

Detecting the Critical States of Type 2 Diabetes Mellitus Based on Degree Matrix Network Entropy by Cross-Tissue Analysis

Abstract
1. Introduction
2. Materials and Methods
2.1. Data Progression and Functional Analysis
2.2. Theoretical Background
- The correlation between any two members of a DNB group rapidly increases;
- The correlation between one member in a DNB group and any other non-DNB molecule sharply decreases;
- The standard deviation for any member in the DNB group drastically increases.
2.3. Data Preprocessing
2.4. Algorithm to Detect the Tipping Point and Identify DNBs of T2DM Based on DMNE
3. Results
3.1. Detecting the Critical State of T2DM
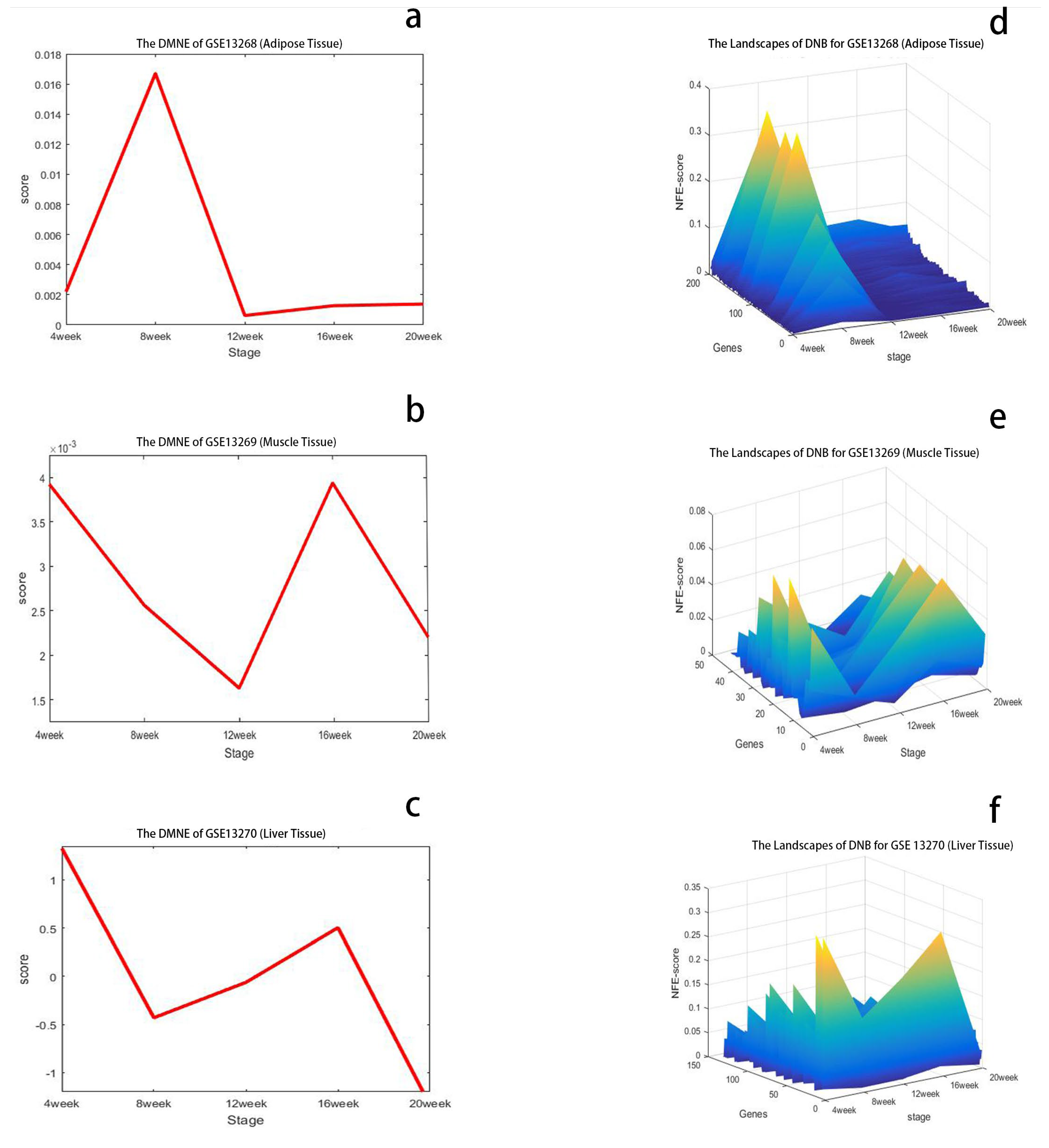
3.1.1. The Critical State of GSE13268
3.1.2. The Critical State of GSE13269
3.1.3. The Critical State of GSE13270
3.2. Tissue-Specific Analysis
3.2.1. Analysis of GSE13268
3.2.2. Analysis of GSE13269
3.2.3. Analysis of GSE13270
3.3. Cross-Tissue Analysis
3.4. DMNE Reveals Non-Differential “Dark Genes”
3.5. Drug Targets
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GEO Datasets List | ||||
| Access ID | Tissue | Rat Species | Condition | GEO Samples |
| GSE13268 | Adipose | Wistar–Kyoto (WKY) rats | Control | GSM334860-GSM334864 |
| GSM334880-GSM334884 | ||||
| GSM334900-GSM334904 | ||||
| GSM334920-GSM334924 | ||||
| GSM334940-GSM334944 | ||||
| Goto–Kakizaki (GK) rats | Diabetic | GSM334850-GSM334854 | ||
| GSM334870-GSM334874 | ||||
| GSM334890-GSM334894 | ||||
| GSM334910-GSM334914 | ||||
| GSM334930-GSM334934 | ||||
| GSE13269 | Gastrocnemius muscle | Wistar–Kyoto (WKY) rats | Control | GSM334961-GSM334965 |
| GSM334981-GSM334985 | ||||
| GSM335001-GSM335005 | ||||
| GSM335021-GSM335025 | ||||
| GSM335041-GSM335045 | ||||
| Goto–Kakizaki (GK) rats | Diabetic | GSM334951-GSM334955 | ||
| GSM334971-GSM334975 | ||||
| GSM334991-GSM334995 | ||||
| GSM335011-GSM335015 | ||||
| GSM335031-GSM335035 | ||||
| GSE13270 | Liver | Wistar–Kyoto (WKY) rats | Control | GSM335062-GSM335066 |
| GSM335082-GSM335086 | ||||
| GSM335102-GSM335106 | ||||
| GSM335122-GSM335126 | ||||
| GSM335142-GSM335146 | ||||
| Goto–Kakizaki (GK) rats | Diabetic | GSM335052-GSM335056 | ||
| GSM335072-GSM335076 | ||||
| GSM335092-GSM335096 | ||||
| GSM335112-GSM335116 | ||||
| GSM335132-GSM335136 | ||||
References
- Liu, R.; Wang, X.; Aihara, K.; Chen, L. Early Diagnosis of Complex Diseases by Molecular Biomarkers, Network Biomarkers, and Dynamical Network Biomarkers. Med. Res. Rev. 2014, 34, 455–478. [Google Scholar] [CrossRef]
- Li, M.; Zeng, T.; Liu, R.; Chen, L. Detecting tissue-specific early warning signals for complex diseases based on dynamical network biomarkers: Study of type 2 diabetes by cross-tissue analysis. Brief. Bioinform. 2013, 15, 229–243. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Liu, R.; Liu, Z.P.; Li, M.; Aihara, K. Detecting early-warning signals for sudden deterioration of complex diseases by dynamical network biomarkers. Sci. Rep. 2012, 2, 342. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Chen, P.; Chen, L. Single-sample landscape entropy reveals the imminent phase transition during disease progression. Bioinformatics 2020, 36, 1522–1532. [Google Scholar] [CrossRef] [PubMed]
