sci. USA 2014, 111, 8351–8356. [Google Scholar] [CrossRef]
- Chen, B.L.; Hall, D.H.; Chklovskii, D.B. Wiring optimization can relate neuronal structure and function. Proc. Natl. Acad. Sci. USA 2006, 103, 4723–4728. [Google Scholar] [CrossRef]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A survey of predictive modeling on imbalanced domains. ACM Comput. Surv. (CSUR) 2016, 49, 1–50. [Google Scholar] [CrossRef]
- Boughorbel, S.; Jarray, F.; El-Anbari, M. Optimal classifier for imbalanced data using Matthews Correlation Coefficient metric. PLoS ONE 2017, 12, e0177678. [Google Scholar] [CrossRef] [PubMed]
- Morselli, C.; Giguere, C. Legitimate strengths in criminal networks. Crime Law Soc. Chang. 2006, 45, 185–200. [Google Scholar] [CrossRef]
- Diviák, T.; Dijkstra, J.K.; Snijders, T.A. Poisonous connections: A case study on a Czech counterfeit alcohol distribution network. Glob. Crime 2020, 21, 51–73. [Google Scholar] [CrossRef]
- Bichler, G. Understanding Criminal Networks: A Research Guide; University of California Press: Oakland, CA, USA, 2019. [Google Scholar]
- Kleemans, E.R.; De Poot, C.J. Criminal careers in organized crime and social opportunity structure. Eur. J. Criminol. 2008, 5, 69–98. [Google Scholar] [CrossRef]
- Campana, P.; Varese, F. Listening to the wire: Criteria and techniques for the quantitative analysis of phone intercepts. Trends Organ. Crime 2012, 15, 13–30. [Google Scholar] [CrossRef]
- Diviák, T. Key aspects of covert networks data collection: Problems, challenges, and opportunities. Soc. Netw. 2022, 69, 160–169. [Google Scholar] [CrossRef]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2071–2080. [Google Scholar]
- Wang, Z.; Ren, Z.; He, C.; Zhang, P.; Hu, Y. Robust embedding with multi-level structures for link prediction. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 5240–5246. [Google Scholar]
- Nicosia, V.; Bianconi, G.; Latora, V.; Barthelemy, M. Growing multiplex networks. Phys. Rev. Lett. 2013, 111, 058701. [Google Scholar] [CrossRef]
- Yu, J.Z.; Baroud, H. Modeling uncertain and dynamic interdependencies of infrastructure systems using stochastic block models. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part B Mech. Eng. 2020, 6, 020906. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, J.Z.; Baroud, H. Generating synthetic systems of interdependent critical infrastructure networks. IEEE Syst. J. 2021, 16, 3191–3202. [Google Scholar] [CrossRef]
- Fügenschuh, M.; Gera, R.; Méndez-Bermúdez, J.A.; Tagarelli, A. Structural and spectral properties of generative models for synthetic multilayer air transportation networks. PLoS ONE 2021, 16, e0258666. [Google Scholar] [CrossRef]
- Jiang, C.; Gao, J.; Magdon-Ismail, M. Inferring degrees from incomplete networks and nonlinear dynamics. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-20), Yokohama, Japan, 7–15 January 2020; pp. 3307–3313. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | CoV of | ||||||
|---|---|---|---|---|---|---|---|
| Co-offender | 1645 | 1808 | 1.32 | 2.19 | 19.00 | 1024 | 5.71 |
| Legitimate | 1022 | 1041 | 2.00 | 2.04 | 10.99 | 462 | 4.43 |
| FCO | 560 | 597 | 3.81 | 2.13 | 14.36 | 150 | 2.24 |
| Kinship | 399 | 308 | 3.88 | 1.54 | 3.22 | 25 | 0.99 |
| Layer | CoV of | ||||||
|---|---|---|---|---|---|---|---|
| Meeting | 101 | 256 | 55.77 | 5.07 | 19.02 | 86 | 1.76 |
| Call | 100 | 124 | 27.45 | 2.48 | 23.50 | 85 | 1.51 |
| Layer | CoV of | ||||||
|---|---|---|---|---|---|---|---|
| Underground | 260 | 225 | 6.68 | 1.73 | 5.65 | 98 | 2.48 |
| Overground | 81 | 62 | 19.14 | 1.53 | 4.26 | 17 | 0.83 |
| Lightrail | 44 | 34 | 35.94 | 1.55 | 4.00 | 8 | 0.54 |
| Layer | CoV of | ||||||
|---|---|---|---|---|---|---|---|
| Electrical | 242 | 450 | 15.43 | 3.72 | 80.67 | 237 | 1.37 |
| Chemical | 260 | 869 | 25.81 | 6.68 | 130.00 | 258 | 0.98 |
| Polyadic | 277 | 1666 | 43.58 | 12.03 | 277.00 | 277 | 0.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.-Z.; Wu, M.; Bichler, G.; Aros-Vera, F.; Gao, J. Reconstructing Sparse Multiplex Networks with Application to Covert Networks. Entropy 2023, 25, 142. https://doi.org/10.3390/e25010142
Yu J-Z, Wu M, Bichler G, Aros-Vera F, Gao J. Reconstructing Sparse Multiplex Networks with Application to Covert Networks. Entropy. 2023; 25(1):142. https://doi.org/10.3390/e25010142
Chicago/Turabian StyleYu, Jin-Zhu, Mincheng Wu, Gisela Bichler, Felipe Aros-Vera, and Jianxi Gao. 2023. "Reconstructing Sparse Multiplex Networks with Application to Covert Networks" Entropy 25, no. 1: 142. https://doi.org/10.3390/e25010142
APA StyleYu, J.-Z., Wu, M., Bichler, G., Aros-Vera, F., & Gao, J. (2023). Reconstructing Sparse Multiplex Networks with Application to Covert Networks. Entropy, 25(1), 142. https://doi.org/10.3390/e25010142