
UPANets: Learning from the Universal Pixel Attention Neworks

 , ,
, , 
Abstract
:1. Introduction
- Propose UPANets with UPA Block equipped with Channel Pixel Attention (CPA) and a combination of Spatial Pixel Attention (SPA) and Extreme Connection (ExC) connecting each UPA Layer Module to find the balance between performance and cost.
- CPA considers pixel information across channels and helps CNNs form complex features even in shallow depth with fewer parameters. In addition, by applying concatenating feature maps in a network, the capturing ability of CPA can be amplified to cross blocks detection.
- SPA and ExC help to generate a smooth learning landscape and contribute to learning spatial information to pass important pixel information, respectively.
- A competitive image classification model surpasses well-known SOTAs in CIFAR-{10, 100} and Tiny ImageNet.
2. Related Works
2.1. Attentions
2.2. Structure Design
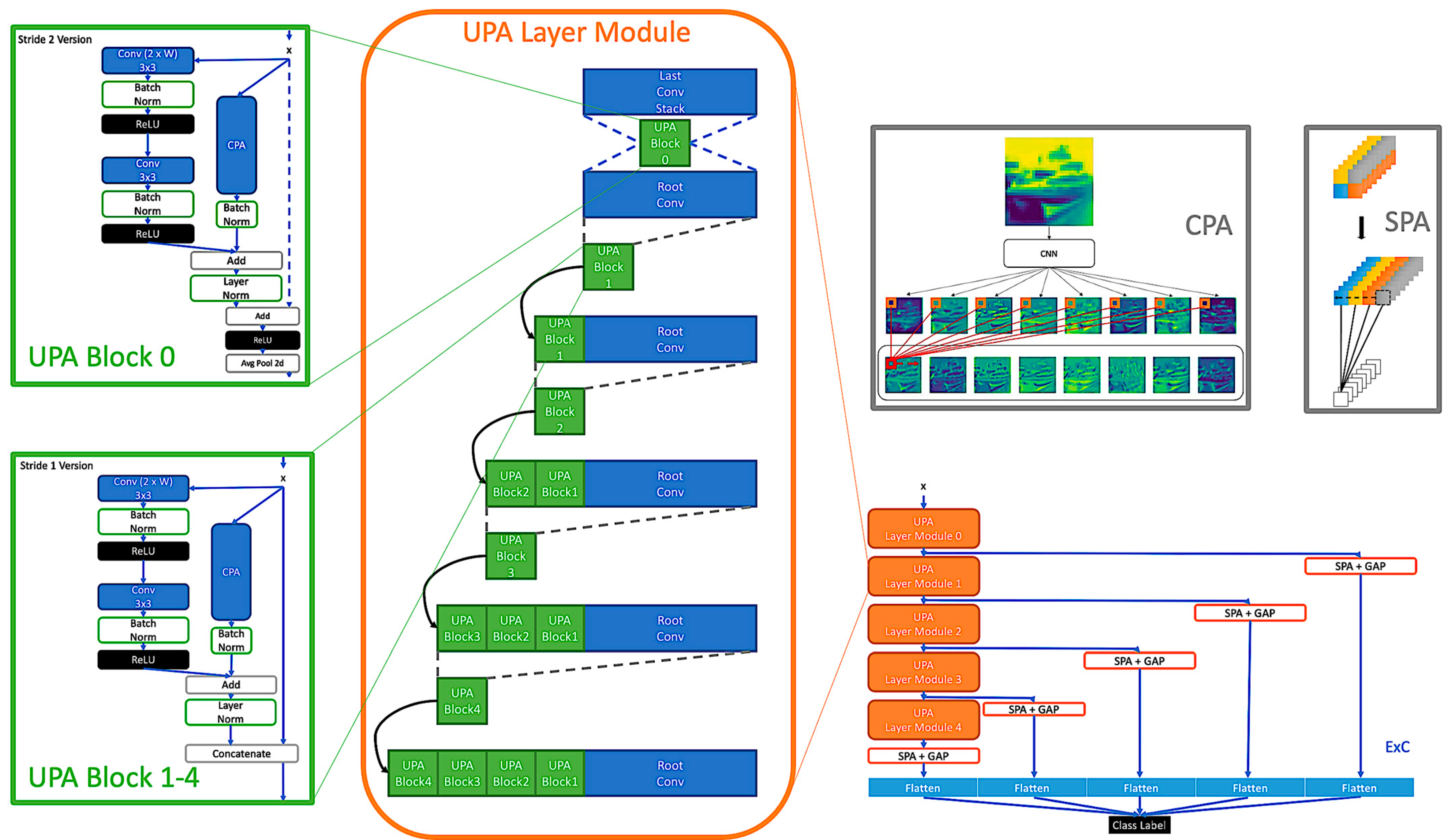
3. UPANets
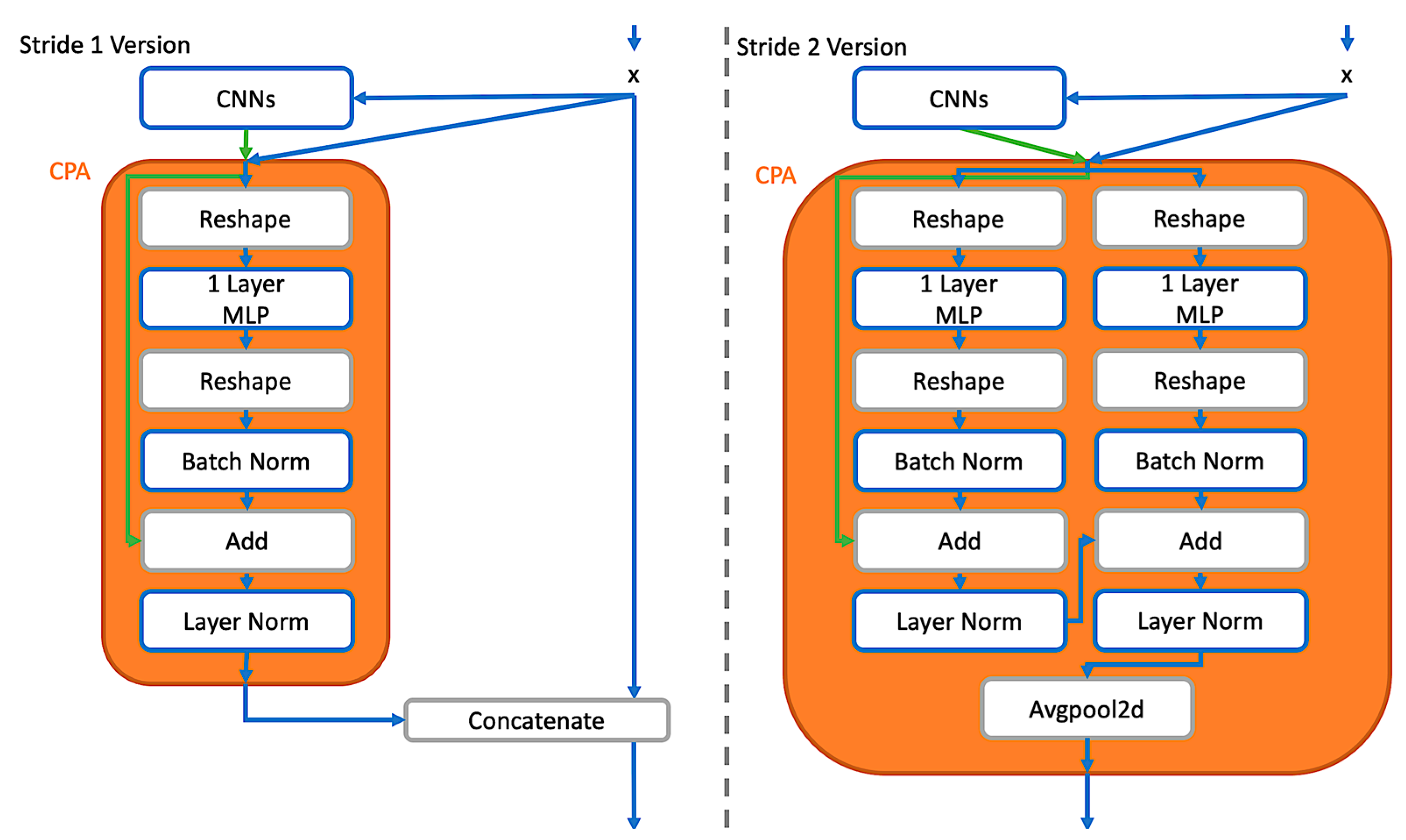
3.1. Channel Pixel Attention
3.2. UPA Blocks
3.3. UPA Blocks
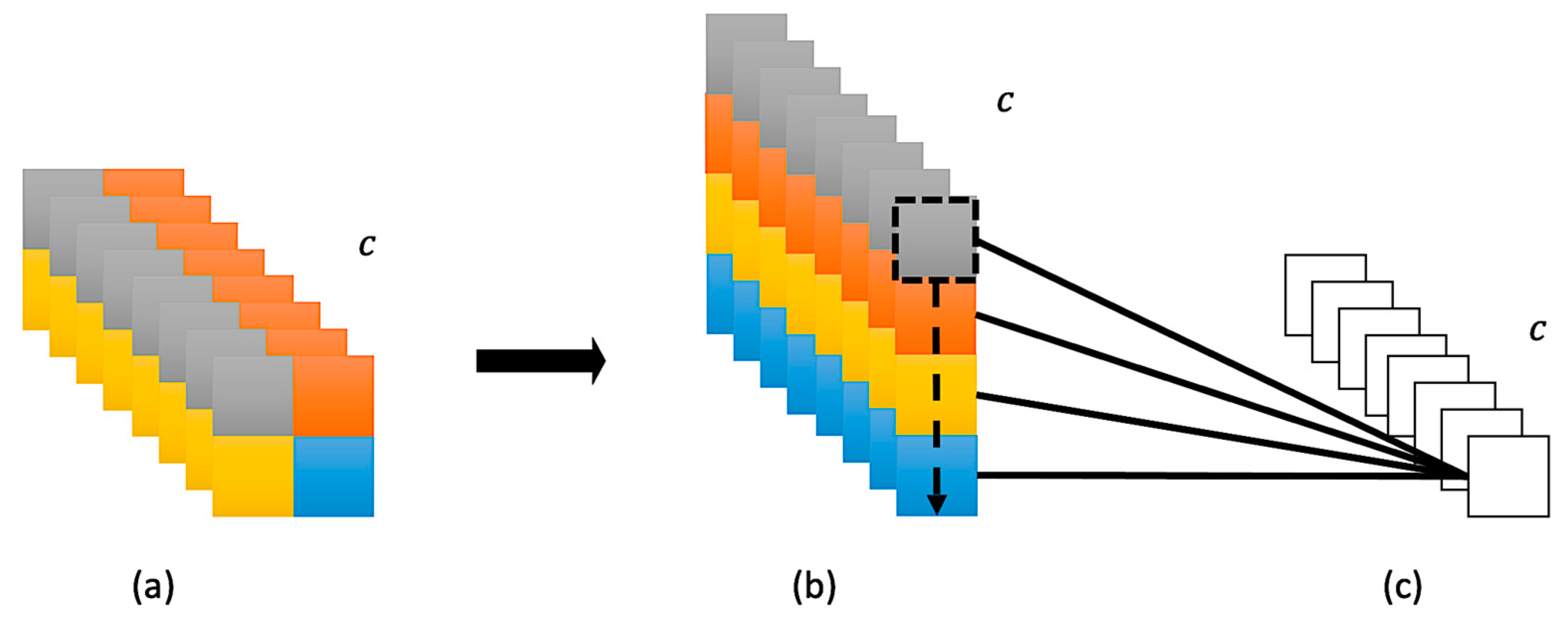
3.4. Spatial Pixel Attention
3.5. Extreme Connection
3.6. UPANets Structure
4. Experiment
4.1. Experiment Environment Settings
4.2. Ablation Study
4.2.1. Global Fusion from Channel Pixel Attention