- Chen, P.; Li, Y.; Liu, X.; Liu, R.; Chen, L. Detecting the tipping points in a three-state model of complex diseases by temporal differential networks. J. Transl. Med. 2017, 15, 217. [Google Scholar] [CrossRef] [PubMed]
- Zhong, J.; Han, C.; Zhang, X.; Chen, P.; Liu, R. Predicting cell fate commitment of embryonic differentiation by single-cell graph entropy. Genomics. Proteom. Bioinform. 2020. [Google Scholar] [CrossRef]
- Yan, J.; Li, P.; Gao, R.; Li, Y.; Chen, L. Identifying Critical States of Complex Diseases by Single-Sample Jensen-Shannon Divergence. Front. Oncol. 2021, 11, 371–374. [Google Scholar] [CrossRef]
- Gao, R.; Yan, J.; Li, P.; Chen, L. Detecting the critical states during disease development based on temporal network flow entropy. Brief. Bioinform. 2022, bbac164. [Google Scholar] [CrossRef]
- Dai, H.; Li, L.; Zeng, T.; Chen, L. Cell-specific network constructed by single-cell RNA sequencing data. Nucleic Acids Res. 2019, 47, e62. [Google Scholar] [CrossRef]
- Almon, R.R.; DuBois, D.C.; Lai, W.; Xue, B.; Nie, J.; Jusko, W.J. Gene expression analysis of hepatic roles in cause and development of diabetes in Goto-Kakizaki rats. J. Mater. 2009, 200, 331–346. [Google Scholar] [CrossRef]
- Wang, J.; Huang, Q.; Liu, Z.P.; Wang, Y.; Wu, L.Y.; Chen, L.; Zhang, X.S. NOA: A novel network ontology analysis method. Nucleic Acids Res. 2011, 39, e87. [Google Scholar] [CrossRef]
- Sherman, B.T.; Hao, M.; Qiu, J.; Jiao, X.; Baseler, M.W.; Lane, H.C.; Imamichi, T.; Chang, W. DAVID: A web server for functional enrichment analysis and functional annotation of gene lists (2021 update). Nucleic Acids Res. 2022, 10, gkac194. [Google Scholar] [CrossRef] [PubMed]
- Krzywinski, M.; Schein, J.; Birol, I.; Connors, J.; Gascoyne, R.; Horsman, D.; Jones, S.J.; Marra, M.A. Circos: An information aesthetic for comparative genomics. Genome Res. 2009, 19, 1639–1645. [Google Scholar] [CrossRef] [PubMed]
- Wishart, D.S.; Feunang, Y.D.; Guo, A.C.; Lo, E.J.; Marcu, A.; Grant, J.R.; Sajed, T.; Johnson, D.; Li, C.; Sayeeda, Z.; et al. DrugBank 5.0: A major update to the DrugBank database for 2018. Nucleic Acids Res. 2018, 46, D1074–D1082. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Zhang, Y.; Lian, X.; Li, F.; Wang, C.; Zhu, F.; Qiu, Y.; Chen, Y. Therapeutic target database update 2022: Facil-itating drug discovery with enriched comparative data of targeted agents. Nucleic Acids Res. 2022, 50, D1398–D1407. [Google Scholar] [CrossRef] [PubMed]
- Thorn, C.F.; Klein, T.E.; Altman, R.B. PharmGKB: The pharmacogenomics knowledge base. In Phar-Macogenomics; Humana Press: Totowa, NJ, USA, 2013; pp. 311–320. [Google Scholar]