4.2.2. Comparing with ShuffleNet
4.2.3. Building Connection with Learnable Pooling
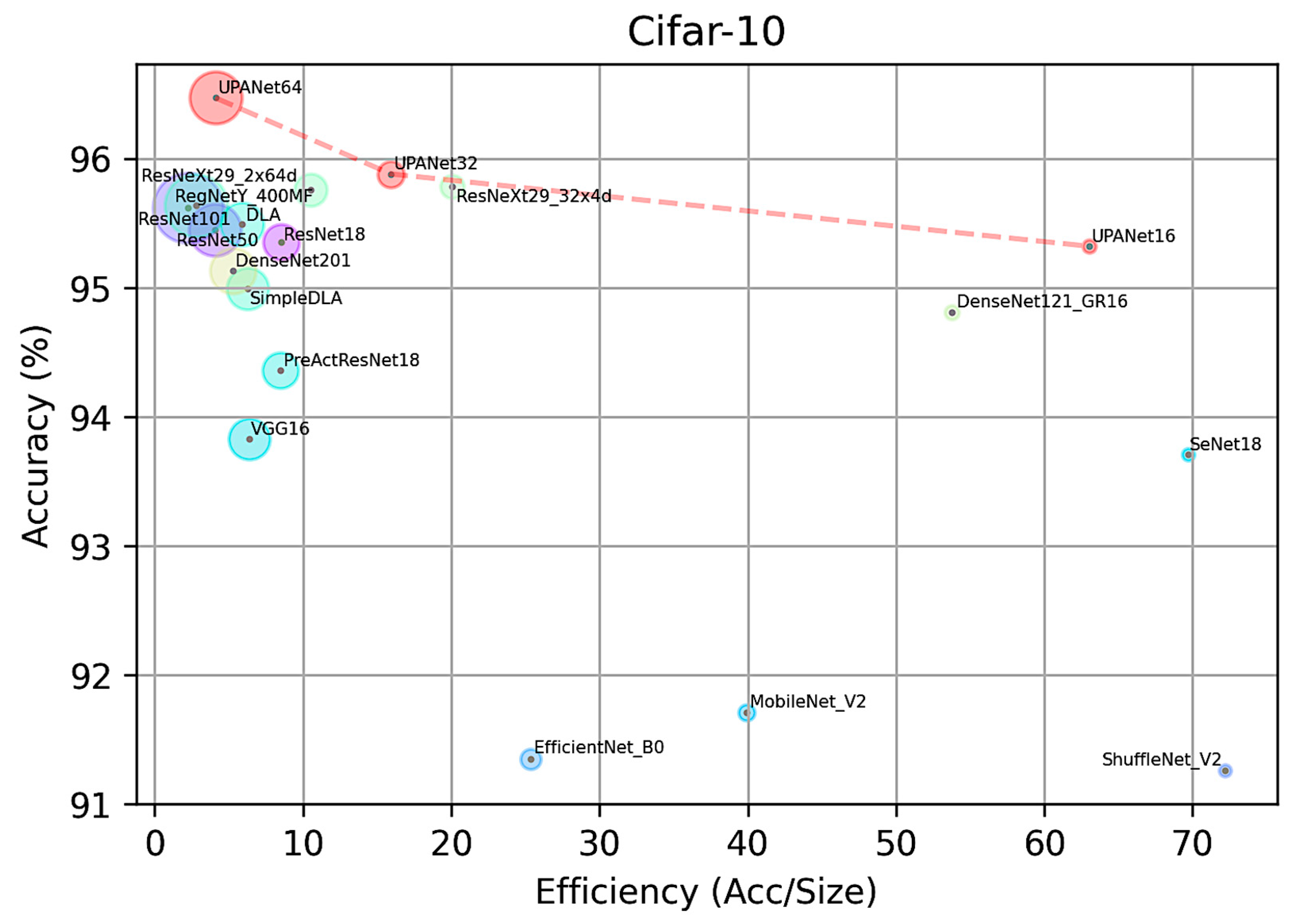
4.3. Comparison with SOTAs
4.3.1. Comparison in CIFARs
4.3.2. Comparison in Tiny ImageNet
5. Conclusions
5.1. CPA in Processing Global Information with Benefits
5.2. SPA with ExC Brings Better Environments for Learning
5.3. SPA with ExC Brings Better Environments for Learning
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Dimension Illustration in UPANets Structure

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Blocks | Input size | Output size | Structure |
|---|---|---|---|---|
| UPA Layer Module 0 | UPA Block 0 | |||
| UPA Layer Module 1 | UPA Block 0 | |||
| UPA Block 1~4d | ||||
| UPA Layer Module 2 | UPA Block 0 | |||
| UPA Block 1~4d | ||||
| UPA Layer Module 3 | UPA Block 0 | |||
| UPA Block 1~8d | ||||
| Ex-Connected Layer | + GAP | |||
| Output Layer |
Appendix B. Comparison of Perceptron and CNNs in Attention
| UPANet16 | CIFAR-10 Acc % (Top 1 Error) | CIFAR-100 Acc % (Top 1 Error) | Size (M) (10, 100) | Efficiency (Acc %/M) (10, 100) |
|---|---|---|---|---|
| CNNs | 94.76 (0.0442) | 74.85 (0.2515) | (1.51, 1.56) | (62.75, 47.98) |
| FC | 94.90 (0.051) | 75.15 (0.2485) | (1.51, 1.56) | (62.85, 48.17) |
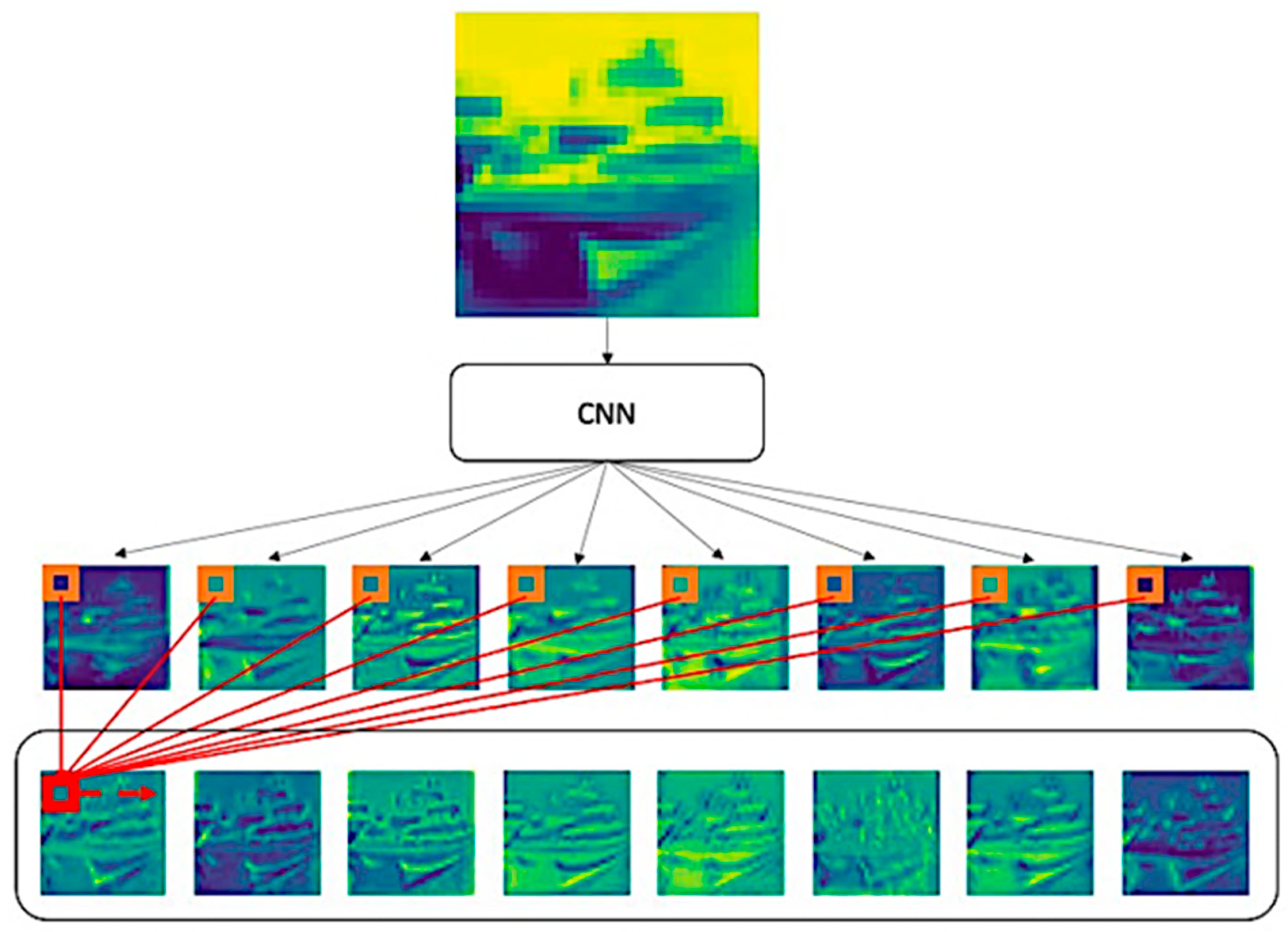
Appendix C. Sample Pattern of the CNN and CPA in UPA Block

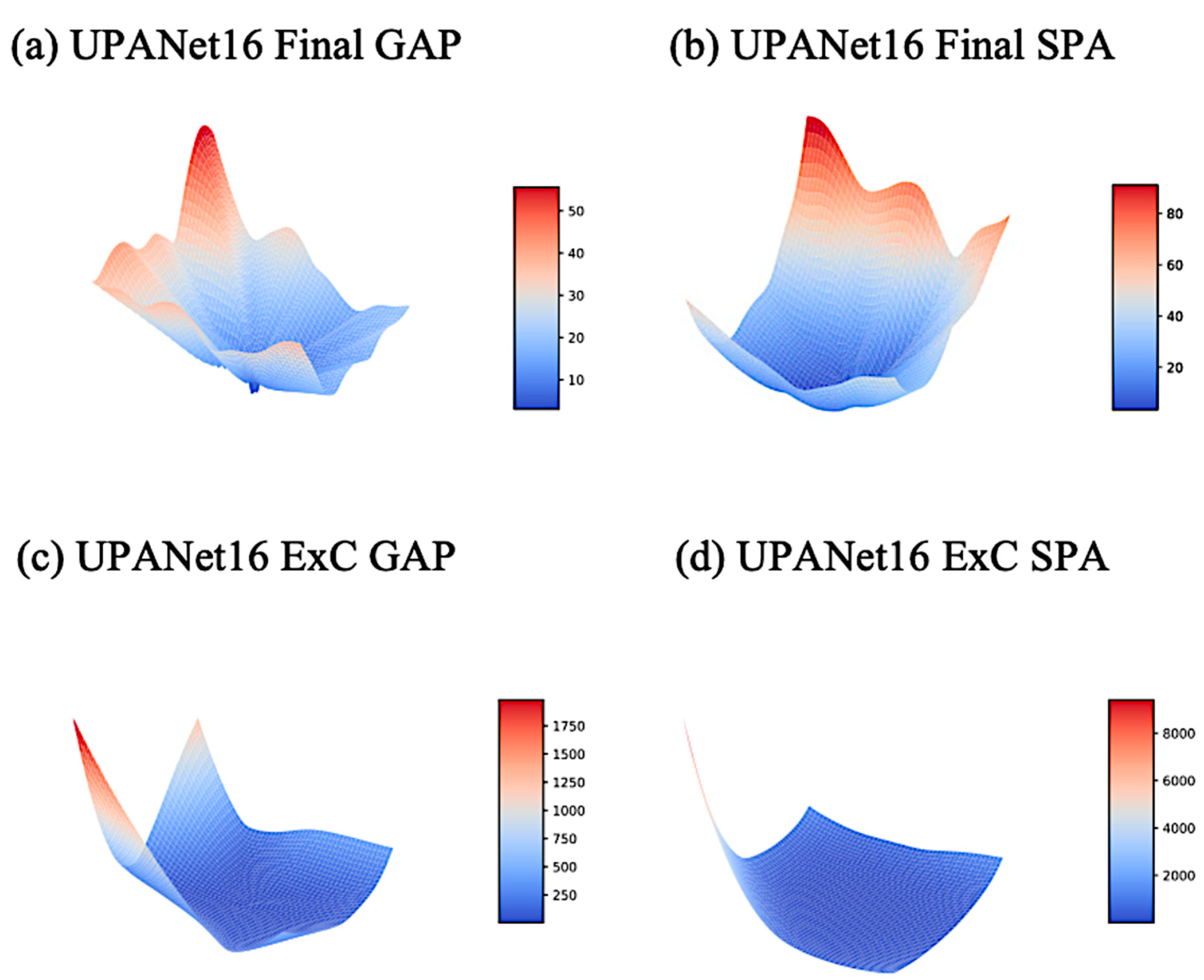
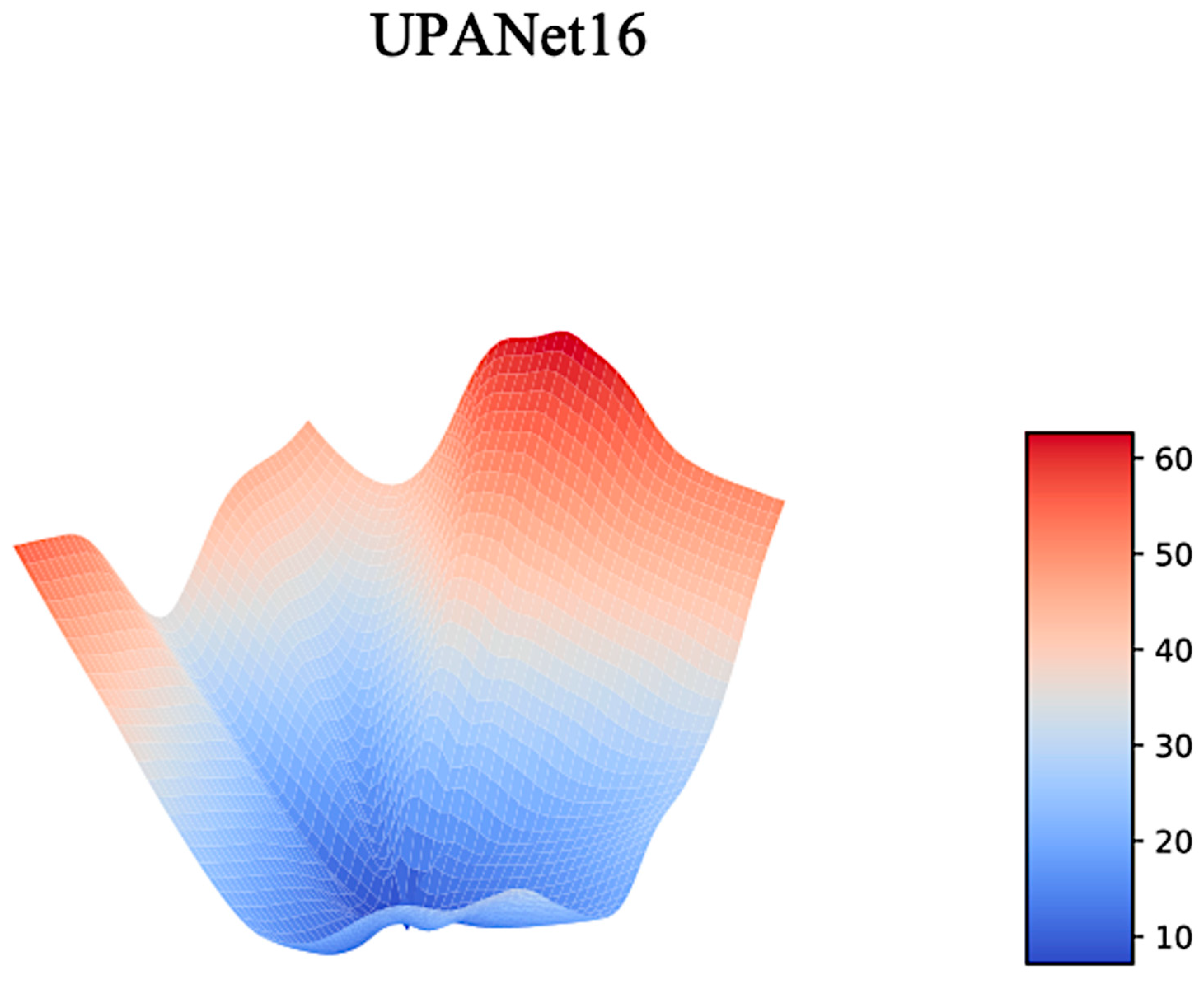
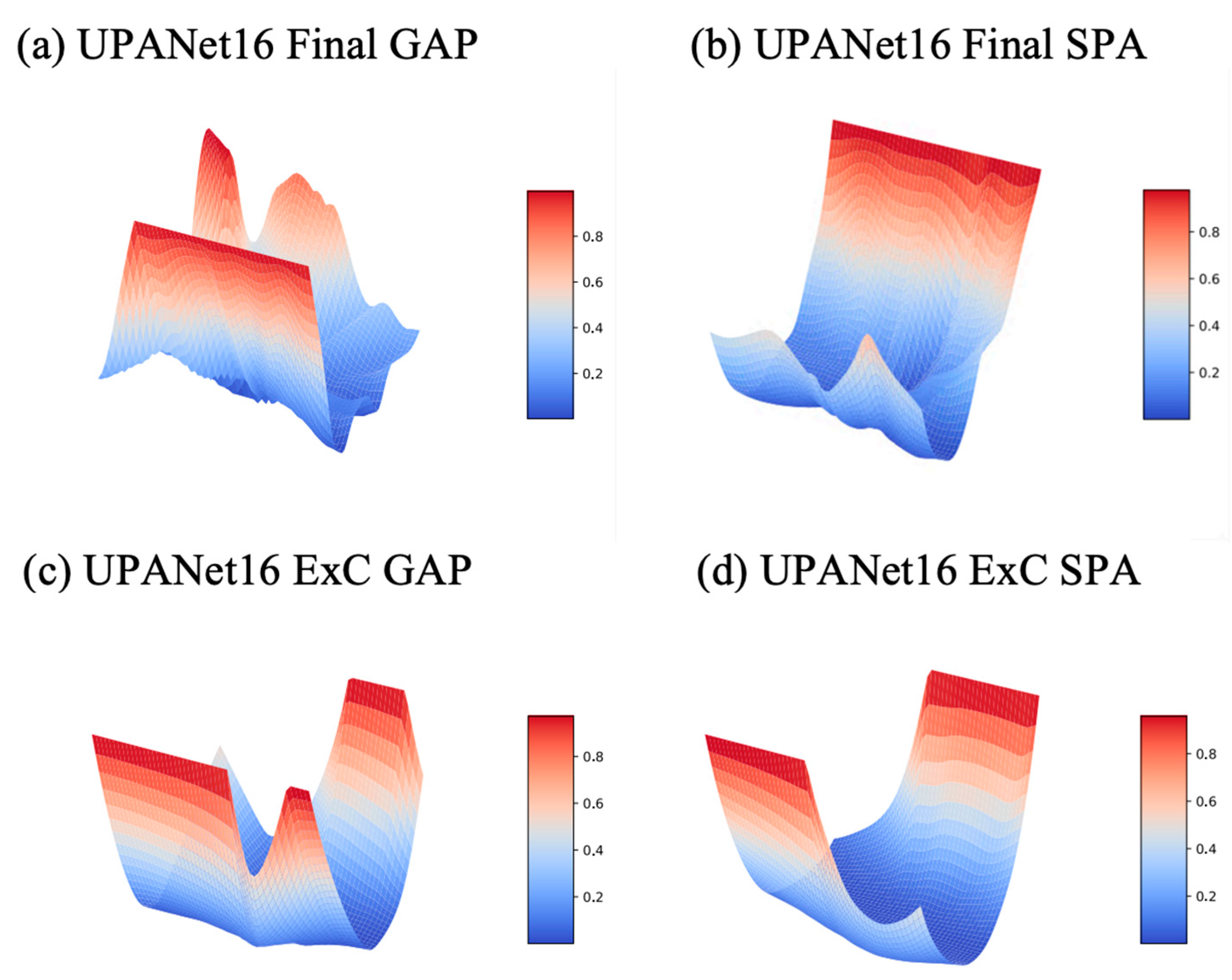
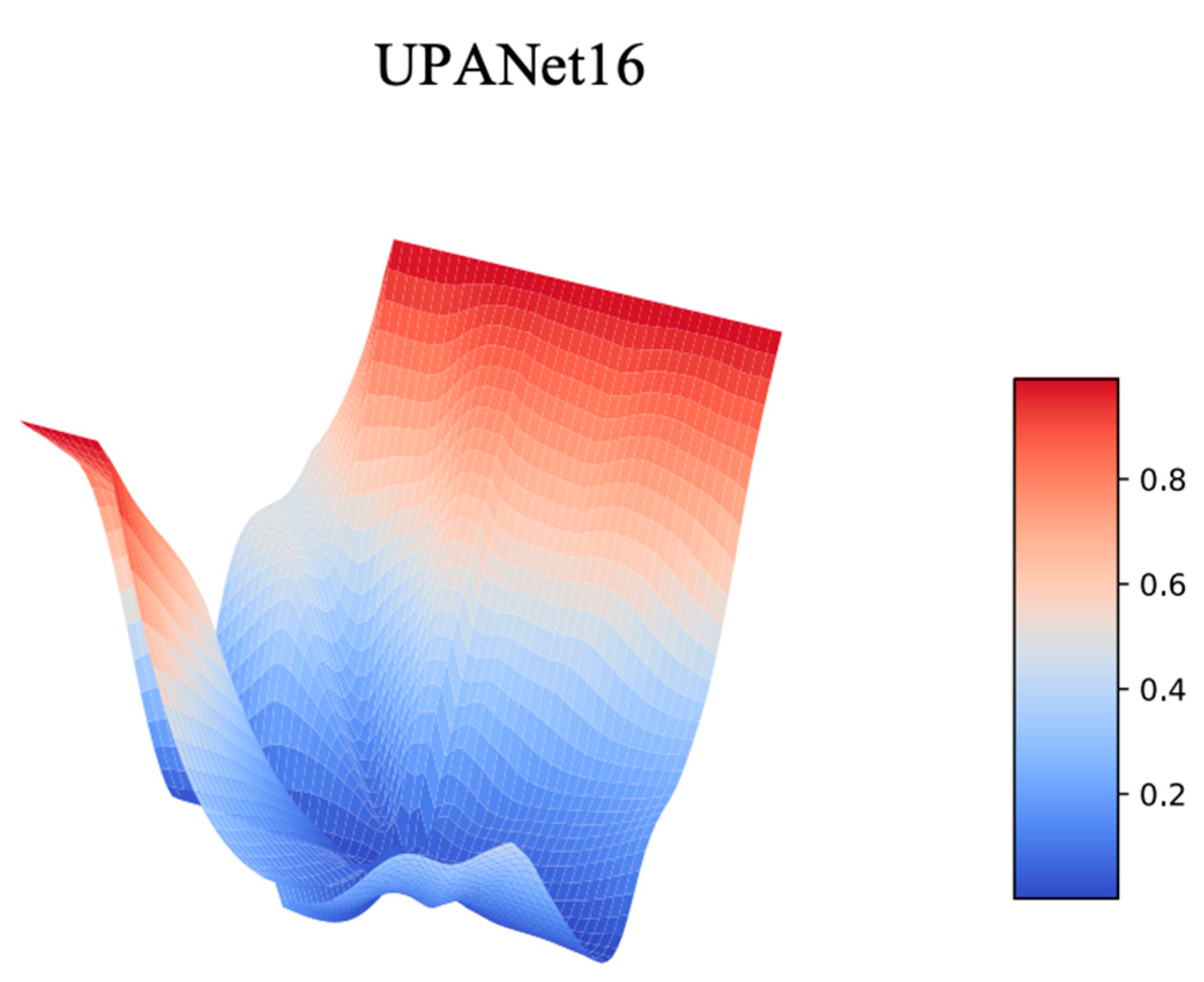
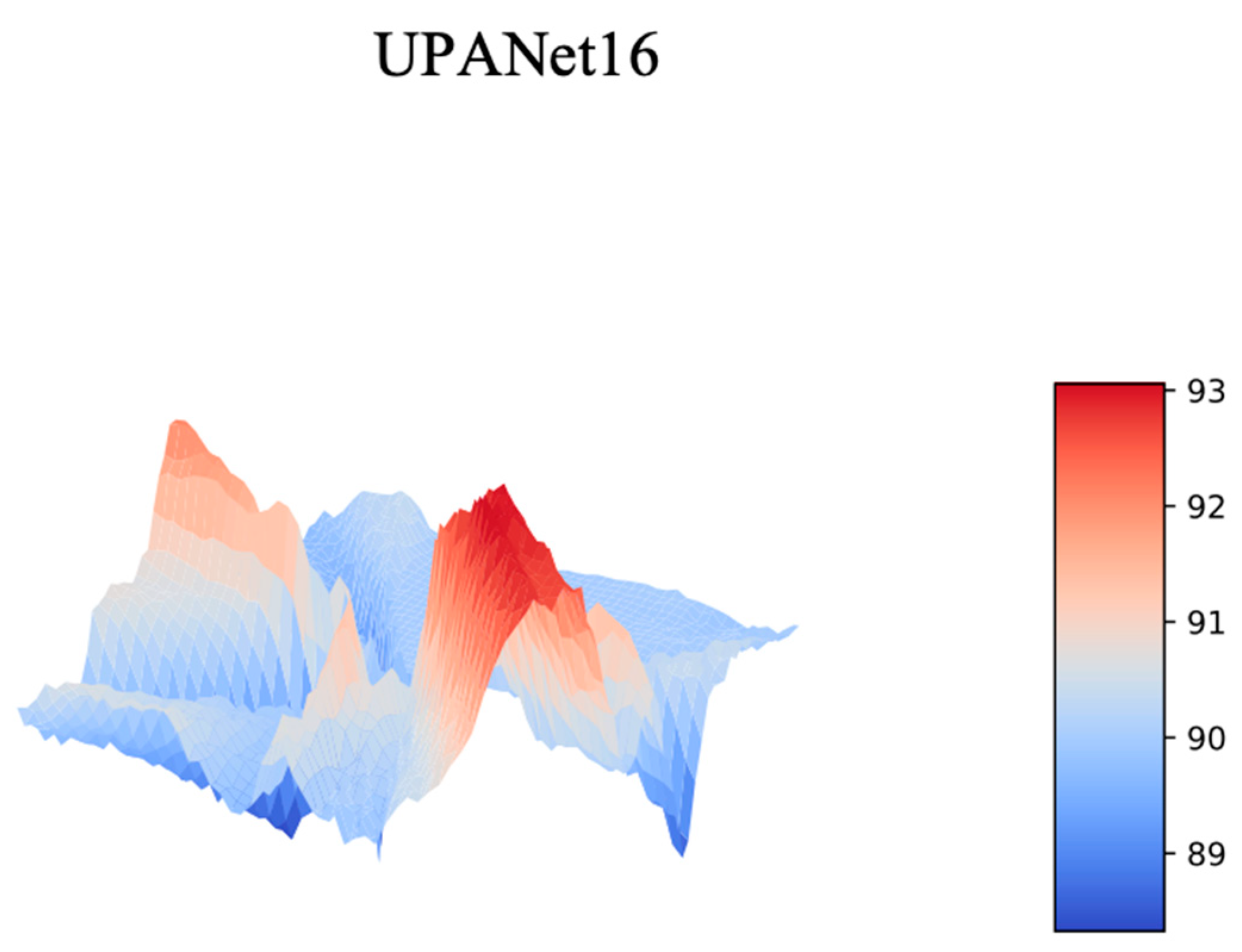
Appendix D. Landscape toward UPANets and Others
Appendix D.1. Comparison with DenseNet
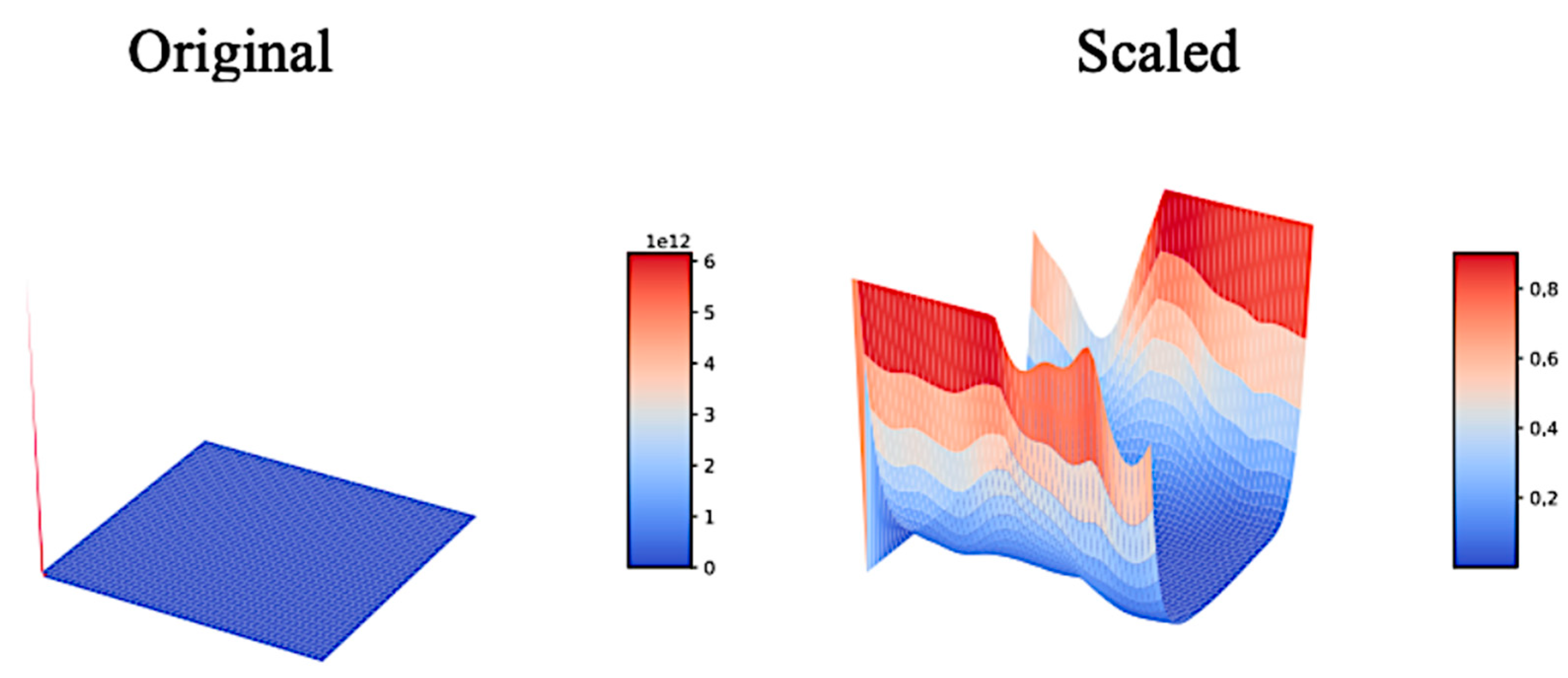
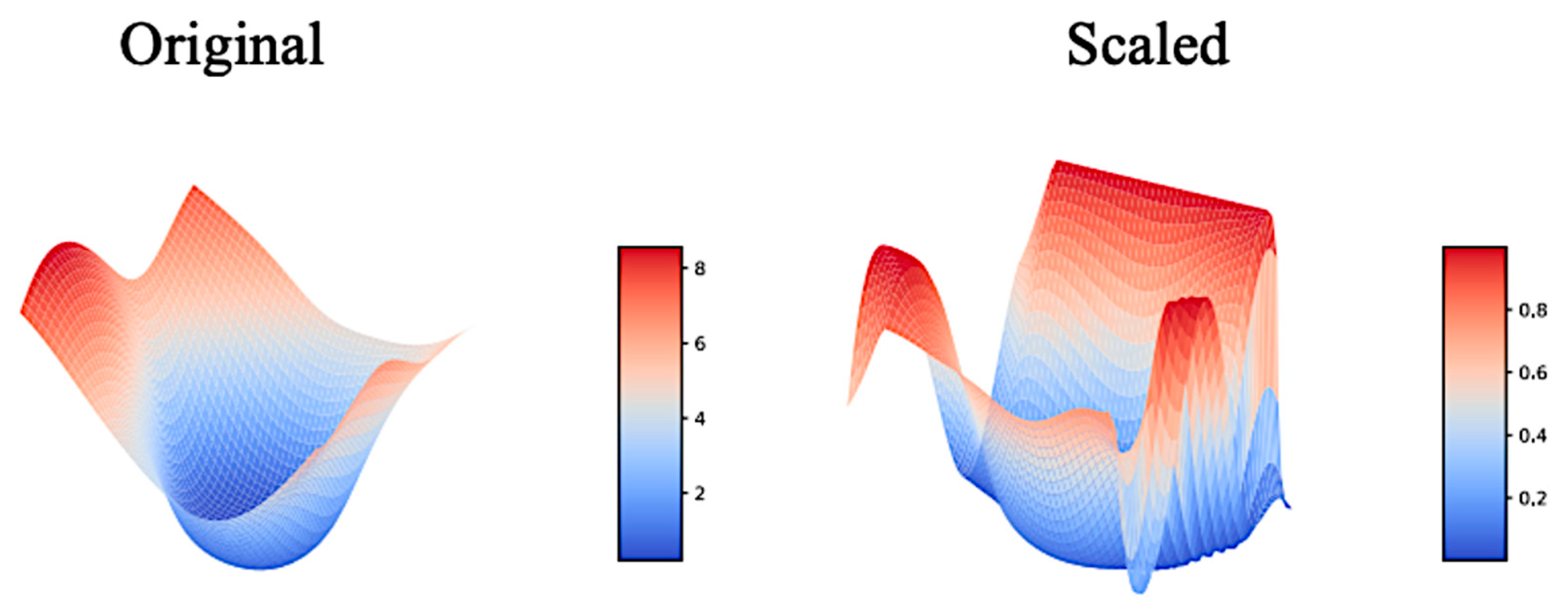

Appendix D.2. UPANet16 Variants Original Landscapes
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Yung, J.; Gelly, S.; Houlsby, N. Big Transfer (BiT): General Visual Representation Learning. arXiv 2020, arXiv:1912.11370. [Google Scholar]
- Ridnik, T.; Lawen, H.; Noy, A.; Baruch, E.B.; Sharir, G.; Friedman, I. Tresnet: High performance gpu-dedicated architecture. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 1400–1409. [Google Scholar]
- Zhao, S.; Zhou, L.; Wang, W.; Cai, D.; Lam, T.L.; Xu, Y. SplitNet: Divide and Co-training. arXiv 2020, arXiv:2011.14660. [Google Scholar]
- Kabir, H.M.D.; Abdar, M.; Khosravi, A.; Jalali, S.M.J.; Atiya, A.F.; Nahavandi, S.; Srinivasan, D. Spinalnet: Deep neural network with gradual input. arXiv 2020, arXiv:2007.03347. [Google Scholar] [CrossRef]