- Chen, P. The Algorithm of Detecting the Critical Transition Point of Complex Diseases. Ph.D. Thesis, South China University of Technology, Guangzhou, China, 2018. [Google Scholar]
- Eisenberg, E.; Levanon, E.Y. Human housekeeping genes are compact. Trends Genet. 2003, 19, 362–365. [Google Scholar] [CrossRef]
- Ma, F.H.; Li, X.J. Islet β Cell self-insulin resistance and type 2 diabetes-a new field of insulin resistance research. Int. J. Endocrinol. Metab. 2004, 24, 154–155. [Google Scholar]
- Wang, Z.; Wu, C.W.; Chen, H.; Shi, S.; Zeng, H.; Liu, Y. Dipeptidyl peptidase—IV inhibitors activate ERK1/2 and NF-κB signaling pathway promotes aortic vascular calcification in type 2 diabetic mice. J. Transl. Med. 2019, 8, 5. [Google Scholar]
- Qin, C.M.; Gong, C.P.; Wei, X.; Wu, W.H.; Liu, J.; Ou, S.T.; Nephrology, D. Renal artery calcification increases progressive renal damage in type 2 diabetic nephropathy rats. Basic Res. Clin. Med. 2017, 2, 217–223. [Google Scholar]
- Jiang, J.; Qin, F.; Liu, J. Analysis of the influence factors for lipid metabolic disturbance of the patients with type 2 diabetes mellitus. Acta Univ. Med. Anhui 2004, 39, 284–286. [Google Scholar]
- Wang, L.; Guan, X.; Yu, M.; Qin, W.; Li, L. The relationship between serum fatty acid binding protein 1, protein 3 and type 2 diabetes mellitus complicated with nonalcoholic fatty liver disease. Int. J. Lab. Med. 2021, 42, 3009–3017. [Google Scholar]
- He, X. The Association of ND3 Gene Variation of Mitochondrial DNA with T2DM. Master’s Thesis, Wenzhou Medical University, Zhejiang, China, 2007. [Google Scholar]
- Ferreira, D.M.; Castro, R.E.; Machado, M.V.; Evangelista, T.; Silvestre, A.; Costa, A.; Coutinho, J.; Carepa, F.; Cortez-Pinto, H.; Rodrigues, C.M.P. Apoptosis and insulin resistance in liver and peripheral tissues of morbidly obese patients is as-so-ciated with different stages of non-alcoholic fatty liver disease. Diabetologia 2011, 54, 1788–1798. [Google Scholar] [CrossRef]
- Kelley, D.E.; He, J.; Menshikova, E.V.; Ritov, V.B. Dysfunction of mitochondria in human skeletal muscle in type 2 diabetes. Diabetes 2002, 51, 2944–2950. [Google Scholar] [CrossRef]
- Sun, X.H.; Wang, Y.; Mou, Y. Alteration of PI3K/Akt/mTOR signaling during development of diabetic cardiomyopathy and regulation of SIRT1. Chin. Pharmacol. Bull. 2017, 33, 793–798. [Google Scholar]
- Liu, J.; Hu, C.; Li, H.; Wang, W.; Zhang, W.; Niu, C.; Chen, M. Based on Kim1/HIF—1 α Signaling pathways explore the mechanism of kidney injury in diabetic rats. Chin. J. Integr. Tradit. West. Nephrol. 2020, 21, 786–788. [Google Scholar]
- Yao, J.; Jiang, A.; Wang, L.; Wei, F.; Chen, H.; Yu, H.; Meng, J. Triptolide upregulated PRDX2 inhibits oxidative stress in type 2 diabetic nephropathy. J. Tianjin Med. Univ. 2019, 25, 466–470. [Google Scholar]
- Nie, J.; Sage, E.H. SPARC functions as all inhibitor of adipogenesis. J. Cell Commun. Signal. 2009, 3, 247–254. [Google Scholar] [CrossRef]
- Kos, K.; Wong, S.; Tan, B.; Gummesson, A.; Jernas, M.; Franck, N.; Kerrigan, D.; Nystrom, F.H.; Carlsson, L.M.S.; Randeva, H.S.; et al. Regulation of the fibrosis and angiogenesis promoter SPARC/osteonectin in human adipose tissue by weight change, leptin, insulin, and glucose. Diabetes 2009, 58, 1780–1788. [Google Scholar] [CrossRef]
- Shi, Q.; Bao, S.; Maxwell, J.A.; Reese, E.D.; Friedman, H.S.; Bigner, D.D.; Wang, X.-F.; Rich, J.N. Secreted protein acidic, rich in eysteine (SPARC), mediates cellular survival of gliomas through AKT activation. J. Biol. Chem. 2004, 279, 52200–52209. [Google Scholar] [CrossRef]
- Jia, G.; Di, F.; Wang, L.; Yu, H.; Li, X. Association between the serum SPARC and FGF21 levels in newly diagnosed T2DM patients. China Diabetes J. 2013, 21, 223–225. [Google Scholar]
- Baron, V.; Muriel, P. Role of glutathione, lipid peroxidation and antioxidants on acute bile-duct obstruction in the rat. Bi-ochim. Biophys. Acta 1999, 1472, 173–180. [Google Scholar] [CrossRef]
- Hafner, M.; Rezen, T.; Rozman, D. Regulation of hepatic cytochromes p450 by lipids and cholesterol. Curr. Drug Metab. 2011, 12, 173–185. [Google Scholar] [CrossRef] [PubMed]
- She, Y.; Gong, W.; Yu, J. Effect of Vitamin A on Islet Fibrois in Type 2 Diabetes Mellitus Animal Model. Lab. Anim. Sci. Adm. 2015, 32, 17–20. [Google Scholar]
- Gross, B.; Pawlak, M.; Lefebvre, P.; Staels, B. PPARs in obesity-induced T2DM, dyslipidaemia and NAFLD. Nature reviews. Endocrinology 2017, 13, 36–49. [Google Scholar] [PubMed]
- Shen, Z.; Zhu, L.; Xu, W. Effects of aerobic exercise on AGE-RAGE axis and NF-κB pathway in type 2 diabetic rats. Kunming Med. Univ. 2018, 39, 16–19. [Google Scholar]
- Liu, J.; Ye, S.; Bi, S.; Zhou, W. Effect of metformin on the expression of macrophage migration inhibitory factor and its receptor CD74 in renal tissue of type 2 diabetic rats. Acta Univ. Med. Anhui 2021, 56, 5. [Google Scholar]
- Jia, G.; Di, F.; Wang, L.; Yu, H.; Li, X. Correlation between serum SPARC and FGF21 levels in patients with new type 2 diabetes mellitus. Chin. J. Diabetes 2013, 21, 5. [Google Scholar]
- Johnson, J.M.; Edwards, S.; Shoemaker, D.; Schadt, E.E. Dark Matter in the Genome: Evidence of Widespread Transcription Detected by Microarray Tiling Experiments. Trends Genet. 2005, 21, 93–102. [Google Scholar] [CrossRef]
- Ben, Q.; Xu, M.; Ning, X.; Liu, J.; Hong, S.; Huang, W.; Zhang, H.; Li, Z. Diabetes mellitus and risk of pancreatic cancer: A meta-analysis of cohort studies. Eur. J. Cancer 2011, 47, 1928–1937. [Google Scholar] [CrossRef]
- Lin, G.; Wan, X.; Liu, D.; Wen, Y.; Yang, C.; Zhao, C. COL1A1 as a potential new biomarker and therapeutic target for type 2 diabetes. Pharmacol. Res. 2021, 165, 105436. [Google Scholar] [CrossRef]