- Lee, H.; Kim, H.-E.; Nam, H. Srm: A style-based recalibration module for convolutional neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1854–1862. [Google Scholar]
- Shah, A.; Kadam, E.; Shah, H.; Shinde, S.; Shingade, S. Deep residual networks with exponential linear unit. In Proceedings of the Third International Symposium on Computer Vision and the Internet, Jaipur, Rajasthan, India, 21–24 September 2016; pp. 59–65. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Deng, W.; Feng, Q.; Gao, L.; Liang, F.; Lin, G. Non-convex Learning via Replica Exchange Stochastic Gradient MCMC. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 2474–2483. [Google Scholar]
- Borji, A.; Cheng, M.-M.; Hou, Q.; Jiang, H.; Li, J. Salient object detection: A survey. Comput. Vis. Media 2019, 5, 117–150. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in Transformer. arXiv 2021, arXiv:2103.00112. [Google Scholar]
- Hudson, D.A.; Zitnick, C.L. Generative Adversarial Transformers. arXiv 2021, arXiv:2103.01209. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. arXiv 2020, arXiv:2012.07436. [Google Scholar]
- Li, H.; Xu, Z.; Taylor, G.; Studer, C.; Goldstein, T. Visualizing the loss landscape of neural nets. arXiv 2017, arXiv:1712.09913. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. arXiv 2020, arXiv:2012.12877. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Hluchyj, M.G.; Karol, M.J. Shuffle net: An application of generalized perfect shuffles to multihop lightwave networks. J. Lightwave Technol. 1991, 9, 1386–1397. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Lin, J.; Zheng, Z.; Zhong, Z.; Luo, Z.; Li, S.; Yang, Y.; Sebe, N. Joint Representation Learning and Keypoint Detection for Cross-view Geo-localization. IEEE Trans. Image Process. 2022, 31, 3780–3792. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Zheng, Z.; Yan, C.; Zhang, J.; Sun, Y.; Zheng, B.; Yang, Y. Each part matters: Local patterns facilitate cross-view geo-localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 867–879. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Abai, Z.; Rajmalwar, N. DenseNet Models for Tiny ImageNet Classification. arXiv 2019, arXiv:1904.10429. [Google Scholar]
- Kim, J.-H.; Choo, W.; Song, H.O. Puzzle mix: Exploiting saliency and local statistics for optimal mixup. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 5275–5285. [Google Scholar]




| UPANet16 | CIFAR-10 Acc % (Top 1 Error) | CIFAR-100 Acc % (Top 1 Error) | Size (Million) (CIFAR-10, CIFAR-100) | Efficiency (Acc % / Million) (CIFAR-10, CIFAR-100) |
|---|---|---|---|---|
| w/o CPA w/o Shuffle CNNs in groups = 1 | 93.54 (0.0646) | 72.98 (0.2702) | (1.43, 1.48) | (65.32, 49.42) |