- Wang, X.; Lu, J. Effect of blood glucose fluctuation on the prognosis of diabetes and the occurrence and development of chronic complications. Sect. Endocrinol. Foreign M Ed. Sci. 2005, 25, 169–171. [Google Scholar] [CrossRef]
- Zhang, W.; Wu, Y.; Fan, W.; Chen, H.; Du, H.; Rao, J. The pattern of plasma BCAA concentration and liver Bckdha gene expression in GK rats during T2D progression. Anim. Models Exp. Med. 2018, 1, 305–313. [Google Scholar] [CrossRef]
- Zeng, R.; Xiong, Y.; Zhu, F.; Ma, Z.; Liao, W.; He, Y.; He, J.; Li, W.; Yang, J.; Lu, Q. Fenofibrate attenuated glucose-induced mesangial cells proliferation and extracellular matrix synthesis via PI3K/AKT and ERK1/2. PLoS ONE 2013, 8, e76836. [Google Scholar] [CrossRef]
- Choi, J.; Kim, K.-J.; Koh, E.-J.; Lee, B.-Y. Gelidium elegans extract ameliorates type 2 diabetes via regulation of MAPK and PI3K/Akt Signaling. Nutrients 2018, 10, 51. [Google Scholar] [CrossRef]
- Hwang, A.; Narayan, V.; Yang, Y.X. Type 2 diabetes mellitus and survival in pancreatic adenocarcinoma: A retrospective cohort study. Cancer 2013, 119, 404–410. [Google Scholar] [CrossRef]
- Biadgo, B.; Abebe, M. Type 2 Diabetes Mellitus and Its Association with the Risk of Pancreatic Carcinogenesis: A Review. Korean J Gastroenterol. 2016, 67, 168–177. [Google Scholar] [CrossRef]
- Rahn, S.; Zimmermann, V.; Viol, F.; Knaack, H.; Stemmer, K.; Peters, L.; Lenk, L.; Ungefroren, H.; Saur, D.; Schäfer, H.; et al. Diabetes as risk factor for pancreatic cancer: Hyperglycemia promotes epithe-li-al-mesenchymal-transition and stem cell properties in pancreatic ductal epithelial cells. Cancer Lett. 2018, 415, 129–150. [Google Scholar] [CrossRef]
- Hoshino, F.; Murakami, C.; Sakai, H.; Satoh, M.; Sakane, F. Creatine kinase muscle type specifically interacts with sa-tu-rated fatty acid-and/or monounsaturated fatty acid-containing phosphatidic acids. Biochem. Biophys. Res. Commun. 2019, 513, 1035–1040. [Google Scholar] [CrossRef]
- Fu, M.; Damcott, C.M.; Sabra, M.; Pollin, T.I.; Ott, S.H.; Wang, J.; Garant, M.J.; O’connell, J.R.; Mitchell, B.D.; Shuldiner, A.R. Polymorphism in the Calsequestrin 1 (CASQ1) Gene on Chromosome 1q21 Is Associated with Type 2 Diabetes in the Old Order Amish. Diabetes 2004, 53, 3292–3299. [Google Scholar] [CrossRef][Green Version]
- Briata, P.; Bordo, D.; Puppo, M.; Gorlero, F.; Rossi, M.; Perrone-Bizzozero, N.; Gherzi, R. Diverse roles of the nucleic ac-id-binding protein KHSRP in cell differentiation and disease. Wiley Interdiscip. Rev. RNA 2016, 7, 227–240. [Google Scholar] [CrossRef]
- Ruby, M.A.; Riedl, I.; Massart, J.; Åhlin, M.; Zierath, J.R. Protein kinase N2 regulates AMP kinase signaling and insulin responsiveness of glucose metabolism in skeletal muscle. Am. J. Physiol. Endocrinol. Metab. 2017, 313, 483–491. [Google Scholar] [CrossRef] [PubMed]
- Anja, B.; Anna-Maria, O.; Jürgen, M.; Mratin, H.; Caroline, K.; Fausto, M.; Fritz, S.; Norbert, S.; Andreas, F.; Hans-Ulrich, H. Common genetic variation in the SERPINF1 locus determines overall adiposity, obesity-related insulin resistance, and circulating leptin levels. PLoS ONE 2012, 7, e34035. [Google Scholar]