| w/o CPA w/o Shuffle CNNs in groups = 2 | 92.64 (0.0736) | 71.0 (0.29) | (0.72,0.77) | (129.67, 92.21) |
| CPA CNNs in groups = 2 | 94.2 (0.058) | 74.52 (0.2548) | (1.02, 1.06) | (92.53, 70.12) |
| Shuffle CNNs in groups = 2 | 93.33 (0.0667) | 71.98 (0.2802) | (0.96, 1.01) | (96.75, 71.31) |
| w/o CPA w/o Shuffle CNNs in groups = 4 | 90.69 (0.0931) | 68.75 (0.3125) | (0.37, 0.41) | (245.11, 167.68) |
| CPA CNNs in groups = 4 | 93.79 (0.0621) | 73.55 (0.2645) | (0.78, 0.83) | (119.58, 88.73) |
| Shuffle CNNs in groups = 4 | 92.93 (0.0707) | 71.33 (0.2837) | (0.73, 0.78) | (127.14, 91.97) |
| CPA CNNs in groups = 1 (Ours UPANet16) | 94.90 (0.0510) | 75.15 (0.2485) | (1.51, 1.56) | (62.85, 48.17) |
| UPANet16 | CIFAR-10 Acc % (Top 1 Error) | CIFAR-100 Acc % (Top 1 Error) | Size (Million) (CIFAR-10, CIFAR-100) | Efficiency (Acc %/Million) (CIFAR-10, CIFAR-100) |
|---|---|---|---|---|
| Final GAP | 94.66 (0.0534) | 74.63 (0.2537) | (1.507162, 1.530292) | (63.11, 48.78) |
| Final SPA | 94.70 (0.0530) | 74.72 (0.2491) | (1.506427, 1.530306) | (63.13, 48.84) |
| ExC + GAP | 94.75 (0.0525) | 74.60 (0.2540) | (1.510042, 1.554772) | (62.75, 48.13) |
| ExC + SPA | 94.60 (0.0542) | 75.09 (0.2491) | (1.512431, 1.557161) | (62.64, 48.45) |
| ExC + SPA + GAP | 94.90 (0.051) | 75.15 (0.2485) | (1.512431, 1.557161) | (62.85, 48.71) |