- Ganic, E.; Johansson, J.K.; Bennet, H.; Fex, M.; Artner, I. Islet-specific monoamine oxidase A and B expression depends on MafA transcriptional activity and is compromised in type 2 diabetes. Biochem. Biophys. Res. Commun. 2015, 468, 629–635. [Google Scholar] [CrossRef] [PubMed]
- Tian, J.; Hu, S.; Wang, F.; Yang, X.; Li, Y.; Huang, C. PPARG, AGTR1, CXCL16 and LGALS2 polymor-phisms are cor-re-lated with the risk for coronary heart disease. Int. J. Clin. Exp. Pathol. 2015, 8, 3138–3143. [Google Scholar]
- Weiss, E.P.; Brown, M.D.; Shuldiner, A.R.; Hagberg, J.M. Fatty acid binding protein-2 gene variants and insulin resistance: Gene and gene-environment interaction effects. Physiol. Genom. 2002, 10, 145–157. [Google Scholar] [CrossRef]
- Andersen, G.; Burgdorf, K.S.; Sparso, T.; Borch-Johnsen, K.; Jorgensen, T.; Hansen, T.; Pedersen, O. AHSG tag single nu-cleotide polymorphisms associate with type 2 diabetes and dyslipidemia: Studies of metabolic traits in 7683 white Danish subjects. Diabetes 2008, 57, 1427–1432. [Google Scholar] [CrossRef]








| Tissue | Case | Term | p-Value | Term Name |
|---|---|---|---|---|
| Adipose | Adipose 8 weeks | GO:0033993 | 3.37 × 10−9 | Response to lipid |
| GO:0050896 | 1.33 × 10−8 | Response to stimulus | ||
| GO:0048583 | 2.51 × 10−5 | Regulation of response to stimulus | ||
| GO:0006629 | 0.0238 | Lipid metabolic process | ||
| GO:0050796 | 0.0238 | Regulation of insulin secretion | ||
| GO:0001932 | 0.0049 | Regulation of protein phosphorylation | ||
| GO:0043434 | 0.0124 | Response to peptide hormone | ||
| GO:0070372 | 0.0159 | Regulation of erk1 and erk2 cascade | ||
| GO:0006874 | 0.0235 | Cellular calcium ion homeostasis |
| Tissue | Case | Term | p-Value | Term Name |
|---|---|---|---|---|
| Adipose | Adipose 8 weeks | GO:0032496 | 0.004939298 | Response to lipopolysaccharide |
| GO:0019901 | 0.008557741 | Protein kinase binding | ||
| GO:0004175 | 0.012946747 | Endopeptidase activity | ||
| GO:0055114 | 0.013323312 | Oxidation–reduction process | ||
| GO:0032868 | 0.016048825 | Response to insulin | ||
| GO:0033700 | 0.01966288 | Phospholipid efflux | ||
| GO:0051384 | 0.020031683 | Response to glucocorticoid | ||
| GO:0048545 | 0.031308927 | Response to steroid hormone | ||
| GO:0006954 | 0.031444423 | Inflammatory response | ||
| GO:0008203 | 0.035288946 | Positive regulation of B cell receptor signaling pathway | ||
| GO:0055088 | 0.03504665 | Lipid homeostasis | ||
| GO:0050729 | 0.038857846 | Positive regulation of inflammatory response | ||
| GO:0008203 | 0.047115437 | Cholesterol metabolic process |
| Tissue | Case | Term | p-Value | Term Name |
|---|---|---|---|---|
| Muscle | Muscle 4 weeks | GO:0006936 | 0.001436732 | Muscle contraction |
| GO:0006096 | 0.005358956 | Glycolytic process | ||