| Model | Test Avg Accuracy | Size (M) | Efficiency |
|---|---|---|---|
| ShuffleNet_V2 | 91.26 | 1.26 | 72.21 |
| EfficientNet_B0 | 91.35 | 3.60 | 25.38 |
| MobileNet_V2 | 91.71 | 2.30 | 39.93 |
| SeNet18 | 93.71 | 1.34 | 69.69 |
| VGG16 | 93.83 | 14.73 | 6.37 |
| PreActResNet18 | 94.36 | 11.17 | 8.45 |
| DenseNets121_16GR | 94.81 | 1.76 | 53.78 |
| SimpleDLA | 94.99 | 15.14 | 6.27 |
| DenseNet201 | 95.13 | 18.10 | 5.25 |
| UPANet16 (Ours) | 95.32 | 1.51 | 63.13 |
| ResNet18 | 95.35 | 11.17 | 8.53 |
| ResNet50 | 95.45 | 23.52 | 4.06 |
| RegNetY_400MF | 95.46 | 5.71 | 16.71 |
| DLA | 95.49 | 16.29 | 5.86 |
| ResNet101 | 95.62 | 42.51 | 2.25 |
| UPANet32 (Ours) | 95.88 | 5.93 | 15.93 |
| ResNeXt29_2x64d | 95.76 | 9.13 | 10.49 |
| ResNeXt29_32x4d | 95.78 | 4.77 | 20.06 |
| UPANet64 (Ours) | 96.47 | 23.60 | 4.09 |
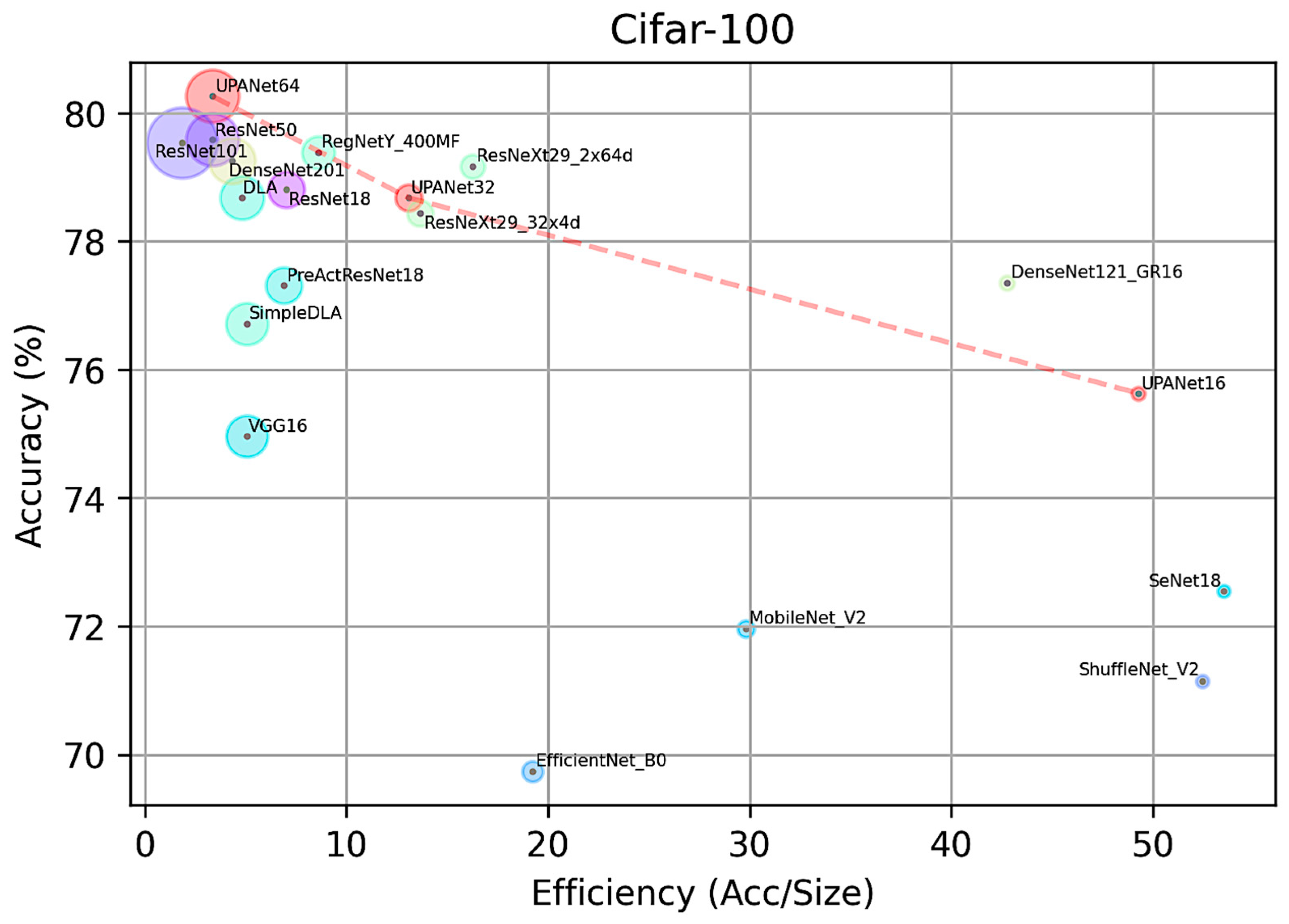
| Model | Test Avg Accuracy | Size (M) | Efficiency |
|---|---|---|---|
| EfficientNet_B0 | 69.74 | 3.63 | 19.22 |
| ShuffleNet_V2 | 71.15 | 1.36 | 52.47 |
| MobileNet_V2 | 71.96 | 2.41 | 29.83 |
| SeNet18 | 72.55 | 1.36 | 53.49 |
| VGG16 | 74.96 | 14.77 | 5.07 |
| SimpleDLA | 76.72 | 15.19 | 5.05 |
| UPANet16 (Ours) | 76.73 | 1.56 | 49.05 |
| preactresnet18 | 77.31 | 11.22 | 6.89 |
| DenseNets121_16GR | 77.35 | 1.81 | 42.76 |