| GO:0016504 | 0.011881481 | Peptidase activator activity | ||
| GO:0009749 | 0.013277291 | Response to glucose | ||
| GO:0031295 | 0.019842374 | T cell co-stimulation | ||
| GO:0071333 | 0.03156758 | Cellular response to glucose stimulus | ||
| GO:0042593 | 0.048961141 | Glucose homeostasis | ||
| rno00190 | 0.019507611 | PI3K-Akt signaling pathway | ||
| Muscle 16 weeks | GO:0052547 | 0.019261847 | Regulation of peptidase activity | |
| GO:0042326 | 0.021460151 | Negative regulation of phosphorylation | ||
| GO:0005975 | 0.017537912 | Carbohydrate metabolic process | ||
| GO:0006096 | 0.000947641 | Glycolytic process | ||
| GO:0031295 | 0.02116544 | T cell co-stimulation | ||
| GO:0042176 | 0.037110591 | Regulation of protein catabolic process | ||
| rno04066 | 0.007510911 | HIF-1 signaling pathway | ||
| rno04151 | 0.006275621 | PI3K-Akt signaling pathway | ||
| Liver | Liver 4 weeks | GO:0006954 | 0.001396509 | Inflammatory response |
| GO:0009725 | 0.002627081 | Response to hormone | ||
| GO:0016491 | 0.002701852 | Oxidoreductase activity | ||
| GO:0003824 | 0.013755671 | Catalytic activity | ||
| GO:0070555 | 0.014842206 | Response to interleukin-1 | ||
| GO:0033993 | 0.027356508 | Response to lipid | ||
| rno00980 | 0.017258367 | Metabolism of xenobiotics by cytochrome P450 | ||
| rno04933 | 0.027963125 | AGE-RAGE signaling pathway in diabetic complications | ||
| Liver 16 weeks | GO:0001889 | 0.00703339 | Liver development | |
| GO:0008289 | 0.00291932 | Lipid binding | ||
| GO:0050777 | 0.005409903 | Negative regulation of immune response | ||
| GO:0035693 | 0.014337447 | NOS2-CD74 complex | ||
| GO:0006776 | 0.028470377 | Vitamin A metabolic process | ||
| rno03320 | 0.003125368 | PPAR signaling pathway | ||
| rno04933 | 0.006912547 | AGE-RAGE signaling pathway in diabetic complications | ||
| rno00982 | 0.008912531 | Drug metabolism—cytochrome P450 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Tian, Z.; Song, M.; Ma, C.; Ge, Z.; Li, P. Detecting the Critical States of Type 2 Diabetes Mellitus Based on Degree Matrix Network Entropy by Cross-Tissue Analysis. Entropy 2022, 24, 1249. https://doi.org/10.3390/e24091249
Yang Y, Tian Z, Song M, Ma C, Ge Z, Li P. Detecting the Critical States of Type 2 Diabetes Mellitus Based on Degree Matrix Network Entropy by Cross-Tissue Analysis. Entropy. 2022; 24(9):1249. https://doi.org/10.3390/e24091249
Chicago/Turabian StyleYang, Yingke, Zhuanghe Tian, Mengyao Song, Chenxin Ma, Zhenyang Ge, and Peiluan Li. 2022. "Detecting the Critical States of Type 2 Diabetes Mellitus Based on Degree Matrix Network Entropy by Cross-Tissue Analysis" Entropy 24, no. 9: 1249. https://doi.org/10.3390/e24091249
APA StyleYang, Y., Tian, Z., Song, M., Ma, C., Ge, Z., & Li, P. (2022). Detecting the Critical States of Type 2 Diabetes Mellitus Based on Degree Matrix Network Entropy by Cross-Tissue Analysis. Entropy, 24(9), 1249. https://doi.org/10.3390/e24091249