| RegNetY_400MF | 78.44 | 5.75 | 13.64 |
| DLA | 78.68 | 16.34 | 4.82 |
| UPANet32 (Ours) | 78.78 | 6.02 | 12.90 |
| ResNet18 | 78.81 | 11.22 | 7.02 |
| ResNeXt29_32x4d | 79.16 | 4.87 | 16.27 |
| DenseNet201 | 79.25 | 18.23 | 4.35 |
| ResNeXt29_2x64d | 79.38 | 9.22 | 8.61 |
| ResNet101 | 79.54 | 42.70 | 1.86 |
| ResNet50 | 79.59 | 23.71 | 3.36 |
| UPANet64 (Ours) | 80.29 | 23.84 | 3.37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tseng, C.-H.; Lee, S.-J.; Feng, J.; Mao, S.; Wu, Y.-P.; Shang, J.-Y.; Zeng, X.-J. UPANets: Learning from the Universal Pixel Attention Neworks. Entropy 2022, 24, 1243. https://doi.org/10.3390/e24091243
Tseng C-H, Lee S-J, Feng J, Mao S, Wu Y-P, Shang J-Y, Zeng X-J. UPANets: Learning from the Universal Pixel Attention Neworks. Entropy. 2022; 24(9):1243. https://doi.org/10.3390/e24091243
Chicago/Turabian StyleTseng, Ching-Hsun, Shin-Jye Lee, Jianan Feng, Shengzhong Mao, Yu-Ping Wu, Jia-Yu Shang, and Xiao-Jun Zeng. 2022. "UPANets: Learning from the Universal Pixel Attention Neworks" Entropy 24, no. 9: 1243. https://doi.org/10.3390/e24091243
APA StyleTseng, C.-H., Lee, S.-J., Feng, J., Mao, S., Wu, Y.-P., Shang, J.-Y., & Zeng, X.-J. (2022). UPANets: Learning from the Universal Pixel Attention Neworks. Entropy, 24(9), 1243. https://doi.org/10.3390/e24091243